alluxio (formerly tachyon): unify data at memory speed at global big data conference san jose 2017
TRANSCRIPT

ALLUXIO (FORMERLY TACHYON): UNIFY DATA AT MEMORY SPEED
Global Big Data Conference, San Jose
March 2017
Gene Pang, Alluxio, Inc.

HISTORY
• Started at UC Berkeley AMPLab In Summer 2012• Originally named as Tachyon• Rebranded to Alluxio in early 2016
• Open Sourced in 2013• Apache License 2.0• Latest Stable Release: Alluxio 1.4.0• Alluxio 1.5.0 Planned For Q2, 2017
2

ALLUXIO DEPLOYMENTS
© 2016 Alluxio Confidential 3

BIG DATA ECOSYSTEM TODAYBIG DATA ECOSYSTEM WITH ALLUXIO
…
…
FUSE Compatible File SystemHadoop Compatible File System Native Key-Value InterfaceNative File System
Unifying Data at Memory Speed
BIG DATA ECOSYSTEM ISSUES
GlusterFS InterfaceAmazon S3 Interface Swift InterfaceHDFS Interface
4
BIG DATA ECOSYSTEM YESTERDAY

5

6

7
• Fastest growing open-source project in the big data ecosystem
• 450+ contributors from 100+ organizations
• Running in large production clusters
• Community members are welcome!
FASTEST GROWING BIG DATA PROJECTS
Popular Open Source Projects’ Growth
Months
Num
ber o
f Con
trib
utor
s

8
Unification
New workflows across any data in any storage system
Orders of magnitude improvement in run time
Choice in compute and storage – grow each independently, buy only what is needed
Performance Flexibility
ALLUXIO BENEFITS

#1 – ACCELERATING REMOTE STORAGE I/O
9
• Scenario: Compute and Storage Separation• Meet different compute and storage hardware requirements
• Scale compute and storage independently
• Store data in traditional filers/SANs and object stores
• Analyze existing data with Big Data compute frameworks
• Limitation
• Accessing data requires remote I/O

I/O WITHOUT ALLUXIO
Spark
Storage
Low latency, memory throughput
High latency, network throughput
10

I/O WITH ALLUXIO
Spark
Storage
AlluxioKeeping data in Alluxio accelerates data access
11

CASE STUDY: BAIDU
12
The performance was amazing. With Spark SQL alone, it took 100-150 seconds to finish a query; using Alluxio, where data may hit local or remote Alluxio nodes, it took 10-15 seconds.
- Baidu
RESULTS
• Data queries are now 30x faster with Alluxio
• Alluxio cluster runs stably, providing over 50TB of RAM space
• By using Alluxio, batch queries usually lasting over 15 minutes were transformed into an interactive query taking less than 30 seconds
Baidu’s PMs and analysts run
interactive queries to gain insights
into their products and business
• 200+ nodes deployment
• 2+ petabytes of storage
• Mix of memory + HDD
ALLUXIO
Baidu File System

#2 – SHARING DATA AT MEMORY-SPEED AMONG APPLICATIONS
• Scenario: Data Sharing Architecture
• Pipelines: output of one job is input of the next job
• Applications, jobs, and contexts reading the same data
• Limitation
• Sharing data requires I/O
13

SHARING WITHOUT ALLUXIO
Spark
Storage
MapReduce Spark
Network I/O
Disk I/O
I/O slows down
sharing
14

SHARING WITH ALLUXIO
Spark
Storage
MapReduce SparkMemory-speed
sharingAlluxio
15

CASE STUDY: BARCLAYS
Thanks to Alluxio, we now have the raw data immediately available at every iteration and we can skip the costs of loading in terms of time waiting, network traffic, and RDBMS activity.
- Barclays
RESULTS
• Barclays workflow iteration time decreased from hours to seconds
• Alluxio enabled workflows that were impossible before
• By keeping data only in memory, the I/O cost of loading and storing in Alluxio is now on the order of seconds
Barclays uses query and machine
learning to train models for risk
management
• 6 node deployment
• 1TB of storage
• Memory only
ALLUXIO
Relational Database
16

#3 – UNIFYING DATA ACCESS FROM DIFFERENT STORAGE
• Scenario: Multiple Storage Systems
• Most enterprises have multiple storage systems
• New (better, faster, cheaper) storage systems arise
• Limitation
• Accessing data from different systems requires different APIs
17

ACCESSING DATA THROUGH ALLUXIO
Storage B
Alluxio
Spark MapReduce Flink
Storage A Storage C
Flexible,
simple
no application changes,
new mount point
18
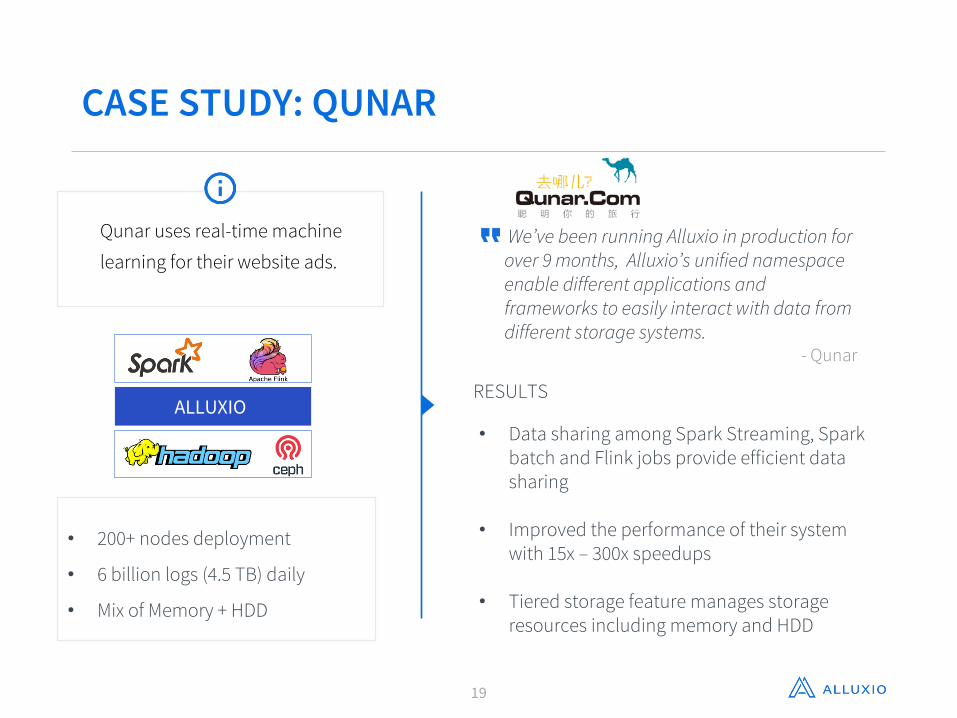
CASE STUDY: QUNAR
We’ve been running Alluxio in production for over 9 months, Alluxio’s unified namespace enable different applications and frameworks to easily interact with data from different storage systems.
- Qunar
RESULTS
• Data sharing among Spark Streaming, Spark batch and Flink jobs provide efficient data sharing
• Improved the performance of their system with 15x – 300x speedups
• Tiered storage feature manages storage resources including memory and HDD
• 200+ nodes deployment
• 6 billion logs (4.5 TB) daily
• Mix of Memory + HDD
ALLUXIO
Qunar uses real-time machine
learning for their website ads.
19

ALLUXIO DEMO

SUMMARY
21
• Adopted by industry leaders
• Unified, memory-speed data access across compute frameworks (Spark, Presto, MapReduce) and storage systems (S3, GCS, ECS, Ceph, HDFS, NFS, etc)
• Rapidly growing OS community

JOIN THE COMMUNITY
22
Contribute @ www.alluxio.org/contributeGet started @ goo.gl/55ApFx

Contact: [email protected]
Twitter: @unityxx
Websites: www.alluxio.com and www.alluxio.org
Thank you!
We are hiring!
Demo Videos: Spark + Alluxio + S3Alluxio Unified Namespace
23