artur borycki - beyond lambda - how to get from logical to physical - code.talk.2015
TRANSCRIPT

Beyond Lambda - how to get from logical to physical
Artur Borycki Director Technology & Innovations

Simplification & Efficiency
Teradata believe in the principles of self-service, automation and on-demand resource allocation. These enable faster, more efficient and more effective data application development and operation.
‹#›
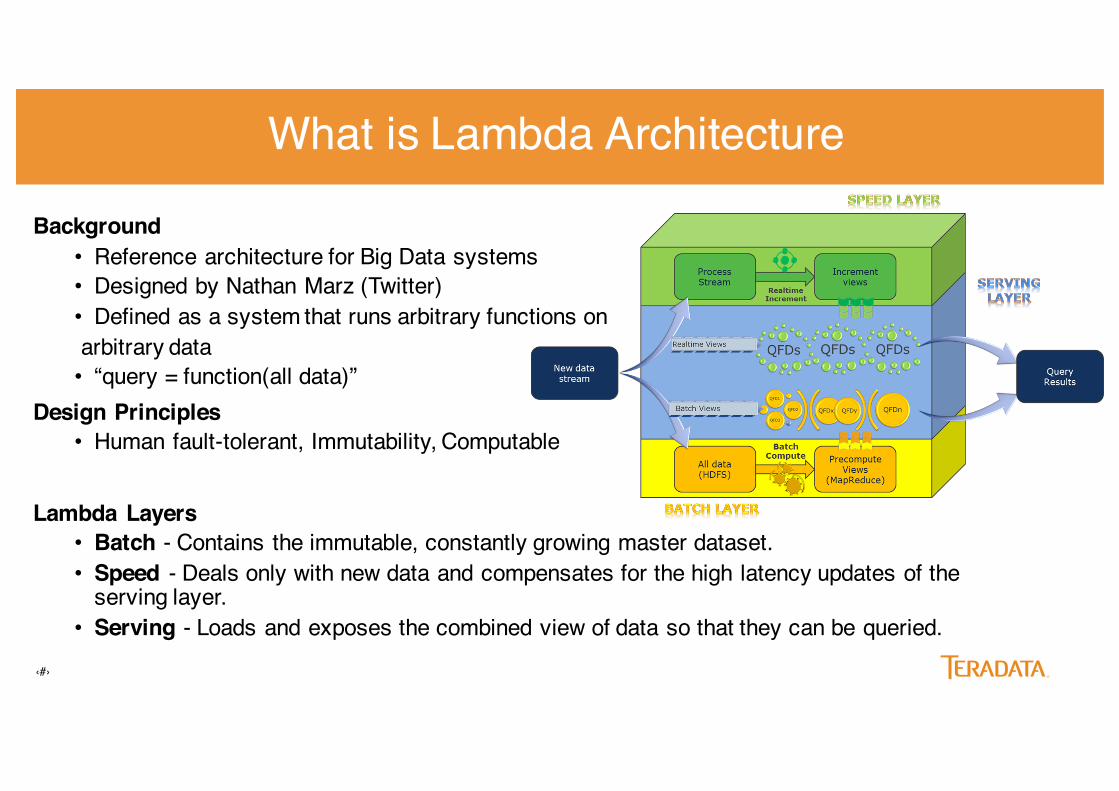
What is Lambda Architecture
Background• Reference architecture for Big Data systems• Designed by Nathan Marz (Twitter)• Defined as a system that runs arbitrary functions onarbitrary data• “query = function(all data)”
Design Principles• Human fault-tolerant, Immutability, Computable
Lambda Layers • Batch - Contains the immutable, constantly growing master dataset.• Speed - Deals only with new data and compensates for the high latency updates of the
serving layer.• Serving - Loads and exposes the combined view of data so that they can be queried.

‹#›
Active Executor Lambda Framework
• The way this works is that an immutable sequence of records is captured and fed into a batch system and a stream processing system in parallel.
• You implement your transformation logic twice, once in the batch system and once in the stream processing system.
• You stitch together the results from both systems at query time to produce a complete answer.
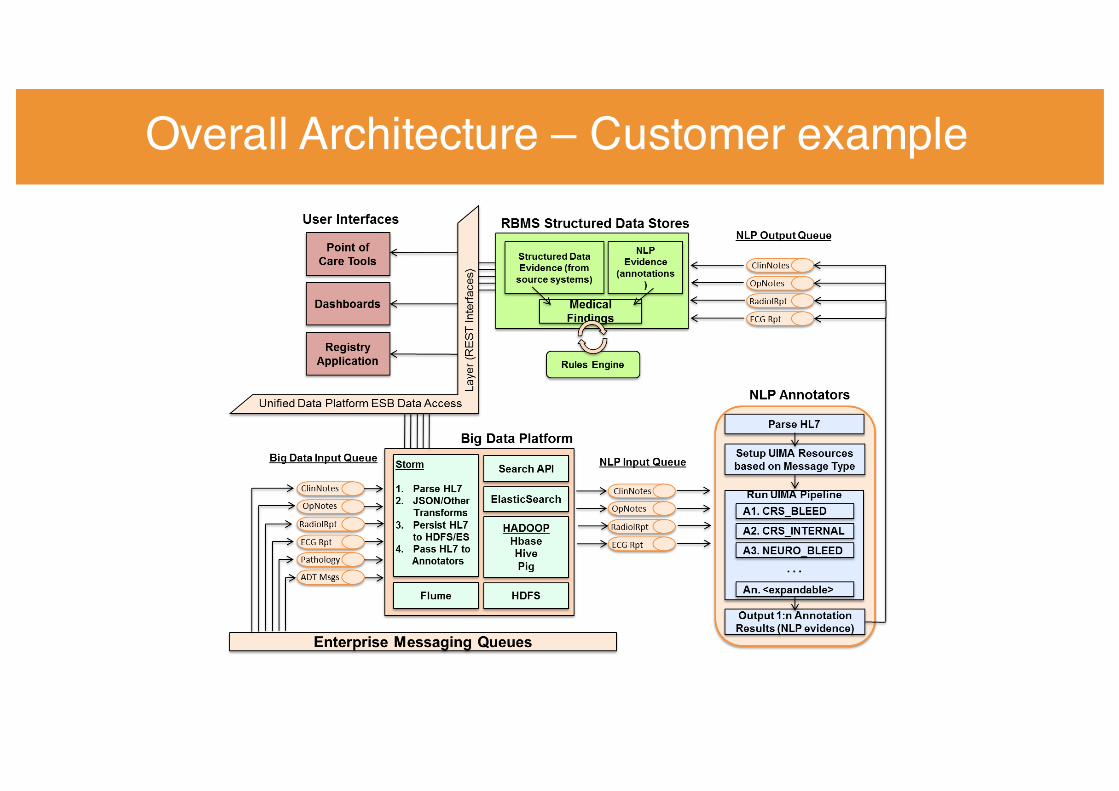
Overall Architecture – Customer example

‹#›
Lambda alternative – Kappa? (Jay Kreps – Linkedin)
Unlike the Lambda Architecture, in this approach you only do reprocessing when your processing code changes
1. Use Kafka or some other system that will let you retain the full log of the data you want to be able to reprocess and that allows for multiple subscribers. For example, if you want to reprocess up to 30 days of data, set your retention in Kafka to 30 days.
2. When you want to do the reprocessing, start a second instance of your stream processing job that starts processing from the beginning of the retained data, but direct this output data to a new output table.
3. When the second job has caught up, switch the application to read from the new table.
4. Stop the old version of the job, and delete the old output table.

Real-time MaturityTypical path for a customer
Customers typically go through four stages on their
path to real-time analysis.
The evolution typically starts with trying to visualize
results or reports more frequently. This leads to the
realization that the underlying data is not refreshed
frequently. The next stage of maturity is to capture and
ingest data more quickly. Once data is flowing faster,
customers then try to process the data as it is flowing.
The final stage is to remove any human intervention.

‹#›
Events / Interactions
Consumer of Information
All data
Streams
Other feeds
Consumer of Information
Discovery
Advance
Analytics
Data binding Repo
rting
Beyond Lambda – Omega ;) (Artur vision)
• We need events that require actions and interactions without much of the analytics
• We need events that are requiring action, but also they need to be enhanced by the analytics in the ecosystem (based on other information sources)
• We need events that will be handled later or they are supporting above cases
‹#›
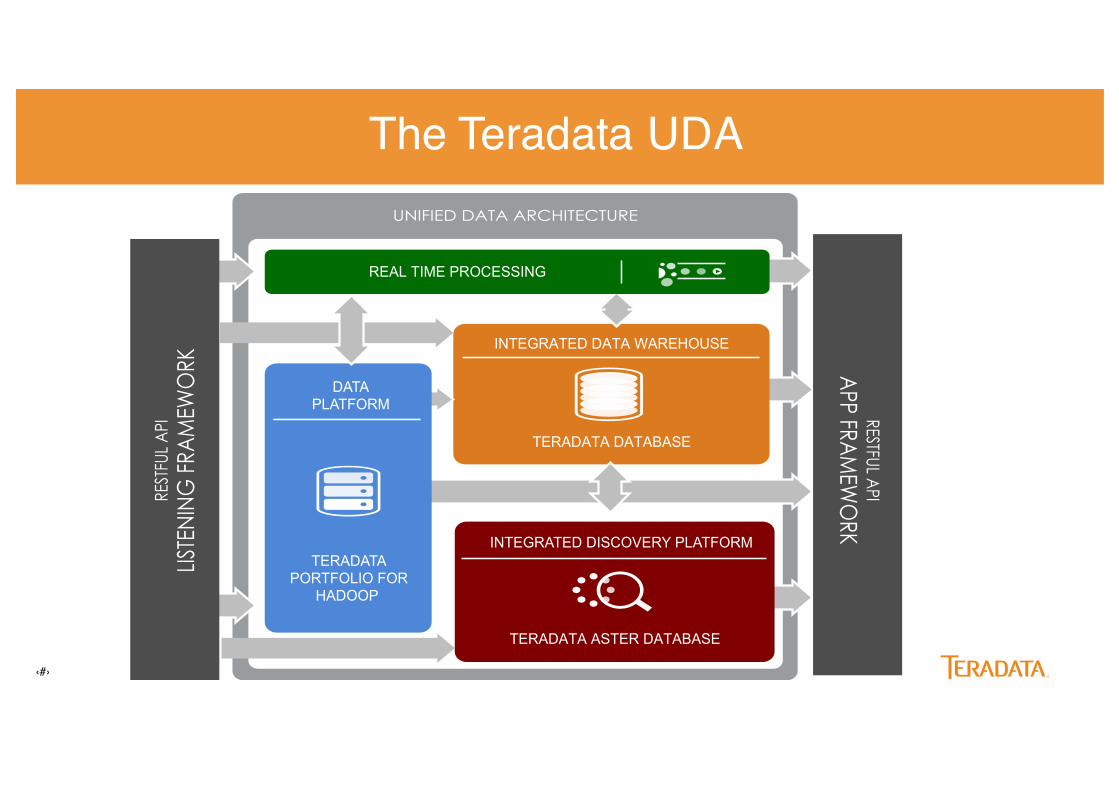
The Teradata UDAUNIFIED DATA ARCHITECTURE
Security, Workload Management
Applications
INTEGRATED DATA WAREHOUSE
DATA PLATFORM
INTEGRATED DISCOVERY PLATFORM
Security, Workload Management REAL TIME PROCESSING
TERADATA PORTFOLIO FOR
HADOOP
TERADATA DATABASE
TERADATA ASTER DATABASE
REST
FUL
API
LISTE
NIN
G F
RAM
EWO
RK
RESTFUL API
APP FRA
MEW
ORK

10
10
BESTAPPEVER!!
Data Service APIsAccess Data on Teradata, Aster,
Hadoop via API calls
LoggingPush and store events about app to
UDA logging services
Ingest / Streaming Stream data into UDA and build
applications on near real-time data
Scheduling / OrchestrationScheduling services allow devs to
build workflows and connect apps.
Search & MetadataExpose search capabilities in your
app via UDA level search services.
WebKitA toolbox of UI templates,
visualizations and javascript libraries
Package/Deploy & PublishA simple package and deployment
application to launch your app in the AppCenter ecosystem
OperateLeverage monitoring & alerting
services to keep track app health.
Key Services, Libraries & Templates
UDA it a concept but also allows to be Development Platform
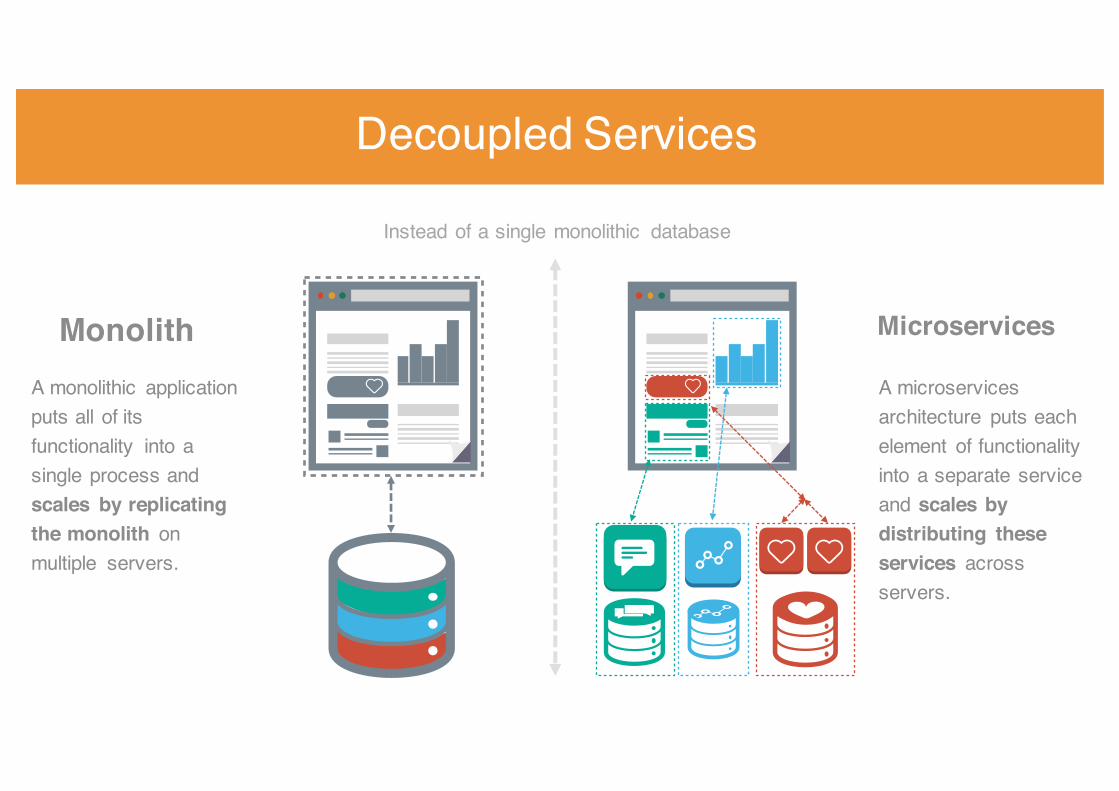
Instead of a single monolithic database
11
MonolithA monolithic application puts all of its functionality into a single process and scales by replicating the monolith on multiple servers.
Microservices
A microservices architecture puts each element of functionality into a separate service and scales by distributing these services across servers.
Decoupled Services

Scale by distributing services and replicating as needed
12
Monolithic AppA monolithic application puts all of its functionality into a single process and scales by replicating the monolith on multiple servers.
MicroservicesA microservices architecture puts each element of functionality into a separate service and scales by distributing these services across servers.
Think Microservice, not Monolithic

‹#›
Access and move data between systems through service APIs
13
UDA
TD TD
INFRASTRUCTURE
DATA SERVICES
REST API Call
Send QueryExecute Query
Send Response
Teradata Data Services

QueryGrid – Data Movement QueryGrid – Remote ExecutionForeign Table Select – Pass Thru
SELECT *FROM FOREIGN TABLE (select parse_url(refer,'HOST') as host, v.key as key, ts as session_ts,v.val, count(*) as count
from http_inline LATERAL VIEW explode(str_to_map(parse_url(refer,'QUERY'),'&','=')) v as key,
valwhere parse_url(refer, 'QUERY') is not nullgroup by parse_url(refer, 'HOST'), v.key, v.val)@hdp21 hdp_dpiWHERE
session_ts = current_date;
Push foreign grammar to remote.Hadoop: permits Hive/Impala query for data reduction on non-partitioned columns.
ImportSELECT source, session FROM
clickstream@Hadoop_sysd WHERE session_ts = ʻ‘2013-01-01ʼ’;
Can be used to:– “Insert/select” & “create table as” to instantiate data locally.– Joins always possible with local tables.
Export
INSERT INTO cust_loc@Hadoop_sysd
SELECT cust_id, cust_zipFROM cust_dataWHERE
last_update = current_date;
Move Data from Teradata to Hadoop– And/or other Data Stores

15
The Data Lake – Customer slide
• This is not skating to where the puck is going to be - It’s skating to the puck.– Your CIO should be sitting you on the bench if you are not doing this already
Most Data Lakes TodayPassive cheap storage•Really only using HDFS
•Limited data governance
•Staging Data
•Archiving Data
•DW offload (cost drivers)
The Data Lakes we Should be BuildingActive balanced nodes•Using full Hadoop stack+•Good data governance•Good information architecture•Processing and enhancing data •Data applications (flexibility drivers)

16
New Architecture Architecture
• Information architectures are distributed– Focus on data and business questions, not integrating separate systems
• Application architectures are variable–Don’t force applications into a single architecture
• Applications are Loosely Coupled–DW is an application–BI is an application (or many)–Data applications are everywhere!
• But let’s be smart about it–Still need strong information architecture and data management practices–Still need to reduce complexity and make strategic choices on technology

17 © 2015 Teradata
Feature Store ApplicationGenerating Analytical FeaturesHDFS, Spark, ElasticSearch
Campaign ApplicationTargeting CustomersTeradata
Customer Registry ApplicationRegistry Model of all CustomersTeradata
BI ApplicationGeneral Query and Access to FeaturesTeradata SQL, Microstrategy, Tableau
Customer Matching ApplicationAssociating CustomersSpark, Python, Scala, R
Loosely Coupled Data Applications

18
Customer– Framework Overview
B2B Gateway
SFTP SFTP SFTP
Flume job Flume job Flume job
Non-SLA Edge Flume DR Edge Flume SLA Edge Flume
Non-SLA HDFS DR HDFS SLA HDFS
Non-SLA HDFS DR HDFS SLA HDFS
Non-SLA Teradata DR Teradata SLA Teradata
External Systems
Customer Gate
Internal DAP
Platform Edge
Hadoop Raw
Processing
Hadoop Access
Teradata Backup/Restore
DistCP
QueryQridQueryQrid

19 © 2014 Teradata
Customer - Microservices Example
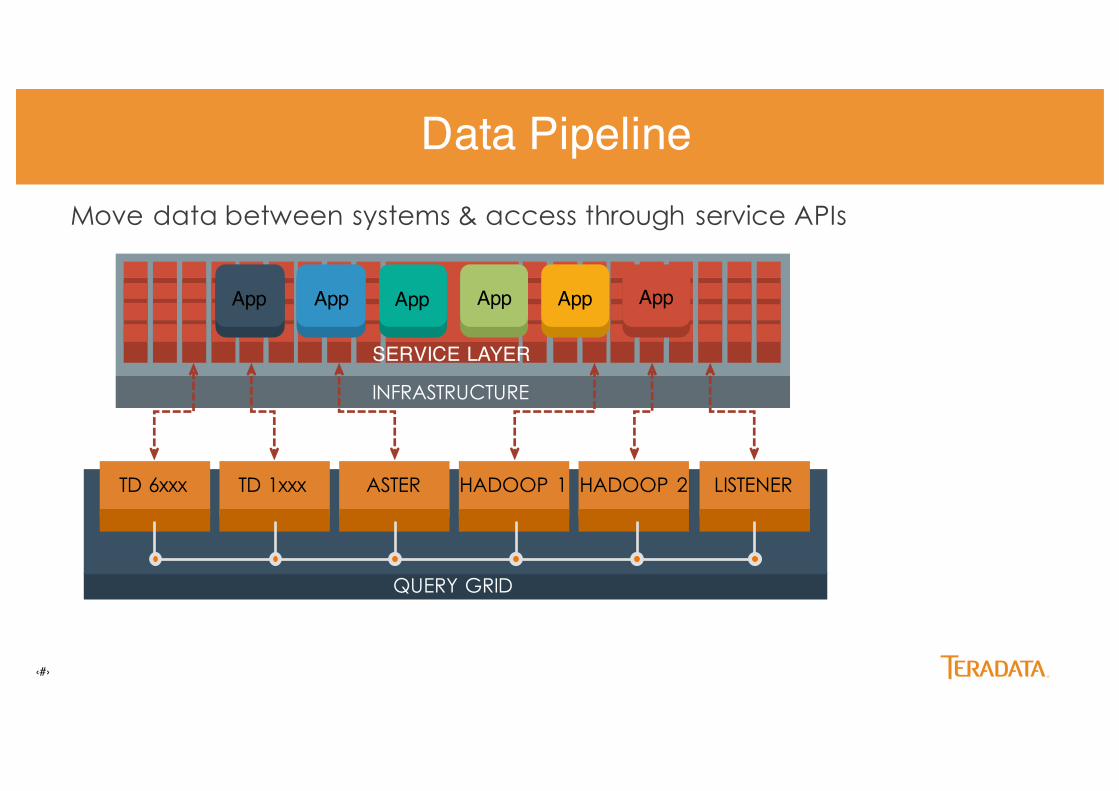
‹#›
INFRASTRUCTURE
QUERY GRID
TD 6xxx TD 1xxx ASTER HADOOP 1 HADOOP 2 LISTENER
Move data between systems & access through service APIs
20
App App App App AppApp
Data Pipeline
SERVICE LAYER

21
Customer example – Integration Flow
• User starts a Workflow from the UI which has a single Pig Job. • Azkaban Web requests that the Azkaban Executor start a new Pig
Job. • Pig Job makes a REST call to the TemplateModule to render the
Pig Template. • TemplateModule fetches config values from the ConfigModule if
needed by the template. The ConfigModule in turn fetches configvalues either from the PCF Data Schema or from external systems.
• TemplateModule renders the Pig Template and returns a complete Pig Script.
• Pig Job executes the Pig Script against the Hadoop cluster. • During the Pig Job execution it makes REST calls to the
EventModule informing about its progress. • As the Job progress is updated Vertx updates the Azkaban Web UI
in real time. • When the Pig Job has completed it makes a REST call to the
AuditModule to log its completion. The AuditModule in turn stores auditing information in the PCF Data Schema.
• Finally the Pig Job returns its execution status back to the Azkaban Executor.
MySQL
Azkaban Web
Azkaban Executor
KAFKA
Azkaban Bridge Service
ConfigService
Template Service
Teradata Service
Event Service
Audit Service
Pig Job
Hadoop
PCF
Pig Templ
Pig Script
JSON
REST

22
Customer – Event Flow
KAFKA
Flume EventModule
Teradata Service
JSON
Azkaban Web Azkaban Executor
HDFS EventModule
HBase EventModule
HCatalogEvent
Module
REST
hdfs.filelanded flume.filelanded hdfs.filelanded hbase.tablemodified
Hcatalog.newpartition
Hcatalog.newpartition

23
Customer – Docker services
Azkaban Nginx Services
LogStashTessera/Graphite
Consul
Consul Consul
Ambassadord
Container Third Party Used For
Nginx No Front end web server/proxy for all the other UIs.
Vert.x No Application server.
Azkaban Yes Workflow management for Hadoop, Teradata etc.
Tessera/Graphite No Aggregating and displaying applications and system level metrics
LogStash Yes Aggregating and displaying application and system level logs
Consul Yes Distributed key value store used for Service Descovery
Ambassadord Yes Makes it easier for Docker containers to access services hosted in other Docker containers
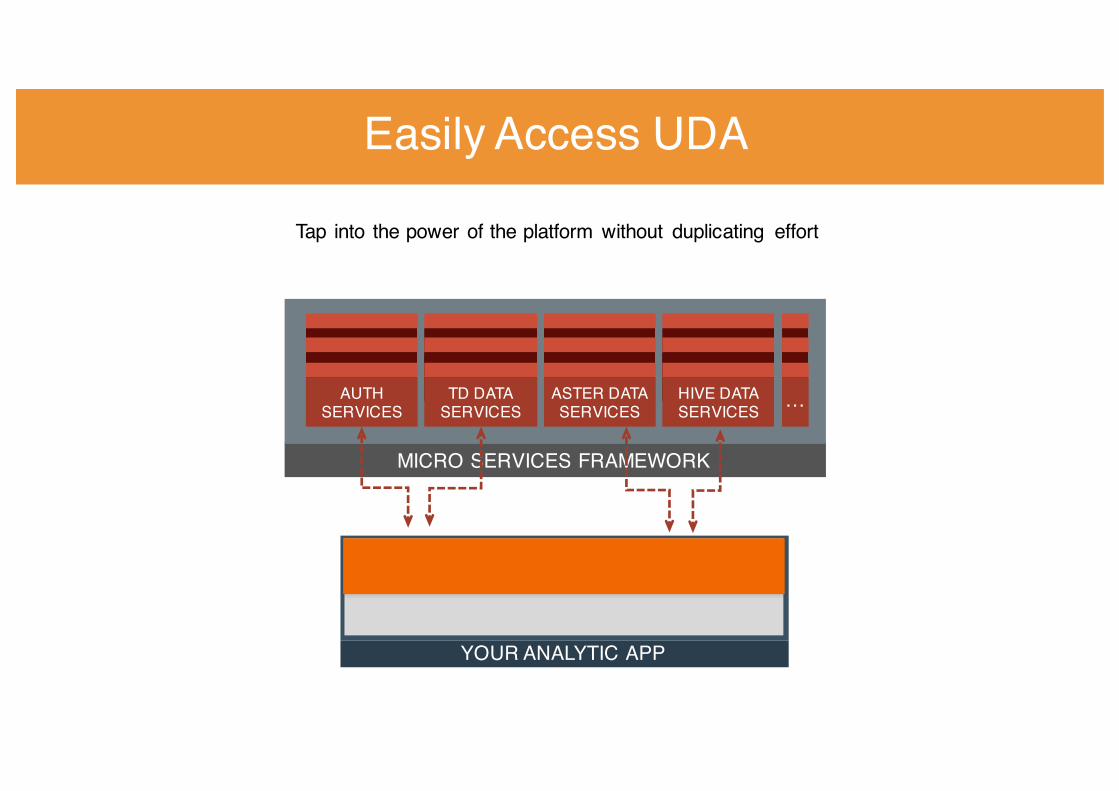
Tap into the power of the platform without duplicating effort
YOUR ANALYTIC APP
MICRO SERVICES FRAMEWORK
ASTER DATA SERVICES …TD DATA
SERVICESHIVE DATA SERVICES
AUTH SERVICES
Easily Access UDA
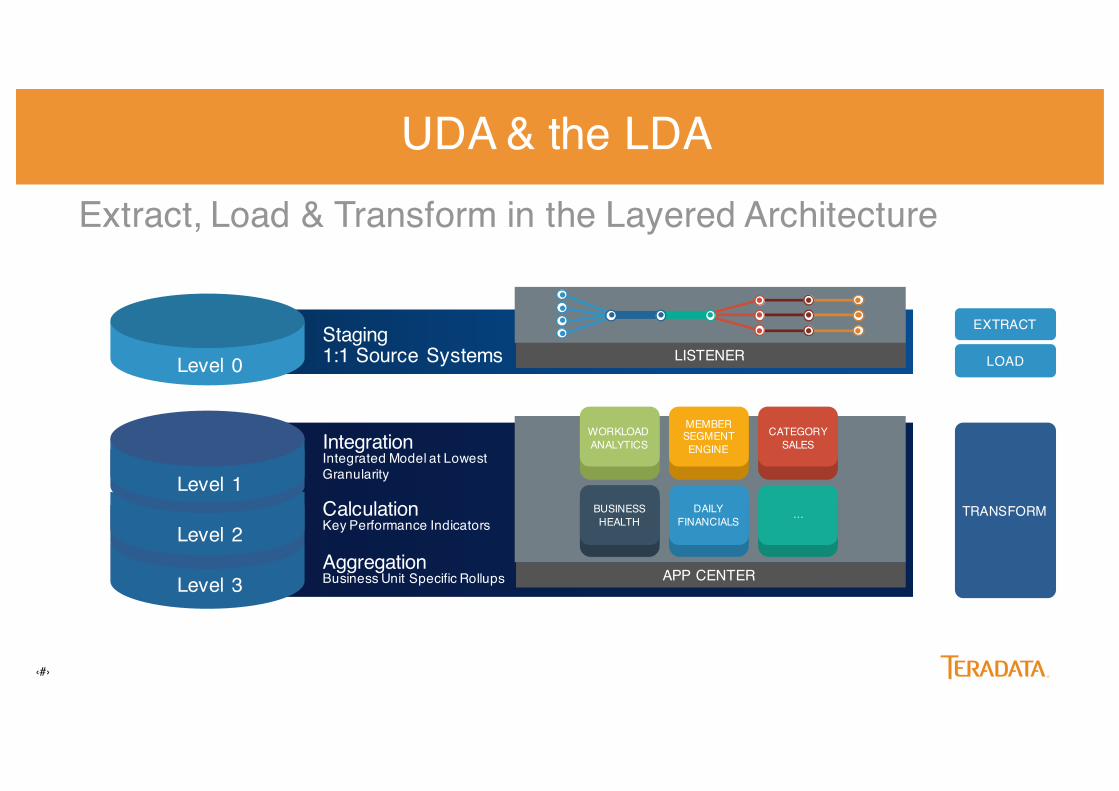
‹#›
Extract, Load & Transform in the Layered Architecture
25
Level 0
AggregationBusiness Unit Specific Rollups
CalculationKey Performance Indicators
Level 3
Level 2
Level 1
IntegrationIntegrated Model at Lowest Granularity
Staging1:1 Source Systems
EXTRACT
LOAD
TRANSFORM
APP CENTER
LISTENER
…BUSINESSHEALTH
WORKLOAD ANALYTICS
MEMBERSEGMENTENGINE
CATEGORYSALES
DAILYFINANCIALS
UDA & the LDA

Questions…

27
THANK YOU