agentes de busca na internet fred freitas cin - ufpe
TRANSCRIPT

Agentes de Busca na Internet
Fred FreitasCIn - UFPE

Necessidade de Busca na Web O volume de Informações é imenso. O tipo e a qualidade da informação varia
largamente. Informações altamente dinâmicas. O usuário atravessa muitos links até
encontrar o que deseja. O surfe deixa muitos usuários perdidos. Fenômeno do museu de arte

Introdução
OBJETIVO:
Encontrar (de forma eficiente) osmelhores documentos que
satisfaçam a query do usuário.
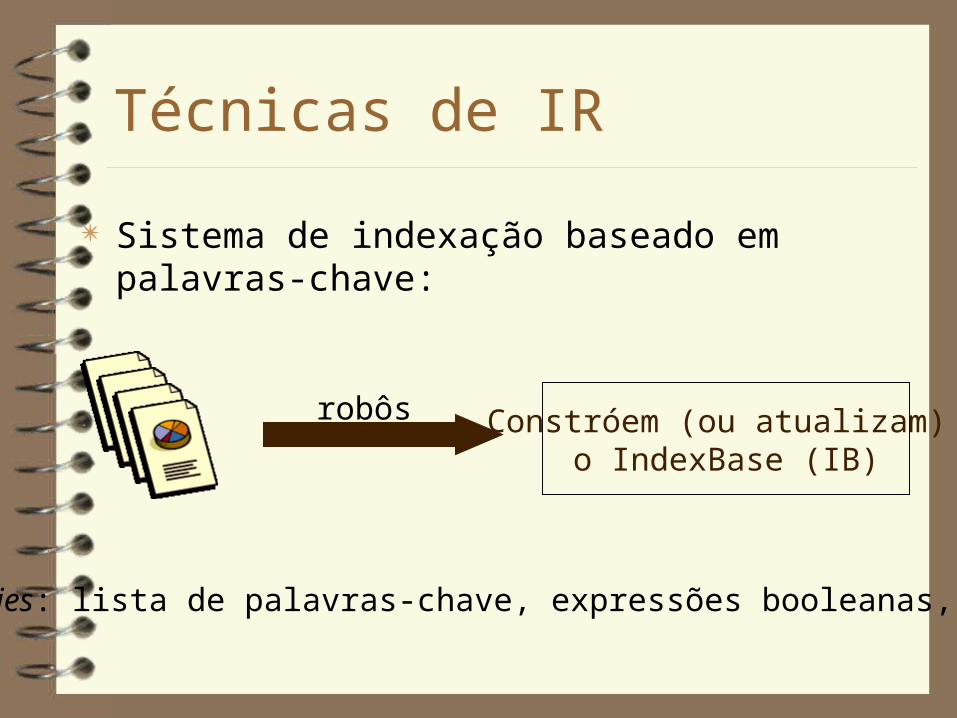
Técnicas de IR
Sistema de indexação baseado em palavras-chave:
Constróem (ou atualizam) o IndexBase (IB)
robôs
queries: lista de palavras-chave, expressões booleanas, etc.

Sistemas de Busca na WebArquitetura
.Database
SearchEngine
QueryServer
AgentsRobots
InternetWebspace

Técnicas de IR
Term Frequency-Inverse Document Frequency (TFIDF): atribui pesos às palavras de um documento. TF(w): frequência da palavra w (número de vezes que w aparece no documento. DF(w): frequência de documentos com a palavra w (número de documentos em que a palavra ocorre).
)(log)()(
DFD
TFTFIDF
D = número total de documentos.

A Indexação da Web (1) Tarefa bastante difícil
– Grande amplitude– Grande taxa de crescimento– Volatilidade dos documentos armazenados
• Tempo médio de vida de um documento na Web é de 75 dias, com uma grande parcela de documentos sendo modificados a cada dez dias.
• 10% dos links armazenados não mais existem– Necessidade de grandes investimentos em
hardware

A Indexação da Web (2)
Mesmo os mecanismos de busca mais poderosos indexam apenas amostras de cada site– AltaVista - máximo de 600 páginas por site
Os mecanismos de pesquisa cobrem a metade ou menos das páginas existentes
Acesso negado por alguns sites aos mecanismos de busca

A Indexação da Web (3) O mais importante hoje não é ser o maior e sim o melhor Tenta-se indexar inteiramente apenas os sites mais
frequentemente visitados As respostas a 90% das perguntas são encontradas dentre
apenas um milhão de páginas Mais de 90% das páginas nunca são acessadas Duplicação de informações Enorme trabalho para manter os índices “limpos”

A Indexação da Web (4) Não existe nenhum mecanismo de busca que indexe
toda a Web– O avanço da tecnologia levou à criação de novos formatos
de armazenamento de documentos que são difíceis ou impossíveis de se indexar criando sites “infinitos” em tamanho
• Bancos de Dados• Conteúdo gerado dinamicamente• Arquivos PostScript, PDF
Bancos de dados não são usados na indexação– Recurso caro
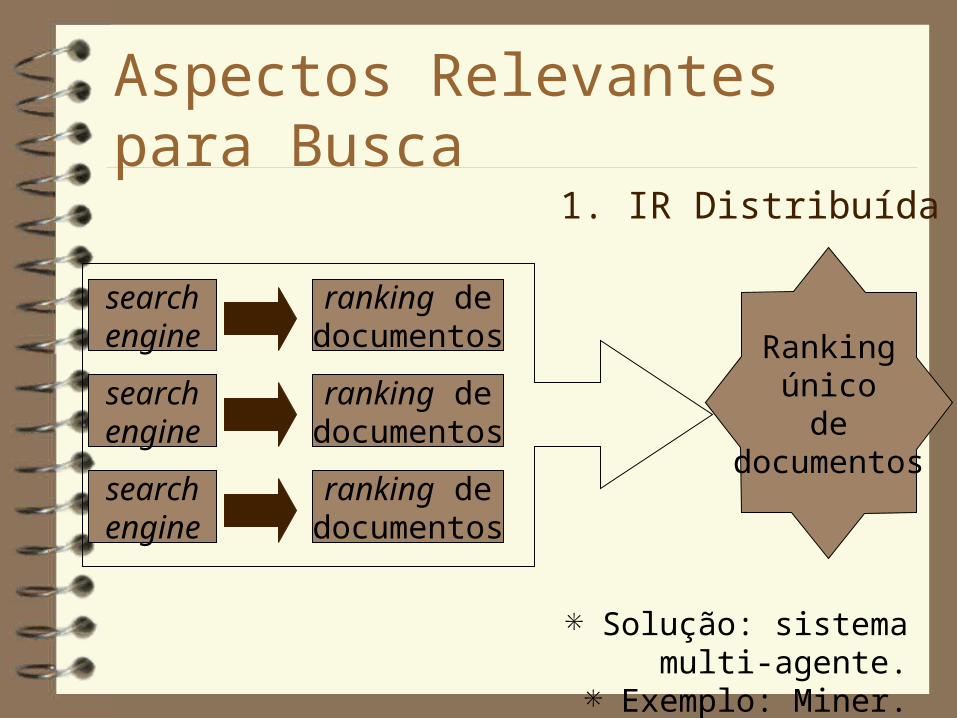
Aspectos Relevantes para Busca1. IR Distribuída
Solução: sistema multi-agente. Exemplo: Miner.
searchengine
searchengine
searchengine
ranking dedocumentos
ranking dedocumentos
ranking dedocumentos
Rankingúnico
dedocumentos

Aspectos Relevantes para Busca2. Eficiência na Indexação
• tempo de resposta da query;• velocidade de indexação.
Pesquisas na área: novos algoritmos para solucionar estes problemas; algoritmos de compressão de textos (diminuindo o tempo de armazenamento e de manipulação); capacidade de lidar com vários tipos de arquivos (SGML, HTML, Acrobat, etc.).

Aspectos Relevantes para Busca4. Expansão do Vocabulário
A informação buscada pode ser expressada pordiferentes palavras nos documentos relevantes.
Latent Semantic Indexing (LSI): transforma o documento e a representação da query; utilizando-se um dicionário de sinônimos..

Aspectos Relevantes para Busca5. Interface do sistema
As interfaces devem tornar o sistema de fácil uso e compreensão.
Devem suportar funções tais como: formulação de queries; apresentação da informação recuperada; feedback; browsing.
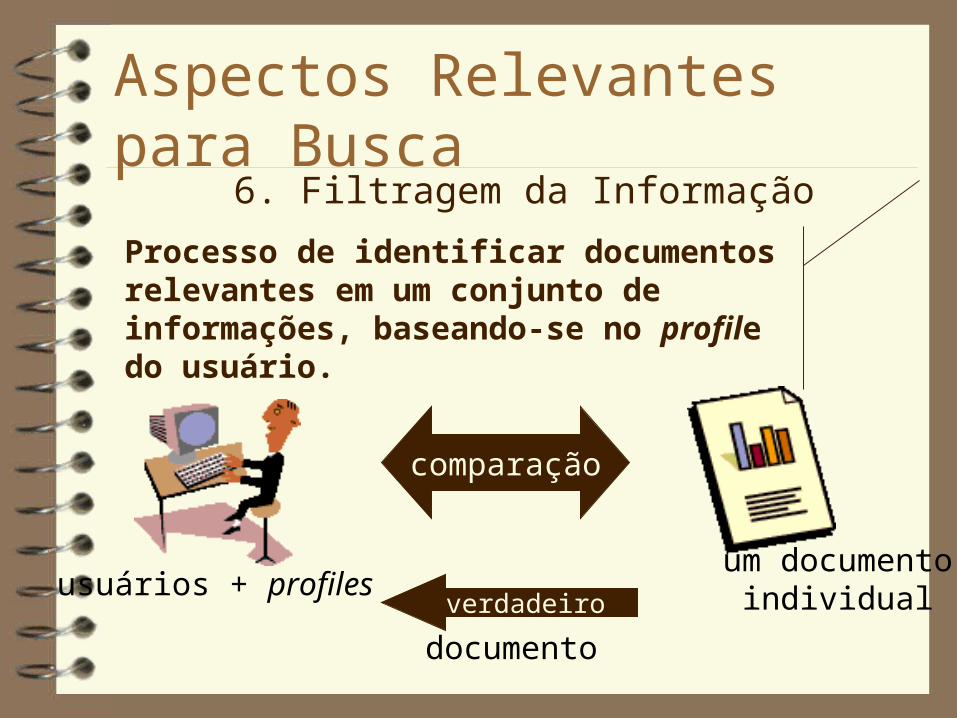
Aspectos Relevantes para Busca6. Filtragem da Informação
Processo de identificar documentos relevantes em um conjunto de informações, baseando-se no profile do usuário.
usuários + profiles
comparação
um documentoindividualverdadeiro
documento

Aspectos Relevantes para Busca6. Filtragem da Informação
Deve lidar com um grande volume de documentos (± 10 MB/hora) e muitos usuários (± 10.000).
Eficiência
Algoritmos que fazem uma “podagem”, para separar os documentos relevantes dos não-relevantes.
Eficácia

Metasearching Vantagens
– Pesquisas submetidas simultaneamente a vários mecanismos de busca
– Economia de tempo Desvantagens
– Pesquisas feitas segundo um mínimo denominador comum entre os serviços de busca
• Exceção: ProFusion– Agrupamento das respostas segundo critérios diferentes

Metasearch Metacrawlers não fazem a indexação da Web à semelhança
dos índices. Eles enviam perguntas a vários mecanismos de busca e constroem suas listagens a partir das respostas obtidas
ProFusion– URL: http://www.designlab.ukans.edu/profusion/
AskJeeves– URL:http://www.askjeeves.com
MetaCrawler– URL: http://www.metacrawler.com

Novas Tendências (1)
Filtragem colaborativa– Alexa
• URL: http://www.alexa.com
Crescimento de mecanismos de pesquisa especializados
Metasearching baseado no cliente– WebSleuth
• URL: http://www.promptsoftware.com

Novas Tendências (2)
Agentes– Inquisit
• URL: http://www.inquisit.com
Colaboradores Humanos– The Mining Company
• URL: http://www.miningco.com– Human Search
• URL: http://www.humansearch.com

Mudança no perfil dos serviços
Objetivo: capturar audiências maiores com mudança do perfil de serviços, mudando de ponto de trânsito para ponto de destino – Oferta de endereços eletrônicos gratuitos– Chat– Áreas para discussão– Canais (Channels)
Pagamento para inclusão nas listagens

Histórico

Busca na WebRobôs na Web (não inteligentes) Worm - Oliver McBryan (03/94)
- Primeiro Spider largamente utilizado - Indexa apenas título e cabeçalho.
RBSE(Repository Based Engineering) - (02/94) - Primeiro Spider a indexar por conteúdo - Objetivo de capturar mais informações.

Busca na WebWebCrawler Projeto - Brian Pinkerton (U.Washington-Seattle)
Apresentado - 04/94 c/ base de dados inicial 6000 servidores, respondendo 6000 perguntas/dia sendo atualizado semanalmente.
Funções - Indexação de Documentos e Navegação em tempo real.

Busca na WebWebCrawler-Características Utilizava sistema de indexação detalhado do texto.
Não sobrecarregava a rede, a carga ocorria somente no servidor.
Usava uma estratégia de busca em largura.
Seu Robô cumpre os padrões - Consenso.

Busca na WebWebCrawler-Algorítmo
1. Inicia com conjunto conhecido de documentos.2. Descobre novos documentos.3. Marca os documentos que são retidos
(adicionados para a base de dados de índices).4. Descobre seus links.5. Indexa o conteúdo do documento(título,cabeçalho,
linhas de texto, data de modificação, tamanho do arquivo)

Busca na WebWebCrawler-Mecanismo de Busca
Modo Indexação- Tantos servidores quanto possível.1.Novo servidor encontrado - lista de visita imediata.
2.Um documento de cada novo servidor é retido e indexado antes de visitar algum outro.
3.Quando não há novos servidores, procura nos que já tem até encontrar 1.

Busca na WebWebCrawler-Mecanismo de Busca
Modo de Busca1.Consulta índice-similaridade2.Desta lista os mais relevantes são escolhidos e os links inexplorados são seguidos.3.Novos documentos recuperados/indexados outra consulta.4.Resultados são escolhidos por relevância e novos documentos próximos ao topo da lista são candidatos a próxima exploração.(fish search)5.O processo continua até encontrar suficiente documentos similares para satisfazer o usuário ou até um tempo limite.

Busca na WebWebCrawler AGENTES.
- Utilizava 15 agentes em paralelo.
- Cada novo documento era entregue a um agente que recupera a URL.
- Um agente qualquer respondia ao mecanismo de busca com um objeto contendo conteúdo ou explanação porque o documento não podia ser recuperado, ficando livre.

Busca na WebWebCrawler DATABASE.
- Atualizada após algumas 100 de documentos.
- Indexava por palavra(relevância)- palavras que apareciam frequentemente no documento e infrequentemente no domínio de referência são atribuídos maior peso. - Cada objeto era armazenado numa árvore binária em separado : documentos, servidores e links.

Busca na WebWebCrawler QUERY SERVER
- Usuário entra com uma palavra chave.
- Os títulos e URLs de documentos contendo algumas ou todas as palavras são recuperadas do índice.
- É apresentada ao usuário lista ordenada por relevância. - Relevância - é uma média ponderada do peso da palavra no documento e seu peso na pergunta.

Busca na WebLycos Projeto - Michael Mauldin ( Carnegie Mellon-08/94)
Lycos(06/95) - características: 5 M URLs, 1,2 M Documentos, 3,9 M URLs a explorar, 1,8 B sumários.
Busca em profundidade.
Explora os espaços - HTTP, FTP e Gopher
Ignora os espaços/ extensões - Wais, Telnet, Usenet etc. - exe, gif, gz, tar, wav etc.

Busca na WebLycos - Indexação OBJETIVO - reduzir armazenamento.
- Título, cabeçalho e Sub.
- 100 mais importantes palavras(TF*IDF).
- Primeiras 20 linhas.
- Tamanho em bytes e Número de palavras.

Busca na WebLycos - Algorítmo Quando 1 URL é recuperada, procura por
outros links e coloca numa fila interna A escolha da próxima URL a explorar é
aleatória entre - HTTP, FTP e Gopher, colocadas em fila por ordem de preferência.
Preferência - Documentos populares (com muitos links) e menores URLs (explorar a raiz)

Arquitetura do BRight!
Brokers
Servidoresde Índices
Web

EscalabilidadeServidores Web Menor carga de trabalho para indexação
Robôs Indexadores Escopos mais restritos
Canais de TransmissãoMenor tráfego redundanteUsuárioEscolha transparente de servidores de índices

Aspectos Relevantes para Busca8. Recuperação Multimídia
Refere-se às técnicas em desenvolvimento para que se possa indexar e acessar imagens, vídeos e sons sem uma descrição para texto.
Soluções gerais para a indexação de de multimídia são difíceis (soluções específicas).
Reconhecimento de faces
Indexação de imagens peladistribuição de cores

Diretrizes ao escrever um robô QUESTIONAR : É necessário ? Posso arcar
com essa responsabilidade ? Não descer muitos níveis. IDENTIFICAR seu robô e a si próprio. Anunciá-lo antes de disponibilizá-lo. Avisar aos administradores se ele visitará
poucos servidores e também seu provedor. Testar localmente antes, extensivamente.

Diretrizes ao escrever um robô NÃO APROPRIAR-SE dos servidores :O
robô deve ir devagar e alternando vários servidores.
Processar apenas os dados que interessam : tipos de arquivos, data dos arquivos.
Não rodá-lo com freqüência, tentando buscar novos links.
Rodá-lo em horário oportuno.

Diretrizes ao escrever um robô Evitar armadilhas : círculos, formulários e
URLs sem trailing. Controlá-lo : Interatividade e um log-BD
público com estatísticas de sucesso, hosts acessados recentes e tamanho de arquivos.
Ética : respeitar o princípio de exclusão. Avisar aos administradores sobre links com
erros.

Prevenindo-se contra robôs# /robots.txt# mail webmaster<server> for criticsUser-agent: webcrawlerDisallow:User-agent: lycraDisallow: \User-agent: *Disallow: \tmpDisallow: \logs
<meta name=“robots” content=“noindex/nofollow”>