1 11. time series analysis and forecasting econ 251 research methods
TRANSCRIPT

1
11. Time Series Analysisand Forecasting
ECON 251
Research Methods

2
Introduction
Any variable that is measured over time in sequential order is called a time series.
We analyze time series to detect patterns. The patterns help in forecasting future values of the time
series.
The time series exhibit a downward trend pattern.
Future expected value
3
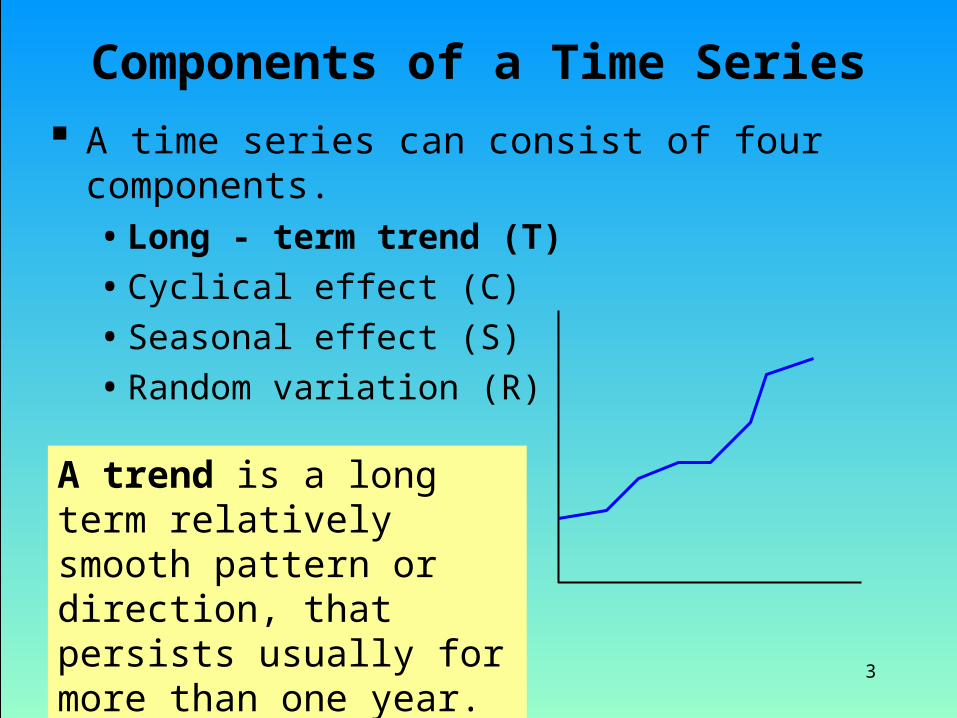
Components of a Time Series
A time series can consist of four components.• Long - term trend (T)• Cyclical effect (C)• Seasonal effect (S)• Random variation (R)
A trend is a long term relatively smooth pattern or direction, thatpersists usually for more than one year.

4
Components of a Time Series
A time series can consists of four components.• Long - term trend (T)• Cyclical effect (C)• Seasonal effect (S)• Random variation (R)
A cycle is a wavelike pattern describing a long term behavior (for more than one year).
Cycles are seldom regular, andoften appear in combination with other components.
6-88 12-88 6-89 12-89 6-90

5
Components of a Time Series
A time series can consists of four components.• Long - term trend (T)• Cyclical effect (C)• Seasonal effect (S)• Random variation (R)
The seasonal component of the time-series exhibits a short term (less than one year) calendar repetitive behavior.
6-88 12-88 6-89 12-89 6-90

6
We try to remove random variation thereby, identify the other components.
Components of a Time Series
A time series can consists of four components.• Long - term trend (T)• Cyclical effect (C)• Seasonal effect (S)• Random variation (R)
Random variation comprises the irregular unpredictable changes in the time series. It tends to hide the other (more predictable) components.

7
There are two commonly used time series models:
The additive model
The multiplicative model
yt = Tt + Ct + St + Rt
yt = Tt x Ct x St x Rt
Time-series models

8
Smoothing Techniques
To produce a better forecast we need to determine which components are present in a time series
To identify the components present in the time series, we need first to remove the random variation
This can be easily done by smoothing techniques:• moving averages• exponential smoothing

9
Moving Averages
A k-period moving average for time period t is the arithmetic average of the time series values where the period t is the center observation.
Example: A 3-period moving average for period t is calculated by
(yt+1 + yt + yt-1)/3. Example: A 5-period moving average for period t is
calculated by (yt+2 + yt+1 + yt + yt-1 + yt-2)/5.

10
Example: Gasoline Sales
To forecast future gasoline sales, the last four years quarterly sales were recorded.
Calculate the three-quarter and five-quarter moving average. Data
Period Year/Quarter Gas Sales1 1 1 392 2 373 3 614 4 585 2 1 186 2 56
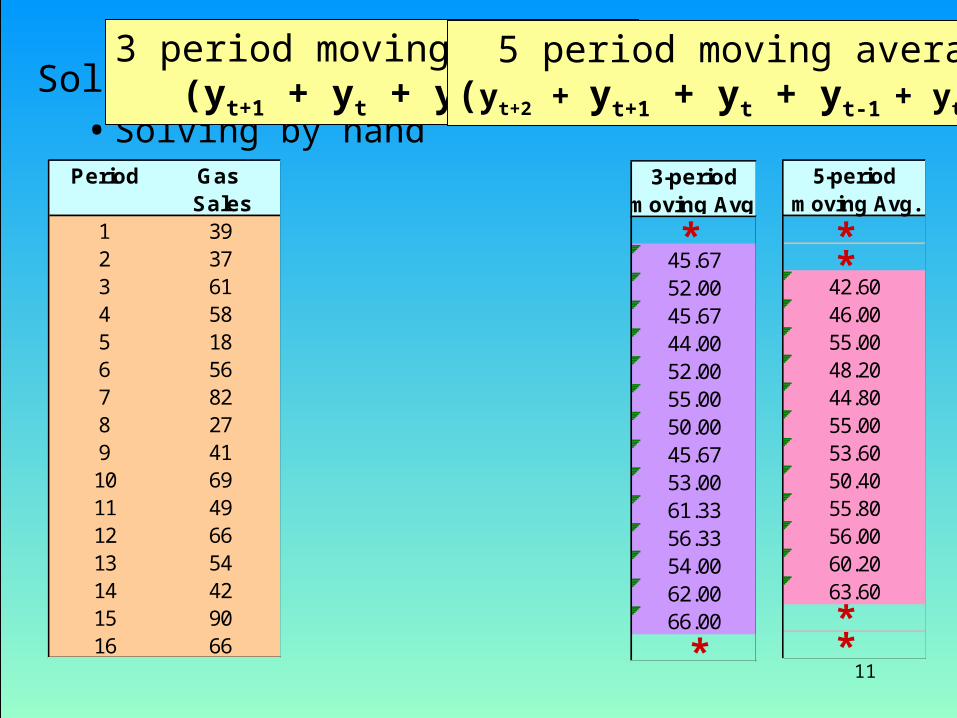
11
Solution• Solving by hand
Period Gas Sales
1 392 373 614 585 186 567 828 279 4110 6911 4912 6613 5414 4215 9016 66
3-periodmoving Avg.
45.6752.0045.6744.0052.0055.0050.0045.6753.0061.3356.3354.0062.0066.00
**
**
*
*
5-periodmoving Avg.
42.6046.0055.0048.2044.8055.0053.6050.4055.8056.0060.2063.60
3 period moving average(yt+1 + yt + yt-1)/3
5 period moving average(yt+2 + yt+1 + yt + yt-1 + yt-2)/5

12
Moving Average
0
50
100
Actual
3pr MA
Notice how the averaging process removes some ofthe random variation.
as well as seasonality.There is some trend component present,
Example: Gasoline Sales

13
0
20
40
60
80
100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
5-period moving average 3-period moving average
The 5-period moving average removes more variation than the 3-period moving average. Too much smoothing
may eliminate patterns of interest. Here, the seasonality component is removed when using 5-period moving average.
Too little smoothing leaves much of the variation, which disguises the real patterns.
Example: Gasoline Sales

14
Example – Armani’s Pizza Sales Below are the daily sales figures for Armani’s pizza.
Compute a 3-day moving average. (Armani TS.xls)
Week 1 Week 2Monday 35 38Tuesday 42 46Wednesday 56 61Thursday 46 52Friday 67 73Saturday 51 58Sunday 39 42
The moving average that is associated with Monday of week 2 is?

15
Centered moving average
With even number of observations included in the moving average, the average is placed between the two periods in the middle.
To place the moving average in an actual time period, we need to center it.
Two consecutive moving averages are centered by taking their average, and placing it in the middle between them.

16
Example – Armani’s Pizza Sales
Calculate the 4-period moving average and center it, for the data given below:
Period Time series Moving Avg. Centerd Mov.Avg.1 152 273 204 145 256 11
20.2519.0(2.5)
21.5(3.5)19.50
17.5(4.5)

17
Example – Armani’s Pizza Sales Armani’s pizza is back. Compute a 2-day centered moving
average. Week 1
Monday 35Tuesday 42Wednesday 56Thursday 46Friday 67Saturday 51Sunday 39
The centered moving average that is associated with Friday of week 1 is?

18
Components of a Time Series
A time series can consist of four components.• Long - term trend (T)• Cyclical effect (C)• Seasonal effect (S)Random variation (R)
A trend is a long term relatively smooth pattern or direction, thatpersists usually for more than one year.

19
Trend Analysis
The trend component of a time series can be linear or non-linear.
It is easy to isolate the trend component by using linear regression.• For linear trend use the model y = 0 + 1t + .
• For non-linear trend with one (major) change in slope use the quadratic model y = 0 + 1t + 2t2 +

20
Example – Pharmaceutical Sales (Identify trend)
Annual sales for a pharmaceutical company are believed to change linearly over time.
Based on the last 10 year sales records, measure the trend component.
Start by renaming your years 1, 2, 3, etc.
Year Sales Year Sales1990 18.0 1995 21.11991 19.4 1996 23.51992 18.0 1997 23.21993 19.9 1998 20.41994 19.3 1999 24.4

21
Regression StatisticsMultiple R 0.829573R Square 0.688192Adj. R Sq 0.649216Std Error 1.351968Observations 10
ANOVAdf SS MS F Sig. F
Regression 1 32.27345 32.27345 17.65682 0.002988Residual 8 14.62255 1.827818Total 9 46.896
Coeffs. S.E. t Stat P-valueIntercept 17.28 0.92357 18.71 6.88E-08t 0.625455 0.148847 4.202002 0.002988
Example – Pharmaceutical Sales (Identify trend)
Solution• Using Excel we have t Line Fit Plot
0
5
10
15
20
25
30
0 5 10 15
Sale
s
11
Forecast for period 111599.24)11(6254.28.17y
t6254.28.17y

22
Example – Cigarette Consumption
Determine the long-term trend of the number of cigarettes smoked by Americans 18 years and older.
Data (Cigarettes.xls)
Per Capita
Year Consumption
1955 36751956 37181957 37621958 38921959 40661960 41971961 4284
. .
. .
Consumption
010002000300040005000
1950 1960 1970 1980 1990 2000
Solution• Cigarette consumption
increased between 1955 and 1963, but decreased thereafter.
• A quadratic model seems to fit this pattern.

23
Example – Cigarette Consumption
Regression StatisticsMultiple R 0.9821756R Square 0.9646688Adj. R Sq 0.962759Std Error 97.98621Observations 40
ANOVAdf SS MS F Sig. F
Regression 2 9699558.4 4849779.2 505.11707 1.38332E-27Residual 37 355248 9601.2974Total 39 10054806
Coeffs S.E. t Stat P-valueIntercept 3730.6888 48.903765 76.28633 2.67E-42t 71.379694 5.5009971 12.975774 2.429E-15t-sq -2.558442 0.130116 -19.66278 3.518E-21
2500
2700
2900
3100
3300
3500
3700
3900
4100
4300
4500
0 10 20 30 402t558.2t380.71689.730,3y
The quadratic model fitsthe data very well.

24
Example
Forecast the trend components for the previous two examples for periods 12, and 41 respectively.•
•
)12(ˆ ty
2558.2380.71689.730,3ˆ tty
ty 6254.28.17ˆ
)41(ˆ ty
)41(ˆ ty
)12(ˆ ty
25
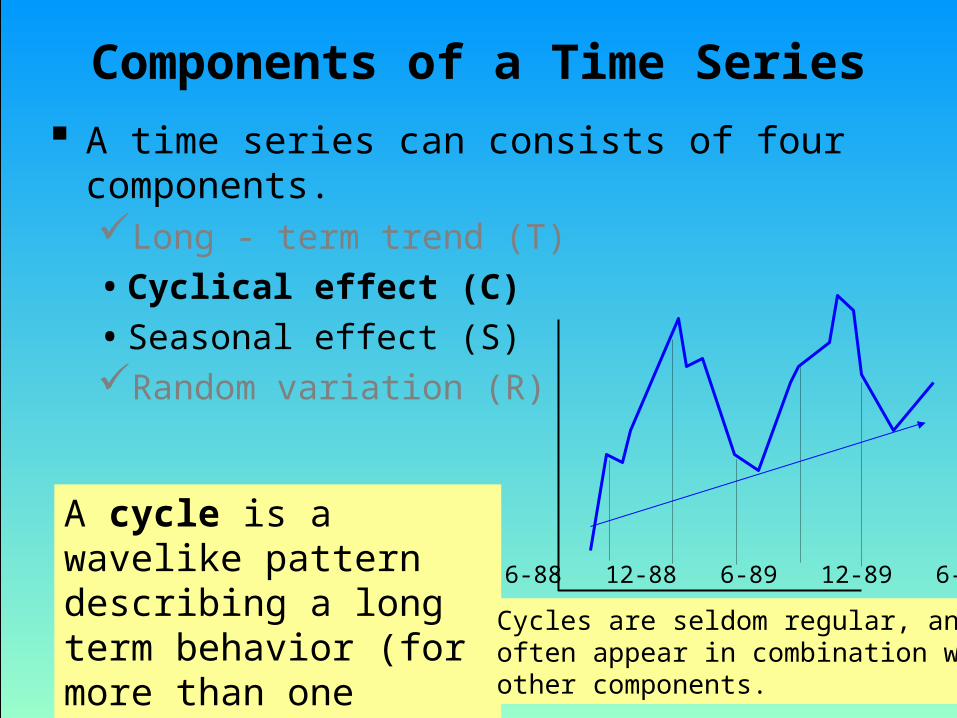
Components of a Time Series
A time series can consists of four components.Long - term trend (T)• Cyclical effect (C)• Seasonal effect (S)Random variation (R)
6-88 12-88 6-89 12-89 6-90
A cycle is a wavelike pattern describing a long term behavior (for more than one year). Cycles are seldom regular, and
often appear in combination with other components.

26
Measuring the Cyclical Effects
Although often unpredictable, cycles need to be isolated. To identify cyclical variation we use the percentage of trend.
• Determine the trend line (by regression).• Compute the trend value for each period t.• Calculate the percentage of trend by
ty
100yy tt

27
Example – Energy Demand
Does the demand for energy in the US exhibit cyclic behavior over time? Assume a linear trend and calculate the percentage of trend.
Data (Energy Demand.xls)• The collected data included annual energy consumption from
1970 through 1993.
Find the values for trend and percentage of trend for years 1975 and 1976.

28
Example – Energy Demand Now consider the multiplicative model
Rate/Predicted Rate
85
90
95
100
105
110
1 3 5 7 9 11 13 15 17 19 21 23
ttt
ttt
t
t RCT
RCT
y
y
ˆ
tttt RCTy
The regression line represents trend.
(Assuming no seasonal effects).
No trend is observed, but cyclicality and randomness still exist.

29
Period Line Fit Plot
60
65
70
75
80
85
90
0 5 10 15 20 25 30
Period
Co
nsu
mp
tio
n t502.3.69y
85.0000
90.0000
95.0000
100.0000
105.0000
110.0000
1 3 5 7 9 11 13 15 17 19 21 23
When groups of the percentage of trendalternate around 100%, the cyclical effectsare present.
Cnsptn Pred. cnsmptn % of trend
66.4 69.8283 95.090369.7 70.3299 99.104472.2 70.8314 101.932274.3 71.3329 104.159572.5 71.8344 100.9265
. . .
. . .
(66.4/69.828)100

30
Components of a Time Series
A time series can consists of four components.Long - term trend (T)Cyclical effect (C)• Seasonal effect (S)Random variation (R)
6-88 12-88 6-89 12-89 6-90
The seasonal component of the time-series exhibits a short term (less than one year) calendar repetitive behavior.

31
Measuring the Seasonal effects
Seasonal variation may occur within a year or even within a shorter time interval.
To measure the seasonal effects we can use two common methods:1. constructing seasonal indexes2. using indicator variables
We will do each in turn

32
Example – Hotel Occupancy
Calculate the quarterly seasonal indexes for hotel occupancy rate in order to measure seasonal variation.
Data (Hotel Occupancy.xls)
Year Quarter Rate Year Quarter Rate Year Quarter Rate
1991 1 0.561 1993 1 0.594 1995 1 0.6652 0.702 2 0.738 2 0.8353 0.800 3 0.729 3 0.8734 0.568 4 0.600 4 0.670
1992 1 0.575 1994 1 0.6222 0.738 2 0.7083 0.868 3 0.8064 0.605 4 0.632

33
0 5 10 15 20t
Rat
e
Example – Hotel Occupancy
Perform regression analysis for the modely = 0 + 1t + where t represents the chronological time, and y represents the occupancy rate.
Time (t) Rate 1 0.561 2 0.702 3 0.800 4 0.568 5 0.575 6 0.738 7 0.868 8 0.605 . . . .
t005246.639368.y
The regression line represents trend.

34
ttt
ttt
t
t RST
RSTyy
Example – Hotel Occupancy Now let’s consider the multiplicative model, and let’s
DETREND data
tttt RSTy (Assuming no cyclical effects)
The regression line represents trend.
Rate/Predicted rate
0
0.5
1
1.5
1 3 5 7 9 11 13 15 17 19
No trend is observed, butseasonality and randomness still exist.

35
Rate/Predicted rate
0
0.5
1
1.5
1 3 5 7 9 11 13 15 17 19
Rate/Predicted rate
0
0.5
1
1.5
1 3 5 7 9 11 13 15 17 19
To remove most of the random variation but leave the seasonal effects, average the terms StRt for each season.
Rate/Predicted rate0.8701.0801.2210.8600.8641.1001.2840.8880.8651.0671.0460.8540.8790.9931.1220.8740.9131.1381.1810.900
Rate/Predicted rate0.8701.0801.2210.8600.8641.1001.2840.8880.8651.0671.0460.8540.8790.9931.1220.8740.9131.1381.1810.900
(.870 + .864 + .865 + .879 + .913)/5 = .878Average ratio for quarter 1:
Average ratio for quarter 2: (1.080+1.100+1.067+.993+1.138)/5 = 1.076
Average ratio for quarter 3: (1.222+1.284+1.046+1.123+1.182)/5 = 1.171
Average ratio for quarter 4: (.861 +.888 + .854 + .874 + .900)/ 5 = .875
Example – Hotel Occupancy

36
Quarter 2 Quarter 3Quarter 3Quarter 2
Interpreting the results• The seasonal indexes tell us what is the ratio between
the time series value at a certain season, and the overall seasonal average.
• In our problem:
Annual averageoccupancy (100%)
Quarter 1 Quarter 4 Quarter 1 Quarter 4
87.8%107.6%
117.1%
87.5%12.2% below theannual average
7.6% above theannual average
17.1% above theannual average
12.5% below theannual average
Example – Hotel Occupancy

37
Creating Seasonal Indexes
Normalizing the ratios:• The sum of all the ratios must be 4, such that the average
ratio per season is equal to 1.• If the sum of all the ratios is not 4, we need to normalize
(adjust) them proportionately. Suppose the sum of ratios equaled 4.1. Then each ratio will be multiplied by 4/4.1
(Seasonal averaged ratio) (number of seasons) Sum of averaged ratiosSeasonal index =
In our problem the sum of all the averaged ratios is equal to 4:.878 + 1.076 + 1.171 + .875 = 4.0.No normalization is needed. These ratios become the seasonal indexes.

38
Example
Using a different example on quarterly GDP, assume that the averaged ratios were:Quarter 1: .97Quarter 2: 1.03Quarter 3: .87Quarter 4: 1.00
Determine the seasonal indexes.

39
Deseasonalizing time series
By removing the seasonality, we can:• compare data across different seasons• identify changes in the other components of the time - series.
Seasonally adjusted time series = Actual time seriesSeasonal index

40
Example – Hotel Occupancy A new manager was hired in Q3 1994, when hotel
occupancy rate was 80.6%. In the next quarter, the occupancy rate was 63.2%. Should the manager be fired because of poor performance?
Method 1:• compare occupancy rates in Q4 1994 (0.632) and Q3 1994
(0.806)• the manager has underperformed he should be fired
Method 2:• compare occupancy rates in Q4 1994 (0.632) and Q4 1993
(0.600)• the manager has performed very well he should get a
raise

41
Example – Hotel Occupancy
Method 3:• compare deseasonalized occupancy rates in Q4 1994 and Q3
1994
the manager has indeed performed well he should be maybe get a raise
Seasonally adjusted time series = Actual time seriesSeasonal index
Recall:
Seasonally adjusted occupancy rate in Q4
1994
Actual occupancy rate in Q4 1994Seasonal index for Q4=
Seasonally adjusted occupancy rate in Q3
1994

42
Recomposing the time series
Recomposition will recreate the time series, based only on the trend and seasonal components – you can then deduce the value of the random component.
0.5
0.6
0.7
0.8
0.9
1 3 5 7 9 11 13 15 17 19
tttt S)t0052.639(.STy
In period #1 ( quarter 1): 566.)878))(.1(0052.639(.STy 111
In period #2 ( quarter 2): 699.)076.1))(2(0052.639(.STy 222 Actual series
Smoothed series
The linear trend (regression) line

43
Example – Recomposing the Time Series
Recompose the smoothed time series in the above example for periods 3 and 4 assuming our initial seasonal index figures of:Quarter 1: 0.878 Quarter 3: 1.171Quarter 2: 1.076 Quarter 4: 0.875 and equation of:
3ytttt S)t0052.639(.STy
4y
3*)*0052.0639.0( SIt171.1*)3*0052.0639.0(
4*)*0052.0639.0( SIt875.0*)4*0052.0639.0(

44
Seasonal Time Series with Indicator Variables
We create a seasonal time series model by using indicator variables to determine whether there is seasonal variation in data.
Then, we can use this linear regression with indicator variables to forecast seasonal effects.
If there are n seasons, we use n-1 indicator variables to define the season of period t:
• [Indicator variable n] = 1 if season n belongs to period t• [Indicator variable n] = 0 if season n does not
belong to period t

45
Example – Hotel Occupancy
Let’s again build a model that would be able to forecast quarterly occupancy rates at a luxurious hotel, but this time we will use a different technique.
Data (Hotel Occupancy.xls)
Year Quarter Rate Year Quarter Rate Year Quarter Rate
1991 1 0.561 1993 1 0.594 1995 1 0.6652 0.702 2 0.738 2 0.8353 0.800 3 0.729 3 0.8734 0.568 4 0.600 4 0.670
1992 1 0.575 1994 1 0.6222 0.738 2 0.7083 0.868 3 0.8064 0.605 4 0.632

46
Example – Hotel Occupancy
Use regression analysis and indicator variables to forecast hotel occupancy rate in 1996 Data
y t Q1 Q2 Q30.561 1 1 0 00.702 2 0 1 00.800 3 0 0 10.568 4 0 0 00.575 5 1 0 00.738 6 0 1 00.868 7 0 0 10.605 8 0 0 0
. . . . .
. . . . .
y t Q1 Q2 Q30.561 1 1 0 00.702 2 0 1 00.800 3 0 0 10.568 4 0 0 00.575 5 1 0 00.738 6 0 1 00.868 7 0 0 10.605 8 0 0 0
. . . . .
. . . . .
Quarter 1 belongs to t = 1
Quarter 2 does not belong to t = 1Quarter 3 does not belong to t = 1
Quarters 1, 2, 3, do not belong to period t = 4.
Qi = 1 if quarter i occur at t
0 otherwise

47
The regression modely = 0 + 1t + 2Q1 + 3Q2 + 4Q3 +
Regression StatisticsMultiple R 0.943022R Square 0.88929Adj R Sq. 0.859767Std. Error 0.03806Observations 20
ANOVAdf SS MS F Sig. F
Regression 4 0.174531 0.043633 30.12217 5.2E-07Residual 15 0.021728 0.001449Total 19 0.196259
Coeffs S.E. t Stat P-valueIntercept 0.55455 0.024812 22.35028 6.27E-13t 0.005037 0.001504 3.348434 0.004399Q1 0.003512 0.02449 0.143423 0.887865Q2 0.139275 0.024258 5.74134 3.9E-05Q3 0.205237 0.024118 8.509752 3.99E-07
Regression StatisticsMultiple R 0.943022R Square 0.88929Adj R Sq. 0.859767Std. Error 0.03806Observations 20
ANOVAdf SS MS F Sig. F
Regression 4 0.174531 0.043633 30.12217 5.2E-07Residual 15 0.021728 0.001449Total 19 0.196259
Coeffs S.E. t Stat P-valueIntercept 0.55455 0.024812 22.35028 6.27E-13t 0.005037 0.001504 3.348434 0.004399Q1 0.003512 0.02449 0.143423 0.887865Q2 0.139275 0.024258 5.74134 3.9E-05Q3 0.205237 0.024118 8.509752 3.99E-07
Good fit
There is sufficient evidence toconclude that trend is present.
There is insufficient evidence to conclude that seasonality causes occupancy rate in quarter 1 be different than this of quarter 4!
Seasonality effects on occupancy rate in quarter 2 and 3 are different than this of quarter 4!

48
Regression StatisticsMultiple R 0.943022R Square 0.88929Adj R Sq. 0.859767Std. Error 0.03806Observations 20
ANOVAdf SS MS F Sig. F
Regression 4 0.174531 0.043633 30.12217 5.2E-07Residual 15 0.021728 0.001449Total 19 0.196259
Coeffs S.E. t Stat P-valueIntercept 0.55455 0.024812 22.35028 6.27E-13t 0.005037 0.001504 3.348434 0.004399Q1 0.003512 0.02449 0.143423 0.887865Q2 0.139275 0.024258 5.74134 3.9E-05Q3 0.205237 0.024118 8.509752 3.99E-07
Regression StatisticsMultiple R 0.943022R Square 0.88929Adj R Sq. 0.859767Std. Error 0.03806Observations 20
ANOVAdf SS MS F Sig. F
Regression 4 0.174531 0.043633 30.12217 5.2E-07Residual 15 0.021728 0.001449Total 19 0.196259
Coeffs S.E. t Stat P-valueIntercept 0.55455 0.024812 22.35028 6.27E-13t 0.005037 0.001504 3.348434 0.004399Q1 0.003512 0.02449 0.143423 0.887865Q2 0.139275 0.024258 5.74134 3.9E-05Q3 0.205237 0.024118 8.509752 3.99E-07
The estimated regression model y = 0 + 1t + 2Q1 + 3Q2 + 4Q3 +
321 205.139.0035.00504.555.ˆ QQQtyt 664.)1(0035.)21(00504.555.y21
805.)1(139.)22(00504.555.y22
876.)1(205.)23(00504.555.y23
675.)24(00504.555.y24
1 2 3 4
b2
b3
b4
Trend line
b0

49
Autocorrelation among the errors of the regression model provides opportunity to produce accurate forecasts.
Correlation between consecutive residuals leads to the following autoregressive model:
This is type of model is termed a first-order autoregressive model, and is denoted AR(1). A model which also includes both yt-1 and yt-2 is a second order model AR(2) and so on.
Selecting between them is done on the basis of the significance of the highest order term. If you reject the highest order term, re-run the model without it. Apply the same criterion for the new highest order term, and so on.
yt = 0 + 1yt-1 + tyt = 0 + 1yt-1 + t
Time-Series Forecasting with Autoregressive (AR) models

50
Example – Consumer Price Index (CPI)
Forecast the increase in the Consumer Price Index (CPI) for the year 1994, based on the data collected for the years 1951 -1993.
Data (CPI.xls)
t Y (t)1 7.92 2.23 0.84 0.5. .. .
43 3
51
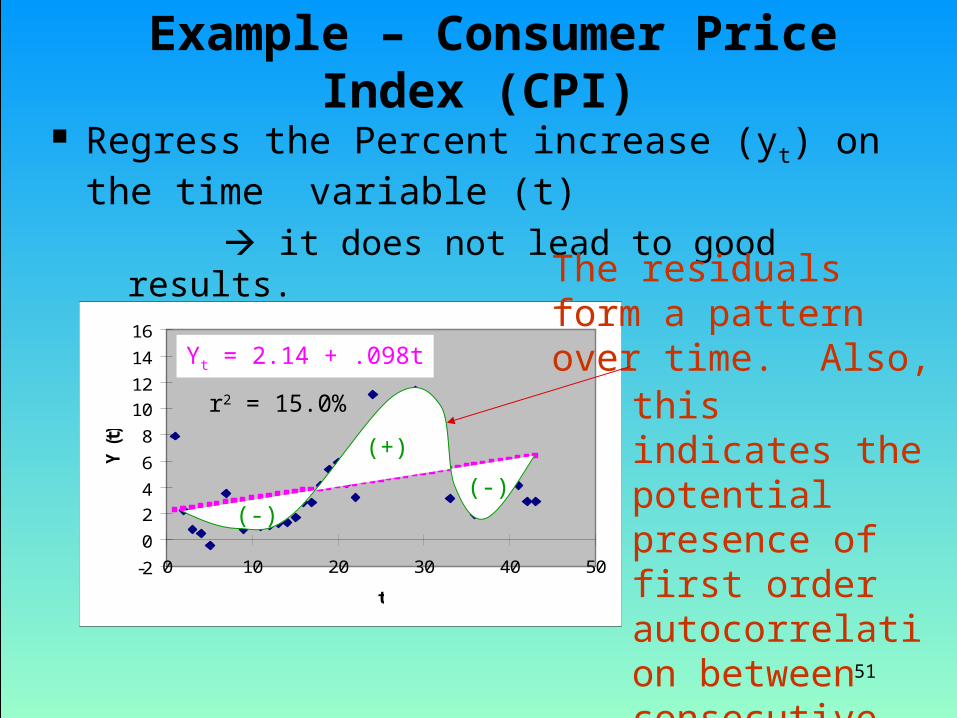
Example – Consumer Price Index (CPI)
Regress the Percent increase (yt) on the time variable (t)
it does not lead to good results.
-2
0
2
4
6
8
10
12
14
16
0 10 20 30 40 50
t
Y (
t)
Yt = 2.14 + .098t
r2 = 15.0% this indicates thepotential presence of first orderautocorrelation betweenconsecutive residuals.
(-)
(+)
(-)
The residuals form a patternover time. Also,
52
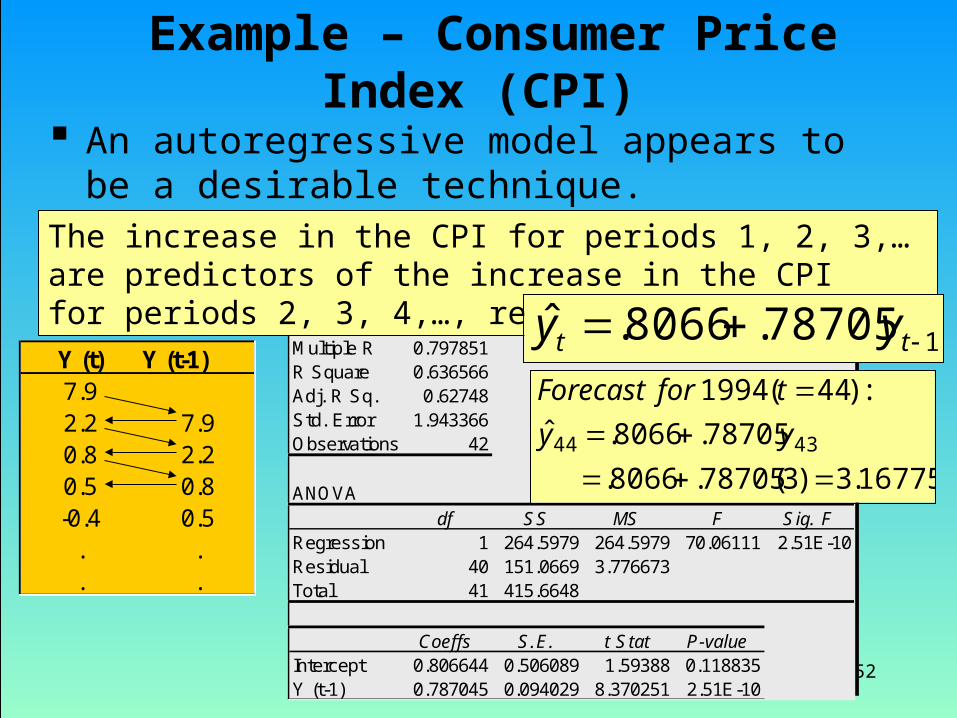
An autoregressive model appears to be a desirable technique.
Y (t) Y (t-1)7.92.2 7.90.8 2.20.5 0.8-0.4 0.5
. .
. .
Regression StatisticsMultiple R 0.797851R Square 0.636566Adj. R Sq. 0.62748Std. Error 1.943366Observations 42
ANOVAdf SS MS F Sig. F
Regression 1 264.5979 264.5979 70.06111 2.51E-10Residual 40 151.0669 3.776673Total 41 415.6648
Coeffs S.E. t Stat P-valueIntercept 0.806644 0.506089 1.59388 0.118835Y (t-1) 0.787045 0.094029 8.370251 2.51E-10
Regression StatisticsMultiple R 0.797851R Square 0.636566Adj. R Sq. 0.62748Std. Error 1.943366Observations 42
ANOVAdf SS MS F Sig. F
Regression 1 264.5979 264.5979 70.06111 2.51E-10Residual 40 151.0669 3.776673Total 41 415.6648
Coeffs S.E. t Stat P-valueIntercept 0.806644 0.506089 1.59388 0.118835Y (t-1) 0.787045 0.094029 8.370251 2.51E-10
The increase in the CPI for periods 1, 2, 3,… are predictors of the increase in the CPI for periods 2, 3, 4,…, respectively.
178705.8066.ˆ tt yy
16775.3)3(78705.8066.
78705.8066.ˆ
:)44(1994
4344
yy
tforForecast
Example – Consumer Price Index (CPI)

53
-202468
10121416
-5 0 5 10 15
Y (t-1)
Y (
t)
-2
0
2
4
6
8
10
12
14
16
0 10 20 30 40 50
t
Y (
t)
Compare
linear trend model
autoregressive model
54
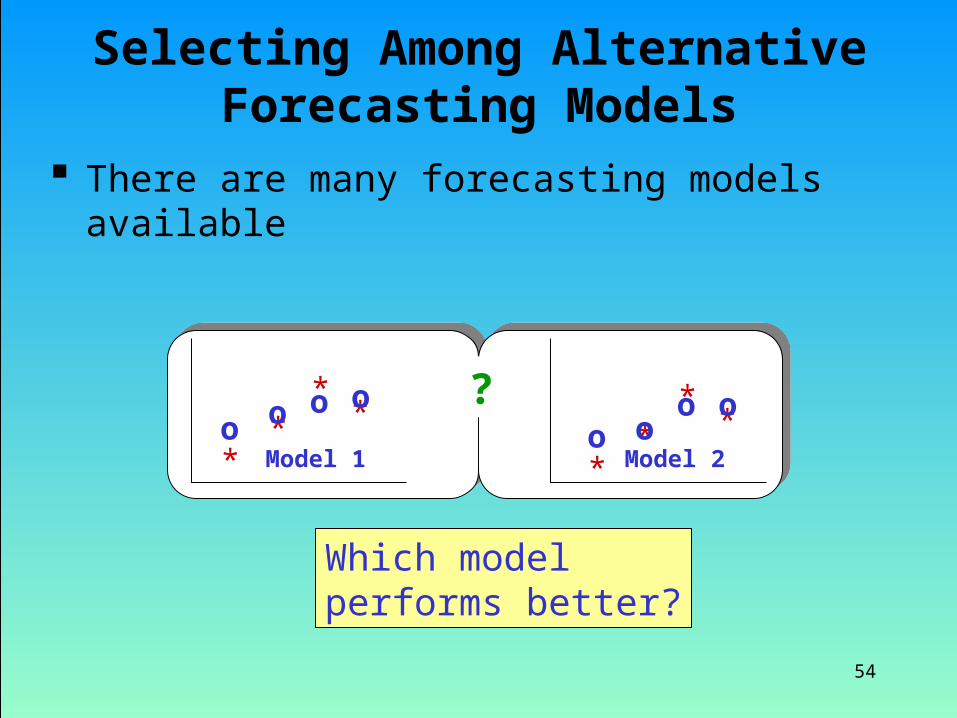
Selecting Among Alternative Forecasting Models
There are many forecasting models available
**
***
*
** o
ooo o
oo
oModel 1 Model 2
Which model performs better?
?

55
Model selection
To choose a forecasting method, we can evaluate forecast accuracy using the actual time series.
The two most commonly used measures of forecast accuracy are:
• Mean Absolute Deviation
• Sum of Squares for Forecast Error
In practice, SSE is SSFE are used interchangeably.
n
Fy
MAD
n
1ttt
n
ttt FySSFESSE
1
2)(

56
Procedure for model selection.1.Use some of the observations to develop several competing
forecasting models.2.Run the models on the rest of the observations.3.Calculate the accuracy of each model using both MAD and
SSE criterion.4.Use the model which generates the lowest MAD value, unless
it is important to avoid (even a few) large errors - in this case use best model as indicated by the lowest SSE.
Model selection

57
Example – Model selection I
Assume we have annual data from 1950 to 2001. We used data from 1950 to 1997 to develop three alternate
forecasting models (two different regression models and an autoregressive model),
Use MAD and SSE to determine which model performed best using the model forecasts versus the actual data for 1998-2001.
Forecast valueYear Actual y Reg 1 Reg 2 AR1998 129 136 118 1301999 142 148 141 1462000 156 150 158 1702001 183 175 163 180

58
Reg 1 Reg 2 ARMAD 6.75 8.5 5.5SSE 185 526 222
Example – Model selection I
Solution• For model 1
• Summary of results
75.64
175183150156148142136129 MAD
Actual yin 1998
Forecast for y in 1998
22 )148142()136129(SSE
185)175183()150156( 22
59
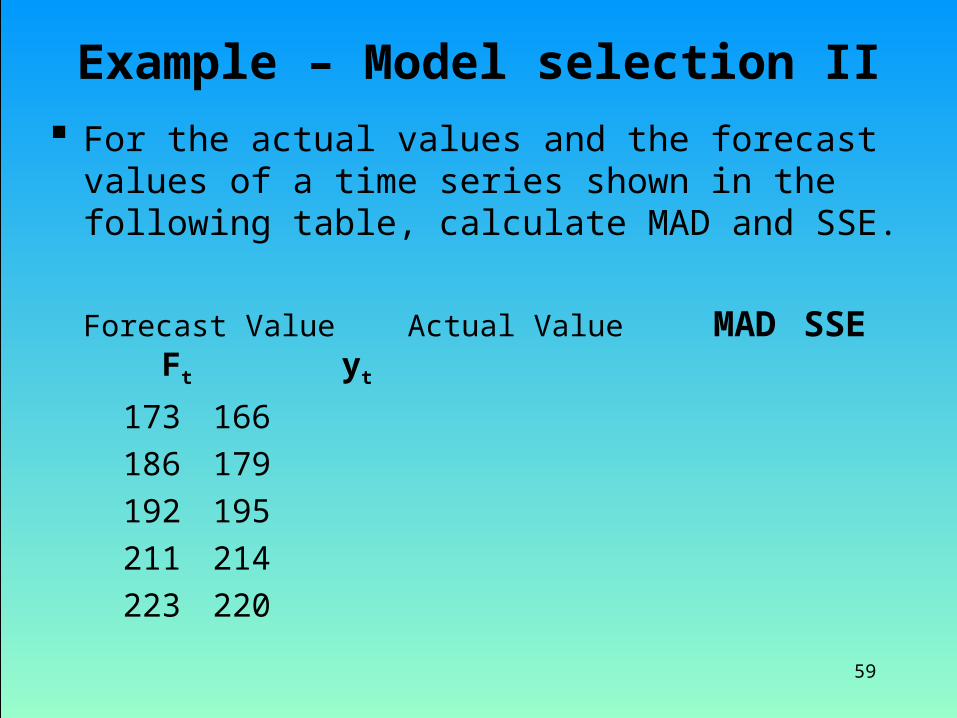
Example – Model selection II
For the actual values and the forecast values of a time series shown in the following table, calculate MAD and SSE.
Forecast Value Actual Value MAD SSE Ft yt
173 166186 179192 195211 214223 220