à partir de données simulées - remede.org · approche à la fois pragmatique, par...
TRANSCRIPT

Master 1 Sciences et Technologies de la Santé
Université d’Auvergne – UFR Médecine
Initiation à la l’analyse statistique sur R
à partir de données simulées
Responsable de stage : Monsieur le Docteur L. Ouchchane
Présenté
par
Guillaume Teluob

GLOSSAIRE
BIP : Bipariétal (diamètre)
CA : Circonférence abdominale
DG : Diabète Gestationnel
DT2 : Diabète de Type 2
EPF : Estimation de Poids Fœtal
FCS : Fausses Couches Spontanées
Fem : Fémur (longueur fémorale)
GEU : Grossesse Extra Utérine
GG : Grossesses gémellaires
HGPO : Hyperglycémie Provoquée Orale
IC : Intervalle de Confiance
IDb : Identifiant bébé
IDm : Identifiant mère
OR : Odds Ratio
PC : Périmètre Crânien
SA : Semaines d’aménorrhée
T1, T2, T3 : Trimestre de grossesse

SOMMAIRE
I. INTRODUCTION........................................................................................................................................ 1
A. PRE-REQUIS ................................................................................................................................................... 2 B. BIBLIOGRAPHIE SUR LE PROGRAMME R® .............................................................................................................. 5
II. SIMULATION DE DONNEES ....................................................................................................................... 6
A. INTRODUCTION ............................................................................................................................................... 6 B. LANGAGE DE BASE SUR R® ................................................................................................................................. 7 C. LA DATA FRAME .......................................................................................................................................... 8 1. Définition ............................................................................................................................................... 8 2. Commandes dans R® ............................................................................................................................. 9
D. EXERCICES D’APPLICATION ................................................................................................................................ 9 E. MATERIEL ET METHODE ................................................................................................................................. 10 F. CREATION D’UNE TABLE « MUM » .................................................................................................................. 13 G. CREATION D’UNE TABLE « FŒTUS »............................................................................................................... 13 H. SIMULATION DE VARIABLES ............................................................................................................................. 14 I. CREATION DE LA TABLE TEMPORAIRE « TMP » .................................................................................................... 16 J. LES LIENS ENTRE LES DIFFERENTES VARIABLES POUR LES VARIABLES FŒTALES ............................................................. 17 1. Echographie du premier trimestre : lien entre clarté nucale et longueur cranio-caudale ................... 17 2. Echographie du deuxième trimestre : lien entre les biométries et le CO expiré................................... 17
K. DIAGRAMME DES FLUX ................................................................................................................................... 21
III. REPRESENTATIONS GRAPHIQUES ........................................................................................................... 22
A. REPRESENTATION GRAPHIQUE DE VARIABLES QUALITATIVES ................................................................................... 22 B. REPRESENTATION GRAPHIQUE D’UNE MOYENNE ET D’UNE VARIABLE QUALITATIVE ..................................................... 25 C. REPRESENTATION GRAPHIQUE DE VARIABLES QUANTITATIVES ................................................................................. 25
IV. ANALYSES STATISTIQUE ..................................................................................................................... 29
A. INTRODUCTION ............................................................................................................................................. 29 B. ANALYSES UNIVARIEES : TEST DE LIAISON ET DE COMPARAISON .............................................................................. 29 1. Test du Chi-carré d’indépendance ....................................................................................................... 29 2. Comparaison de moyennes .................................................................................................................. 32 3. Normalité d’une distribution ............................................................................................................... 33 4. Mesure d’impact .................................................................................................................................. 35
C. ANALYSE MULTIVARIEE : ................................................................................................................................. 36 1. Ajustement .......................................................................................................................................... 36 2. Recherche d’un phénomène dose-effet ............................................................................................... 37 3. Recherche de facteurs associés............................................................................................................ 39
V. CONCLUSION ......................................................................................................................................... 41

1
I. INTRODUCTION L’évolution moderne de la médecine aboutit au concept de médecine fondée sur les
preuves et non plus sur le seul empirisme, la conviction intime, etc. Ceci explique que dans
l’enseignement de la médecine moderne, il soit nécessaire de transmettre des
connaissances de natures scientifiques, mathématiques ou statistiques afin que les futurs
praticiens dans le domaine de la santé (médecins, dentistes, pharmaciens, sages-femmes,
infirmiers, masso-kinésithérapeutes etc) se forgent une solide culture d’évaluation. Les UFR
souhaitent à juste titre produire des professionnels formés à la méthodologie scientifique et
à la démarche de recherche ainsi que des lecteurs avisés et critiques de la littérature
scientifique.
Sage-femme de formation, j’ai été sensibilisé lors de mes études à ces disciplines. Le
diplôme d’état est délivré après soutenance d’un mémoire à forte tendance scientifique et
statistique. Mon expérience m’a conduit à orienter ce travail vers une contribution à rendre
plus concret et plus efficace l’enseignement de la méthodologie statistique au moyen d’une
approche à la fois pragmatique, par l’utilisation d’exemples concrets, et technique, par la
mise en œuvre intégrée des analyses à l’aide du logiciel R®. Le pari de ce travail est qu’en
centrant les questionnements sur les aspects cliniques, en reléguant au rang d’outil les
aspects techniques et en minimisant les aspects théoriques. Les futurs lecteurs trouveront
dans ce recueil, je l’espère, le moyen de se décomplexer vis-à-vis de la méthodologie
statistique et ainsi de lever les principales barrières que rencontrent la plupart des étudiants
lorsqu’ils s’engagent dans une démarche de recherche.
Ce mémoire a été mené dans le cadre de la première année du Master « Sciences et
technologies de la santé ». Il est l’aboutissement d’un stage au laboratoire de Biostatistique,
Informatique Médicale et Technologie de la Communication (service rattaché à l’UMR 6284
CNRS) de la faculté de médecine de Clermont-Ferrand.
Ce laboratoire a des missions d’enseignement, d’activité hospitalière dans le cadre de
la recherche clinique, ainsi qu’une activité de recherche rattachée à l’unité ISIT (Image
Science for Interventional Technics).
Ce stage a pour objectif d’acquérir des connaissances dans les domaines de la
simulation de données, de la méthodologie et de l’analyse statistique rendant indispensable
l’utilisation d’un outil logiciel de traitement statistique de données.

2
Ce stage s’inscrit donc plus largement dans ma démarche de formation à la Santé
Publique et plus particulièrement dans le domaine de la Biostatistique pour faciliter mon
engagement dans un Master.
Par ailleurs, il est prévu que ce travail soit étoffé afin qu’un support d’enseignement
innovant soit rédigé sur le logiciel R® destiné aux étudiants en Santé.
A. Pré-requis
Il est fortement conseillé d’avoir de bonnes bases en mathématiques et statistiques. Nous
allons pour cela tenter de faire un bref rappel. De nombreux ouvrages sur les statistiques
épidémiologiques sont présents dans la littérature française. Ce rappel s’inspire de l’ouvrage
de Monsieur Thierry Ancelle (1). Il synthétise remarquablement bien les bases de
l’épidémiologie et initie avec méthodologie les statistiques avec des applications concrètes.
Au commencement d’une étude, il est essentiel de se poser plusieurs questions :
� Est-ce que l’étude à déjà été faite ailleurs ? Pour répondre à cette question, une
lecture de la littérature internationale doit être rigoureusement faite et mise à jour
régulièrement pour les sujets largement traités. En effet, il n’est pas improbable
qu’une étude similaire à la votre soit publiée au moment où vous la faites.
� Quel type d’étude est envisagé ? Le choix du type d’étude est primordial. En effet il
reflètera une partie de la « puissance » de l’étude. Il existe deux types d’enquêtes :
� Les enquêtes descriptives : elles ont pour objectif de recueillir des données
afin de brosser un état des lieux à un moment précis. Généralement elles sont
utilisées pour :
Evaluer l’impact d’un programme de prévention, de formation ou
d’information (avant-après).
Décrire partiellement un indicateur avant de procéder à une étude
éventuellement plus complète.
Description éphémère d’une maladie dans une population.
� Les enquêtes étiologiques : elles sont plus compliquées que les enquêtes
descriptives puisqu’elles ont pour objectif de supputer un lien de causalité
entre la survenue d’une maladie et un facteur de risque. Il est important de
noter qu’à aucun moment l’investigateur de l’étude n’a de pouvoir sur le

3
statut d’exposé ou non exposé d’un individu à un facteur étudié. On
différencie trois méthodologies d’enquêtes étiologiques. De la plus simple à la
plus compliquée, il y a les enquêtes cas/témoins, les enquêtes transversales
et les enquêtes de cohorte (exposés/non-exposés).
� Les enquêtes Cas/Témoins : Le principe est de prendre 2 groupes
(« Malades » et « Non malades »). Si la survenue de la maladie est liée
à l’exposition au facteur étudié, alors la fréquence d’exposition à ce
facteur doit être plus élevée dans le groupe des « Malades ». Une
mesure d’association de risque peut être calculée. Elle est appelée
Odd Ratio (OR). L’OR est comprit ente] 0 ; +∞ [. Un OR égale à un
signifie que l’association entre le facteur étudié et la maladie est nulle.
En revanche, un OR>1 signifie que le facteur est un facteur de risque,
et un OR<1 un facteur protecteur (1).
� Les enquêtes transversales : Concrètement le recueil de données
s’effectue au même moment que le diagnostic de la maladie. Le
diagnostic est posé et des questions concernant le facteur étudié sont
posées à l’individu. Au fil du temps une prévalence est mesurée dans
chaque groupe (Exposés/Non exposés). Le rapport des ces prévalences
nous indique la présence éventuelle d’un facteur de risque ou d’un
facteur protecteur. Il est important de garder en mémoire, que ce
rapport n’est qu’une indication et ne permet pas de poser une telle
conclusion. En effet une telle enquête ne permet pas de savoir si la
maladie est apparue avant ou après l’exposition (1).
� Les enquêtes de cohortes : Deux groupes d’individus sains sont suivit
dans le temps. Idéalement la seule différence entre ces groupes est
leur statut d’exposé ou de non-exposé à un facteur. A la fin du suivit si
l’incidence de la maladie diffère significativement entre les groupes,
alors le facteur est considéré comme protecteur ou à risque. La
mesure d’association calculée est nommée Risque Relatif (RR). Il doit
être donné avec un intervalle de confiance généralement fixé à 95%
(IC95%). Si l’IC95% est compris entre ]0 ;1[ alors le facteur est

4
protecteur, si il est compris entre ]1 ; +∞[ alors c’est un facteur de
risque (1).
NB : Nous ne traiterons pas des études expérimentales, et des essais thérapeutiques car ce
sont des études extrêmement onéreuses, et compliquées à gérer. Elles n’intéressent pas en
premiers lieux les lecteurs de ce mémoire. La différence entre ces études réside
essentiellement dans le fait que l’investigateur a un rôle dans l’attribution des facteurs
étudiés.
� Qu’elle est la pertinence de l’étude ? Est-ce que l’étude est justifiée ? Il est en effet
important d’évaluer la pertinence de votre projet et de faire ressortir ce que pourrait
apporter votre étude. Cet apport n’est pas nécessairement un apport novateur ou
révolutionnaire. Il peut être un complément d’information, de données scientifiques,
où même une réflexion supplémentaire sur un sujet.
� Quels sont les moyens à disposition pour réaliser l’étude ?
� Est-ce qu’il y a des problèmes éthiques s’opposant à la réalisation de l’étude ? Si tel
est le cas, le protocole de recherche devra être présenté à un conseil de protection
des personnes.
Dans tout les cas, avant de mener une étude, un protocole d’enquête doit être
pensé, et si possible écrit. Il comporte le maximum d’éléments pensé pour mener à bien
l’enquête. L’objectif principal doit être clairement énoncé ainsi que les objectifs secondaires.
Toutes les définitions doivent être dites (définition de la maladie, des cas/témoins ou des
exposés/non-exposés, définition des facteurs étudiés, etc.). Vous devez impérativement
réfléchir aux variables essentielles permettant de répondre aux objectifs, et aux variables
pouvant être des facteurs de confusion. Les facteurs de confusion sont des facteurs agissant
à la fois sur l’exposition et la maladie. On site classiquement l’âge comme éventuel facteur
de confusion (exemple : Il y a quelques années certains médecins ont pensé que le recours à
la Procréation Médicalement Assistée (PMA) notamment à la Fécondation In Vitro était un
facteur de risque de malformation fœtale. Il est fort probable qu’un des facteurs de
confusion soit l’âge, si nous considérons que les couples ayant recours à la FIV sont en
moyenne plus âgés que la population générale désireuse d’enfant. Par ailleurs il est établi
que l’âge avancé de la mère et du père est un facteur de risque de malformations fœtales.

5
Pour s’affranchir des ces facteurs de confusion, il de convenance d’apparier les groupes
étudiés. L’appariement est le procédé de créer des groupes identiquement comparables sur
certaines variables (âge, sexe, IMC, parité, tabagisme, etc.)
Un rappel sur les variables et leur gestion peut être nécessaire. Il existe deux types de
variables :
� Les variables quantitatives : Ce sont toutes les variables numériques. Elles sont
continues (exemples : le poids, la taille, la glycémie, etc.) ou discrètes (exemples : la
gestité, la parité, la quantité de cigarettes fumées/jour, etc.)
� Les variables qualitatives : Ce sont donc toutes les variables que ne prennent pas de
valeur numérique. Elles peuvent être ordinales (exemples : le pronostic : « sévère »,
« modéré », « favorable », niveau de satisfaction : « très satisfait », « satisfait »,
« non satisfait », etc.), nominales (exemples : la voie d’accouchement : « voie basse
spontanée », « voie basse par extraction instrumentale », « césarienne », le groupe
sanguin : « A », « B », « AB », « O », etc.). on note une particularité de cette dernière
catégorie de variables. Certaines peuvent partager toute une population en deux
catégories. On dit que ce sont des variables binaires. Certaines sont qualifiées de
dichotomiques, booléennes (vrai/faux), ou de Bernoulli (0/1) (1).
B. Bibliographie sur le programme R® R étant un programme gratuit, et très largement utilisé, de nombreux ouvrages sont apparus.
Nous nous sommes formés avec principalement l’ouvrage de P. Spector (2) traitant les
manipulations de données et celui de P-A. Cornillon (3) traitant des analyses statistiques.
L’utilisateur novice sur R peut également se former en s’entrainant avec les différents
tutoriels et exercices de niveaux variables présents sur internet le plus fréquemment dans
les sites universitaires.

6
II. SIMULATION DE DONNEES
A. Introduction
Dans la mesure du possible une simulation doit s’appuyer sur des références
bibliographiques. C’est une étape qui s’inscrit dans la méthodologie épidémiologique car
c’est le seul moyen d’obtenir par avance des données proche du recueil final. L’intérêt d’un
tel recueil est de débuter une analyse planifiée des données qui est un gain de temps non
négligeable. Cette planification pourra dans un deuxième temps s’adapter aux données
réelles.
La simulation s’effectue à l’aide du logiciel Tinn-R Editor® GUI for R® Language and
Environment, version 2.3.7.1 sous Windows® 7 (64 bits). Pour les adeptes du système
d’exploitation Linux®, Tinn-R® n’est pas exécutable. Cependant un autre logiciel nommé R
studio® est une excellente alternative.
Ce logiciel est un langage de programmation et un environnement mathématique
utilisés pour le traitement de données et l'analyse statistique. R® est un logiciel libre
distribué selon les termes de la licence GNU GPL et est disponible entre autre sous
GNU/Linux®, Mac® OS X et Windows® (4). R® représente aujourd'hui l'un des logiciels de
statistiques largement utilisé. De ce fait, de nombreux tutoriels de différents niveaux sont
disponibles sur internet.
Le logiciel Tinn-R se présente avec 3 fenêtres principales (Figure 1) qui peuvent être
déplacées voir même scindées (pour les personnes utilisant un dual screen) selon les
préférences des utilisateurs. La première fenêtre est celle de votre programme. Elle contient
votre code et les commandes d’exécution. La deuxième nommée « Rterm » constitue la
console d’exécution. Elle partage son espace alloué avec une fenêtre affichant les messages
d’erreur. La troisième fenêtre nommée « Tools », affiche les éléments crées par le
programme tels que les variables, les vecteurs et les data frames.

7
Figure 1: Environnement de Tinn-R
Toutes les fonctions utilisées dans le programme de simulation sont décrites plus
précisément dans R en tapant « help (fonction) » par exemple :
help(rnorm)
Dans le cadre de ce mémoire nous avons décidé de créer une simulation basée sur
l’analyse de la relation entre le tabagisme maternel et la diminution du poids de naissance
néonatal du à ce dernier facteur. De nos jours cette relation peut paraitre triviale pour les
professionnels de santé, par conséquent, les conclusions tirées ne seront pas une surprise.
Ce sujet à été fixé car il offrait un panel de possibilités et d’analyses important.
B. Langage de base sur R® Le logiciel R® utilise un panel de fonction extrêmement large. Pour les utilisateurs d’autres
logiciels statistiques et novices dans R, le langage et la logique utilisés peuvent paraitre un peu
compliqué au début. Nous allons ici tenter une approche fondamentale du logiciel sous forme de
catalogue. Des exercices simples sont proposés.
1. Utiliser la flèche inversée : <-
La flèche inversée attribue à l’objet situé à sa gauche la fonction ou valeur située à sa droite. C’est
très certainement le symbole le plus couramment utilisé dans un programme.
X <- Y+Z (Figure 3)

8
2. Toujours créer avant d’attribuer :
Z et Y sont des objets qui doivent être créés avant d’être attribués à X. Si un objet X est fonction d’un
objet Y, il est nécessaire que l’objet Y ait été créé et définit avant.
Y <- 125
Z <- 376
X <- Y+Z Résultat : X = 501
3. Les Vecteurs : c()
Ce sont des objets élémentaires essentiellement caractérisés par leur longueur. Nous utilisons la
fonction c().
Y <- c( 125, 120, 134)
Z <- c( 376, 362)
X <- Y+Z (Figure 3) Z <- c( 376, 362, 333)
X <- Y+Z Résultat : X = 501 482 467
Dans le cas ci-dessus nous avons créé deux vecteurs de 3 nombres en séparant chaque nombre par
une virgule. Il est possible de créer des vecteurs beaucoup plus grands en utilisant deux points. Ainsi
le vecteur c( 125 : 376 ) est un vecteur de 251 nombres croissants équidistants, allant de 125 à 376.
C. La DATA FRAME
1. Définition Les data frames sont des ensembles de listes dont les champs sont les colonnes. Ce sont donc
un ensemble d’objets qui ne sont pas tous forcément du même mode (alphanumérique, binaire,
etc.), mais nécessairement de longueur identique.
Véritable interface visuelle, les data frames sont le pilier de la simulation. Elles sont nécessaires à la
création de variables et permettent leur exportation et leur analyse.
Concrètement, dans le cadre d’une étude, les data frames sont l’équivalence du recueil de données.
Figure 2: Exemple de Data frame

9
2. Commandes dans R® Dans R, une data frame est appelée par la fonction « data.frame ». La longueur de la data frame est
déterminée à l’origine par un vecteur. Par la suite, il sera possible de créer des objets (variables)
directement dans la data frame qui ne seront pas des vecteurs mais dont il faudra faire attention à ce
qu’ils soient de la même longueur que la data frame. Pour créer des variables directement dans la
data frame nous nommons la variable, utilisons le symbole « $ » et le nom de la data frame.
Etape 1: créer la data frame Z <- c( 1 : 5)
X <- data.frame (Z) (Figure 3)
Etape 2: Créer une variable dans la data frame Z$X <- 15*Z
Figure 3: Création d'une variable
Î
D. Exercices d’application Afin de se familiariser avec Tinn-R® nous proposons quelques exercices de basiques. Ces exercices
initient l’utilisateur au langage de R®.
Exercice n°1 : attribuer à l’objet nommé « nb de patients » la valeur 10000.
nb de patients <- 10000
Exercice n°2
2a) Créer un objet nommé « ID » qui serait un vecteur de trois nombres ayant la valeur 2, 756, 312.
ID <- c(2, 756, 312)
2b) Faire en sorte que le vecteur « ID » soit organisé par ordre croissant (fonction sort()).

10
ID <- sort(c(2, 256, 312))
Exercice n°3 : Créer un objet nommé « ID » qui serait un vecteur allant de 1 à 800
ID <- c(1 : 800)
Exercice n°4 : Créer un objet nommé « ID » qui serait un vecteur de longueur « nb de patients » et
commençant par la valeur 1.
ID <- c(1 : nb de patients)
Exercice n°5 :
5a) Créer une table (data frame) nommée « TOT » contenant l’objet « ID » qui est un vecteur de
longueur « nb de patients » et commençant par la valeur 1.
nb de patients <- 10000 ID <- c(1 : nb de patients) TOT <- data.frame (ID)
5b) Créer directement dans la data frame « TOT » un objet nommé « Tabac » qui est un vecteur de
longueur 10000, dont les 4000 premières valeurs sont des 1 et les 6000 dernières sont des 0.
TOT$Tabac <- c( rep(4000, 0), rep(6000, 1) )
5c) Créer directement dans la data frame « TOT » un objet nommé « grossesse » qui est un
vecteur de longueur 10000, dont les valeurs sont fixées selon un tirage aléatoire avec remise
de deux valeurs (0 et 1). Pour les ID ayant la valeur 0 pour « Tabac » la probabilité que le 1
sorte est de 32% et que le 0 sorte est de 68%. Pour les ID ayant la valeur 1 pour « Tabac » la
probabilité que le 0 sorte est de 45% et que le 1 sorte est de 55%.
Attention l’exercice devient plus compliqué car il utilise la fonction sample qui génère des
nombres aléatoires et il nécessite de créer 2 vecteurs dont la somme est égale à 10000. TOT$grossesse[TOT$Tabac == 0] <- sample( c(rep(1, 32), rep(0, 68)), sum(TOT$Tabac == 0), replace == TRUE) TOT$grossesse[TOT$Tabac == 1] <- sample( c(rep(1, 55), rep(0, 45)), sum(TOT$Tabac == 1), replace == TRUE)
A quelques fonctions près nous venons de voir toutes celles qui sont nécessaires à la
simulation que nous nous apprêtons à décrire. Nous verrons secondairement les fonctions
générant des nombres aléatoires pouvant obéir à des lois mathématiques (normale,
binomiale, logarithmique, loi de Poisson).
E. Matériel et Méthode
Nous simulons une étude observationnelle de type Exposés/Non-exposés basée sur
le recrutement sur un an à une échelle interrégionale de 10 000 femmes en couple et ayant

11
un désir de grossesse, âgées de 29 à 33 ans. Cet intervalle est justifié car il englobe des
femmes pouvant avoir eu un enfant (voir plus) tout en excluant l’âge charnière de 35 ans où
les pathologies gravidiques sources d’éventuels facteurs de confusion (exemple : la pré-
éclampsie, l’Hyper-tension Artérielle gravidique, sont des facteurs de risque d’une
hypotrophie fœtale) commencent à croitre.
L’étude débute l’année suivante au recrutement par un suivit des ces femmes sur
une période de 2 ans. L’échantillon est divisé en 2 sous-groupes caractérisés par le statut
déclaré de fumeuse ou non.
Durant ces 2 ans ces femmes sont suivies et nous observons la survenue de
l’évènement grossesse. Dans la simulation l’évènement grossesse peut être inscrit dans une
courbe de survie. La simulation a été faite de façon à ce que si une patiente obtient une
grossesse (Fausse Couche Spontannée (FCS), Grossesse Extra-Utérine (GEU), Grossesse
évolutive), elle est écartée du groupe initial et ne pourra pas être réintégrée. Ainsi on peut
critiquer cette simulation car sur un suivi de 2 ans une patiente peut obtenir plus d’une
grossesse (évolutive), de même qu’elle peut présenter plusieurs FCS.
Concernant le suivi de la grossesse, si nous considérons que l’étude cherche à
établir un lien entre le tabac et le poids de naissance, il convient de surveiller plus
fréquemment la croissance fœtale. Par conséquent, 4 échographies au total sur le trimestre
2 (T2) et trimestre 3 (T3) seront faites pour mesurer les biométries fœtales (au lieu des 2
recommandées).
Environ 25.3% des patientes fument (5) et 30% des femmes auront une grossesse évolutive
(n~3 000). Cette proportion arbitrairement fixée s’appuie en partie sur le taux de fécondité
en France de 2011 calculé par l’INSEE pour la tranche d’âge des 30-34 ans (6). Parmi ces
3000 grossesses, environ 22.0% fument (7). 1.5% des grossesses évolutives sont une
grossesse gémellaire et parmi elles, le taux arbitraire de 10% de fumeuses a été fixé.
Voici concrètement comment la construction de l’échantillon total a débuté dans R®.
� Nous avons créé l’objet « NBpatientot » et lui avons attribué une valeur numérique de
10 000.
� Nous avons créé l’objet « ID » et l’avons défini comme un vecteur allant de 1 à 10 00
grâce à la fonction c().
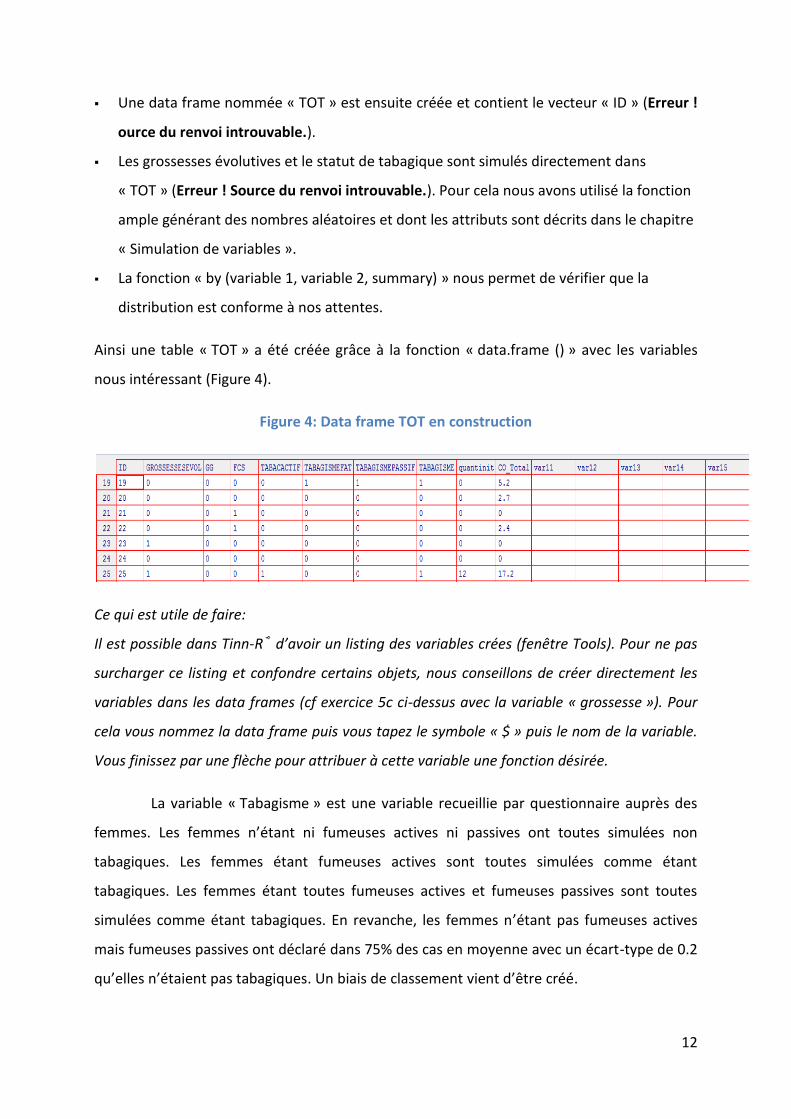
12
� Une data frame nommée « TOT » est ensuite créée et contient le vecteur « ID » (Erreur !
ource du renvoi introuvable.).
� Les grossesses évolutives et le statut de tabagique sont simulés directement dans
« TOT » (Erreur ! Source du renvoi introuvable.). Pour cela nous avons utilisé la fonction
ample générant des nombres aléatoires et dont les attributs sont décrits dans le chapitre
« Simulation de variables ».
� La fonction « by (variable 1, variable 2, summary) » nous permet de vérifier que la
distribution est conforme à nos attentes.
Ainsi une table « TOT » a été créée grâce à la fonction « data.frame () » avec les variables
nous intéressant (Figure 4).
Figure 4: Data frame TOT en construction
Ce qui est utile de faire:
Il est possible dans Tinn-R® d’avoir un listing des variables crées (fenêtre Tools). Pour ne pas
surcharger ce listing et confondre certains objets, nous conseillons de créer directement les
variables dans les data frames (cf exercice 5c ci-dessus avec la variable « grossesse »). Pour
cela vous nommez la data frame puis vous tapez le symbole « $ » puis le nom de la variable.
Vous finissez par une flèche pour attribuer à cette variable une fonction désirée.
La variable « Tabagisme » est une variable recueillie par questionnaire auprès des
femmes. Les femmes n’étant ni fumeuses actives ni passives ont toutes simulées non
tabagiques. Les femmes étant fumeuses actives sont toutes simulées comme étant
tabagiques. Les femmes étant toutes fumeuses actives et fumeuses passives sont toutes
simulées comme étant tabagiques. En revanche, les femmes n’étant pas fumeuses actives
mais fumeuses passives ont déclaré dans 75% des cas en moyenne avec un écart-type de 0.2
qu’elles n’étaient pas tabagiques. Un biais de classement vient d’être créé.
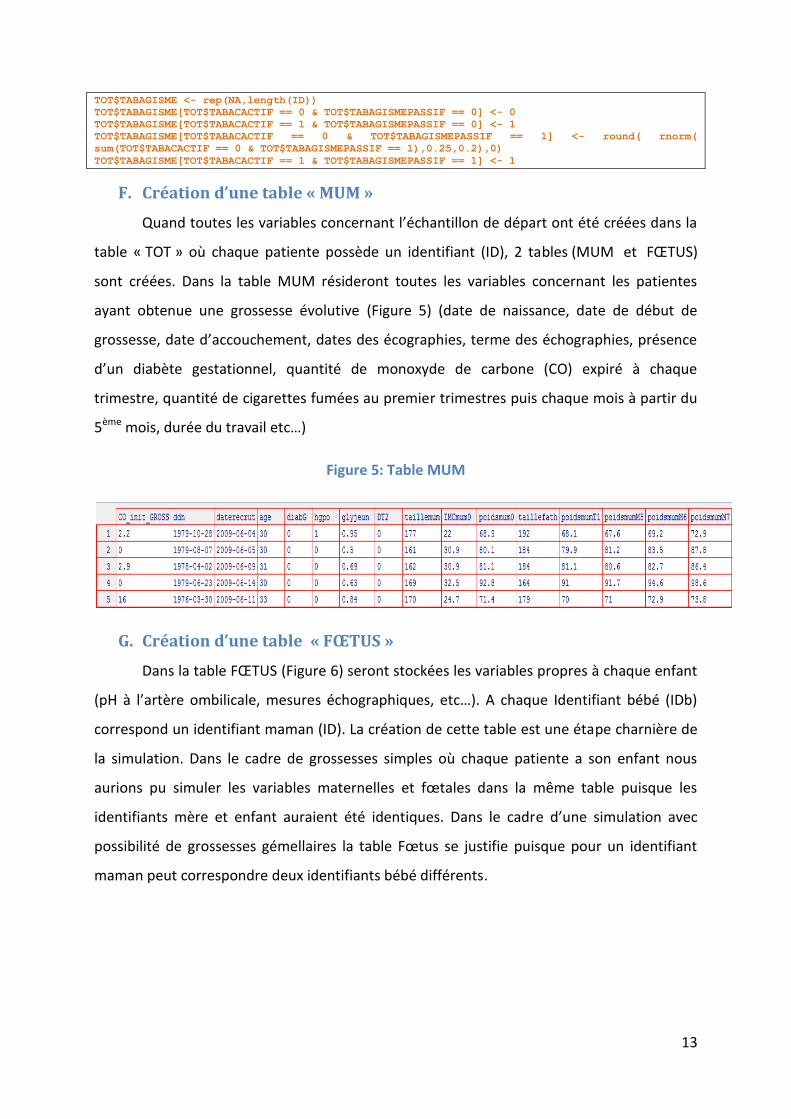
13
TOT$TABAGISME <- rep(NA,length(ID)) TOT$TABAGISME[TOT$TABACACTIF == 0 & TOT$TABAGISMEPASSIF == 0] <- 0 TOT$TABAGISME[TOT$TABACACTIF == 1 & TOT$TABAGISMEPASSIF == 0] <- 1 TOT$TABAGISME[TOT$TABACACTIF == 0 & TOT$TABAGISMEPASSIF == 1] <- round( rnorm( sum(TOT$TABACACTIF == 0 & TOT$TABAGISMEPASSIF == 1),0.25,0.2),0) TOT$TABAGISME[TOT$TABACACTIF == 1 & TOT$TABAGISMEPASSIF == 1] <- 1
F. Création d’une table « MUM »
Quand toutes les variables concernant l’échantillon de départ ont été créées dans la
table « TOT » où chaque patiente possède un identifiant (ID), 2 tables (MUM et FŒTUS)
sont créées. Dans la table MUM résideront toutes les variables concernant les patientes
ayant obtenue une grossesse évolutive (Figure 5) (date de naissance, date de début de
grossesse, date d’accouchement, dates des écographies, terme des échographies, présence
d’un diabète gestationnel, quantité de monoxyde de carbone (CO) expiré à chaque
trimestre, quantité de cigarettes fumées au premier trimestres puis chaque mois à partir du
5ème mois, durée du travail etc…)
Figure 5: Table MUM
G. Création d’une table « FŒTUS »
Dans la table FŒTUS (Figure 6) seront stockées les variables propres à chaque enfant
(pH à l’artère ombilicale, mesures échographiques, etc…). A chaque Identifiant bébé (IDb)
correspond un identifiant maman (ID). La création de cette table est une étape charnière de
la simulation. Dans le cadre de grossesses simples où chaque patiente a son enfant nous
aurions pu simuler les variables maternelles et fœtales dans la même table puisque les
identifiants mère et enfant auraient été identiques. Dans le cadre d’une simulation avec
possibilité de grossesses gémellaires la table Fœtus se justifie puisque pour un identifiant
maman peut correspondre deux identifiants bébé différents.

14
Figure 6: Table Foetus
Voici comment nous avons procédé. Nous avons crée dans la table TOT deux
variables (GROSSESSESMUM, GROSSESSESGGMUM), puis nous avons concaténer (fonction
cbind) dans la table MUM les ID ayant la valeur 1 pour GROSSESSESMUM. Ces ID représentent
uniquement les grossesses évolutives et les grossesses gémellaires. Enfin nous avons
dupliqué les ID ayant eu une grossesse gémellaire en appliquant la fonction « rep (c(x),2) ».
Nous nous retrouvons ainsi avec autant d’ID patientes que d’identifiant enfant.
## les grossesses évolutives TOT$GROSSESSESEVOL <- sample(c(rep(0,700),rep(1,300)),length(ID),replace=T) IDMUM <- cbind(TOT$ID[TOT$GROSSESSESEVOL == 1]) GROSSESSESMUM <- cbind(TOT$GROSSESSESEVOL[TOT$GROSSESSESEVOL == 1]) ## les grossesses gémellaires TOT$GG[TOT$GROSSESSESEVOL == 0] <- 0 TOT$GG[TOT$GROSSESSESEVOL == 1] <- sample(c(rep(0,995),rep(1,15)),sum(TOT$GROSSESSESEVOL == 1),replace=T) ## GROSSESSESGGMUM <- cbind(c(TOT$GG[TOT$GROSSESSESEVOL == 1])) IDb <- c(1 : (sum(TOT$GROSSESSESEVOL == 1) + sum(TOT$GG == 1))) IDFOETUS <- c(c(TOT$ID[TOT$GROSSESSESEVOL == 1 & TOT$GG == 0]),sort(c(rep(ID[TOT$GG == 1],2)))) FOETUS <- data.frame(cbind(ID = IDFOETUS , IDb = IDb)) MUM <- data.frame(ID = IDMUM)
H. Simulation de variables
Pour chaque table il ne reste plus qu’a créer et mettre en relation les variables à
simuler.
Par expérience nous conseillons de simuler les variables de façon inverse à une démarche
diagnostique. Nous prenons l’exemple du DG.
La démarche diagnostique consiste à :
Glycémie à jeun Î Hyper Glycémie Provoquée Orale (HGPO) Î Diabète Gestationnel
La démarche de simulation consiste à simuler les variables dans cet ordre :

15
Diabète Gestationnel Î HGPO Î Glycémie à jeun
Voici un listing non exhaustif des liens entre les différentes variables maternelles :
x Une proportion de femmes enceintes ayant développé un Diabète Gestationnel (DG)
a été simulé. Les variables HGPO (1/0), glycémie à jeun (1/0), DT2 (1/0) ont été
simulé après avoir déterminé le statut de DG. Environ 10% des grossesses simples
développeront un DG tandis que 15% des grossesses multiples auront un DG (8).
x La parité : elle est simulée en fonction du statut tabagique. Si nous avons simulé au
départ une « hypofertilité » chez les fumeuses, il serait donc assez logique que la
parité chez les fumeuses soit en moyenne plus basse que chez les non-fumeuses. La
parité suit arbitrairement une loi normale. Pour les non fumeuses (m=1.5, SD=0.5),
pour les fumeuses (m=1.0, SD=0.5).
MUM$parite <- rep(NA,nrow(MUM)) MUM$parite[MUM$TABAC_ACTIF_GROSS == 0] <- round(rnorm(sum(MUM$TABAC_ACTIF_GROSS == 0),1.5,0.5),0) MUM$parite[MUM$TABAC_ACTIF_GROSS == 1] <- round(rnorm(sum(MUM$TABAC_ACTIF_GROSS == 1),1.0,0.5),0) MUM$parite[MUM$parite <0] <- round(rnorm(sum(MUM$parite <0),0.4,0.001),0)
x La quantité de tabac est simulée afin d’obtenir des données longitudinales.
x La prise de poids maternelle est fonction du DG. Elle forme des données
longitudinales sur chaque mois de grossesses à partir du 1er trimestre.
### poidsmum0 MUM$poidsmum0 <- rep (NA,nrow(MUM)) MUM$poidsmum0 <- round((MUM$IMCmum0*((MUM$taillemum/100)^2)),1) ### 1er Trimestre #MUM$poidsmumT1 <- round((MUM$poidsmum0*runif(nrow(MUM),0.90 ,1)),1) MUM$poidsmumT1[MUM$diabG == 0] <- round(MUM$poidsmum0[MUM$diabG == 0]*runif(sum(MUM$diabG == 0),0.98 ,1),1) MUM$poidsmumT1[MUM$diabG == 1] <- round(MUM$poidsmum0[MUM$diabG == 1]*runif(sum(MUM$diabG == 1),0.98 ,1),1) ### cslt° 5ème mois #MUM$poidsmumM5 <- round((MUM$poidsmumT1*runif(nrow(MUM),0.99,1.03)),1) MUM$poidsmumM5[MUM$diabG == 0] <- round(MUM$poidsmumT1[MUM$diabG == 0]*runif(sum(MUM$diabG == 0),0.99 ,1.02),1) MUM$poidsmumM5[MUM$diabG == 1] <- round(MUM$poidsmumT1[MUM$diabG == 1]*runif(sum(MUM$diabG == 1),0.99 ,1.03),1) ### Etc…
x La durée du W : elle est fonction de la parité. Elle suit une loi normale.
Parité=0 : m=7, SD= 1.5
Parité=1 : m=6, SD=1.8
Parité=2 : m=5.5, SD=2
Parité>= 3 : m=5, SD=1.8

16
x La DEE : elle est fonction de la parité et suit une loi normale.
Parité=0 : m=40, SD= 2.8
Parité>0 : m=20, SD=2.8
x La date de naissance : elle suit une loi normale. Elle est liée aux variables tabac, DG et
DT2 (voir détails sur programme R® en annexe).
I. Création de la table temporaire « tmp »
Une fois la table MUM terminée, une table temporaire nommée « tmp » est créée
(Figure 7). Elle est la résultante de la fonction « merge » qui fusionne les tables selon les
critères demandés. Ici nous avons fusionné les colonnes 1 et 2 de la table FŒTUS avec les
colonnes 1,2,3,…,48 de la table MUM en prenant pour référence la colonne « ID » présente
dans les deux tables avec pour la table FŒTUS des ID supplémentaires pour les jumeaux.
Ainsi les ID de mères ayant une grossesse multiple seront dupliqués et de même pour les
valeurs des autres variables.
tmp <- merge(FOETUS[,c(1:2)],MUM[,c(1,2,3,4,5,9,13,14,15,16,27,28,…,45,46,48)], by =c("ID"))
Figure 7: Data frame temporaire (tmp)
Cette manipulation a pour but de pouvoir simuler des données fœtales à partir de
données maternelles. Par exemple nous pouvons désormais simuler le pH à l’artère
ombilicale propre à chaque enfant en fonction de la durée des efforts expulsifs propre à
chaque parturiente. Nous pouvons également simuler une mesure échographique en
fonction du terme à l’échographie.

17
J. Les liens entre les différentes variables pour les variables Fœtales
1. Echographie du premier trimestre : lien entre clarté nucale et longueur
cranio-caudale
Il est important de noter que la LCC et la CN n’ont pas de lien dans la simulation.
Toutefois il est prévu dans la simulation que la CN peut présenter des valeurs pathologiques
(nuque épaisse). Les MS ont été simulés pathologiques quand la CN>85ème percentile. Pour
des raisons de contraintes de temps, la survenue de T21 n’a pas été simulée, cependant tout
est prévu pour qu’elle soit définie et gérée plus tard ultérieurement.
2. Echographie du deuxième trimestre : lien entre les biométries et le CO
expiré
En ce qui concerne les biométries fœtales, nous avons décidé de les faire varier en
fonction de la variable « Monoxyde de Carbone (CO) expiré » et des variables « DG/DT2 ».
Nous justifions notre choix de la variable CO expiré par l’étude des revues internationales. En
effet les seules données retrouvées sur l’impact du tabac au niveau des biométries fœtales
concernent le CO expiré (9) (10). Quatre catégories ont été prises en compte. Elles sont
décrites ci-dessous en même temps qu’est décrite la simulation du diamètre Bipariétal (BIP).
Interpolation linéaire
L’interpolation linéaire consiste à obtenir des valeurs en millimètres partir de tables
de référence (Tableau 1) faisant correspondre des valeurs en percentile avec des valeurs en
millimètres pour chacun des organes mesurés. Nous pouvons convertir ainsi des percentiles
en millimètres et des millimètres en percentiles. Cela fonctionne aussi pour une masse
(poids de naissance, estimation de poids fœtal (EPF)).
Tableau 1: Références du collège français des échographistes pour le BIP
SA BIP.p3 BIP.p10 BIP.p50 BIP.p90 BIP.p97
…
28 64,5 66,61 71,03 75,52 77,6
29 66,84 68,98 73,5 77,97 80,09
30 69,07 71,21 75,8 80,37 82,52
31 71,22 73,39 78 82,63 84,8
…

18
Les valeurs de percentiles ont été fixes de façon arbitraire et peuvent être discutées
Notes importantes : les associations entre les variables sont strictement arbitraires. Une
lecture de la bibliographie médicale est nécessaire pour affiner ces associations.
Exemple du Diamètre Bi-Pariétal (BIP)
Il suit une loi normale. Les BIP ont été simulés en percentiles pour s’affranchir de la
variable temps. Pour la première mesure, le BIP est « faiblement » fonction du monoxyde de
carbone expiré mesuré au 1er trimestre de grossesse.
Donc pour BIP1 cela donne :
BIP1 [CO_T1 ≥ 0 & CO_T1 ≤ 5] : m=0.5, SD=0.18
BIP1 [CO_T1 > 5 & CO_T1 ≤ 10] : m=0.48, SD=0.18
BIP1 [CO_T1 > 10 & CO_T1 ≤ 20] : m=0.46, SD=0.18
BIP1 [CO_T1 > 20] : m=0.44, SD=0.18
### POUR BIP 1 FOETUS$BIP1 <- rep(NA,nrow(FOETUS)) FOETUS$BIP1[tmp$CO_T1 >= 0 & tmp$CO_T1 <= 5] <- round(100*rnorm(sum(tmp$CO_T1 >= 0 & tmp$CO_T1 <= 5), 0.5, 0.18), 1) FOETUS$BIP1[tmp$CO_T1 > 5 & tmp$CO_T1 <= 10] <- round(100*rnorm(sum(tmp$CO_T1 > 5 & tmp$CO_T1 <= 10), 0.48, 0.18), 1) FOETUS$BIP1[tmp$CO_T1 > 10 & tmp$CO_T1 <= 20] <- round(100*rnorm(sum(tmp$CO_T1 > 10 & tmp$CO_T1 <= 20), 0.46, 0.18), 1) FOETUS$BIP1[tmp$CO_T1 > 20] <- round(100*rnorm(sum(tmp$CO_T1 > 20), 0.44, 0.18), 1) FOETUS$BIP1[FOETUS$BIP1 < 3.0] <- round(100*rnorm(sum(FOETUS$BIP1 < 3.0), 0.10, 0.0001), 1) FOETUS$BIP1[FOETUS$BIP1 > 97] <- round(100*rnorm(sum(FOETUS$BIP1 > 97), 0.80, 0.0001), 1) ### INTERPOLATION LINEAIRE BIPmat <- as.matrix(BIPcsv) FOETUS$BIP1mm <- rep(NA,nrow(FOETUS)) for (i in 1:nrow(FOETUS)) { BIP1v <- as.vector(BIPmat[BIPmat[,1] == tmp$saecho1[i], 2:6]) FOETUS$BIP1mm[i] <- round((approx(x = c(3,10,50,90,97),y = BIP1v, method="linear",rule = 2,xout=FOETUS$BIP1[i])$y),1) }
L’Estimation du Poids Fœtal (EPF)
L’EPF est fonction des biométries ci-dessus. Chaque biométrie possède une influence
plus ou moins importante sur l’EPF.
Les biométries étant simulées par des percentiles, il nous était impossible de calculer
précisément l’EPF. 3 solutions s’offraient à nous. Soit de simuler l’EPF en percentiles de
façon à ce que la moyenne des biométries soit proche de l’EPF. Cette solution n’était pas
satisfaisante car on risquait fortement de perdre en précision. Soit de simuler l’EPF en
percentiles sans prendre en compte les valeurs des biométries. Cette solution était encore

19
moins satisfaisante car nous perdrions l’harmonie que nous avions avec les données
longitudinales simulées pour les biométries fœtales.
La solution retenue était de simuler par une interpolation linéaire les biométries
(BIP, PC, Fem, CA) en millimètres, à l’aide d’abaques (INSERM Unité 155 et collège français
d’échographie fœtale). Au total la formule de L’EPF est donnée par notamment :
LOG10(EPF)= 1.3596 + 0.0064 PC + 0.0424 PA + 0.174 LF + 0.00061 BIP PA - 0.00386 PA LF
EPF = 1.07 x BIP3 + 0.30 x PA2 x LF
C’est cette dernière formule que nous avons utilisé.
Pour l’EPF 4 : Il nous a fallu interpoler l’EPF4 (en grammes à l’origine) en percentiles car un
problème allait se poser pour simuler le poids de naissance à l’aide de références (11).
Le poids de naissance
Il suit une loi normale. Il est comme les biométries fœtales fonction du tabac, DG,
DT2. Il est dans la continuation des données longitudinales concernant les biométries
fœtales.
Figure 8: Schéma de simulation des biométries foetales
pds de naiss interpolation pds de naiss
(g) (perc.) Multiplication par un facteur aléatoire crédible englobant la valeur 1 BIP,PC,Fem,CA (4 valeurs) interpolation BIP,PC,Fem,CA (4 valeurs)
(en perc.) données
longitudinales (en mm) Estimations de Poids Fœtal Formule mathématique (en g) pour obtenir une EPF interpolation Estimations de Poids Fœtal (en perc.)

20
Le PhAO
Il est fonction du tabac. Il suit une loi normale. Par manque de données dur la
relation pHAo et monoxyde de carbone expiré, nous avons décidé de mettre en relation le
pH avec la variable tabagisme actif. Les paramètres de la loi ont été fixé de manière
arbitraire.
pHAo(tabac actif =0) : m=7.22, SD=0.06
pHAo(tabac actif =1) : m=7.19, SD=0.06
Notes: on peut très bien aussi le faire varier avec la DEE et la durée du W. Voir pour
ajustement.
Anomalie du Rythme Cardiaque Foetal
Il suit une loi normale et est fonction du pHAo pathologique (<7.20).
Notes : pH et ARCF sont intimement liés. En réalité le pHAo pathologique est définit à 7.15
mais la prévalence d’une ARCF est supérieure à celle du pH pathologique par conséquent
nous avons augmenté la valeur seuil du pH pour laquelle une ARCF surviendrait.
21
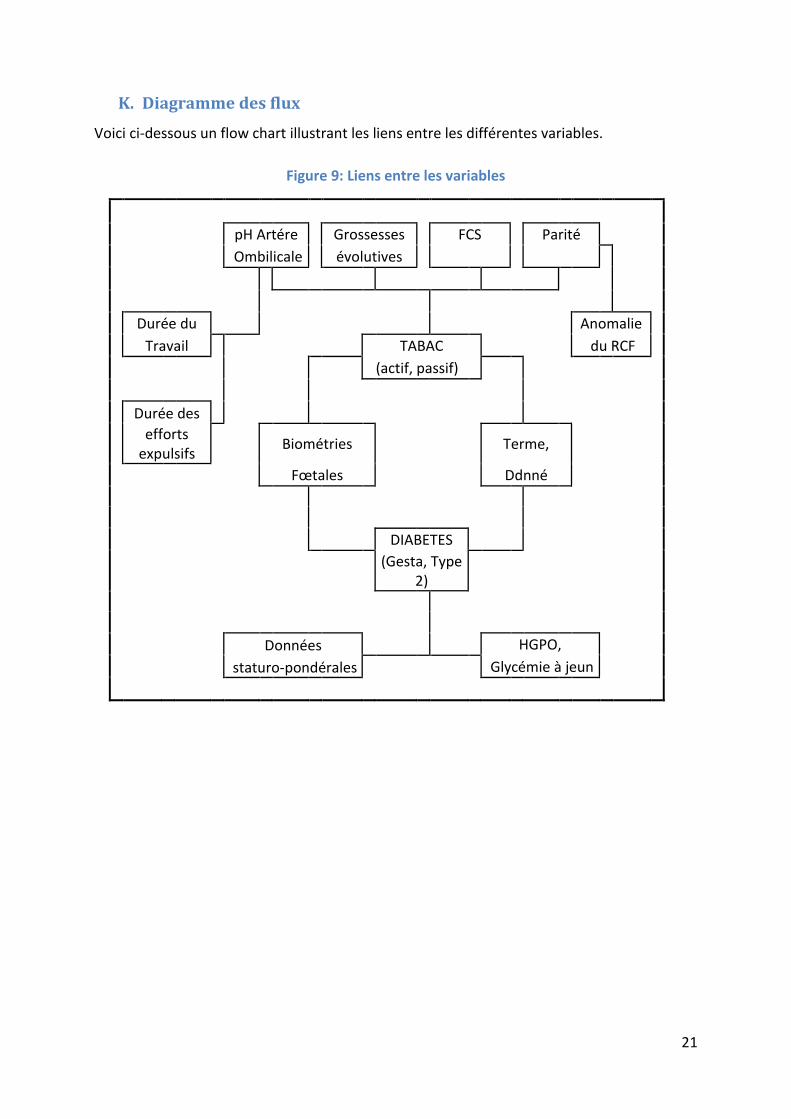
K. Diagramme des flux
Voici ci-dessous un flow chart illustrant les liens entre les différentes variables.
Figure 9: Liens entre les variables
pH Artére Grossesses FCS Parité Ombilicale évolutives Durée du Anomalie Travail TABAC du RCF (actif, passif) Durée des
efforts
expulsifs Biométries Terme, Fœtales Ddnné DIABETES
(Gesta, Type
2) Données HGPO, staturo-pondérales Glycémie à jeun

22
III. REPRESENTATIONS GRAPHIQUES Les graphiques sont souvent le point de départ des analyses statistiques. Il est
essentiel avant de se lancer dans le calcul et l’interprétation des tests statistiques d’obtenir
et de mémoriser une représentation visuelle de différents liens entre les variables. Cette
démarche évite dans bien des cas des erreurs d’interprétation qui peuvent totalement
discréditer le travail de recherche.
Nous allons voir dans ce chapitre comment mettre en forme graphiquement parlant les
variables qualitatives et quantitatives simulées précédemment.
Pour les utilisateurs totalement novices, nous leur conseillons de consulter la
démonstration de quelques représentations graphiques que le logiciel R offre en possibilité.
Pour cela, il faut taper la commande :
demo (graphics)
A. Représentation graphique de variables qualitatives
La simulation a été faite qu’avec des variables quantitatives, c’est pour nous
l’occasion de créer à partir de variables quantitatives tel que le poids de naissance, une
variable qualitative comme la trophicité.
Les nouveau-nés peuvent être classés à la naissance selon leur poids en trois
catégories :
Les macrosomes : ce sont les nouveau-nés dont le poids de naissance est supérieur au 90ème
percentile.
Les hypotrophes : ce sont les nouveau-nés dont le poids de naissance est inférieur au 10ème
percentile (des sous-classes peuvent exister, comme l’hypotrophie sévère si le poids de
naissance est inférieur au 3ème percentile)
Les eutrophes : ce sont les nouveau-nés dont le poids est compris entre le 10ème et le 90ème
percentile.
Nous rappelons que les percentiles des poids de naissance ont été simulés. Nous
allons donc nous servir de cette variable pour créer 3 classes et nous contrôlons le bon
fonctionnement de cette commande avec la fonction « table() »
## Création d'une variable qualitative de 3 classes à partir des percentiles du poids de naissance FINAL$trophicite <- rep(NA,length(FINAL$pdsnneper)) FINAL$trophicite [FINAL$pdsnneper>=90] <- "macrosome" FINAL$trophicite [(FINAL$pdsnneper<90)&(FINAL$pdsnneper>10)] <- "eutrophe" FINAL$trophicite [FINAL$pdsnneper<=10] <- "hypotrophe"

23
table(FINAL$trophicite)
Une fois la variable créée, la fonction « barplot » permet d’afficher à partir d’une table, un
diagramme en barre des différentes catégories de poids de naissance.
## diagramme en barres des catégories de poids de naissance barplot(table(FINAL$trophie))
Figure 10: Répartition des différentes catégories de trophicité
Le graphique ainsi généré (Figure 10) n’a pas grand intérêt dans la mesure où une
seule variable est représentée. Un simple tableau de fréquence est plus parlant et a pour
avantage de ne pas surcharger votre travail. En revanche il est intéressant dans la
construction de graphiques de mettre en relation 2 variables. Notre étude concerne la
relation entre le poids de naissance et le tabac pendant la grossesse. Il serait donc
intéressant de savoir si une interaction peut être présente entre ces deux variables. Nous
allons donc insérer la variable « tabac actif pendant la grossesse » (Figure 11).
## diagramme en barres des catégories de poids de naissance en fonction du tabac actif par(mfrow=c(2,1)) #Pour un affichage sur 2 lignes et 1 colonne barplot(table(FINAL$trophie[FINAL$TABAC_ACTIF_GROSS == 1]), main="catégorie des pdsnne pour tabac actif = 1") #fonction « main= » pour titrer le graphique barplot(table(FINAL$trophie[FINAL$TABAC_ACTIF_GROSS == 0]), main="catégorie des pdsnne pour tabac actif = 0")

24
Figure 11: Trophicité en fonction du tabagisme actif
Ce diagramme en barre semble montrer que la proportion d’enfants hypotrophes
serait supérieure dans le groupe des patientes fumant activement pendant la grossesse. Bien
qu’assez parlant, ce diagramme n’a encore ici pas grand intérêt dans la mesure où un
tableau de fréquence à double entrée serait plus parlant.
prop.table(table(FINAL$trophie, FINAL$TABAC_ACTIF_GROSS))
Cette commande donnant ainsi le Tableau 2:
Tableau 2: Tableau de fréquences de la trophicité fonction de la variable tabagisme actif
0 1
Eutrophe 0,92 0,88
Hypotrophe 0,07 0,11
Macrosome 0,00 0,01
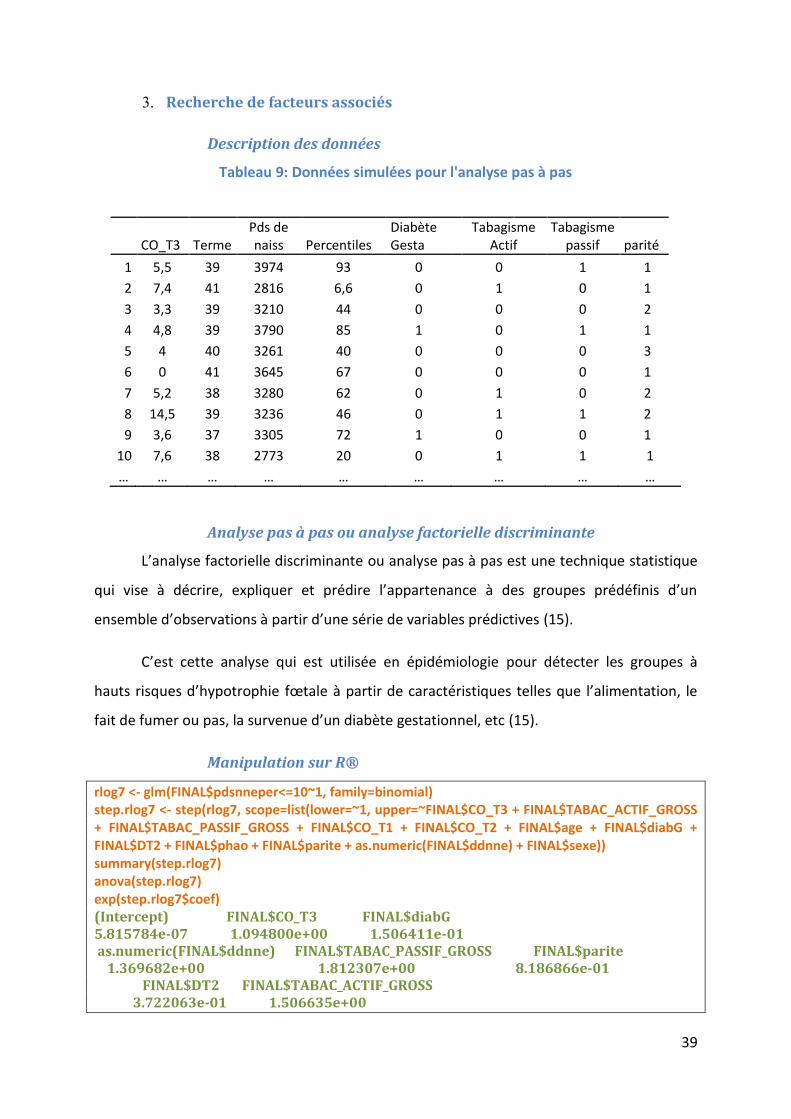
En Erreur ! Source du renvoi introuvable. est présenté des histogrammes de
’acidose fœtale en fonction de la quantité de cigarettes fumées pendant la grossesse. Ce
graphique ne présente que peu d’intérêt si ce n’est qu’il est l’occasion de présenter la
fonction « par(mfrow=c(,)) ». Cette fonction permet d’afficher plusieurs graphiques en un. Le
premier chiffre du vecteur représente le nombre de graphique par colonne et le deuxième
chiffre le nombre de graphique par ligne.

25
B. Représentation graphique d’une moyenne et d’une variable
qualitative
Pour représenter graphiquement la moyenne d’une variable quantitative en
fonction d’une variable qualitative binaire, tout en ayant certains paramètres de dispersion
nous utilisons la fonction « boxplot ». Par exemple, nous souhaitons avoir une idée de la
distribution des poids de naissance en fonction du statut tabagique de la mère (Figure 12).
Pour cela :
boxplot(FINAL$pdsnne[FINAL$TABAC_ACTIF_GROSS == 0],FINAL$pdsnne[FINAL$TABAC_ACTIF_GROSS == 1], main="moyenne pdsnne en fonction de tabac")
Figure 12: Paramètres de dispersion des poids de naissance fonction du « tabagisme actif »
Il est également possible de générer un graphique comme celui du haut avec des
variables catégorielles comme la quantité de CO expiré pendant la grossesse. La difficulté
réside essentiellement à créer ces catégories. Le graphique est présenté en Erreur ! Source
u renvoi introuvable..
Rappel : Créer des catégories FINAL$qTabac <- rep(NA,length(FINAL$quantT3)) FINAL$qTabac [FINAL$quantT3 == 0] <- "abs tabac" FINAL$qTabac [FINAL$quantT3 > 0 & FINAL$quantT3 < 5] <- "moins 5 cig/j" FINAL$qTabac [FINAL$quantT3 >= 5] <- "plus 5 cig/j"
C. Représentation graphique de variables quantitatives
Il est intéressant lorsque l’on rapporte des données longitudinales de pouvoir les
représenter sur une courbe. Cela permet au chercheur d’orienter son analyse, d’évaluer les
Tabac actif=0
Tabac actif=1

26
interactions et d’appréhender d’une certaine manière la physiopathologie. De plus, ils
illustrent bien les résultats de tests statistiques parfois compliqués à comprendre et à
expliquer.
Les graphiques à points font intervenir de nombreuses fonctions de façon redondantes. Par
conséquent, ils ne sont pas spécialement difficiles à créer mais ils demandent d’importantes
lignes de code à écrire.
Nous allons décrire la méthode pour construire le graphique des moyennes des
mesures des BIP en fonction du statut de tabagisme actif. A chaque échographie la mesure
du BIP a été faite. En tout ce sont quatre échographies réalisées pendant la période du 2ème
et 3ème trimestre de grossesse. Pour construire le graphique il faut d’abord appeler le type de
graphique. Nous nommons le type de graphique une seule et unique fois. Le graphique se
construit en plusieurs étapes. Il y a autant d’étapes que de classes. Pour cet exemple nous
avons seulement 2 classes : « tabac actif=0 » et « tabac actif=1 ».
Pour cet exemple le graphique sera un « plot » (graphique en points). Vous définissez le
premier point avec l’abscisse et l’ordonnée, puis vous définissez les limites du graphique
pour chacun des axes. Il est également possible d’ajouter à ce moment là certaines
précisions comme un titre global au graphique ou nommé les axes (cf. ci-après).
## GRAPHIQUE #pour BIP tabac actif = 0 plot(x = 1, y = mean(FINAL$BIP1mm[FINAL$TABAC_GROSS == 0]), ylim = c(0,100), xlim = c(1,4),main = "BIP= f(tabac)", xlab = "echographies", ylab = "moyennes des BIP")
Le premier point est crée, il faut donc maintenant définir les 3 autres points
correspondant respectivement aux échographies 2,3 et 4.
points(x = 2, y = mean(FINAL$BIP2mm[FINAL$TABAC_GROSS == 0])) points(x = 3, y = mean(FINAL$BIP3mm[FINAL$TABAC_GROSS == 0])) points(x = 4, y = mean(FINAL$BIP4mm[FINAL$TABAC_GROSS == 0]))
Une fois tous les points défini, il ne reste plus qu’à les relier entre eux.
for (i in 1:length(mean(FINAL$BIP1mm[FINAL$TABAC_GROSS == 0]))) { lines(x= c(1,2), y = c(mean(FINAL$BIP1mm[FINAL$TABAC_GROSS == 0])[i],mean(FINAL$BIP2mm[FINAL$TABAC_GROSS == 0])[i]), col = "green") lines(x= c(2,3), y = c(mean(FINAL$BIP2mm[FINAL$TABAC_GROSS == 0])[i],mean(FINAL$BIP3mm[FINAL$TABAC_GROSS == 0])[i]), col = "green")

27
lines(x= c(3,4), y = c(mean(FINAL$BIP3mm[FINAL$TABAC_GROSS == 0])[i],mean(FINAL$BIP4mm[FINAL$TABAC_GROSS == 0])[i]), col = "green") }
Il est recommandé d’attribuer une couleur pour chacune des catégories. Dans cet
exemple la catégorie des non-fumeuses sera représentée par la couleur verte.
Il faut ensuite faire la même chose pour la catégorie des fumeuses actives en
n’oubliant pas de leur attribuer une couleur différente.
#pour BIP tabac actif = 1 points(x = 1, y = mean(FINAL$BIP1mm[FINAL$TABAC_GROSS == 1])) points(x = 2, y = mean(FINAL$BIP2mm[FINAL$TABAC_GROSS == 1])) points(x = 3, y = mean(FINAL$BIP3mm[FINAL$TABAC_GROSS == 1])) points(x = 4, y = mean(FINAL$BIP4mm[FINAL$TABAC_GROSS == 1])) for (i in 1:length(mean(FINAL$BIP1mm[FINAL$TABAC_GROSS == 1]))) { lines(x= c(1,2), y = c(mean(FINAL$BIP1mm[FINAL$TABAC_GROSS == 1])[i],mean(FINAL$BIP2mm[FINAL$TABAC_GROSS == 1])[i]), col = "red") lines(x= c(2,3), y = c(mean(FINAL$BIP2mm[FINAL$TABAC_GROSS == 1])[i],mean(FINAL$BIP3mm[FINAL$TABAC_GROSS == 1])[i]), col = "red") lines(x= c(3,4), y = c(mean(FINAL$BIP3mm[FINAL$TABAC_GROSS == 1])[i],mean(FINAL$BIP4mm[FINAL$TABAC_GROSS == 1])[i]), col = "red") }
Comme dit précédemment il est possible d’ajouter au graphique des légendes par la
fonction du même nom (« legend() »). Cette fonction possède un nombre d’attribut important. Tout
d’abord il faut définir avec les coordonnées x et y la position de la légende sur le graphique. Puis
nommer à l’aide d’un vecteur la légende, définir respectivement les couleurs, sélectionner la couleur
du texte de légende, le type de ligne (lty = lines type), le type de point (pch = pitch), fusionner les 2
légendes (merge) et éventuellement définir une couleur de fond.
legend(2.5, 40, c("tabagisme actif = 0", "tabagisme actif = 1"), col = c("green","red"), text.col = "black", lty = c(1, 1), pch = c(1, 1), merge = TRUE, bg = 'gray90')
Concrètement le résultat graphique de ces lignes de programme est illustré en Figure
13. Nous pouvons à partir de cet exemple générer bien d’autres graphiques en modifiant
quelque peu le programme. Ces graphiques sont proposés aux lecteurs en Annexe 2 à
Annexe 11.
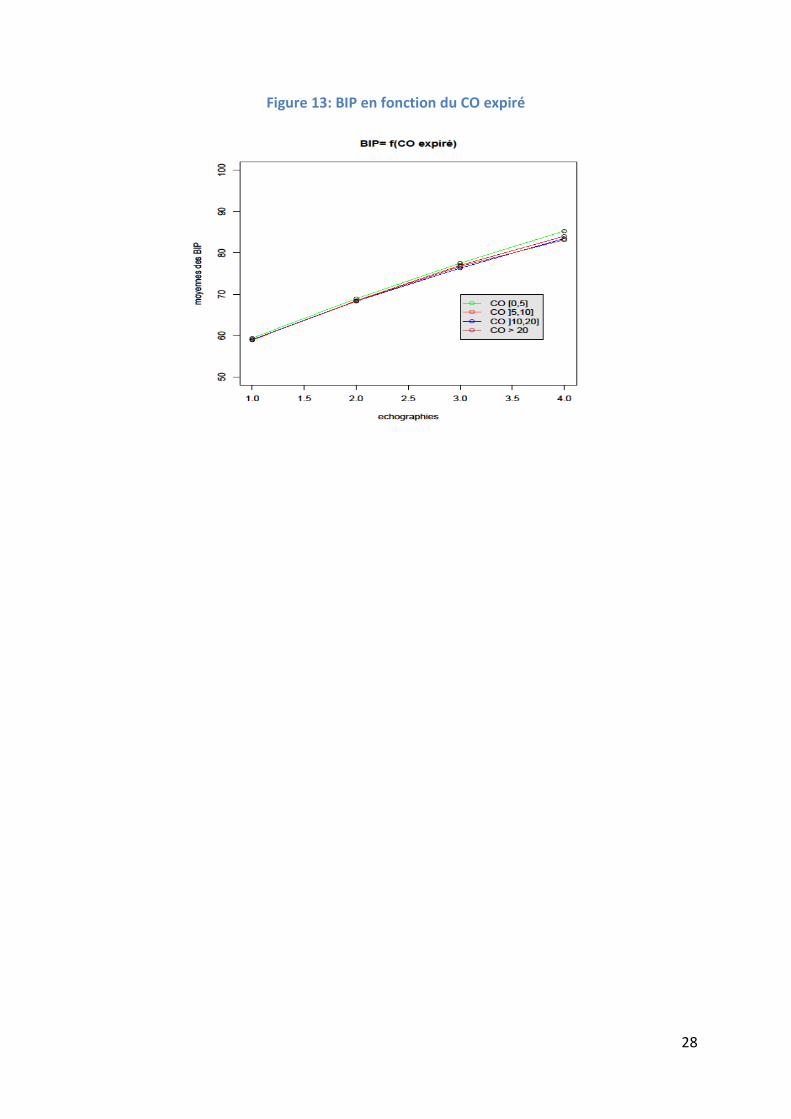
28
Figure 13: BIP en fonction du CO expiré

29
IV. ANALYSES STATISTIQUE
A. Introduction
Notre objectif est d’acquérir une méthodologie nous permettant de mettre en
évidence dans la cadre d’un projet scientifique un éventuel lien de causalité entre la
survenue d’une pathologie (hypotrophie fœtale, petit poids naissance) et un facteur de
risque (tabagisme). Nous avons pour cela simulé précédemment des données,
correspondant à celles que nous aurions pu obtenir en effectuant un classique recueil de
données. Nous avons ensuite généré des graphiques nous permettant de voir concrètement
quels genres de relations lient les variables afin de nous orienter dans notre démarche de
recherche.
B. Analyses univariées : Test de Liaison et de comparaison
1. Test du Chi-carré d’indépendance
Descriptions des données
Tableau 3: Données simulées
Poids de naissance
(percentile) hypotrophie CO_T3≥ 20
1 9.6 1 1 2 62 0 1 3 41 0 0 4 12 0 0 5 79 0 0 6 32 0 0 7 5.5 1 1 8 69 0 0 9 7.8 1 0
10 23 0 1 … … … …
Chi-carré d’indépendance ou Chi-carré de Pearson
Définition : Le test du χ² est un test statistique permettant de tester l'indépendance entre
deux variables qualitatives à plusieurs classes (12).

30
Conditions d’application :
9 Calculer le nombre de degrés de liberté. C’est le nombre de cases d’un tableau de
contingence que l’on peut remplir librement sans modifier les totaux marginaux (1). De façon
plus générale, dans un tableau à i lignes et j colonnes, ddl = (i - 1) (j - 1).
9 La somme des effectifs théorique est supérieure ou égale à 5
Tableau 4: Tableau des effectifs observés
CO_T3 < 20
CO_T3 ≥ 20 Total
hypotrophie=0 106 2260 2366 hypotrophie=1 136 506 642 Total 242 2766 3008
Nous allons calculer le nombre de degrés de liberté pour ce tableau. Pour chaque ligne, il y a 2-1 = 1
variables indépendantes, et pour chaque colonne il y a 2-1 = 1 variable indépendante, ce qui conduit
à 1 x 1 = 1 degré de liberté.
Si on se donne un risque de se tromper (rejeter à tort l'hypothèse nulle) égal à 5 %, la valeur critique
trouvée dans les tables est 3.84
Tableau 5: Tableau des effectifs attendus
CO_T3 < 20 CO_T3 ≥ 20 total hypotrophie=0 190 2176 2366 hypotrophie=1 52 590 642 Total 242 2766 3008
Les effectifs attendus sont calculés par le produit des effectifs marginaux divisés par l’effectif
total. De façon plus commune cela se simplifie de cette manière : (total colonne x total
ligne)/TOT
Tableau 6: Calcul du la statistique du test
X² CO_T3 < 20
CO_T3 ≥ 20 TOT
hypotrophie=0 37 3 40 hypotrophie=1 135 11 147 TOT 172 15 187

31
Pour chaque case il faut appliquer cette formule :
O : Effectifs observés
E : effectifs espérés (ou attendus)
La statistique du test est donnée en additionnant les valeurs retrouvées.
Manipulation sur R®
prop.table(table(FINAL$pdsnneper<=10,FINAL$CO_T3 > 20),2) FALSE TRUE FALSE 0.8153235 0.4398340 TRUE 0.1846765 0.5601660 chisq.test(table(FINAL$pdsnneper<=10,FINAL$CO_T3 > 20)) Pearson's Chi-squared test with Yates' continuity correction data: table(FINAL$pdsnneper <= 10, FINAL$CO_T3 > 20) X-squared = 183.1277, df = 1, p-value < 2.2e-16 ## Calcul des effectifs théoriques: chisq.test(table(FINAL$pdsnneper<=10,FINAL$CO_T3 > 20))$expected FALSE TRUE FALSE 2172.7573 189.24269 TRUE 594.2427 51.75731 by(FINAL$pdsnneper, FINAL$CO_T3 > 20, summary)
Interprétation Pour un tableau à 1 ddl le test du X² est considéré comme significatif lorsqu’il dépasse la valeur
3,8415. Cette valeur correspond au seuil des 5% de se tromper traditionnellement fixé.
NB : La différence entre la statistique calculée par R et la statistique calculée manuellement
dans l’exemple s’explique par le fait que les effectifs observés considérés dans chacun des
exemples sont légèrement différent car ils sont issus de simulations différentes.
32
2. Comparaison de moyennes
Descriptions des données
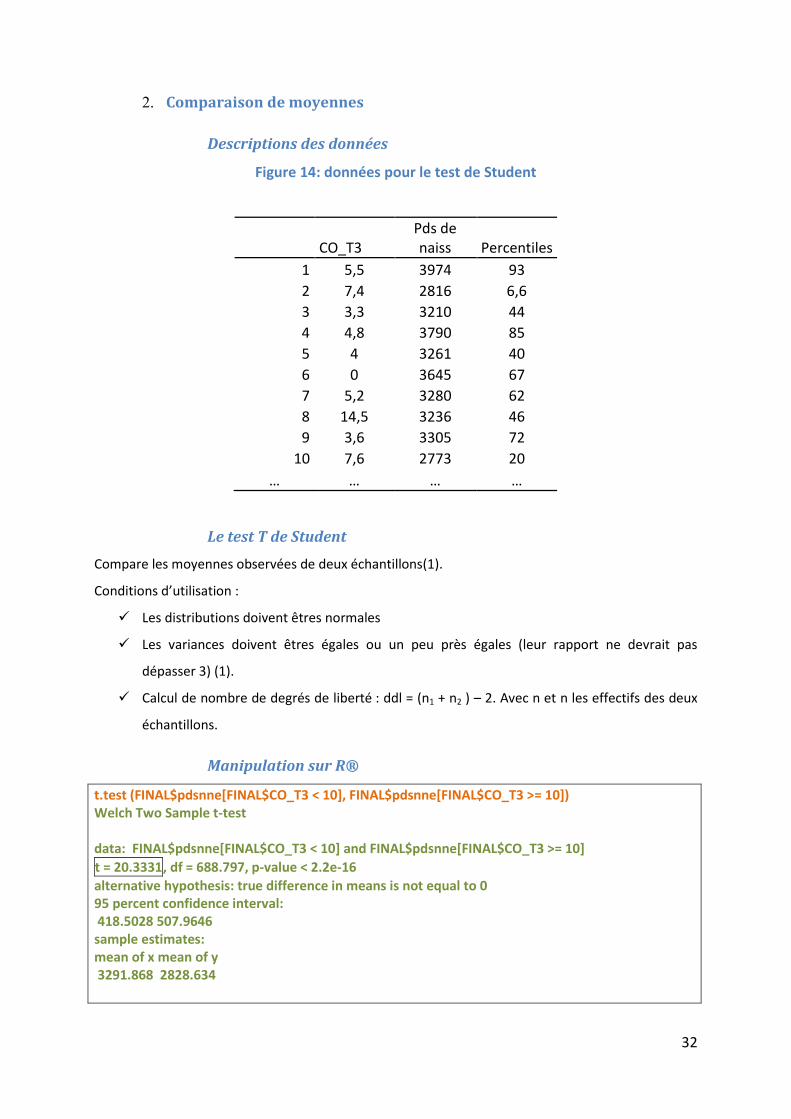
Figure 14: données pour le test de Student
CO_T3 Pds de naiss Percentiles
1 5,5 3974 93 2 7,4 2816 6,6 3 3,3 3210 44 4 4,8 3790 85 5 4 3261 40 6 0 3645 67 7 5,2 3280 62 8 14,5 3236 46 9 3,6 3305 72
10 7,6 2773 20 … … … …
Le test T de Student Compare les moyennes observées de deux échantillons(1).
Conditions d’utilisation :
9 Les distributions doivent êtres normales
9 Les variances doivent êtres égales ou un peu près égales (leur rapport ne devrait pas
dépasser 3) (1).
9 Calcul de nombre de degrés de liberté : ddl = (n1 + n2 ) – 2. Avec n et n les effectifs des deux
échantillons.
Manipulation sur R®
t.test (FINAL$pdsnne[FINAL$CO_T3 < 10], FINAL$pdsnne[FINAL$CO_T3 >= 10]) Welch Two Sample t-test data: FINAL$pdsnne[FINAL$CO_T3 < 10] and FINAL$pdsnne[FINAL$CO_T3 >= 10] t = 20.3331, df = 688.797, p-value < 2.2e-16 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 418.5028 507.9646 sample estimates: mean of x mean of y 3291.868 2828.634
33
Interprétation
La moyenne des poids de naissance dans les catégories CO_T3 < 10 et CO_T3 ≥ 10
sont statistiquement différentes (p<2.2*10-16).
3. Normalité d’une distribution
Description des données
Tableau 7: données simulées
CO_T3 Terme Pds de naiss Percentiles
1 5,5 39 3974 93 2 7,4 41 2816 6,6 3 3,3 39 3210 44 4 4,8 39 3790 85 5 4 40 3261 40 6 0 41 3645 67 7 5,2 38 3280 62 8 14,5 39 3236 46 9 3,6 37 3305 72
10 7,6 38 2773 20 … … … … …
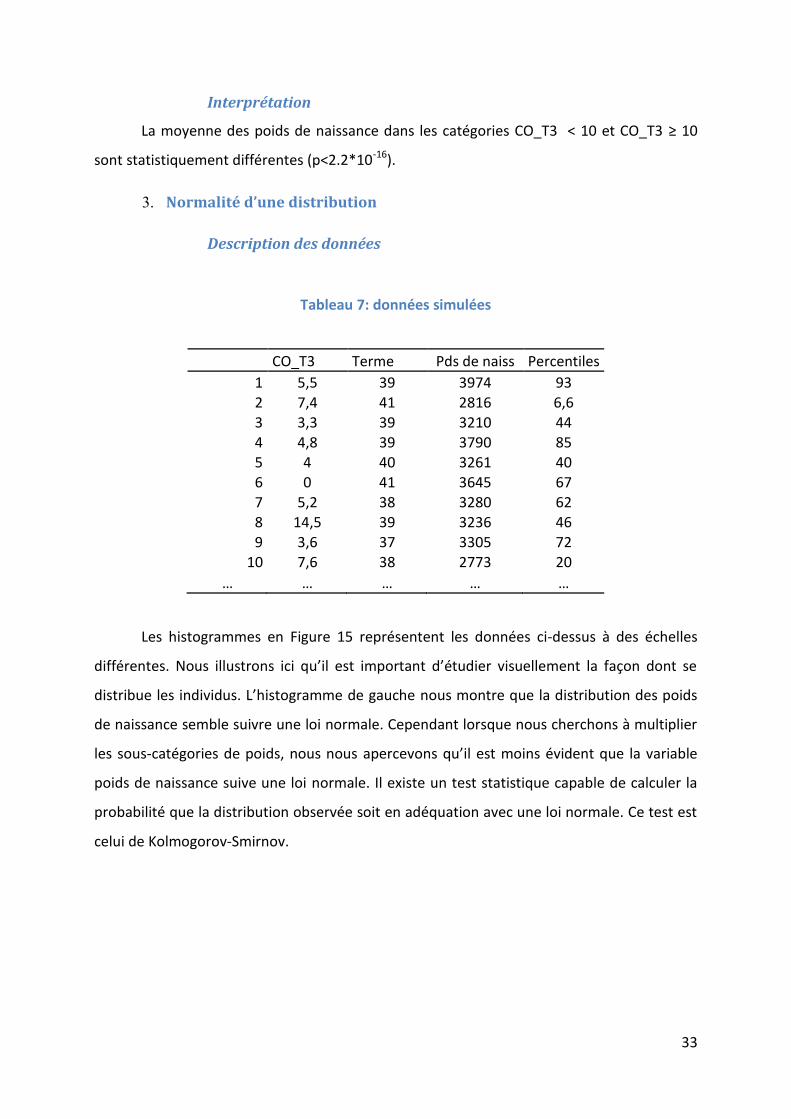
Les histogrammes en Figure 15 représentent les données ci-dessus à des échelles
différentes. Nous illustrons ici qu’il est important d’étudier visuellement la façon dont se
distribue les individus. L’histogramme de gauche nous montre que la distribution des poids
de naissance semble suivre une loi normale. Cependant lorsque nous cherchons à multiplier
les sous-catégories de poids, nous nous apercevons qu’il est moins évident que la variable
poids de naissance suive une loi normale. Il existe un test statistique capable de calculer la
probabilité que la distribution observée soit en adéquation avec une loi normale. Ce test est
celui de Kolmogorov-Smirnov.
34
Figure 15: Distribution des poids de naissance en fonction de CO_T3
Le test de Kolmogorov-Smirnov En statistiques, le test de Kolmogorov-Smirnov est un test d'hypothèse utilisé pour
déterminer si un échantillon suit bien une loi donnée connue par sa fonction de répartition continue,
ou bien si deux échantillons suivent la même loi (13). Ce test peut être important notamment pour
justifier d’un test statistique nécessitant des distributions obéissant à une loi normale.
Dans l’exemple suivant nous avons simulé une loi normale nommée « x » dans R comprenant
1000 observations, de moyenne 100 et d’écart-type 5. Voici son histogramme :
Figure 16: Loi normale nommée "x"

35
x <- rnorm(1000,100,5) hist(x) ks.test(x,"pnorm",mean(x),sd(x)) One-sample Kolmogorov-Smirnov test data: x D = 0.0158, p-value = 0.9644 alternative hypothesis: two-sided
La statistique du test vaut 0.96. La probabilité est ici de 96 %, nous ne rejetons donc pas
l'hypothèse (qui est vraie puisque x est généré selon une loi normale) que x suit une loi normale.
Manipulation sur R® d’un exemple de la simulation
hist(FINAL$pdsnne[FINAL$CO_T3], breaks=6) ks.test(FINAL$pdsnne[FINAL$CO_T3],"pnorm",mean(FINAL$pdsnne[FINAL$CO_T3]),sd(FINAL$pdsnne[FINAL$CO_T3])) One-sample Kolmogorov-Smirnov test data: FINAL$pdsnne[FINAL$CO_T3] D = 0.2373, p-value < 2.2e-16 alternative hypothesis: two-sided
Interprétation
La probabilité est ici très fortement nulle, nous rejetons donc que les poids de
naissance suit une loi normale.
4. Mesure d’impact
Descriptions des données
Les données sont présentées en Tableau 7
Manipulation sur R®
rlog1.02 <- glm(FINAL$pdsnneper<=10~(FINAL$CO_T3>20), family=binomial) summary(rlog1.02) exp(rlog1.02$coef) (Intercept) FINAL$CO_T3 > 20TRUE 0.2046414 7.1889374 exp(confint(rlog1.02)) 2.5 % 97.5 % (Intercept) 0.185398 0.2254074 FINAL$CO_T3 > 20TRUE 5.510063 9.4142077
Interprétation
On démontre que lorsque la prévalence de la maladie dans la population d’origine est faible
(inférieure à 10%), l’odds ratio calculé dans une étude cas-témoins est un estimateur du
risque relatif qui aurait pu être calculé si l’étude avait été construite comme une étude de
cohorte (1). L’odds ratio est donc interprété de la même façon qu’un risque relatif.

36
x Si OR = 1 (la valeur 1 est comprise entre les bornes de l’intervalle de confiance à
95%), cela signifie qu’il n’y a pas de différence d’exposition détectée entre les cas et
les témoins. Il n’y a pas de relation entre la maladie et l’exposition au facteur étudié
(1).
x Si l’OR est significativement supérieur à 1, alors le facteur étudié est un facteur de
risque de survenue de la maladie
x Si l’OR est significativement inférieur à 1, alors le facteur étudié est un facteur
protecteur.
Dans l’exemple ci-dessus, l’OR=7.18, IC95% [5.51 ;9.14]. L’IC95% ne contient pas la valeur 1
et en est bien supérieur. Une valeur de CO expiré supérieure à 20 au 3ème trimestre de
grossesse multiplierai par 7 le risque d’hypotrophie fœtale.
C. Analyse multivariée :
1. Ajustement
Description des données
Tableau 8: Données simulées avec Diabète Gestationnel
CO_T3 Terme Pds de naiss Percentiles Diabète Gesta
1 5,5 39 3974 93 0 2 7,4 41 2816 6,6 0 3 3,3 39 3210 44 0 4 4,8 39 3790 85 1 5 4 40 3261 40 0 6 0 41 3645 67 0 7 5,2 38 3280 62 0 8 14,5 39 3236 46 0 9 3,6 37 3305 72 1
10 7,6 38 2773 20 0
La régression logostique
La régression logistique est un modèle de régression binomiale. Comme pour tous les modèles de régression binomiale, il s'agit de modéliser l'effet d'un vecteur de variables aléatoires (x1,…,xk) sur une variable aléatoire binomiale génériquement notée Y. La
régression logistique est un cas particulier du modèle linéaire généralisé (14).

37
Manipulation sur R®
rlog1.02 <- glm(FINAL$pdsnneper<=10~(FINAL$CO_T3>20)+ FINAL$diabG, family=binomial) summary(rlog1.02) exp(rlog1.02$coef) (Intercept) FINAL$CO_T3 > 20TRUE FINAL$diabG 0.2175484 8.6017461 0.2794290 exp(confint(rlog1.02)) 2.5 % 97.5 % (Intercept) 0.1968724 0.2398979 FINAL$CO_T3 > 20TRUE 6.4985522 11.4575152 FINAL$diabG 0.1758640 0.4278543
Interprétation
L’ajustement sur le diabète gestationnel augmente l’odds ratio de 7.18 à 8.60. Il était donc
essentiel d’ajuster sur cette variable. Ne pas ajuster aurait été une faute méthodologique.
Le choix des variables à ajuster doit se faire selon les connaissances scientifiques
(littérature), l’intuition et le raisonnement clinique du chercheur. Nous pouvons dire que
dans cette situation la variable diabète gestationnel est un authentique facteur de
confusion.
2. Recherche d’un phénomène dose-effet
Description des données
Les données sont présentées en Tableau 8
Notion d’indicatrice binaire
Apres avoir mis en évidence un lien entre un facteur d’exposition et la survenue
d’une pathologie, il peut être intéressant de savoir si ce lien est soumis à un phénomène
dose-effet. Concrètement dans notre exemple, nous cherchons à mettre en évidence un
phénomène dose-effet sur la survenue d’une hypotrophie fœtale (poids de naissance < 10ème
percentile) et la quantité de CO expiré au 3ème trimestre de grossesse. Classiquement plus la
quantité de CO expirée chez la mère est importante et plus le risque d’hypotrophie fœtale
augmente.
Pour cela nous devons manipuler la variable CO_T3 (variable quantitative continue)
pour qu’elle soit en variable catégorielle. C’est une étape essentielle. Nous allons
programmer l’analyse en demandant au logiciel de prendre une catégorie de référence puis
il comparera les autres catégories avec celle de référence.
38
Manipulation sur R®
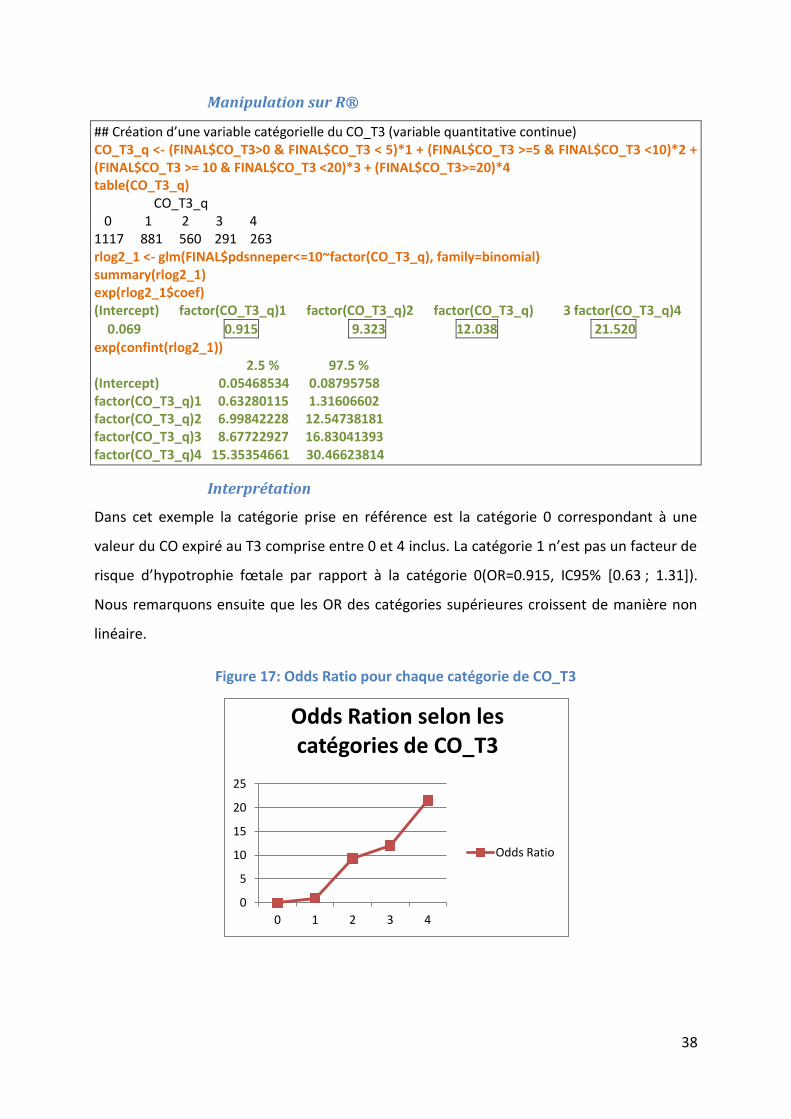
## Création d’une variable catégorielle du CO_T3 (variable quantitative continue) CO_T3_q <- (FINAL$CO_T3>0 & FINAL$CO_T3 < 5)*1 + (FINAL$CO_T3 >=5 & FINAL$CO_T3 <10)*2 + (FINAL$CO_T3 >= 10 & FINAL$CO_T3 <20)*3 + (FINAL$CO_T3>=20)*4 table(CO_T3_q) CO_T3_q 0 1 2 3 4 1117 881 560 291 263 rlog2_1 <- glm(FINAL$pdsnneper<=10~factor(CO_T3_q), family=binomial) summary(rlog2_1) exp(rlog2_1$coef) (Intercept) factor(CO_T3_q)1 factor(CO_T3_q)2 factor(CO_T3_q) 3 factor(CO_T3_q)4 0.069 0.915 9.323 12.038 21.520 exp(confint(rlog2_1)) 2.5 % 97.5 % (Intercept) 0.05468534 0.08795758 factor(CO_T3_q)1 0.63280115 1.31606602 factor(CO_T3_q)2 6.99842228 12.54738181 factor(CO_T3_q)3 8.67722927 16.83041393 factor(CO_T3_q)4 15.35354661 30.46623814
Interprétation
Dans cet exemple la catégorie prise en référence est la catégorie 0 correspondant à une
valeur du CO expiré au T3 comprise entre 0 et 4 inclus. La catégorie 1 n’est pas un facteur de
risque d’hypotrophie fœtale par rapport à la catégorie 0(OR=0.915, IC95% [0.63 ; 1.31]).
Nous remarquons ensuite que les OR des catégories supérieures croissent de manière non
linéaire.
Figure 17: Odds Ratio pour chaque catégorie de CO_T3
0
5
10
15
20
25
0 1 2 3 4
Odds Ration selon les catégories de CO_T3
Odds Ratio
39
3. Recherche de facteurs associés
Description des données
Tableau 9: Données simulées pour l'analyse pas à pas
CO_T3 Terme
Pds de naiss Percentiles
Diabète Gesta
Tabagisme Actif
Tabagisme passif parité
1 5,5 39 3974 93 0 0 1 1 2 7,4 41 2816 6,6 0 1 0 1 3 3,3 39 3210 44 0 0 0 2 4 4,8 39 3790 85 1 0 1 1 5 4 40 3261 40 0 0 0 3 6 0 41 3645 67 0 0 0 1 7 5,2 38 3280 62 0 1 0 2 8 14,5 39 3236 46 0 1 1 2 9 3,6 37 3305 72 1 0 0 1
10 7,6 38 2773 20 0 1 1 1 … … … … … … … … …
Analyse pas à pas ou analyse factorielle discriminante
L’analyse factorielle discriminante ou analyse pas à pas est une technique statistique
qui vise à décrire, expliquer et prédire l’appartenance à des groupes prédéfinis d’un
ensemble d’observations à partir d’une série de variables prédictives (15).
C’est cette analyse qui est utilisée en épidémiologie pour détecter les groupes à
hauts risques d’hypotrophie fœtale à partir de caractéristiques telles que l’alimentation, le
fait de fumer ou pas, la survenue d’un diabète gestationnel, etc (15).
Manipulation sur R®
rlog7 <- glm(FINAL$pdsnneper<=10~1, family=binomial) step.rlog7 <- step(rlog7, scope=list(lower=~1, upper=~FINAL$CO_T3 + FINAL$TABAC_ACTIF_GROSS + FINAL$TABAC_PASSIF_GROSS + FINAL$CO_T1 + FINAL$CO_T2 + FINAL$age + FINAL$diabG + FINAL$DT2 + FINAL$phao + FINAL$parite + as.numeric(FINAL$ddnne) + FINAL$sexe)) summary(step.rlog7) anova(step.rlog7) exp(step.rlog7$coef) (Intercept) FINAL$CO_T3 FINAL$diabG 5.815784e-07 1.094800e+00 1.506411e-01 as.numeric(FINAL$ddnne) FINAL$TABAC_PASSIF_GROSS FINAL$parite 1.369682e+00 1.812307e+00 8.186866e-01 FINAL$DT2 FINAL$TABAC_ACTIF_GROSS 3.722063e-01 1.506635e+00

40
round(exp(confint(step.rlog7)),3) 2.5 % 97.5 % (Intercept) 0.000 0.000 FINAL$CO_T3 1.073 1.118 FINAL$diabG 0.091 0.240 as.numeric(FINAL$ddnne) 1.253 1.501 FINAL$TABAC_PASSIF_GROSS 1.453 2.256 FINAL$parite 0.689 0.972 FINAL$DT2 0.136 0.855 FINAL$TABAC_ACTIF_GROSS 0.997 2.267
Interprétation
L’analyse pas à pas fait ressortir parmi toutes les variables étudiées des facteurs de
risque et protecteurs d’hypotrophie fœtale. Parmi les facteurs de risque figurent le CO_T3, la
variable tabagisme passif et le terme à la naissance. Nous remarquons que le tabagisme actif
n’y figure pas (IC95% [0.997 ; 2.267]). 2 explications : Il est probable qu’un biais de
recrutement (patientes fumeuses se déclarant non-fumeuses) et un biais de classement
(patientes fumeuses ayant sous déclaré leur consommation de tabac). Dans la simulation ces
biais ont été simulés dans le programme et la quantité de cigarettes fumées dépendait
uniquement du statut tabagique actif des patientes. En revanche la quantité de CO expirée
dépendait à la fois du tabagisme actif et passif et de la quantité de cigarettes consommées.
C’est pour cela que le tabagisme actif peut être reconnu comme un facteur neutre. En
revanche le tabagisme passif est une variable déclarative simulée sans biais.
Les variables ayant un effet protecteurs sont la présence d’un diabète gestationnel ou
d’un diabète de type 2. La parité semble aussi être un facteur protecteur. La majorité des
patientes étant des primipares nous retenons que la primiparité est un facteur protecteur.

41
V. CONCLUSION La simulation des données est à notre sens satisfaisante la principale difficulté étant celle
de simuler des données longitudinales cohérentes, en adéquation avec les mécanismes
physiopathologiques et des les conserver au fur et à mesure des successions de « merge » de
dataframe.
Toutefois les mesures d’association de risque retrouvées entre le tabagisme et la
survenue d’une hypotrophie foetale (un OR aux alentours de 2,60 pour les patientes expirant
plus 20 particules de CO/L) sont discutables. En effet certaines études parlent d’un OR
autour de 4,5 pour cette catégorie et autour de 2,4 pour les catégories inférieures. De la
même manière le poids moyen de naissance simulé dans les deux groupes est légèrement en
dessous (environs 300 g) de ceux observés dans les grandes études en périnatalité. Cette
erreur est due à la fois aux discordances dans la littérature et surtout aux données non
exhaustives des études sur les poids de naissance des enfants de mères fumeuses. Dans la
simulation nous nous étions basés sur une distribution de poids de naissance dans une
population générale et nous avions diminué le poids de façon arbitraire des enfants de mère
fumeuses. Cette diminution s’est avérée trop importante. Il est cependant possible d’affiner
cette erreur.
L’analyse statistique a pour but de montrer une liste non-exhaustive de principaux tests
en épidémiologie et d’expliquer aux personnes lisant ce tutoriel comment et dans qu’elles
conditions les appliquer.
Couplée à la simulation, l’analyse à permis une révision des bases épidémiologiques en
mettant en évidence des biais, et des facteurs de confusion justifiant l’intérêt de l’analyse
ajustée.
Plus personnellement, j’ai tenté dans ce travail destiné en premier lieu aux étudiants
sage-femme, de m’introduire dans le monde de l’obstétrique afin de susciter leur intérêt. Ce
procédé est à mon sens une manière plus pédagogique d’enseigner l’Epidémiologie et la
Biostatistique. C’est un support de cours qui à mon avis doit être utilisé dans le cadre
d’enseignements dirigés de façon complémentaire avec le programme de simulation.
Enfin, les études de sages-femmes sanctionnées par un mémoire à forte tendance
scientifique je pense qu’il serait à la fois totalement inédit et précurseur d’une nouvelle
façon de penser en faisant un mémoire intégrant une simulation de données.

BIBLIOGRAPHIE
1. Ancelle T. Statistique, épidémiologie. 2ème éd. Paris: Maloine; 2006.
2. Spector P. Data Manipulation With R. Springer; 2008.
3. Cornillon P-A. Statistiques avec R. Presses universitaires de Rennes; 2008.
4. Wikipedia contributors. GNU R [Internet]. Wikipédia. Wikimedia Foundation, Inc.; 2012 [cité 2012 avr 10]. Available de: http://fr.wikipedia.org/w/index.php?title=GNU_R&oldid=77086569
5. INPES, IPSOS. Enquête sur la prévalence de tabagisme en Décembre 2003 [Internet]. INPES; 2004. Available de: http://www.inpes.sante.fr/30000/pdf/0402_synthese_tabac.pdf
6. Pla, A, Beaumel, C. Bilan démographique 2011: La fécondité reste élevée. 2012 janv;(1385). Available de: http://www.insee.fr/fr/ffc/ipweb/ip1385/ip1385.pdf
7. Blondel B, Lelong N, Kermarrec M, Goffinet F. [Trends in perinatal health in France between 1995 and 2010: Results from the National Perinatal Surveys]. J Gynecol Obstet Biol Reprod (Paris). 2012 avr;41(2):151-66.
8. Garabedian C, Deruelle P. [Delivery (timing, mode, glycemic control) in women with gestational diabetes]. J Gynecol Obstet Biol Reprod (Paris). 2010 déc;39(8 Suppl 2):S274-280.
9. Gomez C, Berlin I, Marquis P, Delcroix M. Expired air carbon monoxide concentration in mothers and their spouses above 5 ppm is associated with decreased fetal growth. Prev Med. 2005 janv;40(1):10-5.
10. Marret S. Effects of maternal smoking during pregnancy on fetal brain development. J Gynecol Obstet Biol Reprod (Paris). 2005 avr;34 Spec No 1:3S230-233.
11. Mamelle N, Munoz F, Grandjean H. [Fetal growth from the AUDIPOG study. I. Establishment of reference curves]. J Gynecol Obstet Biol Reprod (Paris). 1996;25(1):61-70.
12. Wikipedia contributors. Test du χ2 [Internet]. Wikipédia. Wikimedia Foundation, Inc.; 2012 [cité 2012 sept 1]. Available de: http://fr.wikipedia.org/w/index.php?title=Test_du_%CF%87%C2%B2&oldid=80662766
13. Wikipedia contributors. Test de Kolmogorov-Smirnov [Internet]. Wikipédia. Wikimedia Foundation, Inc.; 2012 [cité 2012 sept 2]. Available de: http://fr.wikipedia.org/w/index.php?title=Test_de_Kolmogorov-Smirnov&oldid=82164321
14. Wikipedia contributors. Régression logistique [Internet]. Wikipédia. Wikimedia Foundation, Inc.; 2012 [cité 2012 sept 4]. Available de:

http://fr.wikipedia.org/w/index.php?title=R%C3%A9gression_logistique&oldid=80837533
15. Wikipedia contributors. Analyse discriminante [Internet]. Wikipédia. Wikimedia Foundation, Inc.; 2012 [cité 2012 sept 4]. Available de: http://fr.wikipedia.org/w/index.php?title=Analyse_discriminante&oldid=78270753
16. Becker RA, Chambers JM, Wilks AR. The new S language: a programming environment for data analysis and graphics. Wadsworth & Brooks/Cole Advanced Books & Software; 1988.

TABLES
Table des figures FIGURE 1: ENVIRONNEMENT DE TINN-R ................................................................................................................. 7 FIGURE 2: EXEMPLE DE DATA FRAME ..................................................................................................................... 8 FIGURE 3: CREATION D'UNE VARIABLE ................................................................................................................... 9 FIGURE 4: DATA FRAME TOT EN CONSTRUCTION ................................................................................................ 12 FIGURE 5: TABLE MUM ......................................................................................................................................... 13 FIGURE 6: TABLE FOETUS ...................................................................................................................................... 14 FIGURE 7: DATA FRAME TEMPORAIRE (TMP) ....................................................................................................... 16 FIGURE 8: SCHEMA DE SIMULATION DES BIOMETRIES FOETALES ........................................................................ 19 FIGURE 9: LIENS ENTRE LES VARIABLES ................................................................................................................ 21 FIGURE 10: REPARTITION DES DIFFERENTES CATEGORIES DE TROPHICITE .......................................................... 23 FIGURE 11: TROPHICITE EN FONCTION DU TABAGISME ACTIF ............................................................................. 24 FIGURE 12: PARAMETRES DE DISPERSION DES POIDS DE NAISSANCE FONCTION DU « TABAGISME ACTIF » ..... 25 FIGURE 13: BIP EN FONCTION DU CO EXPIRE ....................................................................................................... 28 FIGURE 14: DONNEES POUR LE TEST DE STUDENT ............................................................................................... 32 FIGURE 15: DISTRIBUTION DES POIDS DE NAISSANCE EN FONCTION DE CO_T3.................................................. 34 FIGURE 16: LOI NORMALE NOMMEE "X" .............................................................................................................. 34 FIGURE 17: ODDS RATIO POUR CHAQUE CATEGORIE DE CO_T3 .......................................................................... 38
Table des tableaux TABLEAU 1: REFERENCES DU COLLEGE FRANÇAIS DES ECHOGRAPHISTES POUR LE BIP ...................................... 17 TABLEAU 2: TABLEAU DE FREQUENCES DE LA TROPHICITE FONCTION DE LA VARIABLE TABAGISME ACTIF ....... 24 TABLEAU 3: DONNEES SIMULEES .......................................................................................................................... 29 TABLEAU 4: TABLEAU DES EFFECTIFS OBSERVES .................................................................................................. 30 TABLEAU 5: TABLEAU DES EFFECTIFS ATTENDUS ................................................................................................. 30 TABLEAU 6: CALCUL DU LA STATISTIQUE DU TEST ............................................................................................... 30 TABLEAU 7: DONNEES SIMULEES .......................................................................................................................... 33 TABLEAU 8: DONNEES SIMULEES AVEC DIABETE GESTATIONNEL ........................................................................ 36 TABLEAU 9: DONNEES SIMULEES POUR L'ANALYSE PAS A PAS ............................................................................ 39
Table des annexes ANNEXE 1: ACIDOSE EN FONCTION DE LA QUANTITE DE CIGARETTES FUMEES PAR JOUR ................................... 4 ANNEXE 2: BIP EN FONCTION DE LA VARIABLE "TABAGISME ACTIF" ..................................................................... 4 ANNEXE 3: BIP EN FONCTION DU CO EXPIRE .......................................................................................................... 5 ANNEXE 4: MOYENNES FEMUR EN FONCTION DE LA VARIABLE « TABAGISME ACTIF » ........................................ 5 ANNEXE 5: FEMUR EN FONCTION DU CO EXPIRE ................................................................................................... 6 ANNEXE 6: MOYENNES CIRCONFERENCE ABDOMINALE EN FONCTION DE LA VARIABLE « TABAGISME ACTIF » .. 6 ANNEXE 7: CIRCONFERENCE ABDOMINALE EN FONCTION DU CO EXPIRE ............................................................. 7 ANNEXE 8: MOYENNES EPF EN FONCTION DE LA VARIABLE « TABAGISME ACTIF » .............................................. 7 ANNEXE 9: EPF EN FONCTION DU CO EXPIRE ......................................................................................................... 8 ANNEXE 10: MOYENNES POIDS MATERNEL EN FONCTION DE LA VARIABLE « TABAGISME ACTIF » ..................... 8 ANNEXE 11: MOYENNES POIDS MATERNEL EN FONCTION DE LA VARIABLE « DIABETE GESTATIONNEL » ........... 9
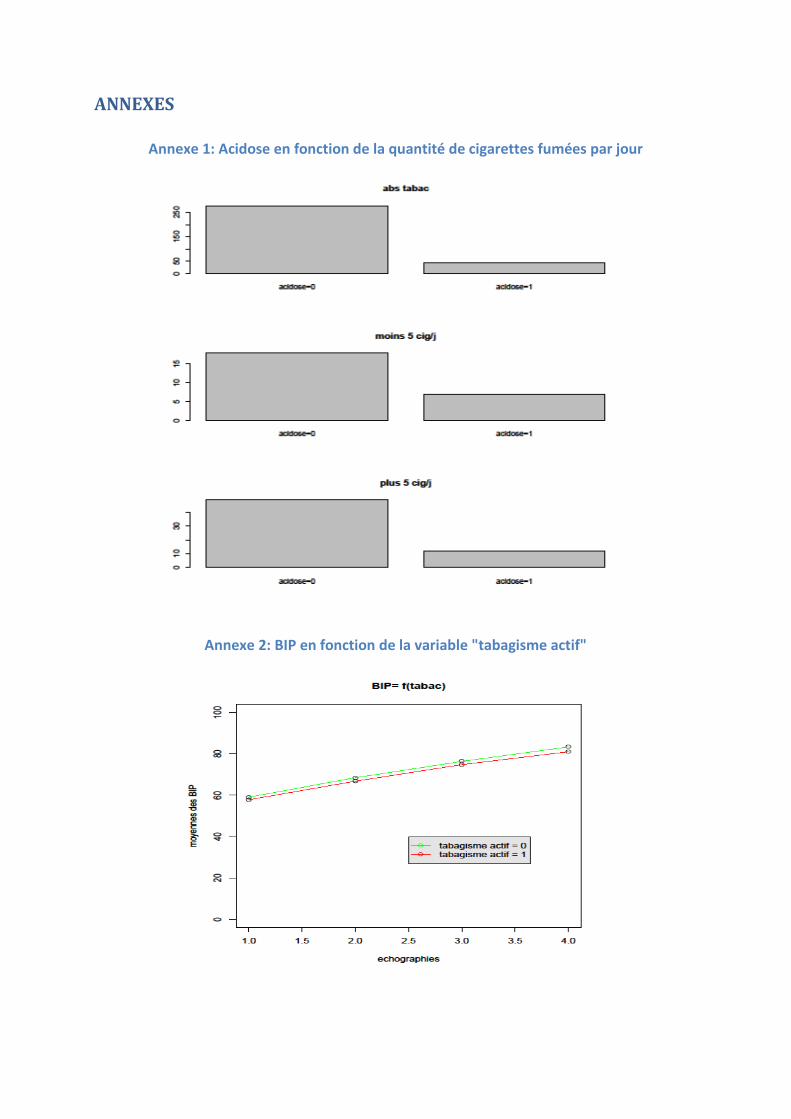
ANNEXES
Annexe 1: Acidose en fonction de la quantité de cigarettes fumées par jour
Annexe 2: BIP en fonction de la variable "tabagisme actif"
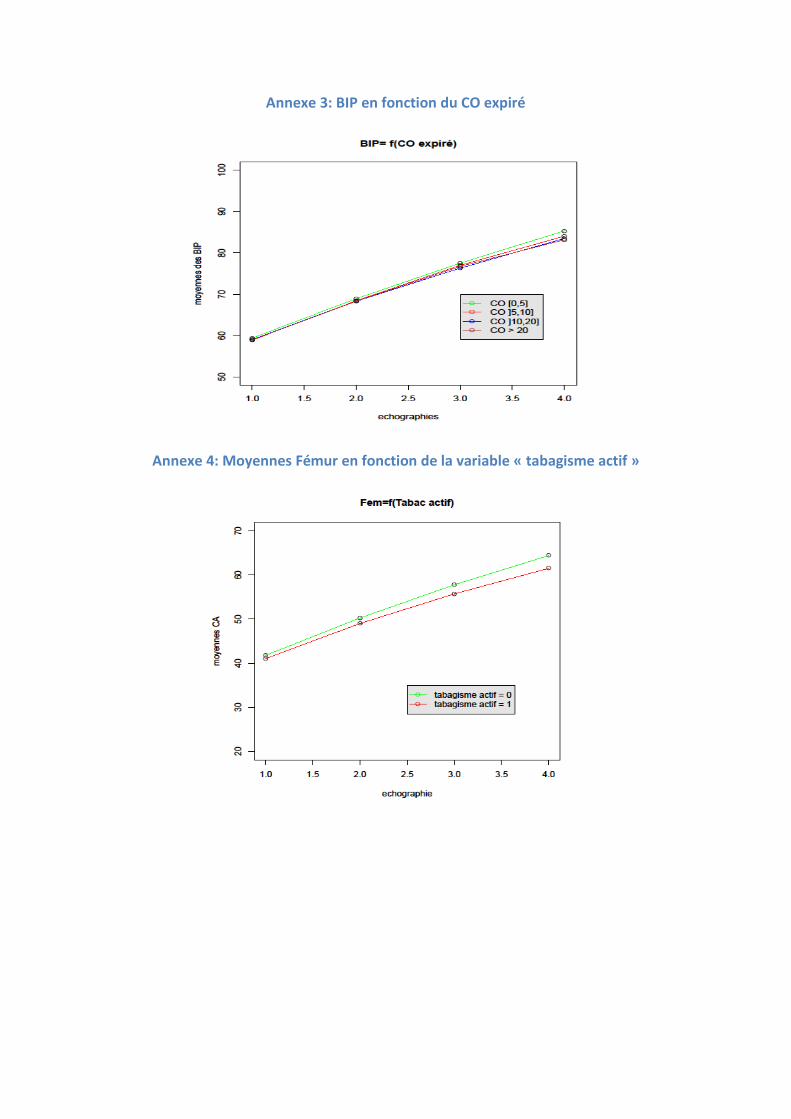
Annexe 3: BIP en fonction du CO expiré
Annexe 4: Moyennes Fémur en fonction de la variable « tabagisme actif »
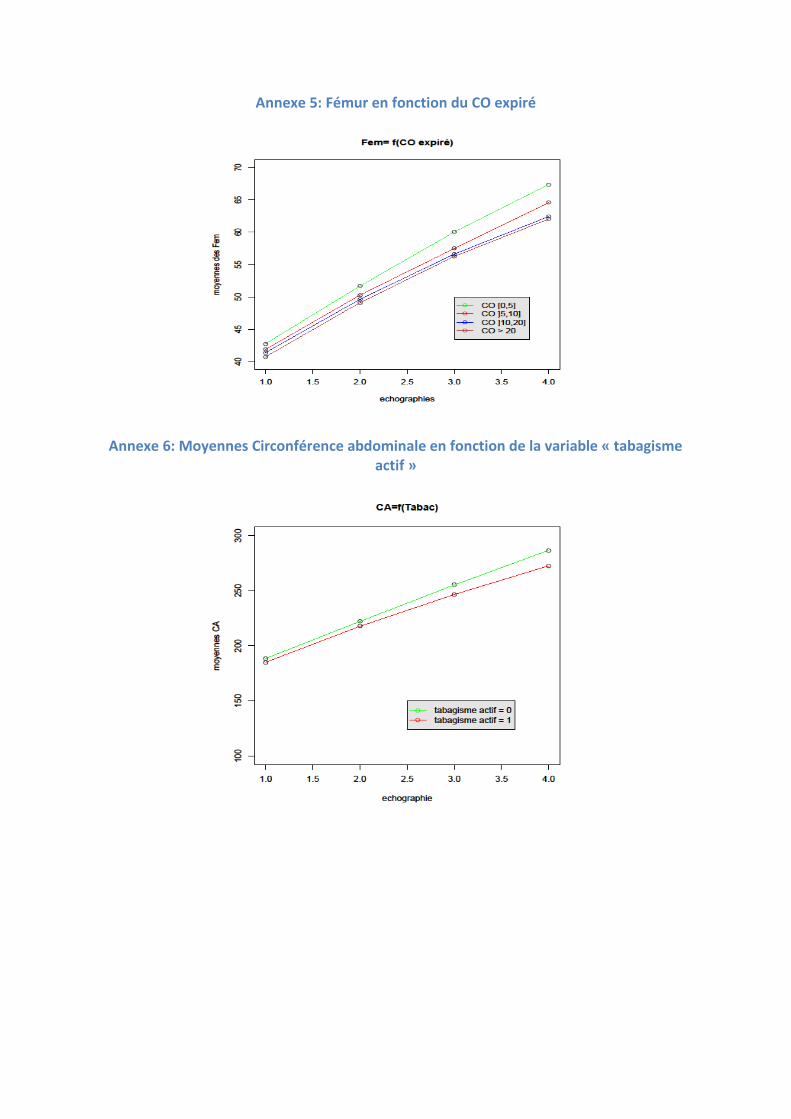
Annexe 5: Fémur en fonction du CO expiré
Annexe 6: Moyennes Circonférence abdominale en fonction de la variable « tabagisme actif »
Annexe 7: Circonférence abdominale en fonction du CO expiré
Annexe 8: Moyennes EPF en fonction de la variable « tabagisme actif »

Annexe 9: EPF en fonction du CO expiré
Annexe 10: Moyennes poids maternel en fonction de la variable « tabagisme actif »
Annexe 11: Moyennes poids maternel en fonction de la variable « Diabète Gestationnel »