anthony joseph
TRANSCRIPT

5/10/2012
AMPLab Overview [email protected] 1
A Berkeley View of Big Data
Anthony D. JosephUC Berkeley
EDUSERV Symposium10 May 2012
Who Am I?
• Research: – Internet-scale systems (RAD Lab, AMP Lab)
– Security (DETERlab Testbed)
– Adversarial machine learning (SecML)
• Teaching (undergrad/grad): operating systems and systems, security, networking
Disclaimer: I don’t speak for UC or our research sponsors

5/10/2012
AMPLab Overview [email protected] 2
Big Data is Massive…• Facebook:
– 130TB/day: user logs– 200-400TB/day: 83 million pictures– >40 Billion photos
• Google: > 25 PB/day processed data
• Data generated by LHC: 1 PB/sec
• Total data created in 2010: 1.ZettaByte (1,000,000 PB)/year– ~60% increase every year
3
…and Diverse…
• Walmart
– >1 million customer transactions/hr
– >2.5 PByte customer DB
• Human genome sequencing
– Analyzing 3 billion base pairs
– Ten years for first one (2003)
– Today, less than one week
4

5/10/2012
AMPLab Overview [email protected] 3
…and Novel…
• Analyzing data from user behavior vs user input
• USGS TED
– Twitter-based Earthquake Detector
• Google Trends: “nowcasting”– http://www.google.org/flutrends/
– US 2009 “Cash for Clunkers” program success
– US State unemployment rates
5
…and Grows Bigger…
• More and more devices
• More and more people
• Cheaper and cheaper storage
– ~50% increase in GB/$ every year
6

5/10/2012
AMPLab Overview [email protected] 4
…and Bigger!
• Log everything!
– Don’t always know what question you’ll need to answer
• Stored data growing faster than bothavailable storage and GB/$
7
Which Big Data to Keep?
• Hard to decide what to delete
– Thankless decision: people know only when you are wrong!
– “Climate Research Unit (CRU) scientists admit they threw away key data used in global warming calculations”
8

5/10/2012
AMPLab Overview [email protected] 5
Data Retention Requirements
• New NSF data retention requirements
– Proposals submitted after 18 January 2011 must include a “Data Management Plan”
– Have to keep all data (including metadata) for 3 years after research award conclusion
– Institutional/org considerations:
• Opportunity to invest in pooled storage: campus, systemwide, regional, …
• Typical cost: 8TB chunks at $1.44/GB/year collaborative space and $0.17/GB/year for archive space
9
Big Data Isn’t Always Big
• You don’t need to be big to have big data problem!
– Inadequate tools to analyze data
– Data management may dominate infrastructure cost
10
Data that is expensive to manage,
and hard to extract value from
Data that is expensive to manage,
and hard to extract value from

5/10/2012
AMPLab Overview [email protected] 6
Big Data is not Cheap!
• Storing and managing 1PB data: $500K-$1M/ year
– Facebook: 200 PB/year
11
• “Typical” cloud-based service startup (e.g., Conviva)
– Log storage dominates infrastructure cost 0%
20%
40%
60%
80%
100%
2007 2008 2009 2010
Storage cluster Other
Infr
astr
uctu
re c
ost
~1PB storage capacity
Hard to Extract Value from Data!
• Data is – Diverse, variety of sources
– Uncurated, no schema, inconsistent semantics, syntax
– Integration a huge challenge
• No easy way to get answers that are– High-quality
– Timely
• Challenge: maximize value from data by getting best possible answers
12

5/10/2012
AMPLab Overview [email protected] 7
Requires Multifaceted Approach
• Three dimensions to improve data analysis
– Improving scale, efficiency, and quality of algorithms (Algorithms)
– Scaling up datacenters (Machines)
– Leverage human activity and intelligence (People)
• Need to adaptively and flexibly combine all three dimensions
13
The State of the Art
Algorithms
Machines
People
search
Watson/IBM
14
• Today’s apps: fixed point in solution space
Need techniques to dynamically pick best
operating point
Need techniques to dynamically pick best
operating point

5/10/2012
AMPLab Overview [email protected] 8
What Is the Big Data Problem?
• For two main reasons:– the more data the greater chance to find any
pattern you’d like to find• the more rows in a table, the more columns
• the more columns, the more hypotheses that can be considered
• indeed, the number of hypotheses grows exponentially in the number of columns
– the more data the less likely a sophisticated ML algorithm will run in an acceptable time frame
• and then we have to back off to cheaper algorithms that may be more error-prone
A Formulation of the Problem
• Given an inferential goal and a fixed computational budget, provide a guarantee (supported by an algorithm and an analysis) that the quality of inference will increase monotonically as data accrue (without bound)
– This is far from being achieved in the current state of the literature!
• It can be achieved by building a scalable system that blends statistical and computational design principles

5/10/2012
AMPLab Overview [email protected] 9
Big Data in the US
• Many Fortune 1000+ companies with huge write once, read none big data collections– For all the reasons I’ve already outlined…
• US Government agencies in same situation– New R&D funding
• Many companies developing proprietary solutions
• Very active open source big data tools committee– Broad international participation– Data Without Borders helping non-profits through pro
bono data collection, analysis, and visualization
17
Significant USG Investment
• 29 March 2012
– US federal agencies announced more than $200 million in new commitments
– Dept of Defense, Dept of Homeland Security, Dept of Energy, Veterans Administration, Office of Scientific and Technical Information, Health and Human Services, Food and Drug Admin, National Archives & Records Admin, National Aerospace & Space Admin, National Institutes of Health, National Science Foundation, National Security Agency, US Geological Service18

5/10/2012
AMPLab Overview [email protected] 10
Active Open Source Community
• On-going development of several elements of Big Data analysis pipeline
• Apache Hadoop (MapReduce)
• Hive
• Apache Pig
• R / Octave
• Much more is needed!
• E.g., new analysis environments
19
The AMP Lab
20
search
Watson/IBM
Machines
People
Algorithms
Make sense of data at scale by tightly
integrating algorithms, machines, and people
Make sense of data at scale by tightly
integrating algorithms, machines, and people

5/10/2012
AMPLab Overview [email protected] 11
AMP Faculty and Sponsors• Faculty
– Alex Bayen (mobile sensing platforms)– Armando Fox (systems)– Michael Franklin (databases): Director– Michael Jordan (machine learning): Co-director– Anthony Joseph (security & privacy)– Randy Katz (systems)– David Patterson (systems)– Ion Stoica (systems): Co-director– Scott Shenker (networking)
• Sponsors:
21
Algorithms
• State-of-art Machine Learning (ML) algorithms do not scale
– Prohibitive to process all data points
22
How do you know
when to stop?
true answer
Estim
ate
# of data points

5/10/2012
AMPLab Overview [email protected] 12
Algorithms
• Given any problem, data and a budget
– Immediate results with continuous improvement
– Calibrate answer: provide error bars
23
Error bars on every
answer!
Estim
ate
# of data points
true answer
Algorithms
• Given any problem, data and a time budget
– Immediate results with continuous improvement
– Calibrate answer: provide error bars
24
Stop when error
smaller than a given
threshold
Estim
ate
# of data pointstime
true answer
5/10/2012
AMPLab Overview [email protected] 13
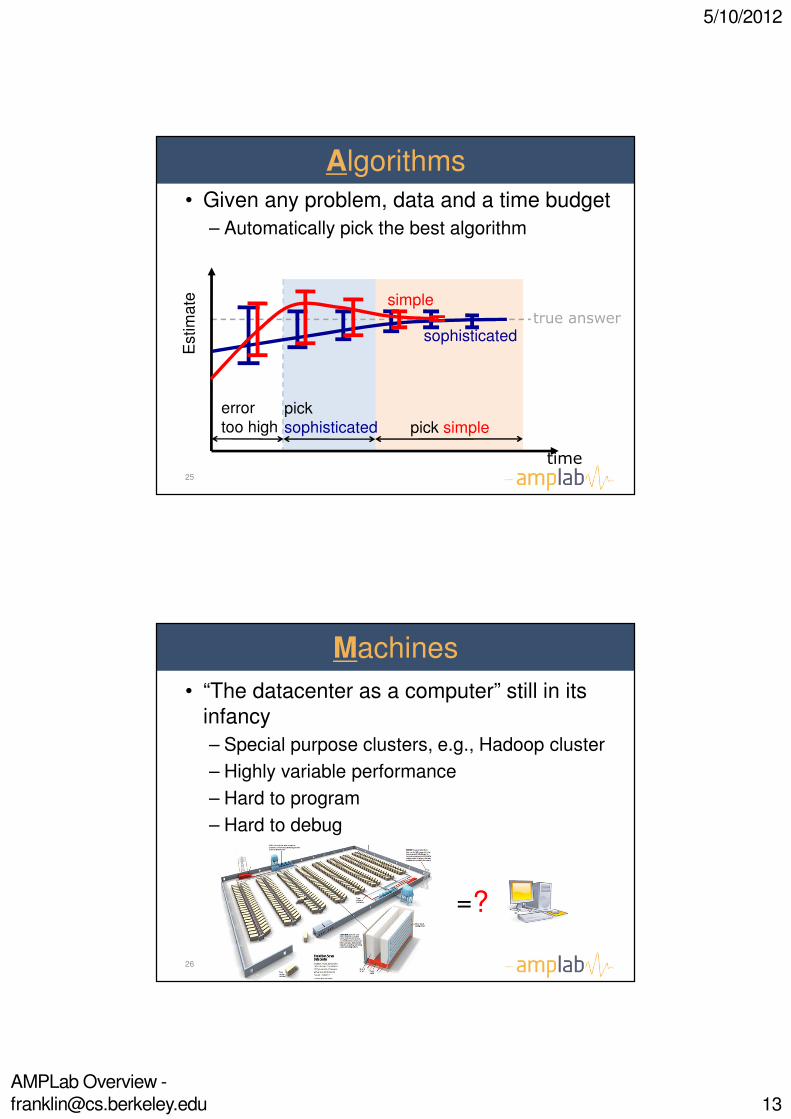
Algorithms
• Given any problem, data and a time budget
– Automatically pick the best algorithm
25
Estim
ate
time
pick sophisticated pick simple
error too high
true answer
sophisticated
simple
Machines
• “The datacenter as a computer” still in its infancy
– Special purpose clusters, e.g., Hadoop cluster
– Highly variable performance
– Hard to program
– Hard to debug
26
=?

5/10/2012
AMPLab Overview [email protected] 14
Machines
• Make datacenter a real computer!
27
Node OS
(e.g. Linux)
Node OS
(e.g. Windows)
Node OS
(e.g. Linux)…
Datacenter “OS” (e.g., Mesos)
• Share datacenter between multiple cluster computing
apps
• Provide new abstractions and servicesAMP stack
Existingstack
Machines
• Make datacenter a real computer!
28
Node OS
(e.g. Linux)
Node OS
(e.g. Windows)
Node OS
(e.g. Linux)…
Datacenter “OS” (e.g., Mesos)
Had
oop
MP
I
Hyp
ertb
ale
…
Ca
ssa
nd
raHiveSupport existing
cluster computing
apps
AMP stack
Existingstack

5/10/2012
AMPLab Overview [email protected] 15
Machines
• Make datacenter a real computer!
29
Node OS
(e.g. Linux)
Node OS
(e.g. Windows)
Node OS
(e.g. Linux)…
Sp
ark
SCADS
…
Datacenter “OS” (e.g., Mesos)
Had
oop
MP
I
Hyp
ertb
ale
…C
ass
an
draHive PIQL
Support interactive
and iterative data
analysis (e.g., ML
algorithms)
Consistency
adjustable data
store
Predictive &
insightful query
language
AMP stack
Existingstack
Machines
• Make datacenter a real computer!
30
Node OS
(e.g. Linux)
Node OS
(e.g. Windows)
Node OS
(e.g. Linux)…
Sp
ark
SCADS
…
Datacenter “OS” (e.g., Mesos)
Applications, tools
Had
oop
MP
I
Hyp
ertb
ale
…
Ca
ssa
nd
raHive PIQL• Advanced ML algorithms
• Interactive data mining
• Collaborative visualizationAMP stack
Existingstack

5/10/2012
AMPLab Overview [email protected] 16
People
• Humans can make sense of messy data!
31
People
• Make people an integrated part of the system!– Leverage human activity
– Leverage human intelligence (crowdsourcing):
• Curate and clean dirty data
• Answer imprecise questions
• Test and improve algorithms
• Challenge– Inconsistent answer quality in all
dimensions (e.g., type of question, time, cost)
32
Machines +
Algorithms
da
ta,
activi
ty
Qu
estio
ns A
nsw
ers

5/10/2012
AMPLab Overview [email protected] 17
Real Applications• Mobile Millennium Project
– Alex Bayen, Civil and Environment Engineering, UC Berkeley
• Microsimulation of urban development– Paul Waddell, College of
Environment Design, UC Berkeley
• Crowd based opinion formation– Ken Goldberg, Industrial
Engineering and Operations Research, UC Berkeley
• Personalized Sequencing– Taylor Sittler, UCSF
33
Personalized Sequencing
34

5/10/2012
AMPLab Overview [email protected] 18
Sequencing
Microsimulation Mobile Millennium
The AMP Lab
35
Machines
People
Algorithms
Make sense of data at scale by tightly
integrating algorithms, machines, and people
Make sense of data at scale by tightly
integrating algorithms, machines, and people
Big Data in 2020
Are you prepared?
• To create a new generation of big data scientist
• For ML to become an engineering discipline
• For people to be deeply integrated in big data analysis pipeline
• Will your institution
– offer a big data curriculum touching all fields?
– have hired cross-disciplinary faculty?
– have invested in (pooled) storage infrastructure?
– have invested in public/private clouds?
– have built inter/intra campus networks?36

5/10/2012
AMPLab Overview [email protected] 19
Summary
• Goal: Tame Big Data Problem
– Get results with right quality at the right time
• Approach: Holistic integration of Algorithms, Machines, and People
• Huge research issues across many domains
3737