第2回nips読み会・関西資料『unsupervised learning for physical interaction through video...
TRANSCRIPT

Unsupervised Learning for Physical Interaction
through Video PredictionChelsea Finn@UC BerkeleyIan Goodfellow@OpenAI
Sergey Levine@Google Brain, UC Berkeley
担当:落合 幸治理化学研究所@ 第 2 回 NIPS 読み会・関西 2016/12/26
※ 発表後追記:動画は画像下のリンクで確認できます https://www.sites.google.com/site/robotprediction/

目次 概要 デモ アーキテクチャー 実験結果 まとめ

目次 概要 デモ アーキテクチャー 実験結果 まとめ

概要 目的
カメラの画像とロボットアームの制御データから未来の画像(ピクセル値)を予測する 工夫
ピクセルの移動を表現するベクトル (motion transformation ) をニューラルネットワークから出力し直前の画像に適用する マスクを使い、変化していないピクセルは直前の状態をそのまま出力する 制御信号を畳み込みの途中で concatenate する
結果 見たことのない物体に対しても移動の予測に成功 制御信号の変更で予測画像も変化

目次 概要 デモアーキテクチャー 実験結果 まとめ

デモGround truth expected
https://www.sites.google.com/site/robotprediction/
学習済みの物体

デモGround truth expected
https://www.sites.google.com/site/robotprediction/
初めて見る物体

何が嬉しい? 教師なし(人によるラベル付け作業無し)で物理法則(画像内の不変量)を学ばせることができる 行動ごとに異なる未来を予測
ゴール指向の行動計画 起こりうる未来の問題の予測(自動運転などで) 予測の文脈における興味深い現象の検出 (物体の領域検出)
応用

目次 概要 デモ アーキテクチャー
バリエーション 実験結果 まとめ
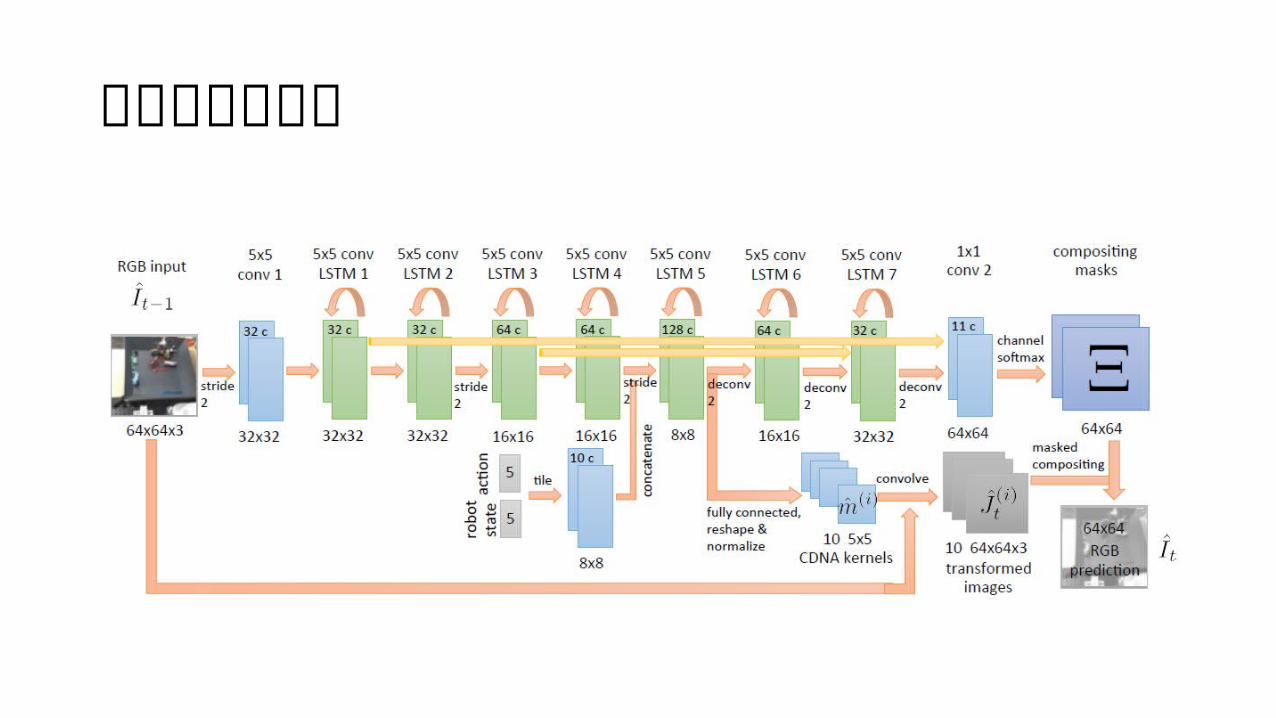
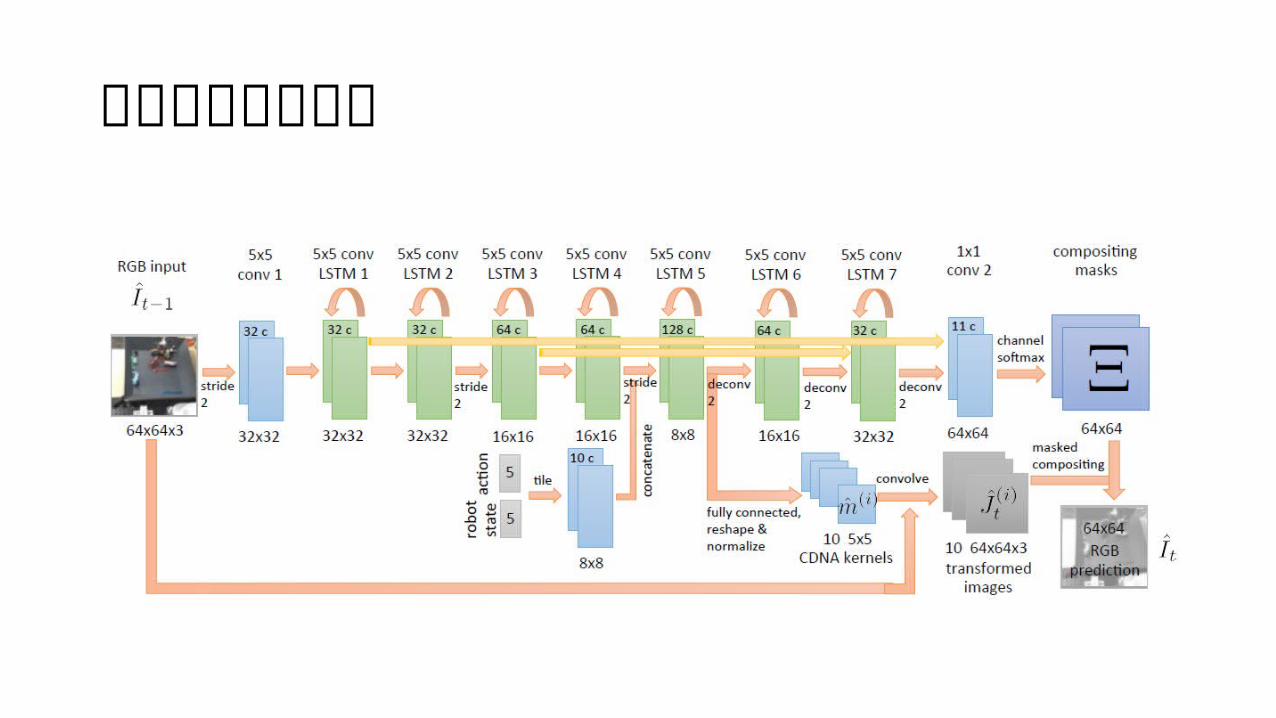
アーキテクチャ
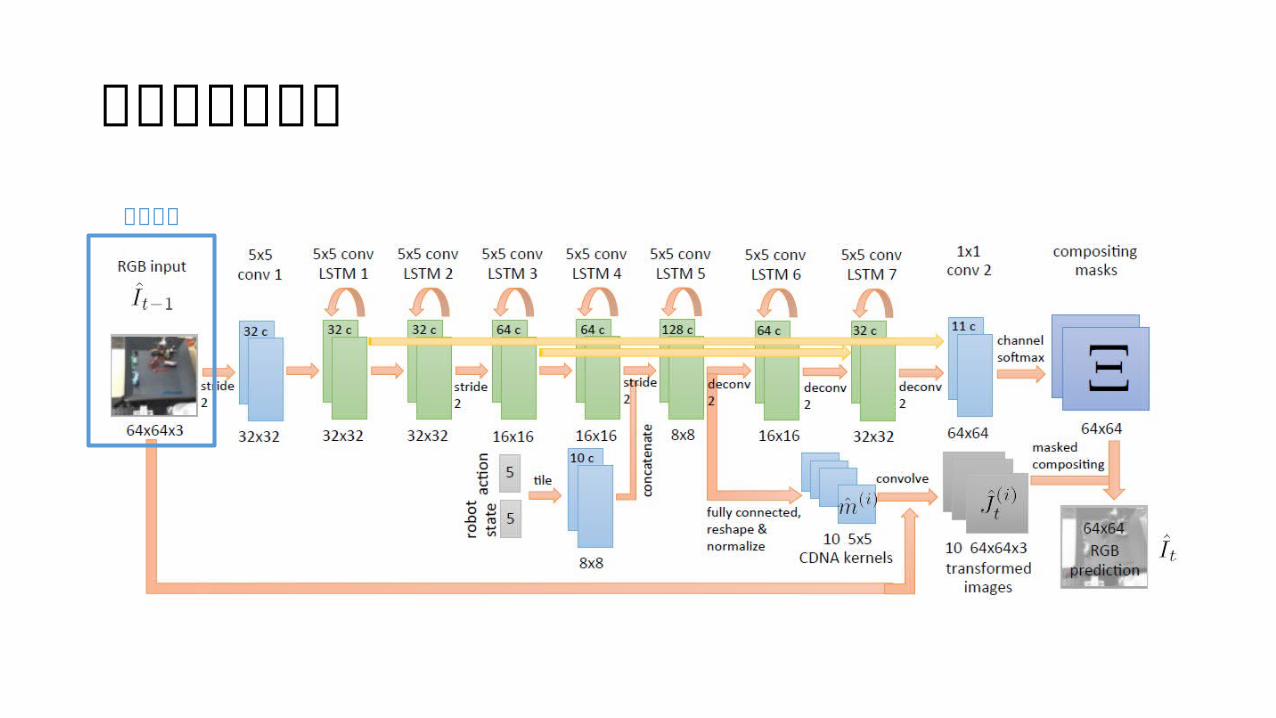
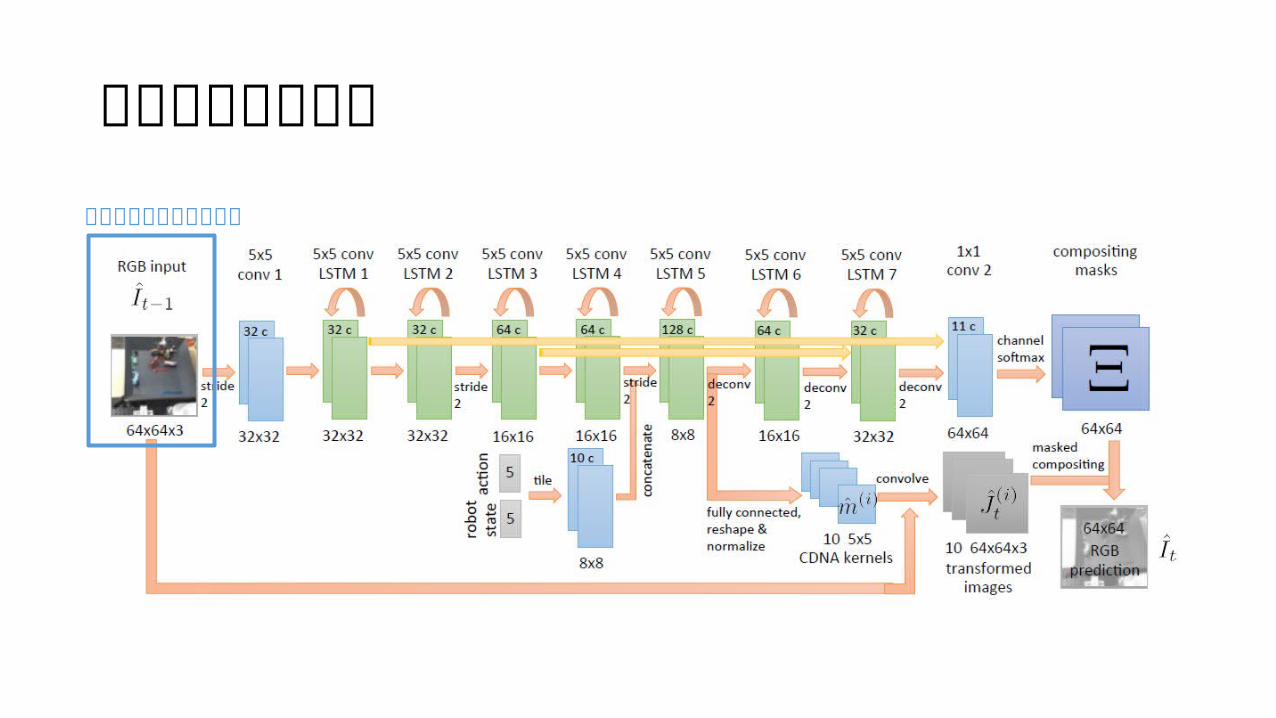
アーキテクチャ入力画像

アーキテクチャ
出力画像

アーキテクチャconvolution に recurrent 結合を持たせたレイヤー
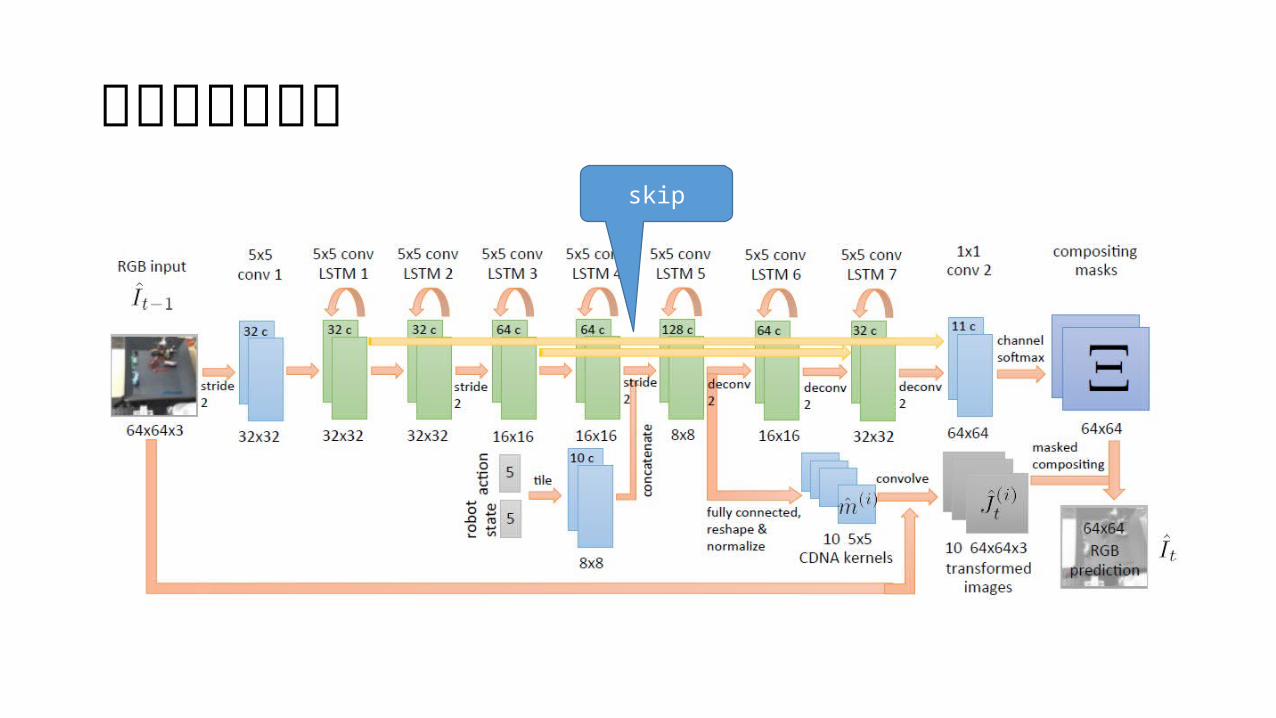
アーキテクチャskip

アーキテクチャ
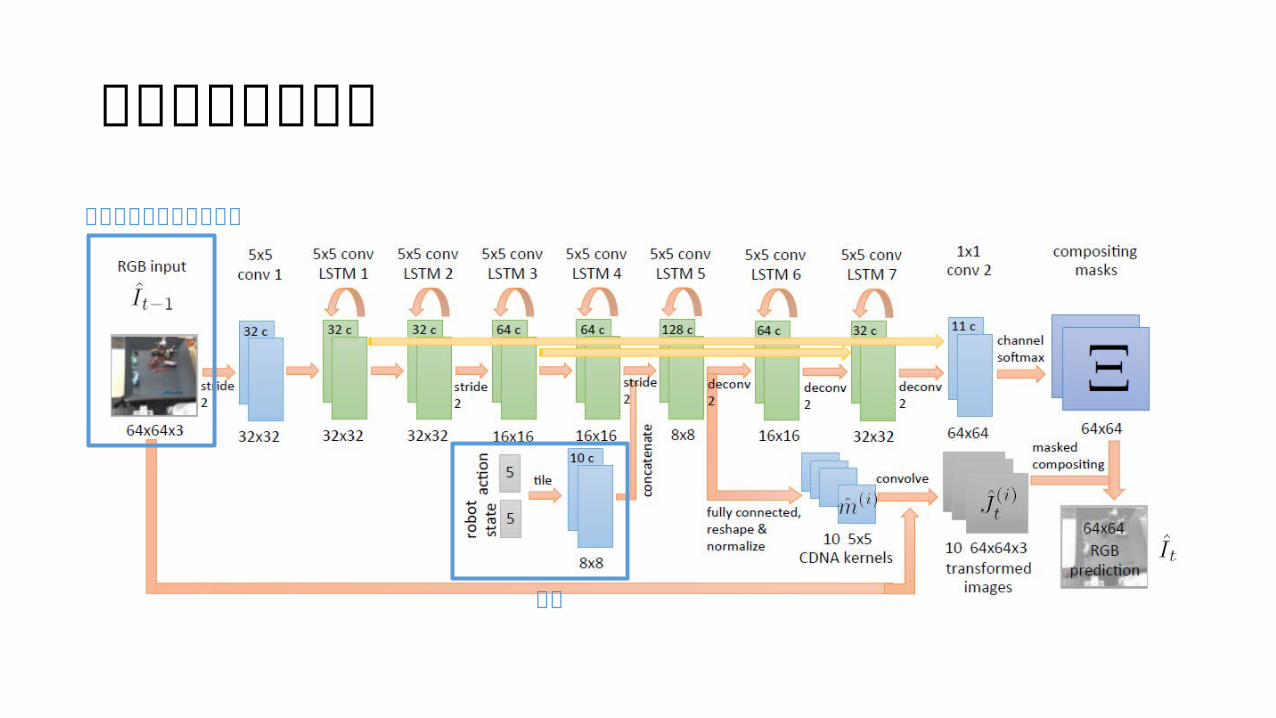
制御信号(アクションと状態)
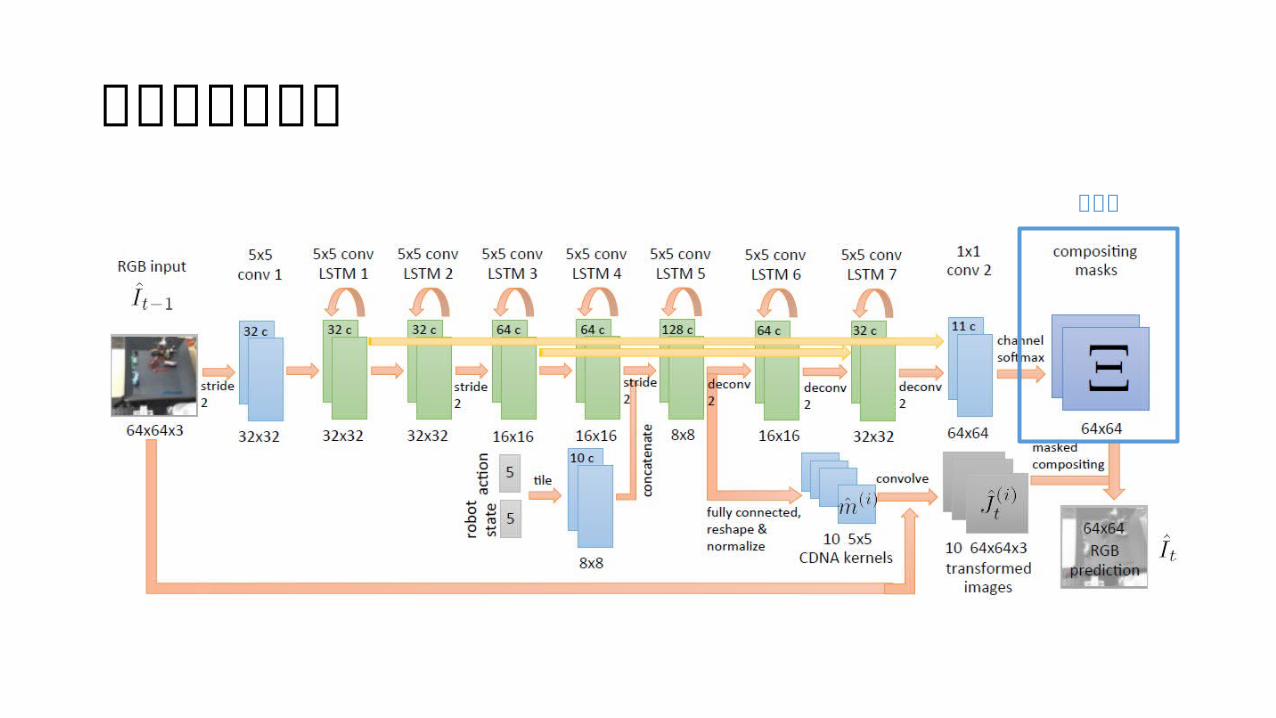
アーキテクチャマスク

アーキテクチャ
motion transformation 𝑚 ̂

バリエーション1. Dynamic Neural Advection(DNA)2. Convolutional Dynamic Neural Advection(CDNA)3. Spatial Transformer Predictors(STP)
motion transformation 𝑚 ̂ の計算方法は以下の3つが提案されている。
どれを選んでも、パフォーマンスはほぼ同じ。

Dynamic Neural Advection(DNA)

Dynamic Neural Advection(DNA)
過去フレームのピクセル

Dynamic Neural Advection(DNA)
予測フレームのピクセル

Dynamic Neural Advection(DNA)
座標

Dynamic Neural Advection(DNA)
重み

Dynamic Neural Advection(DNA)
出力先座標の周りで足し合わせ

Dynamic Neural Advection(DNA)
重み
ここをニューラルネットで推定

Convolutional Dynamic Neural Advection(CDNA)
ここを畳み込みに変更(DNA は画像全体に適用)

Spatial Transformer Predictors(STP)
現在の座標

Spatial Transformer Predictors(STP)
1 フレーム前の座標

Spatial Transformer Predictors(STP)
変換行列

Spatial Transformer Predictors(STP)
ここをニューラルネットで推定

Spatial Transformer Predictors(STP)
ここをニューラルネットで推定
画像生成の式

Spatial Transformer Predictors(STP)
ここをニューラルネットで推定
のとき 1 それ以外 0

Spatial Transformer Predictors(STP)
ここをニューラルネットで推定
のとき 1 それ以外 0

アーキテクチャ元画像

アーキテクチャ元画像 motion transformation
・・・
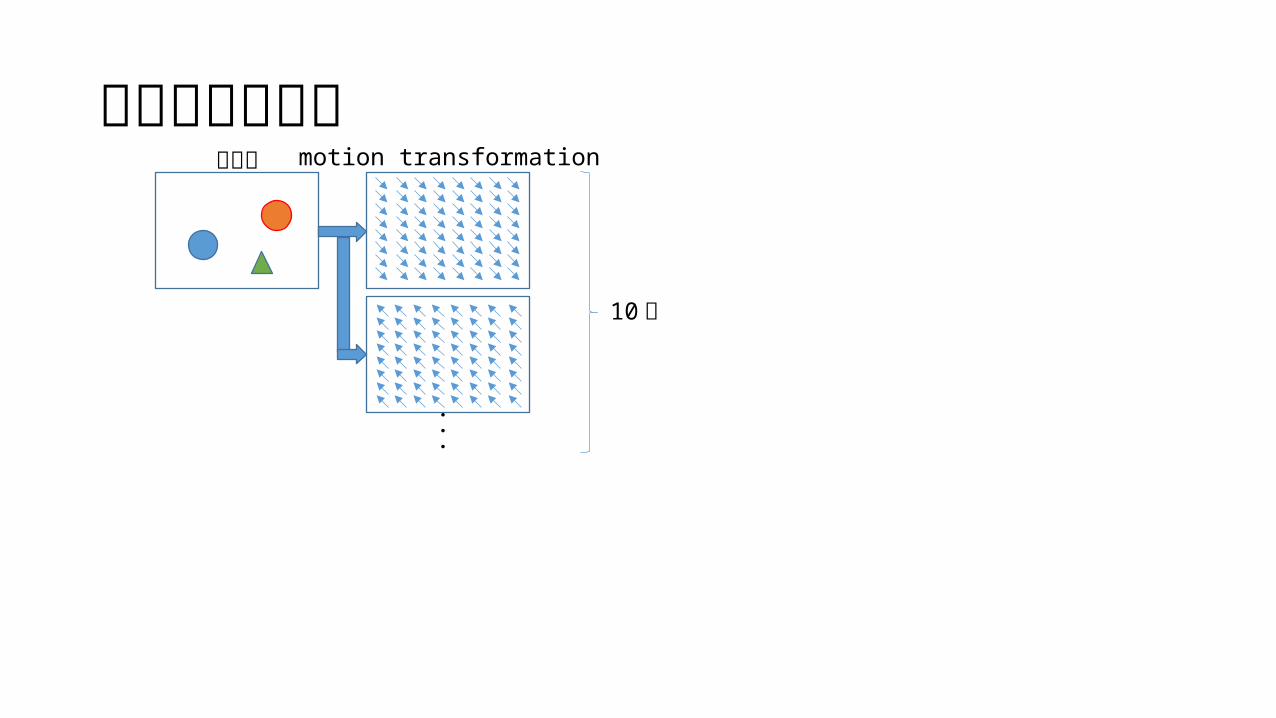
アーキテクチャ元画像 motion transformation
・・・
10 個

アーキテクチャ元画像 motion transformation conv
・・・
・・・
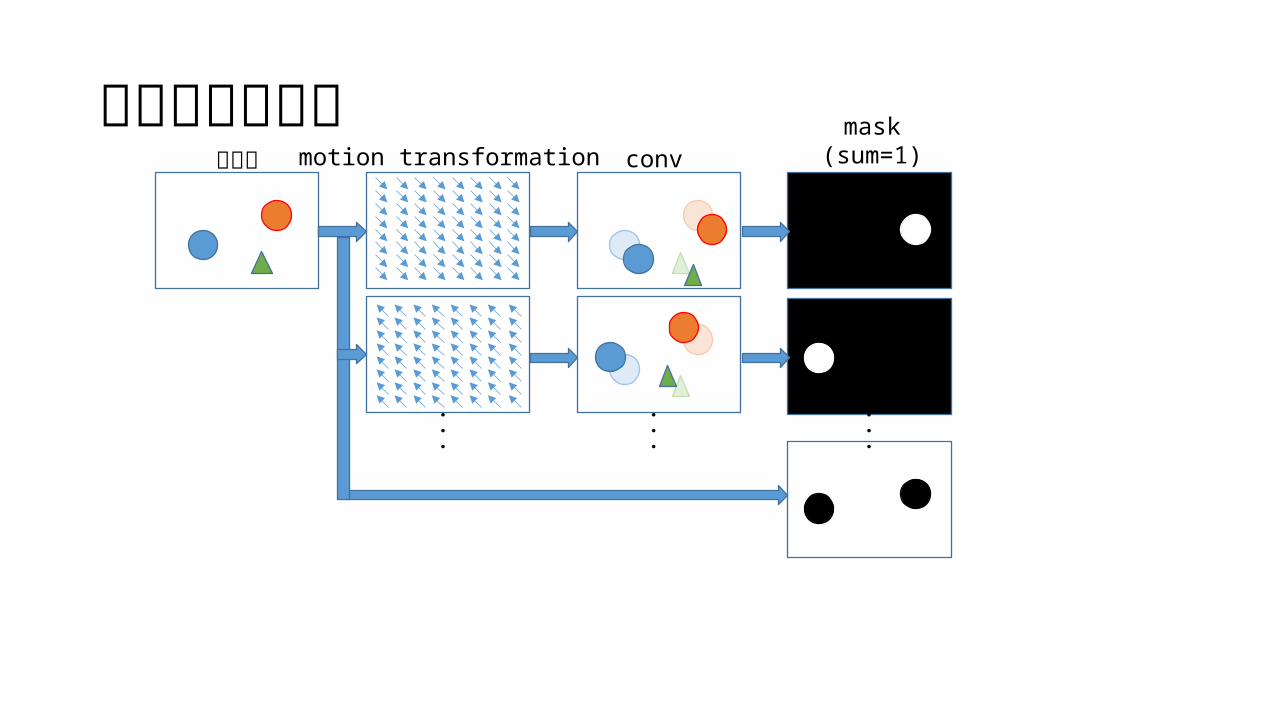
アーキテクチャ元画像 motion transformation conv
mask(sum=1)
・・・
・・・
・・・

アーキテクチャ元画像 motion transformation conv
mask(sum=1)
・・・
・・・
・・・
10+1 個
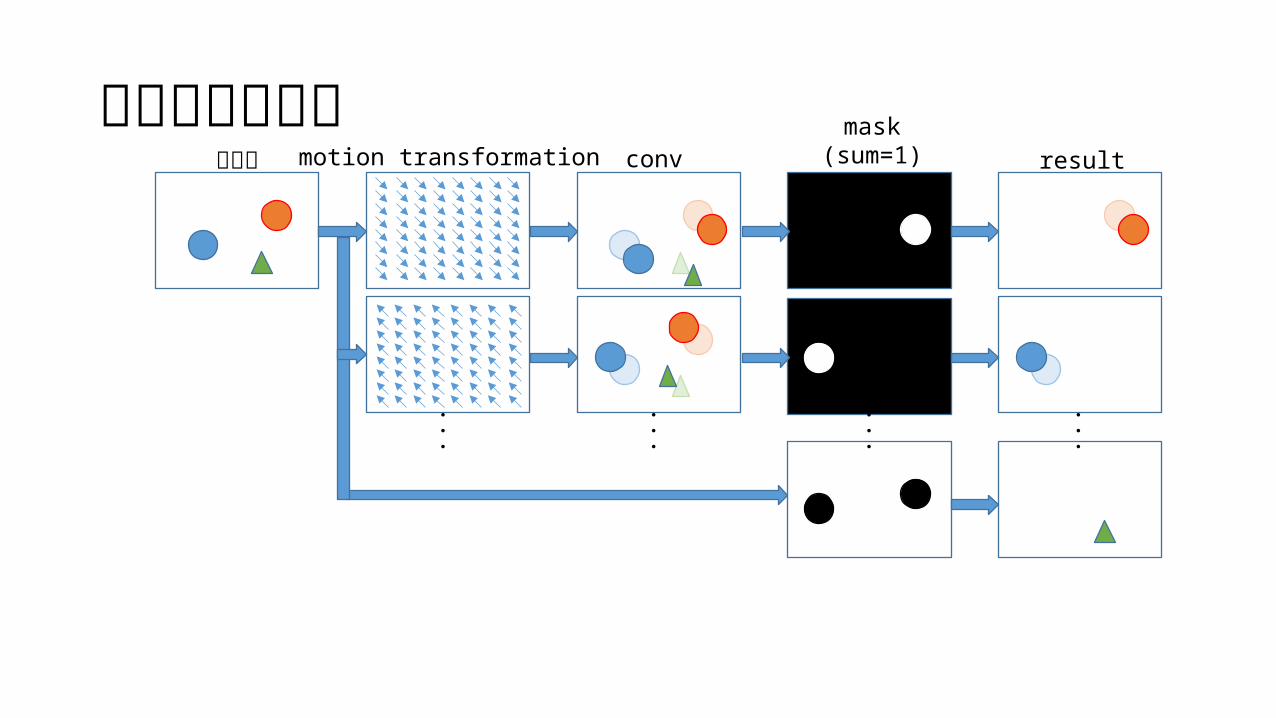
アーキテクチャ元画像 motion transformation conv
mask(sum=1) result
・・・
・・・
・・・
・・・

アーキテクチャ元画像 motion transformation conv
mask(sum=1) result
・・・
・・・
・・・
・・・
画素の補完

アーキテクチャ元画像 motion transformation conv
mask(sum=1) result
・・・
・・・
・・・
・・・
+
+
=
画素の補完

目次 概要 デモ アーキテクチャー 実験結果
定量評価 アクションの変更 マスク可視化
まとめ

定量評価学習済みの物体be
tter
提案手法 画像を直接予測 画像の差分を予測 Skip なし
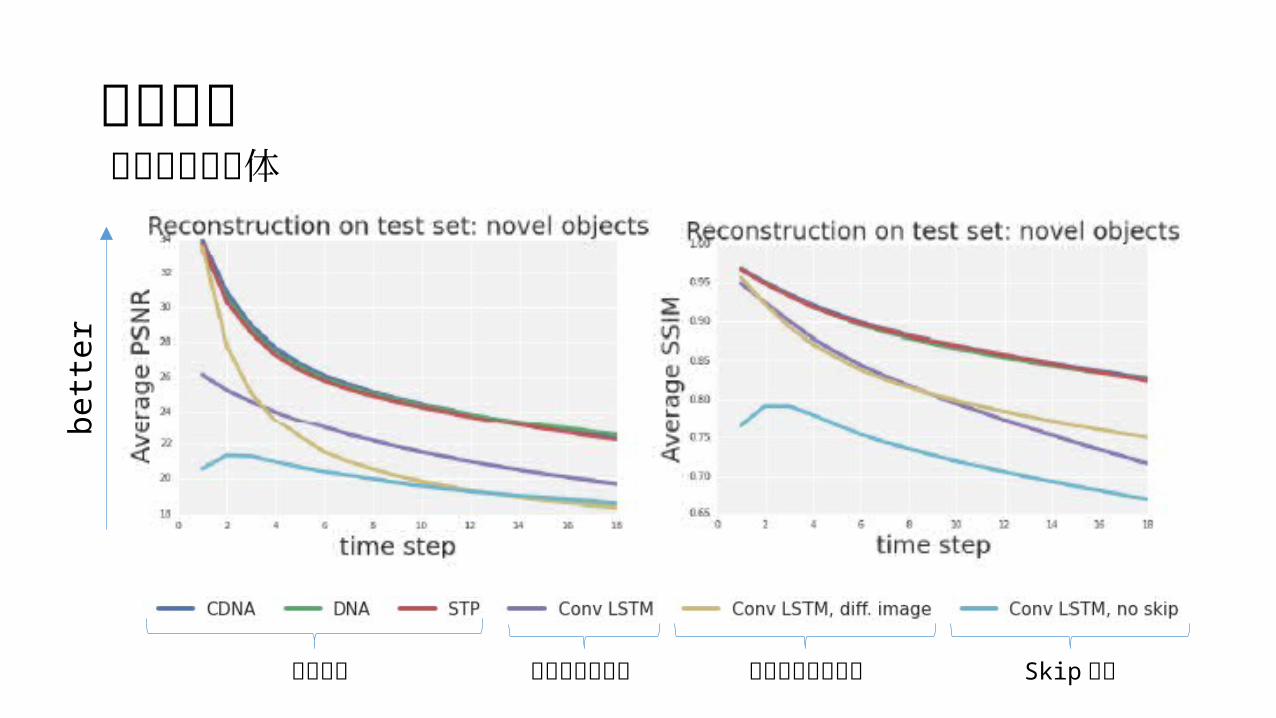
定量評価初めて見る物体
提案手法 画像を直接予測 画像の差分を予測 Skip なし
bette
r
アクションの変更
アクションの変更最初のフレームのみ入力
アクションの変更最初のフレームのみ入力
変更

アクションの変更初めて見る物体Action x 0 Action x 1 Action x 1.5
https://www.sites.google.com/site/robotprediction/

マスク可視化ここを可視化(10+1 個ある)

マスク可視化初めて見る物体prediction Mask 0(background) Mask 2
https://www.sites.google.com/site/robotprediction/

目次 概要 デモアーキテクチャー 実験結果 まとめ

まとめ 目的
カメラの画像とロボットアームの制御データから未来の画像(ピクセル値)を予測する 工夫
ピクセルの移動を表現するベクトル (motion transformation ) をニューラルネットワークから出力し直前の画像に適用する マスクを使い、変化していないピクセルは直前の状態をそのまま出力する 制御信号を畳み込みの途中で concatenate する
結果 見たことのない物体に対しても移動の予測に成功 制御信号の変更で予測画像も変化

以降参考スライド

定量評価
𝑃𝑆𝑁𝑅=10 log10𝑀𝐴𝑋 2
𝑀𝑆𝐸 𝑆𝑆𝐼𝑅 (𝑥 , 𝑦 )=(2𝜇𝑥𝜇 𝑦+𝑐1)(2𝜎𝑥𝑦+𝑐2)
(𝜇𝑥2+𝜇𝑦
2 +𝑐1)(𝜎 𝑥2+𝜎 𝑦
2 +𝑐2)
輝度の max( 通常 255) 𝑐1=(0 .01𝐿 )2
𝑐2=(0 .03𝐿)2
人の感覚に合わせた画像誤差の評価指標-1 ~ 1 の値を取り 1 で完全一致画像評価指標大きいほど誤差が少ない