accounting data structure zhang gang, deng ziyan
TRANSCRIPT

Accounting Data Structure
ZHANG Gang, DENG Ziyan

table_name datasize(M)ac_in_lhcb-production_job 0.2813Mac_in_lhcb-production_jobstep 0.3906Mac_key_lhcb-production_job_finalmajorstatus 0.0156Mac_key_lhcb-production_job_finalminorstatus 0.0156Mac_key_lhcb-production_job_jobclass 0.0156Mac_key_lhcb-production_job_jobgroup 1.5156Mac_key_lhcb-production_job_jobtype 0.0156Mac_key_lhcb-production_job_processingtype 0.0156Mac_key_lhcb-production_job_site 0.0156Mac_key_lhcb-production_job_user 0.0156Mac_key_lhcb-production_job_usergroup 0.0156Mac_key_lhcb-production_jobstep_eventtype 0.0156Mac_key_lhcb-production_jobstep_finalstepstate 0.0156Mac_key_lhcb-production_jobstep_jobgroup 0.0781Mac_key_lhcb-production_jobstep_processingstep 0.0156Mac_key_lhcb-production_jobstep_processingtype 0.0156Mac_key_lhcb-production_jobstep_runnumber 0.1875Mac_key_lhcb-production_jobstep_site 0.0156Mac_type_lhcb-production_job 4905Mac_type_lhcb-production_jobstep 803M

DIRAC / AccountingSystem / DB / AccountingDB.py
Naming Rules def _getTableName( tableType, typeName, keyName = None ):
"""Generate table name"""
if not keyName: return "ac_%s_%s" % ( tableType, typeName ) elif tableType == "key" : return "ac_%s_%s_%s" % ( tableType, typeName,
keyName ) else: raise Exception( "Call to _getTableName with tableType as
key but with no keyName" )

“type_job” tableField TypeJobGroup varchar(64)DiskSpace bigint(20) unsignedInputDataSize bigint(20) unsignedFinalMajorStatus varchar(32)OutputDataSize bigint(20) unsignedInputSandBoxSize bigint(20) unsignedOutputDataFiles int(10) unsignedNormCPUTime int(10) unsignedUser varchar(32)JobType varchar(32)JobClass varchar(32)ProcessingType varchar(32)ExecTime int(10) unsignedCPUTime int(10) unsignedstartTime int(10) unsignedUserGroup varchar(32)FinalMinorStatus varchar(64)Site varchar(32)ProcessedEvents int(10) unsignedOutputSandBoxSize bigint(20) unsignedInputDataFiles int(10) unsignedendTime int(10) unsigned
Field TypeJobGroup varchar(64)DiskSpace bigint(20) unsignedInputDataSize bigint(20) unsignedFinalMajorStatus varchar(32)OutputDataSize bigint(20) unsignedid int(11)InputSandBoxSize bigint(20) unsignedOutputDataFiles int(10) unsignedNormCPUTime int(10) unsignedtakenSince datetimeUser varchar(32)taken tinyint(1)JobType varchar(32)JobClass varchar(32)ProcessingType varchar(32)ExecTime int(10) unsignedCPUTime int(10) unsignedstartTime int(10) unsignedUserGroup varchar(32)FinalMinorStatus varchar(64)Site varchar(32)ProcessedEvents int(10) unsigned
OutputSandBoxSize bigint(20) unsigned
InputDataFiles int(10) unsignedendTime int(10) unsigned
“in_job” table
Red items: group byBlack items: plot to generate
Blue items: not in type_job table

Information from web portal

Key tablesDIRAC / AccountingSystem / Client / Types / Job.py def __init__( self ): BaseAccountingType.__init__( self ) self.definitionKeyFields = [ ( 'User', 'VARCHAR(32)' ), ( 'UserGroup', 'VARCHAR(32)' ), ( 'JobGroup', "VARCHAR(64)" ), ( 'JobType', 'VARCHAR(32)' ), ( 'JobClass', 'VARCHAR(32)' ), ( 'ProcessingType', 'VARCHAR(32)' ), ( 'Site', 'VARCHAR(32)' ), ( 'FinalMajorStatus', 'VARCHAR(32)' ), ( 'FinalMinorStatus', 'VARCHAR(64)' ) ]
Fields in “definitionKeyFields” are items in “Group by”

Key tables self.definitionAccountingFields = [ ( 'CPUTime', "INT UNSIGNED" ), ( 'NormCPUTime', "INT UNSIGNED" ), ( 'ExecTime', "INT UNSIGNED" ), ( 'InputDataSize', 'BIGINT UNSIGNED' ), ( 'OutputDataSize', 'BIGINT UNSIGNED' ), ( 'InputDataFiles', 'INT UNSIGNED' ), ( 'OutputDataFiles', 'INT UNSIGNED' ), ( 'DiskSpace', 'BIGINT UNSIGNED' ), ( 'InputSandBoxSize', 'BIGINT UNSIGNED' ), ( 'OutputSandBoxSize', 'BIGINT UNSIGNED' ), ( 'ProcessedEvents', 'INT UNSIGNED' )
Field in “definitionAccountingFields” are items in “Plot to gengrate”
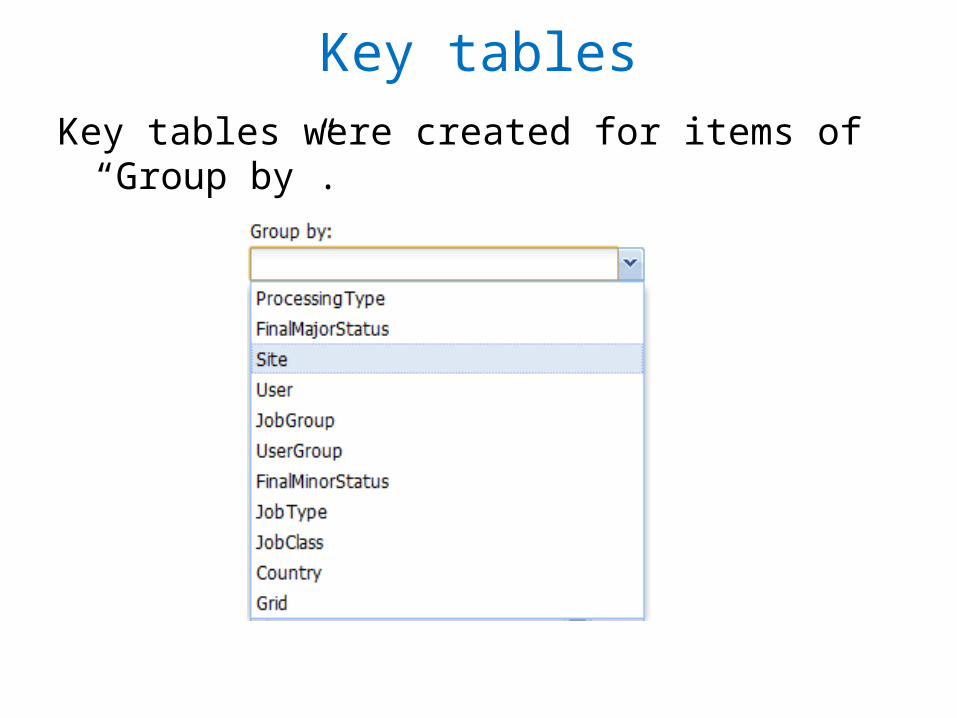
Key tablesKey tables were created for items of “Group by”.

Key tablesac_key_lhcb-production_job_finalmajorstatus 0.0156Mac_key_lhcb-production_job_finalminorstatus 0.0156Mac_key_lhcb-production_job_jobclass 0.0156Mac_key_lhcb-production_job_jobgroup 1.5156Mac_key_lhcb-production_job_jobtype 0.0156Mac_key_lhcb-production_job_processingtype 0.0156Mac_key_lhcb-production_job_site 0.0156Mac_key_lhcb-production_job_user 0.0156Mac_key_lhcb-production_job_usergroup 0.0156M

“key” tables --values
A preview about the contents of these tables
job_finalmajorstatusid value1 Done2 Failed3 Completed
job_jobclassid value
1unknown
2 Single
job_jobtypeid value1 test2 user3 production4 unknown5 sam
6reconstruction
7DataReconstruction
8DataStripping
9 MCStripping
10MCSimulation
job_siteid value1 LCG.LPN.fr
2LCG.Manchester.uk
3 LCG.Liverpool.uk4 LCG.Oxford.uk5 LCG.RAL.uk6 LCG.CESGA.es7 LCG.PIC.es8 LCG.GRIDKA.de9 LCG.CERN.ch10 LCG.Dortmund.de
job_userid value1 joel
2paterson
3 atsareg4 acsmith5 graciani6 roma7 rgracian8 sposs
9szczypka
10 adinolfi
job_usergroupid value1 unknown2 lhcb_user3 lhcb_prod4 lhcb_admin5 diracAdmin6 user
7lhcb_calibration
8 lhcb_conf9 lhcb_data10 lhcb_mc

Key_tables
• These tables store the value of fields. • They only have two fields :id and value.• Usually very small
• The complete information (hyperlinks)• key_job.csv (the “ac_key_job_*”)

in ,type tables

information from in_*,type_* tables Number of records
ac_in_lhcb-production_job 0.2813M about 2000 records
ac_type_lhcb-production_job 4905M millions of records
Show concents hyperlinks:in_job_*type_job_*

The most important part is DIRAC / AccountingSystem / DB / AccountingDB.py In AccountingDB.py ,it define the basic operations to accounting databases systems.There are 5 types in databases,when register a new type ,one must create four kinds of tables for the new type:”ac_in_*_typename”,”ac_tpye_*_typename”,”ac_key_*_typename” and “ac_bucket_*_typename”.There also has a table named ”ac_catalog_*_types” store the information of the five types. self._createTables( { self.catalogTableName : { 'Fields' : { 'name' : "VARCHAR(64)
UNIQUE NOT NULL", 'keyFields' : "VARCHAR(256) NOT NULL", 'valueFields' : "VARCHAR(256) NOT NULL", 'bucketsLength' : "VARCHAR(256) NOT NULL", }, 'PrimaryKey' : 'name' }

About the “ac_bucket_*_typename”,the dump has no information . There are some function are about the “bucket”,and I don’t clearly understand……………..
Here we show some functions in “AccountingDB.py”:

information about in_job table DIRAC / AccountingSystem / DB / AccountingDB.py def __insertInQueueTable( self, typeName, startTime, endTime,
valuesList ):sqlFields = [ 'id', 'taken', 'takenSince' ] + self.dbCatalog[ typeName ][ 'typeFields' ]sqlValues = [ '0', '0', 'UTC_TIMESTAMP()' ] + valuesList + [ startTime, endTime ]
In this Function we can see that “in_*” tables has three more fields than “type_*”tables

‘taken’: 0 and 1 def markAllPendingRecordsAsNotTaken( self ): """ Mark all records to be processed as not taken """ self.log.always( "Marking all records to be processed as not taken" ) for typeName in self.dbCatalog: sqlTableName = _getTableName( "in", typeName ) result = self._update( "UPDATE `%s` SET taken=0" % sqlTableName )
If the record is pending ,set the field “taken”=0

def getWaitingRecordsLifeTime( self ): “Get the time records can live in the IN tables without no retry” def loadPendingRecords( self ):
“Load all records pending to insertion and generate threaded jobs”sqlCond = "WHERE taken = 0 or TIMESTAMPDIFF( SECOND,
takenSince, UTC_TIMESTAMP() ) > %s" % self.getWaitingRecordsLifeTime() result = self._query( "SELECT %s FROM `%s` %s ORDER BY id ASC LIMIT %d" % ( ", ".join( [ "`%s`" % f for f in sqlFields ] ),
sqlTableName, sqlCond,
emptySlots * recordsPerSlot ) )
result = self._update( "UPDATE `%s` SET taken=1, takenSince=UTC_TIMESTAMP() WHERE id in (%s)" % ( sqlTableName,
", ".join( idList ) ) )After load the record ,the field “taken”=1

Fun registerType def registerType( self, name, definitionKeyFields, definitionAccountingFields,
bucketsLength ): “”“Register a new type’’’’” for key in definitionKeyFields: keyTableName = _getTableName( "key", name, key[0] ) if keyTableName not in tablesInThere: self.log.info( "Table for key %s has to be created" % key[0] ) tables[ keyTableName ] = { 'Fields' : { 'id' : 'INTEGER NOT NULL AUTO_INCREMENT', 'value' : '%s UNIQUE NOT NULL' % key[1] }, 'UniqueIndexes' : { 'valueindex' : [ 'value' ] }, 'PrimaryKey' : 'id' } Create ac_key_*_tables for a new type
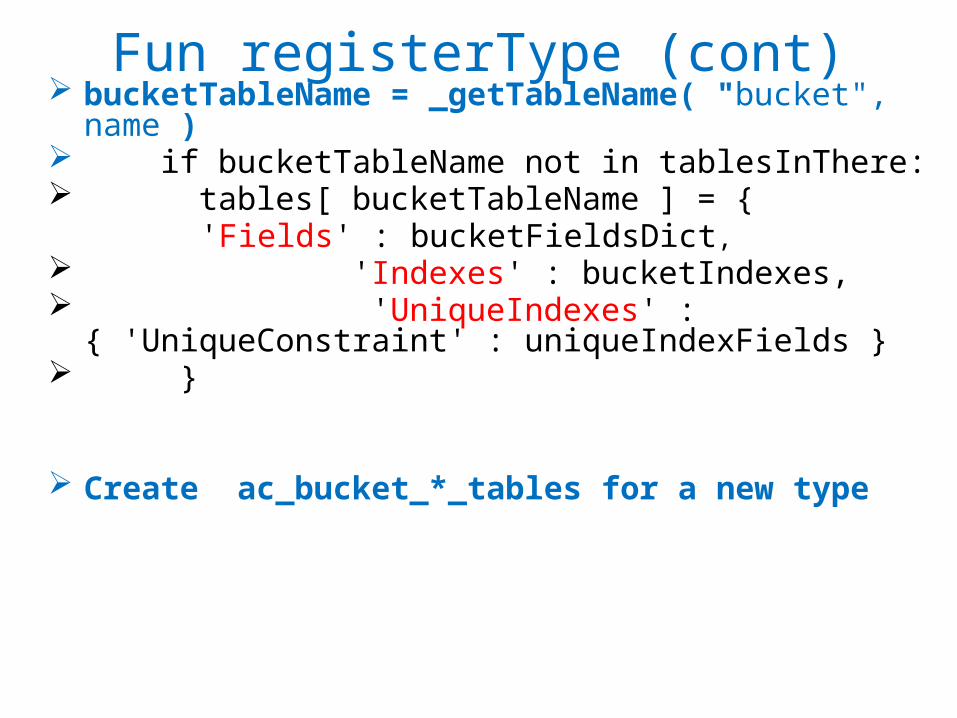
Fun registerType (cont) bucketTableName = _getTableName( "bucket", name ) if bucketTableName not in tablesInThere: tables[ bucketTableName ] = {
'Fields' : bucketFieldsDict, 'Indexes' : bucketIndexes, 'UniqueIndexes' : { 'UniqueConstraint' : uniqueIndexFields } }
Create ac_bucket_*_tables for a new type

Fun registerType (cont) typeTableName = _getTableName( "type", name ) if typeTableName not in tablesInThere: tables[ typeTableName ] = { 'Fields' : fieldsDict } Create ac_type_*_tables for a new type
inTableName = _getTableName( "in", name ) if inTableName not in tablesInThere: tables[ inTableName ] = { 'Fields' : inbufferDict, 'Indexes' : { 'idIndex' : [ 'id' ] }, 'PrimaryKey' : 'id' } Create ac_in_*_tables for a new type

Fun deleteType def deleteType( self, typeName ): """Deletes a type”””
for keyField in self.dbCatalog[ typeName ][ 'keys' ]: tablesToDelete.append( "`%s`" % _getTableName( "key", typeName, keyField ) ) tablesToDelete.insert( 0, "`%s`" % _getTableName( "type", typeName ) ) tablesToDelete.insert( 0, "`%s`" % _getTableName( "bucket", typeName ) ) tablesToDelete.insert( 0, "`%s`" % _getTableName( "in", typeName ) ) retVal = self._query( "DROP TABLE %s" % ", ".join( tablesToDelete ) ) if not retVal[ 'OK' ]: return retVal retVal = self._update( "DELETE FROM `%s` WHERE name='%s'" %
( _getTableName( "catalog", "Types" ), typeName ) ) del( self.dbCatalog[ typeName ] )\
Delete four kinds of tables and delete the information in “ac_catalog_types”and dbCatalog

Fun insertInQueueTable def __insertInQueueTable( self, typeName, startTime, endTime,
valuesList ): sqlFields = [ 'id', 'taken', 'takenSince' ] + self.dbCatalog[ typeName ][ 'typeFields' ] sqlValues = [ '0', '0', 'UTC_TIMESTAMP()' ] + valuesList + [ startTime, endTime ] if len( sqlFields ) != len( sqlValues ): numRcv = len( valuesList ) + 2 numExp = len( self.dbCatalog[ typeName ][ 'typeFields' ] ) return S_ERROR( "Fields mismatch for record %s. %s fields and %s expected" % ( typeName, numRcv, numExp ) ) retVal = self.insertFields( _getTableName( "in", typeName ), sqlFields, sqlValues ) if not retVal[ 'OK' ]: return retVal return S_OK( retVal[ 'lastRowId' ] )
Insert a record in to “in” tables and we can see form the function that “in” tables has three more fields than “type” tables.

Fun insertRecordDirectly def insertRecordDirectly( self, typeName, startTime,
endTime, valuesList ): """Add an entry to the type contents """ retVal = self.insertFields( _getTableName( "type", typeName ), self.dbCatalog[ typeName ][ 'typeFields' ], insertList, conn = connObj )Insert a record to “type” tables.

Fun insertFromINTbale def __insertFromINTable( self, recordTuples ): """Do the real insert and delete from the in buffer table """ result = self.insertRecordDirectly( typeName, startTime, endTime,
valuesList ) if not result[ 'OK' ]: self._update( "UPDATE `%s` SET taken=0 WHERE id=%s" %
( _getTableName( "in", typeName ), iD ) ) self.log.error( "Can't insert row", result[ 'Message' ] ) continue result = self._update( "DELETE FROM `%s` WHERE id=%s" %
( _getTableName( "in", typeName ), iD ) )The function do the real insert .It insert a record from “in”tables to “type” tables and at the same time delete this record in “in” tables

Fun deleteRecord def deleteRecord( self, typeName, startTime, endTime,
valuesList ):"""Add an entry to the type contents"""
Delete a record from the “type” record

Accounting structure
AccountingDB.py
RequestGenerateorHandler.py
DataStoreClient.pyReportClient.py
DataStoreHandler.py
Web protal users
service service
rpcClientrpcClient
User request
User request
my understanding ,may be not right

Web protal

Information from web portal
Provide user to generate five kinds of plots.We should usually use the Job plots.

Information from web portal

Information from web portal

Web code DIRACWeb/dirac/controllers/systems/accountingPlots.pyDIRAC/AccountingSystem/Client/ReportsClient /ReportsClient.py
FUN1 def __getUniqueKeyValues( self, typeName ):rpcClient = getRPCClient( "Accounting/ReportGenerator" )
retVal = rpcClient.listUniqueKeyValues( typeName )FUN2 def __showPlotPage( self, typeName, templateFile ):
repClient = ReportsClient( rpcClient = getRPCClient( "Accounting/ReportGenerator" ) )
retVal = repClient.listReports( typeName )
FUN 3 def __parseFormParams( self ): “parse the Params”return -----> *params

Web code FUN 4 def __queryForPlot( self ):
repClient = ReportsClient( rpcClient = getRPCClient( "Accounting/ReportGenerator" ) )
retVal = repClient.generateDelayedPlot( *params )
FUN 5 def getPlotData( self ): repClient = ReportsClient( rpcClient =
getRPCClient( "Accounting/ReportGenerator" ) ) retVal = repClient.getReport( *params )

Web code
FUN 6 def getPlotImg( self ): “Get plot image”transferClient = getTransferClient(
"Accounting/ReportGenerator" )tempFile = tempfile.TemporaryFile()retVal = transferClient.receiveFile(
tempFile,plotImageFile )

Web code DIRAC / AccountingSystem / Client / ReportsClient.py def getReport( self, typeName, reportName, startTime, endTime, condDict,
grouping, extraArgs = None ): rpcClient = self.__getRPCClient() if type( extraArgs ) != types.DictType: extraArgs = {} plotRequest = { 'typeName' : typeName, 'reportName' : reportName,
'startTime' : startTime, (*Prams) 'endTime' : endTime, 'condDict' : condDict, 'grouping' : grouping, 'extraArgs' : extraArgs } result = rpcClient.getReport( plotRequest ) if 'rpcStub' in result: del( result[ 'rpcStub' ] ) return result

Web code def generateDelayedPlot( self, typeName, reportName,
startTime, endTime, condDict, grouping, extraArgs = None, compress = True ):
if type( extraArgs ) != types.DictType: extraArgs = {} plotRequest = { 'typeName' : typeName, 'reportName' : reportName, 'startTime' : startTime, 'endTime' : endTime, 'condDict' : condDict, 'grouping' : grouping, 'extraArgs' : extraArgs } return codeRequestInFileId( plotRequest, compress )
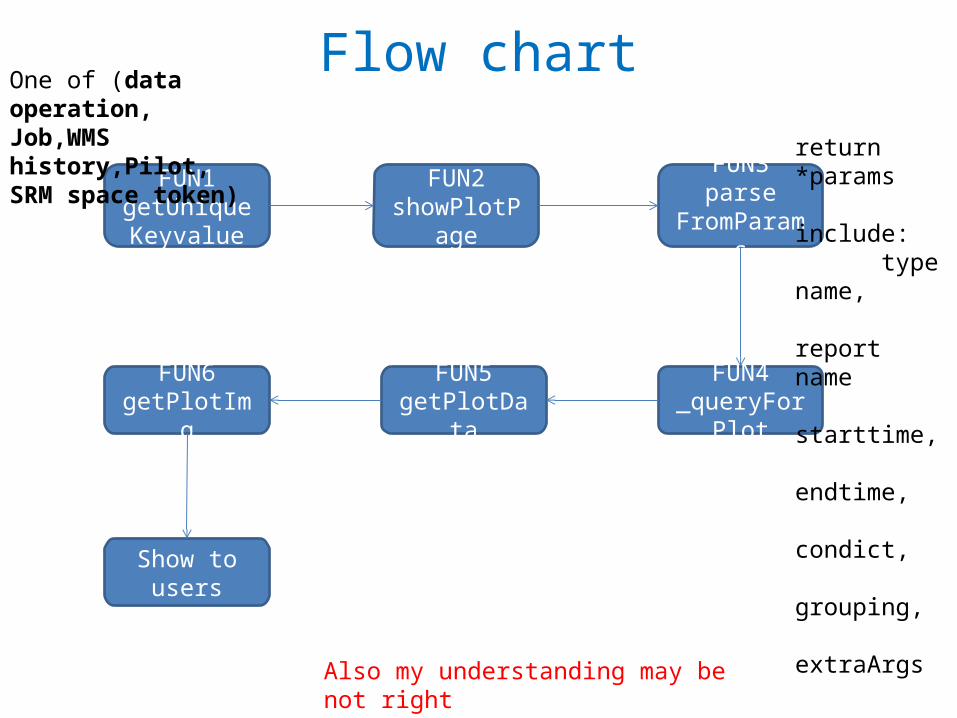
Flow chart
FUN1getUniqueKey
value
FUN2showPlotPage
FUN6getPlotImg
FUN5getPlotData
FUN3parse
FromParams
FUN4_queryForPlot
Show to users
Also my understanding may be not right
One of (data operation,Job,WMS history,Pilot,SRM space token) return *params
include: type name, report name starttime, endtime, condict, grouping, extraArgs

The script :mysqlredis

The script• Compare list and hashes ,seem that lists is
simple ,chose the list to store data in redis• The data fetch from mysql is a dictionary• Each field in table is a list in redis .• When you want to select record ,just select the value in all lists that has the same index.

The script
field1 field2 field n
Record x ………..

The script The key code:Db = MySQLdb.connect(user='root',passwd='y01478',db='myjob', cursorclass=MySQLdb.cursors.DictCursor)
cursorclass=default,the result of fetchall like this:[value1,value2,…..] the value in the list is a strings cursorclass=MySQLdb.cursors.DictCursor ,the result like this:[{k1:v1,k2:v2},{k3:v3,k4:v4},…...,] the values in the list is a
dict ,convenience to transfer to redis.

The script-function
def transToList(self): print 'start transfer...' for items in self.temp(temp= myCurs.fetchall() for key,value in items.items(): if not value: value='0' self.r.rpush(key,value) print 'completed'

The script-function def showList(self): ''' show the data in the list in redis ''' for key in self.temp[0]: print 'The values of %s is
%s'%(key,self.r.lrange(key,0,-1))

The script-function def selectRange(self,start,end):
for recordNum in range(start,end): for key in self.temp[0]: self.r.rpush(recordNum,self.r.lindex(key,recordNum)) print 'The record%s is: %s'%(recordNum+1, self.r.lrange(recordNum,0,-1))
Put the value (has the same index in these lists) in a new list named recordNum.

The script Can :• The script can transfer the data in tables in mysql to
some list in redis.• Can select some records by index
Can not: (need improve)• Can not select records by some specific parameters
such as select records “where id =…”