are we trading consistency too easily? a case for sequential consistency madan musuvathi microsoft...
TRANSCRIPT

Are We Trading Consistency Too Easily?
A Case for Sequential Consistency
Madan MusuvathiMicrosoft Research
Dan Marino
Todd MillsteinUCLA University of Michigan
Abhay Singh
Satish Narayanasamy

MEMORY CONSISTENCY MODEL
Abstracts the program runtime (compiler + hardware) Hides compiler transformations Hides hardware optimizations, cache hierarchy, …
Sequential consistency (SC) [Lamport ‘79] “The result of any execution is the same as if the
operations were executed in some sequential order, and the operations of each individual processor thread in this sequence appear in the program order”

SEQUENTIAL CONSISTENCY EXPLAINED
X = 1;F = 1;
t = F;u = X;
int X = F = 0; // F = 1 implies X is initialized
X = 1;F = 1;t = F;u = X;
X = 1;
F = 1;
t = F;
u = X;
X = 1;
F = 1;
t = F;u = X;
X = 1;F = 1;
t = F;u = X;
X = 1;
F = 1;
t = F;
u = X;
X = 1;F = 1;
t = F;
u = X;
t=1, u=1 t=0, u=1 t=0, u=1 t=0, u=0 t=0, u=1 t=0, u=1
t=1 implies u=1

CONVENTIONAL WISDOM
SC is slow Disables important compiler optimizations Disables important hardware optimizations
Relaxed memory models are faster

CONVENTIONAL WISDOM
SC is slow Hardware speculation can hide the cost of SC hardware
[Gharachorloo et.al. ’91, … , Blundell et.al. ’09] Compiler optimizations that break SC provide negligible
performance improvement [PLDI ’11]
Relaxed memory models are faster Need fences for correctness Programmers conservatively add more fences than necessary Libraries use the strongest fence necessary for all clients Fence implementations are slow
Efficient fence implementations require speculation support
X
?

asm:mov eax [X];
IMPLEMENTING SEQUENTIAL CONSISTENCY EFFICIENTLY
SC-PreservingCompiler
SC Hardware
src:t = X;
Every SC behavior of the binary is a SC behavior of the source
Every observed runtime behavioris a SC behavior of the binary
This talk

CHALLENGE: IMPORTANT COMPILER OPTIMIZATIONS ARE NOT SC-PRESERVING
Example: Common Subexpression Elimination (CSE)
t,u,v are local variables X,Y are possibly shared
L1: t = X*5;L2: u = Y;L3: v = X*5;
L1: t = X*5;L2: u = Y;L3: v = t;

COMMON SUBEXPRESSION ELIMINATION IS NOT SC-PRESERVING
L1: t = X*5;L2: u = Y;L3: v = X*5;
L1: t = X*5;L2: u = Y;L3: v = t;
M1: X = 1;M2: Y = 1;
M1: X = 1;M2: Y = 1;
u == 1 implies v == 5 possibly u == 1 && v == 0
Init: X = Y = 0; Init: X = Y = 0;

IMPLEMENTING CSE IN A SC-PRESERVING COMPILER
Enable this transformation when X is a local variable, or Y is a local variable
In these cases, the transformation is SC-preserving
Identifying local variables: Compiler generated temporaries Stack allocated variables whose address is not taken
L1: t = X*5;L2: u = Y;L3: v = X*5;
L1: t = X*5;L2: u = Y;L3: v = t;

A SC-PRESERVING LLVM COMPILER FOR C PROGRAMS
Modify each of ~70 phases in LLVM to be SC-preserving Without any additional analysis
Enable trace-preserving optimizations These do not change the order of memory operations e.g. loop unrolling, procedure inlining, control-flow simplification,
dead-code elimination,…
Enable transformations on local variables
Enable transformations involving a single shared variable e.g. t= X; u=X; v=X; t=X; u=t; v=t;

AVERAGE PERFORMANCE OVERHEAD IS ~2%
Baseline: LLVM –O3
Experiments on Intel Xeon, 8 cores, 2 threads/core, 6GB RAM
faces
im
bodytrac
k
barnes
strea
mcluste
r
raytra
ce
cannea
l
blacks
choles lu
swap
tionsrad
ix
fluidanim
ate fft
choles
ky
freqmine
fmm
water-s
patial
water-n
square
d avg
-20.00%
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
llvm-noopt
llvm+trace-preserv-ing
SC-preserving
SC-preserving + eager loads
480 373 154 132 200 116 159173 237 298

HOW FAR CAN A SC-PRESERVING COMPILER GO?float s, *x, *y;int i;s=0;for( i=0; i<n; i++ ){ s += (x[i]-y[i]) * (x[i]-y[i]);}
float s, *x, *y;float *px, *py, *e;
s=0; py=y; e = &x[n]for( px=x; px<e; px++, py++){ s += (*px-*py) * (*px-*py);}
float s, *x, *y;int i;s=0;for( i=0; i<n; i++ ){ s += (*(x + i*sizeof(float)) – *(y + i*sizeof(float))) * (*(x + i*sizeof(float)) – *(y + i*sizeof(float)));}
float s, *x, *y;float *px, *py, *e, t;
s=0; py=y; e = &x[n]for( px=x; px<e; px++, py++){ t = (*px-*py); s += t*t;}
noopt.
SC pres
fullopt

WE CAN REDUCE THE FACESIM OVERHEAD (IF WE CHEAT A BIT)
30% overhead comes from the inability to perform CSE in
But argument evaluation in C is nondeterministic The specification explicitly allows overlapped evaluation of function
arguments
return MATRIX_3X3<T>( x[0]*A.x[0]+x[3]*A.x[1]+x[6]*A.x[2], x[1]*A.x[0]+x[4]*A.x[1]+x[7]*A.x[2], x[2]*A.x[0]+x[5]*A.x[1]+x[8]*A.x[2], x[0]*A.x[3]+x[3]*A.x[4]+x[6]*A.x[5], x[1]*A.x[3]+x[4]*A.x[4]+x[7]*A.x[5], x[2]*A.x[3]+x[5]*A.x[4]+x[8]*A.x[5], x[0]*A.x[6]+x[3]*A.x[7]+x[6]*A.x[8], x[1]*A.x[6]+x[4]*A.x[7]+x[7]*A.x[8], x[2]*A.x[6]+x[5]*A.x[7]+x[8]*A.x[8] );

IMPROVING PERFORMANCE OF SC-PRESERVING COMPILER
Request programmers to reduce shared accesses in hot loops
Use sophisticated static analysis Infer more thread-local variables Infer data-race-free shared variables
Use program annotations Requires changing the program language Minimum annotations sufficient to optimize the hot loops
Perform load-optimizations speculatively Hardware exposes speculative-load optimization to the software Load optimizations reduce the max overhead to 6%

CONCLUSION
Hardware should support strong memory models TSO is efficiently implementable [Mark Hill]
Speculation support for SC over TSO is not currently justifiable Can we quantify the programmability cost for TSO?
Compiler optimizations should preserve the hardware memory model
High-level programming models can abstract TSO/SC Further enable compiler/hardware optimizations Improve programmer productivity, testability, and debuggability
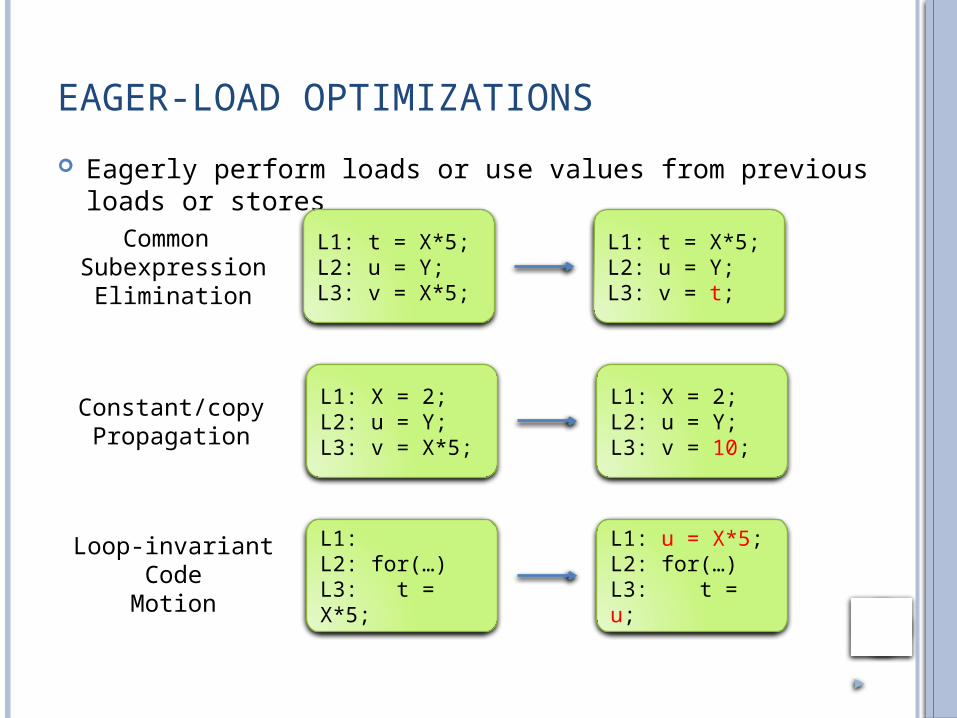
EAGER-LOAD OPTIMIZATIONS
Eagerly perform loads or use values from previous loads or stores
L1: t = X*5;L2: u = Y;L3: v = X*5;
L1: t = X*5;L2: u = Y;L3: v = t;
L1: X = 2;L2: u = Y;L3: v = X*5;
L1: X = 2;L2: u = Y;L3: v = 10;
L1: L2: for(…)L3: t = X*5;
L1: u = X*5;L2: for(…)L3: t = u;
Common Subexpression
Elimination
Constant/copyPropagation
Loop-invariantCode
Motion

PERFORMANCE OVERHEAD
Allowing eager-load optimizations alone reduces max overhead to 6%
faces
im
bodytrac
k
barnes
strea
mcluste
r
raytra
ce
cannea
l
blacks
choles lu
swap
tionsrad
ix
fluidanim
ate fft
choles
ky
freqmine
fmm
water-s
patial
water-n
square
d avg
-20.00%
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
llvm-noopt
llvm+trace-preserv-ing
SC-preserving
SC-preserving + eager loads
480 373 154 132 200 116 159173 237 298

CORRECTNESS CRITERIA FOR EAGER-LOAD OPTIMIZATIONS
Eager-loads optimizations rely on a variable remaining unmodified in a region of code
Sequential validity: No mods to X by the current thread in L1-L3
SC-preservation: No mods to X by any other thread in L1-L3
L1: t = X*5;
L2: *p = q;
L3: v = X*5;
Enable invariant “t == 5.X”
Maintain invariant “t == 5.X”
Use invariant “t == 5.X"to transform L3 to v = t;

SPECULATIVELY PERFORMING EAGER-LOAD OPTIMIZATIONS
On monitor.load, hardware starts tracking coherence messages on X’s cache line
The interference check fails if X’s cache line has been downgraded since the monitor.load
In our implementation, a single instruction checks interference on up to 32 tags
L1: t = X*5;L2: u = Y;L3: v = X*5;
L1: t = monitor.load(X, tag) * 5;L2: u = Y;L3: v = t;C4: if (interference.check(tag))C5: v = X*5;