a head pose and facial actions tracking method based on effecient
TRANSCRIPT


sian mixture methods have been chosen for real-timevideo background substraction and object tracking[4][3][17][2], because of its good features in both the-ory and realization. Jepson et al. [1] introduced onekind of adaptive Guaussian mixture model named on-line appearance model (OAM) for visual tracking. Itis a generative model which combines both stable andmotion constraints. To our advantage, it earns the abil-ity to adapt to appearance variations caused by headpose and face expression.
When it comes to the fitting part, an EM al-gorithm is used in [1]. A gradient descent methodand particle filters are combined to track the param-eters in [2][5]. The main disadvantage of these meth-ods is time-consuming. Inverse Compositional ImageAlignment (ICIA) is an efficient algorithm proposedby [6]. It has been used to improve the search ef-ficiency of AAM [7] and extended to 3D morphablemodels by Romdhani and Vetter [8]. Both applica-tions have proved that the algorithm is efficient, robustand accurate.
In this study, we develop an efficient trackingframework based on OAM and ICIA, and apply it totrack head pose and facial features. The highlights ofthis paper are described as follows:
1. The target model is an adaptive mixture ap-pearance model established from the observationmodel, which is a modified OAM. The mixtureGaussian appearance model is built the same as[2], while the model learning is improved.
2. According to the mixture Gaussian model, theobservation expectation is evaluated as an refer-ence for the fitting, and the cost function is de-fined based on the log-likelihood of observationappearance.
3. A 3D wire-frame model is used to model the fa-cial actions, and a weak perspective projectionmodel is built to model head pose. The parame-ters of head pose are redefined for an unified useof ICIA.
4. Given coefficients, a piece-wise affine transformis taken to warp the image and get an observa-tion. Jacobian is evaluated on condition that thewarping operation is divided into three steps.
The paper is structured as follows: in the next sec-tion, we will establish an efficient tracking frameworkfor combining a modified online appearance modelwith Inverse Compositional Image Alignment algo-rithm. Section 3 presents the details of how to buildan observation and apply the combined algorithm totrack head pose and facial features. Section 4 presents
experimental results from an implementation of the al-gorithm. Finally we draw a conclusion of this workand have a discussion of the future work.
2 An efficient online appearancemodels (EOAM)
In this part, we describe a tracking framework of com-bining online appearance model with Inverse Compo-sitional Image Alignment algorithm. A modified ver-sion of OAM is used to model the appearance and thenICIA is adopted to fit the model.
2.1 Online Appearance Models
Three Gaussian models are used in the original onlineappearance models presented in [1]. The first compo-nent S depicts the stable image observation, the sec-ond part L represents data outliers, and the third partW accounts for the two-frame variation. Occlusioncan be modeled in other easy ways, using robust statis-tics for example. Therefore according to the WSFmodel proposed in [2], a fixed template F takes theplace of the original ’lost’ component L. It can bea shape-free facial texture without expression from afrontal view in facial expression tracking.
2.1.1 WSF Mixture Appearance Model
By assuming that the pixels of object observa-tion are independent of each other, the WSFappearance model at time t, is defined as a mix-ture of three Gaussians At = {Wt, St, Ft}, withmixture centers {µi,t, i = w, s, f}, and corre-sponding variances{σ2
i,t, i = w, s, f}, and themixing probabilities {ωi,t, i = w, s, f}. Note that{µi,t, σ
2i,t, ωi,t, i = w, s, f} are all d-vectors, where
d is the length of the observation. Suppose that theobservation is Yt, its likelihood is written as:
p(Yt|θt) =∏d
j=1{∑
i∈{w,s,f} p(Gi)p(Yt|Gi)}
=d∏
j=1
{∑
i∈{w,s,f}ωi,t(j)N(Yt(j);µi,t(j), σ2
i,t(j))}
(1)where Gi represents the three Gaussian components,N(x;µ, σ2) denotes a normal density:
N(x;µ, σ2) = (2πσ2)−1/2exp{−ϕ(x− µ
σ)} (2)
ϕ(x) =12x2 (3)
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 902 Issue 7, Volume 7, July 2010

2.1.2 Model learning
Initially, after an observation Y0 is obtained by a de-tection algorithm, we set A1 with Y0. To keep thegenerative mixture model adaptive, its parameters,namely the means, variances and mixing probabilities,need to be updated when a new observation Yt is avail-able. The learning process of WSF mixture model isdescribed as follows:
1. Compute the probabilities of new observation Yt
under each gaussian model:
pi,t =
ωi,t ·N(Yt;µi,t, σ2i,t), if |Yt−µi,t
σi,t| < Tσ
0(4)
where i ∈ {s, f, w}, and Tσ is a control variable.
2. If∑
j pj > 0, compute the expected posterior ofeach gaussian model:
qi,t = pi,t/∑
j∈{s,f,w}pj,t; i ∈ {s, f, w} (5)
Then update the mixing probabilities as:
ωi,t+1 = (1− α) · ωi,t + α · qi,t (6)
where α is the learning rate.
If ps,t > 0, update the mean and variance of thestable model as follows:
ct+1 = ct + qs,t (7)
µs,t+1 = (1− η) · µs,t + η · Yt, (8)
σ2s,t+1 = (1− η) · σ2
s,t + η · (Yt − µs,t)2 (9)
where η = qs,t · (1−αct+1
+ α)
3. The parameters of W-component and F-component are set as:
µw,t+1 = Yt, σ2w,t+1 = σ2
s,1 (10)
µf,t+1 = µf,1, σ2f,t+1 = σ2
f,1 (11)
The basic learning procedure of the weights andcomponent S follows the formulation in [3]. Note thatthe variable ct counts the number of effective obser-vations for the S-component, and is used to computean appropriate learning rate.
2.2 Fitting the model to an image
The adaptive appearance model is demonstrated in thecontext of object tracking. Given an input image, a fit-ting algorithm is required to optimize the coefficientswe are going to track. Inverse Compositional Im-age Alignment (ICIA) is an efficient one proposed byBaker and Matthews [6]. It has been applied to ActiveAppearance Model to improve its search performanceand has achieved good results [7]. When it comes tothe object tracking, we encounter the same problem asAAM search. Generally speaking, gradient descent isa good approach to register the appearance model to anew input image. However it is very time consumingif the gradient matrix is recomputed in each iteration,like in [5]. ICIA algorithm gives a key advantage ofpre-calculating the derivatives. Consequently it is agood choice for us.
2.2.1 Observation expectation
Now we would like to determine which portion ofthe mixture model At are most likely to describeYt. In [2], the observation of last frame is simplyused as the template for tracking. However Gaussiandistributions with the most supporting evidence andthe least variance are chosen as the background modelin [4]. In respect that the variances of two Gaussiancomponents are not updated and higher mixingprobability implies more feasibility of happening,the Gaussian with the maximum mixing probabilitycan work equally well [3]. To be more precise, theexpected value of observation is adopted here asboth the representation of the mixture model and thetemplate T in ICIA algorithm:
T = E(Yt) =∑
i∈{s,f,w}E(Yt|Gi)p(Gi)
=∑
i∈{s,f,w}ωi · µi (12)
2.2.2 Cost function
Our goal is to estimate the optimal parameters ofobservation model from input image. Assumingthat the observation model at time t is denoted byYt = W (X, ρ), where X is the input data, and ρis the coefficient of some warping operation W toproject the data to an observation. The log-likelihoodof Yt can be expressed as
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 903 Issue 7, Volume 7, July 2010

L(Yt|At) =
d∑
j=1
log
∑
i=w,s,f
ωi,t(j)N(Yt(j);µi,t(j), σ2i,t(j))
(13)Thus the cost function can be defined as:
et(ρ) =2d
d∑
j=1
∑
i=w,s,f
{ωi,t(j) · ϕ
[Yt(j)− µi,t(j)
σi,t(j)
]}
(14)
2.2.3 Optimization procedure
In this section, a framework of combing ICIA withOAM is built. As we mentioned before, ICIA is usedto optimize the parameters of observation and the ex-pectation of observation is its template. By reason thatthe template is time-varying, only the Jacobians canbe calculated at the beginning. The whole process canbe described as follows:
1. Pre-compute the Jacobian ∂W∂ρ when ρ = 0;
2. Initialization:
µi,1 = Y0, c1 = 0; i ∈ {s, f, w} (15)
3. At time t, set the texture model T for ICIA, inaccordance with equation (12).
4. Evaluate the gradient 5T of the template T;
5. Evaluate the steepest descent images SD and theHessian matrix H:
SD = 5T · ∂W
∂ρ(16)
H =∑x
[5T · ∂W
∂ρ
]T [5T · ∂W
∂ρ
](17)
6. Iterate until converged:
(a) Normalize the input data using some warpoperation with the current parameters ρ,and get a new observation denoted as Yc.
(b) The new observation has to register withthe current mixture model At, and the er-ror is evaluated according to equation (14).Supposing that et records the error of lastρc, and if ec(ρc) < et, update the error andthe parameter:
et = ec(ρc), ρt = ρc, Yt = Yc (18)
If ec(ρc) ≥ et, the error can no longer bereduced, thus convergence is declared, thenparameters ρt and observation Yt are re-turned.
(c) Compute the shift of parameters:
∆ρc = H−1∑x
SDT · [Yc − T ] (19)
(d) Compose the incremental warp with thecurrent warp W (x, ρt) ◦W (x,∆ρc)−1 andget a new parameter ρc
′. Small steps areperformed to the update: ρc ← ρc+λ(ρc
′−ρc) with a factor λ ¿ 1.
7. Update the mixture appearance model At+1 us-ing Yt, according to the steps in section 2.1.2, andset t = t + 1, then return to step 3.
3 Head pose and facial expressiontracking
So far, the efficient online appearance models basedon ICIA has been detailed. Now we are interested inapplying it to head pose and facial actions tracking.
3.1 Building image observation
We explore the application of automatic facial actiontracking. To this end, both facial expression and head-pose have to be recovered. In this section, models offacial action and head-pose are built, and then an ob-servation is obtained from them.
3.1.1 Modeling the facial actions
Our study is based on a 3D wire-frame face modelCandide built by Ahlberg [10], which is designed todepict the diversity between different human beingsas well as different face expressions. The model isgiven as:
g = g +ns∑
i=1
si · Si +na∑
i=1
ai ·Ai (20)
where g is the 3D standard shape, Si denote the shapemodes, Ai denote the animation modes, ns and na
are the numbers of shape and animation modes usedrespectively, si and ai are the respective parameters.
Note that the shape modes represent inter-personvariety, and are ascertained by some detection proce-dure at the beginning. Therefore, only the tracking ofanimation parameters are considered:
a = (a1, a2, . . . , ana)T (21)
This procedure is regarded as a 3D to 3D projection:
M((x, y, z); a) → (x, y, z) (22)
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 904 Issue 7, Volume 7, July 2010

Figure 1: Coordinate system and pose parametersused in our approach
3.1.2 Modeling the head-pose
After the face model is built, it is necessary to projectthe 3D wire-frame to 2D image coordinate system. Aweak perspective projection model is used:
g′ = f ·R · (g +ns∑
i=1
si · Si +na∑
i=1
ai ·Ai) + t (23)
where f is the camera focal length, t = (tx, ty) is de-noted as the translation vector. Figure 1 shows thecoordinate system used in our approach. Supposingthat R′ is the 3× 3 matrix based on the three rotationangles around the respective axes, and is denoted asfollowing:
R′ = Rα ·Rβ ·Rγ =
a1 a2 a3
a4 a5 a6
a7 a8 a9
(24)
where the three rotations around each axis are definedas:
Rα =
1 0 00 cos α sinα0 − sin α cos α
(25)
Rβ =
cos β 0 − sinβ0 1 0
sinβ 0 cos β
(26)
Rγ =
cos γ sin γ 0− sin γ cos γ 0
0 0 1
(27)
The projection matrix R is denoted by:
R =
[a1 a2 a3
a4 a5 a6
](28)
After the translation, a 2D mesh g′ is obtained. Totry to unify the operations for easy computation, wedefine some new parameters as following:
qi =
f · ai − 1, (i = 1, 5)
ai, (i = 2, 3, 4, 6)(29)
q7 = tx, q8 = ty (30)
The corresponding mesh vectors are defined as:
g∗0 = (x1, y1, x2, y2, · · · , xv, yv)T (31)
g∗1 = (x1, 0, x2, 0, · · · , xv, 0)T (32)
g∗2 = (y1, 0, y2, 0, · · · , yv, 0)T (33)
g∗3 = (z1, 0, z2, 0, · · · , zv, 0)T (34)
g∗4 = (0, x1, 0, x2, · · · , 0, xv)T (35)
g∗5 = (0, y1, 0, y2, · · · , 0, yv)T (36)
g∗6 = (0, z1, 0, z2, · · · , 0, zv)T (37)
g∗7 = (1, 0, 1, 0, · · · , 1, 0)T (38)
g∗6 = (0, 1, 0, 1, · · · , 0, 1)T (39)
Then the form of weak perspective projection modelis changed to:
N((x, y, z); q) → g∗(x, y) = g∗0 +6∑
i=1
qi · g∗i (40)
At the same time the number of pose parameters to betracked increases to eight from the original six. Thisis not considered to be a problem, as the computationof the projection has become more direct. In conclu-sion, the tracking problem now consists of updatingthe animation parameters ai and the eight projectingparameters qi. The total parameters of both pose andexpression are denoted as:
ρ = [q, a]T = [q1, q2, . . . , q8, a1, a2, . . . , ana ]T (41)
3.1.3 Image warping
To obtain an normalized texture observation, we makethe standard shape g as the reference mesh by project-ing it onto the image system using a centered frontalpose. Afterward each input image I is warped so thatthe vertices of new mesh with parameter ρ match thecorresponding ones of the reference mesh.
The reference frames of the new mesh and thebase mesh are considered to be different, and denotedas (x, y) and (u, v) respectively. A mesh is set of tri-angles. Suppose that the three vertices of each pixel
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 905 Issue 7, Volume 7, July 2010

Figure 2: Example of observation corresponding to awrong model parameter and a correct model parame-ter
(u, v)T in reference mesh are (ui, vi)T , (uj , vj)T and(uk, vk)T . The corresponding vertices in new meshare (xi, yi)T , (xj , yj)T and (xk, yk)T . Then the pixel(u, v)T can be expressed as:
(u, v)T = λ1(ui, vi)T + λ2(uj , vj)T + λ3(uk, vk)T
(42)where λ1, λ2 and λ3 are the barycentric coordinatesand satisfy:
0 ≤ λ1, λ2, λ3 < 1;λ1 + λ2 + λ3 = 1 (43)
A piece-wise affine transform is used, and the pointsimply maps to:
(x, y)T = λ1(xi, yi)T + λ2(xj , yj)T + λ3(xk, yk)T
(44)Finally, a shape-free image patch as the observation isobtained:
W ((x, y); ρ) → (u, v) (45)
Y (u, v) = I(W ((x, y); ρ)) = I(x, y) (46)
According to [11], all the barycentric coordinates canbe pre-calculated to reduce the CPU time of warpingprocess. Figure 2 shows a example of observation cor-responding to a wrong model parameter and a correctmodel parameter.
What is left to do now is to compute the Jacobianand incremental warp inversion and then get new pa-rameters, when using ICIA. These steps are detailedin next two sections.
3.2 Computing the Jacobian
The warping operation here consists of three steps andcan be expressed as:
W ◦N ◦M((x, y); ρ) = W (N(M((x, y, z); a); q); ρ)(47)
Therefore, to compute the Jacobian at a point (x, y)when ρ = 0, we can get the following equations:
∂W ◦N ◦M((x, y); 0)∂a
=∂W ◦M((x, y, z); 0)
∂a(48)
∂W ◦N ◦M((x, y); 0)∂q
=∂W ◦N((x, y); 0)
∂q(49)
Supposing that there are ν vertices composing the 3Dwireframe and the 2D mesh, which are denoted as:
g = (x1, y1, z1, x2, y2, z2, . . . , xν , yν , zν) (50)
g∗ = (x1, y1, x2, y2, . . . , xν , yν) (51)
Consequently the chain rule is applied to warp andgives ∂W◦M
∂a as:
ν∑
i=1
[∂W ◦M
∂xi
∂xi
∂a+
∂W ◦M
∂yi
∂yi
∂a+
∂W ◦M
∂zi
∂zi
∂a
]
(52)where ∂W◦M((x,y,z);0)
∂xi, ∂W◦M((x,y,z);0)
∂yiand
∂W◦M((x,y,z);0)∂zi
are determined by if (xi, yi, zi)is one vertex of the triangle (x, y, z) belonged to. ∂xi
∂a ,∂yi∂a and ∂zi
∂a are the corresponding values in animationmodes A.
The same way is taken to calculate ∂W◦N∂q :
∂W ◦N
∂q=
ν∑
i=1
[∂W ◦N
∂xi
∂xi
∂q+
∂W ◦N
∂yi
∂yi
∂q
]
(53)
3.3 Computing new coefficients
A first order approximation of the inverse incrementalwarp is derived [6]:
W ◦N◦M((x, y);4ρ)−1 = W ◦N◦M((x, y);−4ρ)(54)
We compute the warp composition and acquire newparameters in a way proposed in [7]. At first, the des-tination of standard shape g under the composition ofW ◦N ◦M((x, y), ρ) and W ◦N ◦M((x, y),4ρ)−1
is obtained, which is denoted as:
ξ = (W◦N◦M)((x, y); ρ)◦(W◦N◦M)((x, y);−4ρ)(55)
Therefore new parameters ρnew should satisfy the fol-lowing condition:
(W ◦N ◦M)((x, y); ρnew) = ξ (56)
Finally the update parameters is computed as follows:
qi = g∗i · (ξ − g) (57)
ai = Ai · (N(ξ; q)−1 − g) (58)
However the first order approximation has beenproved to be not very accurate in [8], and a novel se-lective approach is taken instead [9]. For the reason oftime limit, we leave it for further study.
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 906 Issue 7, Volume 7, July 2010

Figure 3: Head pose and facial expression trackingresults obtained with a 860-frame-long sequence
4 Experiments
The tracking approach proposed in this paper is testedon a series of videos. The size of video frames is320 × 240, and the resolution of observation is set tobe 40 × 46. The platform is a PC with an Intel C2D3.0GHz CPU. In experiments, fourteen shape modesand six animation modes of the Candide model areused. The six animation units contain: (1) upper lipraiser A1; (2) jaw drop A2; (3) lip stretcher A3; (4)eyebrow lowerer A4; (5) lip corner depressor A5; and(6) outer brow raiser A6. Most common facial expres-sion can be represented by these actions.
Model initialization is needed to detect the faceand facial feature points, then determine the shape pa-rameter, and give the pose parameter an initial value.The model initialization is carried out using the firstframe of the sequence, under the assumption that thetarget is facing the camera (out-plane rotations α = 0and β = 0) and has a neutral expression (all action pa-rameters are 0) at this time. In our work, an Adaboostclassifier is used to detect the face, and a weightedAAM algorithm [18] is adopted to detect facial featurepoints. Both of them are very fast. Robust statistics isused to deal with occlusions.
Figure 3 displays the tracking results associ-ated with several frames of a 860-frame-long test se-quence. The right part of each picture shows fiveobservations, which are the means of Component S,Component F and Component W of the mixturemodel, observation expectation and outlier respec-
Method Tracking Speed Fitting SpeedGDM + SOAM 50.7 ms 34.8 msGDM + MOAM 64.4 ms 42.9 msICIA + SOAM 40.9 ms 22.1 msICIA + MOAM 51.2 ms 30.5 ms
Table 1: Speed comparison on a Pentium IV 3.0 GHzPC. These results show the average time of trackingand fitting process for each image on a 1388-frame-long test sequence.
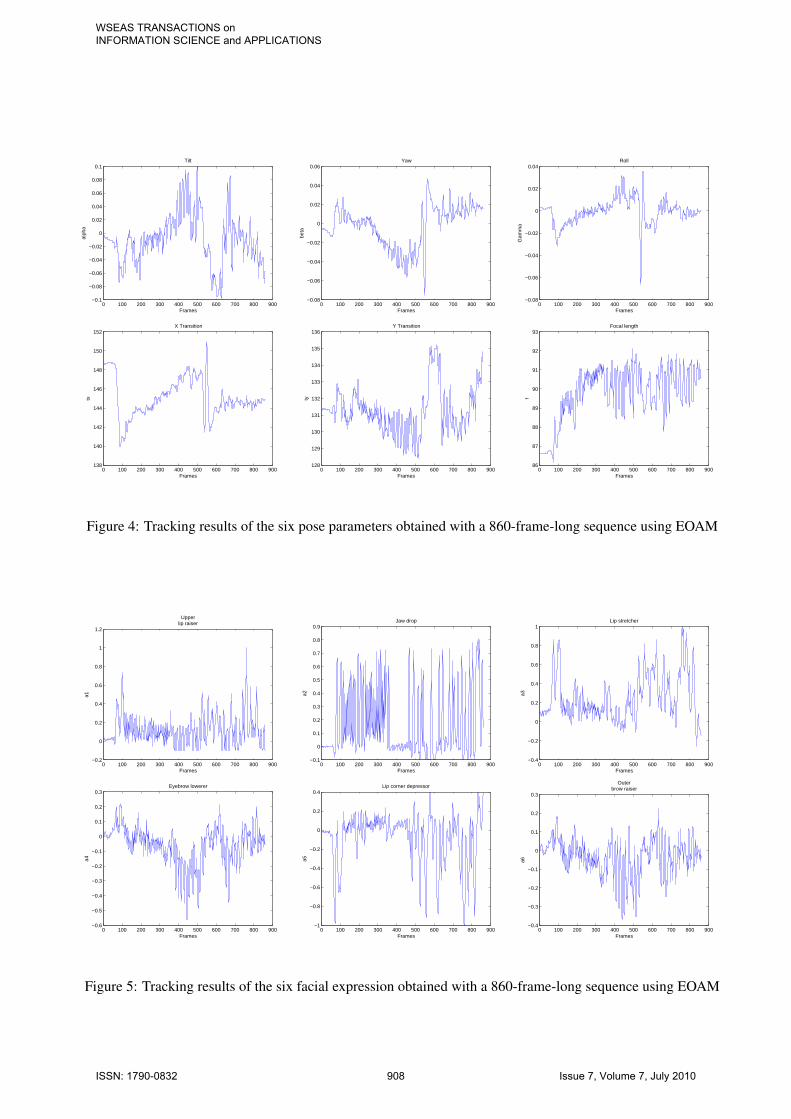
tively from top down. Figure 4 shows the six esti-mated values of pose of the sequence frames. Notethat it was eight parameters when tracking. Figure 5shows the six estimated values of animations of thesequence frames. It can be seen that the sequence con-tains large head movements and facial actions and thealgorithm responds well to them. We find that mostof the mixing weights of component S ascend as timegoes on in this sequence, which make sense becausethis component is designed to represent the stable fea-tures of all the past observations, and its credibility ispromoted by learning if the object keeps moving asthe frames going. It can be seen that our algorithm isrobust and corresponds well to the actual head and fa-cial actions. Both the mouth and eyebrow act well inresponse to the actual expression.
For validation purpose, we use the talking facevideo with ground truth data from the Face and Ges-ture Recognition Working group for tracking. Thevideo consists of 5000 frames taken from a video ofa person engaged in conversation. This correspondsto about 200 seconds of recording. The sequence wastaken as part of an experiment designed to model thebehavior of the face in natural conversation [19]. Fig-ure 6 displays the tracking results associated with sev-eral frames of the test sequence. The right part of eachpicture shows five observations, which are the meansof Component S, Component F and Component Wof the mixture model, and observation expectation re-spectively from top down. It can be seen that our al-gorithm responds well to them.
The talking face video data set has been trackedwith an AAM using a 68 point model. To be pre-cise, we select 49 labeled points that are close to thecorresponding Candide model points from 68 anno-tated points per frame. Figure 7 shows the Candidemodel with points used for evaluation and the averageerror over the whole video sequence for each point us-ing a single Gaussian component(SOAM) and a mix-ture Gaussian model (MOAM). The results shows thatMOAM is more robust.
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 907 Issue 7, Volume 7, July 2010
0 100 200 300 400 500 600 700 800 900−0.1
−0.08
−0.06
−0.04
−0.02
0
0.02
0.04
0.06
0.08
0.1
Frames
Tilt
alph
a
0 100 200 300 400 500 600 700 800 900−0.08
−0.06
−0.04
−0.02
0
0.02
0.04
0.06
Frames
beta
Yaw
0 100 200 300 400 500 600 700 800 900−0.08
−0.06
−0.04
−0.02
0
0.02
0.04Roll
Frames
Gam
ma
0 100 200 300 400 500 600 700 800 900138
140
142
144
146
148
150
152X Transition
Frames
tx
0 100 200 300 400 500 600 700 800 900128
129
130
131
132
133
134
135
136
ty
Frames
Y Transition
0 100 200 300 400 500 600 700 800 90086
87
88
89
90
91
92
93
Frames
f
Focal length
Figure 4: Tracking results of the six pose parameters obtained with a 860-frame-long sequence using EOAM
0 100 200 300 400 500 600 700 800 900−0.2
0
0.2
0.4
0.6
0.8
1
1.2
Frames
a1
Upperlip raiser
0 100 200 300 400 500 600 700 800 900−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9Jaw drop
a2
Frames0 100 200 300 400 500 600 700 800 900
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1Lip stretcher
Frames
a3
0 100 200 300 400 500 600 700 800 900−0.6
−0.5
−0.4
−0.3
−0.2
−0.1
0
0.1
0.2
0.3Eyebrow lowerer
Frames
a4
0 100 200 300 400 500 600 700 800 900−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4Lip corner depressor
Frames
a5
0 100 200 300 400 500 600 700 800 900−0.4
−0.3
−0.2
−0.1
0
0.1
0.2
0.3
Outerbrow raiser
Frames
a6
Figure 5: Tracking results of the six facial expression obtained with a 860-frame-long sequence using EOAM
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 908 Issue 7, Volume 7, July 2010

Figure 6: Head pose and facial expression tracking results
Figure 7: Selected points on model and the average error
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 909 Issue 7, Volume 7, July 2010

Finally the speed of our algorithm is tested andcompared with the method using a single Gaussiancomponent with gradient descent method presented in[2][5]. Four combinations of algorithms are comparedperforming on a 1388-frame-long test sequence. Gra-dient descent method (GDM) or ICIA is used for fit-ting, and a single Gaussian component S (SOAM) orthe three mixture Gaussian model (MOAM) is takento model the appearance. The average speed of eachmethod is shown in Table 1. Note that eight pose pa-rameters have to be tracked using ICIA while thereare six using GDM. ICIA is still more efficient thanGDM, despite more parameters to track. It is sloweddown as the template are time-varying and only theJacobian can be pre-computed before tracking. Thelearning of mixture Gaussian model is a little time-consuming but it is more robust especially when thehead moves quickly or the expression changes fast.
5 Conclusion and future work
A robust and fast tracking algorithm named EOAM isproposed and applied to track head pose and facial ac-tions in this paper. The mixture Gaussian model earnsmore flexibility than a single one and the ICIA pro-vides an efficient fitting to the model. In our approach,the observation expectation of the mixture Gaussianmodel is evaluated as the template for ICIA fitting. Fa-cial expression and head pose are modeled, and then apiece-wise affine transform is used to obtain an obser-vation. Experimental results performed on live videosequences demonstrate that our method is robust andefficient.
The actions of mouth and eyebrows can betracked well with our method, whereas the techniquestill need to be improved so that more expressions canbe expressed and tracked. Initialization is very impor-tant in visual tracking, and most algorithms are verysensitive to the veracity of starting position. It is al-ways very difficult to acquire a good initialization au-tomatically. Therefore how to promote the robustnessof tracking approaches to the initial position is oneof our future work. We don’t pay much attention onocclusion in this paper, although robust statistics hasbeen used to deal with it in the experiments. It willbe another important direction we are going to studyin the future. Future work also contains addressingthe robustness of the tracker to important illuminationchanges and quick movements.
References:
[1] A. D. Jepson, D. J. Fleet, and T. R. El-Maraghi,“Robust online appearance models for visual
tracking,” IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition,vol. 1, no. 10, pp. 415–422, 2001.
[2] S. Zhou, R. Chellappa, and B. Moghaddam, “Vi-sual tracking and recognition using appearance-adaptive models in particle filters,” IEEE Trans-actions on Image Process, vol. 13, no. 11, pp.1491–1506, 2004.
[3] Dar-Shyang Lee, “Effective gaussian mix-ture learning for video background subtraction,”IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, vol. 27, no. 5, pp. 827–832,2005.
[4] C. Grimson and W.E.L. Grimson, “Adaptivebackground mixture models for real-time track-ing,” IEEE Computer Society Conference onComputer Vision and Pattern Recognition, vol.2, no. 6346911, pp. 246–252, 1999.
[5] F. Dornaika and F. Davoine, “On appearancebased face and facial action tracking,” IEEETransactions on Circuits and Systems for VideoTechnology, vol. 16, no. 9, pp. 1107–1124, 2006.
[6] S. Baker and I. Matthews, “Equivalence and ef-ficiency of image alignment algorithms,” IEEEComputer Society Conference on Computer Vi-sion and Pattern Recognition, vol. 1, no. 10, pp.1090–1097, 2001.
[7] I. Matthews and S. Baker, “Active appear-ance models revisited,” International Journal ofComputer Vision, vol. 60, no. 2, pp. 135–164,2004.
[8] S. Romdhani and T. Vetter, “Efficient, robustand accurate fitting of a 3d morphable model,”IEEE International Conference on Computer Vi-sion, vol. 1, no. 8301595, pp. 59–66, 2003.
[9] S. Romdhani and N. Canterakis and T. Vetter,“Selective vs. global recovery of rigid and non-rigid motion,” Tech. Report, University of Basel,Computer Science Dept, 2003.
[10] J. Ahlberg, “Candide-3 - an updated param-eterized face,” 2001, Tech. Report No.LiTH-ISY-R-2326. Image Coding Group, Dept.of EE,Linkping University, Sweden.
[11] J. Ahlberg, “Real-Time facial feature trackingusing an active model with fast image warp-ing,” International Workshop on Very Low Bi-trate Video, pp. 39–43, 2001.
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 910 Issue 7, Volume 7, July 2010

[12] B. Bascle and A. Blake, “Separability of Poseand Expression in Facial Tracking and Anima-tion,” IEEE International Conference on Com-puter Vision, no. 1164, pp. 323–328, 1998.
[13] D. Gavrila, “The visual analysis of human move-ment: a survey,” Computer Vision and ImageUnderstanding, vol. 73, no. 1164, pp. 82–98,1999.
[14] Datong Chen and Jie Yang, “Robust objecttracking via online dynamic spatial bias appear-ance models,” IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 29, no.12, pp. 2157–2169, 2007.
[15] Qiang Chen, Quan-Sen Sun, Pheng-Ann Heng,and De-Shen Xia, “Robust object tracking viaonline dynamic spatial bias appearance models,”Pattern Recognition Letters, vol. 29, no. 2, pp.126–141, 2008.
[16] S. Avidan, “Support vector tracking,” IEEETransactions on Pattern Analysis and MachineIntelligence, vol. 26, no. 8, pp. 1064–1072,2004.
[17] Stephen J. McKenna and Yogesh Raja and Shao-gang Gong, “Object Tracking using AdaptiveColour Mixture Models,” Image and VisionComputing, vol. 17, no. 2, pp. 225–231, 1999.
[18] Shuchang Wang and Yangsheng Wang and Xi-aolu Chen, “Weighted Active Appearance Mod-els”, International Conference on IntelligenceComputing, pp. 1295–1304, 2007
[19] Face and Gesture Recogni-tion Working group, http://www-prima.inrialpes.fr/FGnet/html/benchmarks.html
WSEAS TRANSACTIONS on INFORMATION SCIENCE and APPLICATIONS Xiaoyan Wang, Xiangsheng Huang, Huiwen Cai, Xin Wang
ISSN: 1790-0832 911 Issue 7, Volume 7, July 2010