1 data structures searching techniques namiq sultan
TRANSCRIPT

1
Data Structures
Searching Techniques
Namiq Sultan

2
Searching Techniques
Searching is a process of checking and finding an element from a list of elements.
1. Linear or Sequential Searching
2. Binary Searching
3. Fibanocci Search

3
LINEAR OR SEQUENTIAL SEARCHING
In linear search, each element of an array is read one by one sequentially and it is compared with the desired element.
A search will be unsuccessful if all the elements are read and the desired element is not found.

4
ALGORITHM FOR LINEAR SEARCH
Let A be an array of n elements, A[0],A[1],A[2], ... A[n-1], “data” is the element to be searched. Then this algorithm will find the location “loc” of data in A. Set loc = – 1, if the search is unsuccessful.
Input an array a of n elements and “data” to be searched Initialize loc = – 1, and i = 0Repeat
If (data = a[i]) then loc = i
End if If (loc > -1) then
display “data is found and searching is successful”Else
display “data is not found and searching is unsuccessful”End ifi++
End repeat

5
PROGRAMMING SEQUENTIAL SEARCH
void main()
{
char opt;
int arr[20],n,i,item;
cout << “\nHow many elements in the array : ”;
cin >> n;
for(i=0; i<n; i++)
{
cout << “\nEnter element ” << i+1 << “: “;
cin >> arr[i];
}
cout << “\n\nPress any key to continue....”;
cin.get();

6
PROGRAMMING SEQUENTIAL SEARCHdo{
cout<< “\nEnter the element to be searched : ”;
cin >> item; //Input the item to be searched
for(i=0;i < n;i++){
if(item == arr[i]){
cout << (“Item found at position : ”, i+1);
break;
}
}/*End of for*/
if (i == n)
cout << “\nItem “ << item << “ not found ...\n”;
cout << “\n\nPress (Y/y) to continue : ”;
cin >> opt;
}while(opt == ‘Y’ || opt == ‘y’);
}

7
BINARY SEARCH
Binary search is an extremely efficient algorithm when it is compared to linear
search. Binary search technique searches “data” in minimum possible
comparisons. Suppose the given array is a sorted one, otherwise first we have to
sort the array elements.

8
ALGORITHM OF BINARY SEARCHInput an array A of n elements and “data” to be searched
LB = 0, UB = n-1, mid = int ((LB+UB)/2)
while (LB <= UB) and (A[mid] != data)
If (data < A[mid]) then
UB = mid–1
Else
LB = mid + 1
End if
mid = int ((LB + UB)/2)
End while
If (A[mid]== data) then
Display “the data found”
Else
Display “the data is not found”
End if

9
PROGRAM OF BINARY SEARCH
void main(){
char opt;const n=10;int arr[20], start, end, middle, i, item;for(i=0; i < n; i++){ cout << “\nEnter element: ” << i+1 << “ : “; cin >> arr[i];}cout <<(“\n\nPress any key to continue...”);cin.get();
do {
cout<<“\nEnter the element to be searched : ”;
cin>>item;

10
start=0;
end=n – 1;
middle=(start + end)/2;
while(item != arr[middle] && start < end) {
if (item > arr[middle]) start=middle+1;
else end=middle-1;
middle=(start+end)/2;
}
if (item==arr[middle])
cout<<“Item found at position ”<<middle+1<<endl;
else if(start>end) cout<<“Item not found in array\n”;
cout<<“\n\nPree (Y/y) to continue : ”;
cin >> opt;
}while(opt == ‘Y’ || opt == ‘y’);
}/*End of main()*/
PROGRAM OF BINARY SEARCH

11
• Hashing is a technique where we can compute the location of the desired record in order to retrieve it in a single access (or comparison).
• The information to be retrieved is stored in a hash table which is best thought of as an array of m locations, called buckets. The hash table have a key/value relationship.
• The keys are unique, that is, no two distinct values have the same key.
• Hash table has only a few methods, such as insert, erase, and find.
HASH TABLE
12
• Suppose “persons” is a hash table that will hold up to 1000 values. Each value consists of a unique 3-digit integer (the key), and a name.
HASH TABLE
key name0123
999
index
13
HASH TABLE
key value
108
Jalal351
Dilshad
453 Ali
0
1
108
351
453
999
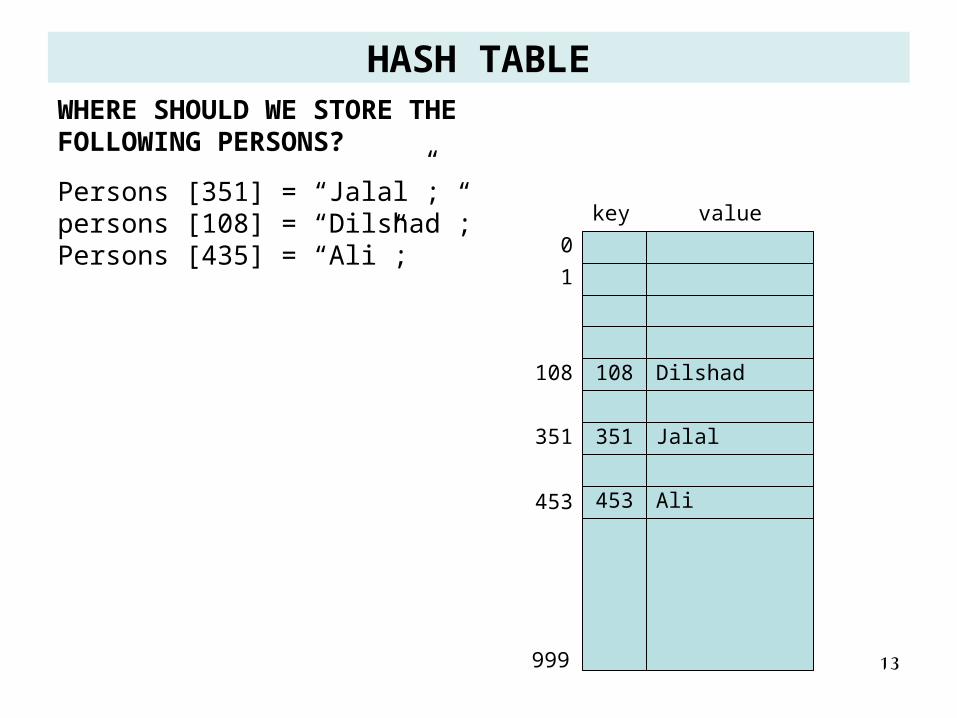
WHERE SHOULD WE STORE THE FOLLOWING PERSONS?
Persons [351] = “Jalal”;persons [108] = “Dilshad”;Persons [435] = “Ali”;

14
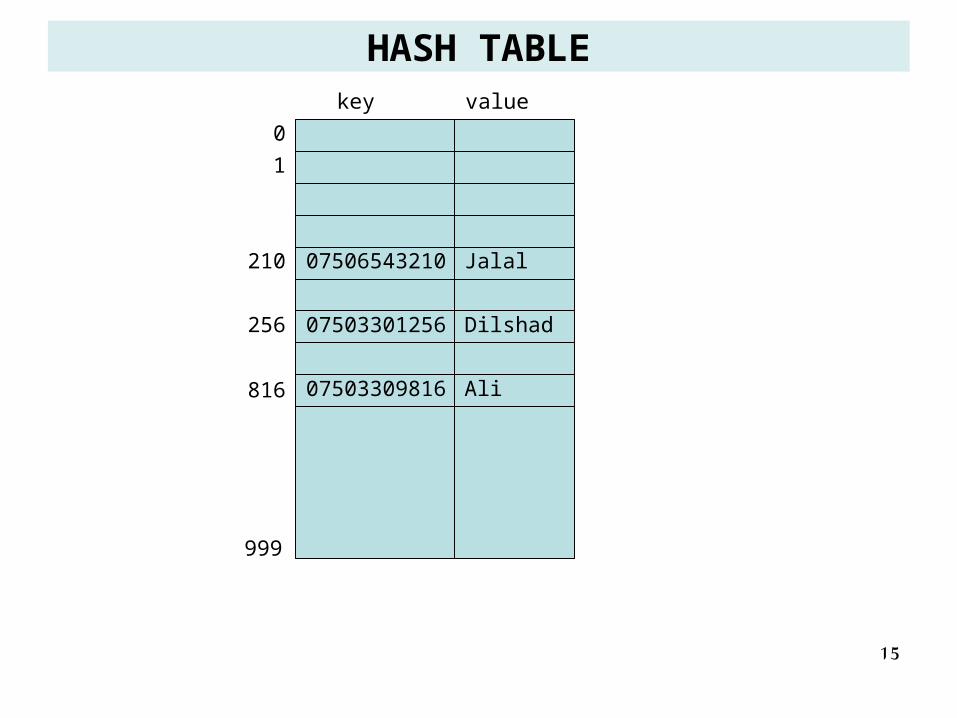
HASH TABLE• Now for something slightly different: suppose “persons” is a hash table that
holds up to 1000 values. Each value consists of a 11-digit telephone number (the key), and a name.
persons [07506543210] = “Jalal”;
persons [07503301256] = “Dilshad”;
persons [07503309816] = “Ali”;
persons [07503576256] = “Dina”; • WHERE SHOULD THESE VALUES BE STORED?
• To make these values fit into the table, we need to mod by the table size; i.e., key % 1000.
07506543210 210
07503301256 256
07503309816 816
07503576256 256 !!!!! Collision
15
HASH TABLEkey value
07506543210 Jalal
07503301256 Dilshad
07503309816 Ali
0
1
210
256
816
999

16
HASH TABLE• when two different keys map to the same index, that is called a
collision.
• hashing: an algorithm that transforms a key into an array index.
• The algorithm has two parts:
1. a hash function: an easily computable operation on the key that
returns an index in the array buckets;
Hash(Key) = Integer
2. a collision handler.

Hash Function
17
• Input: a field of a record; usually its key K (student id, name, … )
• Compute index function H(K)
H(K): K A
To find the address of the record.
H(K) is address of the record with key K
• Example 1:
• Key is student id (six digits), we have 100,000 records positions (0-
99,999)
• H(K): student_id mod 99999
085768 085768 mod 99999 = 85768
134281 134281 mod 99999 = 34282
101004 101004 mod 99999 = 1005

Hash Function
18
Example 2:
• Key is a name
• H(K): Take first two characters, multiply their ASCII decimal values, add
the last three digits and take its mod 9 as H(K)
K = Lokman 76 * 111 = 8436
H(K) = 4+3+6 = 13 mod 9 = 4 key value
0
1
2
3
4 Lokman
5

Collisions
• Usually, ideal hashing is not possible (or at least not guaranteed).
Some data is bound to hash to the same table element, in which
case, we have a collision.
• How do we solve this problem?

Hashing 20
Collision Handlers
• Chaining• Linear Probing (Open Addressing)• Double Hashing• Quadratic Hashing
21
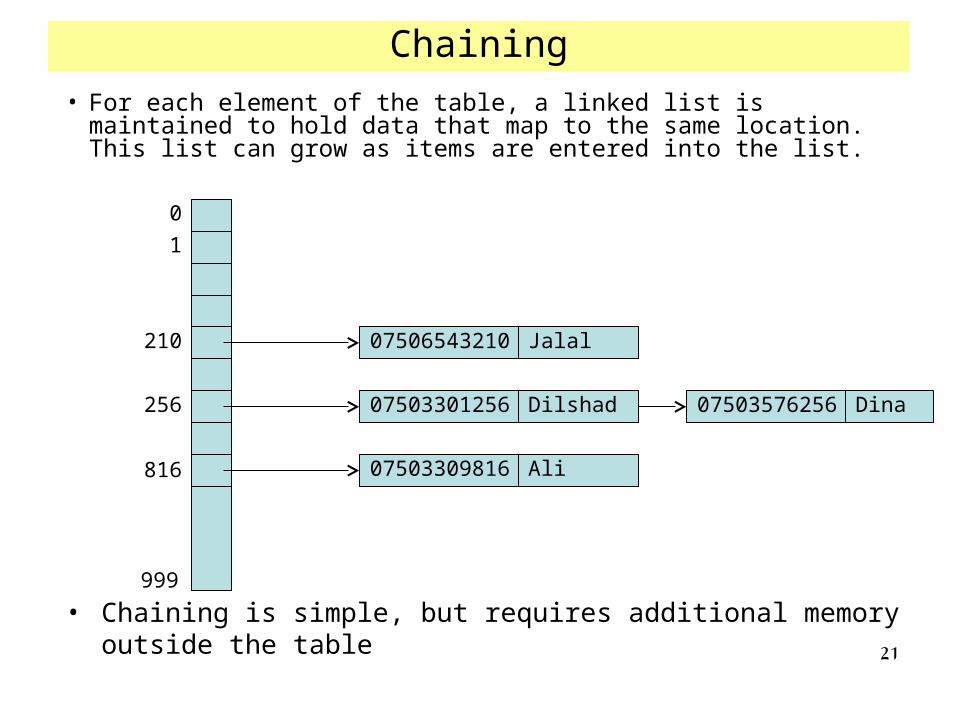
Chaining
07506543210 Jalal
07503301256 Dilshad
07503309816 Ali
0
1
210
256
816
999
07503576256 Dina
• Chaining is simple, but requires additional memory outside the table
• For each element of the table, a linked list is maintained to hold data that map to the same location. This list can grow as items are entered into the list.

Linear Probing• The idea is that even though these number hash to the same
location, they need to be given a slot based on their hash number index. Using linear probing, the entries are placed into the next available position.
• Consider the data with keys: 24, 42, 34,62,73 into a table of size 10. These entries can be placed into the table at the following locations:
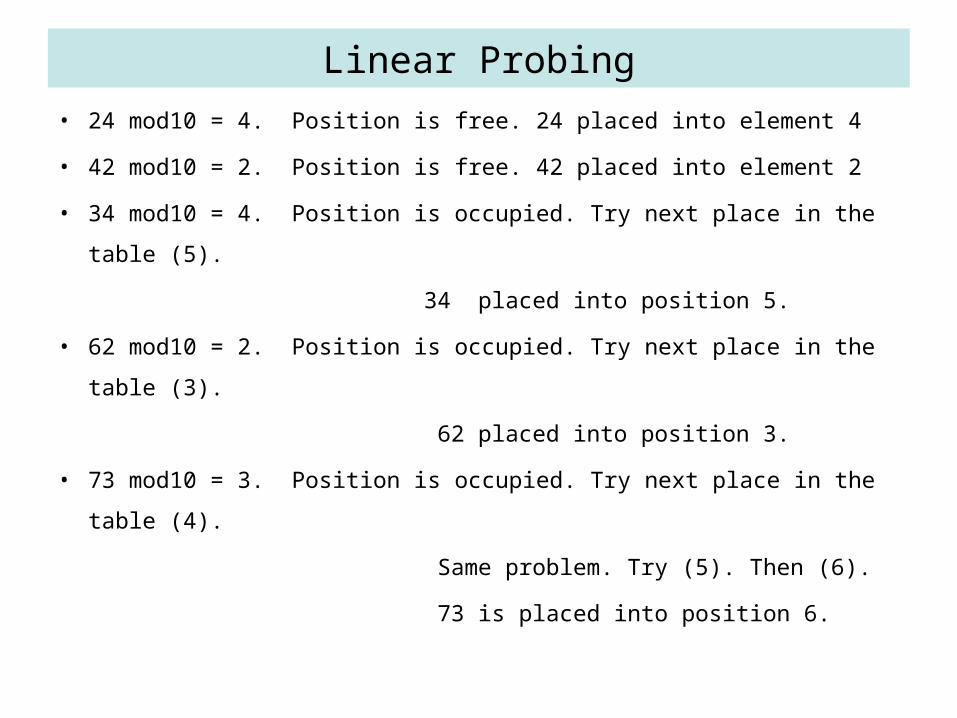
Linear Probing
• 24 mod10 = 4. Position is free. 24 placed into element 4
• 42 mod10 = 2. Position is free. 42 placed into element 2
• 34 mod10 = 4. Position is occupied. Try next place in the table (5).
34 placed into position 5.
• 62 mod10 = 2. Position is occupied. Try next place in the table (3).
62 placed into position 3.
• 73 mod10 = 3. Position is occupied. Try next place in the table (4).
Same problem. Try (5). Then (6).
73 is placed into position 6.

Advantages and Disadvantages of Hash Table+ Very fast insertion and searching.
+ Relatively easy to program as compared to trees.
- Based on arrays, hence difficult to expand.
- No convenient way to visit the items in a hash table in any kind of order.
24

Example//data structure to hold id and data, our data-structure we want to use
struct person{
int id; //to hold a unique id for each person
char name[20]; // name of a person
};
class hasher{
person dt[11]; //the table to hold hashed data structs
int numel; //number of elements in table, to check if it's full
public:
hasher();
int hash(int id);
int rehash(int id);
void add(person d);
void output();
};

Example/*this is the function to give hashed id, it's a simple one...
It's good to use a prime number for table length, thats why I used 11,
it's better because we reduce our collisions*/
int hasher::hash(int id)
{ return (id%11); }
/*in case of any collision we use rehash function instead of hash*/
int hasher::rehash(int id)
{ return ((id+1)%11); }
hasher::hasher() { //create an array of data structure
int i;
for(i=0; i<=10; i++) {
dt[i].id = -1; //set all ids to -1 to show they're empty
strcpy(dt[i].name,""); //set all name values to empty
}
numel = 0;
}

Examplevoid hasher::add(person p) { if(numel < 11) { //table has empty places...
int hashed = hash(p.id);if (dt[hashed].id == -1) { //slot is empty, assign new data
dt[hashed].id = p.id; strcpy(dt[hashed].name, p.name);
} else { //we need to rehash the id
while (1) { //try every place in table to find an empty placehashed = rehash(hashed);if (dt[hashed].id == -1) {
dt[hashed].id = p.id;strcpy(dt[hashed].name, p.name);break;
} }
} } else cout<<"Table is full\n\n";}

Examplevoid hasher::output() { int i; for(i=0; i<11; i++) { cout<< I <<" ->\t“ << dt[i].id << "\t“ << dt[i].name << endl; }}
int main() { person d[11]={ 123, "Ahmed Ali",
733, "Basim Taha", 380, "Careen Fady",
890, "Emad Salah",460, "Fatin Ahmed",156, "Ghali Shukri",222, "Hadi Ali",101, "Iman Edward",444, "Jamal Nassir",611, "Karim Morad",999, "Lolo Kareem“
};
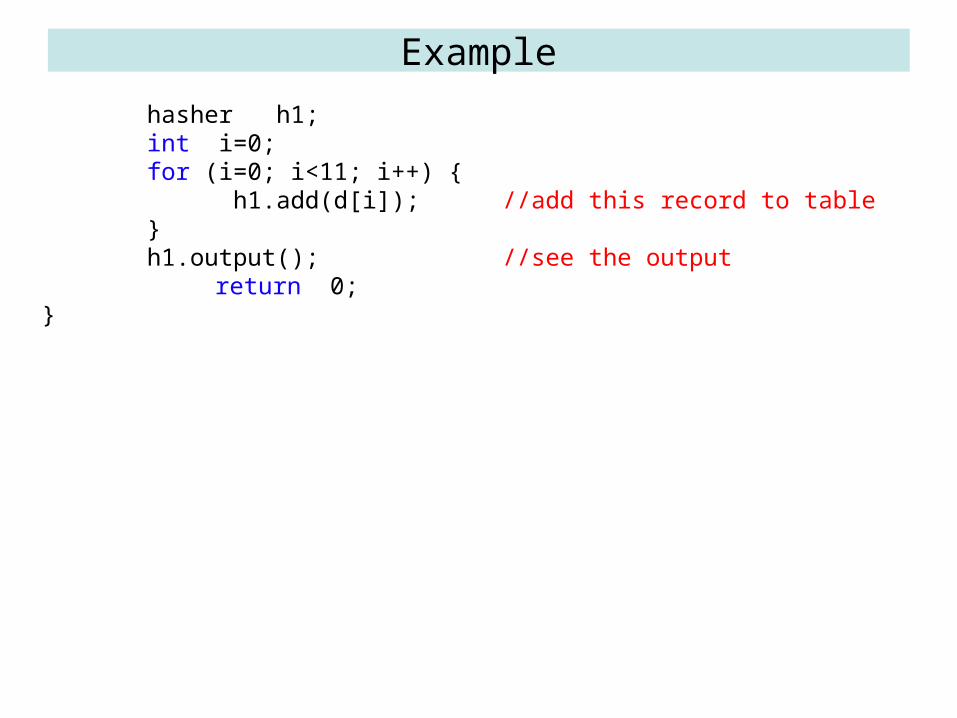
Example
hasher h1; int i=0; for (i=0; i<11; i++) { h1.add(d[i]); //add this record to table } h1.output(); //see the output return 0;
}