© 2004 ibm corporation ibm ^ z/vm module 13: system integrity and high availability
Post on 21-Dec-2015
218 views
TRANSCRIPT

© 2004 IBM Corporation
IBM ^
z/VMModule 13: System Integrity and High Availability

© 2004 IBM Corporation
IBM ^
Objectives
Describe the fundamental aspects of system integrity Read and understand the System Integrity Statement for z/VM issued
by IBM List the characteristics needed to implement system integrity for
z/VM Describe the major elements of integrity, including:
Virtual Memory Virtual Devices CP commands and functions

© 2004 IBM Corporation
IBM ^
Objectives continued
Define high availability and explain its key aspects Describe the different types of devices and resources
associated with high availability: Hardware
Applications
Data
Networks

© 2004 IBM Corporation
IBM ^
Objectives continued
Describe the failover options of z/VM and Linux with GDPS techniques
Give an example showing the use of z/VM site takeover and the two possible scenarios:
Cold-standby
Hot-standby Explain the best way to handle
DASD Sharing
File Systems
for high availability.

© 2004 IBM Corporation
IBM ^
Objectives continued
Describe STONITH and how it is implemented using a: Control guest
REXEC server in z/VM
Remote message to PROP Explain the high availability solution that handles a network
dispatcher in a z/VM environment

© 2004 IBM Corporation
IBM ^
What is System Integrity?
The ability of the CP to operate without interference or harm, intentional or not, from the guest virtual machines
The inability of a virtual machine to circumvent system security features and access controls
The ability for CP to protect virtual machines from each other

© 2004 IBM Corporation
IBM ^
System Integrity Statement for z/VM
IBM has implemented specific design and coding guidelines for maintaining system integrity in the development of z/VM.
It is important to understand the elements of system operation that contribute to system integrity in the z/VM environment.
z/VM General Information (GC24-5991-05) defines the specific limitations placed on virtual machines so that the integrity of the system is maintained at all times.

© 2004 IBM Corporation
IBM ^
System Integrity Statement for z/VM continued
Because the CP and the virtual machine configurations are under the control of the customer, the actual level of system integrity that a customer achieves will depend on how the z/VM environment is set up and maintained.
There is no external proof or certification available that virtual machines are isolated from each other, so maintaining system integrity is very important.
z/VM is specifically designed to maintain the integrity of the virtual machine environment at all times.

© 2004 IBM Corporation
IBM ^
System Integrity Implementation by z/VM
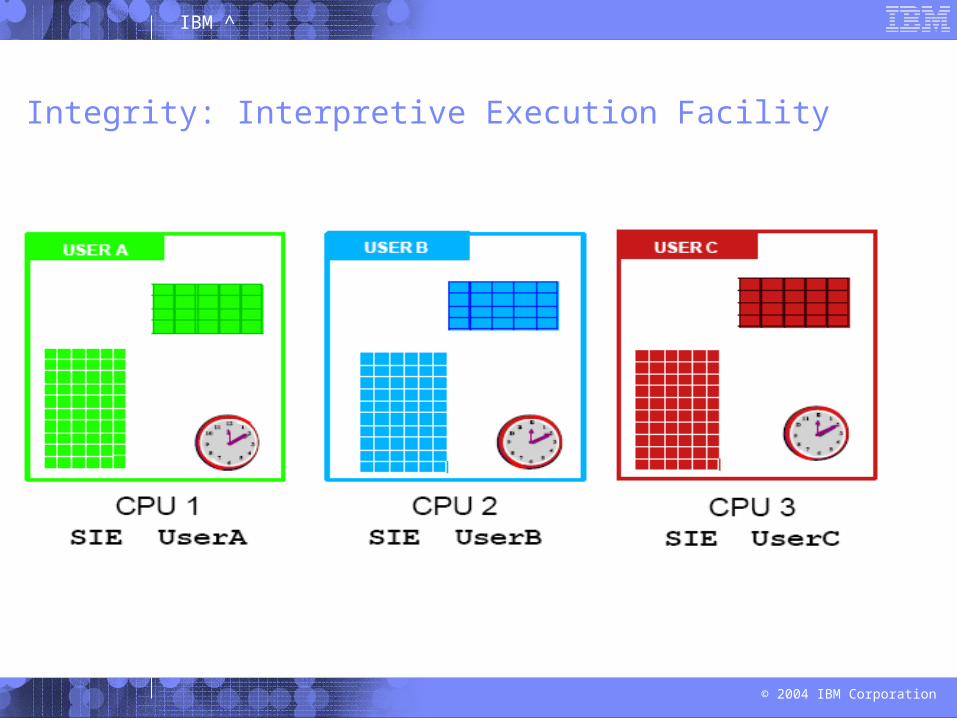
At the center of z/VM integrity is the Interpretive Execution Facility of the zSeries hardware.
Start Interpretive Execution (SIE) is a virtual machine command to initiate the execution of a guest system.
The SIE instructions can manipulate:
– Region, segment and page tables– Interception conditions (SIE break):
• Timer slice expires• Unassisted I/O• Instructions that require authorization and/or simulation• Program interrupts
SIE runs until an interception condition is raised
© 2004 IBM Corporation
IBM ^
Integrity: Interpretive Execution Facility

© 2004 IBM Corporation
IBM ^
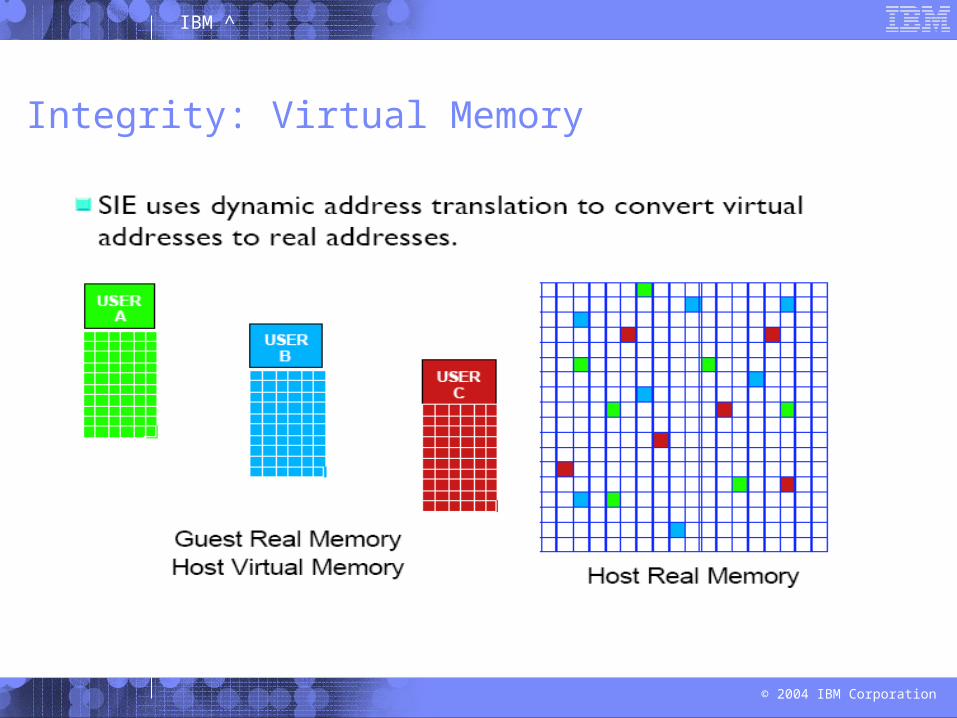
Integrity: Virtual Memory
zSeries provides an address translation capability, allowing an operating system to create virtual address spaces for memory isolation and management.
A virtual machine may not access an address space owned by another virtual machine unless the address space owner allows the virtual machine to do so.
The preferred guests are not paged in or out, but reside in real memory at fixed storage locations called zones.
© 2004 IBM Corporation
IBM ^
Integrity: Virtual Memory

© 2004 IBM Corporation
IBM ^
Integrity: Virtual Devices
A primary function of the CP is to mediate access to real devices in different ways:
Multiple users can share a DASD volume Only one user can have access to a tape drive
When a virtual machine makes an I/O request, the request is intercepted by the CP so that virtual memory addresses in the I/O request can be translated to their corresponding real memory addresses.
Failure to plan for and implement data integrity functions present in applications or the guest operating system may result in data loss on a write-shared minidisk.

© 2004 IBM Corporation
IBM ^
Integrity: CP Commands and Functions
Virtual machines communicate with the CP in one of two ways: A person or automation tool may issue CP commands from the virtual
machine console The programs running in the virtual machine may themselves
communicate with CP using the DIAGNOSE instruction If a virtual machine attempts to use a CP command or DIAGNOSE
instruction that is outside its privilege class, the system ignores the command and an error condition is returned to the virtual machines.

© 2004 IBM Corporation
IBM ^
Integrity: Conclusion
It is not possible to certify that any system has perfect integrity. IBM will accept APARs that describe exposures to the system integrity or that describe problems encountered.
While protection of the customer’s data remains the customer’s responsibility, data security continues to be an area of vital importance to the customer and IBM.
The customer is responsible for the selection, application, adequacy, and implementation of integrity actions and restrictions, and for appropriate application controls.

© 2004 IBM Corporation
IBM ^
z/VM Availability and Reliability

© 2004 IBM Corporation
IBM ^
Availability: Introduction
Maintaining maximum system uptime is becoming increasingly critical to business success.
Linux for zSeries inherits the hardware’s reliability, but software faults can still cause outages.
No high-availability products currently exist that cover both Linux and z/VM requirements; only Linux high availability products are available today.

© 2004 IBM Corporation
IBM ^
Hardware Availability
A general rule for building highly available systems is to identify and avoid single points of failure not only for the software components, but also for the hardware, such as:
Power Supply CPU Memory Network adapters I/O subsystem
IBM zSeries systems are designed for continuous availability. zSeries systems offer a set of RAS features.

© 2004 IBM Corporation
IBM ^
Handling an OSA Failure

© 2004 IBM Corporation
IBM ^
Process/Application High Availability
If an application is not designed for high availability, then it is not possible to build a highly available environment for that application.
An often used approach to achieve application availability is software clustering with a network dispatching component in front of the application.
Monitoring tools must be adapted to the system to report the health of the applications, operating system, and the network connection; without an operating system the applications cannot run.

© 2004 IBM Corporation
IBM ^
Data High Availability
Data high availability means that data survives a system failure and is available to the system that has taken over the failed system.
Data availability in the static data case can be achieved with DASD because only read requests are involved.
Data availability in the active data case is a combination of the Linux network block device and software. RAID can provide an online data mirroring solution.

© 2004 IBM Corporation
IBM ^
Network High Availability
Implementing failover pairs to provide network adapter fault tolerance is a simple and effective approach to increase the reliability of server connections.
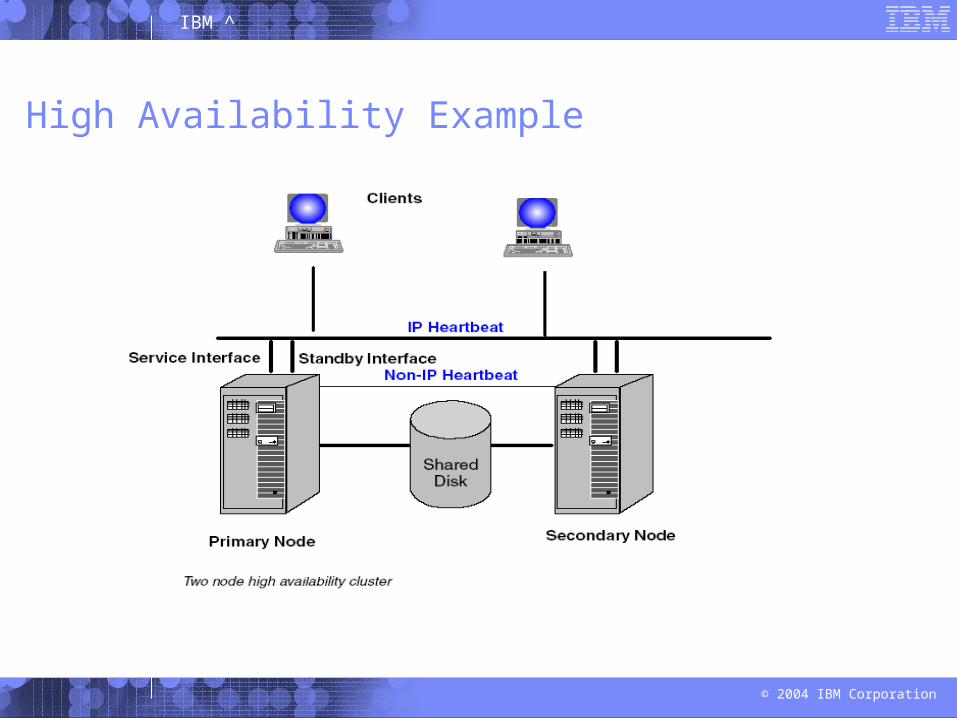
If the primary node in a high availability cluster fails, it is replaced by a secondary node that has been waiting for that moment.
The main purpose of the load-balancing cluster is to spread incoming traffic to more than one server.
© 2004 IBM Corporation
IBM ^
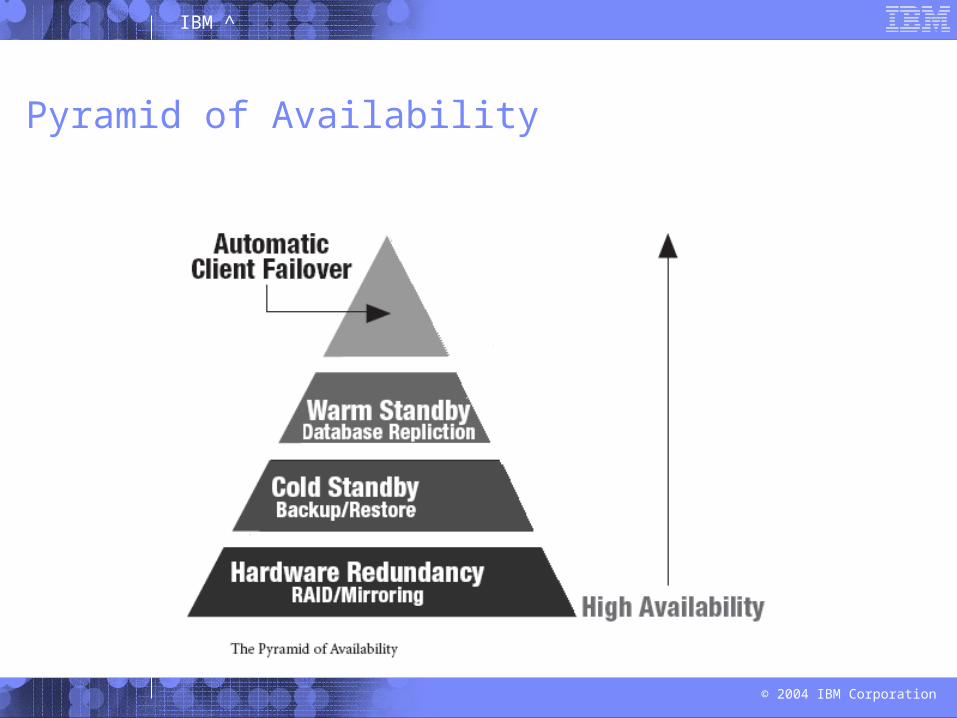
Pyramid of Availability
© 2004 IBM Corporation
IBM ^
High Availability Example

© 2004 IBM Corporation
IBM ^
z/VM View of High Availability
While z/VM is very stable operating system, factors such as human error, hardware failure, planned outages, and so forth make it impossible to guarantee that the system is 100% available.
The zSeries microcode and z/VM try to recover most errors without manual intervention, including intermittent and permanent machine errors and system I/O errors.
The zSeries hardware is able to detect CPU errors and transparently switch to another processor for continuous operation; the function is transparent to the operating system.

© 2004 IBM Corporation
IBM ^
z/VM High Availability
The design principle of a disaster recovery solution can be adapted to implement a z/VM high availability solution.
GDPS is a multi-site application availability solution that provides the ability to manage the remote copy configuration and storage subsystems, automates Parallel Sysplex operational tasks, and performs failure recovery from a single point of control.
GDPS provides switching capability from one site to another site, for planned and unplanned outages.

© 2004 IBM Corporation
IBM ^
Failover of z/VM and Linux with GDPS Techniques
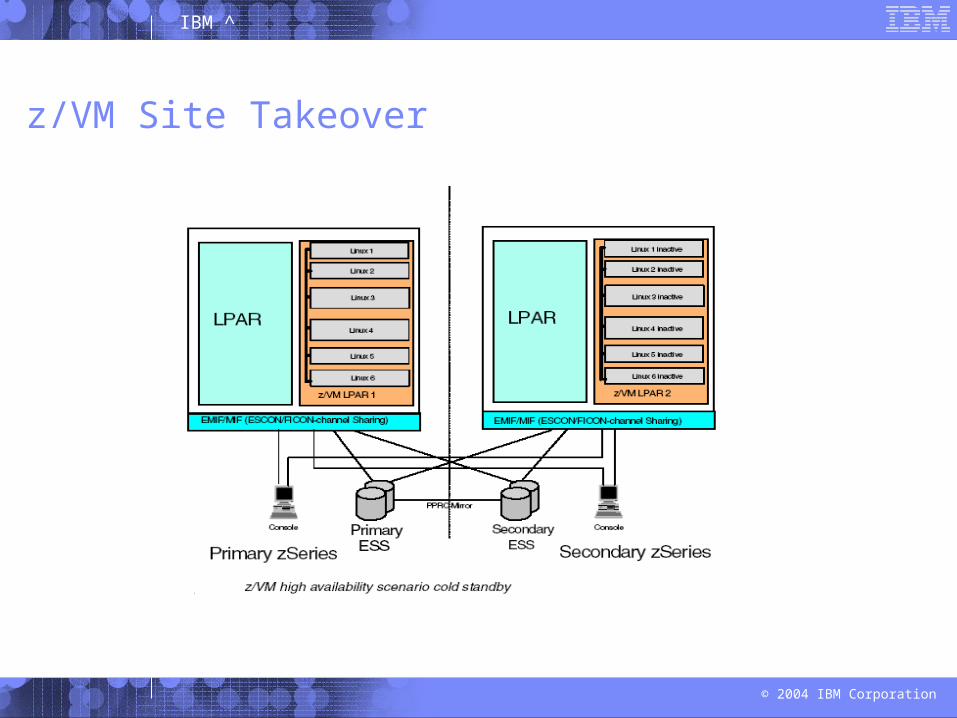
In the case of an outage of the primary z/VM system due to a processor, storage subsystem, or site failure, this configuration enables you to start another z/VM with the Linux guests and provide access to the same data and services.
In this disaster recovery configuration the guest images on both sites, the primary and the secondary, access the data from their local storage subsystems, which is kept in sync by the PPRC.
© 2004 IBM Corporation
IBM ^
z/VM Site Takeover

© 2004 IBM Corporation
IBM ^
RSCS with PROP
RSCS – Remote Spooling Communication Subsystem PROP – Programmable Operator Facility Operational Exchanges:
Deals with system operations over a distance when using RSCS with PROP
Using RSCS in this way, it is possible for one operator to oversee the operation of several systems, even in different cities or states.

© 2004 IBM Corporation
IBM ^
DASD Sharing
From the hardware point of view, the system administrator has to configure the hardware I/O on both nodes to have access to the same DASD.
Not only must the hardware support shared DASD, but also the operating systems has to provide capabilities for DASD sharing.
In a failover situation, the entire zSeries file system must be unmounted from the primary node and mounted to the secondary node.

© 2004 IBM Corporation
IBM ^
File Systems
One major issue in a high available environment is that the data must be available for all nodes in the cluster.
ReiserFS is a file system that uses a variant on the classical balanced tree algorithm.
The ext3 file system is a journaling extension to the standard ext2 file system on Linux. The journaling results in massively reduced time spent recovering a file system after a crash.

© 2004 IBM Corporation
IBM ^
STONITH
Shoot The Other Node In The Head A partitioned cluster situation can lead to damaged data, which can
be avoided by killing the primary node from the secondary node before the resources are transferred.
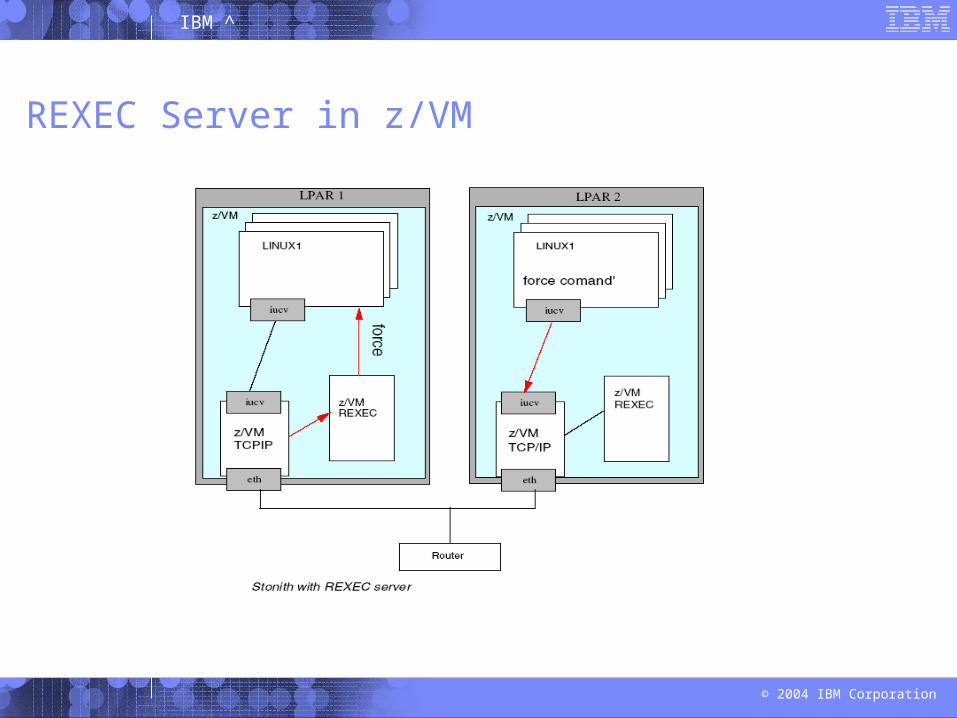
In a z/VM environment we have several possible ways of implementing STONITH:
Control guest
REXEC server in z/VM
Remote message to PROP

© 2004 IBM Corporation
IBM ^
Control Guest
© 2004 IBM Corporation
IBM ^
REXEC Server in z/VM

© 2004 IBM Corporation
IBM ^
Remote Message to PROP

© 2004 IBM Corporation
IBM ^
High Availability of z/VM with Network Dispatcher

© 2004 IBM Corporation
IBM ^
High Availability: Conclusion

© 2004 IBM Corporation
IBM ^
Glossary
Andrew File System (AFS) -- a distributed network file system without a single point of failure. The effort needed to set up and manage this file system is high.
Address Resolution Protocol (ARP) -- Address Resolution Protocol; for mapping an IP address to a physical machine address.
Cold Standby: -- A system in which the redundant component is in an inactive or idle state and must be initialized to bring it online.
Continuous availability: -- a system with nonstop service (High availability does not equate to continuous availability.)
Data high availability: -- means that data survives a system failure and is available to the system that has taken over the failed system.
EXT3: -- a journaling extension to the standard ext2 file system on Linux; it results in massively reducing time spent recovering a file system after a crash.

© 2004 IBM Corporation
IBM ^
Glossary
GDPS: (Geographically Dispersed Parallel Sysplex) is a multi-site application availability solution that provides the ability to manage the remote copy configuration and storage. subsystem, automates Parallel Sysplex operational task, and performs failure recovery from a single point of control.
High Availability: maintaining maximum system uptime.Hot Standby: is a scenario where the secondary components
share some state with the active server; in case of a failure, the takeover time is reduced compared to a Cold Standby.
RAID: Redundant Array of Inexpensive Disks.ReiserFS: -- A file system using a plug-in based object-oriented
variant on classical balanced tree algorithms.Start Interpretive Execution (SIE): -- a virtual machine command
originally introduced for use by VM/XA, to initiate the execution of a guest system.

© 2004 IBM Corporation
IBM ^
Glossary
STONITH: Shoot The Other Node In The Head.System Integrity: allows the z/VM CP to operate without interference or
harm, intentional or not, from guest systems.

© 2004 IBM Corporation
IBM ^
References
Amrehn, Erich and Ronald Annuss. Linux on IBM zSeries and S/390: High Availability for z/VM and Linux. IBM Redbooks, 2002
Altmark, Alan and Cliff Laking. z/VM Security and Integrity. IBM, May 2002.
Altmark, Alan. z/VM Security and integrity. IBM V60, 2002.