a network pruning based approach for subset specific influential detection
TRANSCRIPT

A Network Pruning Based Approach for
Subset-Specific Influential Detection
Praphul Chandra, Arun Kalyanasundaram
Hewlett Packard Labs, Bangalore, India
ACM Web Science 2012


Can they really influence our decisions?

Can they really influence our decisions?

Who else can influence our decisions?

Who else can influence our decisions?

Who else can influence our decisions?

How do we exploit this spread of influence?

How do we exploit this spread of influence?
Viral Marketing

How do we exploit this spread of influence?
Viral Marketing
Influential Detection
• Identify a set of nodes (or individuals) to seed with some
information so as to maximize the spread of the seededinformation in the network. [Domingos, et al. 2001][1]

Influential Detection - Other Applications
Water Distribution Networks [Leskovec, et al. 2007][2]

Influential Detection - Other Applications
Water Distribution Networks [Leskovec, et al. 2007][2]
Preventing the spread of diseases [Christakis, Fowler 2007][3]

Influential Detection - A simple heuristic
b a
c
d
e
f
g
Most Influential
Finding the most influential node using the highest degree heuristic.

Our Problem - Subset Specific Influential Detection
• Aim : Maximize the spread of influence on a subset of nodes inthe network instead of the whole network.

Our Problem - Subset Specific Influential Detection
• Aim : Maximize the spread of influence on a subset of nodes inthe network instead of the whole network.

Subset Specific Influential Detection - Examples
Small Businesses - Locality based marketing Political Campaign[Focus on Supporters / Detractors]
Targeted advertisements - Demographics[Nationality, Age, Gender, etc.]

Subset Specific Influential Detection - Our Motivation
• Increase in size / density of networks.
• Opportunity to improve the efficiency of traditional approaches.
• Current state of the art “adapts” existing algorithms on influentialdetection to the subset specific version. [Kempe, et al. 2003][4][Aggarwal, et al. 2011][5]
• We address the subset specific top-k influential detection problemstandalone.

Subset Specific Influential Detection - A simple heuristic
b a
c
d
e
f
g
Subset of nodes to maximize influence spread
Subset Specific Most Influential
Finding the subset specific influential using the highest relevant degree heuristic.

Our Contribution - A Summary
• An efficient algorithm for subset specific top-k influential detection.
• Performance vs. efficiency trade-off using a tunable parameter - γ.
• Analytical framework: For an iteratively pruned network.
• A lower bound to evaluate the influence spread.
• Proof of sub-modularity of the influence spread function.

Background - Models of Information Diffusion
• Aim: Capture the dynamics of diffusion in social networks.
[Granovetter, Mark 1978][6]
• For Example : Independent Cascade Model (ICM) [Goldenberg,et al. 2001][7]
• Node u activates its neighbor v with an independent probability, puv .• Stochastic.• In general puv = p, the propagation probability.

Background - Models of Information Diffusion
• Aim: Capture the dynamics of diffusion in social networks.
[Granovetter, Mark 1978][6]
• For Example : Independent Cascade Model (ICM) [Goldenberg,et al. 2001][7]
• Node u activates its neighbor v with an independent probability, puv .• Stochastic.• In general puv = p, the propagation probability.
Activation of a node v by a node u can be seen as the outcome of a coin flip with bias puv
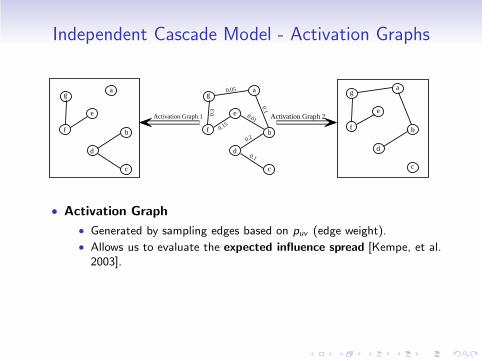
Independent Cascade Model - Activation Graphs
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
a
b
c
d
e
f
ga
b
c
d
e
f
g
Activation Graph 1 Activation Graph 2
• Activation Graph
• Generated by sampling edges based on puv (edge weight).
• Allows us to evaluate the expected influence spread [Kempe, et al.2003].

Evaluating Influence Spread In ICM [Kempe, et al. 2003]• Expected influence spread due to a node u :
• Mean number of nodes reachable from u in N activation graphs.
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
.
.
a
b
c
d
e
f
g Ra = 3
Rb = 3
Rc = 3Rd = 3
Re = 0
Rf = 1
Rg = 1
a
b
c
d
e
f
g Ra = 2
Rb = 2
Rc = 0Rd = 2
Re = 2
Rf = 2
Rg = 2
.
.
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
Most Influential
Activation graph 1
Activation graph N
N Outcomes}
Ru : Number of nodes reachable from u, not including u.

Previous Work - Greedy Algorithm [Kempe, et al. 2003]
• σ(A): Influence spread, due to a seed set A.
• δu : Marginal contribution of u, which is σ(A ∪ {u})− σ(A)
• Approach : Iteratively choose a node u with highest δu .
• Performance guarantee : 63% of optimal solution.
• Running time scales exponentially with network size.

Greedy Algorithm - Pictorial Representation
uab
c
d
f
v
e
y
x
uab
c
d
f
v
e
y
x
Top-k InfluentialIteration 1
Node v chosen as the most influential node. Since, δv > δu > δa > ...

Greedy Algorithm - Pictorial Representation
uab
c
d
f
v
e
y
x
uab
c
d
f
v
e
y
x
Top-k InfluentialIteration 1
Node v chosen as the most influential node. Since, δv > δu > δa > ...
uab
c
d
f
v
e
w
x
uab
c
d
f
v
e
w
x
Iteration 2
After Iteration 1, δu drops below δa. Hence a is chosen next.

Our Approach

Problem Statement
Given a graph, G(V ,E) and a destination set D0 ⊆ V , find the top-k nodes in
V which maximize the spread of influence on D0.
b a
c
d
e
f
g
Destination Set (D0)
b a
c
d
e
f
g
[ Subset specific most influential doesNOT lie in D0 ]
[ Subset specific most influential does lie inD0 ]
Salient features:
• Top-k nodes may or may not be in D0.
• When D0 = V , it reduces to the general form.
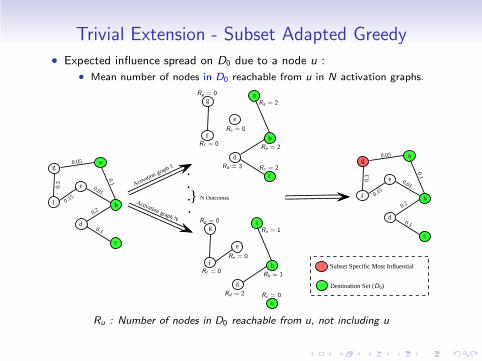
Trivial Extension - Subset Adapted Greedy• Expected influence spread on D0 due to a node u :
• Mean number of nodes in D0 reachable from u in N activation graphs.
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
.
.
a
b
c
d
e
f
g Ra = 2
Rb = 2
Rc = 2Rd = 3
Re = 0
Rf = 0
Rg = 0
a
b
c
d
e
f
g Ra = 1
Rb = 1
Rc = 0Rd = 2
Re = 0
Rf = 0
Rg = 0
.
.
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
Destination Set (D0)
Subset Specific Most Influential
Activation graph 1
Activation graph N
N Outcomes}
Ru : Number of nodes in D0 reachable from u, not including u

Iterative Pruning Approach - Central Idea
Central Idea
• Identify a set of nodes, ψ which are considered “influenced”.
• De-prioritize the spread of influence to all nodes in ψ.

When to consider a node as influenced

When to consider a node as influenced
• Based on a node’s susceptibility to influence.

When to consider a node as influenced
• Based on a node’s susceptibility to influence.
For Example : [S. Aral, D. Walker 2011][8]
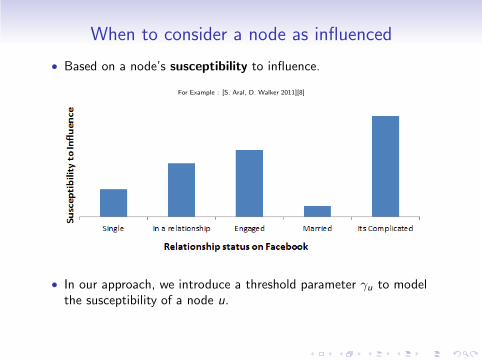
When to consider a node as influenced
• Based on a node’s susceptibility to influence.
For Example : [S. Aral, D. Walker 2011][8]
• In our approach, we introduce a threshold parameter γu to modelthe susceptibility of a node u.

Iterative Pruning Approach - In Three Steps
1. Compute Lu(A) ∈ [0, 1] : Likelihood that a node u would be influenced due
to a seed set, A.
• Lu(A) is the expectation that a node u will be active due to A.
Expected Influence Spread (σ(A)) =∑
u∈V
Lu(A)

Iterative Pruning Approach - In Three Steps
1. Compute Lu(A) ∈ [0, 1] : Likelihood that a node u would be influenced due
to a seed set, A.
• Lu(A) is the expectation that a node u will be active due to A.
Expected Influence Spread (σ(A)) =∑
u∈V
Lu(A)
2. Set a threshold γu : Add a node u to ψ, when Lu ≥ γu.
• Sociological perspective of γ : Susceptibility or Ease of Influencing.
• Incorporates potential influence that can reach from all over the network.

Iterative Pruning Approach - In Three Steps
1. Compute Lu(A) ∈ [0, 1] : Likelihood that a node u would be influenced due
to a seed set, A.
• Lu(A) is the expectation that a node u will be active due to A.
Expected Influence Spread (σ(A)) =∑
u∈V
Lu(A)
2. Set a threshold γu : Add a node u to ψ, when Lu ≥ γu.
• Sociological perspective of γ : Susceptibility or Ease of Influencing.
• Incorporates potential influence that can reach from all over the network.
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
Destination Set (D0)
Subset Specific Influential
Influenced set (ψ)
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.050.
3
0.15
La = 0.05γa = 0.05
Lb = 0.25γb = 0.2
Lc = 0.15γc = 0.2

Iterative Pruning Approach - In Three Steps
1. Compute Lu(A) ∈ [0, 1] : Likelihood that a node u would be influenced due
to a seed set, A.
• Lu(A) is the expectation that a node u will be active due to A.
Expected Influence Spread (σ(A)) =∑
u∈V
Lu(A)
2. Set a threshold γu : Add a node u to ψ, when Lu ≥ γu.
• Sociological perspective of γ : Susceptibility or Ease of Influencing.
• Incorporates potential influence that can reach from all over the network.
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.05
0.3
0.15
Destination Set (D0)
Subset Specific Influential
Influenced set (ψ)
a
b
c
d
e
f
g
0.1
0.2
0.01
0.1
0.050.
3
0.15
La = 0.05γa = 0.05
Lb = 0.25γb = 0.2
Lc = 0.15γc = 0.2
3. Pruning Process : Remove all paths that lead ONLY to nodes in ψ.
• Significantly improves the efficiency. Details to follow.

Iterative Pruning Approach - Pruning Process• ψ : The set of nodes considered influenced.
• Two level pruning process:
1. For each node in ψ, remove all its adjacent edges.
2. Recursively remove all paths that do NOT lead to any node in D0 \ψ.
• How does pruning help?
• Improves efficiency by reducing the density of the underlying graph.
Destination Set (D0)
Subset Specific Influential
Influenced set (ψ)
a
b
c
d
e
f
g
a
b
c
d
e
f
g
a
b
c
d
e
f
gLevel 1
Level 2

Experiments
• Datasets: Two real world co-authorship networks
1. High Energy Physics - Theory (HEPT) section of e-print arXivDense network: 15233 nodes / 58891 edges
2. Conference on Software Maintenance and Re-engineering (SMRE)Sparse network : 1336 nodes / 2200 edges
• Comparison with state of the art:
• Subset Adapted Greedy• Subset Adapted CELF (Cost Effective Lazy Forward) [Leskovec, et
al. 2007]
• System parameter - γ : {p4, p3, p2, p, 2p, 4p}where p is the propagation probability in ICM.

Results: [ Dataset 1 ] Dense Network
• Iterative Pruning (γ = p4) vs. Subset Adapted Greedy:
• 96% improvement in efficiency.• 10% drop in performance (influence spread).
• Iterative Pruning with CELF (γ = p4) vs. Subset Adapted CELF:
• 52% improvement in efficiency.• 10% drop in performance.

Results: [ Dataset 2 ] Sparse Network
• Iterative Pruning (γ = p4) vs. Subset Adapted Greedy:
• 73% improvement in efficiency.• 21% drop in performance (influence spread).
• Iterative Pruning with CELF (γ = p4) vs. Subset Adapted CELF:
• 38% improvement in efficiency.• 21% drop in performance.

Key Inferences
• Low values of γ are highly efficient but at the cost of performance
loss.
• Choose a low value of γ for dense networks and a high value of γ for
sparse networks, in order to achieve a desirable performance.
• The relatively low efficiency gains with CELF is because the pruning
operation causes a simultaneous reduction in marginal contribution
of several nodes.

Analytical Framework
• Known:
Influence spread function σ(A) is sub-modular when the underlying graph
G(V ,E) is static across iterations. [Kempe, et al. 2003]

Analytical Framework
• Known:
Influence spread function σ(A) is sub-modular when the underlying graph
G(V ,E) is static across iterations. [Kempe, et al. 2003]
• Is σ<Gi>(A) sub-modular when the underlying graph Gi (V ,Ei ) is
iteratively pruned? Where Gi is the graph after i th iteration.

Analytical Framework
• Known:
Influence spread function σ(A) is sub-modular when the underlying graph
G(V ,E) is static across iterations. [Kempe, et al. 2003]
• Is σ<Gi>(A) sub-modular when the underlying graph Gi (V ,Ei ) is
iteratively pruned? Where Gi is the graph after i th iteration.
Yes. Details in our paper.

Analytical Framework
• Known:
Influence spread function σ(A) is sub-modular when the underlying graph
G(V ,E) is static across iterations. [Kempe, et al. 2003]
• Is σ<Gi>(A) sub-modular when the underlying graph Gi (V ,Ei ) is
iteratively pruned? Where Gi is the graph after i th iteration.
Yes. Details in our paper.
• Can we estimate the σ(A) from σ<Gi>(A)?

Analytical Framework
• Known:
Influence spread function σ(A) is sub-modular when the underlying graph
G(V ,E) is static across iterations. [Kempe, et al. 2003]
• Is σ<Gi>(A) sub-modular when the underlying graph Gi (V ,Ei ) is
iteratively pruned? Where Gi is the graph after i th iteration.
Yes. Details in our paper.
• Can we estimate the σ(A) from σ<Gi>(A)?
No, but we derive the following lower bound.
σ(A) ≥ σ<Gi>(A) +i−1∑
j=1
∑
u∈ψj\ψj+1
Lu(A)
where ψj is the set of influenced nodes after j th iteration.

Summary
• Iterative network pruning algorithm for subset specific top-k influential
detection.
• Evaluation of our algorithm on two real world datasets showed significant
efficiency gains with an acceptable drop in performance.
• A tunable parameter γ for performance vs. efficiency trade-off.
• Analytical framework to show the sub-modularity of influence spread
function when the underlying graph is iteratively pruned thus enabling
the evaluation of performance guarantees.

Scope for Future Work
• Design of more efficient algorithms.
• Evaluation with real world distributions of γ (susceptibility).
• Extension to non-progressive models of diffusion.

References[1] P. Domingos and M. Richardson, “Mining the network value of customers,” in Proceedings of the seventh
ACM SIGKDD international conference on Knowledge discovery and data mining, ser. KDD ’01. ACM, 2001,
pp. 57–66. [Online]. Available: http://doi.acm.org/10.1145/502512.502525
[2] J. Leskovec, A. Krause, C. Guestrin, C. Faloutsos, J. VanBriesen, and N. Glance, “Cost-effective outbreak
detection in networks,” in Proceedings of the thirteenth ACM SIGKDD international conference on Knowledge
discovery and data mining, ser. KDD ’07. ACM, 2007, pp. 420–429. [Online]. Available:
http://doi.acm.org/10.1145/1281192.1281239
[3] N. A. Christakis and J. H. Fowler, “The spread of obesity in a large social network over 32 years,” The New
England Journal of Medicine, vol. 357, no. 4, pp. 370–379, July 2007. [Online]. Available:
http://health-equity.pitt.edu/767/
[4] D. Kempe, J. Kleinberg, and E. Tardos, “Maximizing the spread of influence through a social network,” in
Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, ser.
KDD ’03. ACM, 2003, pp. 137–146. [Online]. Available: http://doi.acm.org/10.1145/956750.956769
[5] C. C. Aggarwal, A. Khan, and X. Yan, “On flow authority discovery in social networks,” in Proceedings of the
eleventh SIAM international conference on Data mining, ser. SDM ’11. SIAM / Omnipress, 2011, pp.
522–533.
[6] M. Granovetter, “Threshold Models of Collective Behavior,” American Journal of Sociology, vol. 83, no. 6, pp.
1420–1443, 1978. [Online]. Available: http://dx.doi.org/10.2307/2778111
[7] J. Goldenberg, B. Libai, and E. Muller, “Talk of the Network: A Complex Systems Look at the Underlying
Process of Word-of-Mouth,” Marketing Letters, vol. 3, no. 12, pp. 211–223, Aug. 2001. [Online]. Available:
http://www.ingentaconnect.com/content/klu/mark/2001/00000012/00000003/00350022
[8] S. Aral and D. Walker, “Creating Social Contagion Through Viral Product Design: A Randomized Trial of
Questions?
P. Chandra and A. Kalyanasundaram, “A Network Pruning Based Approach
for Subset Specific Influential Detection”, in 4th Annual ACM conference onWeb Science (WebSci 2012), Evanston, Illinois, USA, Jun. 2012.
a
b
c
d
e
f
g
Destination Set (D0)
Subset Specific Influential
Influenced set (ψ)
a
b
c
d
e
f
g
a
b
c
d
e
f
g
a
b
c
d
e
f
g

Thank You