aplace: a general and extensible large-scale placer
DESCRIPTION
APLACE: A General and Extensible Large-Scale Placer. Andrew B. Kahng* Sherief Reda Qinke Wang VLSI CAD Lab UCSD CSE and ECE Departments http://vlsicad.ucsd.edu *Currently on leave of absence at Blaze DFM, Inc. Goals and Plan. Goals: Build a new placer to win the competition - PowerPoint PPT PresentationTRANSCRIPT

APLACE: A General and Extensible Large-Scale Placer
Andrew B. Kahng* Sherief Reda Qinke Wang
VLSI CAD Lab
UCSD CSE and ECE Departments
http://vlsicad.ucsd.edu
*Currently on leave of absence at Blaze DFM, Inc.

Goals and Plan
Goals:• Build a new placer to win the competition• Scalable, robust, high-quality implementation • Leave no stone unturned / QOR on the table
Plan and Schedule:• Work within most promising framework: APlace• 30 days for coding + 30 days for tuning

PhilosophyRespect the competition• Well-funded groups with decades of experience
– ABKGroup’s Capo, MLPart, APlace = all unfunded side projects– No placement-related industry interactions
• QOR target: 24-26% better than Capo v9r6 on all known benchmarks– Nearly pulled out 10 days before competition
Work smart• Solve scalability and speed basics first
– Slimmed-down data structure, -msse compiler options, etc.• Ordered list of ~15 QOR ideas to implement• Daily regressions on all known benchmarks• Synthetic testcases to predict bb3, bb4, etc.
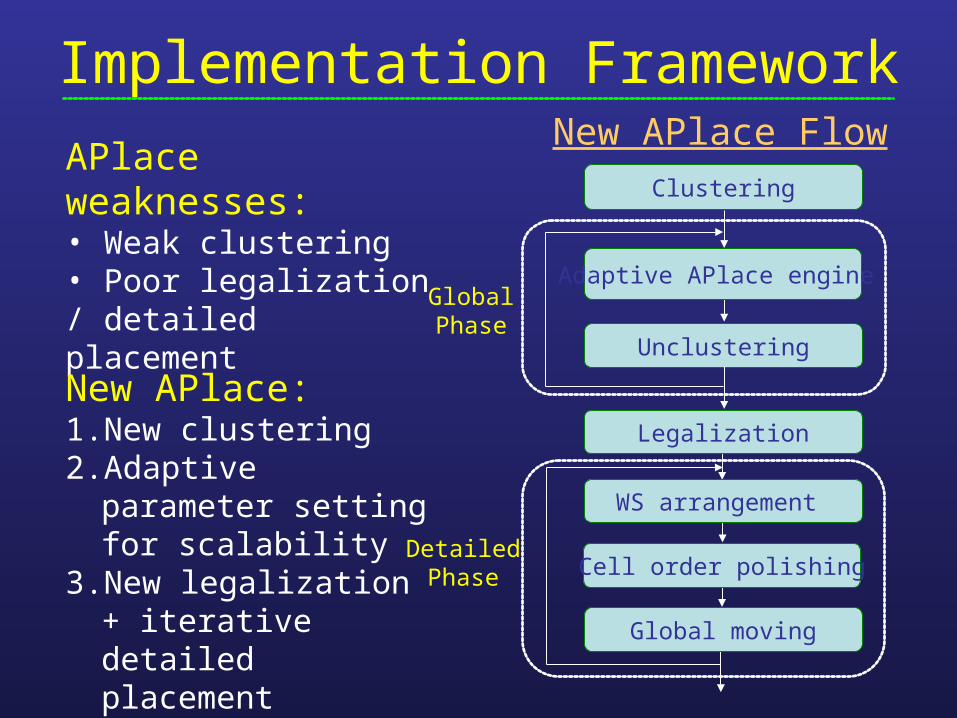
Implementation Framework
APlace weaknesses:• Weak clustering• Poor legalization / detailed placement
Clustering
Adaptive APlace engine
WS arrangement
Cell order polishing
Unclustering
Global moving
Legalization
GlobalPhase
DetailedPhase
New APlace Flow
New APlace:1. New clustering2. Adaptive parameter
setting for scalability3. New legalization +
iterative detailed placement

Clustering/Unclustering A multi-level paradigm with clustering ratio 10
Top-level clusters 2000
Similar in spirit to [HuM04] and [AlpertKNRV05]
For each clustering level:
Algorithm Sketch
Calculate the clustering score of each node to its neighbors based on the number of connections Sort all scores and process nodes in order as long as cluster size upper bounds are not violated If a node’s score needs updating then update score and insert in order

Adaptive Tuning / Legalization
Adaptive Parameterization:
Legalization:1. Sort all cells from left to right: move each cell in order
(or a group of cells) to the closest legal position(s)2. Sort all cells from right to left: move each cell in order
(or a group of cells) to the closest legal position(s)3. Pick the best of (1) and (2)
1. Automatically decide the initial weight for the wirelength objective according to the gradients
2. Decrease wirelength weight based on the current placement process

Whitespace Compaction: For each layout row:
Optimally arrange whitespace to minimize wirelength while maintaining relative cell order. [KahngTZ99], [KahngRM04].
Cell Order Polishing: For a window of neighboring cells
Optimally arrange cell orders and whitespace to minimize wirelength
Detailed Placement
Global Moving:
Optimally move a cell to a better available position to minimize wirelength

Parameterization and ParallelizingTuning Knobs:
Clustering ratio, # top-level clusters, cluster area constraints Initial wirelength weight, wirelength weight reduction ratio Max # CG iterations for each wirelength weight Target placement discrepancy Detailed placement parameters, etc.
Resources: SDSC ROCKS Cluster: 8 Xeon CPUs at 2.8GHz Michigan Prof. Sylvester’s Group: 8 various CPUs UCSD FWGrid: 60 Opteron CPUs at 1.6GHz UCSD VLSICAD Group: 8 Xeon CPUs at 2.4GHz
Wirelength Improvement after Tuning : 2-3%

Artificial Benchmark Synthesis
Synthetic benchmarks to test code scalability and performance
Rapid response to broadcast of s00-nam.pdf Created “synthetic versions of bigblue3 and bigblue4 within 48 hoursMimicked fixed-block layout diagrams in the artificial benchmark creation
This process was useful: we identified (and solved) a problem with clustering in presence of many small fixed blocks
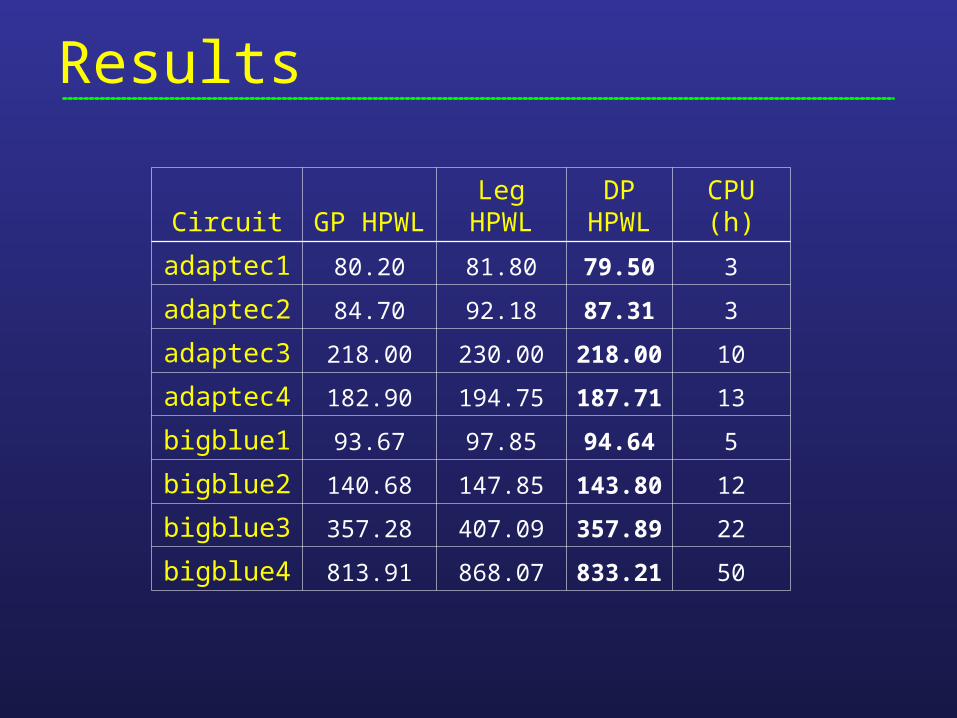
Results
CircuitGP
HPWLLeg
HPWLDP
HPWL CPU (h)
adaptec1 80.20 81.80 79.50 3
adaptec2 84.70 92.18 87.31 3
adaptec3 218.00 230.00 218.00 10
adaptec4 182.90 194.75 187.71 13
bigblue1 93.67 97.85 94.64 5
bigblue2 140.68 147.85 143.80 12
bigblue3 357.28 407.09 357.89 22
bigblue4 813.91 868.07 833.21 50

Bigblue4 Placement
HPWL = 833.21

Conclusions
ISPD05 = an exercise in process and philosophy
At end, we were still 4% short of where we wanted
Not happy with how we handled 5-day time frameAuto-tuning first results ~ best results
During competition, wrote but then left out “annealing” DP improvements that gained another 0.5%
Students and IBM ARL did a really, really great job
Currently restoring capabilities (congestion, timing-driven, etc.) and cleaning (antecedents in Naylor patent)