wlcg technical evolution groups john gordon, stfc gridpp28 manchester, 17 th april 2012
TRANSCRIPT

WLCG Technical Evolution Groups
John Gordon, STFC
GridPP28Manchester, 17th April 2012

Consider that:• Computing models have evolved• Far better understanding of requirements now than 10 years ago
– Even evolved since large scale challenges• Experiments have developed (different!) workarounds to
manage weaknesses in middleware• Pilot jobs and central task queues (almost) ubiquitous• Operational effort often too high; lots of services were not
designed for redundancy, fail-over, etc.• Technology evolves rapidly, rest of world also does (large scale)
distributed computing – don’t need entirely home grown solutions
• Must be concerned about long term support and where it will come from
Background

WLCG must have an agreed, clear, and documented vision for the future; to:• Better communicate needs to EMI/EGI, OSG,…• Be able to improve our middleware stack to address the
concerns• Attempt to re-build common solutions where possible
– Between experiments and between grids• Take into account lessons learned (functional, operational,
deployment, management…)• Understand the long term support needs• Focus our efforts where we must (e.g. data management), use
off-the-shelf solutions where possible• Must balance the needs of the experiments and the sites
Strategy

• To reassess the implementation of the grid infrastructures that we use in the light of the experience with LHC data, and technology evolution, but never forgetting the important successes and lessons, and ensuring that any evolution does not disrupt our successful operation.
• The work should:– Document a strategy for evolution of the technical implementation of the WLCG distributed
computing infrastructure;– This strategy should provide a clear statement of needs for WLCG which can also be used to
provide input to any external middleware and infrastructure projects. • The work should, in each technical area, take into account the current understanding of:
– Experiment and site needs in the light of experience with real data, operational environment(effort, functionality, security, etc.), and constraints;
– Lessons learned over several years in terms of deployability of software;– Evolution of technology over the last several years.
• It should also consider issues of:– Long term support and sustainability of the solutions;– Achieving commonalities between experiments where possible;– Achieving commonalities across all WLCG supporting infrastructures (EGI-related, OSG, NDGF,
etc). • Deliverables
– Assessment of the current situation with middleware, operations, and support structure.– Strategy document setting out a plan and needs for the next 2-5 years. 4
TEG: Mandate

5
• 6 groups were set up– Data management– Storage management– Workload management– Databases– Security– Operations and tools
• Data & storage generally worked together and produced a common report.
Working groups

• WLCG is a collaboration that has made a lot of use of projects such as EDG, EGEE, EGI, PPDG, OSG, etc.
• These are now ending – EMI and EGI (at CERN) end Q2 2013, OSG enters a new round of funding (not yet clear at what level)
• Unlikely to attract generic funding for grid developments in the near future
• So what does WLCG become?– Much complexity has migrated from grid layer to experiment-
specific layer (sometimes in common between experiments)– Sites need to focus on providing a extremely robust physical
infrastructure and key access services• Simplifying the grid complexity can help do this
– Sources of development effort are limited
Some contextWhat does the future look like?

• There will continue to be a certain limited(!) level at CERN (IT and PH-SFT)
• Hope that other large national grid projects can help (INFN? GridPP?)
• Can we build collaborative/community efforts to support key software?– Have not done this successfully very much
• The only way to really have a supportable software is to really collaborate across all the entities in WLCG – experiments and sites– And try to get key focussed developments from external sources where
possible• This really implies common solutions and collaborative efforts• Supporting software and services for a single experiment will be
easy to justify or fund in future
Sources of effort CERN-centric

8
• TEGs only really started in October• Each had face to face and phone conferences in
Autumn 2011• Amsterdam end of January – face to face
meetings of all working groups– except DB which had already ~concluded
• Summary workshop on Feb 7th• Work so far was summarised in February GDB• Final reports were delivered by the end of
March(ish)
History

9
• Lots of people signed up to the mailing lists• Active participation was somewhat lower.• Sites not well represented• True for the UK as well as in general
Participation

10
Security

11
• This TEG set the boundaries by listing the assets under consideration: trust; reputations; intellectual property; data; cpu; identities;...
• Listing the threats: eg misused identities; denial of service; data deletion/corruption.....
• They then drew up a risk register scoring the impact and likelihood of each risk in the range of 1-5x1-5=1-25.
Assets/Threats/Risks
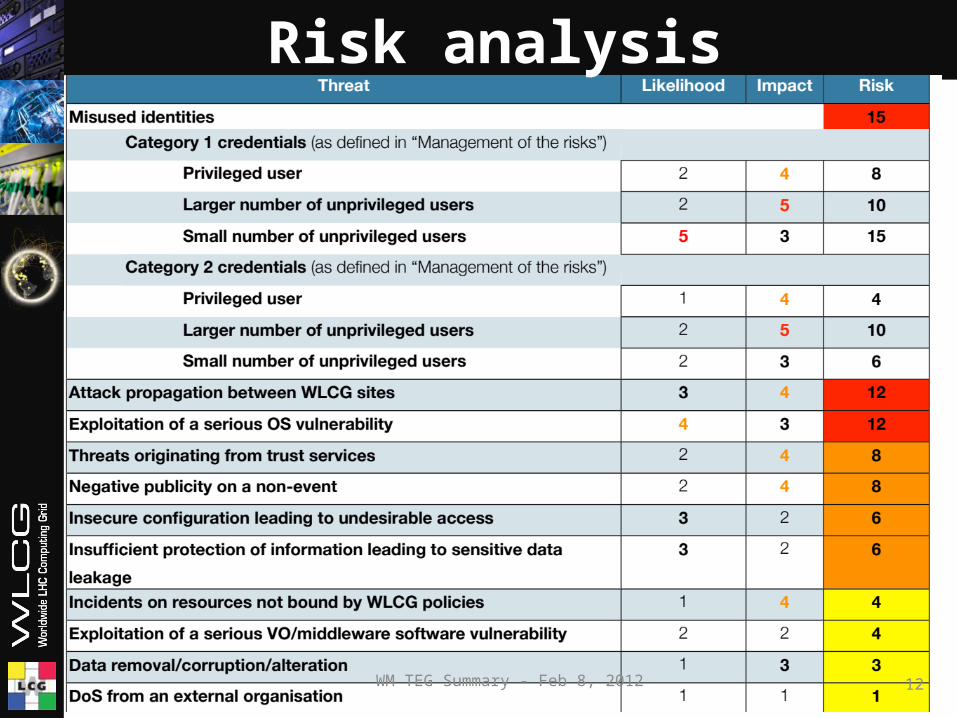
WM TEG Summary - Feb 8, 2012 12
Risk analysis


14
• Need for traceability and user-id switching on the WN has now been agreed as necessary by all experiments– Also agree that glexec is for now a reasonable
approach
• This resolves a long-standing issue with policy that had been put on hold.
WN security

15
Databases

16
• No experiment is planning to revisit substantially the Conditions Database model and the support tools (lack of specialized manpower), – although of course adiabatic improvements are always in the pipeline.
• ATLAS, CMS and LHCb expect that COOL CORAL and CoralServer will be supported by CERN (or WLCG) as long as these tools will be used by the experiments.
• Frontier/Squid should be recognized as a WLCG service and treated accordingly (GOCDB, GGUS, central rpm repository, monitoring).
• CERN IT should deploy a suitably sized Hadoop cluster, focussing on Hadoop and its ecosystem rather than fragmenting effort over a variety of NoSQL tools;
• Experiments would like to be involved in deployment discussions, with the aim of building a community around the tools.
Database Recommendations

17
Workload Management

Item Conclusion
GLExec GLExec was accepted by all VOs to handle pilots. It is recommended by this TEG (in setuid mode) as the standard way of handling pilot jobs.
Streamed submission Recommend extension of CE interfaces to support streamed submissions.
Common ways of running pilots
Recommend longer term evaluation of possible commonalities of a pilot framework beyond those already found within ATLAS and CMS (notably, glideinWMS).
Support of both whole node and multi-core jobs
Recommend extension of CE interfaces, using JDL for job requirements. Define environment information for variable core requests. Define interaction with the Information System. Define concrete testing plan once agreement is reached with middleware providers.
CPU pinning Liaise with other groups (e.g. HEPiX) to continue evaluation of the solutions described in this report.
CPU-bound and IO-bound jobs
Recommend extension of CE interfaces to support tagged jobs. Define concrete testing plan once agreement is reached with middleware providers.
Requirements for a CE Require middleware providers to support the concept of a “virtual CE”. Require support of common LRMS by CEs.
Need for a WMS Recommend a decommissioning plan.
Information System Expectation: WCLG experiments will continue to need mostly a simple discovery service. Recommend evaluation of a possible simplification of the existing IS.
Virtualization technologies Find a more permanent forum to share experiences between sites and VOs.
Cloud computing Adopt HEPiX-virt recommendations for existing WLCG Cloud test sites. Evaluate authentication and authorization issues. Explore dynamic provisiong of resources. Find a more permenent forum to share experiences between sites and VOs.
Other work Define details and possibly priorities for the areas described in this chapter.
18
WM Recommendations

20
Storage and Data Management

21
1 Data Management1.1 Federation1.2 Sequential point to point protocols 1.3 Managed Transfer 1.4 Management of Catalogues and Namespaces
2 Security3 Storage Management
3.1 Separation of archives and disk pools/caches 3.2 Storage Management Interfaces 3.3 Storage and Site Performance1.3.4 Storage and Site Operations: Site-run services
1 Summary of Recommendations

1.1 Federation a) Focussed work on an http plugin for xrootd (to prove exposed placement or
federation protocols can be changed while benefitting from xrootd as an implementation framework).
b) Establish a monitoring of the aggregate network bandwidth used via federation mechanisms to track the relative balance between managed and opportunistic transfers / accesses.
c) Launch and keep alive topical storage working groups to follow up a list of technical topics in the context of the GDB. These should focus on:
● Detailing the process of publishing new data into the read-only placement layer● Investigating a more strict separation of read-only and read-write data for increased scaling, stricter consistency guarantees and possibly definition of pure read-only cache implementations with reduced service levels (i.e. relevance for higher Tier sites).● Feasibility of moving a significant fraction of the current (read-only) data to world readable access avoiding the protocol overhead of fully authenticated protocols (assuming auditing to protect against denial of service attacks).● Investigating federation as repair mechanism of placed data; questions to answers would be: Who initiates repair? Which inter-site trust relationship needs to be in place? How proactive is this repair? (e.g. regular site checksum scans or repair & redirect after checksum mismatch) How is the space accounting done? How do we address the repair of missing metadata?
1 Data Management

23
a) There is currently no standard protocol for this purpose that could fully replace GridFTP as it is used now. Moving to recent versions and exploiting connection re-use will improve the efficiency for sets of small files.
b) All systems should ensure xrootd is well supported, especially in terms of latency and stability under high load.
c) The most promising new standard protocol for bulk data transfer is HTTP. In particular it covers the requirements well and can be also used in the context of storage federation. The recommendation is that the tests of the HTTP -based access should be continued, extended and explored at scale.
1.2 Sequential point to point protocols

24
1.3 Managed Transfer • 1. Update the FTS-3 design and work plan to cover the new requirements,
such as the use of replicas, support for HTTP-based bulk transfers and the management of the automatic staging process from archive storage.
• 2. Design a multi-experiment test to verify that the features implemented in FTS3 meet the experiments’ requirements in terms of functionalities, robustness and scalability.
1.4 Management of Catalogues and Namespaces • 1. The WLCG should plan for the LFC to become experiment-specific
software, then eventually unused as an experiment catalogue in the medium-term. Particularly, we should advise EMI (and subsequent projects) of this fact.
• a. In the meantime, maintenance will likely be needed.• b. We believe the LFC may be repurposed by subsequent EMI projects; i.e.,
as a central redirector for a federation system. • The following areas would need attention in the near term:• 1. Removal of backdoors from CASTOR• 2. Checks of the actual permissions implemented by Storage Elements.• 3. The issues with data ownership listed in Ch. 3 of that document

25
1. Status quo • SE and catalog configurations • Including quotas • Dealing with X509 overhead • Hosts should at most be trusted between services at the same site! • CASTOR still has backdoors for NS and RFIO to be closed 2. Data protection • Do different data classes need the same security model? 3. Issues with data ownership • Missing concept: data owned by the VO or by a service
– Use robot certificates for that? • Mapping a person to/from a credential 4. Quotas • Storage quotas
– Better handled by the experiment framework current practice • Quotas on other resources may be desirable to prevent DoS
– Request rate – Bandwidth – Connections
2 Data Security

26
3.1 Separation of archives and disk pools/caches • 1. The functionality of HSM in managing disk buffer in front of the archive should
not be dropped.• 2. Management of archive storage in the model described potentially moves from
within a single storage system and involves the transfer layer. Experiment workflows may need to be adapted accordingly and so tools such as FTS should support the required features as in the MT recommendations above.
1.3.2 Storage Management Interfaces • 1. Maintain SRM at archive sites. SRM is necessary especially at sites hosting
archive resources (custodial storage), where there is currently no proven and agreed replacement. SRM support will be required for Castor, dCache and GPFS/TSM until these implementations are replaced.
• 2. Experiments, middleware experts and sites should agree on alternatives to be considered for testing and deployment, targeting not the full SRM functionality but the subset detailed here, determined by its actual usage. We strongly recommend a small working group be formed, reporting to the GDB, to evaluate alternatives as they emerge, call for the need of tests whenever interesting, and to recommend those shown to be interoperable, scalable and supportable. Whatever storage management interface and transfer protocol are supported at WLCG sites, they must be supported by FTS and lcg_utils, to allow interoperability with other sites. Until such implementations are available, WLCG storage elements should by default provide an SRM interface unless negotiated otherwise with their user community.
• 3. Develop future interfaces. As of today, broader industry storage interfaces (such as cloud storage) have not proven all the functionality required for these to be widely utilized. The development of these needs to be monitored and different approaches to integrate cloud-based storage resources need to be investigated. Experiments, middleware experts and sites to should work together in this exploration phase.
3 Storage Management

27
3.3 Storage and Site Performance: Experiment I/O usage, LAN protocols and the requirements and evolution of storage systems (p28)
a) Benchmarking and I/O requirement gathering: WLCG should ask the ROOT I/O working group to come up with a synthetic benchmark emulating analysis for sites and others to use. LHC experiments should forecast the estimated IOPS and bandwidth perjob for the next 3 years, and provide these numbers to the WLCG as part of their requirements. Correspondingly, storage solutions should provide the tools to measure perjob IOPS and bandwidth.
b) Protocol support and evolution:c) I/O error management and resilience:d) Future technology review: e) High-throughput computing research:
3.4 Storage and Site Operations:f) Site involvement in protocol and requirement evolution: g) Expectations on data availability and access and the handling of data losses:h) Improved activity monitoring: i) Storage accounting. 3.5 POOL Persistency Framework • POOL has become experiment-specific software, and will become unnecessary in
the medium-term. No future development is foreseen.

28
Operations & Tools

29
R1 WLCG Service Coordination: – improve the computing service(s) provided by the sites – Clarify scope and frequency of current meetings; – Address specific Tier-2 communication needs through topic
driven dedicated service coordination meetings for Tier-2 representatives
– Evolve to “Computing as a Service at Tier-2s”. Fewer experiment-specific services and interactions
– Organize with EGI, NDGF and OSG common site administrator training
R2 WLCG Service Commissioning: – establish a core team of experts from experiments and sites to
validate, commission and troubleshoot WLCG services (UK exemplar?)
Recommendations: Services

TEG Workshop, February 2012 30
• R3: WLCG Availability Monitoring: streamline availability calculation and visualization – Converge on one system for availability calculation and for visualization – Review/add critical tests for VO availability calculation to better match
site usability • expose usability also in regular reports (monthly, MB).
• R4: WLCG Site Monitoring: deploy a common multi-VO tool to be used by sites to locally display the site performance – Site and experiments should agree on a few common metrics between
experiments, relevant from a site perspective
• R5: WLCG Network Monitoring: deploy a WLCG-wide and experiment independent monitoring system for network connectivity
Recommendations: Monitoring

TEG Workshop, February 2012 31
• R6: Software deployment – Adopt CVMFS for use as shared software area at all
WLCG sites (Tier-1 and Tier-2)– Deploy a robust and redundant infrastructure for
CVMFS • Complete the deployment and test the implemented resilience
Software Deployment

TEG workshop, February 2012 32
• R7: Information System (consistent with the recommendations of the GDB from June 2011)– Short term:
• improve the Information System via full deployment of the cached BDII and a strengthening of information validation (for instance via nagios probes)
– Long term:• split the information into optimized tools focused to provide
structural data (static), meta data, and state data (transient) • During refactoring the information elements in the BDII should be
reviewed and unnecessary elements dropped
Information System

TEG Workshop, February 2012 33
• R1: WLCG Service Coordination: improve the computing service(s) provided by the sites – Clarify scope, frequency and outcome of current meetings; – Address specific Tier-2 communication needs
• Dedicated service coordination meetings • Evolve to “Computing as a Service at Tier-2s”
– less experiment-specific services and interactions
– Organize with EGI, NDGF and OSG common site administrator training
• R2: WLCG Service Commissioning: establish a core team of experts (from sites and experiments) to validate, commission and troubleshoot services
Recommendations: Operations

34
• R8: Review site (middleware) services – Refactor existing middleware configurations to establish
consistent procedures and remove unnecessary complexity – Assess services on scalability, load balancing and high
availability aspects– Assess clients on retry and fail-over behaviors– Team of experts to prioritize open bugs and RFEs – Improve documentation based on input from service
administrators and users
Middleware Services

35
• R9: Middleware Distribution, Configuration, and Deployment– Middleware configuration should be improved and should not
be bound to a particular configuration management tool– Endorse middleware distribution via EPEL repository for
additions to the RHEL/SL operating system family • Opportunity to optimize release process
– Encourage sites and experiments to actively participate in the commissioning and validation of middleware components and services
– Maintain compatible middleware clients in the Application Area repository. Establish a compatible UI/WN release in rpm and tar format
– Possibility to produce targeted updates which fix individual problems on request
Middleware Deployment

36
• Surprisingly Conservative• Much short to medium term• Evolution, not revolution• Mentions clouds and virtualisation but no major
“paradigm shift”
• No major new data model– End of LFC
• Identity switching and glexec• End of WMS? Fuller support for CE• Involvement of sites
Summary

• Congratulations to everyone who contributed• ‘Editing team’ will integrate and summarise the reports into
a coherent strategy document– Iterating with TEGs and MB
• Call out areas where it is clear further work needs to be done– Either as continuation of the TEG or– As a dedicated (short term) focused WG
• At future MB/GDBs– Review recommendations and set priorities– Plan for where effort needs to be invested
• Iterate until done
Next steps

Sustainability anyone?