an overview of gene structure & function...
TRANSCRIPT

AN OVERVIEW OF GENE STRUCTURE & FUNCTION PREDICTION Marcus Chibucos, Ph.D. University of Maryland School of Medicine June 2013

Overview & goals • Understand
• 1. How we predict presence & structure of coding and non-coding genes in the genome
• 2. How we know what gene product does & how evidence is used to support this
• When searching databases like FungiDB or InterPro, understand the meaning of terms like: protein motif, domain, ortholog, HMM, EC, GO annotation, and so forth
• Learn fundamentals with prokaryotes... • Overview of eukaryotes…

GENE STRUCTURAL ANNOTATION
3
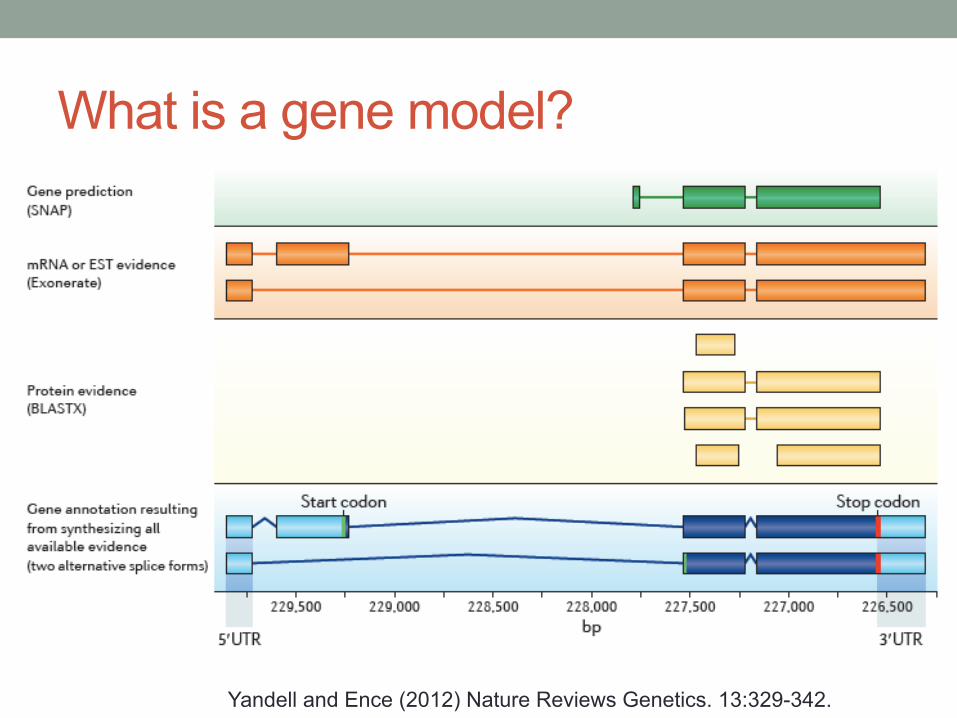
What is a gene model?
Yandell and Ence (2012) Nature Reviews Genetics. 13:329-342.

Fundamental methods of pattern detection • Intrinsic (ab initio/de novo, “from the beginning”)
• Uses only DNA sequence and the inherent patterns within it • Canonical features like start & stop codons
• Extrinsic • Uses additional sources of evidence information
• Homologous proteins • mRNA (ESTs, RNA-Seq) • Synteny
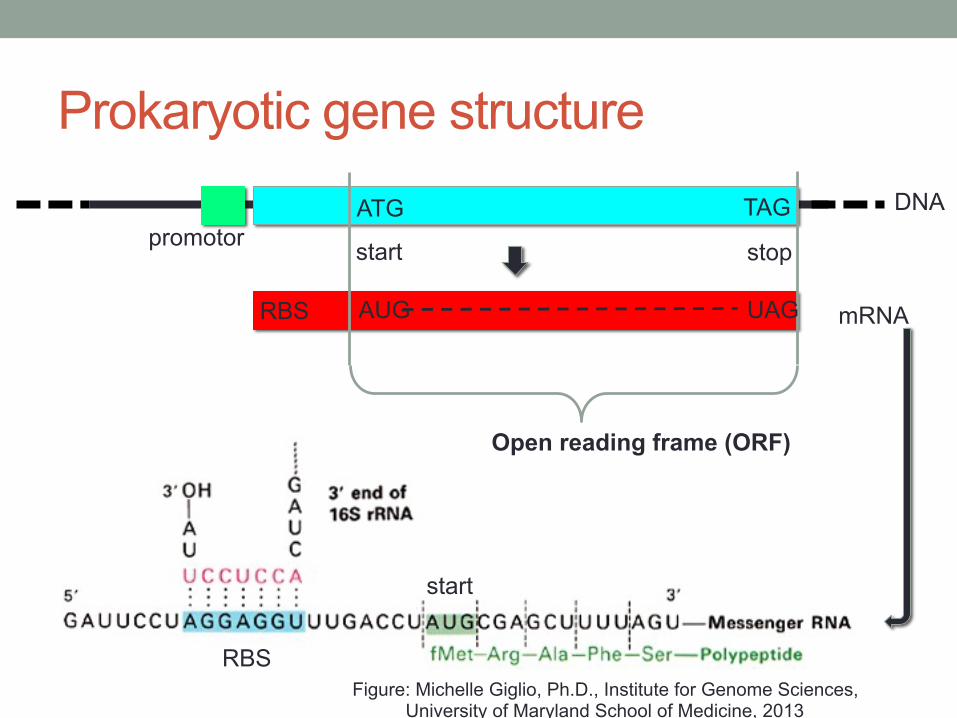
Prokaryotic gene structure
AUG RBS
DNA
mRNA
ATG TAG
UAG
start stop
Open reading frame (ORF)
promotor
RBS
start
Figure: Michelle Giglio, Ph.D., Institute for Genome Sciences, University of Maryland School of Medicine, 2013

Start with DNA sequence

DNA sequence has 6 translation frames • 3 on forward strand, 3 on reverse strand
Figure: Michelle Giglio, Ph.D., Institute for Genome Sciences, University of Maryland School of Medicine, 2013

Each horizontal bar represents one of the translation frames. Tall vertical lines represent translation stops (TAG, TAA, TGA). Short vertical lines represent translation starts (ATG, GTG, TTG).
Graphical display of 6-frame translation
Figure: Michelle Giglio, Ph.D., Institute for Genome Sciences, University of Maryland School of Medicine, 2013

These are examples of the many ORFs in this graphic.
stop
start
Graphical display of 6-frame translation
• What is an “ORF”?

Prokaryotic gene finders • Glimmer
• http://www.cbcb.umd.edu/software/glimmer • prok and euk versions
• Prodigal • http://prodigal.ornl.gov
• GeneMark • http://exon.gatech.edu
• prok and euk versions
• EasyGene • http://www.cbs.dtu.dk/services/EasyGene
• Many others exist…

Glimmer • Tool uses interpolated Markov models (IMMs) to predict which
ORFs in a genome contain real genes.
• Glimmer compares nucleotide patterns it finds in a training set of genes known (or believed) to be real to nucleotide patterns of ORFs in the whole genome. ORFs with patterns similar to the patterns in the training genes are considered real themselves.
• Using Glimmer is a two-part process • Train Glimmer with genes from organism that was sequenced, which
are known, or strongly believed, to be real genes. • Run trained Glimmer against the entire genome sequence. • This is actually how most ab initio gene predictors—including
eukaryotic predictors like Augustus, GeneID, SNAP, and others—work.

these not these
Gathering the training set • Using verified, published sequences ideal… not always possible
• Minimum needed is 250 kb of total sequence • BLAST translated ORFs against a protein database (slow)
• Keep only very strong matches • Gather long non-overlapping ORFs (fast) • Many more complex strategies exist, especially for eukaryotes

Training Glimmer
• All k-mers from size 5-8 in sequence are tracked • Frequency of each nucleotide following any given k-mer is
recorded • This data set is used to build a statistical model that provides
the probability that any given nucleotide will follow any given k-mer
• This model is used to score the ORFs in the genome • Those where the patterns of nucleotides/k-mers match the
model are predicted to be real genes

+1
+2
+3
-1
-2
-3
Candidate ORFs
• Choose a minimum length cut-off • Blue ORFs meet this minimum • Each blue ORF will be scored against the model built from
the training genes
Figure: Michelle Giglio, Ph.D., Institute for Genome Sciences, University of Maryland School of Medicine, 2013

Categorizing ORFs as genes or not • Some ORFs will score well to the model (green) • Some will not (red) • Green ORFs will be retained as predicted genes (blue
arrows depicted along the DNA molecule in black at the bottom of the figure)
+1 +2
+3
-1
-2
-3

Potential problems to watch for • False Positives
• An ORF is predicted to be a gene, but really isn’t • May result in overlaps
• False Negatives • An ORF is not predicted to be a gene, but really is • May result in “gaps” in feature predictions
• Wrong start site chosen • Most genes have multiple start codons near the beginning – it can
be hard to determine which is the true one
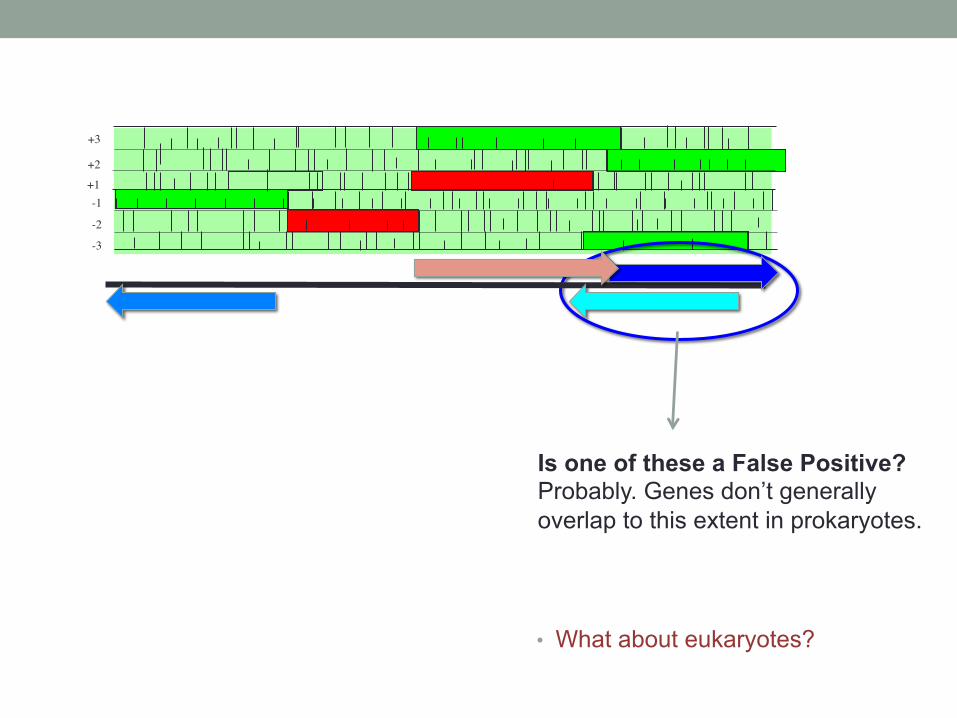
+1 +2
+3
-1
-2
-3
Is one of these a False Positive? Probably. Genes don’t generally overlap to this extent in prokaryotes.
• What about eukaryotes?

+1 +2
+3
-1
-2
-3
Is this a false negative? Probably. There are not large regions without gene content in prokaryotes. Why might this happen? If a region of DNA is different in composition than the rest of the genome then the gene finders will score the ORFs poorly when in fact they are real genes. Different composition may come about in many ways – one common way is through lateral (or horizontal) transfer. Things such as phage integration, transposition, etc.)
• What about eukaryotes?

Translation start site considerations
20
- Start site frequency: ATG >> GTG >> TTG - Ribosome binding site (RBS): AG rich sequence 5-11 bp upstream of the start codon - Similarity to match proteins, in BER & multiple alignments - In example below (showing just the beginning of one BER alignment--here the DNA sequence reads down in columns for each codon), homology starts exactly at the first atg (the current chosen start, aa #1), there is a very favorable RBS beginning 9 bp upstream of this atg (gagggaga). There is no reason to consider the ttg, and no justification for moving to the second atg (this would cut off some similarity and it does not have an RBS).
RBS upstream of chosen start
3 possible start sites
This ORF’s upstream boundary BER match

When two ORFs overlap (boxed areas), the one without similarity to anything (another protein, an HMM, etc.) is removed. If both don’t match anything, other considerations such as presence in a putative operon and potential start codon quality are considered. Small regions of overlap are allowed (circle).
Overlap analysis
21

Areas of the genome with no genes and areas within genes without any kind of evidence (no match to another protein, HMM, etc., such regions may include an entire gene in case of “hypothetical proteins”) are translated in all 6 frames and searched against a non-redundant protein database.
Interevidence regions
22

It’s not just about proteins • Can predict many
genes beyond protein coding ones



Manatee genome viewer
http://manatee.igs.umaryland.edu/ http://manatee.sourceforge.net/igs/index.shtml

Artemis gene model curation tool
http://www.sanger.ac.uk/resources/software/artemis/

…now things get more
complicated
Eukaryotic gene structure prediction

Gene finder evaluation • Sensitivity (Sn) measures false negatives
• The fraction of a known reference feature that is predicted by a gene predictor = TP / (TP + FN)
• Specificity (Sp) measures false positives • The fraction of the prediction that overlaps a
known reference feature = TP / (TP + FP)
• Assessed at different levels – Base – Exon – Transcript – Gene

Intrinsic (ab initio) success rates • Prokaryotic – very good >95% correct • Eukaryotic – not so good ~50% correct (shown below)
http://bioinf.uni-greifswald.de/augustus/accuracy (accessed May 2013)

Complexities of eukaryotic gene finding • Large genomes in eukaryotes
• Low coding density; in proks virtually all long ORFs encode gene, but not so in euks
• Genomic repeats • Non-canonical (ATG) start codon • Splicing (exons & introns)
• Alternative splicing (40-50% genes) • Pseudogenes • Long genes or short genes • Long introns • Non-canonical introns • UTR introns • Overlapping genes on opposite strands • Nested genes overlapping on strand or in intron • Polycistronic peptide coding genes
• One mRNA codes for several very short (~11 aa) peptides… regulatory function • Even if you have some RNA (helpful) transcription not always active
• Need multiple biological conditions

Masking repeats is essential • RepeatMasker (http://www.repeatmasker.org) finds
interspersed repeats & low complexity DNA sequences by comparing DNA sequence to curated genomic-specific libraries • Simple Repeats – 1-5 bp duplications such as A, CA, CGG • Tandem Repeats - 100-200 bases found at centromeres & telomeres • Segmental Duplications - 10-300 kilobases blocks copied to another
genomic region • Interspersed Repeats
• Processed pseudogenes, retrotranscripts (short-interspersed elements- SINES): Non-functional copies of RNA genes reintegrated into the genome via reverse transcriptase
• DNA transposons • Retrovirus retrotransposons • Non-retrovirus retrotransposons (long interspersed elements- LINES)
• ~50% of human genomic DNA currently will be masked
• RepeatModeler searches for repeats ab initio and can find not previously characterized repeats

Repeats yield similarities in non-homologous regions
Alkes L. Price, Neil C. Jones and Pavel A. Pevzner (June 28, 2005) http://bix.ucsd.edu/repeatscout/repeatscout-ismb.ppt
GENE1
GENE2
GENE1
GENE2
Using unmasked genomic DNA
Using masked genomic DNA

Predicted genes that are actually repeats
Using masked genomic DNA
Using unmasked genomic DNA
Gene predictors
Repeats Predicted models
No models

Multiple predictors give different results on same data set • Factors affecting gene predictor results
• Underlying algorithm • Program parameters • Training set (number and quality of models) • Additional extrinsic inputs (expression data, protein/genome alignment)
Fungus species 1 Fungus species 2 GeneMark-ES (self training) 9,024 9,527 Augustus trained on Botrytis 8,194 9,011 Augustus trained on Neurospora 7,335 7,955 GeneID trained on Stagnospora 10,313 12,894 GeneID trained on Sclerotinia 10,691 13,837 GLEAN consensus 8,705 9,523

Which model is “correct”?
Protein alignments
Consensus model
Models from three different predictors/conditions

We rely on certain conventions • Rules are based on gene composition & signal
• First, what is the basic structure of a gene? • Coding region (exon) is inside ORF of one reading frame • All exons on same strand for a given gene • Exons within a gene can have different reading frame
• Inherent frequency patterns exist…

Dimer frequency distribution • Dimer frequency in protein sequence is not evenly
distributed and is organism specific • Some amino acids “prefer” to be next to one another • Most dicodons are biased toward either coding or non-coding, not
neutral
• Expected frequency of dimer • If random = 0.25% (1/20 * 1/20) • If a dimer has lower than expected frequency, protein less likely to
contain it… and the reasoning follows that if a sequence does contain it, it is less likely to exist in a coding region
• Example: In human genome, AAA AAA appears 1% of time in coding regions and 5% of time in non-coding regions

Modified from: http://en.wikipedia.org/wiki/File:Intron_miguelferig.jpg
http://en.wikipedia.org/wiki/File:Pre-mRNA_to_mRNA.svg
Splicing • Find all GT/AG donor/acceptor sites • Score with position-specific scoring matrix
(PSSM) model
splice donor
splice acceptor
poly- pyrimidine
tract branch point

Position Specific Scoring Matrix (PSSM) 1 2 3 4 5 6 7 8
A
G
C
U
1 1 1 0 0 0 1 1
0
4
0
2
1
1
1
2
2 5 0 0 2 1
2
1 0 0 5 0
0 0 4 1
Let’s say you look at 5 splice donor (GU) sites: !ATCGUCGC!UCAGUGGC!CUCGUCCC!GUCGUUAC!CACGUCUA!
Gene Gene finders use this information to predict where gene features are. For this to work, one must have confirmed splice sites to use for training. These are not always available for new genomes… and some splice sites are non-canonical… and some genes are alternatively spliced… so it can become somewhat complex.

Translation start prediction • Position-specific scoring matrix (PSSM)
• Certain nucleotides tend to be in position around start site (ATG), and others not so
• Such biased nucleotide distribution is basis for translation start prediction
Figure courtesy of Sucheta Tripathy http://www.slideshare.net/tsucheta/29th-june2011

Mathematical model • Fi(X): freq. of X (A, G, C, T) in position I • Score string by Σ log (Fi (X)/0.25)
Figure courtesy of Sucheta Tripathy http://www.slideshare.net/tsucheta/29th-june2011

Pattern-based exon & gene prediction • Assess different criteria
• Coding region inside ORF (start & stop, no interrupting stops) • Dimer frequency • Coding score • Donor site score • Acceptor site score
• Other factors to consider • GC content • Exon length distribution • Polymerase II promoter elements (GC box, CCAT box, TATA region) • Ribosome binding site • Polyadenylation signal upstream poly-A cleavage site • Termination signal downstream poly-A cleavage site

Example of ab initio gene predictor flow
http://genome.crg.es/software/geneid/

Confirming a predicted gene with cDNA
http://pasa.sourceforge.net/
26 exons!

Extrinsic evidence & manual curation • Expression data
• EST (expressed sequence tag) sequences • RNA-Seq reads
• mRNAàcDNA • High throughput sequencing • Align reads to genome sequence
• Homology based approaches • Protein (or expression data) sequences from other organisms • Nucleic acid conservation via tblastx or many other methods • Ortholog mapping/synteny
• Experimentally confirmed gene products & gene families • Manual curation is often done by experts in a domain

mRNA
cDNA
GCTAATGCGAAGTCCTAGACCAGATTGAC ATGCGATGCAGCTGACGCTGGCTAATGCG CGCATAGCCAGATGACCATGATGCGATGC TGACAGATTAGACAGTAGGACAGATAGAC ……..many millions of reads
Reads mapped to genome with gene models
?
1. Gene model is confirmed by transcript information 2. Part of the gene model is confirmed but the exons
predicted in the middle do not have transcript evidence. Does this mean they are not real? Not necessarily.
3. Transcript sequencing allows for novel gene detection. There is transcript evidence for the presence of a gene (or at least transcription) in an area of the genome without a gene model currently predicted.
1 2 3
RNA-seq of transcripts as evidence for gene models

Splice boundaries and alternate transcripts
• Some reads will span the intron/exon boundaries
• Allows for verification of gene models
• Observation of alternate transcripts
Intron
http://en.wikipedia.org/wiki/File:RNA-Seq-alignment.png

Multiple genome alignment & conservation

Experimentally based manual curation • We have
experimentally characterized protein • What do I know
about this gene family?
• What do I know about genes in general? • No introns in
multiples of three, short introns, et cetera

Leverage comparative genomics
Arnaud, et al. (2010) Nucleic Acids Res.
38(Database issue): D420-7.

Gather models for ab initio training set • Get models verified via expression, homology, or manual curation
• Use manually curated genes from your organism • Generate preliminary ab initio model set and then do a homology search
at Swiss-Prot, retaining most-conserved genes • Use CEGMA (Core Eukaryotic Genes Mapping Approach) to predict
highly conserved genes • Align proteins from related organisms to your genome with splice-aware
aligner, thus creating models with exon boundaries that have homologs • Align RNA-seq or EST reads to your genome to create or update
existing models.
• Use models with multiple sources & remove highly similar ones OR • Use pre-existing training set related to your organism
• For example, I could use chicken if I am studying finch • Many software packages provide parameter files for common organisms

Run gene finder as online or stand alone • Augustus web has text &
graphical output à Click!
Predictions stored in GFF3 or GFF2 or GTF format

RNA-Seq can show differential expression of alternative transcripts

Combiners • Incorporate multiple evidence types including ab initio
predictions, expression data, and homology—and these usually perform the best • Glean • Evidence Modeler (EVM) • Jigsaw • Maker (actually a whole pipeline that can be used online) • PASA (combines predicted structures with expression data) • And more…
• Note that many ab inito predictors, for example Augustus, incorporate other data types such as protein alignments or expression data

One example, the Glean combiner • Glean paper at http://genomebiology.com/2007/8/1/R13 • Top track below is a statistically derived combination of the ones below it

Example of annotation pipeline • Fungal Genome Annotation Standard Operating
Procedure (SOP) at JGI • Repeat masking • Mapping ESTs (BLAT) from organism and publicly available
proteins from related taxa (BLASTx) • Ab initio (FGENESH, GeneMark), homolgy-based (FGENESH+,
Genewise seeded by BLASTx against nr), EST-based (EST_map) gene prediction
• EST clustering to improve gene models • Filtering overlapping gene models based on protein homology and
EST support to derive “best” model • Non-coding genes with tRNAscan-SE • …ready for functional annotation
http://genome.jgi.doe.gov/programs/fungi/FungalGenomeAnnotationSOP.pdf

nGASP – the nematode genome annotation assessment project
http://www.biomedcentral.com/1471-2105/9/549

Take home message • Intrinsic & extrinsic prediction methods • Intrinsic gene finders need high-quality training datasets in
order to produce good predictions • “Correct” gene predictions are a moving target
• Note the steady decrease in the number of predicted genes as the human genome is further curated
• Gene finders & gene finding pipelines produce predictions, which must be verified and refined – do not take them at face value
• The more pieces of high-quality evidence you add to the process the better
• In eukaryotes especially, there is not necessarily only one correct model

PROTEIN FUNCTIONAL ANNOTATION
60

Annotation defined
61
• annotate – to make or furnish critical or explanatory notes or comment. -- Merriam-Webster dictionary
• genome annotation – the process of taking the raw DNA sequence produced by the genome-sequencing projects and adding the layers of analysis and interpretation necessary to extract its biological significance and place it into the context of our understanding of biological processes.
-- Lincoln Stein, PMID 11433356
• Gene Ontology (GO) annotation – the process of assigning GO terms to gene products… according to two general principles: first, annotations should be attributed to a source; second, each annotation should indicate the evidence on which it is based.
-- http://www.geneontology.org

What do our predicted genes do? • What we would like:
• Experimental knowledge of function • Literature curation • Perform experiment • Not possible for all proteins in most organisms (not even close in most)
• What we actually have: • Sequence similarity
• Similarity to motifs, domains, or whole sequences • Protein not DNA for finding function • Shared sequence can imply shared function • All sequence-based annotations are putative until proven experimentally
62

Basic set of protein annotations • protein name - descriptive common name for the protein
• e.g. “ribokinase”
• gene symbol - mnemonic abbreviation for the gene • e.g. “recA”
• EC number - only applicable to enzymes • e.g. 1.4.3.2
• role - what the protein is doing in the cell and why • e.g. “amino acid biosynthesis”
• supporting evidence • accession numbers of BER and HMM matches • TmHMM, SignalP, LipoP • whatever information you used to make the annotation
• unique identifier • e.g. locus ids
63

Alignments/Families/Motifs
64
• pairwise alignments – two protein’s amino acid sequences aligned next to each
other so that the maximum number of amino acids match • multiple alignments
– 3 or more amino acid sequences aligned to each other so that the maximum number of amino acids match in each column
– more meaningful than pairwise alignments since it is much less likely that several proteins will share sequence similarity due to chance alone, than that 2 will share sequence similarity due to chance alone. Therefore, such shared similarity is more likely to be indicative of shared function.
• protein families – clusters of proteins that all share sequence similarity and
presumably similar function – may be modeled by various statistical techniques
• motifs – short regions of amino acid sequence shared by many
proteins • transmembrane regions • active sites • signal peptides

Important terms to understand • homologs
• two sequences have evolved from the same common ancestor • they may or may not share the same function • two proteins are either homologs of each other or they are not. A protein can
not be more, or less, homologous to one protein than to another. • orthologs
• a type of homolog where the two sequences are in different species that arose from a common ancestor. The fact of the speciation event has created the two copies of the sequence.
• orthologs often, but not always, share the same function • paralogs
• a type of homolog where the two sequences have arisen due to a gene duplication within one species
• paralogs will initially have the same function (just after the duplication) but as time goes by, one copy will be free to evolve new functions, as the other copy will maintain the original function. This process is called “neofunctionalization”.
• xenologs • a type of ortholog where the two sequences have arisen due to lateral (or
horizontal) transfer
65

66
ancestor
speciation to orthologs
duplication to paralogs
one paralog evolves a new function
lateral transfer to a different species
makes xenologs
“neofunctionalization” – the duplicated gene/protein develops a new function

Pairwise alignments • There are numerous tools available for pairwise
alignments • NCBI BLAST resources • FASTA searches • Many more
• At IGS we use a tool called BER (BLAST-extend-repraze) that combines BLAST and Smith-Waterman approaches • Actually much of bioinformatics is based on reusing tools in new
and creative ways…
67

BER
68
BLAST
modified Smith- Waterman Alignment
genome’s protein set vs.
Significant hits (using a liberal cutoff) put into mini-dbs for each protein
non-redundant protein database
vs.
Query protein is extended
mini-database from BLAST search
, mini-db for protein #1
mini-db for protein #2
, mini-db for protein #3
... mini-db for protein #3000
Mini database
BER alignment
Extended Query protein by 300 nt

BER Alignment
69
…to look through in-frame stop codons and across frameshifts to determine if similarity continues

70

Extensions in BER
71
The extensions help in the detection of frameshifts (FS) and point mutations resulting in in-frame stop codons (PM). This is indicated when similarity extends outside the coordinates of the protein coding sequence. Blue line indicates predicted protein coding sequence, green line indicates up- and downstream extensions. Red line is the match protein.
ORFxxxxx 300 bp 300 bp
FS
PM
FS or PM ? two functionally unrelated genes from other species matching one query protein could indicate incorrectly fused ORFs
end5 end3
search protein
match protein
similarity extending through a frameshift upstream or downstream into extensions
similarity extending in the same frame through a stop codon
?
normal full length match
*
!
!

How do you know when an alignment is good enough to determine function? • Good question! No easy answer…
• Generally, you want a minimum of 40%-50% identity over the full lengths of both query and match with conservation of all important structural and catalytic sites
• However, some information can be gained from partial alignments • Domains • Motifs
• BEWARE OF TRANSITIVE ANNOTATION ERRORS
72

Pitfalls of transitive annotation
• Current public datasets full of such errors • A good way to avoid transitive annotation errors is to require
that in a pairwise match, the match annotation must be trusted • Be conservative
• Err on the side of not making an annotation, when possibly you should, rather than making an annotation when probably you shouldn’t.
73
A B
B C
C D
Transitive Annotation is the process of
passing annotation from one protein (or
gene) to another based on sequence
similarity:
A’s name has passed to D from A through several intermediates. -This is fine if A is similar to D. -This is NOT fine if A is NOT similar to D Transitive annotation errors are easy to make and happen often.

Trusted annotations • It is important to know what proteins in our search
database are characterized. • proteins marked as characterized from public databases
• Gene Ontology repository (more on this later) • GenBank (only recently began)
• UniProt • proteins at “protein existence level 1” • Proteins with literature reference tags indicating characterization
74

• Swiss-Prot • European Bioinformatics Institute (EBI) and Swiss Institute of
Bioinformatics (SIB) • all entries manually curated • http://www.expasy.ch/sprot • annotation includes
• links to references • coordinates of protein features • links to cross-referenced databases
• TrEMBL • EBI and SIB • entries have not been manually curated • once they are accessions remain the same but move into Swiss-Prot • http://www.expasy.ch/sprot
• Protein Information Resource (PIR) • http://pir.georgetown.edu
75
UniProt UniProt http://www.uniprot.org

UniProt 76

77

78

79

80

Enzyme Commission
• not sequence based • categorized collection of enzymatic reactions • reactions have accession numbers indicating the type of
reaction, for example EC 1.2.1.5 • http://www.chem.qmul.ac.uk/iubmb/enzyme/ • http://www.expasy.ch/enzyme/
81
Recommendations of the Nomenclature Committee of the International Union of Biochemistry and Molecular Biology on the Nomenclature and
Classification of Enzymes by the Reactions they Catalyse

All ECs starting with #1 are some kind of oxidoreductase Further numbers narrow specificity of the type of enzyme A four-position EC number describes one particular reaction
EC number Hierarchy
82

Example entry for one specific enzyme
83

Metabolic pathway databases • KEGG
• http://www.genome.jp/kegg/
• MetaCyc/BioCyc • http://metacyc.org/ • http://www.biocyc.org/
• BRENDA • http://www.brenda-enzymes.info/
84

85

86

Hidden Markov models (HMMs) • Statistical model of the patterns of amino acids in a multiple alignment of
proteins (called the “seed) which share sequence and, presumably, functional similarity
• Two sets routinely used for protein functional annotation • TIGRFAMs (www.tigr.org/TIGRFAMs/) • Pfam (pfam.sanger.ac.uk)
• Each TIGRFAM model is assigned to a category which describes the type of functional relationship the proteins in the model have to each other – Equivalog - one specific function, e.g. “ribokinase” – Subfamily - group of related functions generally with different substrate
specificities, e.g. “carbohydrate kinase” – Superfamily - different specific functions that are related in a very general
way, e.g. “kinase” – Domain - not necessarily full-length of the protein, contains one functional
part or structural feature of a protein, may be fairly specific or may be very general, e.g. “ATP-binding domain”
87

Annotation attached to HMMs • Functionally specific HMMs have specific annotations
– TIGR00433 (accession number for the model) • name: biotin synthase • category: equivalog • EC: 2.8.1.6 • gene symbol: bioB • Roles:
– biotin biosynthesis (TIGR 77/GO:0009102) – biotin synthase activity (GO:0004076)
• Functionally general HMMs have general annotations – PF04055
• name: radical SAM domain protein • category: domain • EC: not applicable • gene symbol: not applicable • Roles:
– enzymes of unknown specificity (TIGR role 703) – catalytic activity (GO:0003824) – metabolism (GO:0008152)
88

HMM building
Alignments of functionally related proteins act as training sets for HMM building
Statistical Model
Model specific to a family of proteins, generally found across many species
Proteins from many species
Figure: Michelle Giglio, Ph.D., Institute for Genome Sciences, University of Maryland School of Medicine, 2013

HMM scores
90
• When a protein is searched against an HMM it receives a BITS score and an e-value indicating the significance of the match
• The search protein’s score is compared with the trusted and noise cutoff scores attached to the HMM • proteins scoring above the trusted cutoff can be assumed to be
members of the family • proteins scoring below the noise cutoff can be assumed NOT to be
members of the family • when proteins score in-between the trusted and noise cutoffs, the
protein may be a member of the family and may not.
N Statistical
Model
T
Statistical Model
The person building the HMM will search the new HMM against a protein database and decide on the trusted and noise cutoff scores

HMM databases
91
Alignments of functionally related proteins act as training sets for HMM building
N Statistical
Model
T
Database of HMM models, each specific to one protein family and/or functional level
Add this model to the database
Model specific to a family of proteins, generally found across many species
Proteins from many species
Examples: Pfam and TIGRFAM
Figure: Michelle Giglio, Ph.D., Institute for Genome Sciences, University of Maryland School of Medicine, 2013

0 100 -50
0 100 -50
0 100 -50
…above trusted: the protein is a member of family the HMM models
…below noise: the protein is not a member of family the HMM models
…in-between noise and trusted: the protein MAY be a member of the family the HMM models
T N
P
0 100 -50
...above trusted and some or all scores are negative: the protein is a member of the family the HMM models
The cutoff scores attached to HMMs, are sometimes high and sometimes low and sometimes even negative. There is no inherent meaning in how high or low a cutoff score is, the important thing is the query protein’s score relative to the trusted and noise scores.
92
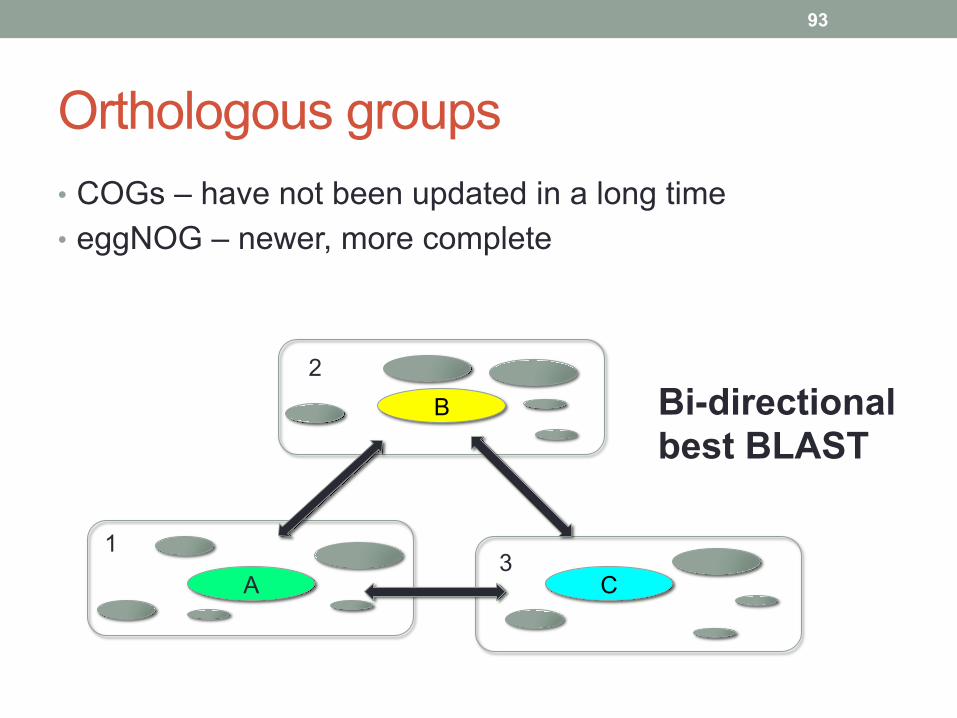
Orthologous groups • COGs – have not been updated in a long time • eggNOG – newer, more complete
93
A
B
C
1
2
3
Bi-directional best BLAST

Motif searches 94
• PROSITE - http://www.expasy.ch/prosite/ – “consists of documentation entries describing protein domains,
families and functional sites as well as associated patterns to identify them.”
• Center for Biological Sequence Analysis - http://www.cbs.dtu.dk/ – Protein Sorting (7 tools)
• Signal P finds potential secreted proteins • LipoP finds potential lipoproteins • TargetP predicts subcellular location of proteins
– Protein function and structure (9 tools) • TmHMM finds potential membrane spans
– Post-translational modifications (14 tools) – Immunological features (9 tools) – Gene finding and splice sites (9 tools) – DNA microarray analysis (2 tools) – Small molecules (2 tools)

One-stop shopping - InterPro • InterPro
• Brings together multiple databases of HMM, motif, and domain information.
• Excellent annotation and documentation • http://www.ebi.ac.uk/interpro/
95

Making annotations • Use the information from the evidence sources to decide
what the gene/protein is doing • Assign annotations that are appropriate to your
knowledge • Name • EC number • Role • Etc.
96

Main Categories: Amino acid biosynthesis Purines, pyrimidines, nucleosides, and nucleotides Fatty acid and phospholipidmetabolism Biosynthesis of cofactors, prosthetic groups, and carriers Central intermediary metabolism Energy metabolism Transport and binding proteins DNA metabolism Transcription Protein synthesis Protein Fate Regulatory Functions Signal Transduction Cell envelope Cellular processes Other categories Unknown Hypothetical Disrupted Reading Frame Unclassified (not a real role)
Each main category has
several subcategories.
TIGR roles

Names (and other annotations) should reflect knowledge
98
• specific function – Example: “adenylosuccinate lyase”, purB, 4.3.2.2
• varying knowledge about substrate specificity – A good example: ABC transporters
• ribose ABC transporter • sugar ABC transporter • ABC transporter
– choosing the name at the appropriate level of specificity requires careful evaluation of the evidence looking for specific characterized matches and HMMs.
• family designation - no gene symbol, partial EC – “Cbby family protein” – “carbohydrate kinase, FGGY family”
• hypotheticals – “hypothetical protein” – “conserved hypothetical protein”

Names can be problematic…. • ….because humans do not always use precise and
consistent terminology
• Our language is riddled with • Synonyms – different names for the same thing • Homonyms – different things with the same name
• This makes data mining/query difficult • What name should you assign? • What name should you use when you search UniProt or NCBI or
any other database?
99

Synonyms • Within any domain do people use precise & consistent language?
• Take biologists, for example… • Mutually understood concepts – DNA, RNA, protein • Translation & protein synthesis
• Synonym: one thing, more than one name • Enzyme Commission reactions
• Standardized id, official name & alternative names
100
http://www.expasy.ch/enzyme/2.7.1.40

Homonyms • Different things known by same name • Common in biology
• Sporulation • Vascular (plant vasculature, i.e. xylem & phloem, or vascular smooth
muscle, i.e. blood vessels?)
101
Endospore formation Bacillus anthracis!
Reproductive sporulation Asci & ascospores, Morchella elata (morel)
http://en.wikipedia.org/wiki/File:Morelasci.jpg ©PG Warner 2008 (accessed 17-Sep-09)
http://www.microbelibrary.org/
ASMOnly/details.asp?id=1426&Lang=
©L Stauffer 2003 (accessed 17-Sep-09)

Standardization with controlled vocabularies (CVs) • An official list of precisely defined terms used to classify
information & facilitate its retrieval • Flat list • Thesaurus • Catalog
102
http://www.nlm.nih.gov/nichsr/hta101/ta101014.html
A CV can be “…used to index and retrieve a body of literature in a bibliographic, factual, or other database. An example is the MeSH controlled vocabulary used in MEDLINE and other MEDLARS databases of the NLM.”
• Benefits of CVs – Allow standardized descriptions – Synonyms & homonyms
addressed – Can be cross-referenced
externally – Facilitate electronic searching

Ontology: CV with defined relationships • Formalizes knowledge of subject with precise textual definitions • Networked terms; child more specific (“granular”) than parent
103
National Drug File

An example is the Gene Ontology with three controlled vocabularies • Molecular Function
• What the gene product is doing
• Biological Process • Why the gene product is doing what it does
• Cellular component • Where a gene product is doing what it does
104

The Gene Ontology
• A good example of a biological ontology
• Relationships among networked, defined terms
• Vascular terms shown with relationships

Example: a GO annotation • Associating GO term with gene product (GP)
• GP has function (6-phosphofructokinase activity) • GP participates in process (glycolysis) • GP is located in part of cell (cytoplasm) • Linking GO term to GP asserts it has that attribute
• Based on literature or • computational methods
• Always involves: • Learning something about gene product • Selecting appropriate GO term • Providing appropriate evidence code • Citing reference [preferably open access] • Entering information into GO annotation file
106

Annotation becomes a series of ids linked to other proteins/genes/features
• GO:0005887 • GO:0008272 • GO:0015419 • GO:0043190
107
This protein is integral to the plasma membrane and is part of an ATP-binding cassette (ABC) transporter complex. It functions as part of a transporter to accomplish the transport of sulfate across the plasma membrane using ATP hydrolysis as an energy source.
=

108 Term name
GO ID (unique numerical identifier)
Precise textual definition that describes some aspect of the biology of the gene product
Synonyms for searching, alt. names, misspellings…
GO slim
Ontology relationships (next page)
Definition reference

Genomes can be compared • High-level biological process terms used to compare
Plasmodium and Saccharomyces (made by “slimming”)
109
MJ Gardner, et al. (2002) Nature 419:498-511

The importance of evidence tracking
110
I conclude that you are a cat.
Why? - You look like other cats I know - I heard you meow and purr
Why? - You look like other protein kinases I know - You have been observed to add phosphate to proteins
I conclude that you code for a protein kinase.
• The process of functional annotation involves assessing available evidence and reaching a conclusion about what you think the protein is doing in the cell and why.
• Functional annotations should only be as specific as the supporting evidence allows • All evidence that led to the annotation conclusions that were made must be stored. • In addition, detailed documentation of methodologies and general rules or guidelines
used in any annotation process should be provided.

Knowledge & annotation specificity
Available evidence for three genes
Corresponding GO annotations • How much can we accurately say?

Types of Evidence • Experiments (the only truth) • Pairwise/multiple alignments • HMM/domain matches scoring above trusted cutoff • Metabolic Pathway analysis • Match to an ortholog group (COG,eggNOG) • Motifs
112

The Evidence Ontology • Two main classes • ECO terms have standardized definitions & references
• Related to GO evidence codes
• Allows standardizing evidence description and searching by evidence type

Evidence Ontolgy & GO Codes
114
Approximately 20 GO codes exist …some of the over 250 ECO terms

The big picture: an example pipeline
115
DNA Sequence (assembly, masking)
Automatic Annotation using the evidence hierarchy of Pfunc
Searches: Pairwise BER searches against UniRef100 HMM searches against Pfam and TIGRfam Motif searches with LipoP, THMHH, PROSITE NCBI COGs Prium profiles
Automated start site and gene
overlap correction
translation
RNA finding: tRNAScan, RNAMMER, homology searches
Predicted RNA Genes
Gene Prediction
Predicted protein coding genes
MySQL database using the Chado
schema
Genome viewer/editor
Flat files of annotation information

Some concluding themes… • The best annotation comes from looking at multiple
sources of evidence • It is important to track and check the evidence used in an
annotation • Do not assume the annotation you see on a protein is
correct unless it comes from a trusted source • Always err on the side of under-annotating rather than
over-annotating • Consider using UniProt (UniRef) for searches, not NCBI
nr, simply for the depth of information it provides.
116