aprendizagem de máquina introdução e exemplos - … · existem muitos métodos de aprendizagem...
TRANSCRIPT

Aprendizagem de Máquina
Introdução e exemplos
Nota: As rotinas de aprendizagem de máquina sofreram grandes mudanças de OpenCV2 paraOpenCV3. Nesta apostila, há exemplos para versão 2 (default no Cekeikon 5.2X) e para versão 3.Compile com a versão correta: -v2 ou -v3).
>compila programa -cek -ver2>compila programa -c -v2>compila programa -cek -ver3>compila programa -c -v3
1
Teoria de aprendizagemde máquina
Redes neurais
Aplicações de aprendizagem de
máquina
Processamento de imagens e vídeo

A aprendizagem de máquina estuda como construir programas computacionais que se melhoramautomaticamente com a experiência.
Def.: Diz-se que um programa computacional aprende com a experiência E no que diz respeito auma classe de tarefas T e medida de desempenho P, se o seu desempenho nas tarefas em T, medidapor P, aumenta com a experiência E.
Exemplo:1) Jogo de dama:
Tarefa T: jogar dama Medida de desempenho P: porcentagem de jogos ganhos. Experiência de treinamento E: jogar partidas.
2) Reconhecer letras caligráficas: Tarefa T: reconhecer e classificar palavras manuscritas em imagem. Medida de desempenho P: porcentagem de palavras corretamente classificadas. Experiência de treinamento E: uma base de dados de palavras manuscritas com classifica-
ção.
3) Detectar pedestres.
4) Detectar rostos humanos. Reconhecer rostos humanos.
Etc, etc.
2

A aprendizagem de máquina divide-se em duas categorias principais:
Aprendizagem supervisionada Aprendizagem não-supervisionada
Aprendizagem supervisionada:
Um “professor” fornece amostras de entrada/saída (ax, ay). O “aprendiz” classifica uma nova ins-tância de entrada (qx) baseado nos exemplos fornecidos pelo professor, gerando a classificação(qp). Para cada instância de entrada (qx) existe uma classificação correta (qy) que o aprendiz desco-nhece. Se a classificação do aprendiz (qp) for igual a classificação verdadeira (qy) então o aprendizacertou a classificação.
Exemplo: Peso da pessoa em kg e classificação em bebê, criança ou adulto.
Amostra de treinamento (AX, AY):ax (features, características, entradas) ay (labels, rótulos, saidas, classificações)
4 B15 C65 A5 B18 C70 A
Instâncias a classificar:A processar ou a classificar
(qx):Classificação ideal ou verda-
deira desconhecida (qy):Classificação pelo aprendiz
(qp):16 C C3,5 B B75 A A
A forma óbvia de classificar: escolher o exemplo mais parecido. Vizinho mais próximo.
Este processo pode ficar mais complicado se acrescentar características "ruído". Exemplo: Cor dapele: 0 = escuro, 100 = claro.
ax ay peso cor da pele
4 6 B15 50 C65 70 A5 7 B18 70 C70 80 A
Classificar (20, 6). Vizinho mais próximo dá errado: o indivíduo será classificado como bebê,quando na verdade é criança. É possível descobrir automaticamente que a segunda característica éirrelevante? É possível.
Estou chamando de ax, ay, qx, qy, qp.
3

Existem muitos métodos de aprendizagem supervisionada.Um bom algoritmo de aprendizagem deve ter alta taxa de acerto e ser rápido computacionalmente.
Rede neural é muito importante e faz muito sucesso atualmente devido ao deep learning.
1) Algoritmos de aprendizagem supervisionada:1a) k-nearest neighbor learning
- Força bruta- Aproximação (FlaNN, kd-tree)
1b) Bayesian Learning (Naive Bayes)1c) Decision tree learning
- Com escolha de melhores características- Sem escolha de melhores características (cut-tree)
1d) Adaboost1e) Random tree (ou random forest).1f) Neural Networks1g) Deep Learning1h) Support Vector Machine1i) Algoritmos Genéticos
Teorias envolvendo aprendizagem supervisionada:1j) Computational Learning Theory (PAC Learning – probably approximately correct lear-
ning)1k) Estimation of hypothesis accuracy
4

Aprendizagem não-supervisionada (clustering):
São dadas um conjunto QX de instâncias para classificar em diferentes classes. Normalmente, for-nece-se também o número de classes k.
Exemplo: Peso da pessoa em kg e classificação em 3 grupos.
Amostra de treinamento (QX):
qx (features, data)4156551870
Classifique em k=3 classes.
classe 1:4, 5
classe 2:15, 18
classe 3:65, 70
2) Alguns algoritmos de aprendizagem não-supervisionados2a) k-means.2b) Median cut.2c) Hierarchical clustering.2d) Kohonen
Bibliografia:
Tom. M Mitchell, Machine Learning, WCB/McGraw-Hill, 1997 Michale Nielsen, “Neural Networks and Deep Learning,” online book available at http://neural-
networksanddeeplearning.com/index.html. Wikipedia verbete “Machine learning”. Wikipedia verbete “Supervised learning”. Wikipedia verbete “Unsupervised learning”. [Ri05] H. Y. Kim, “Binary Halftone Image Resolution Increasing by Decision-Tree Learning,”
IEEE Trans. on Image Processing, vol. 13, no. 8, pp. 1136-1146, Aug. 2004. [Ri03] H. Y. Kim, “Binary Operator Design by k-Nearest Neighbor Learning with Application to
Image Resolution Increasing,” Int. J. Imaging Systems, vol. 11, no. 5, pp. 331-339, 2000. [Ci11] H. Y. Kim and R. L. Queiroz, “Inverse Halftoning by Decision Tree Learning,” in Proc.
IEEE Int. Conf. on Image Processing, (Barcelona, Spain), vol. 2, pp. 913-916, 2003. tes2.pdf (Projeto de Operadores pela Aprendizagem - capítulo da tese de livre docência)
5

Em Processamento de Imagens e Visão Computacional (PIVC), a aprendizagem de máquina super-visionada pode ser aplicada para:
1) Projetar um operador (filtro). Exemplos:1a) Detectar ponta de reta. 1b) Emular filtro (ou operador restrito à janela).1c) Detectar ocorrência de uma letra impressa.1d) Segmentar pela cor (feijão ou fundo).1e) Segmentar pela textura.1f) Aumentar resolução de imagem halftone.1g) Halftone inverso.
2) Classificar, reconhecer uma imagem. Exemplos:2a) Classificar feijões pela cor.2b) Classificar dígito manuscrito.2c) Reconhecer pessoa, gênero, idade, etc.2d) Classificar em pedestre/automóvel.2e) Classificar mudas de plantas.2f) Reconhecer impressão digital, íris, etc..
3) Detectar ou localizar algo. Exemplos:3a) Detectar rostos. Demo:3b) Detectar pessoas em pé. Demo:
4) Categorizar o conteúdo de uma imagem.4a) Reconhecer objeto ou animal presente na imagem. Demo:
5) Segmentar (pixel a pixel)
Uso de aprendizagem de máquina não-supervisionada em PIVC:
6) Aprendizagem não-supervisionada. Exemplos:5a) Escolher palete.5b) Segmentar pela cor. Ex: feijão/fundo, placa/não-placa, pedra/asfalto, bactéria/sujeira.
6

Exemplos:
* Detectar rostos. Demo:c:\cekeikon5\opencv2410\sources\samples\c>facedetect 012.jpgc:\cekeikon5\opencv2410\sources\samples\c>facedetectpos2013-ep2
* Detectar pessoas em pé. Demo:c:\cekeikon5\opencv2410\sources\samples\cpp>peopledetect 093.jpgc:\cekeikon5\opencv2410\sources\samples\cpp>peopledetect 147.jpgpos2015-ep2
* Classificar dígito manuscrito. Demo:http://www.lps.usp.br/hae/apostilaraspi/locarec.avi
7

* Reconhecer objeto ou animal presente na imagem. Demo:(Este programa só pode ser compilado em OpenCV 3.X)https://docs.opencv.org/3.4.0/d5/de7/tutorial_dnn_googlenet.html
.../haepi/deep/caffe_ocv3>caffe_googlenet -help
.../haepi/deep/caffe_ocv3>caffe_googlenet -image=trem_bala.jpgBest class: #466 'bullet train, bullet'Probability: 99.8446%
d:\haewin\haepi\deep\caffe_ocv>caffe_googlenet.exe -image=tiger.JPGBest class: #292 'tiger, Panthera tigris'Probability: 72.9631%
O site:https://www.clarifai.com/ -> demo
Faz operação semelhante (reconhece objetos em imagens).
8

Contar quantos feijões de cada tipo tem:http://www.lps.usp.br/hae/software/beans/index.html
9

Reconhecimento de textura pela aprendizagem de operador
ax ay1 ay2
qx qp1 qp2
qx qp1 qp2
10
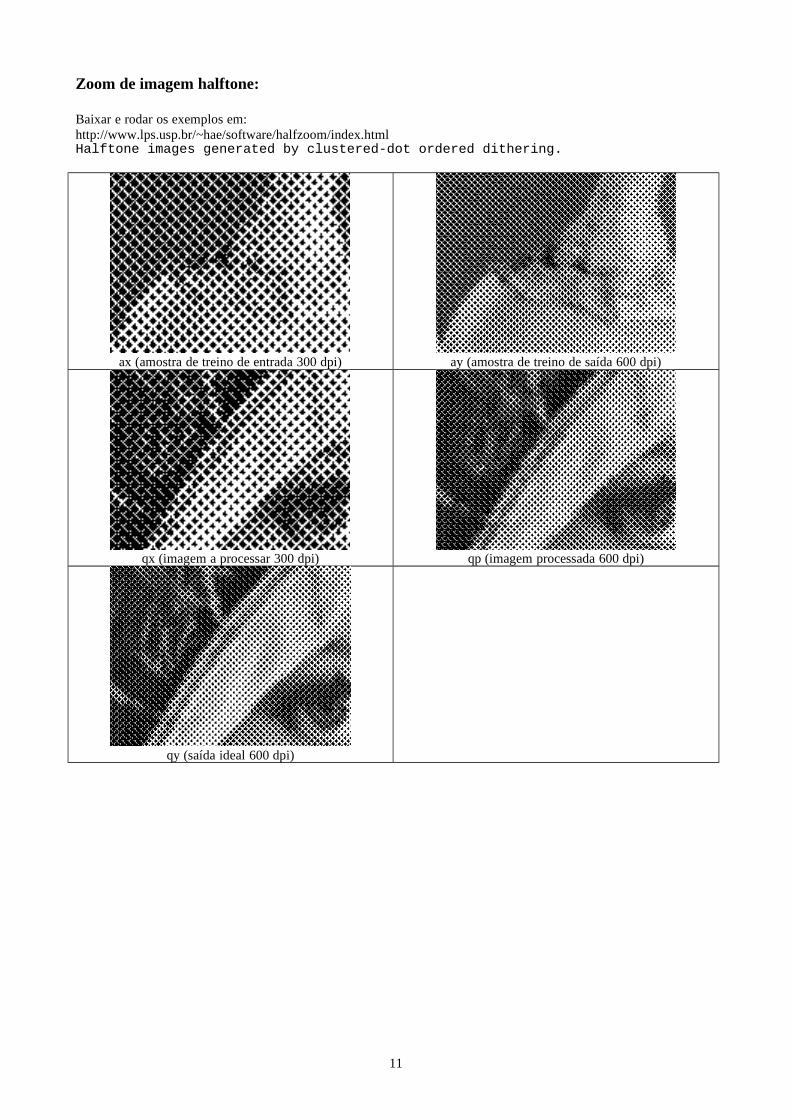
Zoom de imagem halftone:
Baixar e rodar os exemplos em:http://www.lps.usp.br/~hae/software/halfzoom/index.htmlHalftone images generated by clustered-dot ordered dithering.
ax (amostra de treino de entrada 300 dpi) ay (amostra de treino de saída 600 dpi)
qx (imagem a processar 300 dpi) qp (imagem processada 600 dpi)
qy (saída ideal 600 dpi)
11

Halftone images generated by HP LaserJet Driver option "coarse dot."
ax (amostra de treino de entrada 300 dpi) ay (amostra de treino de saída 600 dpi)
qx (imagem a processar 300 dpi) qp (imagem processada 600 dpi)
qy (saída ideal 600 dpi)
12

Halftone inverso:
Baixar e rodar os exemplos em:http://www.lps.usp.br/~hae/software/invhalf/index.html
entrada clustered-dot imagem processada de clustered-dot
entrada dispersed-dot imagem processada de dispersed-dot
entrada difusão de erro imagem processada de difusão de erro
entrada HP laserjet coarse-dot imagem processada de HP laserjet coarse-dot
Os treinos são feitos com outros conjuntos de imagens.
13

Aumentar resolução de letra impressa
(5a) original image Qx at 300 dpi
(5b) ideal output-image Qy at 600 dpi
(5c) resolution-increased image Qy (3´3 window)
Figure 5: Resolution increasing of printed characters (Times, 12 pt.) usingwindowed zoom operators designed by empirically optimal 1-nearest neighbor learning.
14

Aumentar resolução de letra manuscrita
(6a) original image Qx
(6b) ideal output image Qy (supposedly unknown)
(6c) resolution-increased image Q y .
Figure 6: Resolution increasing of handwritten document usingwindowed zoom operators designed by empirically optimal 1-nearest neighbor learning.
15

Emulação de filtro desconhecido
ax ay
ap qx
qy qp
Nota: O filtro foi aprendido nas bandas RGB.
16

Reconhecimento de face:EP2 de 2017http://www.lps.usp.br/hae/psi5796/ep2-2017/index.html
17

Projeto de operador por aprendizagem
Primeiro problema: Detecção de pontas de retas em imagens binárias
ax ay
qx qp (vizinho mais próximo)
qp.tga Pintando de cinza os padrões não vistos.
mle cutb ax.bmp ay.bmp c:\proeikon\ee\e33.ges filtro.ctbmle appb qx.bmp filtro.ctb qp.bmpimg sobrmcb qx.bmp qp.bmp qp.tga g
18

Detecção de pontas de retas em imagens binárias
A B
W(p) B(p)
Filtro ou operador “restrito à janela”
1 1 11 0 01 1 1
111100111 0ponta de reta
1 0 10 0 01 0 1
101000101 1não ponta de reta
1 1 11 1 11 1 1
111111111 1não ponta de reta
1 1 01 0 11 1 1
110101111 0ponta de reta
0 1 01 0 10 1 0
010101010 1não ponta de reta
1 0 10 1 01 0 1
101010101 ? (tanto faz)(quase) nunca aparece
Conteúdos possíveis dentro da janela
O computador deve aprender uma função f :{0,1}9→{0,1} . O domínio da função tem 512 elemen-tos. Vamos usar vizinho mais próximo para achar a saída de instâncias que não aparecem nos exem-plos de treinamento.
19

Detecção de pontas de retas usando janela 3x3 e vizinho mais próximo.
//nn.cpp#include <cekeikon.h>
Mat_<GRY> vizinhanca33(Mat_<GRY> a, int lc, int cc) { Mat_<GRY> d(1,9); int i=0; for (int l=-1; l<=1; l++) for (int c=-1; c<=1; c++) { d(i)=a(lc+l,cc+c); i++; } return d;}
int hamming(Mat_<GRY> a, Mat_<GRY> b) { if (a.total()!=b.total()) erro("Erro hamming"); int soma=0; for (int i=0; i<a.total() ; i++) if (a(i)!=b(i)) soma++; return soma;}
int main() { Mat_<GRY> AX,AY,QX; le(AX,"ax.bmp"); le(AY,"ay.bmp"); le(QX,"qx.bmp"); Mat_<GRY> QP(QX.size(),255); #pragma omp parallel for for (int l=1; l<QP.rows-1; l++) { fprintf(stderr,"%d\r",l); for (int c=1; c<QP.cols-1; c++) { Mat_<GRY> qx=vizinhanca33(QX,l,c); //acha vizinho mais proximo de qp em AX int mindist=INT_MAX; GRY minsai=0; for (int l2=1; l2<AX.rows-1; l2++) for (int c2=1; c2<AX.cols-1; c2++) { Mat_<GRY> ax=vizinhanca33(AX,l2,c2); int dist=hamming(qx,ax); if (dist<mindist) { mindist=dist; minsai=AY(l2,c2); } } QP(l,c)=minsai; } } imp(QP,"qpnn.pgm");}
qpnn.pgm
Demora 250s (4 minutos)!
20

Podemos acelerar o programa acima pedindo para parar a busca quando encontrar umpadrão de treinamento com distância hamming zero.
Nota: distância hamming entre duas sequências de bits é o número de bits diferentesnas duas sequências.
//knn2.cpp - grad2018#include <cekeikon.h>
Mat_<GRY> vizinhanca33(Mat_<GRY> a, int lc, int cc) { Mat_<GRY> d(1,9); int i=0; for (int l=-1; l<=1; l++) for (int c=-1; c<=1; c++) { d(i)=a(lc+l,cc+c); i++; } return d;}
int hamming(Mat_<GRY> a, Mat_<GRY> b) { if (a.total()!=b.total()) erro("Erro hamming"); int soma=0; for (int i=0; i<a.total() ; i++) if (a(i)!=b(i)) soma++; return soma;}
int main() { Mat_<GRY> AX,AY,QX; le(AX,"ax.bmp"); le(AY,"ay.bmp"); le(QX,"qx.bmp"); Mat_<GRY> QP(QX.size(),255); //#pragma omp parallel for for (int l=1; l<QP.rows-1; l++) { fprintf(stderr,"%d\r",l); for (int c=1; c<QP.cols-1; c++) { Mat_<GRY> qx=vizinhanca33(QX,l,c); //acha vizinho mais proximo de qp em AX int mindist=INT_MAX; GRY minsai=0; for (int l2=1; l2<AX.rows-1; l2++) for (int c2=1; c2<AX.cols-1; c2++) { Mat_<GRY> ax=vizinhanca33(AX,l2,c2); int dist=hamming(qx,ax); if (dist<mindist) { mindist=dist; minsai=AY(l2,c2); if (dist==0) goto saida; } } saida: QP(l,c)=minsai; } } imp(QP,"qpnn.png");}
Demora 3,7s.
21

O mesmo programa pode ser usada para detectar bordas, somente mudando os exemplos de treina-mento:
Exemplo de treino de entrada AX Exemplo de treino de saída AY
Imagem a processar QX Imagem processada QP
Imagem a processar QX Imagem processada QP
Vizinho mais próximo "força bruta" é lento.
22

1 1 11 0 01 1 1
111100111 0ponta de reta
1 0 10 0 01 0 1
101000101 1não ponta de reta
1 1 11 1 11 1 1
111111111 1não ponta de reta
1 1 01 0 11 1 1
110101111 0ponta de reta
0 1 01 0 10 1 0
010101010 1não ponta de reta
1 0 10 1 01 0 1
101010101 ? (tanto faz)(quase) nunca aparece
Conteúdos possíveis dentro da janela
O computador deve aprender uma função f :{0,1}9→{0,1} . O domínio da função tem 512 elemen-tos. Deve-se definir a saída para cada ponto do domínio. Dá para construir uma tabela ou vetor ouarray com 512 entradas para acelerar o processamento.
índice decimal índice binário conteúdo da tabela0 000000000 1281 000000001 128... ... ...
325 101000101 255... ... ...
487 111100111 0... ... ...
511 111111111 255
Só precisa armazenar a última coluna no vetor.
É preciso preencher as entradas que não aparecem nas amostras de treinamento de alguma forma(generalização).
23

Detecção de pontas de retas usando janela 3x3 e tabela.A saída de padrões 3x3 não vistos nas amostras de treinamento será considerada branca (255).
//tabela.cpp grad2017#include <cekeikon.h>
int main() { Mat_<GRY> AX; le(AX,"ax.bmp"); Mat_<GRY> AY; le(AY,"ay.bmp"); vector<BYTE> v(512, 255); // nao visto vira branco //vector<BYTE> v(512, 128); // nao visto vira cinza
for (int l=1; l<AX.rows-1; l++) for (int c=1; c<AX.cols-1; c++) { int indice=0; for (int l2=-1; l2<=1; l2++) for (int c2=-1; c2<=1; c2++) { int t=1; if (AX(l+l2,c+c2)==0) t=0; indice = 2*indice+t; } //Aqui, indice vai ser um numero entre 0 e 511 v[indice]=AY(l,c); } //v e' o filtro 3x3
Mat_<GRY> QX; le(QX,"qx.bmp"); Mat_<GRY> QP(QX.size(),255); for (int l=1; l<QX.rows-1; l++) for (int c=1; c<QX.cols-1; c++) { int indice=0; for (int l2=-1; l2<=1; l2++) for (int c2=-1; c2<=1; c2++) { int t=1; if (QX(l+l2,c+c2)==0) t=0; indice = 2*indice+t; } //Aqui, indice vai ser um numero entre 0 e 511 QP(l,c)=v[indice]; } imp(QP,"qptabela.pgm");}
qptabela.pgm
Tempo de processamento: 0.028s. É 9000 vezes mais rápido do que NN e a diferençacresce ainda mais à medida que os tamanhos das imagens aumentam! Só que não acha o vizinho mais próximo verdadeiro.Se mandar pintar de cinza os padrões não vistos, a saída fca com erros.
24

Detecção de pontas de retas usando janela 3x3 e tabela.As entradas da tabela com padrões não vistos nas amostras de treinamento serão preenchidas procu-rando o vizinho mais próximo.
//tabela.cpp pos2017#include <cekeikon.h>
int hamming(int a, int b) { assert(0<=a && a<512); assert(0<=b && b<512); int soma=0; int bit=1; for (int i=0; i<9; i++) { if ( (a & bit) != (b & bit) ) soma++; i = i*2; } return soma;}
int main(int argc, char** argv) { if (argc!=5) erro("tabela ax.pgm ay.pgm qx.pgm qp.pgm"); Mat_<GRY> AX; le(AX,argv[1]); Mat_<GRY> AY; le(AY,argv[2]); //vector<BYTE> v(512, 255); // nao visto vira branco vector<BYTE> v(512, 128); // nao visto vira cinza
for (int l=1; l<AX.rows-1; l++) for (int c=1; c<AX.cols-1; c++) { int indice=0; for (int l2=-1; l2<=1; l2++) for (int c2=-1; c2<=1; c2++) { int t=1; if (AX(l+l2,c+c2)==0) t=0; indice = 2*indice+t; } //Aqui, indice vai ser um numero entre 0 e 511 v[indice]=AY(l,c); } //v e' o filtro 3x3
//Processa os pixels cinza da tabela. //Com isso, temos vizinho mais proximo de verdade. for (int indice=0; indice<512; indice++) { if (v[indice]==128) { //procura vizinho mais proximo na tabela int mindist=INT_MAX; GRY minsai=0; for (int j=0; j<512; j++) { if (v[j]!=128) { int dist=hamming(indice,j); if (dist<mindist) { mindist=dist; minsai=v[j]; } } } v[indice]=minsai; } }
Mat_<GRY> QX; le(QX,argv[3]); Mat_<GRY> QP(QX.size(),255); for (int l=1; l<QX.rows-1; l++) for (int c=1; c<QX.cols-1; c++) { int indice=0; for (int l2=-1; l2<=1; l2++) for (int c2=-1; c2<=1; c2++) { int t=1; if (QX(l+l2,c+c2)==0) t=0; indice = 2*indice+t; } //Aqui, indice vai ser um numero entre 0 e 511 QP(l,c)=v[indice]; } imp(QP,argv[4]);}
[É possível diminuir o número de amostras necessárias, aumentando as amostras de entrada com ro-tações de 90, 180 e 270 graus.]
25

4b) Emulação de operadores pela aprendizagem de máquina:
P1 (120´160) Erosão 3´3
P2 (120´160) Erosão 3´3 (emulação erro zero)
P1 abertura 2´2 P1 abertura
P2 abertura 2´2 P2 abertura emulado (erro zero)
26

4c) Detectar uma letra
lax lay
lqx lqp lqp.tga
Funciona bem usando janelas 7x7.Deve aprender uma função f :{0,1}49→{0,1} . O domínio tem 562.949.953.421.312 elementos! Não dá mais para usar tabela, pois (a) a tabela não caberia no computador; (b) é impossível conse-guir exemplos para preencher toda a tabela; (c) o tempo para preencher toda a tabela é astronômico.Não dá para usar hashing, pois apesar de que hashing ocuparia pouco espaço na memória, não sabe-ria o que fazer com exemplos não vistos. Dá para usar o vizinho mais próximo, pois os exemplos não vistos seriam aproximados para oexemplo visto mais semelhante, mas ficaria muito lento.
Solução: usar árvore.
mle cutb lax.bmp lay.bmp c:\proeikon\ee\e77.ges lfiltro.ctbmle appb lqx.bmp lfiltro.ctb lqp.bmpimg sobrmcb lqx.bmp lqp.bmp lqp.tga g
[Guardar somente exemplos positivos?]
27

Exemplo gráfico de árvore de decisão para construir operadores binários:Exemplos = { [000, 0], [000, 0], [000, 1], [001, 1], [100, 1], [100, 1], [011, 1], [111, 0] }
Nota: [000, 0] indica uma amostra de treinamento com entrada ax=[000] e saída ay=[0].
Todo algoritmo de aprendizagem de máquina deve ter estratégia para lidar com dois "problemas":(a) Generalização: Como classificar uma instância qx que não apareceu nos exemplos de trei-
namento? O vizinho mais próximo é uma estratégia de generalização.(b) Amostras com conflito ou ruído: O que fazer quando uma amostra de entrada ax possui
amostras de saída ay com valores diferentes (conflitantes)? Por exemplo, a entrada ax=[000] desteexemplo tem saídas conflitantes ay=0 e ay=1.
Estrutura de árvore é base para:
(a) Árvore de decisão (decision-tree). É a árvore construída na figura acima. Na construção daárvore, leva-se em conta as amostras de entrada AX e as de saída AY. Na predição (teste), dadauma instância a classificar qx, percorre-se a árvore até chegar a uma folha (um sub-cubo que nãotem mais subdivisões), e a saída qp=f(qx) fica definida pelo rótulo que encontrar nessa folha. A ge-neralização é dada implicitamente pela forma como o espaço das características ficou subdividida.
(b) Aceleração de vizinho mais próximo pela árvore k-dimensional (kd-tree). Na aceleração debusca de vizinho mais próximo, somente os exemplos de entrada AX são levadas em consideraçãona construção da árvore (os exemplos de saída AY não são considerados). Para buscar um vizinhopróximo de uma instância qx, percorre-se a árvore até chegar a uma folha. Na folha, tem uma
28

amostra ax que é um vizinho de qx. Não tem garantia de que ax seja o vizinho mais próximo de qx.Para minimizar a possibilidade de que kd-tree devolva um vizinho ax distante da instância buscadaqx, costuma-se usar duas estratégias:
(b1) Cria-se várias árvores t1, t2, ..., tn escolhendo, para cada uma, diferentes sequências de cor-tes. Para buscar um vizinho próximo de qx, percorre-se todas as n árvores, obtendo n candidatos avizinho próximo de qx. Dentre eles, escolhe-se aquele que for o mais próximo de qx.
(b2) Quando se busca um vizinho próximo qp de qx numa árvore ti, faz-se "backtracking". Istoé, ao chegar a uma folha da árvore f (um cubo sem mais subdivisões), faz buscas nos cubos vizi-nhos de f para verificar se há um vizinho mais próximo do que o vizinho encontrado em f.
29

4d) Segmentação de feijões pela cor
ax ay
qx (f1.jpg)
qp
Deve aprender uma função f : [0 , 255 ]3→{0,1} . O domínio tem 16.777.216 elementos. Dá para usar uma tabela? Dá, mas é difícil preenchê-la.Dá para usar vizinho mais próximo força-bruta? Dá, mas demora muito (8 minutos).Que método dá para usar?
30

>img projcor f1.jpg rg.tga rb.tga gb.tga>kcek projcor f1.jpg rg.png rb.png gb.png
rg.tga rb.tga gb.tgaProjeções do conjunto de pixels da imagem f1.jpg nos planos RG, RB e GB do cubo RGB.
31

Segmentação de feijões pela cor
Usando árvore (“cut-tree” = kd-tree sem backtracking):
>mle cutc ax.tga ay.tga \proeikon\ee\e11.ces filtro.ctc>mle appc f1.jpg filtro.ctc p1.tga>mle appc f2.jpg filtro.ctc p2.tga>mle appc f3.jpg filtro.ctc p3.tga
Leva 2 segundos para aprender e 0,5 segundos para aplicar (usando “cut-tree” ou kd-tree sem backtracking).
Segmentação de feijões pela cor - vizinho mais próximo "força-bruta"
//grad2017 forca.cpp//segmentacao de feijao pela forca-bruta#include <cekeikon.h>
//A funcao abaixo ja esta incluida no Cekeikon//double distancia(COR a, COR b) {// return sqrt(elev2(a[0]-b[0])+elev2(a[1]-b[1])+elev2(a[2]-b[2]));//}
int main() { Mat_<COR> ax; le(ax,"ax.ppm"); Mat_<GRY> ay; le(ay,"ay.ppm"); Mat_<COR> qx; le(qx,"f1.jpg"); Mat_<GRY> qp(qx.rows,qx.cols); for (int l=0; l<qx.rows; l++) { cerr << l << endl; for (int c=0; c<qx.cols; c++) { COR busca=qx(l,c); double mindist=DBL_MAX; int minl, minc; for (int l2=0; l2<ax.rows; l2++) for (int c2=0; c2<ax.cols; c2++) { double d=distancia(busca,ax(l2,c2)); if (d<mindist) { mindist=d; minl=l2; minc=c2; } } qp(l,c)=ay(minl,minc); } } imp(qp,"f1-forca.png"); }
Levaria aproximadamente 500 segundos (8 minutos). Força bruta.
32

Segmentação de feijões pela cor - FlaNN (Fast Approximate Nearest Neighbor Search)
FlaNN é uma sub-biblioteca do OpenCV que permite busca rápida (mas aproximada) do vizinho mais próximo.FlaNN implementa kd-tree (entre outros métodos para acelerar a busca do vizinho mais próximo). kd-tree é uma es -trutura em forma de árvore que permite acelerar a busca do vizinho mais próximo aproximado [Bentley1975, Freid -man1977].
Bentley, J. L. (1975). "Multidimensional binary search trees used for associative searching". Communicati -ons of the ACM. 18 (9): 509.
Freidman, J. H.; Bentley, J. L.; Finkel, R. A. (1977). "An Algorithm for Finding Best Matches in Logari -thmic Expected Time". ACM Transactions on Mathematical Software. 3 (3): 209.
//grad-2017 flann.cpp//segmentacao de feijao usando FlaNN#include <cekeikon.h>
int main() { Mat_<COR> ax; le(ax,"ax.ppm"); Mat_<GRY> ay; le(ay,"ay.ppm"); Mat_<COR> qx; le(qx,"f1.jpg"); if (ax.size()!=ay.size()) erro("Erro dimensao"); Mat_<GRY> qp(qx.rows,qx.cols);
Mat_<FLT> features(ax.rows*ax.cols,3); Mat_<FLT> saidas(ax.rows*ax.cols,1); int i=0; for (int l=0; l<ax.rows; l++) for (int c=0; c<ax.cols; c++) { features(i,0)=ax(l,c)[0]/255.0; features(i,1)=ax(l,c)[1]/255.0; features(i,2)=ax(l,c)[2]/255.0; saidas(i)=ay(l,c)/255.0; i=i+1; }
flann::Index ind(features,flann::KDTreeIndexParams(4)); // Aqui, as 4 arvores estao criadas
Mat_<FLT> query(1,3); vector<int> indices(1); vector<FLT> dists(1); for (int l=0; l<qp.rows; l++) for (int c=0; c<qp.cols; c++) { query(0)=qx(l,c)[0]/255.0; query(1)=qx(l,c)[1]/255.0; query(2)=qx(l,c)[2]/255.0; ind.knnSearch(query,indices,dists,1,flann::SearchParams(0)); // sem backtracking qp(l,c)=255*saidas(indices[0]); // um numero entre 0 e 255 } imp(qp,"f1-flann.png");}
Leva 7 segundos usando FlaNN com 4 árvores e sem backtracking.
33

As rotinas de aprendizagem de máquina de OpenCV exigem que as amostras de treinamento sejam colo-cados em duas matrizes tipo "foat":
Mat_<FLT> features(namostras,nfeatures); Mat_<FLT> saidas(namostras,1);
Ou, usando a minha nomenclatura:
Mat_<FLT> AX(namostras,nfeatures); Mat_<FLT> AY(namostras,1);
Features Saidas
B G R Saida (0 ou 1)
...
34

Segmentação de feijões pela cor
Usando árvore de decisão do OpenCV:
//dtree.cpp grad2017#include <cekeikon.h>
int main() { Mat_<COR> ax; le(ax,"ax.ppm"); Mat_<GRY> ay; le(ay,"ay.ppm"); if (ax.size()!=ay.size()) erro("Erro: Dimensoes diferentes");
Mat_<FLT> features(ax.total(),3); Mat_<FLT> saidas(ay.total(),1); for (unsigned i=0; i<ax.total(); i++) { features(i,0)=ax(i)[0]/255.0; features(i,1)=ax(i)[1]/255.0; features(i,2)=ax(i)[2]/255.0; saidas(i,0)=ay(i)/255.0; }
CvDTree arvore; arvore.train(features,CV_ROW_SAMPLE,saidas);
Mat_<COR> qx; le(qx,"f1.jpg"); Mat_<GRY> qp(qx.rows,qx.cols);
for (unsigned i=0; i<qx.total(); i++) { Mat_<FLT> query(1,3); query(0)=qx(i)[0]/255.0; query(1)=qx(i)[1]/255.0; query(2)=qx(i)[2]/255.0; CvDTreeNode* no=arvore.predict(query); int r=255*(*no).value; // r = 255 * no->value; qp(i)=r; } imp(qp,"f1-dtree.png");}
35

Exemplo gráfico da diferença entre vizinho mais próximo e árvore de decisão:
Considere classificar os pontos com 2 features f0 e f1 em “X” ou “O”, onde a classificação só de-pende do valor f0.
Usando o vizinho mais próximo, “□” será classificada erradamente como “X”.
Usando a árvore de decisão, provavelmente “□” será classificada corretamente como “O”.
36

Segmentação de feijões pela cor - cut-tree
Cut-tree é a minha implementação decision-tree otimizada para velocidade. Aqui, as matrizes de-vem ser do tipo Mat_<GRY>.
//Cuttree.cpp#include <cekeikon.h>
int main(){ Mat_<COR> ax; le(ax,"ax.tga"); Mat_<COR> ay; le(ay,"ay.tga"); if (ax.size()!=ay.size()) erro("Erro: Dimensoes diferentes"); Mat_<COR> qx; le(qx,"f1.jpg"); Mat_<COR> qp(qx.rows,qx.cols);
Mat_<GRY> features(ax.rows*ax.cols,3); Mat_<GRY> saidas(ax.rows*ax.cols,1); int i=0; for (int l=0; l<ax.rows; l++) for (int c=0; c<ax.cols; c++) { features(i,0)=ax(l,c)[0]; features(i,1)=ax(l,c)[1]; features(i,2)=ax(l,c)[2]; saidas(i,0)=ay(l,c)[0]; i=i+1; }
CUTTREE cut; vector<int> ee{0,1,2}; //sequencia de eixos de corte cut.train(features,saidas,ee);
Mat_<GRY> query(1,3); GRY r; for (int l=0; l<qp.rows; l++) for (int c=0; c<qp.cols; c++) { query(0)=qx(l,c)[0]; query(1)=qx(l,c)[1]; query(2)=qx(l,c)[2]; r=cut.predict(query); qp(l,c)=COR(r,r,r); } imp(qp,"qp-cut.ppm");}
Leva 0,24 segundos.
37

Segmentação de feijões pela cor - Bayes
Normal Bayes classifier: “This simple classification model assumes that feature vectors from eachclass are normally distributed (though, not necessarily independently distributed). So, the wholedata distribution function is assumed to be a Gaussian mixture, one component per class. Using thetraining data the algorithm estimates mean vectors and covariance matrices for every class, andthen it uses them for prediction”.
Aqui, a generalização é feita ao supor que as amostras de treinamento são misturas de distribuiçõesgaussianas.
//bayes.cpp grad2017//segmentar feijao#include <cekeikon.h>
int main() { Mat_<COR> ax; le(ax,"ax.ppm"); Mat_<GRY> ay; le(ay,"ay.ppm"); if (ax.size()!=ay.size()) erro("Erro: Dimensoes diferentes"); Mat_<COR> qx; le(qx,"f1.jpg"); Mat_<GRY> qp(qx.rows,qx.cols);
Mat_<FLT> features(ax.rows*ax.cols,3); Mat_<FLT> saidas(ax.rows*ax.cols,1); int i=0; for (int l=0; l<ax.rows; l++) for (int c=0; c<ax.cols; c++) { features(i,0)=ax(l,c)[0]/255.0; features(i,1)=ax(l,c)[1]/255.0; features(i,2)=ax(l,c)[2]/255.0; saidas(i)=ay(l,c)/255.0; i=i+1; }
CvNormalBayesClassifier ba; ba.train(features,saidas);
for (int l=0; l<qp.rows; l++) for (int c=0; c<qp.cols; c++) { Mat_<FLT> query(1,3); query(0)=qx(l,c)[0]/255.0; query(1)=qx(l,c)[1]/255.0; query(2)=qx(l,c)[2]/255.0; FLT result=ba.predict(query); // result e' 0 ou 1 qp(l,c)=result*255; } imp(qp,"qp-bayes.png");}
Processamento leva 1,16s
38

Adequado para Bayes.Adequado para Bayes.
Adequado para Bayes. Inadequado para Bayes.
Pergunta: Quais dos exemplos acima são adequados para vizinho mais próximo? Quais são adequa-dos para árvore de decisão?
Nota: Diremos que um algoritmo de aprendizagem é inadequado para resolver um determinado pro-blema se a sua taxa de erro esperada é alta, mesmo usando parâmetros adequados e um númerogrande de amostras de treinamento.
[Seria interessante implementar Bayes, sem usar rotina de OpenCV.]
39

Segmentação de feijões pela cor
Usando boost do OpenCV:
//boost.cpp pos2017#include <cekeikon.h>
int main() { Mat_<COR> ax; le(ax,"ax.ppm"); Mat_<GRY> ay; le(ay,"ay.ppm"); if (ax.size()!=ay.size()) erro("Erro: Dimensoes diferentes");
Mat_<FLT> features(ax.total(),3); Mat_<FLT> saidas(ay.total(),1); for (unsigned i=0; i<ax.total(); i++) { features(i,0)=ax(i)[0]/255.0; features(i,1)=ax(i)[1]/255.0; features(i,2)=ax(i)[2]/255.0; saidas(i,0)=ay(i)/255.0; }
CvBoost ind(features,CV_ROW_SAMPLE,saidas);
Mat_<COR> qx; le(qx,"f1.jpg"); Mat_<GRY> qp(qx.rows,qx.cols);
for (unsigned i=0; i<qx.total(); i++) { Mat_<FLT> query(1,3); query(0)=qx(i)[0]/255.0; query(1)=qx(i)[1]/255.0; query(2)=qx(i)[2]/255.0; int predicao=255*ind.predict(query); qp(i)=predicao; } imp(qp,"f1-boost.png");}
Boosting combina as saídas de muitos classificadores "fracos" para construir um classificador "for-te". No caso acima, os classificadores "fracos" são árvores de decisão.
Boosting pode devolver a soma ponderada das respostas, em vez de categoria. A resposta real dáuma indicação sobre a “confiança” do classificador. Veja mais adiante nesta apostila como se fazisto.
40

Segmentação de feijões pela cor
Usando rede neural do OpenCV:
//ann.cpp grad2017//usa rede neural do opencv//20 neuronios na camada escondida#include <cekeikon.h>
int main() { Mat_<COR> ax; le(ax,"ax.ppm"); Mat_<GRY> ay; le(ay,"ay.ppm"); if (ax.size()!=ay.size()) erro("Erro: Dimensoes diferentes");
Mat_<FLT> features(ax.total(),3); Mat_<FLT> saidas(ay.total(),1); for (unsigned i=0; i<ax.total(); i++) { features(i,0)=ax(i)[0]/255.0; // entre 0 e 1 features(i,1)=ax(i)[1]/255.0; features(i,2)=ax(i)[2]/255.0; saidas(i,0)=2*(ay(i)/255.0)-1; // -1 ou +1 }
Mat_<int> v = (Mat_<int>(1,3) << features.cols,20,1); CvANN_MLP ind(v); ind.train(features,saidas,Mat()); Mat_<COR> qx; le(qx,"f1.jpg"); Mat_<GRY> qp(qx.size());
Mat_<FLT> query(1,features.cols); Mat_<FLT> saida(1,1); for (unsigned i=0; i<qx.total(); i++) { Mat_<FLT> query(1,3); query(0)=qx(i)[0]/255.0; query(1)=qx(i)[1]/255.0; query(2)=qx(i)[2]/255.0; ind.predict(query,saida); qp(i)=255*cvRound((saida(0)+1.0)/2.0); } imp(qp,"f1-ann.png");}
41

Segmentação de feijões pela cor
Resultados das segmentações
qp-kd4 (9,7s) FlaNN com 4 árvores qp-kd1 (5,2s) FlaNN com 1 árvore
qp-cut (0,24s) Cut-tree qp-bayes (1,16s) Bayes
dtreebean.pgm (0,45s) Decision-tree limiarização de saturação
ANN opencv com 20 neuronios na camadaescondida boost
O que acontece se rodar estes programas em HSI?
42

Como escolher o eixo de corte e o valor de corte da árvore de decisão? Como descobrir que umatributo é ruído? Como descobrir a importância de um atributo para resolver o problema declassifcação?
Usarei o conceito de "ganho de informação" ou "redução de entropia", seguindo o livro [Mit-chell, 1997].
Defnição de entropia: "the entropo of a phosical sostem is the minimum number of bits oouneed to fullo describe the detailed state of the sostem"[http://www.science20.com/hammock_phosicist/what_entropo-89730]
A entropia de um conjunto de amostras S contendo amostras positivas e negativas nas propor-ções p⊕ e p⊖ é:
Entropy (S)=−p⊕ log2 p⊕−p⊖log2 p⊖
A entropia assume valor 1 se p⊕=p⊖=0.5 (precisa de um bit para informar se um exemplo épositivo ou negativo). Assume valor 0 se p⊕=0 ou p⊖=0 (não precisa de nenhum bitpara informar se um exemplo é positivo ou negativo, pois só há exemplos de um único tipo). As-sume valores entre 0 e 1 para as outras proporções.
O ganho de informação ou a redução de entropia ao dividir o conjunto de amostras usando umcerto atributo A é:
Gain(S , A)=Entropy (S)− ∑Sv ⊂Divisao (A, S )
[|Sv||S|
Entropy (Sv)]onde Divisao(S,A) é o conjunto de todos os subconjuntos de S obtido ao dividir o conjunto Susando o atributo A.
Exemplo: Considere as seguintes amostras de treinamento:atributos rótulos
peso cor da pele classifcaaço
baixo escuro bebê
baixo claro bebê
alto claro adulto
alto escuro adulto
Evidentemente, é melhor usar o atributo "peso" pois o atributo "cor" não ajuda em nada a clas -sifcar os indivíduos em bebê ou adulto. Vamos verifcar se é possível descobrir isto usando ga-nho de informação. A entropia da amostra de treinamento é:
Entropy (S)=−p⊕log2 p⊕−p⊖log2 p⊖=−0.5 log20.5−0.5 log20.5=0.5+0.5=1
Se escolher o atributo peso para dividir as amostras, o ganho de informação é um bit.
Gain(S , peso)=Entropy (S)− ∑v∈Values (A )
[|Sv||S|
Entropy (Sv)]=1− 24×0−2
4×0=1
Se escolher o atributo cor da pele para dividir as amostras, o ganho de informação é zero bit.
Gain(S , cor )=Entropy (S)− ∑v∈Values (A )
[|Sv||S|
Entropy (Sv )]=1− 24×1−2
4×1=0
Portanto, não se ganha nada ao escolher o atributo cor para dividir as amostras. Por outrolado, escolhendo o atributo peso para dividir a amostra, os indivíduos fcam perfeitamente clas-sifcados em bebê ou adulto.
43

Classificar um problema com 10 features, quando somente os features 0 e 1 são relevantes.Teste 1:
A saída depende apenas de f0 (linhas) e f1 (colunas): f0+f1<100? Os features f2...f9 são irrele-vantes. Faremos treino com 200 amostras geradas aleatoriamente e testes com outras 200 amostras.Cada feature é um número aleatório entre 0 e 99.
1c) Árvore de decisão 2014//dtree.cpp#include <cekeikon.h>
int nfeatures=10;int ntreinos=200; int ntestes=200;
int classe(float f0, float f1){ if (f0+f1<100) return -1; else return +1;}
void geraTreino(Mat_<float>& features, Mat_<float>& saidas){ srand(7); features.create(ntreinos,nfeatures); saidas.create(ntreinos,1); for (int l=0; l<ntreinos; l++) { for (int c=0; c<nfeatures; c++) features(l,c)=rand()%100; saidas(l)=classe(features(l,0),features(l,1)); }}
int main(){ Mat_<float> features, saidas; geraTreino(features,saidas);
CvDTree ind; ind.train(features,CV_ROW_SAMPLE,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind.predict(query)->value); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}
Acertos= 90.00%
44

problema com 10 features
Quebrando dtree em treino e predição:
A árvore resultante do treino pode ser armazenada num arquivo:
//dt-train.cpp#include <cekeikon.h>
int nfeatures=10;int ntreinos=200; int ntestes=200;
int classe(float f0, float f1)...
void geraTreino(Mat_<float>& features, Mat_<float>& saidas)...
int main(){ Mat_<float> features, saidas; geraTreino(features,saidas);
CvDTree ind; ind.train(features,CV_ROW_SAMPLE,saidas); ind.save("treino.xml");}
//dt-pred.cpp#include <cekeikon.h>
int nfeatures=10;int ntreinos=200; int ntestes=200;
int classe(float f0, float f1)...
int main(){ CvDTree ind; ind.load("treino.xml");
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind.predict(query)->value); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}
Acertos= 90.00%
45

problema com 10 features
Árvore de decisão pode ser usada para determinar a importância de cada feature:
//importa.cpp#include <cekeikon.h>int main(){ CvDTree ind; ind.load("treino.xml"); Mat_<DBL> f=ind.getVarImportance(); cout << f.rows << " " << f.cols << endl; cout << tipo(f) << endl; for (int i=0; i<f.cols; i++) printf("%f\n",f(i));}
1 10CV_64F10.5213500.4786500.0000000.0000000.0000000.0000000.0000000.0000000.0000000.000000
Árvore de decisão detectou corretamente que somente as duas primeiras variáveis são relevantes.Não sei se "getVarImportance" calcula ganho de informação - é provável que sim.
Apesar de só mostrar a importância da variável no primeiro nó, na construção de árvore de decisãocalcula-se ganho de informação em cada nó.
46

problema com 10 features
1a) Vizinho mais próximo 2014, usando CvKNearest
O resto do programa é igual ao dtree.cpp
Versão usando OpenCV 2.4.10://knearest.cppint main(){ Mat_<float> features, saidas; geraTreino(features,saidas);
CvKNearest ind(features,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind.find_nearest(query,1)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}Acertos= 80.50%Surpreendentemente, a taxa de acertos é alta.
Versão usando OpenCV 3.1.0:int main(){ Mat_<float> features; Mat_<int> saidas; geraTreino(features,saidas);
Ptr<ml::KNearest> ind = ml::KNearest::create(); ind->train(features,ml::ROW_SAMPLE,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind->predict(query)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}Acertos= 88.00%Estranhamente, a taxa de acertos aumentou!
47

problema com 10 features
1a) Vizinho mais próximo 2014, usando flann
O resto do programa é igual ao dtree.cpp
//flann.cppint main(){ Mat_<float> features, saidas; geraTreino(features,saidas);
flann::Index ind(features,flann::KDTreeIndexParams(4));
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); vector<int> indices(1); vector<float> dists(1); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; ind.knnSearch(query,indices,dists,1,flann::SearchParams(16)); int predicao=cvRound(saidas(indices[0],0)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}
Acertos= 79.00%Como esperado, as taxas de acertos de CvKNearest e flann são quase iguais. Motivo do mau resultado do vizinho mais próximo: O classificador não sabe que a saída depende sódos features 0 e 1, pois o treino é feito sem informar a classificação. [Porém, estranhamente a taxade acertos é alta! Teria que pensar por que está acertando tanto.]
48

Problema com 10 features
1d) Boosting (2014):
Adaboost soma respostas de várias árvores de decisão (weak classifiers) para tomar uma decisão fi-nal.
//boosting.cpp...
int main(){ Mat_<float> features, saidas; geraTreino(features,saidas);
CvBoost ind(features,CV_ROW_SAMPLE,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind.predict(query)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}
Acertos= 90.50%
Neste exemplo, não houve aumento significativo de acerto em relação à dtree. Em muitos proble-mas, boosting tem taxa de acerto maior que árvore de decisão.Boosting pode devolver a soma ponderada das respostas, em vez de categoria. A resposta real dáuma indicação sobre a “confiança” do classificador.
FLT r=ind.predict(query,Mat(),Range::all(),false,true); // resposta real
Features Predição Saída_ideal[64, 70, 11, 3, 35, 43, 97, 67, 71, 95] 8.77182 1[70, 53, 13, 79, 66, 53, 81, 47, 42, 69] 1.39228 1[96, 66, 2, 87, 9, 57, 41, 74, 33, 19] 16.5835 1[53, 44, 85, 32, 75, 41, 89, 63, 20, 47] -1.84912 -1[98, 68, 53, 58, 12, 95, 80, 51, 33, 19] 16.5835 1[3, 25, 5, 78, 48, 29, 54, 1, 6, 45] -15.2798 -1[59, 30, 92, 20, 80, 80, 67, 17, 24, 79] -6.25987 -1[84, 10, 3, 45, 10, 6, 16, 12, 17, 60 ] -5.68952 -1[53, 85, 36, 70, 98, 53, 4, 94, 48, 46] 7.08097 1[85, 56, 35, 63, 56, 41, 74, 39, 14, 50] 9.20399 1[66, 95, 77, 79, 60, 23, 16, 29, 58, 68] 8.77182 1[59, 50, 96, 3, 60, 4, 63, 16, 43, 81] -0.158262 1 =erro[83, 39, 29, 34, 98, 98, 35, 30, 88, 33] 1.55183 1[61, 88, 64, 95, 94, 30, 83, 30, 4, 88] 8.77182 1[83, 49, 69, 64, 82, 99, 51, 92, 37, 82] 7.65344 1[16, 35, 87, 29, 87, 71, 34, 31, 61, 19] -15.2798 -1[45, 58, 15, 43, 78, 23, 39, 44, 42, 34] -0.298569 1 =erro[66, 2, 49, 99, 81, 95, 32, 38, 42, 25] -13.5012 -1[70, 21, 13, 11, 16, 0, 58, 52, 13, 82] -7.5305 -1[37, 24, 28, 13, 37, 84, 53, 70, 21, 16] -10.5484 -1...
49

Repare que nos casos de erro, adaboost estava “mais ou menos indeciso”. Não tinha evidência clarada decisão que deveria tomar.
Copio o trecho abaixo sobre boosting do manual do OpenCV. Para maiores detalhes, veja o própriomanual do OpenCV e artigos referenciados.
Boosting is a powerful learning concept that provides a solution to the supervised classificati-on learning task. It combines the performance of many “weak” classifiers to produce a powerfulcommittee [HTF01]. A weak classifier is only required to be better than chance, and thus can bevery simple and computationally inexpensive. (...) Decision trees are the most popular weak classi-fiers used in boosting schemes. (...) The desired two-class output is encoded as -1 and +1. Differentvariants of boosting are known as Discrete Adaboost, Real AdaBoost, LogitBoost, and Gentle Ada-Boost [FHT98]. (...) This chapter focuses only on the standard two-class Discrete AdaBoost algori-thm, outlined below.
Initially the same weight is assigned to each sample (step 2). Then, a weak classifier fm(x) istrained on the weighted training data (step 3.1). Its weighted training error and scaling factor cm iscomputed (step 3.2). The weights are increased for training samples that have been misclassified(step 3.3). All weights are then normalized, and the process of finding the next weak classifier con-tinues for another M -1 times. The final classifier F(x) is the sign of the weighted sum over the in-dividual weak classifiers (step 4).
Algoritmo AdaBoost escrito de forma informal (extraído de Wikipedia):
Form a large set of simple features Initialize weights for training images For T rounds
1. Normalize the weights 2. For available features from the set, train a classifer using a single feature and
evaluate the training error 3. Choose the classifer with the lowest error 4. Update the weights of the training images: increase if classifed wronglo bo this
classifer, decrease if correctlo Form the fnal strong classifer as the linear combination of the T classifers (coeficient largerif training error is small)
Two-class Discrete AdaBoost Algorithm (do manual do OpenCV):
Step 1. Set N examples (xi, yi)i = 1, ..., N, with xi R∈ K, yi −1, +1 .∈Step 2. Assign weights as wi = 1/N, i = 1, ..., N.Step 3. Repeat for m = 1, 2, ..., M : 3.1. Fit the classifier fm (x) −1, 1, using weights w∈ i on the training data. 3.2. Compute errm = Ew[1(y≠fm (x))], cm = log( (1 − errm )/errm ) . 3.3. Set wi w⇐ i exp[cm 1(yi≠fm (xi)) ], i = 1, 2, ..., N, and renormalize so that Σi wi = 1 .Step 4. Classify new samples x using the formula: sign(Σm = 1
M cm fm (x)) .
50

problema com 10 features
Usando OpenCV 3.1.0:
int main(){ Mat_<float> features; Mat_<int> saidas; geraTreino(features,saidas);
Ptr<ml::Boost> ind = ml::Boost::create(); ind->train(features,ml::ROW_SAMPLE,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind->predict(query)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}Acertos= 90.50%
Boosting pode devolver a soma das respostas, em vez de categoria. A resposta real dá uma indica-ção sobre a “confiança” do classificador.
float predicao=ind->predict(query,noArray(), ml::DTrees::PREDICT_SUM);
[64, 70, 11, 3, 35, 43, 97, 67, 71, 95] 7.75915 1[70, 53, 13, 79, 66, 53, 81, 47, 42, 69] 0.467799 1[96, 66, 2, 87, 9, 57, 41, 74, 33, 19] 32.72 1[53, 44, 85, 32, 75, 41, 89, 63, 20, 47] -0.822932 -1[98, 68, 53, 58, 12, 95, 80, 51, 33, 19] 33.7011 1[3, 25, 5, 78, 48, 29, 54, 1, 6, 45] -31.1683 -1[59, 30, 92, 20, 80, 80, 67, 17, 24, 79] -8.72437 -1[84, 10, 3, 45, 10, 6, 16, 12, 17, 60] -8.92999 -1[53, 85, 36, 70, 98, 53, 4, 94, 48, 46] 13.7936 1[85, 56, 35, 63, 56, 41, 74, 39, 14, 50] 17.7293 1[66, 95, 77, 79, 60, 23, 16, 29, 58, 68] 13.7936 1[59, 50, 96, 3, 60, 4, 63, 16, 43, 81] 0.467799 1[83, 39, 29, 34, 98, 98, 35, 30, 88, 33] -0.148113 1[61, 88, 64, 95, 94, 30, 83, 30, 4, 88] 13.7936 1[83, 49, 69, 64, 82, 99, 51, 92, 37, 82] 10.0251 1[16, 35, 87, 29, 87, 71, 34, 31, 61, 19] -31.1683 -1[45, 58, 15, 43, 78, 23, 39, 44, 42, 34] -1.07804 1[66, 2, 49, 99, 81, 95, 32, 38, 42, 25] -18.0854 -1[70, 21, 13, 11, 16, 0, 58, 52, 13, 82] -10.8273 -1
51

problema com 10 features
1b) Classificador de Bayes Gaussiano (normal) 2014:
//bayes.cpp
...
int main(){ Mat_<float> features, saidas; geraTreino(features,saidas);
CvNormalBayesClassifier ind; ind.train(features,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind.predict(query)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}Acertos= 94.00%É a maior taxa de acertos até agora.
OpenCV 3.1.0:int main(){ Mat_<float> features; Mat_<int> saidas; geraTreino(features,saidas);
Ptr<ml::NormalBayesClassifier> ind = ml::NormalBayesClassifier::create(); ind->train(features,ml::ROW_SAMPLE,saidas);
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; int predicao=cvRound(ind->predict(query)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}Acertos= 94.00%
52

problema com 10 features
1f) Neural Net (ANN_MLP - artificial neural networks - multi-layer perceptrons)
OpenCV310 tem erro no ANN_MLP. Vamos usar OpenCV2410 e Cekeikon41. Compile com:
>compila ann -cek -ver2 OU>compila ann -c -v2
//ann1.cpp cek41...
int main(){ Mat_<float> features; Mat_<float> saidas; geraTreino(features,saidas); //Mat_<float> weights(saidas.rows,saidas.cols,1); Mat_<int> v = (Mat_<int>(1,4) << nfeatures,6,2,1); CvANN_MLP ind(v); ind.train(features,saidas,Mat());
srand(8); int nacertos=0; Mat_<float> query(1,nfeatures); Mat_<float> saida(1,1); for (int l=0; l<ntestes; l++) { for (int c=0; c<nfeatures; c++) query(c)=rand()%100; ind.predict(query,saida); int predicao=round(saida(0)); int correto = classe(query(0),query(1)); if (predicao==correto) nacertos++; } printf("Acertos=%6.2f%%\n",100.0*nacertos/ntestes);}
Acertos= 94.00%. O maior acerto, juntamente com Bayes.Problema: Tem que chutar adequadamente o número camadas e o número de células em cada ca-mada.
Mat_<int> v = (Mat_<int>(1,4) << nfeatures,8,2,1); // Acertos= 88.00%Mat_<int> v = (Mat_<int>(1,4) << nfeatures,7,2,1); // Acertos= 90.50%Mat_<int> v = (Mat_<int>(1,4) << nfeatures,5,2,1); // Acertos= 86.00%Mat_<int> v = (Mat_<int>(1,4) << nfeatures,4,2,1); // Acertos= 85.50%Mat_<int> v = (Mat_<int>(1,4) << nfeatures,6,4,1); // Acertos= 78.00%
53

problema com 10 features
Resumo das taxas de acerto (classificar um objeto com 10 features, quando somente os features 0 e1 são relevantes.)
Taxa de acerto Taxa de errodtree 90.00% 10%knearest 80.50% ou 88.00% 12%flann 79.00% 21%boosting 90.50% 9.5%Bayes 94.00% 6%ANN_MLP 94.00% 6%
O melhor algoritmo de aprendizagem de máquina costuma depender do problema e dos parâmetrosescolhidos.
Bayes tem taxa de erro muito baixo, pois consegue prever quais são atributos irrelevantes.
ANN tem taxa de erro muito baixo, mas tive que escolher cuidadosamente os números de neurôniosde camadas escondidas.
Surpreendentemente, knearest não se saiu tão mal neste problema.
54