実践 :線形回帰 分析入門
DESCRIPTION
実践 :線形回帰 分析入門. 頻度論とベイジアンの比較 慶應義塾大学 SFC 小暮研究会 梶田幸作. 目的と手法. ジャパンRE( 8952 )とTOPIXのデータ( 2006 年 10 月 24 日から 2007 年 10 月 23 日)を用いて線形回帰分析を行う 実習を通して、 β についての推定を頻度論(ヒストリカルベータ)とベイジアン(ベイジアンベータ ? )の両方の立場から検証する 頻度論の分析を Excel で、ベイジアンの分析(ベイズモデルによる回帰直線を求める)を WinBUGS で行う. β とは. - PowerPoint PPT PresentationTRANSCRIPT

頻度論とベイジアンの比較慶應義塾大学 SFC 小暮研究会
梶田幸作
1

ジャパンRE( 8952)とTOPIXのデータ( 2006年 10月 24日から 2007年 10月 23日)を用いて線形回帰分析を行う
実習を通して、β についての推定を頻度論(ヒストリカルベータ)とベイジアン(ベイジアンベータ?)の両方の立場から検証する
頻度論の分析を Excelで、ベイジアンの分析(ベイズモデルによる回帰直線を求める)をWinBUGSで行う
2

β とは、直感的にはある銘柄の動きがマーケット( TOPIXや日経 225)の動きに対してどの程度感応的かを示す指標。
β > 1 :マーケットより大きな動きをする β = 1 :マーケットと同じ動きをする β < 1 :マーケットより小さな動きをする
種類としてヒストリカルベータ、インプライドベータがある。また、修正ベータやアンレバードベータなどがある。
3
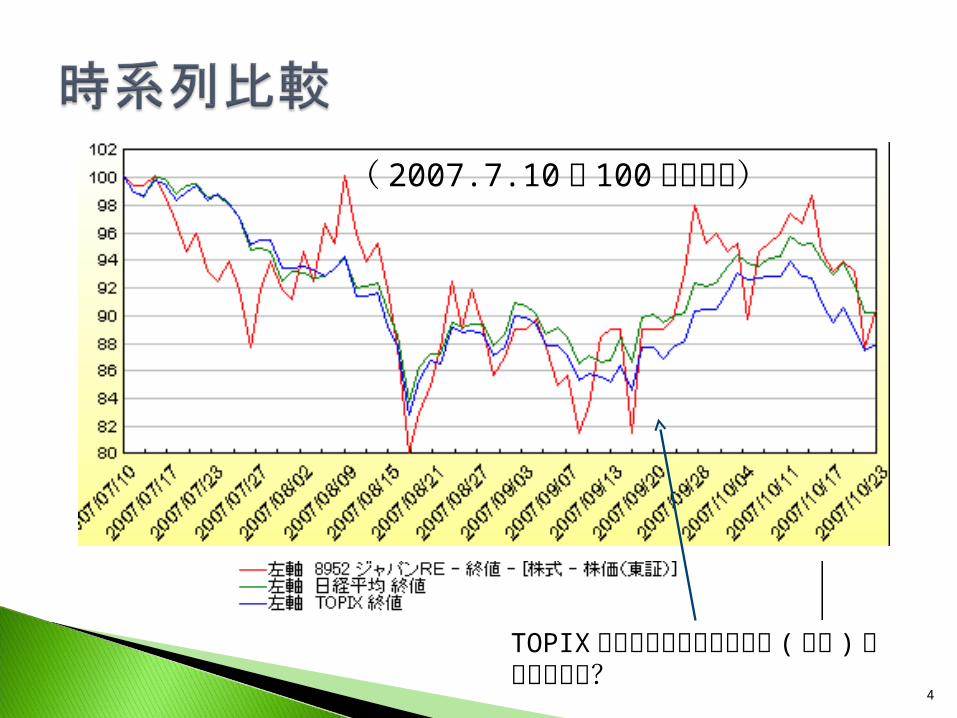
4
TOPIXに対してどのような動き (変動 )をしているか?
( 2007.7.10を 100に基準化)

データ( Bayes1)を開く A-C列に J-REITと TOPIXの終値が1 年分ある 基準化して分析するため、 E-F列にその収益率を計算する
収益率かしたデータを視覚的に把握するため散布図を描く( Alt+I+Hでグラフウィザードを出し散布図を選択する。右クリックで数式も出力する)
ツールバーのデータから分析ツールをクリックして回帰分析を選択。 X 軸に TOPIX、 Y 軸に 8952のデータを指定し、さらに必要な項目にチェックをいれてOKを押す。
5
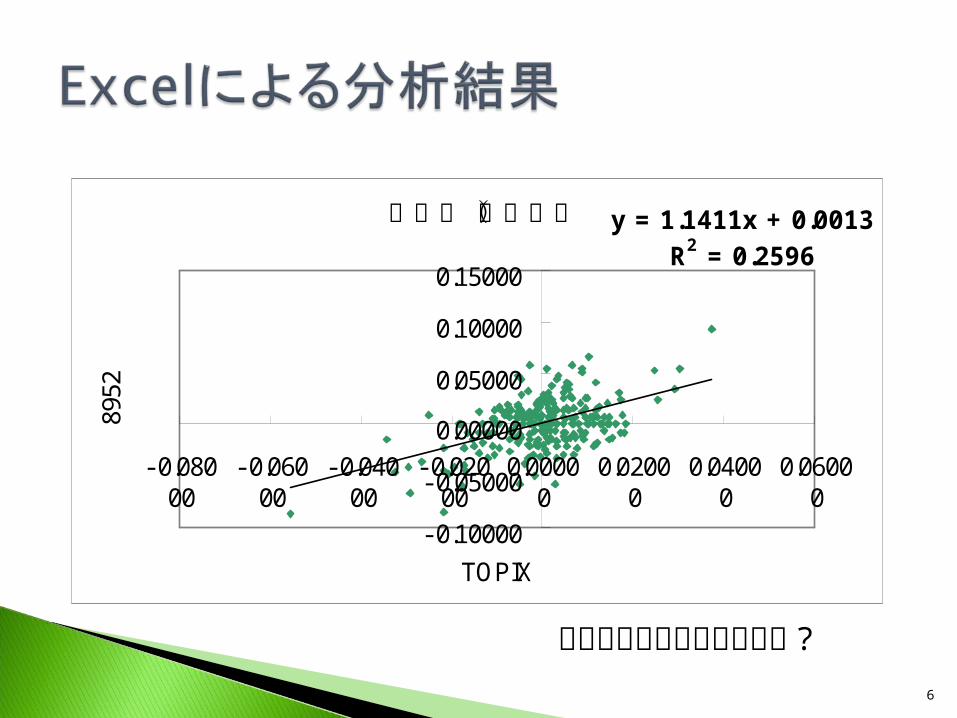
散布図(収益率) y = 1.1411x + 0.0013R2 = 0.2596
- 0.10000
- 0.05000
0.00000
0.05000
0.10000
0.15000
- 0.08000
- 0.06000
- 0.04000
- 0.02000
0.00000
0.02000
0.04000
0.06000
TOPIX
8952
6
この結果から何が言えるか ?

概要
回帰統計 R重相関 0.509519078 R2重決定 0.259609691
R2補正 0.256562817標準誤差 0.021544144観測数 245
分散分析表自由度 変動 分散 観測された分散比 F有意
回帰 1 0.039548035 0.039548035 85.20526815 1.36801E- 17残差 243 0.112788479 0.00046415合計 244 0.152336515
係数 標準誤差 t P-値 95%下限 95%上限 95.0%下限 95.0%上限切片 0.001293862 0.001376565 0.939920697 0.348191607 - 0.001417661 0.004005385 - 0.001417661 0.004005385X 1値 1.141084297 0.123618795 9.230669973 1.36801E- 17 0.897583143 1.38458545 0.897583143 1.38458545
7
y=α+β*x
y=0.001294+1.1411*x
アルファ(切片)
ベータ(傾き)
ベータは Excel関数( linest)でも計算可能

コード 8952銘柄名 ジャパンRE 名称インデックス TOPIX原ベータ 1.1429修正ベータ 1.0958 UL ベータ 0.6999 アルファ 0.1461 標準誤差 2.1564 決定係数 0.2591 相関係数 0.5090
8
Excelの結果とほぼ等しい

モデル、データセットを用意する→尤度、事前分布、初期値⇒ここでは、” 8952TOPIX1.txt”を開く
WinBUGSに取り込んで分析を行う。
ここでのモデルは
9

10
model{ for(i in 1:N){ Y[i] ~ dnorm(mu[i],tau) mu[i] <- alpha + beta * X[i]} alpha ~ dnorm(0,1.0E-3) beta ~ dnorm(0,1.0E-3) tau ~ dgamma(1.0E-3,1.0E-3)}
list(alpha = 0, beta = 0, tau = 1)
尤度
事前分布
初期値
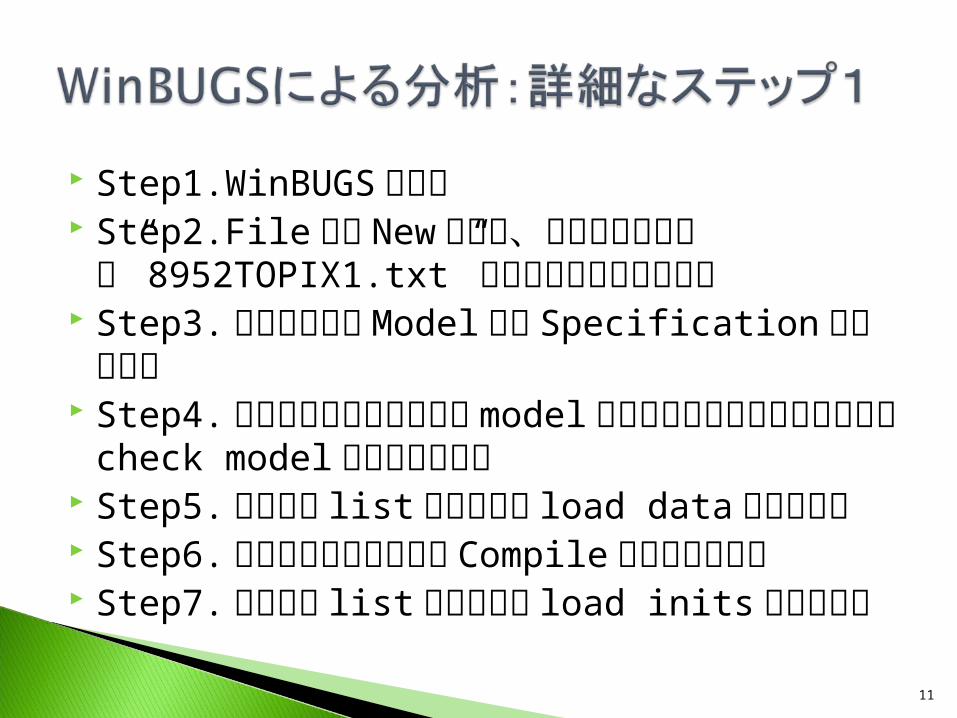
Step1.WinBUGSの起動 Step2.FileからNewを開き、さきほど用意した” 8952TOPIX1.txt”を全選択して貼り付ける
Step3.ツールバーのModelから Specificationをクリック
Step4.貼り付けたプログラムのmodelをダブルクリックして反転させ check modelをクリックする
Step5.データの listを反転させ load dataをクリック Step6.チェーンの本数を決め Compileをクリックする Step7.初期値の listを反転させ load initsをクリック
11

Step8.ツールバーのModelから Updateをクリック
Step9.Update欄の設定をして updateをクリック Step10.ツールバーの Inferenceから Samplesをクリックし、 node欄に変数( alpha,beta,tau)を入力しそれぞれ setをクリック
Step11.再び Update Toolにもどり、回数を設定して( 10000回) updateをクリック
Step12.Sample Monitor Toolで node欄に*と入力
Step13.出力したいものをクリックする
12
alpha chains 1:2 sample: 20000
-0.01 -0.005 0.0 0.005
0.0 50.0 100.0 150.0 200.0
beta chains 1:2 sample: 20000
0.0 0.5 1.0 1.5
0.0 0.5 1.0 1.5 2.0
13
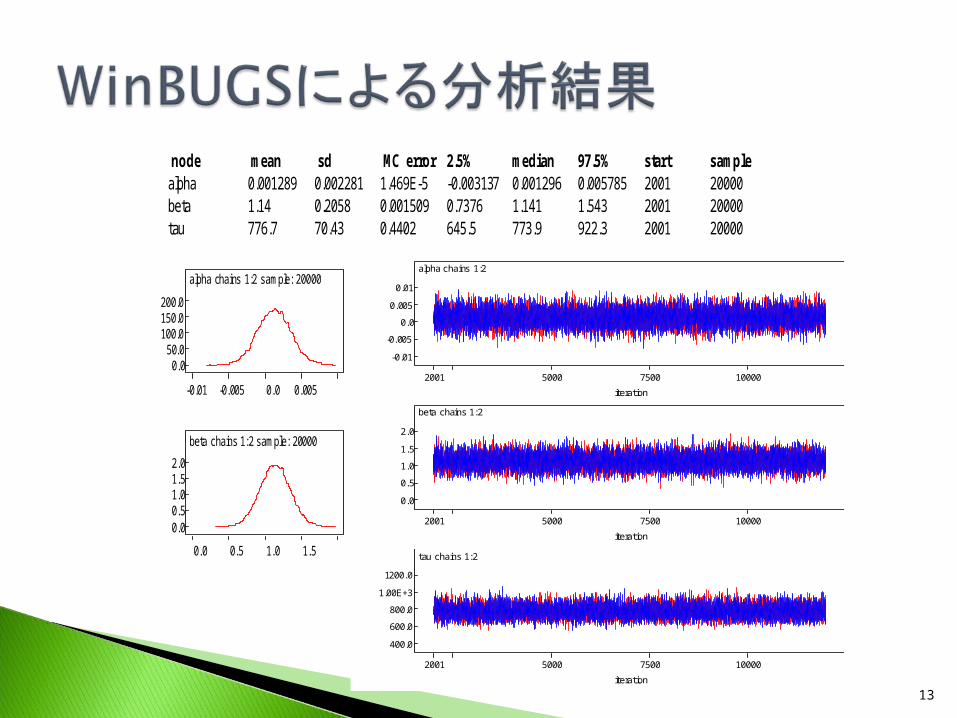
node mean sd MC error 2.5% median 97.5% start samplealpha 0.001289 0.002281 1.469E-5 -0.003137 0.001296 0.005785 2001 20000beta 1.14 0.2058 0.001509 0.7376 1.141 1.543 2001 20000tau 776.7 70.43 0.4402 645.5 773.9 922.3 2001 20000
alpha chains 1:2
iteration
2001 5000 7500 10000
-0.01
-0.005
0.0
0.005
0.01
beta chains 1:2
iteration
2001 5000 7500 10000
0.0
0.5
1.0
1.5
2.0
tau chains 1:2
iteration
2001 5000 7500 10000
400.0
600.0
800.0
1.00E+3
1200.0

Excelによる頻度論の結論はパラメータ( α、β )が 1 つの値として固定されて算出された。一方、WinBUGSによるベイジアンの結論はパラメータそのものが固定されたものではなく、分布の形として算出された。
また、頻度論の結果では決定係数の値が低く、説明力は極めて弱いと結論づけられる(直観的な常識を用いるとこの結果をどう思うであろうか?)。一方、ベイジアンの分析においてはこのようなことを考慮する必要がない。
得られるデータが少ない( 50個以下)場合、頻度論での分析の問題点は何であろうか。
14

MCMC/WinBUGSの研究 AMSUS(実証分析のデータを取得 )木上・風岡( 2007):「新しい統計解析手法とその金融データへの適用」(風岡担当箇所参照:第二部)
15