交互作用与效应修饰
DESCRIPTION
交互作用与效应修饰. 交互作用 ( interaction). 指两个或多个因素相互依赖发生作用而产生的一种效应。生物学上是指两个或多个因素互相依赖发生作用而引起疾病或预防和控制疾病。即生物学交互作用 (biological interaction). 研究资料中各研究因素间存在交互作用时,说明各研究因素的作用不是独立的,一个因素水平改变时与它有交互作用的因素之效应也将发生改变 。 交互作用是描述资料本身所表现出来的关于两个或多个暴露因素联合效应的一个统计学术语,并不表示一定具有生物学意义。有交互作用可能有生物学意义,也可能没有生物学意义。. 效应修饰作用. - PowerPoint PPT PresentationTRANSCRIPT

交互作用与效应修饰

交互作用 ( interaction)
• 指两个或多个因素相互依赖发生作用而产生的一种效应。生物学上是指两个或多个因素互相依赖发生作用而引起疾病或预防和控制疾病。即生物学交互作用(biological interaction) .

• 研究资料中各研究因素间存在交互作用时,说明各研究因素的作用不是独立的,一个因素水平改变时与它有交互作用的因素之效应也将发生改变 。
• 交互作用是描述资料本身所表现出来的关于两个或多个暴露因素联合效应的一个统计学术语,并不表示一定具有生物学意义。有交互作用可能有生物学意义,也可能没有生物学意义。

效应修饰作用• 当暴露因素按第三变量分层后估计暴露
在每一层中与疾病的联系强度时,效应修正被定义为暴露因素在各层中与疾病的联系强度 ( 测量的效应 ) 因第三变量的存在情况不同而大小不同。
• 该第三变量称为效应修正因素 ( effect modification factor )。

• 第三变量在一项研究中是否成为效应修正因素,取决于选用判断暴露和疾病之间联系的指标是用率差 ( rate difference , RD) 还是用率比 ( rate ratio , RR) 。
• 又称效应变异( effect variation ),或效应不一致性或异质性( heterogeneity of effect )。

• 例如,性别与髋骨骨折的联系受到年龄的修饰;– 女性髋骨骨折危险性为男性的 2 至 3 倍
– 年轻组:男性髋骨骨折危险性高于女性
– 年老组:女性髋骨骨折危险性明显高于男性
– 说明性别与骨折的联系被年龄修饰。

• 体重与乳癌的联系受到绝经状态的修饰;
– 肥胖与乳癌之间的联系被绝经状态修饰,
– 肥胖是绝经后妇女乳癌的危险因素,
– 肥胖不是绝经前妇女乳癌的危险因素。

• 孕妇吸烟与婴儿低出生体重的联系
– 吸烟对出生低体重的有害影响在高龄孕妇较低龄孕妇更为
明显。
– 母亲年龄是修饰因素。

• EB 病毒感染与非洲儿童淋巴瘤的联系
– 生命早期感染 EB 病毒与非洲儿童 Burkitt 淋巴瘤的联
系多见于幼年生活在疟疾广泛流行区的儿童,少见于
疟疾非流行区。
– 当地普遍存在疟疾是一种效应修饰因素。

效应修饰与混杂 混杂是一种偏倚,是研究者希望避免的,或在
必要时希望从资料中消除的。
效应修饰是对效应本身的详细描述,它是一种
需要报告的发现,而不是一种需避免的偏倚。
流行病学分析总目的是消除混杂,并发现和描
述效应修饰。

混杂是否存在取决于研究设计。
混杂源于选择研究对象的源人群中混杂变量与研究因素的相关性。因此,在选择研究对象时对研究对象进行适当限制,可以防止一个变量成为混杂因素。
效应修饰并不取决于研究设计,是一种与研究设计无关的自然现象,是研究欲尽可能揭示和描述的现象,它超出了恒定的研究设计概念。

效应修饰是一种恒定的自然现象,这是一种相对(非绝对)的概念,故其并不与任何生物学特性相对应。
在研究效应修饰时必须规定欲测量的是何种效应。 广义上讲,效应修饰是指对一种效应的修饰,但并未指
明修饰何种效应测量。流行病学中有两种常用的危险性效应测量,即率差和率比,以及其它一些不常用的测量。
如果不规定修饰何种测量(率差或率比),效应修饰的概念就太模糊,使人无法描述其特性。

• 暴露组与非暴露组之间的发病率比在不同年龄组是恒定的。
• 但其发病率差则随年龄而增加。以率差为指标,年龄是效应修饰因素。

• 暴露组与非暴露组之间的发病率差在不同年龄时是恒定的。
• 对率比这个效应来说,年龄修饰暴露效应。

如果每天喝 5杯咖啡,可使男性心肌梗死发生
率增加 40% ,(率比 RR=1.4 ),但使女性心
肌梗死发生率只增加 10% ( RR=1.1 ),这种
情况称作性别对 RR 的修饰(或 RR 的性别变异
或性别的 RR 不一致性),性别即为喝咖啡致
心肌梗死 RR 的修饰因素。
例如

又例如,每天喝 5杯咖啡,可使男性心肌梗死
发生率增加到 400/10万人年,但只使女性心肌
梗死发生率增加到 40/10万人年。这种情况称
为性别对率差( AR )的修饰,性别即为喝咖
啡致心肌梗死 AR 的修饰因素。

• 再一例子,如果每天喝 5杯咖啡,无论对男性或女性,都可使心肌梗死发生率增加 22% ( RR=1.22 ),这种情况称为性别间的 RR 一致性( homogeneity ),也即性别不存在效应修饰。
• 需注意的是,效应修饰和效应不一致性并非效应的固有特性,而仅是效应测量方法的一个特征。

• 例如,每天喝 5杯咖啡,可使男性心肌梗死发生率从1000/10万人年增加到 1220/10万人年,而使女性心肌梗死发生率从 400/10万人年增加到 488/10万人年,男女性的RR均 =1.22 ,呈现一致性。
• 男性的 AR=220/10万人年,女性 AR=88/10万人年,男女性的 AR不一致或 AR 被性别所修饰。
• 这个例子说明,效应修饰不一定等于生物学的交互作用( interaction )(如协同或拮抗作用)。

效应修饰作用的分析• 效应修饰可采用分层的方法进行分析,估计每层的效应,
并进行比较。
• 但如果每层观察对象的数目太少,使每层的效应不稳定,尤其在调整了混杂因素后。这样,由于随机误差,层间的效应估计可能波动很大。

• 检验分层资料不一致性的统计学方法,在许多情况下检验效率很低,用常规的显著性水平(如 α=0.05 ),多数的层间不一致性无法检出。用数学模型拟合的方法可以解决其中的一些问题。但由于混杂、测量误差引起的偏倚在各层间不同,对效应修饰无论采用观察或数学模型拟合的方法,仍会有一些偏倚。

交互作用模型• 相加模型 (additive model)
– 相加模型假定若交互作用不存在时,两个或两个以上因子共同作用于某一事件时,其效应等于这些因子单单独作用时的和,有时称之具有可加性。

• R11-R00=(R10-R00)+(R01-R00)

• 相乘模型 ( multiplicative model)– 相乘模型假定若交互作用不存在时,两个或
两个以上因子共同作用于某一事件时,其效应等于这些因子单独作用时的积。

• R11/R00=(R10/R00)(R01/R00)

相加模型: R11 - R00 = 40-1=39
(R10-R00)+(R01-R00)=8-1+5-1=12
相乘模型: R11/R00=40/1=40
(R10/R00)(R01/R00)=(8/1)(5/1)=40

混杂与交互作用的存在形式• 四种形式:①有混杂但无交互作用②无混杂但
有交互作用③混杂和交互作用同时存在④混杂和交互作用均不存在。
• 如一项研究资料的 cRR 与 aRR 不同, 表明其中存在着混杂。将资料按某种特性分层 ( 如可疑的效应修正因子 ) ,计算各层相对危险度,若层别相对危险度不等,说明资料中存在着交互作用。


• 例如:某前瞻性研究观察某团体中甲苯磺丁脲治疗组和安慰剂组各种原因死亡数情况。


交互作用的识别• 交互作用识别的一般过程
– 在判断交互作用存在与否之前,首先要明确所研究的因素与事件之间是否存在统计学联系。如果有联系,接下来看这一联系是否由偏倚或混杂所致。若存在偏倚或混杂因素,采用适当的方法加以改进和调整后再分析交互作用。

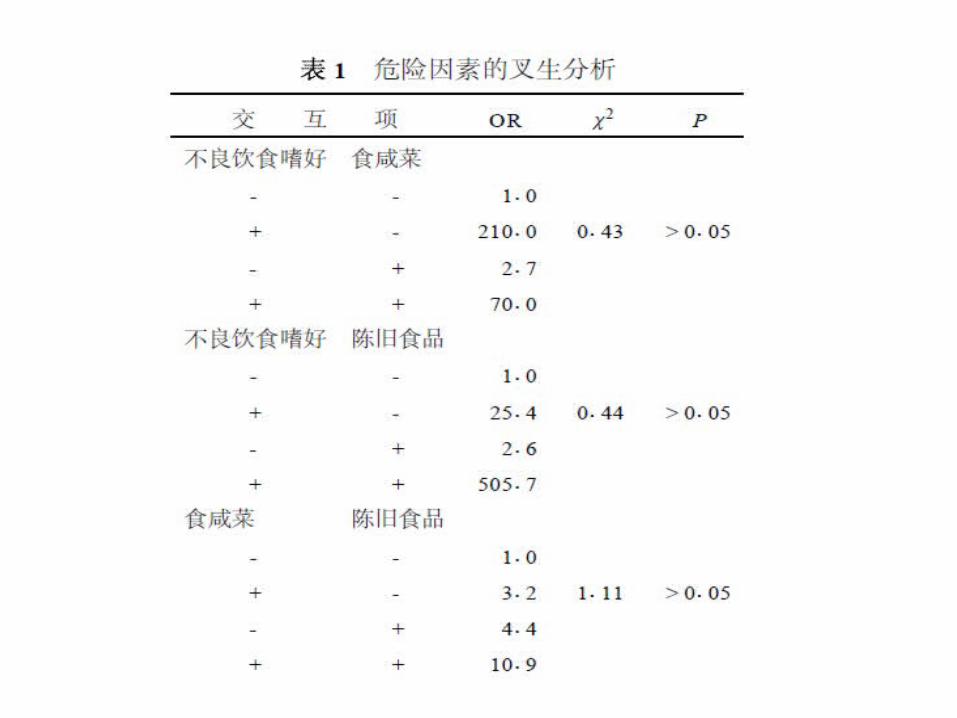
叉生分析• 叉生分析: x 、 y 为两个危险因素 ,
ORx 、 ORy 、 ORxy 分别表示仅有 x ,仅有 y 和 x 、 y 都存联合作用模型。若 :ORxy > ORx + ORy - 1, 则认为 x 、 y 间可能存在交互作用。但要作统计学推断 ,则需作 χ2 检验。

• 叉生分析仅可以给人们提示某两个因素间是否可能存在交互作用 , 并且叉生分析的统计学检验方法本身尚存在一定的缺陷 ;另外 , 在用叉生分析法进行交互作用分析时 ,未考虑其他不参加叉生的危险因素的作用。因此 , 可在多因素 logistic 回归模型中加入交互作用项 , 以平衡其他因素的影响。


• 分层分析– 分层分析是比较经典的识别交互作用的方法。
可以通过比较按照可疑交互因素分层后层间的效应测量值-相对危险度 (RR) 或率差(RD) 来判断是否产生交互作用。如果各层之间的效应测量值 RR 或 RD 不同,则可能存在交互作用。但是鉴于各层 RR 和 RD 变异可能是机遇所致,因此必须进行统计学检验。

• 分层分析– 如果效应一致性的假设不合理,那么按第三变量分层后,
各层中效应不一致的情况,不应采用简单合并估计效应的方法。
– 如果第三变量各层间的效应不同时,即存在效应修饰,资料分析和表达的关键是描述分层因素(即第三变量)是如何修饰效应的。

• 评价效应修饰常依赖于机械地应用统计学检验方法。• 建立在统计学效应评价基础上的流行病学交互作用,有时
是难以捉摸的,用纯粹机械的方法会使问题变得模糊不清。• 用统计学方法评价效应修饰时应小心。• 由于检验的备择假设是非特异性的,一般用于效应修饰检验的普通统计学方法,效率较低。因此,“无显著性的” P值较难正确解释。
分层分析时的注意问题

• 由于选择偏倚、分类错误、混杂、以及其它
偏倚和致病效应,很少期望用任何尺度测量
的效应都会一样精确。
• 一致性效应的无效假设常只是一项统计学设计,这类统计学设计应只能被看作是近似真实情况,仍存有疑问。

分层分析的步骤
• 第一步是按第三变量分层后,检查各层的效应估计。即使基本参数一致,层间估计值还会有某些随机变异,但过大的随机变异或明显的非随机变异可能就是效应修饰的证据。
• 关于效应修饰的判断不应只限于资料的一些表面现象,如果有效应修饰的话,第二步还应在评价过程中结合以往研究的其它知识或一般生物学知识予以考虑。

• 第三步,用多种统计学检验方法来检验层间一致性。
• 不同的危险性指标,如率差和率比,其效应修饰的测量要求有不同的评价方法,比的测量一致性意味差的测量效应修饰,反之,差的测量一致性可能意味比的测量效应修饰。
• 统计学检验效应一致性的无效假设,一般有两类,一是按一致效应的直接加权合并估计,另一是按最大似然估计。

• 效应修饰只能按某一种效应测量指标来进行描述。
• 如果,按率差或按率比,都没有效应修饰,除非未暴露
组的疾病率与可能的效应修饰因素之间没有联系,其仍
可能在其它测量指标(如 SMR )上存在效应修饰。
• 处理效应修饰的基本分析方法是分层分析。
• 将资料按第三变量进行分层分析有两个目的,一个是评
价和消除混杂,另一个是评价和描述效应修饰。
• 分层分析是处理这两种问题的好方法。

以色列缺血性心脏病研究• 心肌梗死与收缩血压关系的病例对照研究──────────────────── 心肌梗死 对照 计────────────────────
• 收缩血压≥ 140 29 711 740
• 收缩血压 < 140 27 1244 1271
• 计 56 1955 2011
────────────────────
cOR=1.88 , χ2=5.56
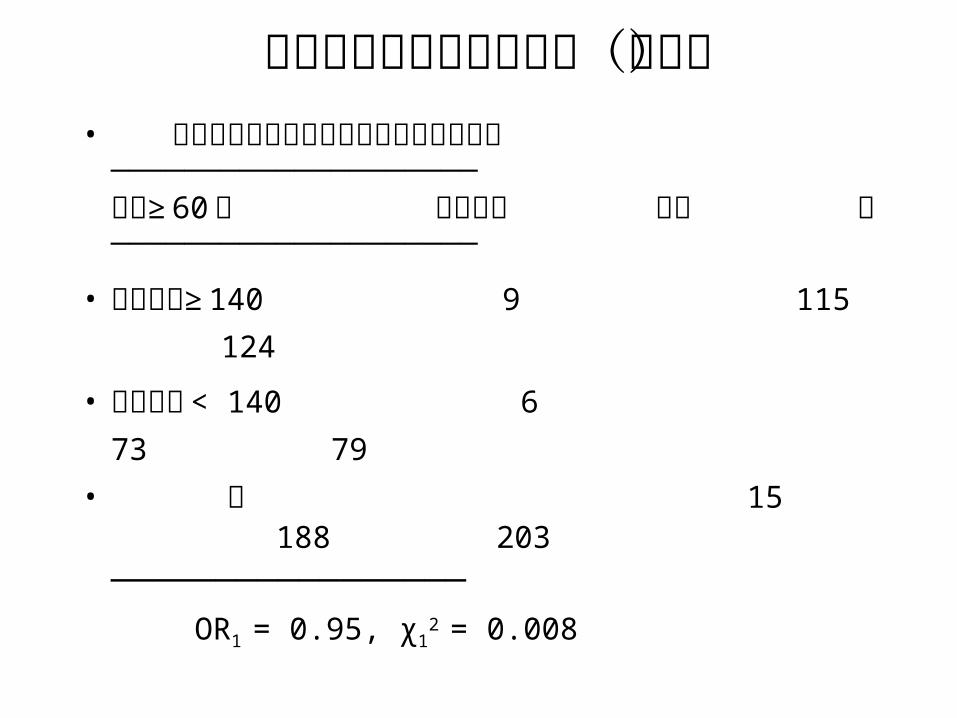
以色列缺血性心脏病研究(分层)• 心肌梗死与收缩血压关系的病例对照研究────────────────────年龄≥ 60岁 心肌梗死 对照 计────────────────────
• 收缩血压≥ 140 9 115 124
• 收缩血压 < 140 6 73 79
• 计 15 188 203
───────────────── OR1 = 0.95, χ1
2 = 0.008

以色列缺血性心脏病研究(分层) • ────────────────────
年龄 < 60岁 心肌梗死 对照 计────────────────────
• 收缩血压≥ 140 20 596 616
• 收缩血压 < 140 21 1171 1192
• 计 41 1767 1808
────────────────────
OR2 = 1.87, χ22 = 4.04

以色列缺血性心脏病研究
• cOR 被看作是不同年龄层 ORi (本例中为 OR1 和 OR2 )
的平均值,如果被平均的各个 ORi 相同,并包括 i 个个
体的所有样本估计,则这种平均值可以解释为只存在抽
样变异。
• 如果血压与心肌梗死的联系在不同年龄层是各异的,我
们就称年龄与血压之间存在交互作用,Miettinen认为
将其称之为效应修饰更合适。

交互作用的检验
• 上例,两个年龄层的 ORi 分别为 0.95 和 1.87 ,也许 OR1=0.95
反映了年龄≥ 60岁者的真正 OR=1.00 , OR2=1.87反映了年龄
<60岁者的真正 OR=2.00 。
• 如果各层的 ORi确实不同,是否可计算它们总的平均值呢?
• 首先,应确定各层的 ORi 是否反映了层间的基本差异。用交互
的检验(即血压对心肌梗死危险性的影响在不同年龄组是否各异?)可回答是否需要将各个 ORi值合并。
• 为了便于计算可信区间和检验是否存在交互作用,将上述两层的数据总结于表下,作一致性检验。

Woolf 法
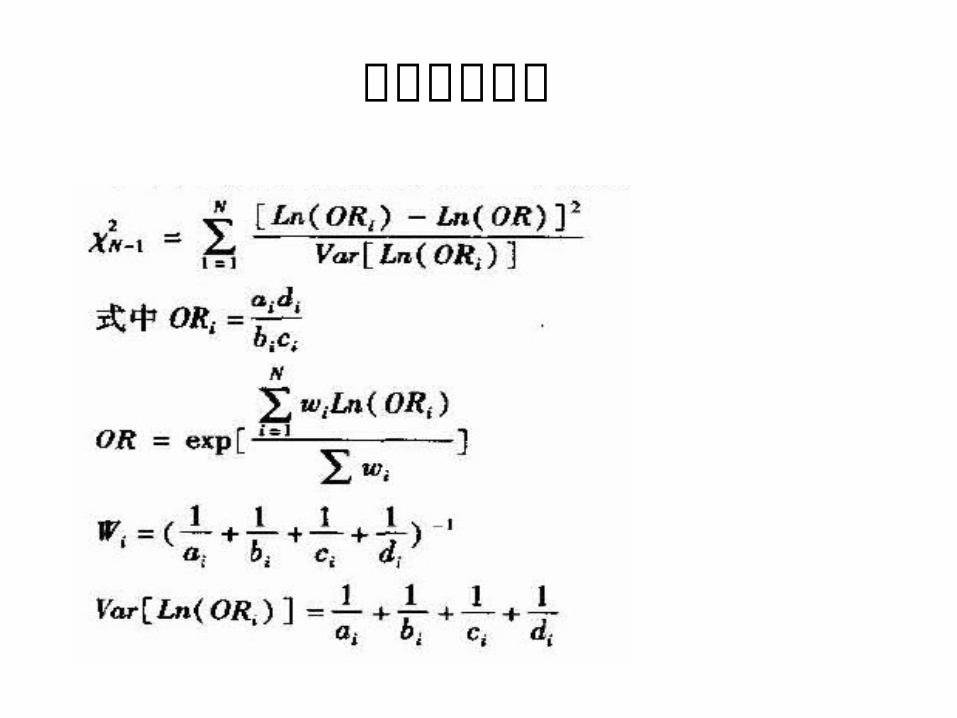
直接分层估计

–为了检验交互作用,可用下式计算 χ2k-1 (一致性检验或同质
性检验),据此来确定各层的 ln ORi 与 ln OR 之间的差异是否超出随机变异所能解释的范围。
( ln ORi − ln OR ) 2
χ22-1 = ∑──────────
Var ( ln ORi )
( − 0.0513 − 0.4567 ) 2 ( 0.6259 − 0.4567 ) 2
= ────────── + ───────── 0.300 0.100 = 1.15 P > 0.20 。

交互作用的检验• 上例的资料总结如下:
层 ORi ln ORi Var ( ln ORi ) 1/ Var ( ln ORi ) =
wi
1 0.95 -0.0513 1/9+1/6+1/115+1/73 = 0.300 3.33
2 1.87 0.6259 1/20+1/21+1/596+1/1171 = 0.100 10.00

–据此,尚缺乏证据说明表 2 中两层的 ORi 不是来自
同一总体,因此,可以认为他们来自同一总体,总估计 ORw 值 1.58 (见下式)就可以被解释为收缩血
压升高与发生心肌梗死危险性之间的总的关系。 3.33 ( − 0.0513 ) + 10.00 ( 0.6259 )ln ORw = = 0.4567 3.33 + 10.00
ORw = e0.4567 = 1.58 ( Hauck加权法)

上例只有 15 例心肌梗死病人大于 60岁,各层 ORi
中,所用的检验方法检出其差异大于机遇可能性(抽样误差)的能力(检验效率)十分有限。
检出样本资料差异的能力称检验效率。其它因素相同时,样本越小,检出差异的检验效率
( 1 − β )也越小。

上例,由于缺乏交互证据,利用前述计算的总估计值ORw 是合理的,并可按下式计算ORw的 95%可信区间:
ln ORw = 0.4567
SE [ln ORw] = 1/√Σwi = 1/√ ( 3.33+10.00 ) = 0.2739
95% 的 ln ORw 的可信区间 = ln ORw ± 1.96 ( 1/√Σwi )
= 0.4567 ±1.96× ( 0.2739 )
= −0.0801 ~ 0.9935
ORw = e-0.0801 ~ e0.9935 = 0.92 ~ 2.70 。




直接加权合并估计
直接加权合并估计检验的基本原则是将各层的估计与合并的估计进行比较,用其差值平方除以层估计效应的方差。
对效应的差测量



对效应的比测量
• 需进行对数转换。• [ln(Ri) − ln(Rw)]2
χ2N-1 = Σ──────────
Var ( ln Ri )• 上式中 Ri = 第 i 层的比效应估计, Rw =
直接合并的比效应。
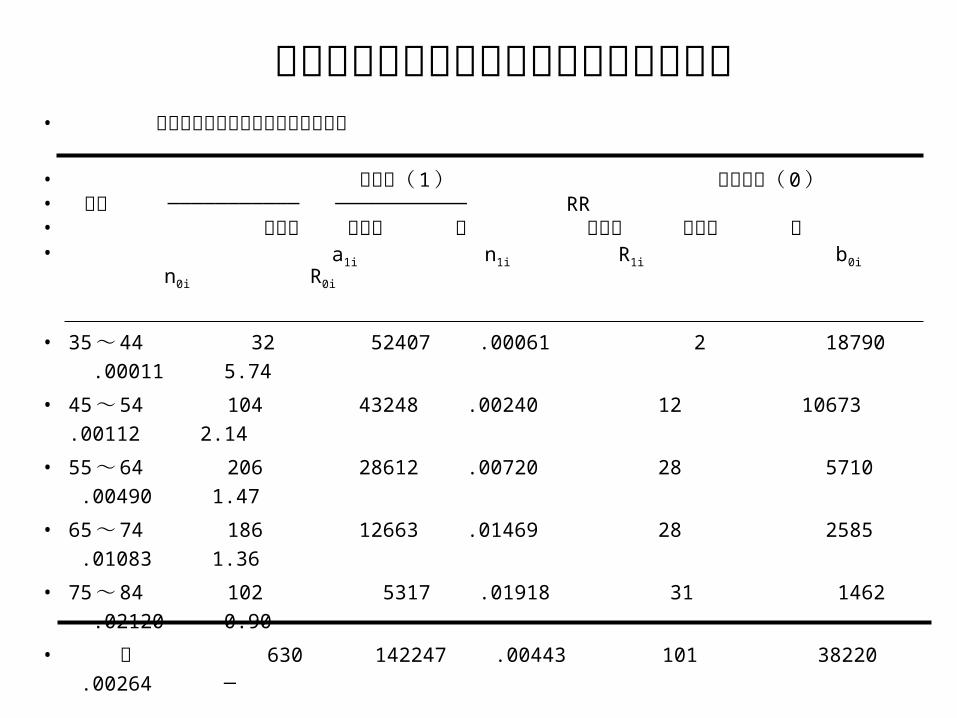
吸烟和不吸烟英国男医生冠心病死亡专率
• 英国男医生的年龄别冠心病死亡专率
• 吸烟者( 1 ) 不吸烟者( 0 )• 年龄 ─────────── ─────────── RR• 死亡数 人年数 率 死亡数 人年数 率• a1i n1i R1i b0i n0i R0i
• 35 ~ 44 32 52407 .00061 2 18790 .00011 5.74
• 45 ~ 54 104 43248 .00240 12 10673 .00112 2.14
• 55 ~ 64 206 28612 .00720 28 5710 .00490 1.47
• 65 ~ 74 186 12663 .01469 28 2585 .01083 1.36
• 75 ~ 84 102 5317 .01918 31 1462 .02120 0.90
• 计 630 142247 .00443 101 38220 .00264 ─

吸烟和不吸烟英国男医生冠心病死亡专率
按上表资料计算的层发病率差估计、以及资料合并的方差和权数───────────────────────────────
发病率差的 方差 权数年龄 估计 (1/ 万 ) [Var(i)] (Wi ) ( 1 ) × ( 3 ) (1) (2) (3) ( 4 )
───────────────────────────────
35 ~ 44 5.04 1.73 57.8 291.312
45 ~ 54 12.8 16.1 6.21 79.488
55 ~ 64 23.0 111 0.90 20.7
65 ~ 74 38.6 585 0.19 7.344
75 ~ 84 20.2 1810 0.06 1.212
计 6.10* 65.16 397.632
───────────────────────────────
* 合并的发病率差估计 = ∑[ ( 1 ) × ( 3 ) ] / ∑ ( 3 ), Wi = 1 / Var ( i )同质性检验 χ2 = 8.38 , ν=4 , P=0.08 ,说明各层率差无明显差异(在 α=0.05 水平上)。

Down氏综合征与母亲孕前使用杀精药 Down氏综合征与母亲孕前使用杀精药病例对照研究──────────────────────────母亲年龄(岁) < 35 ≥ 35 计 ─────── ─────── ────── 杀精药 + − 计 + − 计 + − 计──────────────────────────
Down氏 3 9 12 1 3 4 4 12 16
综合征对照 104 1059 1163 5 86 91 109 1145 1254
计 107 1068 1175 6 89 95 113 1157 1270
──────────────────────────

Down氏综合征与母亲孕前使用杀精药 各层比值比及其对数转换、方差、权数────────────────────────
母亲年龄 比值比 比值比对数 比值比对数的方差 权数 (岁) ( ORi ) ( ln ORi ) Var ( ln ORi ) Wi
────────────────────────
< 35 3.4 1.22 0.46 2.20
≥ 35 5.7 1.75 1.54 0.65
────────────────────────
* Wi = 1 / ( 1/a + 1/b + 1/c + 1/d ),同质性检验 χ2 = 0.14 , ν = 1 ,
P = 0.7 ,说明各层的发病率比无明显差异。

Down氏综合征与母亲孕前使用杀精药
• 直接加权合并估计的假设是各层内观察频数较大,观察
频数小时,这种检验不可靠,当观察频数为零时,就无
法计算各层的方差或效应估计。
• 此时可用另一种统计学检验方法,这种方法是一致性效
应的最大似然估计。

多因素模型分析• 在流行病学病因研究中,可用多因素回归模型识别交互作用。但是这些回归模型大多以相乘模型为基础,比如目前广泛使用的 logistic 回归模型,其前提是这些资料必须符合相乘模型。相乘交互作用的公共卫生学意义不大,公共卫生学感兴趣的是相加交互作用。



广义相对危险度模型• 定义: X= (X1 X⋯⋯ K) 为 K 个回归变量
( 暴露变量 ) , R (X) 为暴露变量的相对危险度 , 建立通用方程式:
• L n R (X , ) = [(1+ X ) -1]/ 。 是回归系数矢量 , Κ 为尺度参数。当
Κ= 1 时 ,R (X , ) = 〔 (1+ X )- 1〕为相乘模型 ; 当 = 0 时 ,R (X , ) = (1+ X ) 为相加模型 ; < 1 为次相加结构 , > 1 为超相乘结构。

• 依据参数值的改变 , 构建从次相加结构到超相乘结构的系列模型。以偏离度 D (负二倍对数似然函数值 ) 衡量模型的拟合效果 ,Pearson 卡方值进行拟合度检验 , 选择最佳模型。

• 在病因流行病学研究中 , Logistic 回归分析已被广泛应用 , 但该模型是以假定多个因素的相对危险度之间为相乘关系作为前提。倘若实际资料不符合此假设条件 , 或事先对实际数据符合何种模型结构还不清楚时 , 就千篇一律地使用Logistic 回归分析是不正确的。

• 因为有不少实际资料是相加作用形式 , 而确定一组资料是否存在交互作用与所选用的模型有密切的关系。广义相对危险度模型不需要预先假定资料的分布类型 , 它通过调节尺度 Κ 来决定联合作用的结构 , 以偏离度 D 作为衡量模型拟合的指标 , 从而能较科学地选择适宜的模型 , 对因素间的相互关系给予较客观的评价