© 2003, prentice-hall chapter 3 - 1 chapter 3: data mining and data visualization modern data...
TRANSCRIPT

© 2003, Prentice-Hall Chapter 3 - 1
Chapter 3: Data Mining andData Visualization
Modern Data Warehousing, Mining, and Visualization: Core Concepts
by George M. Marakas

© 2003, Prentice-Hall Chapter 3 - 2
3-1: A Picture is Worth a Thousand Words
Data mining is the set of activities used to find new, hidden, or unexpected patterns in data.
These techniques are often called knowledge data discovery (KDD), and include statistical analysis, neural or fuzzy logic, intelligent agents or data visualization.
The KDD techniques not only discover useful patterns in the data, but also can be used to develop predictive models.

© 2003, Prentice-Hall Chapter 3 - 3
Verification Versus Discovery
In the past, decision support activities were primarily based on the concept of verification.
This required a great deal of prior knowledge on the decision-maker’s part in order to verify a suspected relationship.
With the advance of technology, the concept of verification began to turn into discovery.

© 2003, Prentice-Hall Chapter 3 - 4
Data Mining’s Growth in Popularity
One reason is that we keep getting more and more data all the time and need tools to understand it.
We also are aware that the human brain has trouble processing multidimensional data.
A third reason is that machine learning techniques are becoming more affordable and more refined at the same time.

© 2003, Prentice-Hall Chapter 3 - 5
Making Accurate Predictions with Data Mining
Although the literature contains statements such as “data mining will allow us to predict who will buy a particular product,” that is against human nature. In situations where data mining is used to predict response to a marketing campaign, only about 5% of the people selected as “likely respondents” actually do respond.

© 2003, Prentice-Hall Chapter 3 - 6
Making Accurate Predictions with Data Mining (cont.)
Although the accuracy of predicting individual behavior is not so good, it is better than it seems, since direct marketing efforts often have “hit rates” of only about 1% without data mining.

© 2003, Prentice-Hall Chapter 3 - 7
3-2: Online Analytical Processing (OLAP)
1. Multidimensional view
2. Transparent to user
3. Accessible
4. Consistent reporting
5. Client-server architecture
6. Generic dimensionality
7. Dynamic sparse matrix handling
8. Multiuser support
9. Cross-dimensional ops
10. Intuitive manipulation
11. Flexible reporting
12. Unlimited dimension and aggregation
Codd developed a set of 12 rules for the development of multidimensional databases:

© 2003, Prentice-Hall Chapter 3 - 8
OLAP as Implemented
To date, it does not appear that any implementation exists that satisfies all 12 rules.
Some people argue it might not even be possible to attain all of them.
More recently, the term OLAP has come to represent the broad category of software technology that enables multidimensional analysis of enterprise data.

© 2003, Prentice-Hall Chapter 3 - 9
Multidimensional OLAP (MOLAP)Data can be viewed across several dimensions. Here sales are arrayed by region and product.A fourth dimension could be added by using several graphs -- perhaps at different time points.Most analyses have many more dimensions than this. MOLAP handles data as an n-dimensional hypercube.
4
3
1
0.3Product
0.4
0.5
2
0.6
0.7
2
Sales
1
3Region

© 2003, Prentice-Hall Chapter 3 - 10
Relational OLAP (ROLAP)
A large relational database server replaces the multidimensional one.The database contains both detailed and summarized data, allowing “drill down” techniques to be applied.SQL interfaces allow vendors to build tools, both portable and scalable.This does require databases with many relational tables which may lead to substantial processor overhead on complex joins.

© 2003, Prentice-Hall Chapter 3 - 11
A Typical Relational Schema

© 2003, Prentice-Hall Chapter 3 - 12
3-3: Techniques Used to Mine the Data
Paralleling the popularity of data mining itself, the development of new techniques is exploding as well.Many innovations are vendor-specific, which sometimes does little to advance the state of the art.Regardless, data-mining techniques tend to fall into four major categories:
1. classification 2. association3. sequencing 4. clustering

© 2003, Prentice-Hall Chapter 3 - 13
Classification methods
The goal is to discover rules that define whether an item belongs to a particular subset or class of data.
For example, if we are trying to determine which households will respond to a direct mail campaign, we will want rules that separate the “probables” from the not probables.
These IF-THEN rules often are portrayed in a tree-like structure.

© 2003, Prentice-Hall Chapter 3 - 14
Association Methods
These techniques search all transactions from a system for patterns of occurrence.
A common method is market basket analysis, in which the set of products purchased by thousands of consumers are examined.
Results are then portrayed as percentages; for example, “30% of the people that buy steaks also buy charcoal”.

© 2003, Prentice-Hall Chapter 3 - 15
Sequencing Methods
These methods are applied to time series data in an attempt to find hidden trends.
If found, these can be useful predictors of future events.
For example, customer groups that tend to purchase products tied-in with hit movies would be targeted with promotional campaigns timed to release dates.

© 2003, Prentice-Hall Chapter 3 - 16
Clustering Techniques
Clustering techniques attempt to create partitions in the data according to some distance metric.
The clusters formed are data grouped together simply by their similarity to their neighbors.
By examining the characteristics of each cluster, it may be possible to establish rules for classification.

© 2003, Prentice-Hall Chapter 3 - 17
Data Mining Technologies
Statistics – the most mature data mining technologies, but are often not applicable because they need clean data. In addition, many statistical procedures assume linear relationships, which limits their use.
Neural networks, genetic algorithms, fuzzy logic – these technologies are able to work with complicated and imprecise data. Their broad applicability has made them popular in the field.

© 2003, Prentice-Hall Chapter 3 - 18
Data Mining Technologies (cont.)
Decision trees – these technologies are conceptually simple and have gained in popularity as better tree growing software was introduced. Because of the way they are used, they are perhaps better called “classification” trees.

© 2003, Prentice-Hall Chapter 3 - 19
The Knowledge Discovery Search Process
Table 3-2 contains a more detailed outline of the process, but the major steps are:Define the business problem and
obtain the data to study it.Use data mining software to model
the problem.Mine the data to search for patterns
of interest.

© 2003, Prentice-Hall Chapter 3 - 20
The Knowledge Discovery Search Process (cont.)
Review the mining results and refine them by respecifying the model.
Once validated, make the model available to other users of the DW.

© 2003, Prentice-Hall Chapter 3 - 21
Creating a Data-Mining Model
Although syntax differs from vendor to vendor, building a model on top of a database is much like creating a table:CREATE MODEL mail_listIncome character input, Age integer input, Respond
character input
To populate it with data, use an SQL INSERT:INSERT INTO mail_listSELECT income, age, respondFROM client_listWHERE region = ‘Southeast”

© 2003, Prentice-Hall Chapter 3 - 22
Creating a Data-Mining Model (cont.)
The process automatically created additional views of the model (mail_list_UNDERSTAND and mail_list_PREDICT). These can be examined:
SELECT * FROM mail_list_UNDERSTANDWHERE input_column_name = ‘income” and
input_column_value = “high” andoutput_column_name = “respond” andoutput_column_value = ‘yes”
Once these are created, they are treated as tables in the database so they can be viewed and joined by other users.

© 2003, Prentice-Hall Chapter 3 - 23
New Applications for Data Mining
As the technology matures, new applications emerge, especially in two new categories, text mining and web mining. Some text mining examples are:Distilling the meaning of a textAccurate summarization of a textExplication of the text theme structureClustering of texts

© 2003, Prentice-Hall Chapter 3 - 24
Web mining
Web mining is a special case of text mining where the mining occurs over a website.It enhances the website with intelligent behavior, such as suggesting related links or recommending new products.It allows you to unobtrusively learn the interests of the visitors and modify their user profiles in real time.They also allow you to match resources to the interests of the visitor.

© 2003, Prentice-Hall Chapter 3 - 25
3-4: Market Basket Analysis: The King of Algorithms
This is the most widely used and, in many ways, most successful data mining algorithm.It essentially determines what products people purchase together.Stores can use this information to place these products in the same area.Direct marketers can use this information to determine which new products to offer to their current customers.Inventory policies can be improved if reorder points reflect the demand for the complementary products.

© 2003, Prentice-Hall Chapter 3 - 26
Association Rules for Market Basket Analysis
Rules are written in the form “left-hand side implies right-hand side” and an example is:
Yellow Peppers IMPLIES Red Peppers, Bananas, Bakery
To make effective use of a rule, three numeric measures about that rule must be considered: (1) support, (2) confidence and (3) lift

© 2003, Prentice-Hall Chapter 3 - 27
Measures of Predictive Ability
1. Support refers to the percentage of baskets where the rule was true (both left and right side products were present).
2. Confidence measures what percentage of baskets that contained the left-hand product also contained the right.
3. Lift measures how much more frequently the left-hand item is found with the right than without the right.

© 2003, Prentice-Hall Chapter 3 - 28
An Example
The confidence suggests people buying any kind of pepper also buy bananas.Green peppers sell in about the same quantities as red or yellow, but are not as predctive.
Rule:
Green Peppers IMPLIES
Bananas
Red Peppers IMPLIES
Bananas
Yellow Peppers IMPLIES
Bananas
Lift 1.37 1.43 1.17
Support 3.77 8.58 22.12
Confidence 85.96 89.47 73.09

© 2003, Prentice-Hall Chapter 3 - 29
Market Basket Analysis Methodology
We first need a list of transactions and what was purchased. This is pretty easily obtained these days from scanning cash registers.
Next, we choose a list of products to analyze, and tabulate how many times each was purchased with the others.
The diagonals of the table shows how often a product is purchased in any combination, and the off-diagonals show which combinations were bought.

© 2003, Prentice-Hall Chapter 3 - 30
A Convenience Store Example (5 transactions)Consider the following simple example about
five transactions at a convenience store:
Transaction 1: Frozen pizza, cola, milkTransaction 2: Milk, potato chipsTransaction 3: Cola, frozen pizzaTransaction 4: Milk, pretzelsTransaction 5: Cola, pretzels
These need to be cross tabulated and displayed in a table.

© 2003, Prentice-Hall Chapter 3 - 31
A Convenience Store Example (5 transactions)
Pizza and Cola sell together more often than any other combo; a cross-marketing opportunity?Milk sells well with everything – people probably come here specifically to buy it.
Product Bought
Pizza also
Milk
also
Cola
also
Chips also
Pretzels
also
Pizza 2 1 2 0 0
Milk 1 3 1 1 1
Cola 2 1 3 0 1
Chips 0 1 0 1 0
Pretzels 0 1 1 0 2

© 2003, Prentice-Hall Chapter 3 - 32
Using the Results
The tabulations can immediately be translated into association rules and the numerical measures computed.
Comparing this week’s table to last week’s table can immediately show the effect of this week’s promotional activities.
Some rules are going to be trivial (hot dogs and buns sell together) or inexplicable (toilet rings sell only when a new hardware store is opened).

© 2003, Prentice-Hall Chapter 3 - 33
Limitations to Market Basket Analysis
A large number of real transactions are needed to do an effective basket analysis, but the data’s accuracy is compromised if all the products do not occur with similar frequency.
The analysis can sometimes capture results that were due to the success of previous marketing campaigns (and not natural tendencies of customers).

© 2003, Prentice-Hall Chapter 3 - 34
Performing Analysis with Virtual Items
The sales data can be augmented with the addition of virtual items. For example, we could record that the customer was new to us, or had children.
The transaction record might look like:Item 1: Sweater Item 2: Jacket Item 3: New
This might allow us to see what patterns new customers have versus old customers.

© 2003, Prentice-Hall Chapter 3 - 35
Computing Measures of Association
Let’s do some of the textbook’s example computations here ……
Pizza Milk Cola Chips Pretzels
Pizza 2 1 2 0 0
Milk 1 3 1 1 1
Cola 2 1 3 0 1
Chips 0 1 0 1 0
Pretzels 0 1 1 0 2

© 2003, Prentice-Hall Chapter 3 - 36
Taxonomies
The presence of items not purchased very frequently is an obstacle to a good market basket analysis.
One way to deal with this is to eliminate products that occur with a frequency less than some threshold.
A better idea would be to try to form groups of products that fall below the threshold. Four flavors of popsicle occur 9% of the time all together, but no more than 3% individually.

© 2003, Prentice-Hall Chapter 3 - 37
Multidimensional Market Basket Analysis
Rules can involve more than two items, for example Plant and Clay Pot IMPLIES Soil.
These rules are built iteratively. First, pairs are found, then relevant sets of three or four.
These are then pruned by removing those that occur infrequently.
In an environment like a grocery store, where customers commonly buy over 100 items, rules could involve as many as 10 items.

© 2003, Prentice-Hall Chapter 3 - 38
3-5: Current Limitations and Challenges to Data Mining
Despite the potential power and value, data mining is still a new field. Some things that that thus far have limited advancement are: Identification of missing information – not
all knowledge gets stored in a databaseData noise and missing values – future
systems need better ways to handle thisLarge databases and high dimensionality –
future applications need ways to partition data into more manageable chunks

© 2003, Prentice-Hall Chapter 3 - 39
3-6: Data Visualization: “Seeing” the Data

© 2003, Prentice-Hall Chapter 3 - 40
Visual Presentation
For any kind of high dimensional data set, displaying predictive relationships is a challenge.
The picture on the previous slide uses 3-D graphics to portray the weather balloon data numbers in text Table 11-4. We learn very little from just examining the numbers .
Shading is used to represent relative degrees of thunderstorm activity, with the darkest regions the heaviest activity.

© 2003, Prentice-Hall Chapter 3 - 41
A Bit of History
An early effort used sequences of two-dimensional graphs to add depth.
Current virtual reality programs allow the user to step through a data set. Try going to a realtor’s website and taking a tour of a house up for sale.

© 2003, Prentice-Hall Chapter 3 - 42
Human Visual Perception and Data Visualization
Data visualization is so powerful because the human visual cortex converts objects into information so quickly.
The next three slides show (1) usage of global private networks, (2) flow through natural gas pipelines, and (3) a risk analysis report that permits the user to draw an interactive yield curve.
All three use height or shading to add additional dimensions to the figure.
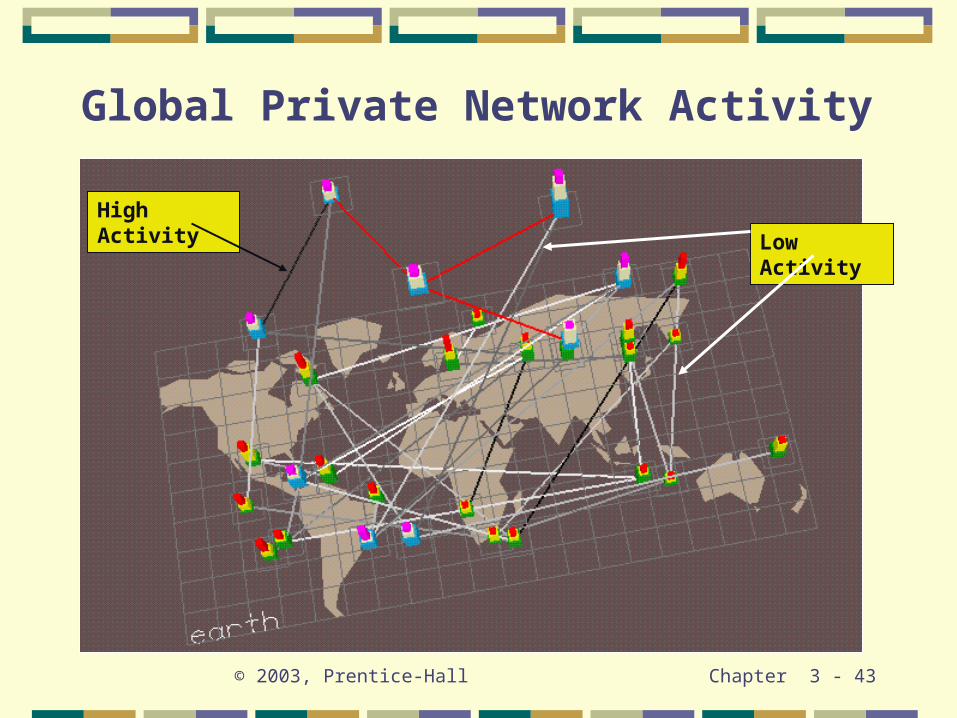
© 2003, Prentice-Hall Chapter 3 - 43
Global Private Network Activity
High Activity
Low Activity

© 2003, Prentice-Hall Chapter 3 - 44
Natural Gas Pipeline Analysis
Note: Height shows total flow through compressor stations.

© 2003, Prentice-Hall Chapter 3 - 45
An “Enlivened” Risk Analysis Report

© 2003, Prentice-Hall Chapter 3 - 46
Geographical Information Systems
A GIS is a special purpose database that contains a spatial coordinate system. A comprehensive GIS requires:
1. Data input from maps, aerial photos, etc.
2. Data storage, retrieval and query
3. Data transformation and modeling
4. Data reporting (maps, reports and plans)

© 2003, Prentice-Hall Chapter 3 - 47
The Special Capabilities of a GIS
In general, a GIS contains two types of data:Spatial data: these elements correspond to a
uniquely-defined location on earth. They could be in point, line or polygon form.
Attribute data: These are the data that will be portrayed at the geographic references established by spatial data.
Example: Data from an opinion poll is displayed for multiple regions in the United States. Clicking on an area allows the user to drill down to the results for smaller areas.

© 2003, Prentice-Hall Chapter 3 - 48
Telephone Polling Results
Note: On the “live” map, clicking on an area allows the user to drill down and see results for smaller areas.

© 2003, Prentice-Hall Chapter 3 - 49
3-7: Siftware Technologies
Although data visualization product vendors seem to enter or leave the market with great frequency, several firms are beginning to develop significant brand loyalty.
Red Brick – Helped category managers at H.E.B. in San Antonio to determine which products to put in which stores. Another application was the consolidation of three old data warehouses at Hewlett-Packard.

© 2003, Prentice-Hall Chapter 3 - 50
Siftware -- Continued
Oracle – A large suite of connectivity products allows transparent access to mainframe databases. Some major customers include John Alden Insurance, ShopKo Stores and Pacific Bell.
Informix – Associated Grocers uses Informix data warehousing products at the heart of its three-tier client-server system.

© 2003, Prentice-Hall Chapter 3 - 51
Siftware -- Continued
Sybase – Sybase Warehouse WORKS is an integrated system designed around the four key functions in data warehousing.
Silicon Graphics – Data mining software is mated to 3-D visualization tools to allow users to fly through data.
IBM – provides a number of decision support tools in its Information Warehouse Solutions.