watson deepqa
DESCRIPTION
Building WatsonTRANSCRIPT

The goals of IBM Research are to advance computer scienceby exploring new ways for computer technology to affectscience, business, and society. Roughly three years ago,
IBM Research was looking for a major research challenge to rivalthe scientific and popular interest of Deep Blue, the computerchess-playing champion (Hsu 2002), that also would have clearrelevance to IBM business interests.
With a wealth of enterprise-critical information being cap-tured in natural language documentation of all forms, the prob-lems with perusing only the top 10 or 20 most popular docu-ments containing the user’s two or three key words arebecoming increasingly apparent. This is especially the case inthe enterprise where popularity is not as important an indicatorof relevance and where recall can be as critical as precision.There is growing interest to have enterprise computer systemsdeeply analyze the breadth of relevant content to more precise-ly answer and justify answers to user’s natural language ques-tions. We believe advances in question-answering (QA) tech-nology can help support professionals in critical and timelydecision making in areas like compliance, health care, businessintegrity, business intelligence, knowledge discovery, enterpriseknowledge management, security, and customer support. For
Articles
FALL 2010 59Copyright © 2010, Association for the Advancement of Artificial Intelligence. All rights reserved. ISSN 0738-4602
Building Watson: An Overview of the
DeepQA Project
David Ferrucci, Eric Brown, Jennifer Chu-Carroll, James Fan, David Gondek, Aditya A. Kalyanpur,
Adam Lally, J. William Murdock, Eric Nyberg, John Prager, Nico Schlaefer, and Chris Welty
� IBM Research undertook a challenge to builda computer system that could compete at thehuman champion level in real time on theAmerican TV quiz show, Jeopardy. The extentof the challenge includes fielding a real-timeautomatic contestant on the show, not merely alaboratory exercise. The Jeopardy Challengehelped us address requirements that led to thedesign of the DeepQA architecture and theimplementation of Watson. After three years ofintense research and development by a coreteam of about 20 researchers, Watson is per-forming at human expert levels in terms of pre-cision, confidence, and speed at the Jeopardyquiz show. Our results strongly suggest thatDeepQA is an effective and extensible architec-ture that can be used as a foundation for com-bining, deploying, evaluating, and advancing awide range of algorithmic techniques to rapidlyadvance the field of question answering (QA).

researchers, the open-domain QA problem isattractive as it is one of the most challenging in therealm of computer science and artificial intelli-gence, requiring a synthesis of informationretrieval, natural language processing, knowledgerepresentation and reasoning, machine learning,and computer-human interfaces. It has had a longhistory (Simmons 1970) and saw rapid advance-ment spurred by system building, experimenta-tion, and government funding in the past decade(Maybury 2004, Strzalkowski and Harabagiu 2006).
With QA in mind, we settled on a challenge tobuild a computer system, called Watson,1 whichcould compete at the human champion level inreal time on the American TV quiz show, Jeopardy.The extent of the challenge includes fielding a real-time automatic contestant on the show, not mere-ly a laboratory exercise.
Jeopardy! is a well-known TV quiz show that hasbeen airing on television in the United States formore than 25 years (see the Jeopardy! Quiz Showsidebar for more information on the show). It pitsthree human contestants against one another in acompetition that requires answering rich naturallanguage questions over a very broad domain oftopics, with penalties for wrong answers. The natureof the three-person competition is such that confi-dence, precision, and answering speed are of criticalimportance, with roughly 3 seconds to answer eachquestion. A computer system that could compete athuman champion levels at this game would need toproduce exact answers to often complex naturallanguage questions with high precision and speedand have a reliable confidence in its answers, suchthat it could answer roughly 70 percent of the ques-tions asked with greater than 80 percent precisionin 3 seconds or less.
Finally, the Jeopardy Challenge represents aunique and compelling AI question similar to theone underlying DeepBlue (Hsu 2002) — can a com-puter system be designed to compete against thebest humans at a task thought to require high lev-els of human intelligence, and if so, what kind oftechnology, algorithms, and engineering isrequired? While we believe the Jeopardy Challengeis an extraordinarily demanding task that willgreatly advance the field, we appreciate that thischallenge alone does not address all aspects of QAand does not by any means close the book on theQA challenge the way that Deep Blue may have forplaying chess.
The Jeopardy ChallengeMeeting the Jeopardy Challenge requires advancingand incorporating a variety of QA technologiesincluding parsing, question classification, questiondecomposition, automatic source acquisition andevaluation, entity and relation detection, logical
form generation, and knowledge representationand reasoning.
Winning at Jeopardy requires accurately comput-ing confidence in your answers. The questions andcontent are ambiguous and noisy and none of theindividual algorithms are perfect. Therefore, eachcomponent must produce a confidence in its out-put, and individual component confidences mustbe combined to compute the overall confidence ofthe final answer. The final confidence is used todetermine whether the computer system shouldrisk choosing to answer at all. In Jeopardy parlance,this confidence is used to determine whether thecomputer will “ring in” or “buzz in” for a question.The confidence must be computed during the timethe question is read and before the opportunity tobuzz in. This is roughly between 1 and 6 secondswith an average around 3 seconds.
Confidence estimation was very critical to shap-ing our overall approach in DeepQA. There is noexpectation that any component in the systemdoes a perfect job — all components post featuresof the computation and associated confidences,and we use a hierarchical machine-learningmethod to combine all these features and decidewhether or not there is enough confidence in thefinal answer to attempt to buzz in and risk gettingthe question wrong.
In this section we elaborate on the variousaspects of the Jeopardy Challenge.
The Categories A 30-clue Jeopardy board is organized into sixcolumns. Each column contains five clues and isassociated with a category. Categories range frombroad subject headings like “history,” “science,” or“politics” to less informative puns like “tutumuch,” in which the clues are about ballet, to actu-al parts of the clue, like “who appointed me to theSupreme Court?” where the clue is the name of ajudge, to “anything goes” categories like “pot-pourri.” Clearly some categories are essential tounderstanding the clue, some are helpful but notnecessary, and some may be useless, if not mis-leading, for a computer.
A recurring theme in our approach is the require-ment to try many alternate hypotheses in varyingcontexts to see which produces the most confidentanswers given a broad range of loosely coupled scor-ing algorithms. Leveraging category information isanother clear area requiring this approach.
The QuestionsThere are a wide variety of ways one can attempt tocharacterize the Jeopardy clues. For example, bytopic, by difficulty, by grammatical construction,by answer type, and so on. A type of classificationthat turned out to be useful for us was based on theprimary method deployed to solve the clue. The
Articles
60 AI MAGAZINE

Articles
FALL 2010 61
The Jeopardy! quiz show is a well-known syndicat-ed U.S. TV quiz show that has been on the airsince 1984. It features rich natural language ques-tions covering a broad range of general knowl-edge. It is widely recognized as an entertaininggame requiring smart, knowledgeable, and quickplayers.
The show’s format pits three human contestantsagainst each other in a three-round contest ofknowledge, confidence, and speed. All contestantsmust pass a 50-question qualifying test to be eligi-ble to play. The first two rounds of a game use agrid organized into six columns, each with a cate-gory label, and five rows with increasing dollarvalues. The illustration shows a sample board for afirst round. In the second round, the dollar valuesare doubled. Initially all the clues in the grid arehidden behind their dollar values. The game playbegins with the returning champion selecting acell on the grid by naming the category and thedollar value. For example the player may select bysaying “Technology for $400.”
The clue under the selected cell is revealed to allthe players and the host reads it out loud. Eachplayer is equipped with a hand-held signaling but-ton. As soon as the host finishes reading the clue,a light becomes visible around the board, indicat-ing to the players that their hand-held devices areenabled and they are free to signal or “buzz in” fora chance to respond. If a player signals before thelight comes on, then he or she is locked out forone-half of a second before being able to buzz inagain.
The first player to successfully buzz in gets achance to respond to the clue. That is, the playermust answer the question, but the response mustbe in the form of a question. For example, validlyformed responses are, “Who is Ulysses S. Grant?”or “What is The Tempest?” rather than simply“Ulysses S. Grant” or “The Tempest.” The Jeopardyquiz show was conceived to have the host provid-ing the answer or clue and the players respondingwith the corresponding question or response. Theclue/response concept represents an entertainingtwist on classic question answering. Jeopardy cluesare straightforward assertional forms of questions.So where a question might read, “What drug hasbeen shown to relieve the symptoms of ADD with
relatively few side effects?” the correspondingJeopardy clue might read “This drug has beenshown to relieve the symptoms of ADD with rela-tively few side effects.” The correct Jeopardyresponse would be “What is Ritalin?”
Players have 5 seconds to speak their response,but it’s typical that they answer almost immedi-ately since they often only buzz in if they alreadyknow the answer. If a player responds to a clue cor-rectly, then the dollar value of the clue is added tothe player’s total earnings, and that player selectsanother cell on the board. If the player respondsincorrectly then the dollar value is deducted fromthe total earnings, and the system is rearmed,allowing the other players to buzz in. This makesit important for players to know what they know— to have accurate confidences in their responses.
There is always one cell in the first round andtwo in the second round called Daily Doubles,whose exact location is hidden until the cell isselected by a player. For these cases, the selectingplayer does not have to compete for the buzzer butmust respond to the clue regardless of the player’sconfidence. In addition, before the clue is revealedthe player must wager a portion of his or her earn-ings. The minimum bet is $5 and the maximumbet is the larger of the player’s current score andthe maximum clue value on the board. If playersanswer correctly, they earn the amount they bet,else they lose it.
The Final Jeopardy round consists of a singlequestion and is played differently. First, a catego-ry is revealed. The players privately write downtheir bet — an amount less than or equal to theirtotal earnings. Then the clue is revealed. Theyhave 30 seconds to respond. At the end of the 30seconds they reveal their answers and then theirbets. The player with the most money at the endof this third round wins the game. The questionsused in this round are typically more difficult thanthose used in the previous rounds.
The Jeopardy! Quiz Show

bulk of Jeopardy clues represent what we wouldconsider factoid questions — questions whoseanswers are based on factual information aboutone or more individual entities. The questionsthemselves present challenges in determiningwhat exactly is being asked for and which elementsof the clue are relevant in determining the answer.Here are just a few examples (note that while theJeopardy! game requires that answers are deliveredin the form of a question (see the Jeopardy! QuizShow sidebar), this transformation is trivial and forpurposes of this paper we will just show theanswers themselves):
Category: General ScienceClue: When hit by electrons, a phosphor gives offelectromagnetic energy in this form.Answer: Light (or Photons)
Category: Lincoln BlogsClue: Secretary Chase just submitted this to me forthe third time; guess what, pal. This time I’maccepting it.Answer: his resignation
Category: Head NorthClue: They’re the two states you could be reenteringif you’re crossing Florida’s northern border.Answer: Georgia and Alabama
Decomposition. Some more complex clues con-tain multiple facts about the answer, all of whichare required to arrive at the correct response butare unlikely to occur together in one place. Forexample:
Category: “Rap” SheetClue: This archaic term for a mischievous or annoy-ing child can also mean a rogue or scamp.Subclue 1: This archaic term for a mischievous orannoying child.Subclue 2: This term can also mean a rogue orscamp.Answer: Rapscallion
In this case, we would not expect to find both“subclues” in one sentence in our sources; rather,if we decompose the question into these two partsand ask for answers to each one, we may find thatthe answer common to both questions is theanswer to the original clue.
Another class of decomposable questions is onein which a subclue is nested in the outer clue, andthe subclue can be replaced with its answer to forma new question that can more easily be answered.For example:
Category: Diplomatic RelationsClue: Of the four countries in the world that theUnited States does not have diplomatic relationswith, the one that’s farthest north.Inner subclue: The four countries in the world thatthe United States does not have diplomatic rela-tions with (Bhutan, Cuba, Iran, North Korea).Outer subclue: Of Bhutan, Cuba, Iran, and NorthKorea, the one that’s farthest north.Answer: North Korea
Decomposable Jeopardy clues generated require-ments that drove the design of DeepQA to gener-ate zero or more decomposition hypotheses foreach question as possible interpretations.
Puzzles. Jeopardy also has categories of questionsthat require special processing defined by the cate-gory itself. Some of them recur often enough thatcontestants know what they mean withoutinstruction; for others, part of the task is to figureout what the puzzle is as the clues and answers arerevealed (categories requiring explanation by thehost are not part of the challenge). Examples ofwell-known puzzle categories are the Before andAfter category, where two subclues have answersthat overlap by (typically) one word, and theRhyme Time category, where the two subclueanswers must rhyme with one another. Clearlythese cases also require question decomposition.For example:
Category: Before and After Goes to the MoviesClue: Film of a typical day in the life of the Beatles,which includes running from bloodthirsty zombiefans in a Romero classic.Subclue 2: Film of a typical day in the life of the Bea-tles. Answer 1: (A Hard Day’s Night)Subclue 2: Running from bloodthirsty zombie fansin a Romero classic. Answer 2: (Night of the Living Dead)Answer: A Hard Day’s Night of the Living Dead
Category: Rhyme TimeClue: It’s where Pele stores his ball.Subclue 1: Pele ball (soccer)Subclue 2: where store (cabinet, drawer, locker, andso on)Answer: soccer locker
There are many infrequent types of puzzle cate-gories including things like converting romannumerals, solving math word problems, soundslike, finding which word in a set has the highestScrabble score, homonyms and heteronyms, andso on. Puzzles constitute only about 2–3 percent ofall clues, but since they typically occur as entirecategories (five at a time) they cannot be ignoredfor success in the Challenge as getting them allwrong often means losing a game.
Excluded Question Types. The Jeopardy quiz showordinarily admits two kinds of questions that IBMand Jeopardy Productions, Inc., agreed to excludefrom the computer contest: audiovisual (A/V)questions and Special Instructions questions. A/Vquestions require listening to or watching somesort of audio, image, or video segment to deter-mine a correct answer. For example:
Category: Picture This(Contestants are shown a picture of a B-52 bomber)Clue: Alphanumeric name of the fearsome machineseen here.Answer: B-52
Articles
62 AI MAGAZINE

Special instruction questions are those that arenot “self-explanatory” but rather require a verbalexplanation describing how the question shouldbe interpreted and solved. For example:
Category: Decode the Postal CodesVerbal instruction from host: We’re going to give youa word comprising two postal abbreviations; youhave to identify the states.Clue: VainAnswer: Virginia and Indiana
Both present very interesting challenges from anAI perspective but were put out of scope for thiscontest and evaluation.
The DomainAs a measure of the Jeopardy Challenge’s breadth ofdomain, we analyzed a random sample of 20,000questions extracting the lexical answer type (LAT)when present. We define a LAT to be a word in theclue that indicates the type of the answer, inde-pendent of assigning semantics to that word. Forexample in the following clue, the LAT is the string“maneuver.”
Category: Oooh….ChessClue: Invented in the 1500s to speed up the game,this maneuver involves two pieces of the same col-or.Answer: Castling
About 12 percent of the clues do not indicate anexplicit lexical answer type but may refer to theanswer with pronouns like “it,” “these,” or “this”or not refer to it at all. In these cases the type of
answer must be inferred by the context. Here’s anexample:
Category: DecoratingClue: Though it sounds “harsh,” it’s just embroi-dery, often in a floral pattern, done with yarn oncotton cloth.Answer: crewel
The distribution of LATs has a very long tail, asshown in figure 1. We found 2500 distinct andexplicit LATs in the 20,000 question sample. Themost frequent 200 explicit LATs cover less than 50percent of the data. Figure 1 shows the relative fre-quency of the LATs. It labels all the clues with noexplicit type with the label “NA.” This aspect of thechallenge implies that while task-specific type sys-tems or manually curated data would have someimpact if focused on the head of the LAT curve, itstill leaves more than half the problems unaccount-ed for. Our clear technical bias for both business andscientific motivations is to create general-purpose,reusable natural language processing (NLP) andknowledge representation and reasoning (KRR)technology that can exploit as-is natural languageresources and as-is structured knowledge ratherthan to curate task-specific knowledge resources.
The MetricsIn addition to question-answering precision, thesystem’s game-winning performance will dependon speed, confidence estimation, clue selection,and betting strategy. Ultimately the outcome of
Articles
FALL 2010 63
Figure 1. Lexical Answer Type Frequency.
0.00%
2.00%
4.00%
6.00%
8.00%
10.00%
12.00% N
A he
coun
try
city
m
an
film
st
ate
she
auth
or
grou
p
here
co
mp
any
pre
side
nt
cap
ital
star
no
vel
char
acte
r w
oman
riv
er
isla
nd
king
so
ng
par
t se
ries
spor
t si
nger
ac
tor
pla
y te
am
show
ac
tres
s an
imal
p
resi
dent
ial
com
pos
er
mus
ical
na
tion
book
tit
le
lead
er
gam
e
40 Most Frequent LATs
0.00%
2.00%
4.00%
6.00%
8.00%
10.00%
12.00%
200 Most Frequent LATs
the public contest will be decided based onwhether or not Watson can win one or two gamesagainst top-ranked humans in real time. The high-est amount of money earned by the end of a one-or two-game match determines the winner. A play-er’s final earnings, however, often will not reflecthow well the player did during the game at the QAtask. This is because a player may decide to bet bigon Daily Double or Final Jeopardy questions. Thereare three hidden Daily Double questions in a gamethat can affect only the player lucky enough tofind them, and one Final Jeopardy question at theend that all players must gamble on. Daily Doubleand Final Jeopardy questions represent significantevents where players may risk all their currentearnings. While potentially compelling for a pub-lic contest, a small number of games does not rep-resent statistically meaningful results for the sys-tem’s raw QA performance.
While Watson is equipped with betting strate-gies necessary for playing full Jeopardy, from a coreQA perspective we want to measure correctness,confidence, and speed, without considering clueselection, luck of the draw, and betting strategies.We measure correctness and confidence using pre-cision and percent answered. Precision measuresthe percentage of questions the system gets right
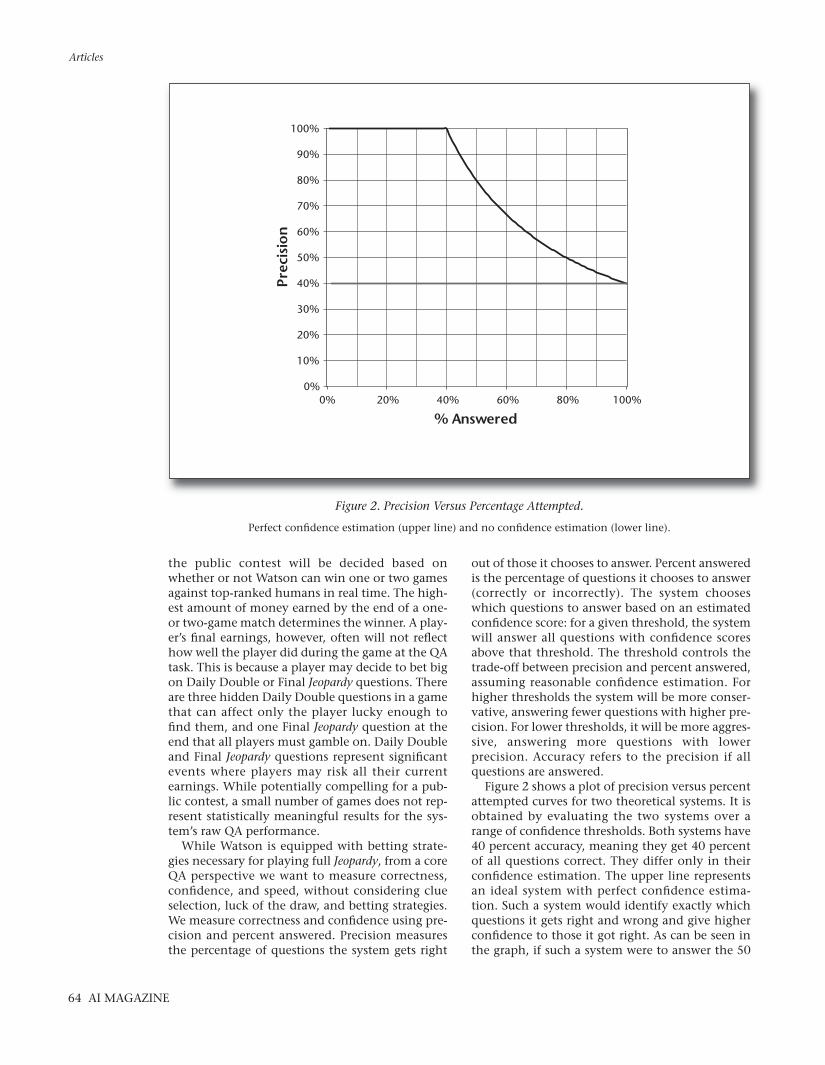
out of those it chooses to answer. Percent answeredis the percentage of questions it chooses to answer(correctly or incorrectly). The system chooseswhich questions to answer based on an estimatedconfidence score: for a given threshold, the systemwill answer all questions with confidence scoresabove that threshold. The threshold controls thetrade-off between precision and percent answered,assuming reasonable confidence estimation. Forhigher thresholds the system will be more conser-vative, answering fewer questions with higher pre-cision. For lower thresholds, it will be more aggres-sive, answering more questions with lowerprecision. Accuracy refers to the precision if allquestions are answered.
Figure 2 shows a plot of precision versus percentattempted curves for two theoretical systems. It isobtained by evaluating the two systems over arange of confidence thresholds. Both systems have40 percent accuracy, meaning they get 40 percentof all questions correct. They differ only in theirconfidence estimation. The upper line representsan ideal system with perfect confidence estima-tion. Such a system would identify exactly whichquestions it gets right and wrong and give higherconfidence to those it got right. As can be seen inthe graph, if such a system were to answer the 50
Articles
64 AI MAGAZINE
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 20% 40% 60% 80% 100%
Pre
cisi
on
% Answered
Figure 2. Precision Versus Percentage Attempted.
Perfect confidence estimation (upper line) and no confidence estimation (lower line).
percent of questions it had highest confidence for,it would get 80 percent of those correct. We refer tothis level of performance as 80 percent precision at50 percent answered. The lower line represents asystem without meaningful confidence estimation.Since it cannot distinguish between which ques-tions it is more or less likely to get correct, its pre-cision is constant for all percent attempted. Devel-oping more accurate confidence estimation meansa system can deliver far higher precision even withthe same overall accuracy.
The Competition: Human Champion Performance
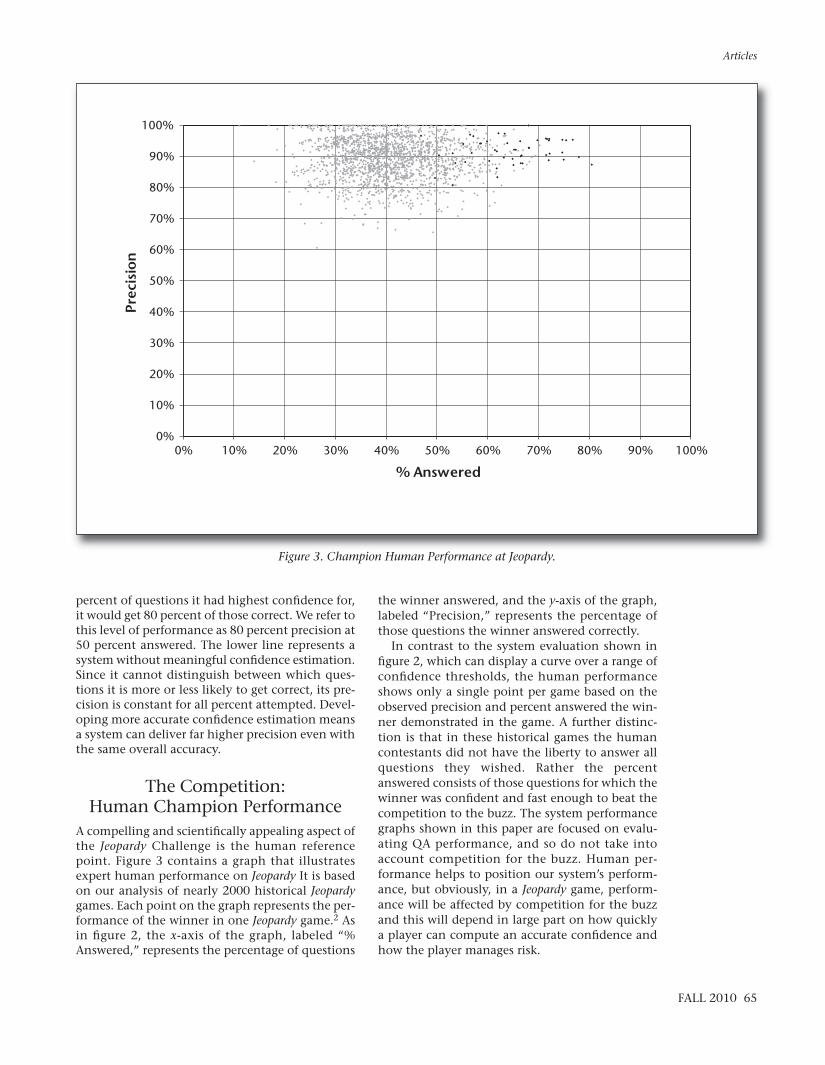
A compelling and scientifically appealing aspect ofthe Jeopardy Challenge is the human referencepoint. Figure 3 contains a graph that illustratesexpert human performance on Jeopardy It is basedon our analysis of nearly 2000 historical Jeopardygames. Each point on the graph represents the per-formance of the winner in one Jeopardy game.2 Asin figure 2, the x-axis of the graph, labeled “%Answered,” represents the percentage of questions
the winner answered, and the y-axis of the graph,labeled “Precision,” represents the percentage ofthose questions the winner answered correctly.
In contrast to the system evaluation shown infigure 2, which can display a curve over a range ofconfidence thresholds, the human performanceshows only a single point per game based on theobserved precision and percent answered the win-ner demonstrated in the game. A further distinc-tion is that in these historical games the humancontestants did not have the liberty to answer allquestions they wished. Rather the percentanswered consists of those questions for which thewinner was confident and fast enough to beat thecompetition to the buzz. The system performancegraphs shown in this paper are focused on evalu-ating QA performance, and so do not take intoaccount competition for the buzz. Human per-formance helps to position our system’s perform-ance, but obviously, in a Jeopardy game, perform-ance will be affected by competition for the buzzand this will depend in large part on how quicklya player can compute an accurate confidence andhow the player manages risk.
Articles
FALL 2010 65
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Prec
isio
n
% Answered
Figure 3. Champion Human Performance at Jeopardy.

The center of what we call the “Winners Cloud”(the set of light gray dots in the graph in figures 3and 4) reveals that Jeopardy champions are confi-dent and fast enough to acquire on averagebetween 40 percent and 50 percent of all the ques-tions from their competitors and to perform withbetween 85 percent and 95 percent precision.
The darker dots on the graph represent Ken Jen-nings’s games. Ken Jennings had an unequaledwinning streak in 2004, in which he won 74 gamesin a row. Based on our analysis of those games, heacquired on average 62 percent of the questionsand answered with 92 percent precision. Humanperformance at this task sets a very high bar forprecision, confidence, speed, and breadth.
Baseline PerformanceOur metrics and baselines are intended to give usconfidence that new methods and algorithms areimproving the system or to inform us when theyare not so that we can adjust research priorities.
Our most obvious baseline is the QA systemcalled Practical Intelligent Question AnsweringTechnology (PIQUANT) (Prager, Chu-Carroll, andCzuba 2004), which had been under developmentat IBM Research by a four-person team for 6 yearsprior to taking on the Jeopardy Challenge. At thetime it was among the top three to five TextRetrieval Conference (TREC) QA systems. Devel-oped in part under the U.S. government AQUAINTprogram3 and in collaboration with external teamsand universities, PIQUANT was a classic QApipeline with state-of-the-art techniques aimedlargely at the TREC QA evaluation (Voorhees andDang 2005). PIQUANT performed in the 33 per-cent accuracy range in TREC evaluations. Whilethe TREC QA evaluation allowed the use of theweb, PIQUANT focused on question answeringusing local resources. A requirement of the JeopardyChallenge is that the system be self-contained anddoes not link to live web search.
The requirements of the TREC QA evaluationwere different than for the Jeopardy challenge.Most notably, TREC participants were given a rela-tively small corpus (1M documents) from whichanswers to questions must be justified; TREC ques-tions were in a much simpler form compared toJeopardy questions, and the confidences associatedwith answers were not a primary metric. Further-more, the systems are allowed to access the weband had a week to produce results for 500 ques-tions. The reader can find details in the TREC pro-ceedings4 and numerous follow-on publications.
An initial 4-week effort was made to adaptPIQUANT to the Jeopardy Challenge. The experi-ment focused on precision and confidence. Itignored issues of answering speed and aspects ofthe game like betting and clue values.
The questions used were 500 randomly sampledJeopardy clues from episodes in the past 15 years.The corpus that was used contained, but did notnecessarily justify, answers to more than 90 per-cent of the questions. The result of the PIQUANTbaseline experiment is illustrated in figure 4. Asshown, on the 5 percent of the clues that PI -QUANT was most confident in (left end of thecurve), it delivered 47 percent precision, and overall the clues in the set (right end of the curve), itsprecision was 13 percent. Clearly the precision andconfidence estimation are far below the require-ments of the Jeopardy Challenge.
A similar baseline experiment was performed incollaboration with Carnegie Mellon University(CMU) using OpenEphyra,5 an open-source QAframework developed primarily at CMU. Theframework is based on the Ephyra system, whichwas designed for answering TREC questions. In ourexperiments on TREC 2002 data, OpenEphyraanswered 45 percent of the questions correctlyusing a live web search.
We spent minimal effort adapting OpenEphyra,but like PIQUANT, its performance on Jeopardyclues was below 15 percent accuracy. OpenEphyradid not produce reliable confidence estimates andthus could not effectively choose to answer ques-tions with higher confidence. Clearly a largerinvestment in tuning and adapting these baselinesystems to Jeopardy would improve their perform-ance; however, we limited this investment sincewe did not want the baseline systems to becomesignificant efforts.
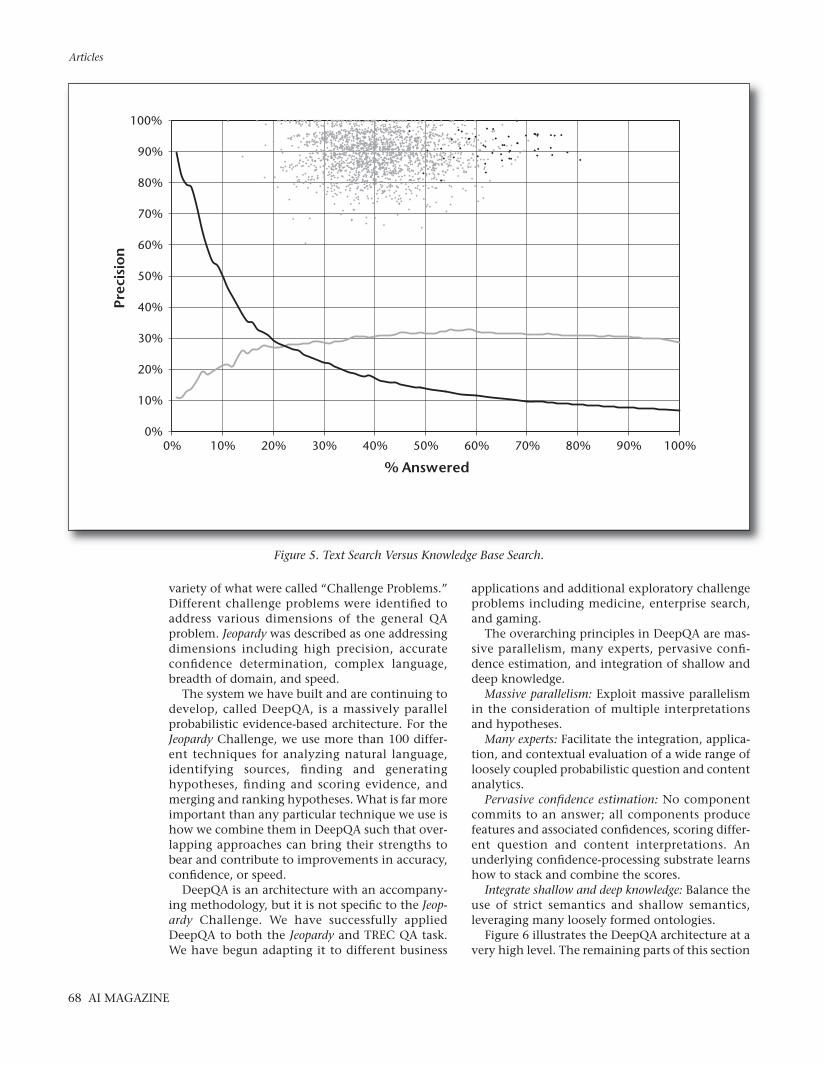
The PIQUANT and OpenEphyra baselinesdemonstrate the performance of state-of-the-artQA systems on the Jeopardy task. In figure 5 weshow two other baselines that demonstrate theperformance of two complementary approacheson this task. The light gray line shows the per-formance of a system based purely on text search,using terms in the question as queries and searchengine scores as confidences for candidate answersgenerated from retrieved document titles. Theblack line shows the performance of a systembased on structured data, which attempts to lookthe answer up in a database by simply finding thenamed entities in the database related to thenamed entities in the clue. These two approacheswere adapted to the Jeopardy task, including iden-tifying and integrating relevant content.
The results form an interesting comparison. Thesearch-based system has better performance at 100percent answered, suggesting that the natural lan-guage content and the shallow text search tech-niques delivered better coverage. However, the flat-ness of the curve indicates the lack of accurateconfidence estimation.6 The structured approachhad better informed confidence when it was ableto decipher the entities in the question and found
Articles
66 AI MAGAZINE
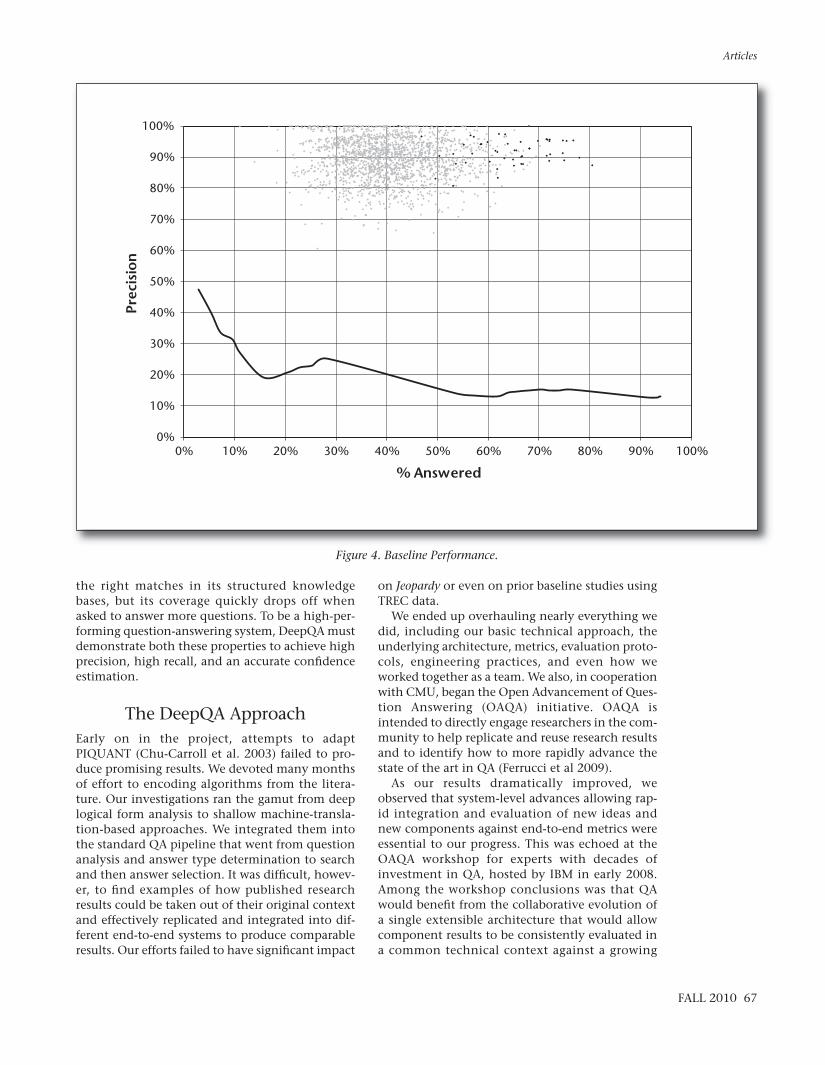
the right matches in its structured knowledgebases, but its coverage quickly drops off whenasked to answer more questions. To be a high-per-forming question-answering system, DeepQA mustdemonstrate both these properties to achieve highprecision, high recall, and an accurate confidenceestimation.
The DeepQA ApproachEarly on in the project, attempts to adaptPIQUANT (Chu-Carroll et al. 2003) failed to pro-duce promising results. We devoted many monthsof effort to encoding algorithms from the litera-ture. Our investigations ran the gamut from deeplogical form analysis to shallow machine-transla-tion-based approaches. We integrated them intothe standard QA pipeline that went from questionanalysis and answer type determination to searchand then answer selection. It was difficult, howev-er, to find examples of how published researchresults could be taken out of their original contextand effectively replicated and integrated into dif-ferent end-to-end systems to produce comparableresults. Our efforts failed to have significant impact
on Jeopardy or even on prior baseline studies usingTREC data.
We ended up overhauling nearly everything wedid, including our basic technical approach, theunderlying architecture, metrics, evaluation proto-cols, engineering practices, and even how weworked together as a team. We also, in cooperationwith CMU, began the Open Advancement of Ques-tion Answering (OAQA) initiative. OAQA isintended to directly engage researchers in the com-munity to help replicate and reuse research resultsand to identify how to more rapidly advance thestate of the art in QA (Ferrucci et al 2009).
As our results dramatically improved, weobserved that system-level advances allowing rap-id integration and evaluation of new ideas andnew components against end-to-end metrics wereessential to our progress. This was echoed at theOAQA workshop for experts with decades ofinvestment in QA, hosted by IBM in early 2008.Among the workshop conclusions was that QAwould benefit from the collaborative evolution ofa single extensible architecture that would allowcomponent results to be consistently evaluated ina common technical context against a growing
Articles
FALL 2010 67
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Prec
isio
n
% Answered
Figure 4. Baseline Performance.
Articles
68 AI MAGAZINE
variety of what were called “Challenge Problems.”Different challenge problems were identified toaddress various dimensions of the general QAproblem. Jeopardy was described as one addressingdimensions including high precision, accurateconfidence determination, complex language,breadth of domain, and speed.
The system we have built and are continuing todevelop, called DeepQA, is a massively parallelprobabilistic evidence-based architecture. For theJeopardy Challenge, we use more than 100 differ-ent techniques for analyzing natural language,identifying sources, finding and generatinghypotheses, finding and scoring evidence, andmerging and ranking hypotheses. What is far moreimportant than any particular technique we use ishow we combine them in DeepQA such that over-lapping approaches can bring their strengths tobear and contribute to improvements in accuracy,confidence, or speed.
DeepQA is an architecture with an accompany-ing methodology, but it is not specific to the Jeop-ardy Challenge. We have successfully appliedDeepQA to both the Jeopardy and TREC QA task.We have begun adapting it to different business
applications and additional exploratory challengeproblems including medicine, enterprise search,and gaming.
The overarching principles in DeepQA are mas-sive parallelism, many experts, pervasive confi-dence estimation, and integration of shallow anddeep knowledge.
Massive parallelism: Exploit massive parallelismin the consideration of multiple interpretationsand hypotheses.
Many experts: Facilitate the integration, applica-tion, and contextual evaluation of a wide range ofloosely coupled probabilistic question and contentanalytics.
Pervasive confidence estimation: No componentcommits to an answer; all components producefeatures and associated confidences, scoring differ-ent question and content interpretations. Anunderlying confidence-processing substrate learnshow to stack and combine the scores.
Integrate shallow and deep knowledge: Balance theuse of strict semantics and shallow semantics,leveraging many loosely formed ontologies.
Figure 6 illustrates the DeepQA architecture at avery high level. The remaining parts of this section
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Prec
isio
n
% Answered
Figure 5. Text Search Versus Knowledge Base Search.

provide a bit more detail about the various archi-tectural roles.
Content AcquisitionThe first step in any application of DeepQA tosolve a QA problem is content acquisition, or iden-tifying and gathering the content to use for theanswer and evidence sources shown in figure 6.
Content acquisition is a combination of manu-al and automatic steps. The first step is to analyzeexample questions from the problem space to pro-duce a description of the kinds of questions thatmust be answered and a characterization of theapplication domain. Analyzing example questionsis primarily a manual task, while domain analysismay be informed by automatic or statistical analy-ses, such as the LAT analysis shown in figure 1.Given the kinds of questions and broad domain ofthe Jeopardy Challenge, the sources for Watsoninclude a wide range of encyclopedias, dictionar-ies, thesauri, newswire articles, literary works, andso on.
Given a reasonable baseline corpus, DeepQAthen applies an automatic corpus expansionprocess. The process involves four high-level steps:(1) identify seed documents and retrieve relateddocuments from the web; (2) extract self-containedtext nuggets from the related web documents; (3)score the nuggets based on whether they are
informative with respect to the original seed docu-ment; and (4) merge the most informative nuggetsinto the expanded corpus. The live system itselfuses this expanded corpus and does not haveaccess to the web during play.
In addition to the content for the answer andevidence sources, DeepQA leverages other kinds ofsemistructured and structured content. Anotherstep in the content-acquisition process is to identi-fy and collect these resources, which include data-bases, taxonomies, and ontologies, such as dbPe-dia,7 WordNet (Miller 1995), and the Yago8
ontology.
Question AnalysisThe first step in the run-time question-answeringprocess is question analysis. During questionanalysis the system attempts to understand whatthe question is asking and performs the initialanalyses that determine how the question will beprocessed by the rest of the system. The DeepQAapproach encourages a mixture of experts at thisstage, and in the Watson system we produce shal-low parses, deep parses (McCord 1990), logicalforms, semantic role labels, coreference, relations,named entities, and so on, as well as specific kindsof analysis for question answering. Most of thesetechnologies are well understood and are not dis-cussed here, but a few require some elaboration.
Articles
FALL 2010 69
Figure 6. DeepQA High-Level Architecture.

Question Classification. Question classification isthe task of identifying question types or parts ofquestions that require special processing. This caninclude anything from single words with poten-tially double meanings to entire clauses that havecertain syntactic, semantic, or rhetorical function-ality that may inform downstream componentswith their analysis. Question classification mayidentify a question as a puzzle question, a mathquestion, a definition question, and so on. It willidentify puns, constraints, definition components,or entire subclues within questions.
Focus and LAT Detection. As discussed earlier, alexical answer type is a word or noun phrase in thequestion that specifies the type of the answer with-out any attempt to understand its semantics.Determining whether or not a candidate answercan be considered an instance of the LAT is animportant kind of scoring and a common source ofcritical errors. An advantage to the DeepQAapproach is to exploit many independently devel-oped answer-typing algorithms. However, many ofthese algorithms are dependent on their own typesystems. We found the best way to integrate pre-existing components is not to force them into asingle, common type system, but to have themmap from the LAT to their own internal types.
The focus of the question is the part of the ques-tion that, if replaced by the answer, makes the ques-tion a stand-alone statement. Looking back at someof the examples shown previously, the focus of“When hit by electrons, a phosphor gives off elec-tromagnetic energy in this form” is “this form”; thefocus of “Secretary Chase just submitted this to mefor the third time; guess what, pal. This time I’maccepting it” is the first “this”; and the focus of“This title character was the crusty and tough cityeditor of the Los Angeles Tribune” is “This title char-acter.” The focus often (but not always) containsuseful information about the answer, is often thesubject or object of a relation in the clue, and canturn a question into a factual statement whenreplaced with a candidate, which is a useful way togather evidence about a candidate.
Relation Detection. Most questions contain rela-tions, whether they are syntactic subject-verb-object predicates or semantic relationshipsbetween entities. For example, in the question,“They’re the two states you could be reentering ifyou’re crossing Florida’s northern border,” we candetect the relation borders(Florida,?x,north).
Watson uses relation detection throughout theQA process, from focus and LAT determination, topassage and answer scoring. Watson can also usedetected relations to query a triple store and direct-ly generate candidate answers. Due to the breadthof relations in the Jeopardy domain and the varietyof ways in which they are expressed, however,Watson’s current ability to effectively use curated
databases to simply “look up” the answers is limit-ed to fewer than 2 percent of the clues.
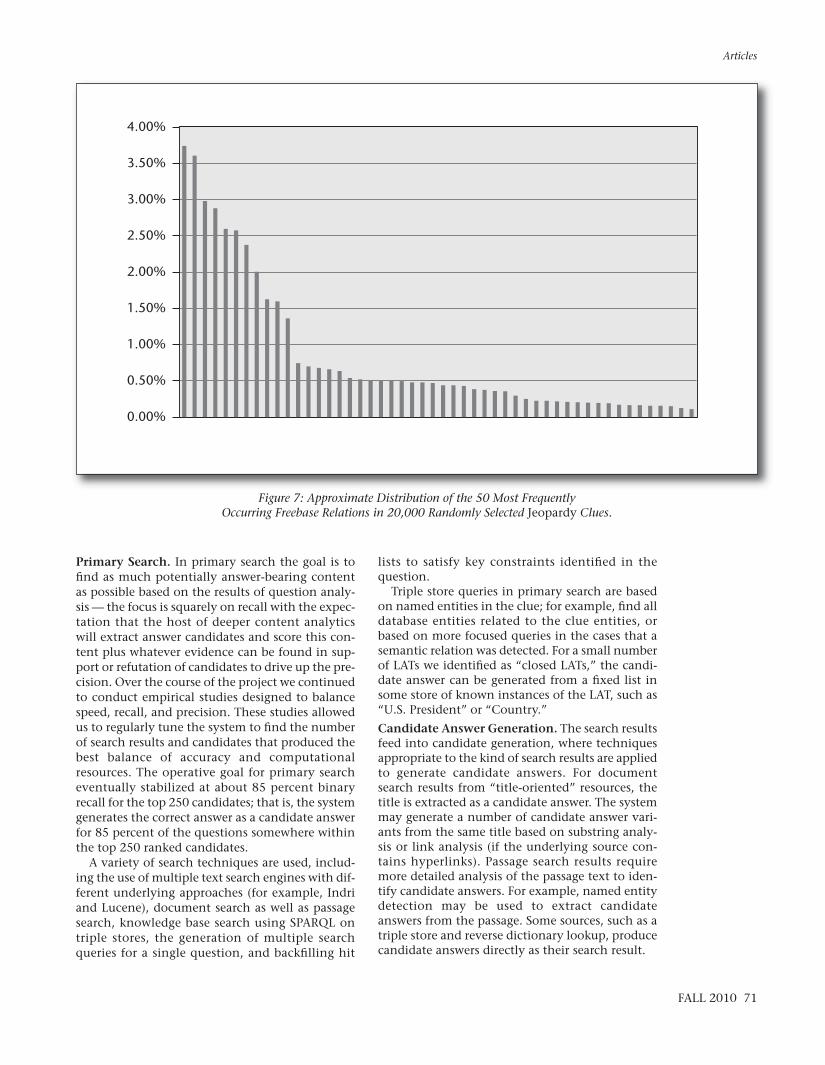
Watson’s use of existing databases depends onthe ability to analyze the question and detect therelations covered by the databases. In Jeopardy thebroad domain makes it difficult to identify themost lucrative relations to detect. In 20,000 Jeop-ardy questions, for example, we found the distri-bution of Freebase9 relations to be extremely flat(figure 7). Roughly speaking, even achieving highrecall on detecting the most frequent relations inthe domain can at best help in about 25 percent ofthe questions, and the benefit of relation detectiondrops off fast with the less frequent relations.Broad-domain relation detection remains a majoropen area of research.
Decomposition. As discussed above, an importantrequirement driven by analysis of Jeopardy clueswas the ability to handle questions that are betteranswered through decomposition. DeepQA usesrule-based deep parsing and statistical classifica-tion methods both to recognize whether questionsshould be decomposed and to determine how bestto break them up into subquestions. The operatinghypothesis is that the correct question interpreta-tion and derived answer(s) will score higher afterall the collected evidence and all the relevant algo-rithms have been considered. Even if the questiondid not need to be decomposed to determine ananswer, this method can help improve the system’soverall answer confidence.
DeepQA solves parallel decomposable questionsthrough application of the end-to-end QA systemon each subclue and synthesizes the final answersby a customizable answer combination compo-nent. These processing paths are shown in medi-um gray in figure 6. DeepQA also supports nesteddecomposable questions through recursive appli-cation of the end-to-end QA system to the innersubclue and then to the outer subclue. The cus-tomizable synthesis components allow specializedsynthesis algorithms to be easily plugged into acommon framework.
Hypothesis GenerationHypothesis generation takes the results of questionanalysis and produces candidate answers bysearching the system’s sources and extractinganswer-sized snippets from the search results. Eachcandidate answer plugged back into the question isconsidered a hypothesis, which the system has toprove correct with some degree of confidence.
We refer to search performed in hypothesis gen-eration as “primary search” to distinguish it fromsearch performed during evidence gathering(described below). As with all aspects of DeepQA,we use a mixture of different approaches for pri-mary search and candidate generation in the Wat-son system.
Articles
70 AI MAGAZINE
Primary Search. In primary search the goal is tofind as much potentially answer-bearing contentas possible based on the results of question analy-sis — the focus is squarely on recall with the expec-tation that the host of deeper content analyticswill extract answer candidates and score this con-tent plus whatever evidence can be found in sup-port or refutation of candidates to drive up the pre-cision. Over the course of the project we continuedto conduct empirical studies designed to balancespeed, recall, and precision. These studies allowedus to regularly tune the system to find the numberof search results and candidates that produced thebest balance of accuracy and computationalresources. The operative goal for primary searcheventually stabilized at about 85 percent binaryrecall for the top 250 candidates; that is, the systemgenerates the correct answer as a candidate answerfor 85 percent of the questions somewhere withinthe top 250 ranked candidates.
A variety of search techniques are used, includ-ing the use of multiple text search engines with dif-ferent underlying approaches (for example, Indriand Lucene), document search as well as passagesearch, knowledge base search using SPARQL ontriple stores, the generation of multiple searchqueries for a single question, and backfilling hit
lists to satisfy key constraints identified in thequestion.
Triple store queries in primary search are basedon named entities in the clue; for example, find alldatabase entities related to the clue entities, orbased on more focused queries in the cases that asemantic relation was detected. For a small numberof LATs we identified as “closed LATs,” the candi-date answer can be generated from a fixed list insome store of known instances of the LAT, such as“U.S. President” or “Country.”
Candidate Answer Generation. The search resultsfeed into candidate generation, where techniquesappropriate to the kind of search results are appliedto generate candidate answers. For documentsearch results from “title-oriented” resources, thetitle is extracted as a candidate answer. The systemmay generate a number of candidate answer vari-ants from the same title based on substring analy-sis or link analysis (if the underlying source con-tains hyperlinks). Passage search results requiremore detailed analysis of the passage text to iden-tify candidate answers. For example, named entitydetection may be used to extract candidateanswers from the passage. Some sources, such as atriple store and reverse dictionary lookup, producecandidate answers directly as their search result.
Articles
FALL 2010 71
0.00%
0.50%
1.00%
1.50%
2.00%
2.50%
3.00%
3.50%
4.00%
Figure 7: Approximate Distribution of the 50 Most Frequently Occurring Freebase Relations in 20,000 Randomly Selected Jeopardy Clues.

If the correct answer(s) are not generated at thisstage as a candidate, the system has no hope ofanswering the question. This step therefore signifi-cantly favors recall over precision, with the expec-tation that the rest of the processing pipeline willtease out the correct answer, even if the set of can-didates is quite large. One of the goals of the sys-tem design, therefore, is to tolerate noise in theearly stages of the pipeline and drive up precisiondownstream.
Watson generates several hundred candidateanswers at this stage.
Soft FilteringA key step in managing the resource versus preci-sion trade-off is the application of lightweight (lessresource intensive) scoring algorithms to a largerset of initial candidates to prune them down to asmaller set of candidates before the more intensivescoring components see them. For example, alightweight scorer may compute the likelihood ofa candidate answer being an instance of the LAT.We call this step soft filtering.
The system combines these lightweight analysisscores into a soft filtering score. Candidate answersthat pass the soft filtering threshold proceed tohypothesis and evidence scoring, while those can-didates that do not pass the filtering threshold arerouted directly to the final merging stage. The softfiltering scoring model and filtering threshold aredetermined based on machine learning over train-ing data.
Watson currently lets roughly 100 candidates passthe soft filter, but this a parameterizable function.
Hypothesis and Evidence ScoringCandidate answers that pass the soft filteringthreshold undergo a rigorous evaluation processthat involves gathering additional supporting evi-dence for each candidate answer, or hypothesis,and applying a wide variety of deep scoring ana-lytics to evaluate the supporting evidence.
Evidence Retrieval. To better evaluate each candi-date answer that passes the soft filter, the systemgathers additional supporting evidence. The archi-tecture supports the integration of a variety of evi-dence-gathering techniques. One particularlyeffective technique is passage search where thecandidate answer is added as a required term to theprimary search query derived from the question.This will retrieve passages that contain the candi-date answer used in the context of the originalquestion terms. Supporting evidence may alsocome from other sources like triple stores. Theretrieved supporting evidence is routed to the deepevidence scoring components, which evaluate thecandidate answer in the context of the supportingevidence.
Scoring. The scoring step is where the bulk of the
deep content analysis is performed. Scoring algo-rithms determine the degree of certainty thatretrieved evidence supports the candidate answers.The DeepQA framework supports and encouragesthe inclusion of many different components, orscorers, that consider different dimensions of theevidence and produce a score that corresponds tohow well evidence supports a candidate answer fora given question.
DeepQA provides a common format for the scor-ers to register hypotheses (for example candidateanswers) and confidence scores, while imposingfew restrictions on the semantics of the scoresthemselves; this enables DeepQA developers torapidly deploy, mix, and tune components to sup-port each other. For example, Watson employsmore than 50 scoring components that producescores ranging from formal probabilities to countsto categorical features, based on evidence from dif-ferent types of sources including unstructured text,semistructured text, and triple stores. These scorersconsider things like the degree of match between apassage’s predicate-argument structure and thequestion, passage source reliability, geospatial loca-tion, temporal relationships, taxonomic classifica-tion, the lexical and semantic relations the candi-date is known to participate in, the candidate’scorrelation with question terms, its popularity (orobscurity), its aliases, and so on.
Consider the question, “He was presidentiallypardoned on September 8, 1974”; the correctanswer, “Nixon,” is one of the generated candi-dates. One of the retrieved passages is “Ford par-doned Nixon on Sept. 8, 1974.” One passage scor-er counts the number of IDF-weighted terms incommon between the question and the passage.Another passage scorer based on the Smith-Water-man sequence-matching algorithm (Smith andWaterman 1981), measures the lengths of thelongest similar subsequences between the questionand passage (for example “on Sept. 8, 1974”). Athird type of passage scoring measures the align-ment of the logical forms of the question and pas-sage. A logical form is a graphical abstraction oftext in which nodes are terms in the text and edgesrepresent either grammatical relationships (forexample, Hermjakob, Hovy, and Lin [2000];Moldovan et al. [2003]), deep semantic relation-ships (for example, Lenat [1995], Paritosh and For-bus [2005]), or both . The logical form alignmentidentifies Nixon as the object of the pardoning inthe passage, and that the question is asking for theobject of a pardoning. Logical form alignmentgives “Nixon” a good score given this evidence. Incontrast, a candidate answer like “Ford” wouldreceive near identical scores to “Nixon” for termmatching and passage alignment with this passage,but would receive a lower logical form alignmentscore.
Articles
72 AI MAGAZINE
Another type of scorer uses knowledge in triplestores, simple reasoning such as subsumption anddisjointness in type taxonomies, geospatial, andtemporal reasoning. Geospatial reasoning is usedin Watson to detect the presence or absence of spa-tial relations such as directionality, borders, andcontainment between geoentities. For example, ifa question asks for an Asian city, then spatial con-tainment provides evidence that Beijing is a suit-able candidate, whereas Sydney is not. Similarly,geocoordinate information associated with entitiesis used to compute relative directionality (forexample, California is SW of Montana; GW Bridgeis N of Lincoln Tunnel, and so on).
Temporal reasoning is used in Watson to detectinconsistencies between dates in the clue andthose associated with a candidate answer. Forexample, the two most likely candidate answersgenerated by the system for the clue, “In 1594 hetook a job as a tax collector in Andalusia,” are“Thoreau” and “Cervantes.” In this case, temporalreasoning is used to rule out Thoreau as he was notalive in 1594, having been born in 1817, whereasCervantes, the correct answer, was born in 1547and died in 1616.
Each of the scorers implemented in Watson,how they work, how they interact, and their inde-
pendent impact on Watson’s performance deservesits own research paper. We cannot do this work jus-tice here. It is important to note, however, at thispoint no one algorithm dominates. In fact webelieve DeepQA’s facility for absorbing these algo-rithms, and the tools we have created for exploringtheir interactions and effects, will represent animportant and lasting contribution of this work.
To help developers and users get a sense of howWatson uses evidence to decide between compet-ing candidate answers, scores are combined into anoverall evidence profile. The evidence profilegroups individual features into aggregate evidencedimensions that provide a more intuitive view ofthe feature group. Aggregate evidence dimensionsmight include, for example, Taxonomic, Geospa-tial (location), Temporal, Source Reliability, Gen-der, Name Consistency, Relational, Passage Sup-port, Theory Consistency, and so on. Eachaggregate dimension is a combination of relatedfeature scores produced by the specific algorithmsthat fired on the gathered evidence.
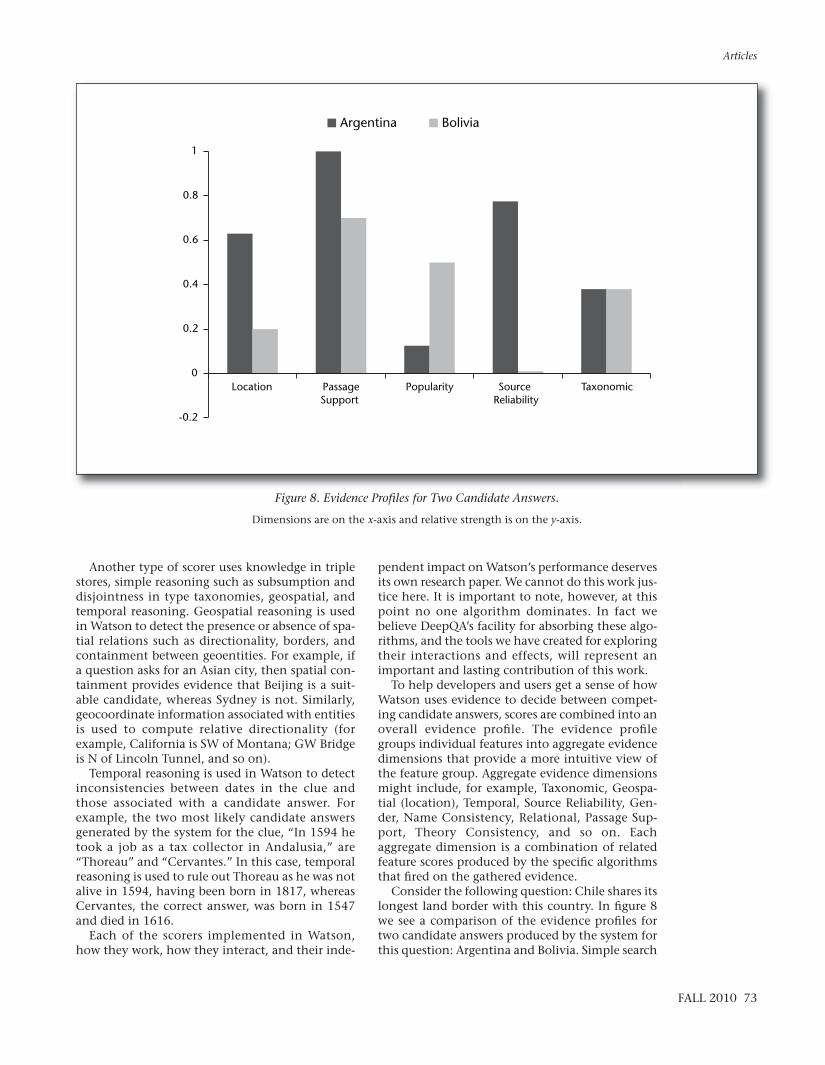
Consider the following question: Chile shares itslongest land border with this country. In figure 8we see a comparison of the evidence profiles fortwo candidate answers produced by the system forthis question: Argentina and Bolivia. Simple search
Articles
FALL 2010 73
-0.2
0
0.2
0.4
0.6
0.8
1
Location PassageSupport
Popularity Source Reliability
Taxonomic
Argentina Bolivia
Figure 8. Evidence Profiles for Two Candidate Answers.
Dimensions are on the x-axis and relative strength is on the y-axis.

engine scores favor Bolivia as an answer, due to apopular border dispute that was frequently report-ed in the news. Watson prefers Argentina (the cor-rect answer) over Bolivia, and the evidence profileshows why. Although Bolivia does have strongpopularity scores, Argentina has strong support inthe geospatial, passage support (for example, align-ment and logical form graph matching of varioustext passages), and source reliability dimensions.
Final Merging and RankingIt is one thing to return documents that containkey words from the question. It is quite another,however, to analyze the question and the contentenough to identify the precise answer and yetanother to determine an accurate enough confi-dence in its correctness to bet on it. Winning atJeopardy requires exactly that ability.
The goal of final ranking and merging is to eval-uate the hundreds of hypotheses based on poten-tially hundreds of thousands of scores to identifythe single best-supported hypothesis given the evi-dence and to estimate its confidence — the likeli-hood it is correct.
Answer MergingMultiple candidate answers for a question may beequivalent despite very different surface forms.This is particularly confusing to ranking tech-niques that make use of relative differencesbetween candidates. Without merging, rankingalgorithms would be comparing multiple surfaceforms that represent the same answer and trying todiscriminate among them. While one line ofresearch has been proposed based on boosting con-fidence in similar candidates (Ko, Nyberg, and Luo2007), our approach is inspired by the observationthat different surface forms are often disparatelysupported in the evidence and result in radicallydifferent, though potentially complementary,scores. This motivates an approach that mergesanswer scores before ranking and confidence esti-mation. Using an ensemble of matching, normal-ization, and coreference resolution algorithms,Watson identifies equivalent and related hypothe-ses (for example, Abraham Lincoln and HonestAbe) and then enables custom merging per featureto combine scores.
Ranking and Confidence Estimation After merging, the system must rank the hypothe-ses and estimate confidence based on their mergedscores. We adopted a machine-learning approachthat requires running the system over a set of train-ing questions with known answers and training amodel based on the scores. One could assume avery flat model and apply existing ranking algo-rithms (for example, Herbrich, Graepel, and Ober-mayer [2000]; Joachims [2002]) directly to these
score profiles and use the ranking score for confi-dence. For more intelligent ranking, however,ranking and confidence estimation may be sepa-rated into two phases. In both phases sets of scoresmay be grouped according to their domain (forexample type matching, passage scoring, and soon.) and intermediate models trained usingground truths and methods specific for that task.Using these intermediate models, the system pro-duces an ensemble of intermediate scores. Moti-vated by hierarchical techniques such as mixtureof experts (Jacobs et al. 1991) and stacked general-ization (Wolpert 1992), a metalearner is trainedover this ensemble. This approach allows for itera-tively enhancing the system with more sophisti-cated and deeper hierarchical models while retain-ing flexibility for robustness and experimentationas scorers are modified and added to the system.
Watson’s metalearner uses multiple trainedmodels to handle different question classes as, forinstance, certain scores that may be crucial to iden-tifying the correct answer for a factoid questionmay not be as useful on puzzle questions.
Finally, an important consideration in dealingwith NLP-based scorers is that the features theyproduce may be quite sparse, and so accurate con-fidence estimation requires the application of con-fidence-weighted learning techniques. (Dredze,Crammer, and Pereira 2008).
Speed and ScaleoutDeepQA is developed using Apache UIMA,10 aframework implementation of the UnstructuredInformation Management Architecture (Ferrucciand Lally 2004). UIMA was designed to supportinteroperability and scaleout of text and multi-modal analysis applications. All of the componentsin DeepQA are implemented as UIMA annotators.These are software components that analyze textand produce annotations or assertions about thetext. Watson has evolved over time and the num-ber of components in the system has reached intothe hundreds. UIMA facilitated rapid componentintegration, testing, and evaluation.
Early implementations of Watson ran on a singleprocessor where it took 2 hours to answer a singlequestion. The DeepQA computation is embarrass-ing parallel, however. UIMA-AS, part of ApacheUIMA, enables the scaleout of UIMA applicationsusing asynchronous messaging. We used UIMA-ASto scale Watson out over 2500 compute cores.UIMA-AS handles all of the communication, mes-saging, and queue management necessary usingthe open JMS standard. The UIMA-AS deploymentof Watson enabled competitive run-time latenciesin the 3–5 second range.
To preprocess the corpus and create fast run-time indices we used Hadoop.11 UIMA annotators
Articles
74 AI MAGAZINE

were easily deployed as mappers in the Hadoopmap-reduce framework. Hadoop distributes thecontent over the cluster to afford high CPU uti-lization and provides convenient tools for deploy-ing, managing, and monitoring the corpus analy-sis process.
StrategyJeopardy demands strategic game play to matchwits against the best human players. In a typicalJeopardy game, Watson faces the following strate-gic decisions: deciding whether to buzz in andattempt to answer a question, selecting squaresfrom the board, and wagering on Daily Doublesand Final Jeopardy.
The workhorse of strategic decisions is the buzz-in decision, which is required for every non–DailyDouble clue on the board. This is where DeepQA’sability to accurately estimate its confidence in itsanswer is critical, and Watson considers this confi-dence along with other game-state factors in mak-ing the final determination whether to buzz.Another strategic decision, Final Jeopardy wagering,generally receives the most attention and analysisfrom those interested in game strategy, and thereexists a growing catalogue of heuristics such as“Clavin’s Rule” or the “Two-Thirds Rule” (Dupee1998) as well as identification of those critical scoreboundaries at which particular strategies may beused (by no means does this make it easy or rote;despite this attention, we have found evidencethat contestants still occasionally make irrationalFinal Jeopardy bets). Daily Double betting turns outto be less studied but just as challenging since theplayer must consider opponents’ scores and pre-dict the likelihood of getting the question correctjust as in Final Jeopardy. After a Daily Double, how-ever, the game is not over, so evaluation of a wagerrequires forecasting the effect it will have on thedistant, final outcome of the game.
These challenges drove the construction of sta-tistical models of players and games, game-theo-retic analyses of particular game scenarios andstrategies, and the development and application ofreinforcement-learning techniques for Watson tolearn its strategy for playing Jeopardy. Fortunately,moderate samounts of historical data are availableto serve as training data for learning techniques.Even so, it requires extremely careful modeling andgame-theoretic evaluation as the game of Jeopardyhas incomplete information and uncertainty tomodel, critical score boundaries to recognize, andsavvy, competitive players to account for. It is agame where one faulty strategic choice can lose theentire match.
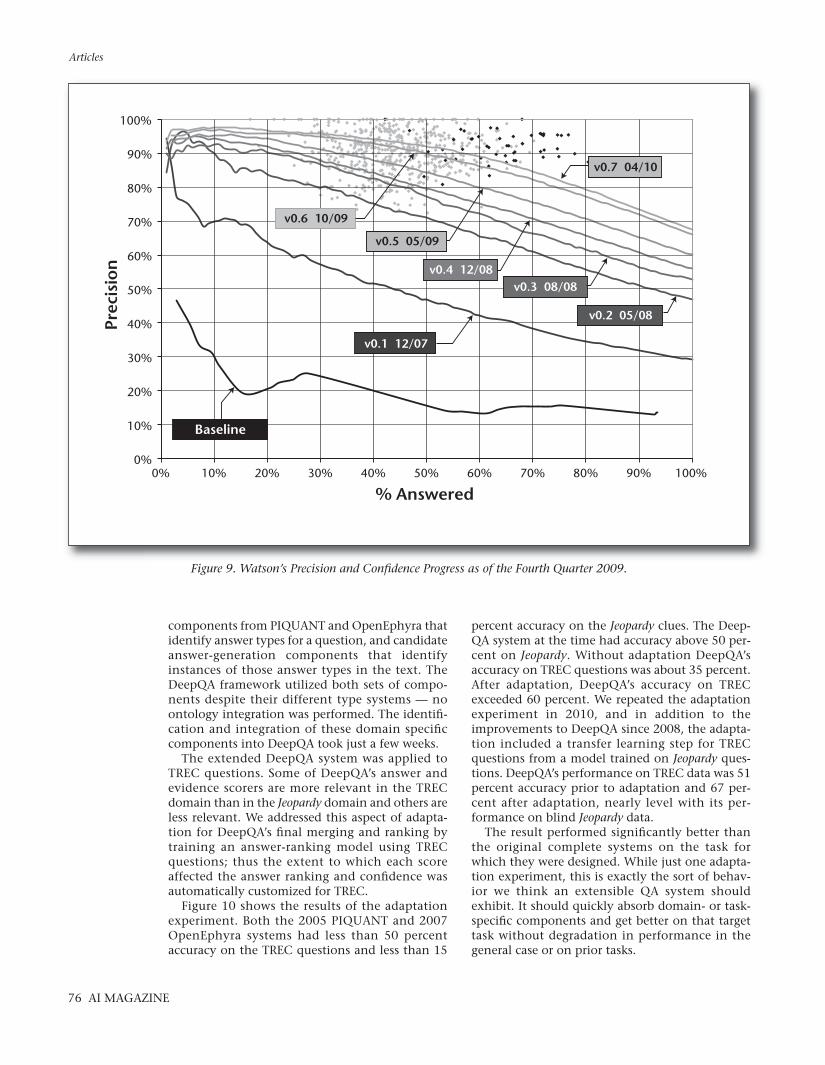
Status and ResultsAfter approximately 3 years of effort by a core algo-rithmic team composed of 20 researchers and soft-ware engineers with a range of backgrounds in nat-ural language processing, information retrieval,machine learning, computational linguistics, andknowledge representation and reasoning, we havedriven the performance of DeepQA to operatewithin the winner’s cloud on the Jeopardy task, asshown in figure 9. Watson’s results illustrated inthis figure were measured over blind test sets con-taining more than 2000 Jeopardy questions.
After many nonstarters, by the fourth quarter of2007 we finally adopted the DeepQA architecture.At that point we had all moved out of our privateoffices and into a “war room” setting to dramati-cally facilitate team communication and tight col-laboration. We instituted a host of disciplinedengineering and experimental methodologies sup-ported by metrics and tools to ensure we wereinvesting in techniques that promised significantimpact on end-to-end metrics. Since then, modulosome early jumps in performance, the progress hasbeen incremental but steady. It is slowing in recentmonths as the remaining challenges prove eithervery difficult or highly specialized and coveringsmall phenomena in the data.
By the end of 2008 we were performing reason-ably well — about 70 percent precision at 70 per-cent attempted over the 12,000 question blinddata, but it was taking 2 hours to answer a singlequestion on a single CPU. We brought on a teamspecializing in UIMA and UIMA-AS to scale upDeepQA on a massively parallel high-performancecomputing platform. We are currently answeringmore than 85 percent of the questions in 5 secondsor less — fast enough to provide competitive per-formance, and with continued algorithmic devel-opment are performing with about 85 percent pre-cision at 70 percent attempted.
We have more to do in order to improve preci-sion, confidence, and speed enough to competewith grand champions. We are finding great resultsin leveraging the DeepQA architecture capabilityto quickly admit and evaluate the impact of newalgorithms as we engage more university partner-ships to help meet the challenge.
An Early Adaptation ExperimentAnother challenge for DeepQA has been to demon-strate if and how it can adapt to other QA tasks. Inmid-2008, after we had populated the basic archi-tecture with a host of components for searching,evidence retrieval, scoring, final merging, andranking for the Jeopardy task, IBM collaboratedwith CMU to try to adapt DeepQA to the TREC QAproblem by plugging in only select domain-spe-cific components previously tuned to the TRECtask. In particular, we added question-analysis
Articles
FALL 2010 75
components from PIQUANT and OpenEphyra thatidentify answer types for a question, and candidateanswer-generation components that identifyinstances of those answer types in the text. TheDeepQA framework utilized both sets of compo-nents despite their different type systems — noontology integration was performed. The identifi-cation and integration of these domain specificcomponents into DeepQA took just a few weeks.
The extended DeepQA system was applied toTREC questions. Some of DeepQA’s answer andevidence scorers are more relevant in the TRECdomain than in the Jeopardy domain and others areless relevant. We addressed this aspect of adapta-tion for DeepQA’s final merging and ranking bytraining an answer-ranking model using TRECquestions; thus the extent to which each scoreaffected the answer ranking and confidence wasautomatically customized for TREC.
Figure 10 shows the results of the adaptationexperiment. Both the 2005 PIQUANT and 2007OpenEphyra systems had less than 50 percentaccuracy on the TREC questions and less than 15
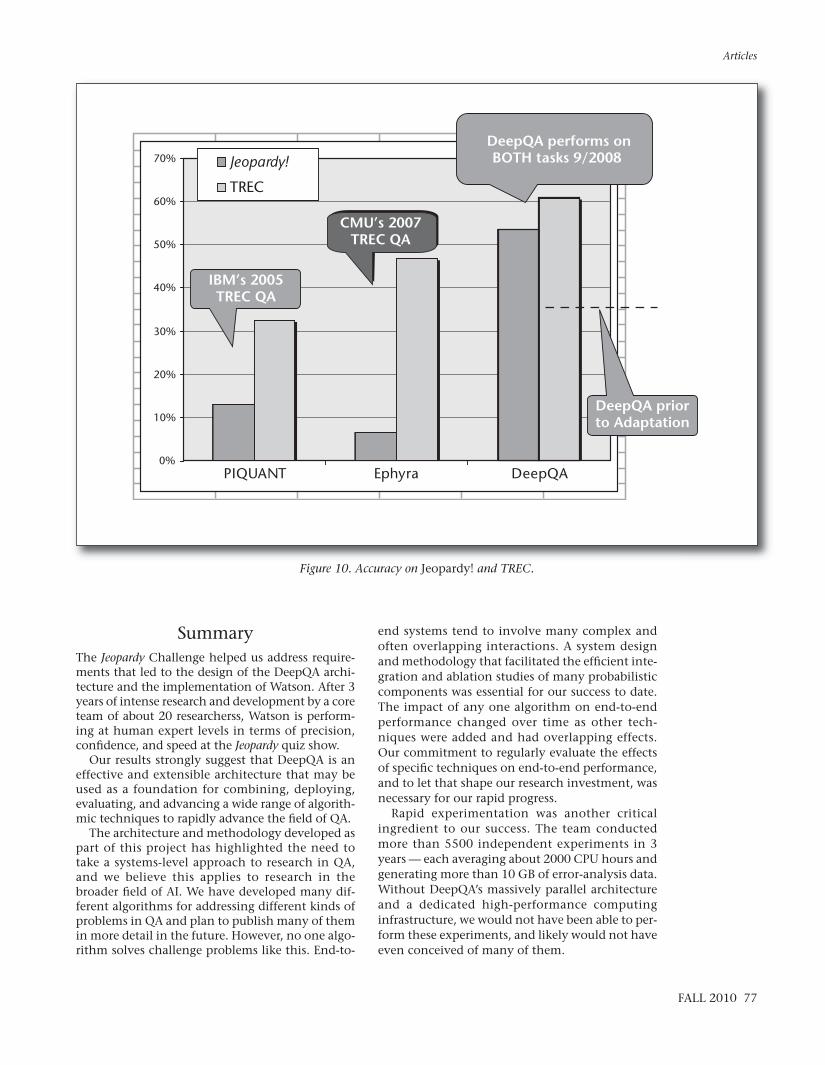
percent accuracy on the Jeopardy clues. The Deep-QA system at the time had accuracy above 50 per-cent on Jeopardy. Without adaptation DeepQA’saccuracy on TREC questions was about 35 percent.After adaptation, DeepQA’s accuracy on TRECexceeded 60 percent. We repeated the adaptationexperiment in 2010, and in addition to theimprovements to DeepQA since 2008, the adapta-tion included a transfer learning step for TRECquestions from a model trained on Jeopardy ques-tions. DeepQA’s performance on TREC data was 51percent accuracy prior to adaptation and 67 per-cent after adaptation, nearly level with its per-formance on blind Jeopardy data.
The result performed significantly better thanthe original complete systems on the task forwhich they were designed. While just one adapta-tion experiment, this is exactly the sort of behav-ior we think an extensible QA system shouldexhibit. It should quickly absorb domain- or task-specific components and get better on that targettask without degradation in performance in thegeneral case or on prior tasks.
Articles
76 AI MAGAZINE
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Prec
isio
n
% Answered
Baseline
v0.1 12/07
v0.3 08/08
v0.5 05/09
v0.6 10/09
v0.7 04/10
v0.4 12/08
v0.2 05/08
Figure 9. Watson’s Precision and Confidence Progress as of the Fourth Quarter 2009.
Summary The Jeopardy Challenge helped us address require-ments that led to the design of the DeepQA archi-tecture and the implementation of Watson. After 3years of intense research and development by a coreteam of about 20 researcherss, Watson is perform-ing at human expert levels in terms of precision,confidence, and speed at the Jeopardy quiz show.
Our results strongly suggest that DeepQA is aneffective and extensible architecture that may beused as a foundation for combining, deploying,evaluating, and advancing a wide range of algorith-mic techniques to rapidly advance the field of QA.
The architecture and methodology developed aspart of this project has highlighted the need totake a systems-level approach to research in QA,and we believe this applies to research in thebroader field of AI. We have developed many dif-ferent algorithms for addressing different kinds ofproblems in QA and plan to publish many of themin more detail in the future. However, no one algo-rithm solves challenge problems like this. End-to-
end systems tend to involve many complex andoften overlapping interactions. A system designand methodology that facilitated the efficient inte-gration and ablation studies of many probabilisticcomponents was essential for our success to date.The impact of any one algorithm on end-to-endperformance changed over time as other tech-niques were added and had overlapping effects.Our commitment to regularly evaluate the effectsof specific techniques on end-to-end performance,and to let that shape our research investment, wasnecessary for our rapid progress.
Rapid experimentation was another criticalingredient to our success. The team conductedmore than 5500 independent experiments in 3years — each averaging about 2000 CPU hours andgenerating more than 10 GB of error-analysis data.Without DeepQA’s massively parallel architectureand a dedicated high-performance computinginfrastructure, we would not have been able to per-form these experiments, and likely would not haveeven conceived of many of them.
Articles
FALL 2010 77
0%
10%
20%
30%
40%
50%
60%
70%
PIQUANT Ephyra DeepQA
Jeopardy!
TREC
DeepQA performs onBOTH tasks 9/2008
IBM’s 2005TREC QA
DeepQA priorto Adaptation
CMU’s 2007TREC QA
Figure 10. Accuracy on Jeopardy! and TREC.

Tuned for the Jeopardy Challenge, Watson hasbegun to compete against former Jeopardy playersin a series of “sparring” games. It is holding itsown, winning 64 percent of the games, but has tobe improved and sped up to compete favorablyagainst the very best.
We have leveraged our collaboration with CMUand with our other university partnerships in get-ting this far and hope to continue our collabora-tive work to drive Watson to its final goal, and helpopenly advance QA research.
AcknowledgementsWe would like to acknowledge the talented teamof research scientists and engineers at IBM and atpartner universities, listed below, for the incrediblework they are doing to influence and develop allaspects of Watson and the DeepQA architecture. Itis this team who are responsible for the workdescribed in this paper. From IBM, Andy Aaron,Einat Amitay, Branimir Boguraev, David Carmel,Arthur Ciccolo, Jaroslaw Cwiklik, Pablo Duboue,Edward Epstein, Raul Fernandez, Radu Florian,Dan Gruhl, Tong-Haing Fin, Achille Fokoue, KarenIngraffea, Bhavani Iyer, Hiroshi Kanayama, JonLenchner, Anthony Levas, Burn Lewis, MichaelMcCord, Paul Morarescu, Matthew Mulholland,Yuan Ni, Miroslav Novak, Yue Pan, Siddharth Pat-wardhan, Zhao Ming Qiu, Salim Roukos, MarshallSchor, Dafna Sheinwald, Roberto Sicconi, HiroshiKanayama, Kohichi Takeda, Gerry Tesauro, ChenWang, Wlodek Zadrozny, and Lei Zhang. From ouracademic partners, Manas Pathak (CMU), ChangWang (University of Massachusetts [UMass]), Hide-ki Shima (CMU), James Allen (UMass), Ed Hovy(University of Southern California/InformationSciences Instutute), Bruce Porter (University ofTexas), Pallika Kanani (UMass), Boris Katz (Massa-chusetts Institute of Technology), Alessandro Mos-chitti, and Giuseppe Riccardi (University of Tren-to), Barbar Cutler, Jim Hendler, and SelmerBringsjord (Rensselaer Polytechnic Institute).
Notes1. Watson is named after IBM’s founder, Thomas J. Wat-son.
2. Random jitter has been added to help visualize the dis-tribution of points.
3. www-nlpir.nist.gov/projects/aquaint.
4. trec.nist.gov/proceedings/proceedings.html.
5. sourceforge.net/projects/openephyra/.
6. The dip at the left end of the light gray curve is due tothe disproportionately high score the search engineassigns to short queries, which typically are not suffi-ciently discriminative to retrieve the correct answer intop position.
7. dbpedia.org/.
8. www.mpi-inf.mpg.de/yago-naga/yago/.
9. freebase.com/.
10. incubator.apache.org/uima/.
11. hadoop.apache.org/.
ReferencesChu-Carroll, J.; Czuba, K.; Prager, J. M.; and Ittycheriah,A. 2003. Two Heads Are Better Than One in Question-Answering. Paper presented at the Human LanguageTechnology Conference, Edmonton, Canada, 27 May–1June.
Dredze, M.; Crammer, K.; and Pereira, F. 2008. Confi-dence-Weighted Linear Classification. In Proceedings of theTwenty-Fifth International Conference on Machine Learning(ICML). Princeton, NJ: International Machine LearningSociety.
Dupee, M. 1998. How to Get on Jeopardy! ... and Win: Valu-able Information from a Champion. Secaucus, NJ: CitadelPress.
Ferrucci, D., and Lally, A. 2004. UIMA: An ArchitecturalApproach to Unstructured Information Processing in theCorporate Research Environment. Natural Langage Engi-neering 10(3–4): 327–348.
Ferrucci, D.; Nyberg, E.; Allan, J.; Barker, K.; Brown, E.;Chu-Carroll, J.; Ciccolo, A.; Duboue, P.; Fan, J.; Gondek,D.; Hovy, E.; Katz, B.; Lally, A.; McCord, M.; Morarescu,P.; Murdock, W.; Porter, B.; Prager, J.; Strzalkowski, T.;Welty, W.; and Zadrozny, W. 2009. Towards the OpenAdvancement of Question Answer Systems. IBM Techni-cal Report RC24789, Yorktown Heights, NY.
Herbrich, R.; Graepel, T.; and Obermayer, K. 2000. LargeMargin Rank Boundaries for Ordinal Regression. InAdvances in Large Margin Classifiers, 115–132. Linköping,Sweden: Liu E-Press.
Hermjakob, U.; Hovy, E. H.; and Lin, C. 2000. Knowl-edge-Based Question Answering. In Proceedings of theSixth World Multiconference on Systems, Cybernetics, andInformatics (SCI-2002). Winter Garden, FL: InternationalInstitute of Informatics and Systemics.
Hsu, F.-H. 2002. Behind Deep Blue: Building the ComputerThat Defeated the World Chess Champion. Princeton, NJ:Princeton University Press.
Jacobs, R.; Jordan, M. I.; Nowlan. S. J.; and Hinton, G. E.1991. Adaptive Mixtures of Local Experts. Neural Compu-tation 3(1): 79-–87.
Joachims, T. 2002. Optimizing Search Engines UsingClickthrough Data. In Proceedings of the Thirteenth ACMConference on Knowledge Discovery and Data Mining (KDD).New York: Association for Computing Machinery.
Ko, J.; Nyberg, E.; and Luo Si, L. 2007. A ProbabilisticGraphical Model for Joint Answer Ranking in QuestionAnswering. In Proceedings of the 30th Annual InternationalACM SIGIR Conference, 343–350. New York: Associationfor Computing Machinery.
Lenat, D. B. 1995. Cyc: A Large-Scale Investment inKnowledge Infrastructure. Communications of the ACM38(11): 33–38.
Maybury, Mark, ed. 2004. New Directions in Question-Answering. Menlo Park, CA: AAAI Press.
McCord, M. C. 1990. Slot Grammar: A System for Sim-pler Construction of Practical Natural Language Gram-mars. In Natural Language and Logic: International ScientificSymposium. Lecture Notes in Computer Science 459.Berlin: Springer Verlag.
Articles
78 AI MAGAZINE

Miller, G. A. 1995. WordNet: A Lexical Database for Eng-lish. Communications of the ACM 38(11): 39–41.
Moldovan, D.; Clark, C.; Harabagiu, S.; and Maiorano, S.2003. COGEX: A Logic Prover for Question Answering.Paper presented at the Human Language TechnologyConference, Edmonton, Canada, 27 May–1 June..
Paritosh, P., and Forbus, K. 2005. Analysis of StrategicKnowledge in Back of the Envelope Reasoning. In Pro-ceedings of the 20th AAAI Conference on Artificial Intelligence(AAAI-05). Menlo Park, CA: AAAI Press.
Prager, J. M.; Chu-Carroll, J.; and Czuba, K. 2004. A Mul-ti-Strategy, Multi-Question Approach to QuestionAnswering. In New Directions in Question-Answering, ed.M. Maybury. Menlo Park, CA: AAAI Press.
Simmons, R. F. 1970. Natural Language Question-Answering Systems: 1969. Communications of the ACM13(1): 15–30
Smith T. F., and Waterman M. S. 1981. Identification ofCommon Molecular Subsequences. Journal of MolecularBiology 147(1): 195–197.
Strzalkowski, T., and Harabagiu, S., eds. 2006. Advances inOpen-Domain Question-Answering. Berlin: Springer.
Voorhees, E. M., and Dang, H. T. 2005. Overview of theTREC 2005 Question Answering Track. In Proceedings ofthe Fourteenth Text Retrieval Conference. Gaithersburg, MD:National Institute of Standards and Technology.
Wolpert, D. H. 1992. Stacked Generalization. Neural Net-works 5(2): 241–259.
David Ferrucci is a research staff member and leads theSemantic Analysis and Integration department at theIBM T. J. Watson Research Center, Hawthorne, New York.Ferrucci is the principal investigator for theDeepQA/Watson project and the chief architect forUIMA, now an OASIS standard and Apache open-sourceproject. Ferrucci’s background is in artificial intelligenceand software engineering.
Eric Brown is a research staff member at the IBM T. J.Watson Research Center. His background is in informa-tion retrieval. Brown’s current research interests includequestion answering, unstructured information manage-ment architectures, and applications of advanced textanalysis and question answering to information retrievalsystems..
Jennifer Chu-Carroll is a research staff member at theIBM T. J. Watson Research Center. Chu-Carroll is on theeditorial board of the Journal of Dialogue Systems, and pre-viously served on the executive board of the North Amer-ican Chapter of the Association for Computational Lin-guistics and as program cochair of HLT-NAACL 2006. Herresearch interests include question answering, semanticsearch, and natural language discourse and dialogue..
James Fan is a research staff member at IBM T. J. WatsonResearch Center. His research interests include naturallanguage processing, question answering, and knowledgerepresentation and reasoning. He has served as a programcommittee member for several top ranked AI conferencesand journals, such as IJCAI and AAAI. He received hisPh.D. from the University of Texas at Austin in 2006.
David Gondek is a research staff member at the IBM T. J.Watson Research Center. His research interests include
applications of machine learning, statistical modeling,and game theory to question answering and natural lan-guage processing. Gondek has contributed to journalsand conferences in machine learning and data mining.He earned his Ph.D. in computer science from BrownUniversity.
Aditya A. Kalyanpur is a research staff member at theIBM T. J. Watson Research Center. His primary researchinterests include knowledge representation and reason-ing, natural languague programming, and questionanswering. He has served on W3 working groups, as pro-gram cochair of an international semantic web work-shop, and as a reviewer and program committee memberfor several AI journals and conferences. Kalyanpur com-pleted his doctorate in AI and semantic web relatedresearch from the University of Maryland, College Park.
Adam Lally is a senior software engineer at IBM’s T. J.Watson Research Center. He develops natural languageprocessing and reasoning algorithms for a variety ofapplications and is focused on developing scalable frame-works of NLP and reasoning systems. He is a lead devel-oper and designer for the UIMA framework and architec-ture specification.
J. William Murdock is a research staff member at theIBM T. J. Watson Research Center. Before joining IBM, heworked at the United States Naval Research Laboratory.His research interests include natural-language seman-tics, analogical reasoning, knowledge-based planning,machine learning, and computational reflection. In2001, he earned his Ph.D. in computer science from theGeorgia Institute of Technology..
Eric Nyberg is a professor at the Language TechnologiesInstitute, School of Computer Science, Carnegie MellonUniversity. Nyberg’s research spans a broad range of textanalysis and information retrieval areas, including ques-tion answering, search, reasoning, and natural languageprocessing architectures, systems, and software engineer-ing principles
John Prager is a research staff member at the IBM T. J.Watson Research Center in Yorktown Heights, New York.His background includes natural-language based inter-faces and semantic search, and his current interest is onincorporating user and domain models to inform ques-tion-answering. He is a member of the TREC programcommittee.
Nico Schlaefer is a Ph.D. student at the Language Tech-nologies Institute in the School of Computer Science,Carnegie Mellon University and an IBM Ph.D. Fellow. Hisresearch focus is the application of machine learningtechniques to natural language processing tasks. Schlae-fer is the primary author of the OpenEphyra questionanswering system.
Chris Welty is a research staff member at the IBMThomas J. Watson Research Center. His background isprimarily in knowledge representation and reasoning.Welty’s current research focus is on hybridization ofmachine learning, natural language processing, andknowledge representation and reasoning in building AIsystems.
Articles
FALL 2010 79