ai + hpc convergence...motivation for convergence • hpc owners constrained in growing compute...
TRANSCRIPT

AI + HPC ConvergencePaul Rietze
Artificial Intelligence Products Group, Intel®
Dell HPC Community Meeting, June 24, 2018
Frankfurt

2
Legal notices and disclaimersSoftware and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to www.intel.com/benchmarks.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com.
Intel does not control or audit third-party benchmark data or the web sites referenced in this document. You should visit the referenced web site and confirm whether referenced data are accurate.
Cost reduction scenarios described are intended as examples of how a given Intel- based product, in the specified circumstances and configurations, may affect future costs and provide cost savings. Circumstances will vary. Intel does not guarantee any costs or cost reduction.
All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps.
Results have been estimated or simulated using internal Intel analysis or architecture simulation or modeling, and provided to you for informational purposes. Any differences in your system hardware, software or configuration may affect your actual performance.
Intel, the Intel logo, the Intel. Experience What’s Inside logo, Intel. Experience What’s Inside, Intel Inside, the Intel Inside logo, and Xeon are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries.
*Other names and brands may be claimed as the property of others.
© Intel Corporation.

Motivation for Convergence
• HPC owners constrained in growing compute while also dealing with increasing complexity and larger data sets
• Call for AI and Analytics services from the research community
• HPC vendors looking to address the much larger data science market
• Desire to utilize existing infrastructure for new workloads (AI & DL)
AI HPC
Analytics

Converged infrastructure
Data Sources
Operational System Machine Data External Data Audio/Video/
documentsLog Data
Batch, Near real time, Real time
Data Management and Data Lake
Classical Analytics: Human led
….
Machine Learning and Deep Learning: Machine led
Predictive Analytics Cloud Applications Reporting
Clustering Graph Linear algebra
Solutions
CNNAI & Analytics Applications
RNN LSTM
….
….….
+
More structured Less Structured & Streaming
Transform DataSource-cleanse-normalize +
DL data on existing and new nodes
Image ClassificationNatural Language Processing
+deep neural
nets on existing or new nodes
Optional neural network processor
*Other names and brands may be claimed as the property of others

HPC and Deep Learning
Learn more: https://arxiv.org/abs/1708.05256
Deep Learning at 15PF: Supervised and Semi-Supervised Classification for Scientific Data
Image courtesy of the National Energy Research Scientific Computing Center
HPC and Deep LearningComplex Global Climate Model generates 400km view of atmospheric rivers and severe weather patterns
Deep Learning across 9600 nodes of the Cori supercomputer generates 25km view – and new insight
Learn more: https://arxiv.org/abs/1801.10277
Cataloging the Visible Universe through Bayesian Inference at Petascale
Image courtesy of the National Energy Research Scientific Computing Center
Statistical Machine Learning Create a catalog of every object in the visible universe from the Sloan Digital Sky Survey (SDSS)
Problem: What is a star? A galaxy? What overlaps?
Machine Learning: “Celeste” project uses Bayesian inference on pixel intensities to infer the object
Result: Created catalog in <15 minutes using a 55 terabyte data set on the NERSC Cori supercomputer
CELESTE Global Climate

6
Smarter AI Through the Industry’s Most Comprehensive Platform
hardware Multi-purpose to purpose-built AI compute from cloud to device
community Partner ecosystem to facilitate AI infinance, health, retail, industrial & more
Intel analytics ecosystem to get your data
ready from integration to
analysis
Driving AI forward
through R&D, investment and policy leadership
Data Future
tools Portfolio of software tools to accelerate time-to-solution

*Other names and brands may be claimed as the property of others.All products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice.
community
Intel AI Builders
builders.intel.com/ai/membership
Your one-stop-shop to find systems, software and solutions using Intel® AI technologies
Reference solutions
builders.intel.com/ai/solutionslibrary
Get a head start using the many case studies, solution briefs and more reference collaterals spanning multiple applications
Partner ecosystem to facilitate AI infinance, health, retail, industrial & more

† Formerly the Intel® Computer Vision SDK*Other names and brands may be claimed as the property of others.Developer personas show above represent the primary user base for each row, but are not mutually-exclusiveAll products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice.
TOOLKITSApplication Developers
DEEP LEARNING (INFERENCE)
OpenVINO™ †
Intel® Movidius™ SDK
Open Visual Inference & Neural Network Optimization toolkit for inference deployment on
CPU/GPU/FPGA for TensorFlow*, Caffe* & MXNet*
Optimized inference deployment on Intel VPUs for
TensorFlow* & Caffe*
TOOLS
librariesData
Scientists
foundationLibrary
Developers
DEEP LEARNING FRAMEWORKS
Now optimized for CPU Optimizations in progress
TensorFlow* MXNet* Caffe* BigDL (Spark)*
Caffe2* PyTorch* CNTK* PaddlePaddle*
DEEP LEARNING
Intel® Deep Learning Studio‡
Open-source tool to compress deep learning
development cycle
REASONING
Intel® Saffron™ AICognitive solutions on CPU for anti-money laundering,
predictive maintenance, more
*
**
*FOR
* * * *
MACHINE LEARNING LIBRARIES
Python R Distributed•Scikit-learn•Pandas•NumPy
•Cart•RandomForest•e1071
•MlLib (on Spark)•Mahout
ANALYTICS, MACHINE & DEEP LEARNING PRIMITIVES
Python DAAL MKL-DNN clDNNIntel distribution
optimized for machine learning
Intel® Data Analytics Acceleration Library
(incl machine learning)
Open-source deep neural network functions for
CPU / integrated graphics
DEEP LEARNING GRAPH COMPILER
Intel® nGraph™ Compiler (Alpha)Open-sourced compiler for deep learning model
computations optimized for multiple devices from multiple frameworks
Portfolio of software tools to accelerate time-to-solution

AI Performance – Software + Hardware
INFERENCE THROUGHPUT
Up to
277x1
Intel® Xeon® Platinum 8180 Processor higher Intel optimized Caffe GoogleNet v1 with Intel® MKL
inference throughput compared to Intel® Xeon® Processor E5-2699 v3 with BVLC-Caffe
1 The benchmark results may need to be revised as additional testing is conducted. The results depend on the specific platform configurations and workloads utilized in the testing, and may not be applicable to any particular user's components, computer system or workloads. The results are not necessarily representativeof other benchmarks and other benchmark results may show greater or lesser impact from mitigations. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specificcomputer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined withother products. For more complete information visit: http://www.intel.com/performance.Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems,components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Formore complete information visit: http://www.intel.com/performance Source: Intel measured as of June 2018. Configurations: See slide 29
TRAINING THROUGHPUT
Up to
241x1
Intel® Xeon® Platinum 8180 Processor higher Intel Optimized Caffe AlexNet with Intel® MKL
training throughput compared to Intel® Xeon® Processor E5-2699 v3 with BVLC-Caffe
Deliver significant AI performance with hardware and software optimizations on Intel® Xeon® Scalable Family
Optimized Frameworks
Optimized Intel® MKL Libraries
Inference and training throughput uses FP32 instructions

All products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice.
Deep Learning
Training
Inference
AI
HARDWAREMainstream intensive
Multi-purpose to purpose-built AI compute from cloud to device
IntelGNA
(IP)
Most other

1GNA=Gaussian Mixture Model and Neural Network AcceleratorAll products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice. Images are examples of intended applications but not an exhaustive list.
IntelGNA(IP)
Integrated graphics
Built-in deep learning
inference
Intel® Movidius™ VPU
Low power computer vision &
inference
Intel® GNA IP1
Ultra low power speech & audio
inference
Intel® Mobileye EyeQAutonomous
driving inference platform
Intel® FPGA
Custom deep learning
inference
Data CenterEdge
DeviceSmall scale clusters to a few on-premise server & workstations
User-touch end-devices typically with lower power requirements
Deep learning inference accelerators

12
Emphysema is estimated to affect more than 3 million people in the U.S.1, and more than 65 million people worldwide2.▪ Severe emphysema (types 3 / 4) are life
threatening– Early detection is important to try to halt
progression
Pneumonia affects more than 1 million people each year in the U.S.3, and more than 450 million4 each year worldwide.▪ 1.4 million deaths per year worldwide
– Treatable with early detection
The Importance of Early DetectionHealthy Lung Severe Emphysema
https://www.ctsnet.org/article/airway-bypass-stenting-severe-emphysema
1. www.emphysemafoundation.org/index.php/the-lung/copd-emphysema2. http://www.who.int/respiratory/copd/burden/en/3. https://www.cdc.gov/features/pneumonia/index.html4. https://doi.org/10.1016%2FS0140-6736%2810%2961459-6

CheXNet
13
Developed at Stanford University, CheXNet is a model for identifying thoracic pathologies from the NIH ChestXray14 dataset
▪ DenseNet121 topology
– Pretrained on ImageNet
▪ Dataset contains 121K images
– Multicategory / Multilabel
– Unbalanced
https://stanfordmlgroup.github.io/projects/chexnet/
*Other names and brands may be claimed as the property of others

14
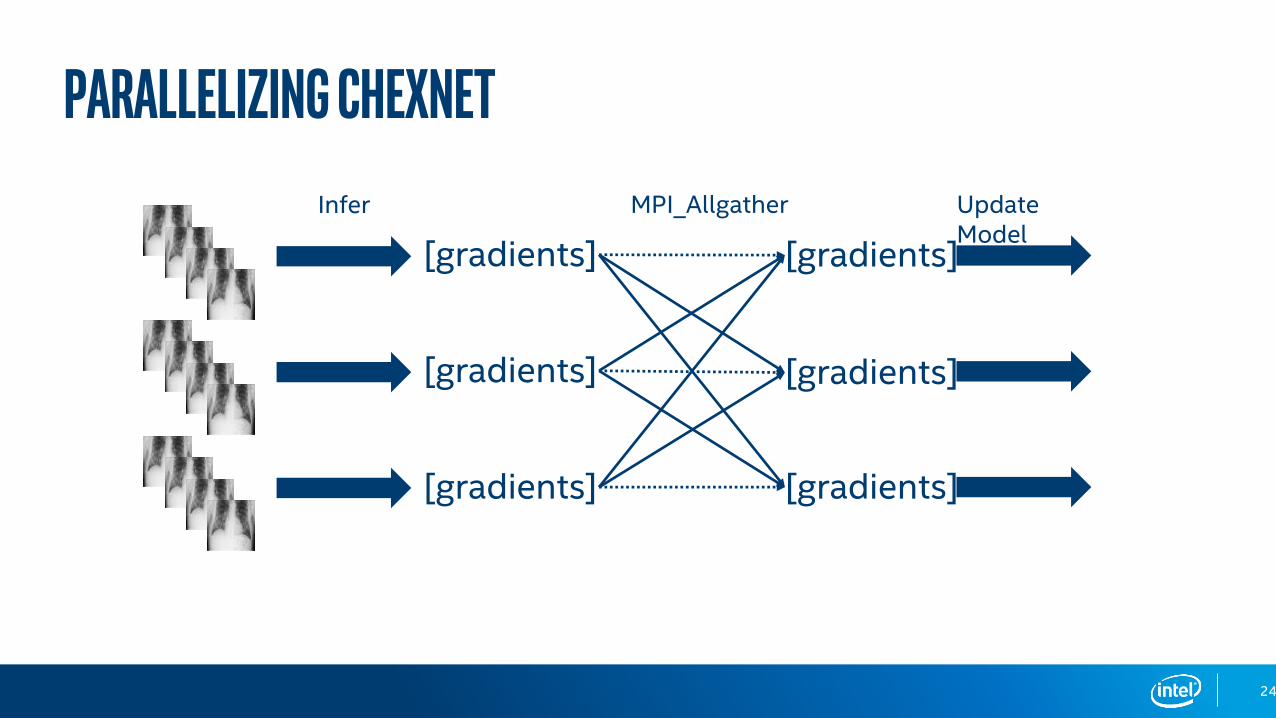
Parallelizing CheXNet
*Other names and brands may be claimed as the property of others

15
Parallelizing CheXNet
Training Data Set(N Images)
To Parallelize:1. Each Process Has Access to Entire Data Set2. Each Process Independently Shuffles Data Set
a. Independent Random Seeds3. Each Process Trains on the First N/P Images4. Repeat Steps 2 + 3 Every Epoch
P Processes

CheXNet – Parallel Speedup
4
186
0
20
40
60
80
100
120
140
160
180
200
P=1,BZ=8 P=64,BZ=64,GBZ=4096
Ima
ge
s p
er
seco
nd
CheXNet Training Throughput
DellEMC C6420 with dual Intel® Xeon® Scalable Gold 6148on Intel® Omni-Path Architecture Fabric
46x Speedup using 32 Nodes!(64 processes)
Training time reduced from 5 hours per epoch to 7 minutes!
Other names and brands may be claimed as the property of others§ Configuration: CPU: Xeon 6148 @ 2.4GHz, Hyper-threading: Enabled. NIC: Intel® Omni-Path Host Fabric Interface, TensorFlow: v1.7.0, Horovod: 0.12.1, OpenMPI: 3.0.0. OS: CentOS 7.3, OpenMPU 23.0.0, Python 2.7.5Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance. See slides 25, 26, and 27 for configuration details and contact info if you wish to repeat this test or learn more

ResNet-50 Scaling Efficiency With TensorFlow (2018)Intel® Xeon® Platinum 8160 processor Cluster Stampede2 at TACC
ResNet-50 with ImageNet-1K on 256 Nodes on Stampede2/TACC:
• Improved single-node perf with multi-workers/node
• 81% scaling efficiency• Batch size of 64 per worker: Global BS=64K• 16400 Images/sec on 256 nodes • 26700 images/sec on 512 nodes• Time-To-Train: ~2 Hrs on 256 Nodes
1.0
2.0
3.8
7.2
14.2
28
55
109
208
1
2
4
8
16
32
64
128
256
1 2 4 8 16 32 64 128 256
Spe
ed
up
Nodes
ResNet-50: Training PerformanceIntel(R) 2S Xeon(R) on Stampede2/TACC, Intel(R) OPA Fabric
TensorFlow 1.6+horovod, IMPI, ImageNet-1K, Core Aff. Intel BKM,s BS=64/Worker
Speedup Ideal
81% Efficiency with TensorFlow+horovod
Other names and brands may be claimed as the property of others§ Configuration: CPU: Xeon 6148 @ 2.4GHz, Hyper-threading: Enabled. NIC: Intel® Omni-Path Host Fabric Interface, TensorFlow: v1.7.0, Horovod: 0.12.1, OpenMPI: 3.0.0. OS: CentOS 7.3, OpenMPU 23.0.0, Python 2.7.5Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance. See slides 37, 38, & 39 for configuration details and contact info if you wish to repeat this test or learn more

18
https://newsroom.intel.com/news/using-deep-neural-network-acceleration-image-analysis-drug-discovery/
Result
20x faster time-to-trainFor processing a 10k image dataset, reducingthe training time from 11 hours to 31 minutes with over 99% accuracy1
Collaborator: Novartis International AG, based in Switzerland, and one of the largest pharmaceutical companies in the world
Challenge: High content screening of cellularphenotypes is a fundamental tool supportingearly stage drug discovery. While analyzingwhole microscopy images would be desirable,these images are more than 26x larger thanimages found typically in datasets such asImageNet*. As a result, the high computationalworkload would be prohibitive in terms of deepneural network model training time.
Solution: Intel and Novartis teams were ableto scale to more than 120 (3.9Megapixel)images per second with 32 TensorFlow*workers.Configuration: A cluster consisting of eightIntel® Xeon® processor servers using anIntel® Omni-Path Fabric interconnect andTensorFlow* optimized for Intelarchitecture.
Intel does not control or audit third-party benchmark data or the web sites referenced in this document. You should visit the referenced web site and confirm whether referenced data are accurate. Configuration details on slide 30. *Other names and brands may be claimed as the property of others

*Other names and brands may be claimed as the property of othersSource: https://research.fb.com/publications/applied-machine-learning-at-facebook-a-datacenter-infrastructure-perspective/

Getting Started with Intel® AI• You’ve invested in Xeon, OPA, & SSDs: utilize this infrastructure for AI
• Learn more about AI and Intel products at Intel AI Academy: https://software.intel.com/en-us/ai-academy
• Try out Intel AI for free through the Intel AI DevCloud: https://software.intel.com/en-us/ai-academy/tools/devcloud
• Become a member of Intel AI Builders for more benefits: https://builders.intel.com/ai
• Read about AI solutions on Intel at the AI Builders Solution Library
• Contact your Account Executive for instructions on obtaining Intel AI packages for installation on your HPC Cluster
Get Started at http://ai.intel.com

22
Learn more about Intel AI at ISC
• Talk to Experts at the Intel Booth and see three AI Demos• Medical Imaging, Image Recognition, and Distributed Deep Learning
• Many Intel presentations, tutorials, workshops, keynotes, panels. A few highlights below:• See Nash Palaniswamy on Monday, June 25 from 13:15 – 13:30 at the vendor
showdown on at Panorama 3
• Attend Raj Hazra’s keynote Supercomputing Circa 2025 at Panorama 2 on Monday, June 25 from 18:00 – 18:45
• Hear the Panel on “The Convergence of AI and HPC” on Tuesday, June 26 at the Intel Booth from 13:00 – 14:00 featuring panelists from CERN, AWS, KAUST, SURFsara, and Intel
• Learn more about Scale-out Deep Learning Training for Cloud and HPC at Panorama 2 on Wednesday, June 27, from13:45 – 14:15

24
Parallelizing CheXNet
[gradients]
[gradients]
[gradients]
[gradients]
[gradients]
[gradients]
Infer Update Model
MPI_Allgather

More information at ai.intel.com/framework-optimizations/
Call To Action
learn
explore
engage Use Intel’s performance-optimized libraries & frameworks
Contact us/Intel for help and collaboration opportunities
• Tensorflow: https://ai.intel.com/tensorflow/• Blog: http://www.techenablement.com/surfsara-achieves-accuracy-performance-
breakthroughs-deep-learning-wide-network-training/• SURFsara-Intel Paper: https://arxiv.org/pdf/1711.04291.pdf• Intel Blog: https://ai.intel.com/accelerating-deep-learning-training-inference-system-
level-optimizations/• SURFsara* Best Practices for Caffe*: https://github.com/sara-nl/caffe• SURFsara Best Practices for TensorFlow:
https://surfdrive.surf.nl/files/index.php/s/xrEFLPvo7IDRARs• HPC at Dell Blog: http://hpcatdell.com

ArtificialI ntelligenceis the ability of machines to learn from experience, without explicit programming, in order to perform cognitive functions associated with the human mind
Artificial Intelligence
Machine learningAlgorithms whose performance improve as they are exposed to
more data over time
Deep learningSubset of machine learning in which
multi-layered neural networks learn from vast amounts of data

CheXNet Testing/optimizations were conducted by this team, contact them for more info

28
Stampede2*/TACC* Configuration Details*Stampede2/TACC: https://portal.tacc.utexas.edu/user-guides/stampede2
Compute Nodes: 2 sockets Intel® Xeon® Platinum 8160 CPU with 24 cores each @ 2.10GHz for a total of 48 cores per node, 2 Threads per core, L1d 32K; L1i cache 32K; L2 cache 1024K; L3 cache 33792K, 96 GB of DDR4, Intel® Omni-Path Host Fabric Interface, dual-rail. Software: Intel® MPI Library 2017 Update 4Intel® MPI Library 2019 Technical Preview OFI 1.5.0PSM2 w/ Multi-EP, 10 Gbit Ethernet, 200 GB local SSD, Red Hat* Enterprise Linux 6.7.
TensorFlow 1.6: Built & Installed from source: https://www.tensorflow.org/install/install_sources
Model: Topology specs from https://github.com/tensorflow/tpu/tree/master/models/official/resnet (ResNet-50); Batch size as stated in the performance chart
Convergence & Performance Model: https://surfdrive.surf.nl/files/index.php/s/xrEFLPvo7IDRARs
Dataset: ImageNet2012-1K: http://www.image-net.org/challenges/LSVRC/2012/
Performance measured on 256 Nodes with:OMP_NUM_THREADS=24 HOROVOD_FUSION_THRESHOLD=134217728 export I_MPI_FABRICS=tmi, export I_MPI_TMI_PROVIDER=psm2 \mpirun -np 512 -ppn 2 python resnet_main.py --train_batch_size 8192 --train_steps 14075 --num_intra_threads 24 --num_inter_threads 2 --mkl=True --data_dir=/scratch/04611/valeriuc/tf-1.6/tpu_rec/train --model_dir model_batch_8k_90ep --use_tpu=False --kmp_blocktime 1
Configuration Details:Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit: http://www.intel.com/performance. Copyright © 2018, Intel Corporation

29
*DellEMC Zenith Cluster Configuration Details*DellEMC Internal Cluster:
Compute Nodes: 2 sockets Intel® Xeon® Platinum 8160 CPU with 24 cores each @ 2.10GHz for a total of 48 cores per node, 2 Threads per core, L1d 32K; L1i cache 32K; L2 cache 1024K; L3 cache 33792K, 96 GB of DDR4, Intel® Omni-Path Host Fabric Interface, dual-rail. Software: Intel® MPI Library 2017 Update 4Intel® MPI Library 2019 Technical Preview OFI 1.5.0PSM2 w/ Multi-EP, 10 Gbit Ethernet, 200 GB local SSD, Red Hat* Enterprise Linux 6.7.
TensorFlow 1.6: Built & Installed from source: https://www.tensorflow.org/install/install_sources
ResNet-50 Model: Topology specs from https://github.com/tensorflow/tpu/tree/master/models/official/resnetDenseNet-121Model: Topology specs from https://github.com/liuzhuang13/DenseNet
Convergence & Performance Model: https://surfdrive.surf.nl/files/index.php/s/xrEFLPvo7IDRARs
Dataset:ImageNet2012-1K: http://www.image-net.org/challenges/LSVRC/2012/ChexNet: https://stanfordmlgroup.github.io/projects/chexnet/
Performance measured with:OMP_NUM_THREADS=24 HOROVOD_FUSION_THRESHOLD=134217728 export I_MPI_FABRICS=tmi, export I_MPI_TMI_PROVIDER=psm2 \mpirun -np 512 -ppn 2 python resnet_main.py --train_batch_size 8192 --train_steps 14075 --num_intra_threads 24 --num_inter_threads 2 --mkl=True --data_dir=/scratch/04611/valeriuc/tf-1.6/tpu_rec/train --model_dir model_batch_8k_90ep --use_tpu=False --kmp_blocktime 1
Configuration Details :Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit: http://www.intel.com/performance. Copyright © 2018, Intel Corporation

Configuration: AI Performance – Software + Hardware INFERENCE using FP32 Batch Size Caffe GoogleNet v1 128 AlexNet 256.
The benchmark results may need to be revised as additional testing is conducted. The results depend on the specific platform configurations and workloads utilized in the testing, and may not be applicable to any particular user's
components, computer system or workloads. The results are not necessarily representative of other benchmarks and other benchmark results may show greater or lesser impact from mitigations. Performance tests, such as SYSmark and
MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to
assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance Source: Intel measured as of
June 2017 Optimization Notice: Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3
instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are
intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding
the specific instruction sets covered by this notice.
Configurations for Inference throughput
Platform :2 socket Intel(R) Xeon(R) Platinum 8180 CPU @ 2.50GHz / 28 cores HT ON , Turbo ON Total Memory 376.28GB (12slots / 32 GB / 2666 MHz),4 instances of the framework, CentOS Linux-7.3.1611-Core , SSD sda RS3WC080
HDD 744.1GB,sdb RS3WC080 HDD 1.5TB,sdc RS3WC080 HDD 5.5TB , Deep Learning Framework caffe version: a3d5b022fe026e9092fc7abc7654b1162ab9940d Topology:GoogleNet v1 BIOS:SE5C620.86B.00.01.0004.071220170215
MKLDNN: version: 464c268e544bae26f9b85a2acb9122c766a4c396 NoDataLayer. Measured: 1449.9 imgs/sec vs Platform: 2S Intel® Xeon® CPU E5-2699 v3 @ 2.30GHz (18 cores), HT enabled, turbo disabled, scaling governor set to
“performance” via intel_pstate driver, 64GB DDR4-2133 ECC RAM. BIOS: SE5C610.86B.01.01.0024.021320181901, CentOS Linux-7.5.1804(Core) kernel 3.10.0-862.3.2.el7.x86_64, SSD sdb INTEL SSDSC2BW24 SSD 223.6GB.
Framework BVLC-Caffe: https://github.com/BVLC/caffe, Inference & Training measured with “caffe time” command. For “ConvNet” topologies, dummy dataset was used. For other topologies, data was stored on local storage and cached in
memory before training. BVLC Caffe (http://github.com/BVLC/caffe), revision 2a1c552b66f026c7508d390b526f2495ed3be594
Configuration for training throughput:
Platform :2 socket Intel(R) Xeon(R) Platinum 8180 CPU @ 2.50GHz / 28 cores HT ON , Turbo ON Total Memory 376.28GB (12slots / 32 GB / 2666 MHz),4 instances of the framework, CentOS Linux-7.3.1611-Core , SSD sda RS3WC080
HDD 744.1GB,sdb RS3WC080 HDD 1.5TB,sdc RS3WC080 HDD 5.5TB , Deep Learning Framework caffe version: a3d5b022fe026e9092fc7abc765b1162ab9940d Topology:alexnet BIOS:SE5C620.86B.00.01.0004.071220170215
MKLDNN: version: 464c268e544bae26f9b85a2acb9122c766a4c396 NoDataLayer. Measured: 1257 imgs/sec vs Platform: 2S Intel® Xeon® CPU E5-2699 v3 @ 2.30GHz (18 cores), HT enabled, turbo disabled, scaling governor set to
“performance” via intel_pstate driver, 64GB DDR4-2133 ECC RAM. BIOS: SE5C610.86B.01.01.0024.021320181901, CentOS Linux-7.5.1804(Core) kernel 3.10.0-862.3.2.el7.x86_64, SSD sdb INTEL SSDSC2BW24 SSD 223.6GB.
Framework BVLC-Caffe: https://github.com/BVLC/caffe, Inference & Training measured with “caffe time” command. For “ConvNet” topologies, dummy dataset was used. For other topologies, data was stored on local storage and cached in
memory before training. BVLC Caffe (http://github.com/BVLC/caffe), revision 2a1c552b66f026c7508d390b526f2495ed3be594

System configuration: CPU: Intel Xeon Gold 6148 CPU @ 2.40GHz; OS: Red Hat Enterprise Linux Server release 7.4 (Maipo); TensorFlow Source Code: https://github.com/tensorflow/tensorflow; TensorFlow Commit ID: 024aecf414941e11eb643e29ceed3e1c47a115ad. Detailed configuration is as follows: CPU Thread(s) per core: 2, Core(s) per socket: 20, Socket(s): 2, NUMA node(s): 2, CPU family: 6, Model: 85, Model name: Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz, Stepping: 4, HyperThreading: ON, Turbo: ON, Memory 192GB (12 x 16GB), 2666MT/s, Disks Intel RS3WC080 x 3 (800GB, 1.6TB, 6TB)(?), BIOS SE5C620.86B.00.01.0013.0309201804 27, OS Red Hat Enterprise Linux Server release 7.4 (Maipo), Kernel 3.10.0-693.21.1.0.1.el7.knl1.x86_64
Refer to : https://ai.intel.com/using-intel-xeon-for-multi-node-scaling-of-tensorflow-with-horovod/
Configuration: Novartis – Software + Hardware