an experimental evaluation of leader election algorithms for ring networks
TRANSCRIPT

Systems and Computers i n Japan, Vol. 2 2 , No. 3, 1991 Translated from Denshi Joho Tsushin Gakkai Ronbunshi, Vol. 73-D1, No. 3 , March 1990, pp. 261-268
An Experimental Evaluation of Leader Election Algorithms for Ring Networks
Yukinori Ikegawa, Nonmember, Masafumi Yamashita and Tadashi A e , Members
Faculty of Engineering, Hiroshima Universi ty , Higashi-Hiroshima, Japan 7 2 4
SUMMARY
The l eade r e l e c t i o n problem i s a prob- l e m of determining a unique l e a d e r , i n t h e sense t h a t t h e e l ec t ed l e a d e r knows t h a t i t i s e l ec t ed and t h e processors which a r e n o t e l ec t ed know t h a t they a r e n o t e l ec t ed . Under t h e assumption t h a t t h e processors have unique i d e n t i f i e r s , t h e problem can b e regarded as t h e maximum ( i d e n t i f i e r ) f i n d i n g problem.
This paper cons ide r s t e n t y p i c a l l e a d e r e l e c t i o n algori thms f o r t h e r i n g network and eva lua te s them i n terms of t h e average num- be r of messages exchanged during computation.
1. In t roduc t ion
The l eade r e l e c t i o n problem, a t y p i c a l d i s t r i b u t e d problem, i s one of s e l e c t i n g a processor from those p a r t i c i p a t i n g i n a network, as t h e l eade r processor of t h e net- work. Networks are c l a s s i f i e d i n terms of t h e network topology, t h e e x t e n t of asyn- chrony of t h e network, t h e network informa- t i o n a v a i l a b l e to t h e d i s t r i b u t e d a lgo r i thm, and t h e a n t i c i p a t e d network f a u l t . For each of those types, i n t e n s i v e s t u d i e s on l e a d e r e l e c t i o n algori thms have been made. Among those, e s p e c i a l l y a l a r g e number of s t u d i e s have been made f o r t h e l e a d e r e l e c t i o n prob- l e m on t h e f u l l y asynchronous r e l i a b l e r i n g network.
The r i n g (network) i s a set of proces- s o r s which are connected i n a r i n g through communication l i n k s so t h a t any two proces- s o r s can communicate with each o t h e r through l i n k s . When t h e communication l i n k i s one- way, i t i s c a l l e d a u n i d i r e c t i o n a l r i n g . I f i t is two-way, i t i s c a l l e d a b id i r ec - t i o n a l r i n g . A s t rong connectedness is assumed f o r t h e u n i d i r e c t i o n a l r i n g . 11: i s assumed t h a t a l l processors p a r t i c i p a t i n g
10
i n t h e network are equ iva len t , and t h e r e does n o t exist a s p e c i a l master processor f o r network c o n t r o l ( i . e . , a d i s t r i b u t e d network is considered) . concerning t h e r e l a t i v e speed of t h e pro- c e s s o r s and t h e t ransmission delay ( i . e . , f u l l y ) asynchronous network i s cons ide red ) . Then t h e l e a d e r e l e c t i o n problem f o r t h e asynchronous r e l i a b l e r i n g i s t h e problem of c o n s t r u c t i n g an e f f i c i e n t a lgori thm ( i . e . , wi th as small a number of messages as poss ib l e ) t o determine t h e l e a d e r , assuming t h a t t h e r e is no f a u l t i n t h e network and each processor i n i t i a l l y knows only i t s own i d e n t i f i e r (we assume t h a t i d e n t i f i e r s a re unique). i n t h i s paper a d i s t r i b u t e d algori thm. That i s , the same a lgo r i thm i s executed on a l l p rocesso r s . This problem i s considered f i r s t and w a s formulated by LeLann as a problem concerning t h e token reproduct ion problem f o r t h e token r ing ( o r token bus) network i l l ] .
Nothing i s assumed
By an algori thm, w e a l w a y s mean
When i d e n t i f i e r s are unique, t h e l eade r e l e c t i o n problem can be considered as t h e maximum ( i d e n t i f i e r ) f i n d i n g problem by pre- determining t h a t " t h e processor w i t h t h e maximum i d e n t i f i e r should be t h e l eade r . I'
It is obvious i n t u i t i v e l y t h a t t h e maximum f i n d i n g problem can be solved, s i n c e by propagating t h e i d e n t i f i e r s along t h e r i n g , each processor eventual ly can know a l l i d e n t i f i e r s . problem can b e solved wi th as small a number of messages as p o s s i b l e .
The d i f f i c u l t y i s how t h e
I n t h e n a i v e a lgo r i thm descr ibed i n t h e foregoing, O(n2) messages obviously are needed i n t h e worst case, where n i s t h e number of p rocesso r s i n t h e network. presented t h i s a lgori thm f o r t h e unidirec- t i o n a l r i n g . For a c e r t a i n per iod a f t e r t h i s , i t was l e f t unsolved whether o r n o t t h e r e exists an algori thm t h a t can s o l v e t h e problem wi th o ( n 2 ) messages even f o r
LeLann
1SSN0882-1666/91/0003-0010$7.50/0 0 1991 S c r i p t a Technica. Inc.

t h e worst case. t h e problem with O(n1ogn) messages even i n t h e worst c a s e are given by Hirschberg and S i n c l a i r [6] f o r t h e b i d i r e c t i o n a l r i n g , and by Peterson [15] f o r t h e u n i d i r e c t i o n a l r i ng .
Then algori thms t h a t s o l v e
The b e s t r e s u l t s known up t o now are summarized i n t h e fol lowing.
For t h e u n i d i r e c t i o n a l r i n g , Dolve, Klawe and Rodeh [3] proposed an algori thm with t h e message complexity 1.356nlogn i n t h e worst case. Pachl, Korach and Rotem [16] showed t h a t a lower bound on t h e aver- age message complexity (and , consequently , i n t h e worst case) Z X H , (z 0.69nlogn), where H is t h e n-th harmonic number.
n
The algori thm by Chang and Roberts [ 2 ] i s optimal i n t h e sense t h a t i t s message complexity co inc ides w i t h t h i s lower bound ( including t h e c o e f f i c i e n t ) . The message complexity of t h i s a lgori thm i n t h e worst ca se is 0.5n2, which i s not opt imal . For t h e b i d i r e c t i o n a l r i n g , van Leeuwen and Tan [ l o ] proposed an algori thm wi th t h e message complexity 1.44nlogn i n t h e worst case. Thus, t h e r e s t i l l exists a gap from t h e known lower bound 0.25nlogn (Pachl, Korach and Rotem [16] on t h e average message com- p l ex i ty (consequently, i n t h e worst ca se ) .
Recently, Lavaul t showed t h a t t h e aver- age message complexity of t h e algori thm by Bodlaender and van Leeuwen [ 11 i s 2-”’n X Ha [9] . Consequently, i t i s shown t h a t t h e b i d i r e c t i o n a l r i n g i s more e f f i c i e n t than t h e u n i d i r e c t i o n a l r i n g in t h e l e a d e r elec- t i o n , a t least i n t h e sense of t h e average message complexity. I n t h e foregoing d i s - cussion, t h e sense of d i r e c t i o n i s no t assumed f o r t h e b i d i r e c t i o n a l r i ng . By sense of d i r e c t i o n , w e mean t h e a b i l i t y of t h e processor t o c o n s i s t e n t l y recognize t h e l e f t r i g h t l i n k s .
In t h e l e a d e r e l e c t i o n algori thm f o r t h e r ing , t h e number of messages r equ i r ed is reduced by using e i t h e r (o r both) of t h e following techniques. F i r s t , t h e number of messages can be reduced by d i sca rd ing those which are no longer necessary t o b e relayed. For example, when a p rocesso r r ece ives a value as a cand ida te of t h e maximum, which i s smaller than t h e already-known maximum, s i n c e i t cannot be t h e maximum, w e do no t need t o send o t h e r processors . Then mess- ages ca r ry ing such small values can be d i s - carded. a lgori thm by Chang and Roberts [ 2 ] and i n
This technique is used i n t h e
t h e a lgo r i thm by Bodlaender and van Leeuwen [ I 1
The second technique reduces t h e num- be r of messages by reducing t h e number of p rocesso r s t h a t o r i g i n a t e t h e messages ( c a l l e d a c t i v e p rocesso r s , which are regard- ed i n t u i t i v e l y as t h e p rocesso r s with a p o s s i b i l i t y t h a t t h e i d e n t i f i e r i s t h e maximum). t o be t h e maximum, t h e i d e n t i f i e r must be l a r g e r than e i t h e r of t h e i d e n t i f i e r s of ad jacen t processors . Based on t h i s i dea , t h e number of a c t i v e p rocesso r s can be re- duced by l o c a l exchange of messages. The algori thm by Hirschberg and S i n c l a i r [ 5 ] , t h a t by Pe te r son [15] , and t h a t by Dolve, K l a w e and Rodeh [ 3 ] employ t h i s technique.
For t h e i d e n t i f i e r of a processor
The message complexity of t h e algori thm employing t h e f i r s t technique i s O(n x H ) n i n t h e average case, which i s good, but i s O(n2) i n t h e worst c a s e , which i s bad. On the o t h e r hand, i t is known t h a t t h e message complexity of t h e a lgo r i thm employing t h e second technique i s O(n1ogn) even i n t h e worst case, which i s good. Few r e p o r t s , however, are found concerning t h e average message complexity, a l though a lower bound on t h e message complexity i s O(n1ogn). It i s t h e r e f o r e meaningful t o compare t h e two techniques, e s p e c i a l l y from t h e viewpoint of t h e average and t h e v a r i a n c e of t h e message complexity .
Another i n t e r e s t i n g problem i s of com- par ing t h e u n i d i r e c t i o n a l and t h e b id i r ec - t i o n a l r i n g s . Pachl , Korach and Rotem posed a problem as to whether o r n o t t h e l e a d e r e l e c t i o n problem can be solved more e f f i c i e n t l y on t h e b i d i r e c t i o n a l r i n g than on t h e u n i d i r e c t i o n a l r i n g . Lavaul t [9] solved the problem p a r t i a l l y ( i n t h e sense of t h e average eva lua t ion ) and a f f i rma t ive - l y . A s t o t h e worst-case eva lua t ion , how- eve r , t h e r e h a s no t been presented an algor- ithm f o r t h e b i d i r e c t i o n a l r i n g which sur- passes t h e best-known a lgo r i thm by Dolve, Klawe and Rodeh [ 31 , and t h e problem is l e f t unsolved.
To o b t a i n a c l u e t o t h e s o l u t i o n of t h e two forementioned problems, a s imula t ion experiment is conducted f o r a number of l e a d e r e l e c t i o n (maximum f i n d i n g ) a lgo r i thms , i nc lud ing a l l a lgo r i thms quoted i n t h i s paper. I n t h e fo l lowing , Sec t . 2 desc r ibes b r i e f l y t h e a lgo r i thms which are t h e o b j e c t of s imula t ion . Sec t ion 3 o u t l i n e s t h e simu- l a t i o n , and Sec t . 4 p r e s e n t s t h e r e s u l t of s imula t ion and g ives d i scuss ion .
11

2. Maximum Finding Algorithms
2.1. Algorithms f o r u n i d i r e c t i o n a l r i n g
(L) LeLann's a lgori thm [ 111
This i s t h e s imples t algorithm. Each processor sends ou t its own i d e n t i f i e r as a message. Upon r e c e i p t of an i d e n t i f i e r , i t is memorized and is s e n t t o t h e ad jacen t processor. When i ts own i d e n t i f i e r r e t u r n s a s a message, t h e processor knows a l l i d e n t i - f i e r s and can determine t h e maximum. The message complexity is n2.
(CR) Chang and R.oberts' a lgori thm [ 21
In L , i f t h e received i d e n t i f i e r i s smaller than i t s own i d e n t i f i e r , t h e i d e n t i - f i e r i s n o t necessary t o be relayed and is discarded s i n c e i t cannot be t h e maximum. I f i t s own i d e n t i f i e r is r e tu rned , i t is t h e maximum. The message complexity of t h i s a lgori thm is 0 . 5 d i n t h e worst case bu t is n x H on the average, which is t h e b e s t
poss ib l e . n
(P) Pe te r son ' s b a s i c a lgori thm [15]
This a lgori thm f i r s t achieved t h e worst c a s e message complexity O(n1ogn) f o r t h e uni- d i r e c t i o n a l r i n g . By reducing t h e number of a c t i v e processors , t h e message complexity of t h e whole system is reduced. The algor- ithm is shown i n t h e fol lowing:
Algorithm P (on processor u )
Active State : / *Wake up ! Start from here. * / tid : =id( u ) ; do forever (
send (tid) ; receive ( nid ; if nid=id(u)
if tid> nid then announce elected ;
then send ( tid 1 else send ( nid) ;
receive ( nnid 1 ; if nnid = id( u
if nid>max(tid, nnid) then announce elected ;
then tid : =nid else go to Passive
( t )
Passive State : do forever {
receive ( tid) ; if tid=id(u)
send ( tid) then announce elected ;
1 I n t h e i n i t i a l phase, a l l p rocesso r s
are a c t i v e . The number of a c t i v e processors i s a t least halved f o r each advance of t h e phase. A t each phase, each processor sends ou t a t most two messages. Consequently, t h e message complexity as a whole i n t h e worst c a s e i s 2nlogn + O(n).
(PI) P e t e r s o n ' s improved a lgo r i thm 1151
I n P , each processor a l w a y s sends two messages a t each phase. However, t h i s a l - gorithm i s improved as fol lows. When a processor s h i f t s t o pas s ive , i t sends o u t one message and then s h i f t s t o pas s ive . The message complexity of t h i s a lgo r i thm i s 1.44nlogn + O(n) i n t h e worst case (Matsu- s h i t a [13 ] ) . Although t h e algori thm pre- sented by Peterson [15] does no t o p e r a t e p rope r ly , Matsushita [ 1 3 ] has shown a cor- r e c t ve r s ion .
(DKR) Dolev, Klawe and Rodeh's a lgo r - ithm [ 3 ]
This is e s s e n t i a l l y an improvement of P I i n t h e fol lowing t h r e e po in t s . L e t t h e message s e n t by t h e send command ind ica t ed by ( t ) i n P b e c a l l e d type 1 , and the mess- age s e n t by t h e send command ind ica t ed by (17) b e c a l l e d type 2 .
I f nid > t i d , type 2 message i s n o t s e n t . I f two type 1 messages are received cont inuously, t h e processor s h i f t s t o pas s ive .
When a pass ive processor r e c e i v e s a type 1 message ca r ry ing a smaller i d e n t i f i e r than its own, t h e corresponding type 2 m e s s - age is not s e n t t o t h e ad jacen t processor .
9 A c r u n t e r i s added t o t h e type 2 message so t h a t each type 2 message gener- a t ed a t phase p cannot t r a v e r s e on more than two p a s s i v e p rocesso r s without a r r i v i n g a t an a c t i v e processor . When a pass ive pro- ces so r r e c e i v e s a type 2 message reaching t h i s d i s t a n c e upper bound, i t behaves i n one of t h e fol lowing ways .
I f t h e i d e n t i f i e r c a r r i e d by t h e mess- age of type 2 is smaller than its own i d e n t i - f i e r , nothing is done. I f otherwise, t h e processor makes t h i s i d e n t i f i e r t i d and
12

s h i f t s t o the state ca l led waiting. I f the next message received by the waiting pro- cessor i s type 2, the processor s h i f t s t o act ive. I f otherwise, t he processor s h i f t s t o passive.
The message complexity of t h i s algor- ithm is 1.356nlogn + O(n) i n t he worst case, which is the most e f f i c i e n t ( i n the sense of the theore t ica l evaluation f o r the worst case) among the leader e lec t ion algorithms fo r the unid i rec t iona l r ing known up t o now.
2.2. Algorithms f o r b id i rec t iona l r ing
(HS) Hirschberg and Sinc la i r
This i s the f i r s t maximum finding algor- ithm f o r t he b id i rec t iona l r ing. t he f i r s t algorithm with message complexity O(n1ogn) i n the worst case. The algorithm is shown i n the following:
It is a l s o
Algorithm HS (on processor u) Active State : / *Wake up ! Start from here. * / f i : = l ; do forever {
sendboth (id( u) , 2’-’) ; repeat I
receive( u, d ) ; if v+id( u) then do {
if v<id(u) then sendecho(u, “N”) else do I
then sendpass( u, d- 1) else sendecho( u, “Y” ) ;
go to Passive}} if u = id( u and d = “N”
then go to Passive : if u=id(u) and d e { Y , N}
if d>l
then announce elected
from each link ; until it has received a reply (Y or N )
p : =$+1
Passive State : Simply relay messages.
I
The message complexity of t h i s algorithm is 8nlogn + O(n) i n the worst case.
(PR) KOrach, Rotem and Santoro’s proba- b i l i s t i c algorithm [7]
This is es sen t i a l ly the same algorithm as CR except t h a t t he message transmission d i r ec t ion i s determined with probabi l i ty 0.5. The message complexity i s the worst , being equal t o t h a t of CR, when the message transmission d i r ec t ion is determined as the same f o r a l l processors. The average mess- age complexity is 2-’”n X H, + O( n) , which is an improvement over CR.
Bodlaender and van Leeuwen [ l ] trans- l a t ed PT i n t o a de te rminis t ic algorithm. It i s shown by Lavault [ 9 ] t ha t t he average message complexity of t h i s algorithm is a l so 2-’”n x H,,+ O( n) .
(F) Frankl in’s algorithm [4]
This is es sen t i a l ly the same algorithm as P. I n t h e i n i t i a l phase, a l l processors are ac t ive . In each phase, each ac t ive pro- cessor exchanges i d e n t i f i e r s with adjacent ac t ive processors. Unless i ts own ident i - f i e r is larger than e i t h e r i d e n t i f i e r of the adjacent a c t i v e processors, i t s h i f t s t o passive. For each phase, t he number of ac t ive processors is a t least halved. The message complexity of t h i s algorithm is 2nlogn + O(n) i n t h e worst case.
(KRS) Korach, Rotem and Santoro’s algorithm [8]
This algorithm can be considered as a modification of F. In each phase, each ac t ive processor t ransmits two messages and re turns a response message. By t h i s scheme, the number of a c t i v e processors i s reduced a t each phase a t least to one-third. The message complexity of t h i s algorithm i s 3 nlogan + O( n ( 1.89 nlogn + O( n)) i n t he worst case.
(LT) Leeuwen and Tan’s algorithm [ l o ]
This can be regarded as a r ea l i za t ion of P I on the b id i r ec t iona l r ing . age complexity of t h i s algorithm i s 1.44nlogn + O(n) i n t h e worst case, which is the most e f f i c i e n t among the leader elec- t ion algorithms f o r t he b id i r ec t iona l r ing known up t o now ( i n the sense of t he theor- et ical evaluat ion i n t h e worst case) . L e t - t i ng the number of remaining a c t i v e pro- cessors a t phase p be A A p - ~ z A p + A p + , holds i n LT and P I . I f the algorithm s tops a t phase T, AT-p ZFp, where F i s the p-th
Fibonacci number. Then fi4(10g((1+5’’~) /2)-’10g%+ o(1). from which the coe f f i c i en t 1.44... der ives .
The mess-
P’
P
13

3. Dis t r ibu ted Algorithm Simulator
An o u t l i n e of t h e s imulator DAS used i n t h i s study is t h e following. DAS is com- posed of t h e main u n i t and t h e inpu t lou tpu t u n i t and is w r i t t e n i n Modula-2. The i n p u t / output u n i t i s descr ibed by t h e use r . input /output u n i t by use r d e s c r i p t i o n is composed of two modules, i.e., t h e d i s t r i b u - t ed algori thm d e s c r i p t i o n and t h e network information d e s c r i p t i o n . Each of t hose modules forms t h e module of Modula-2, i.e., t h e u n i t of compiling. The use r writes t h e s e two modules according t o t h e s p e c i f i e d format. Af t e r compiling, i t is l inked t o t h e main u n i t and t h e s imulat ion i s exe- cuted. DAS records t h e behavior, makes s t a t i s t i c s , and produces t h e output f o r t h e descr ibed d i s t r i b u t e d algori thm and t h e network.
The
3.1. Network model
The network model of DAS i s t h e follow- A network is composed of n processo r s
The topology of ing. and rn communication l i n k s . t h e network i s a f i n i t e d i r e c t e d graph i n which t h e nodes r ep resen t processors and t h e d i r e c t e d edges r ep resen t communication l i n k s . During t h e execution of an algor- ithm, t h e processors and/or t h e l i n k s do no t f a i l , and the network topology remains unchanged.
Each processor is an independent com-
A l l processors can r e f e r t o a clock p u t e r which executes t h e d i s t r i b u t e d algor- ithm. which is common t o t h e whole network. I n t h e l e a d e r e l e c t i o n problem, however, t h e asynchronous network i s assumed and t h e clock i s not used. The l o c a l computation time of a processor is ignored. Each pro- ces so r has t h e input /output p o r t f o r t h e connected l i n k ( a s w i l l be descr ibed la te r , a l l l i n k s are u n i d i r e c t i o n a l ) . The po r t has i t s own i d e n t i f i e r by which t h e l i n k f o r input /output of a message i s s e l e c t e d . The processor exchanges t h e information w i t h o t h e r processors by exchanging mess- ages through l i n k s .
The i n s t r u c t i o n s t h a t can be executed by t h e processor are as follows.
Halt: The execution of t h e d i s t r i b u - t ed algori thm terminates . When a l l pro- ces so r s executed t h i s i n s t r u c t i o n , t h e whole network i s considered as terminated. Then, t h e s imulator s tops .
Wait: The execution of t h e d i s t r i b - uted algori thm i s postponed i n t h e pro- ces so r f o r a u n i t t i m e . The execution i s then s t a r t e d .
Message t ransmission v i a s p e c i f i e d p o r t : corresponding t o t h e p o r t . A f t e r a f i n i t e t i m e , t h e message is s t o r e d a t t h e t a i l of t h e inpu t queue of t h e l i n k .
Reception of message from s p e c i f i e d
A message i s t r a n s f e r r e d t o t h e l i n k
po r t : input queue of t h e p o r t is received.
The message placed a t t h e top of
Local computation: The l i n k i s a u n i d i r e c t i o n a l communication path connect- ing two processors . To realize a b i d i r e c - t i o n a l l i n k , two l i n k s are set between t h e processors . The l i n k has an inpu t queue. A s a l r eady desc r ibed , when a processor con- nected t o t h e l i n k sends a message, i t i s s to red a f t e r a f i n i t e time a t t h e t a i l of t h e inpu t queue. When t h e processor exe- c u t e s r e c e i v e i n s t r u c t i o n , t h e message placed a t t h e top of t h e i n p u t queue is received. There is no e l i m i n a t i o n o r modi- f i c a t i o n of t h e message during t r ansmiss ion and n e i t h e r i s t h e o r d e r of t ransmission a l t e r e d . Since t h e l i n k behaves synchron- ously, t o realize t h e asynchronous network t h e network module is descr ibed s o t h a t t h e communication delay i s determined a t random f o r each communication.
The same d i s t r i b u t e d algori thm i s in- s t a l l e d i n a l l processors and i s executed. A l l processors s t a r t a t t h e same t i m e autonomously t h e exectuion of t h e d i s t r i b u - ted algori thm.
The information t h a t i s a v a i l a b l e t o t h e p rocesso r (algorithm) i s b a s i c a l l y t h e l o c a l information i n t h e network. For con- venience, however, some more inf onnat i o n i s made a v a i l a b l e i n DAS. For example:
- Current t i m e , which i s common t o t h e whole network
To ta l number of p rocesso r s i n t h e network
To ta l number of l i n k s i n t h e network
Processor i d e n t i f i e r s
I d e n t i f i e r s of ou tpu t p o r t s of t h e processor
I d e n t i f i e r s of i npu t p o r t s of t h e processor
Whether t h e r e exists a message i n inpu t queues of t h e processor
Contents of t h e l o c a l memory of t h e processor .
14
L AS KR9
I 10 15 7.0 30 40 50 60 70 80
Number of processors
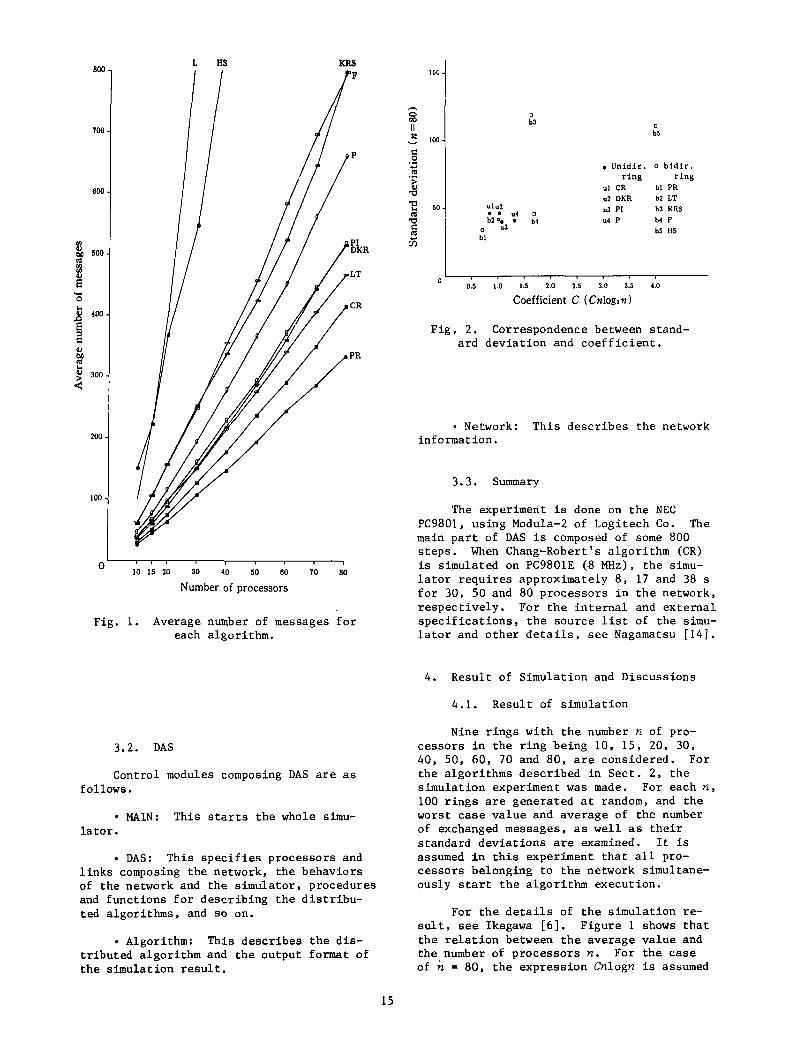
Fig. 1. Average number of messages f o r each algori thm.
3 . 2 . DAS
Control modules composing DAS are as follows.
M A I N : This s tar ts t h e whole simu- l a t o r .
DAS: This s p e c i f i e s processors and l i n k s composing t h e network, t h e behaviors of t h e network and t h e s imula to r , procedures and func t ions f o r desc r ib ing t h e d i s t r i b u - t ed algori thms, and s o on.
Algorithm: t r i b u t e d algori thm and t h e output format of t h e s imula t ion r e s u l t .
This d e s c r i b e s t h e d i s -
0
b3 0 b5
. Unidir . 0 b i d i r . r i n g ring
ul CR b l PR u2 DKR bZ LT "3 PI b3 KRS u4 P b4 F
b6 IIS
0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
Coefficient C (Cn1ogr.M 1
F i g , 2 . Correspondence between stand- a r d d e v i a t i o n and c o e f f i c i e n t .
Network: Th i s d e s c r i b e s t h e network information.
3 . 3 . Summary
The experiment is done on t h e NEC PC9801, using Modula-2 of Logi tech Co. The main p a r t of DAS i s composed of some 800 s t e p s . When Chang-Robert's a lgo r i thm (CR) i s simulated on PC9801E (8 MHz), t h e simu- l a t o r r e q u i r e s approximately 8, 17 and 38 s f o r 3 0 , 50 and 80 processo r s i n t h e network, r e s p e c t i v e l y . For t h e i n t e r n a l and e x t e r n a l s p e c i f i c a t i o n s , t h e source l i s t of the simu- l a t o r and o t h e r d e t a i l s , see Nagamatsu [ 1 4 ] .
4 . Resul t of Simulat ion and Discussions
4.1. Resul t of s imula t ion
Nine r i n g s wi th t h e number n of pro- ces so r s i n t h e r i n g being 10, 15 , 2 0 , 3 0 , 40, 50, 60, 70 and 80, are considered. For t h e algori thms desc r ibed i n Sec t . 2 , t h e s imula t ion experiment w a s made. For each n, 100 r i n g s are generated a t random, and t h e worst case v a l u e and average of t h e number of exchanged messages, as w e l l as t h e i r s tandard d e v i a t i o n s are examined. I t is assumed i n t h i s experiment t h a t a l l pro- ces so r s belonging t o t h e network simultane- ously start t h e a lgo r i thm execut ion.
For t h e d e t a i l s of t h e s imula t ion re- sult, see Ikegawa [6]. Figure 1 shows t h a t t h e r e l a t i o n between t h e average va lue and the,number of p rocesso r s n. of n = 80, t h e expres s ion Cnlogn i s assumed
For t h e case
15

Table 1. Theore t i ca l worst case f o r number of messages, experimental average, and s tandard dev ia t ion f o r n = 80
Unid i r ec t iona l r i n g
B i d i r e c t i o n a l r i n g
Algorithm
L CR P PI
DKR
HS PR I;
KRS LT
Worst ca se evalu.
f o r each curve of Fig. 1 (except f o r L) , and t h e c o e f f i c i e n t C is determined f o r each algorithm. Figure 2 shows t h e r e l a t i o n be- tween t h e standard dev ia t ion and t h e coef- f i c i e n t C (Table 1 shows t h e p r e c i s e values); c' i s a l s o ca l cu la t ed f o r t h e cases o t h e r than n = 80, but no remarkable d i f f e r e n c e is observed. Thus, i t is concluded t h a t t h e average message complexity of t h e algor- ithm is given roughly by Cnlogn.
4 . 2 . Discussions
(1) Algorithm f o r u n i d i r e c t i o n a l r i n g
When t h e a lgori thm f o r t h e unidirec- t i o n a l r i n g i s evaluated i n terms of t h e average message complexity, as is seen from Table 1, CR i s t h e b e s t , followed by DKR, P I and P , w i th L being t h e worst . A s al- ready pointed o u t , by t h e t h e o r e t i c a l worst c a s e evaluat ion, DKR i s t h e b e s t among t h e algori thms known a t p re sen t . po in t of t he average eva lua t ion , however, t h e r e i s no remarkable d i f f e r e n c e between P I and DKR. Considering t h a t t h e worst c a s e evaluat ion i s improved i n DKR compared t o P I , t h e foregoing r e s u l t seems t o i n d i c a t e t h a t DKR i s properly b e t t e r than P I .
From t h e view-
Next, CR and DKR are compared i n de- tai l . I n general , something must b e sacri- f i c e d t o improve t h e worst case eva lua t ion , and i t is no wonder t h a t t h e average evalu- a t i o n of DKR is worse than that of CR. On t h e o t h e r hand, i t seems from t h e fol lowing viewpoint t h a t CR is b e t t e r than DKR, u n l e s s t h e t h e o r e t i c a l worst case va lue i s used as t h e goodness c r i t e r i o n f o r t h e algorithm.
Average evalu.
4.01nlogzn 0 .71n logz~ 1 . 6 9 1 ~ 1 0 ~ i ~ 1.65nlogzn 1.02 nlogz n
Standard dev.
0 46.5 41.0 40.1 46.4
110.2 34.0 45.4
118.8 41.6
A s f a r as t h i s s imula t ion i s concerned, t h e r e i s no case where t h e number of mess- ages i n CR is l a r g e r than t h e worst case evaluat ion of DKR. messages i n CR i s n e a r l y equal t o t h e worst case v a l u e of t h e number of messages i n DKR i n t h e s imulat ion. CR has a s l i g h t l y l a r g e r va r i ance than DKR,' b u t t h e r e are only f o u r cases among 100 f o r n = 30, f o r example, where CR required a l a r g e r number of mess- ages than t h e average number of messages i n DKR.
The average number of
Thus, i t i s concluded t h a t CR can exe- c u t e t h e l e a d e r e l e c t i o n w i t h a s u f f i c i e n t - l y small and s t a b l e number of messages.
( 2 ) Algorithm f o r b i d i r e c t i o n a l r i n g
I t i s seen from Table 1 t h a t , as long as t h e algori thm i s evaluated by t h e average number of messages t o be exchanged, PR i s t h e b e s t , followed by LT, KRS and F, w i th HS being t h e worst .
By t h e same reason as i n t h e comparison of DKR and P I i n (1) , LT is properly b e t t e r than KRS; PR and LT are compared as fo l lows . PR and LT are r e a l i z a t i o n s of CR and P I , r e s p e c t i v e l y , on t h e b i d i r e c t i o n a l r i n g , and DKR i s an improvement of P I . A s i s a n t i c i p a t e d from t h i s r e l a t i o n , t h e rela- t i o n between PR and LT i s almost t h e same as t h a t between CR and DKR. I n o t h e r words, PR is b e t t e r than LT, u n l e s s t h e t h e o r e t i - cal worst case va lue is used as t h e goodness c r i t e r i o n f o r t h e algori thm.
A s pointed ou t i n Sect . 1, t h e average eva lua t ion of t h e messag complexity of CR
16

f o r t h e u n i d i r e c t i o n a l r i n g co inc ides with t h e lower bound known, and t h e r e i s no room f o r improvement. On t h e o t h e r hand, t h e average eva lua t ion of t h e message complexity of PR f o r t h e b i d i r e c t i o n a l r i n g s t i l l h a s a l i t t l e room f o r improvement between t h e b e s t known lower bound 0.25nlogn. I n t h e p a s t , a lgori thms such as LT, f o r which t h e average message complexity has no t been de- r ived t h e o r e t i c a l l y , were considered as t h e candidates f o r b e t t e r a lgori thms. However, t h e r e s u l t of t h i s s imula t ion i n d i c a t e s t h a t t h e r e is l i t t l e p o s s i b i l i t y f o r such an imp rovemen t .
(3) Comparison of techniques 1 and 2
It i s seen from t h e reasoning i n (1) and (2) t h a t technique 1 i s b e t t e r than technique 2, un les s t h e t h e o r e t i c a l worst case eva lua t ion i s used as t h e goodness c r i t e r i o n f o r t h e algori thm. technique 2 i s employed ( i . e . , a s long as t h e message complexity is kept t o O(n1ogn) i n t h e worst c a s e ) , i t i s d i f f i c u l t t o con- s t r u c t an algori thm b e t t e r than CR o r PR even i f technique 1 i s e l a b o r a t e l y combined.
A s long a s
(4) Comparison of u n i d i r e c t i o n a l and bid irec t iona l r i n g s
Pachl, Korach and Rotem posed a ques- t i o n as t o whether o r n o t t h e l e a d e r elec- t i o n problem can be solved more e f f i c i e n t l y on t h e b i d i r e c t i o n a l r i n g than on t h e uni- d i r e c t i o n a l r i n g . This i s solved aff i rma- t i v e l y by Lavaul t [9] i n t h e sense of t h e average eva lua t ion . A s a r e s u l t of t h i s experiment, i t is shown t h a t t h e r e i s no s t rong rela t i o n between t h e average evalua- t i o n and t h e worst case evaluat ion of t h e message complexity. On t h e o t h e r hand, i t i s seen from Fig. 2 t h a t LT i s s l i g h t l y bet- ter than DKR i n t h e sense of t h e average message complexity. Consequently, t h e r e is l e f t a p o s s i b i l i t y t h a t a l e a d e r e l e c t i o n algorithm f o r t h e b i d i r e c t i o n a l r i n g w i l l b e found which i s more e f f i c i e n t than those f o r t he u n i d i r e c t i o n a l r i n g , i n t h e sense of t h e worst case eva lua t ion .
5. Conclusions
This paper considered 10 l e a d e r elec- t i o n (maximum f i n d i n g ) a lgori thms f o r t h e r i n g descr ibed i n Sec t , 2. A s imula t ion experiment i s done and t h e performances of t h e algori thms are compared. I n t h e evalu- a t i o n of t h e algori thms f o r t h e un id i r ec - t i o n a l r i n g from t h e viewpoint of t h e aver- age message complexity, CR i s t h e b e s t , followed by DKR, P I and P, w i th L being t h e worst .
In t h e comparison of t h e a lgo r i thm f o r t h e b i d i r e c t i o n a l r i n g , PR i s t h e b e s t , followed by LT, KRS and F , w i t h HS being t h e w o r s t . Then, techniques 1 and 2, as w e l l as t h e u n i d i r e c t i o n a l r i n g and t h e b i - d i r e c t i o n a l r i n g are compared. It i s shown t h a t , as long as t h e eva lua t ion i s made i n terms of t h e average message complexity, technique 1 and t h e b i d i r e c t i o n a l r i n g have p o s s i b i l i t i e s of c o n s t r u c t i n g a b e t t e r a lgori thm than technique 2 and un id i r ec t ion - a l r i n g , r e s p e c t i v e l y .
In t h i s s tudy , t h e experiment i s con- ducted focusing on t h e number of messages. Another e v a l u a t i o n may be obtained i f o t h e r measures such as t h e b i t complexity are con- s ide red . This i s l e f t f o r a f u r t h e r s tudy.
Acknowledgement. The a u t h o r s appreci- a t e t h e adv ice given by P ro f . R. Aihara i n t h e des ign of DAS, as w e l l as t h e a s s i s t a n c e by Prof . S. F u j i t a i n preparing t h e manu- s c r i p t . a Grant-in-aid from t h e Min. Educ. Sc i . and Culture , Japan.
This work w a s p a r t l y supported by
1.
2.
3 .
4.
5.
6.
7.
8.
REFERENCES
H . L. Bodlaender and J . van Leeuwen. New upper bounds f o r d e c e n t r a l i z e d ex- trema-finding i n a r i n g of p rocesso r s . Eds. B. Monien and G. Vidal-Naquet. Proc. STACS, Lec tu re Notes i n Computer Science, 210, pp. 119-129, Springer- Verlag , Berlin (1 986). E. Chang and R. Roberts. An improved a lgo r i thm f o r d e c e n t r a l i z e d extrema- f ind ing i n c i r c u l a r conf igu ra t ions of processes . Comun. ACM, 22, pp. 281- 283 (1979). D . Dolev, M. K lawe , and M. Rodeh. An 0 (nlogn) u n i d i r e c t i o n a l d i s t r i b u t e d algori thm f o r extrema f i n d i n g i n a c i r c l e . Jou rna l of Algorithms, 2, pp.
W. R. F rank l in . On an improved algor- ithm f o r d e c e n t r a l i z e d extrema f ind ing i n c i r c u l a r conf igu ra t ions of processors . Commun. ACM, 25, pp. 336-337 (1982). D. S. Hirschberg and J. B. S i n c l a i r . Decentral ized extrema-f inding i n c i rcu- l a r c o n f i g u r a t i o n s of processors . Commun. ACM, 23, pp. 627-628 (1980). Y . Ikegawa. Experimental eva lua t ion of l e a d e r e l e c t i o n a lgo r i thms f o r r i n g net- work. Grad. Thes i s , Hiroshima Univ., Japan (1989). E. Korach, D. Rotem, and N . Santoro. A p r o b a b i l i s t i c a lgo r i thm f o r extrema f i n d i n g i n a c i rc le of processors . Technical Report CS-81-19, Universi ty of Waterloo (1981). E. Korach, D . Rotem, and N. Santoro. D i s t r i b u t e d e l e c t i o n i n a c i rc le without
245-260 (1982).
17

a g loba l s ense of o r i e n t a t i o n . J . Computer Math, 14 (1984).
9. C . Lavault . Average number of messages f o r d i s t r i b u t e d leader-f inding i n r i n g s of processors . Information Processing Letters, 2, pp. 167-176 (1989).
10. J . van Leeuwen and R. B. Tan. An i m - proved upperbound f o r d i s t r i b u t e d elec- t i o n i n b i d i r e c t i o n a l r i n g s of proces- s o r s . D i s t r ibu ted Computing, 2, 3,
11. G . LeLann. D i s t r ibu ted systems-Toward
I n t ' l
pp. 149-160 (1987).
a formal approach. Information Pro- cessing '77, pp. 155-160 (1977).
12. A. L. Liestman and J. G . Peters. D i s - t r i b u t e d algori thms. Technical Report TR86-10. Simon Frase r Universi ty (1986).
13. T. A. Matsushita. D i s t r i b u t e d a lgo r - i thms f o r s e l e c t i o n . Technical Report ACT-37. Coordinated Science Lab., Un ive r s i ty of I l l i n o i s a t Urbana- Champaign (1983).
14. S. Nagamatsu. Load balancing algor- i thms for t r ee - s t ruc tu red network. Grad. Thesis , Hiroshima Univ., Japan (1988).
15. G. L. Peterson. An O(n1ogn) un id i r ec - t i o n a l a lgo r i thm f o r t h e c i r c u l a r ex- trema problem. ACM TOPLAS 4, pp. 758- 762 (1982).
Lower bounds f o r d i s t r i b u t e d maximum- f i n d i n g algori thms.
16. J. Pachl , E. Korach, and D. Rotem.
J . ACM, 2, pp. 905-918 (1984).
AUTHORS (from l e f t t o r i g h t )
Yukinori Ikegawa graduated i n 1989 from t h e 2nd C l u s t e r , Fac. Eng., Hiroshima Unive r s i ty , where h e is c u r r e n t l y i n t h e Master's program. m a t e r i a l s .
He i s engaged i n r e sea rch on opto-magnetic
Masafumi Yamashita graduated i n 1974 from t h e Dept. I n f . Eng., Fac. Eng., Kyoto Uni- v e r s i t y , where h e a l s o obtained a Master's degree i n 1977. I n 1980, h e obtained a D r . of Eng. degree from Nagoya Universi ty . H e i s p resen t ly an Assoc. P ro f . , 2nd C l u s t e r , Fac. Eng., Hiroshima Universi ty . H e w a s a V i s i t i n g Assoc. P ro f . f o r one yea r from 1986 a t Simon F r a s e r Un ive r s i ty , Canada. H e i s en- gaged i n research on load balancing problems i n mul t ip rocesso r system, b a s i s of image pro- ces s ing , and combinational problems.
He then served as an A s s i s t a n t a t Toyohashi Tech. Un ive r s i ty .
Tadashi A e graduated i n 1964 from t h e D e p t . Corn. Eng., Fac. Eng., Tohoku Unive r s i ty , where h e obtained a D r . of Eng. degree i n 1969. H e was an A s s i s t a n t a t Tohoku Unive r s i ty , an Assoc. Prof . a t Hiroshima Universi ty , and s i n c e 1982 a Pro f . a t Hiroshima Univ. (Computer Eng. Educ., 2nd C l u s t e r , Fac. Eng.). H e was a V i s i t i n g Researcher f o r one yea r from 1974 a t Grenoble Universi ty , France. P resen t ly , h e i s engaged p r imar i ly i n r e sea rch on t h e des ign , cons t ruc t ion and performance evaluat ion of p a r a l l e l and d i s t r i b u t e d systems. H e i s a member of ACM and of IEEE.
18