algoritmo knuth morris pratt italiano
TRANSCRIPT

Index KMP
➔ Pattern Matching Naive

Pattern Matching Naive (brute force)
● Sia T[n] un Testo di longitude n● Sia P[m] un Pattern di lunghezza m ● Si vuole trovare le posizioni in cui si trova il
P in T

Pattern Matching Naive
●
There are two nested loops; the inner one takes O(m) iterations and the outer one takes O(n) iterations so the total time is the product, O(mn).
● In practice this works pretty well -- not usually as bad as this O(mn) worst case analysis.
● This is because the inner loop usually finds a mismatch quickly and move on to the next position without going through all m steps. But this method still can take O(mn) for some inputs, so mn overall.

Pattern Matching●Per risparmiare confronti Nella Fase di Ricerca “Matching Time”.
➔Si fa prima una pre elaborazione "offline" (prima di eseguire la vera Ricerca)
●Total Running Time for the Algorithm:+ Preprocessing Time (offline)+ Matching Time
Ok, ma come miglioro la versione Ingenua?

Index KMP
● Pattern Matching Naive➔ Quello a cui si vuole arrivare
The Pattern Matching Algorithm Goal Features

Pattern MatchingQuello a cui si vuole arrivare:
● A) Spostare il Pattern P di più di una posizione quando si incontra un missmatch, ma senza spostarlo cosi tanto da perdere qualche occorrenza di P in Ti (a metà dello spostamento del pattern)
● B) Dopo avere fatto un spostamento, accorgersi che le prime X posizioni già matchano con il Pattern (non 'e più necessario confrontarle), quindi iniziare a confrontare a partire della posizione X+1
A questo si arriva pre elaborando il Pattern (oppure il Testo), per imparare qualcosa sulla struttura interna del Pattern (o del testo).

Index KMP
● Pattern Matching Naive● Quello a cui si vuole arrivare
The Pattern Matching Algorithm Goal Features
➔ Prefix Vs Suffix

Prefix vs SuffixSia S=”ababaca” |S|= length = 7
I suoi possibili Prefissi sono:
X7 = ”ababaca” length=7X6 = ”ababac” length=6X5 = ”ababa” length=5X4 = ”abab” length=4X3 = ”aba” length=3X2 = ”ab” length=2X1 = ”a” length=1X0 = ε length=0
|S| = {X1,X2,X3,X4,X5,X6,X7}+{ε}
Tutti i possibili Prefissi Xi hanno un length minore/uguale a S
|Xi| <= n; i = 1..n
I suoi possibili Suffissi sono:
Y7 = ”ababaca” length=7Y6 = ”babaca” length=6Y5 = ”abaca” length=5Y4 = ”baca” length=4Y3 = ”aca” length=3Y2 = ”ca” length=2Y1 = ”a” length=1Y0 = ε length=0
|S|={Y1,Y2,Y3,Y4,Y5,Y6,Y7}+{ε}
Tutti i possibili Suffissi Yi hanno un length minore/uguale a S
|Yi| <= n; i = 1..n

Prefix vs SuffixTransitive Property
X5 prefisso di S (si esprime X5[S) X3 prefisso di S (si esprime X3[S)
X5[S AND X3[SIF |X3| <= |x5|
Allora
X3[x5
Generalizzando:
Xi[Xj
i=0..7; j=i..7i<=j
Y6 suffisso di S (si esprime S]Y6) Y4 suffisso di S (si esprime S]Y4)
S]Y6 AND S]Y4IF |Y4| <= |Y6|
Allora:
Y6]Y4
Generalizzando:
Yj]Yi
i=0..7j=i..7i<=j

Index KMP
● Pattern Matching Naive● Quello a cui si vuole arrivare
The Pattern Matching Algorithm Goal Features
● Prefix vs Suffix➔ Funzione Prefisso

Funzione Prefisso
● Incapsula la conoscenza di come la Stringa fa Match con se stessa.
● Data una stringa S di lunghezza n, definiamo πi come:
La lunghezza del più lungo prefisso di S che occorre in posizione i in S; i=1..n
● S[1,πi] = S[i,i+πi-1] ...Definendo un periodo interiore p = i-1pref [1] = n for i = 2 to n h = 0 while S[1 + h] == S[i + h] AND i+h <= n h = h + 1 pref [i] = h, ℓ = i, r = i + h − 1 , p = i-1return pref

Prefix Function
● -It preprocesses the pattern to find matches of prefixes of the pattern with the pattern itself.
● -It is defined as the size of the largest prefix of P[0..j-1] that is also suffix of P[i..j]
● -It also indicates how much of the last comparison can be reused if it fails.
● -It enables avoiding backtracking on the string 'S'
.

Example: S=“aabcaabdaae”
12345678901 S[1,πi] = S[i,i+πi-1] p = i-1i=1 π1=11 “aabcaabdaae” S[1,11] = S[1,1+11-1]= S[1,11] i=2 π2=1 “a” S[1,1] = S[2,2+2-1]=S[2,2] p = 2-1=1i=3 π3=0 εi=4 π4=0 εi=5 π5=3 “aab” S[1,3] = S[5,5+3-1]=S[5,7] p = 5-1=4i=6 π6=1 “a” S[1,1] = S[6,6+1-1]=S[6,6] p = 6-1=5i=7 π7=0 εi=8 π8=0 εi=9 π9=2 “aa” S[1,2] = S[9,9+2-1]=S[9,10] p = 9-1=8i=10 π10=1 “a” S[1,1]=S[10,10+1-1]=S[10,10] p=11-1=10i=11 π11=0 ε

Example: S = “aabaabcadaabaabce”
12345678901234567
Sia S = “aabaabcadaabaabce” S[1,πi] = S[i,i+πi-1] p = i-1
i=1 π1=17 “aabaabcadaabaabce” S[1,17] = S[1,1+17-1]= S[1,17] i=2 π2=1 “a” S[1,1] = S[2,2+2-1]=S[2,2] p = 2-1=1i=3 π3=0 εi=4 π4=3 “aab” S[1,3] = S[4,4+3-1]=S[4,6] p = 4-1=5i=5 π5=1 “a” S[1,1] = S[5,5+1-1]=S[5,5] p = 5-1=4i=6 π6=0 ε i=7 π7=0 εi=8 π8=1 “a” S[1,1] = S[8,8+1-1]=S[8,8] p = 8-1=7i=9 π9=0 ε i=10 π10=7 “aabaabc” S[1,7]=S[10,10+7-1]=S[10,16] p=11-1=10i=11 π11=1 “a”i=12 π12=0 εi=13 π13=3 “aab” S[1,3]=S[13,13+3-1]=S[13,15] p=13-1=12i=14 π14=1 “a” S[1,1]=S[14,14+1-1]=S[14,14] p=14-1=13i=15 π15=0 εi=16 π16=0 ε S[1,0]=S[16,16+0-1]=S[16,15] i=17 π17=0 ε

Index KMP
● Pattern Matching Naive● Quello a cui si vuole arrivare
The Pattern Matching Algorithm Goal Features
● Prefix vs Suffix● Funzione Prefisso➔ Funzione Prefisso in Tempo Lineare

Funzione Prefisso in tempo lineare
Per motivi di ottimizazzione (raggiungere O(n)), abbiamo aggiunto un carattere $ (sentinella) diverso da tutti i precedenti alla fine di S Pref[] 'e l'array dove mettiamo tutti i valori di π1 .. πn
l'algoritmo mete π1 = |S|e calcola π2 fuori dei cicli, confrontando da sinistra a destra i caratteri di S[2,n] con i caratteri di S finché trova un Missmatch (deve trovarlo per la sentinella) \\ricordando S[1,πi] = S[i,i+πi-1]
l2 = l = 2
r2 = r = π2+1 = i+πi-1 = 2+π2-1 = π2+1
in realtà sono le posizioni di inizio (l) e fine (r) del suffisso (“Prefisso Spostato”)

●Siccome πi-1
'e stato calcolato,
per calcolare i seguenti: πi, l
i, r
i con i=3 .. n
abbiamo 2 casi:● case 1) se i > r
\\ significa che nel πi-1 = 0 , il prefisso πi-1 'e la catena vuota ε
● Quindi non esiste un “prefisso spostato” non abbiamo nessuna informazione per eventualmente risparmiare futuri confronti o spostamenti.
● Si fa come si faceva con l'algoritmo ingenuo:
if r < i h = 0 while S[1 + h] == S[i + h] h = h + 1 pref [i] = h, ℓ = i, r = i + h − 1
.
● case 2) i <= r \\ significa che πi-1 >= 1, esiste un “Prefisso Spostato”, che possiamo sfruttare.
● Quindi possiamo fare 2 cose: (Ricordando lo scopo del pattern matching, slide 3)
A) sposto il pattern più di una posizione in avanti
B) non Confronto dall'inizio (risparmiamo confronti che sono certo che fanno match)
.

Case 2)esiste un (“Prefisso Spostato”)
suffisso, che possiamo sfruttare.Case 2a) πi-1 > πi
● il prefisso anteriore 'e pi'u lungo che quello che stiamo calcolando adesso (πi) in questo caso non dobbiamo fare nuovi Confronti; il risultato dei “possibili confronti” lo conosciamo di già
elseif pref [i − ℓ + 1] < r − i + 1pref [i] = pref [i − ℓ + 1] \\ℓ del ultimo π
● Osserviamo che non si aggiornano i valori ℓ,r. Questo significa che potremmo calcolare ancora succesivi πi con il vecchio ℓ,r che vengono aggiornati solo quando si fanno nuovi confronti
case 2b) πi-1 <= πi
● il prefisso anteriore 'e minore/uguale che quello che stiamo per calcolare in questo step
● in questo caso dobbiamo fare nuovi confronti perche il vecchio πi-1 non ci sta dando abastanza informazione; comunque ci fa risparmiare qualche confronto intermedio.
h = r − i + 1 while S[1 + h] == S[i + h] h = h + 1 pref [i] = h, ℓ = i, r = i + h − 1

●Prefix Function
● Prefix Function ● Un Semplice algoritmo di Pattern Matching tempo O(m+n)
● Basta chiamare la funzione prefisso con un input:● S[n+1+m] = P[n]$T[m]
● Siccome $ 'e diverso di ogni carattere di in P ed in T
● il massimo valore che può avere la funzione prefisso 'e n la lunghezza del Pattern
● Quindi quando πi=n indicare una occorrenza

An ExampleS = “abaaabaabaaabc”
r<i case1 πi=h; l=i; r=h+i−1;
π[i-l+1]<r-i+1 case2a πi=π[i-l+1]
case2b πi=h; l=i; r=i+h−1;
12345678901234
Sia S = “abaaabaabaaabc” S[1,πi] = S[i,i+πi-1] = S[i,r]
i=2 π2=0 ε case base π2=h=0; l=2; r=2+h-1=2+0-1=1;i=3 π3=1 “a” r<i case1 πi=h=1; l=i=3; r=h+i−1=3+1−1=3; S[1,1]=S[3,3] i=4 π4=1 “a” r<i case1 πi=h=1; l=i=4; r=h+i−1=4+1−1=4; S[1,1]=S[4,4] i=5 π5=4 “abaa” r<i case1 πi=h=4; l=i=5; r=h+i−1=5+4−1=8; S[1,4]=S[5,8] i=6 π6=0 ε π[i-l+1]<r-i+1 case2a πi=π[i-l+1]=π[6-5+1]=π[2]=0 i=7 π7=1 “a” π[i-l+1]<r-i+1 case2a πi=π[i-l+1]=π[7-5+1]=π[3]=1 S[1,1]=S[7,7]i=8 π8=1 “a” π[i-l+1]<r-i+1 case2a πi=π[i-l+1]=π[8-5+1]=π[4]=1 S[1,1]=S[8,8]i=9 π9=0 ε r<i case1 πi=h=0; l=i=9; r=h+i−1=0+9−1=8; i=10 π10=1 “a” r<i case1 πi=h=1; l=i=10; r=h+i−1=1+10−1=10; S[1,1]=S[10,10]i=11 π11=1 “a” r<i case1 πi=h=1; l=i=11; r=h+i−1=1+11−1=11; S[1,1]=S[11,11]i=12 π12=2 “ab” r<i case1 πi=h=2; l=i=12; r=h+i−1=2+12−1=13; S[1,1]=S[12,13]i=13 π13=0 ε π[i-l+1]<r-i+1 case2a πi=π[i-l+1]=π[13-12+1]=π[2]=0 i=14 π14=0 ε r<i case1 πi=h=0; l=i=14; r=h+i−1=0+14−1=13;

Index KMP
● Pattern Matching Naive● Quello a cui si vuole arrivare
The Pattern Matching Algorithm Goal Features● Prefix vs Suffix● Funzione Prefisso● Funzione Prefisso in Tempo Lineare➔ Knuth Morris Pratt

Knuth Morris Pratt
● Un Missmatch si vede:
P[1,j-1] = T[i,i+j-2]
● Un Match si vede:
P[1,m]=T[i,i+m-1]
P[1,j-1] = T[i,i+j-2]
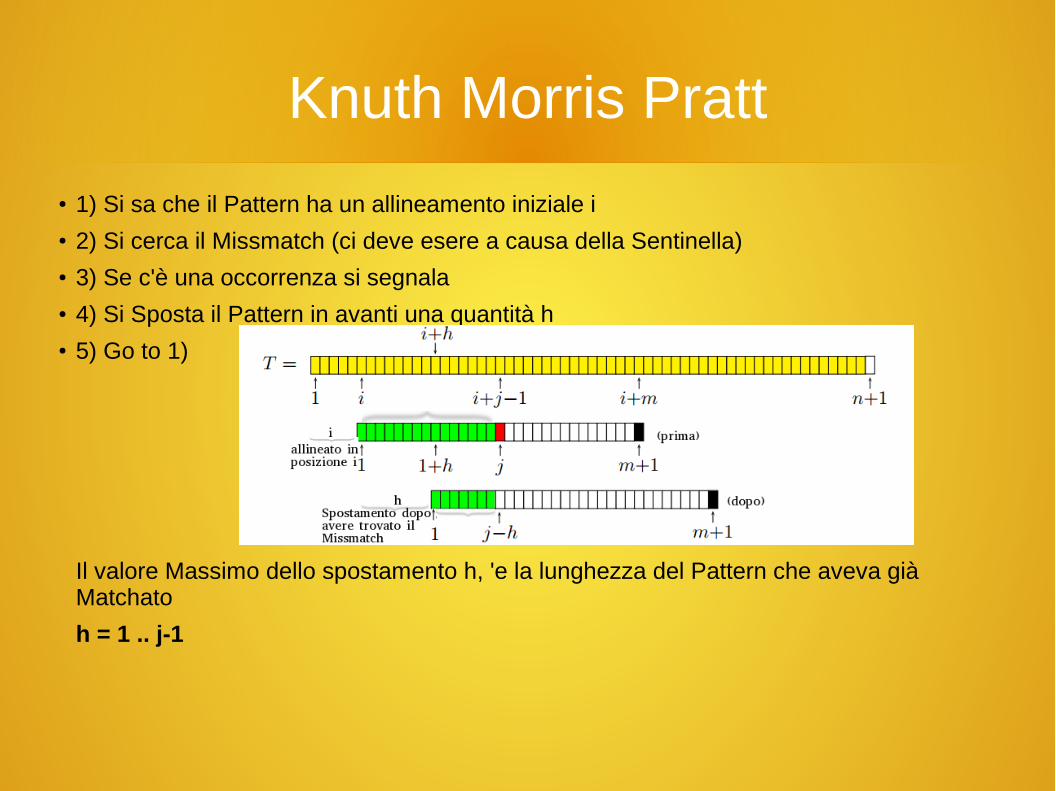
Knuth Morris Pratt
● 1) Si sa che il Pattern ha un allineamento iniziale i● 2) Si cerca il Missmatch (ci deve esere a causa della Sentinella)● 3) Se c'è una occorrenza si segnala● 4) Si Sposta il Pattern in avanti una quantità h● 5) Go to 1)
Il valore Massimo dello spostamento h, 'e la lunghezza del Pattern che aveva già Matchato
h = 1 .. j-1

Knuth Morris Pratt
● Con il Pattern Spostato “(dopo)”
(dopo) ... P[1,j-h-1]=T[i+h,i+j-2]
● Che 'e uguale, confrontando “prima” - “dopo”
(prima) ... P[1+h,j-1] = P[1,j-h-1]... (dopo)
● Per altra parte siccome da “prima”
(prima) ... P[j] != T[i+j-1]
● Quindi
(dopo) ... P[j-h] = T[i+j-1] != P[j]
● Che 'e proprio quel carattere del Missmatch in ''prima”● Giusto il punto dove dovremo iniziare a fare i confronti

Riprendendo la Nomenclatura con i Prefissi
● Dire P[1,j-h-1] = P[1+h,j-1] AND P[j-h] != P[j]
● 'e come dire: π1+h= j-h-1
j = h+π1+h+1
● Quindi gli spostamenti h=1..j-1 per i quali ci può essere una occorrenza del Pattern in posizione i+h● Sono soltanto quelli per cui
j = h+π1+h+1
● E se questa condizione non 'e soddisfatta per nessun spostamento h=1..j-1?● Allora la prima posizione in cui ci potrebbe essere una occorreza del Pattern 'e in i+j
Cio'e fare lo spostamento Massimo del Pattern
.

Knuth Morris Pratt
.

Example:
T=”bacbabababacaab”P="ababaca"
Pre Laborazione
● 1234567 P="ababaca"
i=1 π1=7i=2 π2=0 ε i=3 π3=3 "aba" P[1,3]=P[3,5]i=4 π4=0 εi=5 π5=1 "a" P[1,1]=P[5,5]i=6 π6=0 εi=7 π7=1 "a" P[1,1]=P[7,7]
1+h pref[1+h] d[1+h+pref[1+h]]=h
h=7 8 0 d[8]=7 h=6 7 1 d[8]=6 h=5 6 0 d[6]=5 h=4 5 1 d[6]=4 h=3 4 0 d[4]=3 h=2 3 3 d[6]=2 h=1 2 0 d[2]=1

Matching Time
d[1]=1 d[1]=1d[2]=2 d[2]=1d[3]=3 d[3]=3d[4]=4 d[4]=3d[5]=5 d[5]=5d[6]=6 d[6]=2d[7]=7 d[7]=7d[8]=8 d[8]=6
while i <= n-m+1=15-7+1=9
123456789012345 i=i+d[j] j=MAX(1,j-d[j]) T=”bacbabababacaab”i=1 j=1 P="ababaca" i=1+d[1]=1+1=2 j=MAX(1,1-d[1])=MAX(1,1-1)=1i=2 j=1 "ababaca" j=2 i=2+d[2]=2+1=3 j=MAX(1,2-d[2])=MAX(1,2-1)=1 i=3 j=1 "ababaca" i=3+d[1]=3+1=4 j=MAX(1,1-d[1])=MAX(1,1-1)=1 i=4 j=1 "ababaca" i=4+d[1]=4+1=5 j=MAX(1,1-d[1])=MAX(1,1-1)=1i=5 j=1 "ababaca" j=6 i=5+d[6]=5+2=7 j=MAX(1,6-d[6])=MAX(1,6-2)=4i=7 j=4 "ababaca" OCC j=8 i=7+d[8]=7+6=13 j=MAX(1,8-d[8])=MAX(1,8-6)=2 i=13 j=2 "ababaca" XXX <-- non lo fa, perche i>9


References
● http://www.math.unipd.it/~colussi/CompAlgoritmiB_2012-13/algPattMatch.pdf
● http://cs.indstate.edu/~kmandumula/presentation.pdf● http://www.ics.uci.edu/~eppstein/161/960227.html● http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms
/StringMatch/kuthMP.htm● http://en.wikipedia.org/wiki/Knuth%E2%80%93Morris
%E2%80%93Pratt_algorithm● http://jakeboxer.com/blog/2009/12/13/the-knuth-morris-pratt-
algorithm-in-my-own-words/● http://www.youtube.com/watch?v=lFof0Mx_-Ac