users.pja.edu.pl/~ewcislo/kor/odraprogrammer manual.1.14.doc · web viewexcept one keyword...
TRANSCRIPT

SPECIFIC TARGETED RESEARCH PROJECTINFORMATION SOCIETY TECHNOLOGIES
FP6-IST-2004-26727
Advanced eGovernment Information Service BuseGov-Bus
Virtual Repository Management System ODRA Description and Programmer Manual
Project name: Advanced eGovernment Information Service BusStart date of the project: 01 January 2006Duration of the project: 24 months
Project coordinator: Rodan Systems S.A.Workpackage: WP5
Actual submission date 31.10.2007Status working
Document type: Software documentationDocument acronym: WP05_02
Authors(s) Radosław Adamus, Marcin Daczkowski, Edgar Głowacki, Piotr Habela, Jarosław Jakubowski, Krzysztof Kaczmarski, Tomasz Kowalski, Michał Lentner, Tomasz Pieciukiewicz, Krzysztof Stencel, Kazimierz Subieta, Mariusz Trzaska, Tomasz Wardziak, Jacek Wiślicki, Łukasz Żaczek
Reviewer(s)AcceptingLocation WP05Version 1.14
Dissemination level CO
Project supported by the European Commission within Sixth Framework Programme© Copyright by eGov-Bus Consortium

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Abstract:The purpose of the document is to provide a complete user manual for Virtual Repository Management System (VRMS) that is the central part of the eGov Bus software allowing for virtual integration of distributed, heterogenous, redundant and fragmented data nd service resources into a centralized, homogeneous, non-redundant and non-fragmented whole. VRMS consists of the system ODRA (Object Database for Rapid Application development), a software system provided as a basis for virtual repositories developed under the eGov Bus software. The specification includes installation and administration manual, general architecture of the software, integrated development environment, description of an object-oriented data model, specification of database query and programming language SBQL (Stack-Based Query Language), virtual updateable views, sessions and transactions , a client-server protocol, and various front end and back end interoperability facilities implemented for ODRA.
The eGov-Bus consortium:
Rodan Systems (Rodan) Université Paris-Dauphine (Paris Dauphine) Europaisches Microsoft Innovations Center (EMIC) Uppsala Universitet (UU) Polsko-Japonska Wyzsza Szkoła Technik Komputerowych (PJIIT)Axway Software (Axway) Zentrum Für Sichere Informationstechnologie – Austria (A-SIT)Ministerstwo Spraw Wewnętrznych i Administracji (MSWiA)
CoordinatorPartnerPartnerPartnerPartnerPartnerPartnerPartner
PolandFranceGermanySwedenPolandFranceAustriaPoland
© Copyright by eGov-Bus Consortium2

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
History of changes
Date Version Author Change description
25.04.07 1.01 Kazimierz Subieta document creation
18.05.07 1.02 Kazimierz Subieta Rough description of ODRA
19.05.07 1.03 Radosław Adamus Description of ODRA and SBQL
30.05.07 1.04 Kazimierz Subieta Augmenting the description
05.06.07 1.04 Radoslaw Adamus Augmenting the description
07.06.07 1.05 Kazimierz Subieta Augmenting the description
11.06.07 1.06 Mariusz Trzaska Description of IDE
15.06.07 1.07 Tomasz Pieciukiewicz Decription of transitive closure operators
16.06.07 1.07 Krzysztof Kaczmarski XML Importer and Exporter
18.06.07 1.07 Marcin Daczkowski WS_Wrapper and Interface
18.06.07 1.07 Kazimierz Subieta Integration of contributions
19.06.07 1.08 Tomasz Wardziak Access to Java libraries
29.06.07 1.08 Jacek Wiślicki Detailed ODRA architecture
29.06.07 1.08 Mariusz Trzaska Changes in documentation to IDE and Web interface
29.06.07 1.08 Tomasz Kowalski Indexing in ODRA
04.07.07 1.08 Tomasz Pieciukiewicz Web Services Dynamic Invocation Interface
12.07.07 1.08 Edgar Głowacki Transactions support
04.08.07 1.09 Kazimierz Subieta Integrating all current changes, editing the document
07.08.07 1.10 Jacek Wislicki New version of documentation of OR wrapper
08.08.07 1.10 Kazimierz Subieta Editing the first documentation release
13.08.07 1.10 Łukasz Żaczek ODRA Access Control
15.08.07 1.10 Radoslaw Adamus New version of examples
05.09.07 1.11 Tomasz Kowalski New version of the “Indexing in ODRA” chapter
07.09.07 1.11 Mariusz Trzaska New versions of the Getting Started
12.09.07 1.11 Kazimierz Subieta Editing the new version of the documentation
20.10.07 1.11 Radoslaw Adamus SBQL Classes, Methods and Bidirectional Pointers
31.10.07 1.12 Kazimierz Subieta Integration and edition of the new version
21.01.08 1.13 Tomasz Kowalski New version of the “Indexing in ODRA” chapter
21.01.08 1.13 Radoslaw Adamus New implemented concept of typing updatable views
21.01.08 1.13 Kazimierz Subieta Integration and edition of the new version
25.01.08 1.14 Radoslaw Adamus Description of JOBC and some corections
© Copyright by eGov-Bus Consortium3
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Table of Contents
Abstract:...............................................................................................................................................................- 2 -History of changes................................................................................................................................................- 3 -1. Introduction..................................................................................................................................................- 7 -2. Overview of ODRA, SBQL and other VRMS facilites.............................................................................- 11 -
2.1 Purpose and Scope of the System ODRA............................................................................................- 11 -2.2 Architecture of ODRA and Applications Based on ODRA.................................................................- 11 -2.3 Overview of the ODRA Integrated Development Environment..........................................................- 15 -2.4 Overview of the ODRA Object-Oriented Data Model........................................................................- 15 -2.5 Overview of SBQL..............................................................................................................................- 17 -2.6 Overview of Virtual Updatable Views.................................................................................................- 19 -2.7 Overview of Back-End Interoperability Facilities...............................................................................- 21 -2.8 Overview of Front-End ODRA Application Programming Interfaces................................................- 23 -
3. Getting Started............................................................................................................................................- 25 -3.1 ODRA Operational Environment.........................................................................................................- 25 -3.2 ODRA Installation Guide.....................................................................................................................- 25 -3.3 Your First Tiny Object Base................................................................................................................- 25 -3.4 Your First SBQL Queries and Programs.............................................................................................- 27 -3.5 Using Integrated Development Environment......................................................................................- 27 -
4. ODRA Object-Oriented Store Model.........................................................................................................- 32 -4.1 Modules................................................................................................................................................- 32 -4.2 Objects, Nested Objects.......................................................................................................................- 32 -4.3 Structures.............................................................................................................................................- 34 -4.4 Collections and Cardinalities...............................................................................................................- 35 -4.5 Links.....................................................................................................................................................- 35 -4.6 Procedures, Functions and Transactions..............................................................................................- 36 -4.7 Views...................................................................................................................................................- 36 -4.8 Classes, Inheritance, Polymorphism, Types and Schemata.................................................................- 37 -
5. ODRA Integrated Development Environment...........................................................................................- 38 -5.1 Text Editor...........................................................................................................................................- 38 -5.2 Installing and Running.........................................................................................................................- 41 -5.3 General IDE Information.....................................................................................................................- 41 -5.4 Working with Projects.........................................................................................................................- 42 -5.5 Working with an ODRA Server...........................................................................................................- 44 -5.6 Compiling and Running.......................................................................................................................- 50 -5.7 ODRA IDE CLI (Command Line Interface).......................................................................................- 54 -5.8 More Samples......................................................................................................................................- 55 -
6. SBQL (Stack-Based Query Language) - Queries.......................................................................................- 56 -6.1 Basic Pragmatic, Syntactic and Semantic Assumptions......................................................................- 56 -6.2 Strong Type Checking.........................................................................................................................- 57 -6.3 Results returned by SBQL Queries......................................................................................................- 57 -6.4 Atomic SBQL Queries.........................................................................................................................- 57 -6.5 SBQL Operators...................................................................................................................................- 57 -6.6 Function, Procedure, and Method Calls...............................................................................................- 71 -
7. SBQL Imperative Statements.....................................................................................................................- 72 -7.1 Variable Declarations...........................................................................................................................- 72 -7.2 Object Creation....................................................................................................................................- 74 -7.3 Assignment...........................................................................................................................................- 76 -7.4 Insertion...............................................................................................................................................- 77 -7.5 Create and Insert..................................................................................................................................- 78 -7.6 Deletion................................................................................................................................................- 78 -7.7 Program Control Statements................................................................................................................- 78 -7.8 For Each Statement.............................................................................................................................- 80 -7.9 Comments............................................................................................................................................- 80 -
8. SBQL Procedures.......................................................................................................................................- 81 -8.1 Procedures and Functional Procedures................................................................................................- 81 -8.2 Parameters of Procedures.....................................................................................................................- 81 -
© Copyright by eGov-Bus Consortium4
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
8.3 Return from a Functional Procedure....................................................................................................- 82 -8.4 Examples of procedures.......................................................................................................................- 82 -8.5 Recursive Procedures and Methods.....................................................................................................- 83 -
9. SBQL Classes, Methods and Bidirectional Pointers..................................................................................- 84 -9.1 Class Invariants....................................................................................................................................- 84 -9.2 Syntax of class declaration...................................................................................................................- 84 -9.3 Sample class declarations.....................................................................................................................- 85 -9.4 Declaration of class instances..............................................................................................................- 86 -9.5 Substitutability.....................................................................................................................................- 86 -9.6 SBQL operators specific to the object model with classes..................................................................- 86 -9.7 Bidirectional pointers...........................................................................................................................- 87 -
10. SBQL Updatable Views.......................................................................................................................- 90 -10.1 General Idea of SBQL Updatable Views........................................................................................- 90 -10.2 Seeds of Virtual Objects..................................................................................................................- 90 -10.3 Operators on Virtual Objects...........................................................................................................- 92 -10.4 Nested Views (sub-views)...............................................................................................................- 95 -10.5 Virtual Pointers...............................................................................................................................- 96 -10.6 Local Objects Within Views...........................................................................................................- 97 -10.7 Syntax of SBQL Views.................................................................................................................- 100 -
11. Transactions.......................................................................................................................................- 101 -12. Back-End Interoperability Facilities..................................................................................................- 103 -
12.1 Accessing Java Libraries...............................................................................................................- 103 -12.2 Web Services Proxies....................................................................................................................- 104 -12.3 Web Services Dynamic Invocation Interface................................................................................- 105 -12.4 Generic Wrapper to Relational Databases....................................................................................- 106 -12.5 XML Importer and Exporter.........................................................................................................- 121 -
13. Front-End Application Programming Interfaces................................................................................- 137 -13.1 Web Services Endpoints................................................................................................................- 137 -13.2 ODRA Web API Specification.....................................................................................................- 140 -13.3 Specification of ODRA JOBC......................................................................................................- 140 -
14. ODRA Indexing.................................................................................................................................- 147 -14.1 General Idea of ODRA indexing...................................................................................................- 147 -14.2 Index Management – creating and removing................................................................................- 148 -14.3 Query optimization tips.................................................................................................................- 149 -14.4 Examples.......................................................................................................................................- 150 -
15. ODRA Access Control.......................................................................................................................- 151 -15.1 Architecture of ODRA Access Control.........................................................................................- 151 -15.2 Main Idea of Access Control Mechanism.....................................................................................- 151 -15.3 Roles and Logging........................................................................................................................- 152 -15.4 Working in ODRA........................................................................................................................- 153 -15.5 Permissions....................................................................................................................................- 153 -15.6 Implementation..............................................................................................................................- 153 -
16. Annex A: Methodology for Making a Virtual Repository under ODRA..........................................- 156 -16.1 Design of the Virtual Repository Class Diagram Schema............................................................- 156 -
List of Figures
2-1. Architecture of ODRA................................................................................................................................- 12 -2-2 General reference architecture of a Virtual Repository...............................................................................- 15 -2-3. An object.....................................................................................................................................................- 16 -2-4. An object-oriented schema for ODRA........................................................................................................- 17 -3-1. Creating a new project in the ODRA-IDE..................................................................................................- 28 -3-2. SBQL code for PersonEmpMod.sbql – part (a)..........................................................................................- 28 -3-3. SBQL code for PersonEmpMod.sbql – part (b)..........................................................................................- 29 -3-4. SBQL code for main.sbql............................................................................................................................- 29 -3-5. Connecting to existing ODRA server.........................................................................................................- 29 -3-6. ODRA-IDE after successful build of the sample project............................................................................- 30 -3-7. Running sample procedure in the ODRA-IDE...........................................................................................- 30 -
© Copyright by eGov-Bus Consortium5

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
3-8 Running sample query in the ODRA-IDE...................................................................................................- 31 -4-1. A database schema and corresponding objects...........................................................................................- 34 -4-2. A relational database represented as ODRA objects...................................................................................- 34 -5-1. Screenshot of the plain jEdit.......................................................................................................................- 38 -5-2. IDE after first run........................................................................................................................................- 41 -5-3. Part of the ODRA-IDE window presenting ODRA CLI............................................................................- 42 -5-4. Part of the ODRA-IDE window presenting funstionality for writing queries............................................- 42 -5-5. Window's GUI menu...................................................................................................................................- 42 -5-6. Creating a new project using workspace's context menu............................................................................- 43 -5-7. Workspace with two projects......................................................................................................................- 43 -5-8. ODRA IDE after importing two sample files.............................................................................................- 44 -5-9. File’s context menu.....................................................................................................................................- 44 -5-10. “Connect to a server” dialog.....................................................................................................................- 45 -5-11. Dialog for importing data..........................................................................................................................- 45 -5-12. Sample project's tree after importing bookstore data................................................................................- 46 -5-13. Server's content after importing metadata.................................................................................................- 47 -4-14. Server's content after importing metadata and data..................................................................................- 47 -5-15. Partial result of the query visualized in the ODRA IDE...........................................................................- 48 -5-16. Server's content using Dump Store functionality......................................................................................- 48 -5-17. Special node "Modules" and its context menu..........................................................................................- 49 -5-18. Two kinds of data visualizations...............................................................................................................- 49 -5-19. Server's memory monitor..........................................................................................................................- 50 -5-20. Visualization of the ODRA persistent store..............................................................................................- 50 -5-21. ODRA IDE after compiling sample project..............................................................................................- 51 -5-22. ODRA IDE presenting a compilation error..............................................................................................- 52 -5-23. Different ways of running queries.............................................................................................................- 52 -5-24. ODRA querying tab..................................................................................................................................- 53 -5-25. Using query result’s context menu............................................................................................................- 53 -5-26. Sample query result...................................................................................................................................- 54 -5-27. ODRA IDE CLI after executing help command.......................................................................................- 55 -5-28. Support for CLI variables in the ODRA IDE............................................................................................- 55 -6-1. A Bill-of-Material example schema............................................................................................................- 70 -11-2. General object-to-relations wrapper architecture....................................................................................- 107 -11-3. Base object-oriented schema...................................................................................................................- 108 -11-4. Designed relational schema.....................................................................................................................- 108 -11-5. Legacy relational schema........................................................................................................................- 109 -11-6. Imported object-oriented schema............................................................................................................- 109 -11-7. Automatically generated views...............................................................................................................- 109 -11-8. Final end-user relational schema.............................................................................................................- 110 -11-9. Logically related separate relational schema..........................................................................................- 114 -12-1. Web Service endpoint.............................................................................................................................- 137 -12-2. Web Service remote calls........................................................................................................................- 138 -14-1. Access Control architecture in ODRA....................................................................................................- 151 -14-2. ODRA's Access Control Mechanism......................................................................................................- 152 -
© Copyright by eGov-Bus Consortium6

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
1. IntroductionIntegrated applications build on top of existing data and service resources that are under control of various public administration institutions tend to be very complex. The complexity is caused by many reasons that can be subdivided into the following four groups:
Distribution of data and services: various geographical locations, different servers. Access to them may require different communications protocols.
Heterogeneity of data and services: usually data and services have existed before the decision on building an integrated eGovernment application is made. Hence they can reside on different hardware, work under different operating systems, are supported by different database management systems, can be designed according to different conceptual models and can use different representation formats. Heterogeneity concerns also diverse ontologies that are used for classification, description and discovering of data and services.
Redundancy of data and services: in many cases data and services stored at different servers contain a lot of redundancies, for instance, a citizen register and a social security register can contain the same citizen names. In some cases the redundancy (data replicas or mirrors) is consciously introduced as a method of increasing availability or as a method to improve security or stability of services.
Fragmentation of data and services: in many cases collections of data are stored in fragments on different servers, for instance, citizens data concerning particular sites are stored in local administration offices. Similarly, a service that can be on some abstraction level considered as a whole (e.g. a life event such as getting married) is fragmented into several particular services implemented on different servers.
The complexity of building integrated applications has direct impact on basic features of software development processes and on operational features of software products. This impact may concern the following features:
High development cost.
Unacceptably long development time.
Functionality of the software product, which can be too limited for the given business goals.
Quality of the software product.
Quality of services measured as a degree of user satisfaction.
Flexibility and maintainability of the final product. Low flexibility and maintainability can be dangerous because usually internal or external requirements to the software product and its operation are permanently changing.
Openess of the product to the development of new applications based on the previous conceptual frame.
Openess of the product to new data and service sites and to new kinds of end users.
Scalability of the product expressed in terms of volumes and diversity of data, number and diversity of services, number of concurrent users, etc.
Coping with the software complexity requires a systematic approach. It is commonly believed that the complexity can be reduced by the following basic software engineering principles:
Higher abstraction level of software design and manufacturing, isolating the application programmers and users from physical details of data and service access, data independence, i.e. the design and management of data independently from application programs.
Decomposition of the software processes and software itself into a hierarchy of isolated pieces that share only well defined interfaces.
Reuse and standardization. Reusable software parts can be considered as encapsulated units that can be used in many places without the necessity of understanding their complex interior. Standardization is the basis for software development culture allowing for easier communication between various groups of developers and for physical connection of software units that are manufactured independently.
Following natural human psychology and mentality. The psychology and mentality include a lot of factors that increase or decrease the software development potential, such as perception of the real
© Copyright by eGov-Bus Consortium7

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
world in terms of objects and their behavior, natural tendency to err and to act improperly, limited capacity of human memories, following previously acquired habits and customs, etc.
Lean tools and functionality: homogeneous (non-eclectic) software architecture, lack of redundancy of software development tools and lack of redundancy of the software functionality.
Due to the above issues and principles the development of integrated applications that have to work at the top of distributed, heterogeneous, redundant and fragmented resources must be subdivided into activities that are to be done in different time, by different developers teams and by different software development tools. Following CORBA [OMG], we distinguish three kinds of the activities:
Creating middleware. At this stage a development team creates the general data and service bus that can be used as a common infrastructure supporting data abstraction and function abstraction. Data and function abstraction means that the application programmers are to be isolated from many details concerning distribution, heterogeneity, redundancy and fragmentation of data and services. The programmers have to behave similarly as the entire data and service resources would reside on their local computers in the format and conceptual shape that is most suitable to their work. They have to works on an unified data and service model using unified and homogeneous programming tools.
Creating wrappers and importers of local resources. At this stage external resoursce, including legacy data and applications, are physically connected to the middleware. Wrappers provide non-intrusive adopting external resources to the data and service model assumed by the developed middleware. Wrappers and importers should accept the most popular data and service resources, including relational databases (supported by various RDBMS), web services, XML files, RDF resources, Topic Maps ontologies, and others.
Creating end user applications. After creating the middleware and wrappers and importers the application programmers can use front-end programming tools that allow them to make a complete eGovernment application without considering details, store and data models, communication protocols, etc. to access external data and services resources. The tools can be used from popular programming languages such as Java.
The Virtual Repository Management System (VRMS) ODRA is developed and implemented as a part of the European EGov-Bus project (Advanced eGovernment Information Service Bus) by the Polish-Japanese Institute of Information Technology in Warsaw, Poland. VRMS is a homogeneous and consistent collection of various software tools, languages, technologies and methodologies that support the above three stages of the development of eGovernemnt (and other) applications. A virtual repository supports transparent access to distributed, heterogeneous, redundant and fragmented resources. There are many forms of transparency, in particular location, concurrency, implementation, scaling, fragmentation, heterogeneity, replication, indexing and failure transparency. Due to transparency implemented on the middleware level some complex features of a distributed data/service environment need not be involved in the application code. A virtual repository user gets exactly the relevant data in the shape tailored to the particular use. Thus a virtual repository much amplifies the programmers’ productivity and greatly supports flexibility and maintainability of software products.
Because during the development of VRMS ODRA it was impossible to predict the kind of design, development and implementation problems that may arise during the development of eGovernent applications, VRMS ODRA has been designed as a generic software. It includes the object-oriented database system ODRA (Object Database for Rapid Application development) that supports very powerful object-oriented database model similar to the UML (Unified Modelling Language) data model. For such a powerful datamodel a new query and programming language SBQL (Stack-Based Query Language) has beed developed and implemented. SBQL has all the properties of object-oriented programming languages, it is algorithmically and pragmatically complete concerning all the retrieval and updating operations on an object-oriented database. SBQL supports all the programming abstractions that are assumed for this kind of languages, such as procedures, functions, types, classes, methods and transactions. Next abstractions, such as interfaces (specification of public class properties), exceptions, deductive capabilities, dynamic object roles, etc. are under development.
As follows from the above, applications based on the VRMS ODRA can take into account the authonomy of local servers. Connecting them to the global application related e.g. to support via Web life events or business events can be non-intrusive in the sense that no impact on (legal or organizational) responsibility of local servers can be assured. However, implementation of life events or business events support via Web may require special databases provided for keeping e.g. the state of the current citizen’s session or recording various auxiliary data related to a particular session. It is almost sure that such databases may require updating of their states. Therefore VRMS ODRA does not restrict access to external databases only for reading. All updates of external resources
© Copyright by eGov-Bus Consortium8

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
via the VRMS are possible, providing the administrator of a particular application and/or administrators of local servers grant proper privileges for an application and/or for a particular user.
In contrast to popular object-oriented programming languages, such as Java, C++ and C#, SBQL introduces several new fatures that make the application development, programming and maintenance much easier. Among them we distinguish the following:
Dealing with (nested) collections, including persistent ones.
Unification of queries and programming language expressions. Queries can be used withing imperative statements and as parameters of procedures, functions and methods.
Advanced query optimization methods.
Semi-strong static typing system and type checking.
Integration with procedures, fuctions and methods and with updatable object-oriented database views (that are the heart of virtual repositories).
Client-server and distributed architecture, with sessions and transactions.
The VRMS ODRA includes the mechanism of updatable object-oriented views. The mechanism is just responsible for “virtualization” of the object store. Due to virtual views implemented on top of external data and service resources they change their current format to the format required by the middleware. Moreover, because the views can involve communication protocols, they are able to fuse fragmented and redundant resources into a non-fragmented and non-redundant whole. Virtual views can also be used as customization and administration facility that the system administrator can use to customize and restrict the available data and services to a particular application or a user.
Although the ODRA server can store, process and make available (persistent) objects in an own proprietary format (what is necessary for many purposes), the essence of VRMS is the access to external resources, including legacy applications. VRMS ODRA by itself does not limit the kind of access: external resources can be queried and updated as well. VRMS ODRA supports several methods to access external resources. Among them we list the following (to be extended):
A generic wrapper to relational databases. The currently supported RDBMS are: Axion, Cloudscape, DB2, DB2/AS400, Derby, Firebird, Hypersonic, Informix, InstantDB, Interbase, MS Access, MS SQL, MySQL, Oracle, Postgres, SapDB, Sybase and Weblogic. The wrapper transparently translates SBQL queries addressing an object-orientd database into SQL.
XML exporter and importer. The facility allows for importing XML files making from them ODRA objects; the facility supports typechecking through the import of an XSD file. Similarly, any information from the ODRA store can be exported as an XML file. (XML importer/exporter is also encapsulated as a separate tool XML2XML that allow for any transformation of XML files.)
A generic wrapper to web services. VRMS makes it possible to access any web service, including Enhanced Web Services developed and implemented within the eGov Bus project.
A generic gateway to Java libraries. Any Java library can be integrated with VRMS through a generic facility based on Java reflection capabilities.
A wrapper to SDDS fast and scalable repositories. SDDS (implemented recently as SD SQL Server) is another software implemented within the eGov Bus project. The description is to be the subject of another document.
A wrapper to RDF repositories. VRMS makes it possible to access SWARD (implemented within the eGov Bus project), which is an RDF-oriented virtual interface to relational databases. The wrapper uses RDQL and SQL. The description is to be the subject of another document.
Topic Maps and RDF importers are under development.
To complete the functionality of VRMS it is important how it can be used by application programmers for making eGovernment applications. There are several possibilities:
ODRA, plus SBQL, plus external resources present a self-contained application programming environment that make it possible to create fully fledged eGovernment applications in the client-server architecture, including dynamic Web pages created under JSP.
VRMS ODRA is available as a Java Application Programming Environment.
© Copyright by eGov-Bus Consortium9

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
VRMS ODRA supports Java oriented JOBC, an interface analogous to JDBC, that makes it possible to access any ODRA resources via SBQL.
VRMS ODRA supports Web Services built on the top of its programming capabilities.
VRMS ODRA supports an API to Adminstrative Process Generator, a software that is made under the eGov Bus project. The description is to be the subject of another document.
VRMS ODRA can accept Java libraries for the Qualified Signature software developed within the eGov Bus project. The description is to be the subject of another document.
All the software related to VRMS ODRA is a Java-based application and requires Sun™ JRE (Java Runtime Environment) to run. The current version uses the 1.6+ version of the JRE. In the following we present the features of ODRA, SBQL, updatable views and other facilities in detail.
© Copyright by eGov-Bus Consortium10

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
2. Overview of ODRA, SBQL and other VRMS facilites2.1 Purpose and Scope of the System ODRAVRMS ODRA is an object-oriented database management system developed in Java from scratch. No foreign database server is involved. This decision was conscious, after our negative experience of building an object-oriented DBMS on top of relational DBMS-s. The main goal of the ODRA project is to develop new paradigms of database application development. We are going to reach this goal by increasing the level of abstraction at which the programmer works. To this end we introduce a new, universal, declarative programming language, together with its distributed, database-oriented and object-oriented execution environment. Such an approach provides functionality common to the variety of popular technologies (such as relational/object databases, several types of middleware, general purpose programming languages and their execution environments) in a single universal, easy to learn, interoperable and effective to use application programming environment.
The principle ideas which we are implementing in order to achieve this goal are the following:
Object-oriented design. We are close as far as possible to the UML object model, supporting in this way a seamless transition from analysis, modeling and design phases to the software implementation and maintenance phases. To this end we have introduced for database programming all the popular object-oriented mechanisms (objects, associations, classes, types, inheritance, polymorphism, encapsulation, collections), as well as some new mechanisms (such as virtual updatable views).
Powerful query language extended to a universal programming language. The most important feature of ODRA is SBQL (Stack-Based Query Language), an object-oriented query and programming language. SBQL differs from programming languages and from well-known query languages, because it is a query language with the full computational power of programming languages. SBQL alone makes it possible to create fully-fledged database-oriented applications. The possibility to use the same very-high-level language for most database application development tasks may greatly improve programmers’ efficiency, as well as software stability, performance and maintenance potential.
Virtual repository as a middleware. In a networked environment it is possible to connect several hosts running ODRA. All systems tied in this manner can share resources in a heterogeneous and dynamically changing, but reliable and secure environment. Our approach to distributed computing is based on object-oriented virtual updatable database views. This technology can be perceived as contribution to distributed databases, Enterprise Application Integration (EAI), Grid Computing and Peer-To-Peer networks.
Correspondingly, ODRA consists of three closely integrated components:
Object Database Management System (ODMS)
Compiler and interpreter for object-oriented query programming language SBQL
Middleware with distributed communication facilities based on the distributed databases technologies.
The system is additionally equipped with a set of tools for integrating heterogeneous legacy data sources. The continuously extended toolset includes importers (filters) and/or wrappers to XML, RDF, relational data, web services, etc.
Each installation of ODRA can work as a client and as a server; multiple-client – multiple-server architectures are possible. ODRA makes it possible to create multi-layered architectures, where some client is considered a server for lower-level clients. ODRA has all chances to achieve high availability and high scalability because it is a main memory database system with memory mapping files and makes no limitations concerning the number of servers working in parallel. In ODRA we have implemented many advanced optimization methods that improve the overall performance without compromising universality and genericity of programming interfaces.
2.2 Architecture of ODRA and Applications Based on ODRA
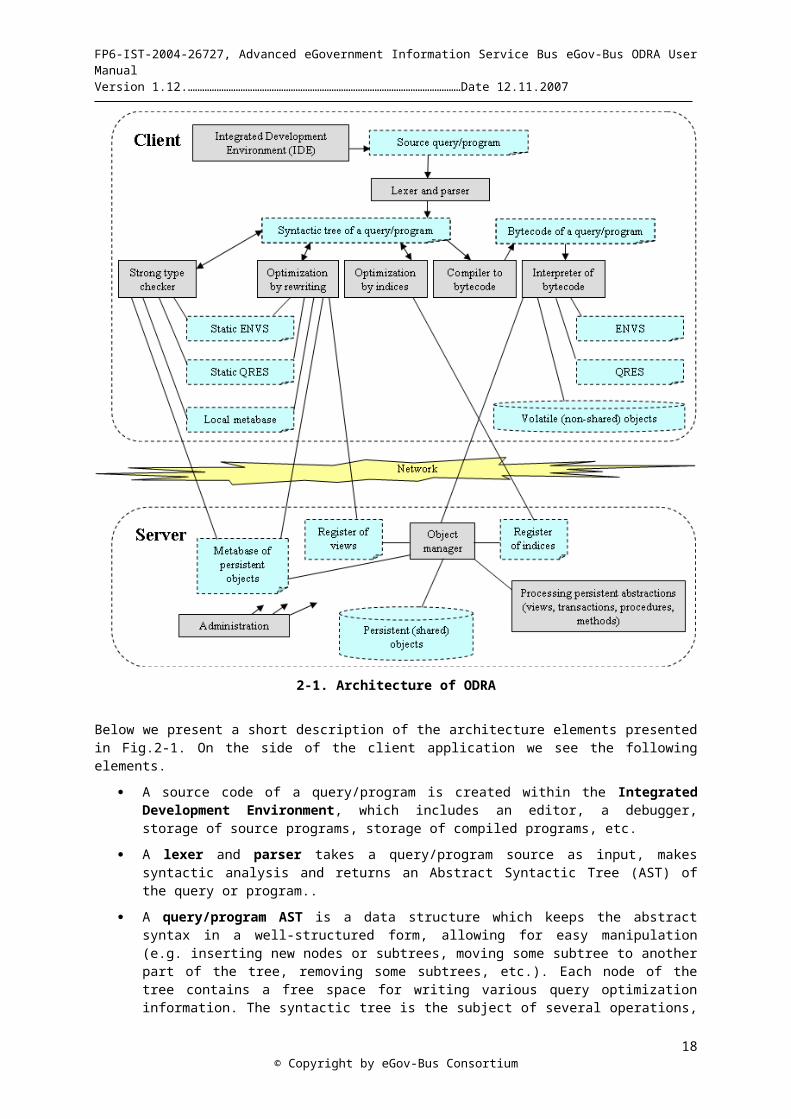
2.2.1 Reference Architecture of ODRAThere are several views on the internal architecture of ODRA. Understanding internal organization of the system can be helpful in understanding of functionalities and modes of using ODRA in applications. In Figure 2.1 we present a view on the architecture, which involves data structures (figures with dashed lines) and program
© Copyright by eGov-Bus Consortium11

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
modules (grey boxes). The architecture takes into account the subdivision of the storage and processing between client and server, strong typing and query optimization (by rewriting and by indices). The subdivision on client and server is only for easier explanation; actually, each ODRA installation can work as a client and as a server. Many clients can be connected to a server and a client can be connected to many servers. Some architectural components and relationships between components are not reflected in this figure.
2-1. Architecture of ODRA
Below we present a short description of the architecture elements presented in Fig.2-1. On the side of the client application we see the following elements.
A source code of a query/program is created within the Integrated Development Environment, which includes an editor, a debugger, storage of source programs, storage of compiled programs, etc.
A lexer and parser takes a query/program source as input, makes syntactic analysis and returns an Abstract Syntactic Tree (AST) of the query or program..
A query/program AST is a data structure which keeps the abstract syntax in a well-structured form, allowing for easy manipulation (e.g. inserting new nodes or subtrees, moving some subtree to another part of the tree, removing some subtrees, etc.). Each node of the tree contains a free space for writing various query optimization information. The syntactic tree is the subject of several operations, in particular, strong type checking, optimization by rewriting, optimization by indices and finally, compilation to a bytecode.
© Copyright by eGov-Bus Consortium12

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The strong type checker takes a query/program syntactic tree and checks if it conforms to the declared types. Types are recorded within a client local metabase and within the metabase of persistent objects that is kept on the server. The metabases contain information from declarations of volatile object types (that are a part of source programs) and from a database schema. The module that organizes the metabases is not shown. The strong type checker uses two stacks, static ENVS (keeping signatures of runtime environments) and static QRES (keeping signatures of query results). The strong static type checker simulates actual execution of a query during compile time. The type checker has several other functions. In particular, it changes the query syntactic tree by introducing new nodes for automatic dereferences, automatic coercions, for typing literals, for resolving elliptic queries and for dynamic type checks (if static checks are impossible). The type checker introduces additional information to the nodes of the query syntactic tree that is necessary further for query optimization.
Static ENVS - static environment stack. It is a compile time counterpart of the environment stack (call stack) known from almost all programming languages.
Static QRES - static result stack. It is a compile time counterpart of the result stack (arithmetic stack) known from almost all programming languages.
Local metabase. It is a data structure containing information of types and specifcations introduced in source programs.
Optimization by rewriting - this is a program module that changes the syntactic tree that is already annotated by the strong type checker. There are several rewriting methods that are developed for SBA, in particular:
Performing calculations on literals.
Changing the order of execution of algebraic operators.
Application of the query modification technique, which changes invocations of views into view bodies. To this end, the optimization module refers to the register of views that is kept on the server.
Removing dead subqueries, i.e. subqueries that do not influence the final query result.
Factoring out independent subqueries: subqueries whose results are not changed within some loop are factored out outside the loop.
Shifting conditions as close as possible to the proper operator, e.g. shifting selection condition before a join.
Methods based on the distributivity property of some query operators.
Other rewriting methods are currently under investigation.
Optimization by indices. This is a program module that changes the syntactic tree that is already annotated by the strong type checker. Changes concerns some subtrees that can be substituted by invocation of indices. To this end, the optimization module refers to the register of indices that is kept on the server. Changes depend on the kind of an index. The module will be extended to deal with cached queries.
Compiler to bytecode. This module takes the strongly checked and optimized syntactic tree of a query/program and produces a bytecode that is ready to execute. In ODRA we have decided do not use in this role the Java bytecode, because the generation of it for SBQL we consider too complex. Instead, we developed our own bytecode format called Juliet.
Interpreter of bytecode. During runtime it takes instructions of a bytecode and triggers proper routines. To this end it uses two run-time stacks, ENVS (environment stack) and QRES (query result stack). The interpreter refers to volatile objects that are kept on a client and to any resources that are available on the server, in particular persistent (shared) objects. All the server resources are available through the object manager.
On the side of the database server we have the following architectural elements:
Persistent (shared) objects - this is a part of the object store commonly known as a database.
Object manager - this is a low-level API that performs everything on persistent objects that is needed.
© Copyright by eGov-Bus Consortium13

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Metabase of persistent objects - this is a compiled database schema plus some additional information, e.g. necessary for optimization.
Processing persistent abstractions (views, transactions, procedures, methods, etc.) - essentially, this module contains all basic elements of the client side and extends them by additional functionalities.
Register of indices and register of views are data structures that contain and externalize the information of created indices and created views. The information is used by the client for query optimization. Internally, this information is fulfilled by the administration module.
Administration module - makes all operations that are necessary on the side of the server, e.g. introducing a new index, removing an index, introducing a new view, changing the database schema, logins and authorization of users, etc.
This view on the ODRA architecture is to be augmented by new architectural elements, e.g. a cost-based query optimizer, user sub-schemas, distributed query optimizer and others. Some of them are or will be the subject of further research and development within the Polish-Japanese Institute of Information Technology.
2.2.2 Reference Architecture of Applications based on ODRAThere are a lot of various software architectures that can be developed on the ODRA system. ODRA is a combination of object-oriented database management system with own query and programming language, virtual updateable views, stored procedures, stored classes and methods and with many interoperability modules that can be used in different configurations, depending on needs of a particular business application. In Fig.2-2 we present some architectural variant for a Virtual Repository that we can be developed for eGovernment applications. The picture presents some possible configuration of developed software units. Many other architectural combinations are possible, depending on the particular eGov-Bus application in question.
The Virtual Repository work package (WP5) provides the development of a scalable and secure access mechanism for combining data and services supplied by different kinds of information sources through the eGov-Bus, including Web pages, XML files, Web services, relational databases, etc. The system will provide access to semantic Web (RDF) representation of the data, allowing the users for efficient management of ontological data for future eGovernment applications.
A central part of the architecture consists of ODRA, an object-oriented DBMS. Existing resources (bottom of the figure) are extended by wrappers and contributory views (or importers/exporters) that convert data/services proprietary to particular existing applications into the format acceptable for ODRA. The application developers can install as many ODRA servers as necessary, addressing the same distributed sources. The integration view on an ODRA server allows for the virtual integration of data and services supplied by distributed sources, supporting data and function abstractions. The virtual repository front-end will provide various APIs to access virtually integrated data, including workflow applications, Java applications, Web services applications, and others. A particular user works with his/her own client view that is a tailored part of the entire virtual repository schema.
Among many other functions, the virtual repository will allow for transparent access to external information resources and for unlimited transformations of complex document structures.
© Copyright by eGov-Bus Consortium14

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
2-2 General reference architecture of a Virtual Repository
2.3 Overview of the ODRA Integrated Development EnvironmentFeatures of a virtual repository for particular eGov applications must be edited, compiled, stored, tested, debugged, administered and maintained. All these functionalities are available through Integrated Development Environment, which is based on the jEdit editor for Java. ODRA IDE will be extended to achieve the functionality of fully-fledged administration, performance tuning and optimization module, which will include granting access privileges for users and for particular virtual resources, creating/removing indices, import/export of files (e.g. XML), determining modes of execution and output, etc. Despite many already developed functions, ODRA IDE is still under development.
Full description of ODRA IDE for Java programmers is the subject of another document, ODRA-IDE API Specification (070621 ODRA-IDE API Specification.doc).
2.4 Overview of the ODRA Object-Oriented Data ModelFor the design of the virtual repository software we have assumed an UML-like object model. Because in general UML is designed for modeling rather than for programming we have made several changes to the UML object model that still do not undermine seamless transition from a UML class diagram to an ODRA database schema. Because the UML object model is richer than XML hierarchical model, the ODRA object model covers also XML (except some of its minor features that are not supported). In the same way it covers a lot of other models, including the RDF model, the Topic Maps model, etc. The ODRA object model covers also the relational model as a particular case; this feature is essential for making wrappers to external sources stored in relational databases.
Objects. The basic concept of the ODRA database model is object. It is an encapsulated data structure storing some consistent bulk of information that can be manipulated as a whole. The UML literature presents a lot of examples of objects. Frequently, objects are machine counterparts of objects from the business domain of applications, but there is no strong rule. A database designer and programmers can create database and programming objects according to their own needs and concepts. Objects can be organized as hierarchical data structures, with attributes, sub-attributes, etc.; the number of object hierarchy levels is unlimited. Any component of an object is considered an object too.
© Copyright by eGov-Bus Consortium15

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Any objects has an external name (or more names) that can be used by the programmer to identify (to bind) the object from a source query or program. External names need not be unique. A name (such as Account, Invoice, DateOfBirth, SocialSecNbr, etc.) usually bears some conceptual meaning in the business domain. Any object has also an internal identifier that is used internally as a reference. Internal identifiers are unique for the given environment of objects. Internal identifiers are non-printable and have no meaning in the business domain. The programmer never uses internal identifiers explicitly. The intention of internal identifiers is twofold: (1) to enable fast access to an object if its identifier is known, and (2) to use identifiers in various contexts requiring references to objects; for instance, for updating operations, for call-by-reference parameter passing method, etc. Fig.2-3 presents an example Emp object that consists of attributes fName, lNname, birthYear, sex, address, eNbr, job, sal, and pointer links worksIn and manages: attribute address has sub-atributes city, street and houseNbr. Each object, attribute, subobject, pointer, etc. has a unique internal identifier (i9, i10,…, i22).
2-3. An object
Collections. Objects within a collection have the same name; the name is the only indicator that they belong to the same collection. Usually objects from a collection have the same type, but this requirement is relaxed for some kinds of heterogeneous collections. Collections can be nested within objects with no limits; in this way we can represent repeating attributes.
Links. Objects can be connected by pointer links. Pointer links represent the notion that is known from UML as association. Pointer links support only binary associations; associations with higher arity and/or with association classes are to be represented as objects and some set of binary associations. This is a minor limitation in comparison to UML class diagrams, introduced to simplify the programming interface. Pointer links can be organized into bidirectional pointers enabling navigation in both directions. If a bidirectional link connects objects A and B, then it is understood as a pointer from A to B and a pointer from B to A. Such bidirectional links behave consistently as twin interrelated pointers: updating of one of them causes immediate and automatic updating of its twin.
Modules. In ODRA the basic unit of database organization is a module. As in popular object-oriented languages, a module is a separate system component. An ODRA module groups a set of database objects and compiled programs and can be a base for reuse and separation of programmers workspaces. From the technical point of view and of the assumed object relativism principle modules can be perceived as special purpose complex objects that store data and metadata.
Types, classes and schemata. A class is a programming abstraction that stores invariant properties of objects, in particular, its type, some behavior (methods, operations) and (optionally) an object name. A class has some number of member objects. During processing of a member object the programmer can use all properties stored within its class. The model introduces atomic types (integer, real, string, date, boolean) that are known from other programming languages. Further atomic types are considered, but not implemented yet. The programmer can also define his/her own complex types. Collection types are specified by cardinality numbers, for instance, [0..*], [1..*], [0..1], etc. Classes can be connected into an ODRA schema, as shown in Fig.2-4.
Inheritance and polymorphism. As in the UML object model, classes inherit properties of their superclasses. Multiple inheritance is allowed, but name conflicts are not automatically resolved. The methods from a class hierarchy can be overridden. An abstract method can be instantiated differently in different specialized classes (due to late binding); this feature is known as polymorphism.
© Copyright by eGov-Bus Consortium16

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
2-4. An object-oriented schema for ODRA
Persistence and object-oriented principles. The model follows the orthogonal persistence principle, i.e. a member of any class can be persistent or volatile. Shared server objects are considered persistent, however, non-shared objects of a particular applications can be persistent too. The model follows the classical compositionality, substitutability and open-close principles assumed by majority of object-oriented programming languages. Shared (server) objects are the subject of transactional ACID semantics based on the 2PL algorithm.
Distinction between proper data and metadata (ontology) is not the property of the ODRA database model. The distinction can be important on the business model level, but from the point of view of ODRA both kinds of resources are treated uniformly.
2.5 Overview of SBQLSBQL (Stack-Based Query Language) is a powerful query and programming language addressing the object model described above. To the best of our knowledge, SBQL is the most powerful query language for object-oriented and XML-oriented models, much more powerful than ODMG OQL, OMG OCL and W3C XQuery standards. Some current limitations of SBQL are caused by static strong typing (that is underdeveloped e.g. in XQuery) and lack of reflexive capabilities (that are under development). SBQL implemented for the eGov Bus project is significantly more powerful than previous SBQL implementations. The power of SBQL concerns a wide spectrum of data structures that it is able to serve and complete algorithmic power of querying and manipulation capabilities.
SBQL is precise with respect to the specification of semantics. SBQL has also been carefully designed from the pragmatic (practical) point of view. The pragmatic quality of SBQL is achieved by orthogonality of introduced data/object constructors, orthogonality of all the language constructs, object relativism, orthogonal persistence, typing safety, introducing all the classical and some new programming abstractions (procedures, functions, modules, types, classes, methods, views, etc.) and following commonly accepted programming languages’ and software engineering principles, including orthogonality (keep unrelated features unrelated), compositionality (avoid big syntactic and semantic patterns, as well as far context dependencies in a program code), universality (the language should cover the assumed domain), generality (using language features for many purposes), parsimony (avoid redundant features), clean formal semantics, openness (use external systems and specialized tools), no semantic anomalies (no exceptional features and irregular treatment), no semantic reefs (programmer’s understanding and machine processing coincide), correspondence (the methods of binding do not depend on a context), conceptual closure (introducing a feature A enforces next features that appear from the combination of A with already existing features), safety (typechecking, assertions, constraints), semantic relativity (identical properties of parent and nested entities), conceptual continuation (bigger tasks are to be smooth extensions of smaller tasks).
SBQL queries can be embedded within statements that can change the database or program state. We follow the state-of-the-art known from majority of programming languages. Typical imperative constructs are creating a
© Copyright by eGov-Bus Consortium17
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
new object, deleting an object, assigning new value to an object (updating) and inserting an object into another object. We also introduce typical control and loop statements such as if…then…else…, while loops, for and for each iterators, and others. Some peculiarities are implied by queries that may return collections; thus there are possibilities to generalize imperative constructs according to this new feature.
SBQL for the eGov Bus project introduces also procedures, functions and methods. All procedural abstractions of SBQL can be invoked from any procedural abstractions with no limitations and can be recursive. SBQL programming abstractions deal with parameters being any queries; thus corresponding parameter passing methods are generalized to take collections into account. We have implemented the strict-call-by-value method which makes it possible to achieve the effects of call-by-value, call-by-reference, and more. Transactions are also considered procedural abstractions, syntactically and semantically very similar to procedures. Nested transactions are supported.
SBQL is a strongly typed language. Each database and program entity has to be associated with a type. However, types do not constraint semi-structured nature of the data. In particular, types allow for optional elements (similar to null values known from relational systems, but with different semantics) and collections with arbitrary cardinality constraints. Strong typing of SBQL is a prerequisite for developing powerful query optimization methods based on query rewriting and on indices.
For SBQL we have implemented a generic gateway to Java libraries. This facility allows one to use calls to Java programs within SBQL programs. The facility is especially useful to extend SBQL with GUI, with string operators, with J2EE capabilities, etc.
Below we present some examples of SBQL queries (cf. Fig.2-4), just to make some impression on the language.
Get all information on departments for employees named Doe:
(Emp where lName = “Doe”).worksIn.Dept
Get the name of Doe’s boss:
(Emp where lName = “Doe”).worksIn.Dept.boss.Emp.lName
Names and cities of employees working in departments managed by Kim:
(Dept where (boss.Emp.lName) = “Kim”).employs.Emp. (lName, if exists(address) then address.city else “No address”)
For each employee get the name and the percent of the annual budget of his/her department that is consumed by his/her monthly salary:
Emp . (lName as n, (((if exists(sal) then sal else 0) as s). ((s * 12 * 100)/(worksIn.Dept.budget)) as percentOfBudget)
For each person having no salary give the minimal salary in his/her department:
for each (Emp where not exists(sal)) as e do e.changeSal( min(e.works_in.Dept.employs.Emp.sal) )
Example of a method: it is a part of the Emp class. The method gives a new salary to an employee. If an employee has not the sal attribute, the method inserts it (operator :<). The method returns false (and does nothing) if the salary is to be decreased; otherwise it returns true.
changeSal(newSal: real): boolean { if not exists(self.sal) then { sal: real[0..1]; self :< create sal(newSal); } else { if self.sal > newSal then return false; else self.sal := newSal; } return true;}
© Copyright by eGov-Bus Consortium18

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
2.6 Overview of Virtual Updatable ViewsVirtual views (known from SQL) are frequently considered as a tool for adapting heterogeneous data to some common schema assumed by the business model of an application. Unfortunately, SQL views (practically, the only kind of views that are in use today) have limitations that restrict their application in this role:
Limited power of a view definition language (an SQL view is defined by a single SQL query, far below the full algorithmic power),
Limited data model (SQL views work only on relational tables),
Limited view updating (updating of virtual tables is prohibited or severely restricted)
Performance penalty (query optimization can be compromised by invocations of views).
During our work on the Virtual Repository Management System for the eGov Bus project we have assumed that it should be based on virtual views. To this end, we have to investigate the problem how to overcome the limitations of SQL views. In effect, we have developed a new method that allows us to achieve the power of updateable views that has not been even considered so far in the database domain. Our method has some commonalities with the instead of trigger views implemented in Oracle, SQL Server and DB2, but it is based on different principles, is much more powerful and efficient, and may address any object-oriented (or XML-oriented) database model.
Classical SQL views do the mapping from stored data into virtual data. However, some applications may require updating of virtual data; hence there is a need for a reverse mapping: updates of virtual data are to be mapped into updates of stored data. This leads to the well-known view updating problem: updates of virtual data can be accomplished by updating of stored data on many ways, but the system cannot decide which of them is to be chosen. In typical solutions these updates are made by side effects of view invocations (as presented, e.g., in the Oracle solution). Due to the view updating problem, many kinds of view updates are limited or forbidden.
We take another point of view. In general, our method is based on overloading generic updating operations (create, delete, update, insert, etc.) acting on virtual objects by invocation of procedures that are written by the view definer. The procedures are an inherent part of the view definition. The procedures have full algorithmic power, thus there are no limitations concerning the mapping of view updates into updates of stored data. SBQL updatable views allow one to achieve full transparency of virtual objects: they cannot be distinguished from stored objects by any programming option. This feature is very important for distributed and heterogeneous databases.
SBQL views present a new method that attempts to achieve two qualities: high-level view definition, as in SQL views, and full algorithmic power (including updating) as e.g. in OMG CORBA adapters or wrappers.
As a simple example of a virtual updateable view we present the view (c.f. Fig.2-4) that delivers virtual objects named EmpBoss that contain virtual attributes name (of an employee) and bossName (of his/her boss). The updating may concern the name of a boss, which means that the corresponding employee is moved to the department managed by this new boss.
© Copyright by eGov-Bus Consortium19

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
view EmpBossDef{ virtual EmpBoss : record{ name: string; bossName: string }[0..*]; seed: record{e:ref Emp;}[0..*]{ return Emp as e; };
view nameDef{ virtual name: string; seed: record{en: string;}{ return e.lName as en;} }; on_retrieve { return en; } };
view bossNameDef{ virtual bossName: string; seed: record{bn: string;}{ return e.worksIn.Dept.boss.Emp.lName as bn; }; on_retrieve { return bn; };
on_update { e.worksIn := ref (Dept where (boss.Emp.lName) = value); } } }
Application of the view: let Doe start to work for Lee’s department (accomplished simply by the assignment to bossName):
(EmpBoss where name = “Doe”).bossName := “Lee”;
Note that the assignment := is overloaded by the invocation of the procedure on_update from the view definition. String “Lee” is passed as the newBoss parameter to this procedure.
SBQL views can have an own persistent state, what is important for various mappings based on dictionaries or ontologies (they can be kept inside views). Because of the full algorithmic power concerning both the mapping of stored objects into virtual ones and the mapping of updates of virtual objects into updates of stored ones, SBQL views can be used for quite a lot of applications. In particular, SBQL views can be used as mediators on top of local resources to convert them virtually to the required format, and as customizers that adopt the data to the needs of a particular end user application. As customizers, SBQL views offer for a database administrator additional facilities for granting access privileges.
SBQL views are also used as integrators that fuse data from different sources. In this role SBQL views are the foundation of the Virtual Repository Management System that is the subject of the eGov Bus project. Procedures that are used to define virtual objects can involve elements of communication and transportation protocols (e.g., based on Web Services), thus can be used to:
Resolve heterogeneities among remote servers and some developed eGov Bus application. Because of the algorithmic completeness of SBQL, every mapping that can be expressed algorithmically can be coded as an SBQL view;
Ping remote servers in order to determine if they are alive and to calculate communication delays;
Determine the most convenient (fastest) replica in case when resources are replicated on different servers;
Integrate (virtually) fragmented collections kept on remote servers. The integration may concern horizontal fragmentation (most frequent), vertical fragmentation and various mixed fragmentations.
Remove redundancies that are discovered among various resources (e.g. the name of a citizen is recorded within many public registers, perhaps in different formats).
In this way SBQL views allow one to achieve a lot of transparencies that are considered in distributed/federated databases, including location and access transparency, heterogeneity transparency, replication transparency,
© Copyright by eGov-Bus Consortium20

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
fragmentation transparency, redundancy transparency, optimization transparency, etc. An important application of SBQL views concerns wrappers that adopt relational database to an assumed object-oriented database model.
SBQL views are optimized by several methods. Queries within views are optimized by rewriting and by indices. Queries with view invocations are optimized by the query modification technique. New optimization techniques are considered, in particular, query tail absorption, query caching and global indexing of virtual objects.
2.7 Overview of Back-End Interoperability Facilities
2.7.1 Wrappers to external relational databases Integration of many servers participating in an eGovernment application requires different design processes in comparison to the situation when e.g. one object-oriented application is to be connected to a relational database. The common (canonical) database schema is the result of negotiations and tradeoffs between business or administrative partners having incompatible (heterogeneous) data and services. The processes may take into account data models of the resources, but first of all the global canonical schema is influenced by the business model of future global applications.
This makes development of an object-relational wrapper more constrained than in a classical Object-Relational Mapping (ORM) case known e.g. from Java or .Net oriented wrappers (such as JDO, EJB, TopLink and Hibernate). The wrapper should deliver virtual objects and services according to the predefined object-oriented canonical schema. There could be little freedom or could be incovenient to change the canonical schema due to limitations of ORM capabilities. Moreover, the mapping to an UML-like object model is much more complex problem than mapping to the Java or C# object model. The mapping should also support both directions: mapping of relational data into virtual objects, and mapping of updating operations on virtual objects into updates of relational tables through SQL. Hence, the architecture and algorithms for ORM aiming at eGovernment applications must be developed with proper universality of the mappings in minds.
The major problem with this architecture concerns how to utilize an SQL optimizer. In all known RDBMS-s the optimizer and its particular structures (e.g. indices) are transparent to the SQL users. A naive implementation of the wrapper causes that it generates primitive SQL queries such as select * from R, and then, processes the results of such queries by SQL cursors. Hence the SQL optimizer has no chances to work. Our experience has shown that direct (static, i.e. compile time) translation of object-oriented queries into SQL is unfeasible even for a typical case.
The solution of this problem that we have implemented in VRMS is based on the object-oriented query language SBQL, virtual object-oriented views defined in SBQL, query modification technique, and an architecture that will be able to detect in a query syntactic tree some patterns that can be directly mapped as optimizable SQL queries. The patterns match typical optimization methods that are used by the SQL query optimizer, in particular, rewriting, indices and fast joins. The idea is fully implemented within the ODRA prototype, including not only retrieval, but also some updating statements. The currently supported RDBMS are: Axion, Cloudscape, DB2, DB2/AS400, Derby, Firebird, Hypersonic, Informix, InstantDB, Interbase, MS Access, MS SQL, MySQL, Oracle, Postgres, SapDB, Sybase and Weblogic.
The idea of this wrapper is that a relational database is treated as a primitive object-oriented database, where each tuple is considered an object. Then, on such a primitive object-oriented database we are defining virtual views that map it to the given object-oriented model that is assumed by the canonical schema. Note that SBQL views (unlike SQL) have full algorithmic power. SBQL queries invoke these views; thus the relational database structure is fully transparent for its users. Due to the power of SBQL views, any complex mapping between a relational schema and an object-oriented canonical schema is feasible. The processing of SBQL queries is done by the following steps:
SBQL query is compiled and then its AST is produced;
Each node in this AST that contains a view invocation is substituted by the view AST; this method is known as query modification;
In the result we obtain a huge AST representing an SBQL query with no view invocations and addressing the relational database. This query is first optimized by the SBQL engine by removing dead subqueries, factoring out independent subqueries from loops, etc.;
The resulting syntactic tree cannot be entirely mapped to SQL, because SBQL is much more powerful than SQL and SBQL queries can refer to a local environment, unavailable for SQL. Hence, the tree is traversed in order to discover largest subtrees that are 1:1 compatible with SQL queries;
© Copyright by eGov-Bus Consortium21
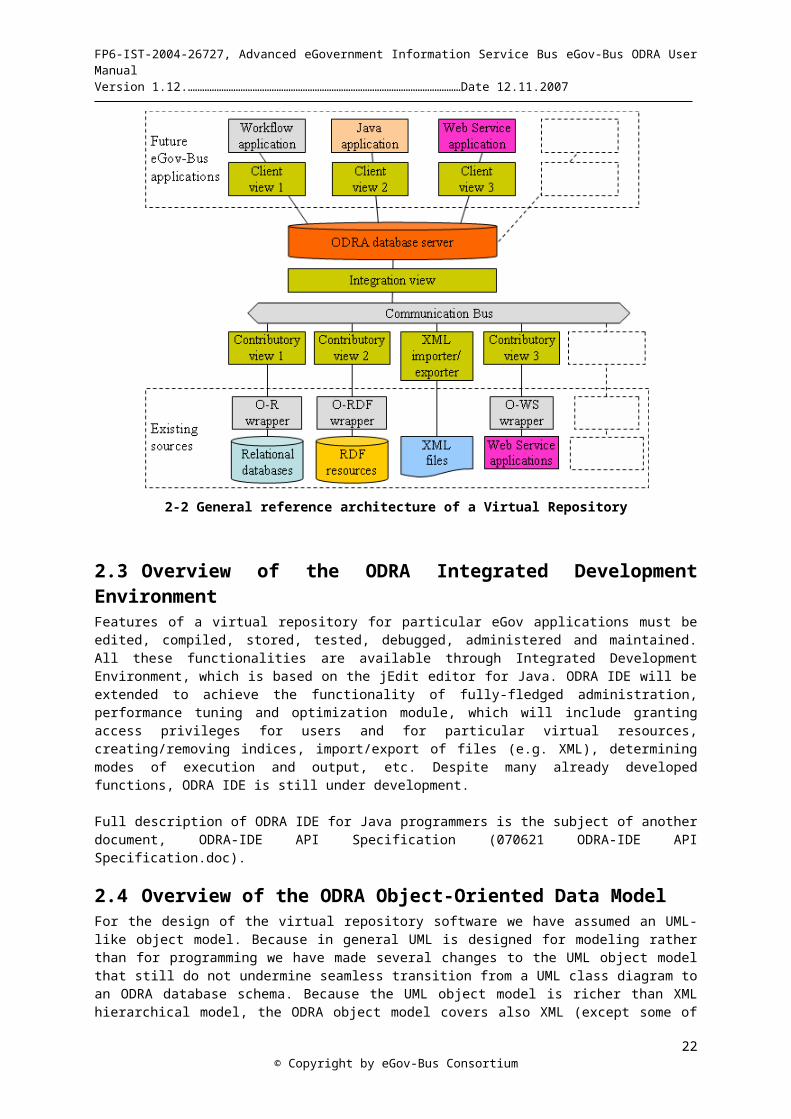
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Such subtrees are then mapped into SQL code using the JDBC interface;
Then the tree is compiled to the SBQL bytecode and executed. The results from JDBC invocations are converted to the SBQL format and stored at SBQL stacks.
Benchmarks have shown that this algorithm behaves quite well and is able to utilize almost all native SQL optimization methods.
2.7.2 XML importer/exporterThe XML importer/exporter is implemented in such a way that no information contained in the original XML file is lost in its ODRA representation. In some cases this assumption implies inconveniencies in asking SBQL queries – they are a bit more complex. In particular, due to XML attributes each atomic value from an XML file is wrapped into an object named _VALUE. This implies that an SBQL reference to such a atomic value must be ended by dot and _VALUE; see examples. Note also that XML attributes id and idref are mapped as pointer links between objects, giving the possibility to use SBQL path expressions.
XML exporter is implemented as a generic utility having an SBQL query as a parameter. XML tags are deduced from ODRA objects returned by a query and/or from auxiliary names that are used within the query. Because SBQL queries have full algorithmic power, the XML importer/exporter has no limitations concerning transformation of XML files into XML (or other) files. The XML importer/exporter can also invoke SBQL views as well as any SBQL functions. Below we present an example XML file, an SBQL query, and then the XML file generated by this query.
Input XML file:
<?xml version="1.0" encoding="UTF-8"?><deptemp> <Emp id="i1"> <name>Doe</name>
<sal>2500</sal><worksIn idref="i17"></worksIn><manages idref="i17"></manages>
</Emp><Emp id="i5">
<name>Poe</name><sal>2000</sal><worksIn idref="i22"></worksIn>
</Emp><Emp id="i9">
<name>Lee</name><sal>900</sal><address>
<city>Rome</city><street>Boogie</street><house>13</house>
</address><worksIn idref="i22"></worksIn>
</Emp><Emp id="i55">
<name>Bert</name><sal>3000</sal><address>
<city>Paris</city><street>Avenue</street><house>34</house>
</address><worksIn idref="i22"></worksIn><manages idref="i22"></manages>
</Emp><Dept id="i17">
<dname>Trade</dname><loc>Paris</loc>
© Copyright by eGov-Bus Consortium22

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
<loc>Rome</loc><budget>100000</budget><employs idref="i1"></employs><boss idref="i1"></boss>
</Dept><Dept id="i22">
<dname>Ads</dname><loc>Rome</loc><budget>200000</budget><employs idref="i5"></employs><employs idref="i9"></employs><employs idref="i55"></employs><boss idref="i55"></boss>
</Dept></deptemp>
SBQL query:
For each interval <n,n+999>, n = 0, 1000, 2000, 3000, ... get the message (string) containing the number of employees having the salary within this interval and the interval itself. Output messages should have proper spelling (nouns with -s for plurals, verbs without -s for plurals).
((((0 union 1000 union 2000 union 3000 union 4000 union 5000 ) as i)join (count(deptemp.Emp where sal._VALUE >= i and sal._VALUE < i+1000) as c) join ((("s" where c<>1) union ("" where c=1)) as n)join ((("s" where c=1) union ("" where c<>1)) as v)).((c + " employee" + n + " earn"+ v +" between "+ i +" and " + (i+999)) as message)) as RESULT;
The XML file generated by ODRA in response to the above query:
<?xml version="1.0" encoding="UTF-8"?><RESULT><message> 1 employee earns between 0 and 999 </message> <message> 0 employees earn between 1000 and 1999 </message> <message> 2 employees earn between 2000 and 2999 </message> <message> 1 employee earns between 3000 and 3999 </message> <message> 0 employees earn between 4000 and 4999 </message> <message> 0 employees earn between 5000 and 5999 </message></RESULT>
The example shows the computation power of SBQL as an XML mapping language. In contrast to such tools as XSLT, the computationally complete power of SBQL makes no limitations concerning the mapping; providing the algorithm or the rule for the mapping is known, it can be coded in SBQL in a declarative or procedural way.
The XML importer/exporter can also import XSchema (XSD) file to the ODRA metamodel. In this way all SBQL queries addressing XML files can be strongly typechecked.
2.8 Overview of Front-End ODRA Application Programming InterfacesCurrently we provided several methods to access Virtual Repository resources from external applications (including APG). All the methods use SBQL.
Call-Level-Interface (CLI). This kind of interface allows one to use the SBQL engine from Java.
Java Object Base Connectivity (JOBC). This interface follows the style of the JDBC interface to relational databases. The differences concern input (SBQL rather than SQL) and output (output Java objects are created from objects returned by ODRA in response to an SBQL query);
Web Services facilities. This interface makes it possible to create Web Services on top of the Virtual Repository resources.
JSP interface. This interface makes it possible to generate dynamic web pages utilizing standard JSP and some web server. Dynamic elements on HTML pages are determined through SBQL.
© Copyright by eGov-Bus Consortium23

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The above interfaces are implemented in prototype versions and will be extended according to the need of eGovernment applications. Implementation of other interfaces are considered, e.g. ADO for .NET.
© Copyright by eGov-Bus Consortium24

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
3. Getting Started3.1 ODRA Operational EnvironmentThe ODRA database system architecture uses the client/server model to communicate with clients creating distributed database environment. It is also possible that the ODRA server can behave as a client for another server. As typical for client/server applications, the client and the server can be on different hosts. In such a case they communicate over the TCP/IP network.
3.1.1 ODRA serverAn ODRA database is a static collection of structures called a “data store”. Data stores can be persistent or transient. In the first case the data are stored in the operating system file (stored in RAM with the use of a facility called memory mapped files that is similar to the swap file mechanism). The transient data store is stored directly in the main memory.
A collection of processes operating on a database is called a database instance. Currently a database instance consists of two main processes:
Communication process – responsible for asynchronous client connections acceptance and service.
Server process – representing client at the server side.
3.1.2 ODRA clientAn ODRA client is an application that is able to communicate with an ODRA server with the use of ODRA client/server protocol or API (e.g. Web Services interface). By default, the ODRA system is equipped with command line interface client (CLI). To create a complex application the IDE (Integrated Development Environment tool) client can be used.
3.2 ODRA Installation GuideODRA is a Java-based application and requires Sun™ JRE (Java Runtime Environment) to run. The current version uses the 1.6+ version of the JRE.
Because ODRA is assumed to be a full development environment the main usage pattern is based on the Integrated Development (IDE) application. IDE contains a graphical editor (which plays the role of rich ODRA client) and the ODRA server itself (for storing programs, compiling and execution). Apart from IDE, ODRA is also equipped with a client that can be used instead of the full IDE tool.
3.3 Your First Tiny Object BaseAfter completing previous steps you are ready to create your own data structures and classes. The following sample code creates PersonClass , extends it by EmpClass and creates DeptClass:
© Copyright by eGov-Bus Consortium25

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
class PersonClass { instance Person : { fName:string; lName:string; sex:string; age:integer; } getLastName():string {return lName;} getFullName():string {return lName + " " + fName;} }
class EmpClass extends PersonClass { instance Emp : { sal:integer; worksIn: ref Dept; } getFullName():string {return "Employee " + lName + " " + fName;} getSal():integer {return salary;} giveRise(amount:integer) { sal := sal + amount; } }
class DeptClass { instance Dept : { dNbr: integer; dName: string; loc: string [1..*]; employs: ref Emp [0..*]; }}
Having classes defined it is possible to fill the database by sample data and to query database using sample queries:
module PersonEmpMod { class PersonClass {…} // as before class EmpClass extends PersonClass {…} // as before class DeptClass {…} // as before Emp: EmpClass [0..*]; Dept: DeptClass [0..*];
create_database(){
e1: ref EmpClass; e2: ref EmpClass;e3: ref EmpClass;d1: ref DeptClass;d2: ref DeptClass;
d1 := create permanent Dept( 445566 as dNbr,"Ads" as dName, bag("Rome", "Paris") groupas loc);
d2 := create permanent Dept( 778899 as dNbr, "Toys" as dName, "London" as loc);
e1 := create permanent Emp( "Tom" as fName,"Jones" as lName,
© Copyright by eGov-Bus Consortium26
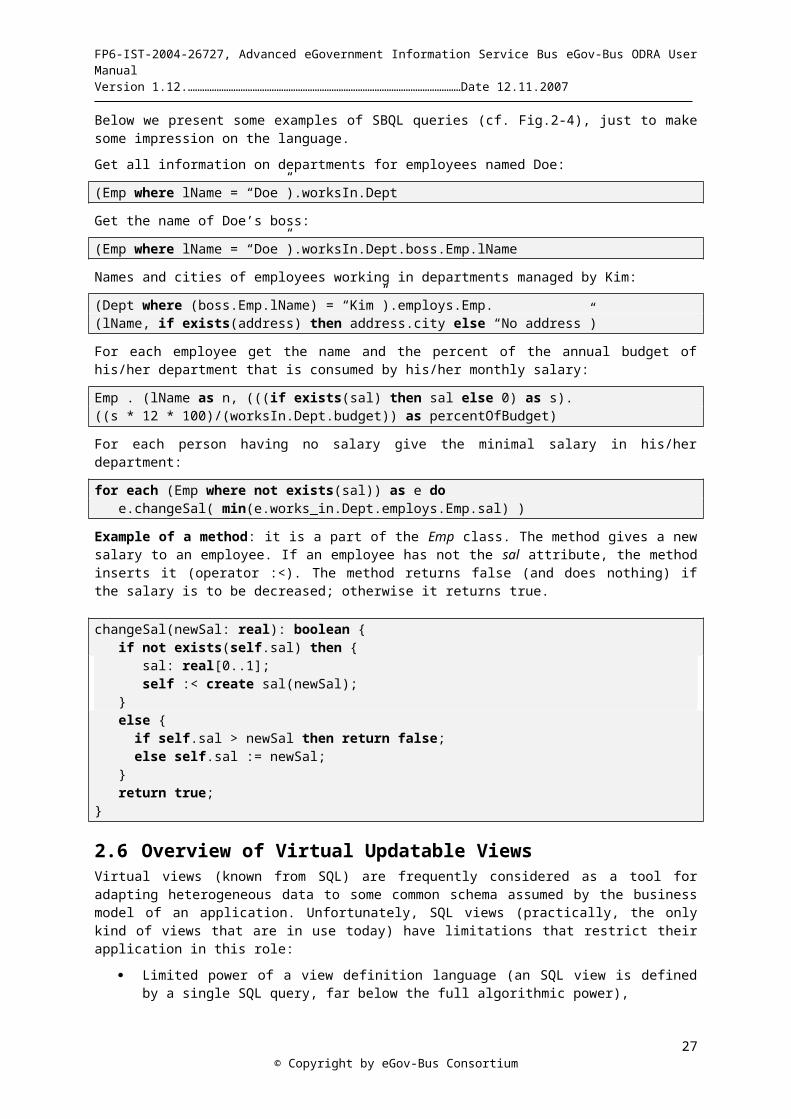
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
"M" as sex,34 as age,3000 as sal, d1 as worksIn );
e2 := create permanent Emp( "John" as fName, "Doe" as lName, "M" as sex, 40 as age, 4000 as sal, d1 as worksIn );
e3 := create permanent Emp("Jane" as fName, "Poe" as lName, "F" as sex, 29 as age, 2000 as sal, d2 as worksIn );
d1.Dept :<< employs( bag(e1,e2));d2.Dept :<< employs (e3);
}}
3.4 Your First SBQL Queries and Programs
Queries (in the context of PersonEmpMod):
Return all employees with last name Doe.
Emp where lName = “Doe”;
Return all employees with salary greater than 2000.
Emp where sal > 2000;
Programs:
Simple application could be implemented like this:
module test { import admin.PersonEmpMod; say_hello():string [0..*] { create_database(); return Emp.(“Hello ” + fName + “ ” + lName + “!”); }}
We can invoke Hello World application invoking say_hello() procedure (in the context of module test):
> say_hello();
The procedure will return the following output:
Hello Tom Jones! Hello John Doe! Hello Jane Poe!
3.5 Using Integrated Development EnvironmentThe comprehensive description of using IDE is the subject of a next chapter of this document. This section contains only quick start guide with the IDE. Notice also that the description of ODRA IDE from the
© Copyright by eGov-Bus Consortium27

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
programmer point of view is the subject of another document, ODRA-IDE API Specification (070621 ODRA-IDE API Specification.doc).
The following steps describe activites needed by the quick start example:
Working with the IDE should be started with creating a new project. This functionality is available using context menu – see Fig. 3-1. A project’s name should be entered (i.e. Tiny Example) and project’s directory has to be selected. Notice that a new project’s directory (with a project’s name) will be created.
3-1. Creating a new project in the ODRA-IDE
Create an empty file (using project’s context menu) named: “PersonEmpMod.sbql” and fill it with the code shown on Fig. 3-2 and Fig. 3-3.
3-2. SBQL code for PersonEmpMod.sbql – part (a)
© Copyright by eGov-Bus Consortium28

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
3-3. SBQL code for PersonEmpMod.sbql – part (b)
Create an empty file (using project’s context menu) named: “main.sbql” and fill it with the code presented on the Fig. 3-4.
3-4. SBQL code for main.sbql
Start a default server (using server’s context menu) or connect to the existing one – see Fig. 3-5.
3-5. Connecting to existing ODRA server
After sucessfuly connection, build the project (using project’s context menu) – Fig. 3-6. Notice that server’s node contains modules node which presents the server’s content. A few new items has been created, i.e. classes (PersonClass, EmpClass), procedure (create_database).
Activate “Odra Query” tab (default location is at the bottom of the screen) and run create_database procedure ( Fig. 3-7). Notice that appropriate context module has been selected.
© Copyright by eGov-Bus Consortium29

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
3-6. ODRA-IDE after successful build of the sample project
3-7. Running sample procedure in the ODRA-IDE
Run other queries or methods, i. e. say_hello and see the results ( Fig. 3-8).
© Copyright by eGov-Bus Consortium30

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
3-8 Running sample query in the ODRA-IDE
© Copyright by eGov-Bus Consortium31

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
4. ODRA Object-Oriented Store ModelODRA is based on UML-like object model, with complex objects, (nested) collections, classes, methods, static inheritance and binary associations. In our plans we assume extension of the UML object model with dynamic object roles and dynamic inheritance. The model fully covers the relational model, as it can be considered as a primitive object model where each tuple is an object and no inheritace, no methods and no associations are supported. This observation is important for making object-relational wrappers for ODRA. The ODRA model covers also the XML model, which (conceptually) offers hierarchies of nested objects with no classes, inheritance and associations. However, some minor features of the XML model have no direct counterparts in the ODRA store model, in particular, the order of XML subobjects is not supported in ODRA. In the same way the ODRA store model can be 1:1 compatible with the RDF model, with the Topic Maps model, etc. These properties of the ODRA store model allow to implement SBQL for a lot of different data environments. Moreover, such implementation can be strongly typechecked and optimized by powerful SBQL query optimization methods.
4.1 ModulesIn ODRA the basic unit of database organization is a module. As in popular object-oriented languages, a module is a separate system component. An ODRA module groups a set of database objects and compiled applications and can be the base for reuse and separation of programmers workspaces. From the technical point of view and the assumed object relativism principle the modules can be perceived as special purpose complex objects that store metadata and data.
4.1.1 Module metabase and databaseEach module includes (apart from some internal system data) two kinds of information: a metadata stored in a metabase and a data stored in a module database.
A metabase stores information needed during compilation of an SBQL source code. It is used for query analysis, type checking and optimization. Objects that are stored in the metabase contain meta-information about objects stored in the database. For example, for a declaration of a particular object (a variable) in the module source code the metabase stores such information as the name of the object, its type and its cardinality. Thanks to this information many type errors can be detected during compilation1. Moreover the information stored in the metabase is essential to query optimization. The module metabase is used both during compilation and during runtime. In contrast, a module database stores only data needed at runtime.
4.1.2 System moduleA new database contains a single default module called system module. A system module is a root for all user defined modules. Additionally it stores the data and metadata that can be perceived as ODRA standard library objects. All user defined modules automatically import the system module.
4.1.3 User defined modulesEach new user account added to a database server is ascribed with a default module that represents the root of the user defined database. The name of the module is the same as the name of the user account. All data created inside this module belong to the corresponding user. The user data can be additionally organized with sub-modules.
4.2 Objects, Nested ObjectsIn this document we primarily use the term object to denote stored data structures. Frequently, there is a correspondence between such data structures and real world objects, but this is rather informal relationship that not always holds. We do not make a difference between objects and variables known from a lot of programming languages. Sometimes the concepts are distinguished according to membership in classes: objects must be members of classes, while variables need not. Because there is very subtle difference between the class and type concepts, such a criterion is not firm. Hence, any stored data structure we will call object or variable, without assuming any syntactic or semantic difference between the concepts.
1 It is also possible to execute the system in the special “unsafe”, un-optimized mode with compile-time query analysis switched off and all the control moved to the runtime environment.
© Copyright by eGov-Bus Consortium32

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Our objects inherit a property of programming variables that says that objects can be stored strucures only. SBQL queries never return objects, but values of objects and references to objects, perhaps within some complex structures, such as records and bags. We reject totally the so-called closure property, which claims that input for queries (i.e. objects) and output from queries belong to the same conceptual domain. Careful analysis of semantic situations convinced us that the closure property, understood in this way, is a conceptual nonsense.
During design of our data model we have assumed important principles that govern semantic properties of objects. They are known as object relativity, total internal identification and orthogonal persistence. The principles are formulated as follows:
Object relativity: If some object O1 can be defined, then object O2 having O1 as a component can also be defined. There are no limitations concerning the number of hierarchy levels of objects. Objects on any hierarchy level is treated uniformly. In particular, an atomic object (having no sub-objects inside) should be allowed as a regular data structure, independent from other structures. The relativity of objects implies the relativity of corresponding query capabilities, i.e. there should be no difference in language concepts and constructs acting on different object hierarchy levels. Traditionally, an object consists of attributes, an attribute consists of sub-attributes, etc. In SBQL there is no need for such distinction: attributes, sub-attributes, pointer links between objects, procedures, methods, views, etc. are objects too. The principle cuts the size of database model, the size of specification of query languages addressing the model, the size of implementation, and the size of documentation. It also supports easier learning of both a database model and a corresponding query language. By minimizing the number of concepts the principle of object relativity supports development of a universal theory of query languages, which is necessary to reason about query optimization methods.
Total internal identification: Each object, which could be separately retrieved, updated, inserted, deleted, authorized, indexed, protected, locked, etc. should possess a unique internal identifier. The identifier is not printable and the programmer never uses it explicitly. A unique internal identifier should be assigned not only to objects on the top level of their hierarchy, but to all sub-objects, including atomic ones. If some atomic objects create a repeating group, e.g. a person has many hobbies, each object in the group should possess a unique identifier. For persistent objects (i.e. database objects) their identifiers should be persistent too, i.e. invariant during all the life of the objects. We are not interested in the structure and meaning of internal identifiers. For us it is essential that all objects and all their sub-objects can be unambiguously identified through its internal unique name. The principle makes it possible to make references and pointers to all possible objects, thus to avoid conceptual problems with binding, scoping, updating, deleting, parameter passing, and other functionalities that require object references as query primitives. Note that object identifier is purely technical term, in contrast to object identity that belongs to another domain of discourse, related to business modeling rather than to data structures.
Orthogonal persistence: No conceptual difference in typing and accessing persistent and volatile objects. In particular, a database can store individual objects (not only collections) and the volatile main memory of an application can contain collections of objects. Persistent objects are usually shared among many clients, hence must obey the transactional semantics. However, persistent (but non-shared) objects can also be stored at a client side; in this case the transactional semantics is not necessary. ODRA introduces three kinds of persistence: permanent that is stored on a server and shared, temporal that is stored at a client and not shared, and local that are assigned to a particular procedure, function, method or transaction call.
According to the object relativity principle each ODRA data element is an object with an internal identifier i, the external name n and the value v. At the lowest (physical) level there are three kind of objects.
1. Atomic (simple) objects represented by a triple < i, n, v >. The supported value types in ODRA are: integer, real, boolean, string, date and binary.
2. Pointer objects represented by a triple < i, n, i1 >, where i1 is an object identifier of the pointed object.
3. Complex objects represented by a triple < i, n, T> where T is a set of objects (of any kind).
Basic data store model (called M0) is a set of objects described above and a set of identifiers of root objects (starting points for database object graph navigation). Usually starting points for objects are identifiers of modules. At the higher logical level a complex object is used to represent different kind of conceptual objects – modules, metabases, classes, views, procedures, database links, indexes, and so on. An example of an ODRA object is presented in Fig.1-4. In Fig.4-1 we present an object schema and 5 objects that correspond to it. In Fig. 4-2 we present how a relational database can be represented in the ODRA data model.
© Copyright by eGov-Bus Consortium33

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
4-1. A database schema and corresponding objects
4-2. A relational database represented as ODRA objects
4.3 StructuresA structure in ODRA differs from structures that are known from Pascal records or structures of C/C++. Concerning stored objects, we distinguish structures in the typing system. For instance, a sequence of objects (<i6, name “Poe”>, <i7, sal, 2000>, <i8, worksIn, “Sales”>) can be considered a structure of the type record{name:string, sal:integer, worksIn: string}. In structure types the number of elements, their order, their names and their type are fixed. However, a structure is a concept related to the typing system only. Actually, in the object store model such a concept is not necessary - structures are simply ordered collections of objects.
In case of query results structures are sequences of elements that are not collections and that are results of queries. ODRA does not require that each structure element have to be named. Any result of a query, except
© Copyright by eGov-Bus Consortium34

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
collections, can be an element of a structures, in particular, atomic values, references to objects and any binders. For instance, <i1, i2, x(5)> is a structure instance having three elements – identifiers i1 and i2 and binder x(5).
4.4 Collections and CardinalitiesIn the ODRA store model we assume no uniqueness of external names on any level of object hierarchy. For instance, in Fig.4-1 name Emp are assigned to three objects and name Dept is assigned to two objects. Within the “Trade” Dept object name location is assigned to two atomic sub-objects and within the “Ads” Dept object name employs is assigned to two pointer sub-objects. This is the way in which we deal with collections. Note that similar assumptions are taken for XML. In this way we unify several concepts related to collections, such as sets, bags, extents and repeating attributes. We also abstract from the concepts of structure, record and tuple, as known e.g. C/C++, Pascal and relational systems. For the goal of building the formal semantics of query and programming languages such notions are secondary and can be expressed in the terms of the ODRA store model as complex objects.
In the ODRA store model a collection does not occur as a single entity having its own unique identitfier. However, it is possible to create a complex object with subobjects of the same type. For instance, one can create an object Employees having many Emp objects. This is the only way in which a collection may obtain a unique identifier.
Because each object differs from other objects at least by its object identifier, it makes little sense to distinguish stored collections by their kinds such as sets and bags (c.f. the ODMG standard). The current ODRA version does not support stored collection kinds known as sequence and array. Such extensions are planned in the next release.
The situation with collections is a bit different when we consider results returned by queries. In general, we consider the unification of collections stored at an object store and collections returned by queries as conceptually doubtful2. Concerning this case, the current ODRA version supports collection types bags and sequences. As a query result, sequences may appear in the result of the order by (sorting) operator. Collection types sets are not supported by the ODRA typing system, however, the programmer can make a set from a bag by applying the function distinct, just like in SQL.
In the ODRA typing system collections are constrained by cardinalities (known e.g. from UML). A cardinality is a pair of two symbols written as [min..max], where min is a non-negative integer denoting the minimal number of collection elements and max is a natural number or * denotin the maximal number of collection elements. The symbol * denotes “as many as you like”. For instance, [0..1] denotes a collection which is empty or contains one element, [1..1] is a collection having exactly one element, [0..*] is a collection having any number of elements and [1..*] is a non-empty collection having any number of elements. Other cardinalities are possible. If max is a number, then min ≤ max. Cardinality [1..1] is the default and can be omitted. Moreover, a collection with exactly one element is considered by the typing system as identical to that element. A cardinality [0..1] denotes an elements which may occur or not. This is the way in which ODRA deals with the concept that is known from relational systems as NULL. In SBQL we apply a liberal typing system (called semi-structured) where any collection having exactly one element e is equivalent to this element e (thus e.g. comparisons of elements and one-element collections are possible) and each single element e can be considered a bag with e as a single element. Note that similar coercion rules are also taken by SQL.
4.5 LinksIn ODRA links are understood as triples <i1, n, i2>, where i1 is a reference to a link, n is an external name used in a source code and i2 is a reference to an object that the link leads to. For instance, <i21, employs, i1> is a link (having the reference i21) that can be inserted into a Dept object and leads to an Emp object with the reference i1. Currently directed links (i.e. pointers) and bidirectional links (i.e. twin pointers) are supported. Bidirectional links are instances of the concept that is known as relationship (in the Entity-Relationship Model or the ODMG standard) or associations (in UML).
Links are strongly typed and can be updated, inserted and deleted. Links follow the orthogonal persistence principle, i.e. we do not restrict links to persistent and shared objects only. Links implement association instances known from UML; however, only binary associations with no properties and no association classes are
2 See SQL, where stored collections (tables) are unordered sets, but collections returned an SQL query can be sets (application of the distinct operator), bags (in a typical case) and sequences (application of the order by operator).
© Copyright by eGov-Bus Consortium35
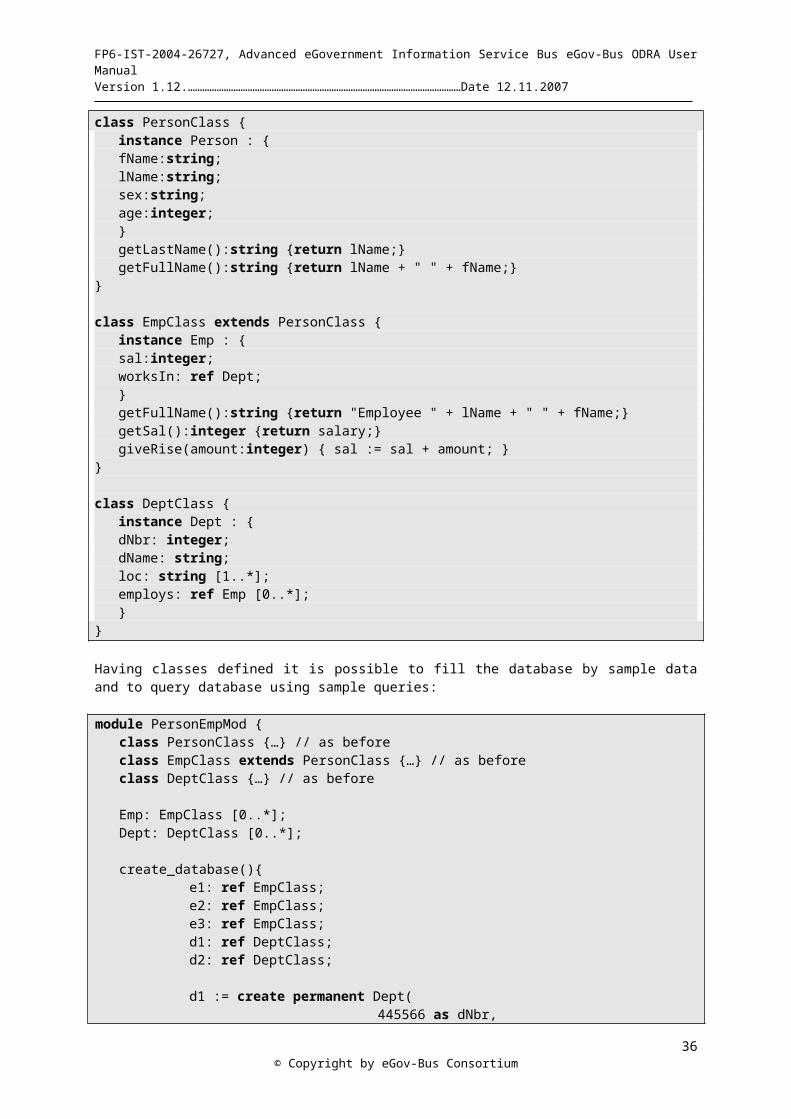
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
supported. Deleting any object A implies that all links leading to A are deleted (or nullified) too; hence no dangling links (links leading to garbage or improper objects) can appear. Note that we do not follow the idea that removing an object A requires removing or nullifying all the links that lead to A; object A is then removed by an automatic garbage collector (c.f. Java). For several reasons, e.g. a restricted client subschema, such an idea is inconsistent for database objects. Due to the limited view and access rights the application programmer may have no possibility to remove or nullify all the links that lead to an object that he/she wants to delete. Hence, ODRA and SBQL explicitly deal with the deletion operator, just like SQL.
4.6 Procedures, Functions and TransactionsODRA supports procedures and functions in the classical variant known from majority of programming languages; arbitrary calls of procedures/functions from procedures/functions are supported, including any recursive calls. The novelty of ODRA procedures and functions concerns parameter passing and a return from a function (a functional procedure). Either the parameters and the return can be determined by SBQL queries. This allow one to make programs much more conceptual and shorter. ODRA basically supports the parameter passing method that is known as strict-call-by-value. The method means that the actual parameter is calculated before the function call, then it is named by the name of the formal parameter, and then the body of the procedure/function is executed. The parameter passing method combines call-by-value and call-by-reference known e.g. from Pascal. No syntax distinguishes call-by-value and call-by-reference, just like in C/C++. The big advantage of the method is that it is simple to implement, fully consistent and allows for declarative and macroscopic (many-data-at-a-time) processing that is implied by queries.
Parameters of ODRA procedures and functions are typed. The result of a function is typed too. Typing is strongly checked during compile time and when necessary, typing is delegated to run time.
Procedures and functions can be persistent, i.e. they can be store at a database server and shared among many clients. This accomplishes the paradigm that is known from relational database systems as database procedures.
Procedure and functions are stored within modules or within classes. In the last case they are called methods and by default they act on an environment that includes internals of a class member object.
Concerning the source code, transactions in ODRA are similar to procedures. Except one keyword transaction and the command abort their semantic and pragmatic properties are the same as for procedures. Transactions are strongly typechecked, may have parameters being queries, may have local data environment and may return a result. As procedures, transactions can be stored within modules or within classes, can be stored on a server side (within the database) or on a client application side. Transactions can invoke other transactions without limitations (hence nested transactions are supported). Transaction invocations differ slightly from procedures during run time because of the ACID semantics on shared resources. A transaction invocation can be aborted and in this case its updates are canceled (rollbacked). During runtime a transaction invocation is represented by a special object. ODRA uses the traditional (pessimistic) 2PL transaction processing algorithm with no deadlocks due to the wait-die method. More detailed description of procedures, functions and transactions will be presented in proper chapters of this documentation.
4.7 ViewsFor Virtual Repository concept within the eGov Bus project we have applied a new approach to database views that allows us to achieve the power of updateable views that has not been even considered so far in the database domain. Our method has some commonalities with instead of trigger views implemented in Oracle, SQL Server and DB2, but it is based on different principles, is much more powerful and efficient, and may address any object-oriented database model, including an XML datamodel. In general, the method is based on overloading generic updating operations (create, delete, update, insert, etc.) acting on virtual objects by invocation of procedures that are written by the view definer. The procedures are the inherent part of the view definition. The procedures have full algorithmic power, thus there are no limitations concerning the mapping of view updates into updates of stored data. ODRA updatable views allow one to achieve full transparency of virtual objects: they cannot be distinguished from stored objects by any programming option. This feature is very important for distributed and heterogeneous databases.
ODRA views can be used as mediators on top of local resources to convert them virtually to the required format, as integrators that fuse fragmented data from different sources, and as customizers that adopt the data to the needs of a particular end user application. ODRA views are the basis for the Virtual Repository Management System that lies in the centre of the eGov Bus software.
© Copyright by eGov-Bus Consortium36

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Concerning storage, views share properties of procedures, functions and transactions. In particular, they can be stored within modules on a database server, within modules of client applications or within classes. In the last case views accomplishes the feature that is known as virtual attributes. Views are first-class entities that can be dynamically inserted or removed into/from a particular environment.
More detailed description of ODRA views will be presented in proper chapters of this documentation.
4.8 Classes, Inheritance, Polymorphism, Types and SchemataA class in ODRA is a programming entity having two forms:
1. A class is an encapsulated and named piece of source code containing specification of class members (their type) and specification of the methods that can be performed on the members
2. After compilation a class is a special run-time object that stores invariant properties of objects, in particular, compiled methods.
A class has some number of member objects. During processing of a member object the programmer can use all properties stored within its class. Classes can be connected into an ODRA schema, as shown in Fig.2-4.
As in the UML object model, classes inherit properties of their superclasses. Multiple inheritance is allowed, but name conflicts are not automatically resolved (similarly to UML). A method from a class hierarchy can be overridden. An abstract method can be instantiated differently in different specialized classes (due to late binding); this feature is known as polymorphism.
ODRA assumes strong or semi-strong type checking of all the programming entities and contexts. Strong typing is a prerequisite for query optimization and for resolving some ambiguities or ellipses that may occur in SBQL queries. For some purposes, however, strong typing can be switched off. The ODRA typing system includes atomic types (integer, real, string, date, boolean) that are known from other programming languages. Further atomic types are considered, but not implemented yet. The programmer can also define his/her own complex types known as records. All type constructors can be nested with no limitations. Collection types are specified by cardinality numbers, for instance, [0..*], [1..*], [0..1], etc.
The ODRA internal typing system checks some attributes that are assigned to type signatures. Currently the following attributes are supported:
Mutability: some operations, e.g. updating, require that the argument must be a reference to an object rather than some value. This is checked statically (during compilation time).
Cardinality: cardinality constraints are checked, mostly dynamically (during run time).
Collection kind: some operations are improper for some kinds of collections, for instance, extraction of i-th element is valid for a sequence but invalid for a bag. This is checked statically.
Other type signature attributes are considered, e.g. type name (for type equivalence based on type names), binary large object (for checking operations on multimedia) and side effects of queries and functions. The typing system makes also several automatic coercions (changing types) and automatic dereferences. For instance, a bag can be coerced to an element of this bag. If necessary, coercions are checked dynamically.
A database schema in ODRA is a specification of object types, classes and declarations that supports majority of elements known from UML.
More detailed specification of the ODRA types, classes and schemata will be given in next chapters of the document.
© Copyright by eGov-Bus Consortium37
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5. ODRA Integrated Development EnvironmentFull description of ODRA IDE for Java programmers is the subject of another document, ODRA-IDE API Specification (070621 ODRA-IDE API Specification.doc).
ODRA Integrated Development Environment simplifies the process of creating ODRA programs and managing an ODRA server. When we have decided to provide an IDE, two approaches come to our minds:
implementing the whole IDE from a scratch,
utilizing some components or libraries providing partial functionality for our environment.
The first approach guarantees more power and flexibility and does not restrict our freedom in designing the IDE. However the price is a lot of development effort. The latter solution limits functionality and design by constraints coming from the utilized components. It also requires extra learning. However, after some research we have chosen to follow the second approach. The main reason was to focus on implementing ODRA specific features rather then on usual text editor functions.
After some analysis we have chosen a text editor called jEdit (http://www.jedit.org/) as a primary text editor component for our ODRA IDE. The editor has been modified and surrounded by dedicated plugins providing easy access to the ODRA system.
5.1 Text EditorAccording to jEdit’s creators, the editor is a mature programmer's text editor with hundreds (counting the time developing plugins) of person-years of development behind it. While jEdit beats many expensive development tools for features and ease of use, it is released as free software with full source code, provided under the terms of the GNU General Public License.
The core of jEdit was originally developed by Slava Pestov. Now the jEdit core, together with a large collection of plugins is maintained by a world-wide developer team.
5-9. Screenshot of the plain jEdit
© Copyright by eGov-Bus Consortium38

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Fig.5 shows a screenshot of the plain (original) jEdit in action. Due to its highly customizable interface the number of possible configurations is very high. Fig.5-1 shows only one of the many possible configurations.
Some of general jEdit's features include:
Written in pure Java, so it runs on Mac OS X, OS/2, Unix, VMS and Windows.
Built-in macro language; extensible plugin architecture. Dozens of macros and plugins available.
Plugins can be downloaded and installed from within jEdit using the "plugin manager" feature.
Auto indent, and syntax highlighting for more than 130 languages.
Supports a large number of character encodings including UTF8 and Unicode.
Folding for selectively hiding regions of text.
Word wrap.
Highly configurable and customizable.
Below we enumerate some detailed jEdit features taken from the official web page:
Combines the best functionality of Unix, Windows and MacOS text editors.
Runs on any operating system with a Java 2 version 1.3 or higher virtual machine - this includes MacOS X, OS/2, Unix, VMS and Windows.
Efficient keyboard shortcuts for everything
Comprehensive online help
Unlimited undo/redo
Copy and paste with an unlimited number of clipboards (known as "registers")
Register contents are saved across editing sessions
"Kill ring" automatically remembers previously deleted text
Rich set of keyboard commands for manipulating entire words, lines and paragraphs at a time
"Markers" for remembering positions in files to return to later
Marker locations are saved across editing sessions
Any number of editor windows may be open, each window may be split into several areas, each area can view a different file. Alternatively, different locations in one file can be viewed in more than one area
Multiple open windows and split windows are remembered between editing sessions
Rectangular selection
Multiple selection (sometimes known as "discontinuous" or "additive" selection) for manipulating several chunks of text at once
Word wrap
Syntax Highlighting
Source Code Editing
o Intelligent bracket matching skips quoted literals and comments
o Auto indent
o Commands for shifting the indent left and right
o Commands for commenting out code
o Soft tabs option
o Abbreviations
© Copyright by eGov-Bus Consortium39
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
o Folding, with two fold modes: indent-based, and explicit (where the buffer is parsed for "{{{" and "}}}")
Search and Replace
o Both literal and regular expression search and replace supported
o Multiple file search and replace; search in either the current file, all open files, or all files in a directory
o "HyperSearch" option to show all found matches in a list
o Reverse search supported
o Incremental search supported
o Option to replace occurrences of a regular expression with the return value of a BeanShell script. As far as we know, no other text editor offers comparable functionalities.
File Management
o Any number of files can be opened at once
o Supports a large number of character encodings including UTF8 and UTF16
o Automatic detection of several character encodings (4.2)
o Automatic compression and decompression of GZipped (.gz) files
o Any character encoding supported by Java can be used to load and save files
o Multi-threaded I/O system supports pluggable "virtual file systems" for listing directories and loading files:
FTP plugin adds support for loading and saving files on FTP servers
Archive plugin adds read-only support for loading files from ZIP and TAR archives
o Custom file system browser component used in open and save dialog boxes
o Powerful keyboard navigation in the file system browser
o Files can be deleted and renamed, and new directories can be created from the file system browser
Customization
o Syntax highlighting modes are defined for XML files; new modes are easy to write
o Many editor settings can be set on a global, per-mode, or per-file basis
o Fully customizable keyboard shortcuts
o Fully customizable tool bar and right-click context menu
o Macros to automate complex editing tasks can be written in the BeanShell scripting language
o Macros can be recorded from user actions
Extensibility
o Plugins can turn jEdit into a very advanced XML/HTML editor, or a full-fledged IDE, with compiler, code completion, context-sensitive help, debugging, visual diff, and many language-specific tools tightly integrated with the editor.
o More than 150 plugins are already available that add a variety of features to jEdit.
o The "Plugin manager" feature downloads and installs plugins (and updates) from within jEdit automatically.
o Plugin windows can either be shown as separate, top-level frames, or as "docked windows" inside the jEdit editor window.
It can be seen that utilizing jEdit makes ODRA IDE really powerful in the scope of working with source code files.
© Copyright by eGov-Bus Consortium40
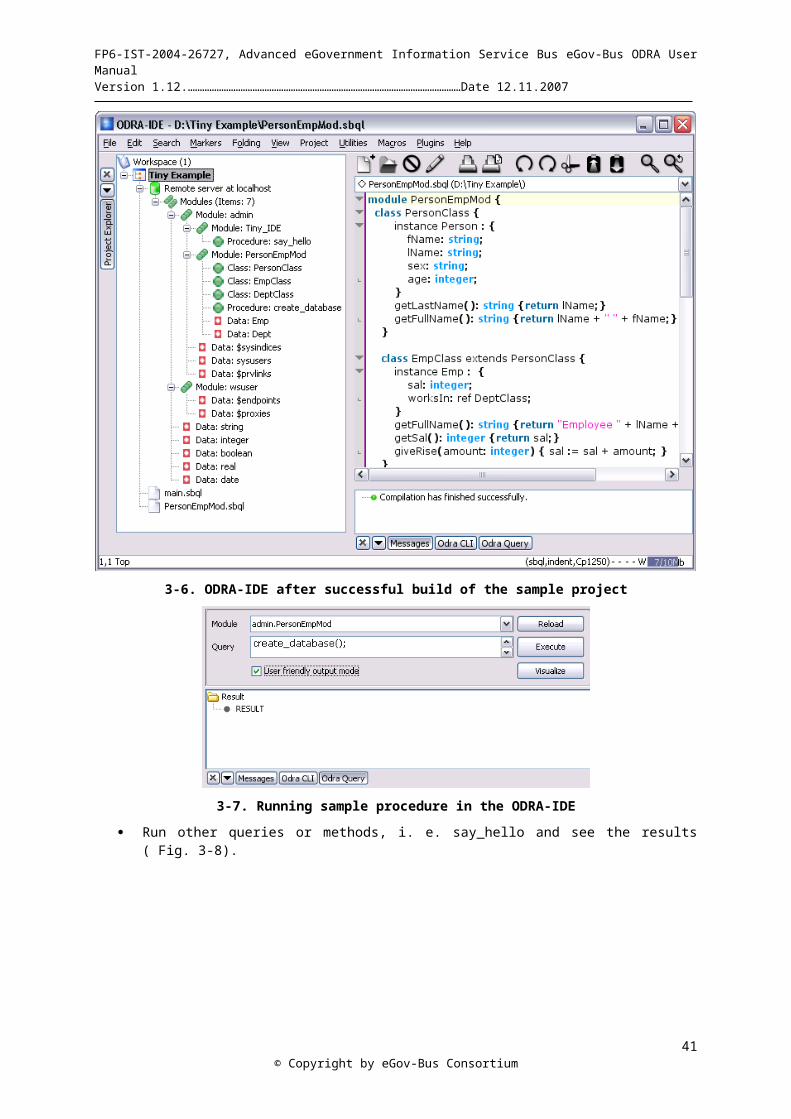
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5.2 Installing and RunningIn order to install ODRA-IDE the user has to follow the procedure described below:
Install Java JRE or JDK (Java SE 6 or later is required by the ODRA). You can download it from: http://java.sun.com/javase/downloads/index.jsp.
Extract the ODRA downloaded archive (ODRA-IDE_x.rar).
Run ODRA-IDE.jar. If *.jar file extension is not properly associated, try this:
<JavaBinPath>\javaw.exe -jar <extracted IDE path>\ODRA-IDE.jar
Make sure that the IDE directory is the current one. After successfully run you should see a splash screen with the progress bar and the IDE itself (Fig.5-10).
5-10. IDE after first run
The IDE is shipped with the most current version of ODRA. However it is possible to update the ODRA library manually by replacing appropriate jars in the “IDE-libs” directory.
5.3 General IDE InformationWe found that the big number of jEdit’s options could be confusing for an ODRA developer. Thus, we have hide/removed some of them, for instance, different syntax highlighting. If the programmer needs such functionalities it is possible to restore them (consult the jEdit manual).
Fig.5-10 shows ODRA-IDE just after a first run. The left panel contains “Project Explorer”, which allows viewing and manipulating workspace (with projects) containing files defining project’s structures. Each item has its own context menu (accessible using a right click). Some options could be called from a few places, i.e. a context menu and the main menu.
The bottom panel contains a few tabs, namely:
Messages showing i.e. compilation errors, warning or just information,
ODRA CLI (see Fig.5-11) encapsulates native ODRA Command Line Interface allowing performing most of the ODRA tasks,
© Copyright by eGov-Bus Consortium41
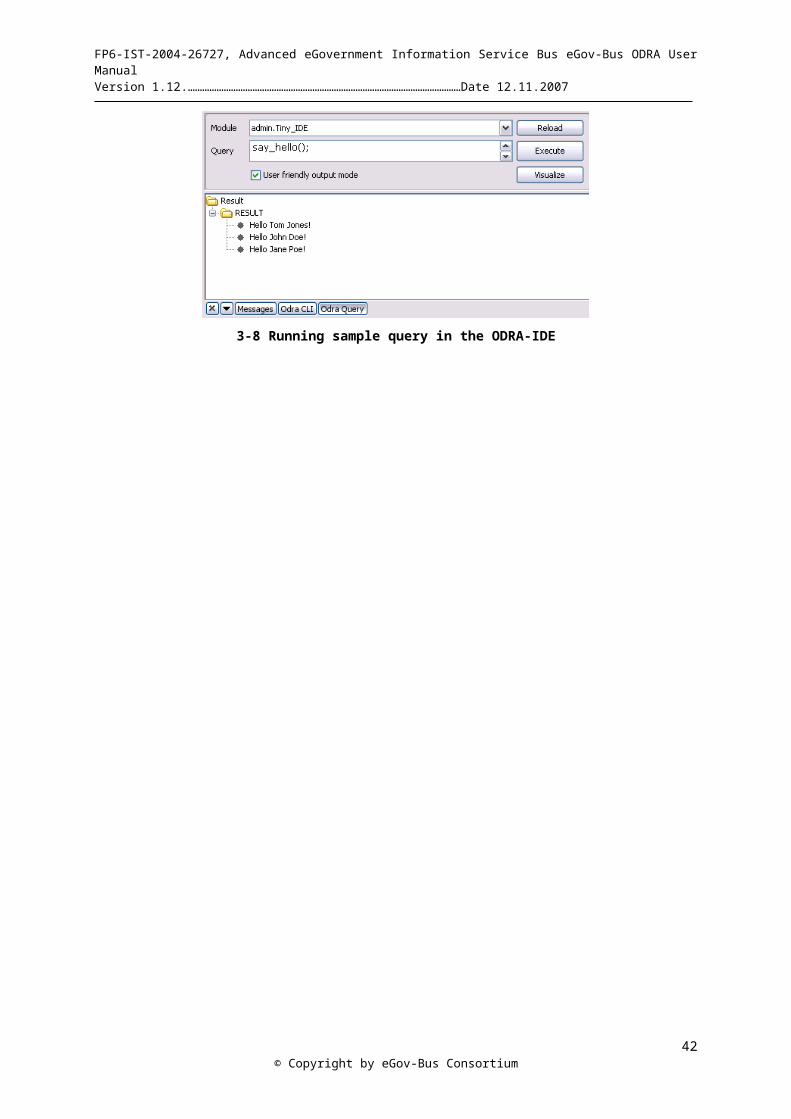
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-11. Part of the ODRA-IDE window presenting ODRA CLI
ODRA Query (Fig.5-12) is dedicated to write queries send to the ODRA server. Actually, it works with all SBQL statements, including the imperatives one.
5-12. Part of the ODRA-IDE window presenting funstionality for writing queries
The main part of the ODRA-IDE window occupies the text editor allowing the programmer for writing source code of SBQL programs. When a user clicks a file in the project tree, its content is presented in this window.
jEdit (and of course ODRA-IDE too) has its own window manager, which supports the following operations:
minimizing/maximizing is done by clicking on window’s label,
docking is accessible using the special menu available “under” the small triangle icon (see Fig.5-2). Available options allow to dock any window at the top, bottom, left or right of the ODRA-IDE main window.
5-13. Window's GUI menu
undocking (floating) is also accessible using the menu.
instantiating a new instance.
closing – self explaining.
Some of the IDE functions are available using different options, i.e. by clicking an icon on a toolbar or choosing appropriate item from a context menu.
5.4 Working with ProjectsSimilarly to other IDEs, ODRA IDE supports an unlimited number of projects. The projects are grouped into a workspace which can be seen at the top of the projects’ tree.
© Copyright by eGov-Bus Consortium42

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5.4.1 Creating a New ProjectIn order to create a new project, follow the procedure:
5-14. Creating a new project using workspace's context menu
Using right mouse button, activate workspace’s context menu and select Create a new project. The result should be similar to Fig.5-14.
Enter a name for the new project. The name should be unique, however it is not checked by IDE.
Select a location for project files. The location is a simply directory in the local file system.
5-15. Workspace with two projects
Fig.5-15 shows a part of the workspace tree containing two projects. The first one is also connected to an ODRA server (see next sub chapters).
Notice that the name of the first project is bolded. It means that this is a default project. All project commands which will be executed without a proper context, will be related to the default one. It is also possible to switch from one default project to another (using an appropriate context menu).
An ODRA project contains an ODRA server and files (SBQL, XML, TXT).
5.4.2 Files in a projectAs mentioned before, an ODRA IDE project contains files. There are two possibilities:
creating a new file in the project’s directory. Select Create a new file from project’s context menu. Then enter the file name. A new file will be created and placed in the project’s directory.
“importing” an existing file into a project. Select “Add an existing file” from project’s context menu. Then select a file(s). Notice that it is possible to import many files using the shift key. Selected file(s) will be added to the project’s structure, but will not be copied to the project’s directory.
© Copyright by eGov-Bus Consortium43

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-16. ODRA IDE after importing two sample files
Fig.5-16 shows an IDE window after importing two sample files located in “_SampleFiles” directory of the ODRA-IDE distribution.
A file’s context menu allows for opening the file in the IDE editor. The same result could be achieved using double click. It is also possible to remove a file from a project (see Fig.5-17).
5-17. File’s context menu
5.4.3 Saving/Loading workspaceThe entire workspace could be saved to a file. Actually information about the workspace is saved rather than the workspace content. That means that not all of the project files are stored in the workspace file. Thus, in case of backuping data, all projects files and workspace information must be stored in a safe place.
Saving or loading a workspace is accessible from a workspace context menu. The programmer has to select Save Workspace or Load Workspace from the workspace context menu.
Notice that currently a workspace records the information on projects and its files as absolute (not relative) paths. This approach will be probably changed in the future (because of problems with moving projects or their parts).
5.5 Working with an ODRA ServerODRA IDE works in the client-server architecture. Thus, the client (IDE) should be connected to an ODRA server. There are two options:
starting a default server working as a part of the IDE. If default server has started successfully, its icon in the project’s tree changes the colour into green. If the operation fails, a message will be presented to the user.
connecting to an existing ODRA server. A dedicated dialog box will be presented to the user. After entering some information, IDE tries to establish a connection. If the operation will succeed, the server’s icon also turns green.
© Copyright by eGov-Bus Consortium44

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-18. “Connect to a server” dialog
In both cases, the success of an operation could be verified by checking if the server’s sub node contains the Module section. After expanding the node, it is possible to peek the server’s content.
One of the easiest way of feeding a server with data is using one of the import plugins. Currently there are two importers:
XMLImporter,
XSDImporter.
Next sub sections describe them from the IDE point of view. More information about importers could be found in Chapter 11.
5.5.1 XML ImporterXML importer reads an XML file and load its content on the server. However notice that an XML file does not have information required by the ODRA’s type checking features. Thus, usability of a plain XML importer is limited, because previously it is necessary to define all types of the resulting ODRA objects. A better approach uses the XSD importer (see chapter 5.5.2), which automatically imports all the types necessary to import an XML file.
The procedure of importing an XML file is as follows:
Create a new project,
Run a default server or connect to an existing one,
Form a server’s context menu, using the right mouse button, select “Import data using plugin”. As a result, a dedicated dialog will be shown (see Fig.5-19),
5-19. Dialog for importing data
Choose a plugin “XMLImporter” (make sure it is not “XSDImporter”),
Select an existing XML file. For testing purposes it is possible to chose a sample file shipped with ODRA IDE: “_SampleFiles\XML\bookstore.xml”,
Select an existing module on the server (e.g. “admin”). An imported data will be placed “inside” the selected module.
Enter necessary parameters. The number and types of the parameters depend on a particular importer (consult the importer’s manual).
© Copyright by eGov-Bus Consortium45

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Depending on the file size and speed of network connection, the import of a process could take a while. If importing will finish successfully, appropriate message will be shown.
5-20. Sample project's tree after importing bookstore data
Note that, in case of the sample file, a new Data section (“bookstore”) has been created under the module admin (see Fig.5-20).
When a data has been successfully imported, it is also possible to execute a query running on the data i.e.: bookstore;. However, queries work only if the metadata is available (not a case in importing plain XML file) or type checking is switched off (default behaviour for type checking is on).
5.5.2 XSD ImporterAs mentioned in the previous chapter, the better way of importing XML data into the ODRA server, is utilizing XSD importer rather then XML importer.The procedure of importing an XML data using XSD importer consists of two steps:
importing metadata located in an XSD file,
importing real data from an XML file.
Both of them are very similar to the procedure described in case of the XML importer. However to make it really clear, following sample scenario is described:
Create a new project,
Run a default server or connect to an existing one,
Form server’s context menu, using the right mouse button, select “Import data using plugin”. As a result dedicated dialog will be shown (see Fig.5-19),
Choose a plugin “XSDImporter” (make sure it is not “XMLImporter”),
Select an existing metadata XSD file, i.e. “_SampleFiles\XML\personnel.xsd”,
Select an existing module on a server (e.g. “admin”). An imported metadata will be placed “inside” the selected module.
Enter necessary parameters. The number and types of the parameters depend on a particular importer (consult the importer’s manual). As a result metadata from the file has been imported by the server. It can be seen on the project’s tree (Fig.5-21). This is the end of the procedure’s first step.
© Copyright by eGov-Bus Consortium46

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-21. Server's content after importing metadata
At the beginning of the step two, from the server’s context menu, using right mouse button, select “Import data using plugin”. As a result dedicated dialog will be shown (see Fig.5-19),
Choose a plugin “XMLImporter” (make sure it is not “XSDImporter”),
Select an existing XML data file, i.e. “_SampleFiles\XML\personnel.xml”,
Select an existing module on a server (e.g. “admin”). An imported metadata will be placed “inside” the selected module.
Enter parameter: “useMetabase”. The number and types of other parameters depend on a particular importer (consult the importer’s manual).
4-22. Server's content after importing metadata and data
The Fig.4-22 presents the server’s content after importing metadata and data.
Because both data and metadata has been imported, it is possible to send a query running on imported data. Fig.5-23 contains partial result of a query personnel; visualized in IDE.
© Copyright by eGov-Bus Consortium47

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-23. Partial result of the query visualized in the ODRA IDE
5.5.3 Viewing database server contentSometimes it is necessary to see a server’s content taking into account internal data structures. It is especially useful for debugging of SBQL queries and programs. ODRA IDE has a dedicated functionality which currently utilizes a simple textual form. The functionality is available using the server’s context menu: “DEBUG: Dump store”. The result of the operation is shown on Fig.5-24.
5-24. Server's content using Dump Store functionality
5.5.4 Showing modules content.An ODRA server node in the project tree contains a very important sub-node called “Modules”. The entire server content is “attached below” this special node. Using an appropriate context menu it is possible to refresh the visualization of the server’s content in IDE (see Fig.5-25).
© Copyright by eGov-Bus Consortium48

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-25. Special node "Modules" and its context menu
Due to the performance reason, it is sometimes necessary to manually call Reload option from the context menu.
5.5.5 Showing a server data valueNode “Modules” contains the entire server content: modules and data. Each data item could be examined by presenting its value. Dedicated context menu has two options:
Show value in the internal mode,
Show value in the user-friendly mode.
The first option (Fig.5-26-b) is useful if we would like to know the internal (server) structure of the data. The latter (Fig.5-26-a) is better if we are interested just in the value not in its build. Notice that the internal data structure is much more complicated (almost unreadable) then the processed user friendly mode.
5-26. Two kinds of data visualizations
5.5.6 Showing server's memory monitorODRA IDE allows monitoring of the server’s RAM memory consumption (see Fig.5-27). Actually it is the memory consumed by the Java Virtual Machine (JVM) running the ODRA server. The monitor is started using the server’s context menu: Show memory monitor. There is also a possibility to run the Java garbage collector (from within the monitor).
© Copyright by eGov-Bus Consortium49

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-27. Server's memory monitor
5.5.7 Showing server's memory utilizationAnother administration functionality (also accessible using the server’s context menu) is presenting the structure of the ODRA server persistent store. Fig.5-28 shows it in action.
5-28. Visualization of the ODRA persistent store
5.6 Compiling and Running
5.6.1 Building a projectBuilding a project is a process when each file in the project is send to the server and compiled. Thus, before the compilation, the project should be connected to a server.
In order to build a project, select “Build” from the project’s context menu. If the project’s server is not running, the default one will be started. After the compilation, there will be some messages in the “Messages” panel
© Copyright by eGov-Bus Consortium50

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
(bottom of the screen). If there will be errors/warnings, you can open appropriate file by clicking error description. Note then a line with an error is highlighted. Try to compile sample files and introduce some errors to see what will happen.
The following procedures shows how to compile sample files:
Start a new project (see subchapter 5.4.1),
Connect to an existing server or start a default one (see subchapter 5.5),
Add sample files to the project according to the procedure described in sub chapter 5.4.2.
Click a button Build default project (upper right part of the window) or select Build from the project’s context menu.
5-29. ODRA IDE after compiling sample project
As a result all project files have been send to the server and compiled. Notice (see Fig.5-29):
A message inside the Messages tab,
Two new modules (data, procedures) have been created on the server (under the module Admin),
Data x has the initial value 0. The value has been put under the node data: x after selecting a dedicated command (see sub chapter 5.5.5).
Edit the sample files, trying to test IDE’s reaction for errors. Fig.5-30 presents error message after introducing some syntax errors to the sample file. Notice that a line with an error is highlighted with red. It is also possible to double click specified error message and directly jump to the line.
© Copyright by eGov-Bus Consortium51

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-30. ODRA IDE presenting a compilation error
5.6.2 Running a projectCurrently ODRA programs do not have an equivalent of the regular programs main method. Such an approach allows running any method or query as an SBQL program. ODRA IDE has a dedicated functionality which supports a similar option. Follow the procedure:
Start a new project (see subchapter 5.4.1),
Connect to an existing server or start a default one (see subchapter 5.5),
Do one of the following:
o select “Debug” from project’s context menu (Fig.5-31a),
o select “Execute a query” from server’s context menu (Fig.5-31b),
o click a button (presenting a running man) at the top right area of the ODRA window (Fig.5-31c).
5-31. Different ways of running queries
Every of the above actions will occur in showing the same querying tab (Fig.5-32),
© Copyright by eGov-Bus Consortium52

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-32. ODRA querying tab
The querying tab consist of the following elements:
o Module combo box allows selecting a module where the query will executed. Sometimes it is necessary to hit Reload button to refresh the list.
o Query text box allows for writing queries (including multiple lines). Clicking on the Execute button will send the query to a server and execute it.
o Checkbox specifying an output mode.
o The result tree contains the answer from a server. Using the dedicated context menu (see Fig.5-33) it is possible to:
copy the result to a clipboard in two different text format (text-like, XML-like),
expand the entire tree. It is especially useful if the tree is complicated.
5-33. Using query result’s context menu
Just to make sure that everything is clear, work out the following example:
Import XSD metadata and XML data (see subchapter 5.5.2)
Enter (or select from the combo box) the module name “admin”,
Enter a query code (method name): personnel; This query will return all persons working as a personnel, which is shown on Fig.5-34.
© Copyright by eGov-Bus Consortium53

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-34. Sample query result
Alternatively it is possible to write
o “admin.procedures” as a module name,
o proc(); as a procedure name (query code). Those information could be utilized in case of sample files (see subchapter 5.6.1).
Of course we advise to try many different queries including mathematical calculations (e.g. 2+2 is a valid SBQL query). More sample queries could be found in other parts of this document.
5.7 ODRA IDE CLI (Command Line Interface). The ODRA Command Line Interface (ODRA CLI) is a basic way of interacting with an ODRA server. ODRA IDE CLI tab (Fig.5-35) just encapsulates the original ODRA CLI with some improvements.
© Copyright by eGov-Bus Consortium54

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5-35. ODRA IDE CLI after executing help command
At the top of the ODRA IDE CLI tab there are four buttons:
Clear input clears all entered commands.
Clear output clears all responses received from a sever.
Connect makes easier connecting to the project’s server.
CLI Variables helps setting and reading various CLI variables. Just select one of the possible states (Fig.5-36). Keep in mind that the variables are linked with the CLI (not the IDE or a server). Another way of interacting with the variables is using workspace’s menu.
5-36. Support for CLI variables in the ODRA IDE
For a list of available CLI commands, just type "help" in the input filed. Please notice that it is possible to resize Input and Output sections (using standard “drag” behaviour).
5.8 More SamplesFull description of the ODRA IDE for Java programmers is the subject of another document, ODRA-IDE API Specification (070621 ODRA-IDE API Specification.doc). The specification allows to use, extend and custopmize the ODRA-IDE using a decicated Java API.
© Copyright by eGov-Bus Consortium55

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
6. SBQL (Stack-Based Query Language) - QueriesODRA and its query and programming language SBQL are based on the Stack-Based Architecture 3 (SBA). It is a formal methodology addressing object-oriented database query and programming languages. SBA is a great come back from database theories such as (relational, object) algebras, calculi, etc. to the well-known concepts that are recognized in the programming languages domain for about 40 years. In SBA we reconstruct query languages’ concepts from the point of view of programming languages (PLs). The approach is motivated by our belief that there is no definite border line between querying and programming; thus there should be a universal theory that uniformly covers both aspects. SBA offers a unified and universal conceptual and semantic basis for queries and programs involving queries, including programming abstractions such as procedures, functions, classes, types, methods, views, etc.
6.1 Basic Pragmatic, Syntactic and Semantic AssumptionsThe power of SBQL concerns a wide spectrum of data structures that it is able to serve and complete algorithmic power of querying and manipulation capabilities. At the same time, SBQL is fully precise with respect to the specification of semantics. SBQL has been carefully designed from the pragmatic (practical) point of view. We were struggling severely with parasite syntactic sugar, redundant operators and semantic reefs (when human intuitive semantics does not match machine semantics). The pragmatic quality of SBQL is achieved by orthogonality of introduced data/object constructors, orthogonality of all the language constructs, object relativism, orthogonal persistence, typing safety, introducing all the classical and some new programming abstractions (procedures, functions, modules, types, classes, methods, views, etc.) and following commonly accepted programming languages’ principles.
The SBA solution relies on adopting a run-time mechanism of PLs and introducing necessary improvements to it. The main syntactic decision is the unification of PL expressions and queries; queries remain the only kind of PL expressions. For instance, in SBA there is no conceptual difference between expressions such as
2+2
and
(x+y)*z
and queries such as
Employee where salary = 1000
or
(Employee where salary = (x+y)*z).name
All such expressions or queries can be used as arguments of imperative statements, as parameters of procedures, functions or methods and as a return from a functional procedure.
SBQL is the first query language that abandons big syntactic and semantic patterns of queries, such as the SQL-like pattern select…from…where…groupby…having…orderby…. We have come back to the tradition of programming languages, where syntactic patterns of expressions are as small as possible and consist of unary or binary operators that can be freely combined. All combination of operators are possible, providing the combination has a sense for the user and does not violate typing constraints. Small syntactic patterns and full orthogonality concerning their combination much supports the robustness and power of the language, keeping at the same time its lean specification, easier learning, shorter documentation, much easier implementation and much more potential for query optimization.
Concerning semantics, we focus on the classical naming-scoping-binding paradigm. Each name occurring in a query is bound to run-time programming entities (persistent data, procedures, actual parameters of procedures, local procedure objects, etc.), according to the actual scope for the name. The common PLs’ approach that we follow in SBA is that the scopes are organized in an environmental stack with the “search from the top” rule. Some extensions to the structure of stacks used in PLs are necessary to accommodate the fact that in a database we have persistent and bulk data structures and the fact that the data is kept on a server machine, while the stack is kept on a client machine. Hence the stack contains references to data rather than data themselves (i.e., we separate the stack from a store of objects), and possibly multiple objects can be simultaneously bound to a name occurring in a query (for processing collections). The operational semantics (abstract implementation) of query
3 In other sources SBA is also referred to as Stack-Based Approach
© Copyright by eGov-Bus Consortium56

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
operators, imperative programming constructs and procedures (functions, methods, views, etc.) is defined in terms of the three abstract data structures: object store, environmental stack (ENVS) and query results stack (QRES). All these structures have their static incarnation that is necessary for strong type checking, that is, a metabase, a static environment stack and a static result stack.
6.2 Strong Type CheckingIn SBQL we assume strong type checking, as in many other programming languages, but we extend the checking to collection types that are determined by cardinalities. Because the cardinality lower number can be 0, e.g. [0..1] or [0..*], the store model assumed in SBQL covers so-called semistructured data. In such cases ODRA is prepared to semi-strong type checking that assumes static checking of everything that can be statically checked, and dynamic (runtime) checking of all the cases that are impossible to check statically.
6.3 Results returned by SBQL QueriesResults of SBQL queries can be defined recursively as follows. A result returned by the SBQL query can be one of:
value of atomic types integer, real, string, boolean and date;
reference to an object (including attributes, subattributes, links, procedures, methods, views, etc.);
structure - a non-empty n-tuple of any query results (including named collections);
binder, that is, a pair name(value), where value can be any result; binder is a named value of any type.
collection (bag or sequence) of results.
6.4 Atomic SBQL QueriesThe atomic SBQL queries are literals (integers, floating points, strings, dates, booleans) and names. Names can represent any data, procedures or methods stored in the object store. Names can also be auxiliary names defined in a query by as or groups operators, names of parameters, names of views, etc.
Example queries:
2
3.14
“Winnie the pooh”
2007-06-12 03:04:12
Person
salary
age
RichEmployee
6.5 SBQL OperatorsSBQL provides a common set of predefined operators for arithmetic, string, logical and other operations. The set of the operators is shown in the following table and described in details in the following sections.
Table 6-1. SBQL operators
Operator category Operator symbols
Numerical + - * / %
Logical and or not
String concatenation +
Comparisons = <> > < >= <=
Auxiliary naming as groupas
Date operators now dateprec
Aggregate functions sum count min max avg
© Copyright by eGov-Bus Consortium57
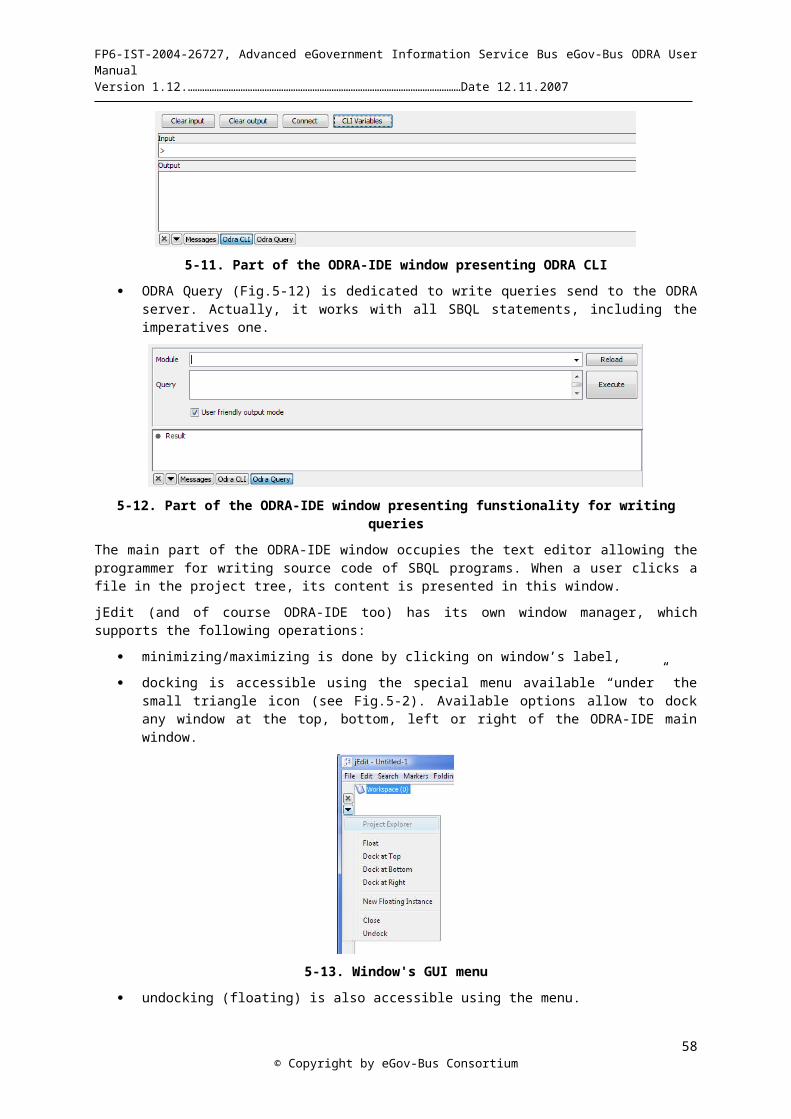
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Algebraic operators on collections bag union struct , subtract in contains intersect unique distinct exists
Non-algebraic operators on collections . join where forall forsome orderby closeby
Reference and dereference ref deref
Conditional if … then … else …
In the following we assume that:
query1 ::= query
query2 ::= query
query3 ::= query
sequenceOfQueries ::= query {, query}
6.5.1 Numerical and String Operators All the numerical and string operators call automatic dereference if one or both subqueries that an operator connects return references. For example, in the query x+1 the subquery x returns a reference to an object x, which is automatically dereferenced to the value stored at x.
query ::= query1 + query2
query ::= - query1
query ::= query1 - query2
query ::= query1 * query2
query ::= query1 / query2
query ::= query1 % query2
The operators are defined for integer and real types. For numeric types their meaning is typical (according to the elementary arithmetics); operator % computes the reminder of dividing the first operand by the second operand. The operators require operands with the cardinality [1..1]; however, other cardinalities do not cause a type error but shifting the type checking to runtime to check whether eventually the argument is a single value. The operators call automatically the dereference of an operand if it returns a reference.
When one or both operands of + are string types, the result is the concatenatation of the string operands.
The precedence of operators is typical, as in the elementary arithmetics; if necessary or in case of doubts parenteses can be used.
Example queries:
2 + 2
4.6 + 5.2
3 + 2.3
“My favourite number is: ” + 27
4 – 2
5.3 – 1.2
2 * 2
5.3 * 1.2
4 / 2
sal + 1000
sal + (10 * age)
"Winnie " + "the " + “Pooh”
fName + “ “ + lName
sal – 100
- (netSal + budget / 10000)
sal * 100
netSal * (age/10)
sal / 100 + budget / 1000
© Copyright by eGov-Bus Consortium58
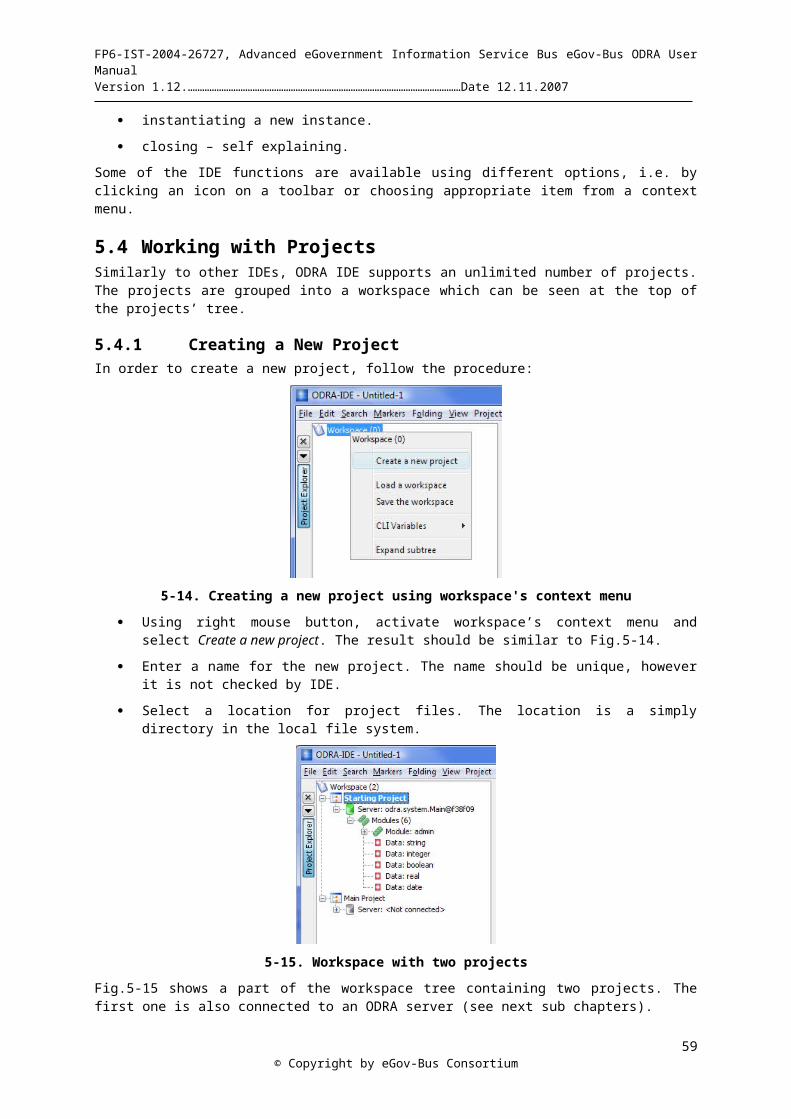
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5.3 / 1.2
15 % 5
netSal / (age + 10)
sal – (sal % 1000) + 500
6.5.2 Comparison OperatorsAll the comparison operators call automatic dereference if one or both subqueries that an operator connects return references.
6.5.2.1 = and <> operators
Binary comparison operator.
query ::= query1 = query2
query ::= query1 <> query2
The equality and inequality operators are defined for numerical values, dates, strings, references, and complex (structure) value types. They return boolean values. The inequality operator returns the boolean negation of the equality operator. For numerical and string values the equality operator returns true if the values of its operands are equal, false otherwise. For references it returns true if its two operands refer to the same object. For structures it returns true if two operands have the same structure. The operator requires operands with the cardinality [1..1]; however, other cardinalities do not cause a type error but shifting the type checking to runtime to check whether eventually the argument is a single value. The operator calls automatically the dereference of an operand if it returns a reference.
The precedence of operators (including all other operators in a query) is typical, as in the elementary arithmetics; if necessary or in case of doubts parenteses can be used.
Example queries:
2 = 2
“Winnie" = “winnie”
(ref x) = (ref y)
(1, "ala") = (1, "ala")
salary = 1000
lName = “Doe”
“Winnie" <> “winnie”
fName <> “Bill”
(address.street) <> “Boogie”
location <> name
6.5.2.2 < , > , <= and => operators
Binary comparison operators.
query ::= query1 < query2
query ::= query1 > query2
query ::= query1 <= query2
query ::= query1 >= query2
The less_than, greater_than, less_or_equal_than and greater_or_equal_than operators are defined for numerical values and date values. The first one returns true if the first operand is less than the second, false otherwise. The second ones – just otherwise. The less_or_equal_than one returns true if the first operand is less or equal than the second, false otherwise. The greater_or_equal – otherwise.The operators require numerical operands with the cardinality [1..1]. The operators call automatically the dereference of an operand if it returns a reference.
The precedence of operators (including all other operators in a query) is typical, as in the elementary arithmetics; if necessary or in case of doubts parenteses can be used.
Example queries:
2 < 2 sal < 1000
© Copyright by eGov-Bus Consortium59
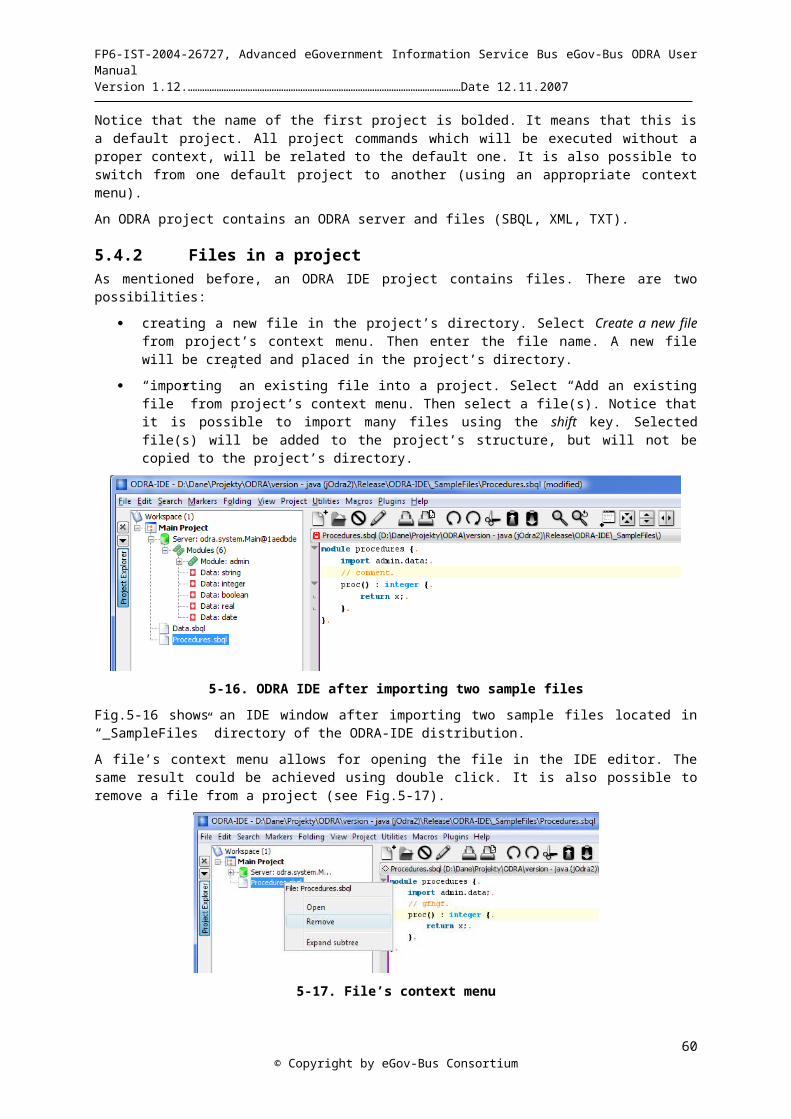
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
2 <= 2
3.5 < 3.1
16.4 >= 3
sal >= 5000
budget >= sum(Emp.salary)
min(Emp.salary) >= 2000
6.5.3 Boolean Operators6.5.3.1 and and or operators
Binary logical operators.
query ::= query1 and query2
query ::= query1 or query2
The operators perform a logical AND and OR on its boolean operands. They should have the cardinality [1..1]. The operators call automatically the dereference of an operand if it returns a reference.
Example queries:
(2 = 2) and (2 <> 3)
sal = 1000 and job = “clerk”
(sal < 3000 or job <> “programmer”) and (address.city) = “Rome”
6.5.3.2 not operator
Unary logical operator.
query ::= not query1
The operator negates its boolean operand. It requires a boolean operand with the cardinality [1..1]. The operator calls automatically the dereference of an operand if it returns a reference.
Example queries:
not forall Emp (sal >= 2000)
not exists(sal)
not ((Emp where sal >= 1000) in (Emp where job = “clerk”))
6.5.4 Date Operators and Comparisons6.5.4.1 now operator
The now operator returns the current day and time with the precision of milliseconds starting from the Unix epoch beginning, i.e. since 00:00:00 UTC of January 1, 1970. The operator returns a value of the ODRA date type (it corresponds to timestamps in other systems).
query ::= now()
6.5.4.2 dateprec operator
The dateprec operator allows for formatting date precision since no separate data types are introduced for expressing different time accuracies used in natural languages for expressing actual date/time semantics, e.g. for a birth date (only a calendar date), a meeting time (a calendar date plus and an hour with minutes, ignoring seconds and milliseconds), etc. The dateprec operator returns the date data type, minus the irrelevant date parts (e.g. an hour, minutes, seconds and milliseconds) are just set to 0. The syntax is following:
query ::= dateprec(query1, formatstring)
where query1 returns a date type value and formatstring can be one of:
"low" – date exact to a day.
© Copyright by eGov-Bus Consortium60

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
"medium" – date and time exact to minutes.
"high" – date and time exact to seconds.
“full” – date and time exact to milliseconds (default).
Example queries:
dateprec(now(), “low”)
dateprec(now(), “full”)
Employee where dateprec(birthDate, “low”) >= dateprec((Employee as e where e.id = “ABC12345”).e.birthDate, “low”)
(Guest where name = “Smith”).checkInTime := dateprec(now(), “medium”)
(Event where dateprec(timestamp, “high”) = 2007-06-12 03:04:12).description
6.5.5 Algebraic Operators on Collections6.5.5.1 union operator (bag constructor)
Binary collection operator.
query ::= query1 union query2
Alternatively:
query ::= bag(sequenceOfQueries)
The union operator returns a bag that is a result of ‘set-sum’ of the operands. If query1 returns bag{a1, a2, ...} and query2 returns bag{b1, b2, ...}, then the query bag( query1, query2) returns bag{ a1, a2, ..., b1, b2, ...}. If query1 or query2 returns an individual element, it is treated as a one-element bag. bag{ a, bag{b, c} } is equivalent to bag{ bag{ a, b}, c } } and is equivalent to bag{ a, b, c }. A bag with one element is equivalent to this element: bag{ a } = a. The strong typing requires that operands of union or bag operators must have the same collection types (with the structural type conformance).
Example queries:
1 union 3
3.4 union 2.0 union 5.1
bag(1, 3, 5)
bag((Emp where sal > 1000), (Emp where job = “analyst”) )
6.5.5.2 struct operator (structure constructor/ cartesian product)
Binary collection operator.
query ::= [struct](sequenceOfQueries)
The struct operator returns a structure that is the result of the Cartesian product of operands (providing the Cartesian product operator is naturally extended to bags). If query1 returns bag{a1, a2, ...} and query2 returns bag{b1, b2, ...}, then the query struct( query1, query2) returns bag{ struct{ a1, b1}, struct{ a1, b2},..., struct{ a2, b1}, struct{ a2, b2}, ...}. If query1 returns an individual element a, and query2 returns an individual element b, then struct(query1, query2) returns an individual element struct{a, b}. In all other cases individual elements are converted to one-element bags. struct{ a, struct{b, c} } is equivalent to struct{ struct{ a, b}, c } } and is equivalent to struct{ a, b, c }. A structure with one element is equivalent to this element: struct{ a } = a, and v/v.
Example queries:
(1 , 3)
struct(“Winnie”, “the”, pooh”)
Emp. struct(sal as s , 2.0 as x , (worksIn.Dept.dName) as d)
© Copyright by eGov-Bus Consortium61

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
6.5.5.3 subtract operator
Binary collection operator.
query ::= query1 subtract query2
The subtract operator returns a bag that includes the elements from first operand that do not occur in the second operand. The strong typing requires that operands must have the same collection types.
Example queries:
(1 union 3 union 2) subtract (3 union 2)
(Emp where job = “clerk”) subtract (Emp where sal > 1000)
6.5.5.4 intersect operator
Binary collection operator.
query ::= query1 intersect query2
The intersect operator returns a bag that includes the elements from first operand that also occur in the second operand.
Example queries:
(1 union 3 union 2) intersect (3 union 2)
(Emp where job = “clerk”) intersect (Emp where sal > 1000)
6.5.5.5 in and contains operators
Binary collection operators.
query ::= query1 in query2
query ::= query1 contains query2
The in operator returns TRUE if the result returned by second operand query includes the result returned by first operand query. The contains operator – just otherwise.
Example queries:
(2 union 3) in (1 union 3 union 2)
(Emp where job = “clerk”) contains ((Emp where sal > 1000)
6.5.5.6 count operator
Unary collection operator.
query ::= count query1
The count operator returns the number of elements in the operand collection.
Example queries:
count (1 union 3 union 5)
count Emp
count (Emp where job = “clerk”)
count (Dept join employs.Emp )
6.5.5.7 exists operator
Unary collection operator.
query ::= exists query1
© Copyright by eGov-Bus Consortium62

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The exists operator returns TRUE if query1 returns at least one element, FALSE otherwise.
Example queries:
exists (Emp where address.city = “Warsaw”)
Emp where not exists(address)
6.5.5.8 deref and ref operators
Unary collection operators.
query ::= deref query1
query ::= ref query1
The deref operator takes a single references or a collection of references returned by the operand query1 and returns a corresponding value or a collection of values stored in the referenced objects. The result of the dereference operator depend on the object type:
dereference of simple objects returns a simple value (e.g. integer, real, etc.)
dereference of a pointer object returns the reference of the pointed object (i.e. the value of the pointer object).
dereference of a complex object returns a structure with named fields (binders). Each field name corresponds to a sub-object name and each filed value corresponds to the (dereferenced) sub-object value.
The ref operator takes a single references or a collection of references returned by the operand query and set the flag informing that the dereference operator is not allowed. The ref operator is used to avoid automatic dereference and to compare references rather than values.
Example queries:
deref(Emp.lName)
ref(Emp where lName = “Kim”) = ref(Emp where id = 4326)
6.5.5.9 unique and distinct operator
Unary collection operators.
query ::= unique query1
query ::= distinct query1
The unique operator removes duplicate object references from the result returned by the operand query1. The result is the unique set of object references. The distinct operator removes duplicate values from the result returned by the operand query1. The result is a set of values; the operator automatically calls the deref operator.
Example queries:
unique (Emp where lName=“Kim” union Emp where (worksIn.Dept.dname) = “pr”)
distinct (Emp.lName)
6.5.6 Aggregate FunctionsODRA SBQL implements the following aggregate functions: count (already described), sum, avg, min and max. They are known from SQL. Aggregate functions are defined very generally thus orthogonal combination of them allows the programmer to achieve all the possibilities that are associated with the SQL group by and having clauses. In SBQL we do not introduce such clauses considering them redundant and unnecessary.
query ::= sum query1
query ::= avg query1
© Copyright by eGov-Bus Consortium63
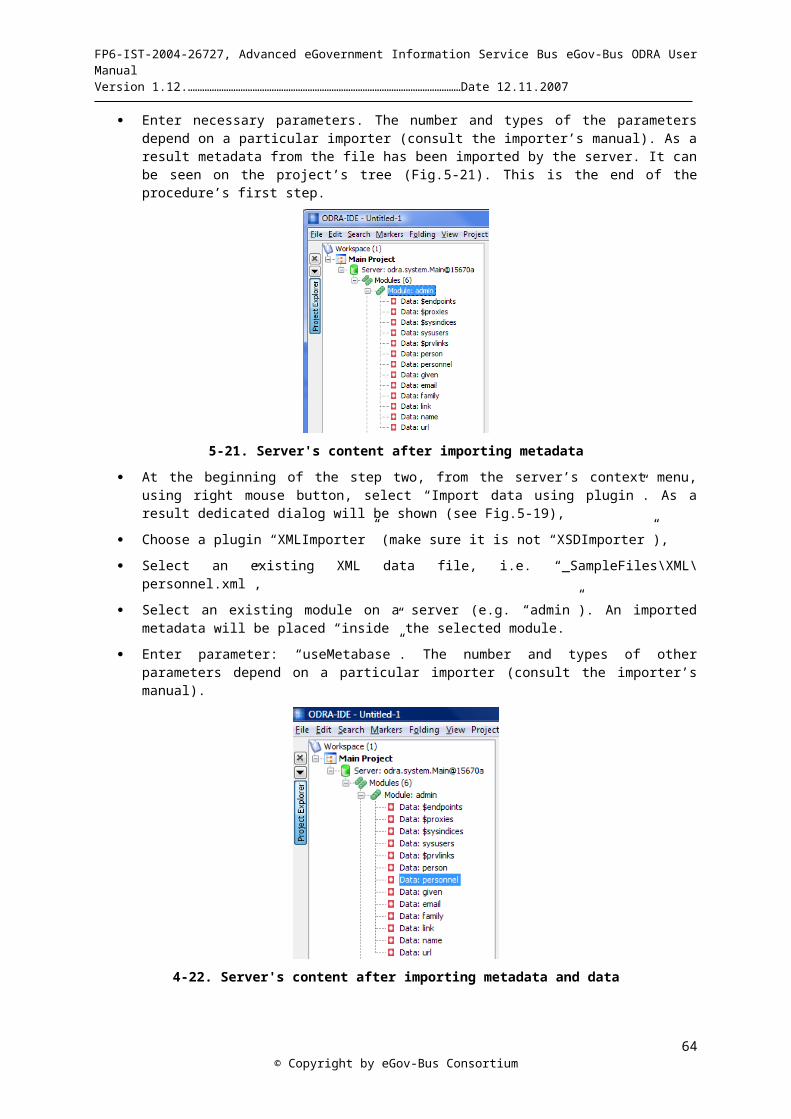
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
query ::= min query1
query ::= max query1
The sum function computes the sum of all the argument collection elements. The avg function computes the average value of a collection of numerical values. min and max return the minimal and maximal value of the argument collection elements, correspondingly. If the collection has only one element, all the functions return the value of the element. An empty result of argument query1 causes a runtime error. Automatic dereferences are performed.
Example queries:
sum(1 union 3 union 5)
sum(Emp.sal)
avg(Emp.sal)
min(3.4 union 2.0 union 5.1)
max(Emp.sal)
sum(3.4 union 2.0 union 5.1)
avg(1 union 3 union 554)
(Dept as d) join avg(d.employs.Emp.sal)
min(Emp.sal)
max(Dept.count(employs))
6.5.7 Non-algebraic operatorsEach non-algebraic SBQL operator is binary and its evaluation differs from the algebraic ones. The difference concerns the use of the environment stack. In effect, the non-algebraic operators, in their full generality, cannot be specified by any mathematically correct algebra built in the style of relational or object algebras. For non-algebraic operators the order of evaluation of operand queries is significant4. The first query is evaluated at the beginning. Then, for each result returned by it the second query is evaluated. The evaluation is performed in the following steps:
1. a new environment is calculated for the currently processed element of the first query result.
2. the second query is evaluated against the environment opened in first step. The result of evaluation depends on the non-algebraic operator and is saved as a partial result of a non-algebraic operator evaluation.
3. The environment opened in first step is destroyed.
Finally, all the partial results are merged into the final result of evaluation. The process of constructing final result from the partial results depends on a non-algebraic operator.
The new environment that is opened for a processed element is calculated by the function nested. For complex object references the function returns the environment referring to all its internal subobjects. For a pointer object the function returns an environment that consists of a single reference to the object that the pointer points to. For a binder n(x) the function returns this binder. For a structure the function returns the union of environments calculated for all structure’s elements. For other elements the function returns an empty environment.
For processing classes the above scenario is a bit modified. If an object X is processed by a non-algebraic operator and X is a member of a class C1 that inherits from C2 that inherits from C3, etc. then the environment stack contains the following environments (starting from its top): the environment of X, the environment of C1, the environment of C2, the environment of C3, etc. More detailed description on how the environment and the qeuery result work for non-algebraic operators can be found at http://www.sbql.pl.
Note that this semantics should be understood in full generality and in combination with arbitrarily complex queries that can use all the SBQL operators.
6.5.7.1 Dot operator (navigation/projection)
Binary collection operator.
query ::= query1 . query2
4 This statement is frequently confused with the assertion“the order of operands is significant”. We are talking about the order of evaluation of operands rather than the order of operands.
© Copyright by eGov-Bus Consortium64
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The dot operator returns a bag that includes the union of results returned by second operand query. If first query returns an empty result, the final result will be an empty bag.
Example queries:
Get references of all salaries of the employees:
Emp.sal
Starting from the Toys department, get references of streets of its employees:
(Dept where dName = “Toys”).employs.Emp.address.street
Path expressions are composed from several binary dot operators, e.g. a.b.c.d.e is understood as (((a.b).c).d).e The programmer can freely combine path expressions with other SBQL operators.
6.5.7.2 where operator (selection)
Binary collection operator.
query ::= query1 where query2
The second operand query2 must return a boolean value. The where operator returns a bag that includes those elements from the first operand query result for which the second query returns true.
Example queries:
Get references to Emp objects with the salary greater than 1000:
Emp where sal > 1000
Get references to Emp objects with the salary lower than 1% of the budget of his/her department:
Emp where sal < ((worksIn.Dept.budget)/100)
6.5.7.3 join operator (dependend or navigational join)
Binary collection operator.
query ::= query1 join query2
The join operator returns a bag of structures that are build up from pairs (e1, e2) where e1 is an element of first query result and e2 is the result of second query evaluated against this e1. If the first query returns an empty result, the final result will be an empty bag. The operator is known as dependent join or navigational join. Semantically it is much different from the join operator known from the relational algebra, but is able to achieve the same power, and much more.
Example queries:
Get references to all employees with the references to their names:
Emp join lName
Get references to all employees with references to their departments:
Emp join worksIn.Dept
For each department get its reference and the maximum and average salary of its employees:
(Dept as d) join (avg(d.employs.Emp.sal)as a, max(d.employs.Emp.sal)as m)
6.5.7.4 forsome and forall operators (quantifiers)
Binary collection operators.
query ::= forsome(query1) query2
query ::= forall(query1) query2
© Copyright by eGov-Bus Consortium65
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Operator forsome returns true if the second operand query at least one returns true, otherwise false. Operator forall returns false if the second operand query at least one returns false, otherwise it returns true. Notice that for query1 returning an empty bag the operator forall always returns true.
Example queries:
Is it true that at least one employee earns less than 1000?
forsome(Emp)sal < 1000
Get departments where all employees are females:
Dept where forall(employs.Emp) sex = “female”
Get departments where at least one employee is female:
Dept where forsome(employs.Emp) sex = “female”
Is it true that each department employs an employee earning more than his/her boss?
forall Dept as d ( forsome employs.Emp.sal as s (d.boss.Emp.sal < s))
6.5.8 Auxiliary Naming OperatorsODRA SBQL introduces two auxiliary naming operators, as and groupas. Both are unary operators parameterized by a name.
6.5.8.1 Operator as
Operator as names each result of the argument query:
query ::= query1 as name
The operand query1 returns a single value r or a bag {r1, r2, …}. Values r, r1, r2, … can be of any type, in particular, they can be references. In the first case the operator returns the binder name(r). In the second case for each result ri in the bag the as operator creates a binder name(ri). The final result is a bag of binders. If the query1 returns an empty bag the result of as operator is an empty bag. There is a lot of contexts where the operator as can be applied, in particular, it can be used to make structures with named components, it can be used as a “variable” bound by a quantifier, as an “iterator variable” in foreach statements, for determining names in results of views, etc.
Example queries:
For each employee return a structure with reference to name attribute as first element and reference to salary attribute as second element. Name the elements N and S correspondingly.
Emp.(lName as N, salary as S)
Get references to employees associated with references to their departments.
Emp as e.(e, e.worksIn.Dept)
6.5.8.2 Operator groupas
Operator groupas names the whole result of the argument query.
query ::= query1 groupas name
The operand query1 may return any result. The groupas operator creates a binder name(result). The final result is a single binder. If query1 returns an empty bag, the result of groupas operator is a binder with the empty bag as a value.
Semantically, the groupas operator has almost nothing in common with the SQL group by operator, although in many cases it allows the programmer to achieve similar effects. Operator groupas is known as the nest operator known from other proposals. SBQL does not introduce the opposite unnest operator, as this role is performed by the implicit operator of binding names (which removes a name from a binder).
Example queries:
Get references to all employees working in the PR department. Name the whole result PR_Staff.
© Copyright by eGov-Bus Consortium66
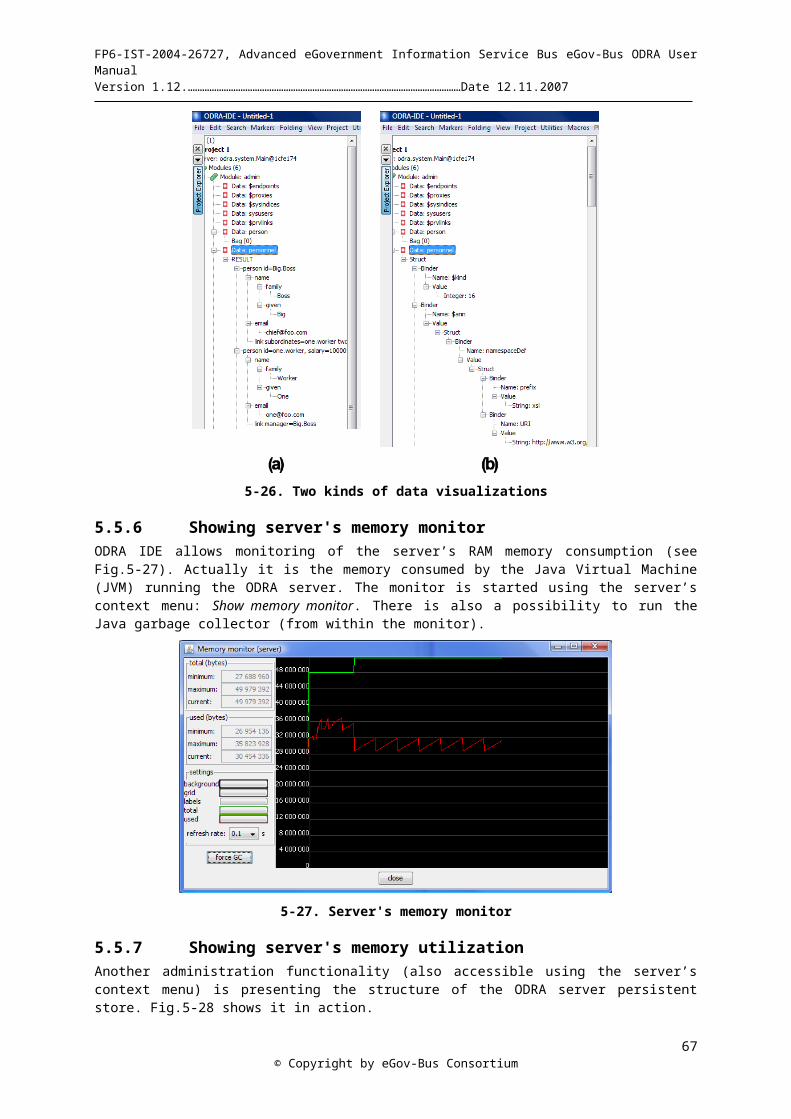
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
(Emp where worksIn.Dept.dName = “PR”) groupas PR_Staff
Get the name of the department and the names of its employees. The employee names should be grouped together and named Staff. The name of the department should be returned also for the departments with no employees.
Dept.(deref(dName), employs.Emp.name groupas Staff)
6.5.9 Explicit and Implicit Type Conversions and Dereferences6.5.9.1 Implicit type conversion
Coercions are functions that change the types and representation of values. In many cases coercions are implicit, to avoid the annoying, too verbose style of programming. For instance, if x is an integer number and y is a real number, then in the query x + y the value returned by x is automatically coerced to a real number. Similarly, in the query:
Emp.(lName + “ earns “ + sal)
the operator + is recognized as concatenation of strings, hence an integer value returned by sal is implicitly coerced to a string.
Implicit type conversion might occur in context of arithmetic and conditional operators as well as in many other situations, including method invocations and assignment statements. Implicit conversion is allowed from integer to real and from integer or real to string when the operator + is recognized as concatenation of strings. The imlicit conversion rule is assigned to many operators, including equality (‘=’) and non-equality (‘<>’) operators.
Another kind of implicit coercions concerns changing bags or sequences into single elements, and v/v. For instance, in SQL a select clause can occur within a where clause, but in this case the result of the select clause is automatically coerced to an individual value. Such coercions are typical for SBQL, which unifies a structure, bag or sequence having one element x and the element x itself. For instance, one can use a query (get employees earning more than Kim):
Emp where sal > ((Emp where lName = “Kim”).sal)
The query assumes implicit coercion of the bag returned by the sub-query:
(Emp where lName = “Kim”).sal
into a single value (of the Kim’s salary). If this is impossible, because the company does not employ a person named Kim, or the company employs more than one person named Kim, the dynamic type check will return a typing error (exception).
6.5.9.2 Implicit dereference
Another commonly assumed kind of implicit coercions are implicit dereferences. Assuming an object <i, n, v>, the dereference of i returns v. For instance in the query:
Emp where lName = “Poe”
the sub-query lName returns a reference; it is automatically dereferenced to a value of the object pointed to by this reference.
In some cases there is also a need for explicit dereference operators. This is possible by the operator deref (described previously).
6.5.9.3 Explicit coercions (casts)
The syntax for an explicit coercion is the following:
query ::= (type_name)query1
where type_name is the name of the simple type and operand query1 returns a simple type value.
The explicit coercion allows the programmer to perform type change other than the default. For instance in the query:
(string)2 + 2
© Copyright by eGov-Bus Consortium67

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
the first operand is explicitly coerced to string. In consequence the operator + performs automatic coercion to string of the second operand and the result of the query is the string “22”.
The explicit simple type coercion follows the rules presented in the following table:
Table 6-2. Type coercions
c
oerce
to:
integer real string date boolea
n
i
nteger
- real string error error
r
eal
truncat
e fraction
- string error error
s
tring
integer
(with runtime
check)
real
(with runtime
check)
- date
(with runtime
check)
boolea
n (with runtime
check)
d
ate
error error string - error
b
oolean
error error string error -
6.5.10 Conditional operator (if…then…else…)The syntax of conditional operator is following:
query ::= if query1 then query2
query ::= if query1 then query2 else query3
The first operand query1 must return a boolean value with the cardinality [1..1]. If it returns true the second operand query2 is evaluated; otherwise the third operand query3 is evaluated. For the first version of the operator (without else) we assume that if query1 returns false, then the result of query is an empty bag.
Example queries:
If the average salary of employees is less than a 1000, get references to employees earning less than a 1000, otherwise get references to employees earning less than average.
avg(Emp.sal) as a.( if a < 1000 then Emp where sal < 1000 else Emp where sal < a )
6.5.11 Ordering OperatorThe ordering operator allows one to sort a query result according to a given key (keys). The syntax is following:
query ::= query1 orderby query2
The first operand query1 returns a bag – a subject to the order by operation. The second operand query2 determines a key. The result of query2 (the key) is a structure (generally a bag of structures) which elements represents sorting keys. The domain of key values must possess the property of linear ordering. If the structure contains one element, this is the only sorting keys. If the structure contains more than one element first the sorting is executed against first element in the structure (the first key), next the result is sorted against second element in the structure (the second key), etc. The process follows until the last structure element (the last key).
Example queries:
© Copyright by eGov-Bus Consortium68
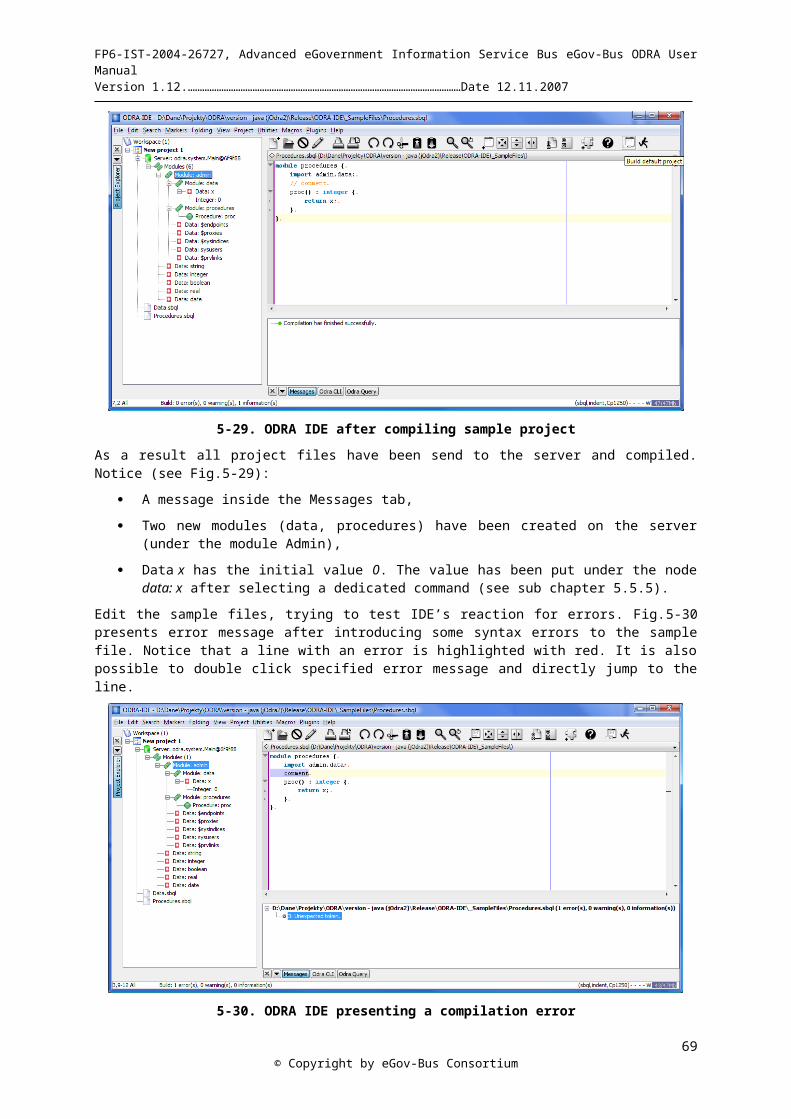
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Order employees by age.
Emp orderby age;
Order employees by age and then by last name.
Emp orderby (age, lName);
Ordering of strings is performed according to the lexical order of characters and strings in English. Till now ODRA does not support alphabetic ordering for other native languages, but such options are considered for further development.
6.5.12 Transitive ClosuresBinary collection operators.
query ::= query1 close by query2
query ::= query1 close unique by query2
query ::= query1 leaves by query2
query ::= query1 leaves unique by query2
A transitive closure in SBQL is an operator having the syntax q1 close by q2, where q1 and q2 are queries. Let final_result be the final result of q1 close by q2, let union denote the bag union and let dot denote projection/navigation (as usual in SBQL). Semantics of this query can be expressed as a least fixpoint equation:
final_result = q1 union (final_result.q2)
or as an infinite iteration (continued till some next component will be ):
final_result = q1 union q1.q2 union q1.q2.q2 union q1.q2.q2.q2 union ...
Note that the transitive closure concerns any query results returned by q1 and q2, thus the relation being the subject of the closure is calculated on-the-fly and need not be stored in the database. This implies that the operator can perform any computations.
SBQL offers the following variants of the transitive closure:
close by, as described above;
leaves by, which returns only leaf objects, i.e. objects which do not result in adding any further element to the result set;
close unique by which eliminates duplicate elements on the fly to avoid infinite cycles;
leaves unique by, which eliminates duplicate elements on the fly to avoid infinite cycles and returns only leaf elements;
Example queries:
Let’s consider a simple data schema concerning parts, similar to descriptions used in Bill of Material (BOM) applications. Each Part has name and kind. If the kind is “detail”, the part has also detailCost and detailMass (the cost and mass of this part) and has no assemblyCost, assemblyMass attributes. If kind is “aggregate”, the part has no detailCost and detailMass, but it has assemblyCost and assemblyMass. The attributes represent the cost of assembling this part and mass added to the mass of the components as the result of the assembly process. Aggregates have one or more Component sub-objects. Each Component has the amount attribute (number of components of specific type in a part), and a pointer object leadsTo, showing the part used to construct this part. A SBQL schema for this example is depicted in Fig.6.1.
© Copyright by eGov-Bus Consortium69
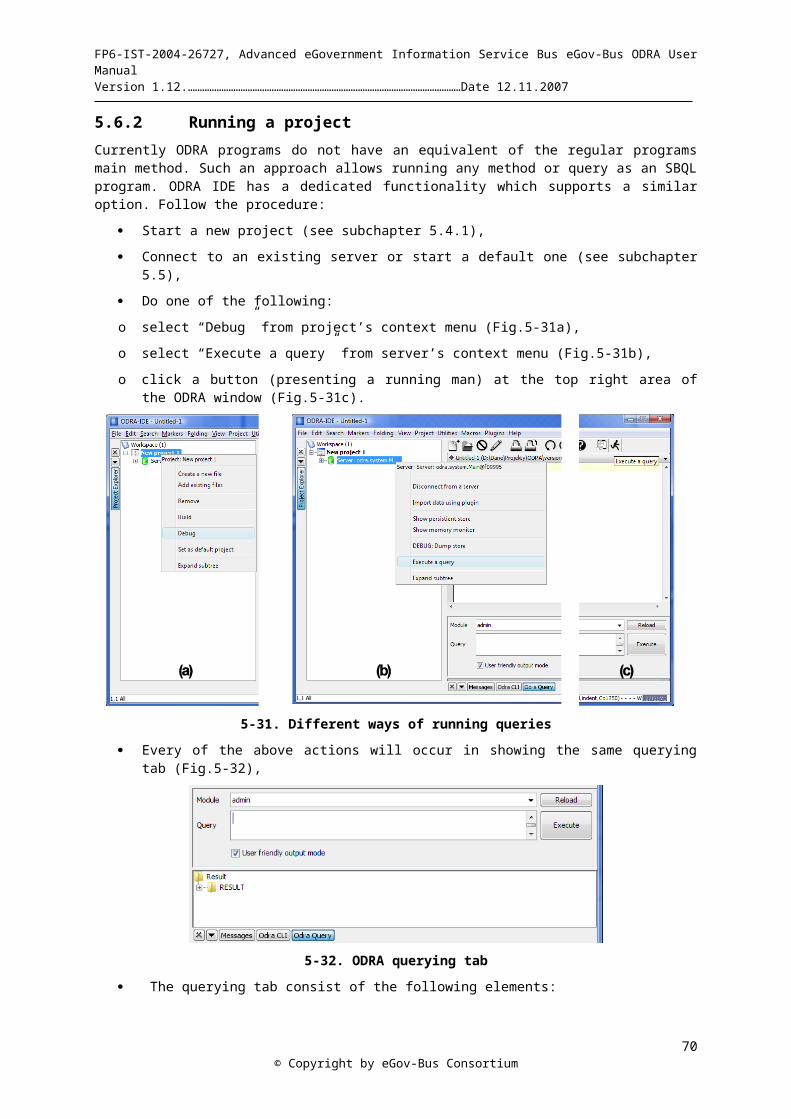
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
6-1. A Bill-of-Material example schema
The simplest transitive closure SBQL query over this schema finds all components of a part named “engine”.
(Part where name = “engine“) close by (Component.leadsTo.Part)
This query first selects parts having name attribute equal to “engine”. The transitive closure relation is described by the subquery (Component.leadsTo.Part). It returns all Part objects which are reached by the leadsTo pointer from already selected objects.
One of the basic BOM problems, i.e. “find all components of a specific part, along with their amount required to make this part”, may be formulated using the transitive closure as follows:
((Part where name=”engine”), (1 as howMany))close by (Component.((leadsTo.Part), (howMany*amount) as howMany))
The query uses a named value in order to calculate the number of components. The number of parts the user wants to assemble (in this case 1) is named howMany and paired with the found part. In subsequent iterations the howMany value from parent object is used to calculate the required amount of child elements. It is also named howMany and paired with the child object.
The above query does not sum up amounts of identical sub-parts from different branches of a BOM lattice. Below we present a modified query which returns aggregated data – sums of distinct components from all branches of the BOM tree:
((((Part where name=”engine”) as x, (1 as howMany)) close by (Component.((leadsTo.Part) as x, (howMany*amount) as howMany)) ) groupas allEngineParts).((distinct(allEngineParts.x) as y).(y, sum((allEngineParts where x=y).howMany)))
This query uses grouping in order to divide the problem into two parts. First, all the components named x, along with their amounts named howMany are found. The pairs are then grouped and named allEngineParts. The grouped pairs are further processed, by finding all distinct elements and summing the amounts for each distinct element.
This query could be further refined, in order to remove all aggregate parts (so only the detail parts will be returned). There are many ways to accomplish this goal. One of them is to use the operator leaves by in place of close by. The operator leaves by returns only leaf objects, i.e. objects which do not result in adding any further objects to the result set:
© Copyright by eGov-Bus Consortium70
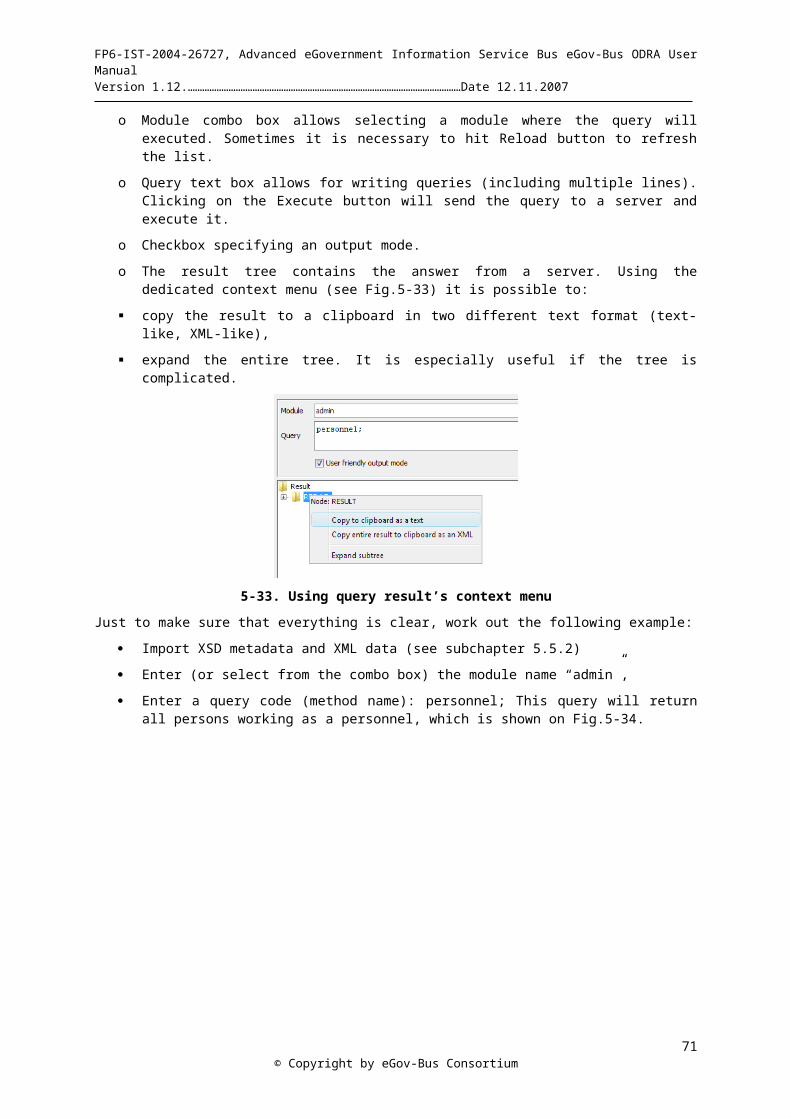
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
((((Part where name=”engine”) as x, (1 as howMany)) leaves by (Component.((leadsTo.Part) as x, (howMany*amount) as howMany))) groupas allEngineParts).((distinct(allEngineParts.x) as y).(y, sum((allEngineParts where x=y).howMany)))
Thanks to the full orthogonality (including orthogonal persistence) SBQL can perform calculations without referring to the database The query below calculates approximation of the square root of a, using the fixpoint equation x = (a/x + x)/2, starting from x=1 and making 5 iterations.
((1 as x, 1 as counter)close by (((a/x + x)/2 as x, counter +1 as counter) where counter <=5)). (x where counter = 5)
If a queried graph contains cycles, to avoid infinite loop the programmer can use operators close unique by and leaves unique by. The operators remove duplicates on the fly after each closure iteration, thus cycles do not imply infinite loops. In all other aspects the operators are similar to close by and leaves by.
6.6 Function, Procedure, and Method CallsThe syntax for a procedure and functional procedure call is the following:
query ::= name([parameters])
where name is the procedure name and the parameters is an optional list of actual procedure parameters (separated by semicolons):
parameters ::= parameter[; parameters]
A method call differs form a procedure call by the context of calling. A method call requires a reference to an object thus can be called in the context of a non-algebraic operator (see: non-algebraic operators) or a non-algebraic-like operator (e.g. transitive closure, ordering, foreach) that operates on class instance references.
Example queries:
Call the procedure named add with two integer parameters:
add(12, 35)
Sum salaries of employees working in the PR department. Assume that Emp are instances of EmpClass with defined methods getDepartmentName() and getSalary()
sum ((Emp where getDepartmentName() = “PR”).getSalary())
© Copyright by eGov-Bus Consortium71
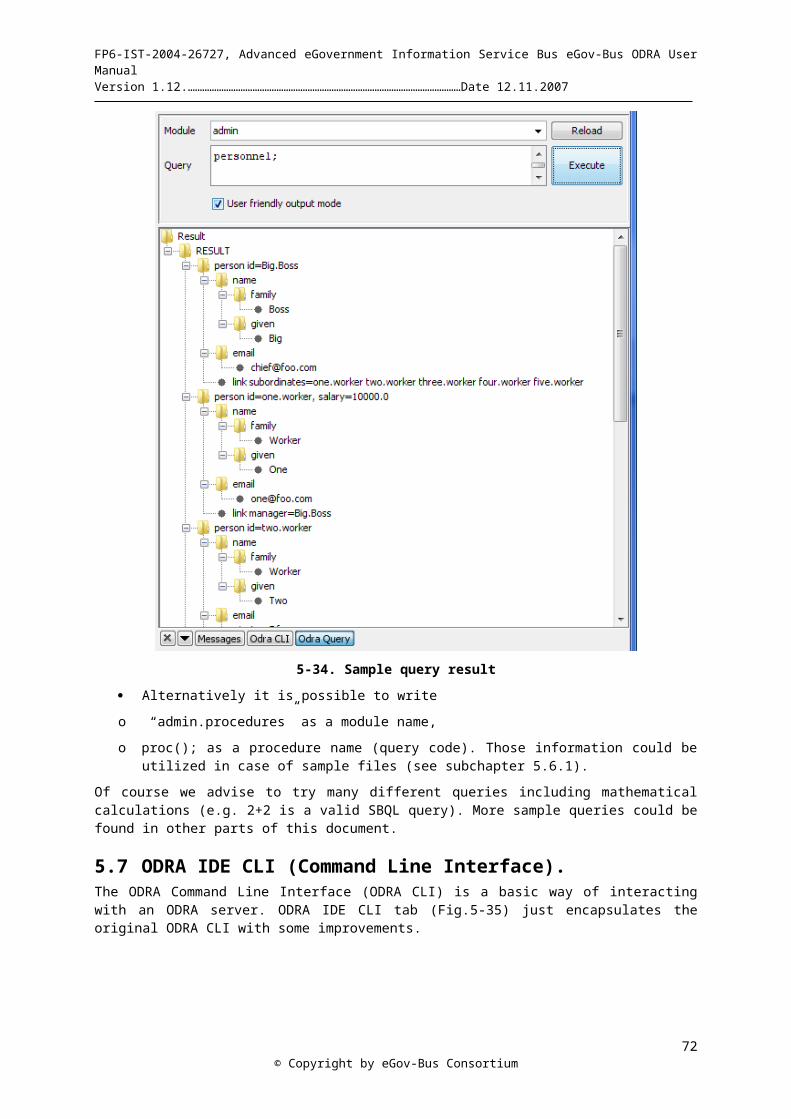
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
7. SBQL Imperative StatementsSBQL supports popular imperative programming language’s constructs and abstractions, including control structures (if, loop, etc.), procedures, classes, methods and others. All are fully orthogonal with SBQL queries and use SBQL queries as their components. The constructs and abstractions do not use any other expression language: all the expressions, in all contexts, are SBQL queries.
7.1 Variable DeclarationsIn ODRA any variable must be declared. To use the name of the variable in a query the declaration environment must be visible to the environment against which the query is executed.
The variable declaration has the following syntax:
name: type [cardinality]
where name declares the variable name, type establishes the variable type (see variable types), and cardinality optionally declares the variable minimal and maximal cardinality constraints (see: variable cardinality).
7.1.1 Variable cardinalityEach variable declaration can be equipped with an optional cardinality specifier. It determines the minimal and maximal cardinality constraints using the following syntax:
[minCard .. maxCard]
Because ODRA is a database system and SBQL is a query language it is a common situation where a variable declaration concerns a collection of objects. Example cardinalities can look as follows:
[0..*] – a collection with unlimited size, including an empty collection.
[1..*] – a collection having at least one element
[0..1] – a collection having zero or one element (optional element); in SBQL this is the only way to say that “null is allowed”.
If the cardinality specification is not present in the variable declaration, the system implicitly assumes the default cardinality [1..1].
7.1.2 Variable types7.1.2.1 Simple types
ODRA has five built-it simple types described with the following keywords:
1. integer
2. real,
3. string,
4. boolean
5. date.
7.1.2.2 Complex types
Apart from simple types ODRA support structural types. The complex type declaration syntax consist of keyword record, followed by the list of the structure field:
record { field1:type[cardinality]; [field2:type[cardinality]; … field:type[cardinality];]}
© Copyright by eGov-Bus Consortium72
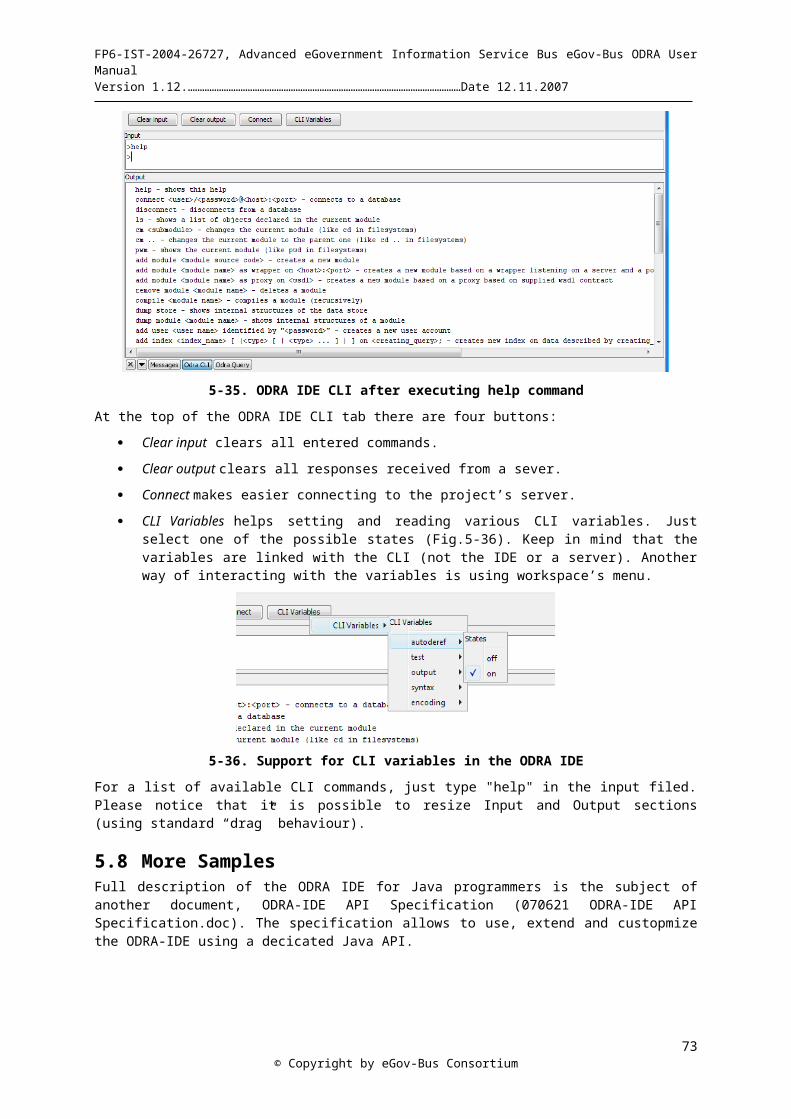
FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
7.1.2.3 Named types
ODRA supports named types that can be introduced with use of keyword type. They are macros that allow the programmer to shorten the source code. The syntax for a named type declaration is the following:
type typename is type
Example:
type PersonT is record { name:string; age:integer; }
declares named type PersonT which is a structure type with two fields.
Declared named types can be used in variable declaration, e.g.:
georg:PersonT;
michael:PersonT;
Note: because ODRA supports structural type equivalence5 only, the above variable declarations are equivalent to:
georg: record { name:string; age:integer; }
michael: record { name:string; age:integer; }
7.1.2.4 Recursive types
In ODRA it is possible to declare a recursive type if one of the fields that cause the recursion is optional. Consider the following example:
type EmpType is record {
fName:string;
lName:string;
age:integer;
married:boolean;
worksIn:FirmType[0..1]; }
type FirmType is record {
name:string;
employs:EmpType[1..*];
}
The EmpType type possesses an optional field worksIn that is of the FirmType type. The FirmType type possesses a non-optional field employs that is a collection of EmpType objects. This kind of a recursive type definition is allowed because of the optionality of the worksIn field.
Notice that in the above example we deal with true recursion: fields worksIn and employs declare structures rather than pointers. Pointers are declared with the use of ref (see next).
7.1.2.5 Pointer types
A pointer type allows for declaring SBQL pointer objects. The value of a pointer object is a reference to an object. Unlike typical object-oriented programming languages we have decided that a pointer type declaration is represented by the variable (object) name that the pointer points to. The variable must be available the environment visible to the context of the pointer declaration. For example if the following variable declaration is available:
Person: record { name:string; age:integer; };
5 The type conformity based on type names (like e.g. in Pascal) is currently unsupported, but considered in next releases.
© Copyright by eGov-Bus Consortium73

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
we can declare a reference variable to the declared Person object as:
refperson: ref Person;
This decision concerning the methods of typing pointers has motivation in the way how database schemata are defined. In database schemata associations (e.g. written in UML) connect objects of given names, disregarding their types. Moreover, the programmer that navigates along a pointer uses (e.g. in a path expression) pointer names and object names rather than their types. For instance (c.f. the schema presented at Fig. 2-4), the programmer can write the following query (get the surname of the Doe’s boss):
(Emp where lName = “Doe”).worksIn.Dept.boss.Emp.lName
If in the schema the pointers worksIn and boss would be typed by the type of their objects, in many cases it would be impossible to see to which objects the pointers lead to. Typing pointers by object names (hence by their types, but indirectly) is much more precise concerning schema specification and much more understandable for the programmers during writing SBQL queries.
7.1.3 Variable declaration environmentThe variables in ODRA can be declared as:
permanent – if the declaration is placed at the module level. These variables are kept in the persistent store.
temporal – if the declaration at the module level is preceded by the keyword session.
local – if the declaration is placed inside a procedure/method body.
The declaration place does not force the persistence status (except objects that are created automatically). The status can be modified with the use of create operation parameters (see: object creation). The general principle says that an object can be created in an environment defined by the declaration or in “less” persistent one. For example, if a variable has been declared at the module level as persistent, it can be created as temporal as well as local (inside the procedure body).
7.1.4 Variable declaration examplesDeclaration of an integer variable named x with the default cardinality:
x:integer;
Declaration of a complex variable named emp with three fields (string name, integer salary and optional pointer object worksIn pointing to a Firm object).
emp: record { name:string;salary:integer;worksIn: ref Firm[0..1];
}
7.2 Object Creation7.2.1 Operator createObjects are created by the create operator. The system automatically checks if an object creation conforms to the declared type and cardinality6. The syntax is the following:
create [where] name(query);
7.2.1.1 Semantics
The create operation is orthogonal to persistency - no difference between creating persistent and transient objects. The operator is macroscopic which means that the parameter query can return a bag and the number of created objects will be equal to the result bag cardinality. The parameter query is automatically dereferenced. The operator is optionally parameterized with the place indicator (where). It can be one of the keywords permanent, temporal and local that have been explained previously.
6 Currently ODRA makes it possibile to switch off type checking, however, this is not recommended.
© Copyright by eGov-Bus Consortium74

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
If no place indicator is specified, the system creates an object in a default environment. It depends on the create execution environment. If the operation is executed dynamically (ad hoc queries), the default environment is the persistent environment (created object will be persistent). If the operation is executed in the context of procedure the default environment is the local procedure environment (the created object will be automatically removed while the local environment disappears).
The operator can be used to create each kind of SBQL objects (simple, complex, pointer).
7.2.2 Simple object creationTo create simple objects the parameter query must return a simple value (or a bag of simple values) or a reference to a simple object (or a bag of such references). In the latter case the result of the query will be automatically dereferenced before passing it to create operator. If the type checker is enabled, the statements requires appropriate declarations.
Examples
Create a simple object of the integer type named amount that value is a result of atomic query; the persistency status depends on the context:create amount(2500);
Create two persistent simple objects of type date named possibleMeetingDate.
create permanent possibleMeetingDate(2007-06-04 union 2007-09-12);
Create (possibly many) local simple string objects named fullName that value is a result of more complex query:
create local fullName( (Emp where worksIn.Dept.dName = “adv”).(fName + “ “ + lName));
Notes that local place indicator is available only inside the procedure/method body.
7.2.3 Pointer object creationTo create a pointer object (or pointer objects) the query must return a reference to an object (or references to objects). If the type checker is enabled, the statements requires appropriate declarations.
Examples
Create (possibly many) persistent reference objects named highPayed that store references to high payed employees
create permanent highPayed( ref (Emp where sal > 3000) );
Create (possibly many) reference objects named johnWorkPlace that store identifiers of all the departments employing employees with the first name ‘John’.
create johnWorkPlace( unique ref (Emp where fName = “John”).worksIn.Dept );
Or equivalently:
create johnWorkPlace( unique (Emp where fName = “John”).worksIn );
It is assumed that worksIn is a reference object. The persistency status depends on the context.
7.2.4 Complex object creationTo create a complex object the result query must return structures with named fields or a reference to a complex object. In the latter case the result will be automatically dereferenced before passing it to create operator. As
© Copyright by eGov-Bus Consortium75

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
previously, if the argument query returns a bag, many objects with the same name are created. If the type checker is enabled, the statements requires appropriate declarations.
Examples
Create a single persistent complex object named Emp.
create permanent Emp( “Tom” as fName, “Jones” as lName, 2500 as sal, ref (Dept where dName = “adv”) as worksIn, ( ref (Dept where dName = “pr”) union ref (Dept where dName = “retail”) )groupas prevJobPlace);
Create (possibly many) temporal complex objects named Car being copies of an existing one:
create temporal Car( Car where (prodYear > 2005 and manufacturer = “Fiat” ));
7.2.5 Default object creationIf an object declaration has the cardinality with the minimal bound greater than 0, the minimal required number of objects must be created during environment (persistent module, session module or local) initialization. For example consider declaration:
x:integer;
The default cardinality ([1..1]) requires presence of one object named x. Thus the process of initialization the declaration environment creates an object with a default value.
7.3 AssignmentThe assignment operator allows for changing an object value. The syntax is the following:
lQuery := rQuery;
where lQuery and rQuery are the left and right hand operand expressions.
7.3.1 SemanticsThe operand queries must return single values (the operator is not macroscopic). The result of left hand operand query is a reference to an object. The result of right hand operand query is automatically dereferenced. The operator can be used to assign a value to an each kind of SBQL object (simple, complex, pointer). The assignment expression returns the reference of the updated object.
7.3.2 Assignment to simple objectSimple object assignment requires a reference to simple object as the left hand operand and a simple value as the right hand operand.
The type of the right hand value must be compatible with updated variable object type. If the types are not the same, the system is trying to perform automatic coercion. If no automatic coercion is available, the type error is reported (see: errors).
7.3.3 Assignment to a complex objectA complex object assignment requires reference to a complex object as the left hand operand and a structure with named elements (binders) as the right hand operand. In this context the assignment operation reassembles create operation except that the updated object does not change its identifier. All its sub-objects are removed and
© Copyright by eGov-Bus Consortium76

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
new sub-objects are created on the basis of right hand assignment operand. Thus the structure must include elements with names that determine sub-object names.
The right hand structure fields have to be named. The types of structure fields have to be compatible with type of corresponding sub-objects declaration (see: automatic coercion). If declared cardinality of a particular sub-object is greater than zero the corresponding structure field must be available in the structure.
The example below updates an employee object with new values:
(Emp where lName = “Jones”) := ( “Tom” as fName, “Jones” as lName, 2500 as sal, ref (Dept where dName = “adv”) as worksIn, (
ref (Dept where dName = “pr”) union ref (Dept where dName = “retail”) ) groupas prevJobPlace);
7.3.4 Assignment to a pointerA pointer assignment is similar to an assignment to a simple object but requires a reference to object as the right hand operand. Because the assignment operator performs automatic dereference on the result returned by rQuery it is usually needed to use ref keyword to avoid the dereference.
The right hand reference have to represent an object having a type declared as a pointer target type.
The example below changes the Doe employee work place by changing the value of the worksIn pointer object.
(Emp where lName = “Doe”).worksIn := ref (Dept where dName = “pr”);
7.4 InsertionInsertion allows to insert object into another object. The syntax is following:
lQuery :< rQuery;
where lQuery and rQuery are the left and right hand operands.
7.4.1 SemanticsThe result of left hand operand query is a reference to a complex object. The result of the right hand operand query is a bag of references to objects being inserted. If the insertion operation concerns objects placed in the same store, the identifier of the inserted object will not be changed (it can be perceived as moving an object from one environment to another one). If the insertion concerns objects that are placed in different stores (e.g. inserting a local object into a persistent one), the identifier of the inserted object may change.
To make types compatible, the name of an inserted object must be declared as the name of one of sub-objects of the left hand operand. The cardinality of the declaration has to be different from the default ( [1..1] ).
The example below inserts new prevJobPlace pointer object into Jones employee:
(Emp where lName=“Doe”):< create prevJobPlace( ref(Dept where dName=“pr”));
7.5 Create and Insert The create and insert operator is a combination of the create operator and the insert operator. It allows the programmer to create a new object directly inside the environment of the target object. The syntax is following:
lQuery :<< name(rQuery);
where lQuery and rQuery are the left and right hand operands.
© Copyright by eGov-Bus Consortium77

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The result of left hand operand query is a reference to a complex object. The right side operand (name plus rQuery) have the same meaning as for the create operator (see Object creation).
The target object must possess a declared sub-object with a name and the type of the declared object must be compatible with the result of the right hand query. In contrast to the create operator, the creating object declaration is not required in the environment where the query is executed.
Example: Insert new prevJobPlace pointer object into Jones employee (compare it to 6.4.1):
(Emp where lName=“Doe”):<< prevJobPlace( ref(Dept where dName=“pr”));
7.6 DeletionThe delete operator makes it possible to remove objects from the store. The operation is fully orthogonal to the persistence status. The syntax is following:
delete query;
7.6.1 SemanticsThe result of the operand query have to be a reference or a bag of references (the operator is macroscopic). The operator can be used to delete each kind of SBQL objects (simple, complex, pointer).
The declared cardinality of deleted object must be different from the default ([1..1]). If the declared minimal cardinality is greater that zero, the runtime check is performed to assure that after deletion the number of objects will not be lower than the minimal cardinality constraint.
Examples
Delete the Marketing department.
delete Dept where dName = ”Marketing”;
Delete the location London from the Marketing department.
delete (Dept where dName = ”Marketing”).(loc as x where x = ”London”).x;
7.7 Program Control StatementsODRA SBQL implements typical program control flow instructions. In most cases the syntax is similar to Java.
7.7.1 Conditional operator7.7.1.1 Syntax
ifstatement ::= if query then statement else statement1
ifstatement ::= if query then statement
7.7.1.2 Semantics
The query must return a boolean value. If the query returns true then statement is executed; otherwise statement1 is executed. In the second case if the query returns false, no action is performed.
Example: If the number of employees hired in year 2006 is greater than in 2005, insert to the report a note “assumed employment increase achieved” otherwise insert note “assumed employment increase unachieved”,
if count(Emp where (hiredate > 2005-12-31 and hiredate < 2007-01-01)) > count(Emp where (hiredate > 2004-12-31 and hiredate < 2006-01-01)) + 100 )then {
report :<< note(“employment increase achieved”);}else { report :<< note(“employment increase not achieved”);
© Copyright by eGov-Bus Consortium78

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
}
7.7.2 While, do-while loops statements7.7.2.1 Syntax
whilestatement ::= while query do statement
dowhilestatement ::= do statement while(query)
7.7.2.2 Semantics
The query must return a single boolean value. In the first case statement is executed repeatedly, where each next iteration is started if query returns true. The second case is similar, but for the first time statement is executed without testing query; all next iterations depend on whether query returns true.
7.7.2.3 Examples
i:integer;i := 50;while i > 50 do {
i := i – 10;}
The final result: i = 50 (no loop is performed)
i:integer;i := 50;do{i := i – 10;}while(i > 50);
The final result: i = 40 (one loop is performed).
7.7.3 For loop7.7.3.1 Syntax
forstatement ::= for(initstmnt; cquery; incrstmnt) do statement
7.7.3.2 Semantics
The semantics is similar to C/C++. The statement is executed till cquery returns false. The initstmnt determinies the statement that initiates the loop. The incrstmnt determines the incremental statement.
7.7.3.3 Examples
for(x:=0; x <= 20; x:= x+1) do { y := 1000 * x; print(y, count(Emp where sal >= y and sal < y+1000));}
7.8 For Each StatementA foreach statement allows to iterate through elements of a collection. The collection is determined by a query and the element of the collection parameterizes the statement executed in each iteration loop. The semantics is similar to the semantics of non-algebraic operators described before.
7.8.1 Syntaxforeachstatement ::= foreach query do statement
© Copyright by eGov-Bus Consortium79

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
7.8.2 SemanticsThe query is evaluated first. It should return a bag; an individual element is coerced to a bag with one element. For each bag element r its environment is calculated (see: SBQL non-algebraic operators) and the statement is executed against this environment. After statement execution the environment is destroyed.
7.8.3 ExamplesThe statement below increases the salary by 100 to all the employees working in the marketing department if the employee previous salary was below the average.
Without “iteration variable”:
foreach (avg(Emp.sal) as a.(Emp where sal < a and worksIn.Dept.dName = “Marketing”)) do
sal := sal + 100;
With the “iteration variable”7 over Emp objects:
foreach (avg(Emp.sal) as a. (Emp where sal < a and worksIn.Dept.dName = “Marketing”) as e) do
e.sal := e.sal + 100;
7.9 CommentsComments follow the Java convention:
// precedes the comment to the end of a line
/* and */ are comment parantheses for comments that span several lines. Nested comments are not supported.
7 Note that “iteration variable” is not an SBQL term. It is used as an informal notion in a lot of other proposals. In SBQL the “as” operator has formal and very simple semantics.
© Copyright by eGov-Bus Consortium80

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
8. SBQL ProceduresODRA procedures are determined by a source code (as usual) and by a runtime environment. During runtime procedures are special complex objects stored inside modules. Such procedures are treated as global. Procedures stored inside classes are named “methods” and called in a class instance context. Procedures are also components of updatable views, where they play special roles. Procedures encapsulate arbitrary complex computation and can be called many times in many places of the code. Their behaviour can be parameterized by the use of parameters and/or by the state of the execution environment. In all kinds of procedures we assume that local procedure objects and their actual parameters are invisible from outside and are invisible for called procedures; thus each procedure creates its own local name space. This is a typical assumption for practically all programming languages, greatly supporting reuse and independent work of programmers.
8.1 Procedures and Functional ProceduresIn ORDA there is little distinction between procedures and functional procedures. Semantically, the only difference is that a functional procedure returns an output on its invocation; thus, an invocation can be treated as a query and can be nested as a part of other queries. A non-functional procedure cannot be a part of a query because it returns no value.
Each procedure is uniquely identified by its name (overloading is not supported). The result of a functional procedure is typed, similarly to other programming languages. Each functional procedure can also be used as a proper procedure; in this case its return value is neglected.
8.1.1 Procedure declaration syntaxProcedure declaration consists of the procedure name, typed parameter list type of its output and some list of statements.
name([parameter_list])[:returntype] {statement_list}
8.2 Parameters of ProceduresProcedures can have parameters. Parameter specification determine its formal name, parameter type and cardinality. The parameter passing technique implemented in the ODRA system is known as strict-call-by-value. It means that each actual parameter determined by a query is evaluated before the procedure execution and the result is stored at the procedure activation record as a binder which name is the name of the corresponding formal parameter. Thus, (like Pascal and unlike Java or C/C++) procedure parameters do not have the “local variable” semantics. If the result of an argument query is a value, it is passed directly as a (named) value (passing by value). If the result of an argument query is an object reference it will be passed directly as a (named) reference (passing by reference). This parameter transmission method combines call-by-value with call-by-reference in a very general fashion, which allows the programmer to pass as a parameter the result of any complex query that combines atomic values, references, auxiliary names, structures, bags, sequences, etc.
8.2.1 Parameters declaration Procedure parameter declaration syntax determines its name, type and cardinality:
parameter_declaration ::= name:type [ cardinality ]
If the cardinality is not specified, the default cardinality [1..1] is assumed. In the procedure signature parameter declarations are separated by semicolons.
8.2.2 Local variablesLocal variables (objects) can be declared in procedures and statement blocks. According to the scope rules the visibility of each declaration is constrained to its declaration block and sub-blocks (unless it is overwritten by a new declaration). See variable declaration for the syntax of local variable declaration.
Inside a procedure body a local variable can be created with use of a create statement (see: object creation). A locally created object can be declared inside the current code block or in any visible environment (e.g. an outer block and a module).
© Copyright by eGov-Bus Consortium81

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
8.3 Return from a Functional ProcedureTo return a value from a functional procedure the return statement must be used. The return value is calculated with use of a query. The syntax is as follows:
return query;
The statement causes immediate terminating the procedure. The query can be any SBQL query returning a result that conforms to the return type in the procedure specification signature. Returning references to local variables is forbidden (dynamic type checking rejects it).
The return value can also be build up from a query that returns a named result (see: auxiliary names). For example:
return (Emp where worksIn.Dept.name = “PR”) as PR_Staff;
returns references to employees working in the PR department. The references are named PR_Saff. The name is available outside of the procedure body.
8.4 Examples of proceduresA functional procedure add returns the sum of two integer values passed as parameters.
add(a:integer;b:integer):integer { return a + b;}
Usage:
add(12; 5);add(5 + count(Emp); 64) – 10;
A proper procedure giveRise rises salaries of employees (passed as parameter emp, which is a bag of references) with a value (passed as parameter value). The procedure returns no value.
giveRise(emp:ref Emp[0..*]; value:integer) {foreach emp as e do {
e.sal := e.sal + value;}
}
Usage:
giveRise(Emp where worksIn.Dept.dName = “PR”; 200);
A procedure lowPayed for each employee earning less that the average and having the position within the pos parameter (bag of strings) returns a structure containing tree named fields (adequately: employee name N, salary S and department name D).
lowPayed(pos:string[1..*]): record{N:string; S:integer; D:string;}{ return (avg(Emp.sal) as a). (Emp where sal < a and pos contains position). (lName as N, sal as S, worksIn.Dept.dName as D);}
Usage:
lowPayed(“bricklayer”).(N, S, D);
lowPayed(bag(“programmer”, “designer”)).(N, S);
© Copyright by eGov-Bus Consortium82

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
8.5 Recursive Procedures and MethodsIn ODRA SBQL recursive procedures do not imply any special syntax. All procedures can be recursive. Such a feature is common in popular programming languages implementations. ODRA SBQL extends the property to query languages. This allows for smart specification of some inherently recursive tasks. The use of recursive procedures needs some attention from the programmer concerning the following aspects:
Depth of the recursion: SBQL does not limit it physically, but too large depth may compromise performance.
The depth cannot be infinite, hence the programmer is responsible for ensuring that the recursion eventually will be terminated.
Performance: in many cases iterations or transitive closures are faster than recursive procedures.
Example
factorial(n:integer):integer { if n = 0 or n = 1 then return 1; return n * factorial(n - 1);}
© Copyright by eGov-Bus Consortium83

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
9. SBQL Classes, Methods and Bidirectional PointersThe ODRA object model deals with classes and static inheritance8. Classes are pieces of a source code, as usually in object oriented programming languages. After compilation classes in ODRA are database objects similar to regular objects described before. Compiled classes are stored in an object store on usual principles. Operationally, however, classes behave differently than objects. The difference concerns the assumption that classes are created in a special manner and are used to introduce and store invariants of objects - class instances. In the current implementation classes are not directly accessible through a query language. The use of classes is indirect, through the use of objects being class instances.
ODRA classes follow static inheritance known from UML and many programming languages such as C++ and Java. The ODRA object model allows for multiple inheritance, i.e. a class can inherit from more than one classes. No special means for resolving name conflicts concerning properties inherited from different classes is provided (just like e.g. in UML and CORBA). We have concluded that name conflicts can be easily avoided by some naming convention, hence the problem is not sufficiently significant to be treated by special syntactic, semantic and pragmatic options. In the further ODRA releases we plan to implement dynamic object roles and dynamic inheritance that are perhaps the only radical solution for all the problems with inheritance.
9.1 Class InvariantsInvariants introduced by the class belong to the following kinds:
Type – the data structure describing a class instance
Methods – the behavior of class instances
Name – optional name of class instances
Below we describe them in detail.
Type. A class instance type is described by structural (complex) declaration, with optional set of fields declaration in curly brackets, preceded with the keyword instance and the optional instances_name:
instance [instance_name] : { [field_declaration_list]
}
Methods. A method is an ODRA procedure stored inside a class. The current implementation of ODRA introduces only instance methods (called in the context of class instance). Class methods are not supported.
Inside a method body the current instance against which the metod is accessible with the keyword self.
getName():integer { return self.name; }
Instance name. The class can optionally introduce an invariant name for its instances. Such a name is optional. However, it the name is not present, a class instance cannot be the subject of the substitutability principle (decribed later in this chapter).
9.2 Syntax of class declarationclass name [extends superclass_names_list] {
instance [instance_name] : { [field_declaration_list]
}[metod_declaration_list]
}
8 Interfaces, i.e. specifications of public properties of classes, are planned in the next ODRA release.
© Copyright by eGov-Bus Consortium84

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
9.3 Sample class declarationsclass PersonClass {
instance Person : { f_name : string; s_name : string; age : integer; address : record { city : string; street : string; number : integer;
}}getFullName():string{ return f_name + “ “ + l_name; }
}
class EmployeeClass extends PersonClass {instance Employee : { salary : integer; works_in : ref Department; prev_job : record { comp_name : string; from : integer; till : integer; }}changeSalary(amount : integer){ salary := amount; } moveEmployee(newDept : ref Department){
//...}
}
class StudentClass extends PersonClass { instance Student : {
scholarship:integer; }
changeScholarship(amount:integer){ scholarship : = amount;
}setSholarship(newScholar:integer) { scholarship := newScholar; }
}
class EmpStudentClass extends EmpClass, StudentClass { instance EmpStudent : { }
getTotalIncomes():integer { return self.(salary + scholarship); }
}
© Copyright by eGov-Bus Consortium85

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
9.4 Declaration of class instancesAlthough a class may determine an instance name, by itself it does not declare the default collection (an extent) of class instances. Declaration of of class instances is to be done separately. The syntax for a declaration is the same as for ordinary variables. The only difference is that a class name is to be used instead of type. For example, declarations presented below introduce four variables that identify collections of class instances:
Person: PersonClass[0..*];
Emp: EmpClass[1..*];
Student: StudentClass[0..*];
EmpStudent: EmpStudentClass[0..*];
9.5 Substitutability If a given class defines an instance name then instances of the class can be a subject of the substitutability principle. It allows for passing instances of a sub-class everywhere a super-class instance is expected. Because SBQL addresses data structures rather that data models, the substitutability is available on the level of object collections and their names rather than class names. For sample classes and data introduced in the previous sections it means that instances of the most specific class named EmpStudent are also available through the instance names defined in its super-classes (Student, Emp and Person). Thus the simple query
Person;
returns all the persons, also those that are instances of the PersonClass sub-classes. We didn’t find a consistent definition of the substitutability when names of class instances are not determined by their classes. The main problem with this case concerns typing and binding rules in connection with collections and the open-close principle.
9.6 SBQL operators specific to the object model with classes
9.6.1 Operator instanceof query ::= query1 instanceof class_name
The query1 returns a single reference to a class instance. The instanceof operator tests if the referenced object is an direct or indirect instance of the class identified with name class_name. Returns boolean TRUE if the test succeeds, FALSE otherwise.
The type checker rises an error if it discovers that the reference cannot be an instance of any class or if the class_name is not the name of any class.
Examples
(Emp where f_name = “Poe”) instanceof EmpClass // returns TRUE(Emp where f_name = “Poe”) instanceof PersonClass // returns TRUE(Emp where f_name = “Poe”) instanceof StudentClass //returns FALSE(Emp where f_name = “Poe”) instanceof EmpStudentClass // the result depends// on the database state, because EmpStudentClass instances // are also accessible through name Emp.
9.6.2 Operator cast to a class query ::= (class_name)query1
© Copyright by eGov-Bus Consortium86

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
query1 returns a bag of references to class instances. The result of the class cast is a sub bag of references that contains only those instances references from the source bag that belongs to a class we cast to (identified with name class_name). If none such reference exists, the result is the empty bag.
We can distinguish three types of class cast:
Downcast – cast to a sub-class
Upcast – cast to a super-class
Crosscast – cast to a class that is neither sub- nor super-class.
Examples(StudentClass) (Person where age > 23);
The result of this downcast is a bag of references to person objects that value of age sub-objects is greater that 23 and are instances of StudentClass (i.e. that are students older that 23). This kind of cast is equivalent to the selection:
Student where age > 23;
The result of the query presented below (including down- and up-cast) is a bag of references to objects having the value of age greater that 23 and are instances of both StudentClass and EmpClass. First, the query selects all persons that are older that 23, then the persons that are students. In the next step the result is casted up to the PersonClass. Final ly, the downcast selects those students that are also employees.
((EmpClass)((PersonClass)((StudentClass) (Person where age > 23))))
The same result can be obtained with use of crosscast that allows us to omit the upcast to the PersonClass.
((EmpClass) ((StudentClass) (Person where age > 23)))
9.7 Bidirectional pointersThe goal of bidirectional pointers is to support automatic update of “twin” pointer objects that are instances of a modeling construct commonly referred to as relationship (in the Entity-Relationship model and in the ODMG standard) or association (in UML). Bidirectional pointers support only binary relationships (associations) with no attributes (or association classes). Before the definition of their semantics we outline the problem that was the motivation for the construct.
9.7.1 The problem of binary associationsIf the object model of an application introduces a binary association, the update of one of its side implies an appropriate update of its opposite side. Consider the following example (from “Your First Tiny Object Base”; for the full example see section 2.3).
© Copyright by eGov-Bus Consortium87

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
//(…)class EmpClass extends PersonClass { instance Emp : { sal:integer; worksIn: ref Dept; } //the rest of the definition}
class DeptClass { instance Dept : { dNbr: integer; dName: string; loc: string [1..*]; employs: ref Emp [0..*]; }}
//declaration of class instances collections
Emp: EmpClass [0..*];Dept: DeptClass [0..*];
The classes define a binary association implemented by two kinds of pointer objects: worksIn in EmpClass and employs in DeptClass. The definition implicitly assumes that for a worksIn pointer there is a Dept object having a pointer sub-object employs that points to the Emp object having this worksIn pointer. Without automatic support this implicit constraint must be managed by application programmers. Such management implies the following requirements:
a. Creation
If a new Emp object is created the programmer is forced to create a “reverse” pointer in the appropriate Dept object, as shown below:
//create Emp object and insert employs pointer into Dept //object
(Dept where dName = “Ads”) :<< employs( create permanent Emp(
//… , (Dept where dName = “Ads”) as worksIn)) );
(Note: create permanent returns a reference to the newly created object.)
b. Updating
If an employee has to be moved to another department, the worksIn sub-object of the corresponding Emp object must be updated. Together, the associated employs object has to be moved to the new Dept object. The example below illustrates the situation:
//move employee to from Ads to Toys department//first update worksIn pointer(Emp where lName = “Doe”).worksIn := (Dept where dName = “Toys”);//then move corresponding employs pointer(Dept where dName = “Toys”) :< (Dept where dName = “Ads”).employs where Emp.lName = “Doe”;
c. Deletion
If an Emp object is to be deleted, the associated employs pointer must be removed, to avoid dangling pointers. In ODRA this problem does not exist because an object store automatically deletes all the pointer objects while the object pointed by them is being deleted. The problem that is not solved is connected with the direct deletion of an employs pointer. Semantically this operation should be associated with the deletion of associated worksIn pointer. Because the declared cardinality of the employs pointer variable is [0..*] the type control system permits for the deletion of the employs objects. The information about the associated worksIn object is not accessible in
© Copyright by eGov-Bus Consortium88

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
this context to the type-checker and the mechanism is unable to discover that the cardinality of worksIn ([1..1]) does not allow for such deletion.
9.7.2 The solution – bidirectional pointersA bidirectional pointer object is similar to an ordinary pointer object (with some exceptions). There is no distinction in the SBQL syntax and semantics concerning navigation through ordinary and bidirectional pointers. The syntax for update operation is also the same but there are significant changes in the update semantics. The difference is based on the assumption that bidirectional pointer always has an associated “twin” pointer (that also must be bidirectional). When a bidirectional pointer is created, an associated bidirectional pointer is created too. If a bidirectional pointer is updated, then the appropriate action is automatically taken on its counterpart.
Bidirectional pointer declaration
Bidirectional pointers can be declared only within classes. A declaration is similar to a declaration of an ordinary pointer object with addition of the keyword reverse and the name of an associated pointer. For instance, a declaration of a worksIn pointer in the EmpClass as the bidirectional pointer can be as follows:
class EmpClass extends PersonClass { instance Emp : { sal:integer; worksIn: ref Dept reverse employs; } //the rest of the definition}
The above declaration requires the existence of employs pointer in the DeptClass that also has to be declared as bidirectional:
class DeptClass { instance Dept : { dNbr: integer; dName: string; loc: string [1..*]; employs: ref Emp [0..*] reverse worksIn; }}
The combination of those two declaration allows to simplify the process of creating and updating bidirectional pointers.
a. Creating a bidirectional pointer
//create Emp object (insertion of an employs pointer into a Dept object is automatic)
create permanent Emp( //… ,
(Dept where dName = “Ads”) as worksIn));
b. Updating a bidirectional pointer
//move an employee from Ads to Toys department through updating worksIn(Emp where lName = “Doe”).worksIn := (Dept where dName = “Toys”);//the corresponding employs pointer is moved automatically
e. Deleting a bidirectional pointer
In our example the deletion of worksIn pointer is not allowed because of it is declared as required (cardinality [1..1]). Thus if one tries to delete associated employs pointer the compiler raises a type error.
© Copyright by eGov-Bus Consortium89

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
10. SBQL Updatable ViewsSBQL database updatable views are the main programmer’s facility for implementing virtual repositories. They present the most distinguishable part of the VRMS ODRA. Below we present a motivation for them, technical assumptions and detailed programmer’s specification. This description does not include implementation mechanism that we have used for views.
A database view is a virtual image of the data stored in a database. The most important property of views is transparency, which means that the user formulating a query needs not to distinguish between stored and virtual data. Transparency is relatively easy to achieve for read-only views (no updates). In such a case a view is nothing more than a function (returning a collection) that is known from a lot of programming languages, including SBQL.
A really challenging problem concerns the transparency of view updates. Updates of virtual objects have to be automatically mapped as updates of stored objects with no anomalies and no warping a user intention. This problem is known for about 35 years and considered very challenging. It has some partial solutions for relational databases (see e.g. the Oracle RDBMS), but concerning object–oriented databases the problem was till now not well understood. The SBQL updatable views present the first in the IT history universal, consistent and implemented solution of the view updating problem for object databases (actually, for any kind of databases). The method reminds the instead_of trigger views known from relational database system, but it is much more general concerning the data model and the algorithmic power of a view definition language. Moreover our method is much more promising concerning performance, as (in contrast to instead_of trigger views) it can avoid materialization of view results. Our solution for updatable views is supported by sophisticated query optimization methods, which are not applicable to other proposals concerning updatable views.
10.1 General Idea of SBQL Updatable ViewsClassical database views, as known from SQL, are able to map stored data into virtual data. Such views can be used only for retrieval. The idea and implementation of them are rather obvious, with no conceptual or implementation challenges. In contrast, if virtual data are to be updatable, the view must somehow map updates of virtual data into updates of stored data. This is very challenging issue, which during last 35 years has raised a lot of interest (several hundreds of papers). Unfortunately, all this effort has very little practical impact.
SBQL updatable views present a revolutionary change concedrning this issue. The idea of SBQL updateable object views relies in augmenting the definition of a view with the information on users’ intents with respect to updating operations. An SBQL updatable view definition is subdivided into two parts. The first part is the functional procedure, which maps stored objects into virtual objects (similarly to SQL). The second part contains redefinitions of generic operations on virtual objects. These procedures express the users’ intents with respect to update, delete, insert and retrieve operations performed on virtual objects. A view definition usually contains definitions of sub-views, which are defined on the same rule, according to the relativity principle. Because a view definition is a regular complex object, it may also contain other elements, such as procedures, functions, state objects, etc.
A view definition deals with two names. The first one is a managerial name that can be used to perform administration operations on the view definition, for instance, delete it, insert an object into it, etc. The second name is the name of virtual objects that are delivered by the view. The managerial name is optional. If it is not specified it is assumed by default that the managerial name will be the name of virtual objects suffixed with the string “Def”.
The general syntax for a view definition is following:
view_def ::= view [ manag_name ] { view_body }
where manag_name is the managerial view name.
10.2 Seeds of Virtual ObjectsIn contrast to all existing approaches to views, SBQL views do to return complete virtual objects as the result of view invocation. This decision is motivated both by the new concept of views and by performance. Invocation of an SBQL view returns only seeds of its virtual ojects. A seed is a small piece of a virtual object that uniquely identifies it. The rest of an virtual object is delivered according to the need of an application that uses it. For
© Copyright by eGov-Bus Consortium90

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
instance, if a virtual object has a virtual attribute address, but an application does not use it, then address is not delivered. Seeds are also the conceptual basis for updating virtual objects: they parameterize updating operations that are specified by the view designer.
The first part of a view definitition is a declaration of a virtual object. The declaration is similar to a variable declaration preceded with keyword virtual.
virtual_variable_decl ::= virtual name:type[cardinality]
where:
name is a name of virtual objects used in queries.
type is a type of virtual objects. The type will be (implicitly) used for the view operators and sub-views type check (as described later in the chapter).
cardinality is a cardinality of virtual objects.
The second part of a view definition body has the form of a functional procedure named seed. The name of the virtual objects procedure is the name of virtual objects that the view returns. The seed procedure returns bag of seeds. Seeds are then (implicitly) passed as parameters of procedures that overload operations on virtual objects (see: operators on virtual objects). Usually, seeds have to be named (i.e. they are binders), to identify them in the body of procedures. This is not obligatory if another identification method is possible. This name is then used in procedures that overload operators on virtual objects and within sub-views definitions.
The general syntax for the seed procedure definition is the following:
seed_def ::= seed:type[cardinality] { statements }
where:
type is the return type of a seed procedure.
cardinality is a cardinality of a seed return value. This value has to be the same as the cardinality of a virtual objects.
10.2.1 Sample ViewLets assume the following declaration of EmpType and DeptType types and Emp and Dept objects collections:
type EmpType is record {name: string;deptName: string;salary: integer;opinion: string [0..1];
}
type DeptType is record {name: string;location: string;
}
Emp: EmpType [0..*];
Dept: DeptType [0..*];
The example below defines the view returning only those employees that earn more than 2000. The name of virtual objects is RichEmp and the managerial view name is RichEmpDef.
view RichEmpDef {virtual RichEmp : record {name:string; salary:integer; worksIn: ref Dept;}[0..*];
seed: record {e: ref Emp;}[0..*] { return (Emp where salary > 2000) as e; }
//the rest of the view definition
© Copyright by eGov-Bus Consortium91

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
}
First RichEmpDef view declares the virtual variable named RichEmp (our virtual objects). As we can see virtual objects are structurally different from the Emp objects. RichEmp contains a name and a salary amount that are similar to those in Emp object. Instead of department name (deptName attribute) virtual object defines a (virtual) pointer to Dept object. The opinion attribute is not visible through virtual object.
The second part is a definition of virtual object seed. The seed procedure returns seeds of the declared type. In this case it returns named values (binders) that are represented as structures with one element named e. A binder value is an id of the Emp object. The cardinality is same as the cardinality of virtual variable.
From the programmer point of view (in his/her imagination) the presence of this view definition can be perceived as the database contains virtual objects named RichEmp. A simple query:
RichEmp;
returns identifiers of virtual objects (so-called virtual identifiers), having seeds as main components. Currently, however, no operation on them is possible, because they have to be expliciltly defined in the further part of the definition.
10.3 Operators on Virtual ObjectsThe operations that can be performed on virtual objects are defined in the second part of a view definition. They allow the programmer to create the behaviour of virtual objects in the context of the following generic operations:
retrieve: (dereference) returns the value of a given virtual object;
update: modifies the value of the given virtual object;
create/insert : create a new virtual object, insert an object into a virtual object;
delete: removes the given virtual object;
navigate: navigates according to a virtual pointer.
If there is no definition of a particular operator inside a view definition it is assumed that the operation is forbidden for the virtual objects generated by the view.
10.3.1 Defining operatorsThe definitions of the operators have procedural semantics. Each operator has a predefined name.
on_retrieve – retrieving value of virtual object
on_update – update virtual object
on_delete – delete virtual object
on_new – create virtual object
on_navigate – navigates according to a virtual pointer
The execution of given operator is implicit. If the system detects that the parameter of the operation is a virtual object, instead of taking system default action the appropriate view operator procedure is invoked. A seed describing a virtual object is implicitly passed as a default parameter to the procedure through the environment stack. After the execution the control is passed back to the user program.
The above description is similar for all operators except the operator for creating virtual objects (on_new). This operator is not executed in the context of a virtual object. The system passes the control to the on_new procedure if in the environment where the virtual objects with the given name are defined a new object with the same name appears (e.g. it was created by the create operator or inserted by the insert operator). The value of the object is passed as an argument to the on_new procedure. After the on_new procedure ends, the object is automatically deleted (i.e. a material object is substituted by a virtual object).
The procedure on_new performs (determined by the view definer) actions on stored objects that result in the effect that the new virtual object appears in the database environment. To this end, new stored objects can be
© Copyright by eGov-Bus Consortium92

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
created in the database, but the questions which objects and how they are created depend on the current need that is recognized by the view definer.
10.3.1.1 on_retrieve - retrieve operator
To describe the result of the dereference operation on the virtual object the on_retrieve procedure definition must be introduced into a view definition. The syntax is as follows:
onretrieve_oper ::= on_retrieve {statements}
The operator does not define the return type and the cardinality of a return value because it is implicitly assumed that the type is same as the type of a virtual object defined inside the view.
10.3.1.2 on_update – update operator
To describe the behaviour of updating a virtual object, the on_update procedure definition must be introduced into a view definition. The syntax is as follows:
onupdate_oper ::= on_update [parameter_name] {statements}
where parameter_name is optional name for the on_update argument (update operator right hand operand) that can be used inside the operator procedure body. If the name is omitted the default name: ’value’ is assumed. The operator does not define the type of a parameter because it is implicitly assumed that the type is same as the type of a virtual object defined inside the view. The cardinality of a parmeter is [1..1] (because update operator in SBQL is not macroscopic).
When an assignment operation is performed on a virtual object, the right side of the assignment is passed as the parameter of the on_update procedure (as usual, in the strict-call-by value mode). Passing the parameter is implicit, the programmer processing a virtual object need not to deal with that.
10.3.1.3 on_delete – delete operator
To describe the behaviour of deleting virtual objects the on_delete procedure definition must be introduced into a view definition. The syntax is as follows:
ondelete_oper ::= on_delete {statements}
The on_delete procedure has only a seed of a virtual object as an implicit parameter.
10.3.1.4 on_new – create operator
To describe the behaviour of creating virtual objects the on_new procedure definition must be introduced into a view definition. The syntax is as follows:
onnew_oper ::= on_new [parameter_name] {statements}
where parameter_name is optional name for the on_new argument (create operator operand) that can be used used inside the operator procedure body. If the name is omitted the default name: ’value’ is assumed. The operator does not define the type of a parameter because it is implicitly assumed that the type is same as the type of a virtual object defined inside the view. As for the on_update operator, this parameter is passed implicitly and the programmer that uses the view need not to deal with that.
10.3.2 Examples (…continued)Now we can extend the RichEmpDef view with the operators. Assume that we want to allow to perform all the operation on the virtual object except the deletion that will be forbidden:
First we define dereference operator.
view RichEmpDef {virtual RichEmp : record {name:string;
© Copyright by eGov-Bus Consortium93

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
salary:integer; worksIn: ref Dept;}[0..*]; seed: record {e: ref Emp;}[0..*] { return (Emp where salary > 2000) as e;}
on_retrieve { return e.(name as name, salary as salary, ref (Dept where name = deptName) as worksIn); }//…
}
The on_retrieve procedure used the implicit parameter e (the seed of a virtual object) to construct the required structure of dereferenced virtual object (accordint to its typw defined insode the view). Because binding to name of the seed returns reference to Emp object (see the seed procedure type) the programmer has full control on the transformation of regular object (Emp) to virtual object (RichEmp) (note that explicit deref operator can be omitted here because the system can add it implicitly basing on the return type). In more complex examples the operator can perform additional tasks (as it is a regular procedure).
Next we extend the virtual objects with update operator:
view RichEmpDef { virtual RichEmp : record {name:string; salary:integer; worksIn: ref Dept;}[0..*]; seed: record {e: ref Emp;}[0..*] { return (Emp where salary > 2000) as e;}
on_retrieve { return e.(name as name, salary as salary, ref (Dept where name = deptName) as worksIn); }
on_update { e.name := value.name;e.deptName := value.worksIn.name;
if(e.salary < value.salary) { e.salary := value.salary; }
}//…
}
As in described above for on_retrieve the on_update operator has also implicit parameter that is the virtual object seed. The sample update operator does not define the name of a parameter (but it is not a rule). It means that the default ‘value’ name has to be used inside the operator procedure body. Note that the type of a parameter is (implicilty) the type of the virtual object (RichEmp) but we update the regular object (Emp). In other words, on_update operator maps virtual data onto regular (in contrary to on_retrieve operator that maps regular data onto the virtual one).
The semantics of sample update operation assumes that the name of a virtual RichEmp object is directly maped to the name of a regular Emp object. Because the virtual object defines a worksIn pointer object, the value of name subobject of the target Dept object (the pointer points to) is mapped onto the deptName value. The definition assumes that the salary field value in Emp is updated only if is less that the salary value inside virtual object.
Finally we define on_new operator to allow creating new RichEmp virtual objects. But assume the semantic that he object will be created only when the attribute salary will be greater than 2000.
view RichEmpDef { virtual RichEmp : record {name:string;
© Copyright by eGov-Bus Consortium94

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
salary:integer; worksIn: ref Dept;}[0..*]; seed: record {e: ref Emp;}[0..*] { return (Emp where salary > 2000) as e;}
on_retrieve { return e.(name as name, salary as salary, ref (Dept where name = deptName) as worksIn); }
on_update { e.name := value.name;e.deptName := value.worksIn.name;
if(e.salary < value.salary) { e.salary := value.salary; }
}
on_new newEmp { if(newEmp.salary > 2000) create permanent Emp(newEmp.name as name, newEmp.salary as salary, newEmp.worksIn.name as deptName); }//…
}
In this sample on_new definition the name of the parameter was given explicitly and can be used inside of the operator procedure body. As in case of on_update operator the on_new operator maps virtual data onto corresponding regular one.
10.4 Nested Views (sub-views)Each view can contains sub-views. The number of view nesting levels is unlimited. Syntax and semantics of nested sub-view definitions is the same as for enclosing views. If a virtual object has attributes they can be defined by sub-views. In principle, there is no way to declare attributes and sub-attributes of virtual objects in another way, but this is only temporary decision that can be changed.
From the point of type control the type, name and cardinality of a nested vitual object have to conform to one of the field defined for the virtual object in eclosing view.
Sub-views define their own seeds and on_xxx operators procedures. Additionally, the procedures have access to seeds generated by enclosing views.
10.4.1 Example (…continued)The RichEmp virtual objects defined in the previous sections currently does not have any attribute (sub-object), even though it seed is based ob the complex Emp object. To define virtual attributes we need to define sub-views. In our example we can decide which Emp attributes become a virtual attributes of RichEmp. For each attribute we can separately decide which operators will be available for it. Below a definition of an attribute name is shown:
© Copyright by eGov-Bus Consortium95

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
view RichEmpDef {//…view nameDef {
virtual name:string;seed : record {n:string;}{ return e.name as n;}on_retrieve { return n; }
//…
}
The view nameDef introduces a virtual attribute name of RichEmp virtual objects. The RichEmp virtual object in eclosing view declares name of tyle string and default cardinality [1..1] as one of its fields. The declaration of our nested virtual object conforms to this specification. The seed procedure for the name virtual object access the eclosing virtual object seed and returns a binder n with string representing the RichEmp name. Notice that the virtual object definition has access to the seed defined in the RichEmpDef view.
The view definition contains only one operator – dereference. Other operations are forbidden for the name virtual attribute.
Similar approach has to be taken for the salary attribute (ofcourse the programmer can decide on the range of available operators).
10.5 Virtual PointersUp to now virtual objects can be perceived by the user as simple objects (defined by the view without nested sub-views) or complex objects (defined by the view with nested sub-views describing attributes). For completeness of the transparency we need also to define virtual entities that can be perceived as pointer objects.
A pointer object allows to navigate in an object graph. The unique property of SBQL is that the environment of a pointer object is represented by the binder named with the name of pointed object; thus, navigation through the pointer object requires typing the name of the target object. This property allows us to separate the reference to pointer itself and the reference to pointed object. For example if we assume that friend is a pointer sub-object of Person object the query:
(Person where name = “Kim”).friend
Returns the reference (bag of references) of pointer object named friend. Such reference can be the subject of imperative operations (e.g. updated, deleted). To return the references to objects pointed by the friend objects one must write:
(Person where name = “Kim”).friend.Person
To define a virtual pointer with analogous semantics we need to introduce into the view definition a new operator.
10.5.1 Defining virtual pointer – on_navigateA virtual object acts as a virtual pointer if its definition is augmented by the operator on_navigate:
onnavigate_oper ::= on_navigate {statements}
As usual, the operator is defined as a functional procedure. It must return a reference (or a virtual reference) of a “virtually” pointed object. As for the other operators its return type implicitly corresponds to the declared type of a virtual object. These two assumptions enforce that only those virtual objects that return refrence to the other objects can possess on_navigate operator and be perceived as (virtual) pointers.
The operator procedure is implicitly executed during the process of calculating a nested environment in the context of a non-algebraic operator (see: non-algebraic operators). The result reference of a on_navigate call is then available within the virtual object environment (the semantics is the same as for regular pointer objects).
© Copyright by eGov-Bus Consortium96

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
10.5.2 Example (…continued)At this stage we’ll introduce to the RichEmp virtual object the virtual pointer worksIn that will point at the department the given rich employee works in. The definition of the virtual pointer attribute requires addition of a suitable sub-view. To transform virtual object into virtual pointer we’ll define the on_navigate operator. We also assume that the virtual pointer is a subject of dereference and update operation and define on_retrieve and on_update operators.
view RichEmpDef {//…
view worksInDef {virtual worksIn:ref Dept; seed :record{ dn:Emp.deptName; }{ return e.deptName as dn;}
on_navigate { return Dept where name = dn; }
on_retrieve { return Dept where name = dn; }
on_update { dn := value.name; }}//…
}
The seed procedure returns reference to deptName attribute inside the Emp object. The on_navigate operator returns a reference to a Dept object that name is equal to the employee deptName attribute value. The result of on_navigate is a reference of a virtual pointer target object.
The sample code inside the on_retrieve operator procedure is the same as for the on_navigate. Both operators have to return the value of the type declared for the virtual object. But the code can performe some additional tasks different for navigating and updating9.
The update semantics is straightforward. An argument is a reference of a Dept object. To change an employee’s department we simply update the deptName attribute value with the value of the argument department name object.
10.6 Local Objects Within ViewsA view definition can include local objects. This is necessary for stateful views, which have a lot of applications, for example, to store security data or the state of network connections. The situation can be compared to instance and class invariants known from popular object-oriented programming languages. The sub-views define non-static (virtual objects) attributes and the local view objects are like static (class) attributes.
The definition of a view local objects is similar to declaring global or local variables (see: variable declaration) but the declaration is placed inside the view definition.
10.6.1 Example (…continued)We extend the RichEmpDef view with a state. Assume that the employee’s richness level is parameterized by the database administrator. RichEmp virtual objects procedure will use this parameter to select those employees that salary is greater than a parameter value. To do this we must introduce the state to the view and modify RichEmp virtual objects procedure (and all operators that depend on the earning threshold).
view RichEmpDef { virtual RichEmp : record {name:string;
9 It is possibile hat In the future versions those two operators will be merged.
© Copyright by eGov-Bus Consortium97

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
salary:integer; worksIn: ref Dept;}[0..*]; seed: record {e: ref Emp;}[0..*] { return (Emp where salary > threshold) as e;}
on_retrieve { return e.(name as name, salary as salary, ref (Dept where name = deptName) as worksIn); }
on_update { e.name := value.name;e.deptName := value.worksIn.name;
if(e.salary < value.salary) { e.salary := value.salary; }
}
on_new newEmp { if(newEmp.salary > threshold) create permanent Emp(newEmp.name as name, newEmp.salary as salary, newEmp.worksIn.name as deptName); }
//the rest of the definition//declaration of the view local objectthreshold: integer;
}
The threshold object is local to the view definition and accessible through the view managerial name. Now the entitled user can change the threshold level with use of the following query:
RichEmpDef.threshold := 2500;
10.6.2 More complex statefull view exampleAssume that a boss periodically performs inspection of his employees. A view named EmpInspectionDef delivers him the convenient interface to do this task. A virtual object EmpInspection defined by the view has four attributes (defined by a sub-views):
name and opinion that comes from an Emp object.
annotation and assessed that are local to the EmpInspection virtual object.
The boss can read the attributes name, opinion and annotation and is able to set the annotation value to any string. Setting and changing an annotation value does not have any impact on the data in the database because the value is stored locally inside the view definition. Each new employee will be automatically accessible through the EmpInspection view. The last attribute named assessed cannot be read. The boss is able only to set it value to boolean true. Setting this value means that the corresponding employee inspection process has been ended. The employee won’t appear it the view any more. If the annotation value for the employee was set before it was set as inspected the value of virtual attribute annotation will be concatenated with the value stored in the employee opinion attribute (if the attribute was present) or the new opinion attribute will be inserted into the employee with a value equals to the annotation value (if employee did not have the attribute).
view EmpInspectionDef { virtual EmpInspection : record {name:string; opinion:string[0..1]; annotation:string[0..1]; assessed:boolean;}[0..*];
seed : record {e: Emp; }[0..*] {return (Emp as e) where not
© Copyright by eGov-Bus Consortium98

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
(ref e in ref EmpInspectionDef.inspected.Emp); }
view nameDef { virtual name:string;
seed : record{n:string;}{ return e.name as n;}
on_retrieve { return n; }
}view opinionDef {
virtual opinion : string[0..1]; seed :record { eo:string; }[0..1] { return e.opinion as eo; }
on_retrieve { return eo; }
}view annotationDef {
virtual annotation: string[0..1];seed :record {a:EmpInspectionDef.note;}[0..1] { return (EmpInspectionDef.note where
ref e = ref(concern.Emp)) groupas a; }
on_retrieve {if(exists a)
return a.text;else
return "no annotation";}on_update newText {
if(exists a) {a.text := newText;
}else {EmpInspectionDef :<<
note(ref e as concerns, newText as text);}
}}view assessedDef {
virtual assessed:boolean;seed:boolean {return false;}on_update done { if(done) {
EmpInspectionDef :<< inspected(ref e);if( exists(EmpInspectionDef.note where
(ref concerns.Emp = ref e))){
if(exists e.opinion) {e.opinion := (e.opinion +
(EmpInspectionDef.note where ((ref concerns.Emp) = (ref e))).text);
}else {e :<<
opinion((EmpInspectionDef.note where ((ref concerns.Emp) = (ref e))).text);
}}
}}
}
© Copyright by eGov-Bus Consortium99

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
inspected: ref Emp[0..*];note: record {
concerns:Emp; text:string;
}[0..*];}
10.7 Syntax of SBQL Viewsview_def ::= view [ manag_name ] { view_body }
manag_name ::= name;
view_body ::= view_body_sections
view_body_sections :: = view_body_section
| view_body_section view_body_sections
view_body_sections ::= virtual_variable_decl
| seed_def
| view_operator_def
| variable_declaration
virtual_variable_decl ::= virtual name:type[cardinality]
seed_def ::= seed:type[cardinality] { statements }
view_operator_def ::= onretrieve_oper | onupdate_oper | ondelete_oper
| onnew_oper | onnavigate_oper
onretrieve_oper ::= on_retrieve {statements}
onupdate_oper ::= on_update [parameter_name] {statements}
ondelete_oper ::= on_delete {statements}
onnew_oper ::= on_new [parameter_name] {statements}
onnavigate_oper ::= on_navigate {statements}
© Copyright by eGov-Bus Consortium100

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
11. TransactionsThe source code of transactions is ODRA is similar to procedure declarations as much as possible. Semantics and pragmatics of transactions is also similar to procedures. Actually, there are only minor differences related to special transaction’s features, such as the abort operation and returning the result status of a transaction invocation. All other features, including parameter passing, stack-based semantics, local environment and invocations of transactions from transactions (i.e. nested transactions) are the same as for procedures.
During run time each invocation of a transaction is registered as a special transaction object having a given class. The object augments other server objects and can be the subject of administrative management. Transaction objects can be queried by SBQL and can be processed by the predefined methods that are defined in the transaction class. The access to transaction objects can be made available for any ODRA client and server installation. Such a freedom makes it possible to resolve some problems with transaction, such as long transactions and transaction isolation levels known from SQL. Moreover, the approach assumed in ODRA makes it possible to define sophisticated algorithms of distributed transaction processing, including protocols that are known as 2PC and 3PC.
The transactions support in ODRA is based on physical isolation at the data pages level. All local elements (objects, meta-data, etc.) stored by the given ODRA instance are physically represented as a sequence of bytes that is divided into data pages of some predetermined size (currently by default 4096 bytes).
ODRA is a typical database management system which enables concurrent access to the same data within parallel sessions. Establishing a session entails instantiating a new transaction at the server side. A user may explicitly trigger a nested transaction within an existing one.
11.1.1 Locking data at physical levelEach transaction can perform two kinds of locks:
1. a read lock,
2. an exclusive lock,
which may be attached/deattached to/from particular data pages. Setting a read lock on a data page marks that the given transaction has retrieved data from the given page without no changes on it. Since reading the data does not disturb its consistency, as usual ODRA allows simultaneous read-only access by multiple transactions. Any modification of the data within a transaction requires sole access to the particular data pages, and so marking them with an exclusive lock. A transaction may attach its exclusive lock to a data page (with one exception discussed below) only if no concurrent transaction has marked its access to the given page with either read or exclusive lock. Analogously, a data page may not be locked for read-only access if it has been attached an exclusive lock by any other transaction. A transaction may elevate the lock level from shared read-only access to exclusive read-write access provided that it does not violate the mentioned condition. If a transaction is not able to set the requested lock (i.e. either read or exclusive one) on a data page it suspends regular processing until all the locks which prevent the required access are released.
Ensuring isolation and consistency with locks inevitably entails the risk of deadlocks. To preclude this undesirable side-effect, the current implementation of transaction engine of ODRA platform supports widely known “wait-die” deadlock resolution strategy – i.e. a transaction is aborted after a predetermined time (timeout) has been elapsed since the transaction was suspended to await access to the requested data page(s).
The discussed above general rules for locking data pages do not precisely describe how the transactions support inherent in ODRA platform actually works. The ODRA run-time environment supports nested transactions, and therefore attaching either a read or an exclusive lock to a data page by a less deeply nested transaction would result with a deadlock in case the more deeply nested transaction in a chain attempted to access the given page. Granting access to the more nested transaction along a chain does not disturb consistency even if the data pages have been modified by the parent (i.e. less deeply nested) transaction. The sole stipulation is that the transaction engine should be able to withdraw all the changes introduced at an arbitrary level (and above – i.e. by the nested transactions). ODRA transaction implementation resolves this issue in a traditional method – i.e. with a transaction log which overrides the original data pages for nested transactions.
© Copyright by eGov-Bus Consortium101

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
11.1.2 Transactions as meta-base objectsEach transaction instantiated within the ODRA run-time environment is a meta-base object with its own identity and various properties, such as owner, time of creation, locked data pages, etc. A user may query ODRA instance for transactions as any meta-base objects.
Currently ODRA features transaction capable procedures (or methods) which semantically do not differ from regular procedures apart from the fact that their changes may be withdrawn if the transaction has been aborted. Since each session instantiates a transaction, both transaction capable procedures, as well as regular ones invoked within different sessions are isolated from each other by default.
11.1.3 SyntaxCurrently a programmer may control the behaviour of the transactions support engine of ODRA platform with two keywords: (1) transaction and (2) abort.
transaction precedes procedure definition and transforms a regular procedure into a transaction capable one.
abort explicitly aborts and undoes all the modifications performed within the current transaction.
11.1.4 ExamplesThe following examples illustrate usage of keywords which control the behaviour of transactions engine of ODRA.
A procedure givePayRise increases the salary of each employee contained in a collection employees by value. If the payroll of all the employees included in the pay rise exceeds predetermined limit all the changes are withdrawn.
transaction givePayRise (employees:ref Emp[0..*]; value:integer; limit:integer) { foreach employees as emp do { emp.salary := emp.salary + value; } if sum(employees.salary) > limit then { abort; }}
11.1.5 Further extensions of the transaction supportODRA as well semantics and syntax of the ODRA run-time environment native language SBQL still evolve. Current internal design of transactions support inherent in ODRA enables introducing other language constructs which are sensible for running in an isolated environment provided by transactions. The further description will contain specification of the transaction class, together with attributes of transaction objects and methods that can be used to process them. The issue involves also nested transations and distributed transactions. This is the subject of the current development.
© Copyright by eGov-Bus Consortium102

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
12. Back-End Interoperability FacilitiesThe facilities include all the software that can be used to access some external libraries, services and data. VRMS ODRA is currently equipped with several such facilities that include accessing Java libraries, generic wrappers to external relational databases, an XML exporter and importer, an acces to SWARD, an RDF-oriented virtual database, an access to SD SQL Server implementing the SDDS paradigm and an generic interface to Web Services. Other facilities are under development, in particular, access to Topic Maps repositories, to RDF files, to ADO interface, and perhaps others, according to the current needs and requests.
12.1 Accessing Java LibrariesODRA server has built in support for calling external Java code directly from SBQL programs. You can invoke any arbitrary code written in Java, pass parameters to it and consume its return value.
The following example creates a new java.util.Random object and invokes the nextInt method:
rndref:integer; //1rndref:=external load_class("java.util.Random"); //2external new_object(rndref); //3external init_parameters(rndref); //4external add_parameters(rndref, 5); //5external invoke_integer(rndref, "nextInt"); //6
Operations defined above will return random number between 0 and 5.
Line 1 is responsible for creation of rndref variable that will store the reference to an external Java object.
Line 2 loads the java.util.Random class and stores its reference on the rndref variable. You can load any Java class this way.
Line 3 creates a new instance of Java Random object.
Line 4 is always mandatory. It initializes an internal collection of parameters that will be used to invoke a method from an object.
Line 5 adds one parameter that will be used as an argument for the nextInt method. In this case number 5 is loaded as a first and only argument of the method. You can load as many arguments as the Java method requires. Consult Java documentation for method signatures.
Line 6 performs execution of external call and returns value to the SBQL stack (unless the return value is of type void). In this case invoke_integer method is executed, but you should choose one of the following methods to invoke depending of a return type of Java method:
Invoke_integer – method’s return type is integer
Invoke_void – method’s return type is void
Invoke_library – method’s return type is reference
Invoke_string – method’s return type is string
Invoke_boolean – method’s return type is boolean
Invoke_real – method’s return type is double
At this moment Java arrays are not supported and methods returning Java arrays should be wrapped with methods returning Java collections.
Sample external invocations:
data:integer;data:=external load_class("java.util.Date");external new_object(data);return external invoke_string(data, "toString");
Returns current date as a string.
© Copyright by eGov-Bus Consortium103

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
ToUpper(val:string):string{ string_lib:=external load_class("odra.sbql.external.lib.StringLib"); external new_object(string_lib); init_string();
result:string; external init_parameters(string_lib); external add_parameters(string_lib, val); result:=external invoke_string(string_lib, "ToUpper"); return result;}
Method ToUpper takes string as a parameter and returns this string in uppercase. It uses ToUpper method defined in odra.sbql.external.lib.StringLib.
SBQL code creating standard SBQL library can be found in res/standard_library folder.
12.2 Web Services ProxiesThe ODRA system provides native support for consuming web services. The Web Services Proxies mechanism allows to include volatile and external data into a database.
Interaction with remote services is achieved through strongly typed stubs. They are realized as regular database objects. That makes them transparent for database – any of its mechanisms can be applied to them. For example they can profit from query, type checking and authorization database features. That makes remote and local resources interaction very similar from the developer’s point of view.
Currently ODRA proxies support subset of WS-I BP 1.1 compliant web services. They can be used to consume only those of them, which are developed with “document/literal” style. Both “wrapped” and “bare” dialects are supported and are detected automatically.
11-1. Web Services Proxies
In order to create a new proxy module the user needs to use the following DDL command:
add module proxyName as proxy on "contractUrl"
Options for this command are described in the following table:
Table 11-1. Create proxy command options description.
Option name Allowed values Description
proxyName any valid database Name of module which will be created
© Copyright by eGov-Bus Consortium104

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
object name
contractUrl URL Determines an object to expose. Currently it can be a procedure or class name.
Because proxy module is (from developer perspective) a regular database object, the standard module deletion command can be used to remove it:
remove module proxyName
Below we present example proxy usage scenario. Consider creating proxy for stock quote web service:
add module StockProxy as proxy on "http://www.swanandmokashi.com/HomePage/WebServices/StockQuotes.asmx?WSDL"
After creating the above, user may use generated stub to make remote calls. Note that remote calls are mixed with standard query constructs. For example calling:
(GetStockQuotes("MSFT,YHOO,GE").GetQuotesResult.Quotewhere (real) StockQuote > 25 ).(CompanyName, StockQuote);
It will end up with a similar result to the following output:
bag {struct {
"MICROSOFT CP""30.49"
}struct {
"GEN ELECTRIC CO""38.12"
}}
12.3 Web Services Dynamic Invocation InterfaceThe ODRA includes also support for stubless, dynamic invocation of web services. Realized as a part of an external method call interface, it allows the user to create a document that is sent to a webservice during runtime, creating any valid XML structure. Returned results may be consumed like results of any other SBQL query.
Currently the interface support a subset of WS-I BP 1.1 compliant web services. They can be used to consume only those of them, which are developed with the “document” style. Utilization of the interface requires knowledge of the consumed web service’s interface.
In order to make a DII call, the user has to initialize new web service service object first:
external new_webservice (namespace,endpoint_url,wsdl_url, operation_name);
This method accepts four parameters: document namespace URL, service endpoint URL, WSDL document URL and operation name. For example:
external new_webservice ("http://sample/","http://localhost:8080/SampleApp/SampleService","http://localhost:8080/SampleApp/SampleService?wsdl", "sampleOperation");
This function returns an integer identifier of service object, which should be recorded for future use
If the web service accepts any parameters, a document containing the parameters should be constructed. There are three functions which are used to create such document:
external addfield_webservice(service_id,parent_object,field_name);
The addfield_webservice function adds a new tag to the document. It accepts three parameters: integer identifier of the service object, integer identifier of the parent tag (the document tag has ID=100) and the name of the added tag. It returns the integer identifier of the added tag. For example:
© Copyright by eGov-Bus Consortium105

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
external addfield_webservice(100,100,"sampleparameter");
The second function is used to add attributes:
external addattr_webservice(service_id,parent_object,attribute_name, attribute_value);
The addattr_webservice function adds an attribute to a tag in the document It accepts four parameters: an integer identifier of the service object, an integer identifier of the parent tag (the document tag has ID=100), a name of the added parameter and a value of the added parameter. For example:
external addattr_webservice(100,101,"type","xs:string");
The third function is used to add text to tags:
external addtxt_webservice(100,101,text_to_add);
The addtxt_webservice function adds a text value to a tag in the document. It accepts three parameters: integer identifier of the service object, integer identifier of the parent tag and string added as a text value to the tag. For example:
external addtxt_webservice(100,101,"sample text");
After the document is created, the web service may be invoked:
external invoke_webservice(service_id);
The invoke_webservice function accepts a single parameter – the id of a service object to be invoked. It returns the return message from the webservice converted to an ODRA result. For example:
external invoke_webservice(100);
Document assigned to a service object may be reset, e.g. if after a call another call to the same web service, but with a different set of parameters has to be made. It may be reset with the reset_webservice function, which accepts a single parameter – the id of the service object. For example:
external reset_webservice(100);
When the service object is no longer necessary, it should be deleted using the delete_webservice function. It accepts the id of the service object. For example:
external delete_webservice(100);
12.4 Generic Wrapper to Relational DatabasesThe goal of the generic wrapper to relational databases is to enable integration of data stored in a relational database into the eGov-Bus virtual repository. Wrapped relational tables can be transparently queried and updated with SBQL. They can also be transformed with updateable object-oriented views so that they comply with the global schema of the virtual repository and the relational data can be made indistinguishable from other ODRA objects. The wrapper puts much effort in effective query optimisation (both at the ODRA side and the wrapped resource side) so that minimum time and resource consumption occurs during query evaluation.
The wrapper can realize two main goals:
Integration of existing relational databases into a virtual repository (bottom-up approach),
Storage of data presented in the virtual repository in relational databases (top-down approach).
The first goal strictly complies with the eGov-Bus project objectives, i.e. assembling, integrating and combining pre-existing information systems and business solutions (based mainly on relational databases) in the final environment. The other one is implied by the reasonable assumption that designers of future systems integrated with the virtual repository would still tend to use familiar relational databases, being somehow afraid of the new object-oriented database technology. Both usage scenarios can be successfully realized by the wrapper.
© Copyright by eGov-Bus Consortium106

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
12.4.1 Wrapper ArchitectureThe wrapper is realized in a client-server architecture. The client is transparently embedded in the ODRA server, while the wrapper server is a standalone application. The schematic wrapper structure is presented in Fig.11-2:
11-2. General object-to-relations wrapper architecture
An ODRA virtual repository uses object-oriented views to map virtual data delivered by the wrapper to the form assumed by the virtual repository canonical data model. The virtual repository itself does not see the wrapper, since the ODRA database is opaque – the wrapped relational schema is presented via a regular ODRA schema. The actual processing is executed between the wrapper server and the client. The client is responsible for issuing SQL queries (implied by SBQL queries from global virtual repository clients) to the server, receiving results and creating temporary ODRA results returned to the ODRA database. Such temporary results are then returned to the virtual repository and to the global client.
12.4.2 Adding and Querying WrappersWhen the wrapper server is running and its host is available from the ODRA server machine, the wrapper can be used from within ODRA (the server configuration and startup procedures are described with illustrative examples below). The wrapper is realized as an ODRA database module, therefore the syntax is similar:
add module <modulename> as wrapper on <host>:<port>
where <modulename> is a name of a module to add, <host> is a wrapper server host (IP or name), and <port> is its listener port. A new wrapper module is created as a submodule of the current module.
A wrapper is instantiated when a wrapper module is created. A wrapper module is a regular database module, but it asserts that all the names within the module are “relational” (i.e. imported from a relational schema) except for automatically generated views referring to these names (this procedure is described in the following paragraphs). A wrapper instance contains a wrapper client capable of communication with the appropriate server. All the wrapper instances are stored in a global (static) session object and are available with a wrapper module name. Thus, once a wrapper is created, it is available to any session (including the ones initialized in the future) as its module is.
A wrapper module can be dropped with the same command as any other ODRA module.
All relational names appearing in the wrapped resource XML description are available with a View postfix (e.g. an employees table is visible as employeesView, its name column is nameView, etc.). The primary wrapper views are introduced automatically so that virtual pointers corresponding to primary-foreign key relations and integrity constraints are preserved. The wrapper objects can be queried as any other ODRA objects, also queries combining both can be issued.
Before querying wrappers make sure that the current optimization sequence contains view rewriting and wrapper optimization. Otherwise queries are not sent to appropriate wrappers and empty results are returned.
© Copyright by eGov-Bus Consortium107

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
12.4.3 Top-Down Usage ScenarioAssume that some object-oriented schema is given (according to the virtual repository integration and contribution model) and its data is to be stored in a relational database. This is the case of the top-down design, i.e. the system designer is obliged to create a relational database schema capable for storing and retrieving data being a part of the virtual repository.
The main relational schema designing rule is that all the tables must have unique row identifiers – primary keys (the current prototype implementation supports only single-column keys, this limitation will be removed in the future wrapper development). The unique identifiers are used (usually in background) for data updates, as they allow for keeping data integrity.
The designer must also realize that the wrapper creates virtual pointers for each primary-foreign key pair. Therefore whenever a pointer appears in the assumed object-oriented schema, the foreign key must be created in the corresponding relational schema. Another temporary wrapper prototype limitation that is to be removed in the future is that only a single primary-foreign key constraint per table is supported.
The top-down designing procedure can be illustrated with the following simple example. Consider an object-oriented schema for people and their cars, Fig.11-3:
11-3. Base object-oriented schema
This simple schema corresponds to a two-table relational schema. Each table should have its primary key (some automatically incremented sequences are a good choice). The pointers (owns and isOwnedBy) should be realized as foreign keys. The resulting relational schema could look as the one shown in the figure below:
personid (PK)
name
surname
car_id (FK)
carid (PK)
make
birth_date
model
year
colour
person_id (FK)
11-4. Designed relational schema
During the relational schema wrapping procedure the wrapper creates automatically views covering plain metaobjects. The procedure is described in details in the following. The resulting names differ from the ones in the relational database, thus the designer should cover the wrapped schema with additional views mapping the automatic wrapper views one-to-one to the desired names (assumed in the target object-oriented schema), including virtual pointers.
In case of more complex object-oriented schemata the designer may need to create a more sophisticated relational schema (introducing additional tables not resulting directly form the object-oriented schema) that can be adjusted to the desired object-oriented one with appropriate views – a single SBQL view can operate on an arbitrary join of wrapped tables so that the actual relational schema is not visible to the users.
12.4.4 Bottom-Up Usage ScenarioConsider wrapping an existing (legacy) relational database, used e.g. by some company or public organization . In eGovernment domain this is the main wrapper application. The approach we call bottom-up. In this approach some object-oriented model, preferably a set of views, must be designed to cover the existing relational schema.
We present the following very simple example. It consists of three tables: employees, departments and locations. The tables are related by primary-foreign key constraints: an employee works in some department that in turn is located in some town/location. Each table has a primary key column (named id); there are also non-unique
© Copyright by eGov-Bus Consortium108

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
(secondary) indices on employees’ surnames and salaries, departments’ names and locations’ names. The schema is presented in Fig. 11-5.
employeesid (PK)
name
surname
department_id (FK)
departmentsid (PK)
name
location_id (FK)
locationsid (PK)
name
sex
salary
info
birth_date
11-5. Legacy relational schema
The primary step of creation of the schema description expressed as an XML document; technical issues are described in details below. This wrapper reads this description and it creates appropriate metadata in the ODRA metabase (one-to-one mapping applied, each table is represented as a single complex object). The corresponding object-oriented schema is presented in the next figure.
11-6. Imported object-oriented schema
Please notice that the names generated are prefixed with $, which prevents them from using in ad-hoc queries. Thus, the metaobjects are covered by automatically generated views. This is the final automatically generated stage for of the wrapped relational schema. It can be already queried or covered by a set of views so that it can contribute to the global schema of the virtual repository.
The views shown below are query-ready, however they do not realize relational integrity constraints and they allow full access to wrapped data (including updating and deleting), which is not always a good choice.
11-7. Automatically generated views
The next stage is performed by the administrator/programmer who should design end-user views.
Relational integrity constraints and table relations should be realized as virtual pointers (notice that in these views subobjects corresponding to foreign key columns are expressed as virtual pointers). The resulting relational schema representation (already available for querying and further processing) is shown in the next figure:
© Copyright by eGov-Bus Consortium109
$employees$id $name$surname$sex$salary$info$birth_date$department_id
$departments $locations$id $name$location_id
$id $name
employeesidnamesurnamesexsalaryinfobirth_datedepartment_id
department locationsViewid namelocation_id
idname

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
11-8. Final end-user relational schema
The end-user views provide virtual pointers instead of foreign-key columns, for simplicity of the example they do not modify the schema further. The assumed security constraints do not allow updating foreign-key columns (virtual pointers) and primary key columns. Sample code for the views is listed below:
add view EmployeeDef {virtual objects Employee: record { e: employees; }[0..*] {
return (employees) as e; } on_retrieve: record { id: integer; name: string; surname: string; sex:
string; salary: real; info: string; birthDate: date; worksIn: integer; } {return ( deref(e.id) as id, deref(e.name) as name, deref(e.surname) as
surname, deref(e.sex) as sex, deref(e.salary) as salary, deref(e.info) as info, deref(e.birth_date) as birthDate, deref(e.department_id) as worksIn );
}on_delete {
delete e;}view idDef {
virtual objects id: record { _id: employees.id; } { return e.id as _id;
}on_retrieve: integer {
return deref(_id); }
}view nameDef {
virtual objects name: record { _name: employees.name; } { return e.name as _name;
}on_retrieve: string {
return deref(_name); }on_update(newName: string) {
e.name := newName; }
}view surnameDef {
virtual objects surname: record { _surname: employees.surname; } { return e.surname as _surname;
}on_retrieve: string {
return deref(_surname); }on_update(newSurname: string) {
e.surname := newSurname; }
}view sexDef {
virtual objects sex: record { _sex: employees.sex; } { return e.sex as _sex;
}
© Copyright by eGov-Bus Consortium110
Employeeid namesurnamesexsalaryinfobirthDate
Department Locationid name
idname
worksIn isLocatedIn*► *►

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
on_retrieve: string { return deref(_sex);
}on_update(newSex: string) {
e.sex := newSex; }
}view salaryDef {
virtual objects salary: record { _salary: employees.salary; } { return e.salary as _salary;
}on_retrieve: real {
return deref(_salary); }on_update(newSalary: real) {
e.salary := newSalary; }
}view infoDef {
virtual objects info: record { _info: employees.info; } { return e.info as _info;
}on_retrieve: string {
return deref(_info); }on_update(newInfo: string) {
e.info := newInfo; }
}view birthDateDef {
virtual objects birthDate: record { _birthDate: employees.birth_date; } {
return e.birth_date as _birthDate; }on_retrieve: date {
return deref(_birthDate); }on_update(newBirthDate: date) {
e.birth_date := newBirthDate; }
}view worksInDef {
virtual objects worksIn: record { _worksIn: employees.department_id; } {
on_navigate: Department {return Department where id = _worksIn;
}}
}
add view DepartmentDef {virtual objects Department: record { d: departments; }[0..*] {
return (departments) as d; } on_retrieve: record { id: integer; name: string; isLocatedIn: integer; }
{return ( deref(d.id) as id, deref(d.name) as name,
deref(d.location_id) as location );}on_delete {
delete d;
© Copyright by eGov-Bus Consortium111

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
}view idDef {
virtual objects id: record { _id: departments.id; } { return d.id as _id;
}on_retrieve: integer {
return deref(_id); }
}view nameDef {
virtual objects name: record { _name: departments.name; } { return d.name as _name;
}on_retrieve: string {
return deref(_name); }on_update(newName: string) {
d.name := newName; }
}view isLocatedInDef {
virtual objects isLocatedIn: record { _isLocatedIn: departments.location_id; } {
return d.location_id as _isLocatedIn; }on_navigate: Location {
return Location where id = _isLocatedIn;}
}}
add view LocationDef {virtual objects Location: record { l: locations; }[0..*] {
return (locations) as l; } on_retrieve: record { id: integer; name: string; } {
return ( deref(l.id) as id, deref(l.name) as name );}on_delete {
delete l;}view idDef {
virtual objects id: record { _id: locations.id; } { return l.id as _id;
}on_retrieve: integer {
return deref(_id); }
}view nameDef {
virtual objects name: record { _name: locations.name; } { return l.name as _name;
}on_retrieve: string {
return deref(_name); }on_update(newName: string) {
l.name := newName; }
}}
© Copyright by eGov-Bus Consortium112

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The sample queries concerning directly the given schema (i.e. the views designed by the administrator/programmer) are presented below:
Retrieve names and surnames of employees earning more than 1000:
(Employee where salary > 1000).(name, surname)
Retrieve employees with their departments (application of a join by a virtual pointer):
Employee join worksIn.Department
Calculate the sum of salaries of all employees named Smith working in any department located in Warsaw (navigation via virtual pointers):
sum((Employee where surname = "Smith" and worksIn.Department.isLocatedIn.Location.name = "Warsaw").salary)
Retrieve the surname and the department’s location name for the employee with the ABC12345 identifier:
((Employee where id = “ABC12345”) as e join e.worksIn.Department as d join d.isLocatedIn.Location as l).(e.surname, l.name)
The wrapped schema transformations for the global schema are performed by means of updateable object-oriented views. Below, there are shown a few sample views covering the wrapped sample schema. Please, notice that views’ definitions can completely rearrange the wrapped schema, also relational integrity constraints expressed as virtual pointers can be overridden (ignored) as other virtual pointers can be introduced in the upper-level views covering the presented wrapper schema.
The view retrieves full names, sexes and salaries of rich employees, i.e. employees earning more than 2000:
add view RichEmployeeDef {virtual objects RichEmployee: record { e: Employee; }[0..*] {
return (Employee where salary > 2000) as e; } on_retrieve: record { fullname: string; sex: string; salary: real; } {
return ((deref(e.name) + " " + deref(e.surname)) as fullname, deref(e.sex) as sex, deref(e.salary) as salary);
}view fullnameDef {
virtual objects fullname: record { _fullname: string; } { return (deref(e.name) + " " + deref(e.surname)) as _fullname; }
on_retrieve: string { return _fullname;
} }view sexDef {
virtual objects sex: record { _sex: Employee.sex; } { return e.sex as _sex;
} on_retrieve: string {
return deref(_sex); }
}view salaryDef {
virtual objects salary: record { _salary: Employee.salary; } { return e.salary as _salary;
} on_retrieve: real {
return deref(_salary); }
}}
The next presented view presents employees’ full names and salaries with names of departments they work in:
add view EmployeeDepartmentDef {
© Copyright by eGov-Bus Consortium113

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
virtual objects EmployeeDepartment: record { e: Employee; d: Department; }[0..*] {
return Employee as e join e.worksIn.Department as d; } on_retrieve: record { fullname: string; salary: real; department: string;
} {return ((deref(e.name) + " " + deref(e.surname)) as fullname,
deref(e.salary) as salary, deref(d.name) as department);}view fullnameDef {
virtual objects fullname: record { _fullname: string; } { return (deref(e.name) + " " + deref(e.surname)) as _fullname;
} on_retrieve: string {
return _fullname; }
}view salaryDef {
virtual objects salary: record { _salary: real; } { return deref(e.salary) as _salary;
} on_retrieve: real {
return _salary; }
}view departmentDef {
virtual objects department: record { _department: string; } { return deref(d.name) as _department;
} on_retrieve: string {
return deref(d.name);}
}}
The RichEmployee and EmployeeDepartment views can be queried directly or further referenced by other views, e.g. in the data integration process executed by the virtual repository. Some simple direct queries referring these views are presented below:
count(RichEmployee)
min(RichEmployee.salary)
(RichEmployee where salary = 5000).fullname
sum(EmployeeDepartment.salary)
(EmployeeDepartment where salary < 2000).(fullname, department)
The next view example presents integration of two separate schemata – the “employees” schema is the same wrapped relational schema as the one used above, the “cars” schema is wrapped from another relational database whose model is shown below. The wrapping process description is skipped as it is performed analogically to the previous one. This example realizes a very simple case of integration of distributed data.
11-9. Logically related separate relational schema
© Copyright by eGov-Bus Consortium114
carsid (PK)
owner_id
year
model_id (FK)
modelsid (PK)
name
make_id (FK)
makesid (PK)
name
colour

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The cars.owner_id column (marked with light gray) is logically related to the employees.id column in the other database, nevertheless both schemata are maintained locally in different locations and they are physically independent.
The EmployeeCar view combines both wrapped schemata and retrieves employees’ full names and salaries with their cars’ make names, model names, colours and manufacturing years:
add view EmployeeCarDef {virtual objects EmployeeCar: record { e: Employee; c: Car; ma: Make; mo:
Model; }[0..*] { return Employee as e join (Car where ownerId = e.id) as c join (Model
where id = c.modelId) as mo join (Make where id = mo.makeId) as ma;}on_retrieve: record { fullname: string; salary: real; make: string;
model: string; colour: string; year: integer; } {return ((deref(e.name) + " " + deref(e.surname)) as fullname,
deref(e.salary) as salary, deref(ma.name) as make, deref(mo.name) as model, deref(c.colour) as colour, deref(c.year) as year);
}view fullnameDef {
virtual objects fullname: record { _fullname: string; } { return (deref(e.name) + " " + deref(e.surname)) as _fullname;
} on_retrieve: string {
return _fullname; }
}view salaryDef {
virtual objects salary: record { _salary: real; } { return deref(e.salary) as _salary;
} on_retrieve: real {
return _salary; }
}view makeDef {
virtual objects make: record { _make: string; } { return deref(ma.name) as _make;
} on_retrieve: string {
return _make; }
}view modelDef {
virtual objects model: record { _model: string; } { return deref(mo.name) as _model;
} on_retrieve: string {
return _model; }
}view colourDef {
virtual objects colour: record { _colour: string; } { return deref(c.colour) as _colour;
} on_retrieve: string {
return _colour; }
}view yearDef {
virtual objects year: record { _year: integer; } { return deref(c.year) as _year;
© Copyright by eGov-Bus Consortium115

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
} on_retrieve: integer {
return _year; }
}}Here are some simple queries targeting the EmployeeCar view:
(EmployeeCar where salary > 2000).(fullname, colour)(EmployeeCar where salary > 2000 and colour = "white").(fullname, make + " " + model)
Similarly, the wrapped data can be combined with native ODRA objects, including local declarations in views. All the queries, including views’ retrieved objects, are processed by the ODRA optimizers and their executed in the resources; the partial results are then composed and the final result is returned to the client.
12.4.5 Type MappingThe wrapping procedure requires some deterministic mapping between relational data types and primitive ODRA data types. The default type applied for an undefined relational data type (due to enormous heterogeneity between various RDBMSs there might be some types not covered by the prototype definitions, still) is string. The string type is also assumed for relational data types currently not implemented in ODRA (including binary data types like BLOB).
The type mapping table is presented below:
Table 11-4. Type mapping between SQL and SBQL
SQL SBQLvarcharvarchar2chartextmemoclob
string
integerintint2int4int8serialsmallintbigintbyteserial
integer
numberfloatrealnumericdecimal
real
boolbooleanbit
boolean
datetimestamp
date
12.4.6 Wrapper Configuration and RunningThe wrapper is realized in the client-server architecture. A client is embedded in the ODRA database; a server however needs individual configuration and startup (usually it runs on a separate machine).
The wrapper server requires a JDBC driver for a database to be connected. The currently supported databases are: Axion, Cloudscape, DB2, DB2/AS400, Derby, Firebird, Hypersonic, Informix, InstantDB, Interbase, MS Access, MS SQL, MySQL, Oracle, Postgres, SapDB, Sybase and Weblogic. The default ODRA distribution
© Copyright by eGov-Bus Consortium116

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
provides the drivers for Firebird 2 (jaybird-full-2.1.1.jar), Postgres 8 (postgresql-8.1-405.jdbc3.jar) and MS SQL 2005 (jtds-1.2.jar), any other driver must be made available to the wrapper server classpath (the server main class is included in the same JAR as ODRA server) prior to other operations described below.
12.4.6.1 Resource Connection ConfigurationA connection configuration file is connection.properties whose sample can be found the project root directory is the standard Apache Torque configuration file. Its content is listed below:
torque.database.default = postgres_employees
#configuration for the postgres database (employees)torque.database.postgres_employees.adapter = postgresqltorque.dsfactory.postgres_employees.factory = org.apache.torque.dsfactory.SharedPoolDataSourceFactorytorque.dsfactory.postgres_employees.connection.driver = org.postgresql.Drivertorque.dsfactory.postgres_employees.connection.url = jdbc:postgresql://localhost:5432/wrappertorque.dsfactory.postgres_employees.connection.user = wrappertorque.dsfactory.postgres_employees.connection.password = wrapper
#configuration for the firebird database (employees)torque.database.firebird_employees.adapter = firebirdtorque.dsfactory.firebird_employees.factory = org.apache.torque.dsfactory.SharedPoolDataSourceFactorytorque.dsfactory.firebird_employees.connection.driver = org.firebirdsql.jdbc.FBDrivertorque.dsfactory.firebird_employees.connection.url = jdbc:firebirdsql:localhost/3050:c:/tmp/wrapper.gdbtorque.dsfactory.firebird_employees.connection.user = wrappertorque.dsfactory.firebird_employees.connection.password = wrapper
#configuration for the postgres database (cars)torque.database.postgres_cars.adapter = postgresqltorque.dsfactory.postgres_cars.factory = org.apache.torque.dsfactory.SharedPoolDataSourceFactorytorque.dsfactory.postgres_cars.connection.driver = org.postgresql.Drivertorque.dsfactory.postgres_cars.connection.url = jdbc:postgresql://localhost:5432/wrapper2torque.dsfactory.postgres_cars.connection.user = wrappertorque.dsfactory.postgres_cars.connection.password = wrapper
#configuration for the ms sql database (SD-SQL)torque.database.sdsql.adapter = mssqltorque.dsfactory.sdsql.factory = org.apache.torque.dsfactory.SharedPoolDataSourceFactorytorque.dsfactory.sdsql.connection.driver = net.sourceforge.jtds.jdbc.Drivertorque.dsfactory.sdsql.connection.url = jdbc:jtds:sqlserver://212.191.89.51:1433/SkyServertorque.dsfactory.sdsql.connection.user = satorque.dsfactory.sdsql.connection.password =
The sample file contains four data sources defined (named postgres_employees, firebird_employees, postgres_cars and sdsql) for different RDBMSs and schemata – the same configuration file can be used for different wrapped databases. However, a separate server must be started for each resource. A torque.database.default property defines a default database if none is specified as an input of an application (e.g., a wrapper server). The other properties mean:
torque.database.xxx.adapter – JDBC adapter/driver name, torque.dsfactory.xxx.factory – a data source factory class, torque.dsfactory.xxx.connection.driver – a JDBC driver class, torque.dsfactory.xxx.connection.url – a JDBC resource-dependent connection URL,
© Copyright by eGov-Bus Consortium117

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
torque.dsfactory.xxx.connection.user – a database user name, torque.dsfactory.xxx.connection.password – a database user password.
The xxx word should be substituted with a unique data source name that is further used for pointing at the resource.
12.4.6.2 Relational Schema Description GenerationA schema description file in a XML document similar to the one used by Apache Torque. Its DTD is available at http://jacenty.kis.p.lodz.pl/relational-schema.dtd. In most cases the file is automatically generated, nevertheless if such solution for some reasons is impossible or some changes must be introduced (e.g. only selected relational tables or views should be exposed to the wrapper), the file can be also created or edited manually. The schema description file is generated (typed) only once and it can be reused until resource schema changes. After, the wrapper server must be restarted too and a new description is to be loaded.
The automatic generation process requires the connection configuration file described above available. Once a configuration.properties is defined for a wrapped RDBMS, the schema generator can be launched by odra.wrapper.generator.SchemaGeneratorApp. The application can run without parameters (a configuration.properties file is searched in the application home directory) and the default database name is used. One can also specify an optional parameter for a configuration file path. If it is specified, also a database name can be provided as the second parameter.
The schema generator application standard output is as below:
Schema generation started...Schema generation finished in 5875 ms...
As a result the schema description XML file is created in the application home (launch) directory. The file name is created according to a pattern <dbnam>e-schema.generated.xml, where <dbname> is a database name specified as an application startup parameter or a default one in the properties file.
12.4.6.3 Wrapper Server RunningThe server (odra.wrapper.net.Server) is a multithreaded application (a separate parallel thread is invoked for each client request). It can be launched as a standalone application or as a system service.
12.4.6.3.1 Standalone LaunchA standalone launch should not be used in a production environment, its aim are only testing purposes. In order to start the server a system service, read the instructions in the next subsection.
If the server is launched without startup parameters, it searches for the connection.properties file in the application home directory and uses a default database name declared in this file. Other default values are a listener port (specified as 2000) and a verbose mode (specified as true). If one needs to override these values, use syntax as in the sample below:
odra.wrapper.net.Server -Ddbname -Vfalse -P5124 -C/path/to/config/
All the startup parameters are optional and their order is arbitrary:
-D prefixes a database name (to override the default one in a properties file),
-V toggles a verbose mode (true/false),
-P specifies the listener port,
-C specifies a path to the server configuration files (including schema description XML documents).
The path denoted with a -C parameter must be a valid directory where all the configuration files are stored, including connection.properties and schema description XML document(s).
A server output at a successful startup is shown below:
Database model successfully build from schema in './postgres-schema.generated.xml'SBQL wrapper listener started on port 2000...SBQL wrapper listener is running under Java Service WrapperBig thanks to Tanuki Software <http://wrapper.tanukisoftware.org>
12.4.6.3.2 Service Launch
© Copyright by eGov-Bus Consortium118

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Running the server as a system service is realized with the Java Service Wrapper (JSW, http://wrapper.tanukisoftware.org). The JSW can be downloaded as binaries or a source code. It can be run on different platforms (e.g., MS Windows, Linux, Solaris, MacOS X) and the appropriate version must be installed in a system (binary download should be enough).
The following instructions refer to MS Windows environment (they are similar on other platforms). Detailed descriptions and examples of installation and configuration procedures are available at the JSW web site. Below, $JSW_HOME denotes a home directory of JSW.
The main JSW configuration is defined in $JSW_HOME/conf/wrapper.conf. The file example is listed below:
#********************************************************************# TestWrapper Properties## NOTE - Please use src/conf/wrapper.conf.in as a template for your# own application rather than the values used for the# TestWrapper sample.#********************************************************************# Java Applicationwrapper.java.command=java
# Java Main class. This class must implement the WrapperListener interface# or guarantee that the WrapperManager class is initialized. Helper# classes are provided to do this for you. See the Integration section# of the documentation for details.wrapper.java.mainclass=org.tanukisoftware.wrapper.WrapperSimpleApp
# Java Classpath (include wrapper.jar) Add class path elements as# needed starting from 1wrapper.java.classpath.1=../lib/wrapper.jarwrapper.java.classpath.2=C:/Documents and Settings/jacek/eclipse/EGB/dist/lib/jodra.jarwrapper.java.classpath.3=C:/Documents and Settings/jacek/eclipse/EGB/lib/postgresql-8.1-405.jdbc3.jarwrapper.java.classpath.4=C:/Documents and Settings/jacek/eclipse/EGB/lib/jaybird-full-2.1.1.jarwrapper.java.classpath.5=C:/Documents and Settings/jacek/eclipse/EGB/lib/jdom.jarwrapper.java.classpath.6=C:/Documents and Settings/jacek/eclipse/EGB/lib/zql.jarwrapper.java.classpath.7=C:/Documents and Settings/jacek/eclipse/EGB/lib/commons-configuration-1.1.jarwrapper.java.classpath.8=C:/Documents and Settings/jacek/eclipse/EGB/lib/commons-collections-3.1.jarwrapper.java.classpath.9=C:/Documents and Settings/jacek/eclipse/EGB/lib/commons-lang-2.1.jarwrapper.java.classpath.10=C:/Documents and Settings/jacek/eclipse/EGB/lib/commons-logging-1.0.4.jar
# Java Library Path (location of Wrapper.DLL or libwrapper.so)wrapper.java.library.path.1=../lib
# Java Additional Parameterswrapper.java.additional.1=-ea
# Initial Java Heap Size (in MB)#wrapper.java.initmemory=3
# Maximum Java Heap Size (in MB)#wrapper.java.maxmemory=64
© Copyright by eGov-Bus Consortium119

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
# Application parameters. Add parameters as needed starting from 1wrapper.app.parameter.1=odra.wrapper.net.Serverwrapper.app.parameter.2=-C"C:/Documents and Settings/jacek/eclipse/EGB/"wrapper.app.parameter.2.stripquotes=TRUE#wrapper.app.parameter.3=-Dfirebird#wrapper.app.parameter.4=-P2000#wrapper.app.parameter.5=-Vtrue
#********************************************************************# Wrapper Logging Properties#********************************************************************# Format of output for the console. (See docs for formats)wrapper.console.format=PM
# Log Level for console output. (See docs for log levels)wrapper.console.loglevel=INFO
# Log file to use for wrapper output logging.wrapper.logfile=../logs/wrapper.log
# Format of output for the log file. (See docs for formats)wrapper.logfile.format=LPTM
# Log Level for log file output. (See docs for log levels)wrapper.logfile.loglevel=INFO
# Maximum size that the log file will be allowed to grow to before# the log is rolled. Size is specified in bytes. The default value# of 0, disables log rolling. May abbreviate with the 'k' (kb) or# 'm' (mb) suffix. For example: 10m = 10 megabytes.wrapper.logfile.maxsize=1m
# Maximum number of rolled log files which will be allowed before old# files are deleted. The default value of 0 implies no limit.wrapper.logfile.maxfiles=10
# Log Level for sys/event log output. (See docs for log levels)wrapper.syslog.loglevel=NONE
#********************************************************************# Wrapper Windows Properties#********************************************************************# Title to use when running as a consolewrapper.console.title=ODRA wrapper server
#********************************************************************# Wrapper Windows NT/2000/XP Service Properties#********************************************************************# WARNING - Do not modify any of these properties when an application# using this configuration file has been installed as a service.# Please uninstall the service before modifying this section. The# service can then be reinstalled.
# Name of the servicewrapper.ntservice.name=ODRAwrapper
# Display name of the servicewrapper.ntservice.displayname=ODRA wrapper server
© Copyright by eGov-Bus Consortium120

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
# Description of the servicewrapper.ntservice.description=ODRA relational database wrapper server
# Service dependencies. Add dependencies as needed starting from 1wrapper.ntservice.dependency.1=
# Mode in which the service is installed. AUTO_START or DEMAND_STARTwrapper.ntservice.starttype=AUTO_START
# Allow the service to interact with the desktop.wrapper.ntservice.interactive=false
The most important properties in wrapper.conf are: wrapper.java.command – which JVM use (depending on a system configuration one might need to
specify a full path to the java program), wrapper.java.mainclass – an JSW integration method (with the value specified in the above listing it
does not require a JSW implementation, do not modify this one), wrapper.java.classpath.N – Java classpath elements (do not modify the first classpath element, as it
denotes a JSW JAR location, the other elements refer to libraries used by the ODRA wrapper server, including JDBC drivers),
wrapper.java.additional.N – JVM startup parameters (in the example only -ea used for enabling assertions),
wrapper.java.maxmemory – JVM heap size, probably it would require more than the default 64 MB for real-life databases,
wrapper.app.parameter.1 – ODRA wrapper server main class (do not modify this one), wrapper.app.parameter.2 – a path to ODRA wrapper server configuration files directory (i.e.
connection.properties and <dbname>-schema.generated.xml) passed as a server startup parameter, wrapper.app.parameter.2.stripquotes – important when a parameter name contains extra quotes, wrapper.app.parameter.3 – database name passed as a server startup parameter, wrapper.app.parameter.4 – server listener port passed as a server startup parameter, wrapper.app.parameter.5 – server verbose mode passed as a server startup parameter, wrapper.logfile.maxsize – a maximum size of a single log file before it is split, wrapper.logfile.maxfiles – a maximum number of log files until the old ones are deleted.
Notice that wrapper.app.parameter.[2...5] conform server startup parameters syntax described above. They are optional and their order is arbitrary. Other configuration properties' descriptions are available at the JSW web site.
In order to test a configuration one can run $JSW_HOME/bin/test.bat. The JSW is launched as a standalone application and runs the ODRA wrapper server (any misconfiguration can be easily detected). If a test succeeds, a JSW is ready to install as a system service. A service is installed with install.bat and deinstalled with uninstall.bat. A sample preconfigured JSW installation for MS Windows can be downloaded from http://jacenty.kis.p.lodz.pl/jsw.win.zip – only some paths need to be adjusted.
12.5 XML Importer and Exporter12.5.1 IntroductionAn XML document consists of three basic elements: named nodes, text nodes and node attributes. The example below shows them in a simple XML document.
<Person id=”0000123”><Name>John</Name><Surname>Smith</Surname><Phone type=”mobile”>+48-888-88-00-12</Phone><Info>Likes <animal>cats</animal> but not <animal>dogs</animal></Info>
</Person>
Named nodes: Person, Info, Name, Surname, Phone, animal
Text nodes: John, Smith, +48-888-88-00-12, Likes, cats, but not, dogs
© Copyright by eGov-Bus Consortium121

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Node attributes: id=”0000123”, type=”mobile”
The above nomenclature will be used in this document. Please note the following problems with XML structures when imported into an object database and addressed in a query language.
1) Named nodes may be simple, single valued nodes or complex nodes (containing other nodes). If some nodes are optional then the type of a containing node may vary on presence of the optional part. Consider for example the Phone node. If the type attribute is present then phone must be a complex object, it clearly contains two subobjects: type (mobile) and string (+48-888-88-00-12). If type is not present then the phone object is to be perceived as a simple type string object.
2) Similarly an object may be seen as a complex one if an optional subobject is present. For example, if someone does not use animal tags in the info object then the info object may be understood as a simple string object.
3) Objects may contain nameless subobjects. Let us consider Info node. If Info is the name for the whole node than we have no name for “Likes” and “but not” text nodes. Objects having no name cannot be used in queries. Some query languages solves this problem by simply enumerating subobjects.
These problems of unpredictably changing structure of objects may result in queries that will change semantics and results in a way hard to understand.
For example let us consider the following XML input data:
<Person id=”0000123”><Name>John</Name><Surname>Smith</Surname><Phone type=”mobile”>+48-888-88-00-12</Phone><Phone>+48-22-234-22-22</Phone>
</Person>
Here, the first Phone object seems to be complex object, while the second one may be seen as a simple object. If the type attribute is optional then the structure and semantics of the Phone objects may change unexpectedly. Another problem appears if someone adds type attribute to the second Phone object. It must become a complex object.
Our XML importer is designed to avoid these problems. If fact, there are two problems to be solved when dealing with XML input: attributes and nameless object content. The XML import procedure offers two ways of solving these problems.
12.5.1.1 Naming the nameless content
As it was shown in the previous section sometimes XML tags may contain data that is nameless from the object database’s point of view. What’s even more confusing sometimes character of data may change when container object changes but the data itself is not touched.
Let us recall the previous example:
<Phone>+48-888-88-00-12</Phone>
The phone element may be seen as a simple string object named Phone.
But, if someone alters the Phone tag by adding an attribute:
<Phone type=”mobile”>+48-888-88-00-12</Phone>
then phone becomes a complex object because it has two properties: type and nameless value. Now a user must access the same object in different way. Therefore XML Importer always treats all objects as complex objects. Simple type values are always stored in subobjects named _VALUE.
So the phone element before the modification is perceived as if it contains another element named _VALUE:
<Phone><_VALUE>+48-888-88-00-12</VALUE></Phone>
The second one looks similarly:
<Phone type=”mobile”><_VALUE>+48-888-88-00-12</VALUE></Phone>
In both cases a user has got the same access path to the phone number value:
© Copyright by eGov-Bus Consortium122

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Phone._VALUE;
12.5.1.2 Accessing attributes
The main problem with the elements’ attributes is that they must be properly treated when exporting XML data. If an object has been created from an attribute it should also result in the attribute creation when exported to XML. Hence those objects must be distinguished from normal objects. XML Importer uses two independently exclusive solutions to this problem: addition of ‘@’ prefix to an object’s name and attaching an annotation to imported attribute object.
12.5.1.2.1 ‘@’ attribute prefix
In this case the phone object from the previous section will be imported as if it looks like this:
<Phone> <@type>mobile</@type> <_VALUE>+48-888-88-00-12</VALUE></Phone>
Please note that now a user must use name @type to access the attribute subobject value while accessing the main value of the object remains the same.
This kind of import procedure may be executes using the M0 importer option. Please refer to importing XML using CLI command line section.
12.5.1.2.2 Attribute annotations
Another way to mark object coming from attributes is to attach an annotation. Annotations are hidden from the user and may be used and created only by the system. However, they are recognized when an object is exported to XML and the expected XML data format is produced.
An example from the previous section is loaded as if it looks like this:
<Phone> <type><_VALUE>mobile<_VALUE></type> <_VALUE>+48-888-88-00-12</VALUE></Phone>
You may observe that all objects are treated in the same way. All simple type values are accessed using the same uniform construct:
Phone.type._VALUE;
Phone._VALUE;
Importing XML with annotations is the default option for the importer when executed in the CLI command line. Please refer to the proper section for more details.
12.5.1.3 XML namespaces
XML elements may be equipped with namespace information. Generally it means that an element’s name is preceded by a namespace:
<addr:Phone>+48-888-88-00-12</addr:Phone>
Here Phone is the name of the object while addr is the namespace information. Namespaces must be properly declared before use:
<?xml version="1.0" encoding="UTF-8"?><addr:Addressbook xmlns:addr=”http://www.company.com/addressbook”> <addr:Phone>+48-888-88-00-12</addr:Phone></addr:Addressbook>
Here, xmlns:addr=”http://www.company.com/addressbook” is a namespace declaration. Please refer to W3C XML specification for detailed information about namespaces.
The XML Importer can handle nemespaces automatically by annotating imported objects. For each namespace declaration and usage an annotation is created. Please refer to XML import procedure section for more details.
© Copyright by eGov-Bus Consortium123

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Since a user cannot see annotations, namespace information so far remains invisible, that is, it cannot be accessed using the query language. However, after exporting namespaces may appear in the resulting XML again.
12.5.2 Importing XML using CLI command lineGeneral structure of XML importer execution command is as follows:
load “resource” using XMLImporter(“params”)
or
load “resource” using XMLImporter
where
resource – a path to a XML file that is to be imported
params – a list of parameters recognized by the importer, separated by: “[space] , ; \n \t \r \f ”.
For example:
load “res/xml/bookstore.xml” using XMLImporter
load “foo/myshop/bookstore.xml” using XMLImporter(“M0, noGuessType”)
When no parameters are specified then the import procedure assumes that annotations must be used for marking attributes and namespace information, simple type value must be automatically guessed and references between object using id, idref attribute pairs.
12.5.2.1 XML importer parameters
Currently the list of recognized XML importer parameters contains:
– M0 – do not use annotated object during import procedure (contradictory to useMetabase). See import procedure description for details. By default this option is not used so it must be stated explicitly when needed.
– noGuessType – do not perform automatic type guessing (contradictory to useMetabase, using metabase will always use explicit type information). See automatic type guessing for details. By default this option is not used, so simple types are guessed.
– noAutoRefs – do not perform automatic id/idref recognition and reference object creation. See automatic references for details. By default this option is not used so references between objects are created automatically.
– useMetabase – import XML using type information from metabase (contradictory to M0, using metabase for type inferring will always use annotated objects). Metabase may be created in any way but in most cases will be constructed by importing XSD file.
12.5.3 XML Import Procedure The import procedure is able to deal with complex objects and attributes, resolve idref and id attribute pairs to create references and import namespace information. Generally when an XML document is imported into an ODRA object store, all information found in XML is converted to appropriate SBA objects.
12.5.3.1 Complex structures and attributes.
Complex XML structures, simple values and attributes are imported according to the following rules:
1. Tagged element is converted to a complex object. A tag name is used as the object's name.
2. Text inside tagged element is stored in simple type object named _VALUE. Type may be guessed or taken from metabase.
3. Element's attributes are stored in subobjects:
1. in case of simple import procedure, the created subobject is a simple type object with name preceded by ‘@’. Its type may be guessed automatically. Please note that this way of attribute
© Copyright by eGov-Bus Consortium124

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
importing will work only when parameter M0 in XMLImporter is used. Sign ‘@’ distinguishes an attribute and a normal objects.
Example:
XML ODRA store
<Text font="Arial"> Foo.</Text><Text> Boo. <NestedText> Moo. </NestedText></Text>
Text{@font="Arial”_VALUE=“Foo.”
}Text{
_VALUE=”Boo.”NestedText{ _VALUE=”Moo.”}
}
2. in case of import using annotated objects, the created subobject is a complex object containing single simple type object named _VALUE. The subobject's name is equal to attribute's name but an appropriate annotation is created (attribute=true). In this way attributes are treated in the same way as all other objects. The annotation is the only way to distinguish non attribute and attribute objects.Example:
XML ODRA store
<Text font="Arial"> Foo.</Text><Text> Boo.</Text>
Text{Font[attribute=”true”]{
_VALUE=“Arial”}_VALUE=“Foo.”
}Text{
_VALUE=”Boo.”}
12.5.3.2 Type guessing.
For some purposes (mainly comparing values or selecting minimal value) the XML importing procedure tries to guess the type of imported simple type value. If it is a parseable double then a double object is produced. If it is a parseable integer then an integer object is produced. Otherwise string is produced. Please note that this option does not use any kind of schema. For example, if an XML file contains:
<avg>-10.20</avg><count>40</count><descr>40-50-40</descr>then after the XML import with automatic type guessing avg will be a double object, count will be an integer object and descr will be a string object.
Type guessing may be switched off by “noGuessType” plugin option. Type may be also assigned to an object using metabase entries. Please refer to the proper section for more information.
12.5.3.3 Automatic references between elements.
XML Importer may automatically create reference objects using the following algorithm:
1. if an element Y contains attribute idref=”X” it is interpreted as a pointer to another element;
2. if appropriate element Z with id=”X” attribute is found, then element Y is imported as a reference object pointing to object Z. If more than one Z is found, then only the first one is connected (it is generally impossible since id attributes have to be unique);
3. if appropriate element identified by X is not found then Y is created as a complex object containing string object named idref with value X.
© Copyright by eGov-Bus Consortium125

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
4. id and idref attributes are not created in resulting ODRA's store objects. User will not be able to access them until automatic references creation is turned off.
Automatic creation of reference objects upon id/idref attributes may be turned off by import parameter “noAutoRefs”.
12.5.3.4 Namespaces.
Namespace information may be also imported but please note that SBQL has no constructs to access those information right now. However it will be visible when an object with namespace information will be produces as a query result. In case of a simple import procedure (M0) all namespace declarations and prefixes are omitted. One must use annotating import procedure to handle namespaces correctly, since namespaces are converted to annotation objects:
1. namespace definition is converted to an annotation object: namespaceDef( prefix:String, uri:String )
2. a single object may have many namespaceDef annotations;
3. namespace assignment creates a reference annotation namespaceRef pointing to an appropriate namespaceDef object;
4. an object may contain only one namespaceRef annotation;
5. if an object is assigned to a namespace it must contain namespaceRef annotation, even if it points to its own namespaceDef;
6. attributes may contain only single namespaceRef annotation.
12.5.3.5 Type inferring using metabase objects.
XML Importer may use type information taken from objects in metabase. In such case, simple objects and attributes will not be imported as strings nor any type guessing will be done. Structure of imported XML objects must exactly reflect structures described in the metabase. Type assignment do XML object may be done in two (alternative) ways:
1. by name of an XML object, which must be exactly the same as name of declared variable, structure or typedef existing in metabase
2. by type attribute, which points to metaobject with name equal to value of the attribute. Type declaration attribute must be assigned to namespace http://www.w3.org/2001/XMLSchema-instance (other namespaces, also undefined namespace will result in omitting the type attribute).
Please note that the second case makes sense only for simple type objects because name of the XML object must exactly fit name of variable declaration (in case of a root object) or structure field's name declaration in (case of an object embedded in other object). Otherwise type checking will fail.
Example:XML fragment:
<shipTo exportCode="1" xsi:type="ipo:UKAddress"> <name>Helen Zoe</name> <street>47 Eden Street</street> <city>Cambridge</city> <postcode>CB1 1JR</postcode></shipTo>XSD fragment:
<element name="shipTo" type="ipo:UKAddress"/><complexType name="UKAddress"><complexContent> <sequence> <element name="name" type="string"/> <element name="street" type="string"/>
<element name="city" type="string"/> <element name="postcode" type="ipo:UKPostcode"/> </sequence>
© Copyright by eGov-Bus Consortium126

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
<attribute name="exportCode" type="positiveInteger"/></complexContent></complexType>Above XML and XSD will create object named shipTo with type referring to UKAddress typedef but the metabase will also declare variable shipTo with the same type.
Importing XML schema and XML commands using types taken from metabase:
load "res/xml/personnel.xsd" using XSDImporterload "res/xml/personnel.xml" using XMLImporter("useMetabase")
If one wants to infer type upon information from matabase XML must be imported with annotations, thus M0 option is forbidden.
12.5.4 Example XML files and queriesNow, we shall present several examples of queries.
12.5.4.1 Example 1 – Books and Authors
The XML file contains information about books and authors. Each book has got title, possibly many authors, publisher, price and optionally editor.
Let us assume, that the file named bib.xml contains:
<?xml version="1.0" encoding="UTF-8"?><bib> <book year="1994"> <title>TCP/IP Illustrated</title> <author><last>Stevens</last><first>W.</first></author> <publisher>Addison-Wesley</publisher> <price>65.95</price> </book> <book year="1992"> <title>Advanced Programming in the Unix environment</title> <author><last>Stevens</last><first>W.</first></author> <publisher>Addison-Wesley</publisher> <price>65.95</price> </book> <book year="2000"> <title>Data on the Web</title> <author><last>Abiteboul</last><first>Serge</first></author> <author><last>Buneman</last><first>Peter</first></author> <author><last>Suciu</last><first>Dan</first></author> <publisher>Morgan Kaufmann Publishers</publisher> <price>39.95</price> </book> <book year="1999"> <title>The Economics of Technology and Content for Digital TV</title> <editor> <last>Gerbarg</last><first>Darcy</first> <affiliation>CITI</affiliation> </editor> <publisher>Kluwer Academic Publishers</publisher> <price>129.95</price> </book></bib>
It may be loaded using CLI command:
load "bib.xml" using XMLImporter
© Copyright by eGov-Bus Consortium127

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
The second XML file contains books’ reviews (reviews.xml):
<?xml version="1.0" encoding="UTF-8"?><reviews> <entry> <title>Data on the Web</title> <price>34.95</price> <review> A very good discussion of semi-structured database systems and XML. </review> </entry> <entry> <title>Advanced Programming in the Unix environment</title> <price>65.95</price> <review> A clear and detailed discussion of UNIX programming. </review> </entry> <entry> <title>TCP/IP Illustrated</title> <price>65.95</price> <review> One of the best books on TCP/IP. </review> </entry></reviews>
It may be loaded using CLI command:
load "reviews.xml" using XMLImporter
Here are the valid queries and corresponding results:
1. List books published by Addison-Wesley after 1991, including their year and title.
(((bib.book where (publisher._VALUE="Addison-Wesley") and (year._VALUE>1991)).(title as title, year as year)) as book ) groupas bib;
Result:
<?xml version="1.0" encoding="UTF-8"?><bib> <book year="1994"> <title>TCP/IP Illustrated</title> </book> <book year="1992"> <title>Advanced Programming in the Unix environment</title> </book></bib>
2. For each book in the bibliography, list the title and authors, grouped inside a "result" element.
bib.book.((author as author union title as title) groupas result) groupas results;
Results:
<?xml version="1.0" encoding="UTF-8"?><results> <result> <author>
© Copyright by eGov-Bus Consortium128

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
<last>Stevens</last> <first>W.</first> </author> <title>TCP/IP Illustrated</title> </result> <result> <author> <last>Stevens</last> <first>W.</first> </author> <title>Advanced Programming in the Unix environment</title> </result> <result> <author> <last>Abiteboul</last> <first>Serge</first> </author> <author> <last>Buneman</last> <first>Peter</first> </author> <author> <last>Suciu</last> <first>Dan</first> </author> <title>Data on the Web</title> </result> <result> <title>The Economics of Technology and Content for Digital TV</title> </result></results>
3. Create a flat list of all the title-author pairs, with each pair enclosed in a "result" element.
bib.book.((title as title, author as author) groupas result )groupas results;
Result:
<?xml version="1.0" encoding="UTF-8"?><results> <result> <title>TCP/IP Illustrated</title> <author> <last>Stevens</last> <first>W.</first> </author> </result> <result> <title>Advanced Programming in the Unix environment</title> <author> <last>Stevens</last> <first>W.</first> </author> </result> <result> <title>Data on the Web</title> <author> <last>Abiteboul</last> <first>Serge</first>
© Copyright by eGov-Bus Consortium129

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
</author> </result> <result> <title>Data on the Web</title> <author> <last>Buneman</last> <first>Peter</first> </author> </result> <result> <title>Data on the Web</title> <author> <last>Suciu</last> <first>Dan</first> </author> </result> <result/></results>
4. For each author in the bibliography, list the author's name and the titles of all books by that author, grouped inside a "result" element.
(unique(deref(bib.book.author)) as anAuthor).((anAuthor as author union(bib.(book where anAuthor in author)).title as title) groupas result)groupas results;
Results:
<?xml version="1.0" encoding="UTF-8"?><results> <result> <author> <last>Abiteboul</last> <first>Serge</first> </author> <title>Data on the Web</title> </result> <result> <author> <last>Buneman</last> <first>Peter</first> </author> <title>Data on the Web</title> </result> <result> <author> <last>Stevens</last> <first>W.</first> </author> <title>TCP/IP Illustrated</title> <title>Advanced Programming in the Unix environment</title> </result> <result> <author> <last>Suciu</last> <first>Dan</first> </author> <title>Data on the Web</title> </result></results>
© Copyright by eGov-Bus Consortium130

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
5. For each book found at both bib.xml and reiews.xml, list the title of the book and its price from each source. We assume that the files has been loaded as shown previously.
((unique(bib.book.title as aBookTitle)).((aBookTitle as title unionreviews.(entry where title = aBookTitle).price as price_bstore1 union(bib.book where title=aBookTitle).price as price_bstore2) groupas book_with_prices))groupas results;
Results:
<?xml version="1.0" encoding="UTF-8"?><results> <book_with_prices> <title>TCP/IP Illustrated</title> <price_bstore1>65.95</price_bstore1> <price_bstore2>65.95</price_bstore2> </book_with_prices> <book_with_prices> <title>Advanced Programming in the Unix environment</title> <price_bstore1>65.95</price_bstore1> <price_bstore2>65.95</price_bstore2> </book_with_prices> <book_with_prices> <title>Data on the Web</title> <price_bstore1>34.95</price_bstore1> <price_bstore2>39.95</price_bstore2> </book_with_prices> <book_with_prices> <title>The Economics of Technology and Content for Digital TV</title> <price_bstore2>129.95</price_bstore2> </book_with_prices></results>
6. For each book that has at least one author, list the title and first two authors, and an empty "et-al" element if the book has additional authors.
((((bib.book where count(author)<2 and count(author)>0) as b).((b.title as title union b.author as author) groupas book))union((bib.book where count(author)>=3) as b).(((b.title as title) union (b.author[0] as author) union (b.author[1] as author) union (("") as et_al)) groupas book))groupas bib;
Results:
<?xml version="1.0" encoding="UTF-8"?><bib> <book> <title>TCP/IP Illustrated</title> <author> <last>Stevens</last> <first>W.</first> </author> </book> <book> <title>Advanced Programming in the Unix environment</title>
© Copyright by eGov-Bus Consortium131

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
<author> <last>Stevens</last> <first>W.</first> </author> </book> <book> <title>Data on the Web</title> <author> <last>Abiteboul</last> <first>Serge</first> </author> <author> <last>Buneman</last> <first>Peter</first> </author> <et-al/> </book></bib>
7. List the titles and years of all books published by Addison-Wesley after 1991, in alphabetic order.
((bib.book where (publisher._VALUE="Addison-Wesley") and (year._VALUE>1991)).((title as title, year as @year) as book) orderby deref(book.title._VALUE)) groupas bib;
Results:
<?xml version="1.0" encoding="UTF-8"?><bib> <book year="1992"> <title>Advanced Programming in the Unix environment</title> </book> <book year="1994"> <title>TCP/IP Illustrated</title> </book></bib>
8. In the document prices.xml, find the minimum price for each book, in the form of a "minprice" element with the book title as its title attribute.
Let us assume that the file contains:
<?xml version="1.0" encoding="UTF-8"?><prices> <book> <title>Advanced Programming in the Unix environment</title> <source>bstore2.example.com</source> <price>65.95</price> </book> <book> <title>Advanced Programming in the Unix environment</title> <source>bstore1.example.com</source> <price>65.95</price> </book> <book> <title>TCP/IP Illustrated</title> <source>bstore2.example.com</source> <price>65.95</price> </book>
© Copyright by eGov-Bus Consortium132

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
<book> <title>TCP/IP Illustrated</title> <source>bstore1.example.com</source> <price>65.95</price> </book> <book> <title>Data on the Web</title> <source>bstore2.example.com</source> <price>34.95</price> </book> <book> <title>Data on the Web</title> <source>bstore1.example.com</source> <price>39.95</price> </book></prices>
It may be loaded using CLI command:
load "prices.xml" using XMLImporter
SBQL query solving the task:
(unique(deref(prices.book.title._VALUE)) as t).((t as @title, (min((prices.book where title._VALUE = t).price._VALUE) as price) ) as minprice) groupas results;
9. For each book with an author, return the book with its title and authors. For each book with an editor, return a reference with the book title and the editor's affiliation.
bib.(((book where exists(author)) as b).((b.title as title union b.author as author) groupas book) union((book where exists(editor)) as b).(b.title as title, b.editor.affiliation as affiliation) as reference)groupas bib;
Results:
<?xml version="1.0" encoding="UTF-8"?><bib> <book> <title>TCP/IP Illustrated</title> <author> <last>Stevens</last> <first>W.</first> </author> </book> <book> <title>Advanced Programming in the Unix environment</title> <author> <last>Stevens</last> <first>W.</first> </author> </book> <book> <title>Data on the Web</title> <author> <last>Abiteboul</last> <first>Serge</first> </author>
© Copyright by eGov-Bus Consortium133

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
<author> <last>Buneman</last> <first>Peter</first> </author> <author> <last>Suciu</last> <first>Dan</first> </author> </book> <reference> <title>The Economics of Technology and Content for Digital TV</title> <affiliation>CITI</affiliation> </reference></bib>
10. Find pairs of books that have different titles but the same set of authors (possibly in a different order).
bib.((book where exists(author)) as b1, (book where exists(author)) as b2).(b1 where ((title._VALUE <> b2.title._VALUE) and forall(author as a) (a in b2.author))).title as titlegroupas book_pair groupas bib;
Results:
<?xml version="1.0" encoding="UTF-8"?><bib> <book-pair> <title>TCP/IP Illustrated</title> <title>Advanced Programming in the Unix environment</title> </book-pair></bib>
12.5.4.2 Example 2 – Departments and Employees
The XML file contains two kinds of objects: employees and departments. An employee may contain reference to a department he works in and optionally to a department he manages. Each department contains bidirectional references to employed employees and to the boss.
Let us assume that the file is named deptemp.xml:
<?xml version="1.0" encoding="UTF-8"?><deptemp>
<Emp id="i1"> <name>Doe</name>
<sal>2500</sal><worksIn idref="i17"></worksIn><manages idref="i17"></manages>
</Emp><Emp id="i5">
<name>Poe</name><sal>2000</sal><worksIn idref="i22"></worksIn>
</Emp><Emp id="i9">
<name>Lee</name><sal>900</sal><address>
<city>Rome</city><street>Boogie</street><house>13</house>
© Copyright by eGov-Bus Consortium134

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
</address><worksIn idref="i22"></worksIn>
</Emp><Emp id="i55">
<name>Bert</name><sal>3000</sal><address>
<city>Paris</city><street>Avenue</street><house>34</house>
</address><worksIn idref="i22"></worksIn><manages idref="i22"></manages>
</Emp><Dept id="i17">
<dname>Trade</dname><loc>Paris</loc><loc>Rome</loc><budget>100000</budget><employs idref="i1"></employs><boss idref="i1"></boss>
</Dept><Dept id="i22">
<dname>Ads</dname><loc>Rome</loc><budget>200000</budget><employs idref="i5"></employs><employs idref="i9"></employs><employs idref="i55"></employs><boss idref="i55"></boss>
</Dept></deptemp>
Now, the file may be loaded using the following CLI command:
load “deptemp.xml” using XMLImporter
Here are the valid queries that may be executed:
1. Get departments together with the average salaries of their employees:
deptemp.((Dept as d) join avg(d.employs.Emp.sal._VALUE));
deptemp.(Dept join avg(employs.Emp.sal._VALUE));
2. Get name and department name for employees earning less than 2222
deptemp.(Emp where sal._VALUE < 2222).(name._VALUE, worksIn.Dept.dname._VALUE);
3. Get names of employees working for the department managed by Bert.
deptemp.(Emp where (worksIn.Dept.boss.Emp.name._VALUE) = "Bert").name._VALUE;
4. Get the name of Poes boss:
deptemp.(Emp where name._VALUE = "Poe").worksIn.Dept.boss.Emp.name._VALUE;
5. Names and cities of employees working in departments managed by Bert:
deptemp.(Dept where (boss.Emp.name._VALUE) = "Bert").employs.Emp.
(name._VALUE, ((address.city._VALUE) union ("No address" where not exists(address))));
© Copyright by eGov-Bus Consortium135

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
6.Get the minimal, average and maximal number of employees in departments:
deptemp.(min(Dept.count(employs)), avg(Dept.count(employs)), max(Dept.count(employs)) );
7. For each department get its name and the sum of salaries of employees being not bosses:
deptemp.(((Dept as d) join ((sum(d.employs.Emp.sal._VALUE) - (d.boss.Emp.sal._VALUE)) as s )).(d.dname._VALUE, s));
8. Is it true that each department employs an employee earning the same as his/her boss?:
deptemp. forall (Dept as d) forany ((d.employs.Emp minus d.boss.Emp) as e) forany (e.sal as s) (s._VALUE = d.boss.Emp.sal._VALUE);
9. For each employee get the message containing his/her name and the percent of the annual budget of his/her department that is consumed by his/her monthly salary:
deptemp. Emp . ("Employee " + name._VALUE + " consumes " +((sal._VALUE * 12 * 100)/(worksIn.Dept.budget._VALUE)) + "% of the " + worksIn.Dept.dname._VALUE + " department budget.");
10. Get cities hosting all departments:
deptemp.(unique(deref(Dept.loc._VALUE)) as deptcity) where forall(deptemp.Dept)(deptcity in loc._VALUE);
© Copyright by eGov-Bus Consortium136

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
13. Front-End Application Programming Interfaces13.1 Web Services EndpointsThe ODRA database system provides native support for exposing web services. That allows external applications to take advantage of ODRA features through a web services interface.
There are three kinds of web services endpoints in ODRA: generic, procedure and class based. Each of them works in the context of a special web service user account. Moreover they are all designed to met WS-I BP 1.1 compliance.
Web services endpoints access interface may be customized to meet exact deployment expectations. The endpoints specific configuration parameters are described in next subsections.
13.1.1 Generic Web Service EndpointGeneric endpoint provides unlimited and flexible access to database resources through a web service. Due to its usage characteristics there are no DDL commands to manipulate it. There can be at most one such endpoint in a database. It can be configured (i.e. enabled or disabled) in database configuration file.
12-1. Web Service endpoint
Because of high dynamicity of possible generic endpoint response results, its WSDL contract is static. It exposes one remote method Execute, which takes in two string parameters:
sbql – any valid SBQL program, module name (global name) – indicates the context of the above program execution.
Generic web method response is XML fragment, which is serialization of provided SBQL program result. If any error occurs during the processing (i.e. incorrect SBQL code, non-existing module usage), it is delivered through standard web service error reporting mechanisms.
13.1.2 Procedure and Class based Web Service EndpointsAdditionally to previously described generic endpoints, a typed endpoint is available in ODRA. Its instances are attached to regular objects in a database. Currently a global procedure and a class are supported. In the first case a web service contains only one remote method (connected to a local procedure). In the second case it has as many methods as the class being exposed.
For this endpoint type, the input and output shape is known in advance. This allows fine-grained remote interaction, because all type information may be included in a web service contract. WSDL document is build dynamically. Its shape depends on a type of the exposed object and user provided options. All exposed services are compliant with WS-I BP 1.1 and use “wrapped” version of “document/literal” SOAP encoding/style.
© Copyright by eGov-Bus Consortium137

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
12-2. Web Service remote calls
In order to create a new endpoint the following DDL command is to be executed:
add endpoint endpointName on objectName with (
state={started|stopped}, path="relativePath",service="serviceName",port="portName",ns="namespaceURI"
)
Options for this command are described in the following table:
Table 11-2. Create endpoint command options description.
Option name Allowed values Description
endpointName any valid database object name
Provides name, which may be further used to refer to this endpoint.
objectName any valid database object name
Determines the object to expose. Currently it can be procedure or class name.
state started or stopped Indicates whether endpoint processes incoming requests (started) or skips them (stopped).
path relative URL starting from /
Determines web service endpoint access URL. Relative within HTTP embedded server domain.
serviceName Any non empty combination of letter, digits and '.', '-', '_' and ':’
Provides name, which will be used as Service name in generated WSDL document.
portName Any non empty combination of letter, digits and '.', '-', '_' and ':’
Provides name, which will be used as PortType name in generated WSDL document.
ns URI Provides namespace, which will be used as target namespace in generated WSDL document.
In order to remove an endpoint, the user needs to use a dedicated DDL command:
© Copyright by eGov-Bus Consortium138

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
remove endpoint endpointName
Additionally there may be a need to stop request processing for a given endpoint but without really removing it. It can be accomplished by:
suspend endpoint endpointName
After the previous command is executed the following one can be used for bring endpoint back to live:
start endpoint endpointName
Below we present an example of a class based web service endpoint usage scenario. We assume that a database is placed on the machine available at address http://egov-bus.org and that an embedded HTTP server is configured to use the 8888 port. We will expose the following module, which provides simple auction implementation. The user may acquire list of offered items and make a bid. Topmost bids are kept in the global variable “items”.
module AuctionModule { type Item is record {
id : integer; name: string; description: string; price: real;
}items:Item[0..*];
class AuctionClass { instance Auction : { } getItems():Item[0..*] { return items; }
makeBid(itemId:integer; newBid:real):Item { price:integer; name:string;
price = (items where id = itemId)[0].price; name = (items where id = itemId)[0].name;
if price < newBid then { (items where id = itemId).price := newBid; }
return (items where id = itemId)[0]; } }}
Before going further we need to pre populate auction items with some example data:
create permanent items(1 as id, "mercedes" as name, "brand new" as description, 15.5 as price)
create permanent items(2 as id, "audi" as name, "4 years old" as description, 12.5 as price)
In order to make it available as a web service we need to run the following command in the AuctionModule context:
add endpoint AuctionEndpoint on AuctionClass with (state=STARTED, path="/Auction", service="AuctionService",
port="AuctionPort", ns="http://www.egovbus.org/endpoints/tests")
After executing the above command the web service will be immediately available. Its contract may be found at http://www.egov-bus.org:8888/Math?wsdl. Any web service platform, which supports WS-I BP 1.1 compliant web services may be used to interact with Auction web service.
© Copyright by eGov-Bus Consortium139

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
Please note that topmost bids are kept between subsequent web service calls. The presented example shows how it is easy to create stateful web services in ODRA. Web services created in ODRA may be stateless as well.
13.1.3 ConfigurationThere are several parameters, which determine web services an endpoints operation. They are placed in the main database configuration file. Options directly connected with endpoints are listed in the following table.
Table 11-3. Web services endpoints feature configurable parameters
Option name Allowed values Description
E n d p o i n t s s p e c i f i c o p t i o n s ( w s . e n d p o i n t s )
server.address URL Determines base server address, which will be used to host web services endpoints
server.port 1 - 65535 Determines base server port, which will be used to host web services endpoints
context.username any valid database user name
Determines user context of web service endpoints execution.
generic.enabled yes/no Indicates whether generic web service endpoint functionality should be enabled.
generic.path relative URL starting from /
Determines web service endpoint access URL. Relative within HTTP embedded server domain.
generic.servicename
Any non empty combination of
letter, digits and '.', '-', '_' and ':’
Provides name, which will be used as Service name in generated WSDL document.
generic.portname
Any non empty combination of
letter, digits and '.', '-', '_' and ':’
Provides name, which will be used as PortType name in generated WSDL document.
generic.namespace URI Provides namespace, which will be used as target namespace in generated WSDL document.
13.2 ODRA Web API SpecificationThe ODRA Web API Specification for Java programmers is the subject of another document: 070621-02 ODRA Web API Specification.doc
13.3 Specification of ODRA JOBCODRA JOBC (Java Object Base Connectivity) is defined and implemented exactly following the idea, syntax and semantics of JDBC (Java Data Base Connectivity). The differences concerns input: SBQL queries rather than SQL queries, and output: serialized ODRA objects rather than serialized relational tables. This section introduces fundamentals of the use of ODRA JOBC API. It explains how to configure and connect an application to an ODRA database, how to prepare a query and how to execute it and process its result.
The implemented ODRA JOBC API driver is compatible with Java 1.4+.
13.3.1 Configuring connectionConnection configuration is accomplished during instantiating an JOBC class instance. Available constructor signatures are the following:
public JOBC(String user, String password, String host, int port);
public JOBC(String user, String password, String host);
© Copyright by eGov-Bus Consortium140

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
where:
user – the name of the database user
password – the user password
host – the IP/DNS address of the ODRA serwer.
port – optional ODRA database instance port number (if not provided the default is assumed which is 1521).
Example:
Connection to localhost on the default port as user ‘admin’ with password ‘admin’.
JOBC db = new JOBC("admin", "admin", "localhost");
13.3.2 Connecting to and disconnecting from an ODRA databaseConnection to a database is performed by the connect method. If connection cannot be established, an JOBC exception is thrown. The connect method signature is as follows:
void connect() throws IOException;
An opened connection can be explicitly closed by calling the close() method.
Example:
db.connect();
. . . . . . //execute queries
db.close();
13.3.3 Setting up a working moduleAn ODRA data is stored in a hierarchical structure of modules. Each user has its own root environment that is named with the username. A root module can contain any number of sub-modules storing programs and data. After connecting to the database the current module indicator is set to the user root module. To switch the current module the programmer can call the following method in the JOBC class:
void setCurrentModule(String moduleGlobalName) throws JOBCException;
where:
moduleGlobalName – the global name of the requested module. The global name starts with the username and contains zero or more sub-module names separated by dots.
Example:
Switch to the module ‘reports’ that is a sub-module of ‘current’ module owns by the user ‘admin’:
db.setCurrentModule(“admin.current.reports”);
13.3.4 Executing SBQL queriesSBQL query execution can be performed in the following ways:
1. Call the execute method on the JOBC class instance that takes the SBQL query string as a single parameter. In case the query without parameters this is the simplest way.
public Result execute(String query) throws JOBCException
2. If the query is includes parameters (describe later) first an instance of SBQLQuery class has to be obtained from JOBC class instance with use of the getSBQLQuery method call:
SBQLQuery getSBQLQuery(String query)
© Copyright by eGov-Bus Consortium141

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
where ‘query’ is a string containing the SBQL query.
A query stored in an SBQLQuery class instance can be performed through a call to the overloaded execute method of the JOBC class instance.
public Result execute(SBQLQuery query) throws JOBCException
The execute method returns an instance of the Result class, as described below. The same method is used to read and update the data stored in the database.
Examples:
Result result = db.execute(“2+2”);
Result result = db.execute(“startService()”);
Result result = db.execute(“(Employee where lName=\”York\” and worksIn.Dept.name = \“IT\”).salary := 2000”);
SBQLQuery query = db.getSBQLQuery(“Person where lName=\”York\””);
Result result = db.execute(query);
13.3.5 Query parameterizationThe SBQL query can be parameterized. Parameters in a query string are represented by names enclosed in curly brackets. To set a parameter value, first the SBQLQuery class instance has to be obtained from a JOBC instance (as described in the previous sub-section). Setting actual values for query parameters of different types can be performed through the following SBQLQuery class instance methods:
void addIntegerParam(String name, int param) throws JOBCException
void addBooleanParam(String name, boolean param) throws JOBCException
void addStringParam(String name, String param) throws JOBCException
void addRealParam(String name, double param) throws JOBCException
where:
name – the parameter name
param – the actual value for the parameter
A parameter with a given name can occur in a query more than once. All the parameter occurrences will be substituted by an actual value set for it. An instance of JOBCException is thrown if the name does not match the parameter name in the target query.
Examples:
SBQLQuery query = db.getSBQLQuery(“Person where name = {pname}”);
query.addString(“pname”, “Smith”);
SBQLQuery query = db.getSBQLQuery(“Person where name = {pname} and age > {page}”);
query.addStringParam(“pname”, “Smith”);
query.addIntegerParam(“page”, 30);
© Copyright by eGov-Bus Consortium142

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
SBQLQuery query = db.getSBQLQuery(“Book where (pagesNo >= {pnumber} – {range} and pagesNo <= {pnumber} + {range}).(title, genre)”);
query.addIntegerParam(“pnumber”, 150);
query.addIntegerParam(“range”, 20);
13.3.6 Processing query resultsResults of SBQL queries are represented by the Result’s class instance. It can represent different types of SBQL query results. The following types of results are supported:
1. primitive value of the following types:
a. integer
b. real
c. string
d. date
2. object reference
3. structure of results
4. bag of results
5. named result (i.e. a binder) – each of the result kinds equipped with a name.
13.3.6.1 Getting a primitive value
To check if the result is primitive the following method is to be used:
boolean isPrimitive();
If the result is primitive, its value can be obtained with the use of the following methods in the Result class that maps an ODRA result to a value of a Java equivalent type:
int getInteger() throws JOBCException;
double getReal() throws JOBCException;
String getString() throws JOBCException;
String getString() throws JOBCException;
boolean getBoolean() throws JOBCException;
Date getDate() throws JOBCException;
Examples:
Result result = db.execute(“2+2”);
int value = result.getInteger();
Result result = db.execute(“avg(Employee.salary)”);
double value = result.getReal();
Result result = db.execute(“forall(Person) address.city = \“Warsaw\””);
boolean result = result.getBoolean();
13.3.6.2 Object referencesSBQL queries can return object references. Because in the context of JOBC calls object references are currently not supported, they are represented as string constant values - “object reference”.
© Copyright by eGov-Bus Consortium143

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
13.3.6.3 Complex resultsAn SBQL query can return a structure, which can be the result of operators used in a query or can be returned by the dereference acting on an identifier of a complex object. Fields of a structure can be named or unnamed. To check if the result is complex the following method is to be used:
boolean isComplex();
Fields of a complex result can be accessed in the following ways:
1. By calling the fields() method that returns a bag of results representing structure fields. The bag can be processed by iteration.
2. If a field is named, it can be accessed with the use of getByName(String name) method.
Example:
The query returns two elements structure ( {integer, string} ) containing the Smith’s age and home address. We assume that there is only one Person with that name and the cardinality of fields ‘age’ and ‘address’ is [1..1].
Result result = db.execute(“(Person where lName = \“Smith\”).(deref(age), deref(address))”);
Result fields = result.fields();
System.out.println(fields.get(0) + “,” + fields.get(1));
13.3.6.4 Bag of results and empty resultsSBQL queries can return a bag of results (primitive, structs, object references or named). The JOBC API allows for iteration over the results in a bag result. The Result class implements Iterable<Result> interface.
To check if the result is complex the following method is to be used:
boolean isBag();
An empty result has the following properties:
result.isBag(); // returns true
result.size(); // returns 0
result.isEmpty(); // returns true
Example:
Result result = db.execute(“(Person where age > 20).lName”);
//java 1.5+ foreach loop (in java1.4 use result.iterator())
for(Result res : result.toArray()){
System.out.println(res.getString());
}
13.3.6.5 Named resultsResults returns by SBQL queries can be named. A name can be given explicitly with the SBQL auxiliary names operators (‘as’ and ‘groupas’) or can be a consequence of dereference operation on an identifier of a complex object. The difference between ‘as’ and ‘groupas’ SBQL operators is that the first names all the results in the result bag and the latter names the whole bag.
In JOBC the names are to be used to navigate in the result searching for a sub-result with a given name. In other situations the result name is transparent.
Example:
Result result = db.execute(“2 + 2 as result”);
© Copyright by eGov-Bus Consortium144

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
int ires = result.getInteger();
Result result = db.execute(“(Person where age > 21).(name as personName, age as personAge) as adult”);
13.3.6.6 Filtering results by nameA result name can be used to search for a sub-result with a particular name. The search can be performed with the use of Result class instance method getByName taking the string representing a result name as a parameter:
Result getByName(String name)
Result returned by the getByName method call is an Result class instance representing a sub-result that was named and the name is equal to the parameter. If nothing was found the empty result is returned. The search is performed to the first occurrence of a named result, thus if the searched named result is a part of the other named result it wont be returned.
Examples:
Result result = db.execute(“(2 + 2) as result”);
Result intresult = result.getByName(“result”);
Result namedAdults = db.execute(“(Person where age > 21).(name as personName, age as personAge) as adult”); //we assume that there is more
//than one person
//satisfying the condition
namedAdults.isNamed(); //returns true
namedAdults.isBag(); //returns true (the names are transparent)
//java 1.5+ foreach loop
for(Result adult : namedAdults.toArray()) {
adult.isNamed(); //returns true (operator as was used in the //query)
adult.isComplex(); //return true (the names are transparent)
}
//java 1.4
for(Iterator iter = unnamedResult.iterator();iter.hasNext();) {
Result adult = (Result)iter.next();
adult.isNamed(); //returns true (operator as was used in the query)
adult.isComplex(); //returns true (the names are transparent)
}
Result unnamedAdults = namedAdults.getByName(“adult”);
unnamedAdults.isNamed(); //returns false
unnamedAdults.isBag(); //returns true
© Copyright by eGov-Bus Consortium145

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
//java 1.5+ foreach loop
for(Result adult : unnamedAdults.toArray()) {
adult.isNamed(); //returns false
adult.isComplex(); //returns true
}
//java 1.4
for(Iterator iter = unnamedResult.iterator();iter.hasNext();) {
Result adult = (Result)iter.next();
adult.isNamed(); //returns false
adult.isComplex(); //return true
}
Result names = result.getByName(“adult”).getByName(“name”);
names.isNamed(); //returns false
names.isBag();returns true
Result ages = result.getByName(“adult”).getByName(“age”);
ages.isNamed(); //returns false
ages.isBag(); //returns true
© Copyright by eGov-Bus Consortium146

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
14. ODRA IndexingIndices are auxiliary (redundant) database structures stored at a server. A database administrator manages a pool of indices generating a new index or removing an index depending on the current need. As indices at the end of a book are used for quick page finding, a database index makes quick retrieving objects (or records) matching given criteria possible. Because indices have relatively small size (comparing to a whole database) the gain in performance fully justifies some extra storage space. Due to single aspect search, which allows one for very efficient physical organization and very fast search algorithms, the gain in performance can be even several orders of magnitude. Indices, however, consume some extra time when a database is updated. Hence introducing indices is mainly constrained by the proportion of searches and updates. For ODRA no simple rule for decisions concerning the presence or absence of indices is available; they depend on the experience of a database administrator.
14.1 General Idea of ODRA indexingObjects can be indexed using a wide range of selection criteria (i.e. search key). The value of a search key must depend on a current object. It can be:
An objects attribute or a sub-object attribute (using path-expressions),
The result of an expression, which can contain build-in query language functions or user defined functions calculated from objects attributes or sub-objects attributes (function-based indices).
The last approach enables the administrator to create an index matching exactly predicates within frequently occurring queries, so their evaluation is faster and uses the minimal amount of I/O operations.
Currently the implementation supports indices based on Linear Hashing structures which can be easily extended to its distributed version SDDS in order to optimally utilize data grid computational resources.
14.1.1 Example on indexingIn query optimization indices are used in the context of the where operator, when the left-hand operand is indexed by key values of the right-hand selection predicate. For instance, if the administrator will establish the index named idxEmpSalary returning references to Emp objects depending on their salaries, then the following queries will produce the same result (the second query is generated by the automatic query optimizer).
(Emp where sal = 2000 and worksIn.Dept.dName = “Sales”).fName;
(idxEmpSalary(2000) where worksIn.Dept.dName = “Sales”).fName;
In case of big databases replacing the where evaluation with an index function call may cause performance gain in orders of magnitude. However to achieve this effect, the database should ensure index transparency and automatic index updating.
14.1.2 Physical Properties of IndicesThe idea of indexing implies two important properties:
Index transparency from a point of view of a database application programmer. The programmer should not be aware of the indices existence. They are used automatically during query evaluation. Therefore, the administrator of a database can freely generate new indices and remove them without a need to change the code of applications. The mechanism responsible for index transparency during query evaluation is called index optimizer. Its function is to replace a part of a query (transparently for a user) with an index call in order to minimize the amount of processed data.
Automatic index updating which is the consequence of changes in the database. Indices, like all redundant structures, can lose cohesion when the database is updated. An automatic mechanism should improve, eliminate or generate a new index in case of database updates. Automatic index updating makes modifying, removing and inserting objects slower. An index makes no sense and should be removed when the indexed objects are modified more frequently than queried via the index.
© Copyright by eGov-Bus Consortium147

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
14.2 Index Management – creating and removingAll indices existing in a database are registered and managed by the ODRA Index Manager. Each index is associated with a module where it has been created. Its name is to be unique. The index manager will be described in detail in a separate technical documentation.
The administrator issues the 'add index' command in CLI to create an index in the database. The syntax of this command is the following:
add index <indexname> [<type_indicators>] on <creating_query>
This is the only command necessary to install new index in the databse. The type indicators are optional and are described more in the further sections.
The next section briefly discusses a creating query structure and current rules and constrains concerning creating single-key indices.
The syntax of command for removing an index from the register is simple:
remove index <indexname>
14.2.1 Creating a single-key index<creating_query> is a SBQL query, which returns references to objects with associated key values. In order to create an index the administrator must provide the 'add index' command with such a query as a parameter.
Syntax of <creating_query> is the following:
<object_expression> join <key_expression>;
where:
<object_expression> - generates references to objects.
<key_expression> - generates key values for given objects.
add index idxPerCity on Person join birthYear;
E.g. if such an index is added it is transparently used in optimization of the following queries evaluation:
Person where birthYear = 1980;
Person where “Warsaw” in address.city and birthYear = 1980;
The current syntax can be changed in the future to be more user friendly (e.g. join can be replaced with parentheses embracing <key_expression>).
Indexed objects are defined by <object_expression> which is to be bound in the database section (root objects). The <object_expression> is to be built using only dot operators and names (i.e., by a path expression).
<key_expression> sub-expressions should be bound in the join operator stack section. They are allowed to return a value of the following types: integer, double, string, reference and boolean. In the simplest case <key_expression> can be an objects attribute, however derived attributes and expressions containing procedure calls are allowed.
An important property of a created index is a cardinality of a key. It indicates the number of key values, which can be returned for the given object. The index optimization is simplest if one key value is always returned for an indexed object (singular cardinality [1..1]). Currently the optimization for keys with a maximal cardinality greater then 1 is not supported. The optional cardinality [0..1] of a key enforces more strict rules for query optimization utilizing index in order to preserve query semantics after optimization. In a following example a key cardinality is optional because manages attribute is optional for Emp objects.
add index idxManagerDName on Emp join manages.Dept.dName;
Example queries which can be transparently optimized by applying idxManagerDName index are shown in section 14.3.
© Copyright by eGov-Bus Consortium148

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
14.2.2 Dense, Range and Enum type indicatorsThe creating index syntax allows the administrator to specify general index key properties, i.e. concerning key values or the optimization goal. These are achieved by introducing optional <type_indicators>: dense, range and enum.
The dense indicator implies that the optimization of selecting queries which use a given key value as a condition will be used only for selection predicates based on '=' or in operators. Therefore the distribution of indexed objects in an index (e.g. in hash table) can be more efficient for optimization of such cases.
add index EmpSal(dense) on Emp join sal;
The range indicator implies that optimization will concern selection predicates based not only on '=' or in operators but also on range operators: '>', '≥', '<' and '≤'.
add index idxperage(range) on Person join (2007 - birthYear);
E.g. if administrator would like to optimize evaluation of following range queries:
Person where 23 <= 2007 – birthYear and 2007 - birthYear < 23;
Person where “Smith” = lName where 2007 - birthYear > 50;
she should issue the command mentioned above, which adds the idxperage index.
The enum indicator was introduced in order to take advantage of keys with countably limited set of distinct values. The performance of an index can be strongly deteriorated if key values have low cardinality e.g. person eye colour, a marriage status (boolean value) or the year of birth. Using the enum key type, an index internally stores all possible key values and uses this information to optimize the index structure.
The enum key type can deal with optimizing selection predicates exactly like in the case of the range indicator, i.e. for: '=', in, '>', '≥', '<' and '≤' operators.
add index idxempdnbr(enum) on Emp join worksIn.Dept.dNbr;
The default type indicator for integer, string, double or reference values is dense. In case of boolean values, the enum type is always used. The dense indicator should always be used for reference values.
add index idxempdept on Emp join worksIn;
The next section describes ODRA's optimization rules which can be helpful in applying good indexing.
14.3 Query optimization tipsCurrently the index optimizer analysing the right operand of the where operator takes into consideration all selection predicates joined with an and and or operators.
Building selection criteria with the non [1..1] key cardinalities may cause runtime errors. Selection predicates based on '=', '>', '≥', '<' and '≤' operators force using single values as left and right operands. Unexpected number of operand values causes a runtime error. More operand values are allowed only if the in operator is used as a predicate because it does not constrain the cardinality of a right operand. To enable full optimization of queries with optional cardinality [0..1] suitable predicate based on exists expression should be used.
Example queries
unsafe predicate evaluation (may cause run-time error): the left side of the equality expression has cardinality [0..1] like the manages attribute.
Emp where manages.Dept.dName = “Sales”;
safe predicate evaluation as in operator is used (this query is optimizable with idxManagerDName index).
Emp where “Sales” in manages.Dept.dName;
safe predicate evaluation as exists operator ensures it (this query is optimizable with idxManagerDName index).
Emp where exists(manages.Dept.dName) where “Sales” = manages.Dept.dName;
© Copyright by eGov-Bus Consortium149

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
14.4 ExamplesMore examples are available through ODRA SVN repository in batch files stored in the folder “EGB/res/index/batch/”. Batch files include queries and CLI commands and can be executed using following syntax:
batch <batch_file_name>
Short description of batch files contents:
res\sampledata\batch\createM0.cli - creates a module with sample set of data necessary to perform batch test's and examples.
res\index\batch\add.cli – creates a set of indices.
res\index\batch\remove.cli – removes a set of indices.
res\index\batch\test-error_idxmgr.cli – test for index manager containing several errors.
res\index\batch\test-xml.cli – test for optimizing data from XML import (done for medium database).
res\index\batch\startall.cli – starts all mentioned above tests.
res\index\batch\start.cli – starts some of tests mentioned above.
© Copyright by eGov-Bus Consortium150

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
15. ODRA Access Control15.1 Architecture of ODRA Access ControlODRA Access Control (AC) operates between interfaces and the system layer (Fig.14-1). All interfaces must be controlled by AC as they give a way to access to data. When a user with some role tries to access data, he or she communicates with interfaces through methods from the application layer. The methods are client side commands. Executing one of them sends a request to the server. It receives it and the tries to communicate through the interface. Then every interface makes a call to the AC method grantAccess(). AC checks if the user has proper privileges and if system layer commands can be executed. If the access is granted then system’s methods can obtain data from the database.
14-1. Access Control architecture in ODRA
15.2 Main Idea of Access Control MechanismFig.14-2 shows the general schema of the Access Control mechanism. It starts to work when the user tries to log in to the ODRA system. During the login process AC checks if the role putted by the user exists in the system. If a user account exists and the role exists then the user is logging to the system. From now on, he or she may execute some methods, for example, operations on views. Executing the methods causes setting up an access mode value in a UserContext object. This value informs later the AC mechanism what a kind of operation the user tries to do (creating, updating etc...). To make any operations on ODRA database objects, there must be a modeling database object on a DBView class object. This is the point where all calls to database’s objects must pass by. Because of that, this point in ODRA’s architecture was the best place to put Access Control method for checking access. Here is a call to an Access Control method – grantAccess() – which checks privileges for the current user role. The method gets access mode value from the UserContext object and determines if there are permissions for that kind of operation for that role.
© Copyright by eGov-Bus Consortium151

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
14-1. ODRA's Access Control Mechanism
15.3 Roles and LoggingThe Access Control in ODRA uses a schema of the Role-Based Access Control (RBAC). The model establishes some roles, for example, administrator, client, civil, etc. Each role has an own set of privileges. The system supports adding new roles. The users are assigned with one or more roles. After a successful log on, the user takes all privileges from his/her role.
Modifying role’s privileges changes rights for all the users who use this role. Hence in this system there are no users with individual rights. Permissions are set for a role, which means for a group of concrete users. This feature is very important to take into consideration before modifying role’s privileges. In most cases the users are
© Copyright by eGov-Bus Consortium152

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
not allowed to change the rights. Only a group of administrators should have rights for modifying role’s privileges.
The Access Control in ODRA starts to operate at the beginning, after a successful user’s logon. The logging process requires from the user to put the user’s login, password and the user’s role. When the user puts all these values and sends a request to the system, the Access Control at first checks if the given role exists in the system and then if the given user is allowed to use a given role. Every user may have more than one role. If a role does not exist in the system, or if a given user is not allowed to use it, then the access control exception is thrown and the user will not be log on to the ODRA system. If the role exists in system and the user is allowed to use it then log in to ODRA system is granted. After successful login a user’s session file and a context file are created. The context file keeps information about the current user role. Also it keeps information about current kind of operation (access mode) making by user. It is used by AC Mechanism to determine if user with current role is allowed to do this kind of operation.
15.4 Working in ODRAAfter successful log on to ODRA, the user can execute methods. Not all of these methods involve Access Control Mechanism to operate because the Access Control mechanism operates on low level executions. It means that it does not checks every method execution but only these which refer to the View Objects Type. For example, the Access Control mechanism will execute its checking methods when the user will try to create, update or delete some view. AC will check if the given role has permissions to do operations on this object.
When the user executes some method, for example createView(), in the user’s context file the system sets a kind of operation value. Currently it will set the access value on ‘create’. After that, the Access Control method grantAccess() is executed. It searches for the system value ‘roles’. By this value the system keeps information on all roles in the system and privileges for every role. The AC mechanism finds the role for which the access is being checked and searches for privileges. When ‘create’ operation is being executed then privileges regard only to kind of operation, not a concrete object. In the cases where the user executes methods like updateView(), deleteView(), the privileges will regard to concrete view objects which are passed as an argument to these methods.
15.5 PermissionsPermissions are rights to perform some kind of operations. Usually, permissions are set by administrators. In many systems, also in ODRA, there is an implicit deny rule during granting the access to users. That makes system more secure and ensures that the users can’t access any information more that they have been allowed.
In ODRA the permission consists of information about an object, a role, a mode of access and an access value which determine if access is granted or not. Information about an object tells if the permission is set for type of objects for example Views or if it is a concrete object. The role tells for which role the permission will be added.
The mode tells about the operation kind. In ODRA there are 4 modes: create, read, update and delete. A mode is connected to an access value. Together the mode determines if the access is allowed, when the access value is set to ‘allow’, or forbidden when the access value is set to ‘deny’.
Permission with the access value flag set to ‘deny’ should be treated as restriction. The use of this negative value guarantees that sensitive data won’t be read by an undesirable person.
Permissions can be added to the View Type in general or to some concrete object from View Type, which is more specific and AC will make decision on that. For example, assume that there is a “CarView” object in the ODRA database. The user who log on to the system with role “client”, tries to update that view. AC checks privileges for the role “client” and sees that this role is forbidden to update View Type objects. But also sees that the role client is allowed to update the object “CarView”. In this case, rights for updating “CarView” objects are more specific than rights for updating View Type objects. AC will make a decision to grant access for the operation and the user will be able to update view.
15.6 Implementation
15.6.1 Added Java classes AccessControl
AccessControlException
RoleManager
© Copyright by eGov-Bus Consortium153

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
15.6.2 Most important Java methodsIn class RoleManager:
registerSystemRole(String rolename) – registers a role with the name given as an argument in the system variable “sysroles”
hasSystemRole(String rolename) – checks if the role of a name given in the argument exists in the system variable “sysroles”
unregisterSystemRole(String rolename) – unregisters the role from the system (not yet implemented)
In class AccessControl:
grantPrivilegeToRole(String rolename, int objectType, OID objectID, int accessMode, int accessValue, int grantFlag) – creates and adds privileges and permissions to the role given as an argument and to the object or action.
grantAccess( int objKind, OID object, UserContext ctx) – determines if the user with the current role can access an object
15.6.3 How it works.The access control in ODRA is based on two classes: AccessControl and RoleManager. At first, users’ roles must be created by a method from the class RoleManager. By default, the administrator role is created in the database. Roles are kept in the system variable “sysroles”. Every role has an aggregate object privileges which stores privileges for objects and permissions for making operations on them. Those privileges and permissions are created and added by the method grantPrivilegeToRole from class AccessControl. At first, this method checks for existence of privilege for the object given as an argument. If the privilege doesn’t exist then it is created. If the privilege for given object already exist, then it is only updated to the current value from the argument. It means that creating and updating access value for the object is done by one method – grantPrivilegeToRole. So this method can be executed many times, with even the same arguments and doesn’t create duplicates of privileges.
The method takes as an argument:
grantPrivilegeToRole(string rolename, int objectType, OID objectID, int accessMode, int accessValue, int grantFlag)
rolename – the name of role for which privilege will be added.
objectType – the type of object for which access will be defined.
objectID – concrete existing object for which access will be defined or null. (If null then more general permission is created, just for CRUD actions).
accessMode – is type of operation on the object (create, read, update, delete).
accessValue – determine if access is given or forbidden (allow / deny).
grantFlat – determine if user can pass on privilege to other user (not yet implemented)
The second most important method in the class AccessControl is the method grantAccess. It is executed when there is a try to access the view objects from the database (in future maybe not only views).
At first, method searches for role for which is access checking and after that, checks privileges for that role. If privilege is found then access is given, if not, then an exception from the class AccessControlException is thrown.
The method takes as an argument:
grantAccess( int objKind, OID object, UserContext ctx)
objKind - the type of object for which access will be defined.
object - concrete existing object for which access will be checked or null. (If null then more general permission is checked, just for CRUD actions).
ctx – user context object, which keeps information about user role, and current action which will be executed.
© Copyright by eGov-Bus Consortium154

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
If the object is null, then the method checks if a role has permission to do given kind of CRUD operation on given object kind. If object is not null, then access is determined on two ways. More detailed privilege takes higher priority. For example if role is forbidden for updating Views but there is privilege allowing updating given view (given object) then access for this operation is given.
References to the method grantAccess are kept in several places: in methods managing Views(create, update...) in the class ViewOrganizer and in the constructor of class DBView. Before references from the class ViewOrganizer there is a reference to the UserContext class object, in which there is setting up kind of operation which will be made.
Reference to the method grantAccess in the constructor of class DBView assure that every access to View objects from database will invoke the access control mechanism.
When the kind of operation is set up in a UserContext object, then the grantAccess method is executed and checks the existence of privilege for this action.
Users can log in with one role. During log on time, the method hasSystemRole from class RoleManger is executed. Method checks if the role exists in system. After successful log on, the user takes all privileges belonging to the role.
© Copyright by eGov-Bus Consortium155

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
16. Annex A: Methodology for Making a Virtual Repository under ODRA16.1 Design of the Virtual Repository Class Diagram SchemaThe Virtual Repository class diagram schema comprises information object classes and relationships that need to be materialised from external data sources, such as relational databases, binary content files (e.g. .pdf documents) or Web information published as XML files. The VR information objects will appropriately be referenced by the ontology items to be used within the corresponding administrative process. References to information objects will be constructed in the form of VR SBQL queries.
Typically, the external data sources will be the referential registers (e.g. the population or the company registers), and to assorted textual information supporting the explanation features of a life event administrative process.
The design process for a virtual repository for a particular eGovernment application should take into account several factors, in particular:
UML use cases concerning both the interaction of end users with the application and the interaction of the administrative staff with the application. For instance, for a life event “birth of child” there are several use cases from the end user side, such as “register the user”, “register the life event”, “assign proper data for the child”, “correct/augment the data”, etc. From the administrative staff the use cases could be “find user data in a public register”, “introduce proper data for the child into a public register”, “propagate the information to healthcare institution”, etc.
Recognize the structure, access modes and the ontology of public registers that will participate in the application. If these are public registers, recognize if the application can read from them on-line and which security rules must be obeyed. In some cases there will be a need to create such public registers. It is necessary to recognize rules of updating public registers, in particular, can they be updated on-line or off-line via the message to the proper administrative staff member.
Recognize if the application will be based on a single user session or on a multiple user sessions. Usually this kind of eGovernemnt applications require multiple user sessions model. For this model some internal databases must be kept, e.g. temporary database of life event data according to their XML format.
Recognize security issues and decide if they would require some special persistent data structures to be kept, e.g. audit trails, user accounts, access privileges, etc.
On the basis of the above points an UML class diagram is developed that will be the most adequate for the APG software that will arrange all the user interaction with the application.
The UML class diagram is to be refined in order to determine the following information:
o Which elements of the diagram correspond to legacy resources (e.g. existing public registers)?
o Which elements of the diagram correspond to non-existing public resources that must be established for the application?
o Is there a need to map heterogeneous resources, to resolve redundancies, to optimize using of replicas, to fuse fragmented collections, etc.
o Which elements of the diagram correspond to persistent data and services that are to be kept by the application and which database system is to be used (relational, XML, RDF, object-oriented, etc.) ?
The above information is the basis for creating integration views – the essence of the virtual repository. In the result of the above steps the application designer has to design formally the following schemas:
o Contribution schema for each public legacy resource. These schemata show which parts of the public resources are to be published for the needs of the given eGovernement application.
o Integration schema that explains heterogeneities between different public servers and heterogeneities between public servers and global canonical schema, the necessity for resolving fragmentations, redundancies and replicas.
© Copyright by eGov-Bus Consortium156

FP6-IST-2004-26727, Advanced eGovernment Information Service Bus eGov-Bus ODRA User Manual Version 1.12.……………………………………………………………………………………………………Date 12.11.2007
o Global canonical schema for the entire virtual repository that will be the part of the programmer interface when programming the application.
o Schemas that are necessary for particular use cases or particular kinds of end users.
The corresponding schemas and informal explanation of the mapping between them are the basis for the design and programming of corresponding views, including contributory views on top of local remote resources, customization views that are prepared for particular use cases or particular end user kinds, and integration views that virtually fuse data and services from different remote resources.
The middleware based on a virtual repository supports three-level architecture of applications. On the first (bottom) level there are database programmers who prepare the server-side database schema and implement (in SBQL + classical object-oriented languages) database classes together with methods. Concerning legacy applications (e.g. existing public registers) they are also considered the first level and can be on this level enhanced by the application by special views, which include implemented classes and methods. On the second (middle) level there are server-side administrative programmers who determine integration views, access privileges and external views for use cases and users kinds. The integration and external views are determined by virtual updateable views, which might accomplish sophisticated mappings between stored and virtual data and mappings between updating of virtual data and updating of stored data. Such mappings require programming in SBQL. These two level correspond to preparation of the middleware for future applications. On the third (upper) layer there are client-side application programmers, who use interfaces to virtual views delivered by the second layer. The subdivision on these three layers could make business and public administration applications very flexible for development and maintenance. It qualifies programmers of business-oriented software to a few kinds with independent jobs and specializations. To a large extent, such an architecture is inevitable in distributed applications and closely related to the methodology of building this kind of applications.
More detailed methodology for creating the UML schema for a virtual repository and for creating virtual integration views require analysis of some real-life case and comprehensive examples.
© Copyright by eGov-Bus Consortium157