qaistc.comqaistc.com/.../09/...using-new-generation-tools-technolog… · web viewthere are...
TRANSCRIPT

Final Paper De-mystifying Big Data Testing using new
generation tools / technology
Manish Singhal: Test ManagerMohit Saini : Test Data analyst
SopraSteria

Abstract
Current Business Scenario
Digital Blast has enabled vast population of this world into digital usage of technology. This includes social media, online marketing, online shopping, online payment, customer preferences.
All this gets converted into data which is used by companies to do real time analysis and offer faster services to the clients.
As per International Institute for Analytics (IIA), worldwide revenues for big data and business analytics will grow from $130.1 billion in 2016 to more than $203 billion in 2020, at a compound annual growth rate (CAGR) of 11.7%.
There is a growing needs to ensure that all aspects of testing ( Data integration, Data scalability , Speed of data transformation / processing ) is covered in Big Data testing with key focus on reducing testing turnaround time.
This white paper will focus on:
• Challenges on big data testing
• Generation of Test data for Big data projects
• Usage of tools (Test Data Maker, Agile Requirement Designer, QuerySurge Blue Prism)

The Importance of Big Data
Investment in Big Data initiatives has grown sharply in past few years. Over the past few years, firms have started investing in Big Data initiatives. According to NewVantage Partners Big Data Executive Survey 2017, 37.2% of executives report their organizations have invested more than $100MM on Big Data initiative within past 5 years, with 6.5% investing over $1B.
This White paper discusses the challenges in the big data testing projects and how these can be overcome by the usage of cutting edge tools.

Key Challenges in Big Data Testing
There are software programmes delivered across the world which requires a huge amount of data to be processed. This ranges into social media domains, financial domains where the transaction size is huge. Millions of transactions are carried in a day which needs to be processed and then stored. The functionality needs to be tested and some of the key challenges are:
Ensuring the test coverage for all the possible negative and positive data combinations as per the complex business rules / requirements
Identifying & covering the edge conditions Testing coverage with in the test schedule Ensuring data integrity is maintained Data consistency
Using traditional ways of testing which involves manual design of test cases and traditional excel based creation of test data will require a huge amount of effort and is error prone. Due to the sheer complexity of the business rules / requirement of large data set, test coverage will be limited. Also, with the new agile ways of working where the requirements are consistently changing, it is time consuming to keep changing manual written test cases / test data and re-work effort will be more than the creation effort.

Suggested Tools
Following are the some of the tools which helps in resolving the above challenges:
Test Data maker assists in creating, maintaining and provisioning of the test data needed to rigorously test evolving applications. It uniquely combines elements of data sub-setting, masking and synthetic, on-demand data generation to enable testing teams to meet the agile needs of the organization
QuerySurge is the Data Testing solution built specifically to automate the testing of Data Warehouses & Big Data, ensuring that the data extracted from data sources remains intact in the target data store by analyzing and pinpointing any differences quickly. It makes it easy for both novice and experienced team members to validate their organization's data quickly through Query Wizards while still allowing power users the flexibility they need to get their job done.
It can be used to test any Big Data implementation, whether it be Hadoop, MongoDB, Oracle, Teradata, IBM, Microsoft, Cloudera, HortonWorks, Amazon, DataStax, MapR, or any of the other Hadoop and NoSQL vendors.
BluePrism: BluePrism is process automation tool. This helps on automating the manual repeated process which has similar set of steps. This also helps in connecting to different tools and then running the end to end scripts. Details will be explored in next section.
Agile Requirements Designer is an end-to-end test automation and test case design tool. The optimal set of manual or automated tests can be derived automatically from requirements modeled as unambiguous flowcharts and are linked to the right data and expected results. These tests are updated automatically when the requirements change, allowing organizations to deliver quality software which reflects changing user needs.
Identification of Test Tools
Test Strategy of a big data project is the most important thing. It needs to be seen as what is the project all about, what is the normal and peak volume data requirement and most important on the complexity of business rules / business requirements. Selection of tools is the most important aspect. Doing a POC will be another important activity to be done to see whether the tools chose are compatible with the project requirements or not. Sometimes POC is done with tools on simpler requirements and deemed as successful. Later on in the project cycles, the tool is not utilized in full due to limitations and hence, testing team has to go back to traditional ways resulting in poor quality, bad coverage and effort overrun.

Hence, it is important that POC is done on the complex requirements.
An important aspect is to keep in mind the number of licenses required for the tool. As per the size of project and effort, there is a tendency to assume that most of the team might use the tool and more licenses that required are purchased. We should keep in mind that we need team members who have either working knowledge of these new generation tools OR have the desired skills (good aptitude / knowledge of SQL / Knowledge of any programming language). Skilled resources are also required for this many challenges in terms of setup of tools (especially if on cloud services)
Approach to Testing
Agile Requirement Designer / Test Data Maker
One of the ley aspects is to understand the business requirements and identify the test data requirements. In the big data projects, we have to generate huge volume of data. The number of test data files along will the volume cannot be generated using manual approach. Test data models needs to be created for each requirement. Following steps are followed to generate the model:
1. Analyse the requirement to identifya. Variables used in the requirementb. Constants used in the requirement
2. Identify different decision points3. Identify different data types for different constants or variables4. Identify the source for constants. Mostly this should be master data 5. Design the model based on the constant and variables using regular
expressions / SQL queries6. Based on the test requirement, generate test data for :
a. Positive flowsb. Negative Flowsc. All Test conditions
Test data can also be generated for individual test cases.

If we take example for a sample online food ordering side:
Requirement: Able to book food online for my present location for a choice of restaurant
Sample Test Data Model

Sample Test Data
The above example indicates that for a simplest 1 line requirement, there can be huge test cases for complete coverage and for all the coverage flows, test data can be generated. Tools like Test Data Maker can ensure that data is generated in any format i.e. csv, excel, xml.
QuerySurge
With huge volume of data, matching actual result and expected result can be a challenge. To take an example with above test data, let’s assume that there is a test case where we have below combinations:
1. Data file with 10 records, out of which 5 records should be accepted , 3 should go to Pending and 2 should be rejected, result of each record is stored in an
2. Data file with 1000 records, out of which 350 should be accepted, 200 should be pending and 450 should be rejected
In the 1st case, it is manually possible to check each record, look in the output file and analyse the failures in respective databases / fields.
In the 2nd case, it is not possible to check each record manually specially when there are many tests (assume 100 files to be processes for different rules) in a day and analysis for failures. This becomes more complex if there are 100,000 records or more in each file.

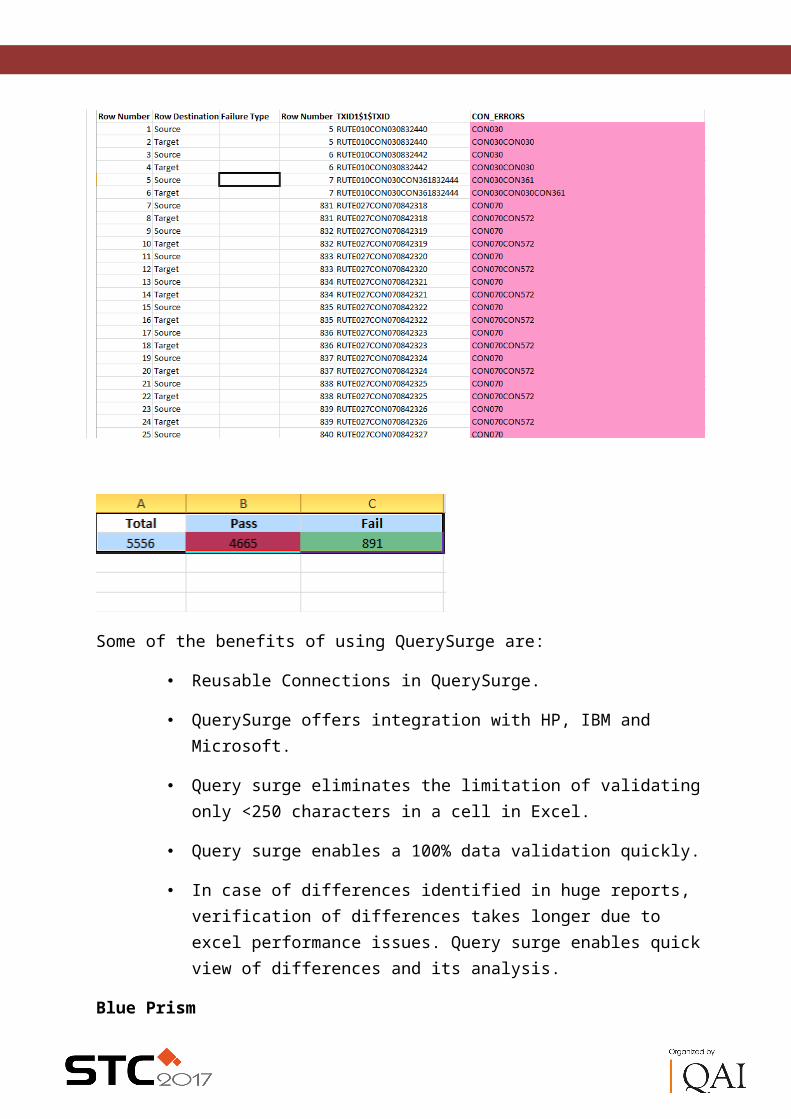
Solution lies in using QuerySurge which can compare source and destination. It can compare source and destination xml / excel files / tables in database and can give the output in desired format.
Sample result from QuerySurge where difference in source and destination is highlighted at the end of test:


Some of the benefits of using QuerySurge are:
Reusable Connections in QuerySurge.
QuerySurge offers integration with HP, IBM and Microsoft.
Query surge eliminates the limitation of validating only <250 characters in a cell in Excel.
Query surge enables a 100% data validation quickly.
In case of differences identified in huge reports, verification of differences takes longer due to excel performance issues. Query surge enables quick view of differences and its analysis.
Blue Prism
In the journey of our testing, we have now ensured that we automated the tests which were mainly related to handle the huge volume of data for testing. Rather than going through each and every record in a large file, we now use QuerySurge to give us a result where we now which records are failed and then investigate the failed rows.
Another challenge is to run the complete process where we have to:
1. Take file from the source control system2. Place it in desired servers / folders3. Wait for file to be processed4. Wait for the output files to be generated5. Ready the source and result files for query Surge6. Initiate QuerySurge7. Run comparison scripts8. Verify the results
If the above steps are to be done once, that it is a simple process. Assume a scenario where there are 1000 such files to be run in a day and each files have thousands of records. A tester will waste lots of effort in waiting / processing.
Note that all of the above steps are manual and repeatable. Hence is the need for process automation tools like “Blue Prism”.

All Blue Prism needs is a step by step guide as how to connect to the test environment, manual steps to be performed, which tools to invoke and what to run. Once this is provided, end to end automation can be done which will simulate work of a tester.
Moreover, this can be run as a scheduled process which can be triggered for overnight run. This can also be integrated with tools like Jenkins to ensure that it runs as a part of smoke / regression test after every build.

Summary:With efficient usage of tools, we have made testing of a big data very simpler. We are following Model based testing using Agile Requirements Designer, we are generating test cases covering ensuring complete coverage, with the help of Test Data Maker, ensuring that test data is generated for all the combinations, ensuring that requirement changes does not involve a huge rework as only models needs to be changed, ensure that test execution does not take huge effort by using QuerySurge and the automate repeatable tasks (which are prone to human error) by doing end to end process automation using Blue Prism.
Few points to consider:1. Requirement of high end infrastructure to support the tools2. License cost of the tools3. Availability of skilled resources for the test tools4. Learning curve on these tools so to utilize tools effectively5. Availability of good quality requirements6. Understanding of the domain
References & Appendix
1. NewVantage Partners Big Data Executive Survey 2017 http://newvantage.com/wp-content/uploads/2017/01/Big-Data-Executive-Survey-2017-Executive-Summary.pdf
2. International Institute for Analytics (IIA), worldwide revenues for big data and business analytics

Author Biography
Manish Singhal has total IT experience of over 20 years with Test Management, Software quality assurance & control, Black Box Testing, Client interaction, managing SDLC and software development process with leading software consulting companies and clients. Manish is current working as Senior Test Manager in SopraSteria and is handling key account on Big Data Testing space for a leading financial institution in UK.
Manish is specialist in Formulating Testing Process & Methodologies with comprehensive hands on experience in designing Test proposals, Creation of estimates, Test strategy formulations, Test management and Test execution with strong people management capabilities.
Manish has extensive experience in managing large cross-functional, geographically dispersed IT Testing and Quality Assurance projects on time and within budget. Manish also is proficient in setting up Quality procedures & processes of Software Development Life Cycle Management along with responsibility for driving and sustaining CMMi Level 5 assessment for Testing Service line.
Mohit Saini: With over 5.5 years of experience in IT industry, worked as part of the Quality Assurance teams across various Projects where clients affiliated to Finance Domain such as Debt Management, Share market etc. Proficient in SQL queries, Functional, Database/ETL with zeal to be more technical oriented. Recently acquired command on CA Grid tools such as Agile Requirements Designer as part of the data team. Always supportive for the team and have good soft skills.

THANK YOU!