apache cassandra - wprowadzenie do architektury, modelowania i narzędzi
TRANSCRIPT

Apache Cassandra
Wprowadzenie do architektury, modelowania danych i narzędzi
Maciej Migacz ///// [email protected] ///// www.semantive.comwww.stacja.it, 20.05.2016

§ RDBMS vs NoSQL§ Twierdzenie CAP§ Spójność, dostępność i odporność na
rozłączenie w sieci§ Rodzaje baz nierelacyjnych§ Czym jest Cassandra?§ Zastosowania bazy Cassandra
Plan

§ NoSQL = Not Only SQL§ Brak schematu – zbiory danych nie mają określonej
struktury– np. każdy wiersz może wyglądać zupełnie inaczej – tzn.
mieć inne kolumny§ Architektura Shared Nothing
– węzły są równorzędne i niezależne– brak maszyn, których uszkodzenie powodowałoby awarię
systemu (no single point of failure)§ Replikacja – dane są zwielokrotnione na wielu
węzłach klastra (replikach)§ Sharding – podział danych na rozłączne partycje
Charakterystyka baz NoSQL

§ ACID– Atomicity (atomowość transakcji) – operacje zawarte w
transakcji wykonają się w całości albo wcale– Consistency (spójność) – stan bazy danych po
zatwierdzeniu transakcji będzie spójny – tzn. zgodny ze wszystkimi nałożonymi na niego ograniczeniami
– Isolation (izolacja) – jedna transakcja nie będzie widziała przejściowego stanu bazy danych spowodowanego przez niezakończoną inną transakcję
– Durability (trwałość) – kiedy dane zostaną zatwierdzone przez transakcję będą one utrwalone
ACID vs BASE

§ BASE – Basically Available, Soft state, Eventually consistent– Większość danych dostępna przez cały czas– Dane wystarczająco świeże– Osiągnięcie spójność odsunięte w czasie, ale
osiągalne
ACID vs. BASE

ACID vs BASE
§ ACID– Silna spójność– Izolacja– Transakcje i
zagnieżdżone transakcje– Pesymistyczne
podejście do wielodostępu
– Schemat danych
§ BASE– Słaba spójność– Wysoka dostępność– Przybliżone odpowiedzi– Optymistyczne
podejście do wielodostępu
– Szybsze i łatwiejsze– Brak schematu

Twierdzenie CAP (Brewer'a)
C
A P
Consistency(spójność)- wszystkiewęzłymająjednakowe
dane
Partition tolerance -odpornośćnautratę
częściwęzłów
Availability(dostępność)– każdeżądaniedoczekasię
odpowiedzi
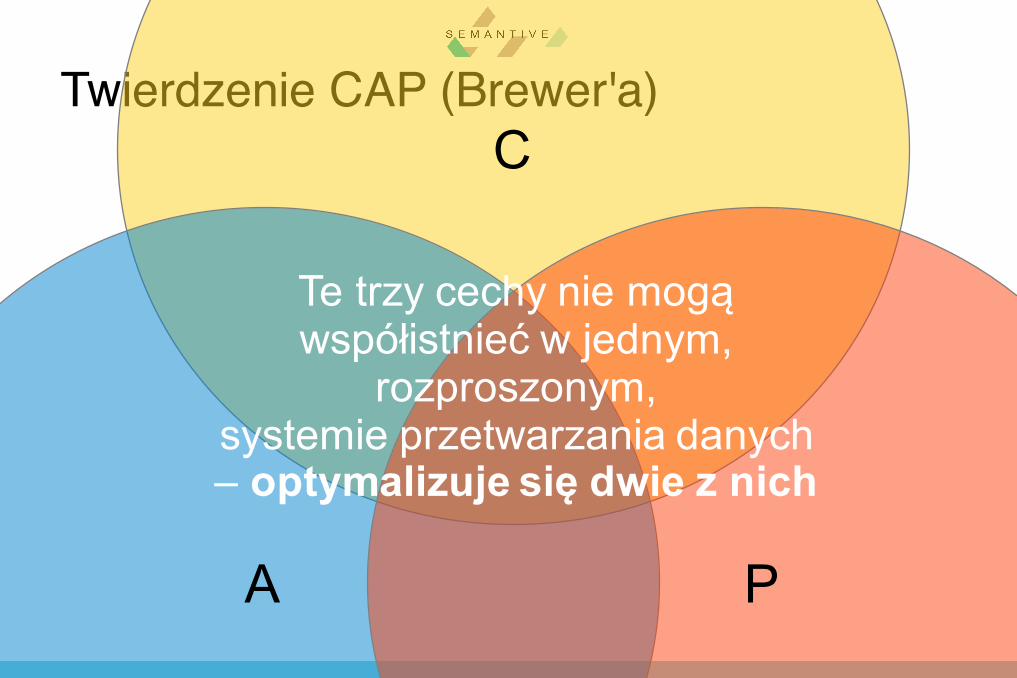
Twierdzenie CAP (Brewer'a)C
A P
Te trzy cechy nie mogą współistnieć w jednym,
rozproszonym, systemie przetwarzania danych – optymalizuje się dwie z nich

Określenie priorytetów baz NoSQL
§ Wydajny zapis§ Wydajny odczyt§ Wysoka spójność
§ N – liczba replik przechowujących te same dane
§ R – liczba replik, z których pobierane są dane podczas żądania odczytu
§ W – liczba replik, do których zapisywane są dane podczas żądania zapisu

§ Wysoka spójność, bardzo szybki odczyt– R = 1, W = N
§ Wysoka spójność, bardzo szybki zapis– R = N, W = 1
§ Niska spójność, bardzo szybki odczyt i zapis– R = 1, W = 1
§ Spójność jest zachowana gdy– R + W >= N + 1
Przypadki charakterystyczne

Rodzaje baz NoSQL§ Bazy danych oparte o
model Column Familly(BigTable)– Cassandra– Hbase– Azure Tables– BigTable
§ Dokumentowe bazy danych– Couch DB– Mongo DB– Riak
§ Bazy typu klucz-wartość– Memcached– Redis– BarkeleyDB– DynamoDB– Riak
§ Bazy grafowe– Neo4J– OrientDB– Allegro Graph– Titan (bazuje na
Cassandra)
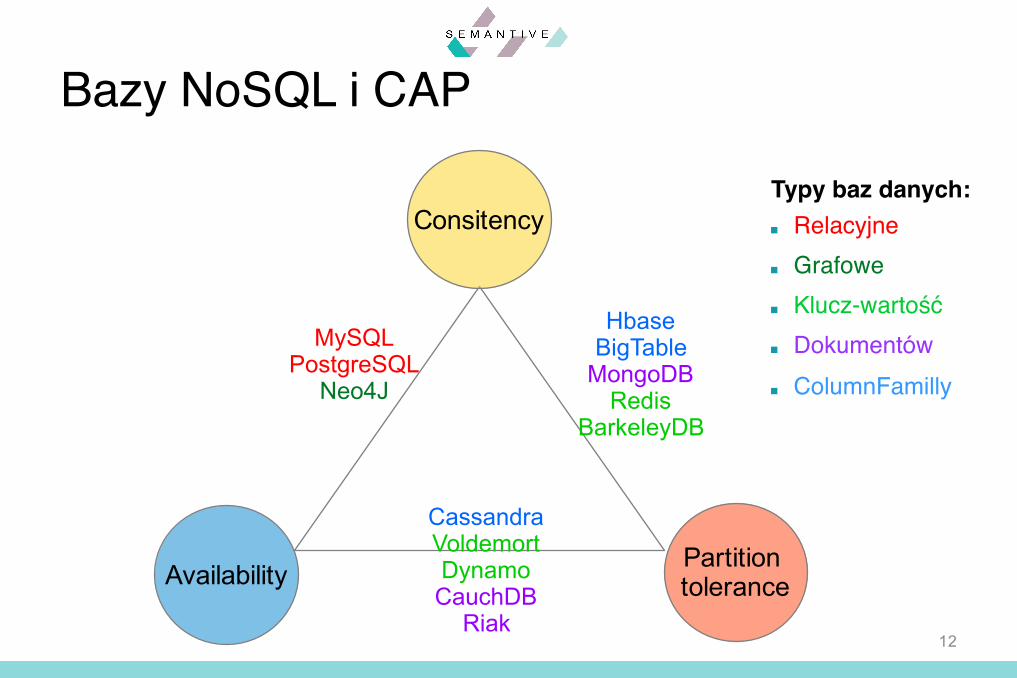
Bazy NoSQL i CAP
12
Consitency
Availability Partition tolerance
MySQLPostgreSQL
Neo4J
HbaseBigTable
MongoDBRedis
BarkeleyDB
CassandraVoldemort DynamoCauchDB
Riak
Typy baz danych:■ Relacyjne■ Grafowe■ Klucz-wartość■ Dokumentów■ ColumnFamilly

§ Wysokoskalowalna, zdecentralizowana i rozproszona baza danych NoSQL
§ Obsługa dowolnej liczby węzłów, dowolnej liczby centrów danych
§ Automatyczna replikacja danych§ Obsługa heterogenicznej infrastruktury§ Napisana w języku Java§ Opensource z bardzo aktywną społecznością, topowy
projekt fundacji Apache§ Współpraca z Hadoop i Spark, możliwość
wykonywania algorytmów opartych o MapReduce
Czym jest Cassandra

§ Wysokoskalowalna, zdecentralizowana baza danych NoSQL– Rozproszona, „No Single Point of Failure”– Liniowe skalowanie przepustowości
Cassandra - cechy

§ Skalowanie horyzontalne klastra– No Single Point of Failure– Liniowe skalowanie przepustowości– Odczyt/zapis w dowolnym węźle
Cassandra - cechy
Źródło: http://docs.datastax.com/

§ Model danych oparty o BigTable– Tabele z wierszami, w których komórki są
uporządkowane po nazwie– Wiersze są od siebie niezależne i każdy wiersz może
mieć zestaw komórek o innych nazwach– Brak schematu
§ Spełnia wymagania Dynamo (zbiór technik)– Skalowanie horyzontalne– Symetryczna– Decentralizacja– Dostosowana do niejednorodnego środowiska
Cassandra = BigTable + Dynamo

Cassandra - Distributed Hash Table
§ Distributed HashTable– O(1) –
wyszukiwanie węzła
– Replikacja– Liniowe
skalowanie

§ RowType– SortedMap<String, Tuple>
§ TableType– Map<String, RowType>
§ KeySpaceType– Map<String, TableType>
§ ClusterType– Map<String, KeySpaceType>
Cassandra – model danych

§ Konfigurowalny poziom spójności przy każdej instrukcji odczytu i zapisu (ustawiany na poziomie sterownika –pojedynczy statement)
§ Zmiany na pojedynczym fizycznym wierszu są wykonywane atomowo i w izolacji (od wersji 1.2)
§ Wsparcie dla lekkich transakcji opartych na protokole Paxos, umożliwiających operację porównaj-i-zmień (CAS, od wersji 2.0)
§ Uwzględnienie lokalizacji węzłów – Cassandra bierze pod uwagę czy poszczególne węzły są umieszczone w tej samej szafie, w tym samym centrum danych, czy w zupełnie różnych lokalizacjach geograficznych (replikacja NetworkTopologyStrategy)
Spójność w bazie Cassandra

§ Cassandra sprawdza się, gdy wymagany jest– Bardzo szybki zapis danych w czasie rzeczywistym– „No single point of failure”– Elastyczny, łatwy w zmianie model danych– Wysoka skalowalność– Replikacja danych w różnych centrach danych
§ RDBMS radzi sobie lepiej niż Cassandra, gdy wymagane jest:– Wsparcie dla transakcji ACID (np. transfery
bankowe)
Kiedy stosować Cassandrę?

§ Listy i kolekcje (Spotify)§ Systemy rekomendacji (eBay)§ Obsługa wiadomości i powiadomień w czasie
rzeczywistym (Istagram)§ Systemy analityczne, np. do wykrywania oszust
finansowych § Dane z sensorów – internet rzeczy (Zonar)§ Rozwiązania grafowe (TITAN)§ …§ Więcej na
– http://planetcassandra.org/apache-cassandra-use-cases/
Do czego stosować Cassandrę?

INSTALACJA, KONFIGURACJA I URUCHAMIANIE CASSANDRY

§ Wymagania i przygotowanie instalacji§ Wybór i instalacja dystrybucji Cassandry§ Konfiguracja Cassandry dla pojedynczego
węzła§ Uruchamianie i zatrzymywanie Cassandry
Plan

§ Najnowsza wersja Java 7 (min 1.7.0_25) lub 8 (min 1.8.0_40)– Rekomendowana Oracle Java 7+, 64bit– Oracle JDK 1.7+ wymagane dla Cassandra 2.0+
§ Konfiguracja JAVA_HOME§ Instalacja Java Native Access (JNA), dla wcześniejszych niż C*2.1
– Wymagane dla systemów produkcyjnych§ Python 2.7.x – wymagany m.in. przez cqlsh, nodetool§ Wyłączyć swap (sudo swapoff -all)
– Lepiej pozwolić Cassandrze na zamknięcie z powodu braku pamięci -„mniejsze zło”
§ Synchronizacja czasu na wszystkich węzłach (np. NTP)
Przygotowanie systemu operacyjnego

Sprawdzić dostępność portów
§ Publiczne– 22 – ssh– 8888 – Interfejs webowy OpsCenter
§ Wewnątrz klastra– 7000 – komunikacja pomiędzy węzłami klastra– 7001 – komunikacja ssl pomiędzy węzłami – 7199 – JMX dla Cassandra
§ Porty klienckie– 9042 – protokół natywny (cqlsh)– 9160 – Thrift, (cassandra-cli)
Konfiguracja portów

§ Apache Cassandra– http://cassandra.apache.org/download/
§ DataStax Community Edition (DSC)– Najnowsza, najbardziej stabilna wersja C*– OpsCenter– Przykłady, instalator – http://planetcassandra.org/cassandra/
§ DataStax Enterprise Edition (DSE), OpsCenter, Drivers, DevCenter– Najbardziej stabilna, certyfikowana wersja C*– Integracja z M-R (Hadoop, Spark)– Indeksy tekstowe (Solr)– http://www.datastax.com/download
Wybór dystrybucji
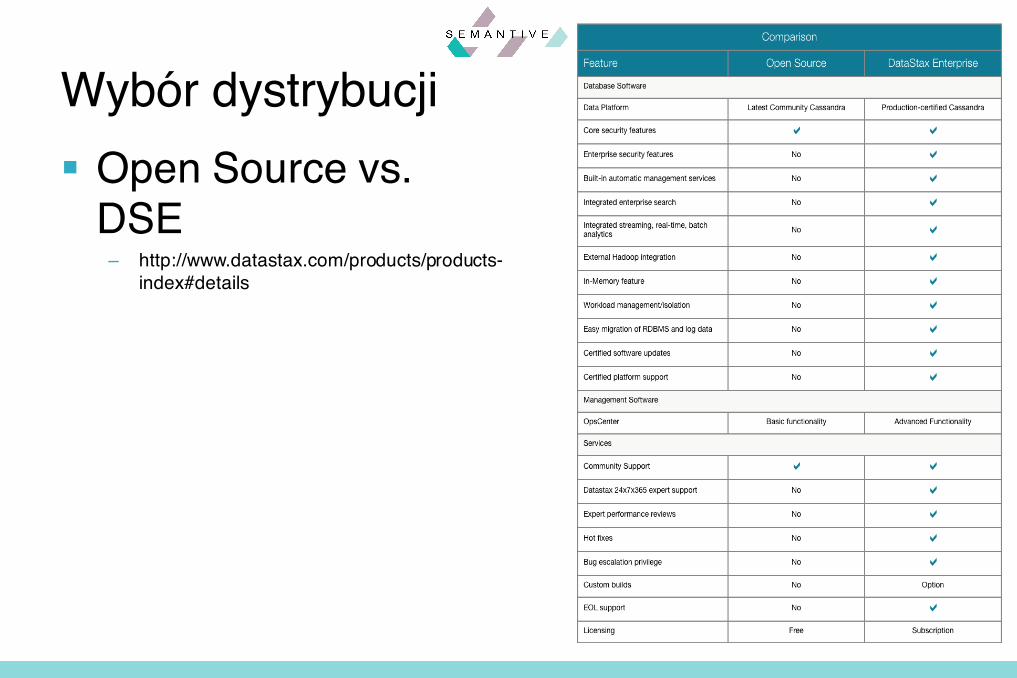
§ Open Source vs. DSE
– http://www.datastax.com/products/products-index#details
Wybór dystrybucji

§ DSC i DSE może być zainstalowane z pakietów (RPM – yum, DEB – apt-get, MSI – Windows)
§ Struktura instalacji:– /var/lib/cassandra - dane (SSTable, CommitLog)– /var/log/cassandra – logi– /var/run/cassandra – runtime– /usr/share/cassandra/lib – biblioteki JAR– /etc/cassandra – pliki konfiguracyjne (cassandra.yaml)– /etc/init.d – skrypt do uruchomiania usłgi– /etc/security/limits.d – limity dla użytkownika– /etc/default – domyślna konfiguracja
Instalacja Cassandry z pakietu

§ Wszystkie foldery w jednej lokalizacji– /bin – pliki wykonywalne (cassandra,
cqlsh, nodetool)– /conf – pliki konfiguracyjne
(cassandra.yaml)– /javadoc – javadoc kodu C*– /lib – biblioteki *.jar– /pylib – biblioteki Python (wymagane
np. przez cqlsh)– /toos – dodatkowe narzędzia (np.
cassandra-stress do testowania klastra)
Instalacja Cassandry z archiwum

§ cassandra.yaml – najważniejszy plik konfiguracyjny (np. katalogi danych)
§ cassandra-env.sh – konfiguracja JVM (MAX_HEAP_SIZE, JMX_PORT)
§ logback.xml – konfiguracja logowania§ cassandra-rackdc.properties –
przypisanie węzła do szafy i centrum danych
§ cassandra-topology.properties –konfiguracja adresów szaf i centrów danych w klastrze
§ /bin/cassandra.in.sh – JAVA_HOME, CASSANDRA_HOME, CASSANDRA_CONF
Konfiguracja

§ cluster_name (domyślnie: „Test Custer”)– Wszystkie węzły w jednym klastrze muszą mieć tą samą
nazwę§ listen_address (domyślnie: localhost)
– Adresy IP lub nazwy innych węzłów, używane do ustalenia klastra (nie muszą być wszystkie, min. zbiór, który pozwala na wykrycie połączeń peer-to-peer)
§ rpc_address / rpc_port (domyślnie: localhost / 9160)– Port protokołu Thrift
§ native_transport_port (domyślnie: 9042)– Port dla protokołu binarnego (Native Java Driver),
używany przez sterownik, cqlsh itd.
cassandra.yaml – kluczowe parametry

§ commitlog_directory (domyślnie: /var/lib/cassandra/commitlog lub $CASSANDRA_HOME/data/commitlog)– Zalecane montowanie na oddzielnym dysku, szczególnie jeżeli
nie jest to dysk SSD§ data_file_directories (domyślnie: /var/lib/cassandra/data
lub $CASSANDRA_HOME/data/data)– Katalog na pliki tabel (SSTable)
§ saved_caches_directory (domyślnie: /var/lib/cassandra/saved_caches lub $CASSANDRA_HOME/data/saved_caches)– Katalog na cache kluczy i wierszy
cassandra.yaml – kluczowe parametry

§ {install_dir}/bin/cassandra§ Parametry
– -f§ Uruchamia Cassandrę w pierwszym planie (domyślnie
w tle)– -p <nazwa_pliku>
§ Zapisuje PID w pliku, wykorzystywany do zatrzymania za pomocą PID
– -v§ Wyświetla wersje Cassandry bez jej uruchamiania
Uruchamianie Cassandry

§ Instalacja z archiwum– sudo {install_dir}/bin/cassandra -f
§ Uruchamia w pierwszym planie, logi na ekranie
§ Instalacja z pakietu– sudo service cassandra start
Uruchamianie Cassandry

§ Instalacja z archiwum– Cassandra uruchomiona w pierwszym planie
§ ctrl + c– Cassandra uruchomiona w tle – należy
sprawdzić PID§ ps auxw | grep cassandra§ sudo kill <pid>
§ Instalacja z pakietu (serwis)– sudo service cassandra stop
Zatrzymywanie Cassandry

NARZĘDZIA

§ cqlsh§ nodetool§ ccm – Cassandra Cluster Manager§ cassandra-stress§ Pozostałe narzędzia
Plan

§ Interaktywny, działający z linii poleceń, klient CQL– Domyślnie łączy się do lokalnej instancji– Uzupełnia komendy (TAB)– {install_dir}/bin/cqlsh
– Opcje:§ -k [keyspace] – uruchamia cqlsh dla wybranej przestrzeni kluczy§ - f [file_name] – uruchamia komendę CQL ze skryptu i kończy pracę§ -u [user] –p[password] – autentykacja użytkownika§ -h – wyświetla pomoc§ …
cqlsh
cqlsh [options] [host [port]]

§ cqlsh pozwala na:– Wykonywanie komend CQL
§ Uniwersalny język zapytań Cassandry– Wykonywanie poleceń cqlsh
§ Pomocne do wykonywania poleceń CQL§ Polecenia dostępne tylko z cqlsh§ Bardzo bogata pomoc
– cqlsh>help; - lista tematów– Cqlsh>help [nazwa_tematu]; - pomoc dot. komend
Możliwości cqlsh
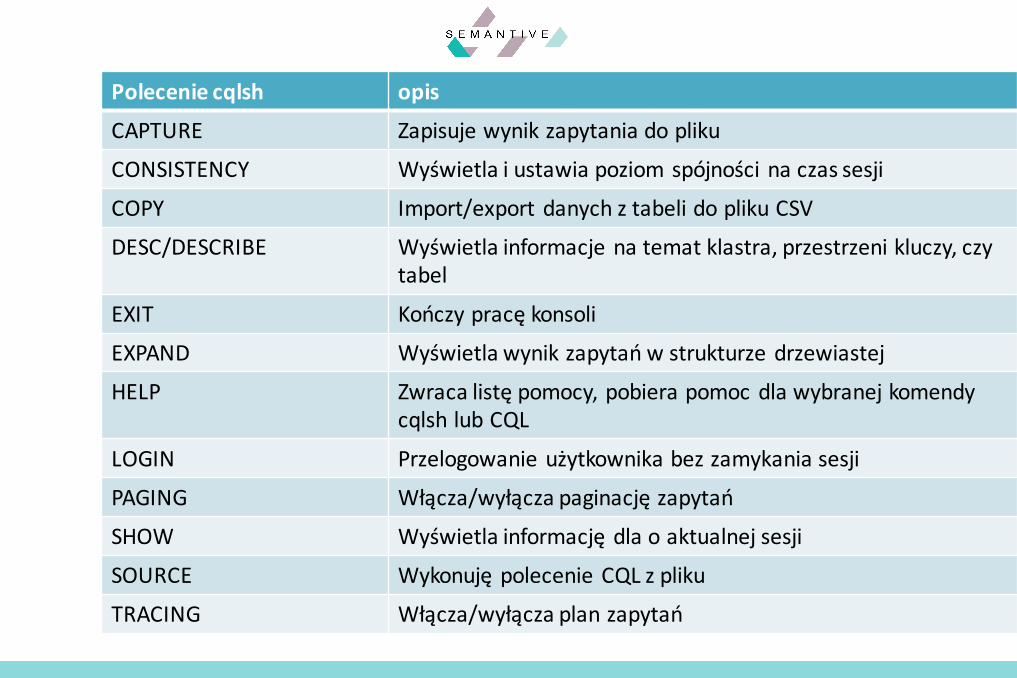
Poleceniecqlsh opis
CAPTURE Zapisujewynikzapytaniadopliku
CONSISTENCY Wyświetla iustawiapoziom spójnościnaczassesji
COPY Import/export danychztabelidoplikuCSV
DESC/DESCRIBE Wyświetla informacjenatematklastra,przestrzenikluczy,czytabel
EXIT Kończypracękonsoli
EXPAND Wyświetlawynik zapytańwstrukturzedrzewiastej
HELP Zwraca listępomocy,pobiera pomocdlawybranejkomendycqlsh lubCQL
LOGIN Przelogowanieużytkownikabezzamykania sesji
PAGING Włącza/wyłączapaginacjęzapytań
SHOW Wyświetlainformacjędlaoaktualnejsesji
SOURCE WykonujępolecenieCQLzpliku
TRACING Włącza/wyłącza planzapytań

§ Funkcje– Informacyjne– Zmieniające parametry pracy– Utrzymania– Naprawy– Kopii bezpieczeństwa
Narzędzie nodetool

§ Narzędzie do zarządzania klastrem z linii poleceń– {install_dir}/bin/nodetool
§ Umożliwia podłączenie się do zdalnego węzła– JMX_PORT – konfigurowany w cassandra-env.sh– Domyślnie JMX_PORT = 7199
42
Narzędzie nodetoolnodetool -h HOSTNAME [-p JMX_PORT -u JMX_USERNAME -pw
JMX_PASSWORD ] COMMAND

§ nodetool status– zwraca informacje o węzłach pracujących w
klastrze
Funkcje informacyjne

§ nodetool describecluster– wyświetla podstawowe informacje o klastrze,
takie nazwa, snitch, czy partitioner
Funkcje informacyjne

§ nodetool info– wyświetla podstawowe informacje o wybranym węźle, takie jak
ilość danych, czas działania, lokalizacja (centrum danych, rack), ilość wolnej pamięci oraz stan cache
Funkcje informacyjne

§ Szybkie tworzenie klastrów z wielu węzłów na lokalnej maszynie– Przydatne do dewelopmentu i testów (tylko)– Komunikacja tylko z localhost
§ Narzędzie OpenSource– https://github.com/pcmanus/ccm– Wymagania: Python 2.7, pyYAML, six, ant, psutil
CCM - Cassandra Cluster Manager

§ Tworzenie klastra– ccm create –v 2.1.6 –n 3 –s
§ Tworzenie klastra – szczegółowo– ccm create –v 2.1.6– ccm populate –n 3– ccm start
CCM – podstawowe funkcje

§ ccm list§ ccm switch§ ccm create/remove§ ccm populate§ ccm start/stop§ ccm flush/compact
CCM - klastry

§ ccm node1 start/stop§ ccm node1 status § ccm node1 showlog§ ccm node1 ring§ ccm node1 flush/drain/compact§ ccm node1 cqlsh§ ccm node1 hadoop/hive/spark
CCM – węzły

§ Narzędzie z linii poleceń do generowania testu obciążeniowego– Tworzy: Keyspace1 z tablicami Standard1,
Super1, Counter3– install/tools/bin/cassandra-stress
cassandra-stress
cassandra-stress [command][options]

§ Używana tylko jedna opcja naraz – read – wiele równoległych odczytów wcześniej zapisanych
danych– write – wiele równoległych zapisów do klastra– mixed – interwałowy zapis i odczyt, parametry konfigurowalne– counter_write – wiele równoległych zapisów do tabli licznikowej– counter_read – równoległe odczyty liczników– user – przeplatanie zapytań zdefiniowanych przez użytkownika– help – pomoc– print – wyświetla parametry rozkładów testu
§ Komendy mogą mieć dodatkowe opcje konfiguracyjne
cassandra-stress

§ Linie są raportowane co -log interval=?– total ops – całkowita liczba operacji od początku testu– adj row/s – przybliżona prędkość zapisu wierszy w interwale– op/s – prędkość operacji w interwale– pk/s – prędkość zapisu partycji– row/s – prędkość zapisu wierszy w interwale– mean – średnie opóźnienie operacji w interwale– med – mediana opóźnienia operacji– .95 – 95% przypadków, gdy opóźnienie było mniejsze niż liczba wyświetlona w kolumnie
§ .99, .999– max – maksymalne opóźnienie w ms
stress-test – interpretacja loga

§ sstablekeys – wyświetla klucze partycjonujące z pliku SSTable
§ sstableloader – masowe ładowanie danych do klastra§ sstablescrub – używane razem z nodetool do naprawiania
klastra§ sstable2json, json2sstable – import/eksport danych z/do
JSON§ sstableupgrade – migracja SSTable do aktualnej wersji C*§ sstablemetadata – informacje o SSTable§ sstablerepairedset – oznacza SSTable jako naprawioną§ sstablesplit – dzieli duże pliki SSTable§ token-generator – ręczne generowanie tokenów dla C*
Pozostałe narzędzia

§ {install_dir}/bin/cassandra-cli– Klient Thrift do C*– Deprecated – usunięty w C* 2.2– Lista komend zbliżona do cqlsh– Operuje na modelu natywnym
§ Użyteczny do podglądu struktury mapowania CQL na model natywny
Pozostałe narzędzia

NATYWNY MODEL DANYCH

§ W bazie danych Cassandra dane zorganizowane są w następujący sposób:– Przestrzenie kluczy (key spaces)– Rodziny kolumn (column families)– Wiersze (rows)– Krotki (tuples) – nazywane także kolumnami
§ Uwaga: w natywnym modelu danych Cassandraznaczenie kolumny jest zupełnie inne niż w bazach SQL
Model danych
57
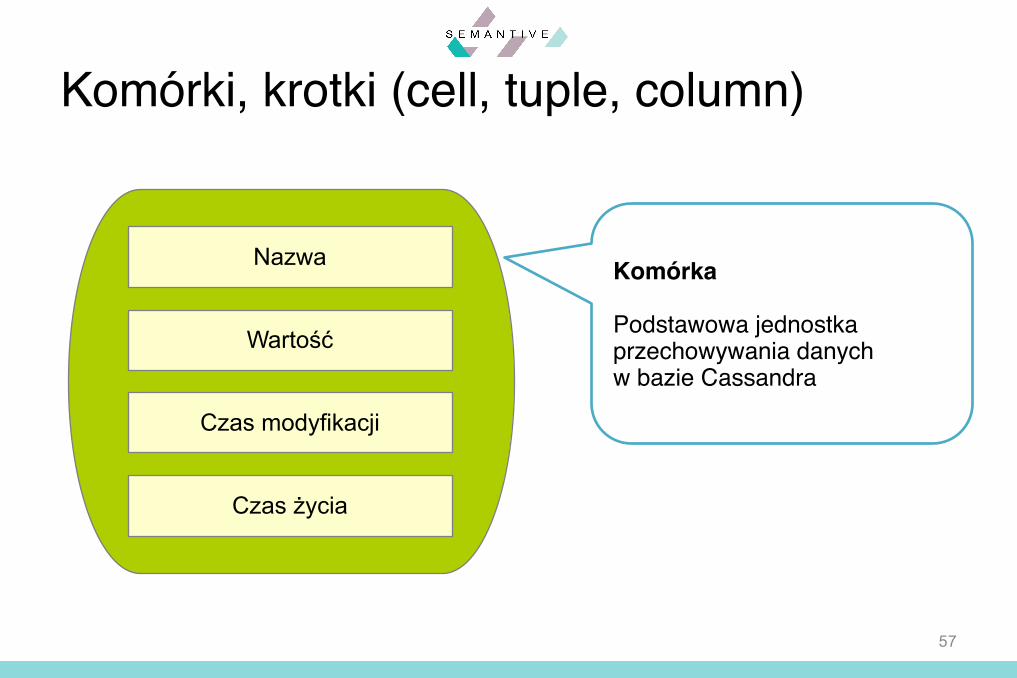
Komórki, krotki (cell, tuple, column)
Nazwa
Wartość
Czas modyfikacji
Czas życia
Komórka
Podstawowa jednostkaprzechowywania danychw bazie Cassandra
58
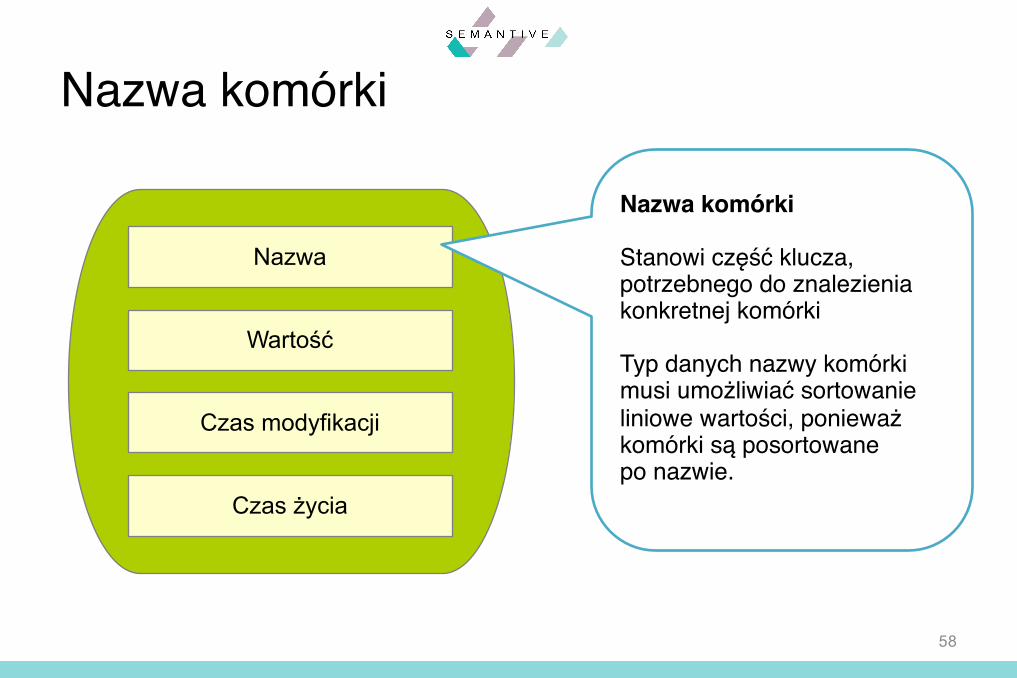
Nazwa komórki
Nazwa
Wartość
Czas modyfikacji
Czas życia
Nazwa komórki
Stanowi część klucza,potrzebnego do znalezieniakonkretnej komórki
Typ danych nazwy komórkimusi umożliwiać sortowanieliniowe wartości, ponieważkomórki są posortowanepo nazwie.

59
Wartość komórki
Nazwa
Wartość
Czas modyfikacji
Czas życia
Wartość komórki
Właściwe dane przechowywane w komórce.
Wielkość danych w komórcenie może przekraczać 2 GB.
Zaleca się, żeby nie przekraczała kilku MB.
60
Czas modyfikacji komórki
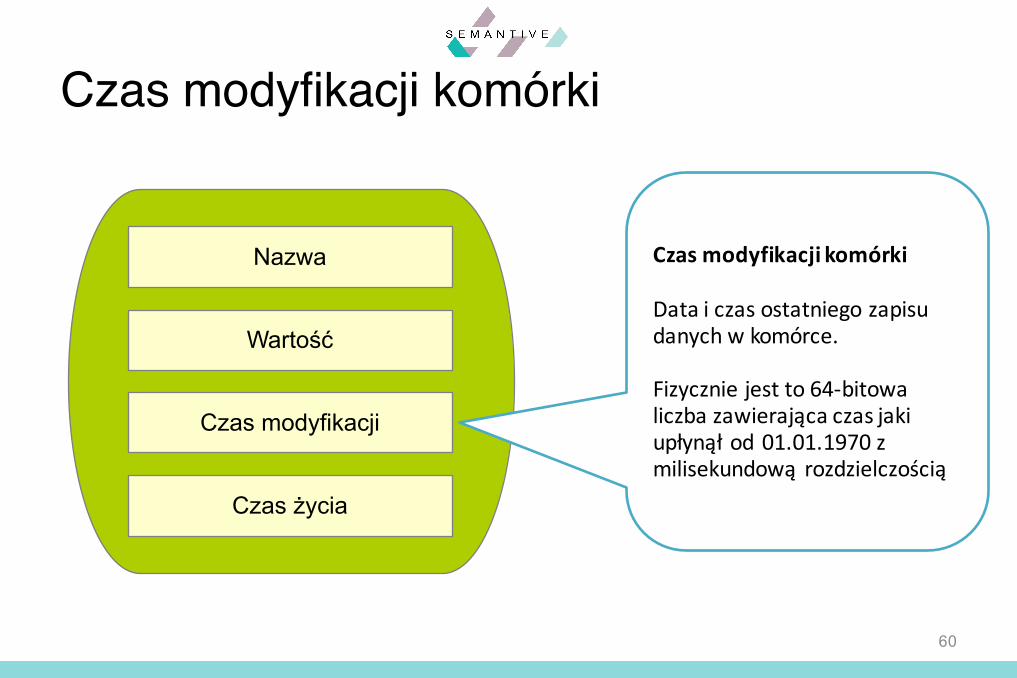
Nazwa
Wartość
Czas modyfikacji
Czas życia
Czas modyfikacji komórki
Data i czas ostatniego zapisudanych w komórce.
Fizycznie jest to 64-bitowaliczba zawierająca czas jakiupłynął od 01.01.1970 zmilisekundową rozdzielczością

61
Czas życia komórki
Nazwa
Wartość
Czas modyfikacji
Czas życia
Czas życia komórki
Jest to czas [s] po jakim komórkama zostać automatycznieusunięta z bazy danych.
Nie musi być określony – tzn.komórki mogą być permanentne.
62
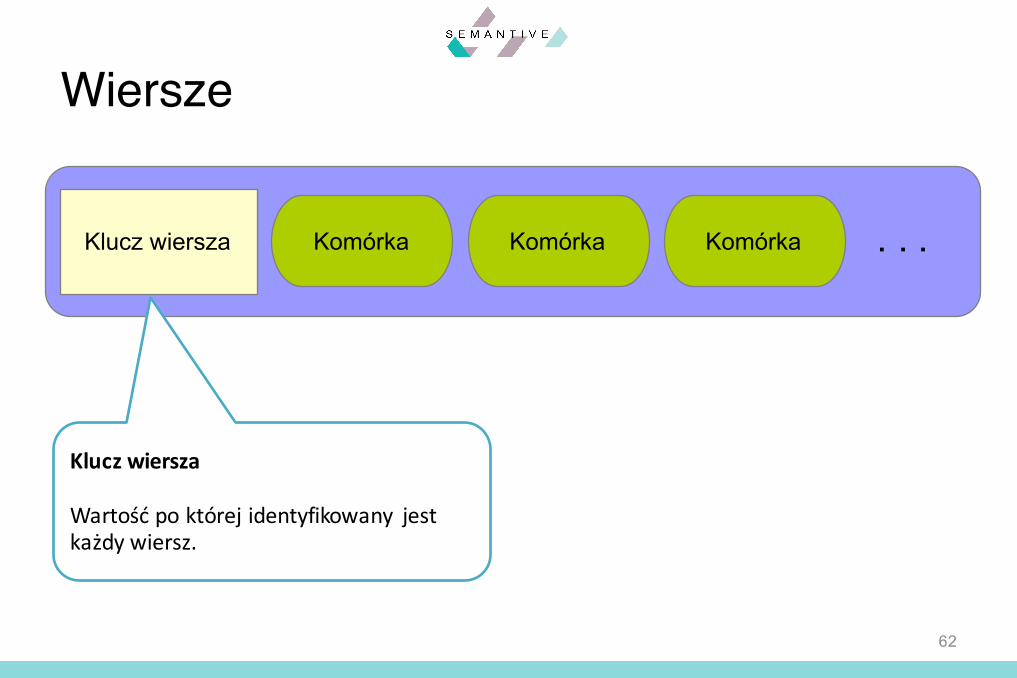
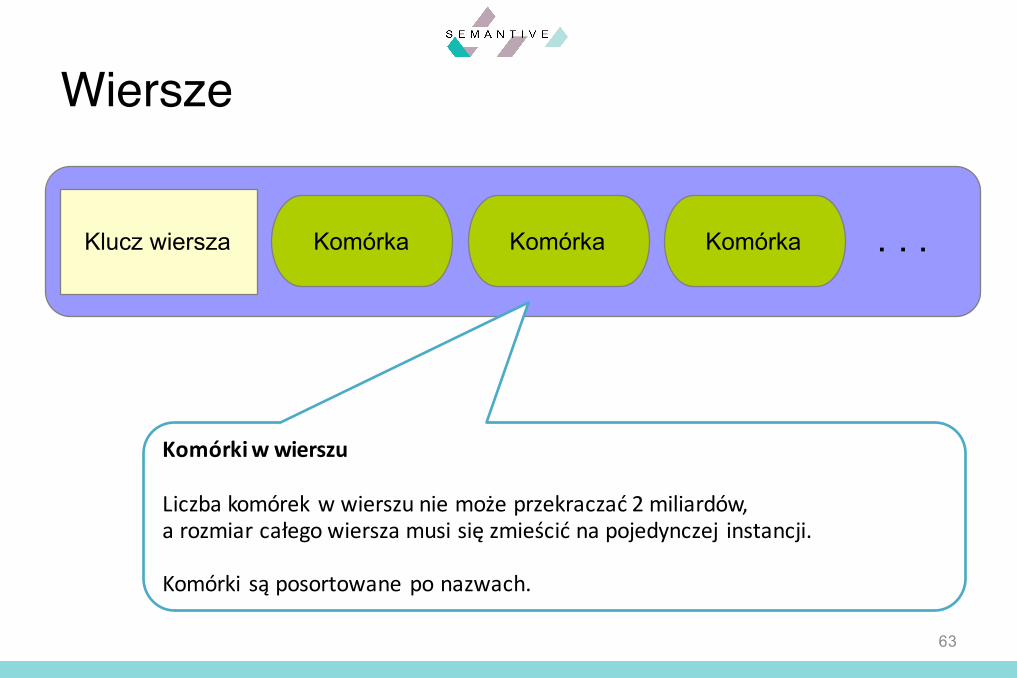
Wiersze
Klucz wiersza Komórka Komórka Komórka . . .
Klucz wiersza
Wartość po której identyfikowany jestkażdy wiersz.
63
Wiersze
Klucz wiersza Komórka Komórka Komórka . . .
Komórkiw wierszu
Liczba komórek w wierszu nie może przekraczać 2 miliardów,a rozmiar całego wiersza musi się zmieścić na pojedynczej instancji.
Komórki są posortowane po nazwach.
64
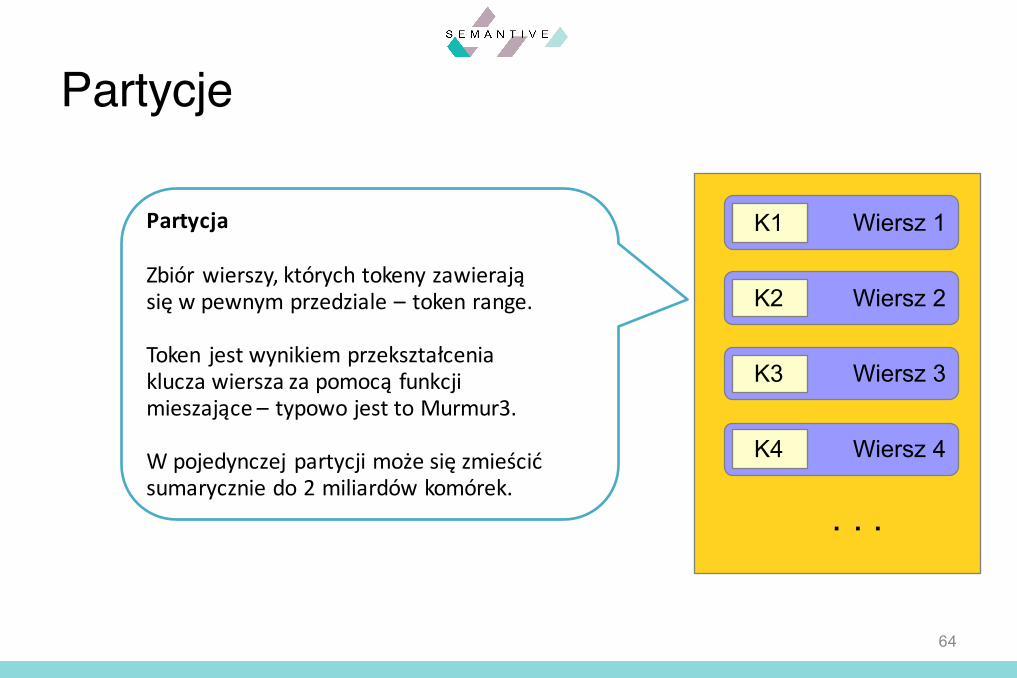
Partycje
Wiersz 1
Wiersz 2
Wiersz 3
Wiersz 4
. . .
K1
K2
K3
K4
Partycja
Zbiór wierszy, których tokeny zawierająsię w pewnym przedziale – token range.
Token jest wynikiem przekształceniaklucza wiersza za pomocą funkcjimieszające – typowo jest to Murmur3.
W pojedynczej partycji może się zmieścićsumarycznie do 2 miliardów komórek.
K1
65
Tabele
. . .
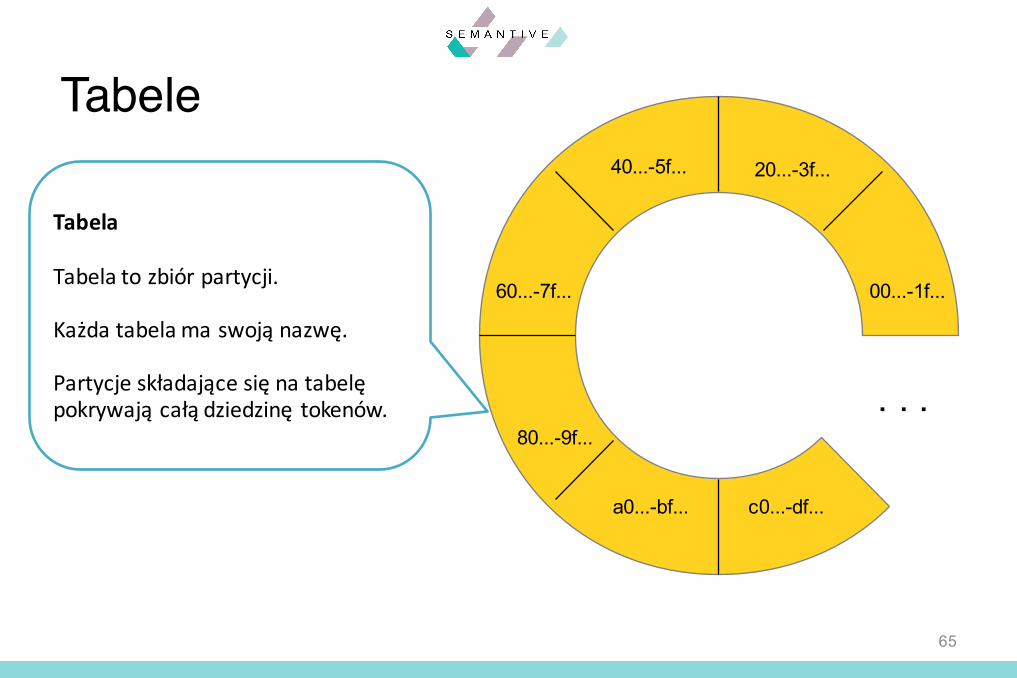
Tabela
Tabela to zbiór partycji.
Każda tabela ma swoją nazwę.
Partycje składające się na tabelępokrywają całą dziedzinę tokenów.
00...-1f...
20...-3f...40...-5f...
60...-7f...
80...-9f...
a0...-bf... c0...-df...

66
Przestrzenie kluczy
Przestrzeń kluczy
Przestrzeń kluczy to odpowiednikpojedynczej bazy danych.
Przestrzeń kluczy zawiera zbiór tabeldostępnych po ich nazwach.

§class Tuple<KeyType, ValueType> {§ KeyType key;
§ ValueType value;
§ long timestamp;
§ int ttl;
§}
67
Model danych - analogia

RowType = SortedMap<String,Tuple>
TableType = Map<String,RowType>
KeySpaceType = Map<String,TableType>
ClusterType = Map<String,KeySpaceType>
68
Model danych - analogia

§ Dostęp do danych realizowany jest na poziomie komórek
§ Możliwe jest pobranie:– Pojedynczej komórki– Zakresu komórek– Zbioru zakresów komórek
§ Zakres komórek jest uporządkowaną kolekcją następujących po sobie komórek w pojedynczym wierszu– Komórki w wierszu posortowane są według nazw
Metody dostępu do danych

§ Pobranie jakichkolwiek danych wymaga podania przestrzeni kluczy, nazwy tabeli (rodziny kolumn) oraz klucza wiersza
§ Pobranie pojedynczej komórki wymaga podania dodatkowo:– nazwy komórki
§ Pobranie zakresu komórek wymaga podania dodatkowo:– dolnego i górnego ograniczenia zakresu komórek
§ Pobranie zbioru zakresów komórek wymaga podania dodatkowo:– zbioru par dolnych i górnych ograniczeń komórek
§ Można także określić maksymalną liczbę komórek, która może być zwrócona (umożliwia to np. paginację)
Metody dostępu do danych

§ Jak w takim modelu danych przechować typowe zbiory danych, takie jak?– Dane użytkowników– Dzienniki zdarzeń– Lista zamówień– Hierarchia produktów
Przechowywanie typowych danych

§ Najpierw należy określić w jaki sposób będzie uzyskiwany dostęp do tych danych – od tego zależy jak zostaną one zamodelowane
Przechowywanie typowych danych

§ Cel:– Przechowywanie danych o użytkownikach
serwisu internetowego(login, email, imię - opcjonalnie, nazwisko,
hasło)– Możliwość wyszukiwania użytkowników po
loginie
Przykład 1: Dane użytkowników

§ Realizacja:– Tabela, w której kluczem wiersza jest login
użytkownika, a komórki w wierszu przechowują pozostałe atrybuty
Przykład 1: Dane użytkowników
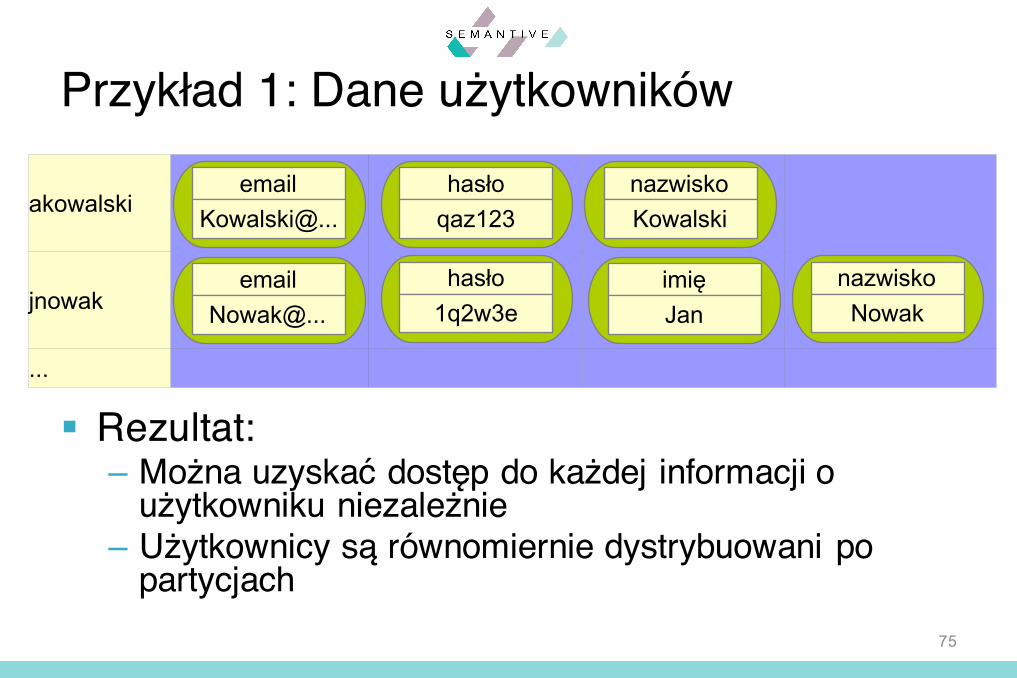
§ Rezultat:– Można uzyskać dostęp do każdej informacji o
użytkowniku niezależnie– Użytkownicy są równomiernie dystrybuowani po
partycjach75
Przykład 1: Dane użytkowników
akowalski
jnowak
...
emailKowalski@...
imięJan
nazwiskoKowalski
hasłoqaz123
emailNowak@...
hasło1q2w3e
nazwiskoNowak

§ Cel:– Przechowywanie informacji o zdarzeniach w
systemie (data i czas, typ, rezultat, użytkownik)– Zdarzenia można wyszukiwać na podstawie
zakresu daty i czasu oraz typu zdarzenia
Przykład 2: Dziennik zdarzeń

§ Realizacja 1:– Tabela, której kluczem wiersza jest typ zdarzenia– Nazwy poszczególnych komórek w danym
wierszu są datą i czasem zdarzenia– Komórka zawiera zserializowaną informację o
użytkowniku i rezultacie zdarzenia
Przykład 2: Dziennik zdarzeń, realizacja 1
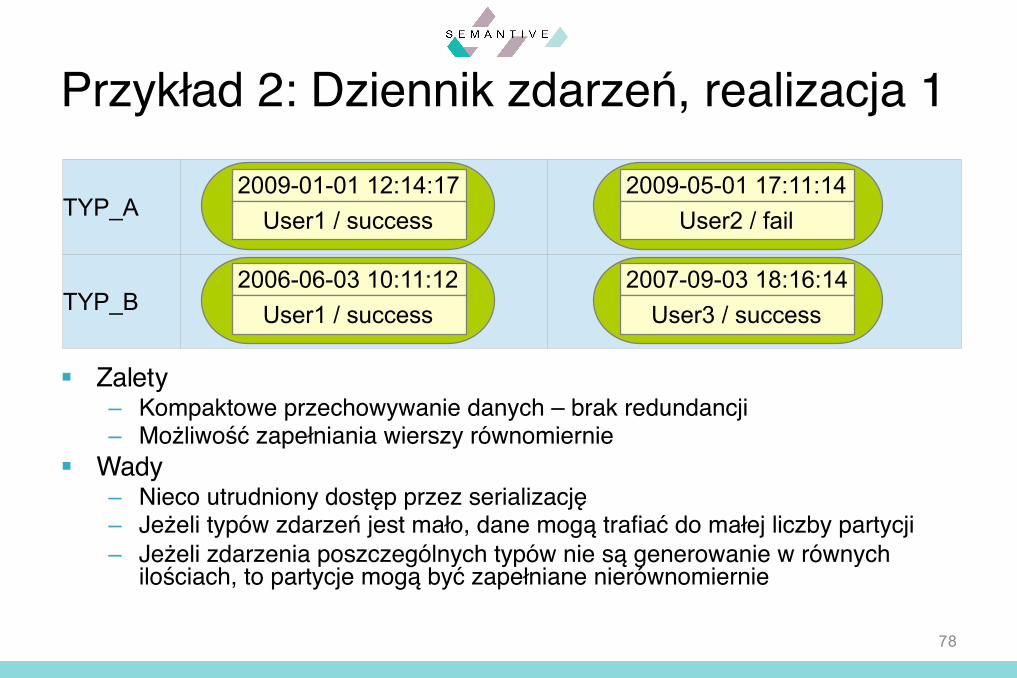
§ Zalety– Kompaktowe przechowywanie danych – brak redundancji– Możliwość zapełniania wierszy równomiernie
§ Wady– Nieco utrudniony dostęp przez serializację– Jeżeli typów zdarzeń jest mało, dane mogą trafiać do małej liczby partycji– Jeżeli zdarzenia poszczególnych typów nie są generowanie w równych
ilościach, to partycje mogą być zapełniane nierównomiernie
78
Przykład 2: Dziennik zdarzeń, realizacja 1
TYP_A
TYP_B
2009-01-01 12:14:17User1 / success
2009-05-01 17:11:14User2 / fail
2006-06-03 10:11:12User1 / success
2007-09-03 18:16:14User3 / success

§ Cel (przypomnienie):– Przechowywanie informacji o zdarzeniach w
systemie (data i czas, typ, rezultat, użytkownik)– Zdarzenia można wyszukiwać na podstawie
zakresu daty i czasu oraz typu zdarzenia
Przykład 2: Dziennik zdarzeń, realizacja 2

§ Realizacja 2:– Tabela, której kluczem wiersza jest typ zdarzenia– Nazwy poszczególnych komórek w danym
wierszu są konkatenacją daty/czasu zdarzenia i nazwy atrybutu (użytkownik/rezultat)
– Komórka zawiera wartość danego atrybutu dla danego zdarzenia
Przykład 2: Dziennik zdarzeń, realizacja 2
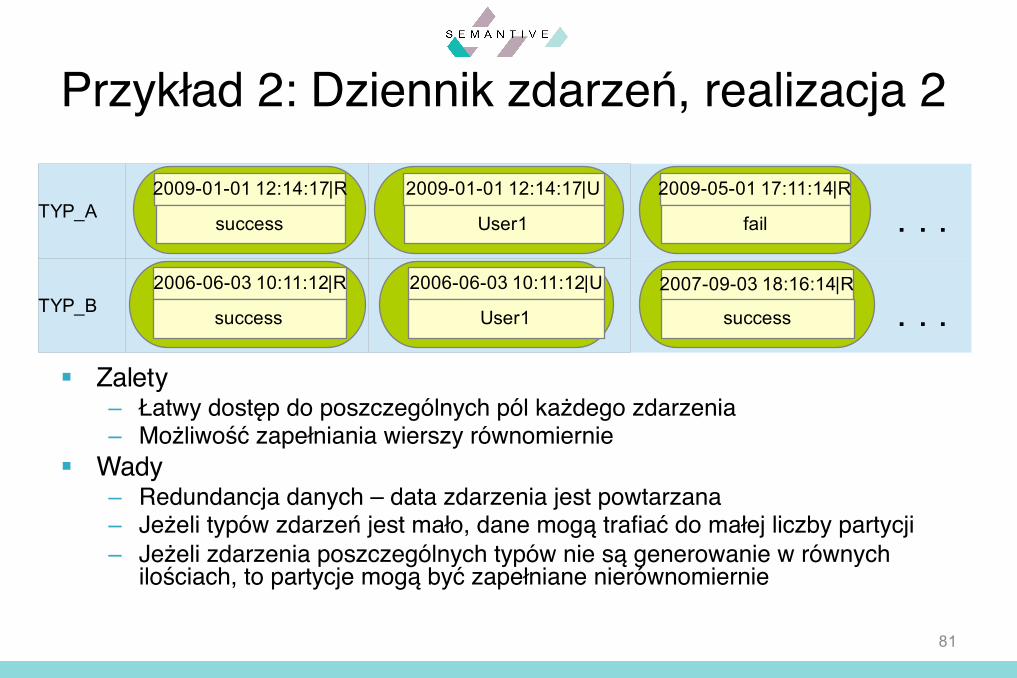
§ Zalety– Łatwy dostęp do poszczególnych pól każdego zdarzenia– Możliwość zapełniania wierszy równomiernie
§ Wady– Redundancja danych – data zdarzenia jest powtarzana– Jeżeli typów zdarzeń jest mało, dane mogą trafiać do małej liczby partycji– Jeżeli zdarzenia poszczególnych typów nie są generowanie w równych
ilościach, to partycje mogą być zapełniane nierównomiernie
81
Przykład 2: Dziennik zdarzeń, realizacja 2
TYP_A
TYP_B
2009-01-01 12:14:17|R
success
2006-06-03 10:11:12|R
success
2009-01-01 12:14:17|U
User1
2009-05-01 17:11:14|R
fail . . .2006-06-03 10:11:12|U
User1
2007-09-03 18:16:14|R
success . . .

§ Cel (przypomnienie):– Przechowywanie informacji o zdarzeniach w
systemie (data i czas, typ, rezultat, użytkownik)– Zdarzenia można wyszukiwać na podstawie
zakresu daty i czasu oraz typu zdarzenia
Przykład 2: Dziennik zdarzeń, realizacja 3

§ Realizacja 3:– Tabela, której kluczem wiersza część daty i czasu
– np. rok lub miesiąc lub inna część daty i czasu– Nazwy poszczególnych komórek w danym
wierszu są konkatenacją typu zdarzenia, daty/czasu zdarzenia oraz atrybutu
– Komórka zawiera wartość danego atrybutu dla danego zdarzenia
Przykład 2: Dziennik zdarzeń, realizacja 3
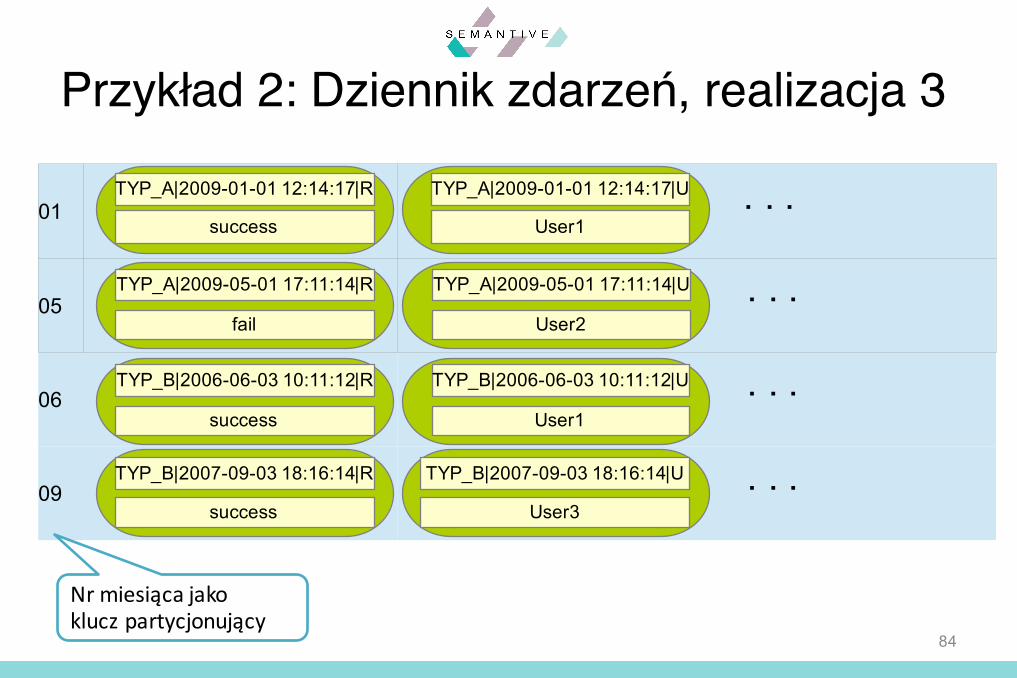
84
Przykład 2: Dziennik zdarzeń, realizacja 3
01
05
06
09
TYP_A|2009-01-01 12:14:17|R
success
TYP_B|2006-06-03 10:11:12|R
success
TYP_A|2009-01-01 12:14:17|U
User1
TYP_A|2009-05-01 17:11:14|R
fail
. . .
TYP_B|2006-06-03 10:11:12|U
User1
TYP_B|2007-09-03 18:16:14|R
success
. . .
. . .
. . .
TYP_A|2009-05-01 17:11:14|U
User2
TYP_B|2007-09-03 18:16:14|U
User3
Nr miesiąca jakoklucz partycjonujący

§ Zalety– Łatwy dostęp do poszczególnych pól każdego zdarzenia– Możliwość zapełniania wierszy równomiernie– Umieszczenie cyklicznie zmieniającego się fragmentu
daty jako klucza partycjonującego umożliwia równomierne wypełnianie poszczególnych partycji
§ Wady– Redundancja danych – data i typ zdarzenia są
powtarzane– Nieco utrudniony dostęp do uporządkowanej kolekcji
zdarzeń – wymagane jest scalanie
Przykład 2: Dziennik zdarzeń, realizacja 3

§ Wada wszystkich realizacji:– Uniemożliwienie wstawienia więcej niż jednego
zdarzenia danego typu w ciągu danej jednostki czasu§ W celu rozwiązania wady można:
– Zwiększyć rozdzielczość przechowywanej daty i czas do wystarczającej dla potrzeb systemu
– Dodać dodatkowy licznik cykliczny na poziomie aplikacji
– Dodać identyfikator węzła jeżeli system jest rozproszony
Przykład 2: Dziennik zdarzeń, podsumowanie

MODEL DANYCH CQL

§ Język podobny do SQL, umożliwiający dostęp do bazy danych Cassandra
§ Pozwala na definiowanie i zarządzanie modelem danych na wyższym poziomie abstrakcji w stosunku do modelu natywnego (interfejs relacyjny na nierelacyjnej bazie danych)
§ Pozwala na wykonywanie zapytań§ Pozwala na zarządzanie danymi – wstawianie,
modyfikacja, usuwanie§ Umożliwia kontrolę spójności
CQL

§ Model zdenormalizowany– Modelowanie konkretnych zastosowań (zapytań),
a nie domeny§ Podczas modelowania należy koncentrować
się na modelu fizycznym
CQL – modelowanie

Model CQL
KlasterPrzestrzeńkluczy(keyspace)
Tabela(table)
Wiersz(row)Kolumna_1• Krotka (tupple)
Kolumna_2• Krotka (tuple)
Kolumna_3• …
OdpowiadabazidanychwRDBMS

§ Przestrzenie kluczy to inaczej bazy danych§ Pojedyncza tabela zorganizowana jest w
pojedynczej rodzinie kolumn – pojedyncza rodzina kolumn zawiera jedną tabelę (mapowanie 1 - 1)
§ Przestrzeń kluczy (tak jak w modelu natywnym) zawiera zbiór tabel (rodzin kolumn)
§ Wiersze jednej kolumny są rozsiane po strukturze klastra
Przestrzenie kluczy i tabele

92
Struktura tabeliKolumna 1
...
Kolumna n
Kolumna n+1
...
Kolumna n+m
Kolumna n+m+1
...
Kolumna n+m+k
Kolumny klucza partycjonującego(kolejność nieistotna)
Kolumny klucza sortującego(kolejność istotna)
Pozostałe kolumnyz danymi(kolejność nieistotna)
Kolumny stanowiąceklucz główny

§ Kluczem wiersza jest klucz partycjonujący. – konkatenacja wartości kolumn klucza
partycjonującego§ Kolejnych k krotek w wierszu odpowiada k
kolejnym kolumnom danych– Kluczem krotki jest konkatenacja wartości kolumn
klucza sortującego i nazwy jednej kolumny danych
– Wartością krotki jest wartość kolumny danych, której ta krotka odpowiada
Odwzorowanie tabeli w rodzinie kolumn

94
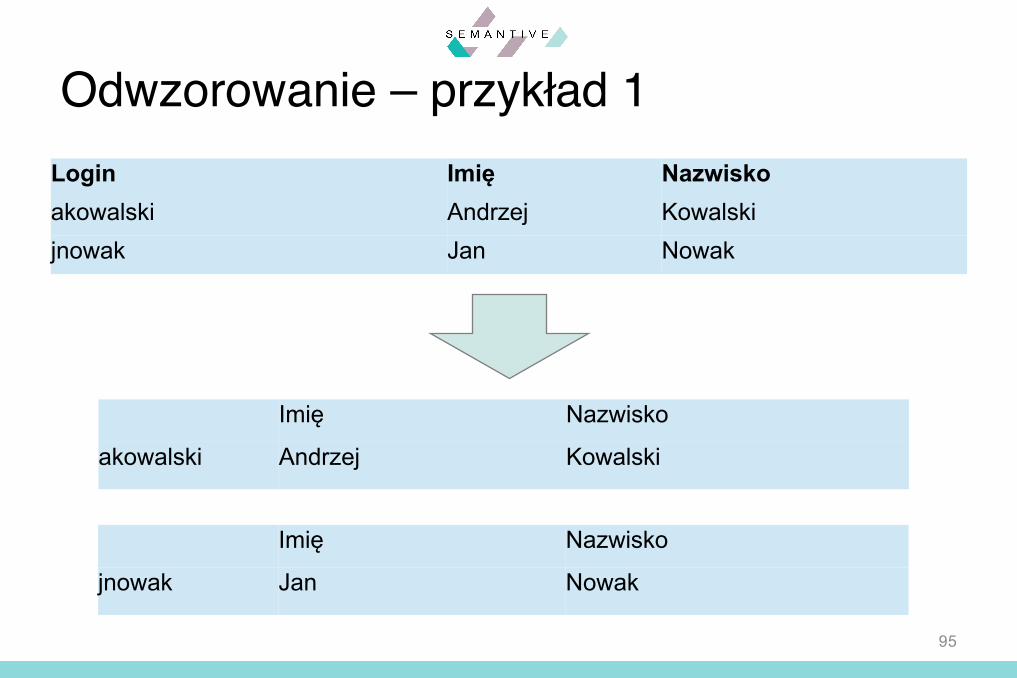
Odwzorowanie – przykład 1
Login Imię Nazwiskoakowalski Andrzej Kowalskijnowak Jan Nowak
Kolumny klucza partycjonującego Kolumny danych
95
Odwzorowanie – przykład 1Login Imię Nazwiskoakowalski Andrzej Kowalskijnowak Jan Nowak
Imię Nazwisko
akowalski Andrzej Kowalski
Imię Nazwisko
jnowak Jan Nowak

Odwzorowanie – przykład 1
Definicjatabeli
DanewmodeluCQL
Modelnatywny
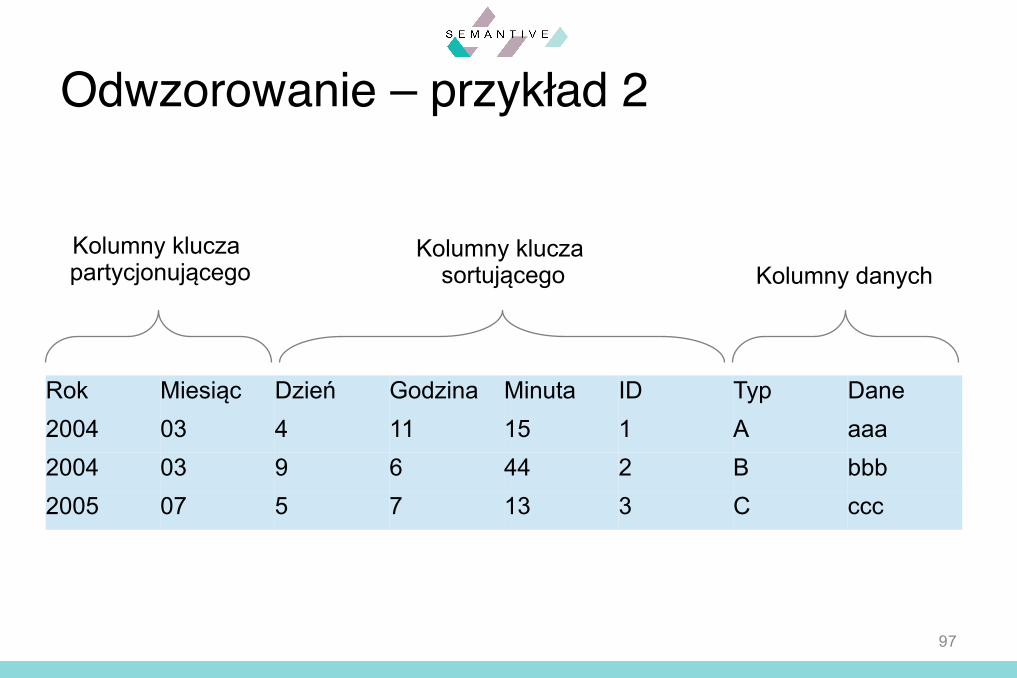
97
Odwzorowanie – przykład 2
Rok Miesiąc Dzień Godzina Minuta ID Typ Dane2004 03 4 11 15 1 A aaa2004 03 9 6 44 2 B bbb2005 07 5 7 13 3 C ccc
Kolumny klucza partycjonującego
Kolumny klucza sortującego Kolumny danych
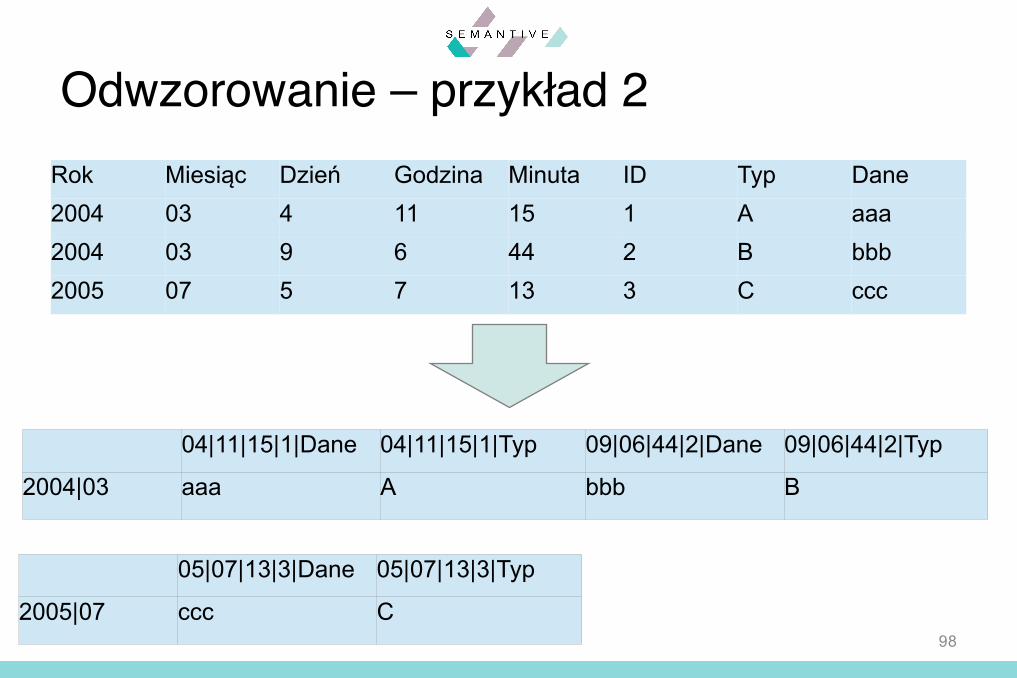
98
Odwzorowanie – przykład 2Rok Miesiąc Dzień Godzina Minuta ID Typ Dane2004 03 4 11 15 1 A aaa2004 03 9 6 44 2 B bbb2005 07 5 7 13 3 C ccc
04|11|15|1|Dane 04|11|15|1|Typ 09|06|44|2|Dane 09|06|44|2|Typ
2004|03 aaa A bbb B
05|07|13|3|Dane 05|07|13|3|Typ
2005|07 ccc C
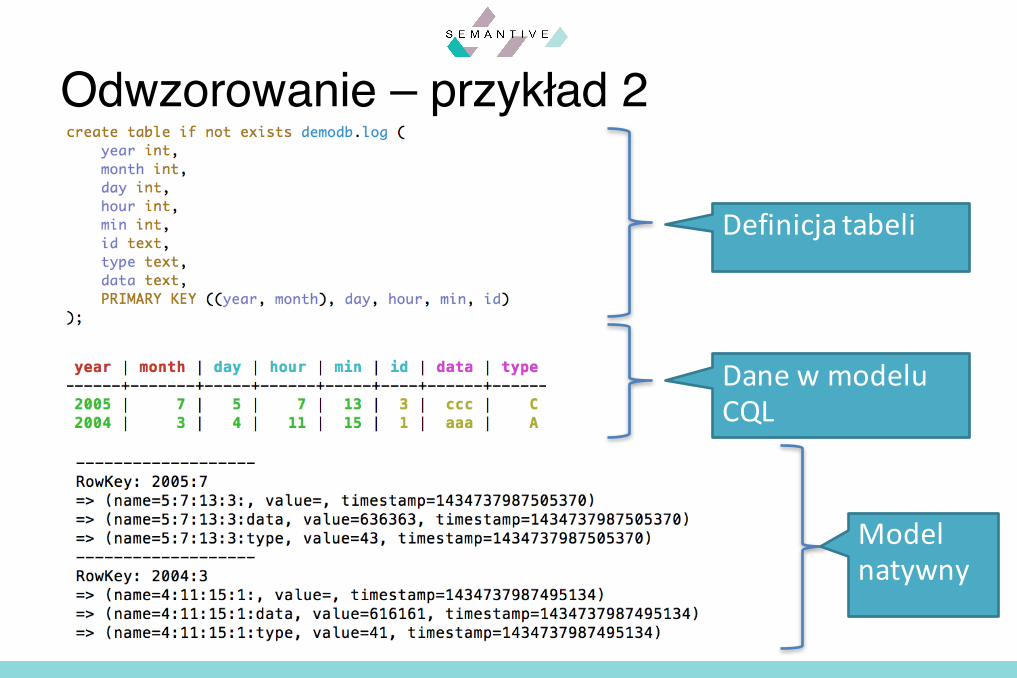
Odwzorowanie – przykład 2
Definicjatabeli
DanewmodeluCQL
Modelnatywny

§ Dane są partycjonowane po kluczu partycjonującym i równomiernie dystrybuowane pomiędzy węzłami
§ Dane o takim samym kluczu partycjonującym są sortowane po wszystkich kolumnach z klucza sortującego, w takiej kolejności, w jakiej są zdefiniowane
§ Dane o takim samym kluczu partycjonujący można pobierać spójnymi fragmentami
Możliwości wynikające z odwzorowania

§ Aby odczytać pojedynczy wiersz trzeba znać cały klucz główny
§ Aby odczytać jakiekolwiek dane potrzebny jest przynajmniej klucz partycjonujący
§ Dane mogą być sortowane tylko po kolumnach zdefiniowanych jako klucz sortujący podczas definiowania tabeli – nie można tego zmieni
Ograniczenia wynikające z odwzorowania
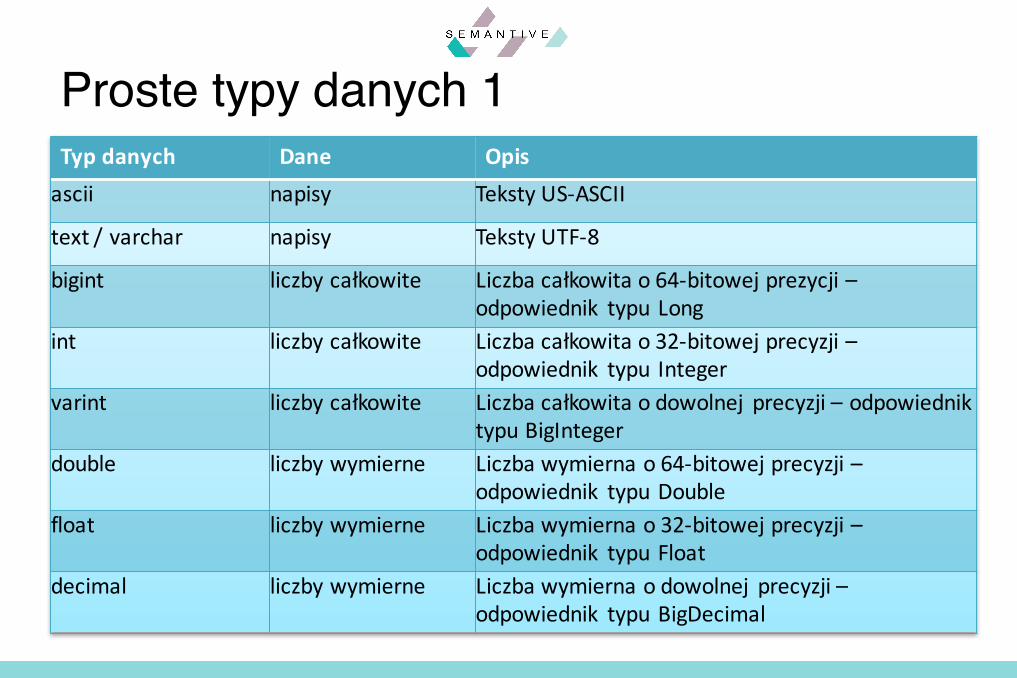
Typdanych Dane Opisascii napisy TekstyUS-ASCII
text /varchar napisy TekstyUTF-8
bigint liczbycałkowite Liczbacałkowitao64-bitowejprezycji –odpowiednik typuLong
int liczbycałkowite Liczbacałkowitao32-bitowejprecyzji–odpowiednik typu Integer
varint liczbycałkowite Liczbacałkowitaodowolnej precyzji– odpowiedniktypuBigInteger
double liczbywymierne Liczbawymiernao64-bitowejprecyzji–odpowiednik typuDouble
float liczbywymierne Liczbawymiernao32-bitowejprecyzji–odpowiednik typuFloat
decimal liczbywymierne Liczbawymiernaodowolnej precyzji–odpowiednik typuBigDecimal
Proste typy danych 1

Typdanych Dane Opisblob dane Dowolnedanebinarne
boolean prawda/fałsz Odpowiednik typuBoolean
counter licznik Rozproszonylicznikcałkowity,64-bitowy
inet adresinternetowy AdresinternetowyIP4lub IP6
timestamp dataiczas Dataiczas– odpowiednik Date.getTime()
uuid uuid StandardowyUUID
timeuuid uuid UUIDtypu1
Proste typy danych 2

Typdanych Opislist<typprosty> Uporządkowanakolekcjawartościtypu
prostegoset<typprosty> Kolekcjaunikalnychwartościtypuprostego
map<typprosty,typprosty> Tablicaasocjacyjna,gdziekluczeiwartościsątypuprostego
Złożone typy danych

§ Od C* 2.1 CQL pozwala na definiowanie własnych typów danych
105
Własne złożone typy danych w CQL

CQL

Dokumentacja dostępna na: http://docs.datastax.com/en/cql/3.3/cql/cqlIntro.html
CQL

MECHANIZMY WEWNĘTRZNE

§ Przechowywanie danych w Cassandrzeopiera się na logach– Dane są sekwencyjnie dopisywane, a nie
wstawiane do ściśle adresowanej przestrzeni, jak w RDBMS
Dlaczego zapis do Cassandry jest szybki?

§ Plik na dysku, do którego zapisywane są wszystkie zmiany dokonywane w bazie
§ Dane do tego pliku są jedynie dopisywane – nic nie jest zmieniane
§ Jeżeli plik ten jest umieszczony na osobnym dysku, to zapis nie wymaga losowego dostępu i wykonywany jest sekwencyjnie → jest bardzo szybki
§ Wszelkie zmiany trafiają najpierw do Commit-Log i do MemTable (odmiana SSTable, która jest trzymana w pamięci jako cache)
CommitLog

§ Tablica przechowywana pamięciowa, odpowiadająca tabeli CQL– Dane w MemTable nie są trwałe– Każdy węzeł posiada posiada MemTable dla każdej tabeli CQL w
przestrzeni kluczy– Dane, które nie zostały zapisane (flush) są modyfikowane i
odczytywane z MemTable– Aktualizacje MemTable dotyczą partycji przechowywanych w pamięci– W przypadku awarii i utraty MemTable, zmiany zapisane w Commit-
Log są odtwarzane na świeżym MemTable.
MemTablepk1 age:40 name1:John name2:Doe
pk2 Age:30 name1:Michael

§ Sorted String Table– Niemodyfikowalne pliki zawierające posortowane partycje– Zapisywane szybko na dysk, sekwencyjne I/O– Przechowuje MemTable, zrzucone podczas operacji flush– Przechowuje część danych partycji
§ Na aktualny stan danych tabeli składają się– Dane z odpowiednich MemTable– Wszystkie aktualne SSTable
§ Pliki SSTable podlegają okresowemu kompaktowaniu
SSTable

§ SSTable składa się z trzech elementów:– Dane
§ Uporządkowany zbiór par klucz-wartość§ Podzielony na bloki (typowo 64kb)§ Zapewnia operację wyszukiwania par i iteracji po parach
– Indeks (partition index)§ Zapewnia szybkie wyszukiwanie odpowiedniego bloku§ Mapa kluczy partycjonujących na pozycje początku wierszy w pliku§ Przechowywany na dysku
– Filtr Bloom'a§ Zapewnia błyskawiczne przybliżone sprawdzenie czy dany klucz znajduje się
w danym SSTable– jeżeli filtr Bloom'a stwierdzi, że obiektu nie ma w SSTable – wtedy nie ma go na pewno– jeżeli stwierdzi, że jest – to może być, a może go nie być (błąd false-positive).
§ Przechowywany w pamięci
SSTable

§ Zapisuje MemTable na dysk jako kolejna, niemutowalna SSTable– MemTable jest czyszczona – zwalnia pamięć na
JVM– Powiązany CommitLog jest oznaczany jako
zapisany (flushed)– Zapisanie danych z MemTable do SSTable jest
sekwencyjne → szybkie
Flushing

§ Każdorazowo kiedy wykonywany jest Flushing, powstaje nowy SSTable
§ Żeby odczytać aktualną wersję danych, należy uwzględnić wszystkie SSTable dotyczące danego zbioru danych
§ W plikach SSTable może być dużo nieaktualnych danych– jeżeli jedna komórka była często aktualizowana, to występuje
wielokrotnie w plikach SSTable– komórki, które zostały usunięte także występują w plikach
SSTable§ Im więcej plików SSTable, tym odczyt staje się bardziej
skomplikowany
Kompaktowanie

§ W momencie zapisu klient łączy się do wybranego węzła – koordynatora– Każdy węzeł może być koordynatorem– Brak „single point of failure”
§ Klient wysyła żądanie zapisu do wszystkich replik przechowujących dany wiersz
§ Jeżeli wyspecyfikowana w poziomie spójności liczba węzłów potwierdzi zapis, klient otrzymuje potwierdzenie utrwalenia zmian
§ W przypadku wielu centrów danych, wybierany jest jeden węzeł z każdego zewnętrznego centrum i do niego jest kierowane żądanie rozpropagowania żądania zapisu po centrum danych do którego należy
Zapis danych

§ Dane zapisywane są w pierwszej kolejności do Commit-Log'a (dysk) oraz do MemTable(pamięć)
§ Kiedy MemTable osiągnie określony rozmiar dane są Flush'owane na dysk do plików SSTable– Zapisywana jest największa MemTable
§ Pliki SSTable są niemutowalne i są ostatecznie łączone w większe pliki SSTable podczas procesu kompaktowania
Zapis danych – mechanizm wewnętrzny

§ Podczas usuwania wierszy z tabeli, fizyczne komórki nie są całkowicie usuwane
§ Tworzone są na ich miejsce tzw. Tombstone'y§ Tombstone jest znacznikiem, informującym Cassandrę, że
komórka została usunięta§ Gdyby nie było Tombstone, to podczas synchronizacji
usunięta komórka mogłaby zostać przywrócona na podstawie danych z repliki
§ Dlatego Tombstone musi pozostać w bazie tak długo dopóki nie zostanie on zsynchronizowany ze wszystkimi replikami w klastrze
§ Przedawnione Tombstone'y są usuwane podczas kompaktowani
Usuwanie danych

§ Czas pozostawania w bazie Tombstone jest konfigurowalny przez użytkownika – domyślnie jest to 10 dni
§ Konfiguruje się go per tabela, parametr nazywa się gc_grace_seconds
§ Aby zapobiec przywracaniu usuniętych danych, administrator powinien regularnie uruchamiać mechanizm naprawy (synchronizacji) węzłów
§ Duży czas pozostawania Tombstone w bazie, w której komórki są często usuwane, a na ich miejsce nie są wstawiane nowe, może mieć znaczący wpływ na rozmiar bazy danych na dysku
Usuwanie danych

§ Klient wysyła żądanie odczytu danych z określonym poziomem spójności
§ Koordynator (węzeł, z którym jest połączony klient) wysyła żądanie odczytu danych do tylu replik przechowujących odczytywaną komórkę ile jest wyspecyfikowane w poziomie spójności– Jeżeli jakiś węzeł wolno odpowiada, koordynator może
przekierować żądanie do innej repliki (eager retries)§ Działa dla stopnia replikacji > 1, od C* 2.0
§ Po otrzymaniu danych z replik, koordynator zwraca klientowi najświeższą wersję danych
Odczyt danych

§ Struktury pamięciowe biorące udział w odczycie:– MemTable – tabela pamięciowa, przechowuje część danch– Cache wierszy – ostatnio odczytane wiersze (opcjonalny)– Filtr Bloom’a – sprawdzenie, czy klucz partycjonujący prawdopodobnie jest w
SSTable– Cache kluczy – fragment indeksu kluczy, ostatnio odczytane klucze -
pozycja wiersza w pliku– Podsumowanie indeksu partycji – próbka z indeksu kluczy
§ Struktury plikowe w odczycie– Indeks kluczy – mapuje klucz -> pozycja wiersza względem początku pliku– SSTable
§ Scalanie – używa klucza partycjonującego do wyszukania i pobrania wartości z MemTable i powiązanych SSTable– Przy każdym odczycie pobierane dane dla KP z pary MemTable i najnowszej
SSTable – pobierane najnowsze– Nie występuje, gdy pobierany z Cache’a wierszy
Odczyt – mechanizm wewnętrzny

§ Współdzielony przez wszystkie węzły– Dane w cache odpowiadają temu co jest w bazie– Cache na uszkodzonym węźle może zostać
odtworzony z innego– Przechowywane w pamięci– Kopiowane na dysk
Cache wierszy i kluczy
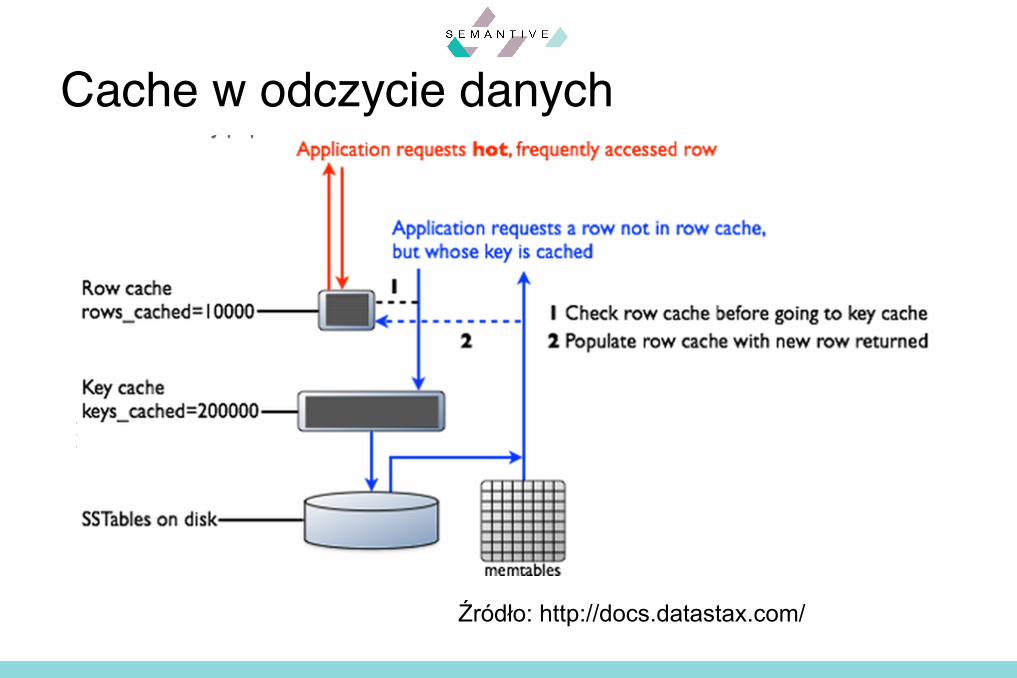
Cache w odczycie danych
Źródło: http://docs.datastax.com/

§ Jeżeli klucz nie zostanie znaleziony w cache’ukluczy, wówczas odczyt musi szukać partycji na dysku
§ Podsumowanie indeksu, jest to struktura pamięciowa, używana do przybliżenia pozycji klucza w pełnym indeksie– Domyślna wielkość próbki to 1 na 128 kluczy
partycjonujących w indeksie– Ustawiane za pomocą parametrów tabeli
§ min_index_interval – domyślnie 128§ max_index_interval – domyślnie 2048
Podsumowanie indeksu

ZADANIA

§ Zaprojektować sposób przechowania następujących danych:– pracowników wraz z przydziałem do odpowiedniego departamentu
§ dla pracownika określone są następujące atrybuty: imię, nazwisko, adres email, data zatrudnienia, zarobki, aktualny dział, w którym pracuje pracownik
§ dla działu określone są następujące atrybuty: nazwa, opis, data powstania– Pracownik:
§ imię, nazwisko, adres email, data zatrudnienia pracownika są niezmienne, natomiast zarobki i aktualny dział mogą się zmieniać
§ email jest unikalny– Dział
§ nazwa działu jest unikalna§ nazwa działu jest niezmienna
Zadanie 1 – baza pracowników (1)

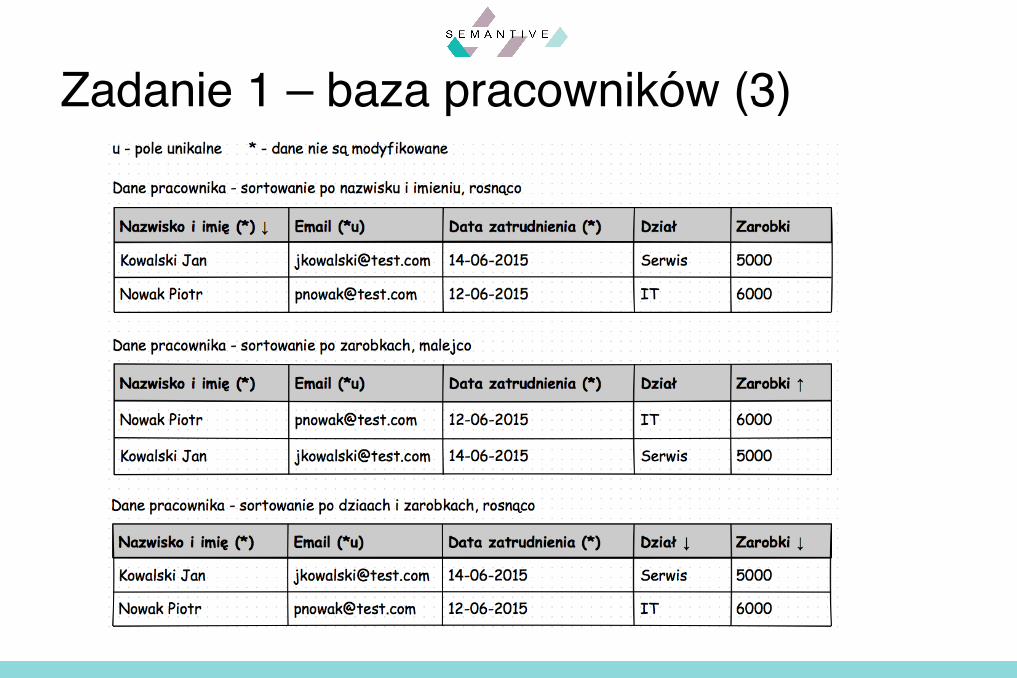
§ Prezentacja danych§ Pracownicy: wyświetlani (imię, nazwisko, email,
data zatrudnienia, zarobki, nazwa aktualnego działu):§ w porządku rosnącym po nazwisku i imieniu§ w porządku malejącym po zarobkach§ w porządku rosnącym po nazwach działów i
zarobkach
Zadanie 1 – baza pracowników (2)
Zadanie 1 – baza pracowników (3)
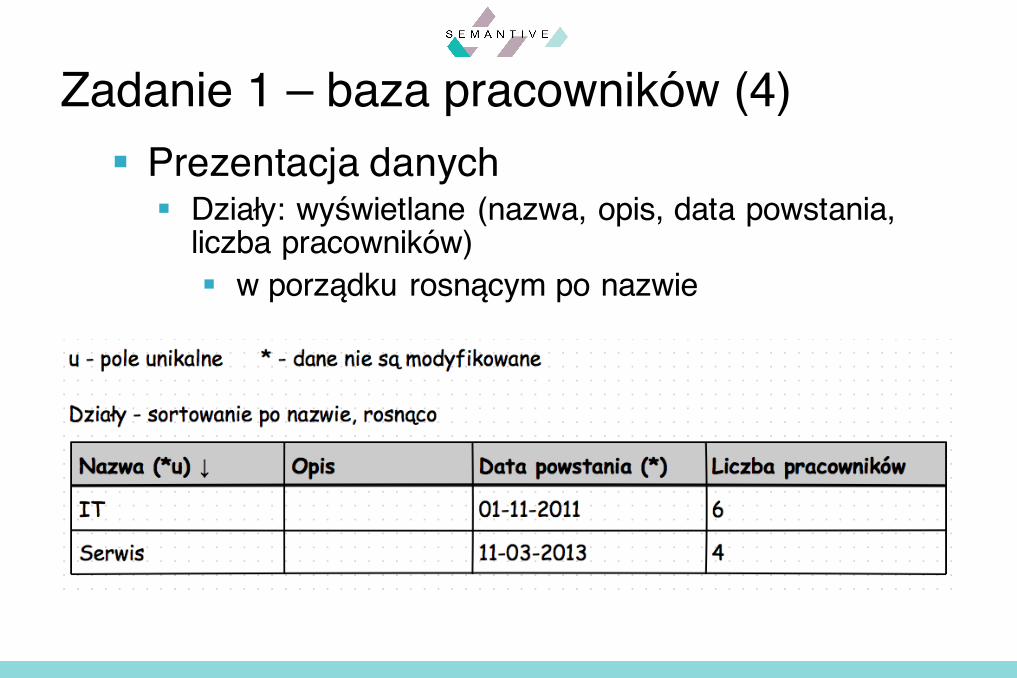
§ Prezentacja danych§ Działy: wyświetlane (nazwa, opis, data powstania,
liczba pracowników) § w porządku rosnącym po nazwie
Zadanie 1 – baza pracowników (4)

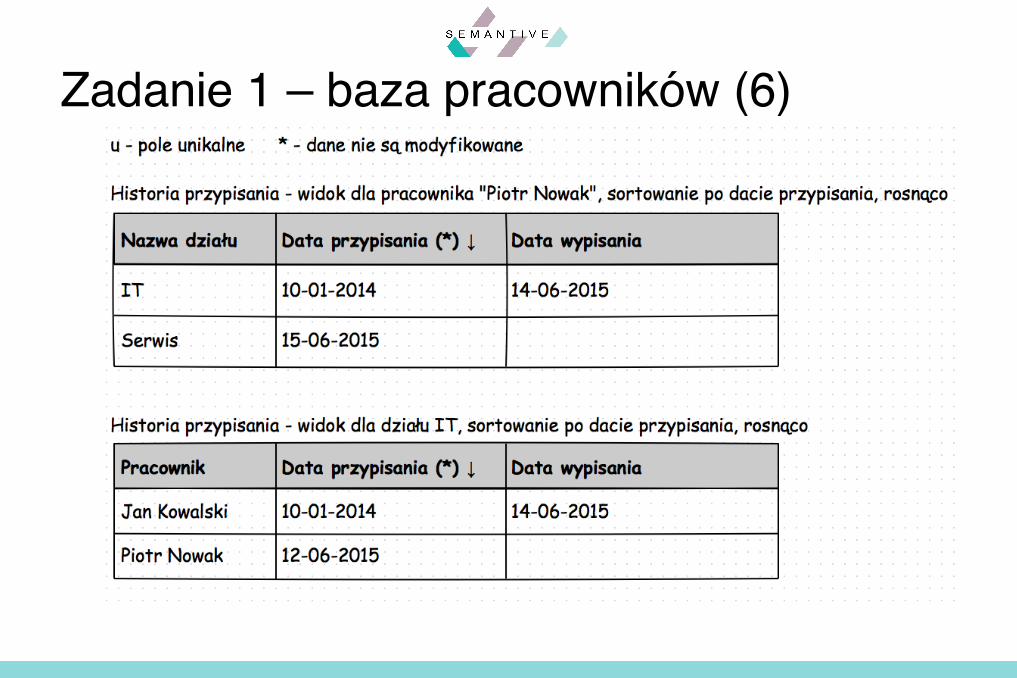
§ Prezentacja danych– historia przydziałów do działów:
§ dla każdego przypisania pracownika do działu należy zachować informację o tym kiedy pracownik został do tego działu przypisany oraz kiedy został z niego wypisany, oraz nazwę działu
§ historia przypisania do działów będzie wyświetlana (imię pracownika, nazwisko pracownika, data przypisania, data wypisania, nazwa działu) dla:
– każdego pracownika z osobna po dacie przypisania– każdego działu po dacie przypisania
Zadanie 1 – baza pracowników (5)
Zadanie 1 – baza pracowników (6)