word sense disambiguation and information retrieval byguitao gao qing ma prof:jian-yun nie
TRANSCRIPT

Word Sense Disambiguation and Information Retrieval
By Guitao Gao
Qing Ma
Prof:Jian-Yun Nie

Outline
Introduction
WSD Approches
Conclusion

Introduction
Task of Information Retrieval Content Repesentation Indexing Bag of words indexing Problems:
– Synonymy: query expansion– Polysemy: Word Sense Disambiguation

WSD Approaches
Disambiguation based on manually created rules
Disambiguation using machine readable dictionaries
Disambiguation using thesauri Disambiguation based on unsupervised
machine learning with corpora

Disambiguation based on manually created rules
Weiss’ approach [Lesk 1988] :– set of rules to disambiguate five words – context rule: within 5 words– template rule: specific location– accuracy : 90%– IR improvement: 1%
Small & Rieger’s approach [Small 1982] :– Expert system

Disambiguation using machine readable dictionaries Lesk’s approach [Lesk 1988] :
– Senses are represented by different definitions– Looked up context words definitions – Find co-occurring words – Select most similar sense– Accuracy: 50% - 70%. – Problem: no enough overlapping words
between definitions

Disambiguation using machine readable dictionaries Wilks’ approach [Wilks 1990] :
– Attempt to solve Lesk’s problem– Expanding dictionary definition – Use Longman Dictionary of Contemporary
English ( LDOCE )– more word co-occurring evidence collected – Accuracy: between 53% and 85%.
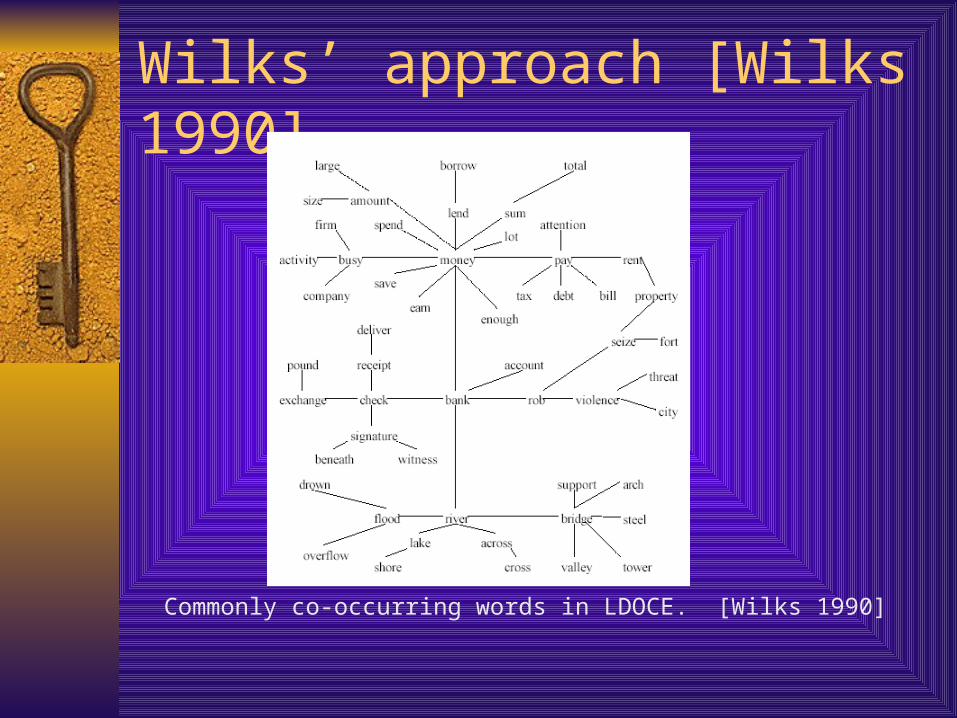
Wilks’ approach [Wilks 1990]
Commonly co-occurring words in LDOCE. [Wilks 1990]

Disambiguation using machine readable dictionaries Luk’s approach [Luk 1995]:
– Statistical sense disambiguation – Use definitions from LDOCE– co-occurrence data collected from Brown
corpus – defining concepts : 1792 words used to write
definitions of LDOCE– LDOCE pre-processed :conceptual expansion

Luk’s approach [Luk 1995]:Entry in LDOCE Conceptual expansion
1. (an order given by a judge which fixes) a punishment for a criminal found guilty in court
found guilty in court{ {order, judge, punish, crime, criminal,find, guilt, court},
2. a group of words that forms a statement, command, exclamation, orquestion, usu. contains a subject and a verb, and (in writing) beginswith a capital letter and ends with one of the marks. ! ?
{group, word, form, statement,command, question, contain, subject,verb, write, begin, capital, letter, end,mark} }
Noun “sentence” and its conceptual expansion [Luk 1995]

Luk’s approach [Luk 1995] cont.
Collect co-occurrence data of defining concepts by constructing a two-dimensional Concept Co-occurrence Data Table (CCDT)– Brown corpus divided into sentences – collect conceptual co-occurrence data for each
defining concept which occurs in the sentence – Insert collect data in the Concept Co-
occurrence Data Table.
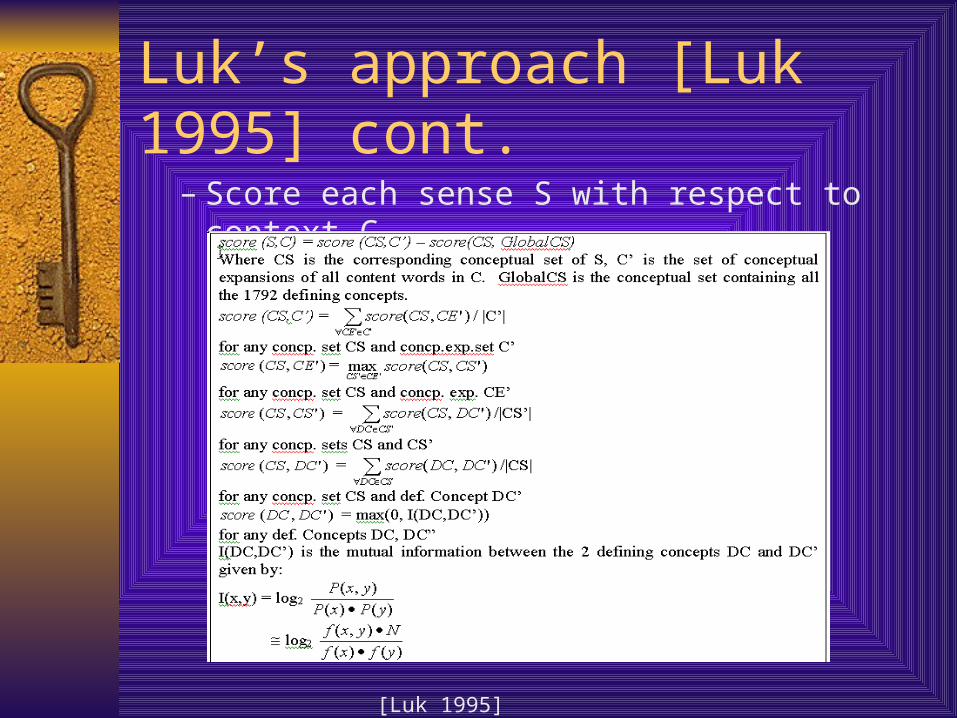
Luk’s approach [Luk 1995] cont.
– Score each sense S with respect to context C
[Luk 1995]

Luk’s approach [Luk 1995] cont.
– Select sense with the highest score– Accuracy: 77%– Human accuracy: 71%
Approaches using Roget's Thesaurus [Yarowsky 1992] Resources used:
– Roget's Thesaurus – Grolier Multimedia Encyclopedia
Senses of a word: categories in Roget's Thesaurus
1042 broad categories covering areas like, tools/machinery or animals/insects

Approaches using Roget's Thesaurus [Yarowsky 1992] cont. tool, implement, appliance, contraption, apparatus,
utensil, device, gadget, craft, machine, engine, motor, dynamo, generator, mill, lathe, equipment, gear, tackle, tackling, rigging, harness, trappings, fittings, accoutrements, paraphernalia, equipage, outfit, appointments, furniture, material, plant, appurtenances, a wheel, jack, clockwork, wheel-work, spring, screw,
Some words placed into the tools/machinery category [Yarowsky 1992]

Approaches using Roget's Thesaurus [Yarowsky 1992] cont. Collect context for each category:
– From Grolier Encyclopedia
– each occurrence of each member of the category
– extracts 100 surrounding words
Sample occurrence of words in the tools/machinery category [Yarowsky 1992]
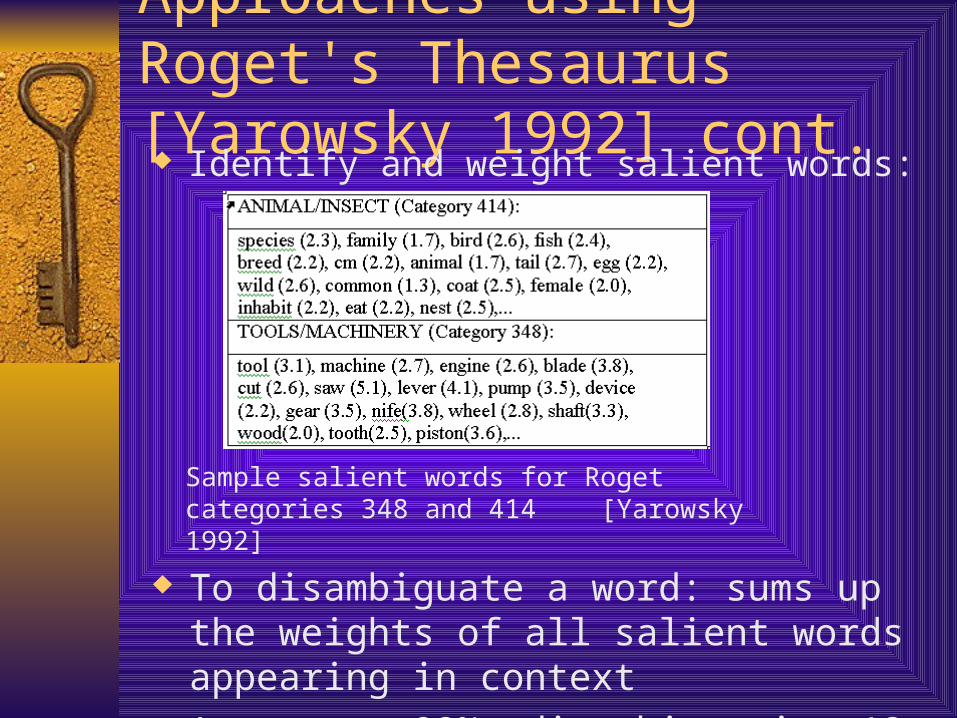
Approaches using Roget's Thesaurus [Yarowsky 1992] cont. Identify and weight salient words:
Sample salient words for Roget categories 348 and 414 [Yarowsky 1992]
To disambiguate a word: sums up the weights of all salient words appearing in context
Accuracy: 92% disambiguating 12 words

Introduction to WordNet(1)
Online thesaurus system
Synsets: Synonymous Words
Hierachical Relationship
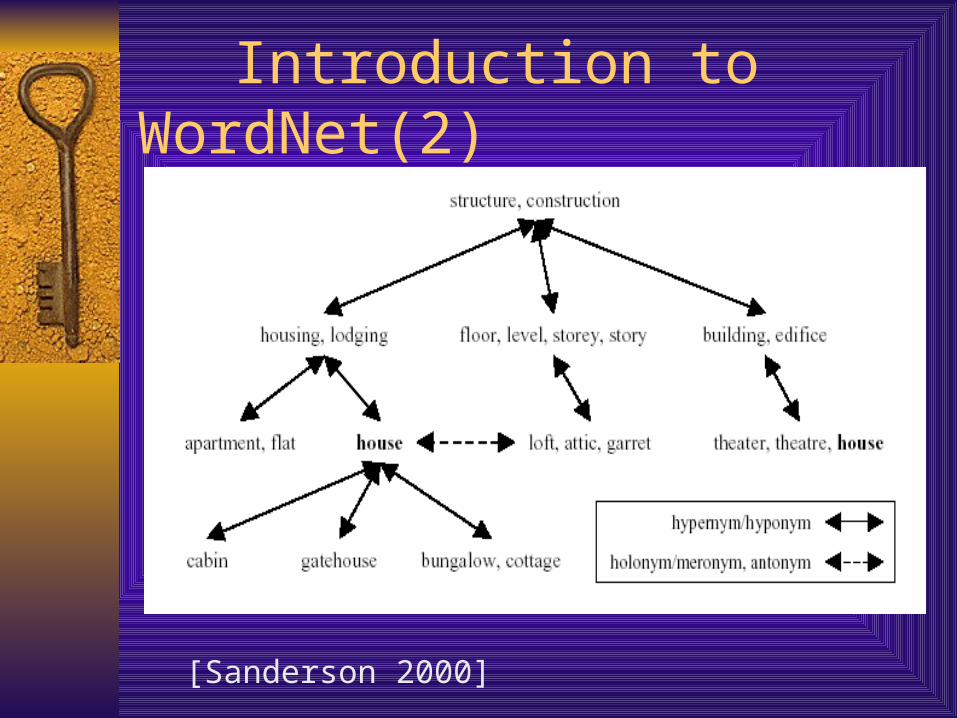
Introduction to WordNet(2)
[Sanderson 2000]

Voorhees’ Disambg. Experiment
Calculation of Semantic Distance: Synset and Context words
Word’s Sense: Synset closest to Context Words
Retrieval Result: Worse than non-Disambig.

Gonzalo’s IR experiment(1)
Two Questions Can WordNet really offer any potential for
text retrieval
How is text Retrieval performance affected by the disambiguation errors?

Gonzalo’s IR experiment(2)
Text Collection: Summary and Document
Experiments 1. Standard Smart Run 2. Indexed In Terms of Word-Sense 3. Indexed In Terms of Synset 4. Introduction of Disambiguation Error
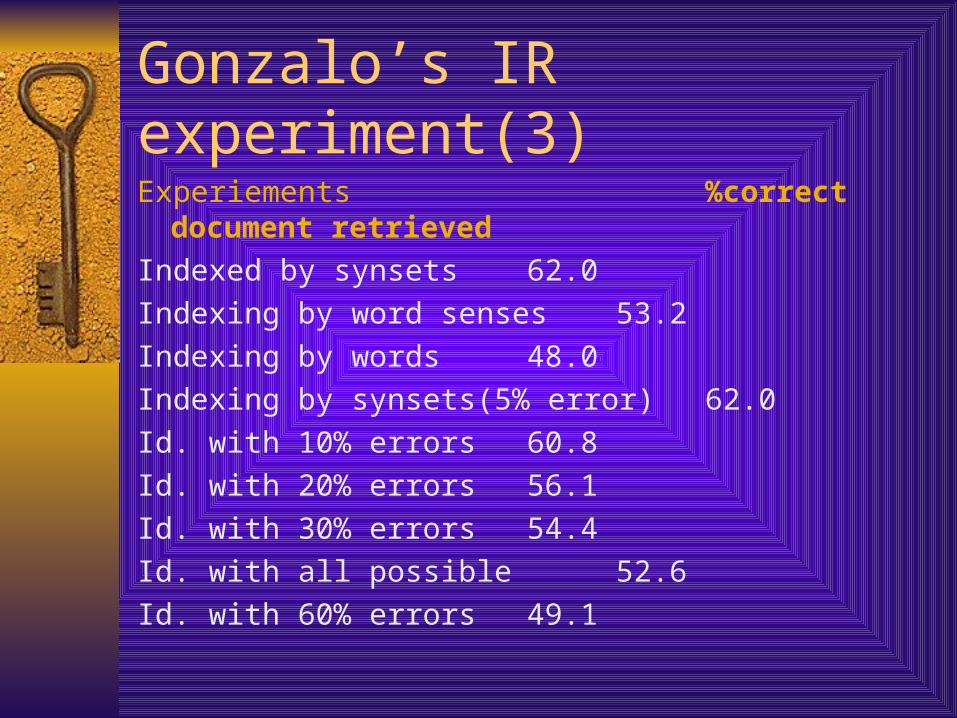
Gonzalo’s IR experiment(3)
Experiements %correct document retrieved
Indexed by synsets 62.0
Indexing by word senses 53.2
Indexing by words 48.0
Indexing by synsets(5% error) 62.0
Id. with 10% errors 60.8
Id. with 20% errors 56.1
Id. with 30% errors 54.4
Id. with all possible 52.6
Id. with 60% errors 49.1

Gonzalo’s IR experiment(4)
Disambiguation with WordNet can improve text retrieval
Solution lies in reliable Automatic WSD technique

Disambiguation With Unsupervised Learning
Yarowsky’s Unsupervised Method
One Sense Per Collocation
eg: Plant(manufacturing/life)
One Sense Per Discourse
eg: defense(War/Sports)

Yarowsky’s Unsupervised Method cont.
Algorithm Details Step1:Store Word and its contexts as line
eg:….zonal distribution of plant life…..
Step2: Identify a few words that represent the word Sense
eg. plant(manufacturing/life) Step3a: Get rules from the training set
plant + X => A, weight
plant + Y => B, weight
Step3b:Use the rules created in 3a to classify all occurrences of plant sample set.
Yarowsky’s Unsupervised Method cont.
Step3c: Use one-sense-per-discourse rule to filter or augment this addition
Step3d: Repeat Step 3 a-b-c iteratively.
Step4: the training converges on a stable residual set.
Step 5: the result will be a set of rules. Those rules will be used to disambiguate the word “plant”.
eg. plant + growth => life plant + car => manufacturing

Yarowsky’s Unsupervised Method cont.
Advantages of this method:
Better accuracy compared to other unsupervised method
No need for costly hand-tagged training sets(supervised method)

Schütze and Pedersen’s approach[Schütze 1995] Source of word sense definitions
– Not using a dictionary or thesaurus– Only using only the corpus to be disambiguated
(Category B TREC-1 collection ) Thesaurus construction
– Collect a (symmetric ) term-term matrix C– Entry cij : number of times that words i and j
co-occur in a symmetric window of total size k – Use SVD to reduce the dimensionality

Schütze and Pedersen’s approach[Schütze 1995] cont.
– Thesaurus vector: columns– Semantic similarity: cosine between columns– Thesaurus: associate each word with its nearest
neighbors– Context vector: summing thesaurus vectors of context
words

Schütze and Pedersen’s approach[Schütze 1995] cont. Disambiguation algorithm
– Identify context vectors corresponding to all occurrences of a particular word
– Partition them into regions of high density– Tag a sense for each such region– Disambiguating a word:
• Compute context vector of its occurrence
• Find the closest centroid of a region
• Assign the occurrence the sense of that centroid

Schütze and Pedersen’s approach[Schütze 1995] cont. Accuracy: 90% Application to IR
– replacing the words by word senses
– sense based retrieval’s average precision for 11 points of recall increased 4% with respect to word based.
– Combine the ranking for each document:• average precision increased: 11%
– Each occurrence is assigned n(2,3,4,5) senses;• average precision increased: 14% for n=3
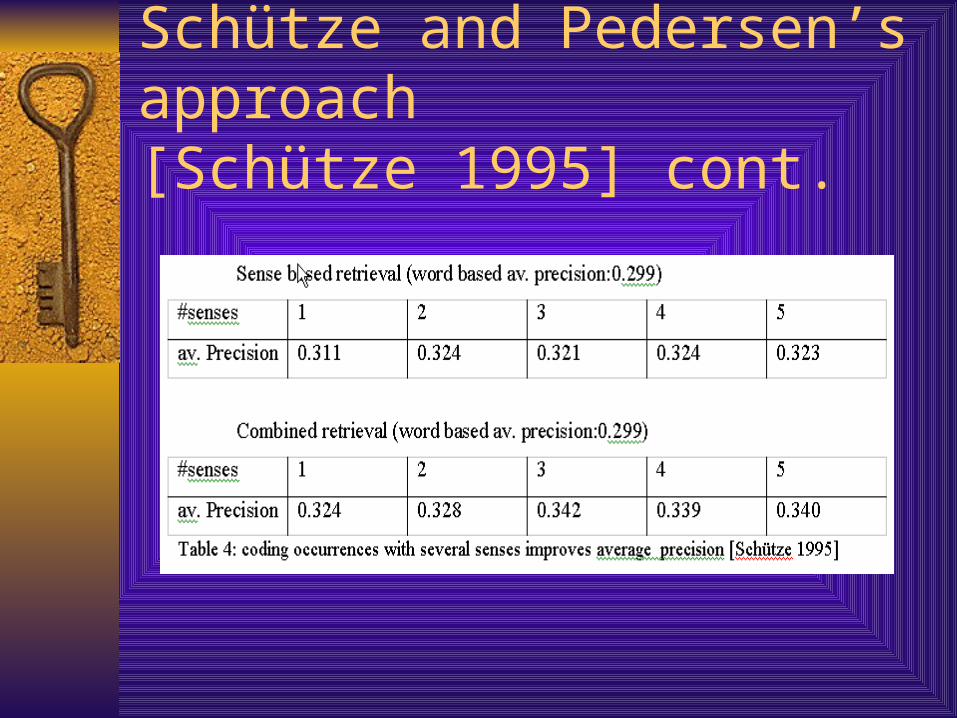
Schütze and Pedersen’s approach[Schütze 1995] cont.

Conclusion How much can WSD help improve IR
effectiveness? Open question– Weiss: 1%, Voorhees’ method : negative– Krovetz and Croft, Sanderson : only useful for short queries– Schütze and Pedersen’s approaches and Gonzalo’s experiment :
positive result
WSD must be accurate to be useful for IR Schütze and Pedersen’s, Yarowsky’s algorithm:
promising for IR Luk’s approach : robust for data sparse, suitable
for small corpus.

References[Krovetz 92] R. Krovetz & W.B. Croft (1992). Lexical Ambiguity and Information
Retrieval, in ACM Transactions onInformation Systems, 10(1). Gonzalo 1998] J. Gonzalo, F. Verdejo, I. Chugur and J. Cigarran, “Indexing with
WordNet synsets can improve Text Retrieval”, Proceedings of the COLING/ACL ’98 Workshop on Usage of WordNet for NLP, Montreal,1998
[Gonzalo 1992] R. Krovetz & W.B. Croft . “Lexical Ambiguity and Information Retrieval”, in ACM Transactions on Information Systems, 10(1), 1992
[Lesk 1988] M. Lesk , “They said true things, but called them by wrong names” – vocabulary problems in retrieval systems, in Proc. 4th Annual Conference of the University of Waterloo Centre for the New OED, 1988
[Luk 1995] A.K. Luk. “Statistical sense disambiguation with relatively small corpora using dictionary definitions”. In Proceedings of the 33rd Annual Meeting of the ACL, Columbus, Ohio, June 1995. Association for Computational Linguistics.
[Salton 83] G. Salton & M.J. McGill (1983). Introduction To Modern Information Retrieval. The SMART and SIRE experimental retrieval systems, in New York: McGraw-Hill
[Sanderson 1997] Sanderson, M. Word Sense Disambiguation and Information Retrieval, PhD Thesis, Technical Report (TR-1997-7) of the Department of Computing Science at the University of Glasgow, Glasgow G12 8QQ, UK.
[Sanderson 2000] Sanderson, Mark, “Retrieving with Good Sense”, http://citeseer.nj.nec.com/sanderson00retrieving.html , 2000
References cont.[Schütze 1995] H. Schütze & J.O. Pedersen. “Information retrieval based on word
senses”, in Proceedings of the Symposium on Document Analysis and Information Retrieval, 4: 161-175.
[Small 1982] S. Small & C. Rieger , “Parsing and comprehending with word experts (a theoryand its realisation) ” in Strategies for Natural Language Processing, W.G. Lehnert & M.H. Ringle, Eds., LEA: 89-148, 1982
[Voorhees 1993] E. M. Voorhees, “Using WordNet™ to disambiguate word sense for text retrieval, in Proceedings of ACM SIGIR Conference”, (16): 171-180. 1993
[Weiss 73] S.F. Weiss (1973). Learning to disambiguate, in Information Storage and Retrieval, 9:33-41, 1973
[Wilks 1990] Y. Wilks, D. Fass, C. Guo, J.E. Mcdonald, T. Plate, B.M. Slator (1990). ProvidingMachine Tractable Dictionary Tools, in Machine Translation, 5: 99-154, 1990
[Yarowsky 1992] D. Yarowsky, `“Word sense disambiguation using statistical models of Roget’s categories trained on large corpora, in Proceedings of COLING Conference”: 454-460, 1992
[Yarowsky 1994] Yarowsky, D. “Decision lists for lexical ambiguity resolution:Application to Accent Restoration in Spanish and French.” In Proceedings of the 32rd Annual Meeting of the Association for Computational Linguistics, Las Cruces, NM, 1994
[Yarowsky 1995] Yarowsky, D. “Unsupervised word sense disambiguation rivaling supervised methods.” In Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics, pages 189-- 196, Cambridge, MA, 1995