20170126 big data processing
TRANSCRIPT

Big Data ProcessingJanuary 2017

• Data Architect at unbelievable machine Company• Software Engineering Background
• Jack of all Trades who also dives into Business topics, Systems Engineering and Data Science.
• Big Data since 2011• Cross-Industry: From Automotive to Transportation
• Other Activities• Trainer: Hortonworks Apache Hadoop Certified Trainer• Author: Articles and book projects• Lector: Big Data at FH Technikum and FH Wiener Neustadt
Stefan Papp

Agenda
• Big Data Processing• Evolution in Processing Big Data• Data Processing Patterns• Components of a Data Processing Engine
• Apache Spark• Concept • Ecosystem
• Apache Flink• Concept • Ecosystem

Big Data Processing Engines on a Hadoop 2.x Reference(!) Stack
HADOOP 2.x STACK
HDFS(redundant, reliable storage)
YARN(cluster resource management)
BatchMapReduce
Direct
Java
Search
SolrAPI
Engine
Data Operating
System
File System
Batch & InteractiveTez
Script
Pig
SQL
Hive
Cascading
Java
Real-TimeSlider
NoSQL
HBase
Stream
Storm
RDD & PACTSpark, Flink
MachineLearningSparkML
Other
Application
Graph
Giraph
Applications

Evolutionin Processing

Big Data Roots – Content Processing for Search Engines

IO Read Challenge: Read 500 GB Data (as a Reference)
• Assumption • Shared nothing, plain read• You can read 256 MB in 1.9 seconds
• Single Node• Total Blocks in 500 GB = 1954 Blocks• 1954 * 1,9 / 3600 = approx. 1 hour sequential read.
• A 40 node cluster with 8 HDs on each node• 320 HDs -> 6 to 7 blocks on each disk• 7 blocks * 1,9 = 13,3 seconds total read time

Parallelism and Concurrency are Complex
a = 1a = a + async_add(1)a = a * async_mul(2)

Data Flow Engine to Abstract Data Processing
• Provide a programming interface• Express jobs as graphs of high-level operators
• System picks how to split each operator into task• and where to run each task
• Solve topics such as• Concurrency• Fault recovery

MapReduce: Divide and Conquer
Map
Map
Map
Reduce
Reduce
Input Output
Read Read Read ReadWrite Write Write Write
Iter. Iter. Iter. Iter.
Iteration:MapReduce


Evolution of Data Processing
2004
2007
2010 2010

Data Processing Patterns
Classification and Processing Patterns

Batch Processing
14
Source
SourceStorage Layer
Periodic ingestion
Batch Processor
Periodic analysis job
Consumer
Job scheduler
SQL Import
File Import

Stream processor / Kappa Architecture
15
Source
Source
Consumer
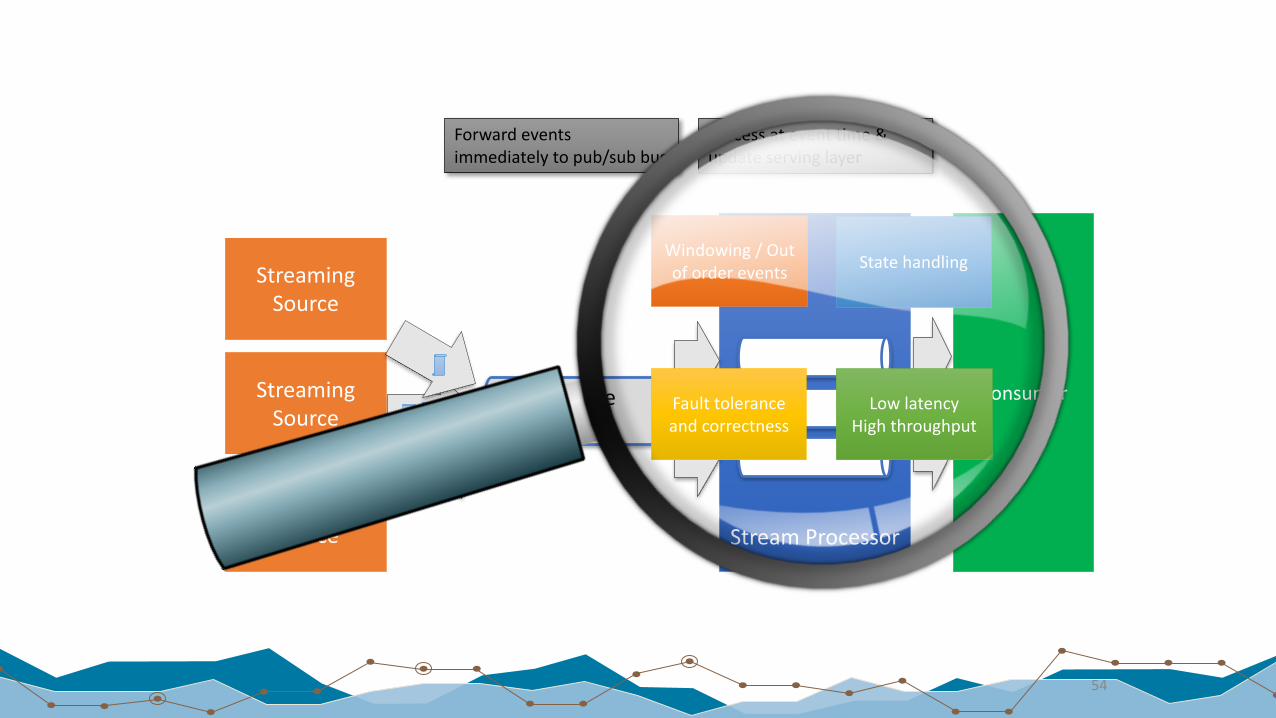
Forward events immediately to pub/sub bus
Stream Processor
Process at event time & update serving layer
MessagingSystem

Hybrid / Lambda processing
16
Storage Layer
Batch job(s) for analysis
Serving layer
Job scheduler
Stream ProcessorMessaging
System Consumer
Source
Source
Source

Technology Mapping
MessagingSystem
StorageLayer
Processing
Serving layer
Job scheduler

Data Processing Engines
Essential Components

General Purpose Data Processing Engines
Processing Engine (with API)
Abst
ract
ion
Engi
nes
SQL/
Que
ry
Lang
. eng
ine
Real
-tim
e Pr
oces
sing
Mac
hine
Le
arni
ng
Gra
ph
Proc
essi
ng
<interface to> Storage Layer
Apache Spark
Pig
Spar
kSQ
L,
Spar
kR
Spar
k St
ream
ing
MLL
ibH
20
Grp
ahX
Cloud, Hadoop, Local Env…..
Apache Flink
Had
oop
MR,
Ca
scad
ing
Tabe
API
CEP
Flin
kM
L
Gel
ly
Cloud, Hadoop, Local Env…..

Features of Data Processing Engines
• Processing Mode: Batch, Streaming, Hybrid• Category: DC/SEP/ESP/CEP• Delivery guarantees: at least once/exactly once• State management: distributed snapshots/checkpoints• Out of ordering processing: y/n• Windowing: time-based, count-based• Latency: low or medium

Apache SparkJanuary 2017

A Unified engine across data workloads and platforms

Diffentiation to Map Reduce
• MapReduce was designed to process shared nothing data
• Processing with data sharing:• complex, multi-pass analytics (e.g. ML, graph)• interactive ad-hoc queries• real-time stream processing
• Improvements for coding:• Less boilerplate code, richer API• Support of various programming languages

Two Key Innovation of Spark
24
Execution optimization via DAGs
Distributed data containers(RDDs) to avoid Serialization.
Query
Input
Query
Query


Start REPL locally, delegate execution via cluster manager
Execute on REPLØ ./bin/spark-shell --master local
Ø ./bin/pyspark --master yarn-client Execute as application
Ø ./bin/spark-submit--class
org.apache.spark.examples.SparkPi--master spark://207.184.161.138:7077 --executor-memory 20G --total-executor-cores 100 /path/to/examples.jar1000
Execute within Application

Components of a spark application
Driver program• SparkContext/SparkSession as Hook to Execution
Environment• Java, Scala, Python or R Code (REPL or App)• Creates a DAG of Jobs and
Cluster manager • grants executors to a Spark application• Included: Standalone, Yarn, Mesos or local• Custom made: e.g. Cassandra• Distributes Jobs to executors
Executors• Worker processes that execute tasks and store
dataResourceManager(defaultport4040)•Superviseexecution


Spark in Scala and Python
// Scala:
val distFile = sc.textFile("README.md")
distFile.map(l => l.split(" ")).collect()
distFile.flatMap(l => l.split(" ")).collect()
29
// Python:distFile = sc.textFile("README.md")distFile.map(lambda x: x.split(' ')).collect()distFile.flatMap(lambda x: x.split(' ')).collect()
// Java 7:JavaRDD<String> distFile = sc.textFile("README.md");
JavaRDD<String> words = distFile.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String line) {
return Arrays.asList(line.split(" "));
}});
// Java 8:
JavaRDD<String> distFile = sc.textFile("README.md");
JavaRDD<String> words =
distFile.flatMap(line -> Arrays.asList(line.split(" ")));

History of Spark API Containers

SparkSession / SparkContext – the standard way to create container
• SparkSession (starting from 2.0) as Hook to the Data, • SparkContext still available (can be created via SparkSession.sparkContext())
• Use SparkSession to create DataSets• Use SparkContext to create RDD
• A session object knows about the execution environment• Can be used to load data into a container

Operations on Collections: Transformations and Actions
val lines = sc.textFile("hdfs:///data/shakespeare/input") // Transformationval lineLengths = lines.map(s => s.length) // Transformationval totalLength = lineLengths.reduce((a, b) => a + b) // Action
Transformation: • Create a new distributed data set from Source or from other data set• Transformations are stacked until execution (Lazy Loading)
Actions: • Trigger an Execution• Create the most optimal execution path

Common Transformationsvalrdd=sc.parallelize(Array("Thisisalineoftext","Andsoisthis"))
map- applyafunctionwhilepreservingstructurerdd.map(line=>line.split("\\s+"))→Array(Array(This,is,a,line,of,text),Array(And,so,is,this))
flatMap- applyafunctionwhileflatteningstructurerdd.flatMap(line=>line.split("\\s+"))→Array(This,is,a,line,of,text,And,so,is,this)
filter- discardelementsfromanRDDwhichdon’tmatchaconditionrdd.filter(line=>line.contains("so"))→Array(Andsoisthis)
reduceByKey - apply afunction to each value for each keypair_rdd.reduceByKey((v1,v2)=>v1+v2)→Array((this,2),(is,2),(line,1),(so,1),(text,1),(a,1),(of,1),(and,1))

Common Spark Actions
collect- gatherresultsfromnodesandreturnfirst- returnthefirstelementoftheRDDtake(N)- returnthefirstN elementsoftheRDDsaveAsTextFile- writetheRDDasatextfilesaveAsSequenceFile- writetheRDDasaSequenceFilecount- countelementsintheRDDcountByKey- countelementsintheRDDbykeyforeach- processeachelementofanRDD(e.g.,rdd.collect.foreach(println))

WordCount in Scala
val text = sc.textFile(source_file)words = text.flatMap( line => line.split("\\W+") )val kv = words.map( word => (word.toLowerCase(), 1) )val totals = kv.reduceByKey( (v1, v2) => v1 + v2 )totals.saveAsTextFile(output)


BDAS – Berkeley Data Analytics Stack

How to use SQL on Spark
• Spark SQL: Component direct on the Berkeley ecosystem• Hive on Spark: Use Spark as execution engine for hive• BlinkDB: Approximate SQL Engine

Spark SQL
Spark SQL uses DataFrames (Typed Data Containers) for SQL
Hive:c = HiveContext(sc)
rows = c.sql(“select * from titanic”)
rows.filter(rows[‘age’] > 25).show()
JSON:c.read.format(‘json’).load(’file:///root/tweets.json”).registerTe
mpTable(“tweets”)
c.sql(“select text, user.name from tweets”)
3928.01.17

Spark SQL Example
4028.01.17

BlinkDB
• An approximate query engine for running interactive SQL queries. • allows to trade-off query accuracy for response time,• enabling interactive queries over massive data by running queries on data samples and
presenting results annotated with meaningful error bars.

StreamingSpark Streaming and Structured Streaming

Spark Streaming Streaming on RDDs
Structured StreamingStreaming on DataFrames

Machine Learning and Graph Analytics
SparkML, Spark MLLib, GraphX, GraphFrames,

Typical Use Cases
Classification and regression• Linear support vector machine • Logistic regression• Linear least squares, Lasso, ridge regression• Decision tree• Naive Bayes
Collaborative filtering• Alternating least squares
Clustering• K-means
Dimensionality reduction• Singular value decomposition • Principal component analysis
Optimization• Stochastic gradient descent• Limited-memory BFGS
http://spark.apache.org/docs/latest/mllib-guide.html

MLLIb and H2O
• DataBricks-ML Libraries: inspired by the sci-kit learn library. • MLLIB works with RDDs• ML works with DataFrames
• H2O- library: Library build by the company H2O.• H2O can be integrated with Spark with the 'Sparkling Water' connector.

Graph Analytics
Graph Engine that analyzes tabular data• Nodes: People and things (nouns/keys)• Edges: relationships between nodes
AlgorithmsPageRankConnected componentsLabel propagationSVD++Strongly connected componentsTriangle count
OneFrameworkperContainer-API•GraphX isdesignedforRDDs,•GraphFrames forDataFrames

Survival of the “Fastest“Apache Flink
0 4,000,000 8,000,000 12,000,000 16,000,000
Storm
Flink
Flink (10 GigE)
Throughput: msgs/sec10 GigE end-to-end
15m msgs/sec

49
Streaming: continuous processing on data that is continuously produced
Sources MessageBroker
Streamprocessor
collect publish/subscribe analyse serve&store

Apache Flink Ecosystem
50
Gelly
Table
ML
SAMOA
DataSet (Java/Scala)DataStream (Java / Scala)
Hadoop
M/R
LocalClusterYARN
Apache Beam
Apache Beam
Table
Cascading
Streaming dataflow runtime
Storm API
Zeppelin
CEP

Expressive APIs
51
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ").map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ").map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):

Flink Engine – Core Design Principles
1. Execute everything as streams
2. Allow some iterative (cyclic) dataflows
3. Allow some (mutable) state
4. Operate on managed memory

Memory Management
furtherreading:https://flink.apache.org/news/2015/05/11/Juggling-with-Bits-and-Bytes.html
54
StreamingSource
StreamingSource
StreamingSource
Consumer
Forwardeventsimmediatelytopub/subbus
StreamProcessor
Processateventtime&updateservinglayer
MessageBroker
LowlatencyHighthroughput
Windowing/Outoforderevents Statehandling
Faulttoleranceandcorrectness

WindowingApache Flink
Low latencyHigh throughput
State handlingWindowing
Fault tolerance and correctness

Building windows from a stream
“Number of visitors in the last 5 minutes per country”
56
source Kafka topic
Stream processor
// create stream from Kafka sourceDataStream<LogEvent> stream = env.addSource(new KafkaConsumer());
// group by countryDataStream<LogEvent> keyedStream = stream.keyBy(“country“);
// window of size 5 minuteskeyedStream.timeWindow(Time.minutes(5))
// do operations per window.apply(new CountPerWindowFunction());

Building windows: Execution
57
Kafka Source
Window Operator
S
S
S
W
W
Wgroup bycountry
// window of size 5 minuteskeyedStream.timeWindow(Time.minutes(5));
Jobplan Parallelexecutiononthecluster
Time

Streaming: Windows
58
Time
Aggregates on streamsarescopedbywindows
Time-driven Data-drivene.g.lastXminutes e.g.lastXrecords

Window types in Flink
Tumbling windows
Sliding windows
Custom windows with window assigners, triggers and evictors
59
Further reading: http://flink.apache.org/news/2015/12/04/Introducing-windows.html

1977 1980 1983 1999 2002 2005 2015
Processing Time
EpisodeIV
EpisodeV
EpisodeVI
EpisodeI
EpisodeII
EpisodeIII
EpisodeVII
Event Time
Event Timevs.ProcessingTime
60

State HandlingApache Flink
LowlatencyHighthroughput
StatehandlingWindowing
Faulttoleranceandcorrectness

Batch vs. Continuous
62
• Nostateacrossbatches
• Faulttolerancewithinajob
• Re-processingstartsempty
BatchJobs ContinuousPrograms
• Continuousstateacrosstime
• Faulttoleranceguardsstate
• Reprocessingstartsstateful

Streaming: Savepoints
63
Savepoint A Savepoint B
Globallyconsistentpoint-in-timesnapshotofthestreamingapplication

Re-processing data (continuous)
• Draw savepoints at times that you will want to start new jobs from (daily, hourly, …)• Reprocess by starting a new job from a savepoint
• Defines start position in stream (for example Kafka offsets)• Initializes pending state (like partial sessions)
64
Savepoint
Runnewstreamingprogramfromsavepoint

Streamprocessor:Flink
Managed state in Flink
• Flink automatically backups and restores state• State can be larger than the available memory• State back ends: (embedded) RocksDB, Heap memory
65
Operatorwithwindows(largestate)
Statebackend(local)DistributedFile
System
Periodicbackup/recovery
Source Kafka

Fault ToleranceApache Flink
Low latencyHigh throughput
State handlingWindowing 7
Fault tolerance and correctness

Fault tolerance in streaming
• How do we ensure the results are always correct?
• Failures should not lead to data loss or incorrect results
67
Source Kafka topic
Stream processor

Fault tolerance in streaming
• At least once: ensure all events are transmitted• May lead to duplicates
• At most once: ensure that a known state of data is transmitted• May lead to data loss
• Exactly once: ensure that operators do not perform duplicate updates to their state• Flink achieves exactly once with Distributed Snapshots

Low LatencyApache Flink
Low latencyHigh throughput
State handlingWindowing
Fault tolerance and correctness

Yahoo! Benchmark
• Count ad impressions grouped by campaign• Compute aggregates over a 10 second window• Emit window aggregates to Redis every second for query
70
Full Yahoo! article: https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at
“Storm […] and Flink […] show sub-second latencies at relatively high throughputs with Storm having the lowest 99th percentile latency.
Spark streaming 1.5.1 supports high throughputs, but at a relatively higher latency.”
(Quote from the blog post’s executive summary)

Windowing with state in Redis
• Original use case did not use Flink’s windowing implementation.• Data Artisans implemented the use case with Flink windowing.
71
KafkaConsumermap()
filter()group
Flink event time windows
realtime queries

Results after rewrite
72
0 750,000 1,500,000 2,250,000 3,000,000 3,750,000
Storm
Flink
Throughput: msgs/sec
400k msgs/sec
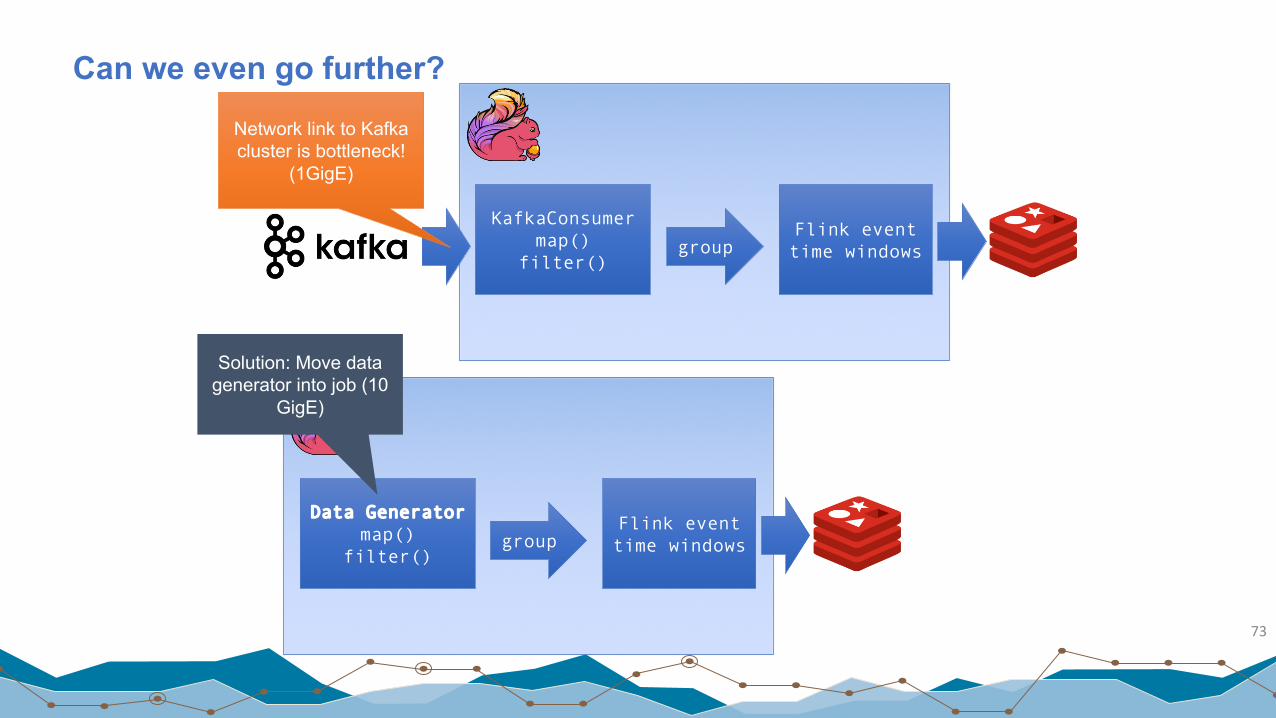
Can we even go further?
73
KafkaConsumermap()
filter()group
Flink event time windows
Network link to Kafka cluster is bottleneck!
(1GigE)
Data Generatormap()
filter()group
Flink event time windows
Solution: Move data generator into job (10
GigE)

Results without network bottleneck
74
0 4,000,000 8,000,000 12,000,000 16,000,000
Storm
Flink
Flink (10 GigE)
Throughput: msgs/sec10 GigE end-to-end
15m msgs/sec
400k msgs/sec
3m msgs/sec

Survival of the Fastest – Flink Performance
• throughput of 15 million messages/second on 10 machines• 35x higher throughput compared to Storm (80x compared to Yahoo’s runs)• exactly once guarantees
• Read the full report: http://data-artisans.com/extending-the-yahoo-streaming-benchmark/

Theunbelievable Machine CompanyGmbHMuseumsplatz 1/10/131070Wien
Contact:StefanPapp,[email protected].+43- 1- 3619977- 215Mobile:+436642614367