architecting agile data avp, field engineering
TRANSCRIPT

Architecting Agile Data Applications for ScaleRichard GarrisAVP, Field Engineering @ Databricks

Agenda
▪ About Me▪ The World’s Most
Valuable Companies▪ Waterfall to Agile ▪ Traditional Data
Platforms▪ Modern Data Platforms▪ Summary

About Me Ohio State and CMU Graduate
Almost 2 decades in the data spaceIMS Database IBM Mainframe ➤ Oracle / SQL Server ➤ Big Data (Hadoop, Spark)
• 3 years as an independent consultant• 5 years at PwC in the Data Management practice• 3.5 years at Google on their data team• 6 years at DatabricksCertified Scrum Master
Other Talks• Apache Spark and Agile Model Development on Data Science Central
• https://vimeo.com/239762464
• ETL 2.0: Data Engineering using Azure Databricks and Apache Spark on MSDN Channel 9• https://channel9.msdn.com/Events/Connect/2017/E108

The World’s Most Valuable Companies (in Billions)
Top 15 Companies in 2021Top 15 Companies in 1993
Source: Data is Beautiful https://www.youtube.com/channel/UCkWbqlDAyJh2n8DN5X6NZyg
Source: MGMResearchhttps://mgmresearch.com/top-us-companies-by-market-cap/


What do the top five companies do differently?

What do the top five companies do differently?
Not really. FAAMG may have some unique datasets e.g. 2.7 B user profiles, search results, etc.. but the other Fortune 500, commercial, mid-market, and digital native companies and public sector organizations have a lot of data too!
Not really. They did at one point in time but many of the AI, DL and ML algorithms are available in Open Source (TensorFlow, PyTorch, Mxnet, LightGBM) or has been released in research papers.
Better AI, DL, ML algorithms?
Not really. At one point, Google, Amazon, Microsoft, Facebook and Apple had the best infrastructure in the world to process data but public cloud gives everyone access to most of that. There are also open source and commercial software available to anyone who want to process Big Data at scale
Better data processing?Lots and lots of data?

36,000 60,000 90,00020,000 60,000
Any guesses to what these numbers are?
Number of Engineers**Estimated using Glassdoor, Public Job postings, financials (R&D spend as a % of total FTE) – no confidential information was used to derive these values and the exact number of engineers is not public information

What do engineers bring to the modern enterprise?
Agile Application Development Lifecycle

Startups don’t change the world, they adapt to the world faster than everyone else
-Jacques Benkoski, USVP

But what does this have to do with Data Applications?
These companies also brought Agile to Data Applications and that’s what makes them competitive!

What are Agile Data Applications?
▪ Self contained end-to-end projects to a data problem▪ Built by data developers using open source programming
languages ▪ Follow good software engineering principles▪ Can leverage algorithms and analytics▪ Scalable both in terms of big data and total cost of
ownership▪ Meets the responsiveness requirements of end users▪ Deployable into a production environment

The Waterfall Development Methodology1990-early 2000s
Concept & Requirements
Analysis & Design
Develop & Implement
Test & QA
Deploy & Maintain
One stage always follows the previous one and it’s hard to accommodate changes
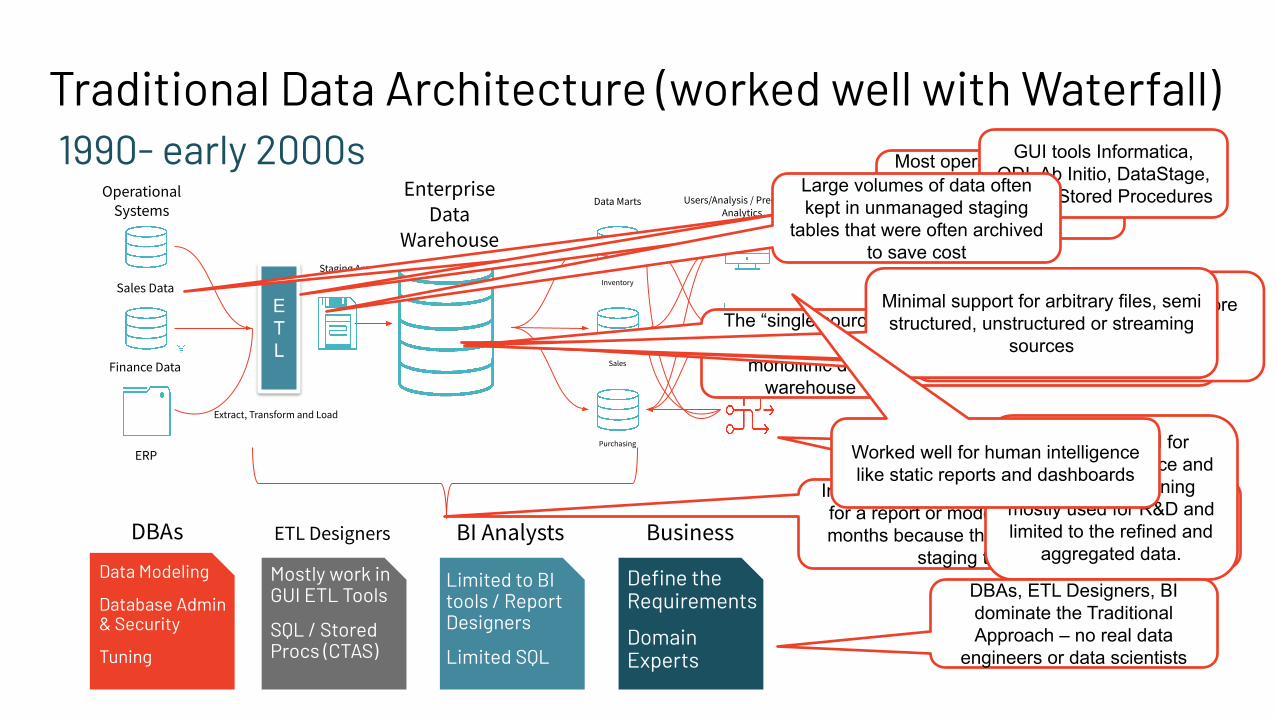
Traditional Data Architecture (worked well with Waterfall)
Operational Systems
Staging Area
Enterprise Data
Warehouse
Data Marts Users/Analysis / Predictive Analytics
Inventory
Sales
Purchasing
ERP
Sales Data
Finance Data
ETL
Extract, Transform and Load
DBAs ETL Designers BI Analysts
Data Modeling
Database Admin & Security
Tuning
Mostly work in GUI ETL Tools
SQL / Stored Procs (CTAS)
Limited to BI tools / Report Designers
Limited SQL
Business
Define the Requirements
Domain Experts
1990- early 2000s Most operational systems only housed structured
data with small data volumes
GUI tools Informatica, ODI, Ab Initio, DataStage, SQL or Stored ProceduresLarge volumes of data often
kept in unmanaged staging tables that were often archived
to save cost
The “single source of truth” was the
monolithic data warehouse
Inflexible model because to add a single column for a report or model downstream could take 6 months because the tight coupling from ETL to
staging to EDW to report
Didn't work well for machine intelligence and
AI / ML. Data mining mostly used for R&D and limited to the refined and
aggregated data.
DBAs, ETL Designers, BI dominate the Traditional Approach – no real data
engineers or data scientists
Most EDWs were sold as expensive appliances with data locked into a proprietary format with combined
compute and storage
Only way to scale out is to buy more appliances
Minimal support for arbitrary files, semi structured, unstructured or streaming
sources
Worked well for human intelligence like static reports and dashboards

Pure Agile Development MethodologyMid 2000s – early 2010s • Agile Manifesto
• Agile introduced change as part of the process
• Early versions of Agile (Scrum and XP) worked well for small self-managed teams
• It didn’t scale well to larger teams and the needs of larger enterprises
• It also lacked some of the discipline of Waterfall

Open Data Lake Architecture (like pure Agile)
Hadoop Data Lake
Hadoop Admin Hadoop Dev AnalystsAdminister the Cluster
Manage HDFS, YARN, Applications
Tuning
Map Reduce, Pig, Spark, Cascading, Mahout …
Java Developers
Hive, Impala, Drill, LLAP
(or BI tools)
Mid 2000s to early 2010s
HDFS
Map Reduce Spark Hive Mahout
Enterprise Data Warehouse
YARN Scheduler
Machine Data
CRM
Finance Data
New Sources
Geospatial
Sensor / Logs
Clickstream Data
ERPFinance Data
Supports new sources like web scale data, SaaS sources, operational systems with structured data (sequence files, parquet),
semi structured (logs, JSON) and unstructured (images, audio, video)
because everything is a file
Distributed file system built on commodity servers
Could handle high volumes, velocity, and variety of data
Applications could be written and deployed inside Hadoop using YARN in Java, Scala, Python, Hive (SQL), Pig, Mahout for ML
Commodity servers used to scale out compute for analytics
Initially cheaper because you used commodity servers versus specialized
hardware like with an EDW, but because compute and storage were paired together
you had to buy more servers for storage even if you didn’t need more compute
Mixed bag on performance – allowed scale out of compute resources but tuning Hadoop and YARN as well as the query engines like Impala, Hive, Hive variants like Hive LLAP is difficult
Schema on read versus schema on write created a ton of agility, but the lack of schema enforcement and reliability of the data became an issue at scale (hence the Data Lake becoming a Data Swamp)
Still had some monolithic attributes that are a better fit for waterfall (e.g because all of the applications run inside Hadoop you have to upgrade all your applications when you upgrade the cluster
The goal and promise of Hadoop was to offload or replace the EDW but that didn’t really happen
Required specialized people to manage and develop on Hadoop (Admin, trained developers) and
ultimately difficult with so many specialized divergent frameworks (MapReduce, Tez, Hive, SQL
on Hadoop, Spark, Flink, Storm, Mahout, Cascading)
Analysts and Business Users don’t concern themselves with the infrastructure so were
shielded from the complexity but would complain if SLAs weren’t being met and
would fallback to the EDW

Modern Agile (Hybrid, Disciple Agile Delivery, SAFe)Mid 2010s – Today
Source: PMI Institute

The Next Hybrid is the Modern Lakehouse Platform(Data Lake + Data Warehouse)
Late 2010s – 2020s and beyond
Machine Data
CRM
Finance Data
New Sources
Geospatial
Sensor / Logs
Clickstream Data
BRONZE SILVER DOGECOIN
Landing Refined Aggregates
Open Cloud Storage (S3, ADLS, GCS)Schema / ACID (Delta Lake, Iceberg, HUDI)
(Ingestion Tools)
Customer Facing Applications
The Modern Open Lakehouse
Downstream Specialized Data Stores
ERPFinance Data
Legacy Stores
Internal Analytics
Supports Old and New Sources
Stored in Open Storage (Open
Format, Reliable and Infinitely Scalable)
Data management layer for reliability
and schema
Multiple layers to support staging to production grade
tables
Agile data application platform that separates compute and code from
storage
Internal applications (dashboards, reports,
custom apps)
External customer facing applications (end
to end model lifecyle, recommendation
systems, customer facing applications
Move downstream specialized data stores like graph databases, NoSQL, SQL like MPP
or EDWs
Supports structured (tables), semi-structured
(logs, JSON) and unstructured (Images,
Audio, Video), Live Data ( Streaming)
Scalability of the cloud and multi-cloud

Modern Data Personas
▪ Great for Data Scientists ▪ Data Science is a science – constant evolution through experiments and hypotheses is part of the
process▪ Moves data scientist toward secure and scalable compute and off their laptops with R / Python / SAS▪ Data scientists often need access to the raw or bronze transaction data for modeling and that’s often
expensive or hard to justify storing in the EDW or get access to and use from Hadoop
▪ Great for Data Engineering▪ Data Engineers are developers▪ Write code in standard programming languages (Java, Scala, Python) not proprietary stored procedures▪ They should write high quality production code that is testable, reusable and modular and can be
continuously integrated and deployed (CI/CD)
▪ Great for Data Analysts▪ Data Analysts want more data and they want data faster▪ SQL skills are expected and even some light Python or R for advanced analytics
A Lakehouse is a Hybrid that supports the Modern Data Scientist, Data Engineer and Data Analysts

Why Cloud?
▪ Agile infrastructure that is infinitely scalable ▪ Separates compute from storage (scale compute as needed, scale storage without thinking about it)▪ Infrastructure as code and part of the CI/CD process▪ No need to hard code to the infrastructure for deployment
▪ Reliable, fault tolerant and recoverable▪ Pipeline runs independent of the compute so server outages don’t stop production pipelines▪ Can handle cases where a node or two fails but the job continues because failure is inevitable at scale▪ If a job does fail, then the integrity of the data is not compromised and you can recover
▪ Portable▪ Portable across different types of compute▪ Portable across different clouds
Cloud brings agility to Data Applications when done right

What about Data Mesh?Data Mesh is an architectural pattern introduced by Zhamak Dehghani of Thoughtworks in How to Move Beyond a Monolithic Data Lake to a Distributed domain-driven design
• Data is a product• Data is a business asset• Data should be monetized
otherwise it becomes a liability
• Data belongs to decentralized domains or product owners
• Each team is self managed• But the governance and
standards are centralized to allow for interoperability and data sharing
• Sounds a lot like the Hybrid Agile + Lakehouse in the Cloud approach!
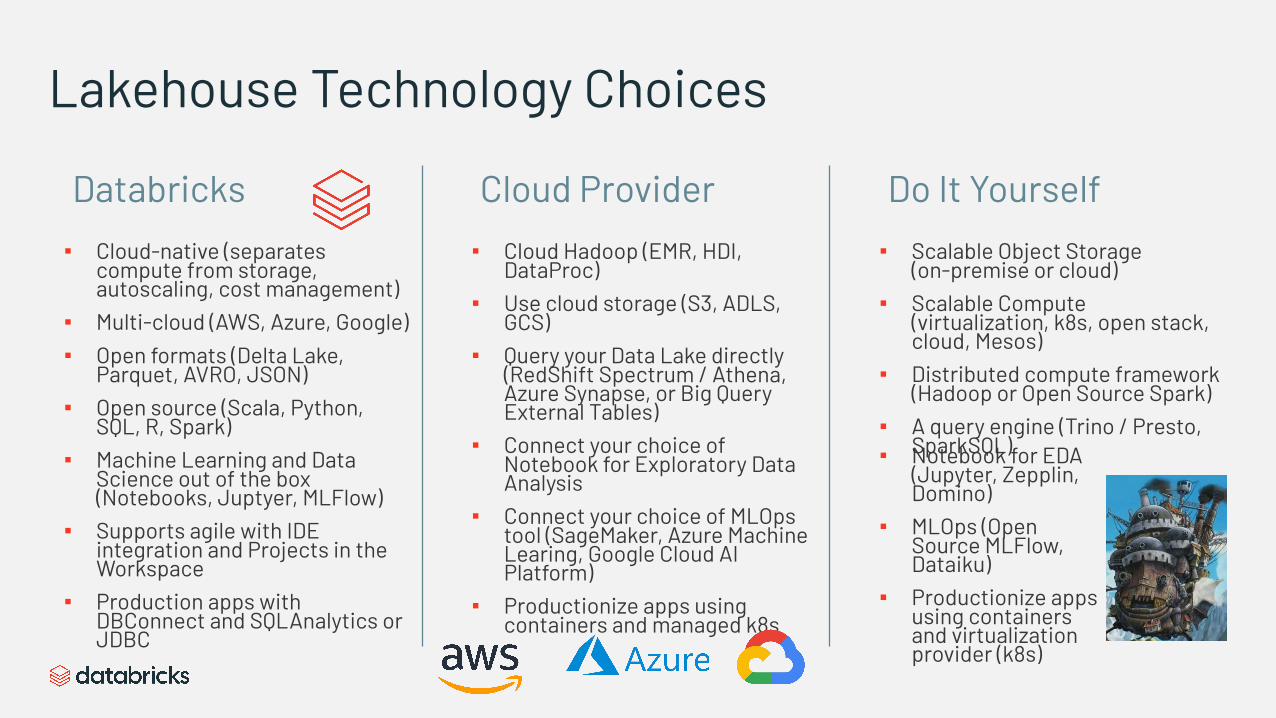
Lakehouse Technology Choices
▪ Cloud-native (separates compute from storage, autoscaling, cost management)
▪ Multi-cloud (AWS, Azure, Google)▪ Open formats (Delta Lake,
Parquet, AVRO, JSON)▪ Open source (Scala, Python,
SQL, R, Spark)▪ Machine Learning and Data
Science out of the box (Notebooks, Juptyer, MLFlow)
▪ Supports agile with IDE integration and Projects in the Workspace
▪ Production apps with DBConnect and SQLAnalytics or JDBC
▪ Cloud Hadoop (EMR, HDI, DataProc)
▪ Use cloud storage (S3, ADLS, GCS)
▪ Query your Data Lake directly (RedShift Spectrum / Athena, Azure Synapse, or Big Query External Tables)
▪ Connect your choice of Notebook for Exploratory Data Analysis
▪ Connect your choice of MLOps tool (SageMaker, Azure Machine Learing, Google Cloud AI Platform)
▪ Productionize apps using containers and managed k8s
▪ Scalable Object Storage (on-premise or cloud)
▪ Scalable Compute (virtualization, k8s, open stack, cloud, Mesos)
▪ Distributed compute framework (Hadoop or Open Source Spark)
▪ A query engine (Trino / Presto, SparkSQL)
Cloud Provider Do It YourselfDatabricks
▪ Notebook for EDA (Jupyter, Zepplin, Domino)
▪ MLOps (Open Source MLFlow, Dataiku)
▪ Productionize apps using containers and virtualization provider (k8s)

Why build your Agile Data Applications in a Lakehouse
▪ Often have to pay more for storage and over provision your compute
▪ Rework, change is expensive – not built for agility
▪ Data is monolithic and hard to support Data Mesh and Self Managed Data Domains
▪ Only pay for what you use (Lower TCO)▪ Agility and change is part of the Data
Application Lifecycle▪ Easily supports Data Applications per
Project, Team or Domain easily supporting Data Mesh paradigm
Agile Data Applications in Lakehouse
Datawarehouse or First Gen Data Lake

Feedback
Your feedback is important to us.
Don’t forget to rate and review the sessions.