algoritmos paralelos - ic.uff.brboeres/slidesap2014/introalgparalelos.pdf · complexo c • z 0 = 0...
TRANSCRIPT

Algoritmos Paralelos
Profa: Cristina Boeres página do curso: www.ic.uff.br/~boeres/AlgoritmosParalelos.html
Pós Graduação em Computação IC – Instituto de Computação

Programa do Curso
Introdução Histórico e classes
Definições e conceitos a serem utilizados
Medidas de desempenho
Modelos de Programação Paralela e Algoritmos histórico e motivação para modelagem
o modelo PRAM e suas classes
complexidade de algoritmos paralelos
técnicas básicas
Avaliação de Desempenho e Escalonamento de Aplicações Modelos de Comunicação
Proposta de Classificação de Heurística de Escalonamento
Heurísticas de escalonamento de construção

Bibliografia
J. Jájá, Introduction to Parallel Algorithms, Addison-Wesley, 1992.
Ian Foster , Designing and Building Parallel Programs, Addison-Wesley , 1995. (online)
J. Dongarra et. al., Sourcebook of Parallel Computing, Morgan Kaufmann, 2003.
T. G. Robertazzi, Networks and Grids - technology and theory, Springer, 2007.
H. Casanova, A. Legrand and Y. Robert, Parallel Algorithms, CRC Press, 2008.
S. Akl, Parallel Computation – Models and Methods , Prentice Hall 1997.
A. Grama, A. Gupta, G. Karypis, and V. Kumar Introduction to Parallel Computing, 2nd edition, Addison-Wesley, 2003.
Artigos a serem definidos

Introdução e Conceitos Básicos
Por que computação paralela e distribuída
Computação de Alto Desempenho
Arquitetura de computadores
Ambientes de programação paralela
Modelos de programação paralela

Por que computação paralela e distribuída?
Sistemas de computadores seqüenciais cada vez mais velozes
– velocidade de processador
– memória
– comunicação com o mundo externo
Quanto mais se tem, mais se quer......
– Demanda computacional está aumentando cada vez mais: visualização, base de dados distribuída, simulações, etc.
limites em processamento seqüencial
– velocidade da luz, termodinâmica
– custo X benefício

Por que computação paralela e distribuída?
que tal utilizar vários processadores?
dificuldades encontradas
– mas como?
– paralelizar uma solução?
Existem vários desafios em Computação Paralela e Distribuída

Computação de Alto Desempenho
Os grandes desafios (Levin 1989):
– química quântica, mecânica estatística e física relativista;
– cosmologia e astrofísica;
– dinâmica e turbulência computacional dos fluídos;
– projeto de materiais e supercondutividade;
– biologia, farmacologia, seqüência de genomas, engenharia genética, dobramento de proteínas, atividade enzimática e modelagem de células;
– medicina, modelagem de órgãos e ossos humanos;
– clima global e modelagem do ambiente

1a.8
Demanda para velocidade computacional
• Existem várias áreas que demandam processamento computacional mais veloz: – modelagem numérica
– simulação de problemas científicos
• Computação deve ser finalizada em um tempo razoável

1a.9
“GrandChallenge”
• São problemas que não podem ser resolvidos em uma quantidade de tempo razoável nos computadores atuais – para resolver o problema computacionalmente, 10
anos seriam razoáveis?
• Modelagem de estruturas longas de DNA
• previsão de tempo global
• simulação e modelagem do movimento de corpos celestes (astronomia)

1a.10
Movimento de Corpos Celestes
Cada corpo é atra[ido pelo outro atrav[es de forças
gravitacionais
O movimento de cada corpo é previsto através do cálculo
da força total de cada corpo

1a.11
Movimento de Corpos Celestes
• Existindo N corpos – N – 1 cálculo de força para cada corpo
– ou aproximadamente N2 cálculos, i.e. O(N2) *
• Depois deste cálculo, determinar as novas
posições dos corpos, repetindo esse
procedimento – N2 × T cálculos no total, sendo T o número de passos
* Existe um algoritmo O(N log2 N)

1a.12
• A galáxia deve ter em torno de 1011 estrelas
• Se cada cálculo da força leva em torno de 1 ms
(sendo extremamente otimista), então, são
necessários:
– 109 anos para uma iteração utilizando um algoritmo N2
Movimento de Corpos Celestes

1a.13
Astrophysical N-body simulation by Scott Linssen (undergraduate
UNC-Charlotte student).

Evolução nas comunicações
TCP/IP
HTML
Mosaic
XML
PHASE 1. Packet Switching Networks 2. The Internet is Born 3. The World Wide Web 4. with XML 5. The Grid
1969: 4 US Universities linked to form ARPANET TCP/IP becomes core protocol HTML hypertext system created 1972: First e-mail program created Domain Name System created
IETF created (1986)
CERN launch World Wide Web
1976: Robert Metcalfe develops Ethernet NCSA launch Mosaic interface
0
20
40
60
80
100
120
140
1965 1970 1975 1980 1985 1990 1995 2000 2005 2010
The'NetworkEffect’
kicks in, and the web
goes critical'
Nu
mb
er
of h
osts
(mill
ion
s (
cortesia de Rajkumar Buyya

Definindo melhor alguns conceitos
Concorrência
termo mais geral, um programa pode ser constituído por mais de um thread/processo concorrendo por recursos
Paralelismo
uma aplicação é executada por um conjunto de processadores em um ambiente único (dedicado)
Computação distribuída
aplicações sendo executadas em plataformas distribuídas

Definindo melhor alguns conceitos
Qualquer que seja o conceito, o que queremos?
estabelecer a solução do problema
lidar com recursos independentes
aumentar desempenho e capacidade de memória
fazer com que usuários e computadores trabalhem em espírito de colaboração

Definindo melhor alguns conceitos
Melhor Desempenho
– Suponha que seja necessário computar a série abaixo para cada número complexo c
• Z0 = 0
• Zn+1= Zn2 + c
– Se a série convergir, um ponto preto é desenhado em c
– Poderíamos utilizar 4 processadores, cada um processando um quadrante de imagem
– Seria 4 vezes mais rápido?

O que paralelizar?
Pode estar em diferentes níveis de sistemas computacionais atuais
– Hardware
– Sistema Operacional
– Aplicação
As principais questões que são focadas são
– Desempenho
– Corretude
– Possibilidade de explorar o paralelismo

Por que paralelizar?
Aplicação Paralela
– várias tarefas
– vários processadores
• redução no tempo total de execução

Modelos de Programação Paralela
Criação e gerenciamento de processos
– estático ou dinâmico
Comunicação
– memória compartilhada: visão de um único espaço de endereçamento global
– memória distribuída: troca explícita de mensagens

Modelos de Programação Paralela
Expressão de Paralelismo: Paradigmas
– SPMD ( Single Program Multiple Data )
– MPMD (Multiple Program Multiple Data )
Metas
– aumento no desempenho
– maior eficiência

Objetivos
Visão geral
– arquitetura de computadores
– ambientes de programação paralela
– modelos de programação paralela
Motivar Sistemas de Alto Desempenho

Arquitetura de Computadores
Classificação de Computadores
– Computadores Convencionais
– Memória Centralizada
– Memória Distribuída

Plataforma de Execução Paralela
Conectividade rede de interconexão
Heterogeneidade hardware e software distintos
Compartilhamento utilização de recursos
Imagem do sistema como usuário o percebe
Escalabilidade + nós > desempenho/eficiência
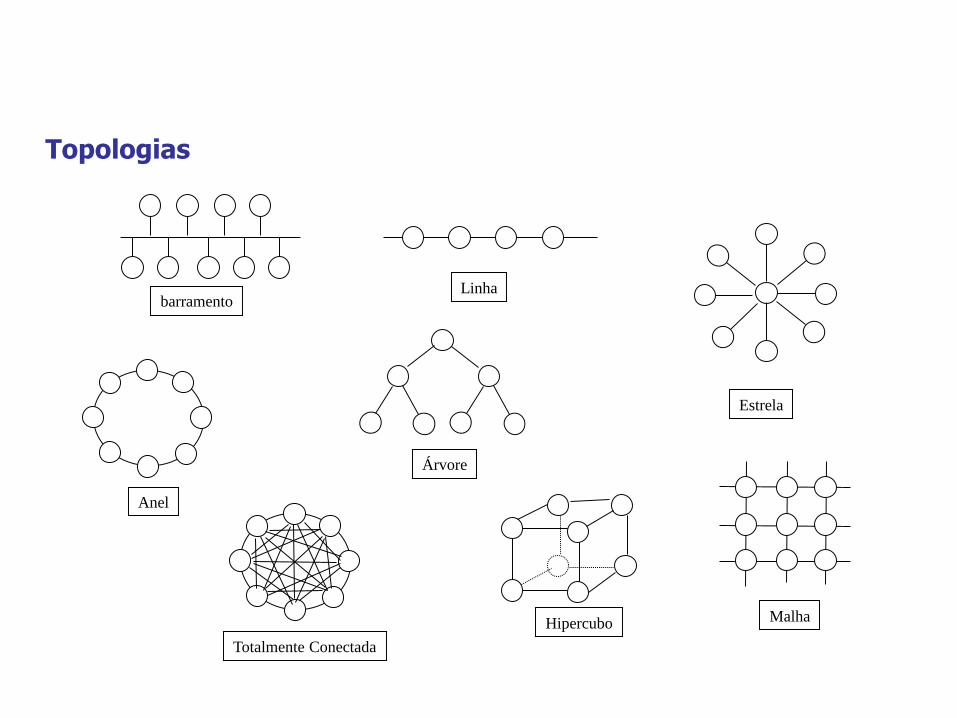
Topologias
Estrela
barramento Linha
Árvore
Malha
Anel
Totalmente Conectada
Hipercubo

Classificação de Sistemas Paralelos
Proposta por Flynn
– quantidade de instruções e dados processados em um determinado momento
SISD (single instruction single data)
– Um contador de programa
– Computadores seqüenciais
SIMD (single instruction multiple data)
– Um contador de programa, uma instrução executada por diversos processadores sobre diferentes dados
– Computadores paralelos como PRAM

Classificação de Sistemas Paralelos
Proposta por Flynn
MISD (multiple instructions single data)
– Não aplicável
MIMD (multiple instructions multiple data)
– Vários contadores de programa
– Diferentes dados
– Os vários computadores paralelos e distribuídos atuais

Plataforma de Execução Paralela
Diferentes plataformas do MIMD de acordo com os seguintes critérios
– espaço de endereçamento
– mecanismo de comunicação

Plataforma de Execução Paralela
SMPs (Symmetric MultiProcessors)
MPPs (Massively Parallel Processors)
Cluster ou NOWs (Network Of Worstations)
Grades Computacionais
Nuvens

SMPs
SMPs ou Multiprocessadores
– único espaço de endereçamento lógico
• mecanismo de hardware (memória compartilhada)
– comunicação espaço de endereçamento compartilhado
• operações de loads e stores
– Acesso a memória é realizada através de leitura (load) e escrita (store), caracterizando desta forma, a comunicação entre processadores

SMPs
Sistema homogêneo
Compartilhamento
– Compartilhamento total da mesma memória
Uma única cópia do Sistema Operacional
Imagem única do sistema
Excelente conectividade
– fortemente acoplados
Não escalável
Exemplos:
– Sun HPC 10000 (StarFire), SGI Altix, SGI Origin, IBM pSeries
– atualmente:
• multiprocessadores multicores
• heterogeneidade

SMPs
Multiprocessadores
Memória
CPU
CPU
... CPU


MPPs (Multicomputadores)
Diferem quanto a implementação física
Módulos ou elementos de processamento contendo:
– múltiplos processadores com memória privativa
– computadores completos
Espaço de endereçamento
– não compartilhado - memória distribuída
Comunicação
– troca de mensagens
Rede de interconexão
– diferentes topologias
Fracamente acoplados
Escaláveis

MPPs
Sistema homogêneo ( ou heterogêneo )
Interconexão: redes dedicadas e rápidas
Cada nó executa sua própria cópia do Sistema Operacional
Imagem única do sistema
– visibilidade dos mesmos sistemas de arquivo
Um escalonador de tarefas
– partições diferentes para aplicações diferentes

MPPs
Partições dedicadas a cada aplicação
Aplicações não compartilham recursos
– Pode ocorrer que uma aplicação permaneça em estado de espera
Exemplos:
– Cray T3E, IBM SP2s, clusters montados pelo próprio usuário, com propósito de ser um MPP

MPPs
Multicomputadores
... CPU CPU CPU
Mem. Mem. Mem.
requisições
Escalonador

Cluster de computadores ou NOWs
Conjunto de estações de trabalho ou PCs
Interconexão: redes locais
Nós: elementos de processamento = processador + memória
Diferenças em relação a MPPs:
– não existe um escalonador centralizado
– redes de interconexão tendem a ser mais lentas

Cluster de computadores ou NOWs
Resultado das diferenças:
– Cada nó tem seu próprio escalonador local
– Compartilhamento de recursos sem partição dedicada a uma aplicação
– Aplicação deve considerar impacto no desempenho
não tem o sistema dedicado
– Possibilidade de compor um sistema de alto desempenho e um baixo custo (principalmente quando comparados com MPPs).

Cluster ou NOWs
... CPU CPU CPU
Mem. Mem. Mem.
requisições requisições requisições

Máquinas atuais
Olhando melhor as máquinas modernas.....

Real computer system have cache memory between the main
memory and processors. Level 1 (L1) cache and Level 2 (L2) cache.
Example Quad Shared Memory Multiprocessor
Processor
L2 Cache
Bus interface
L1 cache
Processor
L2 Cache
Bus interface
L1 cache
Processor
L2 Cache
Bus interface
L1 cache
Processor
L2 Cache
Bus interface
L1 cache
Memory controller
Memory
Processor/ memory b us
Shared memory

“Recent”innovation
(since 2005) • Dual-core and multi-core processors
• Two or more independent processors in one package
• Actually an old idea but not put into wide practice until recently
with the limits of making single processors faster principally
caused by:
– Power dissipation (power wall) and clock frequency
limitations
– Limits in parallelism within a single instruction stream
– Memory speed limitations

“TheFreeLunchIsOver:AFundamentalTurnTowardConcurrencyin
Software”HerbSutter,http://www.gotw.ca/publications/concurrency-ddj.htm
Power
dissipation
Clock
frequency

Single quad core shared memory
multiprocessor
L2 Cache
Memory controller
Memory Shared memory
Chip
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache

Multiple quad-core multiprocessors
(example coit-grid05.uncc.edu)
Memory controller
Memory Shared memory
L2 Cache
possible L3 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache
Processor
L1 cache

Message-Passing Multicomputer

Message-Passing Multicomputer
Complete computers connected through an
interconnection network:
Processor
Interconnection network
Local
Computers
Messages
memory
Many interconnection
networks explored in the
1970s and 1980s
including 2- and 3-
dimensional meshes,
hypercubes, and multistage
interconnection networks

Networked Computers as a
Computing Platform
• A network of computers became a very attractive
alternative to expensive supercomputers and
parallel computer systems for high-performance
computing in early 1990s.
• Several early projects. Notable:
– Berkeley NOW (network of workstations)
project.
– NASA Beowulf project.

Key advantages:
• Very high performance workstations and PCs
readily available at low cost.
• The latest processors can easily be
incorporated into the system as they become
available.
• Existing software can be used or modified.

Beowulf Clusters*
• Agroupofinterconnected“commodity”computers achieving high performance with low cost.
• Typically using commodity interconnects - high speed Ethernet, and Linux OS.
* Beowulf comes from name given by NASA Goddard Space Flight Center cluster
project.

Cluster Interconnects
• Originally fast Ethernet on low cost clusters
• Gigabit Ethernet - easy upgrade path
More specialized/higher performance interconnects available including Myrinet and Infiniband.

1b.53
Dedicated cluster with a master node
and compute nodes
User
Master node
Compute nodes
Dedicated Cluster
Ethernet interface
Switch
External network
Computers
Local network

GPU clusters
• Recent trend for clusters – incorporating
GPUs for high performance.
• At least three of the five fastest computers in
the world are GPU clusters
http://www.top500.org/

Top500 description • Na lista TOP500 ordenação e de acordo com:
1) Rmax
2) Rpeak
3) tamanho de memória
4) alfabética
• Campos da lista:
– Rank- Position within the TOP500 ranking
– Location - Location and country
– System – name, configuration and manufacturer
– #Proc. - Number of processors (Cores)
– Rmax - Maximal LINPACK performance achieved
– Rpeak - Theoretical peak performance
– Power - energy

Grades Computacionais (Computational Grids)
Utilização de computadores
– independentes
– geograficamente distantes
Diferenças: clusters X grades
– heterogeneidade de recursos
– alta dispersão geográfica (escala mundial)
– compartilhamento
– múltiplos domínios administrativos
– controle totalmente distribuído

Grades Computacionais
Componentes – PCs, SMPs, MPPs, clusters
– controlados por diferentes entidades diversos domínios administrativos
Não têm uma imagem única do sistema a princípio – Vários projetos tem proposto o desenvolvimento de middlewares de
gerenciamento camada entre a infra-estrutura e as aplicações a serem executadas na grade computacional
Aplicação deve estar preparada para: – Dinamismo
– Variedade de plataformas
– Tolerar falhas

Grades Computacionais
Sistema não dedicado e diferentes plataformas
– Usuários da grades devem obter autorização e certificação para acesso aos recursos disponíveis na grade computacional
Falhas nos recursos tanto de processamento como comunicação são mais freqüentes que as outras plataformas paralelas
– Mecanismos de tolerância a falhas devem tornar essas flutuações do ambiente transparente ao usuário
Para utilização eficiente da grade computacional
– Gerenciamento da execução da aplicação através de políticas de escalonamento da aplicação ou balanceamento de carga
– Escalonamento durante a execução da aplicação se faz necessário devido as variações de carga dos recursos da grade

Grades Computacionais
Escalonador
de Aplicação
Escalonador
de Aplicação
Escalonador
de Recursos
Escalonador
de Recursos
Escalonador
de Recursos
usuário usuário usuário
MPP SMP
SMP
Cluster

Grades Computacionais
Cluster
Workstation
Internet
MPP
MPP SMP
SMP
Computador
convencional
Servidor
Workstation

Computação em Cluster
Um conjunto de computadores (PCs)
não necessariamente iguais heterogeneidade
Filosofia de imagem única
Conectadas por uma rede local
Para atingir tais objetivos, necessidade de uma camada de software ou middleware

Computação em Grid
Computação em Cluster foi estendido para computação ao longo dos sites distribuídos geograficamente conectados por redes metropolitanas
Grid Computing
Heterogêneos
Compartilhados
Aspectos que devem ser tratados
Segurança
Falhas de recursos
Gerenciamento da execução de várias aplicações

Computação em Grid
O sonho do cientista (The Grid Vision)
Computação em Grid adota tanto o nome quanto o conceito semelhantes aqueles da Rede de Potência Elétrica para capturar a noção ou a visão de:
− Oferecer desempenho computacional eficientemente;
− De acordo com a demanda;
− A um custo razoável;
− Para qualquer um que precisar.
O sucesso da computação em grid depende da comunidade de pesquisadores
– A possibilidade de construir tal ambiente (hardware e software)
– Necessidade de atingir seus objetivos.

Computação em Grid

SETI@home: Search for Extraterrestrial Intelligence at Home

SETI@home: Search for Extraterrestrial Intelligence at Home
• “ETI@home is a scientific experiment that uses Internet-connected computers in the Search for Extraterrestrial Intelligence (SETI).” (from setiathome.berkeley.edu/)
A abordagem:
• radio telescopes para ouvir sinais do espaço
• tais sinais podem ser ruídos de origem celeste ou provenientes da terra (estações de TV, radares e satélites)
• SETI analisa esse ruídos e digitalmente
• Maior poder computacional possibilita cobrir uma procura maior de ruídos
• Primeiramente – supercomputadores especiais foram utilizados
• Em 1995 (iniciado na verdade em 1999), David Gedye propos o uso de um “supercomputador virtual”

Computação em Grid
• Grid middlewares: tem como objetivo facilitar a utilização de um ambiente grid
APIs para isolar usuários ou programas da complexidade deste ambiente
Gerenciar esses sistemas automaticamente e eficientemente para executar aplicações no ambiente grid (grid-enabled applications)
E as aplicações não habilitadas a execução em ambiente grids?

Computação em Grid
Como o usuário (dono da aplicação) escolhe?
• Vários middlewares existem, qual o mais apropriado?
• Vários estão ainda sendo desenvolvidos
• Não há a garantia de suporte
• Pouca comparação entre os middlewares, por exemplo, desempenho, grau de intrusão.
• É difícil encontrar grids com o mesmo tipo de software instalado

Cloud Computing
• Computação provida como um serviço sobre a internet
• Infra-estrutura geograficamente distribuída
• Com algumas características de autonomic computing
– Que características são essas?
• O middleware não está embutido na aplicação
• Exemplos
– Googleaps, facebook, amazon
– Ex. de aplicação – gerenciamento de documentos distribuídos geograficamente

Cloud Computing
Modelo econômico de utilização dos serviços
Ambiente que prove uma quantidade maior de serviços a baixo custo
Baixo consumo de energia
Não acontece sem Virtualização

Diferenças entre Grid e Cloud Computing
AlHakami, H. et al, Comparison Between Cloud and Grid Computing: Review Paper, in International
Journal on Cloud Computing: Services and Architecture (IJCCSA),Vol.2, No.4, August 2012
•Recursos
• os recursos na grade estão disponíveis e compartilhados
• na nuvem, os recursos são providos de acordo com a demanda
•Heterogeneidade de recursos
• os dois agregam recursos heterogêneos
•Segurança
• segurança do usuário não foi atacado em grades (mais segurança de acesso)
• no caso de nuvem, cada usuário tem seu ambiente virtual e seguro
•Gerenciamento
• maior experiência no caso de grades
• muito a fazer em nuvem

Features Grid Cloud
Resource Sharing Collaboration (VOs, fair share) not shared.
Virtualization Virtualization of data and
computing resources
Virtualization of hardware and
software platforms.
Security Security through credential
delegations
Security through isolation.
High Level Services Plenty of high level services. No high level services defined
yet.
Architecture Service orientated User chosen architecture.
Software Dependencies Application domain dependent
software
Application domain
independent software
Platform Awareness The client software must be Grid-
enabled
The software works on a
customized environment
Scalability Nodes and sites scalability Nodes, sites, and hardware
scalability
Standardization Standardization and interoperability Lack of standards for Clouds
interoperability.
User Access Access transparency for the end
user.
Access transparency for the
end user.
Payment Model Rigid Flexible