atmosphere conference 2015: service operations evolution at spotify
TRANSCRIPT

Operations Engineering Evolution at Spotify
Lev Popov Site Reliability Engineer @nabamx

Who am I?
§ Lev Popov § Service Reliability Engineer in Spotify § Joined Spotify in 2014 § Previous QIK – Skype – Microsoft
§ Background in services and networks operations

What is Spotify?

Some Numbers
• Over 60 million MAU (monthly active users) • Over 15 million paying subscribers • Over 30 million tracks • Over 1.5 billion playlists • Over 20.000 songs added per day

Capacity We Own
• 4 Data Centers • Over 7000 bare metal servers • Many different services • Pushing an average of 35GBps to the Internet • 24/7/365

But let's talk about operations

Service
Service
Service
Service
Dev owner
In the beginning was the…
Dev owner
Ops owner
Dev owner
Ops owner
Opera0ons team
Dev owner
On-‐call Monitoring
Build systems
Backups DB Networks …

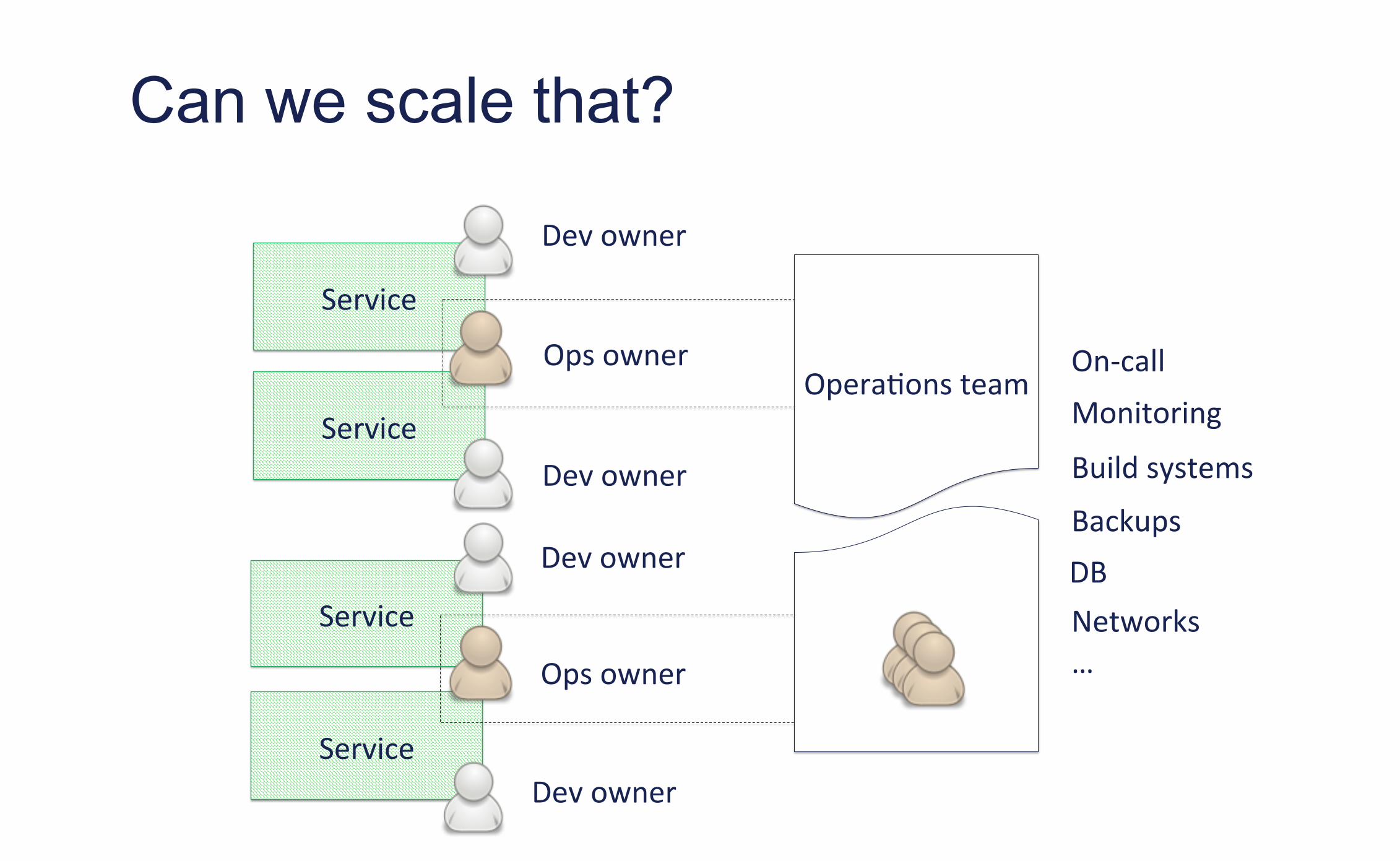
Operations Team in 2011
Thin group of 5 people
• Over 10 million users • Over 2 million paying subscribers • 12 Countries • Over 15 million tracks • Over 400 million playlists • 3 datacenters • Over 1300 servers

Operations Team Now
? • Over 60 million users • Over 15 million paying subscribers • 58 Countries • Over 30 million tracks • Over 1.5 billion playlists • 4 datacenters • Over 5000 servers

Operations Team Now
No team
• Over 60 million users • Over 15 million paying subscribers • 58 Countries • Over 30 million tracks • Over 1.5 billion playlists • 4 datacenters • Over 5000 servers


Spotify Engineering Culture

How We Scale
• Service oriented architecture Separate services for separate features
• UNIX way Small simple programs doing one thing well
• KISS principle Simple applications are easier to scale
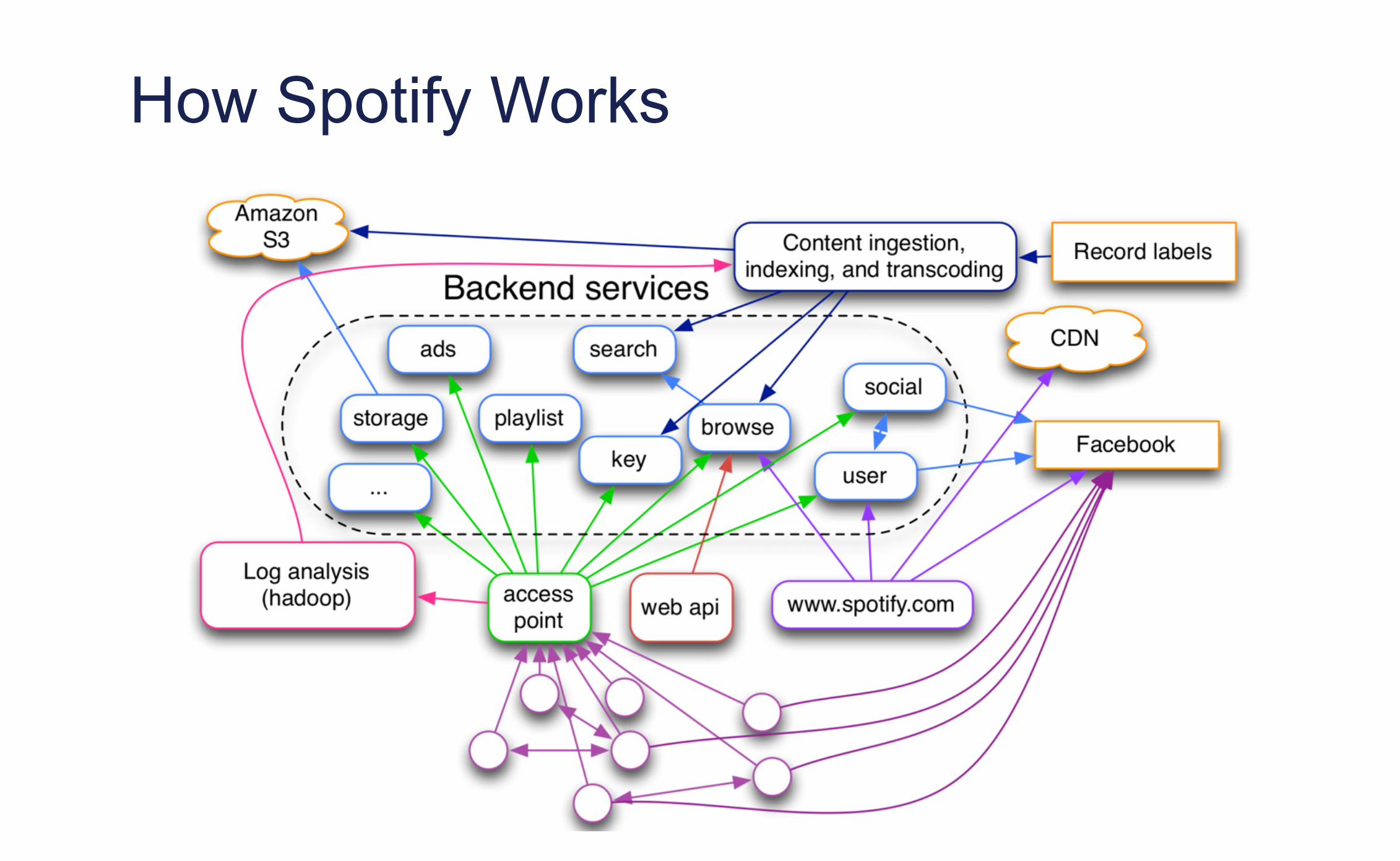
How Spotify Works
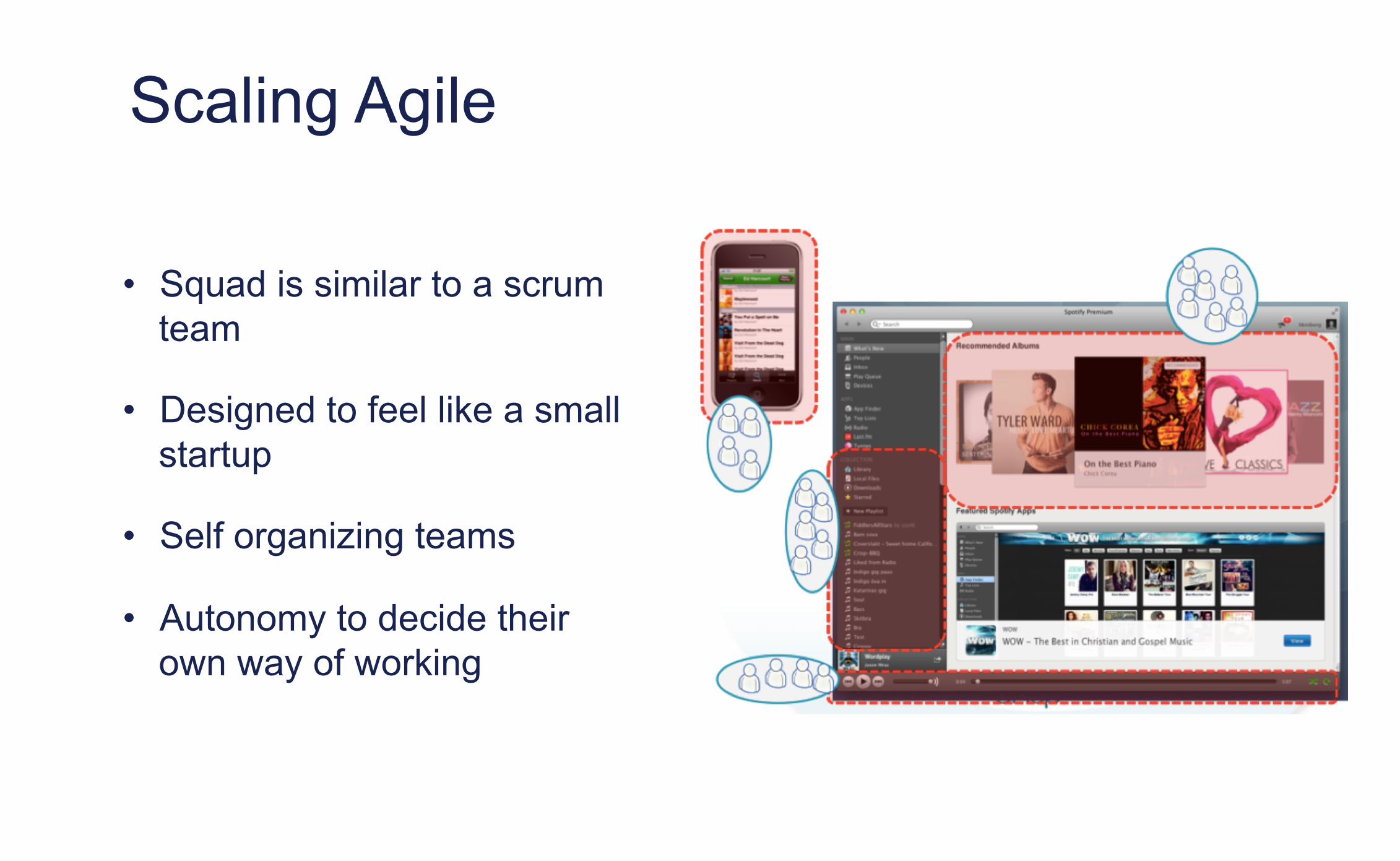
Scaling Agile
• Squad is similar to a scrum team
• Designed to feel like a small startup
• Self organizing teams
• Autonomy to decide their own way of working
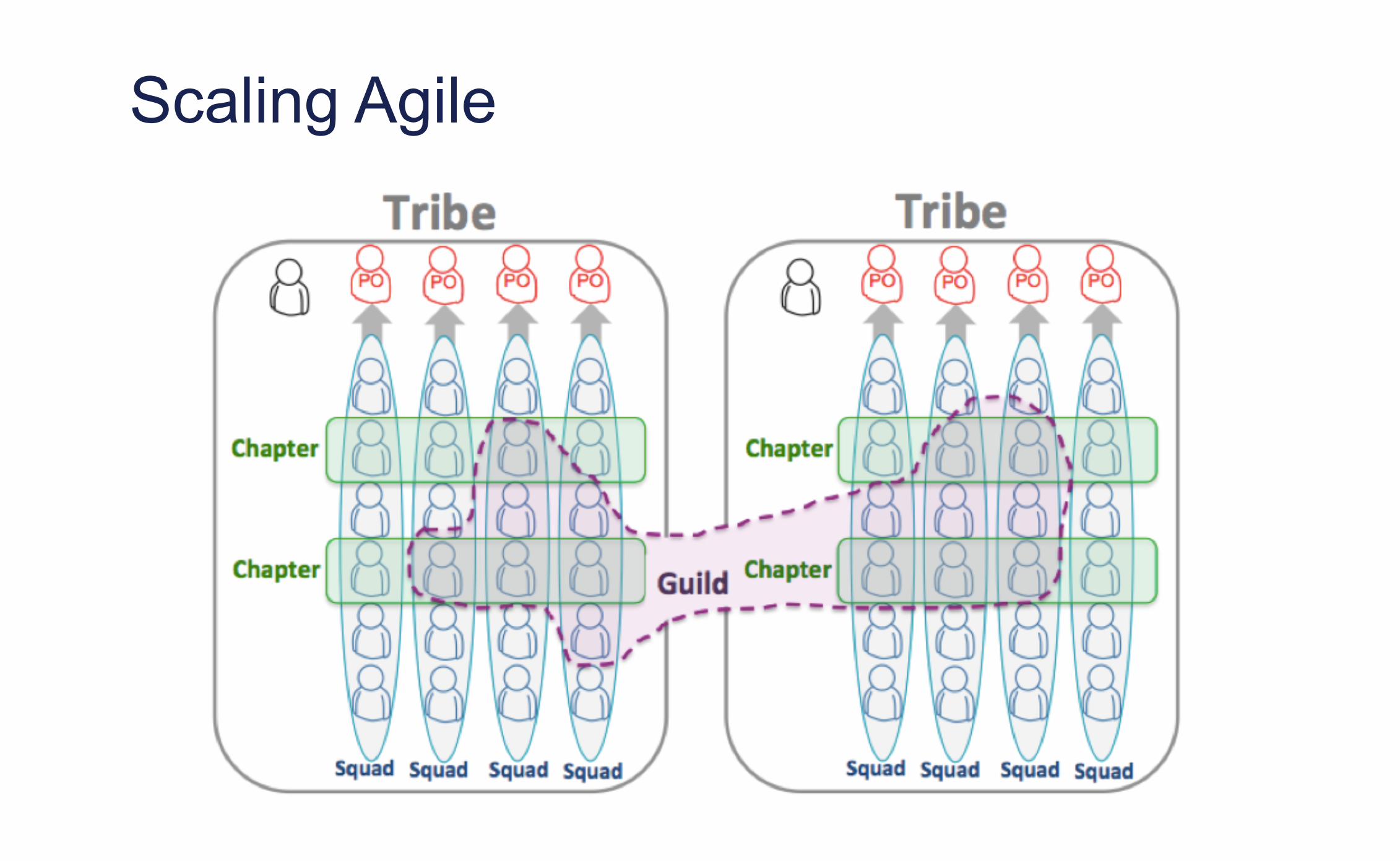
Scaling Agile
Service Dev owner
Service
Can we scale that?
Service
Dev owner
Ops owner
Service
Dev owner
Ops owner
Opera0ons team
Dev owner
On-‐call Monitoring
Build systems
Backups DB Networks …


Ops in Squads

Ops in Squads Background
Impossible to scale a central operations team • Understaffed • Difficult to find generalists
We believe that operation has to sit close to development
Our bet for autonomy • Break dependencies • End to end responsibility
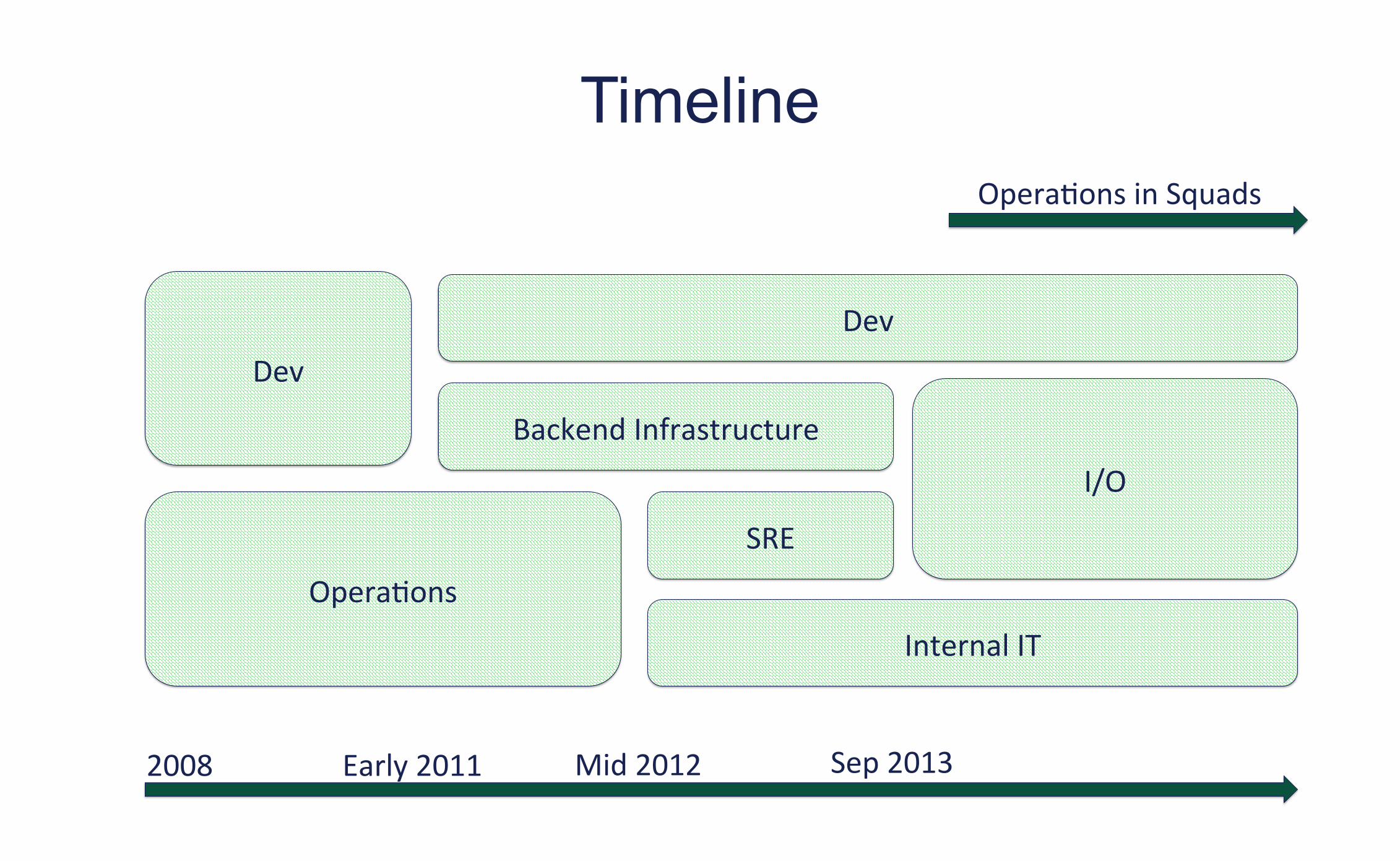
Timeline
Dev Dev
Backend Infrastructure
I/O
Opera0ons
SRE
Internal IT
Opera0ons in Squads
2008 Early 2011 Mid 2012 Sep 2013
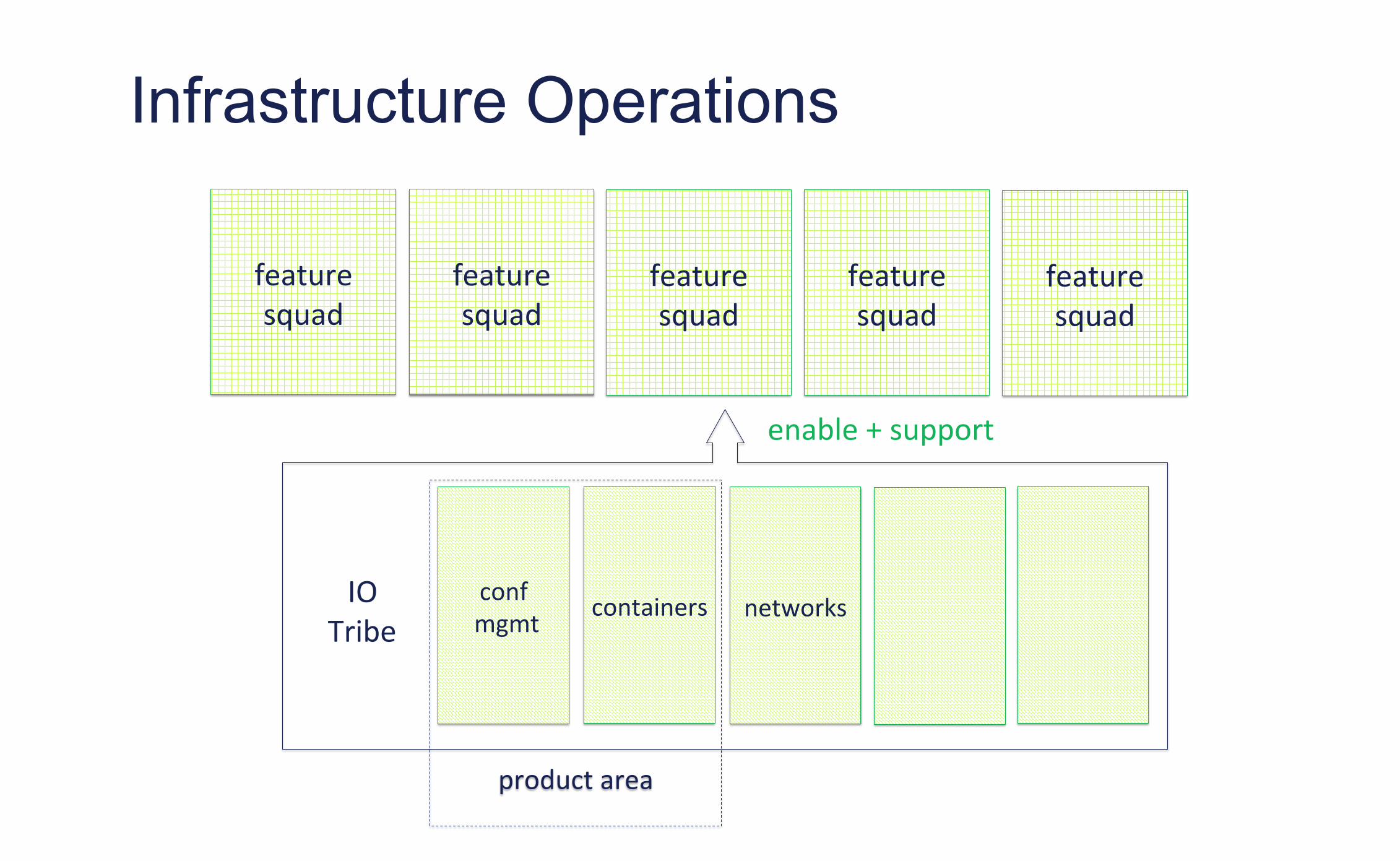
Infrastructure Operations
feature squad
feature squad
feature squad
feature squad
IO Tribe
networks conf mgmt containers
feature squad
enable + support
product area

Ops in Squads Expecta1ons

Wait, wait, but what if…


squad
Core SRE
Core SRE
IO Tribe
Major Incidents Scalability Issues Systems Design Problems
Teaching Best Prac0ces in General
squad squad squad squad

Incident Management
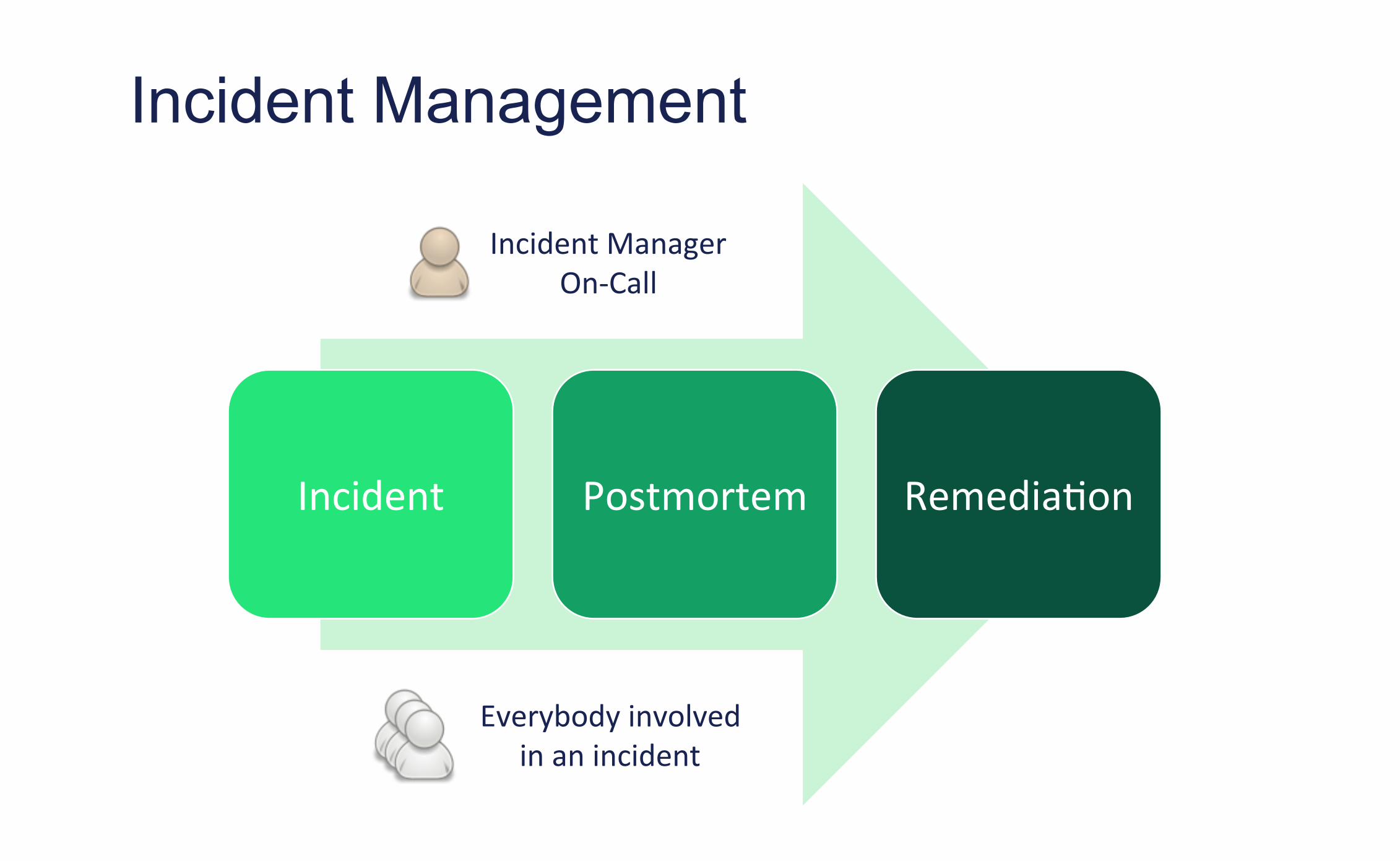
Incident Management
Incident Postmortem Remedia0on
Incident Manager On-‐Call
Everybody involved in an incident

Postmortems
• Plan for post-mortems • Keep it close in time • Record the project details • Involve everyone • Get it in writing • Record successes as well as failures • It's not for punishment • Create an action plan • Make it available

On-call follows the sun
Stockholm New York
Stockholm New York
Stockholm New York L0
SA Product Owners L1
SA Lead L2
19 CET
01 EST
19 CET
01 EST
07 CET 07 CET
13 EST 13 EST
19 CET
13 EST

Areas of Improvement

Areas of Improvement
• The expectations we place on squads are sometimes unclear
• Communication between feature teams and infrastructure teams
• It’s hard to measure ops in squads success
• Abandoned services and other ownership issues
