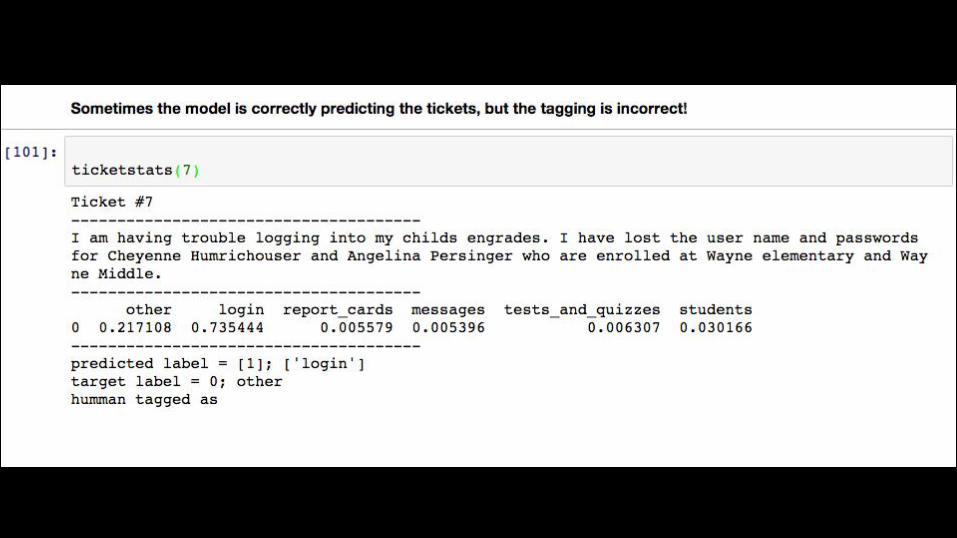
zendesk and nlp
TRANSCRIPT

Zendesk Ticketsand Natural Language Processing

Overview
Zendesk is a customer support ticketing system. I will be taking a look at 80k tickets created over ~2 years, hoping to classify tickets based on the text of the customer support request.

About the Data
● Wide variety of issues related to an online education platform
● Users include administrators, teachers, and students/parents
● Sender type is gathered programmatically based on username
● “Page,” aka general area the complaint relates to, is tagged by human customer support

Two Goals:
1) Predict the “Affected Page” and determine if an automated, page-specific response should be sent (as opposed to a generic response).
2) Determine if the user is a student or an adult

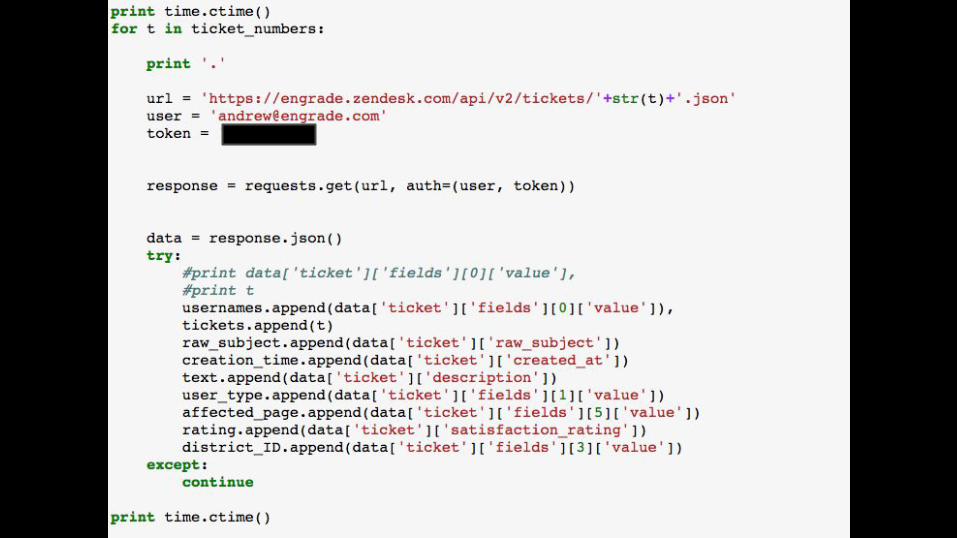
Zendesk has a bulk csv export available, but the actual message content is not included. Instead, I had to request 1 ticket per call, which took about 1 second. The whole process took 20+ hours. Takeaways:● Use “requests” and “json” in python for api
calls & parsing● Need to build in exception handling because
some ticket IDs are not available
Gathering Data: Zendesk API
Carrier pigeons may have been faster
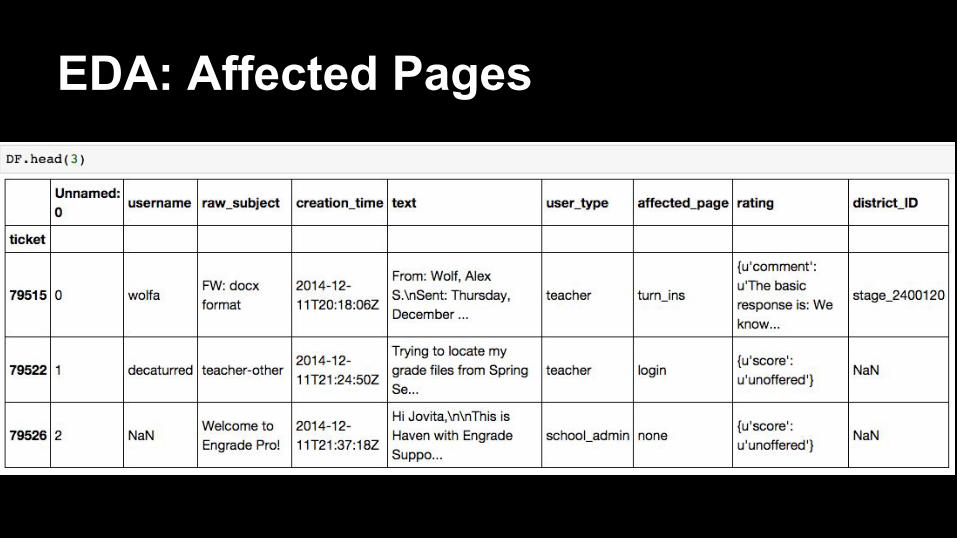
EDA: Affected Pages

45 unique page types tagged
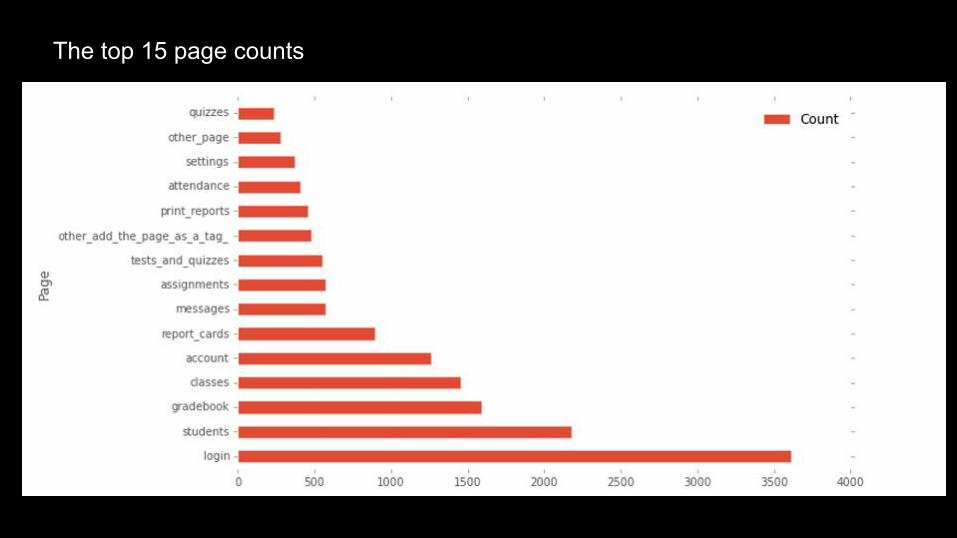
The top 15 page counts
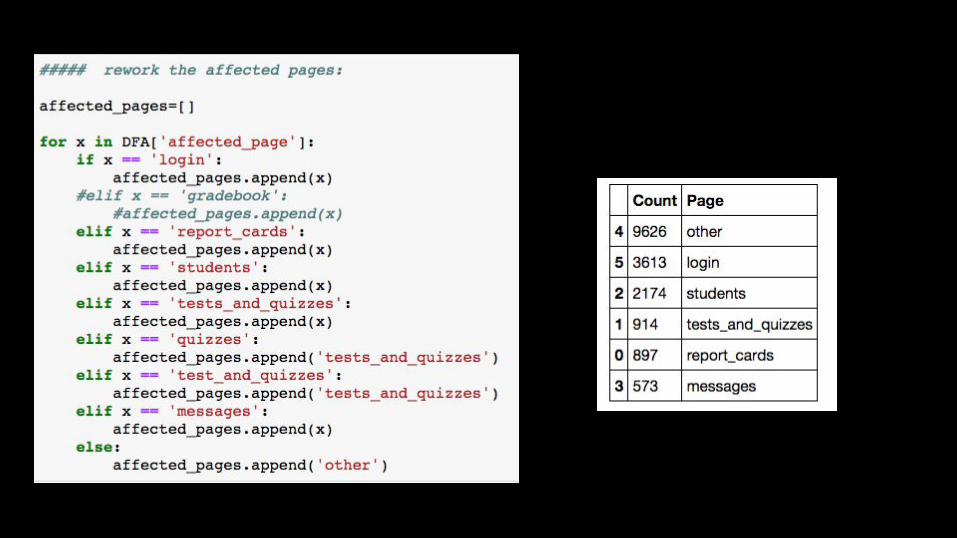
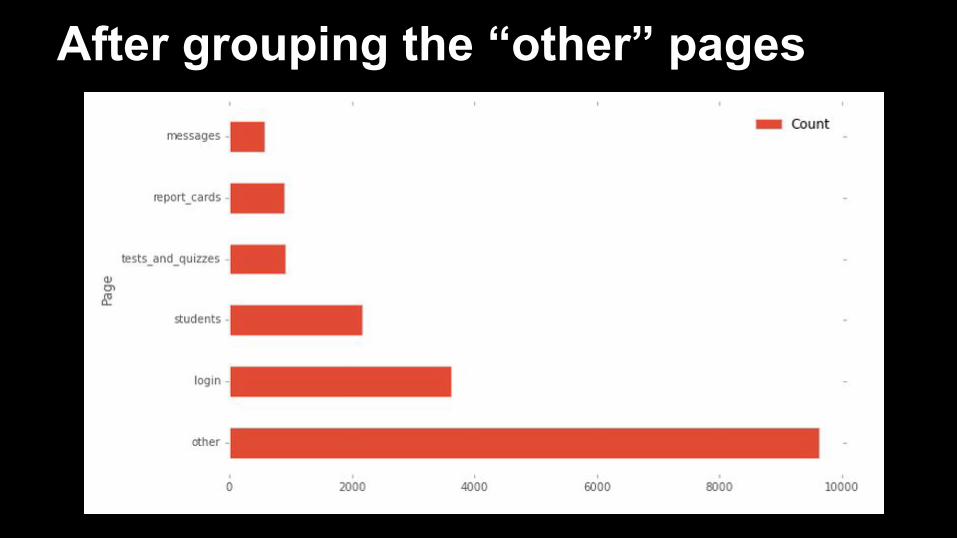
After grouping the “other” pages

Prep Data Set
1) factorize target values:○ y = pd.factorize(affected_pages)○ Y=y[0]
2) Use the count vectorizer to convert the text into a numerical matrix:○ vectorizerA = CountVectorizer(ngram_range = (1, 2))○ freq_term_matrixA = vectorizerA.fit_transform(DFA.text)
3) Use StratifiedKFold to train-test-split:○ n_folds=2
This is the data --->
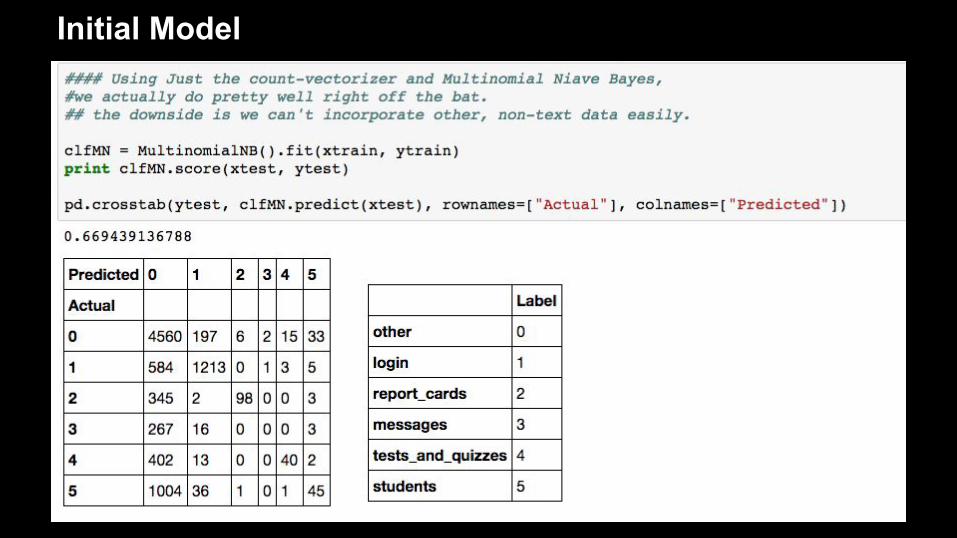
Initial Model
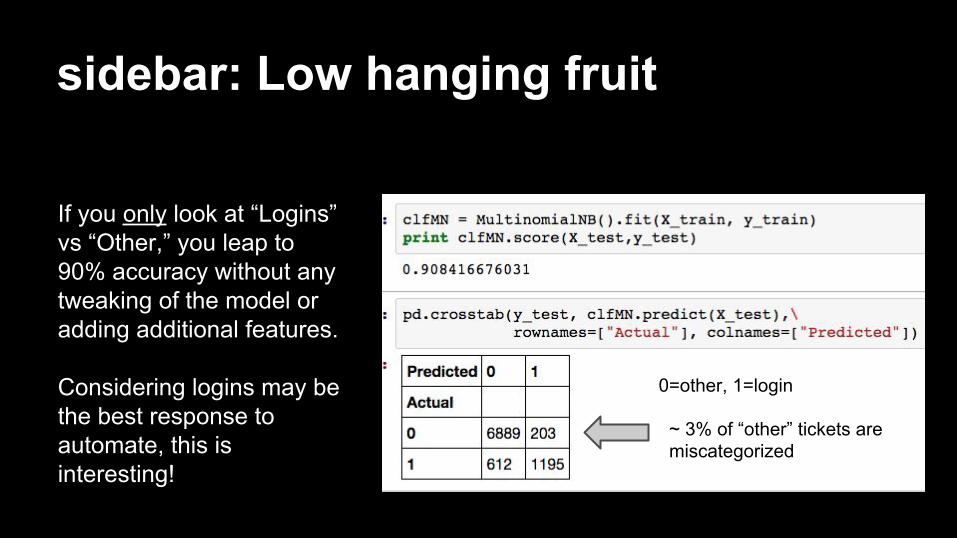
sidebar: Low hanging fruit
If you only look at “Logins” vs “Other,” you leap to 90% accuracy without any tweaking of the model or adding additional features.
Considering logins may be the best response to automate, this is interesting!
~ 3% of “other” tickets are miscategorized
0=other, 1=login

Further Analysis of resultsSupport Vector machine w/ linear kernel returns a score around .75
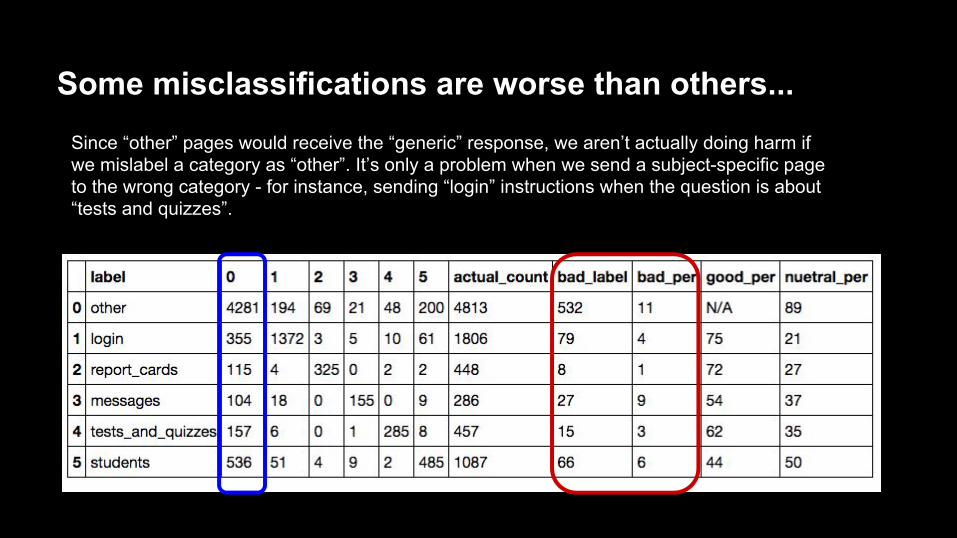
Some misclassifications are worse than others...Since “other” pages would receive the “generic” response, we aren’t actually doing harm if we mislabel a category as “other”. It’s only a problem when we send a subject-specific page to the wrong category - for instance, sending “login” instructions when the question is about “tests and quizzes”.

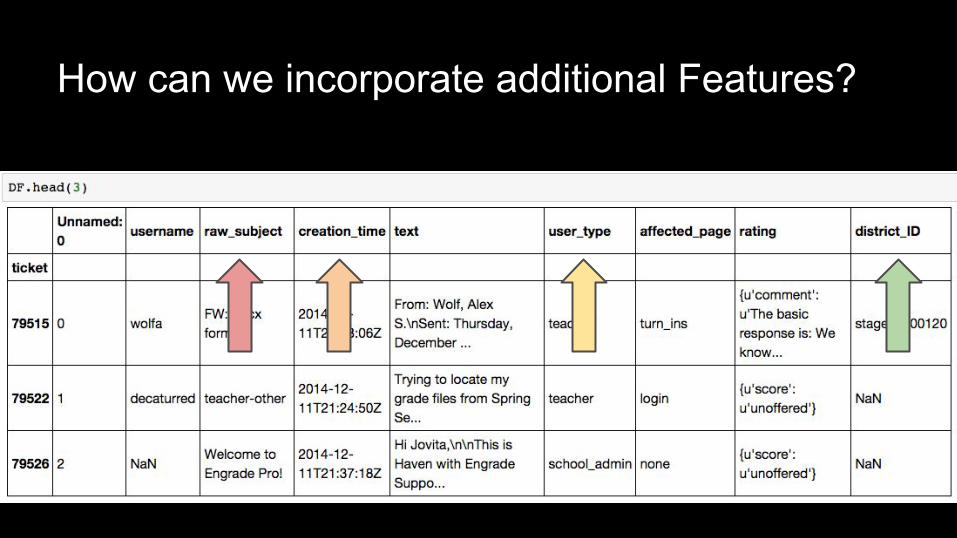
How can we incorporate additional Features?

TF-IDFterm frequency-inverse document frequency:
Takes into account both the frequency of a particular word in the document, as well as the frequency of this word across ALL the documents.
The other benefit is that the end result is a sparse matrix, to which we can append other data (if we convert back to a regular “dense” matrix).
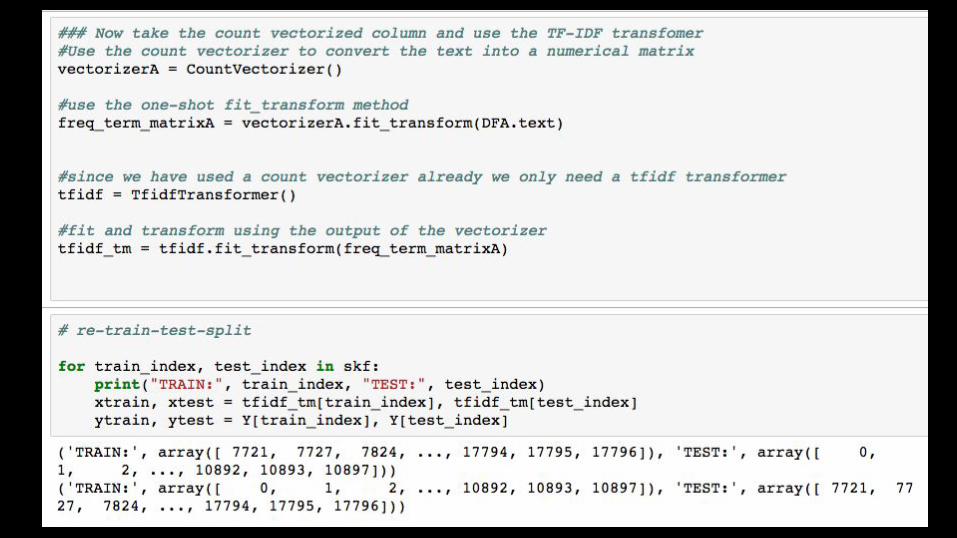

After converting to TF-IDF the scores for various models will fluctuate
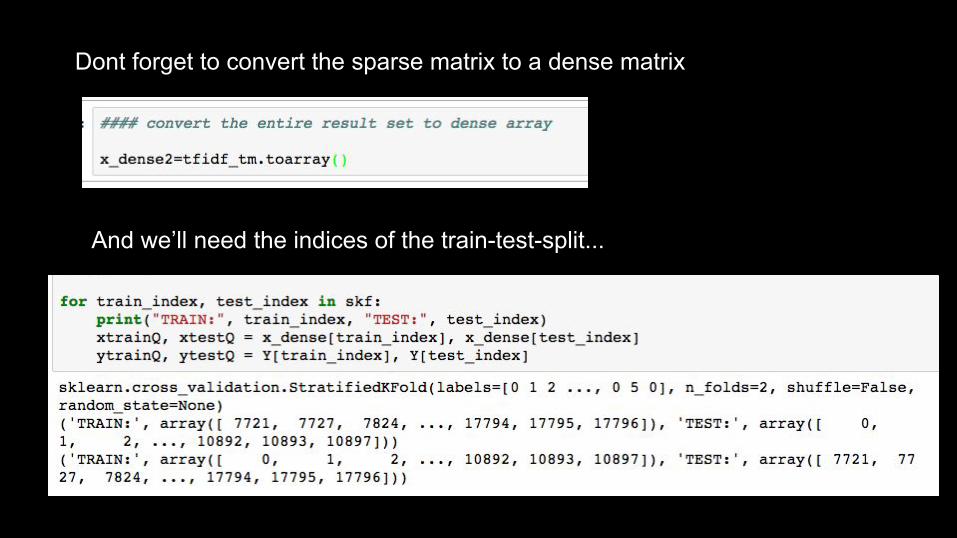
Dont forget to convert the sparse matrix to a dense matrix
And we’ll need the indices of the train-test-split...
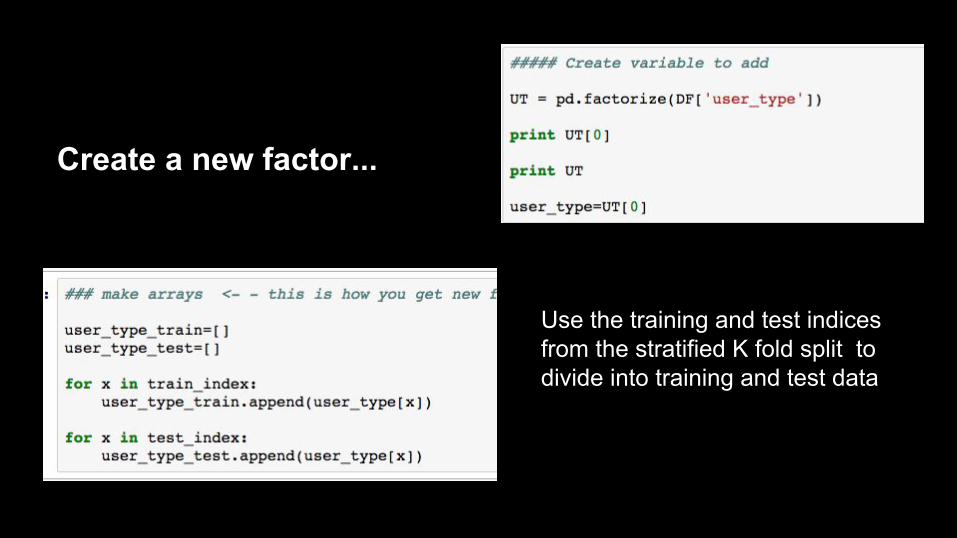
Create a new factor...
Use the training and test indices from the stratified K fold split to divide into training and test data
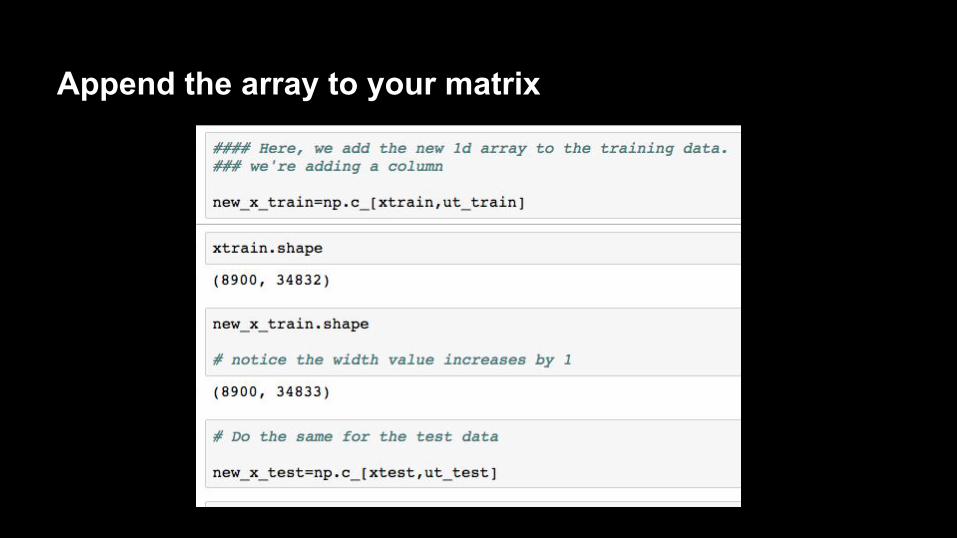
Append the array to your matrix

Fit a model...
For imperceptible gains...
<-old score…

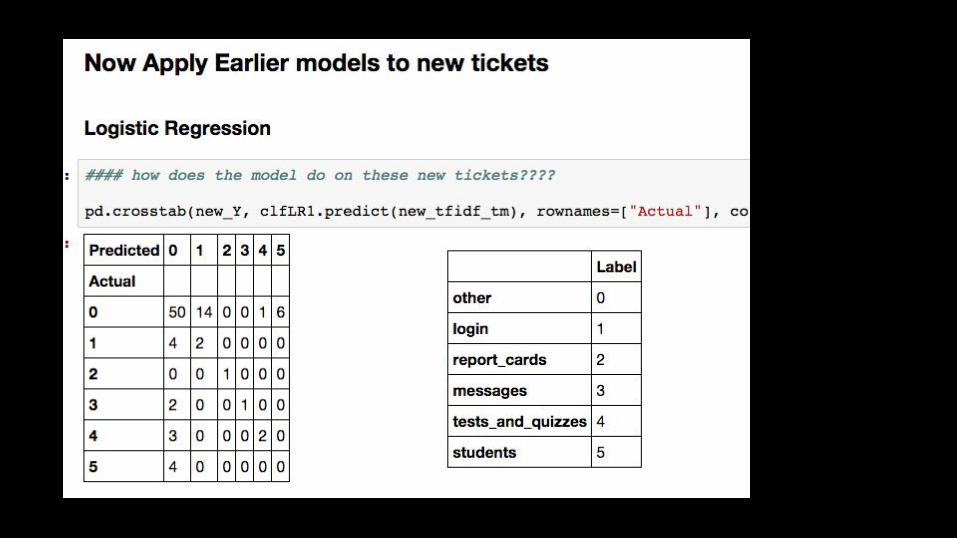
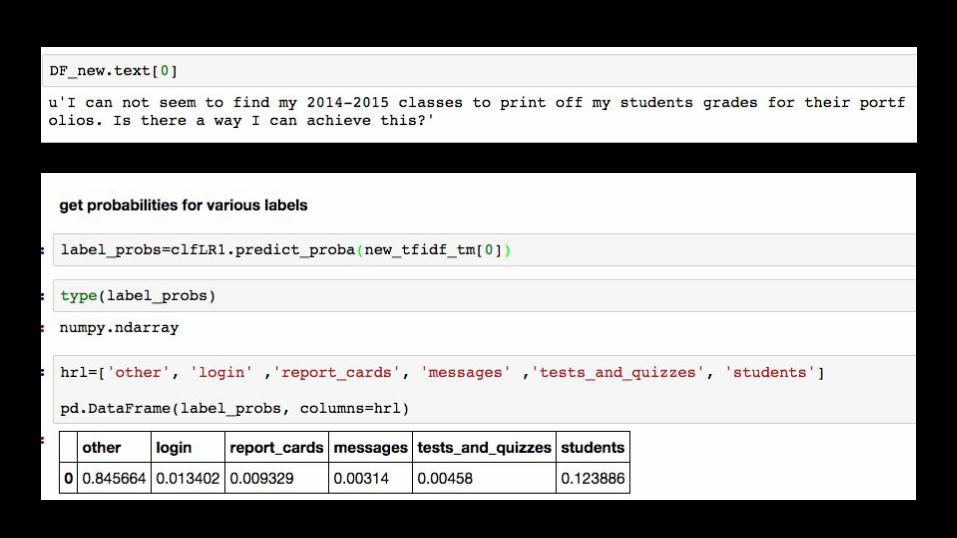
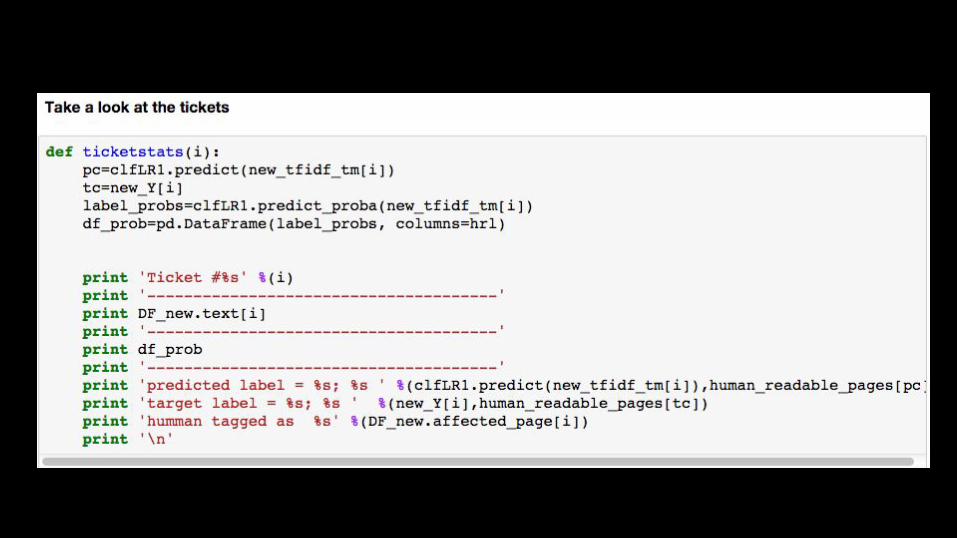
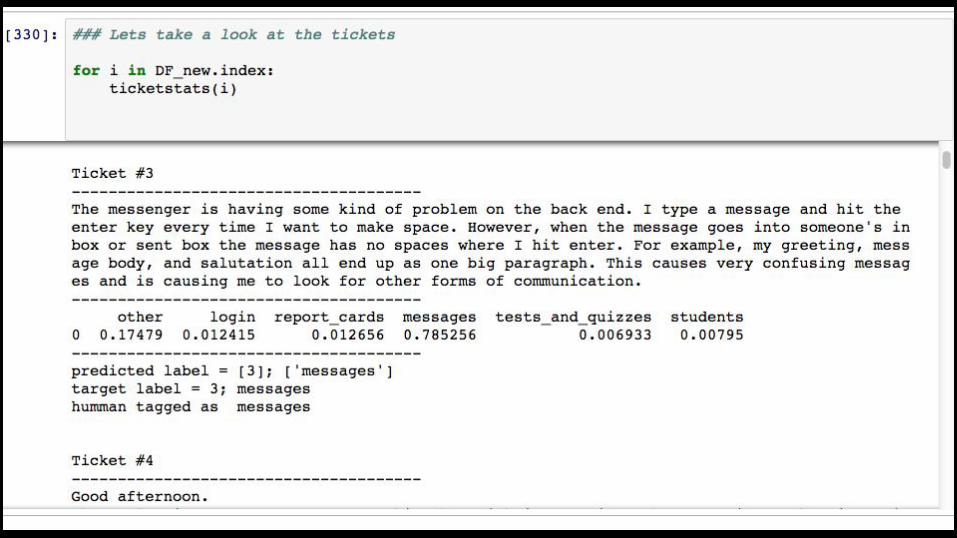
Returning values for new tickets
- First pull new tickets via the API that the model has not seen before
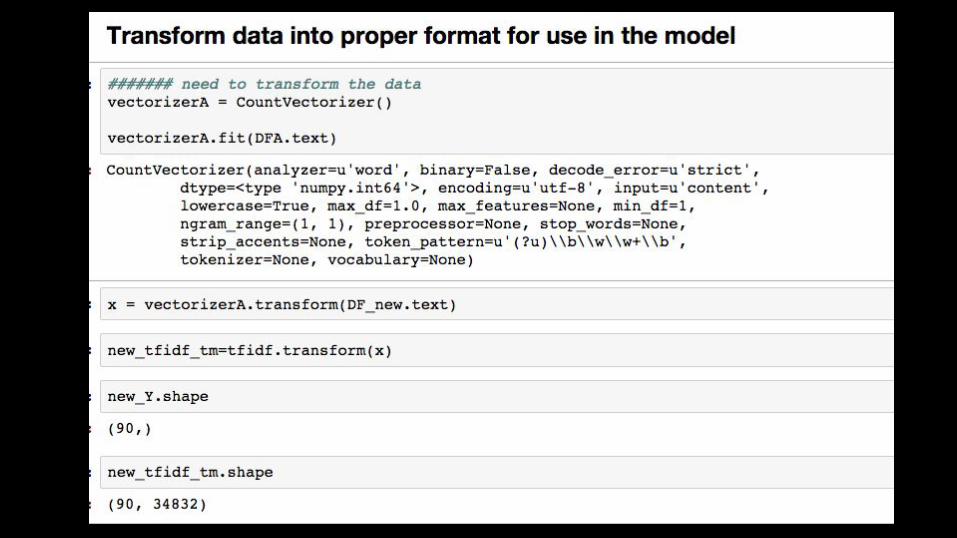
- Then convert them using the same methods as before- Apply the model that was trained on the big data set- get predictions / classifications for new tickets
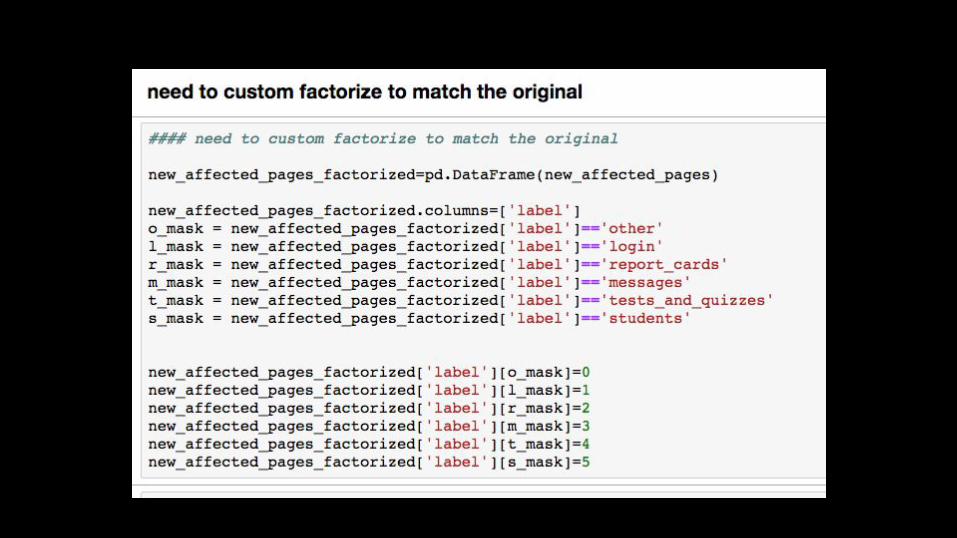
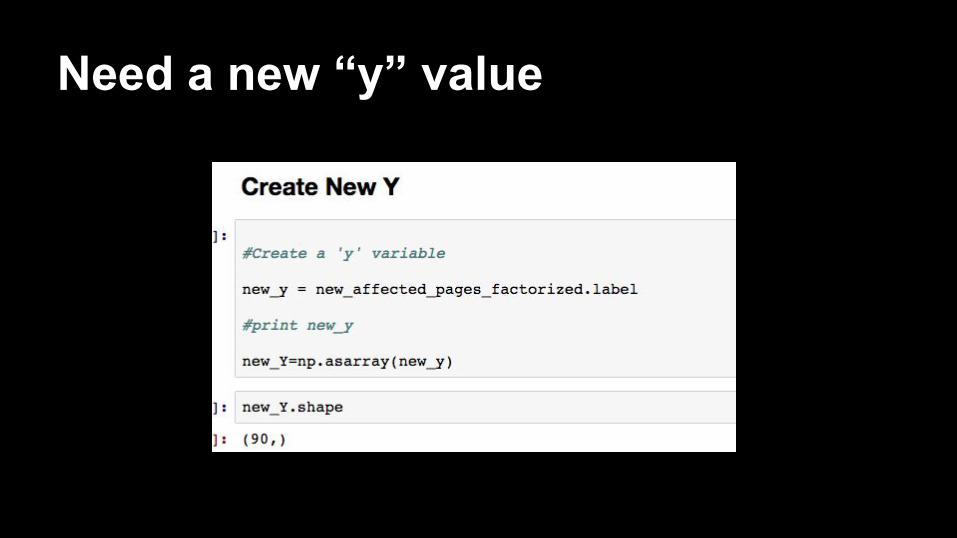
Need a new “y” value
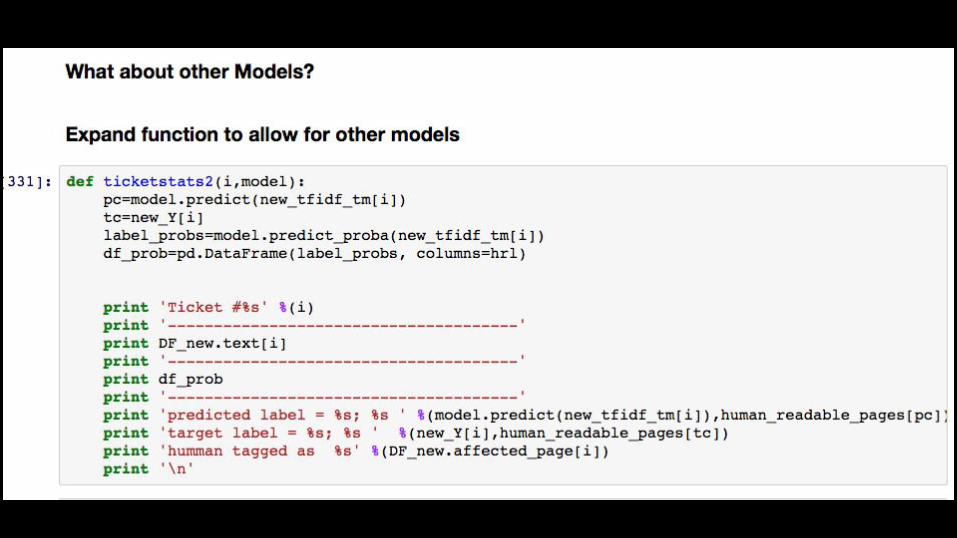

More ticket predictionshttps://docs.google.com/a/engrade.com/document/d/1VZKYwkzsY-nBHVbB26MXSIMlKUAqzCyhrKvRhZrcoSI/edit?usp=sharing

Students vs TeachersUsing only the “logins” page results, I followed the above process and to classify student vs teacher:
Model: Logistic Regression (C=5)Score = 0.7170

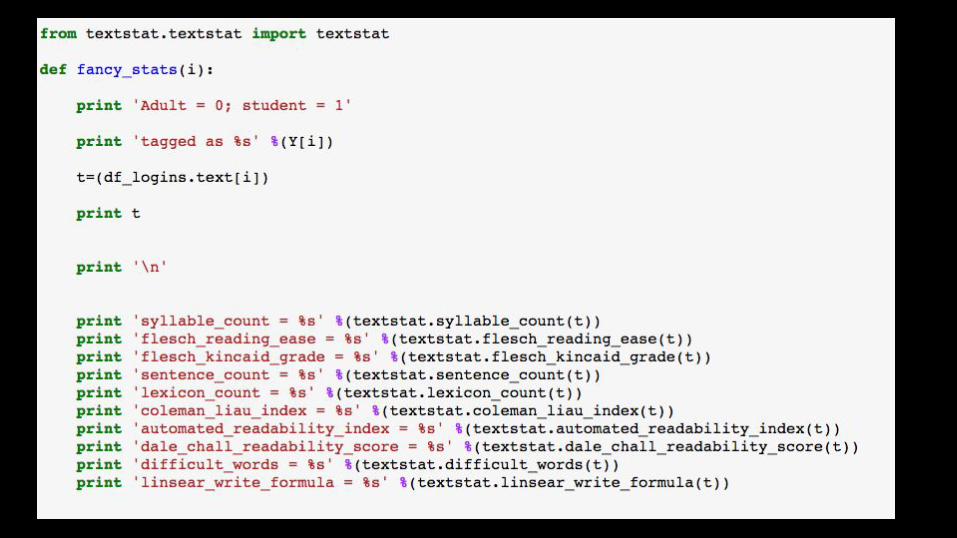
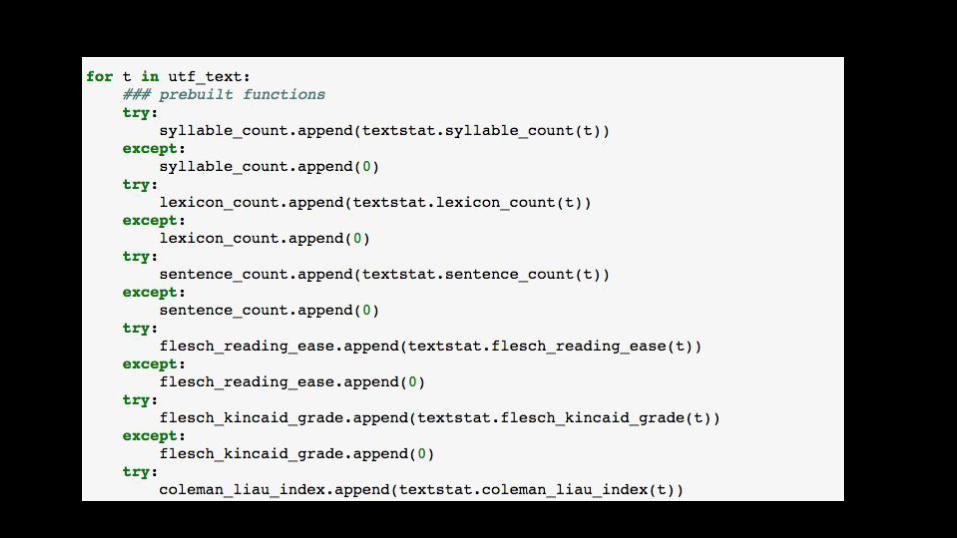
TEXTSTAT library:
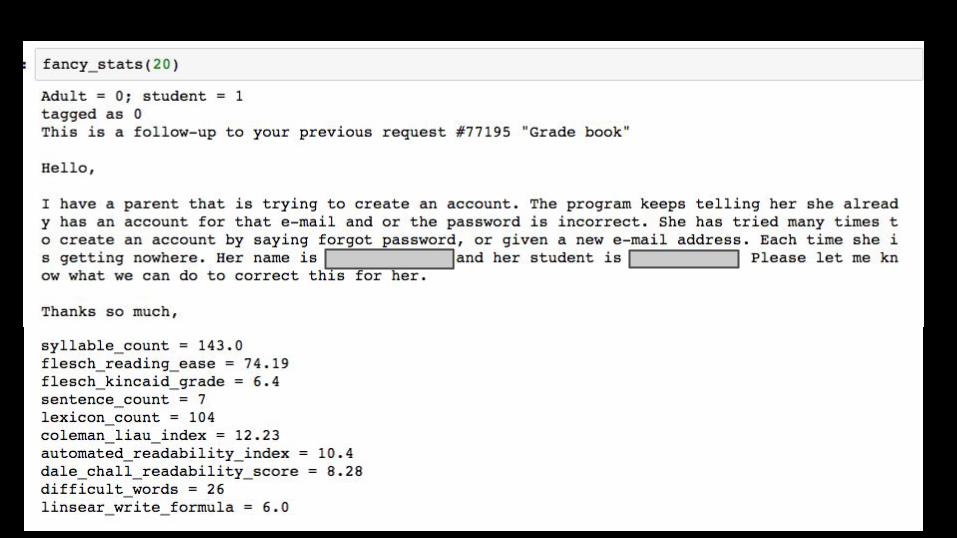
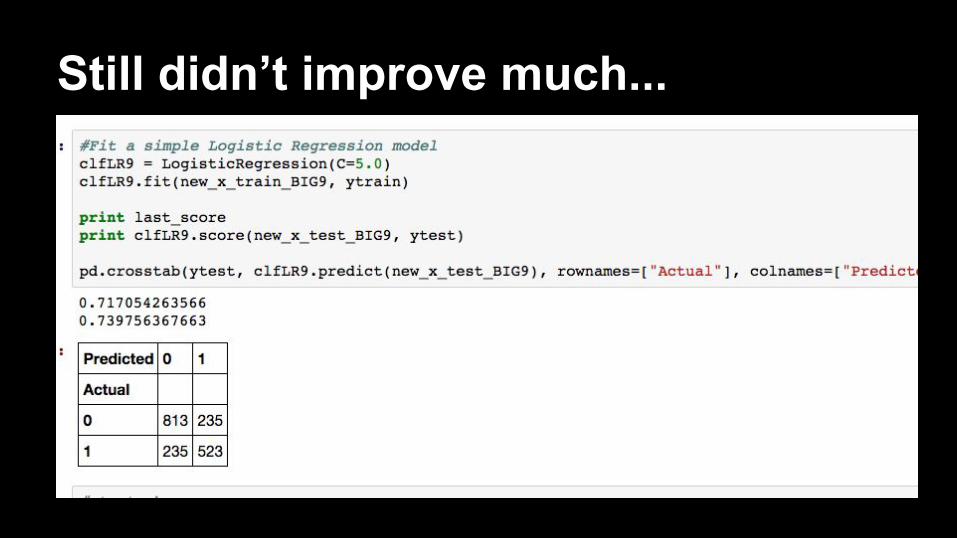
Still didn’t improve much...

What next?
● Pickle to save best model for use in production● Determine risk threshold for sending wrong emails and
try to tweak model to perform as desired ● Looping through C values, etc, to get best model.● looping through various page types to see what is easily
classified● Using other features…