ai&bigdata lab 2016. Григорий Кравцов: Модель вычислений на...
TRANSCRIPT

«Модель вычислений на классификациях»
Докладчик:
к.т.н. Кравцов Г.А.,
директор по науке
Одесса, 2016

Постановка задачи
Актуальной задачей семантического поиска [1] является автоматическое
нахождение близких по значению концептуальных понятий [2]. Если представить
концептуальное понятие как некоторую классификацию, то указанная выше задача
сводится к нахождению меры между двумя классификациями.
Актуальной научной задачей является разработка модели вычислений на
классификациях, позволяющей представить классификацию как метрическое
пространство и определить меру схожести или меру отличия на классификации.
Более того, известные автору работы, посвящённые исследованию или применению
классификаций, ограничиваются одной плоскостью деления классификации, что не
позволяет эти результаты применить к исследованию классификаций с несколькими
плоскостями деления.

Понятие классификации и её формальное представление
Согласно [3]: «Классификация - это особого вида деление или система
мереологических или таксономических делений». Формальным представлением
классификации является математическая структура ориентированное дерево, в
котором вершинами являются математические классы [9, 10].
Класс в классификации — это тройка <F ,i ,Y > , обозначаемая как FYi , где F -
классификация, i - плоскость деления классификации F , а Y - путь уточнения
плоской классификации F i . Путь уточнения Y - это последовательность вида
[a,b , c , ...] однозначно определяющая место класса в некоторой плоскости деления
классификации.

Неоднозначность терминологии
Согласно Ивлеву [3] «… классификация - это особого вида деление или система
мереологических или таксономических делений». Очевидно, что данное
определение классификации неоднозначно в силу использования союза «или» и не
позволяет ответить на вопрос: классификация — это процесс или результат?
Шаталкин [4] рассматривает классификацию как систему объединения таксонов,
отражающую их свойства. В тоже время он пишет: «...таксономия, по существу,
совпадает с классификационной деятельностью (в значении классифицирования).
Иными словами, таксономия предстаёт в виде формальной дисциплины,
описывающей принципы выделения классов, общие как для природных тел, так и
для идеальных конструкций, артефактов и других объектов». Следовательно, автор
работы [4] однозначно определяет классификацию как результат

классифицирования, где классифицирование есть деятельность как совокупность
мереологических или таксономических делений.
Ушаков [5] в своём толковом словаре даёт следующее определение (цитата с
сохранением знаков пунктуации): «классификация (аси), классификации, ж.
(книжн.). 1. действие по глаг. классифицировать. 2. система распределения
предметов или понятий какой-нибудь области на классы, отделы, разряды и т. п.
классификация растений. классификация минералов. классификация наук». Как
видим, определение Ушакова так же неоднозначно, как и определение Ивлева [3].
Термин классификация активно используется в теории и практике машинного
обучения [6], базируясь на понятии функции классификации или правиле. Как
известно, в машинном обучении решается задача отнесения объекта к некоторому
классу, т. е. существует совокупность классов, такая что любой объект, к которому
применяется правило (функция классификации), будет отнесён только к одному из

множества классов с ошибкой, не превышающей заданную. По сути, методы
машинного обучения отвечают на вопрос классовой принадлежности согласно
принципу свёртывания [7]. Автор встречал чаще формулировку «задача
классификации» в русскоязычных источниках и «statistical classification» в
англоязычных источниках. Русскоязычный вариант в силу рассмотренных выше
толкований не корректен, т. к. по сути отражает лишённое смысла словосочетание
«задача результата», очевидно требующее добавления слова «получения» либо его
синонимов. В таком случае, мы снова приходим к путанице понятий. Автор
полагает, что и англоязычный вариант некорректен, но надеется, что данный вопрос
будет разрешён коллегами — лингвистами.

Вводимая терминология
Классификация — математическая структура ориентированное дерево,
отражающее систему мереологических или таксономических делений.
Классифицирование — процесс построения классификации.
Определение классовой принадлежности — задача отнесения объекта к
некоторому классу построенной ранее классификации с точностью, не
превышающую заданную;
Классификатор — инструмент определения классовой принадлежности;
Классифицированный объект — объект, в отношении которого была
выполнена задача определения классовой принадлежности.

Общее замечание
Мы утверждаем, что каждая классификация является ориентированным деревом
[8], но не каждое ориентированное дерево является классификацией. Например,
следующее ориентированное древо не является классификацией (рис.1):
Рис.1. Ориентированное дерево, не являющееся классификацией.
A i
A [1]i

Плоскость сечения классификации как дерево
Проиллюстрируем использование обозначений на некоторой условной
классификации Ai :
Рис.2. Классификация.
A i
A [1]i A [2]
i
A [1,1 ]i A [1,2 ]
i A [2,1 ]i
A [2,2 ]iA [1,3 ]
i

Операции над классами плоской классификации. Обобщение
Пусть даны классы классы A[a]i , A[b]
i , A[a ,b]i классификации A .
Ассоциативную бинарную операцию обобщения классов классификации определим
как:
A[a]i⋅A[b]
i=A ,
A[a]i⋅A[a ,b]
i=A[a]
i ,
A[b]i⋅A [a ,b ]
i=A ,
A[a]i⋅A=A ,
(1)
в которой A является идемпотентом или нулём операции обобщения классов
относительно самой себя A⋅A=A и всех уточняющих классов классификации
A Ii⋅A=A .

Операции над классами плоской классификации. Уточнение
Пусть даны классы классы A[a]i , A[b]
i , A[a ,b]i классификации A .
Ассоциативную бинарную операцию уточнения класса + определим как
A[a]i
+A=A[a]i ,
A[a]i
+A [b ]
i=A[a]
i+A[b]
i ,
A[a]i
+A [a ,b ]
i=A[a ,b]
i ,
A[b]i
+A [a ,b ]
i=A[b]
i+A [a ,b ]
i .
(2)
Семантически, операция уточнения класса эквивалента дуге дерева [10] в
случаях A[a]i
+A=A[a]i и A[a]
i+A [a ,b ]
i=A[a ,b]
i . Уравнения A[a]i
+A [b ]
i=A[a]
i+A[b]
i и
A[b]i
+A [a ,b ]
i=A[b]
i+A [a ,b ]
i отражают семантику уточнения одного класса другим, при
условии, что оба класса находятся на разных ветках дерева. Наличие бинарной
ассоциативной операции и идемпотенты (1) позволяет заключить, что
классификация представляет собой конечную полугруппу классов [9].

Метрическое пространство плоской классификации. Относительное
расстояние.
Относительным расстоянием R между двумя классами A[a]i и A[b]
i
классификации A назовём неотрицательное целое число, равное числу уникальных
операций уточнения от ближайшего общего обобщающего класса.
Так, R (A [a]i , A[b]
i)=2 потому, что потребуется выполнить две операции уточнения
A+A [a]i=A[a]
i и A+A [b]i=A[b]
i к каждому из классов из ближайшего обобщающего
класса A . Согласно данному определению относительного расстояния
R (A Ii , AY
i)=R (AY
i , A Ii) , (симметричность)
R (A Ii , A I
i)=0 , (рефлексивность)
(3)
где I , Y - произвольные пути уточнения (деления) классификации A в
плоскости деления i .

Относительное расстояние. Неравенство треугольника.
Относительное расстояние R (A Ii , A) , где I - произвольный путь уточнения
(деления) классификации A , есть ранг [4]. Для относительного расстояния между
двумя классами A Ii и AY
i в A верно равенство:
R (A Ii , AY
i)=R (A , A I
i)+R (A , AY
i)−2R (A , A I
i⋅AY
i) (4)
где I , Y - произвольные пути уточнения (деления) классификации A .
Если R (A , A Ii⋅AY
i)=0 , то (4) принимает вид R (A I
i , AYi)=R (A , A I
i)+R (A , AY
i) .
Если же R (A , A Ii⋅AY
i)>0 , то верно неравенство R (A I
i , AYi)<R (A , A I
i)+R(A , AY
i) .
Основываясь на (4) приведённые выше равенство и неравенство могут быть
обобщены как
R (A Ii , AY
i)≤R (A I
i , A)+R (A , AYi) , (5)
что есть условие неравенства треугольника. Следовательно, R (A Ii , AY
i) - мера.

Модификация меры Жоккара
Мера сходства [12] для двух классов одной плоскости деления классификации
может быть определена как мера Жаккара [13], если положить, что для
множественной меры Жоккара
K−1,1=n (A∩B)
n (A∪B)
(6)
определено следующее соответствие
O(A Ii , AY
i)=
R (A , A Ii⋅AY
i)+1
R (A , A Ii+AY
i)+1
=R(A , A I
i⋅AY
i)+1
R (A , A Ii⋅AY
i)+R (A I
i , A Ii⋅AY
i)+R (AY
i , A Ii⋅AY
i)+1
,(7)
где A Ii и AY
i - классы в A , I , Y - произвольные пути уточнения (деления)
плоскости деления классификации Ai .

Мера сходства. Мера ли?
Строго говоря, мера O(A Ii , AY
i) не является математической мерой в силу
невыполнения условия неравенства треугольника, о чем так же сказано в [12].
Однако, следует заметить, что O(A Ii , AY
i)=1−O(A I
i , AYi) обладает свойствами
симметричности и рефлексивности
O(A Ii , AY
i)=O (AY
i , A Ii) , (симметричность)
O(A Ii , A I
i)=0 . (рефлексивность)
(8)
Пусть даны три меры O(A Ii , AY
i) , O(A I
i , A ) и O(AYi , A ) . Воспользовавшись (7)
получим
O(A Ii , AY
i)=1−
R (A , A Ii⋅AY
i)+1
R (A , A Ii⋅AY
i)+R (A I
i , A Ii⋅AY
i)+R (AY
i , A Ii⋅AY
i)+1
,(9)

O(A Ii , A )=1−
1
R(A Ii , A )+1
, (10)
O(AYi , A )=1−
1
R (AYi , A )+1
. (11)
Относительное расстояние R (A Ii , A)=R (A , A I
i⋅AY
i)+R (A I
i , A Ii⋅AY
i) по
определению, аналогично R (AYi , A )=R (A , A I
i⋅AY
i)+R (AY
i , A Ii⋅AY
i) . Тогда (10) и (11)
могут быть представлены в виде
O(A Ii , A )=
R (A , A Ii⋅AY
i)+R (A I
i , A Ii⋅AY
i)
R (A , A Ii⋅AY
i)+R (A I
i , A Ii⋅AY
i)+1
,(12)
O(AYi , A )=
R (A , A Ii⋅AY
i)+R(AY
i , A Ii⋅AY
i)
R(A , A Ii⋅AY
i)+R (AY
i , A Ii⋅AY
i)+1
,(13)
а (9) как

O(A Ii , AY
i)=
R(A Ii , A I
i⋅AY
i)+R (AY
i , A Ii⋅AY
i)
R (A , A Ii⋅AY
i)+R (A I
i , A Ii⋅AY
i)+R (AY
i , A Ii⋅AY
i)+1
.(14)
Произведём замену переменных: a=R (A , A Ii⋅AY
i) , b=R (A I
i , A Ii⋅AY
i) и
c=R (AYi , A I
i⋅AY
i) . Выразим O(A I
i , A )+O (AYi , A)−O(A I
i , AYi) через переменные
a , b и c :
O(A Ii , A )+O (AY
i , A)−O(A Ii , AY
i )=a+b
a+b+1+
a+ca+c+1
−b+c
a+b+c+1. (15)
Сделаем замену переменной O(A Ii , A )+O (AY
i , A)−O(A Ii , AY
i)=f (a ,b ,c) и
приведём правую часть (15) к общему знаменателю
W=(a+b+1)(a+c+1)(a+b+c+1) . Тогда f (a ,b , c)=VW
, где
V=2a3+3a2b+3a2c+4 a2
+ab2+4abc+3ab+ac2
+3ac+2a+b2c+bc2+2bc .
Учитывая, что a≥0 , b≥0 и c≥0 (по определению относительного

расстояния), то W≥1 и V≥0 . Из чего следует, что
O(A Ii , A )+O (AY
i , A)−O(A Ii , AY
i)≥0 или
O(A Ii , A )+O (AY
i , A)≥O(A Ii , AY
i) . (16)
Неравенство (16) — неравенство треугольника. Следовательно, с учётом (8) и (16)
O(A Ii , AY
i) - мера отличия на классификации.

Свойства меры отличия
Мера отличия (16) обладает свойством: если выбрать два произвольных класса,
относительное расстояние между которыми постоянно и конечно, то мера отличия
(16) убывает с ростом относительного расстояния от самой общей классификации до
ближайшего обобщающего класса выбранных классов. Так если
C=R (A Ii , A I
i⋅AY
i)+R(AY
i , A Ii⋅AY
i) , тогда O(A I
i , AYi)=1−
R(A , A Ii⋅AY
i)+1
R (A , A Ii⋅AY
i)+C+1
, где
C≥0 по определению относительного расстояния.
Следовательно :
O(A Ii , AY
i)=1− lim
R (A , A Ii⋅AY
i)→∞
R(A , A Ii⋅AY
i)+1
R (A , A Ii⋅AY
i)+C+1
=0 . (17)
В то же время

O(A Ii , AY
i)=1− lim
R (A , A Ii⋅AY
i)→0
limC→1
R (A , A Ii⋅AY
i)+1
R (A , A Ii⋅AY
i)+C+1
=12
. (18)
Уточнение классификации по одному классифицируемому признаку на каждом
уровне приводит нас к мере различия, равной
O(A Ii , AY
i)=1− lim
R (A , A Ii⋅AY
i)→0
R (A , A Ii⋅AY
i)+1
R (A , A Ii⋅AY
i)+С+1
=C
С+1. (19)
Если в выражение (19) вместо константы C подставить удвоенную
максимальную длину пути уточнения (максимальный ранг), то в таком случае
получим максимальное значение меры отличия на плоскости деления
классификации Ai . Из (19) следует, что
O(A Ii , AY
i)= lim
R(A , A Ii⋅AY
i)→0
R (A , A Ii⋅AY
i)+1
R (A , A Ii⋅AY
i)+С+1
=1
С+1.

Модель вычисления на классификациях
Если определены плоские классификации F1, ... ,F i , ... , FN , где i=1,N ,
совокупность которых представляет собой классификацию F=F1×F2
×...×FN с
мерой отличия
O(F )=1N∑i=1
N
O (Fi) . (20)
Мера (20) есть среднее арифметическое мер отличия плоских классификаций.
Несложно показать, что если O(F i)=1 где i=1,N , то O(F )=1 .
Если существуют такие p(F i) , где i=1,N , что K=∑
i=1
N
p (F i) , то
OK (F )=1NK
∑i=1
N
O (F i) p(F i)(21)
есть нормированная мера отличия на классификации F , в которой p(F i) - вес

или степень влияния F i на нормированную меру отличия OK (F ) . Очевидно, что
если p(F i)=1 , то OK (F )=O (F) . Так же очевидно, что если существуют такие
p(F i) , среди которых только один весовой коэффициент, например, p(F y
)=1 , где
0< y<N , а остальные p(F i)=0 , где i=1,N и i≠ y , то OK (F )=O (F y
) .
Несложно заметить, что в выражение (21) отношение p(F i)
K есть вероятность, т. к.
K=∑i=1
N
p (F i) , следовательно OK (F ) есть математическое ожидание меры отличия
классификации, если O(F i) считать случайными величинами.
Если для любых p(Fk) и p(Fk+1
) выполняется неравенство p(Fk+1)>p (Fk
)
так, что справедливо рекурсивное неравенство

min(O (F k+1))p (Fk+1)>∑i=1
k
max(O (Fi)) p (F i) ,(22)
то мера (21) обладает определённой степенью доверия.
Выражение min(O (F k+1)) в (23) мы уже поясняли ранее. Максимальное
значение сходства по определению max (O (Fk+1))=1 . Основываясь на сказанном
и полагая, что LFk - есть максимальный ранг плоской классификации Fk ,
неравенство (22) может быть представлено виде
p(Fk+1)>(2 LF k +1+1)∑i=1
k
p (F i) .(23)
Система

{ OK (F)=1NK ∑
i=1
N
O(F i) p(F i)
p(F k+1)>(2 LF k+1+1)∑
i=1
k
p(F i)
,(24)
представляет собой модель вычисления с определённой степенью доверия, как будет
показано ниже. Свойствами такой модели вычисления на классификациях являются:
- независимость от принципа выбора плоскостей деления классификации;
- масштабируемость, ограниченная лишь целесообразностью;
- определённость влияния неучтенных плоскостей деления классификации F .
Последнее свойство поясним. Т. к. каждый последующий весовой коэффициент
больше предыдущего p(Fk+1)> p(Fk
) и выполняется условие (23), то

K=p (F1
)
2LF1+1+K - теоретическая сумма весовых коэффициентов, где p(F1
)
2LF1+1-
максимальная абсолютная погрешность вычисления K при наличии неучтенных
плоскостей деления классификации F . Теоретическая мера отличия будет равна
OK(F )=
p(F1)+∑i=1
N
O(F i) p (F i)
(N+1)((2 LF1+1)K+ p(F1))
. Относительная погрешность модели равна
ρ=OK (F)−O
K(F )
OK (F )и отражает степень доверия к модели. Если положить, что
O(F i)=1 , то получим OK (F )=
1N
и O K (F )=p (F1
)+K
(N+1)((2 LF1+1)K+ p(F1))
.

Следовательно, ρ=1−N (p (F1
)+K )
(N+1)(2LF1 K+K+p(F1))
.
Если для для любых p(Fk) и p(Fk+1
) выполняется неравенство
p(Fk+1)≥p (F k
) или выполняется равенство p(Fk+1)>p (Fk
) , но не выполняется
условие (23), то возникают трудности следующего характера. Допустим, что
теоретически K=∑i=1
N
p (F i)+∑j=1
M
p(F j) , где N - количество учтённых плоскостей
деления классификации F , а M - количество неучтённых плоскостей деления,
которое нам не известно, и при этом min(p (F i))≥max( p(F j
)) . Очевидно, что при
таких условиях вычислить K не представляется возможным. Следовательно,
определить степень доверия к модели

{OK (F )=1NK ∑
i=1
N
O (Fi) p(F i)
p(Fk+1)≥p (F i)
(25)
так же не представляется возможным. Как следствие, к свойствам модели с
неопределённой степенью доверия можно отнести лишь независимость от
принципа выбора плоскостей деления классификации и масштабируемость.

Корректно построенная плоская классификация
Под корректно построенной плоской классификацией будем понимать такую
систему мереологических или таксономических делений, при которой для двух
классов классификации A Ii и AY
i таких, что R (A Ii , A I
i⋅AY
i)=R (AY
i , A Ii⋅AY
i)=1
выполняется следующая система равенств:
{Q (A Ii , A I
i⋅AYi )=Q (AY
i , A Ii⋅AY
i )
Q (A Ii , AY
i )=0.5.
(26)
Система уравнений (26) и требование R (A Ii , A I
i⋅AY
i)=R (AY
i , A Ii⋅AY
i)=1 следует
понимать так: «Если у произвольного класса A Ii⋅AY
i ранга K существует не менее

двух уточняющих классов A Ii и AY
i ранга K +1 , то мера отличия на плоскости
деления (измерении) Q (A Ii , AY
i) есть величина постоянная, равная 0.5, независимо
от выбора A Ii и AY
i , если I≠Y ».
Следствием из сказанного выше является требование, что у любого класса,
являющегося вершиной ориентированного дерева — классификации, должно быть
не менее 2 уточняющих классов, ранг которых на единицу больше от ранга
произвольно выбранного класса, или не должно быть ни одного. Именно поэтому,
рис.1 изображает некоторое произвольное ориентированное дерево, которое не
является классификацией.
Интуитивно понятно, при классифицировании мы не можем допустить такую
ошибку между одним и тем же классом ибо это единственное исключение, когда
мера ошибки известна априори и равна нулю. Поэтому, мы можем говорить только о

ошибке при наблюдении меры между двумя разными классами. В таком случае,
определим ошибку при наблюдения меры отличия между двумя разными классами
как разность между теоретической мерой отличия, равной 0.5, и наблюдаемой мерой
в виде
{Q (A Ii , A I
i⋅AYi )=Q (AY
i , A Ii⋅AY
i )=1
E (A Ii , AY
i )=0.5−Oo(AYi , A I
i ),
(27)
где
- Oo(AYi , A I
i) - наблюдаемое (обсервованное) значение меры отличия между двумя
классами A Ii и AY
i ;
- E (AYi , A I
i) - ошибка наблюдения меры отличия, такая что −0.5≤E (AY
i , A Ii)≤0.5 ,
если I≠Y , и E (AYi , A I
i)=0 , если I=Y .
Очевидно, что если некоторый класс Ai делится на N классов A[ j ]i , где

j=1,N , то существует N 2 неуникальных значений E (A [ j ]i , A[k ]
i) , где k=1,N .
Т. к. Oo(A[ j ]i , A[k ]
i)=Oo(A[k ]
i , A [ j ]i) (8) , то E (A [ j ]
i , A[k ]i)=E (A [k ]
i , A[ j ]i) согласно (27).
Теоретически количество уникальных значений E (A [ j ]i , A[k ]
i) равно N2
−N2
.
Среднее абсолютное значение ошибки наблюдения меры отличия составит
E (A i)=1
N 2−N
∑j=1
N
∑k=1
N
|E (A [ j ]i , A[k ]
i )| ,(28)
где |E (A[ j ]i , A [k ]
i)| - абсолютное значение ошибки. Очевидно, что если мера отличия
Oo(AYi , A I
i)=0.5 для любых двух классов, удовлетворяющих (27) и таких, что
I≠Y , то E (A i)=0 . По сути, величина (28) отражает интегральный показатель
согласованности деления класса ранга K на кассы ранга K+1 и удовлетворяет
условию 0≤ E(A Ii)≤0.5 .
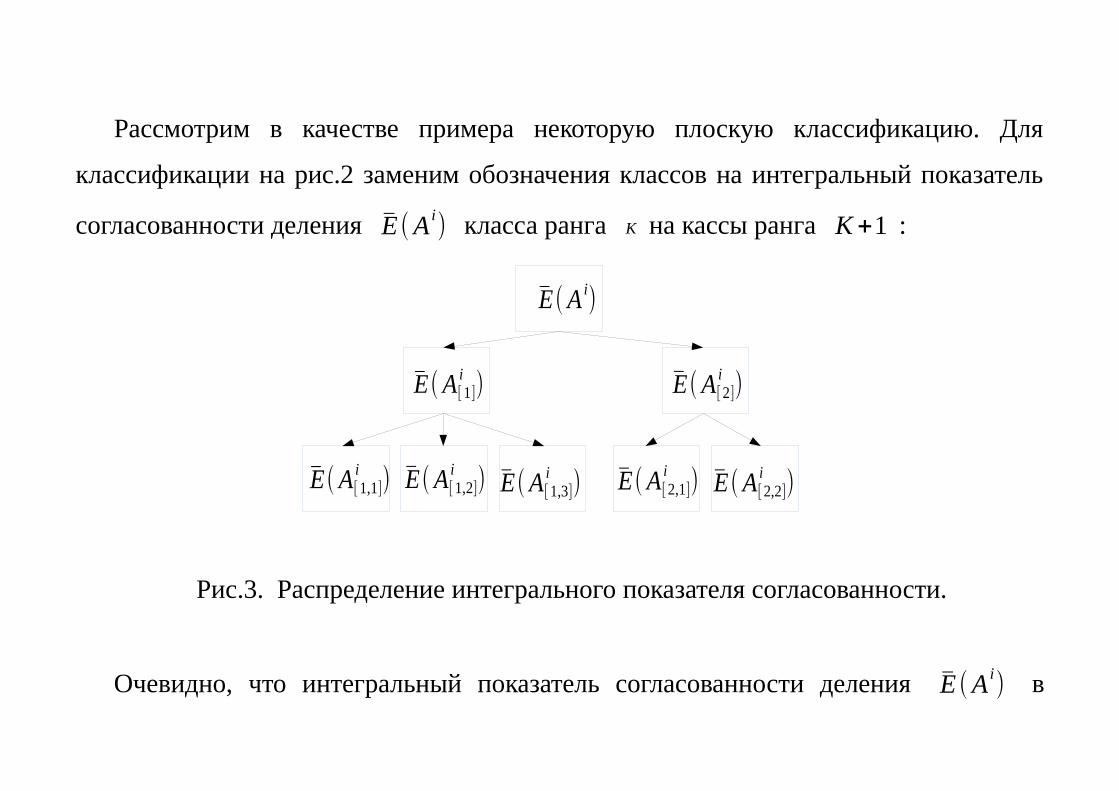
Рассмотрим в качестве примера некоторую плоскую классификацию. Для
классификации на рис.2 заменим обозначения классов на интегральный показатель
согласованности деления E (A i) класса ранга K на кассы ранга K+1 :
Рис.3. Распределение интегрального показателя согласованности.
Очевидно, что интегральный показатель согласованности деления E (A i) в
E(A i)
E(A[1]i) E(A[2]
i)
E(A[1,1]i
) E(A[1,2]i
) E(A[2,1]i
) E(A[2,2]i
)E(A[1,3]i
)

листьях деревьев равен нулю согласно (28). Количественный показатель
согласованности (англ.: consistency) плоской классификации определим как
С (Ai)=∑I
E(A Ii )
(R (A Ii , Ai)+1)M , (29)
где I - множество известных путей уточнения классификации Ai , M - среднее
число уточняющих классов в узлах ориентированного дерева, не являющихся
листьями (параметр полноты).
На рис.2 заменим обозначения классов с рангом K числами, равными
количеству уточняющих классов с рангом K+1 :

Рис.4. Представление классификации с рис.2 через количество уточняющих
классов.
Очевидно, что на рис.4 нулями обозначены листья дерева. Для классификации на
рис.4 параметр полноты будет равен
M=2+3+2
3=2.(3) . (30)
2
3 2
0 0 0 00

Мы видим, что для полных ориентированных деревьев M есть арность (для
полного бинарного ориентированного дерева M=2 ).
Семантически, (29) есть интегральная оценка внутренней согласованности
плоской классификации Ai , которая находит применение при взаимооценке
построения экспертных плоских классификаций [14].

Изоморфность классификаций
Код Прюфера [15], позволяющий записать n -вершинное помеченное дерево
(т. е. с пронумерованными вершинами) последовательностью n−2 его вершин,
оказывается бесполезным для кодирования ориентированного дерева, так как не
позволяет ориентацию рёбер при произвольном нумеровании вершин. Однако, если
положить, что существует некоторый строгий алгоритм нумерации вершин
классификации, то код Прюфера может оказаться полезным.
Положим, что мы не стеснены в выборе принципов разметки и следующий
принцип имеет место.

Восходящий ранговый принцип разметки
Любая вершина классификации ранга K имеет больший номер разметки, чем
любая вершина ранга K+1 .
Согласно восходящему ранговому принципу разметки, одним из возможных
вариантов разметки классификации, изображённой на рис.2, может быть:
Рис.5. Вариант разметки классификации с рис.2.
8
6 7
1 2 4 53

Несложно показать, что код Прюфера для ориентированного дерева с рис.5 будет
выглядеть как «6,6,6,7,7,8 » . Если внимательно присмотреться, то можно увидеть,
что при восходящем ранговом принципе разметки код Прюфера указывает на корень
дерева «8 » . Более короткая запись может быть представлена так: «63 72 81 » . Эта
запись так же говорит нам о том, что корень дерева «8 » .
Мы видим, что у «7 » существует два уточняющих класса, а у «6 » - три. Но у
«8 » в коде значится только один уточняющий класс, что не соответствует
действительности. Данный факт — следствие из алгоритма формирования кода
Прюфера и чтобы ответить на вопрос сколько всего уточняющий классов первого
ранга у классификации, достаточно показатель степени при корне увеличить на
единицу. Для удобства будем использовать запись «63 72 82 » которую будем
называть модифицированным кодом Прюфера.

Рассмотрим классификацию, которая изоморфна классификации с рис.2:
Рис.6. Изоморфная классификация
Представим вариант разметки классификации с рис.6 согласно восходящему
принципу:
A i
A [1]i A [2]
i
A [1,1 ]i
A [1,2 ]i A [2,1 ]
i A [2,2 ]i
A [2,3 ]i

Рис.7. Разметка изоморфной классификации
Снова выпишем код Прюфера для классификации, изображённой на рис.7
«6,6,7,7,7,8 » и представим его в виде модифицированного кода «62 73 82 » . Итак,
для двух изоморфных классификаций на рис.2 и рис.6, мы получили
модифицированные коды «63 72 82 » и «62 73 82 » соответственно. Очевидно, что
решающую роль играет число уточняющих классов классификаций, что может
рассматриваться как критический параметр алгоритма нумерации вершин.
8
6 7
1 2 3 4 5

Восходящий рангово-арный принцип разметки
Любая вершина классификации ранга K имеет больший номер разметки, чем
любая вершина ранга K+1 , при условии, что для любых двух вершин ранга K ,
вершина с большим числом уточняющих классов имеет меньший номер разметки и
ее уточняющие классы имеют меньшие номера разметки, чем уточняющие классы
класса с меньшим числом уточняющих классов.
Очевидно, что восходящая рангово-арная разметка есть вариант восходящая
ранговой разметки. Для классификации с рис.2 восходящая рангово-арная разметка
показана на рис.5.
Выполним рангово-арную разметку для изоморфной классификации с рис.6:

Рис.8. Разметка изоморфной классификации
Выпишем код Прюфера для классификации с разметкой на рис.8 «6,6,6,7,7,8 »
и представим его в виде модифицированного кода «63 72 82 » . Полученный код
совпадает с кодом при восходящая рангово-арная разметка изоморфной
классификации на рис.2, из чего делается заключение: «Если модифицированный
код Прюфера ориентированного дерева, размеченного согласно восходящему
рангово-арному принципу, совпадает, то ориентированные деревья изоморфны».
8
7 6
4 5 1 2 3

Нисходящий ранговый принцип разметки
Любая вершина классификации ранга K имеет меньший номер разметки, чем
любая вершина ранга K+1 . Представим вариант разметки классификации с рис.2
согласно нисходящему ранговому принципу.
Рис.9. Разметка согласно нисходящему принципу
1
3 2
8 7 5 46

Выпишем код Прюфера для классификации, согласно разметке рис.9
«2,2,3,3,3,1 » и представим его в виде модифицированного кода «22 33 12 » .
Следует обратить внимание, что «1» - корень ориентированного дерева.
Если по коду «62 73 82 » видно, что в классификации 8 классов по «8 » , которая
представляет собой корень, то как понять, что код «22 33 12 » так же представляет
классификацию из 8 классов? Все очень просто: если к сумме степеней
модифицированного кода добавить единицу, то получим количество классов
классификации (вершин ориентированного дерева).
Сведём в таблицу 1 некоторые интересные свойства модифицированного кода
Прюфера для классификаций на примере классификации с рис.2:

Таблица 1.
Свойствоклассификации
Значение Алгоритм получения значения из модифицированногокода Прюфера
Восх.: «62 73 82 » Нисх.: «22 33 12 »Количество классов 8 Сумма степеней кода, увеличенная на единицу:
2+3+2+1=8Количество листьев 5 Равно количеству классов минус количество уникальный
оснований в модифицированном коде Прюфера 8−3=5Максимальный рангкласса вклассификации
2 Начинаем с корня, который записан как самое правое число.Ранг корня классификации равен нулю . Степень корня
показывает, сколько элементов кода имеет ранг, на единицубольший, чем ранг корня, т.е.1. Таких чисел 2. Последним
числом, имеющим ранг 1, есть последние число вмодифицированном коде, а так как в модифицированномкоде не отражены уточняющие классы, то максимальный
ранг равен 2.
Параметр полнотыM
2.(3)(5)
2+3+23
=2.(3)

Нисходящий рангово-арный принцип разметки
К сожалению, сформулированный нисходящий ранговый принцип разметки не
позволяет судить об изоморфности классификаций, поэтому мы уточним его.
Любая вершина классификации ранга K имеет меньший номер разметки, чем
любая вершина ранга K+1 , при условии, что для любых двух вершин ранга K ,
вершина с большим числом уточняющих классов имеет меньший номер разметки и
ее уточняющие классы имеют меньшие номера разметки, чем уточняющие классы
класса с меньшим числом уточняющих классов.
Представим вариант разметки классификации с рис.2 согласно нисходящему
рангово-арному принципу.

Рис.10. Разметка согласно нисходящему рангово-арному принципу
Выпишем код Прюфера для классификации, согласно разметке рис.10
«3,3,2,2,2,1 » и представим его в виде модифицированного кода «3223 12 » .
Итак, для одной и той же классификации с рис.2. получим следующие коды:
1
2 3
6 5 8 74

Таблица 2
Изображениеклассификации
Рангово-арный принцип разметки
Восходящий Нисходящий
Рис.2 «62 73 82 » «3223 12 »
Из табл.2 становиться очевидным, что порядок следования степеней
модифицированного кода Прюфера не зависит от выбора направления рангово-
арного принципа разметки (восходящий или нисходящий), т. е. для подтверждения
изоморфности двух классификаций достаточно получить степени
модифицированного кода Прюфера. Очевидно, что записи «2,3,2» , которую
назовём раногово-арным кодом, достаточно, чтобы восстановить структуру
классификации. Покажем это для двух подходов разметки:

Таблица 3
Шаг восстановления структурыклассификации по рангово-арному коду «2,3,2»
Рангово-арный принцип разметки
Восходящий Нисходящий
Восстановление количестваклассов в классификации
2+3+2+1=8
Восстановлениемодифицированного кодаПрюфера
«62 73 82 » «3223 12 »
Короткая форма кода Прюфера «62 73 81 » «3223 11 »
Полная форма кода Прюфера «6,6,7,7,7,8 » «3,3,2,2,2,1 »
Графическое преставлениедерева с разметкой
Рис.8 Рис.10
Исходная классификация(ориентированное дерево)
Рис.2

Применимость нисходящего и восходящего рангово-арных принципов разметки
Объективно, восходящий рангово-арный принцип разметки с точки зрения
практики уступает нисходящему по следующим причинам:
1. При добавлении вершины в классификацию или при удалении вершины из
классификации при восходящем рангово-арном принципе прийдётся переразмечать
все оставшиеся вершины, что не прийдется делать при нисходящем рангово-арном
принципе, т. к. при нисходящем рангово-арном принципе разметка корня дерева
никогда не меняется.
2. В программировании структура данных, представляющая дерево, передаётся
указателем на корень и рекурсивная разметка, начинающаяся с корня, является
приоритетной, что делает использование нисходящего рангово-арного принципа
разметки целесообразным.

Рангово-арная структура и проверка корректности рангово-арного кода
Рангово-арная структура данных — это структура данных, отражающая
структуру классификации согласно рангово-арного принципа разметки, где рангу
ставиться в соответствие упорядоченный согласно нисходящему или восходящему .
Например, для кода «2,3,2» описательно алгоритм выглядит следующий образом,
учитывая, что код читается справа на лево (т. е. с конца):
1. Выписываем первое значение степени, которое соответствует нулевой арности:
Ранг Показатели
степени
Число классов
Ожидаемое Реальное Ошибка
0 2 1 1 0
2. Сумма показателей степеней говорит, что следует ожидать два показателя
степени, релевантных первому рангу:

Ранг Показатели
степени
Число классов
Ожидаемое Реальное Ошибка
0 2 1 1 0
1 2, 3 2 2 0
3. Т.к. мы выбрали все показатели степней из «2,3,2» , то построение рангово-
арной структуры данных завершено.
Следует обратить внимание, что число ожидаемых классов нулевого ранга всегда
равно 1 по определению,т. к. указывает на корень дерева. Каждая последующая
строка в колонке ожидаемое число содержит сумму показателей степеней
предыдущей строки. На этом факте и базируется подход в проверке корректности
рангово-арного кода. Например, рассмотрим код «2,3,3» в виде рангово-арной

структуры:
Ранг Показатели
степени
Число классов
Ожидаемое Реальное Ошибка
0 3 1 1 0
1 2, 3 3 2 1
Не сложно увидеть, что предложенная структура данных позволяет определить
является ли некоторая последовательность чисел рангово-арным кодом.
Представим классификацию A и следующие классификации

Рис.11. Классификации B и C
в виде кортежа модифицированных кодов Прюфера в комбинации с рангово-арной
разметкой.
Классификация
Кортеж модифицированных кодов Прюфера, определяющийдекомпозицию классификации
A (2,3,2), (3), (2)
B (3,3,2), (3), (3)
C (2,2,2), (2), (2)
Ci
C[1 ]i C[2 ]
i
C[2,1 ]i
C[2,2 ]iC[1,1 ]
iC[1,2 ]
i
B i
B[1]i B[2]
i
B[1,1]i B[1,2]
iB[1,3]
i B[2,1]i B[2,2]
iB[2,3]
i

Воспользовавшись идеей меры Жаккара [16], определим структурную меру
подобия кортежей как I (X ,Z ) единица минус отношение количества одинаковых
кодов в кортежах к сумме количества одинаковых (неуникальных) кодов и
количества отличных (уникальных) кодов в кортежах, где X ,Z - некоторые полные
корректные классификации.
Мера I (X ,Z ) является мало пригодной. Например, для классификаций D и
F мера отличия равна I (D ,F )=1.0 :
Рис.12. Мера I (D, F )=1.0 для классификаций D и F .
Di
D[1]i D[2]
iD[3]
i
Fi
F[1 ]i
F[2 ]i

Казалось бы, I (D ,F )=1.0 для классификаций классификаций D и F
свидетельствует, что классы, которые делимы на разное число уточняющих классов,
являются абсолютно разными классами, а система деления таких классов - разными
классификациями. Для классификаций, представленныхкодами (2,3,4,3) и (2,3,2)
I ((2,3,4,3),(2,3,2))=1−25=0.6 , что говорит о том, что уточнение неделимых
классов классификаций D и F могло бы значительно уменьшить меру отличия
двух классификаций.
Модифицированный кодПрюфера
Кортеж модифицированных кодов Прюфера, определяющийдекомпозицию классификации
(2,3,4,3) (2,3,4,3), (2), (3), (4)
(2,3,2) (2,3,2), (2), (3)

Понятно, что рассмотренный выше пример является выбранным специально в
целях иллюстрации поведения меры структурного отличия. Так же очевидно, что
для классификаций, закодированных последовательностями (k , k , ... , k ,m) и
(n ,n, ... ,n ,m) , где n , k≥2 , k≠n и k ,n ,m∈N , мера структурного отличия
I ((k ,k , ... , k ,m) ,(n ,n , ... , n ,m))=1 .
Становится понятным, что определить является ли одна классификация классом
другой по кортежу модифицированных кодов Прюфера не представляет сложности.
Для этого достаточно выполнить шаги как показано ниже:

Таблица 5. Иллюстрация определения вложения одной классификации в другую
Шаг (представление) Классификация
A (рис.2) D (рис.12)
Модифицированный код Прюфера 2,3,2 3
Кортеж модифицированных кодовПрюфера, определяющийдекомпозицию классификации
(2,3,2), (3), (2) (3)
Определение кортежа сминимальной длиной
Длина кортежа: 3(кортеж с
максимальнойдлиной)
Длина кортежа: 1(кортеж с минимальной
длиной)
Самый длинный код кортежа (2,3,2) (3)
Содержит ли кортеж смаксимальной длиной наиболеедлинный код из кортежа сминимальной длиной
Да: (3)

Следовательно, для того, чтобы утверждать содержит ли одна классификация
другую, достаточно ответить на вопрос содержит ли кортеж модифицированных
кодов Прюфера с максимальной длиной наиболее длинный код из кортежа с
минимальной длиной.

Синонимичные классификации и дуализм меры отличия
Выдвинем следующую гипотезу: если у двух классификаций совпадает
структура и все классы, кроме класса нулевого ранга, то классы нулевого ранга этих
классификаций семантически есть синонимы. Синонимами в биологической
таксономии называют два или более названия, относящиеся к одному и тому же
биологическому таксону [4]. Проиллюстрируем выдвинутую гипотезу на примерах:
Рис.13. Классификации H и F с одинаковыми структурой и неделимыми
классами.
D[1]i D[2]
iD[3]
i
H i Fi
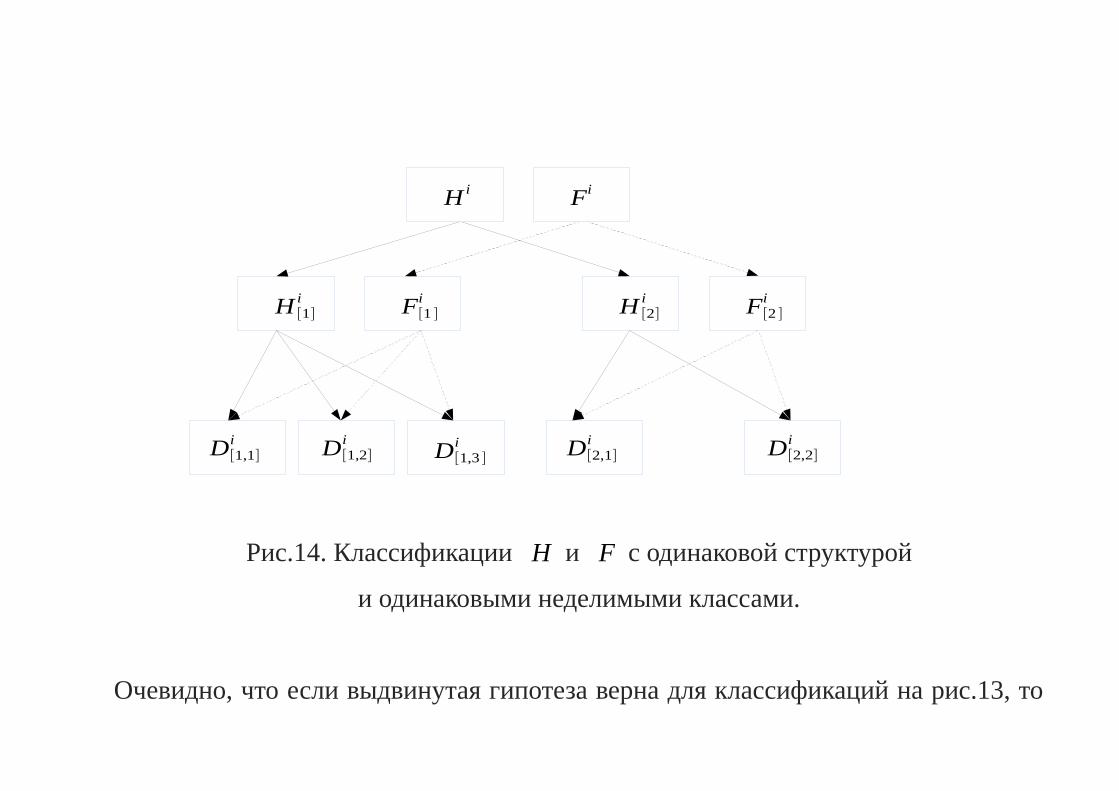
Рис.14. Классификации H и F с одинаковой структурой
и одинаковыми неделимыми классами.
Очевидно, что если выдвинутая гипотеза верна для классификаций на рис.13, то
D[1,1]i D[1,2]
iD[1,3 ]
i
H [1]i F[1 ]
i
D[2,1]i D[2,2]
i
H [2]i F[2 ]
i
H i Fi

по индукции она верна для классификаций на рис.14 и, как следствие, можно
допустить следующий вывод: «Две классификации являются синонимичными, если
у них одинаковые неделимые классы».
Это позволяет нам ввести ещё одну меру на классификациях — меру
несинонимичности, которая эквивалентна множественной мере Жаккара [16] для
множеств неделимых классов двух классификаций:
S (A , B)=1−n(L(A )∩L(B))
n(L(A )∪L(B)),
где S (A , B) - мера несинонимичности, n(L(A )) - мощность множества неделимых
классов классификации A , L(A ) - множество неделимых классов классификации
A , n(L(B)) - мощность множества неделимых классов классификации B и

L(B) - множество неделимых классов классификации B .
Как было показано выше, для двух классификаций A и B могут быть
определены две меры - мера структурного отличия I (A ,B) и мера
несинонимичности S (A , B) , где мера I (A ,B) отвечает за форму, а мера S (A , B) -
за содержание.
Дуальная мера отличия классификаций есть двойка вида:
M (A ,B)=⟨ I (A , B), S (A , B)⟩ ,
отражающая известную проблему формы и содержания в философии [17].
Дуальная мера не является строгой математической мерой.

Соответствие принципам математического моделирования
Свойство мат. модели[18]
Соответствие
Множественность Позволяет исследовать различные свойства классификаций какметрического пространства
Единство Модель позволяет исследовать различные классификациинезависимо от принципа выбора плоскостей деленияклассификации
Конечность Модель конечна
Адекватность Обеспечивается представлением любой плоской классификацииориентированным деревом
Эффективность Подтверждена экспериментально
Простота Модель достаточно проста
Устойчивость Соответствует принципу моноцентризма Богданова [19]
Модель (25) соответствует теореме Бирса [20] , «жизнеспособная система,
содержащая в себе другую жизнеспособную систему, тогда их организационные
структуры рекурсивны».

Пример применения. Оценка классификатора
Матрица неточностей [21] в оценке классификатора – это матрица размера N на
N , где N — количество классов. Столбцы этой матрицы резервируются за
экспертными решениями, а строки за решениями классификатора. Матрица
неточностей активно используется в машинном обучении.
Рис.3. Матрица неточностей. Пример.

Пример применения. Оценка классификатора
Численная оценка базируется на таблице контингентности:
Категория i Экспертная оценка
Положительная Отрицательная
Оценка системы Положительная TP FP
Отрицательная FN TNВ таблице содержится информация сколько раз система приняла верное и сколько
раз неверное решение по документам заданного класса. А именно, решения: TP —
истино-положительное; TN — истино-отрицательное; FP — ложно-
положительное; FN — ложно-отрицательное. Тогда, точность и полнота:
Precission=TP
TP+FP - точность,
Recall=TP
TP+FN- полнота.
(31)

Пример применения. Оценка классификатора
Точность равняется отношению соответствующего диагонального элемента
матрицы и суммы всей строки класса. Полнота – отношению диагонального
элемента матрицы и суммы всего столбца класса.
Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни
максимальная точность и полнота не достижимы одновременно и приходится искать
некий баланс. Мера F определяется как [21]:
F=(β2+1)Precission×Recall
β2Precission+Recall.
(27)
Однако, как было показано выше, классы в классификации могут иметь разные
ранги (существующие методы не учитывают этого факта). При использовании (8)
получим решение не только численно верное, но и семантически корректное. Кроме
того, (8) и (27) пропорциональны при однораговых классификаций.

Краткие результаты. Часть первая
1. Введена терминология, разрешающая неоднозначность толкования терминов:
классификация, классифицирование, определение классовой принадлежности,
классификатор, классифицированный объект.
2. Введены ассоциативные бинарные операции уточнения и обобщения классов
классификации, показана идемпотента. Доказано, что классификация есть
полугруппа классов.
3. Доказано, что плоская классификация есть метрическое пространство, на
котором дано определение меры отличия классов на основании предложенной
модифицированной меры Жокара.
4. Изучены и объяснены свойства меры отличия на классификациях.

Краткие результаты. Часть вторая
5. Предложена модель вычислений на классификациях и объяснены ее свойства.
Показано соответствие предложенной модели принципам математического
моделирования.
6. Предложен математический формализм, позволяющий однозначно определить
корректность построения классификаций, на базе которого предложены критерии
построения корректных классификаций.
7. Предложен подход, позволяющий оперировать некорректно построенными
классификациями как корректными.
8. Предложен рангово-арный подход, позволяющий кодировать деревья с меньшей
длиной кода, чем того требует теорема Келли. Предложенный рангово-арный код
является наилучшим решением компактного хранения ориентированных деревьев.
9. Предложен алгоритм проверки корректности рангово-арного кода.

Краткие результаты. Часть третья
10. Введено понятие синонимичной классификации и определена дуальная мера
отличия, отражающая известную философскую проблему формы и содержания.
11. Преложен подход, позволяющий корректное определение функции ошибки
классификатора.

Нерешенные задачи. Часть первая
1. Можно ли дуальную меру представить в виде функции, позволяющей
сохранить отношение мер отличия трёх объектов при замене одной
пространственной классификации на другую?
2. Как соотносятся меры отличия двух произвольных объектов, если по
отношению к ним выполнены процедуры определения классовой принадлежности в
двух произвольных пространственных классификациях?
3. Будут ли применимы проекционные методы [22] (линейная проекция,
многомерное шкалирование, отображение Семмона, неметрическое многомерное
шкалирование и т. п.) для представления совокупности объектов,
классифицированных в одной пространственной классификации, в виде
совокупности точек на плоскости?

Нерешенные задачи. Часть вторая
4. Если применимы проекционные методы, то какую семантику несут две
координаты на плоскости?
5. Можно ли рассматривать дуальную меру отличия классификаций как
плоскость проекции?
6. Если при классифицировании используется одно и то же множество условий
деления (инвариант классифицирования), но элементы множества берутся в разных
порядках, можем ли мы отказаться от определения структурного сходства двух
классификаций и ограничится исключительно мерой семантического сходства?

Выводы
Отталкиваясь от проекции классификации на математическую структуру
ориентированное дерево, благодаря введению набора операций на плоскости
деления классификации, удалось показать, что относительное расстояние между
классами на плоскости деления классификации является мерой.
Доказано, что классификации с несколькими плоскостями деления представляют
собой метрическое пространство. Введена дуальная мера отличия двух
классификаций, позволяющая ответить на вопрос близости двух классификаций при
семантическом поиске.
Для модели вычислений на классификациях показано соответствие принципам
математического моделирования.
Показано применение модели для оценки качества алгоритмов классификации.

Литература1. Басипов А. Семантический поиск: проблемы и технологии / А.А.Басипов, О.В.Демич // Вестник Астраханского государственного
технического университета. Серия: Управление, вычислительная техника и информатика, № 1/ 2012. - Астрахань, 2012. - с.104-11.
2. Хабрахабр [Электронный ресурс]: Концептуальное описание индивидов / Александр Болдачев. - Режим доступа:
https://habrahabr.ru/post/276271/ . - Дата доступа: май, 2016.
3. Ивлев Ю.В. Логика [Текст] : Учебник. Изд.четвертое, пер. и доп. / Ю. В. Ильев // ТК «Велби», Изд-во «Проспект». - Москва, 2008. -
304 с.
4. Шаталкин А.И. Таксономия. Основания, принципы и правила [Текст] / А.И.Шаталкин // Товарищество научных изданий КМК. -
Москва, 2012. - 600 с.
5. Ушаков Д.Н. Толковый словарь русского языка / Д.Н.Ушаков // Альта-Принт. - Москва, 2005. - 1216 с.
6. Вьюгин В. Математические основы теории машинного обучения и прогнозирования / В. В. Вьюгин . - Москва, 2013. - 387 с.
7. Голдблатт Р. Топосы. Категорный анализ логики / Р. Голдблатт // Мир. - Москва, 1983. - 488 с.
8. Альфс Берзтисс. Структуры данных / А.Т. Берзтисс //Статистика. - Москва, 1974. — 408 с.
9. Фейс К. Алгебра: кольца, модули и категории [Текст] / Карл Фейс // Изд—во «Мир». — т. 1. — Москва, 1977. — 688 с.
10. Альфс Берзтисс. Структуры данных [Текст] / А.Т. Берзтисс //Статистика. - Москва, 1974. — 408 с.
11. Скворцов В. А. Примеры метрических пространств. [Текст] / В. А. Скворцов // Из-во Московского центра непрерывного
математического образования. - Москва, 2002. - 24 с.
12. Загоруйко Н. Меры сходства , компактности, информативности и однородности обучающей выборки [Текст] / Н. Г. Загоруйко, И. А.
Борисова, В. В. Дюбанов, О. А. Кунтенко // Труды Всеросийской конференции «Знания - Онтологии — Теории» (ЗОНТ-09). Том 1. -
Новосибирск, 2009. - с.93-102.
13. Елисеева И. Группировка, корреляция, распознавание образов. Статистические методы классификации и измерения связей [Текст] /

И.И.Елисеева, В.О.Рукавишников // Статистика. - Москва, 1977. - 144 с.
14. Тоценко В.Г. Методы и системы поддержки принятия решений. Алгоритмический аспект / В.Г. Тоценко //Наукова думка. - Киев, 2002.
– 382 с.
15. Касьянов В.Н. Графы в программировании: обработка, визуализация и применение / В.Н.Касьянов, В.А.Евстигнеев // БХВ-Петербург.
- Санкт-Петербург, 2003. - 1104 с.
16. Семкин Б.И. Аксиоматическое введение мер сходства, различия, совместимости и зависимости для компонентов биоразнообразия /
Б.И.Семкин, М.В.Горшков // Известия Дальневосточного федерального университета. Экономика и управление, № 4. - 2008. - с. 31-46.
17. Карелина Е.В. Теоретическая строгость как соответствие системы и метода в философии. Монография / Е.В.Карелина // Сибирский
федеральный университет. - Красноярск, 2012. - 120 с.
18. Самарский А.А. Математическое моделирование: Идеи. Методы. Примеры [Текст] / А. А. Самарский, А. П. Михайлов // Физматлит. -
Москва, 2001. — 320 с.
19. Богданов А. А. Тектология: Всеобщая организационная наука [Текст] / А. А. Богданов // «Финансы». - Москва, 2003. - 287 c.
20. Бир С. Т. Мозг фирмы [Текст] / С. Т. Бир //«Едиториал УРСС». - Москва, 2005. — 416 c.
21. Nicolas P. Scala for machine learning / Patric R. Nicolas // Packt Publishing. - Bermingem, UK, 2014. - 420 p.
22. Кохонен Т. Самоорганизующиеся карты / Тойво Кохонен // Бином. Лаборатория знаний. - Москва, 2008. - 655 с.

Благодарю за внимание!
Пожалуйста, Ваши вопросы…