anleitung für statgraphics - tu-freiberg.de · regressionsgerade nach der methode der kleinsten...
TRANSCRIPT
Statgraphics-Anleitung (Oktober 2007)
basierend auf STATGRAPHICS Centurion XV Version 15.1.02

2
Inhalt
0 Allgemeines & Einleitung Data Book StatGallery StatReporter Dateneingabe und Speichern der Beispieldaten
1 Beschreibende Statistik Eindimensionale Daten
Häufigkeitsdiagramme/Histogramme Stamm-Blatt-Diagramm Lageparameter und Streumaße für metrisch skalierte Daten Box-Plot
Zweidimensionale Daten Kontingenztafeln Korrelationskoeffizienten Streudiagramm/Scatterplot Regressionsgerade nach der Methode der kleinsten Quadrate Tukey-Ausgleichsgerade
Zeitreihen Trendschätzung, Trendabspaltung
Kleinste-Quadrate-Anpassung Glättung Trendabspaltung
Schätzung der Saisonkomponente, Saisonbereinigung 2 Grundlagen der Wahrscheinlichkeitstheorie
Stetige Verteilungen Normalverteilung Exponentialverteilung Gleichverteilung logistische Verteilung Chi-Quadrat-Verteilung F-Verteilung t-Verteilung
Diskrete Verteilungen Geometrische Verteilung Hypergeometrische Verteilung Binomialverteilung Poissonverteilung
3 Grundlagen des statistischen Schließens I Parameterschätzungen
Punktschätzungen Konfidenzschätzungen Konfidenzschätzungen für die Parameter einer Normalverteilung Konfidenzschätzungen für eine (unbekante) Wahrscheinlichkeit p

3
4 Grundlagen des statistischen Schließens II - Tests Signifikanztests für Verteilungsparameter Wichtige Tests bei normalverteilten Grundgesamtheiten
Mittelwerttest - Signifikanztest für den Erwartungswert μ Streuungstest - Signifikanztest für die Standardabweichung σ Mittelwertvergleich bei gleichen (unbekannten) Varianzen (doppelter t-Test) Mittelwertvergleich bei möglicherweise ungleichen Varianzen (Welch-Test)
Beispiele sogenannter verteilungsfreier Tests Vorzeichentest Rangtest nach Wilcoxon
Monte-Carlo-Tests Nichtparametrische Tests
Test auf Vorliegen einer bestimmten Verteilung (χ2-Anpassungstest) Test auf Unabhängigkeit zweier Merkmale X und Y (Kontingenztafeln)
Stichprobenpläne zur Qualitätskontrolle Testen der Hypothese H0: p<p0, einstufige Stichprobenpläne – (n,c)-Stichprobenplan
Laufende Kontrolle - Mittelwertkarte 5 Varianzanalyse
Einfache Klassifikation F-Test Kruskal-Wallis-Test Test paarweise: Test von Scheffé
Zweifache Klassifikation F-Test Zweifache Varianzanalyse mit Mehrfachbesetzung und Wechselwirkungen
Mehrfaktoranalyse 6 Korrelationsanalyse
Zwei Merkmale Einfache Korrelation zwischen zwei (zufälligen) Merkmalen X und Y Rangkorrelation
p>2 Merkmale Korrelationsmatrix multiple Korrelation kanonische Korrelation partielle Korrelation
7 Regressionsanalyse Lineare Regressionsmodelle Einfache lineare Regression Multiple parameterlineare Regression Nichtlineare Regression
Anpassung an logistische Funktion

Allgemeines & Einleitung In dieser Anleitung geht es um die Umsetzung des in Vorlesung und Übung Statistik I & II behandelten Stoffes mit Statgraphics. Beim Start von Statgraphics öffnet sich automatisch der StatWizard. Dieser dient dazu Einsteigern die Arbeit mit Statgraphics zu erleichtern und beim Auffinden der gewünschten Funktionalität behilflich zu sein. Durch entfernen des Häkchens im Feld Show the StatWizard at Setup erreicht man das dieser nicht mehr automatisch beim Start geöffnet wird. Nach Auswahl der entsprechenden Menüpunkte öffnet Statgraphics die jeweilige Prozedur. In dieser Anleitung wird auf die Verwendung des StatWizards verzichtet und die Auswahl der Prozeduren über das normale Hauptmenü vorgenommen. In Statgraphics gibt es zwei Varianten des Hauptmenüs: Six Sigma Menu und Standard Menu. In dieser Anleitung werden immer die Wege im Standard Menu beschrieben. Ein Wechsel zwischen den Menüarten ist unter Edit -> Preferences... möglich. Wenn in der Registerkarte General unter System Options Use Six Sigma Menu ausgewählt wird, wird das Six Sigma Menu verwendet. Sonst wird das Standard Menu benutzt. Unter Preferences können außerdem weitere Einstellungen vorgenommen werden. Es können zum Beispiel die Default-Werte für einige Prozeduren eingestellt werden. Das Statgraphics Fenster ist im Wesentlichen in zwei Teile eingeteilt. Auf der linken Seite werden die einzelnen Teile eines Projekts angezeigt.
Das DataBook enthält alle eingegebenen oder aus externen Quellen eingelesenen Daten. Der StatAdvisor soll helfen die Ergebnisse der statistischen Prozeduren zu erklären. In die StatGallery können mehrere Grafiken aufgenommen werden um sie gegenüberstellend zu vergleichen oder um sie zu überlagern. Im StatReporter können Dokumentationen aus den Berechnungen erstellt und als rtf - Datei gespeichert werden. Unter StatFolio Comments können Beschreibungen des StatFolios abgelegt
werden Die rechte Seite entspricht der eigentlichen Arbeitsfläche. Diese hat eine eigene Menüleiste mit folgenden für uns im Weiteren wichtigen Schaltflächen:
Es sind nur die jeweils für alle im aktiven Fenster angezeigten Felder gültigen Schaltflächen anklickbar. Einzelne Felder in einem Fenster können durch Doppelklick in das entsprechende Feld maximiert werden. Durch nochmaligen Doppelklick gelangt man zur Ausgangsansicht zurück.
4

5
Pane Options und Analysis Options kann man in der Gesamtansicht aufrufen, indem man mit der rechten Maustaste in das entsprechende Feld klickt und Pane Options bzw. Analysis Options im Kontextmenü auswählt. Der Aufruf von Pane Options und Analysis Options über die Menüleiste ist ebenfalls möglich. Was unter Pane Options und Analysis Options einstellbar ist, hängt von der verwendeten Prozedur ab und wird deswegen im Rahmen der Beschreibung der einzelnen Prozeduren weiter ausgeführt. Ist das aktive Fenster ein Grafikfenster, so kann im Kontextmenü (rechte Maustaste) Graphics Options gewählt werden. Dort können Änderungen der Graphikeinstehlungen vorgenommen werden. Data Book Das DataBook enthält die Daten mit denen später gearbeitet werden soll. Diese können in die 10 Tabellen (A-J) entweder per Hand eingegeben oder aus einer Datenquelle eingelesen werden. Um Daten aus einer Datenquelle einzulesen die Tabelle auswählen, in die die Daten eingefügt werden sollen. Nun im Menü File -> Open -> Open Data Source... auswählen. Um mit Statgraphics erzeugte Daten einzulesen STATGRAPHICS Data File wählen. In Excel gespeicherte Daten werden nach Auswahl von External Data File eingelesen. Es können auch Daten mittels einiger Funktionen erzeugt werden, hierfür die Spalte markieren und im Menü Edit -> Generate Data wählen. Bei Operators die gewünschten Operatoren auswählen und die ? jeweils durch die gewünschten Werte ersetzen. Nachdem man die Spalte markiert gelangt man auch durch Rechtsklick in das Kontextmenu und kann auch dort Generate Data wählen. Man kann die Daten auch einfach in die gewünscht Tabelle eingeben. Um Einstellungen bezüglich des Datentyps vorzunehmen auf den Spaltennamen doppelklicken. Nun kann ausgewählt werden, von welchem Datentyp die eingegebenen Werte sind. Außerdem kann nun auch der Name der Spalte geändert werden (Name) oder ein Kommentar zur Spalte, welcher später unter dem Spaltennamen angezeigt wird, eingegeben werden (Comment). Um die Daten im DataBook zu sichern im Menü File -> Save As -> Save Data File As... auswählen. StatGallery Die StatGallery hat mehrere Seiten, zwischen denen mit Hilfe der Buttons Next Page (eine Seite vor), Prev Page (eine Seite zurück), First Page (erste Seite) und Last Page (letzte Seite) hin und her gewechselt werden kann. Standardmäßig hat jede Seite der StatGallery 4 Felder. Man kann die Anzahl und die Anordnung der Felder jedoch verändern indem man im Kontextmenü, welches sich nach Rechtsklick in die StatGallery öffnet, Arrange Panes auswählt. Nun kann man das gewünschte Layout auswählen. Dieses Layout gilt nur für die aktuelle Seite. Um eine Grafik in die StatGallery einzufügen diese irgendwo in Statgraphics kopieren. Rechtsklick in das Feld, in welches die Grafik eingefügt werden soll und Paste bzw. Paste Link wählen. Wird Paste Link gewählt wird die Grafik mit ihrem Ursprungspunkt verknüpft (funktioniert nur bei gespeicherten StatFolios) und ändert sich automatisch, wenn dort eine Änderung auftritt. Um mehrere Grafiken zu überlagern eine Grafik in ein Feld einfügen in dem schon eine Grafik vorhanden ist und im sich öffnenden Dialog Overlay wählen. Um den Inhalt der StatGallery zu speichern im Hauptmenü File -> Save As -> Save StatGallery As... auswählen (*.sgg Format). Eine Speicherung in anderen Graphikformaten ist nicht möglich.

StatReporter Der StatReporter soll die Erstellung von Dokumentationen in Statgraphics vereinfachen. Er ist nach dem Vorbild von Microsoft Wordpad aufgebaut und liefert als Ergebnis rtf – Dateien. Tabellen und Grafiken können mittels Copy & Paste in den StatReporter übernommen werden. Spätere Änderungen werden nicht berücksichtigt. Text kann wie in einer Textverarbeitung üblich hinzugefügt und die entsprechenden Einstellungen daran vorgenommen werden. Um den Inhalt des StatReporters zu speichern im Hauptmenü File -> Save As -> Save StatReporter As... auswählen. Um Alles zusammen abzuspeichern File -> Save As -> Save StatFolio As... auswählen. Dabei wird das gesamte aktuelle Projekt abgespeichert. Das sind neben den Daten, der Gallery und den Reporter auch die statistischen Auswertungen. Die Daten, die Gallery und der Reporter müssen dabei vorher extra abgespeichert werden
Dateneingabe und Speichern der Beispieldaten Mit diesen Daten werden die Beispiele in der Anleitung gerechnet. Im DataBook in Blatt A in der ersten Spalte (Col_1) die nebenstehenden Daten eintragen. Dann auf den Spaltenkopf (da wo der Spaltenname steht) doppelklicken und bei Name Zahlen1 eintragen. Bei Type Numeric auswählen. In die zweite Spalte (Col_2) die folgenden zwanzig Zahlen eintragen:
9, 12, 7, 11, 13, 17, 16, 11, 10, 11, 20, 10, 11, 8, 10, 10, 9, 14, 17, 17
Den Namen der Spalte in Zahlen2 ändern und bei Type Numeric auswählen. In die dritte Spalte (Col_3) die folgenden Zahlen eintragen: 8, 9, 4, 6, 0, 2, 7, 6, 3, 1 Den Namen der Spalte in Zahlen3 ändern und bei Type Numeric auswählen. In die vierte Spalte (Col_4) die folgenden Zahlen eintragen: 24, 28, 19, 17, 11, 21, 18, 27, 21, 22 Den Namen der Spalte in Zahlen4 ändern und bei Type Numeric auswählen. In die fünfte Spalte (Col_5) die folgenden Zahlen eintragen: 7, 3, 4, 8, 7, 5, 9, 2, 5, 2 Den Namen der Spalte in Zahlen5 ändern und bei Type Numeric auswählen.
6
Im Menü File -> Save As -> Save Data File As... auswählen. Als Namen beispiele.sf6 wählen und abspeichern.
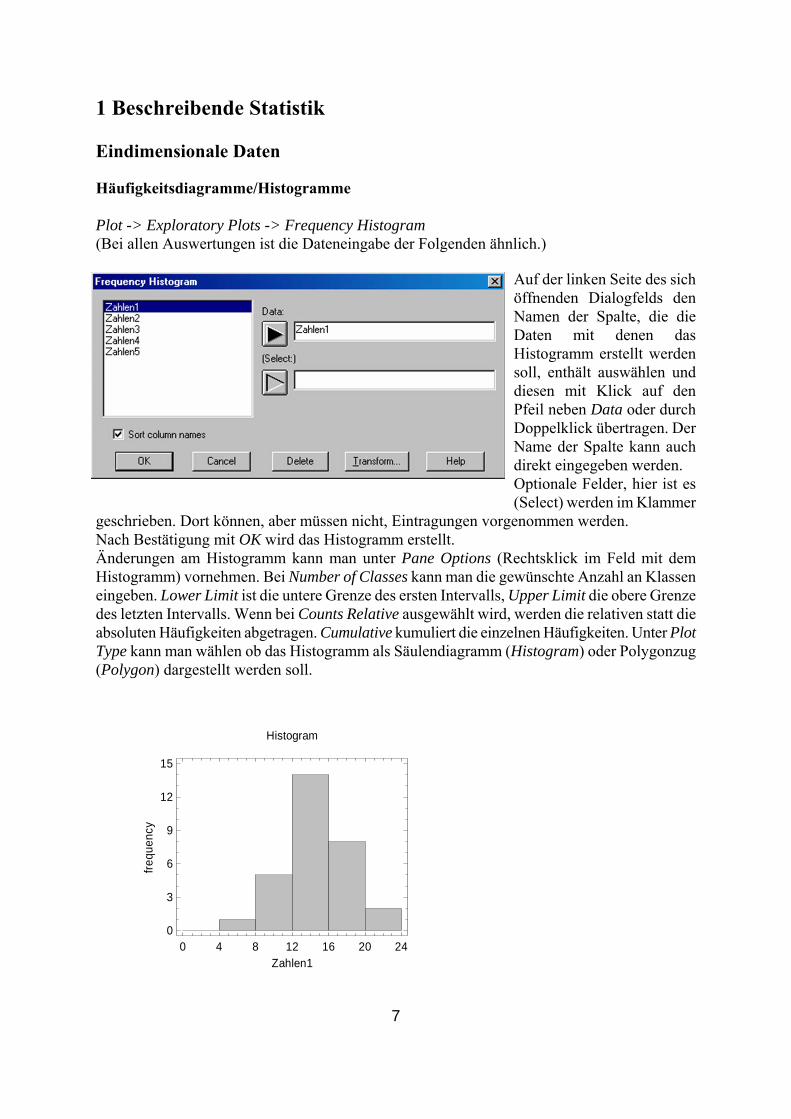
1 Beschreibende Statistik Eindimensionale Daten
Häufigkeitsdiagramme/Histogramme Plot -> Exploratory Plots -> Frequency Histogram (Bei allen Auswertungen ist die Dateneingabe der Folgenden ähnlich.)
Auf der linken Seite des sich öffnenden Dialogfelds den Namen der Spalte, die die Daten mit denen das Histogramm erstellt werden soll, enthält auswählen und diesen mit Klick auf den Pfeil neben Data oder durch Doppelklick übertragen. Der Name der Spalte kann auch direkt eingegeben werden. Optionale Felder, hier ist es (Select) werden im Klammer
geschrieben. Dort können, aber müssen nicht, Eintragungen vorgenommen werden.
Nach Bestätigung mit OK wird das Histogramm erstellt. Änderungen am Histogramm kann man unter Pane Options (Rechtsklick im Feld mit dem Histogramm) vornehmen. Bei Number of Classes kann man die gewünschte Anzahl an Klassen eingeben. Lower Limit ist die untere Grenze des ersten Intervalls, Upper Limit die obere Grenze des letzten Intervalls. Wenn bei Counts Relative ausgewählt wird, werden die relativen statt die absoluten Häufigkeiten abgetragen. Cumulative kumuliert die einzelnen Häufigkeiten. Unter Plot Type kann man wählen ob das Histogramm als Säulendiagramm (Histogram) oder Polygonzug (Polygon) dargestellt werden soll.
Histogram
0 4 8 12 16 20 24Zahlen1
0
3
6
9
12
15
frequ
ency
7

Stamm-Blatt-Diagramm Describe -> Numeric Data -> One-Variable-Analysis Den Namen der Spalte, die die zu betrachtenden Daten enthält, auswählen und bestätigen. Falls das Stamm-Blatt-Diagramm bei der nun geöffneten Analyse nicht mit angezeigt wird, die Tables-Schaltfläche drücken und Stem-and-Leaf-Display auswählen. am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Describe -> Numeric Data -> One-Variable-Analysis Bei Data Zahlen1 eintragen. Mit OK bestätigen. Es sollte folgender Ausdruck erhalten werden:
8

Lageparameter und Streumaße für metrisch skalierte Daten Describe -> Numeric Data -> One Variable Analysis Bei Data den Namen der Spalte eingeben, welche die Werte enthält, die betrachtet werden sollen. Falls die Summary Statistics noch nicht angezeigt werden, auf die Tables-Schaltfläche klicken und diese auswählen. Mit der rechten Maustaste in das Feld mit den Summary Statistics klicken und Pane Options (Rechtsklick) wählen. In der sich nun öffnenden Liste kann man wählen, was alles berechnet werden soll. Um die Quantile anzuzeigen auf die Tables-Schaltfläche klicken und Percentiles auswählen. Unter Pane Options im Feld mit den Quantilen kann man die zu berechnenden Quantile angeben. Hierfür bei Percentiles die gewünschten Werte für α eingeben.
In der Graphs-Schaltfläche sind auch hier Histogramme und der Box-Plot wählbar.
am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Describe -> Numeric Data -> One-Variable-Analysis Bei Data Zahlen1 eintragen. Mit OK bestätigen. Nach Treffen der folgenden Auswahl im Feld Summary Statistics und beibehalten der voreingestellten Werte im Feld Percentiles, erhält man die untenstehenden Ergebnisse.
9
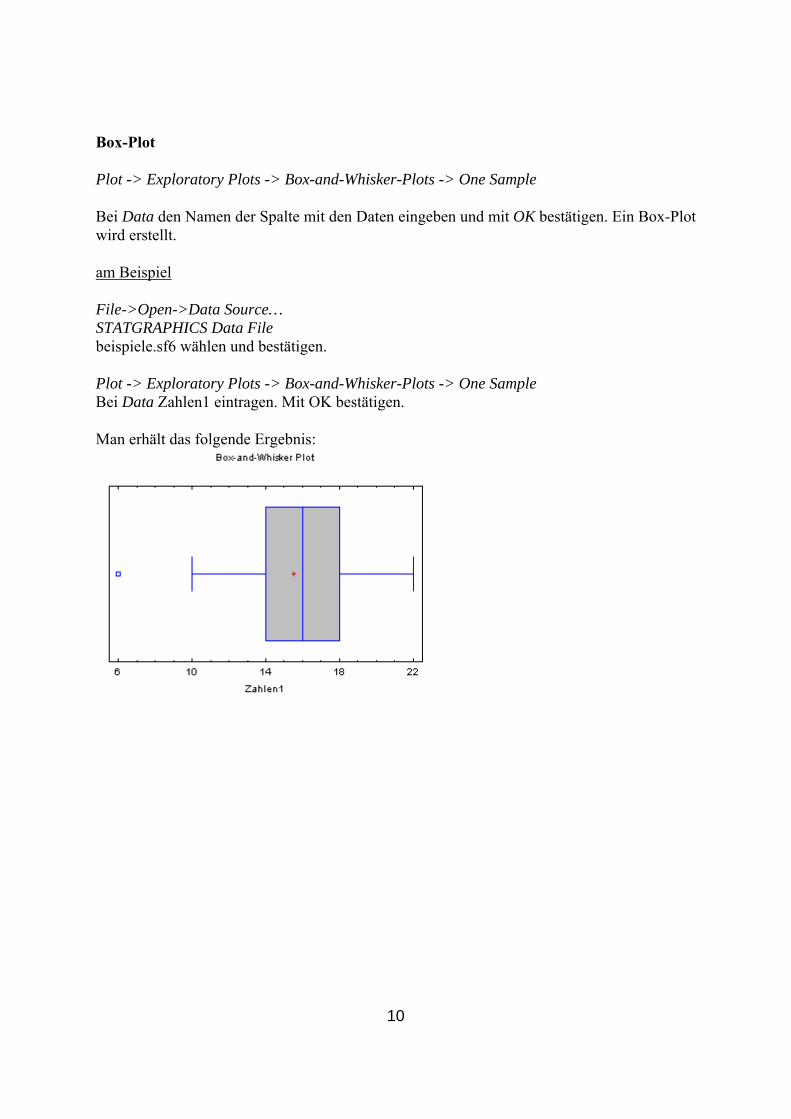
Box-Plot Plot -> Exploratory Plots -> Box-and-Whisker-Plots -> One Sample Bei Data den Namen der Spalte mit den Daten eingeben und mit OK bestätigen. Ein Box-Plot wird erstellt. am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Plot -> Exploratory Plots -> Box-and-Whisker-Plots -> One Sample Bei Data Zahlen1 eintragen. Mit OK bestätigen. Man erhält das folgende Ergebnis:
10
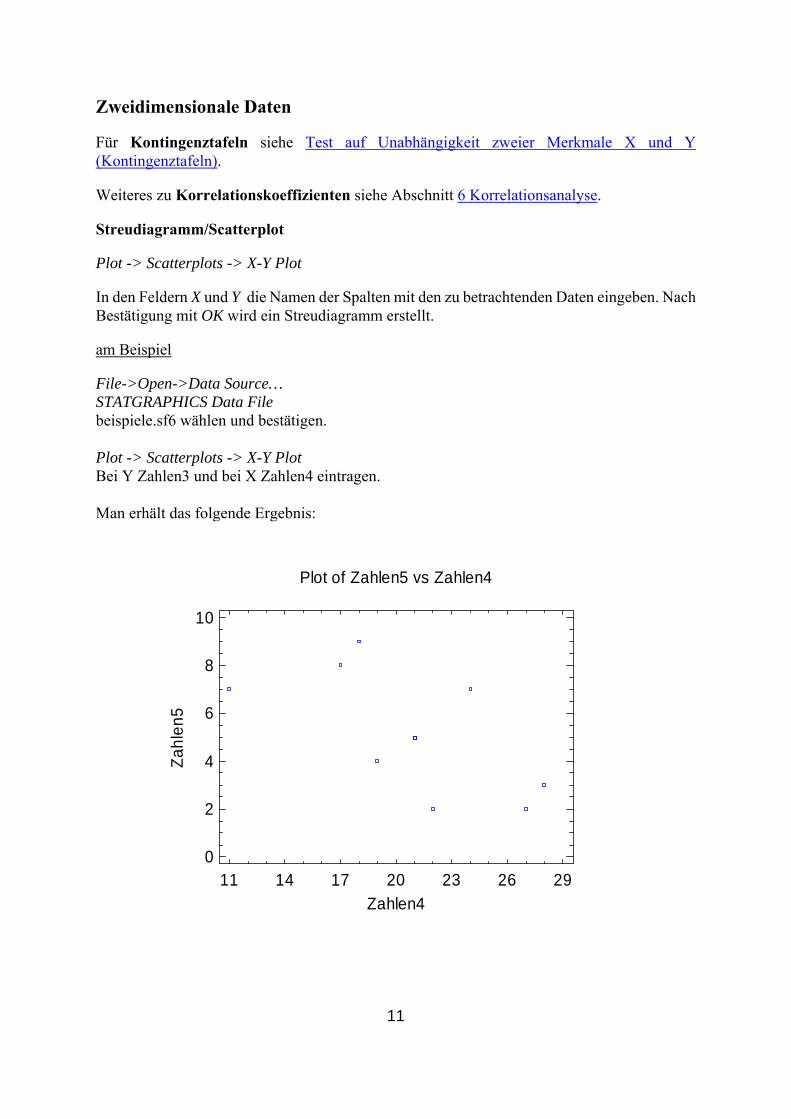
Zweidimensionale Daten Für Kontingenztafeln siehe Test auf Unabhängigkeit zweier Merkmale X und Y (Kontingenztafeln). Weiteres zu Korrelationskoeffizienten siehe Abschnitt 6 Korrelationsanalyse. Streudiagramm/Scatterplot Plot -> Scatterplots -> X-Y Plot In den Feldern X und Y die Namen der Spalten mit den zu betrachtenden Daten eingeben. Nach Bestätigung mit OK wird ein Streudiagramm erstellt. am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Plot -> Scatterplots -> X-Y Plot Bei Y Zahlen3 und bei X Zahlen4 eintragen. Man erhält das folgende Ergebnis:
Plot of Zahlen5 vs Zahlen4
11 14 17 20 23 26 29Zahlen4
0
2
4
6
8
10
Zahl
en5
11
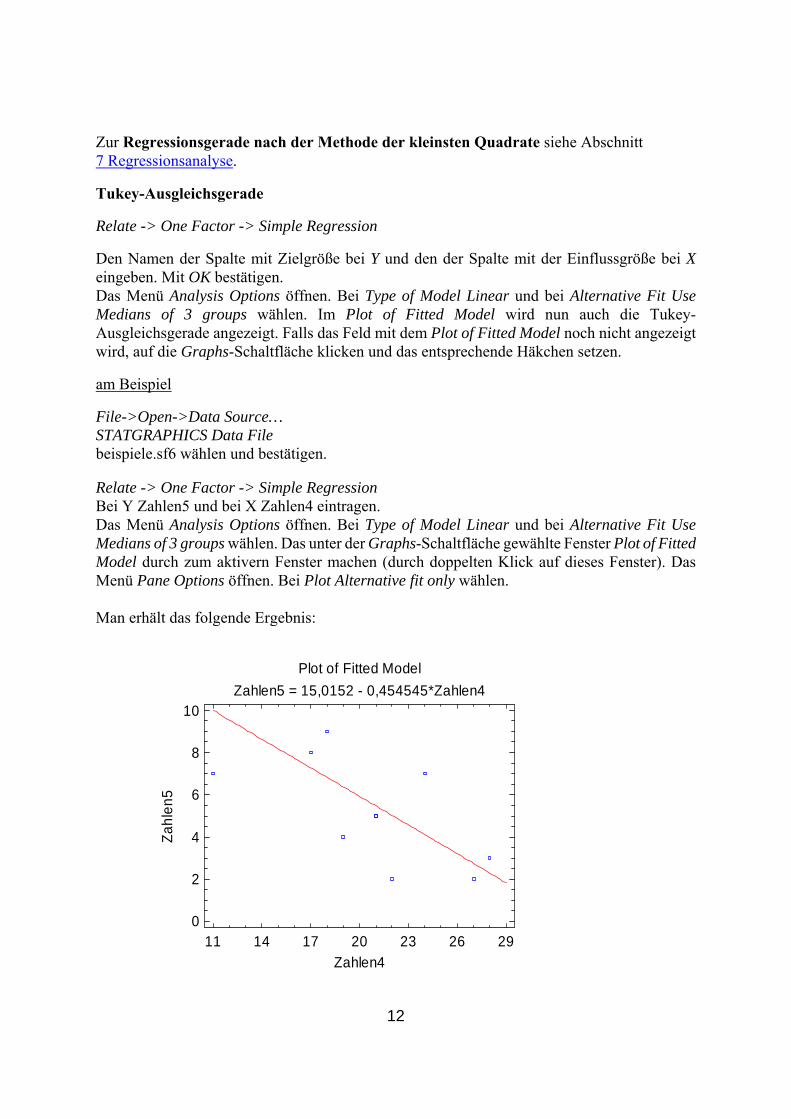
Zur Regressionsgerade nach der Methode der kleinsten Quadrate siehe Abschnitt 7 Regressionsanalyse. Tukey-Ausgleichsgerade Relate -> One Factor -> Simple Regression Den Namen der Spalte mit Zielgröße bei Y und den der Spalte mit der Einflussgröße bei X eingeben. Mit OK bestätigen. Das Menü Analysis Options öffnen. Bei Type of Model Linear und bei Alternative Fit Use Medians of 3 groups wählen. Im Plot of Fitted Model wird nun auch die Tukey-Ausgleichsgerade angezeigt. Falls das Feld mit dem Plot of Fitted Model noch nicht angezeigt wird, auf die Graphs-Schaltfläche klicken und das entsprechende Häkchen setzen. am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Relate -> One Factor -> Simple Regression Bei Y Zahlen5 und bei X Zahlen4 eintragen. Das Menü Analysis Options öffnen. Bei Type of Model Linear und bei Alternative Fit Use Medians of 3 groups wählen. Das unter der Graphs-Schaltfläche gewählte Fenster Plot of Fitted Model durch zum aktivern Fenster machen (durch doppelten Klick auf dieses Fenster). Das Menü Pane Options öffnen. Bei Plot Alternative fit only wählen. Man erhält das folgende Ergebnis:
12
Plot of Fitted ModelZahlen5 = 15,0152 - 0,454545*Zahlen4
11 14 17 20 23 26 29Zahlen4
0
2
4
6
8
10
Zahl
en5

Zeitreihen Trendschätzung, Trendabspaltung
Kleinste-Quadrate-Anpassung Vorgehen wie bei der einfachen linearen Regression. Es muss jedoch zunächst eine neue Spalte hinzugefügt werden, die die Werte der unabhängigen Variable enthält. Als unabhängige Variable wird eine `DurchnummerierungA der Werte der anderen Spalte eingeführt. Die neue Spalte soll also die Zahlen von 1 bis n enthalten. Dazu die leere Spalte durch Klick auf den Spaltennamen markieren und im Hauptmenü Edit -> Generate Data wählen. Bei Expression COUNT(?;?;?) eingeben. Die drei Fragezeichen sind in der Reihenfolge von, bis, Schrittweite durch Zahlen zu ersetzen. Es müsste also stehen: COUNT(von;Anzahl der abhängigen Werte;1). Glättung Describe -> Time Series -> Smoothing Bei Data den Namen der Spalte mit den Zeitreihendaten eingeben und bestätigen. Unter Pane Options (Rechtsklick ins Grafikfenster) kann man die Fensterlänge für die gleitenden Durchschnitte ändern. Hierfür bei Length of Moving Average die gewünschte Länge eingeben. Die dazugehörigen Daten kann man sich anzeigen lassen, indem man auf die Tables-Schaltfläche klickt und Data am Beispiel
Table auswählt.
13
File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen.
Describe->Time Series->Smoothing Zahlen1 eintragen und OK klicken.
nster Pane Options wählen. Bei Smoother 1 Simple Moving Average auswählen und bei Smoother 2 None. Bei Length of Moving Average 5 eingeben. Als Ergebnis erhält man die linksstehende Grafik und
eine Datentabelle mit den geglätteten Werten, aus der rechts ein Ausschnitt zu sehen ist. Wählt man unter der Tabels-Schaltfläche Data Table so erhält man:
Bei DataIm Grafikfe

14
Trendabspaltung (durch Differenzenbildung)
riptive Methods
> Time Series -> Seasonal Decomposition
ei Data den Namen der Spalte eingeben, welche die zu betrachtenden Daten enthält. e oft die Daten erhoben wurden. Es kann ausgewählt
erden ob dies jährlich (Year(s) (4-digit)), vierteljährlich (Quarter(s)), monatlich (Month(s)),
escribe -> Time Series -> DescD
Bei Data den Namen der Spalte mit den Werten der Zeitreihe eingeben und bestätigen. Auf die Tables-Schaltfläche klicken und Data Table auswählen. Hier werden die Werte der Zeitreihe und auch die Werte der trendbereinigten Zeitreihe dt
(q) angezeigt. q kann man unter Analysis Options ändern. Bei Differencing Nonseasonal Order kann der gewünschte Wert von q eingegeben werden. Schätzung der Saisonkomponente, Saisonbereinigung Describe - BUnter Once Every: wird eingetragen, wiwtäglich (Day(s)), stündlich (Hour(s)), minütlich (Minute(s)), sekündlich (Second(s)) oder auf sonstige Art (Other) geschah. Bei Starting At wird der Startzeitpunkt der Erhebung angegeben. Unter Seasonality schließlich wird die Saisonalität eingetragen. am Beispiel Flie->Open->STATGRAPHICS Data File
Data Source...
beispiele.sf6 wählen und bestätigen Describe -> Time Series -> Seasonal De
composition
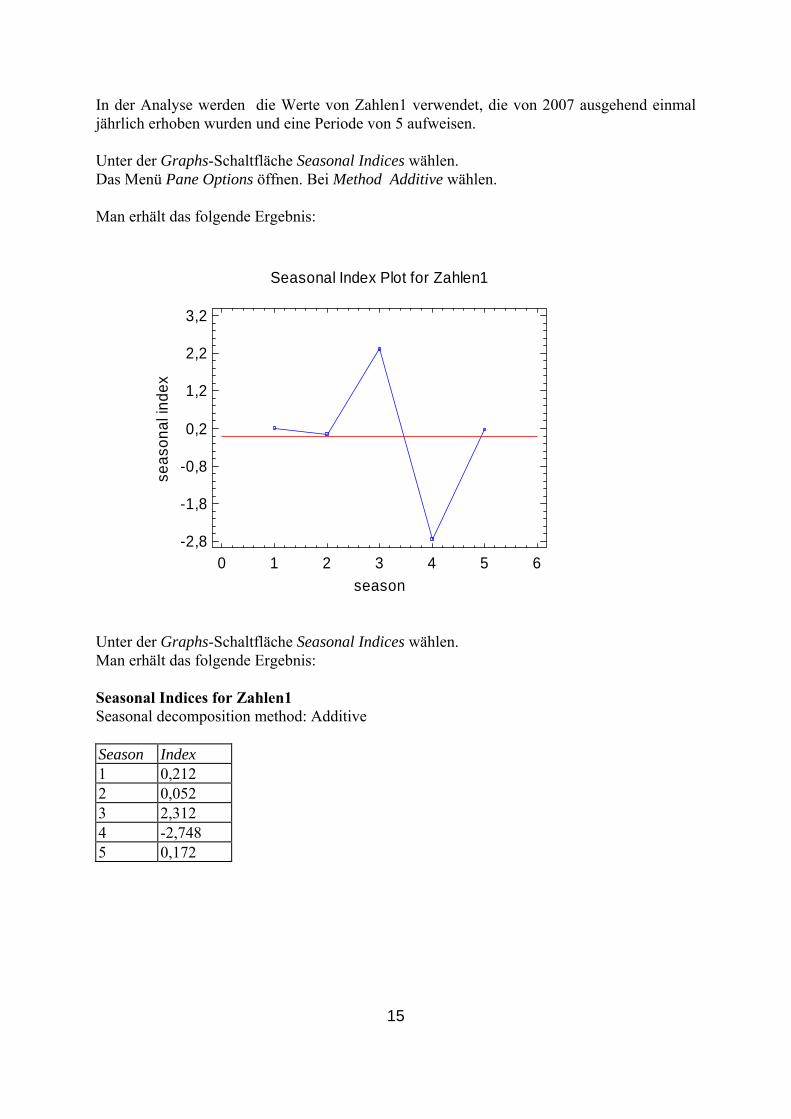
15
der Analyse werden die Werte von Zahlen1 verwendet, die von 2007 ausgehend einmal hrlich erhoben wurden und eine Periode von 5 aufweisen.
ählen. as Menü Pane Options öffnen. Bei Method Additive wählen.
an erhält das folgende Ergebnis:
Injä Unter der Graphs-Schaltfläche Seasonal Indices wD M
Seasonal Index Plot for Zahlen1
3,2
2,2
0 1 2 3 4 5 6season
-2,8
1,2
ndex
n.
an erhält das folgende Ergebnis:
easonal Indices for Zahlen1 easonal decomposition method: Additive
eason Index
-1,8
-0,8
0,2
seas
onal
i
Unter der Graphs-Schaltfläche Seasonal Indices wähleM SS S1 0,212 2 0,052 3 2,312 4 -2,748 5 0,172
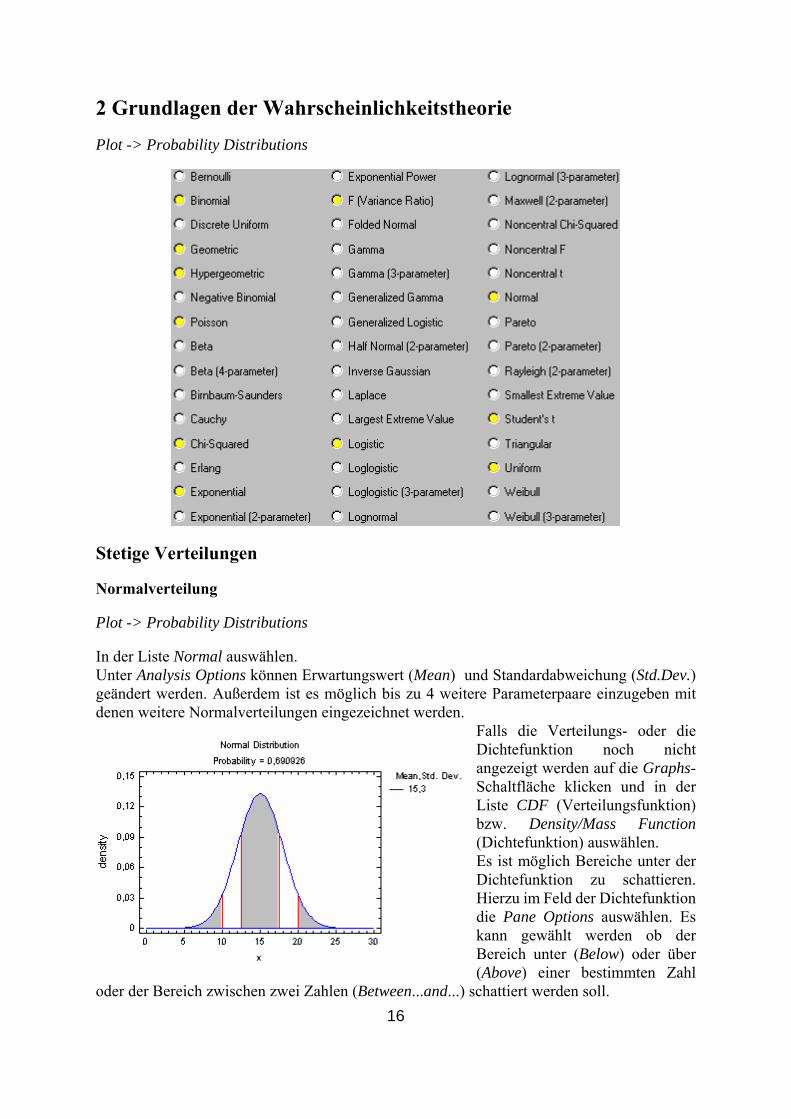
2 Grundlagen der Wahrscheinlichkeitstheorie Plot -> Probability Distributions
16
Stetige Verteilungen Normalverteilung Plot -> Probability Distributions
artungswert (Mean) und Standardabweichung (Std.Dev.) es möglich bis zu 4 weitere Parameterpaare einzugeben mit
chnet werden. Falls die Verteilungs- oder die Dichtefunktion noch nicht angezeigt werden auf die Graphs-Schaltfläche klicken und in der Liste CDF (Verteilungsfunktion) bzw. Density/Mass Function (Dichtefunktion) auswählen. Es ist möglich Bereiche unter der Dichtefunktion zu schattieren. Hierzu im Feld der Dichtefunktion die Pane Options auswählen. Es kann gewählt werden ob der Bereich unter (Below) oder über (Above) einer bestimmten Zahl
der der Bereich zwischen zwei Zahlen (Between...and...) schattiert werden soll.
In der Liste Normal auswählen.
nter Analysis Options können ErwUgeändert werden. Außerdem istdenen weitere Normalverteilungen eingezei
o

17
und Std. Dev.: 3 ane Options: Below 10,0, Between 12,5 and 17,5 und Above 20,0
und die Häkchen vor Below, Between…and…, Above setzt. Um Wahrscheinlichkeiten (der gewählten Verteilung) zu bestimmen klickt man auf die Tables-Schaltfläche und wählt Cumulative Distribution. Wählt man unter Analysis Options Mean: 15 und Std.Dev.: 3 und unter Pane Options:
bige Abbildung erhält man, wenn man folgende Eingaben macht: O
Analysis Options: Mean: 15 P
so erhält man das Ergebnis auf der linken Seite.
an auf die Tables-Schaltfläche und wählt Inverse CDF. Mean: 0,0 und Std. Dev.: 1,0 und unter Pane Options:
Zur Bestimmung von Quantilen klickt mWählt man unter Analysis Options
so erhält man das folgende Ergebnis:
Zum Erzeugen von Zufallszahlen (der gewählten Verteilung)und Random Numbers wählen. Um die Anzahl der zu erzeugder rechten Maustaste in das Feld klicken und Pane Option Unter Analysis Options kann man den Mittelwert und erzeugenden Stichprobe eingeben.
auf die Tables-Schaltfläche klicken enden Zufallszahlen zu ändern mit s auswählen.
die Standardabweichung der zu

18
Zum Erzeugen der ufallszahlen auf die Save Z
results-Schaltfläche klicken und ein Häkchen vor Random Numbers for Dist. 1 setzen. Bei Datasheet kann das Blatt ausgewählt werden, in welches die Zufallszahlen
im DataBook eingetragen werden sollen. Bei Target Variables wird der Name eingegeben, den die Spalte mit den Zufallszahlen erhalten soll. Wird ein bereits existierende ragt Statgraphics ob es die bisherigen r Spaltenname verwendet, fWerte in dieser Spalte ersetzen soll.
Das Vorgehen bei den anderen Verteilungen folgt analog.
Plot -> Probability Distributions
Exponentialverteilung
In der Liste Exponential auswählen. Unter Analysis Options kannDer Parameter λ der Exponentialverteilung ist dabei 1/EX. Gleichverteilung
In der Liste Uniform auswählen. Um a und b zu ändern, das Analysis Options-Menü öffnen. Lower Limit ist a und Upper Limit ist b.
Analysis Option weichung (Std. Dev.) ändern. Chi-Quadrat-Verteilung
In der Liste Chi-Squared auswählen. Die Anzahl der Freiheitsgrade (D.F.) kann unter Analysis Options geändert werden. F-Verteilung
F (Varian
der Erwartungswert geändert werden.
logistische Verteilung
der Liste Logistic auswählen. InUnter s kann man Erwartungswert (Mean) und Standardab
ce Ratio) auswählen. In der Liste Unter Analysis Options kann man die beiden Freiheitsgrade ändern. t-Verteilung
der Liste Student’s t auswählen. InDie Anzahl der Freiheitsgrade (D.F.) kann unter Analysis Options geändert werden.

19
Diskrete Verteilungen Geometrische Verteilung Plot -> Probability Distributions In der Liste Geometric auswählen. Die Wahrscheinlichkeit (nach der Formelsammlung die Wahrscheinlichkeit für Misserfolg) kann unter Analysis Options geändert werden.
ie Eintrittswahrscheinlichkeit M/N (Event.Prob.), die Anzahl nd die Losgröße N (Pop. Size) ändern.
Hypergeometrische Verteilung Plot -> Probability Distributions
HypergeometricIn der Liste auswählen. Unter Analysis Options kann man dder Versuche n (Trials) u Achtung: Leider kann man nicht M eingeben, sondern muss erst p=M/N berechnen. Daraus und
ird eine Fehlermeldung rt. Zum Beispiel bei N=7 und M=4
57142875 einzugeben, sondern man muss eine noch größere Genauigkeit für
lot -> Probability Distributions
n der Liste Poisson auswählen. das Analysis Options-Menü aufrufen und den dort angegebenen Wert ändern.
aus N wird M berechnet. Ist dieser Wert nicht ganzzahlig so wausgegeben. Damit ist die Eingabe einiger Parameter erschwereicht es nicht p=0,p wählen. Binomialverteilung P In der Liste Binomial auswählen. Unter Analysis Options kann man Wahrscheinlickeit p (Event.Prob.) und Anzahl der Wiederholungen n (Trials) eingeben. Poissonverteilung Plot -> Probability Distributions IUm λ zu ändern

20
atistischen Schließens I
3 Grundlagen des st Parameterschätzungen Punktschätzungen siehe Lageparameter Konfidenzschätzungen Konfidenzintervalle für die Parameter einer Normalverteilung
Variable Analysis
alverteilte Stichprobe) die
vorgenommen werden. Im Eingabefeld Confidence Level kann das Konfidenznivau 1-α geändert werden. Bei Interval Type kann ausgewählt werden, ob das zentrale
ie obere Konfidenzgrenze (Upper Bound) oder die untere
Describe -> Numeric Data -> One Die Spalte mit den gewünschten Daten auswählen und mit OK bestätigen. Falls die Konfidenzintervalle nicht mit angezeigt werden, die Tables-Schaltfläche anklicken und Confidence Intervalls auswählen. Es werden (für eine normKonfidenzintervalle für Erwartungswert und Standardabweichung ausgegeben. In beiden Fällen wird der jeweils andere Parameter aus der Stichprobe geschätzt.
Einstellungen können unter Pane Options im Fenster mit den Konfidenzintervallen
Konfidenzintervall (Two-Sided), dKonfidenzgrenze (Lower Bound) berechnet werden soll. am Beispiel File->Open->DataSTATGRAPHICS D
Source… ata File
n.
Variable Analysis
Die Einstellungen unter Pane Options wie in der obigen Darstellung wählen. Als Ergebnis erhält man: Confidence Intervals for Zahlen1 95,0% confidence interval for mean: 15,5333 +/- 1,28132 [14,252; 16,8147] 95,0% confidence interval for standard deviation: [2,73281; 4,61292]
beispiele.sf6 wählen und bestätige Describe->Numeric Data->One Bei Data Zahlen1 eintragen und bestätigen. Auf die Tables-Schaltfläche klicken und Confidence Intervals auswählen.

onfindenzintervalle für eine (unbekannte) Wahrscheinlichkeit p K
21
ypothesis Test
e -> Categorical Data ->Hypothesis Test )
Unter Parameter wählt man Binomial Proportion. Weiter gibt man unter Sample Size den
(im Beispiel n=100) an Proportion die relative
eit k (im Beispiel ist die absolute eit 21) an.
lichen Alternatihypothesen und ein iveau Alpha (das Konfidenzniveau ist damit 1-Alpha) wählen. Man erhält das zur
zugehörige Konfidenzinterval.
escribe ->Numeric Data ->HD
oder auch: Describ(
Stichprobenumfang n und im Feld Sample HäufigkHäufigk
/n
Als Ergebnis erhält man: Sample proportion = 0,21 Sample size = 100 Approximate 95,0% confidence interval for p: [0,134944;0,302915]
Unter Analysis Options kann man jetzt zwischen den mögNTestalterative
Wählt man im obigen Beispiel Less Than, so erhält man die obere Konfidenzgrenze
pproximate 95,0% upper confidence bound for p: [0,288135] A W ählt man Greater Than, so ist das Ergebnis die untere Konfidenzgrenze
pproximate 95,0% lower confidence bound for p: [0,145245 A

22
Grundlagen des statistischen Schließens II - Tests
erttest - Signifikanztest für den Erw Describe -> Numeric Data -> One Variable A Die Spalte mit den gewünschten Daten auswäFalls die Tests nicht mit angezeigt werden, dTests auswählen. Die nötigen Einstellungen kann man im Pane Options it den Tests vornehmen. Unter Normalverteilungsvoraussetzung sollte t ean/Median wird der Erwartungswert eingetragen, bei Alpha kann das Signifikanzniveau in Prozent angegeben werden und die Auswahl der Alternativhypothese erfo μ≠μ0, Less Than μ<μ0 oder Greater Than μ>μ0. am Beispiel
4 Signifikanztests für Verteilungsparameter Wichtige Tests bei normalverteilten Grundgesamtheiten Mittelw artungswert μ
nalysis
hlen und mit OK bestätigen. ie Tables-Schaltfläche drücken und Hypothesis
-Menü im Feld m Test gewählt werden. Bei M
lgt unter Alt. Hypothesis: Not Equal
File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Describe->Numeric Data->One Variable Analysis
Data Zahlen1 eintragen und bestätigen.
Man erhält als Ergebnis:
Bei Auf die Tables-Schaltfläche klicken und Hypothesis Tests auswählen. Unter Pane Options folgende Einstellungen machen:
Diesen Test und auch den folgenden Test für die Standardabweichung kann man auch über das
enu
urchführen. Dieses dient aber in erster Linie zur Bestimmung der Gütefunktion bei obenumfanges bei
M
Describe ->Numeric Data ->Hypothesis Test
dvorgegebenem Stichprobenumfang, bzw. zur Bestimmung des Stichprvorgegebener Güte.
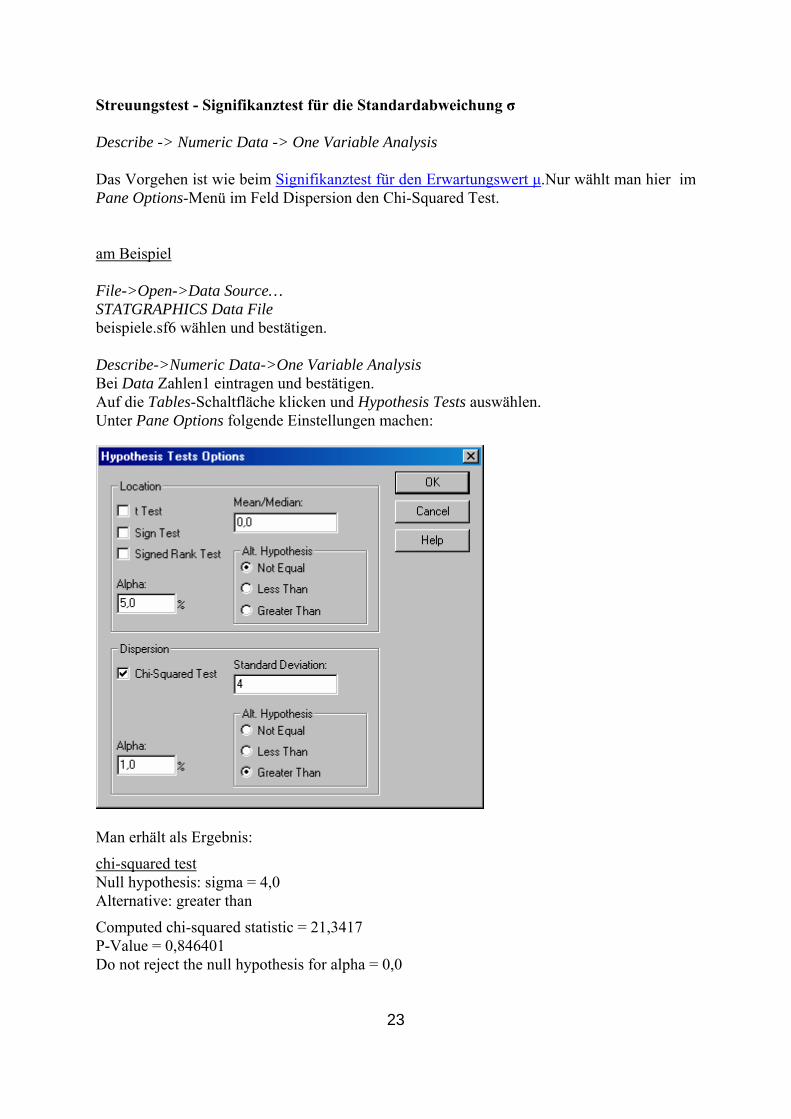
Streuungstest - Signifikanztest für die Standardabweichung σ
23
rt μ
Describe -> Numeric Data -> One Variable Analysis Das Vorgehen ist wie beim Signifikanztest für den Erwartungswe .Nur wählt man hier im P
ane Options-Menü im Feld Dispersion den Chi-Squared Test.
am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Describe->Numeric Data->One Variable Analysis Bei Data Zahlen1 eintragen und bestätigen. Auf die Tables-Schaltfläche klicken und Hypothesis Tests auswählen. Unter Pane Options folgende Einstellungen machen:
an erhält als Ergebnis: M
chi-squared test Null hypothesis: sigma = 4,0 Alternative: greater than
Computed chi-squared statistic = 21,3417 P-Value = 0,846401 Do not reject the null hypothesis for alpha = 0,0

24
pelter t-Test)
olumns auswählen. alls noch nicht angezeigt bei Tables Comparisons of Means
Menü Pane Options diesen Feldes können die eiteren Einstellungen vorgenommen werden.
angenommene Differenz der angegeben. Die Auswahl der
. Hypothesis. Bei Alpha as Signifikanzniveau in % angeben.
me Equal
Mittelwertvergleich bei gleichen (unbekannten) Varianzen (dop Compare -> Two Samples -> Independent Samples Bei Sample 1 und Sample 2 die Namen der Spalten mit den zu betrachtenden Werten eingeben und bei Input Two Data CFauswählen. ImwBei Null Hypothesis wird diebeiden Mittelwerte Δ=μ1-μ2Alternativhypothese erfolgt unter AltdFür den doppelten t-Test muss das Häkchen vor AssuSigmas gesetzt sein. am Beispiel File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen. Compare->Two Samples->Independent Samples Bei Sample 1 Zahlen1 und bei Sample 2 Zahlen2 eintragen. Bei Input Two Data Columns auswählen. Mit OK bestätigen. Nach Klicken auf die Tables-Schaltfläche Comparisons of Means auswählen. Unter Pane Options die oben dargestellten Einstellungen treffen. Als Ergebnis erhält man: t test to compare means Null hypothesis: mean1 = mean2 Alt. hypothesis: mean1 NE mean2 assuming equal variances: t = 3,3716 P-value = 0,00148389 Reject the null hypothesis for alpha = 0,05 Mittelwertvergleich bei möglicherweise ungleichen Varianzen (Welch-Test)
-> Independent Samples
wie beim doppelten t-Test
Compare -> Two Samples Vorgehensweise , nur dass das Häkchen vor Assume Equal Sigmas nicht gesetzt wird.

Beispiele sogenannter verteilungsfreier Tests
25
ples -> Paired Samples
n.
entspricht dem ebnis des Sign Tests noch nicht
e Options auswählen und ein Häkchen vor Sign Test setzen. Man kann hier ußerdem unter Alt. Hypothesis die gewünschte Alternativhypothese (Not Equal , Less Than oder
) auswählen und unter Alpha das Signifikanzniveau in Prozent eingeben.
dent Samples
eiden Spalten mit den Werten eingeben und
klicken und Comparison of Medians auswählen. hypothese (Not
a das Signifikanzniveau in n.
Vorzeichentest Compare -> Two Sam Die Wertepaare so eingeben, dass die jeweils zusammengehörigen Werte nebeneinander steheBei Sample 1 und Sample 2 die Spaltennamen der beiden Spalten mit den Werten eingeben und bestätigen. Nun auf die Tables-Schaltfläche klicken und Hypothesis Tests auswählen. Der Sign Test Vorzeichentest, wie in der Vorlesung vorgestellt. Falls das Ergausgegeben wird PanaGreater Than Rangtest nach Wilcoxon Compare -> Two Samples -> Indepen Bei Sample 1 und Sample 2 die Spaltennamen der bmit OK bestätigen. Nun auf die Tables-SchaltflächeUnter Pane Options können unter Alt. Hypothesis die gewünschte AlternativEqual, Less Than oder Greater Than) ausgewählt und unter AlphProzent eingegeben werde Achtung: Da Statgraphics eine andere Teststatistik verwendet, weichen die ausgegebenen
uster der Vorlesung und Übung berechneten ab. Die n Methoden gleich.
Zahlenwerte von den nach dem MTestentscheidung ist jedoch bei beide

Monte-Carlo-Tests
26
eise soll hier, analog des Vorlesungsbeispiels, am Beispiel eines Tests der ypothese λ=λ0 für den Parameter der Exponentialverteilung bei kleinem n dargelegt werden.
Menü Plot -> Probability Distributions wählen. In der Liste Exponential auswählen und mit andom Numbers auswählen. Mit der
ons auswählen. Nun kann die Anzahl der zu werden. Unter Analysis Options kann ichprobe, also 1/λ0 eingeben.
klicken und ein Häkchen vor Random Numbers for Dist. 1
ragen werden sollen. Bei Target Variables wird der Name eingegeben, den die Spalte mit den Zufallszahlen erhalten soll. Wird ein
n soll.
is 1000 mit einer Schrittweite von 1 erstellt, wobei jede Zahl 10 al hintereinander aufgeführt wird.
Describe -> Numeric Data -> Subset Analysis auswählen. Bei Data den Namen der, die exponential verteilten Zufallszahlen enthaltenden, Spalte eingeben. Den Namen der Spalte, welche die Nummerierung enthält, bei Codes eintragen. Nach Erstellung der Analyse auf die Save results-Schaltfläche klicken
Bei Save ein Häkchen vor Means setzen und bei Datasheet das Datenblatt auswählen, welchem die Werte hinzugefügt werden sollen. Bei Target Variables steht der Name, den die Spalte erhält, in
welche die Mittelwerte gespeichert werden. Hier wird der Name dieser Spalte also MEAN. Um jetzt das Histogramm und die Quantilstabelle, wie in der Vorlesung gesehen, zu erstellen im Menü Describe -> Numeric Data -> One-Variable Analysis auswählen. Bei Data 1/MEAN eingeben. Nun bei Tables Percentiles und bei Graphs Frequency Histogram auswählen.
Die VorgehenswH ImOK bestätigen. Auf die Tables-Schaltfläche klicken und Rrechten Maustaste in das Feld klicken und Pane Optierzeugenden Zufallszahlen, hier also 10000, eingegebenman den Erwartungswert (Mean) der zu erzeugenden StZum Erzeugen der Zufallszahlen auf die Save results-Sch
setzen. Bei Datasheet kann das Blatt ausgewählt werden, in welches die Zufallszahlen im DataBook einget
altfläche
bereits existierender Spaltenname verwendet, fragt Statgraphics ob es die bisherigen Werte in dieser Spalte ersetze Nun die nächste Spalte im Data Book markieren, mit der rechten Maustaste anklicken und im Kontextmenü Generate Data wählen. Hier bei Expression: Rep(Count(1;1000;1);10) eingeben. Es werden die Zahlen von 1 bmEine Stichprobe entspricht jetzt den zehn exponential verteilten Zufallszahlen, denen in der zweiten Spalte die gleiche Zahl zugeordnet ist. Um die Mittelwerte der 1000 Stichproben zu berechnen im Menü

27
e Tests
escribe -> Distribution Fitting -> Fitting Uncensored Data
en, falls
kann das durchzuführende Testverfahren ausgewählt werdenAnpassungstest. Wenn man use equiprobable classes auswählt, wvorgenommen, dass alle Klassen gleichwahrscheinlich sind. Nach Klick auf die Graphs-Schaltfläche können verschiedene GrBei Auswahl von Frequency Histogram kann man die Einteilung dein diesem Feld durch Rechtsklick die Pane Options aufruft uEinstellungen vornimmt. Diese Klasseneinteilung beeinflusst auTabelle des Goodness-of-Fit Tests. am Beispiel
Nichtparametrisch Test auf Vorliegen einer bestimmten Verteilung (χ2-Anpassungstest) D Bei Data den Namen der Spalte eingeben, welche die zu überprüfenden Werte enthält. Analysis Options auswählen und im nun geöffneten Dialogfenster auswählen auf welche Verteilungen hin die Stichprobe überprüft werden soll. Anschließend auf die Tables-Schaltfläche klicken und Goodness-of-Fit Tests auswähldiese noch nicht angezeigt werden. Rechtsklick in dieses Feld und Pane Options auswählen. Hier
. Chi-squared ist der χ2-ird die Klasseneinteilung so
aphiken ausgewählt werden. r Klassen ändern, indem man nd hier die entsprechenden ch die Klasseneinteilung der
TATGRAPHICS Data File
nalysis Options bei Distribution Normal auswählen.
Frequency Histogramm auswählen. In diesem
File->Open->Data Source…Sbeispiele.sf6 wählen und bestätigen. Describe->Distribution Fitting->Fitting Uncensored Data Bei Data Zahlen1 eintragen. Unter A Danach auf die Graphs-Schaltfläche klicken undFeld die Pane Options folgende Eintragungen vornehmen.
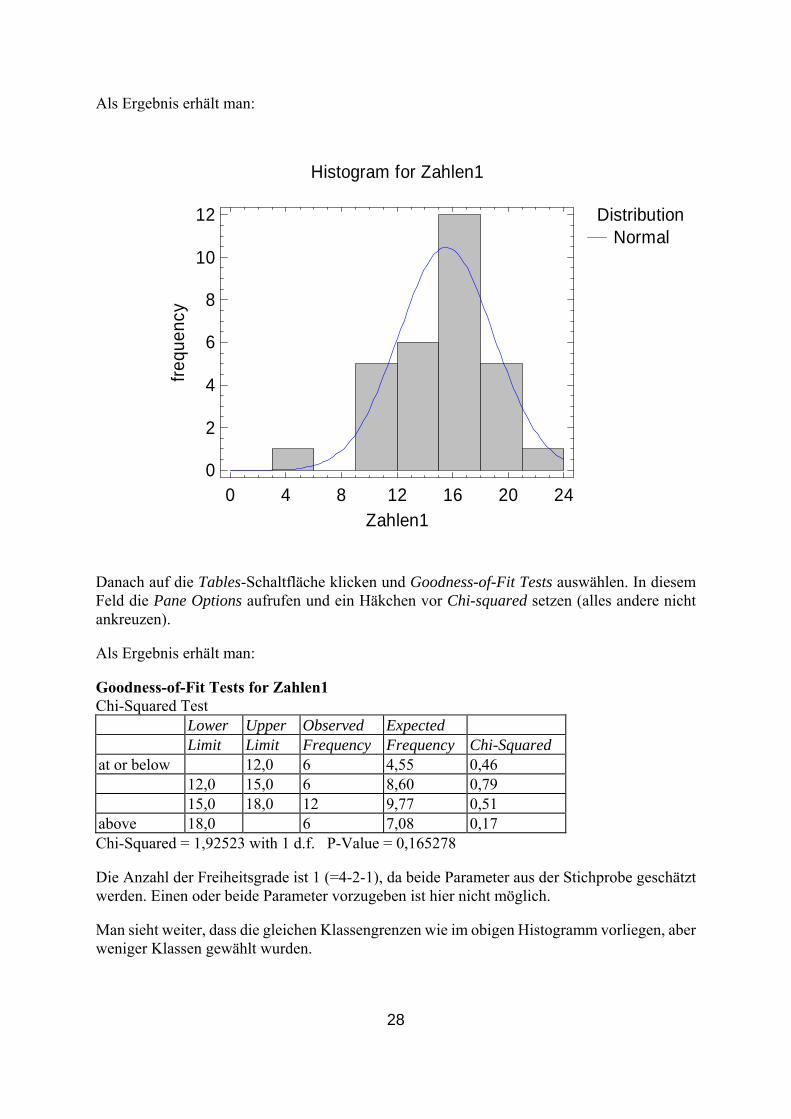
Als Ergebnis erhält man:
Histogram for Zahlen1
0 4 8 12 16 20 24Zahlen1
0
tion
of-Fit Tests auswählen. In diesem
cht
oodness-of-Fit Tests for Zahlen1 Chi-Squared Test Lower Upper Observed Expected
10Normal
12 Distribu
2
4fr
6
8
eque
ncy
Danach auf die Tables-Schaltfläche klicken und Goodness-Feld die Pane Options aufrufen und ein Häkchen vor Chi-squared setzen (alles andere ninkreuzen). a
Als Ergebnis erhält man: G
Limit Limit Frequency Frequency Chi-Squared at or below 12,0 6 4,55 0,46 12,0 15,0 6 8,60 0,79 15,0 18,0 12 9,77 0,51 above 18,0 6 7,08 0,17 Chi-Squared = 1,92523 with 1 d.f. P-Value = 0,165278 Die Anzahl der Freiheitsgrade ist 1 (=4-2-1), da beide Parameter aus der Stichprobe geschätzt werden. Einen oder beide Parameter vorzugeben ist hier nicht möglich. Man sieht weiter, dass die gleichen Klassengrenzen wie im obigen Histogramm vorliegen, aber weniger Klassen gewählt wurden.
28
29
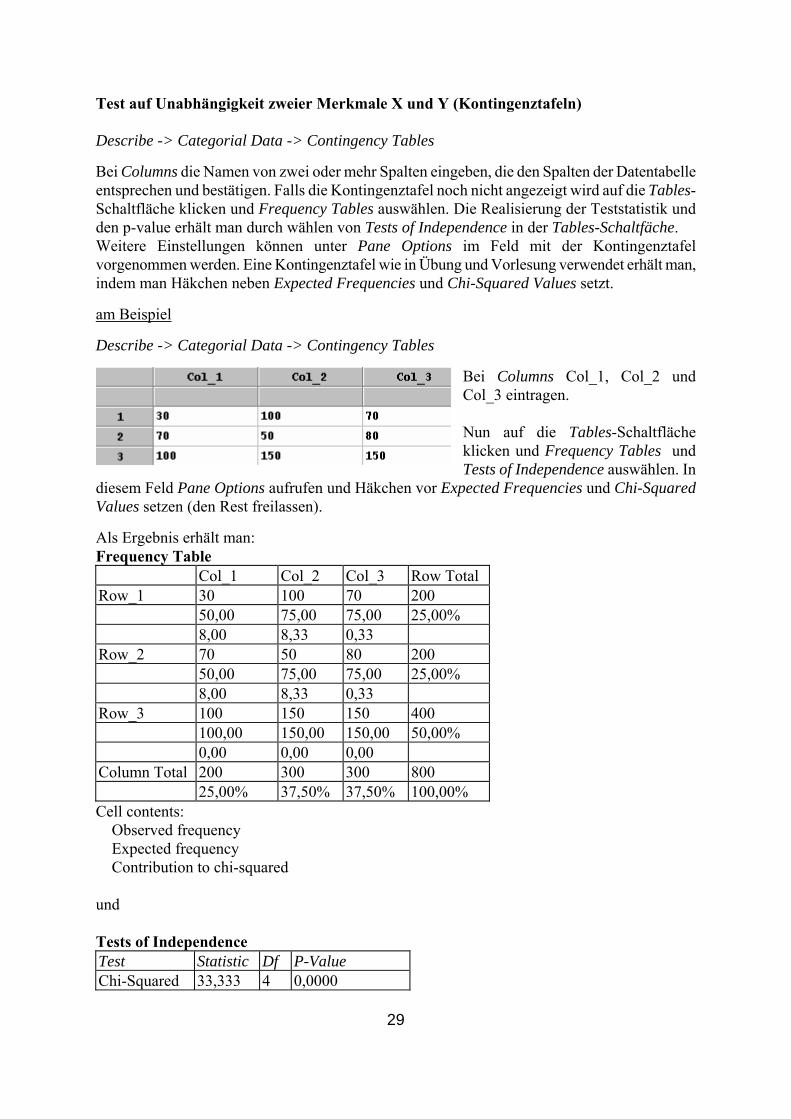
zweier Merkmale X und Y (Kontingenztafeln) Describe -> Categorial Data -> Contingency Tables
Bei Columns die Namen von zwei oder mehr Spalten eingeben, die den Spalten der Datentabelle entsprechen und bestätigen. Falls die Kontingenztafel noch nicht angezeigt wird auf die Tables-Schaltfläche klicken und Frequency Tables auswählen. Die Realisierung der Teststatistik und den p-value erhält man durch wählen von Tests of Independence in der Tables-Schaltfäche. Weitere Einstellungen können unter Pane Options im Feld mit der Kontingenztafel vorgenommen werden. Eine Kontingenztafel wie in Übung und Vorlesung verwendet erhält man, indem man Häkchen neben Expected Frequencies und Chi-Squared Values setzt.
am Beispiel
Test auf Unabhängigkeit
Describe -> Categorial Data -> Contingency Tables
Bei Columns Col_1, Col_2 und Col_3 eintragen. Nun auf die Tables-Schaltfläche klicken und Frequency Tables und Tests of Independence auswählen. In
diesem Feld Pane Options aufrufen und Häkchen vor Expected Frequencies und Chi-Squared Values setzen (den Rest freilassen).
Als Ergebnis erhält man: Frequency Table Col_1 Col_2 Col_3 Row Total Row_1 30 100 70 200 50,00 75,00 75,00 25,00% 8,00 8,33 0,33 Row_2 70 50 80 200 50,00 75,00 75,00 25,00% 8,00 8,33 0,33 Row_3 100 150 150 400 100,00 0 0 15 ,00 150, 0 50,00% 0,00 0,00 0,00 Column Total 300 300 0 200 80 25,00% 37,50% 37,50% 0,00% 10 Cell co Obse
ntents:
rved fr cy
Expected frequency equen
Contribution to chi-squared nd u
Tests of Independence
est Statistic Df P-ValueTChi-Squared 33,333 4 0,0000
Stichprobenpläne zur Qualitätskontrolle
30
robenpläne – (n,c)-Stichprobenplan
nd das Konsumentenrisiko β (Consumer’s risk (beta)) eingegeben werden. Bei Quality Levels werden pα
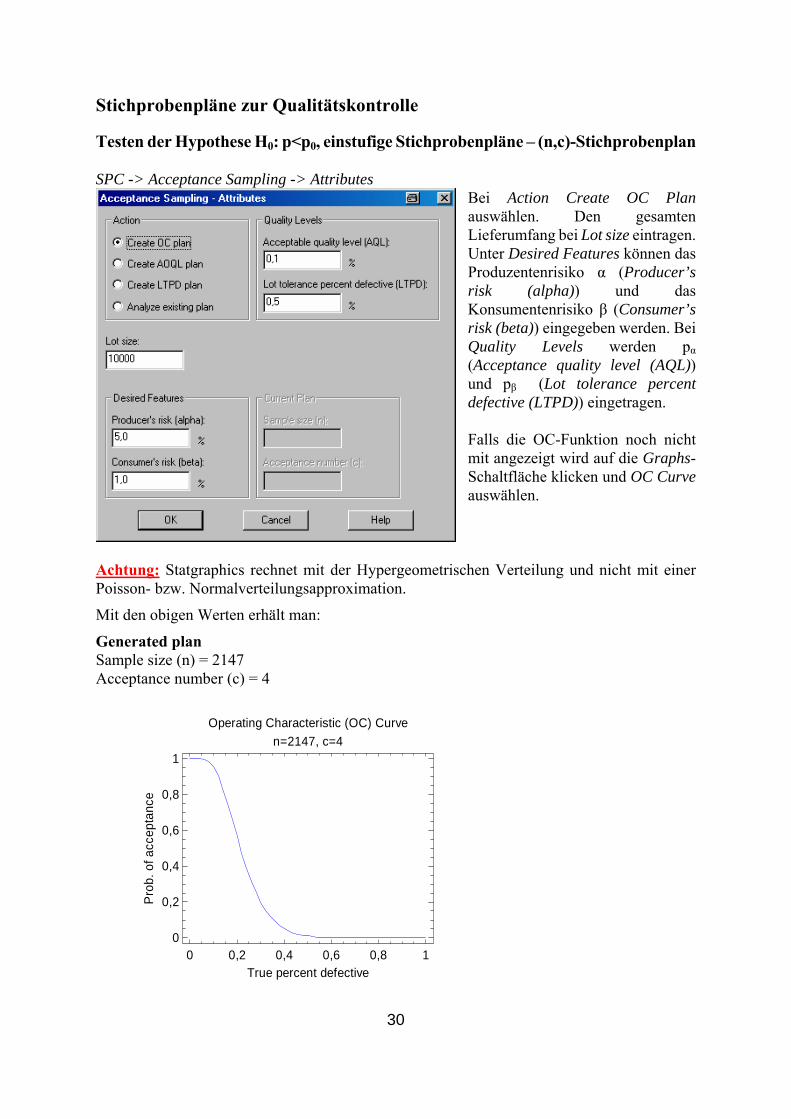
Testen der Hypothese H0: p<p0, einstufige Stichp SPC -> Acceptance Sampling -> Attributes
Bei Action Create OC Plan auswählen. Den gesamten Lieferumfang bei Lot size eintragen. Unter Desired Features können das Produzentenrisiko α (Producer’s risk (alpha)) u
(Acceptance quality level (AQL)) und pβ (Lot tolerance percent defective (LTPD)) eingetragen. Falls die OC-Funktion noch nicht mit angezeigt wird auf die Graphs-Schaltfläche klicken und OC Curve auswählen.
Achtung: Statgraphicsalverteilungsapproxim
rech de rge Verteilung und nicht mit einer bzw. N n.
it den obigen erhäl
ed planize (n) 47
cceptance num = 4
net mit r Hypeatio
ometrischenPoisson-
orm
M Werten t man:
GeneratSample s
= 21
A ber (c)
Operating Ch c ven 4
4 0,8 1r e tive
0,2
0,8
Prob
.e
aracteristi=2147, c=
(OC) Cur
1
0,6epta
nc
0,4 of a
cc
00
0,2 0, 0,6cT ue p rcent defe

Laufende Kontrolle - Mittelwertkarte) SPC -> Control Charts -> Basic Variables
31
Charts -> X-bar and R… Es gibt zwei Möglichkeiten: 1. In eine Spalte die Werte aus allen zu betrachtenden Teimüssen die Werte, die zu einer Teilstichprobe, aus welchewerden soll, gehören untereinander stehen. Bei Data – Observations den Namen dieser Spalte eintragBei Subgroup Numbers or Size wird die Anzahl der Wertejeweils besteht eingetragen. 2. Die Werte die zu einer Teilstichprobe gehören werden geschrieben. Die Werte der nächsten Teilstichprobe darunwerden die Namen der Spalten eingetragen. Statgraphics fZeile stehen zu einer Teilstichprobe zusammen. Die Anzahl der Zeilen entspricht also der Anzahl der TeilNumbers or Size bleibt leer. Das weitere Vorgehen ist für beide Möglichkeiten gleich. Die Mittelwertkarte erhält man, indem man auf die Graph e klickt und X-bar Chart auswählt. Unter Analysis Options können Einstellungen bezüglich der Kontrollgrenzen, des Sollwertes und der Standardabweichung vorgenommen werden.
alls Sollwert und
sind bei Type of Study Control to Standard auswählen. Unter Control to Standard Specify Parameters den vorgegebenen Sollwert (Mean:) und die vorgegebene Standardabweichung (Std. Dev.:) eintragen. Falls Sollwert und Standardabweichung nicht vorliegen bei Type of Study Initial Study auswählen. Statgraphics
berechnet dann die Kontrollgrenzen aufgrund der Schätzungen für Mittwelwert und Standardabweichung anhand der vorliegenden Daten. Bei den Kontrollgrenzen (X-bar Control Limits) den Wert der Standardnormalverteilung an der Stelle 1-α/2 eintragen. In Europa wird normalerweise α=0,01 verwendet. (z0, 995=2,576) Um nun noch die Warngrenzen einzuzeichnen im Feld mit der Kontrollkarte Pane Options aufrufen. Ein Häkchen vor Outer Warning Limits setzen und bei Sigma den Wert der Standardnormalverteilung an der Stelle 1-α/2 eintragen. Üblicherweise wird α=0,05 verwendet. (z0, 975=1,96) Nach Klick auf die Graphs-Schaltfläche kann man auch noch die OC-Kurve (OC Curve) und die Kurve der erwarteten Lauflänge bis zum Eingriff (ARL Curve) anzeigen lassen.
lstichproben eingeben. Dabei r jeweils der Mittelwert berechnet
en. , aus denen eine Teilstichprobe
in mehrere Spalten nebeneinander ter usw. Bei Data – Observations asst jetzt alle Werte, die in einer
stichproben und das Feld Subgroup
s-Schaltfläch
FStandardabweichung vorgegeben

32
5 Varianzanalyse
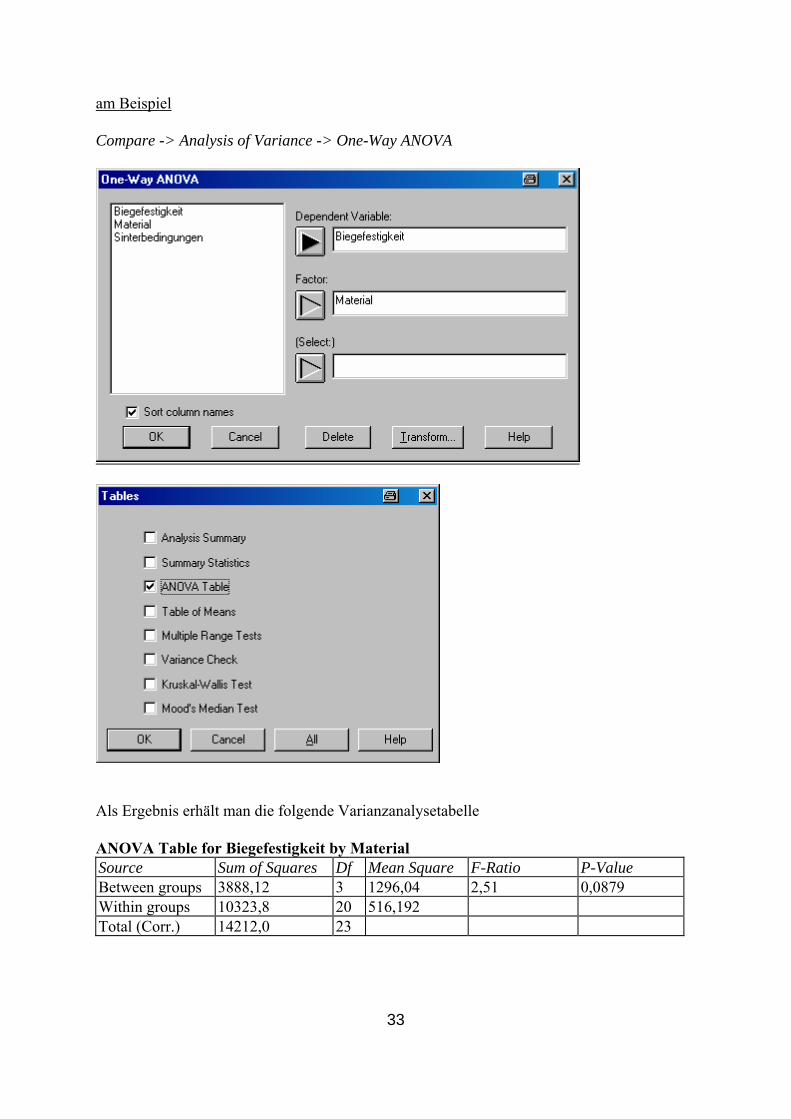
Einfache Klassifikation F-Test Compare -> Analysis of Variance -> One-Way ANOVA
Bei Dependent Variable die Spalte mit den Werten des zufälligen Merkmals eFactor die Spalte mit den Werten des Faktors.
intragen und bei
Falls die ANOVA-Tafel noch nicht angezeigt wird, auf che klicken und ANOVA Table auswählen.
die Tables-Schaltflä
am Beispiel Compare -> Analysis of Variance -> One-Way ANOVA
Als Ergebnis erhält man die folgende Varianzanalysetabelle ANOVA Table for Biegefestigkeit by Material Source Sum of Squares Df Mean Square F-Ratio P-Value Between groups 3888,12 3 1296,04 2,51 0,0879 Within groups 10323,8 20 516,192 Total (Corr.) 14212,0 23
33

34
e -> Analysis of Variance -> One-Way ANOVA
fälligen Merkmals eintragen und bei actor die Spalte mit den Werten des Faktors.
Falls der Kruskal-Wallis-Test noch nicht angezeigt wird, auf die Tables-Schaltfläche klicken und Kruskal-Wallis Test auswählen. am Beispiel
ruskal-Wallis-Test K
omparC
ei Dependent Variable die Spalte mit den Werten des zuB
F
Compare -> Analysis of Variance -> One-Way ANOVA Das gleiche Vorgehen wie im Beispiel vom F-Test, nur in der Tabels-Schaltfläche wählt man Kruskal-Wallis Test. Als Ergebnis erhält man: Kruskal-Wallis Test for Biegefestigkeit by Material Material Sample Size Average Rank 1 6 16,0 2 6 14,8333 3 6 7,75 4 6 11,4167 Test statistic = 4,97816 P-Value = 0,1734
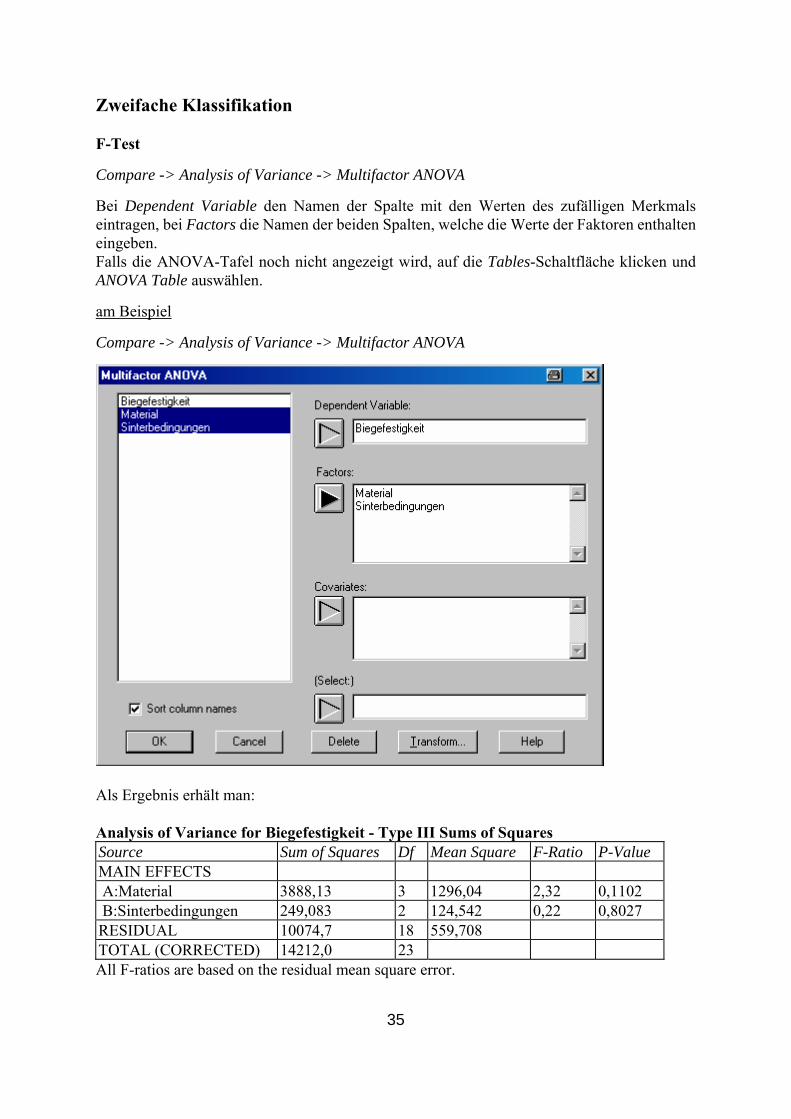
35
Klassifikation
Compare -> Analysis of Variance -> Multifactor ANOVA
Bei Dependent Variable den Namen der Spalte mit den Werten des zufälligen Merkmals eintragen, bei Factors die Namen der beiden Spalten, welche die Werte der Faktoren enthalten eingeben. Falls die ANOVA-Tafel noch nicht angezeigt wird, auf die Tables-Schaltfläche klicken und ANOVA Table auswählen.
am Beispiel
Zweifache F-Test
Compare -> Analysis of Variance -> Multifactor ANOVA
Als Ergebnis erhält man:
nalysis of Variance for Biegefestigkeit - Type III Sums of Squares Mean Square F-Ratio P-Value
ASource Sum of Squares Df MAIN EFFECTS A:Material 3888,13 1296,0 2,32 2 3 4 0,110 B:Sinterbedingun 249,083 124,542 0,22 0,8027 gen 2 RESIDUAL 10074,7 18 559,70 8TOTAL (CORRECTED) 14212,0 23 All F-ratios are based on the residual mean square error.
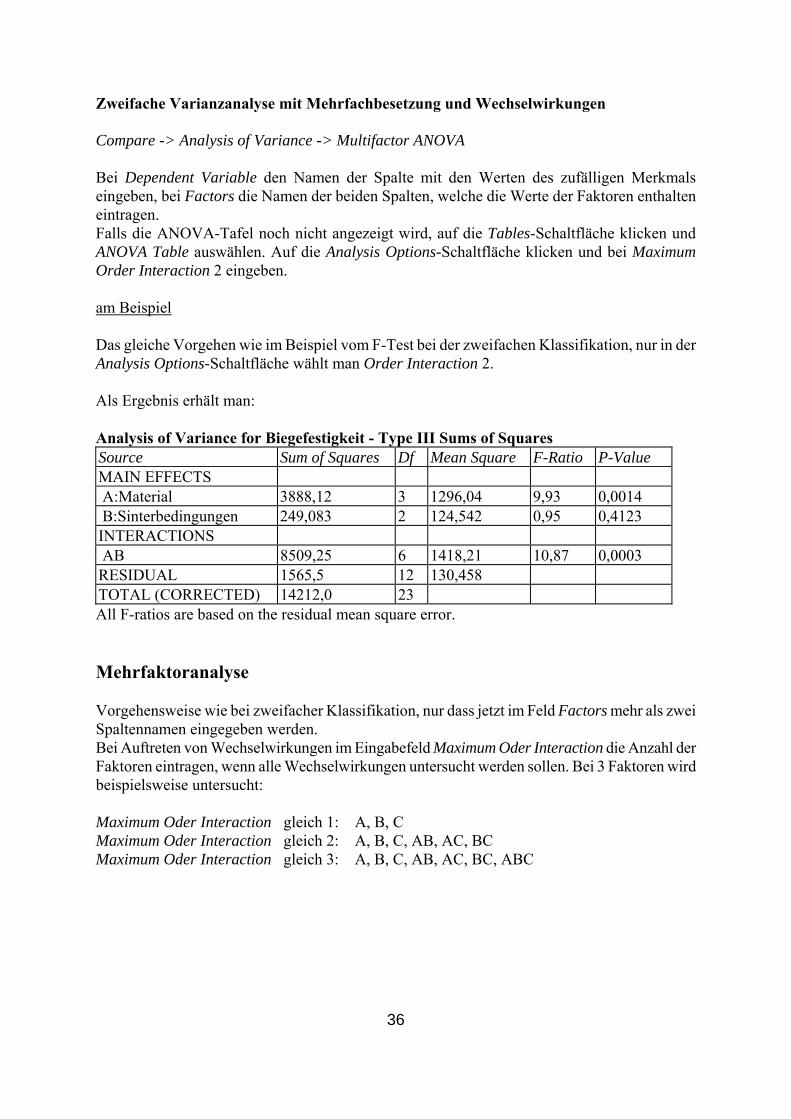
36
Zweifache Varianzanalyse mit Mehrfachbesetzung und Wechselwirkungen Compare -> Analysis of Variance -> Multifactor ANOVA
ei Dependent Variable den Namen der Spalte mit den Werten des zufälligen Merkmals che die Werte der Faktoren enthalten
intragen.
tions-Schaltfläche klicken und bei Maximum
m Beispiel
Beingeben, bei Factors die Namen der beiden Spalten, weleFalls die ANOVA-Tafel noch nicht angezeigt wird, auf die Tables-Schaltfläche klicken und ANOVA Table auswählen. Auf die Analysis OpOrder Interaction 2 eingeben. a
as gleiche Vorgehen wie im Beispiel vom F-Test bei der zweifachen Klassifikation, nur in der on 2.
nalysis of Variance for Biegefestigkeit - Type III Sums of Squares Sum of Squares Df Mean Square F-Ratio P-Value
DAnalysis Options-Schaltfläche wählt man Order Interacti Als Ergebnis erhält man: ASource MAIN EFFECTS A:Material 3888,12 3 1296,04 9,93 0,0014 B:Sinterbedingungen 249,083 2 124,542 0,95 0,4123 INTERACTIONS AB 09,25 6 1418,21 10,87 0,0003 85RESIDUA 12 130,458 L 1565,5TOTAL (C RRECTED) 212,0 23 O 14All F-ratio re based on al mean square error.
ehrfaktoranalyse
Vorgehensweise wie bei zweifacher Klassifikation, nur dass jetzt im Feld Factors mehr als zwei Spaltennamen eingegeben werden. Bei Auftreten von Wechselwirkungen im Eingabefeld Maximum Oder Interaction die Anzahl der Faktoren eintragen, wenn alle Wechselwirkungen untersucht werden sollen. Bei 3 Faktoren wird beispielsweise untersucht: Maximum Oder Interaction gleich 1: A, B, C Maximum Oder Interaction gleich 2: A, B, C, AB, AC, BC Maximum Oder Interaction gleich 3: A, B, C, AB, AC, BC, ABC
s a the residu M

6 Korrelationsanalyse
37
erkmale
it der Korrelation noch nicht angezeigt wird, auf die Tables-Schaltfläche klicken ions auswählen.
Zwei M
wischen zwei (zufälligen) Merkmalen X und Y Einfache Korrelation z Describe -> Numeric Data -> Multiple Variable Analysis Bei Data die Namen der beiden Spalten mit den Werten der zu analysierenden Merkmale eingeben. Falls das Feld mund Correlat
Beispielam File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen.
Describe->Numeric Data->Multiple Variable Analysis Bei Data Zahlen3 und Zahlen4 eingeben. Auf die Tables-Schaltfläche klicken und Correlations auswählen. Man erhält das nebenstehende Ergebnis.
Rangkorrelation Describe -> Numeric Data -> Multiple Variable Analysis
it den Werten der zu analysierenden Merkmale
Tables-Schaltfläche
n der Spearmansche u man staste in d s Feld mit der Rangkorrelation klickt und Pane Options auswählt.
Method zwisch man und nd hselt n.
Bei Data die Namen der beiden Spalten meingeben. Falls das Feld mit der Rangkorrelation noch nicht angezeigt wird, auf die klicken und Rank Correlations auswählen. Zwische n Rangkorrelation nd Kendall>s τ kann man wechseln, indemmit der rechten Mau aNun kann bei en Spear Ke all gewec werde

am Beispiel File->Open->Data Source… STATGRAPHICS Data File
Describe->Numeric Data->Multiple Variable Analysis
auswählen. Wählt man unter Pane Options Spearman so erhält das nebenstehende Ergebnis.
W hl r Pan ons e ält unters e al is:
beispiele.sf6 wählen und bestätigen.
Bei Data Zahlen3 und Zahlen4 eingeben. Auf die Tables-Schaltfläche klicken und Rank Correlations
ä t man unte e Opti Kendall so rh man das tehend s Ergebn
38

p>2 Merkmale
39
lysierenden Merkmale eingeben. Tables-Schaltfläche klicken und
Korrelationsmatrix Describe -> Numeric Data -> Multiple Variable Analysis Bei Data die Namen der Spalten mit den Werten der zu ana
alls die Korrelationsmatrix noch nicht angezeigt wird, auf die FCorrelations auswählen. am Beispiel
ile->Open->Data Source… FSTATGRAPH
eispiele.sf6ICS Data File
wählen und bestätigen.
Describe->Numeric Data->Multiple Variable Analysis
lation
ns
ultiple Korrelation
ie multiple Korrelation ist ein Spezialfall der Kanonischen Korrelation.
b
Zahlen5 Bei Data Zahlen3, Zahlen4 und
eingeben und auf die Tables-Schaltfläche klicken und Correlations auswählen. Man erhält das nebenstehende Ergebnis.
kanonische Korre Describe -> Multivariate Methods -> Canonical Correlatio Der kanonische Korrelationskoeffizient dient der Berechnung des linearen Zusammenhanges zwischen zwei Gruppen von Merkmalen. Die Namen der Spalten mit den Merkmalen einer Gruppe sind bei First Set of Variables einzutragen, die der anderen Gruppe bei Second Set of Variables. Falls es in den Gruppen eine unterschiedliche Anzahl von Merkmalen gibt, sind die Namen der Spalten, die die Merkmale aus der größeren Gruppe enthalten, bei First Set of Variables einzugeben.
enn alle Namen eingetragen sind mit OK bestätigen. W m D
40
ultivariate Methods -> Canonical Correlations
kmals X, derren lineare Abhängigkeit überprüft werden soll, bei ragen. Die Namen der Spalten der p Merkmale von denen X
iables eingeben und mit OK bestätigen.
m Beispiel
Describe -> M
Den Namen der Spalte des MertSecond Set of Variables ein
abhängig sein soll bei First Set of Var
a
File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen
Describe -> Multivariate Methods -> Canonical Correlations
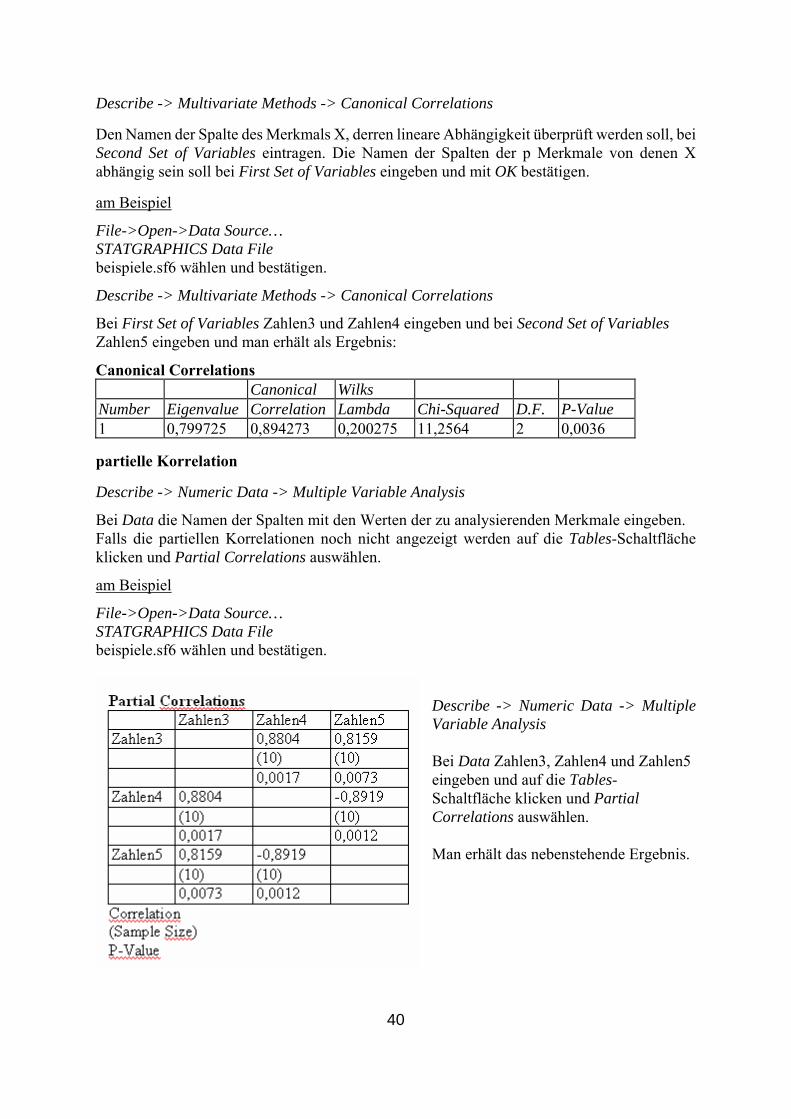
Bei First Set of Variables Zahlen3 und Zahlen4 eingeben und bei Second Set of Variables Zahlen5 eingeben und man erhält als Ergebnis:
Canonical Correlations Canonical Wilks
.
Number Eigenvalue Correlatio Lambda Chi-Squared D.F. P-Value n 1 0,799725 0,894273 0,200275 11,2564 2 0,0036
partielle Korrelation
Describe -> Numeric Data -> Multiple Varia
Bei Data die Namen der Spalten mit den Wer n. Falls die partiellen Korrelationen noch nicht angezeigt werden auf die Tables-Schaltfläche klicken und Partial Correlations auswählen.
am Beispiel
ble Analysis
n der zu analysierenden Merkmale eingebete
File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen.
Describe -> Numeric Data -> Multiple Variable Analysis Bei Data Zahlen3, Zahlen4 und Zahlen5 eingeben und auf die Tables-Schaltfläche klicken und Partial Correlations auswählen. Man erhält das nebenstehende Ergebnis.

41
nalyse
nsmodelle
en. hs-Schaltfläche klicken und Plot of Fitted Model auswählen - es wird die Grafik mit nd Prognoseschlauch erstellt. Es können außerdem verschiedene Residualplots
n werden, wenn man auf die Tables-Schaltfläche klickt und austaste ins entsprechende Feld klicken und Pane Options eingetragen werden für die die zugehörigen Y-Werte
orhergesagt werden sollen. am Beispiel
7 Regressionsa Lineare Regressio
Einfache lineare Regression Relate -> One Factor -> Simple Regression Den Namen der Spalte mit Wirkgröße bei Y und den der Spalte mit der Einflussgröße bei X ingeben. Mit OK bestätige
Auf die Graponfidenz- uK
ausgewählt werden. feVorhersagen können getrof
Forecasts auswählt. Mit der rechten Muswählen, bei X können die Wertea
v
File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestätigen.
Relate -> One Factor -> Simple Regression Als Y Variable Zahlen5 und als X Variable Zahlen4 eingeben.
Simple Regression - Zahlen5 vs. Zahlen4 Dependent variable: Zahlen5 Independent variable: Zahlen4 Linear model: Y = a + b*X Coefficients
Least Squares Standard T Parameter Estimate Error Statistic P-Value Intercept 11,7674 2,91074 4,04277 0,0037 Slope -0,315742 0,136457 -2,31385 0,0494 Analysis of Variance Source Sum of Squares Df Mean Square F-Ratio P-Value Model 22,2914 1 22,2914 5,35 0,0494 Residual 33,3086 8 4,16357 Total (Corr.) 55,6 9 Correlation Coefficient = -0,633186 R-squared = 40,0925 percent
-squared (adjusted for d.f.) = 32,604 percent RStandard Error of Est. = 2,04048
Mean absolute error = 1,47996Durbin-Watson statistic = 2,01107 (P=0,4732) Lag 1 residual autocorrelation = -0,243567
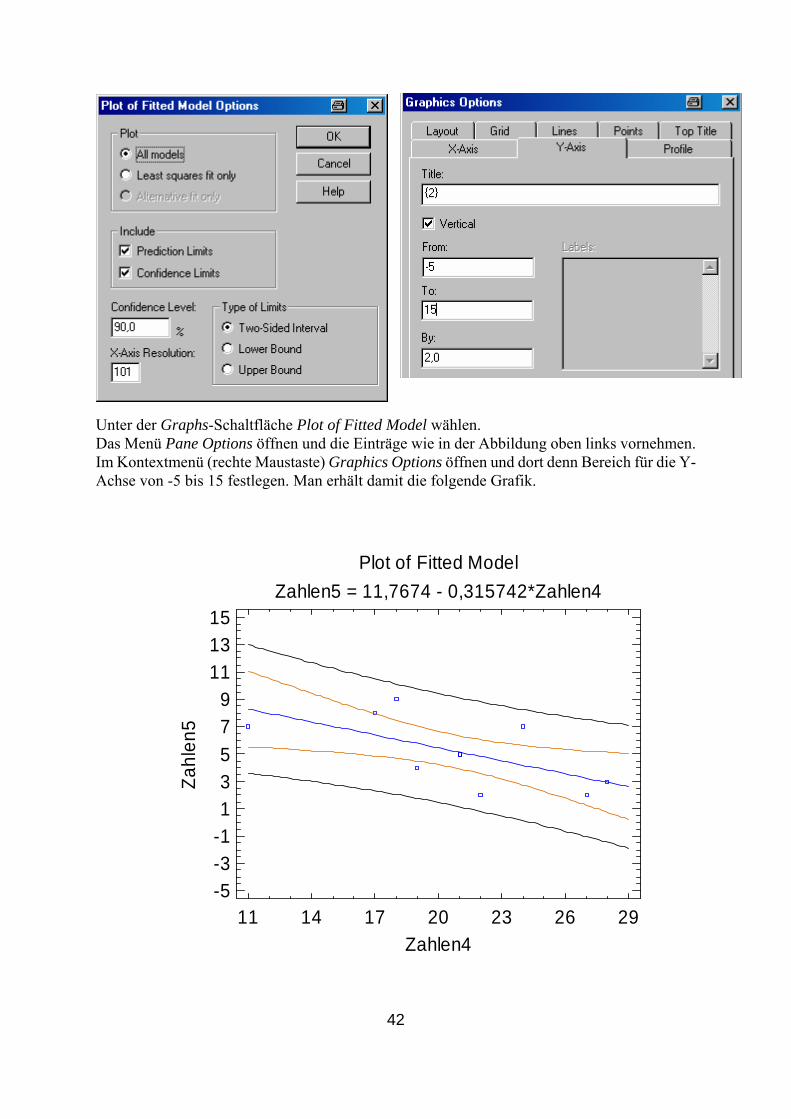
ter der G al t o d . as Menü Pane Options öffnen und die Einträge wie in der Abbildung oben links vornehmen.
e Maustaste) Graphics Options öffnen und dort denn Bereich für die Y-
Un raphs-Sch tfläche Plo f Fitted Mo el wählenDIm Kontextmenü (rechtAchse von -5 bis 15 festlegen. Man erhält damit die folgende Grafik.
Plot of Fitted ModelZahlen5 = 11,7674 - 0,315742*Zahlen4
11 14 17 20 23 26 29Zahlen4
-5-3-113579
11
Zahl
en5
1513
42
43
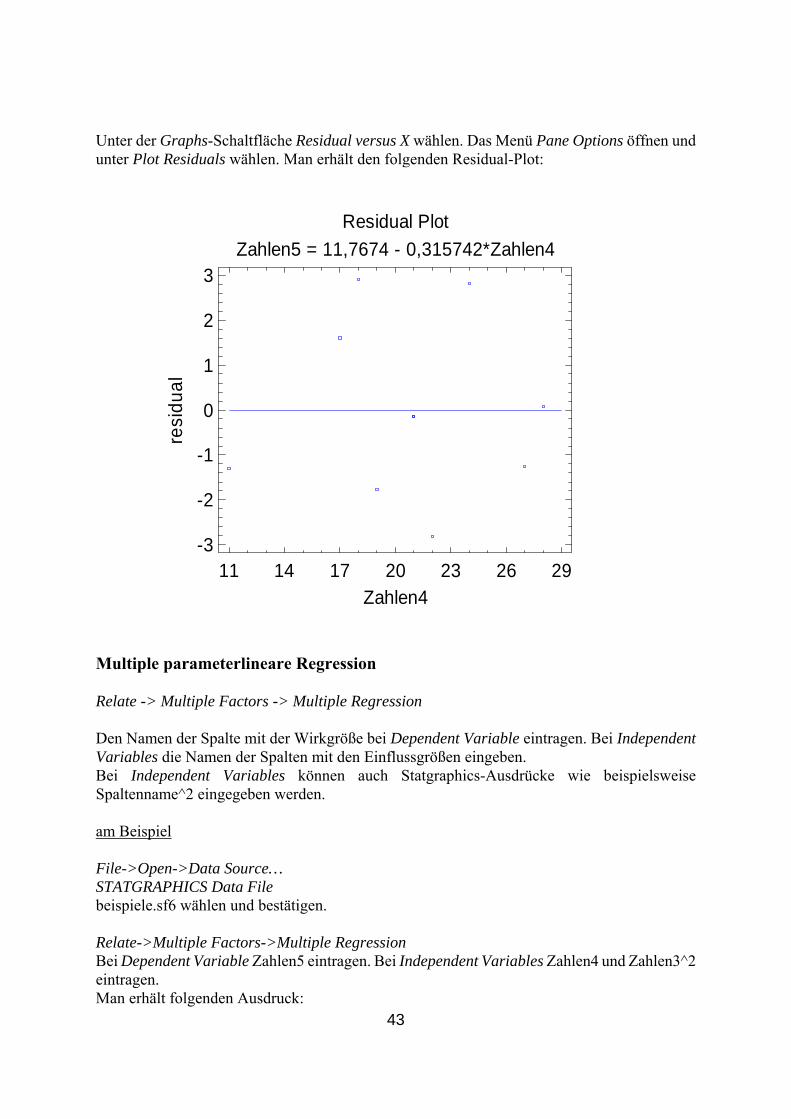
ual versus X wählen. Das Menü Pane Options öffnen und Unter der Graphs-Schaltfläche Residunter Plot Residuals wählen. Man erhält den folgenden Residual-Plot:
Residual Plot
20 23 26 29Zahlen4
0i
re R
u tors -> M egr
men der Spalte mit der W e nt e eintragen. Bei Independent er Spalten mit den Einflussgrößen eingeben.
ame^2 e
l
Zahlen5 = 11,7674 - 0,315742*Zahlen4
2
3
1
dual
res
-1
-2
-311 14 17
Multiple parameterlinea egression Relate -> M ltiple Fac ultiple R ession Den Na irkgröße b i Depende VariablVariables die Namen dBei Independent Variables können auch Statgraphics-Ausdrücke wie beispielsweise
eingegeben werdSpaltenn n. am Beispie
tigen.
ple Regression Variables Zahlen4 und Zahlen3^2
File->Open->Data Source… STATGRAPHICS Data File beispiele.sf6 wählen und bestä Relate->Multiple Factors->MultiBei Dependent Variable Zahlen5 eintragen. Bei Independenteintragen. Man erhält folgenden Ausdruck:
44
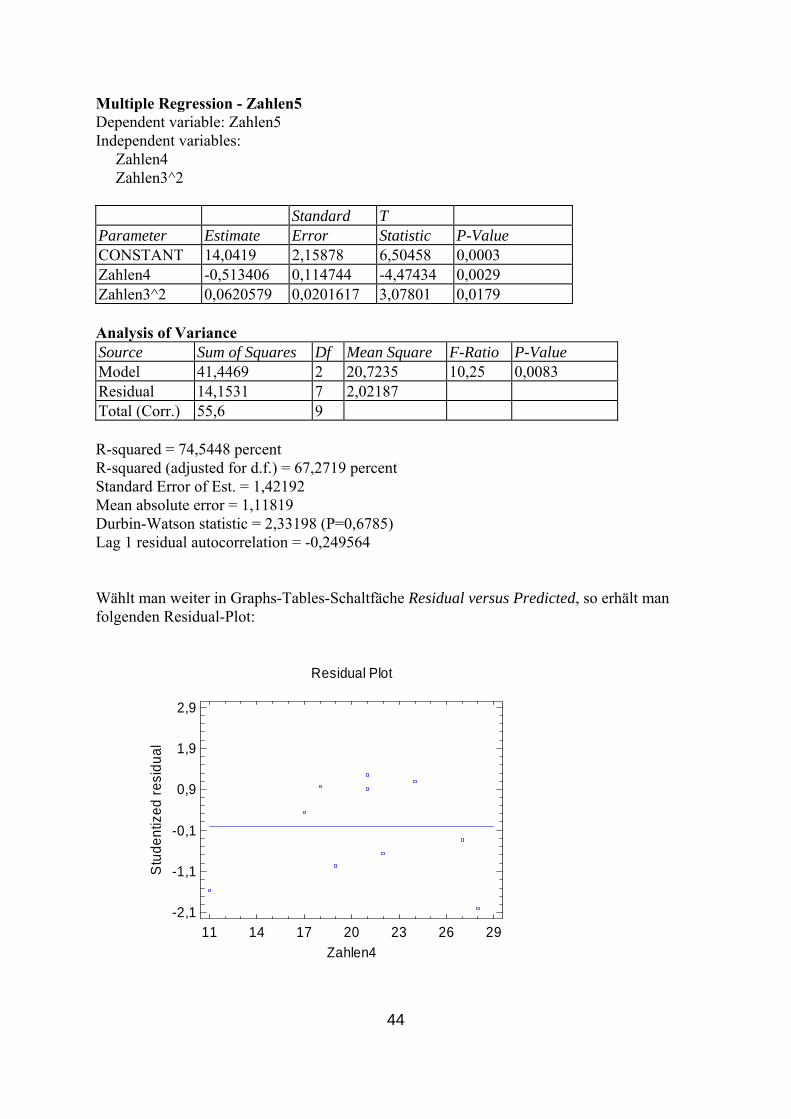
Multiple Regression - Zahlen5 Dependent variable: Zahlen5 Independent variables: Zahlen4 Zahlen3^2 Standard T Parameter Estimate Error Statistic P-Value CONSTANT 14,0419 2,15878 6,50458 0,0003 Zahlen4 -0,513406 0,114744 -4,47434 0,0029 Zahlen3^2 0,0620579 0,0201617 3,07801 0,0179 Analysis of Variance Source Sum of Squares Df Mean Square F-Ratio P-Value Model 41,4469 2 20,7235 10,25 0,0083 Residual 14,1531 7 2,02187 Total (Corr.) 55,6 9 R-squared = 74,5448 percent R-squared (adjusted for d.f.) = 67,2719 percent Standard Error of Est. = 1,42192 Mean absolute error = 1,11819 Durbin-Watson statistic = 2,33198 (P=0,6785) Lag 1 residual autocorrelation = -0,249564 Wählt man weiter in Graphs-Tables-Schaltfäche Residual versus Predicted, so erhält man folgenden Residual-Plot:
Residual Plot
11 14 17 20 23 26 29Zahlen4
-2,1
-1,1
-0,1
0,9
1,9
2,9
Stu
dent
ized
resi
dual

45
ichtlineare Regression
Die Vorgehensweise soll hier am Vorlesungsbeispiel dargelegt werden. Die erste Spalte mit wird t und die zweite Spalte mit y_t bezeichnet. Durch einen Doppelklick auf die jeweilige Spalte gelangt man zu Modify Column und kann die Namen der Spalten ändern. In die erste Spalte werden die Zeitpunkte 1,…,10 eingetragen und in die zweite Spalte die dazugehörigen y-Werte.
Als nächstes wird die dritte Spalte in z_t umbenannt. Über Generate Data im Kontextmenü (Klick aus Spaltennamen und Rechtsklick) werden in dieser Spalte neue Werte erzeugt. Dazu wird bei Expression 1/y_t eingetragen.
Die nächste Spalte wird in z_t_1 umbenannt. In diese Spalte werden die Werte aus der Spalte z_t um eine Position verschoben hinein kopiert. Man erhält die folgenden Eintragungen:
N Anpassung an die logistische Funktion
Jetzt werden die Parameter a und b über die einfache lineare Regression geschätzt. Relate -> One Factor -> Simple Regression Als Y Variable z_t und als X Variable z_t_1 eingeben. Coefficients
Least Squares Parameter Estimate Intercept 0,00633285 Slope 0,870867 Die geschätzten Regressionskoeffizienten kopiert man in zwei neue Spalten und bezeichnet diese mit a und b.

Die nächste Spalte wird mit alpha bezeichnet. er Generate Data im Kontextmenü wird der Wert von alpha
errechnet. Dazu wird bei Expression –log(b) eingetragen.
Die folgende Spalte wird mit gamma bezeichnet. Hie na Wahl von Generate Data bei Expression 1-e ha))/a
amit die folgenden Ergebnisse:
Üb
r trägt man ch ( xp(-alp ein.
Man erhält d
Alle Y-Werte s iner als (das sc ätzte) gamma. Damit ist die Berechnung von beta die
olgende. Als Hilfsvariable wird eine neue Spalte mit h bezeichnet. Über Generate Data werden stimmt, indem man bei Expression log(20,390772061/y_t-1)
palte mit beta und berechnet in dieser, wieder er Werte in Spalte h.
ind kle ge hFdie einzelnen Summanden beeinträgt. Als letztes bezeichnet man eine neue Süber Generate Data, die Summe d
46
Als Ergebnisse erhält man: