20160906 pplss ishizaki public
TRANSCRIPT

2016年9月6日石崎 一明 http://ibm.biz/ishizaki [email protected]日本アイ・ビー・エム(株) 東京基礎研究所(資料作成協力:井上拓、大平怜、小笠原武史、菅沼俊夫、仲池卓也)
PPLサマースクール2016「商用Java処理系の研究開発」
Java Just-In-Timeコンパイラの実装技術
1 Java Just-In-Timeコンパイラの実装技術/石崎 一明
JavaTMおよびすべてのJava関連の商標およびロゴはOracleやその関連会社の米国およびその他の国における商標または登録商標です

© 2016 IBM Corporation
商用Java処理系の研究開発
2 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
概要:日本アイ・ビー・エム(株)東京基礎研究所はJava言語の黎明期からその処理系に関する研究開発をリードし,IBM開発部門と協業して業務アプリケーションの基盤として使われるJava処理系を世に送り出してきた.特に,Just-In-TimeコンパイラとJava仮想マシンの主要構成要素については各種の先進的技術を考案し,世界トップクラスの性能を達成するとともに,多数の学会発表も行ってきている.本セミナーでは,この商用Java処理系の研究開発に関する経験をもとに,以下の内容について述べる.
1 Javaの登場と発展(30分,講師:小野寺民也)1995年のJavaの登場とその後の受容の過程を概観し,Java登場時にどのような性能上の課題があったかを述べ,続く2つのセッションへの導入とする.また,性能向上の研究開発における標準ベンチマークの重要さについても言及する.
2 Java仮想マシンの実装技術(2時間,講師:河内谷清久仁)Java言語処理系の実装について詳説する.まずJava仮想マシンの概要について述べ,その主要な構成要素として,クラス管理とインタープリタ,ヒープ管理とガベージコレクション,スレッド管理と同期機構,JITコンパイラとの連携,などについて説明する.性能改善のために行った各種手法についても触れる.
3 Java Just-In-Timeコンパイラの実装技術(2時間,講師:石崎一明)Javaの動的コンパイラの実装について詳説する.まず構成の概要について述べ,主な最適化,動的コンパイラ特有の最適化,Java言語特有の最適化,について説明する.また,Java言語からSIMDやGPUなどのハードウェア機構を使う試みについても述べる.商用コンパイラの実装に関する経験談についても触れる.
4 まとめと展望(1時間,講師:小野寺民也)まとめとして,プログラミング言語の実装技術の歴史を概観し,Javaの誕生と発展に果たした役割について考えてみたい(内容は予告なく変更することがありますw).

© 2016 IBM Corporation
講師紹介
3 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
小野寺民也(おのでらたみや) http://ibm.biz/onodera日本アイ・ビー・エム(株)技術理事,東京基礎研究所サービス型コンピューティング部長.1988年東京大学大学院理学系研究科情報科学専門課程博士課程修了.同年日本アイ・ビー・エム(株)入社.以来,同社東京基礎研究所にて,プログラミング言語およびミドルウェアおよびシステムソフトウェアの研究開発に従事.情報処理学会第41回(平成2年後期)全国大会学術奨励賞,同平成7年度山下記念研究賞,同平成16年度論文賞,同平成16年度業績賞,各受賞.理学博士.日本ソフトウェア科学会会員(元・理事),情報処理学会シニア会員,ACM Distinguished Scientist.
河内谷清久仁(かわちやきよくに) http://ibm.biz/kawatiya日本アイ・ビー・エム(株)シニア・テクニカル・スタッフ・メンバー,東京基礎研究所ディープ・コンピューティング&アナリティクス部長.1987年東京大学大学院理学系研究科情報科学専攻修士課程修了.同年日本アイ・ビー・エム(株)入社.以来,同社東京基礎研究所にてOSやプログラミング言語処理系などの研究に従事.最近は,Javaの性能問題分析などにも携わる.博士(政策・メディア).1994年情報処理学会大会奨励賞,2005年同・論文賞,2008年日本ソフトウェア科学会高橋奨励賞,各受賞.日本ソフトウェア科学会編集副委員長(元・理事),情報処理学会シニア会員,ACM Distinguished Engineer.
石崎一明(いしざきかずあき) http://ibm.biz/ishizaki日本アイ・ビー・エム(株)東京基礎研究所リサーチ・スタッフ・メンバー.1992年早稲田大学理工学研究科修士課程修了.同年日本アイ・ビー・エム(株)入社.以来,同社東京基礎研究所にて,Fortran言語の並列化コンパイラ,Java言語の動的コンパイラ,Python言語の動的コンパイラ,などのプログラミング言語処理系の研究に従事.最近は,JavaやApache Sparkからの,GPUその他アクセラレータ活用方法に興味を持つ.情報処理学会平成16年度業績賞受賞.博士(情報科学).日本ソフトウェア科学会理事,情報処理学会会員,ACM Senior Member.

© 2016 IBM Corporation
Java Just-In-Timeコンパイラの実装技術
この2時間で、お話する内容– 動的コンパイラの実装について 90分– 商用コンパイラ実装の経験談 30分
4 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
動的コンパイラの構成
主に下記のような構成を取る– 最適化アルゴリズムのオーダーが高いものは、あまり使わない
例:精度の高いポインタ解析
5 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
中間コード生成
プラットフォーム共通最適化
コード生成
プラットフォーム固有最適化
最終コード生成
インライニング、脱仮想化(de-virtualization)、共通部分式削除、等
コントロールフローグラフ機種非依存の中間表現
プラットフォーム固有の命令列
レジスタアロケーション、命令スケジューリング、等
プロファイル情報

© 2016 IBM Corporation
インタプリタと協調した動的コンパイラの特徴
実行中のハードウェアに特化したコードを生成可能
実行環境に特化した最適化を適用可能– インタプリタ、コンパイルコード、ハードウェアで、実行時プロファイルを取得・利用する コールグラフ(メソッドの呼び出し頻度) 基本ブロック(Basic block, BB)(実行頻度) エッジ(コントロールフローグラフのエッジの実行頻度) 値やその型(ループの繰り返し回数や、メソッドのレシーバーの型) ハードウェアが持つカウンタ(命令実行アドレス、キャッシュミス、など)
実行時に再コンパイル可能
すべてのコードをコンパイルしなくてもよい– 頻繁に実行されないコードは、インタプリタで実行してもよい
インタプリタにシンボルのResolveを任せることができる– Resolveに付随する副作用の考慮を緩和できる6 Java Just-In-Timeコンパイラの実装技術/石崎 一明

© 2016 IBM Corporation
もし、コンパイル時にシンボルがUnresolveだと
コンパイル時にシンボルをResolveすると、動作が変わることがある– 初めてResolveしたクラスに関して、class initializerが実行される
•
実行時にResolveするコードを生成する必要がある– 自己書き換えコードを生成する(マルチスレッド対応が必要)
UnResolveなシンボルを持つ参照は、移動・削除等の最適化を阻害する– Class initializerが実行されて、例外など副作用が起きるかもしれない
7 Java Just-In-Timeコンパイラの実装技術/石崎 一明
class Cls1 { static { System.out.println(“Hello Java”); } static float f1; }class test { float foo(Boolean c1) { if (c1) { return Cls1.f1; } else { return 0; } }
jmp resolveCall_ClsF1RefF1:load r4, offsetF1(r10) // 命令の2,3 byte目がoffsetF1...
resolveCall_ClsF1:mov r3, Cls1_f1call ResolveClass // r3: offsetstores (RefF1 + 2), r3store (RefF1 – 4), nopsyncret
CPU命令
nopload r4, 8(r10)...

© 2016 IBM Corporation
動的コンパイラの実装(最適化)について、今日お話すること
メソッドインライニングとコンパイル単位
例外処理最適化– 例外チェック除去– 例外処理オーバヘッドの軽減
スレッド局所性を利用した最適化
ハードウェア機構の活用– 文字列処理命令
– Transactional memory (TM)
– Single instruction multiple data (SIMD)
– General-purpose computing on graphics processing units (GPGPU)
8 Java Just-In-Timeコンパイラの実装技術/石崎 一明
※コンパイラの教科書などで説明されているような基本的な最適化は、こちらなどをご参照くださいhttp://www.slideshare.net/ishizaki/20151112-kutech-lectureishizakipublic

メソッドインライニングとコンパイル単位

© 2016 IBM Corporation
メソッドインライニング(インライン展開)
あるメソッド呼び出しを、そのメソッド呼び出しによって呼びされるメソッド(呼び出し先)の本体のコピーで、置き換えること
10 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Top {static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
static int calc() {int r = 3 + Top.div(2);return r;
}}
static int calc() {int r = 3 + return r;
}
static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
((2 != 0) ? (4 / 2) : 0);

© 2016 IBM Corporation
なぜメソッドインライニングを行うのか?
コンパイラが生成するコードの質の問題の軽減– コンパイル単位を大きくして、最適化をより適用したい
一般にオブジェクト指向言語では、メソッドの大きさが小さくなりがち
– メソッド呼び出しのオーバヘッドの削減
プロセッサ上での性能問題の軽減– 直接メソッド呼び出しや仮想メソッド呼び出しが使用する命令が、プロセッサ内のパイプライン実行を乱す
実行コードの空間的局所性の向上
しかし、コストは抑えたい– コンパイル時間の増加は、できるだけ抑えたい– コードサイズの増加は、できるだけ抑えたい
11 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
コンパイラが生成するコードの質の問題の軽減(1)
コンパイル単位の範囲の増加によるコードの質の向上– 最適化(特にデータフロー解析)の適用範囲が広がる
12 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Top {static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
static int calc() {int r = 3 + Top.div(2);return r;
}}
static int calc() {int r = 3 + ((2 != 0) ? (4 / 2) : 0);return r;
}
static int calc() {return 5;
}
Top.div(2)を呼び出し先のコードで置き換え
コンパイル時に式を評価する

© 2016 IBM Corporation
コンパイラが生成するコードの質の問題の軽減(2)
引数渡しの際にプログラムからは見えない重い処理を伴うことがあるが、インライニング後の最適化の結果、削減可能な場合がある– Javaでは、可変長引数を使用すると、javacがvalueOfメソッドを挿入し、メソッドでオブジェクトが生成される
13 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Top {void print(int i, int j, int k) {System.out.printf(“%d %d¥n”, i, j);
}}
class Top {void print(int i, int j, int k) {
System.out.printf("%d %d¥n", new Object[] {Integer.valueOf(i), Integer.valueOf(j)
});}
}
プログラム
javacでコンパイルされた結果

© 2016 IBM Corporation
コンパイラが生成するコードの質の問題の軽減(3)
メソッド呼び出しの際には、プログラムからは見えない、application
binary interface(ABI)にもとづいた処理が必要になる
14 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
// t.add(2)の呼び出し...mov r4 = 2 // 第2引数 2mov r3 = r10 // 第1引数 tcall method_addmov r4 = r3 // 戻り値
...
CPU命令
sp
loweraddress
スタックフレーム

© 2016 IBM Corporation
コンパイラが生成するコードの質の問題の軽減(3)
メソッド呼び出しの際には、プログラムからは見えない、application
binary interface(ABI)にもとづいた処理が必要になる– メソッド呼び出しがなくなれば、これらの処理は減る
15 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
// t.add(2)の呼び出し...mov r4 = 2 // 第2引数 2mov r3 = r10 // 第1引数 tcall method_addmov r4 = r3 // 戻り値
...
CPU命令
loweraddress
スタックフレーム
// t.add(2)のメソッド入り口method_add:store (sp+8), return // 前のスタックフレーム上へ
// 戻りアドレスを保存mov r0 = sp // 古いスタック値の保存sub sp = sp + 64 // 新しいスタックの作成store (sp+0), r0 // 新しいスタックから
// 古いスタックへのリンク作成mov r16 = r4 // 第2引数の受け取り... sp
t.add() 作業領域

© 2016 IBM Corporation
メソッドインライニングを行うか行わないかの判断
(私見では)決定解はこれまでにはない。– 実際の実装では、さまざまなヒューリスティックスも使われている
時代(プロセッサアーキテクチャ、言語)によって良い解法が異なるのでは?– 静的情報
呼び出し先メソッドの大きさ 制御フローの形
• 呼び出し先メソッドを先読みして、インライニングを行った場合最適化が適用できるか判断する
…
– 動的情報 実行中に集められた引数の値にもとづいて、インライニングを行った場合最適化が適用できるか判断する
実行中に集められた実行時のメソッド実行頻度に基づく
• ハードウェアカウンタ(OSのサポートも必要)から、メソッド実行頻度を推定可能
16 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
1. 再コンパイル時に、コールグラフエッジeに対して費用対効果CBを計算
2. CB(e)が高い順にコールグラフエッジをソート• CB(e1) = (44/55) / (10/100) = 8, CB(e2) = (11/55) / (50/100) = 0.4
3. 上位のエッジ(の先の呼び出し先メソッド)から順にインライニング
4. 中間コード総サイズが、コンパイラが定めた閾値に達したら終了
void foo() {bar();bar(); baz();
}
実行時プロファイル情報を用いた判断 [Nakaike2014]
17 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
)(
)( )(
eCalleeSize
encyCallFrequeeCB encyTotalFrequ
encyCallFreque )(
izeCallGraphS
eCalleeSize )(
ハードウェアカウンタとコールスタックから取得
コンパイル情報から取得
Callerメソッド
コールエッジと呼び出し頻度
CalleeメソッドCalleeメソッド
foo[40]
bar[10] baz[50]
e1(44) e2(11) メソッドとその大きさ

© 2016 IBM Corporation
実行性能とコンパイル時間の改善
実行時情報を使わない場合に比べ、– 最大10%(平均2%)実行性能向上– 最大29%(平均5%)コンパイル時間短縮
18 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
90
92
94
96
98
100
102
104
106
108
110
112
cc cs cmp aes rsa sv db mpg sr snf xt xv 平均
Re
lative
th
rou
gh
pu
t (%
)
IBM Java, 5.5 GHz zEC12 4 cores, z/OS
0
20
40
60
80
100
120
140
cc cs cmp aes rsa sv db mpg sr snf xt xv 平均
Rela
tive t
ime (
%)
← L
ow
er
is b
ett
er
SPECjvm2008ベンチマークの実行性能向上 SPECjvm2008ベンチマークのコンパイル時間増加
→ H
igh
er
is b
ett
er

© 2016 IBM Corporation
直接メソッド呼び出し(direct method call)
コンパイル時に、プログラム上の情報から呼び出し先が一意に決定可能– 直接分岐命令(call address)の使用
19 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Top {static finalint div(int i) { ... }
static int calc() {... Top.div(2) ......
}}
...call method_div...
method_div:...ret
プログラム CPU命令

© 2016 IBM Corporation
仮想メソッド呼び出し(virtual method call)
コンパイル時に、呼び出し先が一意に決定できない– 実行時に呼び出し先を決定する機構(表引き、など)が必要– 間接分岐命令(call register)の使用
20 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Sub1 extends Top {int add(int i) { ... }
static int calc1(Top t) {... t.add(2) ......
}}
...// r3 = object of Topload r2, (r3+offset_class_in_object)load r1, (r2+offset_vtableadd_in_class)load r0, (r1+offset_code_in_method)call r0
プログラム CPU命令
Top object t class Sub1
div
foo
virtual tableadd
code
method Sub1.add
r3 r2 r1
binary code
r0
同じメソッドはクラス階層内で同じオフセットを持つ

© 2016 IBM Corporation
メソッドインライニングを行うメソッドの特定
呼び出し先メソッドが、容易に一意に特定できる場合– 直接メソッド呼び出しの場合
21 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Top {int add(int i) { return i + 9; }
static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
static int calc() {int r = Top.div(2) + 3;return r;
}}

© 2016 IBM Corporation
メソッドインライニングを行うメソッドの特定
メソッドの呼び出し先を一意に特定することが難しい場合– 仮想メソッド呼び出し– インターフェースメソッド呼び出し
22 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
call t.add()
foo(Top t) { t.add(); }
CPU命令

© 2016 IBM Corporation
Devirtualizationによって特定
複数の呼び出し先を、特定した1つとその他、に分ける– 仮想呼び出しではなくなっている、のでdevirtualization(脱仮想化)
分ける方法– Guarded devirtualization
– Direct devirtualization
23 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
call t.add() Sub1.add()Top.add()
Sub2.add()...
call t.add()call Sub2.add()

© 2016 IBM Corporation
Guarded devirtualizationによって特定
複数の呼び出し先を条件分岐(ガード)によって、特定した1つとその他、に分ける
実行時情報などからガードを挿入して、呼び出し先を特定– Method test [Calder1994], Class test [Grove1995]
複数の呼び出し先を特定– Polymorphic inline cache [Hölzle1991]
24 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
call t.add() Sub1.add()Top.add()
Sub2.add()...
call t.add()call Sub2.add()
ガード
© 2016 IBM Corporation
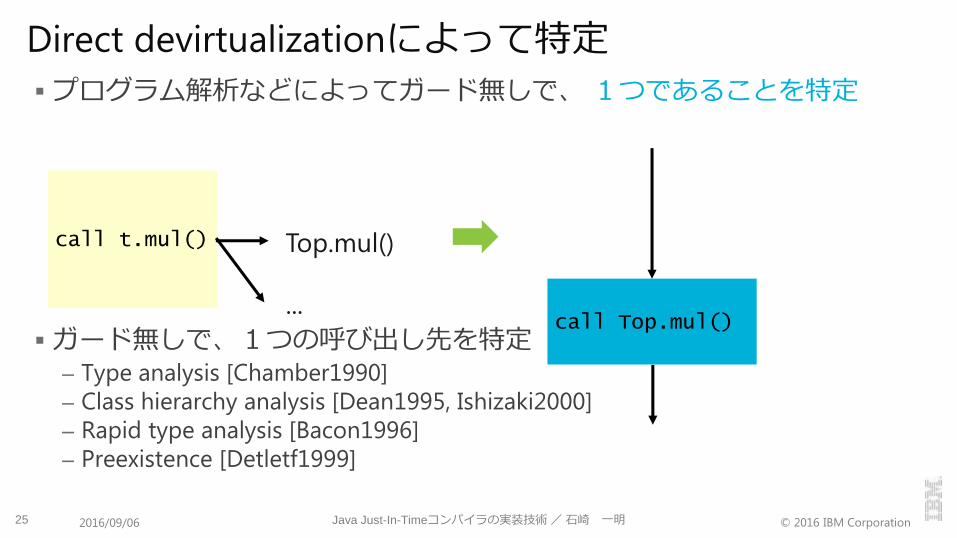
Direct devirtualizationによって特定
プログラム解析などによってガード無しで、1つであることを特定
ガード無しで、1つの呼び出し先を特定– Type analysis [Chamber1990]
– Class hierarchy analysis [Dean1995, Ishizaki2000]
– Rapid type analysis [Bacon1996]
– Preexistence [Detletf1999]
25 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
call t.mul() Top.mul()
...call Top.mul()

© 2016 IBM Corporation
Guarded devirtualizationの手法
元のコード
直接メソッド呼び出しもしくはメソッドインライニングされているコードを呼び出してよいか、ガードの比較結果に基づいて判断する。
26 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
...// r3 = object in tload r2, offset_class_in_object(r3)load r1, offset_vtableadd_in_class(r2)load r0, offset_code_in_method(r1)call r0...
Top object t class Sub1
div
foo
virtual tableadd
code
method Sub1.add
// r3 = object in tload r2, offset_class_in_object(r3)if (r2 == #address_of_classSub1) {call Sub2.add // exec inlined code
} else {load r1, offset_vtableadd_in_class(r2)load r0, offset_code_in_method(r1)call r0
}
// r3 = object in tload r2, offset_class_in_object(r3)load r1, offset_vtableadd_in_class(r2)if (r1 == #address_of_methodSub1add) {call Sub2.add // exec inlined code
} else {load r0, offset_code_in_method(r1)call r0
}
Class test(クラスの一致で判断)Method test(メソッドの一致で判断)
CPU命令

© 2016 IBM Corporation
Polymorphic inline cache (PIC)
複数の呼び出し先を持つメソッド呼び出しの高速化のために、複数のガードを挿入する– 複数のメソッドがオーバライドしている仮想メソッド呼び出し– 複数のクラスがimplementしているインターフェース呼び出し
27 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
// r1 = object in tload r2, offset_class_in_object(r1)if (r2 == #address_of_classTop) {call Top.add // exec inlined code
else if (r2 == #address_of_classSub1) {call Sub1.add // exec inlined code
else if (r2 == #address_of_classSub2) {call Sub2.add // exec inlined code
} else {load r3, offset_vtableadd_in_class(r2)load r4, offset_code_in_method(r3)call r4
}
class Topadd()
class Sub1add()
class Sub2add()

© 2016 IBM Corporation
Direct devirtualizationの必要性
ガードを挿入したguarded devirtualization、はSmalltalkなどの動的型付け言語で盛んに研究されてきた– 仮想メソッド呼び出しの実行コストが大きいので、実行時間の短縮に貢献
Javaなどの静的型付け言語では、仮想メソッド呼び出しの実行コストと、guarded devirtualization+直接呼び出しによる実行コストは、あまり差がない– guarded devirtualization+メソッドインライニング– ガード無しのdirect devirtualizationによる、実行時間の短縮の要求
28 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
Direct devirtualizationの手法
クラス階層解析(Class hierarchy analysis, CHA)を必要としない方法– Type analysis [Chamber1990]
– Value type analysis (VTA) [Sundaresan2000]
– Extended type analysis (XTA) [Tip2000] Type analysisをメソッド間に拡張
クラス階層解析を必要とする方法– Class hierarchy analysis (CHA) [Dean1995]
– Class hierarchy analysis with code patching [Ishizaki2000]
– Rapid type analysis (RTA) [Bacon1996]
– Preexistence [Detletf1999]
29 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
型解析(type analysis)
メソッド呼び出しのレシーバーに到達するオブジェクトの型を、データフロー解析によって求める。– 型が一意に決定する場合には、呼び出し先のメソッドを一意に決定可能。– 仮想メソッド呼び出しを、直接メソッド呼び出しに変換、もしくはメソッドインライニングが可能
30 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int bar() {
Top t = new Sub1();...... t.add(4) ...
}
...// r3 = tcall method_Sub1add...
method_Sub1add:...ret
レシーバー
CPU命令
t.add()のtに到達する型はSub1だけなので、Sub1.add()が必ず呼び出される

© 2016 IBM Corporation
クラス階層解析(Class hierarchy analysis - CHA)
プログラム全体のクラス階層においてどのメソッドが定義されているかを調べる– 各クラスがとり得るメソッド集合を集める
集合内のメソッド数が少ないほど、devirtualizationの効率が高くなる
31 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Topmul()
class Sub3 class Sub4mul()
Top: {Top.mul(),Sub4.mul()}
Sub3: {Top.mul()}
Sub4: {Sub4.mul()}
Classがレシーバーの型となった時とり得るメソッド集合 {}
class Topmul()
class Sub3
Top: {Top.mul()}
Sub3: {Top.mul()}
Classがレシーバーの型となった時とり得るメソッド集合 {}
foo(Top t) {t.mul(3)
}

© 2016 IBM Corporation
CHAを使ったdevirtualization
CHAや求めたメソッド集合を用いて、メソッド呼び出しのレシーバーのオブジェクトの型から、呼び出し先となり得るメソッド集合を取得する
メソッド集合の中にメソッドが1つだけ存在するならば、呼び出し先のメソッドを一意に決定可能– 直接メソッド呼び出しに変換、もしくはメソッドインライニングが可能
32 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int foo(Top t) {... t.mul(3) ...
}
...// r3 = tcall method_Topmul...
method_Topmul:...ret
CPU命令
class Topmul()
class Sub3Top: {Top.mul()}
Sub3: {Top.mul()}
Classがレシーバーの型となった時とり得るメソッド集合 {}
t.mul()ではTop.mul()が必ず呼び出される

© 2016 IBM Corporation
CHAとcode patchingによるdevirtualization
Javaの場合、実行中にクラスロード・アンロードが発生するので、常に正しい状態に保つ必要がある
コンパイル時に一意であった呼び出し先メソッドが、実行中に複数になることがある
– 直接メソッド呼び出しと間接メソッド呼び出しの両方を用意し、最初は直接メソッド呼び出しを実行する
33 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int foo(Top t) {... t.mul(3) ...
}
...call method_Topmul // 直接呼び出し
after_call:...
dynamic_call:load r2,(r3+offset_class_in_object)load r1,(r2+offset_vtablemul_in_class)load r0,(r1+offset_code_in_method)call r0 // 間接呼び出しjmp after_call
CPU命令
class Topmul()
class Sub3
Top: {Top.mul()}

© 2016 IBM Corporation
動的クラスローディング発生時
Javaの場合、実行中にクラスロード・アンロードが発生するので、常に正しい状態に保つ必要がある
コンパイル時に一意であった呼び出し先メソッドが、実行中に複数になることがある
– 動的クラスローディングの結果、クラスSub4がロードされメソッドmul()がオーバライドされた時は、コードを書き換えて間接メソッド呼び出しを実行する
34 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int foo(Top t) {... t.mul(3) ...
}
...jmp dynamic_call
after_call:...
dynamic_call:load r2,(r3+offset_class_in_object)load r1,(r2+offset_vtablemul_in_class)load r0,(r1+offset_code_in_method)call r0 // 間接呼び出しjmp after_call
CPU命令
class Topmul()
class Sub3
Top: {Top.mul(),Sub4.mul()}
class Sub4mul()

© 2016 IBM Corporation
CHAとcode patchingによるdevirtualizationの問題点
データーフロー解析結果の精度が悪くなる– メソッドインライニングした場合と仮想メソッド呼び出しの制御が合流する
Method test, Class test
CHA + code patching
– 例えば、rの値は?
35 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Sub2 extends Top {int add(int i) { return i + 2; }
static int calc2(Top t) {int r = t.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
r = t.add(-2)r = Sub2.add(-2)-> -2 + 2 = 0
ガード
r != 0
// 長いコード

© 2016 IBM Corporation
Deoptimization [Hölzle1992]
コンパイラ内部表現は、ある条件を満たさなかったとき、分岐先がコンパイルコード外となる– コンパイルするコード量が減る– コンパイラコード内の制御合流点が減る
典型的な使われ方– Specialization(特殊化)を行った場合、その効果を高める
– デバッガを有効化するとき、インタプリタに遷移する
36 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Sub2 extends Top {int add(int i) { return i + 2; }
static int calc2(Top t) {int i = 1;int r = t.add(-2);if (r != 0) { ... // 長いコード }return r + i;
}}
r = t.add(-2)r = Sub2.add(-2)-> -2 + 2 = 0
条件
r != 0
// 長いコード

© 2016 IBM Corporation
Deoptimizationを用いた最適化適用
コンパイルコード内では、rの値が0と決まるので、rを参照する条件分岐と条件が成立しない場合のコードを削除可能
コンパイルコード外に実行を移行する際に、補償コードが必要– コンパイラが生成した中間変数、削除した変数、から、インタプリタ、デバッガで参照される値の復元 コンパイラは、i = 1を定数伝搬後削除する
37 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Sub2 extends Top {int add(int i) { return i + 2; }
static int calc2(Top t) {int i = 1;int r = t.add(-2);if (r != 0) { ... // 長いコード }return r + i;
}}
i = 1r = Sub2.add(-2)-> -2 + 2 = 0
条件
インタープリタで
実行
r = t.add(-2)
t = r + it = r + 1

© 2016 IBM Corporation
コンパイルコードとインタープリタ間の実行遷移
コンパイルコードからインタープリタへ(Deoptimization)
インタープリタからコンパイルコードへ(On-stack replacement)
38 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
コンパイルされたコードbar() {......
}
インタープリタのコードfoo() {...bar();...
}
インタープリタのコードfoo() { bar() {... ...bar(); ...... }
}
コンパイルされたコードbar() {... ...
}
通常はメソッドの先頭で実行遷移する
メソッドの途中で実行遷移したいこともある

© 2016 IBM Corporation
On-Stack Replacement [Chamber1994][Kawahito2003]
インタプリタ実行中から、コンパイルコードの途中に遷移する– 一般的には、インタプリタでプログラムのループのback edgeを検出した際に、コンパイルコードのループの先頭に移ることが多い
実行例1. main()がインタプリタ実行され、ループのイテレーションが何度も実行される2. ある回数を超えるとループのback edgeで、main()のコンパイル要求が発行さ
れる3. main()は、div()をメソッドインライニングしながら、コンパイルされる
• コンパイルされたコードは、メソッド先頭とメソッド途中、の複数の入口を持つ
39 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int div(int i) { return (i != 0) ? (4/i) : 0; }
public static void main(String args[]) {for (int j = 0; j < 100000; j++) {
int r = div(2) + 3;System.println(r);
}}

© 2016 IBM Corporation
コンパイル単位について
コンパイル単位は、これまで(暗黙のうちに)下記を単位として話をしてきた– メソッド– インライン展開を行うことによって複数メソッド
メソッドの実行途中で遷移するなら、コンパイル単位の開始・終了点を、自由に設定すればよいのでは?– Advanced research topics
Region-based compilation [Suganuma2003]
Trace-based compilation [Wu2011, Inoue2012]
40 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
リージョンに基づくコンパイル
プログラム解析やプロファイル情報を元に、コンパイル単位(リージョン)を決定– 開始はメソッド先頭– 頻繁に実行される基本ブロック(BB) の連続からregionを構成する
あまり実行されないBB は含まない
– メソッドの途中で、実行を他に移行可能 Region Exit BB 経由
– メソッドインライニングも可能 部分的なメソッドインライニングも可
利点– 最適化の適用範囲が広がる
制御合流点の減少
– コンパイル時間短縮– コンパイルコード量減少
41 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
Method B
Invokemethod B
Region
exit BB
Method A
Invokemethod C
Region
exit BB
Method C

© 2016 IBM Corporation
実行性能とコンパイル時間の改善
メソッド単位のコンパイル方式に比べ、– 最大13%実行性能向上– 最大45%コンパイル時間短縮
42 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
IBM Java 1.3.1,Pentium Xeon 2.8GHz, 1GB Memory, Windows XP SP1
12.5
9.2
0.1
3.3
0.8
6.3
0.9
0
2
4
6
8
10
12
14
従来手法に比べた改善
(%)
プログラム
SPECjvm98の実行性能改善
→ H
igh
er
is b
ett
er
33.136.5
0
44.6
12.3
18.8
11.9
05
101520253035404550
従来手法に比べた減少
(%)
プログラム
SPECjvm98のコンパイル時間短縮
→ H
igh
er
is b
ett
er

© 2016 IBM Corporation
トレースに基づくコンパイル
トレースに基づくコンパイル方式は、高い性能を示してきた– TraceMonkey[Gal2009], PyPy [Bolz2009], SPUR[Bebenita2010]
J2EE*サーバなど複雑なプログラム(メソッド呼出し100段程度)から、頻繁に実行される部分だけを取り出し、大きなコンパイル単位を生成したい
43 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
method 1Web
Container
ok?
search for a handler
error!
printlog?
method 2JavaServer
Pages
ok?
search for a bean
error!
printlog?
method 3EnterpriseJavaBeans
ok?
create an SQL
error!
printlog?
method 4JDBCDriver
ok?
send the SQL to DB
error!
printlog?
*J2EE: Java Platform,
Enterprise Edition

© 2016 IBM Corporation
トレースの形成
制御フローが単純なコンパイル単位を形成する– 開始・終了はメソッドの任意の点
頻繁に実行される基本ブロックから、トレースを延伸する
– 途中、制御合流点を含まない ループを含まない
44 Java Just-In-Timeコンパイラの実装技術/石崎 一明
メソッド呼び出し
ループありメソッド
ループ無しメソッド
2016/09/06
3つ(茶、緑、青)の連続したトレース
←トレース とメソッドインライニング→
の比較
3つの階層的なコンパイル単位

© 2016 IBM Corporation
実行性能と生成コードサイズの改善
メソッド単位のコンパイル方式に比べ、– 最大28%実行性能向上– 最大88%コンパイル時間短縮
45 2016/09/06
← L
ow
er
is b
ett
er
IBM Java 6,POWER7 3GHz 2cores x 8SMT, AIX 7
0.0
0.2
0.4
0.6
0.8
1.0
1.2
avro
raba
tik
eclip
se fop h2
jyth
on
luin
dex
luse
arch
pmd
sunf
low
tom
cat
trade
bean
s
xalan
geom
ean
rela
tive p
erf
orm
ance o
ver
meth
od-J
IT (
warm
opt)
.
method-JIT (Xjit:optLevel=warm)
method-JIT
our trace-JIT
0
50
100
150
200
250
300
350
400
450
me
tho
d-J
IT
(op
tLe
ve
l=w
arm
)
me
tho
d-J
IT
tra
ce
-JIT
tota
l co
mp
ila
tio
n tim
e (
se
c)
0
500
1000
1500
2000
2500
3000
3500
me
tho
d-J
IT
(op
tLe
ve
l=w
arm
)
me
tho
d-J
IT
tra
ce
-JIT
pe
ak th
rou
gh
pu
t (p
ag
es/s
ec)
→ H
igh
er
is b
ett
er
プログラム実行時の性能比較
Dacapo 9.12
コンパイル時間比較
Java Just-In-Timeコンパイラの実装技術/石崎 一明
J2EE application (DayTrader)
on WebSphere 7
28%
88%

© 2016 IBM Corporation
残念ながらこの2つの機能は製品には搭載されなかった
学術的視点からは良い結果が得られている– 標準ベンチマークの実行性能は高い– コンパイル時間は短縮されている– コード生成量も減少している
製品となる新しい技術とは– 得られる性能向上と実装の複雑さのトレードオフ– 安定した性能向上– 性能比較の対象– 性能改善とは– タイミング
46 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

例外処理最適化

© 2016 IBM Corporation
なぜ例外処理最適化を行うのか?
Java言語は、プログラムの安全性のために例外検査が必要である
Java言語は、正確な例外発生を要求する– 例外の発生順序が変わってはいけない
例外検査の存在が、性能向上の妨げになる場合がある– 例外検査を行うコスト– 命令の移動が制限される
例外発生命令の順序を変更できない 例外検査より前に、検査される変数を参照する命令を移動できない
例外は正しく発生させながら性能は向上させたい
48 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Testint n;void foo(float[] a, Test t) {
int nn = t.n; // tがnullではないか?int n2 = nn / 2; // 0での除算が発生しないか?for (int i = 0; i < n2; i++) {
a[i] = i; // aがnullではないか?// iはaの範囲に収まっているか?
}}
}

© 2016 IBM Corporation
例外処理最適化
頻繁には発生しない例外に関する検査を最適化する– プログラム解析による例外検査除去[Kawahito2000]
– OS・ハードウェア機構の利用による例外検査コスト抑制[ishizaki1999,
Kawahito2000]
– Loop versioning[Artigas2000, Suganuma2000]
頻繁に発生する例外処理を最適化する– Exception Driven Optimization [Ogasawara2001]
49 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
Scalar replacementと例外検査除去の組み合わせ
問題点:Javaの正確な例外発生のため、命令の移動が制限される– 例外検査より前に、検査された変数を参照する命令を移動できない– 例外発生命令の順序を変更できない
解決方法:下記操作の繰り返しで命令移動の範囲を広げる1. 例外検査操作の移動2. 例外検査を伴う操作へのscalar replacementとコード移動
例:インスタンス変数、配列変数読み書き
50 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
do {i += (a.b.c + a.b.d);} while (cond);
do {nullcheck aT1 = a.bnullcheck T1T2 = T1.c
nullcheck aT3 = a.bnullcheck T3T4 = T3.d
i += T2 + T4} while (cond)
nullcheck ado {T1 = a.bnullcheck T1T2 = T1.c
T3 = a.bnullcheck T3T4 = T3.d
i += T2 + T4} while (cond)
nullcheck aTb = a.bdo {nullcheck TbT2 = Tb.c
nullcheck TbT4 = Tb.d
i += T2 + T4} while (cond)
nullcheck aTb = a.bnullcheck TbTc = Tb.cTd = Tb.ddo{i += Tc + Td
} while (cond)
コンパイラ中間言語
ソースプログラム
例外検査操作の移動scalar replacementとコード移動
例外検査操作の移動、scalar replacementとコード移動

© 2016 IBM Corporation
OS・ハードウェアの利用による例外検査コスト抑制
OS機構の利用– Zeroページの読み書きでOS Trapが発生する(Linux, Windows) メモリアクセスに伴う明示的なnull例外検査を除去可能
• メモリアドレスがZeroページ内を指すときのみ利用可
– Zeroページを読むと常に0が返る(AIX) 値の読み出しを、例外検査を超えて移動可能
• 例:配列の長さを読みだすbytecode(arraylength)
ハードウェア機構の利用– 条件比較&分岐が1命令で高速に実行可能
条件が成立しなければ1サイクルで実行可能。成立するとOS Trapが発生するので遅い
• 例:PowerPCのTrap命令
例外の種類は、例外ハンドラで命令をdecodeして決定する51 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
// nullcheck a a: r1// T1 = a.b T1: r3
cmp r1, 0 // nullcheckjeq Handle_nullexceptionload r3,(r1 + small_offset_for_b)
twi r3, 0 // null checktw ge, r4, r6 // array bound...twi llt, r7, 1 // divide by 0
// nullcheck array array: r2// T2 = array.arraylength T2: r4
load r4,(r2 + offset_for_length)cmp r2, 0jeq Handle_nullexception

© 2016 IBM Corporation
実行性能の改善
従来手法(前向きデータフローによる冗長なnullcheck削減 + OS機構の利用[Whaley1999])に比べ、最大10%の性能向上を確認
52 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
IBM Java 1.2.2,Pentium III 600MHz, 384MB Memory, Windows NT 4.0 SP5
9.9
2.5
0.61.2
0.1
4.1
0.9
0
2
4
6
8
10
12
mtrt jess compress db mpegaudio jack javac
従来手法に比べた改善
(%)
プログラム
SPECjvm98を実行した際の性能改善
→ H
igh
er
is b
ett
er

© 2016 IBM Corporation
Loop versioning
問題点:ループ本体において配列が参照されると、例外検査が頻繁に実行され、CやFortranに比べて実行性能が低くなる– 数値計算では、ループ内で配列を参照することが多い
解決方法:ループ本体の例外発生条件をループ実行前に一度だけ調べて、例外が発生しないことが保証できる、高速実行可能なループを、コンパイラが作成する
53 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int[] a = ...int m = ...for (int i = 0; i < n; i++) {a[i] = i / m;
}
if (a != null && a.length <= n && m != 0) {for (i = 0; i < n; i++) { // 例外検査のない
a[i] = i / m; // 高速なループ}
} else {for (i = 0; i < n; i++) { // 例外検査を持つループ
zerodivcheck mnullcheck aboundcheck i, aa[i] = i / m;
}}
ソースプログラム
コンパイラ中間言語

© 2016 IBM Corporation
Exception Driven Optimization
問題点– 例外が頻繁に発生するプログラムが存在する
大域jumpに利用
– 例外が発生した時のコストは、比較的高い 午前中の講演を思い出してください
解決方法:頻繁に発生する例外に関する処理を、コンパイル時に最適化する1. 頻繁に発生する例外のthrow-catchのペアを
実行時プロファイルで特定2. throw-catchが発生する実行パスに沿って
コンパイル時にメソッドインライニング3. throwする点をcatchハンドラへのgotoに置き換え
• 実行時スタック巻き戻し処理の除去• exceptionオブジェクト e作成の除去
54 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
void m11() { throw new E();}void m1() { m11(); m12(); }void foo() {try {
m1();m2();
} catch (E e) {..
}}
void foo() {try {
throw new E();goto Handler;m12();m2();
} catch (E e) {Handler:
.. // eが参照されない}
}
m11 → fooの例外パターンが多い

© 2016 IBM Corporation
実行性能の改善
従来手法(スタック巻き戻し方式)に比べ、最大18%の性能向上を確認– プログラム中で例外が発生しないプログラムでは、オーバヘッドはない
55 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
0 0 0 0 0
18.3
13.8
0
2
4
6
8
10
12
14
16
18
20
mtrt jess compress db mpegaudio jack javac
従来手法に比べた改善
(%)
プログラム
SPECjvm98を実行した際の性能改善
プログラム中で例外が発生しない
IBM Java,Pentium III 800MHz, 256MB Memory, Windows NT 4.0

スレッド局所性を利用した最適化

© 2016 IBM Corporation
なぜスレッド局所性が大事か?
Javaは,言語自体がスレッドによる並列処理をサポートしている– マルチスレッドであることを前提に考えないといけない
マルチスレッド前提だと– オブジェクトは、他のスレッドとの同期に使われるかもしれない– オブジェクトは、他のスレッドからアクセスされるかもしれない
オブジェクトが他のスレッドからアクセスされない(スレッド局所性)ことが分かると、可能な最適化がある
57 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Test {int n;void foo() {
Test t = new Test(1); // tは他スレッドがアクセスするかもsynchronized (t) { // tは他スレッドとの同期に使われるかもt.n += 1;
}System.out.println(t.n);
}}

© 2016 IBM Corporation
脱出解析(escape analysis)
オブジェクトの生存区間が、ある区間に閉じるか脱出するか [Park1992]
Javaでは、生存区間がスレッド内の局所的範囲に閉じているかどうか知りたい[Choi1999][Whaley1999]– 条件
解析範囲外へのメソッドの引数として渡されない returnの返り値として渡されない 脱出するオブジェクトのインスタンス変数、またはスタティック変数に保存されない
– 解析結果 脱出しない メソッドから脱出するが、スレッドから脱出しない
スレッドとメソッドから脱出する
58 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Testint n;void foo(int i, int j) {Test t = new Test(i);synchronized (t) {t.n += j;
}System.out.println(t.n);
}}

© 2016 IBM Corporation
オブジェクトがスレッドから脱出しないことが分かったら
他のスレッドとの同期は発生しない– 同期を除去できる
オブジェクトは他スレッドから参照されない– オブジェクト生成を除去する
オブジェクトのインスタンス変数は、ローカル変数に置き換える
– スタック上に、オブジェクトを生成する59 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Test {int n;Test(int i) { this.n = i; }void foo(int i, int j) {Test t = new Test(i);synchronized (t) {t.n += j;
}System.out.println(t.n);
}}
class Test {int n;Test(int i) { this.n = i; }void foo(int i, int j) {int t_n = i;
t_n += j;
System.out.println(t_n);}
}

© 2016 IBM Corporation
オブジェクトが脱出することが分かってしまっても
めったに脱出しないなら、脱出するときだけオブジェクトを生成する– オブジェクトを生成しない高速なコードを、多くの場合に実行できる
60 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
class Test {int n;Test(int i) { this.n = i; }void foo(int i, int j) {Test t = new Test(i);try {
t.n += j;...
} catch (Exception e) {
bar(t);}System.out.println(t.n);
}...
}
class Test {int n;Test(int i) { this.n = i; }void foo(int i, int j) {int t_n = i;try {t_n += j;...
} catch (Exception e) {Test t = new Test(i);t.n = t_n;bar(t);t_n = t;
}System.out.println(t_n);
}...
} ※bar()の先で、tが同期に使われるかもしれないので、sychronizedが存在する場合は除去できない

ハードウェア機構の活用

© 2016 IBM Corporation
ハードウェア機構をJavaから利用しようと思った時
最近のプロセッサには、特定の処理を高速化する命令・ハードウェアが用意されているが、利用が容易ではない– プロセッサごとに、形式・意味が異なる– 命令・ハードウェアによっては事前用意が必要で、初心者には利用が難しい
一度書いたJavaプログラムが、実行するプロセッサに応じて専用ハードウェアを利用するコードに自動的にコンパイルされて、実行が高速化されるとうれしい– 文字列処理命令[Kawahito2006]
– Transactional Memory[Nakaike2010]
– Single instruction multiple data (SIMD)
– General-purpose computing on graphics processing units (GPGPU)[Ishizaki2015]
62 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
Idiom Recognition by Topological Embedding
問題点:ストリング命令などのより高機能なCISC命令を生成するには単純な完全一致検索では限界がある
解決方法:下記の手法によって、CISC命令生成の機会を増やす1. Topological embedding[fu1997]手法による検索候補列挙
途中に無関係な命令があってもパターンマッチ可
2. プログラム変形による完全一致検索
63 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 00x00
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00xF0
: :
256-byte Function Table for TRT
b = bytes[index];while (true) {if (b==0x00||b==0x0A||b==0x0D)
break;b = bytes[++index];
}
R3 = FunctionTable // R3: テーブルアドレスR1 = bytes + index // R1: 先頭アドレス// R1から1byteずつ取り出し、R3のテーブルの中で// 非0に対応する値があったら、見つけたアドレスをR1に返すTRT 0(0,R1),0(R3)
while (true) {b = bytes[++index];if (b==0x00||b==0x0A||b==0x0D)
break;} index = index + 1
以下同命令列

© 2016 IBM Corporation
実行性能の改善
従来手法(専用命令を使用しない)に比べ、最大122%の性能向上を確認
64 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
17
53
122
0
20
40
60
80
100
120
140
short middle long
従来手法に比べた改善
(%)
デリミタ検索ループの繰り返し長
IBM XML Parserを実行した際の性能改善
IBM Java,System z990,8GB Memory, Linux

© 2016 IBM Corporation
トランザクショナルメモリ
クリティカルセクションを楽観的に並行実行後、正当性を検査する– プログラムからの利用方法
クリティカルセクションをトランザクション開始・終了命令で囲む
– 実行時 トランザクション中のメモリ操作は1ステップで行われたかのように他スレッドからは観測
複数のトランザクションはメモリ操作が衝突しない限りは並列実行可→ロックよりも高い並列性
ハードウェアで高速に処理を行う– Hardware Transactional Memory (HTM)
2012: Blue Gene/Q, zEC12
2013: Intel 4th Generation Core Processor
2014: IBM POWER8
65 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
lock();a->count++;unlock();
xbegin();a->count++;xend();
xbegin();a->count++;xend();
tbegin();b->count++;xend();
xbegin();a->count++;xend();
tbegin();a->count++;xend();
Thread X Thread Y
tim
e

© 2016 IBM Corporation
Java処理系でのHTMの利用方法
Synchronized block・メソッドの置き換え– synchronized block・メソッドのクリティカルセクションを、HTMで実行することで高い並列性
– HTM実行で性能向上が得られない場合は、従来のロックによる実行に移行– IBM Java 8、OpenJDKに実装
java.util.concurrentライブラリでの活用– 複雑なロックフリーアルゴリズムの代わりに、HTMを使用することで実行パスが単純になり高速化
– IBM Java 8に実装
66 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
© 2016 IBM Corporation
SIMD
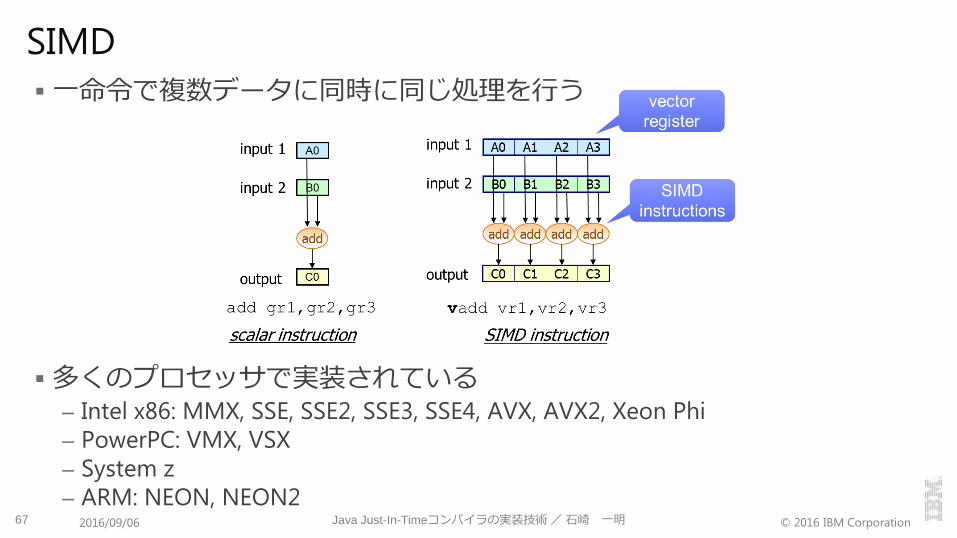
一命令で複数データに同時に同じ処理を行う
多くのプロセッサで実装されている– Intel x86: MMX, SSE, SSE2, SSE3, SSE4, AVX, AVX2, Xeon Phi
– PowerPC: VMX, VSX
– System z
– ARM: NEON, NEON267 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
Java処理系でのSIMDの利用方法
単純ループの自動SIMD変換– 複雑なループも技術的には変換可能だが、動的コンパイラでは時間がかかる解析を行うことは難しい
– Loop versioningを適用することで、SIMD変換するループを単純化している Matrix multiplicationを行うループなどは変換可能(IBM Java)
演算対象が一次元のprimitive type配列であること
– IBM Java 8、Open JDKに実装
Javaクラスライブラリでの活用– ループ処理が多いライブラリで使用
java/lang/String
Java/util/Arrays
String encoding converter
– IBM Java 8に実装
68 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
GPGPU
並列計算可能な大量のデータを、演算可能なアクセラレータ– 長所:高速– 短所:プログラミングが容易ではない
GPGPUデバイスの管理 データ転送 並列性の表現
69 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
void fooCUDA(N, float *A, float *B, int N) {int sizeN = N * sizeof(float);cudaMalloc(&d_A, sizeN); cudaMalloc(&d_B, sizeN);cudaMemcpy(d_A, A, sizeN, Host2Device);GPU<<<N, 1>>>(d_A, d_B, N);cudaMemcpy(B, d_B, sizeN, Device2Host);cudaFree(d_B); cudaFree(d_A);
}// code for GPU__global__ void GPU(float* d_A, float* d_B, int N) {
int i = threadIdx.x;if (N <= i) return;d_B[i] = d_A[i] * 2.0;
}
void fooJava(float A[], float B[], int N) {// similar to for (idx = 0; i < N; i++)IntStream.range(0, N).parallel().forEach(i -> { B[i] = A[i] * 2.0;
});}
NVIDIA社のCUDAで書いた並列コード Java parallel stream APIで書いた並列コード
© 2016 IBM Corporation
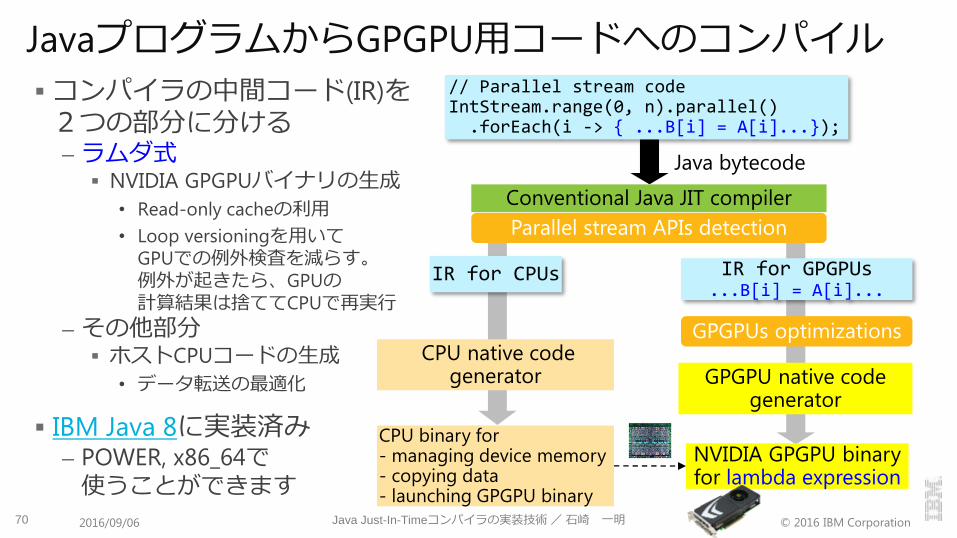
JavaプログラムからGPGPU用コードへのコンパイル
コンパイラの中間コード(IR)を2つの部分に分ける– ラムダ式
NVIDIA GPGPUバイナリの生成
• Read-only cacheの利用
• Loop versioningを用いてGPUでの例外検査を減らす。例外が起きたら、GPUの計算結果は捨ててCPUで再実行
– その他部分 ホストCPUコードの生成
• データ転送の最適化
IBM Java 8に実装済み– POWER, x86_64で使うことができます
70 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
NVIDIA GPGPU binaryfor lambda expression
CPU binary for- managing device memory- copying data- launching GPGPU binary
Conventional Java JIT compiler
Parallel stream APIs detection
// Parallel stream codeIntStream.range(0, n).parallel()
.forEach(i -> { ...B[i] = A[i]...});
IR for GPGPUs...B[i] = A[i]...
IR for CPUs
Java bytecode
CPU native code generator GPGPU native code
generator
GPGPUs optimizations

© 2016 IBM Corporation
実行性能の改善
POWER8 1threadに比べ、最大2068倍の性能向上を確認
POWER8 160threadに比べ、最大33倍の性能向上を確認
71 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
IBM Java 8,POWER8 3.69GHz 20coresx 8SMTs, 256GB Memory, K40m GPGPU, Ubuntu 14.10, CUDA 5.5

商用コンパイラ実装の経験談

© 2016 IBM Corporation
商用コンパイラ実装の経験談、で今日お話すること
開発体制
出荷前
ベンチマーキング
出荷後
73 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
これからお話するのは1995~2002年のことです
Sovereign JVM/JITコンパイラの時代の話
74 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
Jav
Sovereign JVM/JIT J9/TestarossaJava
May 231995
Java 2 v1.4June 42002
Java 5Sep 302004
Java 6Dec 112006
Java 2 v1.3May 82000
Java 7July 282011
Java 8Mar 112014
Java 2 v1.2Dec 81998

© 2016 IBM Corporation
1995~2002年とは
学生の方には想像がつかないことがほとんどだと思います。例えば、– ハードウェア
プロセッサのクロックの1GHz超えは2000年(1995年のPentium Proは200MHz) マルチプロセッサが可能になったのは、Pentium専用チップで1994年 Streaming SIMD Extensions (SSE)が実装されたのは1999年 IA32アーキテクチャ64ビット拡張が実装されたのは、AMDで2003年、Intelで2004年 プロセッサの性能は、グラフ参照
– ソフトウェア Linuxが商用で使われはじめたのは
2000年ころから バージョン管理システム、Continuous
Integrationシステムの最初のリリース
• CVS: 1990/11, svn: 2000/10,
git: 2005/12, github: 2009/2,
Bugzilla: 1998/8, CruiseControl: 2001/3,
Jenkins: 2011/2
75 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
Jav
出典: Computer Architecture: A Quantitative Approach (5th edition)

© 2016 IBM Corporation
研究部門だけでは製品を作ることはできません
製品として出荷するためには、社内の様々な部門が関わっています– 様々な分野のプロフェッショナルが協力してチャレンジを乗り越えてきた
76 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
製品開発部門(例: J2EEサーバ)
パフォーマンスチーム
JVM/コンパイラ
開発部門
サポート
製品保証
研究部門パフォーマンス
チーム
サポート
製品保証
お客様開発部門研究部門
営業
サービス 技術支援
マーケティング

© 2016 IBM Corporation
IBMの研究開発は世界中で行われています
商用JVM / JITコンパイラの研究は日本、GCの研究はイスラエル
JVM/コンパイラ開発部門、JVM/コンパイラ製品保証はイギリス・カナダ
製品開発部門・製品保証、パフォーマンスはアメリカ各地
お客様は世界中にいらっしゃいます
77 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
複数プラットフォームサポート
10以上のプラットフォームをサポート– IA32: Windows, Linux, OS/2
– IA64: Windows, Linux
– PowerPC 32bit: AIX, Linux,
– PowerPC 64bit: OS/400
– System z 31bit: OS/390, Linux
下記の2つに大別して、各研究者が担当した– プラットフォーム非依存
最適化モジュール毎
– プラットフォーム依存 プラットフォーム毎
78 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
このロゴ、ご存じですか?
79 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
認証を得たJava処理系だけが使えます
Java Compatibility Kit(JCK)をパスした処理系だけがつけてよいロゴ
JCKに含まれる、(当時)10,000程度のテストケースをパスする必要がある– Java virtual machineの仕様を満たしているかのテスト– Java class library APIの仕様を満たしているかのテスト
80 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
※JCKは、現在ではTechnology Compatibility Kit (TCK)となっています

© 2016 IBM Corporation
ある日。。。
研究部門では、新しい最適化機能を追加して性能向上することが優先で、性能が上がると評価版を作成して、開発部門に渡していた– Javaが発表された当初はJCKはなかった
JCKができると、渡した評価版に対して、製品保証チームがJCKを実行し始めた– すると、failの山が築かれて、直して欲しい、とメールの山が来た
原因追求に時間がかかり、機能追加どころではなくなってきた
研究部門で普段からJCKをパスさせておかないと、研究&開発にならなくなった
81 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
© 2016 IBM Corporation
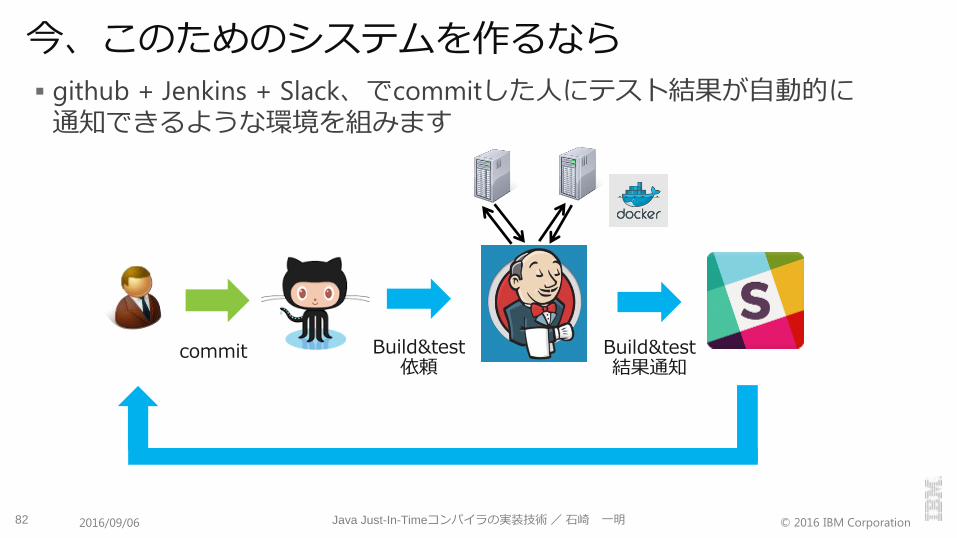
今、このためのシステムを作るなら
github + Jenkins + Slack、でcommitした人にテスト結果が自動的に通知できるような環境を組みます
82 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
commit Build&test依頼
Build&test結果通知

© 2016 IBM Corporation
当時、そんな気の利いたものはないので解決策は
Githubでのバージョン管理の代わりに– Microsoft社のVisual Source Safe
GUIで操作を行う、バージョン管理ツール
Jenkinsの代わりに– cronによるnightly build & test
Visual Source Safeのコマンドライン版でcheckout
Build & test run(7時間程度かかった)
• プロジェクト初期のCPU性能では、研究所に数台しかないサーバでしか、処理が間に合わない
Githubでのissue管理の代わりに– Lotus Notesの文書でissue管理
毎朝test runの結果を見て、手動でissue ownerをアサイン、statusを管理
83 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
そんなある日、どうしてもJCKのfailが直らなかった
インタープリタで動かすとfailしない
Just-in-timeコンパイラを何度見なおしてもおかしな所はない、はず
84 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
そんなある日、どうしてもJCKのfailが直らなかった
インタープリタで動かすとfailしない(ベリファイヤも通る)
Just-in-timeコンパイラを何度見なおしてもおかしな所はない、はず
実は、あるテストが、Java virtual machineの仕様を満たしていなかった– Java virtual machineの仕様では、各bytecode命令における
Javaスタックの各位置の型は一意でなければならない、が– Javaスタック上で、命令によって実際には使用されない位置(pop命令によって捨てられる)の値の型が一意ではなかった
Sunに報告して、直していただいて一件落着85 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
int
int / float
基本ブロック先頭でのJavaスタックの型 バイトコード
int / float
istore
バイトコード
pop
※この当時は、JITコンパイラにデータフロー解析を実装していませんでしたスタックの一番底の型が、実行パスに依存していた

© 2016 IBM Corporation
ベンチマークの思い出
プロジェクト初期の時代に使われていたCaffeineMarkが突然アップデート– いくつかのJVMが下記のようなことを行った結果、ベンチマーク結果のめざましい向上がおきた
IBM Javaは、汎用的なコンパイラ最適化のみで、同等のスコアを達成した
86 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06
出典http://www.benchmarkhq.ru/cm30/info.htmlhttp://www.benchmarkhq.ru/cm30/optimize.html
Why do some VM's obtain astronomical scores on CaffeineMark 2.5?
Some Java Virtual Machines (VM's) have begun to post extremely high scores on the CaffeineMark2.5 benchmark. In some cases, individual scores were as high as 1 million!
The reason for these high scores is that the Loop and Method tests were too optimizable. The Just-In-Time compilers realize that the calculations performed in these tests are not used, so the VM's don't execute the computations. While the high scores are an indicator of superior performance, the benchmark is misleading in these cases because real world performance is not 10,000 times better than it was a year ago.

© 2016 IBM Corporation
ベンチマークの変遷
初期の頃は、ベンチマークのサイズが小さかった Caffeinemark, JMark
– 最適化技術の研究が、コンパイラに閉じることが多く容易だった 初期の頃は、生成したコードの大きさが性能に大きな影響を与えることもあった
徐々に、ベンチマークのサイズが大きくなってきた SPECjvm98/2008, SPECjbb2000/2005/2013/2015
– 最適化技術の研究が、複数JVMコンポーネントに渡るようになってきた コンパイラ、インタプリタ、GC、クラスライブラリ、など
さらに、JVM単体では実行できなくなってきた SPECjAppServer2001/2002/2004, SPECjEnterprise2010
• インストールするだけでも、かなりの経験が必要だった
さまざまなソフトウェア(J2EE web server、Database、OSのスケジューリング・ネットワーク・ディスクI/O周りなど)の知識が要求される
– 最適化技術の研究は、複数ソフトウェアスタックに渡るものも出てきた
87 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
不具合の修正
問題の状況を、容易に手元で再現できるかが重要– 動的コンパイルが行われた後プログラムが終了すると、生成されたコードは残らないので、手元で再現できないと不具合の対応が難しい
初期の問題は、単体のJavaプログラムで起こることが多かったので、こちらで再現ができ、容易に修正できるものが多かった
Javaがお客様先で広く使われるようになると、問題再現が容易ではない場合が出てきた
Web server、database、LDAP server、など他のソフトウェアが必要 お客様の固有のデータが必要
– coreファイルとクラスファイルだけが送られてくることも多かった
IBM JavaはOracle JDKよりサポート期間が長いので、思わぬ古いバージョンの不具合が報告されてくることもあった
88 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
講演最後のまとめ
動的コンパイラの実装における、いくつかの最適化について– メソッドインライニングとコンパイル単位– 例外処理最適化– スレッド局所性を利用した最適化– ハードウェア機構の活用
商用コンパイラ実装の経験談– 開発体制– 出荷前– ベンチマーキング– 出荷後
89 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
参考文献(講演で参照していないものも挙げています) 適応最適化のサーベイ論文
– Arnold et al. A Survey of Adaptive Optimization in Virtual Machines, Proceedings of the IEEE 93(2), 2005.
Method inlining
– Nakaike et al. Characterization of Call-Graph Profiles in Java Workloads, IISWC 2014.
– Suganuma et al. An Empirical Study of Method Inlining for a Java Just-In-Time Compiler, JVM, 2002.
Devirtualization
– Calder et al. Reducing Indirect Function Call Overhead In C++ Programs, POPL, 1994.
– Grove et al. Profile-guided receiver class prediction, OOPSLA, 1995
– Hölzle et al. Optimizing dynamically-typed object-oriented languages with polymorphic inline caches, ECOOP, 1991
– Arnold et al. Thin Guards: A Simple and Effective Technique for Reducing the Penalty of Dynamic Class Loading, ECOOP, 2002.
– Chambers et al. Interactive type analysis and extended message splitting; optimizing dynamically-typed object-oriented programs, PLDI, 1990.
– Palsberg et al. Object-Oriented Type Inference, OOPSLA, 1991.
– Gagnon et al. Efficient Inference of Static Types for Java Bytecode, SAS, 2000.
– Sundaresan et al. Practical Virtual Method Call Resolution for Java, OOSPLA, 2000.
– Tip et al. Scalable propagation-based call graph construction algorithms, OOSPLA, 2000.
– Dean et al. Optimization of object-oriented programs using static class hierarchy, ECOOP, 1995.
– Bacon et al. Fast Static Analysis of C++ Virtual Function Calls, OOPSLA, 1996.
– Ishizaki et al. A Study of Devirtualization Techniques for a Java Just-In-Time Compiler, OOPSLA, 2000.
– Detlefs et al. Inlining of virtual methods, ECOOP, 1999.
On stack replacement / deoptimization
– Holzle et al. Debugging Optimized Code with Dynamic Deoptimization, PLDI, 1992.
– Paleczny et al. The Java HotSpot Server Compiler, JVM, 2001.
– Fink et al. Design, Implementation and Evaluation of Adaptive Recompilation with On-Stack Replacement, CGO, 2003.
– Soman et al. Efficient and general on-stack replacement for aggressive program specialization, PLC, 2006.
– Steiner et al. Adaptive inlining and on-stack replacement in the CACAO virtual machine, PPPJ, 2007.
90 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
参考文献(講演で参照していないものも挙げています) On stack replacement / deoptimization (続き)
– Lameed et al. A Modular Approach to On-Stack Replacement in LLVM, VEE, 2013.
– Kedlaya et al. Deoptimization for Dynamic Language JITs on Typed, Stack-based Virtual Machines, VEE, 2014.– 川人他, 実行環境が異なる2つのコード間の遷移を行う際の効果的な最適化手法, 情報処理学会論文誌:プログラミング, 2013
コンパイル単位
– Gal et al. Trace-based Just-in-Time Type Specialization for Dynamic Languages, PLDI, 2009.
– Bolz et al. Tracing the meta-level: PyPy's tracing JIT compiler, ICOOOLPS, 2009.
– Bebenita et al. SPUR: a trace-based JIT compiler for CIL, OOPSLA, 2010.
– Suganuma et al. A Region-Based Compilation Technique for a Java Just-In-Time Compiler, PLDI, 2003.
– Inoue et al. Adaptive Multi-Level Compilation in a Trace-based Java JIT Compiler, OOPSLA, 2012.
– Wu et al. Reducing Trace Selection Footprint for Large-scale Java Applications with no Performance Loss, OOPSLA, 2011.
– Hayashizaki et al. Improving the Performance of Trace-based Systems by False Loop Filtering, ASPLOS, 2011.
例外処理最適化
– Kawahito et al. Effective Null Pointer Check Elimination Utilizing Hardware Trap, ASPLOS, 2000.
– Ishizaki et al. Design, Implementation, and Evaluation of Optimizations in a Just-In-Time Compiler, JavaGrande, 1999.
– Artigas et al. Automatic loop transformations and parallelization for Java, ICS, 2000.
– Suganuma et al. Overview of the IBM Java Just-In-Time Compiler, IBM Systems Journal, 2000.
– Ogasawara et al. A Study of Exception Handling and Its Dynamic Optimization in Java, OOPSLA, 2001.
スレッド局所性を利用した最適化
– Park et al. Escape analysis on lists, PLDI, 1992.
– Choi et al. Escape analysis for java, OOPSLA, 1999.
– Whaley et al. Compositional Pointer and Escape Analysis for Java Programs, OOSPLA, 1999.
91 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06

© 2016 IBM Corporation
参考文献(講演で参照していないものも挙げています) ハードウェア機構の活用
– Kawahito et al. A New Idiom Recognition Framework for Exploiting Hardware-Assist Instructions, ASPLOS, 2006.
– Fu, Directed graph pattern matching and topological embedding, Journal of Algorithms, 1997
– Nakaike et al. Real Java Applications on Software Transactional Memory, IISWC, 2010.
– Ishizaki et al. Compiling and Optimizing Java 8 Programs for GPU Execution, PACT, 2015.
その他の日本IBM東京基礎研究所メンバーの論文は、http://ibm.biz/trljava-pub でご確認いただけます。
92 Java Just-In-Timeコンパイラの実装技術/石崎 一明2016/09/06