application of nlp in information retrieval nirdesh chauhan ajay garg veeranna a.y. neelmani singh
TRANSCRIPT

Application of NLP in Information Retrieval
Nirdesh ChauhanAjay Garg
Veeranna A.Y.Neelmani Singh

Presentation Outline
Overview of current IR Systems Problems with NLP in IR Major applications of NLP in IR

Motivation
Most successful general purpose retrieval methods are statistical methods.
Sophisticated linguistic processing often degrade performance.

What is IR ??
“Information retrieval system is one that searches a collection of natural language documents with the goal of retrieving exactly the set of documents that pertain to a users question”
Have their origins in library systems Do not attempt to deduce or generate
answers
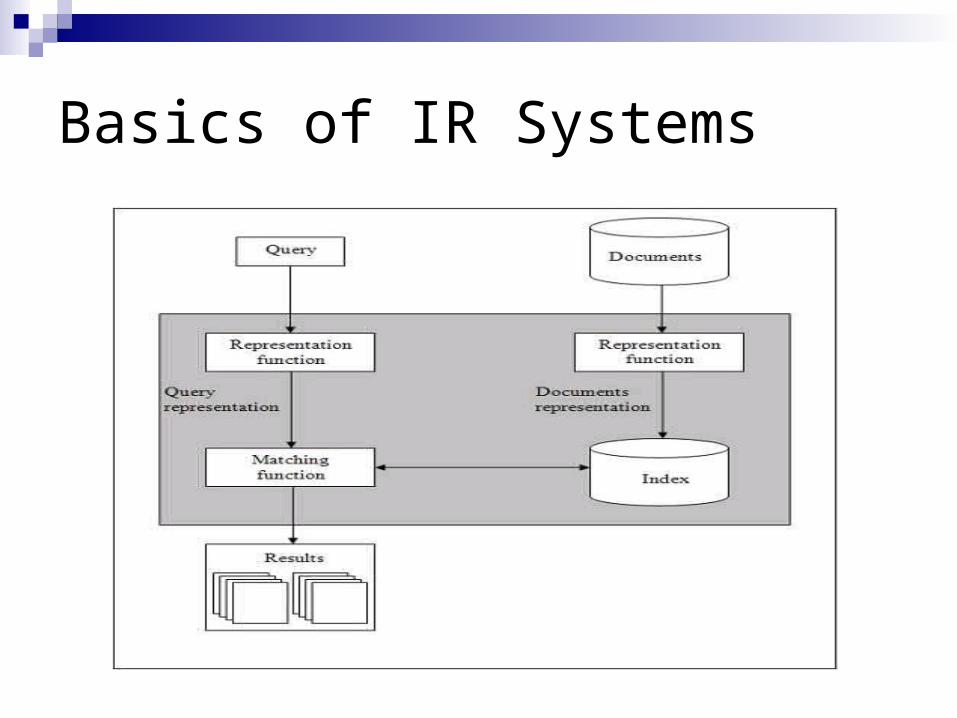
Basics of IR Systems

Basics of IR Systems (contd…)
Indexing the collection of documents.
Transforming the query in the same way as the document content is represented.
Comparing the description of each document with that of the query.
Listing the results in order of relevancy.

Basics of IR Systems (contd…)
Retrieval Systems consist of mainly two processes: IndexingMatching

Indexing Indexing is the process of selecting terms to
represent a text.
Indexing involves: Tokenization of string Removing frequent words Stemming
Two common Indexing Techniques: Boolean Model Vector space model

Information Retrieval Models
A retrieval model consists of: D: representation for documents R: representation for queries F: a modeling framework for D, Q R(q, di): a ranking or similarity function which
orders the documents with respect to a query.

Boolean Model Queries are represented as Boolean
combinations of the terms. Set of documents that satisfied the
Boolean expression are retrieved in response to the query.
DrawbackUser is given no indication as to whether some
documents in the retrieved set are likely to be better than others in the set

Vector Space Model
In this model documents and queries are represented by vectors in T dimensional space.
T is the number of distinct terms used in the documents.
Each axis corresponds to one term. Ranked list of documents ordered by similarity to
the query where similarity between a query and a document is computed using a metric on the respective vectors.

Matching Matching is the process of computing a measure
of similarity between two text representations. Relevance of a document is computed based on
following parameters: tf - term frequency is simply the number of times a
given term appears in that document.tfi.j = (count of ith term in jth document)/(total terms in jth document)
idf - inverse document frequency is a measure of the general importance of the termidfi = (total no. of documents)/(no. of documents containing ith term)
tfidfi,j score = tf * idf

Evaluation of IR Systems
Two common effectiveness measures include:Precision: Proportion of retrieved documents
that are relevant.Recall: Proportion of relevant documents that
are retrieved. Ideally both precision and recall should be
1. In practice, these are inversely related.

Problems regarding NLP in IR
Linguistic techniques must be essentially perfect Errors occurs in linguistic processing e.g. POS
tagging, sense resolution, parsing etc. Effect of these errors on retrieval performance must
be considered. Incorrectly resolving two usages of the same sense
differently is disastrous for retrieval effectiveness. Disambiguation accuracy of at least 90% is required
just to avoid degrading retrieval effectiveness.

Problems regarding NLP in IR (contd…) Queries are difficult
Queries are especially troublesome for most NLP processing.
They are generally quite short and offer little to assist linguistic processing.
But to have any effect whatsoever on retrieval queries must also contain the type of index terms used in documents.
Compensated by query expansion and blind feedback.

Problems regarding NLP in IR (contd…)
Linguistic knowledge is implicitly exploitedStatistical techniques implicitly exploit the
same information the linguistic techniques make explicit.
So linguistic techniques may provide little benefit over appropriate statistical techniques.

Problems regarding NLP in IR (contd…) Term normalization might be beneficial.
Map various formulations and spellings of a same lexical item to a common form.
E.g. somatotropin and somatotrophin
analyzer and analyser

Application of NLP in IR
We discuss here the following applications:Conceptual IndexingEnhancement in MatchingSemantically Relatable Sets

Conceptual Indexing
Matching of concepts in document and query instead of matching words.
Use of WORDNET synsets as concepts. Word Sense Disambiguation for nouns:
noun disambiguated to a single synset.

Conceptual Indexing
Extended Vector space model. Query and Document represented as set of vectors,
each of them representing different aspects of them. stems of words not found in WordNet or not
disambiguated. synonym set ids of disambiguated nouns. stems of the disambiguated nouns.
Weights are applied to similarity measure of corresponding vector.
Failed w.r.to stemming due to poor disambiguation

Enhancement in Matching
For example, if index terms are noun phrases then a partial match may be made if two terms share a common head but are not identical.

Semantically Relatable Sets
This method enhances indexing. Documents and queries are represented
as Semantically Relatable Sets (SRS). Example “A new book on IR”
SRS corresponding to this query are:{A, book}, {new, book}, {book, on, IR}

SRS Based Search The relevance score for a document d,
where Rq(d) = Relevance of the document d to the query q
|Sd| = Number of sentences in the document d
rq(s) = Relevance of sentence s to the query q
The relevance of the sentence s to the query q
where weight(srs) = weight of the SRS srs depending on its type.press(srs) = 1 if srs is present in sentence s, 0 otherwise.

Improving performance of SRS based Search Stemming
Words in document and query SRS are stemmed based on WordNet. Takes care of the morphological divergence problem. “children_NN” stemmed to “child_NN”, but the word “childish_JJ” will not be stemmed to
“child_NN”, since the word “childish” is an adjective, whereas “child” is a noun.
Using Word Similaritysynonymy/hypernymy/hyponymy problem is tackled by this method.
The relevance of the sentence s to the query q is reformulated as:
t() is the SRS similarity measure , t(srs,srs’) = (cw1,cw1’)*equal(fw,fw’)*t(cw2,cw2’)
For (FW,CW) matching, t(cw1,cw1’) is set to one and for (CW,CW) matching, equal(fw,fw’) is set to one. In all other cases, t(w1,w2) gives the relatedness measure of w1 and w2 (calculated using the baseline similarity measure “path”).

Improving performance of SRS based Search (contd…) SRS Augmentation
Rule: (noun1, in/on, noun2) => (noun2, noun1) Example: (defeat, in, election) will create an augmented SRS as
(election, defeat)
Rule: (adjective, noun) => (noun, adjective_in_noun_form) Example: (polluted, water) will augment (water, pollution)
Rule: (adjective, with, noun–(ANIMATE)) => (noun, adjective_in_noun_form)
Example: (angry, with, result) will augment (result, anger), whereas (angry, with, John) will not augment (John, anger).

Case StudyQuery: I need to know the gas mileage for my audi a8 2004 model
Source: Yahoo search (search.yahoo.com)

Case Study (contd…)Query: I need to know the gas mileage for my audi a8 2004 model
Source: Y!Q search (yq.search.yahoo.com)

Case Study (contd…)Query: I need to know the gas mileage for my audi a8 2004 model
Source: Google search (www.google.com)

Case Study (contd…) Yahoo Search
Pure text-based search. Result generates instance of same text containing
documents. Y!Q Search
Use of semantics but not efficient. Attempts to generate answer. However this is done
less efficiently here. Google Search
Efficient use of NLP for deduction of answer form given question.
A step towards question-answering !!

Conclusion
Research efforts to address appropriate tasks are underway.E.g. document summarization, generating answers.
Achieving extremely efficient NLP techniques is an idealization.

References
Voorhees, EM, "Natural Language Processing and Information Retrieval," in Pazienza, MT (ed.), Information Extraction: Towards Scalable, Adaptable Systems, New York: Springer, 1999.
Salton G Wong A Yang CS A Vector Space Model for Automatic Indexing Communications of the ACM (1975) 613-620.
Mari Vallez; Rafael Pedraza-Jimenez. Natural Language Processing in Textual Information Retrieval and Related Topics "Hipertext.net", num. 5, 2007.
Sanjeet Khaitan, Kamaljeet Verma and Pushpak Bhattacharyya, Exploiting Semantic Proximity for Information Retrieval, IJCAI 2007, Workshop on Cross Lingual Information Access, Hyderabad, India, Jan, 2007.
Wikipedia

Questions ??

Thank You !!!!!