11/15: planning in belief space contd.. home work 3 returned; homework 4 assigned avg.61.66667 std....
Post on 18-Dec-2015
214 views
TRANSCRIPT

11/15: Planning in Belief Space contd..
Home Work 3 returned; Homework 4 assigned
Avg. 61.66667
Std. Dev. 19.16551
Median 57
Agenda: Long post-mortem on Kanna Rajan Talk Progression/Regression in Belief Space

Discussion on Kanna Rajan Talk
Qn: What did you mean by the comment to KR that the difficulty of modeling search control may be more acute because of hand-coded search control? HSTS/RAX (the planner underlying MAPGEN) depends on hand-coded search
control rules to tell the planner how to deal with the choice points during its search. To write these, you need expertise with both the HSTS planner and the domain. And the rules change if the domain changes. I was wondering if the latter difficulty may be alleviated if you were to use domain-independent (or even domain-specific but declarative—a la TLPLAN—search control). [Kanna thinks the latter techniques may not scale]
The domain specific search control rules are also used in ASPEN—JPL’s own temporal planner that uses local search. In ASPEN’s case, the control rules tell it which of the many possible plan repairs should be picked first. The experience with ASPEN was that it takes NASA folks time to (a) encode the new domain AND (b) write the domain specific rules. The first cannot be avoided. The second could be, if we use domain-independent local search heuristics (e.g. LPG planner)

Explaining Plans
Qn: KR mentioned that it was very important for the users to get exlanations for the decisions the planner made. How do we get them?
There are two types of explanations: Explanations of correctness—e.g. why is this action in the plan?
Can be given through causal links… the action is in the plan because of the causal links it is giving. Following them will tell us whether or not the action is (in)directly supporting some toplevel goal
Can be computed after the fact (doesn’t matter who made the plan—if I have the domain theory, I can compute its explanation of correctness)
Rationale for decision—e.g. Why was this action chosen as against some other action giving similar effects?
This information needs to be captured during the search [See Kambhampti’s 1990 paper on Information Requirements for Modification]
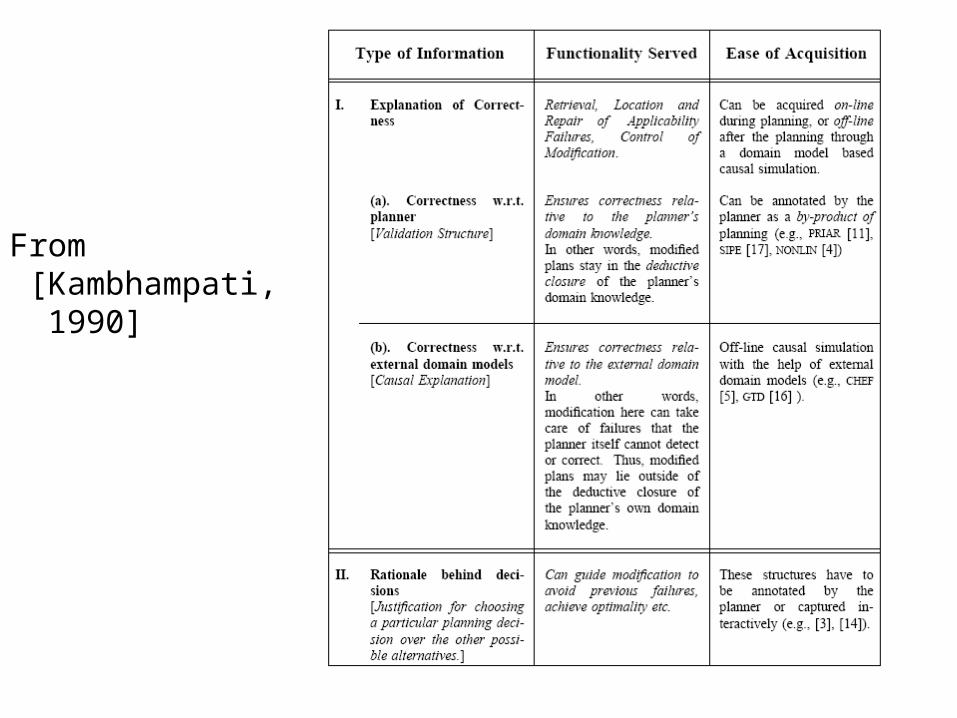
From [Kambhampati, 1990]

Soft Goals
Qn: KR mentioned that MAPGEN needs to handle soft goals. What are these and how are they handled?
Soft Goals are those that don’t have to be achieved for the plan to be considered valid. However, achieving them can improve the “value” of the plan. Soft Goals give planning a more distinct optimization flavor (If all goals are soft, then any executable sequence is a valid plan, and what we are looking for are valid plans with high quality)
The way MAPGEN handles these seems to be sort of ad hoc—the goals are given priorities. All tier 1 goals are first handled, then tier 2 goals are handled etc.
A related qn: How do we handle soft goals in a more principled and automated way? See the papers in AAAI-2004 (by Rao et al) and ICAPS-2004 (by Smith) … and a summary of the issues in the next slide

Handling Soft Goals—an approach Consider the variant of classical planning problem called PSP Net Benefit, defined as
follows: There are n goals to be achieved. Each goal g, when achieved gives a reward Rg Each action a in the domain has a cost Ca (expressed in the same units as the reward) Objective is to find a plan that has the highest net benefit (which is the difference between
cumulative reward of all the goals achieved by the plan, and the cumulative cost of all the actions used in the plan)
How do we solve PSP Net Benefit problem? Naïve (but guaranteed optimal) idea: Consider all possible subset of the n goals. For each
find the least costly plan (using cost-based planning graphs). Among all these, pick the one with the best benefit.
You die because there are 2n different calls to the planning algorithm Cheap (but pretty inoptimal idea): Rank the n goals in terms of the expected net benefit of
the plans for achieving them. Work just on the subset of goals with +ve net benefit You can do this by finding a (cost-sensitive) relaxed plan for each of the goals. The net benefit is
the reward of the goal minus the cost of the relaxed plan. Problem: The cost of achieving a goal depends on what other goals we are planning to achieve in
conjunction. We need to consider residual cost of achieving a goal gk+1 in the context of goals {g1..gk} that have already been selected
A less greedy idea: Generalize the relaxed plan extraction procedure such that it takes the relaxed plan P for achieving {g1…gk} and attempts to re-use as many of the actions in P as possible while finding a relaxed plan for gk+1
See AltAltps system (in AAAI 2004) for details

Belief State Search: An Example Problem
Initial state: M is true and exactly one of P,Q,R are true
Goal: Need G
Actions:A1: M P => KA2: M Q => KA3: M R => LA4: K => GA5: L => G
Init State Formula: [(p & ~q & ~r)V(~p&q&~r)V(~p&~q&r)]&MDNF: [M&p&~q&~r]V[M&~p&~q&~r]V[M&~p&~q&r]CNF: (P V Q V R) & (~P V ~Q) &(~P V ~R) &(~Q V ~R) & M
DNF good for progression(clauses are
partial states)
CNF goodFor regression
Plan: ??

Progression & Regression
Progression with DNF The “constituents” (DNF clauses) look like partial states already. Think of
applying action to each of these constituents and unioning the result Action application converts each constituent to a set of new constituents Termination when each constituent entails the goal formula
Regression with CNF Very little difference from classical planning (since we already had partial
states in classical planning). THE Main difference is that we cannot split the disjunction into search
space Termination when each (CNF) clause is entailed by the initial state

Progression Example

Regression Search ExampleActions:A1: M P => KA2: M Q => KA3: M R => LA4: K => GA5: L => G
Initially: (P V Q V R) &
(~P V ~Q) & (~P V ~R) & (~Q V ~R) &
M
Goal State:G
G
(G V K)
(G V K V L)
A4
A1
(G V K V L V P) & M
A2
A5
A3
G or K must be true before A4For G to be true after A4
(G V K V L V P V Q) & M
(G V K V L V P V Q V R) &M
Each Clause is Satisfied by a Clause in the Initial Clausal State -- Done! (5 actions)
Initially: (P V Q V R) &
(~P V ~Q) & (~P V ~R) & (~Q V ~R) &
M
Clausal States compactly represent disjunction to sets of uncertain literals – Yet, still need heuristics for the search
(G V K V L V P V Q V R) &M
Enabling preconditionMust be true beforeA1 was applied

What happens if we restrict uncertainty?
• If initial state contains only the known variables (either known to be true or known to be false), – DNF formula has one single constituent– CNF clauses are all singletons– So you can see how we go from 2^(2n) to 3n

11/17
… after all the money we spend on wardrobe and cosmetic surgeries

No. 42: HOW NOT TO BE SEEN
(aka Monty Python on Conformant Planning)Video shown in class
Conformant Planning in Real World™: 2 examples

Heuristics for Conformant Planning
• First idea: Notice that “Classical planning” (which assumes full observability) is a “relaxation” of conformant planning– So, the length of the classical planning solution is a
lowerbound (admissible heuristic) for conformant planning
– Further, the heuristics for classical planning are also heuristics for conformant planning (albeit not very informed probably)
• Next idea: Let us get a feel for how estimating distances between belief states differs from estimating those between states

Three issues: How many states are there? How far are each of the states from goal? How much interaction is there between states? For example if the length of plan for taking S1 to goal is 10, S2 to goal is 10, the length of plan for taking both to goal could be anywhere between 10 and Infinity depending on the interactions [Notice that we talk about “state” interactions here just as we talked about “goal interactions” in classical planning]
Need to estimate the length of “combined plan” for taking all states to the goal

Belief-state cardinality alone won’t be enough…
• Early work on conformant planning concentrated exclusively on heuristics that look at the cardinality of the belief state – The larger the cardinality of the belief state, the higher its uncertainty, and
the worse it is (for progression)• Notice that in regression, we have the opposite heuristic—the larger the
cardinality, the higher the flexibility (we are satisfied with any one of a larger set of states) and so the better it is
• From our example in the previous slide, cardinality is only one of the three components that go into actual distance estimation. – For example, there may be an action that reduces the cardinality (e.g.
bomb the place ) but the new belief state with low uncertainty will be infinite distance away from the goal.
• We will look at planning graph-based heuristics for considering all three components – (actually, unless we look at cross-world mutexes, we won’t be considering
the interaction part…)

Using a Single, Unioned GraphPM
QM
RM
P
Q
R
M
A1
A2
A3
Q
R
M
K
LA4
GA5
PA1
A2
A3
Q
R
M
K
L
P
G
A4K
A1P
M
Heuristic Estimate = 2
•Not effective•Lose world specific support information
Union literals from all initial states into a conjunctive initial graph level
•Minimal implementation

Using Multiple GraphsP
M
A1 P
M
K
A1 P
M
KA4
G
R
MA3
R
M
L
A3R
M
L
GA5
PM
QM
RM
Q
M
A2Q
M
K
A2Q
KA4
G
M
G
A4K
A1
M
P
G
A4K
A2Q
M
GA5
L
A3R
M
•Same-world Mutexes
•Memory Intensive•Heuristic Computation Can be costly
Unioning these graphs a priori would give much savings …

What about mutexes?• In the previous slide, we considered only relaxed plans (thus ignoring any
mutexes)– We could have considered mutexes in the individual world graphs to get better
estimates of the plans in the individual worlds (call these same world mutexes)– We could also have considered the impact of having an action in one world on
the other world. • Consider a patient who may or may not be suffering from disease D. There is a
medicine M, which if given in the world where he has D, will cure the patient. But if it is given in the world where the patient doesn’t have disease D, it will kill him. Since giving the medicine M will have impact in both worlds, we now have a mutex between “being alive” in world 1 and “being cured” in world 2!
• Notice that cross-world mutexes will take into account the state-interactions that we mentioned as one of the three components making up the distance estimate.
• We could compute a subset of same world and cross world mutexes to improve the accuracy of the heuristics…– …but it is not clear whether or not the accuracy comes at too much additional
cost to have reasonable impact on efficiency.. [see Bryce et. Al. JAIR submission]

Connection to CGP
• CGP—the “conformant Graphplan”—does multiple planning graphs, but also does backward search directly on the graphs to find a solution (as against using these to give heuristic estimates)– It has to mark sameworld and cross world
mutexes to ensure soundness..

Using a Single, Labeled Graph(joint work with David E. Smith)
P
Q
R
A1
A2
A3
P
Q
R
M
L
A1
A2
A3
P
Q
R
L
A5
Action Labels:Conjunction of Labels of Supporting Literals
Literal Labels:Disjunction of LabelsOf Supporting Actions
PM
QM
RM
KA4
G
K
A1
A2
A3
P
Q
R
M
GA5
A4L
K
A1
A2
A3
P
Q
R
M
Heuristic Value = 5
•Memory Efficient•Cheap Heuristics•Scalable•Extensible
Benefits from BDD’s
~Q & ~R
~P & ~R
~P & ~Q
(~P & ~R) V (~Q & ~R)
(~P & ~R) V (~Q & ~R) V(~P & ~Q)
M
True
Label Key
Labels signify possible worldsunder which a literal holds

Sensing Actions• Sensing actions in essence “partition” a
belief state– Sensing a formula f splits a belief state
B to B&f; B&~f– Both partitions need to be taken to the
goal state now– Tree plan– AO* search
• Heuristics will have to compare two generalized AND branches
– In the figure, the lower branch has an expected cost of 11,000
– The upper branch has a fixed sensing cost of 300 + based on the outcome, a cost of 7 or 12,000
• If we consider worst case cost, we assume the cost is 12,300
• If we consider both to be equally likey, we assume 6303.5 units cost
• If we know actual probabilities that the sensing action returns one result as against other, we can use that to get the expected cost…
As
A
7
12,000
11,000
300

Cost models of conditional plans
• The execution cost of a conditional plan isCost of O5 +[Prob(p=T)* {cost of A1 + A3} +
Prob(p=F)*{cost of A2 +A3} ]• Can take max(cost A1+A3; cost
A2+A3 )
• The planning cost of a conditional plan is however is proportional to the total size of the plan (num actions)
O5:p?
A1
A3
A2
YN
O5:p?
A1A2
YN
Need to estimate cost of leaf belief states

Slides beyond this point not covered

Logistics Total Time
10
100
1000
10000
100000
1000000
1 2 3 4 5
Problem
To
tal T
ime
(m
s)
CAltAlt
KACMBP
HSCP
GPT
CGP
Logistics Plan Length
05
1015202530354045
1 2 3 4 5Problem
Pla
n L
eng
th
CAltAlt
KACMBP
HSCP
GPT
CGP
OptimalApproachesscale poorly
Cardinality approaches are fasterBut quality suffers
Relaxed Plan approaches Scale better with time approximate to cardinalityAnd quality comparable to optimal