ajustar distribuciones datos
DESCRIPTION
Simulación de SistemasTRANSCRIPT

Variables Aleatorias 1 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
AJUSTE DE DISTRIBUCIONES DE LAS VARIABLES ALEATORIAS Definición de la Variable Aleatoria A lo largo de clases anteriores hemos mencionado que un modelo de simulación permite lograr un mejor entendimiento de prácticamente cualquier. Sistema. Para ello resulta indispensable obtener la mejor aproximación a la realidad, lo cual se consigue componiendo el modelo a base de variables aleatorias que interactúan entre sí. Pero, ¿Cómo podemos determinar qué tipo de distribución tiene una variable aleatoria? En esta clase comentaremos los métodos y herramientas que pueden dar contestación a estas interrogantes clave para la generación del modelo. Podemos decir que las variables aleatorias son aquellas que tienen un comportamiento probabilístico en la realidad. Por ejemplo, el número de clientes que llegan hora a un banco depende del momento del día, del día de la semana y de otros factores: por lo general, la afluencia de clientes será mayor al mediodía que muy temprano por la mañana, le demanda será más alta el viernes que el miércoles; habrá más clientes un día de pago que un día normal, etc. Dadas estas características, las variables aleatorias deben cumplir reglas de distribución de probabilidad como éstas: o La suma de las probabilidades asociadas a todos los valores posibles de la variable aleatoria x es
uno. o La probabilidad de que un posible valor de las variables x se presente siempre es mayor que o igual
a cero. o El valor esperado de la distribución de la variable aleatoria es la media de la misma, la cual a su
vez estima la verdadera media de la población. o Si la distribución de probabilidad asociada a la variable aleatoria está definida por más de un
parámetro, dichos parámetros pueden obtenerse mediante un estimador no sesgado. Por ejemplo,
la varianza de la población puede ser estimada usando la varianza de una muestra que es S2.
De la misma manera, la desviación estándar de la población, , puede ser estimada mediante la desviación estándar de la muestra S.
Tipos de Variables Aleatorias Podemos diferencia las variables aleatorias de acuerdo con el tipo de valores aleatorios que representan. Por ejemplo, si habláramos del número de clientes que solicitan cierto servicio en un periodo de tiempo determinado, podríamos encontrar valores tales como 0,1,2,…,n, es decir, un comportamiento como el que presentan las distribuciones de probabilidad discretas. Por otro lado, si habláramos del tiempo que tarda en ser atendida una persona, nuestra investigación tal vez arrojaría resultados como 1.54 minutos, 0.028 horas o 1.37 días, es decir, un comportamiento similar al de las distribuciones de probabilidad continuas. Considerando lo anterior podemos diferenciar entre variables aleatorias discretas y variables aleatorias continuas. Variables Aleatorias Discretas Este tipo de variables deben cumplir con estos parámetros:
P(x) 0
= 1
P(a ) = Pa + …+ Pb
Algunas distribuciones discretas de probabilidad son Uniforme Discreta, la de Bernoulli, la Hipergeométrica, la de Poisson y la Binomial. Podemos asociar a estas u otras distribuciones de probabilidad el comportamiento de una variable aleatoria. Por ejemplo, si nuestro propósito al analizar un muestreo de calidad consiste en decidir si la pieza bajo inspección es buena o no, estamos realizando un experimento con dos posibles resultados: la pieza es buena o la pieza es mala. Este tipo de comportamiento está asociado a una distribución de Bernoulli. Por otro lado, si lo que queremos es modelar el número de usuarios que llamaran a un teléfono de atención a clientes, el tipo de comportamiento puede llegar a parecerse a una distribución de Poisson . Incluso podría ocurrir que el comportamiento de la variable no se pareciera a otras distribuciones de probabilidad conocidas. Si éste fuera el caso, es perfectamente válido usar una distribución empírica que se ajuste a las condiciones reales de probabilidad. Esta distribución puede ser una ecuación o una suma de términos que cumplan con las condiciones necesarias para ser consideradas una distribución de probabilidad.
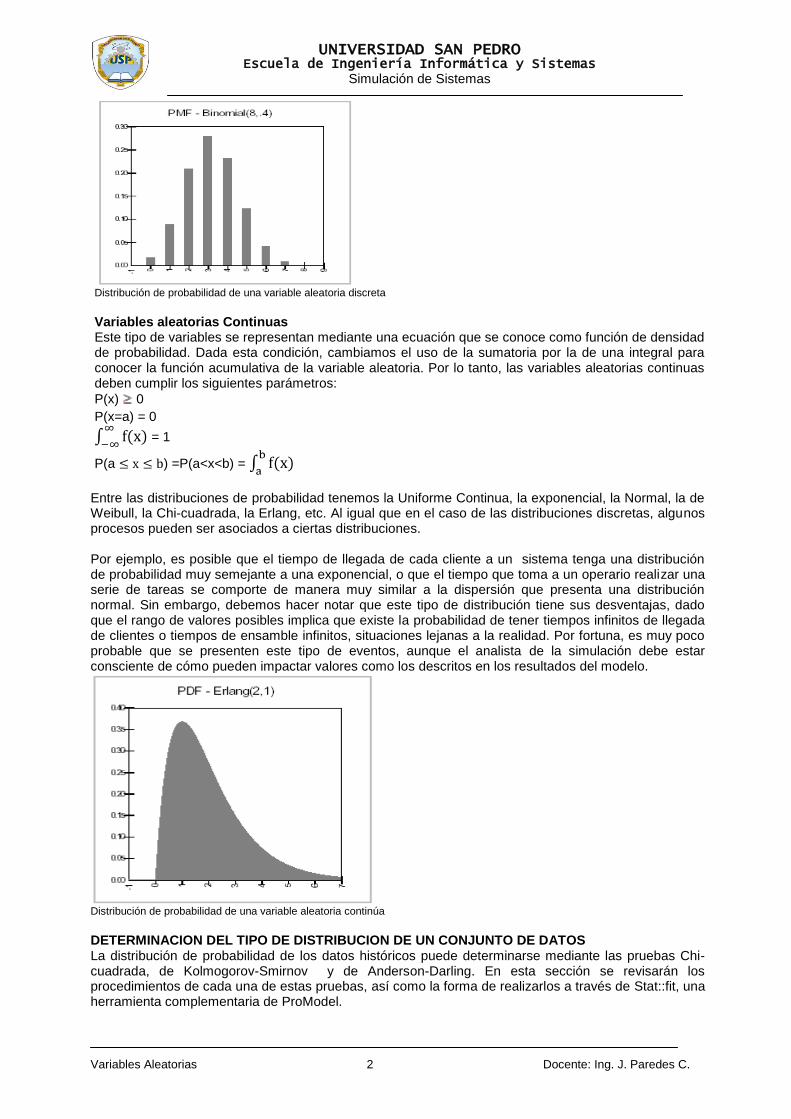
Variables Aleatorias 2 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Distribución de probabilidad de una variable aleatoria discreta
Variables aleatorias Continuas Este tipo de variables se representan mediante una ecuación que se conoce como función de densidad de probabilidad. Dada esta condición, cambiamos el uso de la sumatoria por la de una integral para conocer la función acumulativa de la variable aleatoria. Por lo tanto, las variables aleatorias continuas deben cumplir los siguientes parámetros:
P(x) 0
P(x=a) = 0
= 1
P(a ) =P(a<x<b) =
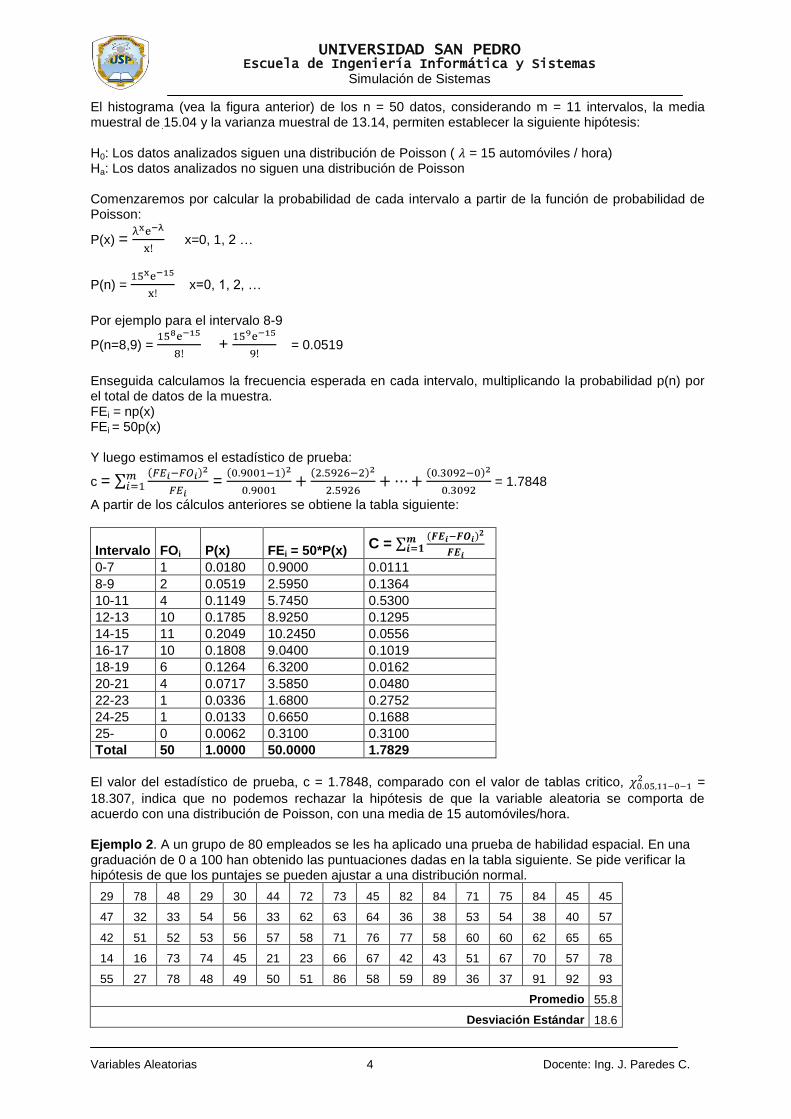
Entre las distribuciones de probabilidad tenemos la Uniforme Continua, la exponencial, la Normal, la de Weibull, la Chi-cuadrada, la Erlang, etc. Al igual que en el caso de las distribuciones discretas, algunos procesos pueden ser asociados a ciertas distribuciones. Por ejemplo, es posible que el tiempo de llegada de cada cliente a un sistema tenga una distribución de probabilidad muy semejante a una exponencial, o que el tiempo que toma a un operario realizar una serie de tareas se comporte de manera muy similar a la dispersión que presenta una distribución normal. Sin embargo, debemos hacer notar que este tipo de distribución tiene sus desventajas, dado que el rango de valores posibles implica que existe la probabilidad de tener tiempos infinitos de llegada de clientes o tiempos de ensamble infinitos, situaciones lejanas a la realidad. Por fortuna, es muy poco probable que se presenten este tipo de eventos, aunque el analista de la simulación debe estar consciente de cómo pueden impactar valores como los descritos en los resultados del modelo.
Distribución de probabilidad de una variable aleatoria continúa
DETERMINACION DEL TIPO DE DISTRIBUCION DE UN CONJUNTO DE DATOS La distribución de probabilidad de los datos históricos puede determinarse mediante las pruebas Chi-cuadrada, de Kolmogorov-Smirnov y de Anderson-Darling. En esta sección se revisarán los procedimientos de cada una de estas pruebas, así como la forma de realizarlos a través de Stat::fit, una herramienta complementaria de ProModel.

Variables Aleatorias 3 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
1. Prueba Chi-cuadrada Se trata de una prueba de hipótesis a partir de datos, basada en el cálculo de un valor llamado estadístico de prueba, al cual suele comparársele con un valor conocido como valor crítico, mismo que se obtiene, generalmente, de tablas estadísticas, el procedimiento general de la prueba es: a. Obtener al menos 30 datos de la variable aleatoria a analizar b. Calcular la media y varianza de los datos
c. Crear un histograma de m = intervalos, y obtener la frecuencia observada en cada intervalo FOi
d. Establecer explícitamente la hipótesis nula, proponiendo una distribución de probabilidad que se ajuste a la forma del histograma.
e. Calcular la frecuencia esperada, FEi , a partir de la función de probabilidad propuesta
f. Calcular el estadístico de prueba: c =
g. Definir el nivel de significancia de la prueba, , y determinar el valor critico de la prueba, (k
es el número de parámetros estimados en la distribución propuesta) h. Comparar el estadístico de prueba con el valor crítico. Si el estadístico de prueba es menor que el
valor critico no se puede rechazar la hipótesis nula.
Ejemplo 1: Estos son los datos del número de automóviles que entran a una gasolinera cada hora.
Determinar la distribución de probabilidad con un nivel de significancia de 5%.
0-7 1
8-9 2
10-11 4
12-13 10
14-15 11
16-17 10
18-19 6
20-21 4
22-23 1
24-25 1
25- 0
14 7 13 16 16 13 14 17 15 16
13 15 10 15 16 14 12 17 14 12
13 20 8 17 19 11 12 17 9 18
20 10 18 15 13 16 24 18 16 18
12 14 20 15 10 13 21 23 15 18
Variables Aleatorias 4 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
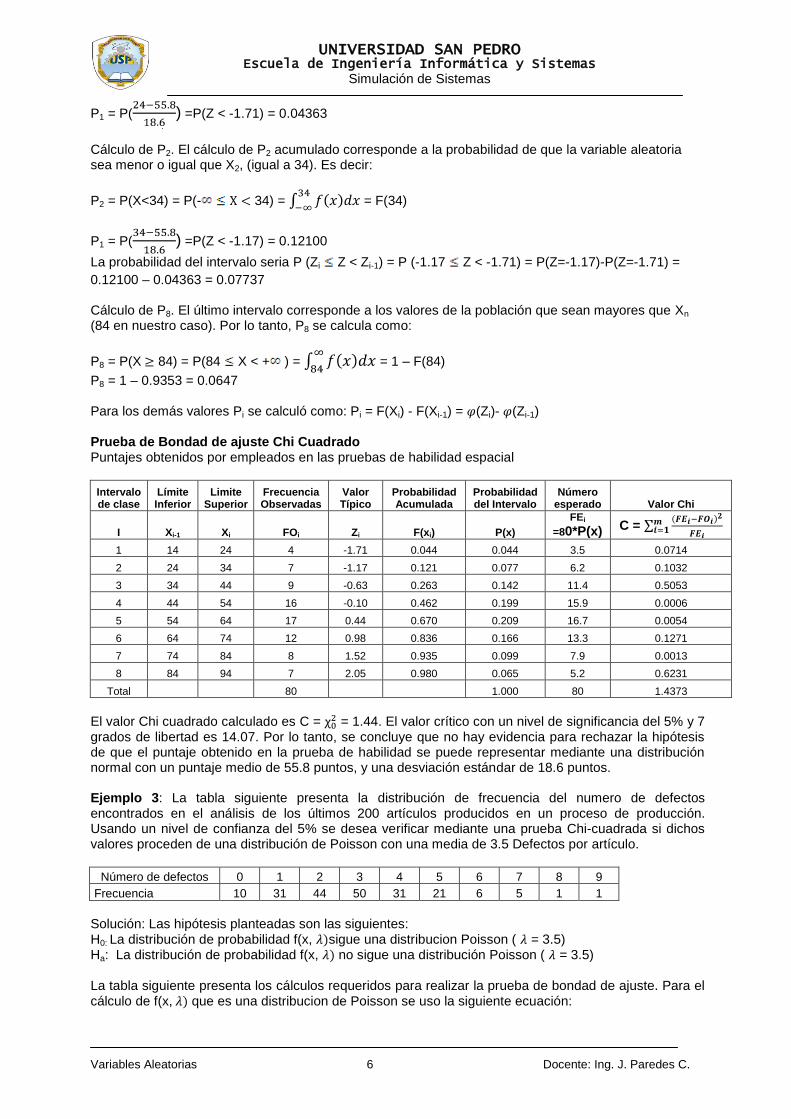
El histograma (vea la figura anterior) de los n = 50 datos, considerando m = 11 intervalos, la media muestral de 15.04 y la varianza muestral de 13.14, permiten establecer la siguiente hipótesis: H0: Los datos analizados siguen una distribución de Poisson ( = 15 automóviles / hora) Ha: Los datos analizados no siguen una distribución de Poisson Comenzaremos por calcular la probabilidad de cada intervalo a partir de la función de probabilidad de Poisson:
P(x) = x=0, 1, 2 …
P(n) = x=0, 1, 2, …
Por ejemplo para el intervalo 8-9
P(n=8,9) = + = 0.0519
Enseguida calculamos la frecuencia esperada en cada intervalo, multiplicando la probabilidad p(n) por el total de datos de la muestra. FEi = np(x) FEi = 50p(x) Y luego estimamos el estadístico de prueba:
c = = = 1.7848
A partir de los cálculos anteriores se obtiene la tabla siguiente:
Intervalo FOi P(x) FEi = 50*P(x) C =
0-7 1 0.0180 0.9000 0.0111
8-9 2 0.0519 2.5950 0.1364
10-11 4 0.1149 5.7450 0.5300
12-13 10 0.1785 8.9250 0.1295
14-15 11 0.2049 10.2450 0.0556
16-17 10 0.1808 9.0400 0.1019
18-19 6 0.1264 6.3200 0.0162
20-21 4 0.0717 3.5850 0.0480
22-23 1 0.0336 1.6800 0.2752
24-25 1 0.0133 0.6650 0.1688
25- 0 0.0062 0.3100 0.3100
Total 50 1.0000 50.0000 1.7829
El valor del estadístico de prueba, c = 1.7848, comparado con el valor de tablas critico, =
18.307, indica que no podemos rechazar la hipótesis de que la variable aleatoria se comporta de acuerdo con una distribución de Poisson, con una media de 15 automóviles/hora. Ejemplo 2. A un grupo de 80 empleados se les ha aplicado una prueba de habilidad espacial. En una graduación de 0 a 100 han obtenido las puntuaciones dadas en la tabla siguiente. Se pide verificar la hipótesis de que los puntajes se pueden ajustar a una distribución normal.
29 78 48 29 30 44 72 73 45 82 84 71 75 84 45 45
47 32 33 54 56 33 62 63 64 36 38 53 54 38 40 57
42 51 52 53 56 57 58 71 76 77 58 60 60 62 65 65
14 16 73 74 45 21 23 66 67 42 43 51 67 70 57 78
55 27 78 48 49 50 51 86 58 59 89 36 37 91 92 93
Promedio 55.8
Desviación Estándar 18.6

Variables Aleatorias 5 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Solución. A continuación se hace el desarrollo completo de la prueba de bondad de ajuste, partiendo
de distribución de los datos en intervalos de frecuencia y la construcción del histograma.
La muestra tiene un puntaje promedio de 55.8 y una desviación estándar de 18.6 puntos. El puntaje mínimo fue de 14 y el máximo de 93. La amplitud o rango está dado por Rango = R = Rango = Xmax - Xmin = 93 - 14 = 79 El número de intervalos de clase, calculado usando la fórmula de Sturgess, está dado por:
k = 1 +3.32 Log10(80) = 7.32 8
La amplitud o ancho del intervalo está dado por = = = 9.875 10
La distribución de frecuencia muestra que los puntajes se pueden aproximar razonablemente bien por una distribución normal. Por lo tanto la hipótesis formuladas son: Polígono de Frecuencia. Valores observados en cada intervalo de clase
H0: Los datos analizados siguen una distribución Normal N( , ) con = 55.8 y = 18.6 Ha: Los datos analizados no siguen una distribución Normal La tabla siguiente presenta los valores distribuidos en los intervalos de clase y la frecuencia absoluta de cada intervalo, correspondiente al número de observaciones que caen en él. Igualmente se presentan en la tabla los cálculos necesarios para realizar la prueba Chi cuadrado. Los principales cálculos se resumen a continuación: En general Pi, la probabilidad de que una observación quede en el intervalo i está dada por:
Pi = P(Xi-1 X Xi ) = = F(Xi) – F(Xi-1)
Como la variable aleatoria X se distribuye normalmente ( ), entonces Pi puede expresarse como:
Pi = P( ) = P(Zi-1 Zi) =
Donde (Zi-1) y (Zi) son las probabilidades de que la variable aleatoria normal estándar Z sea menor o igual a Zi-1 y Zi, respectivamente. Al realizar los cálculos para Pi se tuvieron en cuenta los intervalos extremos como casos especiales, a saber: Cálculo de P1. El cálculo de P1 corresponde a la probabilidad de que la variable aleatoria sea menor o igual que X1, (igual a 24). Es decir:
P1 = P(X<24) = P(- 24) = = F(24)
0
5
10
15
20
14 24 34 44 54 64 74 84
LimiteSuperior
LimiteSuperior
Variables Aleatorias 6 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
P1 = P( ) =P(Z < -1.71) = 0.04363
Cálculo de P2. El cálculo de P2 acumulado corresponde a la probabilidad de que la variable aleatoria sea menor o igual que X2, (igual a 34). Es decir:
P2 = P(X<34) = P(- 34) = = F(34)
P1 = P( ) =P(Z < -1.17) = 0.12100
La probabilidad del intervalo seria P (Zi Z < Zi-1) = P (-1.17 Z < -1.71) = P(Z=-1.17)-P(Z=-1.71) =
0.12100 – 0.04363 = 0.07737 Cálculo de P8. El último intervalo corresponde a los valores de la población que sean mayores que Xn
(84 en nuestro caso). Por lo tanto, P8 se calcula como:
P8 = P(X 84) = P(84 X < + ) = = 1 – F(84)
P8 = 1 – 0.9353 = 0.0647
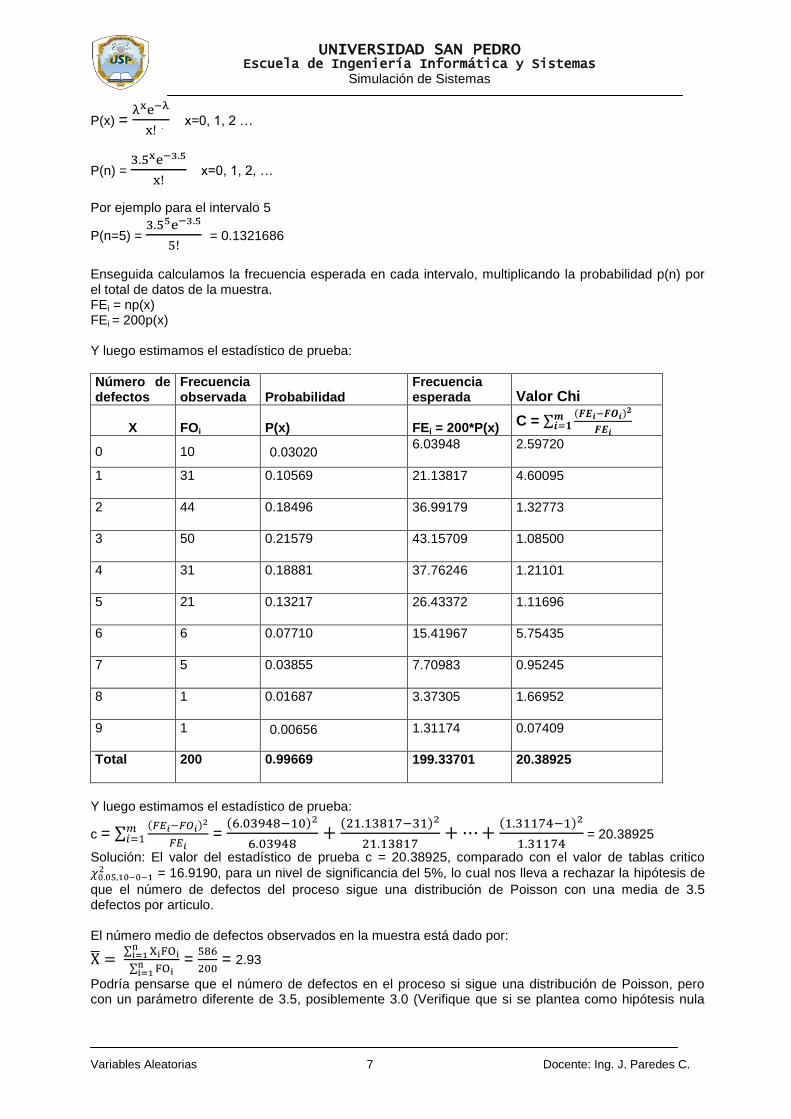
Para los demás valores Pi se calculó como: Pi = F(Xi) - F(Xi-1) = (Zi)- (Zi-1) Prueba de Bondad de ajuste Chi Cuadrado Puntajes obtenidos por empleados en las pruebas de habilidad espacial
Intervalo de clase
Límite Inferior
Limite Superior
Frecuencia Observadas
Valor Típico
Probabilidad Acumulada
Probabilidad del Intervalo
Número esperado Valor Chi
I Xi-1 Xi FOi Zi F(xi) P(x)
FEi
=80*P(x) C =
1 14 24 4 -1.71 0.044 0.044 3.5 0.0714
2 24 34 7 -1.17 0.121 0.077 6.2 0.1032
3 34 44 9 -0.63 0.263 0.142 11.4 0.5053
4 44 54 16 -0.10 0.462 0.199 15.9 0.0006
5 54 64 17 0.44 0.670 0.209 16.7 0.0054
6 64 74 12 0.98 0.836 0.166 13.3 0.1271
7 74 84 8 1.52 0.935 0.099 7.9 0.0013
8 84 94 7 2.05 0.980 0.065 5.2 0.6231
Total 80 1.000 80 1.4373
El valor Chi cuadrado calculado es C = = 1.44. El valor crítico con un nivel de significancia del 5% y 7 grados de libertad es 14.07. Por lo tanto, se concluye que no hay evidencia para rechazar la hipótesis de que el puntaje obtenido en la prueba de habilidad se puede representar mediante una distribución normal con un puntaje medio de 55.8 puntos, y una desviación estándar de 18.6 puntos. Ejemplo 3: La tabla siguiente presenta la distribución de frecuencia del numero de defectos encontrados en el análisis de los últimos 200 artículos producidos en un proceso de producción. Usando un nivel de confianza del 5% se desea verificar mediante una prueba Chi-cuadrada si dichos valores proceden de una distribución de Poisson con una media de 3.5 Defectos por artículo.
Número de defectos 0 1 2 3 4 5 6 7 8 9
Frecuencia 10 31 44 50 31 21 6 5 1 1
Solución: Las hipótesis planteadas son las siguientes: H0: La distribución de probabilidad f(x, sigue una distribucion Poisson ( = 3.5) Ha: La distribución de probabilidad f(x, no sigue una distribución Poisson ( = 3.5) La tabla siguiente presenta los cálculos requeridos para realizar la prueba de bondad de ajuste. Para el cálculo de f(x, que es una distribucion de Poisson se uso la siguiente ecuación:
Variables Aleatorias 7 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
P(x) = x=0, 1, 2 …
P(n) = x=0, 1, 2, …
Por ejemplo para el intervalo 5
P(n=5) = = 0.1321686
Enseguida calculamos la frecuencia esperada en cada intervalo, multiplicando la probabilidad p(n) por el total de datos de la muestra. FEi = np(x) FEi = 200p(x) Y luego estimamos el estadístico de prueba:
Número de defectos
Frecuencia observada Probabilidad
Frecuencia esperada Valor Chi
X FOi P(x) FEi = 200*P(x) C =
0 10 0.03020
6.03948 2.59720
1 31 0.10569 21.13817 4.60095
2 44 0.18496 36.99179 1.32773
3 50 0.21579 43.15709 1.08500
4 31 0.18881 37.76246 1.21101
5 21 0.13217 26.43372 1.11696
6 6 0.07710 15.41967 5.75435
7 5 0.03855 7.70983 0.95245
8 1 0.01687 3.37305 1.66952
9 1 0.00656
1.31174 0.07409
Total 200 0.99669 199.33701 20.38925
Y luego estimamos el estadístico de prueba:
c = = = 20.38925
Solución: El valor del estadístico de prueba c = 20.38925, comparado con el valor de tablas critico
= 16.9190, para un nivel de significancia del 5%, lo cual nos lleva a rechazar la hipótesis de
que el número de defectos del proceso sigue una distribución de Poisson con una media de 3.5 defectos por articulo. El número medio de defectos observados en la muestra está dado por:
= = 2.93
Podría pensarse que el número de defectos en el proceso si sigue una distribución de Poisson, pero con un parámetro diferente de 3.5, posiblemente 3.0 (Verifique que si se plantea como hipótesis nula

Variables Aleatorias 8 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
H0; f(x, ) = Poisson ( = 3.0) el estadistico de prueba es 2.6 y en este caso no se rechaza la hipotesis nula) Prueba de Kolmogorov-Smirnov Se comparan la función de distribución teórica y la función de distribución de los datos (Empírica). Esta prueba permite –al igual que la prueba Chi-cuadrada-determinar la distribución de probabilidad de una serie de datos. Una limitante de la prueba de Kolmogorov-Smirnov estriba en que solamente se puede aplicar al análisis de variables continuas. El procedimiento general de la prueba es: a. Obtener al menos 30 datos de la variable aleatoria a analizar b. Calcular la media y la varianza de los datos
c. Crear un histograma de m = intervalos, y obtener la frecuencia observada en cada intervalo FOi
d. Calcular la probabilidad observada en cada intervalo POi = , esto es, dividir la frecuencia
observada FOi entre el número total de datos n. e. Acumular las probabilidades POi para obtener la probabilidad observada hasta el i-ésimo intervalo,
POAi. f. Establecer explícitamente la hipótesis nula, proponiendo una distribución de probabilidad que se
ajuste a la forma del histograma. g. Calcular la probabilidad esperada acumulada para cada intervalo, PEAi, a partir de la función de
probabilidad propuesta. h. Calcular el estadístico de prueba:
C = Max|PEAi – POAi| i = 1, 2, 3, …., k, ….m
i. Definir el nivel de significancia de la prueba , y determinar el valor critico de la prueba,
(Consulta la tabla de valores criticos de la prueba de Kolmogorov-Smirnov) j. Comparar el estadístico de prueba con el valor crítico. Si el estadístico de prueba es menor que el
valor critico no se puede rechazar la hipótesis nula.
Ejemplo 4: Estudio del comportamiento del tiempo entre roturas de cierto filamento, medido en minutos/rotura, se muestra a continuación:
4.33 1.61 2.16 2.88 0.70 0.44 1.59 2.15 8.59 7.36
9.97 7.86 5.49 0.98 4.52 2.12 4.44 0.82 6.96 3.04
2.81 14.39 3.44 9.92 4.38 8.04 2.18 6.19 4.48 9.66
4.34 1.76 2.30 5.24 11.65 10.92 12.16 6.60 0.85 4.82
1.36 3.53 6.58 1.45 8.42 3.69 2.44 0.28 1.90 2.89
Determinar la distribución de probabilidad con un nivel de significancia de de 5%.
El histograma (vea la figura siguiente) de los n = 50 datos con m = 8 intervalos, la media muestral de 4.7336 y la varianza muestral de de 12.1991 permiten estimar un parámetro de forma de 1.38 y un parámetro de escala de 5.19, y establecer la hipótesis:
H0 : Weibull ( = 1.38, = 5.19) minutos/rotura
Ha : Otra distribución Histograma de frecuencias del tiempo entre roturas
0
2
4
6
8
10
12
14
Series1

Variables Aleatorias 9 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Iniciamos el procedimiento calculando la probabilidad observada en cada intervalo
POi = = =
Para después calcular la probabilidad observada acumulada hasta el intervalo i.
POAi = = = = {0.24, 0.50, …,1}
Posteriormente calculamos la probabilidad esperada acumulada de cada intervalo PEAi a partir de la función de probabilidad acumulada de Weibull:
F(x) =
F(x) = 1 -
F(x) = 1 - Por ejemplo para el intervalo con el límite superior de 8:
PEA8 = F(x) = 1 - = 0.8375
Por último, calculamos el estadístico de prueba C = Max|POAi – PEAi| = Max{|0.24-0.2353|, |0.50-0.5025|, …, |1-1|} = 0.0375 A partir de los cálculos anteriores se obtiene la tabla siguiente: Cálculos para la prueba de Kolmogorov-Smirnov
Intervalo FOi POi POAi PEAi |POAi - PEAi|
0-2 12 0.24 0.24 0.23526 0.00474
2-4 13 0.26 0.50 0.50247 0.00247
4-6 9 0.18 0.68 0.70523 0.02523
6-8 6 0.12 0.80 0.83747 0.03747
8-10 6 0.12 0.92 0.91559 0.00441
10-12 2 0.04 0.96 0.95839 0.00161
12-14 1 0.02 0.98 0.98042 0.00042
14-∞ 1 0.02 1.00 1 0.0000
50 1 c 0.03747
El valor del estadístico de prueba, c = 0.0375, comparado con el valor de tablas critico, D0.05, 50 = 0.18841, indica que no podemos rechazar la hipótesis de que la variable aleatoria se comporta de acurdo con una distribución de Weibull con parámetro de escala 5.19 y parámetro de forma 1.38 Ejemplo 5: Supóngase que los 50 tiempos interarribos (en minutos) son coleccionadas sobre los siguientes 100 minutos de intervalo (pág. 349)
0.44 0.53 2.04 2.74 2.00 0.30 2.54 0.52 2.02 1.89 1.53 0.21
2.80 0.04 1.35 8.32 2.34 1.95 0.10 1.42 0.46 0.07 1.09 0.76
5.55 3.93 1.07 2.26 2.88 0.67 1.12 0.26 4.57 5.37 0.12 3.19
1.63 1.46 1.08 2.06 0.85 0.83 2.44 2.11 3.15 2.90 6.58 0.64
La hipótesis nula y alternativa son las siguientes H0: Los tiempos interarribos están distribuidos exponencialmente Ha: Los tiempos interarribos, no están distribuidos exponencialmente
= 2.01
= = = 0.4975
Variables Aleatorias 10 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
P(x) = 1 -
P(0.75) = 1 - = 0.0.3114
Intervalo Marca de clase (Mi) FOi POi POAi PEAi |POAi - PEAi|
0.00 - 1.50 0.75 23 0.4792 0.4792 0.3114 0.1678
1.50 - 3.00 2.25 17 0.3542 0.8333 0.6735 0.1598
3.00 - 4.50 3.75 3 0.0625 0.8958 0.8452 0.0506
4.50 - 6.00 5.25 3 0.0625 0.9583 0.9266 0.0317
6.00 – mas 6.75 2 0.0417 1 0.9652 0.0348
48 1 c 0.1678
0.4975 El valor del estadístico de prueba, c = 0.1678, comparado con el valor de tablas critico, D0.05, 48 = 0.19221, indica que no podemos rechazar la hipótesis de que la variable aleatoria se comporta de
acuerdo con una distribución de exponencial con parámetro de escala = 0.4975
Ejemplo 6: Considere de nuevo el ejemplo 2 de la prueba de habilidad aplicada a un grupo de 80 empleados. Mediante la prueba de Kolmogorov-Smirnov, con un nivel de significancia del 5%, pruebe la hipótesis de que los puntajes obtenidos siguen una distribución normal. H0: Los datos analizados siguen una distribución Normal N( , ) con = 55.8 y = 18.6 Ha: Los datos analizados no siguen una distribución Normal Solución: De la tabla construida para realizar la prueba Chi-cuadrado tomaremos la información pertinente y la complementaremos con la información faltante. Los cálculos se muestran a continuación:
Prueba de Bondad de Ajuste Kolmogorov-Smirnov
Puntajes obtenidos por empleados en las pruebas de habilidad espacial
Intervalo de clase
Límite inferior
Límite superior
Frecuencia observada
Probabilidad observada
Probabilidad observada acumulada
Valor típico
Probabilidad esperada acumulada
Diferencia
|POAi - PEAi|
I Xi-1 Xi FOi POi POAi Zi PEAi
1 14 24 4 0.0500 0.0500 -1.71 0.0436 0.0064
2 24 34 7 0.0875 0.1375 -1.17 0.1210 0.0165
3 34 44 9 0.1125 0.2500 -0.63 0.2644 0.0144
4 44 54 16 0.2000 0.4500 -0.10 0.4602 0.0102
5 54 64 17 0.2125 0.6625 0.44 0.6700 0.0075
6 64 74 12 0.1500 0.8125 0.98 0.8365 0.0240
7 74 84 8 0.1000 0.9125 1.52 0.9357 0.0232
8 84 94 7 0.0875 1.0000 2.05 0.9798 0.0202
80 1.0000 c 0.0240
H0: Los datos analizados siguen una distribución Normal N( , ) con = 55.8 y = 18.6 Ha: Los datos analizados no siguen una distribución Normal
PO1 = = 0.0500
Z1 = = -1.71
PEA1 se busca en la tabla de distribución normal con z1 = -1.71, es igual a 0.0436 El valor critico para n = 80 valores y un nivel de significancia del 5% se encuentra de la siguiente forma
D0.05, 80 = = 0.1521. Como la diferencia maxima observada fue de c = Max|PEAi – POAi| = 0.0240
no hay razón para dudar que los puntajes se pueden aproximar mediante una distribución normal.

Variables Aleatorias 11 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Ejemplo: Se necesita estudiar a los tiempos de interarribo de vehículos al estacionamiento de un centro comercial y para ello es necesario analizar los siguientes datos que se proporcionan: Tiempos entre arribos de autos a un centro comercial (en segundos): 1 25 28 52 79 89 115 3 5 38 48 45 31 57 65 138 2 23 49 37 25 18 98 21 4 43 32 10 163 5 40 9 1 2 76 85 72 19 52 17 15 10
El promedio o la media es 45.42
Determine si es posible ajustarlos (o representarlos) con una función exponencial con parámetro =
= 0.022 de los datos agrupados. Agrupe los datos en 6 clases de ancho 30 seg.
Paso 1. Agrupar los datos para generar un histograma.
Intervalo
Nro. de Observaciones
FOi
0 - 30 20
30 - 60 12
60 - 90 6
90 - 120 2
120 - 150 1
150 - 180 1
Total 42
Paso 2. Calcule la probabilidad acumulada con base en las frecuencias que generó en el paso 1. Probabilidad
0
5
10
15
20
25
0 - 30 30 -60
60 -90
90 -120
120 -150
150 -180
Nro de Observaciones F0i
Nro de Observaciones F0i

Variables Aleatorias 12 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Intervalo Marca de clase (Mi) FOi POi POAi PEAi |POAi - PEAi|
0 – 30 15
20 0.4762
0.4762 0.2811 0.1951
30 – 60 45 12 0.2857 0.7619 0.6284 0.1335
60 – 90 75 6 0.1429 0.9048 0.8080 0.0968
90 - 120 105 2 0.0476 0.9524 0.9007 0.0516
120 – 150 135 1 0.0238 0.9762 0.9487 0.0275
150 – 180 165 1 0.0238 1.0000 0.9735 0.0265
0.022 c 0.1951 Paso 3. Encontrar la expresión para la función exponencial de probabilidad acumulada F(x).
F(x) = = dx = 1 -
Ejemplo:
F(15) = 1 - = 1 - 0.7189 = 0.2811
Paso 4. Encuentre la máxima diferencia en valor absoluto entre la probabilidad acumulada observada y la esperada (Dmax). Para ello, tabule los valores de F(x) evaluada en las marcas de clase como se muestra en la anterior
tabla: (recuerde que el mejor estimador para es 1/ )
Media ( ) 45.4211 0.022 Paso 5. Se calcula la diferencia máxima en valor absoluto entre las probabilidades acumuladas |POAi - PEAi| calculadas para los distintos valores de las marcas de clases y se le llama Dmax. Total datos Máxima diferencia|POAi - PEAi| Valor de tablas D0.05, 42 42 0.1951 0.207743 Como la diferencia máxima encontrada (Dmax) es menor que la diferencia máxima permitida (la tabulada para la prueba de Kolmogorov-Smirnov) entonces se dice que: "no se encuentra evidencia estadística para afirmar que los datos no siguen el comportamiento que el propuesto, con el nivel de significancia que se emplee en la prueba (usualmente 5 %)". Es decir; se acepta que la exponencial con media = 45.4211, ajusta al histograma de los datos, con significancia del 5%.
AJUSTE DE DATOS CON STAT::FIT
La herramienta Stat::Fit de Promodel se para analizar y determinar el tipo de distribución de probabilidad de un conjunto de datos. Esta utilería permite comparar los resultados entre varias distribuciones analizadas mediante una calificación. Entre sus procedimientos emplea las pruebas Chi-cuadrada, de Kolmogorov-Smirnov y de Anderson –Darling. Además calcula los parámetros apropiados para cada tipo de distribución, e incluye información estadística adicional como media, moda, valor mínimo, valor máximo y varianza, entre otros datos. Stat::Fit se puede ejecutar desde la pantalla de inicio de Promodel, o bien desde el comando Stat::Fit del menú Tools, como se aprecia en la figura siguiente:

Variables Aleatorias 13 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Pantalla de inicio de ProModel
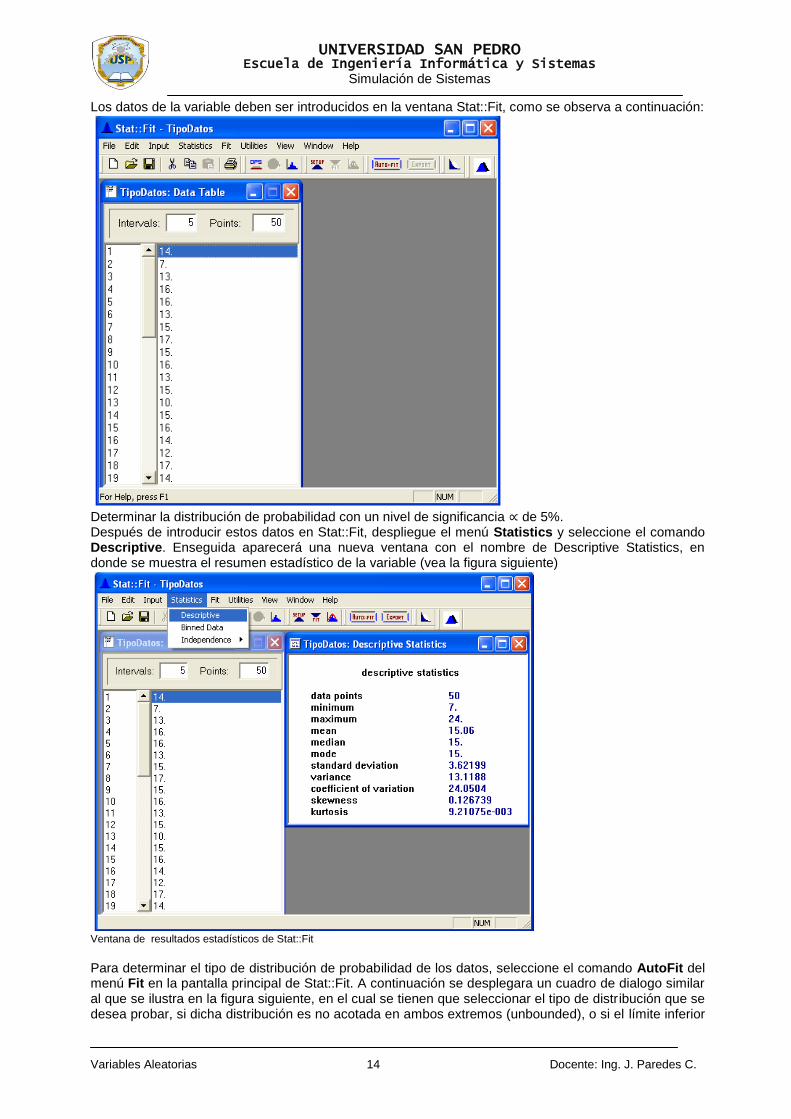
Una vez que comience a ejecutarse el comando Stat::Fit, haga clic en el icono de la hoja en blanco de la barra de herramientas estándar para abrir un nuevo documento (también puede abrir el menú File y hacer clic en New). Enseguida se desplegara una ventana con el nombre Data Table (vea la figura siguiente), en la que, deberá introducir los datos de la variable a analizar, ya sea utilizando el teclado o mediante los comandos Copiar y Pegar (Copy/Paste) para llevar dichos datos desde otra aplicación, como puede ser Excel o el Bloc de notas de Windows.
Introduzca los datos de la variable que desea analizar en esta ventana de Stat::Fit
Una vez introducida la información es posible seleccionar una serie de opciones de análisis estadístico, entre ellas las de estadística descriptiva y las de pruebas de bondad de ajuste, de las cuales nos ocuparemos en los siguientes ejemplos. Ejemplo 1: Los datos del número de automóviles que entran a una gasolinera por hora son:
14 7 13 16 16 13 14 17 15 16
13 15 10 15 16 14 12 17 14 12
13 20 8 17 19 11 12 17 9 18
20 10 18 15 13 16 24 18 16 18
12 14 20 15 10 13 21 23 15 18
Haga clic acá
Variables Aleatorias 14 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Los datos de la variable deben ser introducidos en la ventana Stat::Fit, como se observa a continuación:
Determinar la distribución de probabilidad con un nivel de significancia de 5%. Después de introducir estos datos en Stat::Fit, despliegue el menú Statistics y seleccione el comando Descriptive. Enseguida aparecerá una nueva ventana con el nombre de Descriptive Statistics, en donde se muestra el resumen estadístico de la variable (vea la figura siguiente)
Ventana de resultados estadísticos de Stat::Fit
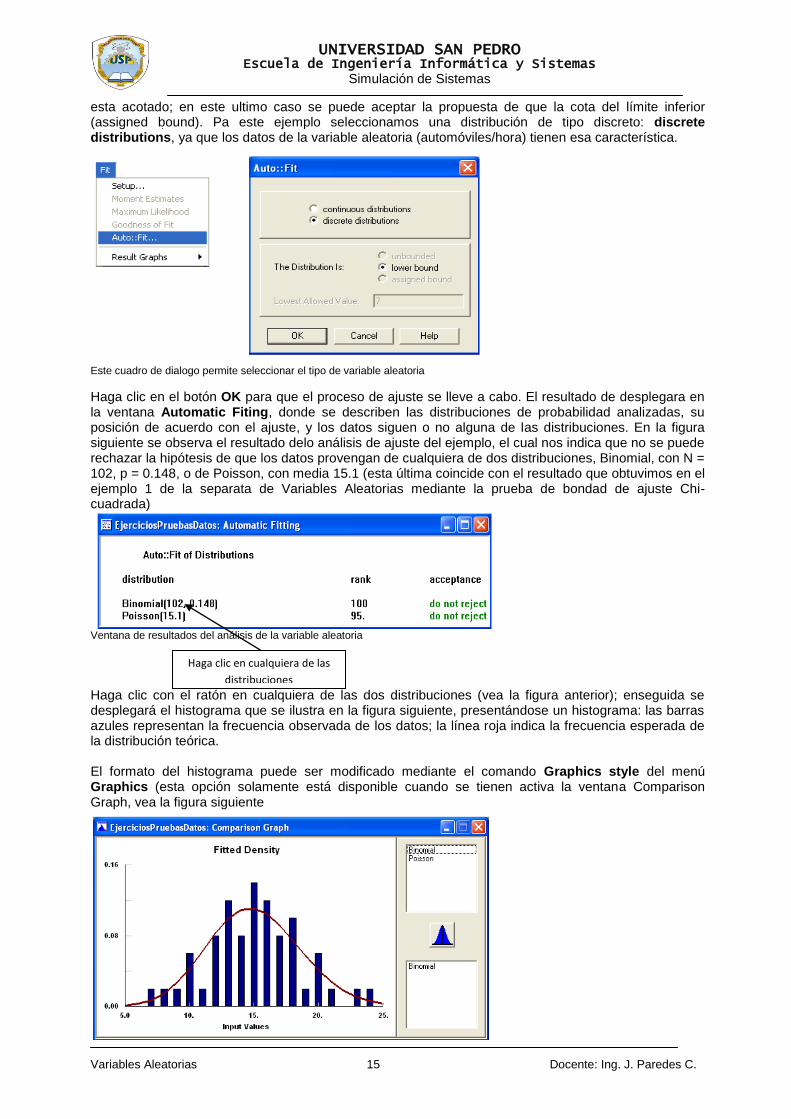
Para determinar el tipo de distribución de probabilidad de los datos, seleccione el comando AutoFit del menú Fit en la pantalla principal de Stat::Fit. A continuación se desplegara un cuadro de dialogo similar al que se ilustra en la figura siguiente, en el cual se tienen que seleccionar el tipo de distribución que se desea probar, si dicha distribución es no acotada en ambos extremos (unbounded), o si el límite inferior
Variables Aleatorias 15 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
esta acotado; en este ultimo caso se puede aceptar la propuesta de que la cota del límite inferior (assigned bound). Pa este ejemplo seleccionamos una distribución de tipo discreto: discrete distributions, ya que los datos de la variable aleatoria (automóviles/hora) tienen esa característica.
Este cuadro de dialogo permite seleccionar el tipo de variable aleatoria
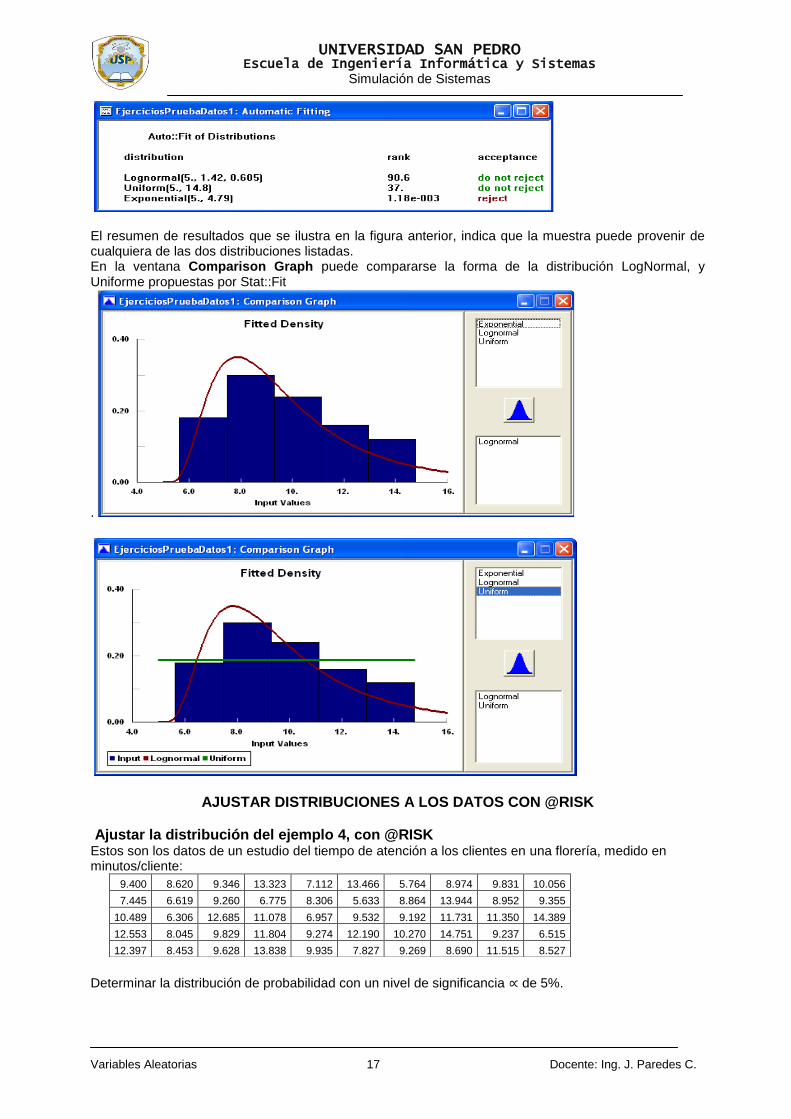
Haga clic en el botón OK para que el proceso de ajuste se lleve a cabo. El resultado de desplegara en la ventana Automatic Fiting, donde se describen las distribuciones de probabilidad analizadas, su posición de acuerdo con el ajuste, y los datos siguen o no alguna de las distribuciones. En la figura siguiente se observa el resultado delo análisis de ajuste del ejemplo, el cual nos indica que no se puede rechazar la hipótesis de que los datos provengan de cualquiera de dos distribuciones, Binomial, con N = 102, p = 0.148, o de Poisson, con media 15.1 (esta última coincide con el resultado que obtuvimos en el ejemplo 1 de la separata de Variables Aleatorias mediante la prueba de bondad de ajuste Chi-cuadrada)
Ventana de resultados del análisis de la variable aleatoria
Haga clic con el ratón en cualquiera de las dos distribuciones (vea la figura anterior); enseguida se desplegará el histograma que se ilustra en la figura siguiente, presentándose un histograma: las barras azules representan la frecuencia observada de los datos; la línea roja indica la frecuencia esperada de la distribución teórica. El formato del histograma puede ser modificado mediante el comando Graphics style del menú Graphics (esta opción solamente está disponible cuando se tienen activa la ventana Comparison Graph, vea la figura siguiente
Haga clic en cualquiera de las
distribuciones

Variables Aleatorias 16 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Histogramas teórico y real de la variable aleatoria.
Ejemplo 2: Estos son los datos de un estudio del tiempo de atención a los clientes en una florería, medido en minutos/cliente:
Determinar la distribución de probabilidad con un nivel de significancia de 5%.
Dadas las características de la variable aleatoria a analizar, al desplegarse el cuadro de dialogo Auto::Fit (vea la figura siguiente) debemos activar la opción Continuous distributions.
9.400 8.620 9.346 13.323 7.112 13.466 5.764 8.974 9.831 10.056
7.445 6.619 9.260 6.775 8.306 5.633 8.864 13.944 8.952 9.355
10.489 6.306 12.685 11.078 6.957 9.532 9.192 11.731 11.350 14.389
12.553 8.045 9.829 11.804 9.274 12.190 10.270 14.751 9.237 6.515
12.397 8.453 9.628 13.838 9.935 7.827 9.269 8.690 11.515 8.527
Variables Aleatorias 17 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
El resumen de resultados que se ilustra en la figura anterior, indica que la muestra puede provenir de cualquiera de las dos distribuciones listadas. En la ventana Comparison Graph puede compararse la forma de la distribución LogNormal, y Uniforme propuestas por Stat::Fit
.
AJUSTAR DISTRIBUCIONES A LOS DATOS CON @RISK
Ajustar la distribución del ejemplo 4, con @RISK Estos son los datos de un estudio del tiempo de atención a los clientes en una florería, medido en minutos/cliente:
Determinar la distribución de probabilidad con un nivel de significancia de 5%.
9.400 8.620 9.346 13.323 7.112 13.466 5.764 8.974 9.831 10.056
7.445 6.619 9.260 6.775 8.306 5.633 8.864 13.944 8.952 9.355
10.489 6.306 12.685 11.078 6.957 9.532 9.192 11.731 11.350 14.389
12.553 8.045 9.829 11.804 9.274 12.190 10.270 14.751 9.237 6.515
12.397 8.453 9.628 13.838 9.935 7.827 9.269 8.690 11.515 8.527
Variables Aleatorias 18 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
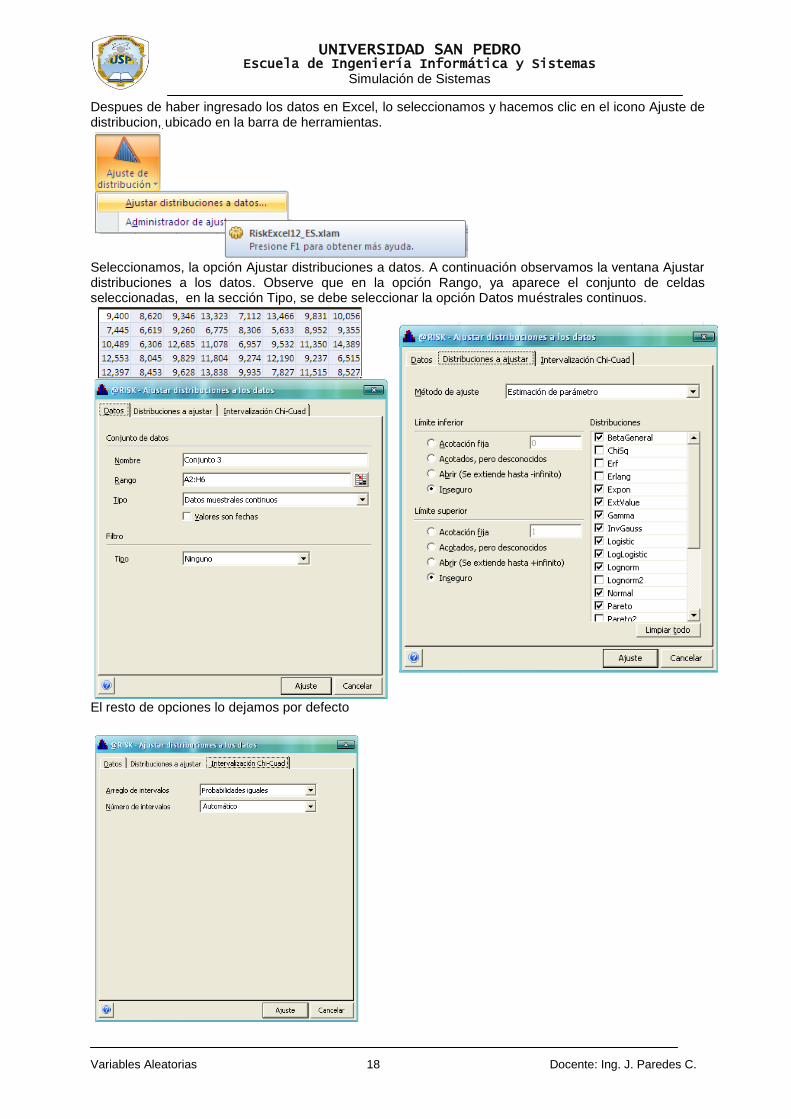
Despues de haber ingresado los datos en Excel, lo seleccionamos y hacemos clic en el icono Ajuste de distribucion, ubicado en la barra de herramientas.
Seleccionamos, la opción Ajustar distribuciones a datos. A continuación observamos la ventana Ajustar distribuciones a los datos. Observe que en la opción Rango, ya aparece el conjunto de celdas seleccionadas, en la sección Tipo, se debe seleccionar la opción Datos muéstrales continuos.
El resto de opciones lo dejamos por defecto
Variables Aleatorias 19 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
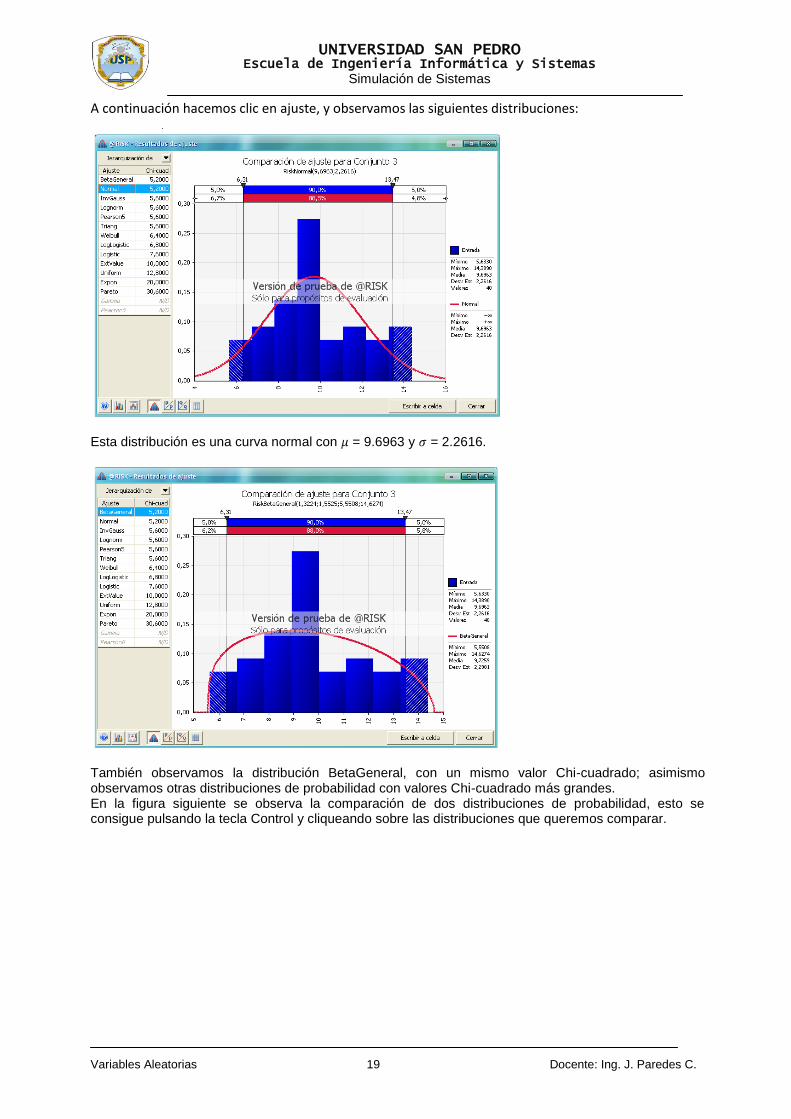
A continuación hacemos clic en ajuste, y observamos las siguientes distribuciones:
Esta distribución es una curva normal con = 9.6963 y = 2.2616.
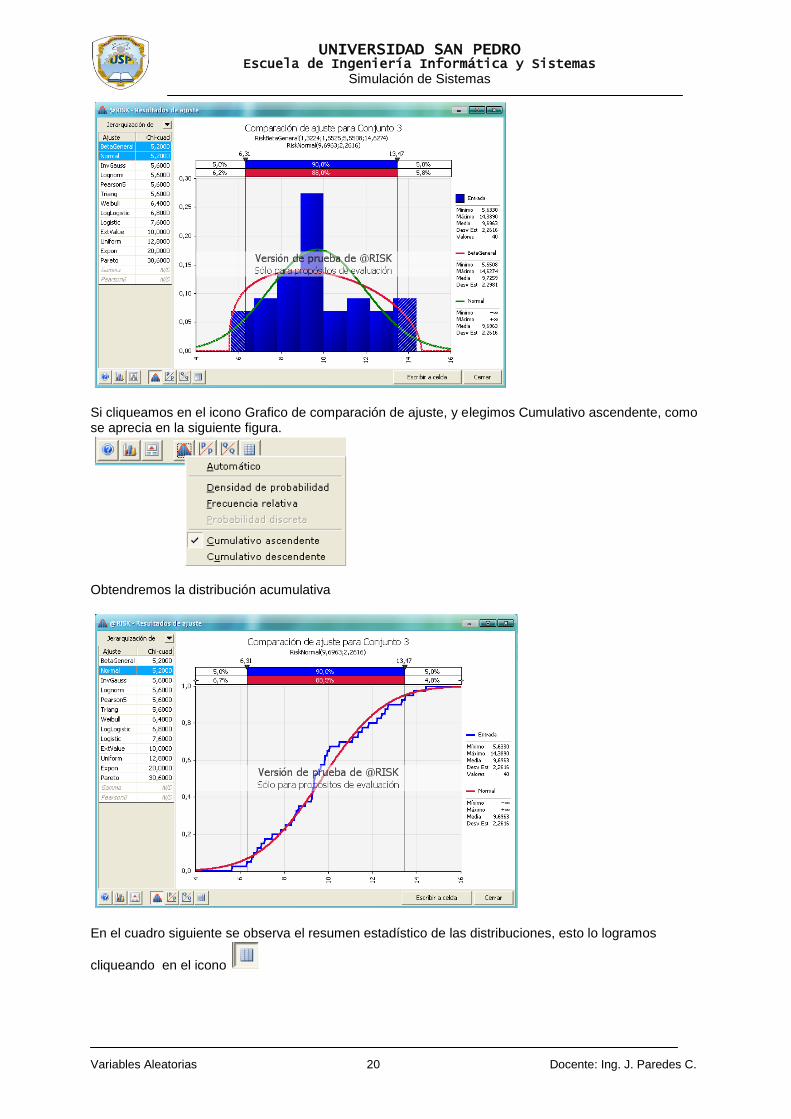
También observamos la distribución BetaGeneral, con un mismo valor Chi-cuadrado; asimismo observamos otras distribuciones de probabilidad con valores Chi-cuadrado más grandes. En la figura siguiente se observa la comparación de dos distribuciones de probabilidad, esto se consigue pulsando la tecla Control y cliqueando sobre las distribuciones que queremos comparar.
Variables Aleatorias 20 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Si cliqueamos en el icono Grafico de comparación de ajuste, y elegimos Cumulativo ascendente, como se aprecia en la siguiente figura.
Obtendremos la distribución acumulativa
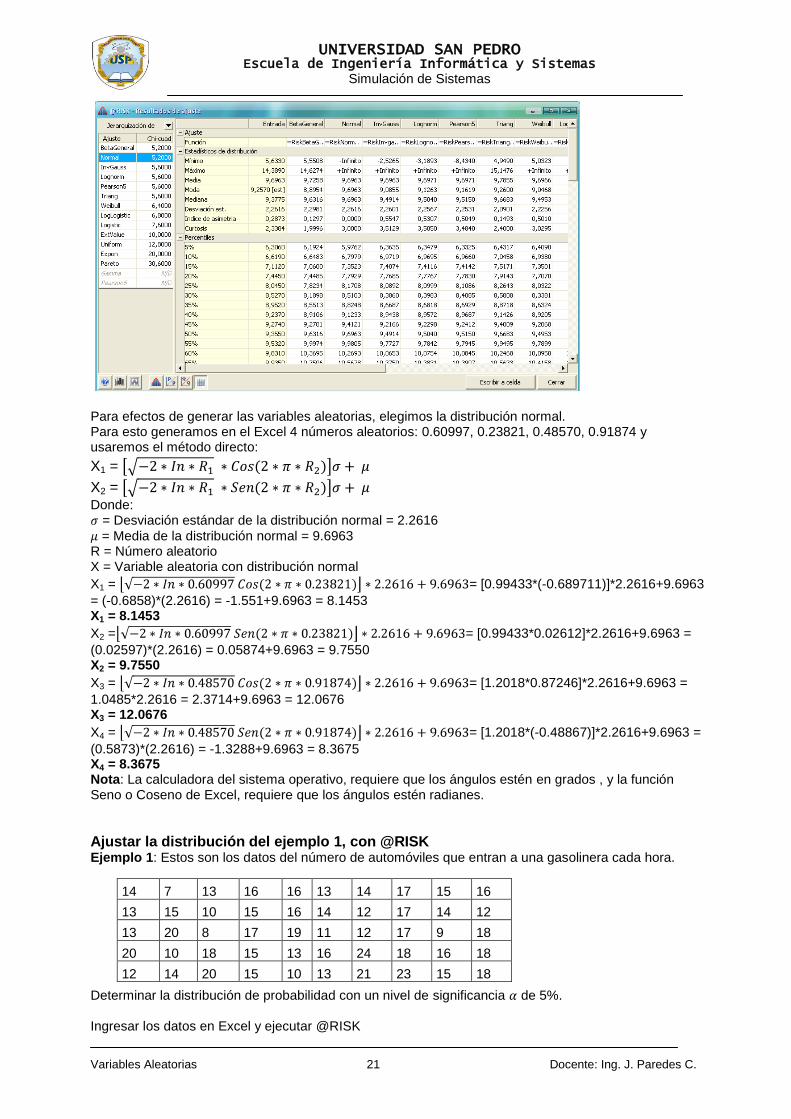
En el cuadro siguiente se observa el resumen estadístico de las distribuciones, esto lo logramos
cliqueando en el icono
Variables Aleatorias 21 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Para efectos de generar las variables aleatorias, elegimos la distribución normal. Para esto generamos en el Excel 4 números aleatorios: 0.60997, 0.23821, 0.48570, 0.91874 y usaremos el método directo:
X1 =
X2 = Donde:
= Desviación estándar de la distribución normal = 2.2616
= Media de la distribución normal = 9.6963 R = Número aleatorio X = Variable aleatoria con distribución normal
X1 = = [0.99433*(-0.689711)]*2.2616+9.6963
= (-0.6858)*(2.2616) = -1.551+9.6963 = 8.1453 X1 = 8.1453
X2 = = [0.99433*0.02612]*2.2616+9.6963 =
(0.02597)*(2.2616) = 0.05874+9.6963 = 9.7550 X2 = 9.7550
X3 = = [1.2018*0.87246]*2.2616+9.6963 =
1.0485*2.2616 = 2.3714+9.6963 = 12.0676 X3 = 12.0676
X4 = = [1.2018*(-0.48867)]*2.2616+9.6963 =
(0.5873)*(2.2616) = -1.3288+9.6963 = 8.3675 X4 = 8.3675 Nota: La calculadora del sistema operativo, requiere que los ángulos estén en grados , y la función Seno o Coseno de Excel, requiere que los ángulos estén radianes.
Ajustar la distribución del ejemplo 1, con @RISK Ejemplo 1: Estos son los datos del número de automóviles que entran a una gasolinera cada hora.
Determinar la distribución de probabilidad con un nivel de significancia de 5%. Ingresar los datos en Excel y ejecutar @RISK
14 7 13 16 16 13 14 17 15 16
13 15 10 15 16 14 12 17 14 12
13 20 8 17 19 11 12 17 9 18
20 10 18 15 13 16 24 18 16 18
12 14 20 15 10 13 21 23 15 18

Variables Aleatorias 22 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
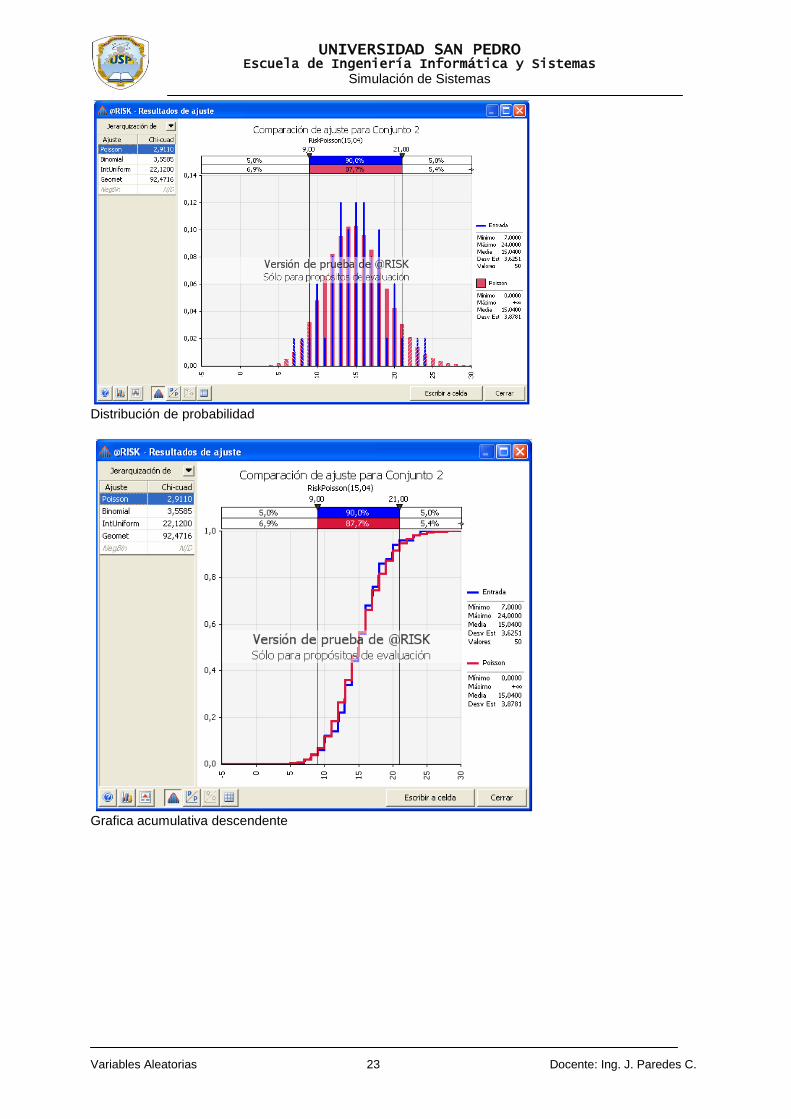
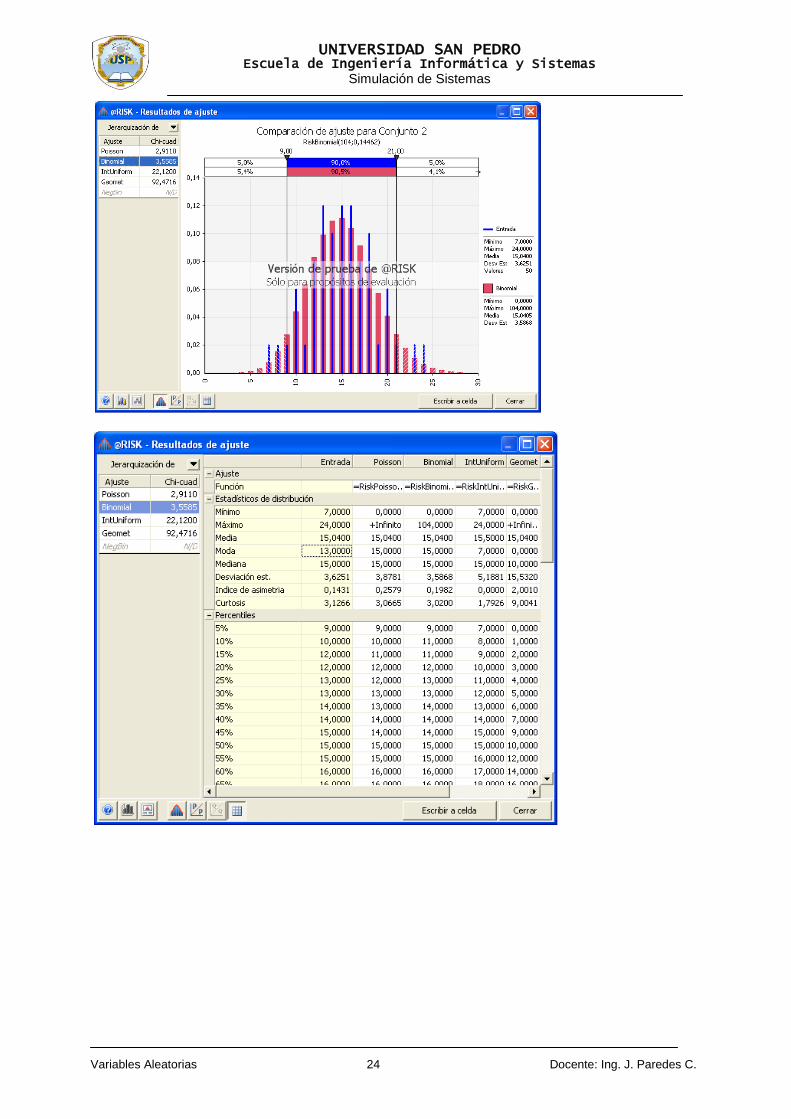
Seleccione el rango de datos y del cuadro de dialogo, seleccione en la opción tipo: Datos muéstrales discretos, porque así son los arribos, de acuerdo al problema; y en arreglo de intervalos: Intervalos iguales. A continuación haga clic en el botón de comando Ajuste.
Variables Aleatorias 23 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas
Distribución de probabilidad
Grafica acumulativa descendente
Variables Aleatorias 24 Docente: Ing. J. Paredes C.
UNIVERSIDAD SAN PEDRO Escuela de Ingeniería Informática y Sistemas
Simulación de Sistemas