an interactive approach to multiobjective clustering of gene expression patterns
TRANSCRIPT

AN INTERACTIVE AN INTERACTIVE APPROACH TO APPROACH TO
MULTIOBJECTIVE MULTIOBJECTIVE CLUSTERING OF GENE CLUSTERING OF GENE
EXPRESSION PATTERNSEXPRESSION PATTERNS

Base Paper
An Interactive Approach to An Interactive Approach to Multiobjective Clustering of Multiobjective Clustering of Gene Expression PatternsGene Expression Patterns
Anirban Mukhopadhyay∗, Senior Member, IEEE, Ujjwal Maulik, Senior Member, IEEE, and Sanghamitra Bandyopadhyay, Senior Member, IEEEIEEE TRANSACTIONS ON BIOMEDICAL ENGINEERING, VOL. 60, NO. 1, JANUARY 2013
Abstract1

To find the best set of validity indices that should be optimized simultaneously to obtain good clustering results.
In this project, a proposed interactive genetic algorithm-based multi objective approach is used that simultaneously finds the clustering solution as well as evolves the set of validity measures that are to be optimized simultaneously.
The proposed method interactively takes the input from the human decision maker during execution and adaptively learns from that input to obtain the final set of validity measures along with the final clustering result. The algorithm is applied for clustering real-life benchmark gene expression datasets and its performance is compared with that of several other existing clustering algorithms to demonstrate its effectiveness.

Introduction2

Clustering is an important unsupervised data mining tool where a set of patterns, usually vectors in multidimensional space, are grouped into K clusters based on some similarity or dissimilarity criteria.
Data interdisciplinary subfield of computer science is the computational process of discovering patterns in large data sets involving methods at the intersection of artificial intelligence, machine learning, statistics, and database systems.
The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use.Aside from the raw analysis step, it involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.

• Disadvantages
Existing System3

In the existing approaches of GA-based multi objective clustering, the algorithms simultaneously optimize two or three chosen cluster validity measures.
The algorithm uses the fuzzy c-means clustering control the similar individuals gathered in a class and for each class construct non-dominated set with arena's principle.
For fuzzy clustering of categorical data is proposed that encodes the cluster modes and simultaneously optimizes fuzzy compactness and fuzzy separation of the clusters.
The final clustering solution from the set of resultant Pareto-optimal solution is involved. This is based on majority voting among Pareto front solutions followed by k-nn classification.

DisadvantagesDisadvantages
It cannot be guaranteed that these predefined set of objective functions for validity measures.
Point-based encoding techniques are straightforward, but suffer from large chromosome lengths and hence slow rates of convergence.
Produce highly redundant chromosomes.

• Advantages
Proposed System4

The proposed interactive clustering algorithm is Interactive Multi Objective Clustering.
The multi objective optimization problem has been modeled as a minimization problem where all the objective functions are minimized.
The main NSGA-II procedure is modified to incorporate the interaction with the DM in order to evolve the best set of objective functions as well as the clustering simultaneously.
The final clustering solution has been obtained from the non-dominated front produced in the final generation using support vector machine classifier based ensemble method.

AdvantagesAdvantages
The form of validity measures to be optimized simultaneously.
The most suitable subset of the validity measures for the dataset.
Objective functions are more suitable for the dataset.
Human decision maker.
Center-based encoding is that the chromosome length is shorter.
A faster convergence rate than point-based encoding techniques.

Hardware Requirements5

System : Dual Core Processor Hard Disk : 80 GBMonitor : 15 VGA colorMouse : LogitechRAM : 1 GB

Software Requirements6

Operating System : Windows XP.Language : Java 7.IDE : Net Beans 6.9.1.Database : MySQL.

Modules7
• Pre-process• Optimization• Multiobjective Clustering • Genetic Approach• IMOC Algorithm

Results8
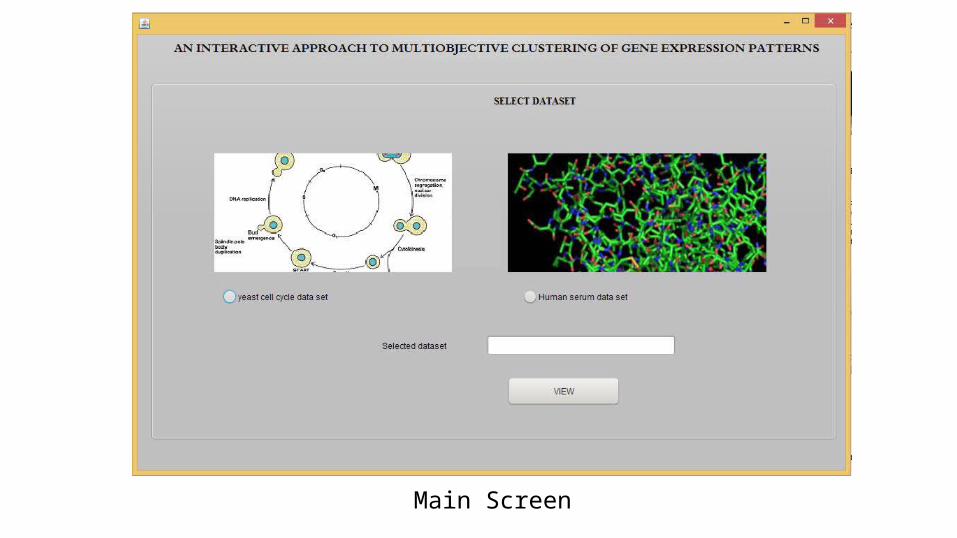
Main Screen

Load data into Database

Pre-process the data

Interactive DM
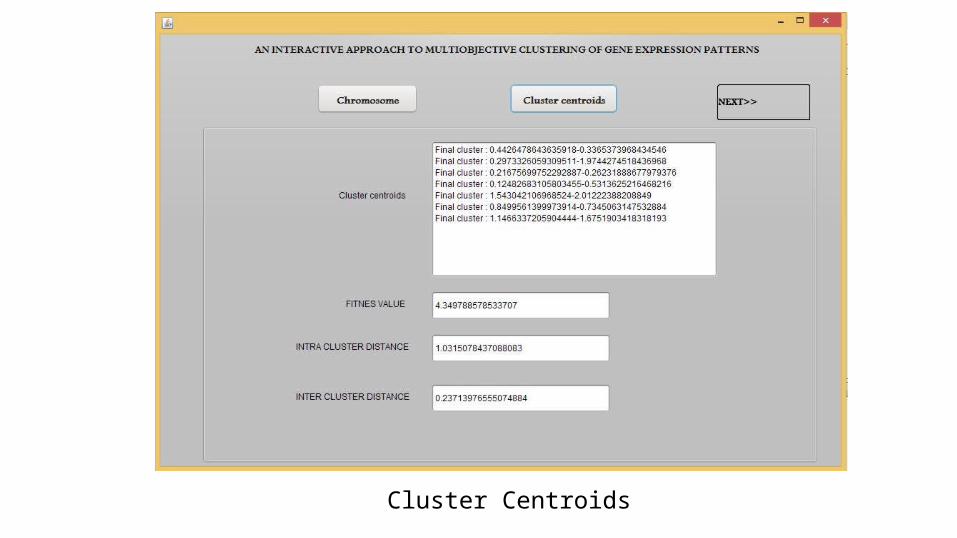
Cluster Centroids
Generated Heat Map

Performance Analysis of IMOC Algorithm

9. Conclusion The performance of IMOC has been
demonstrated for two real-life gene expression datasets and compared with that of several other existing clustering algorithms.
Results indicate that IMOC produces more biologically significant clusters compared to the other algorithms and the better result provided by IMOC is statistically significant.

References10

An Interactive Approach to Multiobjective Clustering of Gene Expression Patterns, Anirban Mukhopadhyay∗, Senior Member, IEEE, Ujjwal Maulik, Senior Member, IEEE, and Sanghamitra Bandyopadhyay, Senior Member, IEEE
A. K. Jain and R. C. Dubes, “Data clustering: A review,” ACM Comput. Surv., vol. 31, no. 3, pp. 264–323, 1999.
U.Maulik, S.Bandyopadhyay, and A.Mukhopadhyay, Multiobjective Genetic Algorithms for Clustering: Applications in Data Mining and Bioinformatics. New York: Springer-Verlag, 2011.
D. E. Goldberg, Genetic Algorithms in Search, Optimization and Machine Learning. New York: Addison-Wesley, 1989.
U. Maulik and S. Bandyopadhyay, “Genetic algorithm based clustering technique,” Pattern Recognit., vol. 33, pp. 1455–1465, 2000.
K. Deb, A. Pratap, S. Agrawal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,” IEEE Trans. Evol. Comput., vol. 6, no. 2, pp. 182–197, Apr. 2002.
J. Handl and J. Knowles, “An evolutionary approach to multiobjective clustering,” IEEE Trans. Evol. Comput., vol. 11, no. 1, pp. 56–76, Feb. 2007.
