Вопросы передачи и защиты информации: Сборник статей
TRANSCRIPT

ВОПРОСЫ ПЕРЕДАЧИИ ЗАЩИТЫ ИНФОРМАЦИИ
Сборник статей
Под редакцией доктора технических наук,
профессора Е. А. Крука
Санкт&Петербург2006
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
Государственное образовательное учреждениевысшего профессионального образования
САНКТ&ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТАЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ

2
УДК 621.391ББК 32.811
В74
В74 Вопросы передачи и защиты информации: Сборник статей /СПбГУАП. СПб., 2006. 226 с.: ил.ISBN 5&8088&0168&0
Предлагаемый сборник статей посвящен вопросам создания безо&пасных информационных технологий. Само понятие «безопасные тех&нологии» рассматривается здесь в самом широком смысле: техноло&гии обеспечения надежной передачи и хранения информации, защи&ты информации от несанкционированного доступа, построения эффек&тивных сетевых протоколов.
Темы статей фокусируются, в основном, на двух направлениях ис&следования: методов повышения достоверности передачи информациии систем защиты информации на основе открытых (публичных) клю&чей. Большинство статей объединяет использование идей и методовтеории помехоустойчивого кодирования.
Сборник будет полезен для специалистов и студентов, интересую&щихся практикой использования кодов, исправляющих ошибки.
Рецензенты:
заведующий кафедрой распределенных вычисленийи компьютерных сетей Санкт&Петербургского государственного
политехнического университета,доктор технических наук, профессор Ю. Г. Карпов;
директор лаборатории передачи дискретной информацииСанкт&Петербургского государственного университета телекоммуникаций
им. профессора М. А. Бонч&Бруевича,кандидат технических наук, доцент М. Я. Лесман
© ГОУ ВПО «СПбГУАП», 2006ISBN 5&8088&0168&0

3
ПРЕДИСЛОВИЕ
Теория помехоустойчивого кодирования появилась и долгое времяразвивалась как дисциплина, занимающаяся разработкой средств борь&бы с помехами, возникающими при передаче цифровой информации поканалам связи. Полученные в последние 10–15 лет результаты показа&ли возможность существенного расширения области применения ко&дов, исправляющих ошибки. Это дало новый импульс для проведенияисследований в области применения теории кодирования в сетях пере&дачи данных (СПД), послужило стимулом и для ряда работ, помещен&ных в публикуемой книге.
Помехоустойчивое кодирование является универсальным методомзащиты от ошибок, однако в большинстве известных работ кодирова&ние используется только для повышения надежности передачи в лини&ях связи. Между тем каждый уровень СПД (уровень звена передачи дан&ных, сетевой, транспортный уровни и т. д.) может рассматриваться какнекоторый информационный канал со своим квантом передаваемойинформации (бит, кадр, пакет, сообщение), своим способом передачи,своими специфическими искажениями (ошибки типа замещения, встав&ки, выпадения, «обгоны», «дубликаты»). При таком рассмотрении за&дача кодирования становится глобальной по отношению к СПД в це&лом, так как требует анализа не только физических источников оши&бок, но и протокольного обеспечения сети, а ее решение связано с разра&боткой нестандартных методов кодирования, обеспечивающих согла&сование кодов на различных сетевых уровнях.
Использование избыточного кодирования на верхних сетевых уров&нях всегда ограничивалось представлением о том, что связанное с ним(кодированием) увеличение загрузки сети приводит к безусловному уве&личению задержки передаваемых сообщений.
В ряде работ последнего десятилетия была доказана принципиаль&ная возможность использования кодирования не только с целью повы&шения надежности сети, но и с целью улучшения параметров ее функ&ционирования, в частности, с целью уменьшения средней задержки со&общений в сети.
Менее исследованы возможности применения помехоустойчивогокодирования на уровне приложений сети. Криптосистемы с публичнымключом, основанные на использовании кодов, исправляющих ошиб&ки, возникли одновременно с теоретико&числовыми. И хотя именно те&оретико&числовые криптосистемы легли в основу криптографическихстандартов, кодовые криптосистемы остаются предметом многочислен&ных исследований как наиболее серьезная альтернатива теоретико&чис&ловых стандартов. В ряде работ настоящего сборника рассматриваются

возможности развития кодовых криптосистем. Однако перспективыкодовых криптосистем определяются, по&видимому, не столько их соб&ственными достоинствами, сколько перспективами создания комп&лексных систем защиты от ошибок, предназначенных для борьбы как сестественными помехами, так и с искусственными воздействиями. Этиперспективы сегодня не весьма определены, но представляется, что ма&териал настоящей книги может послужить основой для их установле&ния.
Сформулируем задачи, для которых найдены решения средствамипомехоустойчивого кодирования (все они в той или иной степени рас&сматриваются нами в дальнейшем):
��кодирование для обеспечения надежной передачи в каналах пере&дачи данных (физический уровень сети);
��кодирование в системах с обратной связью (уровень звена передачиданных);
��кодирование на транспортном уровне сети;��кодирование для защиты от несанкционированного доступа (уро&
вень приложений);��кодирование для сжатия информации с потерями (уровень прило&
жений).Эти задачи имеют разную степень разработанности. Безусловно, тра&
диционное кодирование на физическом уровне изучено в значительнобольшей степени. Но примеры решения задач на уровнях сети вышефизического позволяют рассматривать помехо&устойчивое кодированиекак универсальный инструмент, пригодный для применения к широко&му классу сетевых задач.
Более того, актульной становится проблема совместного кодирова&ния на различных уровнях сети передачи данных с целью оптимальногораспределения алгоритмической избыточности в сети. Представляет&ся, что настоящий сборник внесет определенный вклад в ее решение.
Почти все авторы сборника являются сотрудниками кафедры безо&пасности информационных систем Санкт&Петербургского государствен&ного университета аэрокосмического приборостроения (бывшего Ленин&градского института авиационного приборостроения), известного сво&ей школой в области кодирования и передачи информации.
Доктор технических наук профессор Е. А. Крук

НАДЕЖНЫЕ МЕТОДЫ ПЕРЕДАЧИДИСКРЕТНОЙ ИНФОРМАЦИИ

6

7
А. А. Овчинников,канд. техн. наук, ассистентСанкт�Петербургский государственный университетаэрокосмического приборостроения
К ВОПРОСУ О ПОСТРОЕНИИ LDPC�КОДОВНА ОСНОВЕ ЕВКЛИДОВЫХ ГЕОМЕТРИЙ
Введение
Коды с малой плотностью проверок на четность (LDPC&коды) быливпервые предложены Р. Галлагером [1, 2] и позднее исследовалисьв работах [3–6]. Несмотря на то, что в течение долгого времени LDPC&коды были практически исключены из рассмотрения, в последниегоды наблюдается увеличение количества исследований в этой обла&сти. Это связано с тем, что, обладая плохим минимальным расстоя&нием, коды с малой плотностью, тем не менее, обеспечивают высо&кую степень исправления ошибок при весьма малой сложности ихдекодирования. Было показано, что с ростом длины некоторые LDPC&коды могут превосходить турбокоды и приближаться к пропускнойспособности канала с аддитивным белым гауссовским шумом (АБГШ)[7]. Вместе с тем, многие предложенные конструкции LDPC&кодовявляются циклическими или квазициклическими, что позволяет про&изводить не только быстрое декодирование, но и эффективные про&цедуры кодирования. Кроме того, даже для LDPC&кодов, не облада&ющих свойством цикличности, были предложены эффективные про&цедуры кодирования [8].
Код с малой плотностью проверок на четность задается своей про&верочной матрицей H, обладающей свойством разреженности, т. е. еестроки и столбцы содержат мало ненулевых позиций по сравнениюс размерностью матрицы. Наравне с традиционным заданием кодакак нулевого пространства проверочной матрицы, LDPC&коды частозадаются с помощью графа, для которого матрица H является мат&рицей смежности (так называемого графа Таннера). Это двудольныйграф, вершины которого делятся на два множества: 1) n символьныхвершин, соответствующих столбцам; 2) r проверочных вершин, со&ответствующих строкам проверочной матрицы. Ребра, соединяющиевершины графа, соответствуют ненулевым позициям в матрице H.Пример такого графа приведен на рис. 1.
LDPC&коды, у которых строки и столбцы содержат одинаковоечисло единиц, принято называть регулярными кодами, в то времякак коды с неравным числом единиц называются нерегулярными.

8
Как правило, построение хорошихнерегулярных кодов использует ве&роятностные методы, анализ такихкодов производится в асимптотике,тогда как регулярные конструкцииоснованы на объектах (например,комбинаторных) с известными свой&ствами и могут анализироваться сучетом свойств этих объектов.
Настоящая статья рассматриваетпостроение LDPC&кодов, основанныхна евклидовых геометриях. Евкли&дово&геометрические коды известныдовольно давно [9–11], однако в ка&честве кодов с малой плотностью онистали рассматриваться только в пос&
ледние годы [12]. Мы анализируем свойства LDPC&кодов, основан&ных на евклидовой геометрии, и предлагаем методы построения но&вых кодов, используя свойства евклидовых геометрий и проведен&ный анализ.
Конструкции и декодирование
Как и для всякого линейного (n, k)&кода, одной из оценок качестваLDPC&кода является вероятность ошибочного декодирования, кото&рая обычно характеризуется долей ошибочных бит в декодирован&ном сообщении (BER), при заданных длине кода n и скорости R���k / n.
Одним из главных параметров, влияющих на вероятность оши&бочного декодирования, является кодовое минимальное расстояние d0.В случае LDPC&кодов, однако, часто минимальное расстояние кодамало, и низкая вероятность ошибки достигается за счет хорошихспектральных свойств кода (небольшого количества слов малого веса).
Р. Галлагером были предложены алгоритмы декодирования LDPC&кодов как для дискретных (bit&flipping decoding), так и для полуне&прерывных (belief propagation decoding) каналов. Общим свойствомLDPC&декодеров является то, что они представляют собой итератив&ные процедуры, оперирующие не с блоками, а с отдельными символа&ми принятого сообщения. Параметром декодера является максималь&ное число итераций, после которого декодер принимает решениео передававшемся слове. На практике часто бывает достаточно не&большого числа итераций, чтобы правильно продекодировать при&нятое слово. В работе М. С. Пинскера и В. В. Зяблова [3] показано,
�������������������
Символьные вершины
Проверочныевершины
n r
Рис. 1. Граф Таннера LDPC�кода

9
что сложность декодирования LDPC&кода составляет порядка n logn. В работах [12, 13] рассмотрены ускоренные процедуры декодиро&вания LDPC&кодов, дающие незначительное увеличение вероятнос&ти ошибки.
Работа декодера LDPC&кода ухудшается, если в графе Таннерасоответствующего LDPC&кода присутствуют циклы небольшойдлины. Как правило, циклы длины 6 не оказывают существенноговлияния на качество декодирования, поэтому существующие насегодня конструкции должны обеспечивать отсутствие циклов дли&ны 4. Для этого достаточно, чтобы любые два столбца провероч&ной матрицы LDPC&кода не имели более одной общей ненулевойпозиции.
В работах [6, 14] проведен асимптотический анализ декодера Гал&лагера «belief propagation» для некоторых каналов связи. Показано,что при использовании этого декодера существует некий порог, та&кой, что при определенном уровне помех в канале (превышающемэтот порог) вероятность ошибки декодирования не стремится к нулюс ростом числа итераций. Величина этого порога зависит от распреде&ления весов строк и столбцов проверочной матрицы LDPC&кода, иэти веса можно оптимизировать с помощью предлагаемой в работах[6, 14] процедуры «density evolution». Коды с распределениями, по&лученными с помощью этой процедуры, дают выигрыш на низкихотношениях сигнал/шум (в канале с АБГШ), однако, как правило,обладают так называемым эффектом «error&floor», т. е. более мед&ленным уменьшением вероятности ошибки при увеличении отноше&ния сигнал/шум.
В последние годы было предложено много конструкций LDPC&ко&дов. Некоторые из них основывались на свойствах известных комби&наторных объектов – разностных множеств, блок&схем, геометрий[15, 16], другие – на различного рода вероятностных методах [7, 14].В последнем параграфе данной работы приведены сравнительные ре&зультаты моделирования некоторых из них.
Конечные евклидовы геометрии
Опишем вкратце евклидовы геометрии [9, 10]. Приведенные здесьсоотношения будут использоваться нами в дальнейшем для оценкипараметров получаемых LDPC&кодов.
Евклидовой геометрией EG называется совокупность объектов –точек и прямых, удовлетворяющих следующим аксиомам.
1. Через любые две точки можно провести прямую, причем толькоодну.

10
2. Для любой прямой L и любой точки p, не лежащей на L, можнопровести прямую, проходящую через p и не пересекающую L (т. е.прямую, параллельную прямой L).
3. Существуют три точки, не лежащие на одной прямой.Следует отметить, что приведенный набор аксиом не является
единственным, с помощью которого задается евклидова геометрия,однако другие наборы аксиом могут быть сведены к этим трем, и на&оборот.
Одной из наиболее часто используемых и практически важныхформ задания евклидовых геометрий является описание их с помо&щью конечных полей. Евклидова геометрия EG (m, q), где q���ps, p –простое, задается с помощью конечного поля GF (qm) [расширенияполя GF (q)] следующим образом: точками евклидовой геометрииявляются элементы поля ( ),j mGF q� � , 0, 1, , 2,mj q� �� �� � – при&митивный элемент поля GF (qm). Заметим, что в множество точекевклидовой геометрии входит и нулевая точка – нулевой элемент ���поля GF (qm). Тогда линия, проходящая через нулевую точку и неко&торую ненулевую точку �j, задается уравнением
(0, ) { } { : ( ), ( ), 0},j j j j m jL GF q GF q� � �� � �� �� � � � � (1)
т. е. проходит через точки 0��� � �и 0j� � и содержит элементы поля,получаемые из �j умножением на все элементы � (включая нулевой)подполя GF (q). Если некоторые элементы �i и �j линейно независи&мы, то есть �i не лежит на прямой L(0, �j ), то, в соответствии с акси&омой 2, можно провести линию, параллельную линии L(0, �j ) и про&ходящую через точку �i :
( , ) { } { : ( )}.i j i j i jL GF q� � � � ��� � � ��� �� (2)
Так как элемент� в уравнениях (1), (2) принимает q���ps различ&ных значений, каждая прямая в евклидовой геометрии содержит
sq p� � � (3)
точек. Всего существует
1| | ( 1)/( 1)m mL q q q�� � � (4)
линий в EG (m, q). Каждая линия имеет qm–1 – 1 параллельных, черезкаждую точку проходит
( 1)/( 1)mq q� � � � (5)
прямых (или, другими словами, в каждой точке пересекается � пря&мых).

11
Евклидова геометрия EG (2, q) называется плоскостью. Точкиплоскости могут быть получены как линейные комбинации трех то&чек �i, �j , �k, не лежащих на одной прямой:
{ }, , ( ).i j k GF q� ��� ��� � �� (6)
Из соотношений (4) и (6) следует, что плоскость содержит q2 точеки q (q 1) прямых.
Теперь рассмотрим способы задания кодов, основанных на конеч&ных евклидовых геометриях.
Коды EG�LDPC
Евклидово&геометрические коды строятся как система инциден&ций геометрии EG (m, q) [9, 11, 17]. Так как число единиц в прове&рочной матрице евклидово&геометрического кода мало по сравнениюс размерами матрицы, такой код можно рассматривать как LDPC&код.
LDPC&код, основанный на евклидовой геометрии, с проверочнойматрицей HEG, строится следующим образом: строки проверочнойматрицы соответствуют линиям евклидовой геометрии, столбцы —ненулевым точкам в EG (m, ps). Элементы матрицы HEG определяют&ся из векторов инциденций линий евклидовой геометрии (рис. 2):
1, если точка лежит на прямой ;( , )
0, в противном случае.EG
j ii j
�� ��
H (7)
Из уравнений (1)–(5) следует, что проверочная матрица HEG имеетmn q� (8)
столбцов и1( 1)/( 1)m mr q q q�� � � (9)
строк. Каждый столбец матрицы содержит
( 1)/( 1)mq q� � � � (10)
единиц, каждая строка содержитsp� � (11)
единиц.Обычно рассматриваются евклидово&геометрические коды при
p���2, не содержащие нулевой точки [12, 18]. Такие коды иногда на&зываются EG&кодами типа 0, они являются циклическими [9, 11],их параметры
2 1;msn � � (12)

12
( 1)(2 1)(2 1)/(2 1).m s ms sr �� � � � (13)
Число информационных символов таких кодов оценено в работе[19].
Наряду с заданием проверочной матрицы, как показано на рис. 2,можно рассматривать EG&LDPC&код с матрицей, транспонированнойк матрице (7). Тогда ее строки соответствуют точкам геометрии,а столбцы – линиям. В обоих случаях задания матрицы свойства гео&метрии и (8)–(11) обеспечивают выполнение следующих свойств про&верочной матрицы.
1. Каждая строка содержит �единиц [следует из (11)].2. Каждый столбец содержит � единиц [следует из (10)].3. Любые два столбца имеют не более чем одну общую ненулевую
позицию (так как через две точки можно провести только одну пря&мую).
4. Любые две строки имеют не более одной общей ненулевой пози&ции (так как две прямые пересекаются не более чем в одной точке).
Свойства 3 и 4 означают, что граф Таннера как для кода с прове&рочной матрицей HEG, так и для кода с проверочной матрицей T
EGH неимеет циклов длины 4.
Параметры некоторых EG&LDPC&кодов (включающих в себя точ&ку 0) приведены в табл. 1. Параметры кодов с проверочной матрицей
TEGH �помечены как EGT. Результаты моделирования EG&LDPC&ко&
дов в канале с АБГШ приведены в последней части.Так как столбцы проверочной матрицы (7) имеют не более одной
общей ненулевой позиции, любые � столбцов матрицы линейно неза&висимы и, значит, не могут образовать нулевой синдром. Тогда ми&нимальное расстояние кода с проверочной матрицей (7) оцениваетсякак
0 1.d � � � (14)
Рис. 2. Проверочная матрицаEG�кода
���� �����
�����

13
Далее мы получим более точные оценки минимального расстоя&ния EG&кодов.
Укорочение EG�LDPC�кодов
В исследованиях [12, 20] приведены некоторые методы укороче&ния EG&LDPC&кодов. С помощью моделирования показано, что веро&ятность ошибки при укорочении может уменьшаться, однако не при&водится аналитических обоснований для выбора того или иного ме&тода укорочения.
Рассмотрим методы укорочения LDPC&кодов и проведем анализминимального расстояния некоторых евклидово&геометрическихкодов.
Рассмотрим евклидово&геометрические коды, проверочная матри&ца которых является транспонированной к матрице (7):
1, если точка лежит на прямой ;( , )
0, в противном случае.EG
i ji j
�� ��
H (15)
n k R d0 � � GE ( q,m ) пиТ
61 7 5734,0 6 5 4 )4,2(
–46 73 1875,0 01 9 8 )8,2(
652 571 6386,0 81 71 61 )61,2(
4201 187 7267,0 43 33 23 )23,2(
46 31 1302,0 22 12 4 )4,3(–
215 931 5172,0 47 37 8 )8,3(
02 11 55,0 5 4 5 )4,2( GE T
27 54 526,0 9 8 9 )8,2( GE T
272 191 2207,0 71 61 71 )61,2( GE T
6501 318 9967,0 33 23 33 )23,2( GE T
633 582 2848,0 5 4 12 )4,3( GE T
2764 9924 2029,0 9 8 37 )8,3( GE T
09 9 1,0 9 8 37 )9,2( GE T
657 72 7530,0 9 8 37 )72,2( GE T
1737 2466 1109,0 01 9 19 )9,3( GE T
Таблица 1

14
Рассмотрим евклидово&геометрическое пространство, т. е. геомет&рии EG (3, q), q���ps. Такие коды имеют длину
2 3( 1)/( 1),n q q q� � � (16)
их проверочная матрица H состоит из3r q�H (17)
строк. Заметим, что H не обязательно имеет полный ранг, поэтому rHможет использоваться только как верхняя оценка числа провероч&ных символов.
Рассмотрим прямую в такой евклидовой геометрии. Прямая со&держит q точек. Через каждую точку, не лежащую на прямой, можнопровести единственную прямую, параллельную данной. Каждая та&кая прямая также содержит q точек. Так как всего в геометрии q3
точек, всего существует q2 прямых, параллельных друг другу. Назо&вем построенное таким образом множество прямых параллельнымклассом. Геометрия содержит q2(q3–1)(q–1) прямых, которые могутбыть разбиты на (q3–1)(q–1) параллельных классов по q2 прямыхв каждом. Укорачивая проверочную матрицу EG&кода на столбцы,соответствующие параллельным классам, мы будем получать код,в котором число единиц в строках и столбцах остается равным, таккак каждая точка геометрии присутствует в параллельном классеровно один раз. При этом расстояние кода не ухудшилось, а числоединиц в строке стало меньшим, что может улучшить работу итера&тивного декодера.
Описанный метод укорочения позволяет оптимизировать парамет&ры кодов для требуемых длин, выбирая параметры геометрий и вели&чину укорочения с учетом получающихся весов строк.
Попробуем оценить, как укорочение на параллельные классы вли&яет на дистанционные характеристики кода. Для этого рассмотримевклидову плоскость, т. е. геометрию EG (2, q). Плоскость содержитq(q 1) прямых, которые могут быть разбиты на q 1 параллельныхклассов по q прямых в каждом. Каждая точка плоскости присутству&ет в параллельном классе ровно один раз. Пример разбиения плоско&сти на параллельные классы P1, ..., P5 приведен на рис. 3 для плоско&сти EG(2, 22).
Рассмотрим отдельно случаи p���2 и 2.p � �Пусть 2.p � Далее, пусть
0
( , )n
n i ii
i
W x y A x y�
�
�� (18)
– весовая функция кода [10], где Ai – число слов веса i в коде; x –число нулей; y – число единиц. Тогда справедлива следующая теорема.

15
Теорема 1. Если проверочная матрица (15) евклидово&геометри&ческого кода при m���2, q���ps, 2p � имеет полный ранг, тогда коэффи&циент Ai весовой функции (18) вычисляется как
/1, 2 ;
0, в противном случае.
i qq
iC i q
A ���� ���
�(19)
Доказательство. Если ранг матрицы (15) является полным, т. е.равен q2, то число информационных символов кода
2( 1) .k n r q q q q� � � � � � (20)
Разобьем множество прямых плоскости на q 1 параллельных клас&сов по q прямых в каждом. Заметим, что при 2p � �число q всегда нечет&но, тогда как число q 1 всегда четно. Так как все точки присутствуют впараллельном классе ровно один раз, сумма всех столбцов проверочнойматрицы, соответствующих параллельному классу, дает столбец из всехединиц. Тогда очевидно, что сумма всех столбцов четного числа парал&лельных классов даст нулевой столбец, т. е. задаст кодовое слово. Заме&тим, что, так как q 1 четно, максимальное четное число классов равноq 1, что соответствует кодовому слову из всех единиц. Четное число 2iпараллельных классов можно выбрать из евклидова пространства 2
1i
qC�
способами. Таким образом, общее количество кодовых слов, образо&ванных параллельными классами, равно
Рис. 3. Разбиение на параллельные классы для плоскости EG (2, 4)
0001 0100 1000 0100 01000001 0001 0001 0001 00010010 0100 0010 0010 00010010 1000 1000 0001 00100100 1000 0100 0100 00010010 0001 0100 1000 01000001 1000 0010 1000 10001000 0100 0100 0001 10001000 0010 1000 1000 00010010 0010 0001 0100 10001000 1000 0001 0010 01000001 0010 0100 0010 00100100 0100 0001 1000 00100100 0001 1000 0010 10001000 0001 0010 0100 00100100 0010 0010 0001 0100
1P�������
2P�������
3P�������
4P�������
5P�������

16
( 1)/20 2 4 6 1 2
1 1 1 1 110
.q
q iq q q q qq
i
C C C C C C�
�
� � � � ��
�
� � � � � � �� (21)
Как следствие биномиальной теоремы [21], имеем следующие тож&дества:
0
2 ;n
i nn
i
C�
�� (22)
0
( 1) 0.n
i in
i
C�
� �� (23)
Пусть n четно. Тогда из тождества (23) имеем
/2 /2 12 2 1
0 0
,n n
i in n
i i
C C�
�
� �
�� �т. е. суммы четных и нечетных членов ряда i
nC равны. Тогда с учетомтождества (22)
/22 1
0
2 .n
i nn
i
C �
�
�� (24)
Из равенств (21) и (24) получаем
( 1)/22
10
2 .q
i qq
i
C�
�
�
�� (25)
Но из (20) следует, что в (25) учтены все кодовые слова. Отсюдаследует утверждение теоремы.
Таким образом, пользуясь теоремой 1, можно указать минималь&ное расстояние для рассматриваемых кодов.
Следствие 1. Минимальное расстояние кода из теоремы 1
0 2 .d q� (26)
Для каждого конкретного кода ранг проверочной матрицы можетбыть вычислен экспериментально. Проведенные тесты показывают,что для рассматривавшихся параметров геометрий при m���2, 2p �ранг проверочной матрицы действительно является полным.
В табл. 2 приведены параметры некоторых LDPC&кодов, с их ми&нимальными расстояниями, полученными на основе результатов те&оремы 1. Здесь 0d� означает оценку минимального расстояния, d0 –точное минимальное расстояние.
Теперь рассмотрим случай p���2. Для поля характеристики 2 соот&ношение (20) не выполняется, т. е. проверочная матрица (15) содер&
17
жит линейно зависимые строки. Таким образом, слова, образован&ные параллельными классами, не являются всеми кодовыми слова&ми. В этом случае можно сформулировать следующие утверждения.
Теорема 2. Если код с проверочной матрицей (15) при m���2, p���2имеет минимальное расстояние q 1, тогда для слова веса q 1 ника&кие две из линий, соответствующих ненулевым позициям этого сло&ва, не лежат в одном параллельном классе.
Доказательство. Минимальное расстояние кода определяетсяминимальной линейной комбинацией столбцов проверочной матри&цы, дающей в результате нулевой столбец&синдром. В случае рассмат&риваемых кодов столбец проверочной матрицы соответствует линиив евклидовой геометрии. Каждая позиция синдрома соответствуетточке евклидовой плоскости и является суммой позиций столбцов,вошедших в линейную комбинацию. Таким образом, чтобы позициясиндрома равнялась нулю, необходимо, чтобы через соответствую&щую точку либо не проходили прямые из данной линейной комбина&ции, либо число прямых, проходящих через точку, было четным.
Следовательно, чтобы построить кодовое слово, нужно найти мно&жество прямых L, такое, что через каждую точку геометрии либо непроходят прямые из L, либо в этой точке пересекается четное числопрямых из L.
Тогда нахождению слова минимального веса соответствует нахож&дение множества L0 минимальной мощности. Попробуем построитьтакое множество минимальной мощности.
n k R d0 � � GE ( q,m ) пиТ
02 11 55,0 5 5 4 5 )4,2( GE T
27 54 526,0 9 9 8 9 )8,2( GE T
272 191 2207,0 71 71 61 71 )61,2( GE T
6501 318 9967,0 33 33 23 33 )23,2( GE T
633 582 2848,0 5 5 4 12 )4,3( GE T
2764 9924 2029,0 9 9 8 37 )8,3(
09 9 1,0 9 81 8 37 )9,2( GE T
657 72 7530,0 9 45 8 37 )72,2( GE T
1737 2466 1109,0 01 81 9 19 )9,3( GE T
Таблица 2Точное минимальное расстояние некоторых EG�LDPC�кодов
0d�

18
Допустим, что на некотором шаге k уже сформировано множествопрямых ( )
0 .kL �Обозначим P* те точки из ( )0 ,kL через которые проходит
нечетное число прямых, P** – те точки, через которые проходит чет&ное число прямых. Чтобы число прямых в L0 было минимальным,необходимо, чтобы каждая следующая добавляемая прямая прохо&дила через как можно большее число точек P*, не проходила черезточки P** и добавляла как можно меньшее число новых точек, кото&рые на следующем шаге увеличат множество P*. Построение l(1) за&кончится тогда, когда множество точек P* станет пустым.
Это эквивалентно тому, что на шаге k новая прямая должна пере&секать как можно большее число прямых, уже содержащихся в ( 1)
0 ,kL �
причем пересечение должно идти по точкам P*.Рассмотрим прямую l(0) евклидовой плоскости. Эта прямая содер&
жит q точек и принадлежит какому&то классу параллельности. Сле&дующая проведенная прямая l(1) может либо не пересечь данную, еслиона принадлежит тому же классу параллельности, что и l(0), либо пе&ресечь в одной точке, если l(1) не параллельна l(0). Следующая прово&димая прямая l(2) может пересечь либо одну прямую из уже выбран&ных, если она параллельна одной из них, либо пересечь обе, в про&тивном случае.
Пример построения множества L0 для случая q���4 приведен нарис. 4. Точки множества P** обведены на этом рисунке кругами (кро&ме заключительный фигуры).
Рис. 4. Графическая интерпретация построениявектора минимального веса для EG (2, 4):а – начальная линия; б – добавление вто�рой линии; в – добавление третьей линии;г – замкнутая фигура
а) б)
в) г)

19
Таким образом, выбирая каждый раз прямую из еще не использо&вавшегося класса параллельности, мы будем пересекать все прямые,выбранные на предыдущих шагах. Добавление прямой к множеству
( 1)0 ,kL � в котором уже содержатся k прямых, добавляет q – k новых
точек. Всего в ( )0kL �содержится
1( )0
0
| | ( ), 0k
kk
i
N L q i k�
�
� � � �� (27)
точек. Оценим число *kN �точек типа P* на k&м шаге. На нулевом
шаге (0)0L �содержит единственную прямую, и все N0���q точек являют&
ся P*&точками. На первом шаге добавляемая прямая пересекает ужевыбранную в одной точке, таким образом, в (1)
0L �содержится одна точ&ка типа P** и N1–1 точек типа P*. На втором шаге новая прямая пере&секает две существующие еще в двух точках, и, таким образом, в (2)
0Lсодержится уже три точки типа P** и N2–3 точек типа P*. В общемслучае
1*
0
, 0k
k ki
N N i k�
�
� � �� (28)
или, с учетом (27):
1 1 1*
0 0 0
( ) ( 2 ).k k k
ki i i
N q i i q i� � �
� � �
� � � � �� � � (29)
Теперь найдем минимальное число линий, которые нужно провес&ти, чтобы получить кодовое слово, т. е. найдем L0. Для этого нужнопросто определить номер шага k, при котором (29) обратится в ноль:
*0| | { : 0}, 0.kL k N k� � � (30)
Применив формулу суммы арифметической прогрессии, из соот&ношений (29) и (30) получим условие остановки построения L0:
1
0
( 2 2))( 2 ) ( 1) 0.
2
k
i
q q k kq i q k k
�
�
� � �� � � � � �� (31)
При условии k�> 0 выполнение условия (31) возможно только приk���q. Таким образом, при указанном методе построения требуется q 1прямых из разных классов параллельности, чтобы построить L0, а вевклидовой плоскости содержится как раз q 1 классов параллель&ности. Тогда из (30) и (31) имеем
0| | 1,L q� �
что и завершает доказательство.

20
Однако в отношении теоремы 2 можно сформулировать следую&щее утверждение.
Замечание 1. Минимальное расстояние кода из теоремы 2 равноq 1 только в том случае, если можно провести прямые указаннымспособом, т. е. только через точки типа P*. Это утверждение не явля&ется доказанным, однако эксперименты показывают, что для полейхарактеристики 2 это действительно так. Таким образом, возможно,теорема 2 задает точное минимальное расстояние.
Следствие 2. Укорочение кода (15) при m���2, p���2 и с учетомзамечания 1 на прямые, содержащие любой параллельный класс,приводит к коду с минимальным расстоянием
0 2.d q� � (32)
Доказательство. Как было показано в доказательстве теоремы 2,для построения L0 требуется q 1 прямых из разных классов парал&лельности, которых в евклидовой плоскости ровно q 1. Таким обра&зом, любое ненулевое кодовое слово минимального веса имеет q 1ненулевых позиций, по одной в каждом классе параллельности. Уда&ление любого класса параллельности приведет к тому, что в коде неостанется слов веса q 1, отсюда следует утверждение следствия.
Сравнение конструкций в канале с АБГШ
Здесь мы приводим результаты моделирования для кодов, полу&ченных с помощью укорочения на параллельные классы, описанно&го выше. Моделирование проводилось в канале с АБГШ, двоичнойфазовой модуляцией, для декодирования использовался ускоренныйдекодер, описанный в работе [13], с ограничением максимальногочисла итераций 10.
В качестве исходного кода рассматривался евклидово&геометриче&ский код с проверочной матрицей (15), полученной с помощью конеч&ной геометрии EG (2, 26). Укоротим этот код на 10, 20 и 30 параллель&ных классов, что приведет к кодам с разными длинами и скоростями.Результаты их моделирования в канале с АБГШ показаны на рис. 5.
Для сравнения корректирующей способности полученных кодовс другими кодами рассмотрим конструкцию RS&LDPC, основаннуюна укороченных кодах Рида–Соломона [22]. На рис. 6–9 приведенырезультаты моделирования укороченных евклидово&геометрическихкодов и кодов RS&LDPC. Как видно из графиков, исходный евклидо&во&геометрический код и его укорочения дают выигрыш по сравне&нию с кодом RS&LDPC при сравнимых длинах и кодовых скоростях.Таким образом, предложенный метод построения укороченных евкли&

21
Рис. 6. Евклидово�геометрический код из EG (2, 26) и код RS�LDPC (6,63, 35)
Рис. 5. Евклидово�геометрический код из EG (2, 26) и его укорочения
10–1
10–2
10–3
10–4
10–5
BE
R
3,5 3,6 3,7 3,8 3,9 4,1 4,2 4,3 4,4 4,54SNR, дБ
3,6 3,7 3,8 3,9 4 4,1 4,2 4,3 4,4 4,5SNR, дБ
3,5
10–1
10–2
10–4
10–3
BE
R

22
Рис. 7. Укорочение кода EG на 10 параллельных классов и код RS�LDPC(6, 55, 35)
Рис. 8. Укорочение кода EG на 20 параллельных классов и код RS�LDPC(6, 45, 35)
3,5 3,6 3,7 3,8 4,24,143,9SNR, дБ
4,3
10–1
10–2
10–3
10–4
10–5
BE
R
3,55 3,6 3,65 3,7 3,75SNR, дБ
3,8 3,85 3,9 3,95 43,5
10–1
10–2
10–3
10–4
10–5
BE
R

23
дово&геометрических кодов дает способ получения новых эффектив&ных кодов для различных скоростей и кодовых длин.
Заключение
В данной статье рассмотрены свойства евклидово&геометрическихкодов. Для ряда EG&кодов получено описание их спектра, найденыболее точные оценки минимального расстояния некоторых EG&ко&дов и их укорочений. Предложен метод построения LDPC&кодов, ос&нованный на укорочении на параллельные классы. Данный методпозволяет более гибко задавать такие параметры кода, как длина искорость. Проведенное моделирование в канале с АБГШ подтверж&дает эффективность кодов, полученных таким способом.
Литература
1. Gallager R. G. Low&density parity check codes // IRE Trans actions information theory. Jan. 1962.
2. Gallager R. G. Low density parity check codes. Cambridge, MA: MIT Press,1963.
3. Зяблов В. В., Пинскер М. С. Оценка сложности исправления ошибокнизкоплотностными кодами Галлагера // Проблемы передачи информации.1975. Т. XI. № 1.
Рис. 9. Укорочение кода EG на 30 параллельных классов и код RS�LDPC(6, 35, 35)
3,553,5 3,6 3,65 3,7 3,75 3,8 3,85 3,9 3,95 4SNR, дБ
10–1
10–2
10–3
10–4
10–5
BE
R

24
4. MacKay D., Neal R. M. Near shannon limit performance of low&density parity&check codes // IEEE Transactions on Information Theory. Vol. 47. Feb. 2001.
5. MacKay D. Good error correcting codes based on very sparse matrices //IEEE Transactions on information theory. Vol. 45. Mar. 1999.
6. Richardson T. J., Urbanke R. L. The capacity of low&density parity&checkcodes under message&passing decoding // IEEE transactions on information theory.Vol. 47. Feb. 2001.
7. On the design of low&density parity&check codes within 0.0045 db of theshannon limit / G. Forney, T. J. Richardson, R. L. Urbanke et al. // IEEEcommunications letters. Vol. 5. Feb. 2001.
8. Richardson T. J., Urbanke R. L. Efficient encoding of low&density parity&check codes // IEEE transactions on information theory. Vol. 47. Feb. 2001.
9. Питерсон У., Уэлдон Э. Коды, исправляющие ошибки. М.: Мир, 1976.10. Мак�Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих
ошибки. М.: Связь, 1979.11. Блейхут Р. Теория и практика кодов, контролирующих ошибки. М.:
Мир, 1986.12. Kou Y., Lin S., Fossorier P. C. Low&density parity&check codes based on
finite geometries: A rediscovery and new results // IEEE transactions oninformation theory. Vol. 47. Nov. 2001.
13. Fossorier M. P. C., Mihaljevic M., Imai H. Reduced complexity iterativedecoding of low&density parity&check codes based on belief propagation // IEEEtransactions on communications. Vol. 47. May 1999.
14. Richardson T. J., Urbanke R. L., Shokrollahi M. Design of capacity&approaching irregular low&density parity&check codes // IEEE transactions oninformation theory. Vol. 47. Feb. 2001.
15. Johnson S. J., Weller S. R. Regular low&density parity&check codes fromcombinatorial designs // In Proc. IEEE Information Theory Workshop (Cairns,Australia). Sept. 2001.
16. Johnson S. J., Weller S. R. Codes for iterative decoding from partialgeometries // ISIT2002, submitted.
17. Теория кодирования / Т. Касами, Н. Токура, Е. Ивадари и др. М.:Мир, 1978.
18. Lin S. Shortened finite geometry codes // IEEE transactions on informationtheory. Sept. 1972. P. 692.
19. Lin S. On the number of information symbols in polynomial codes // IEEEtransactions on information theory. Vol. 18. Nov. 1972. P. 785–794.
20. Lin S. Shortened finite geometry codes // IEEE transactions on informationtheory. Vol. 18. Sept. 1972. P. 692–696.
21. Грэхем Р., Кнут Д., Паташник О. Конкретная математика. Основаниеинформатики. М.: Мир, 1998.
22. A class of low&density parity&check codes constructed based on reed&solomon codes with two information symbols / I. Djurdjevic, J. Xu, K. Ab&del&Ghaffar et al. // IEEE communications letters. Vol. 7. July 2003.

25
А. В. Белоголовый,канд. техн. наук, ассистентЕ. А. Крук,доктор техн. наук, профессорСанкт�Петербургский государственный университетаэрокосмического приборостроения
МНОГОПОРОГОВОЕ ДЕКОДИРОВАНИЕ КОДОВС НИЗКОЙ ПЛОТНОСТЬЮ ПРОВЕРОК НА ЧЕТНОСТЬ
Коды с низкой плотностью проверок на четность
Коды с низкой плотностью проверок на четность были впервые пред&ложены Р. Галлагером в 1963 году как высокоскоростные коды с малойвероятностью ошибки для передачи по каналам с шумом [1, 2].
Коды с низкой плотностью проверок на четность – это линейныекоды, определяемые проверочной матрицей, содержащей в основномнулевые элементы и относительно небольшое количество ненулевых.Для случая двоичных кодов с низкой плотностью проверок на чет&ность проверочная матрица состоит из небольшого числа единиц инулей на всех остальных позициях матрицы. Пример проверочнойматрицы с низкой плотностью проверок на четность:
1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0
0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0
0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0
0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 1
1 0 0 0 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 0
0 1
�H
0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 1 0 0
0 0 1 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 1 0
0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 0 0 0 0 1
1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0
.
0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1
� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� ��� ��� �
Для всего класса кодов с низкой плотностью проверок на четность[1–3] существуют декодеры, основывающиеся только на свойствахразреженности проверочной матрицы и не использующие никакие

26
свойства самого пространства кодовых слов. Эти алгоритмы декоди&рования имеют низкую сложность и позволяют достичь малой веро&ятности ошибки при передаче в канале с аддитивным нормально рас&пределенным (гауссовским) шумом [1–7].
Традиционное декодирование кодов с низкой плотностьюпроверок на четность
Рассмотрим итеративное декодирование кодов с низкой плотнос&тью проверок на четность в двоичном симметричном канале и каналес аддитивным белым гауссовским шумом.
Симметричные каналы с двоичным входом. Симметричным ка&налом с двоичным входом будем называть дискретный по времениканал со следующими свойствами:
входной алфавит X состоит из двух символов, обозначаемых 0 и 1;выходной алфавит Y может быть представлен как дискретное либо
непрерывное вещественное множество чисел;выход y в заданный отсчет времени зависит только от одного вход&
ного символа x;для всех выходов y выполняется свойство симметрии:
0 1( ) ( ).P y P y� � Здесь под Px(y) понимается плотность распределениявероятности, если y – непрерывный выход, и условная вероятность,если Y – дискретное множество.
На рис. 1 приведены примеры симметричных каналов с двоичнымвходом.
Под вектором ошибки для кодового слова c � {c0, ..., cN–1} длины Nбудем понимать вектор e � {e0, ..., eN–1} такой же длины, соответ&ствующие элементы которого равны разностям между вектором y �� {y0, ..., yN–1}, принятым из канала, и передаваемым кодовым словом:ei � yi–ci, 0 .i N� � Эта запись равносильна представлению принятоговектора как суммы кодового слова и ошибки: yi � ciei, 0 .i N� �
Рис. 1. Симметричные каналы с двоичным входом: а – двоичный сим�метричный канал; б – канал с аддитивным гауссовским шу�мом
а) б)
�����
����������
����
���������������
�
�
�
�
�
�
�����
�����
�
�
�
�����

27
Декодирование ошибок канала. Декодирование – это процедурапоиска и исправления ошибки, наложенной каналом на кодовое сло&во, по принятому из канала вектору или собственно поиск кодовогослова по вектору, принятому из канала.
Декодирование по максимуму правдоподобия кода C обозначаетнахождение по заданному принятому вектору y такого кодового сло&ва c � C, которое максимизирует вероятность того, что передавалосьслово c при условии принятия вектора : ( / ) maxp �y c y [8]. Задачадекодирования по максимуму правдоподобия является NP&полной.
Для оценки качества работы различных декодеров используетсяоценка вероятности ошибки декодирования (BER) на информацион&ный бит, вычисляемая как отношение количества ошибочных ин&формационных бит после декодирования к общему количеству пере&данных информационных бит.
Итеративные схемы декодирования кодов с низкой плотностьюпроверок на четность не являются декодерами по максимуму правдо&подобия, но позволяют получить разумный баланс по сложности ивероятности ошибки декодирования по сравнению с декодированиемпо максимуму правдоподобия. Итеративное декодирование подразу&мевает, что нахождение кодового слова будет производиться не заодин проход, а за несколько, с последовательным уточнением резуль&тата на каждом шаге [1–3, 7].
«Жесткое» декодирование – это схема декодирования для двоич&ного симметричного канала при небольшом количестве ошибокв канале. «Жесткое» декодирование инвертированием битов – самаяпростая по сложности схема декодирования кодов с низкой плотнос&тью проверок на четность [1, 2].
Как уже говорилось, под проверкой понимается любая строкаh � {h0, ..., hN–1} из проверочной матрицы кода с низкой плотностьюпроверок на четность. Будем говорить, что проверка для некоего век&тора y � {y0, ..., yN–1} выполняется тогда, когда скалярное произведе&ние вектора y на проверку дает ноль. Будем говорить, что элемент yiпринятого вектора y участвует в проверке h � {h0, ..., hN–1} тогда,когда соответствующий элемент проверки hi не равен нулю.
Одна итерация «жесткого» декодирования инвертированием би&тов производится следующим образом.
1. Для принятого вектора вычисляются все проверки.2. Если некоторый бит принятого вектора участвовал более чем
в половине невыполнившихся проверок, бит инвертируется.3. После такого анализа всех символов принятого вектора вектор
проверяется на принадлежность коду. Если вектор является кодо&

28
вым словом, декодирование заканчивается, в противном случае вы&полняется следующая итерация алгоритма.
Такая процедура декодирования применима для кодов с низкой плот&ностью проверок на четность потому, что большинство проверок в та&ком случае будут содержать одну ошибку или не будут содержать оши&бок вообще, и тогда нарушение большого количества проверок для сим&вола принятого слова будет обозначать наличие в нем ошибки.
Сложность одной итерации «жесткого» декодирования инверти&рованием бит является линейной, количество итераций декодирова&ния обычно выбирается около log2(N), где N – длина кодового слова.
Декодирование по вероятностям является «мягким» декодиро&ванием, т. е. декодированием на основе вектора, состоящего не издискретных значений (0 и 1), а из вещественных величин, получен&ных на выходе канала [1–3, 6, 7] путем пересчета вероятностей (англ. –«belief propagation decoding»).
Будем называть множеством N(m) множество символов принято&го вектора, которые входят в m&ю проверку: N(m) � {n : Hm,n � 1}, гдеH – проверочная матрица кода с низкой плотностью проверок на чет&ность. Будем называть множеством M(n) множество проверок, в кото&рых участвует n&й символ принятого вектора: M(n) � {m : Hm,n � 1}.
На основе принятого из канала вектора формируются два (для дво&ичного случая) вектора вероятностей того, что в принятом векторена данной позиции находился заданный символ:
0 0 0 00 1( , , ), ( 0)N i if f f P y
�
� � �f �и
1 1 1 10 1( , , ), ( 1),N i if f f P y
�
� � �f �
где yi – элементы принятого вектора. Каждому ненулевому элементупроверочной матрицы кода с низкой плотностью проверок на чет&ность приписываются две величины: ,
xi jq и , .x
i jr Величина ,xi jq являет&
ся вероятностью того, что j&й символ принятого вектора имеет значе&ние x по информации, полученной из всех проверок, кроме i&й. Вели&чина ,
xi jr является вероятностью того, что проверка i выполняется,
если j&й символ принятого вектора равен x, а все остальные символыпроверок имеют распределение вероятностей, заданное величинами
,{ : ( ) \ }.xi jq j N i j�Перед началом работы алгоритму требуется инициализация, за&
ключающаяся в том, что значения 0,i jq и 1
,i jq принимаются равны&ми 0
jf и 1jf соответственно, а далее алгоритм работает по принципу
пересчета вероятностей символов принятого вектора (beliefpropagation), используя для пересчета вероятностей правило Байеса

29
для апостериорной вероятности события. Одна итерация алгоритмапредставляет собой следующую последовательность действий.
1. Для всех проверок вычисляются величины
0 1, , ' ,
( )\
( )i j i j i jj N i j
r q q �
��
� � � и пересчитываются вероятности
,,
1 ( 1)
2
xi jx
i j
rr
� � �� для x � {0, 1}.
2. Для всех символов принятого вектора пересчитываются веро&
ятности , , ,( )\
x x xi j i j j i j
i M j i
q f r �
��
� � � для x � {0, 1}, где �i,j – нормирующие
коэффициенты, обеспечивающие равенство 0 1, , 1.i j i jq q� �
3. Формируются векторы псевдоапостериорной вероятности 0jq
и 1jq следующим образом: ,
( )
x x xj j j i j
i M j
q f r�
� � � , где �j – нормирующие ко&
эффициенты, обеспечивающие равенство 0 1 1.j jq q� �4. Формируется вектор решения c� по следующему правилу:
11 при 1/2.
0 иначе
jj
qc
� ��� � ����
Если вектор c� является кодовым словом, деко&
дирование заканчивается, в противном случае выполняется следую&щая итерация алгоритма.
Сложность данного алгоритма выше, чем сложность «жесткого»декодирования инвертированием битов, однако качество декодиро&вания повышается за счет использования дополнительной информа&ции на выходе канала. Однако качество работы такого алгоритмазависит от инициализации: чем точнее она произведена, тем точнеебудет конечный результат. Для канала с гауссовским шумом иници&ализация может быть произведена при помощи информации о дис&персии шума в канале. Для других распределений шума в канале илипри неизвестных характеристиках шума точная инициализация ал&горитма может являться сложной задачей.
Быстрое декодирование LDPC
Несмотря на то, что декодирование пересчетом вероятностей яв&ляется эффективным методом для каналов с непрерывным выходом,тот факт, что сложность его значительно выше, чем сложность «же&

30
сткого» декодирования, оставляет место для поиска более быстрыхалгоритмов декодирования, обладающих приемлемым качеством.
Среди известных алгоритмов быстрого декодирования кодов с низ&кой плотностью проверок на четность для каналов с непрерывнымвыходом наиболее известен алгоритм «min&sum», являющийся уп&рощением декодера «belief propagation», а также алгоритм UMP(Uniformly Most Powerful [7]), который рассматривается ниже.
Пусть из канала был принят вещественный («мягкий») векторy � {y0, ..., yN–1}. Будем считать надежностью i&го символа вектора yвеличину ri, характеризующую удаление принятого значения yi от не&коего порогового значения thr, при котором все значения переданныхсимволов равновероятны: thr : (1/ ) (0/ ),i iP y P y� thr .i ir y� � Дляслучая двоичной модуляции, при которой все биты кодового слова ото&бражаются во множество {–1, 1} и передаются по симметричному ка&налу с двоичным входом, надежность принятого символа yi будет, та&ким образом, равна абсолютной величине принятого значения: .i ir y�
Быстрое декодирование по надежностям являет собой баланс меж&ду «жестким» декодированием и декодированием по вероятностям[1–3]. При декодировании используется вектор «жестких» решенийx � {x0, ..., xN–1} (вектор, состоящий из 0 и 1 и представляющий собойнабор дискретных решений) и вектор надежностей r � {r0, ..., rN–1}(вектор, состоящий из вещественных величин из интервала � �0, �� ).По аналогии с вероятностным декодированием, каждому ненулево&му символу проверочной матрицы приписываются два числа: xi,j и ri,j,представляющие собой «жесткое» решение относительно символа i,полученное при помощи всех проверок, кроме i&й, и надежность сим&волов i&й проверки без учета j&го символа соответственно. Декодиро&вание также является итеративным, одна итерация представляетсобой следующую последовательность действий.
1. Для всех проверок и всех символов проверок вычисляется на&дежность проверок относительно символа j, представляющая собойминимальное значение надежностей всех символов, входящих в про&верку, кроме самого символа j:
, ,( )\
min .i j i jj N i j
r r�
��
� �
2. Для всех символов принятого вектора и всех проверок произво&дится пересчет надежностей символов проверок: если проверка,в которую входил некоторый символ, не выполняется, то надежностьri,j уменьшается на величину надежности проверки , ,i jr� в противномслучае надежность ri,j увеличивается на , ;i jr� учитываются все провер&ки, кроме i&й. Если после применения всех проверок для какого&то

31
символа j величина ri,j стала меньше нуля, то обновленная надеж&ность ri,j берется по модулю, а жесткое решение xi,j инвертируется.
3. Аналогично пересчитываются надежности принятого вектора:если i&я проверка, в которую входит j&й символ, нарушается, то изнадежности ri вычитается надежность i&й проверки, иначе надежностьсимвола увеличивается на надежность проверки. Если после приме&нения всех проверок для какого&то символа j величина ri стала мень&ше нуля, то обновленная надежность ri,j берется по модулю, а «жест&кое» решение xi,j инвертируется.
4. Если «жесткое» решение x является кодовым словом, декодиро&вание заканчивается, иначе декодер начинает следующую итерацию.
Сложность декодера UMP (быстрого декодирования по надежнос&тям) значительно ниже, чем сложность декодера, пересчитывающеговероятности, за счет того, что пересчет надежностей выполняется поупрощенной схеме (схеме «взвешенного» мажоритарного голосования,в качестве «весов» используется надежность проверок), а также за счетвозможности использования исключительно целочисленных операцийсложения и сложения по модулю два. Общую сложность одной ите&рации можно оценить как сумму сложностей M(2J log2J – 2) срав&нений, 2NJ сложений по модулю два и 2N(J l4)(J – 1) сложений, гдеN – длина кодового слова, M – количество информационных бит в кодо&вом слове, J – количество единиц в столбце проверочной матрицы кодас низкой плотностью проверок на четность.
Также к достоинствам быстрого декодера по надежностям можноотнести то, что декодеру не требуется знать характеристики шума вканале (дисперсию и т. д.), а следовательно, такой декодер может рабо&тать в любом симметричном канале с двоичным входом. Далее в работебудет показано, как это свойство быстрого декодера по надежностямможет быть использовано при кодовом квантовании изображений.
Недостатком быстрого декодера по надежностям является оценкавероятности ошибки декодирования, которая для канала с аддитив&ным гауссовским шумом оказывается на 0,5 дБ хуже, чем вероят&ность ошибки декодирования вероятностного декодера. Ниже будетописана модификация алгоритма, позволяющая добиться прибли&жения вероятности ошибки декодирования к вероятности, получае&мой при вероятностном декодировании.
Многопороговое декодирование
Быстрый декодер по надежностям, рассмотренный выше, прини&мает решения относительно символов принятого вектора на основепересчета надежностей и инвертирования символов «жесткого» ре&

32
шения, причем инвертирование символов производится всегда, ког&да соответствующая надежность после пересчета становится меньшенуля. Нуль в данном случае является порогом инвертирования сим&вола, причем на всех итерациях этот порог остается неизменным,несмотря на то, что на первых итерациях декодирования надежнос&ти символов битов еще плохо определены, и инвертирование такихсимволов может привести как к исправлению ошибок, так и, наобо&рот, к внесению новых и последующему их размножению.
Основная идея многопорогового декодирования по надежностямсостоит в том, чтобы изменять значения порогов инвертированиясимволов от одной итерации к другой следующим образом (рис. 2):
на первых итерациях порог инвертирования символов выбирает&ся так, чтобы количество инвертированных символов было мини&мальным (вплоть до инвертирования только одного символа на пер&вой итерации);
на последующих итерациях пороги инвертирования постепенноповышаются.
Общая схема работы многопорогового декодера по надежностямприведена на рис. 3.
1. Инициализация декодера и вычисление надежностей символовпроверок производится так же, как и в алгоритме быстрого декоди&рования по надежностям: для всех элементов принятого вектора Yiвычисляется «жесткое» решение Xi и надежность Ri, надежность яв&ляется абсолютным значением Yi, а также для всех m�� M(n) присва&иваются Ym,n � Rn и Xm,n � Xn.
2. Для каждой итерации i вычисляется пороговое значение THRi.
���������� ��������� ���������
���
�
��
��
Рис. 2. Пороги для многопорогового декодирования:
– пересчитанные надежности; – пороги
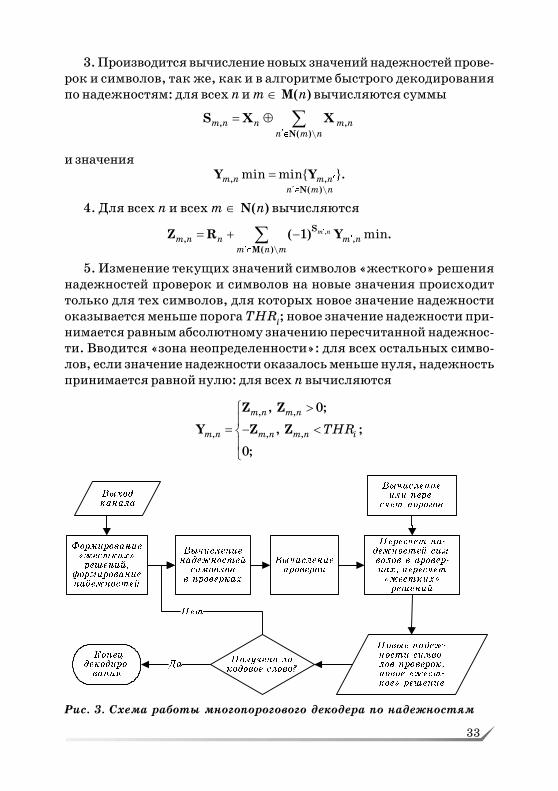
33
3. Производится вычисление новых значений надежностей прове&рок и символов, так же, как и в алгоритме быстрого декодированияпо надежностям: для всех n и m�� M(n) вычисляются суммы
, ,( )\
m n n m nn m n��
� � �N
S X X
и значения
, ,( )\
min min{ }.m n m nn m n
�
��
�N
Y Y
4. Для всех n и всех m�� N(n) вычисляются
,, ,
( )\
( 1) min.m nm n n m n
m n m
�
�
��
� � �� S
M
Z R Y
5. Изменение текущих значений символов «жесткого» решениянадежностей проверок и символов на новые значения происходиттолько для тех символов, для которых новое значение надежностиоказывается меньше порога THRi; новое значение надежности при&нимается равным абсолютному значению пересчитанной надежнос&ти. Вводится «зона неопределенности»: для всех остальных симво&лов, если значение надежности оказалось меньше нуля, надежностьпринимается равной нулю: для всех n вычисляются
, ,
, , ,
, 0;
, ;
0;
m n m n
m n m n m n iTHR
���
� � ����
Z Z
Y Z Z
��������������� ������������
�������������������� ��
�����������
������������������ ��
������������������
������������������
������������������
��� �������
������� ��������� ������������������������������ ��� �����������
�������������� ��������������������������� ������������
����������������������
��
!�"���#
�������������$
Рис. 3. Схема работы многопорогового декодера по надежностям

34
, ,,
, ,
, ;
1 , ;
m n m n im n
m n m n i
THR
THR
���� � � ���
X ZX
X Z
,,
( )
( 1) min;m nn n m n
m n�
� � �� S
M
Z R Y
, 0;
1 , 0.n n
nn n
��� � � ��
X ZC
X Z
6. Декодирование итеративно продолжается до тех пор, пока век&тор C не станет кодовым словом или не будет выполнено заданноечисло итераций.
При многопороговом декодировании, если на первой итерации былаисправлена хотя бы одна ошибка, декодирование на последующих ите&рациях становится значительно проще и общее качество декодирова&ния улучшается [8]. По&прежнему для работы декодеру не требуетсяинформация о шуме в канале, достаточно лишь задать надежности.
Декодер, работающий по многопороговой схеме, позволяет получитьвероятность ошибки декодирования на 0,1–0,4 дБ лучшую, чем обеспе&чивает быстрый декодер по надежностям UMP, практически прибли&жаясь к вероятности ошибки, получаемой при вероятностном декоди&ровании кодов с низкой плотностью проверок на четность. На рис. 4приведены кривые BER двоичных кодов в канале с аддитивным гауссов&ским шумом, имеющим математическое ожидание, равное нулю, и энер&гию шума N0, при использовании трех различных декодеров: декодерапо вероятностям, быстрого декодера по надежностям и многопорогово&го декодера.
Помимо независимости от характеристик канала многопороговыйдекодер обладает свойством декодеров кодов с низкой плотностьюпроверок на четность, а именно – универсальность и применимостьдля любой конструкции таких кодов.
Критерии качества и сложности декодирования
Так как декодирование LDPC является итеративным, то в общемслучае сложность декодирования можно представить как произведе&ние сложности одной итерации на общее количество итераций:
.complete one iteration iterationsC C N�
Сложность одной итерации декодирования пропорциональна чис&лу единиц в проверочной матрице [1–3, 7]. Таким образом, чтобыанализировать всю сложность декодирования, необходимо учиты&

35
вать не только сложность одной итерации декодера, но и количествоитераций, требуемых для обеспечения заданного качества декодиро&вания.
Будем понимать под скоростью сходимости зависимость вероят&ности ошибки декодирования от количества итераций, за котороеданная вероятность ошибки декодирования была получена.
На рис. 5–7 приводятся гистограммы сходимости многопорогово&го декодера для различных конструкций LDPC&кодов из расчета мак&симального количества итераций, равного 20. На осях гистограммотложено количество итераций и количество попыток, в которыхдекодер закончил работу за данное число итераций. Во всех случаяхконструкции кодов анализировались на отношении сигнал/шум,обеспечивавшем вероятность ошибки 10–5.
Из гистограмм видно, что требуемое количество итераций не яв&ляется постоянной величиной для различных конструкций кодов, инаименьшее количество итераций требуется для декодирования евк&лидово&геометрических кодов (EG&LDPC). Следовательно, общая
��
�
��� � ��� � ��� ���
��
��
����
����
����
����
����
���
����� �
Рис. 4. Вероятность ошибки при декодировании (2048, 1649) – кодас низкой плотностью проверок на четность при помощи раз�личных декодеров для различных отношений сигнал/шумв канале:
– вероятностный декодер; – быстрый декодер; – многопороговый декодер

36
�
�
�
�
�
��
��
��
��
��
� � � � � �� �� �� �� �� ��
Рис. 5. Число итераций, затраченных на де�кодирование LDPC�кодов, основанныхна евклидовых геометриях [4]
�
���
�
���
�
���
�
���
�
���
� � � � � �� �� �� �� �� ��
Рис. 6. Число итераций, затраченных на де�кодирование LDPC�кодов, основанныхна кодах Рида–Соломона с двумя ин�формационными символами [5]
� � � � � �� �� �� �� �� ��
�
�
��
��
��
��
Рис. 7. Число итераций, затраченных на де�кодирование LDPC�кодов, построенныхпо принципу density evolution [6]
� 104
� 104
� 102

37
сложность декодирования для этой конструкции будет минимальна,несмотря на большое количество единиц в проверочной матрице EG&LDPC&кодов.
Заключение
В данной работе предложен алгоритм многопорогового декодиро&вания для кодов с низкой плотностью проверок на четность. Явля&ясь представителем класса «быстрых» декодеров, алгоритм по слож&ности равен алгоритму UMP, рассмотренному в работе, и требуетсложности декодирования в 10 раз меньшей, нежели сложность тра&диционных алгоритмов. При этом многопороговый алгоритм деко&дирования позволяет в гауссовском канале получить вероятностьошибки декодирования всего на 0,1–0,2 дБ хуже, чем при использо&вании локально&оптимальных алгоритмов, а по сравнению с быст&рыми алгоритмами декодирования новый алгоритм выигрывает 0,3–0,4 дБ по вероятности ошибки.
Литература
1. Gallager R. G. Low&density parity&check codes. PhD thesis. 1963. 90 p.2. Gallager R. G. Low&density parity&check codes // IEEE Trans. on Inform.
Theory. Vol. IT&8. Jan. 1968. P. 21–28.3. MacKay D. J. C., Neal R. M. Near Shannon limit performance of low
density parity check codes // IEE Electronics Letters. Vol. 32. N 18. 29 Aug.1996. P. 1645–1655.
4. A class of low&density parity&check codes constructed based on Reed&Solomon codes with two information symbols / I. Djurdjevic, J. Xu, K. Abdel&Ghaffar et al. // IEEE Communications Letters. Vol. 7. N 7. July 2003.P. 317–319.
5. Kou Y., Lin S., Fossorier M. P. C. Low&density parity&check codes basedon finite geometries: A rediscovery and new results // IEEE Transactions onInformation Theory. Vol. IT&47. Nov. 2001. P. 2711–2736.
6. Richardson T. J., Shokrollahi M. A., Urbanke R. L. Design of capacityapproaching irregular low&density parity&check codes // IEEE Trans.Information Theory. Vol. 47. Feb. 2001. P. 619–637.
7. Fossorier M. P. C., Mihaljevic M., Imai H. Reduced complexity iterativedecoding of low&density parity check codes based on belief propagation //IEEE Transactions on Communications. 47(5). May 1999. P. 673–680.
8. Колесник В. Д., Мирончиков Е. Т. Декодирование циклических ко&дов. М.: Связь, 1968. 252 с.

38
А. Г. Ефимов,аспирантСанкт�Петербургский государственный университетаэрокосмического приборостроения
ОБ АППАРАТНОЙ РЕАЛИЗАЦИИ ДЕКОДЕРОВ LDPC�КОДОВ
Введение
Рассматривается несколько подходов к аппаратной реализациидекодеров LDPC&кодов на примере наиболее известных алгоритмовдекодирования: Belief Propagation (BP) [1], Uniformly Most PowerfulBelief Propagation (UMP BP) [2], многопороговое декодирование (MT)[3] и турбодекодирование [4] на примере турбодекодера с ядром BCJR.Для различных схем реализации декодеров в статье приведено срав&нение основных характеристик схем (пропускной способности и пло&щади кристалла), имеющих значение для аппаратной реализации.Сравнение различных схем рассматривается на примере LDPC&кода(2048, 1723), принятого в стандарт IEEE 802.3an (стандарт физи&ческого уровня сети 10G Ethernet).
Параллельная архитектура декодеров LDPC�кодов
Алгоритмы декодирования, рассматриваемые в статье, – это ите&ративные алгоритмы декодирования, которые предназначены дляисправления ошибок, возникающих в каналах с полунепрерыв&ным выходом, например в канале с аддитивным белым гауссов&ским шумом.
Кратко рассмотрим работу декодера LDPC&кода. Для этого вос&пользуемся представлением LDPC&кода в виде графа, для которо&го проверочная матрица кода выступает в качестве матрицы инци&дентности. Такой граф принято называть графом Таннера [5]. ГрафТаннера – это двудольный граф, вершины которого разделены надва множества: множество символьных вершин, соответствующихстолбцам проверочной матрицы, и множество проверочных вер&шин, соответствующих строкам проверочной матрицы. Ребра вграфе Таннера соответствуют ненулевым позициям в проверочнойматрице кода.
Одна итерация каждого алгоритма декодирования состоит из двухфаз: в первой фазе происходит обновление надежностей всех прове&рочных вершин на основании надежностей символьных вершин, вовторой – обновление всех надежностей символьных вершин на ос&

39
новании надежностей проверочных вершин. В каждой фазе обновле&ние надежностей для каждой вершины происходит независимо и, сле&довательно, может выполняться параллельно.
Представление проверочной матрицы LDPC&кода в виде графа Тан&нера дает простой и естественный способ аппаратной реализации де&кодера. Этот способ был предложен в статье [6]. В данном случае сим&вольные и проверочные вершины графа Таннера реализуются аппа&ратно как соответствующие вычислительные элементы (символьныеи проверочные), а ребра графа задают систему связей (шин и прово&дов) между вычислительными элементами и блоками памяти, хра&нящими значения вычисляемых в процессе декодирования надежно&стей. Далее вычислительные элементы, соответствующие провероч&ным вершинам, будем обозначать CNU (check node processing unit), аэлементы, соответствующие символьным элементам, – VNU (variablenode processing unit).
Основное преимущество такой архитектуры состоит в том, что об&новления надежностей битов, соответствующих разным строкам(столбцам) проверочной матрицы, могут выполняться полностью па&раллельно. Это позволяет достичь максимальной пропускной спо&собности декодера, которая может составлять до нескольких гига&
Рис. 1. Схема декодера, соответствующая полностью параллельнойархитектуре для кода (7, 5), содержащего 4 единицы в стро�ках и 3 единицы в столбцах проверочной матрицы
���
���
���
���
���
���
���
���
���
���
���
����������
���������
��������� ��
�����
���
������

40
бит в секунду. Однако общая вычислительная сложность такого де&кодера оказывается достаточно большой из&за большого количествавычислительных элементов и сложной неструктурированной систе&мы связей между этими элементами.
Укрупненная схема алгоритма декодирования, построенная в со&ответствии с полностью параллельной архитектурой, показана нарис. 1.
Частично�параллельная архитектура декодеров LDPC�кодов
Поскольку площадь кристалла является критическим парамет&ром в аппаратной реализации, может оказаться, что для уменьше&ния площади придется пожертвовать скоростью работы декодера.В таком случае имеет смысл использовать схему, выполняющую об&новление надежностей не для всех символьных (проверочных) вер&шин графа Таннера параллельно (рис. 2). В этом случае обновляе&мые надежности сохраняются в памяти, а один или несколько вы&числительных элементов обрабатывают последовательно эти надеж&ности.
Для коммутации сигналов между ячейками памяти и вычисли&тельными элементами используется специальный блок «маршрути&затор», который может быть выполнен на базе стандартных логичес&ких элементов: мультиплексоров и демультиплексоров. При этомпотребуется:
1. NCNU w&битныхCNU
1R
N
� ��� �
� � мультиплексоров для коммутации
сигналов, передаваемых от ячеек памяти к проверочным элементам,
Рис. 2. Схема работы декодера, соответствующая частично�парал�лельной архитектуре
������
�����������
���� ������������ ����
���
��������

41
где NCNU – количество проверочных элементов в схеме; – количе&ство единиц в строке проверочной матрицы; w – разрядность комму&тируемых надежностей (количество битов, требуемое для храненияодной надежности); R – количество строк в проверочной матрице.Как правило, это число равно 5–7 битам в зависимости от алгоритмадекодирования и реализации.
2. NCNU w&битныхCNU
1R
N
� �� � �� �
демультиплексоров для коммута&
ции сигналов, передаваемых от проверочных элементов к ячейкампамяти.
3. VNU ( 1)N � � w&битныхVNU
1N
N
� ��� �
� � мультиплексоров для ком&
мутации сигналов, передаваемых от ячеек памяти к символьным эле&ментам, где NVNU – количество символьных элементов в схеме; � –количество единиц в столбце проверочной матрицы; N – длина кода.
4. NVNU ��w&битных1VNU
N
N
� �� � �� �
демультиплексоров для коммута&
ции сигналов, передаваемых от символьных элементов к ячейкам па&мяти.
Видно, что количество логических элементов, требуемых для реа&лизации «маршрутизатора», не зависит от количества вычислитель&ных элементов в схеме, а зависит лишь от размеров проверочной мат&рицы кода и количества единиц в строках и столбцах этой матрицы.
Пропускная способность декодеров LDPC�кодов
Под пропускной способностью декодера традиционно понимаетсясреднее количество битов в единицу времени, обрабатываемое иливыдаваемое декодером. Здесь под пропускной способностью будем по&нимать количество информационных битов, выдаваемых декодером.Пропускная способность декодера зависит не только от степени па&раллельности вычислений в схеме декодирования. Другим важнымфактором является время работы вычислительных элементов. Дляразличных декодеров это время различно. В табл. 1 приведено времяработы вычислительных элементов (символьных и проверочных) длярассматриваемых в статье декодеров. Для каждого декодера оценкавремени работы была получена путем синтеза вычислительных эле&ментов для реализации на ASIC при использовании библиотеки эле&ментов TSMC 0.18 мкм.
42
Из табл. 1 видно, что для одного и того же кода и одной и той жестепени параллельности схемы декодирования максимальная про&пускная способность разных декодеров будет различна, посколькув разных декодерах отличается время работы вычислительных эле&ментов. В табл. 2 приведены оценки пропускной способности каждо&го декодера для различных схем. Здесь и далее сравнение различныхсхем декодирования проводится на примере декодеров, построенныхдля декодирования (2048, 1723) LDPC&кода, содержащего 384 про&верки, 32 единицы в строках и 6 единиц в столбцах проверочной мат&рицы. Предполагается, что декодирование состоит из 10 итераций.
редокеДсн,атнемелэытобарямерВ
огоньловмис огончореворп
noitagaporPfeileB 58.01 37.7
PBPMU 71.51 34.01
редокедйывогоропогонМ 71.51 25.01
редокедобруТRJCBмордяс
]7[яицазилаеряанноицидарТ 04.361 едивмонвяВтеувтстусто]8[яицазилаеряартсыБ 90.13
Таблица 1
Таблица 2
редокеД
&отсаЧ&арат
ытоб&окед,аред
цГМ
ялдеомеуберт,воткатовтсечилоKяанксупорП/аволсогондояинаворидокед
с/бМ,ымехсьтсонбосопс
&аводелсоП&раяаньлет
аруткетихи&UNCнидо(
&UNVнидо)тнемелэ
&ап&ончитсаЧяаньлеллараруткетихра&апьнепетс(итсоньлеллар
)4/1
юьтсонлоПяаньлелларап
аруткетихра&ларапьнепетс(
)1итсоньлел
noitagaporPfeileB 2.29 35.6/12342 93.0691/18 15.1657/12
PBPMU 9.56 76.4/12342 08.1041/18 49.6045/12
йывогоропогонМредокед
9.56 76.4/12342 08.1041/18 49.6045/12
&обруТредокедмордяс
RJCB
яанноицидарТяицазилаер
1.6 57.2/1483 57.34/142 68.271/16
яартсыБяицазилаер
2.23 34.4/1483 29.922/142 93.809/16

43
Как правило, все вычислительные элементы, расположенные наодном кристалле, тактируются одной тактовой частотой. Таким об&разом, частота работы декодера определяется частотой работы наи&более медленного среди всех элементов – символьного.
Потенциально пропускная способность декодеров BP, UMP BP иMT может быть увеличена за счет использования двух тактовых ге&нераторов и независимого тактирования символьных и проверочныхэлементов. Но использование двух тактовых генераторов сильноусложнило бы процесс работы с памятью (чтение/запись надежнос&тей), а как следствие, и аппаратную реализацию декодера в целом.
Второй способ увеличения пропускной способности состоит в ис&пользовании конвейерных вычислений в вычислительных элемен&тах. Использование конвейеров разной длины в проверочных и сим&вольных элементах позволяет «выровнять» частоты работы этихэлементов и увеличить, таким образом, общую пропускную способ&ность декодера. Пример реализации конвейера длины 3 в провероч&ном элементе алгоритма MT приведен схематично на рис. 3. Пропус&кная способность различных декодеров при использовании конвей&ерных вычислений представлена в табл. 3.
редокеД
&илДан
&нок&ейев
вар/UNC&UNV&емелэ
хатн
&отсаЧат
&обарыт
&окед,аред
цГМ
ялдеомеуберт,воткатовтсечилоKяанксупорП/аволсогондояинаворидокед
с/бМ,ымехсьтсонбосопс
&аводелсоПяаньлет
аруткетихраи&UNCнидо(
&UNVнидо)тнемелэ
&ап&ончитсаЧяаньлеллараруткетихра
ьнепетс(&оньлелларап
)4/1итс
юьтсонлоПяаньлелларап
аруткетихраьнепетс(
&оньлелларап)1итс
feileBnoitagaporP
2/3 3.252 58.71/15342 95.5193/111 61.2258/15
PBPMU 2/3 8.581 51.31/15342 80.4882/111 31.7726/15
йывогоропогонМредокед
2/3 3.581 11.31/15342 67.6782/111 81.1626/15
&обруТредокедмордяс
RJCB
&идарТяанноиц&азилаер
яиц
23 2.361 23.94/1075 48.331/1012 83.641/1291
яартсыБ&азилаер
яиц
6 0.081 39.47/1414 85.375/145 75.958/163
Таблица 3

44
Рис. 3. Схема реализации проверочного элемента МТ�декодера: а – безиспользования конвейера; б – c использованием конвейера длины 3
����
����
����
����
����
����
����
����
������
������
������
����
����
����
����
����
����
����
����
������
� � ��� ���� � ��� ����
� � ���� ����� � �������
� � ��� ���� � ���������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
�������
���
���
��
��
��
��
����
����
����
����
����������
������
���� ������
� � ���� ���� � �������
���
���
��������
��������
��������
��������
��������
��������
��
��
���
��
��
���
����
����
����
����
����
����
����
����
а)
б)

45
Из табл. 2 и 3 видно, что прирост производительности от исполь&зования конвейерных вычислений для различных декодеров разли&чен и зависит от степени параллельности в схеме реализации. Дляполностью параллельной схемы прирост может быть получен толькодля декодеров BP, MT и UMP BP, поскольку для них конвейерныевычисления позволяют «выровнять» частоты проверочных и сим&вольных вычислительных элементов. Для этих декодеров приростпроизводительности в полностью параллельной схеме составил 13–16%. В полностью параллельной реализации турбодекодера, наобо&рот, наблюдается некоторое падение производительности. Происхо&дит это из&за того, что элементы памяти, формирующие задержки вконвейерах, увеличивают время работы символьного вычислитель&ного элемента, а из&за отсутствия в явном виде проверочного вычис&лительного элемента не «выравниваются» частоты.
Для частично&параллельной схемы реализации прирост произво&дительности от использования конвейерных вычислений существу&ет для всех декодеров, в том числе для турбодекодера. Причем, чемменьше степень параллельности и чем больше длина конвейеров, темвыше прирост производительности. Так, для декодеров BP, MT и UMPBP использование конвейерных вычислений в схеме с одним прове&рочным и одним символьным вычислительным элементом обеспечи&вает прирост производительности приблизительно в 3 раза, а длятурбодекодера – в 5 и 18 раз для быстрой и традиционной схем реали&зации алгоритма BCJR соответственно.
Для схемы, в которой количество вычислительных элементов рав&но 1/4 от количества, необходимого для полностью параллельнойреализации, т. е. для схемы со степенью параллельности 1/4, при&рост производительности для декодеров BP, MT и UMP BP составил100–106%, а для турбодекодера – 150 и 200% для быстрой и тради&ционной схем соответственно.
Платой за такое увеличение пропускной способности является уве&личение количества элементов памяти, необходимых для формиро&вания задержки сигналов в конвейерах, которое приводит к ростуобщей площади кристалла. Причем, чем больше длина конвейера,тем больше требуется элементов памяти и тем сильнее увеличивает&ся площадь кристалла. Так, для полностью параллельной реализа&ции декодеров BP, MT и UMP BP при использовании конвейеров дли&ны 2 и 3 в символьных и проверочных элементах соответственно ростплощади составил 12–34%, для быстрой реализации турбодекодерас конвейером длины 6–15%, для традиционной реализации с кон&вейером длины 32 – почти в 2 раза.

46
Оценка пропускной способности и площади кристалладля различных схем реализации декодеров
Оценка пропускной способности и площади для различных схемреализации рассматриваемых декодеров представлена на рис. 4–7.Оценка пропускной способности была получена путем независимогосинтеза всех вычислительных элементов декодера, определения час&тоты работы каждого элемента и последующего вычисления оценкипо формуле
Рис. 4. Характеристики декодера BP: а – оценка пропускной способно�сти; б – оценка площади;
а)
б)
��������� ������������ ��
�
�
�
�
�
�
�
�
�
� � �� �� �� ��� ��� ��� ���� ����
� � � � �� �� �� � �� ���
������������ ��� ��������
������������
�
��
��
��
��
��
��
��
� � �� �� �� ��� ��� ��� ���� ����
� � � � �� �� �� � �� ���
������������ ��� ��������
� ��� �������������� � ����� ���
� ������������������������������������� ��� ��� ��

47
min / ,clksC Fb N K�где Fbmin – частота работы наиболее медленного элемента декодера;Nclks – количество тактов, необходимых для декодирования одногокодового слова; K – количество информационных символов в одномкодовом слове.
Оценка площади была получена по формуле
CNU CNU VNU VNU 0,S S N S N S� � �где SCNU – площадь проверочного элемента; NCNU – количество прове&рочных элементов в схеме; SVNU – площадь символьного элемента;
Рис. 5. Характеристики декодера MT: а – оценка пропускной способ�ности; б – оценка площади;
��������� ������������ ��
�
�
�
�
�
�
�
�
� � �� �� �� ��� ��� ��� ���� ����
� � � � �� �� �� � �� ���
������������ ��� ��������
������������
�
��
��
��
��
��
��
��
��
�
� � �� �� �� ��� ��� ��� ���� ����
� � � � �� �� �� � �� ���
������������ ��� ��������
а)
б)
� ��� �������������� ������� ���
� ��������������������� �������������� �������� ��

48
NVNU – количество символьных элементов; S0 – сумма площадей ос&тальных вычислительных элементов, включая входные и выходныебуферы, блок инициализации, блок управления, блоки коммутациисообщений между памятью и вычислительными элементами и т. д.Полученная таким образом оценка площади является минимальновозможным значением площади, при этом качество оценки ухудша&ется с ростом количества используемых в схеме символьных и прове&рочных вычислительных элементов.
��������� ������������ ��
�
�
�
�
�
�
� � � �� � ��� �� ��� ���� ����
� � � �� �� �� � ��� ���
����������� ��������������
������������
�
��
��
��
��
��
�
�
��
� � � �� � ��� �� ��� ���� ����
� � � �� �� �� � ��� ���
����������� ��������������
Рис. 6. Характеристики декодера UMP BP: а – оценка пропускной спо�собности; б – оценка площади;
а)
б)
� ��� �������������� ������� ���
� ��������������������� �������������� �������� ��

49
��������� ������������ ��
�
���
���
���
���
�
� � � � �� � ��
������������� �������
������������
�
��
��
�
��
��
��
� � � � �� � ��
������������� �������
Заключение
Были рассмотрены два известных подхода к аппаратной реализа&ции декодеров LDPC&кодов: полностью параллельная и частично&параллельная архитектуры.
При использовании полностью параллельной архитектуры (см.рис. 4–7) пропускная способность декодеров BP, UMP BP и MT до&стигает 6–8,5 Гб/с. Таким образом, параллельная архитектура мо&жет быть использована на физическом уровне высокоскоростных про&токолов передачи данных (например, в сети 10G Ethernet или в дру&гих средствах связи, пропускная способность которых составляет до10 Гб/с) для исправления ошибок, возникающих при передаче дан&
Рис. 7. Характеристики турбодекодера с ядром BCJR: а – оценкапропускной способности; б – оценка площади;
а)
б)
� ��� ������������� ���������������� ������ �
� ����������� ������� ���������������� ���� ��� �
� ��� ��������������������������� ��� ��� �
� ��������������������������������� ��������

50
ных в каналах связи. Сравнивая площади различных декодеров,можно видеть, что площадь декодера Belief Propagation оказываетсянаименьшей. Однако так называемые «быстрые декодеры» (UMP BPи MT) могут быть эффективно реализованы с использованием парал&лельных ассоциативных вычислений (ассоциативных процессоров)[9]. При этом при использовании ассоциативных вычислений кажетсявозможным уменьшить площадь декодеров минимум в 1,5–2 раза,хотя для получения точных оценок требуются дополнительные ис&следования. Таким образом, с учетом качества декодирования алго&ритмы Belief Propagation и Multi&Threshold являются наиболее под&ходящими кандидатами для реализации в высокоскоростных схе&мах передачи.
В приложениях, где требуемая пропускная способность не превы&шает 1–2 Гб/с (например, в протоколах беспроводной связи), можетиспользоваться частично&параллельная архитектура. В таком слу&чае наилучшим вариантом оказывается турбодекодер, пропускнаяспособность которого оказывается достаточной, а качество работывыше, чем у других декодеров [4].
Литература
1. Gallager R. G. Low Density Parity Check Codes. Cambridge, MA: MITPress, 1963.
2. Fossorier M.P.C., Mihaljevic M., Imai H. Reduced Complexity IterativeDecoding of Low&Density Parity&Check Codes Based on Belief Propagation //IEEE Transactions on Communications. Vol. 47(5). May 1999.
3. Belogolovyi Andrey V., Krouk Evguenii A., Trifonov Peter V. Multi&Threshold Reliability Decoding Of Low Density Parity Check Codes. Пат.США.
4. Mansour M. M., Shanbhag N. R. High&Throughput LDPC decoders//IEEE Transactions on VLSI Systems. 2003. Vol. 11. N 6.
5. Tanner R. A recursive approach to low complexity codes// IEEETrans.Inform. Theory. 1981. Vol. IT&42. P. 533–547.
6. Blanksby A., Howland C. A 690&mw 1&gb/s 1024&b, rate&1/2 low&densityparity&check code decoder// IEEE Journal on Solid&State Curcuits. Mar. 2002.Vol. 37. N 3. P. 404–412.
7. Mansour M. M., Shanbhag N. R. High&Throughput LDPC decoders//IEEE Transactions on VLSI Systems. 2003. Vol. 11. N 6.
8. Hu et al. X. Y. Efficient implementations of the sum&product algorithmfor decoding LDPC codes// Proc. IEEE GLOBECOM, San Antonio: TX, 2001.Vol. 2. P. 1036–1036E.
9. Фостер К. Ассоциативные параллельные процессоры. М.: Энергоиз&дат, 1981.