transient fault tolerance via dynamic process-level redundancy
DESCRIPTION
Transient Fault Tolerance via Dynamic Process-Level Redundancy. Alex Shye, Vijay Janapa Reddi, Tipp Moseley and Daniel A. Connors University of Colorado at Boulder Department of Electrical and Computer Engineering DRACO Architecture Research Group - PowerPoint PPT PresentationTRANSCRIPT

Transient Fault Tolerance via Dynamic Process-Level Redundancy
Alex Shye, Vijay Janapa Reddi, Tipp Moseley and Daniel A. Connors
University of Colorado at Boulder
Department of Electrical and Computer Engineering
DRACO Architecture Research Group
Workshop on Binary Instrumentation and Applications
San Jose, CA
10.22.2006

Outline
• Introduction
• Background/Terminology
• Software-centric Fault Detection
• Process-Level Redundancy
• Experimental Results
• Conclusion

Introduction
• Process technology trends– Single transistor error rate expected to stay close to constant– Number of transistors is increasing exponentially with each generation
• Transient faults will be a problem for microprocessors!
• Hardware Approaches– Specialized redundant hardware, redundant multi-threading
• Software Approaches– Compiler solutions: instruction duplication, control flow checking– Low-cost, flexible alternative but higher overhead
• Goal: Leverage available hardware parallelism in SMT and CMP machines to improve the performance of software transient fault tolerance

Background/Terminology
• Types of transient faults (based upon outcome)– Benign Faults– Silent Data Corruption (SDC)– Detected Unrecoverable Error (DUE)
• True DUE
• False DUE
• Sphere of Replication (SoR)– Indicates the scope of fault detection and containment
• Input Replication
• Output Comparison
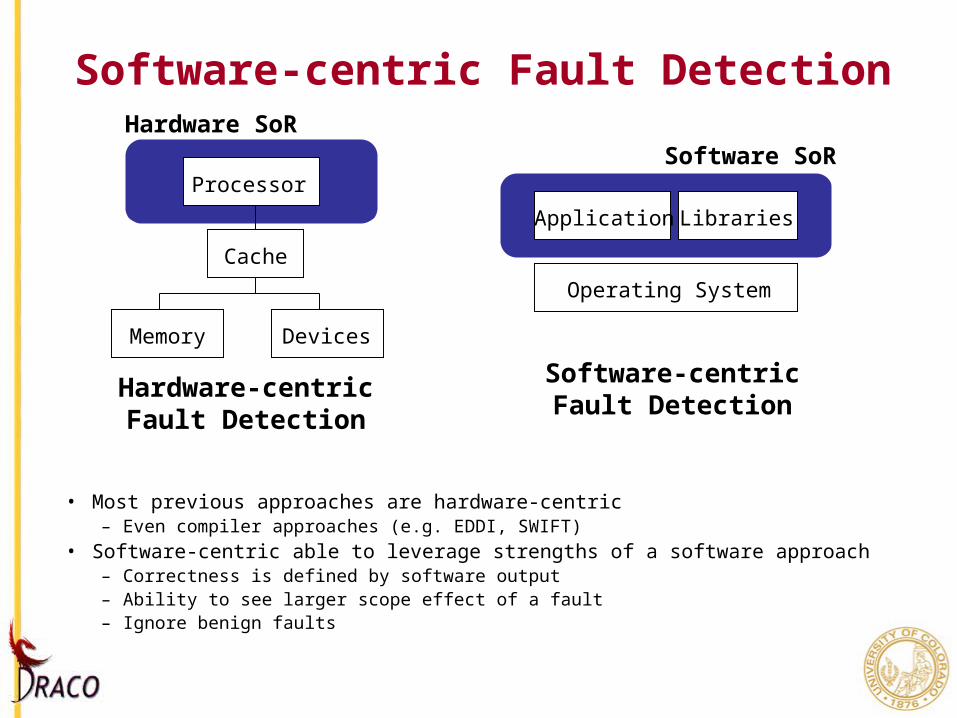
Software-centric Fault Detection
• Most previous approaches are hardware-centric– Even compiler approaches (e.g. EDDI, SWIFT)
• Software-centric able to leverage strengths of a software approach– Correctness is defined by software output– Ability to see larger scope effect of a fault– Ignore benign faults
Processor
Cache
Memory Devices
Application Libraries
Operating System
Hardware-centricFault Detection
Software-centricFault Detection
Software SoRHardware SoR
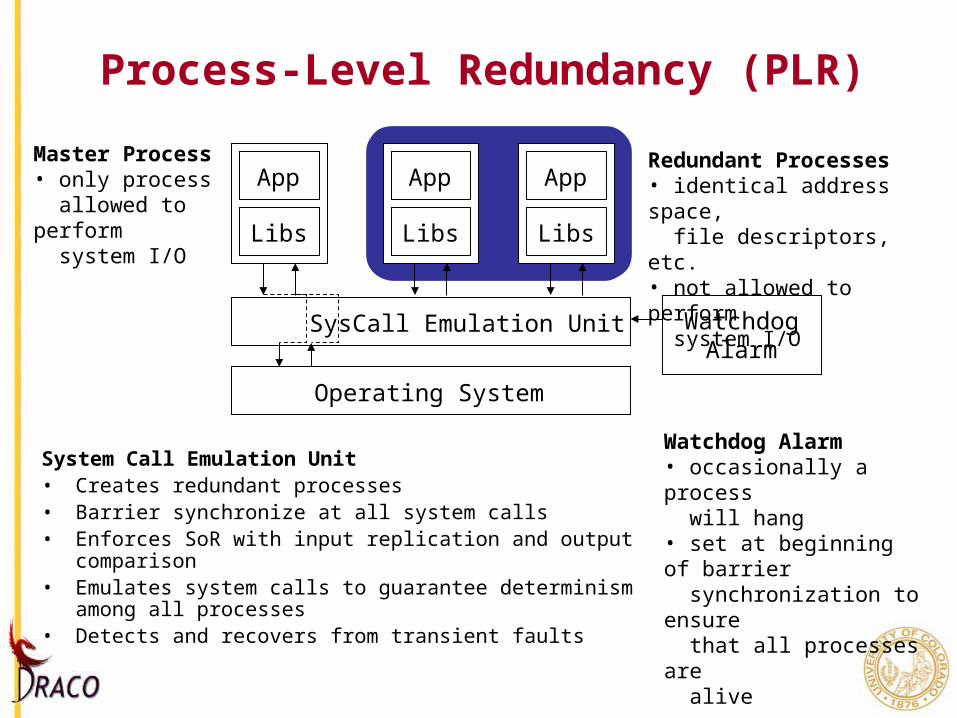
Process-Level Redundancy (PLR)
System Call Emulation Unit• Creates redundant processes• Barrier synchronize at all system calls• Enforces SoR with input replication and output comparison• Emulates system calls to guarantee determinism among all
processes• Detects and recovers from transient faults
App
Libs
App
Libs
App
Libs
SysCall Emulation Unit
Operating System
WatchdogAlarm
Master Process• only process allowed to perform system I/O
Redundant Processes• identical address space, file descriptors, etc.• not allowed to perform system I/O
Watchdog Alarm• occasionally a process will hang• set at beginning of barrier synchronization to ensure that all processes are alive

Enforcing SoR and Determinism
• Input Replication– All read events: read(),
gettimeofday(), getrusage(), etc.– Return value from all system calls
• Output Comparison– All write events: write(), msync(, etc.– System call parameters
• Maintaining Determinism at System Calls– Master process executes system call– Redundant processes emulate it
• Ignore some: rename(), unlink()• Execute similar/altered system call
– Identical address space: mmap()– Process-specific data: open(), lseek()
Compare syscall type and cmd line parameters
Write cmd line parameters and
syscall type toshmem
read()
Write resulting file offset and read buffer to shmem
Copy the read buffer from
shmem
lseek() to correct file offset
Master ProcessRedundant Processes
Barrier
Example of handling aread() system call

Fault Detection and Recovery
• PLR supports detection/recovery from multiple faults by increasing number of redundant processes and scaling the majority vote logic
Output Mismatch
Detected as a mismatch of compare buffers on an output comparison
Use majority vote ensure correct data exists, kill incorrect process, and fork() to create a new one
Program Failure System call emulation unit registers signal handlers for SIGSEGV, SIGIOT, etc.
Re-create the dead process by forking one of existing processes
Timeout Watchdog alarm times out Determine the missing process and fork() to create a new one
Type of Error Detection Mechanism Recovery Mechanism

Experimental Methodology
• Use a set of the SPEC2000 benchmarks• PLR prototype developed with Pin
– Intercept system calls to implement PLR
• Fault Injection– Gather an instruction count profile– Use profile to generate a test case
• Test case: an instruction and a particular execution of the instruction to fault
– Run with Pin in JIT mode and use IARG_RETURN_REGS to alter a random bit of the instructions source or destination registers
• Fault Coverage– Use fault injector on test inputs generating 1000 test cases per benchmark– specdiff in SPEC2000 harness determines output correctness
• PLR Performance– Run PLR (in Probe mode using Pin Probes) on reference inputs with two
redundant processes– 4-way SMP machine, each processor is hyper-threaded– Use sched_set_affinity() to simulate various hardware platforms
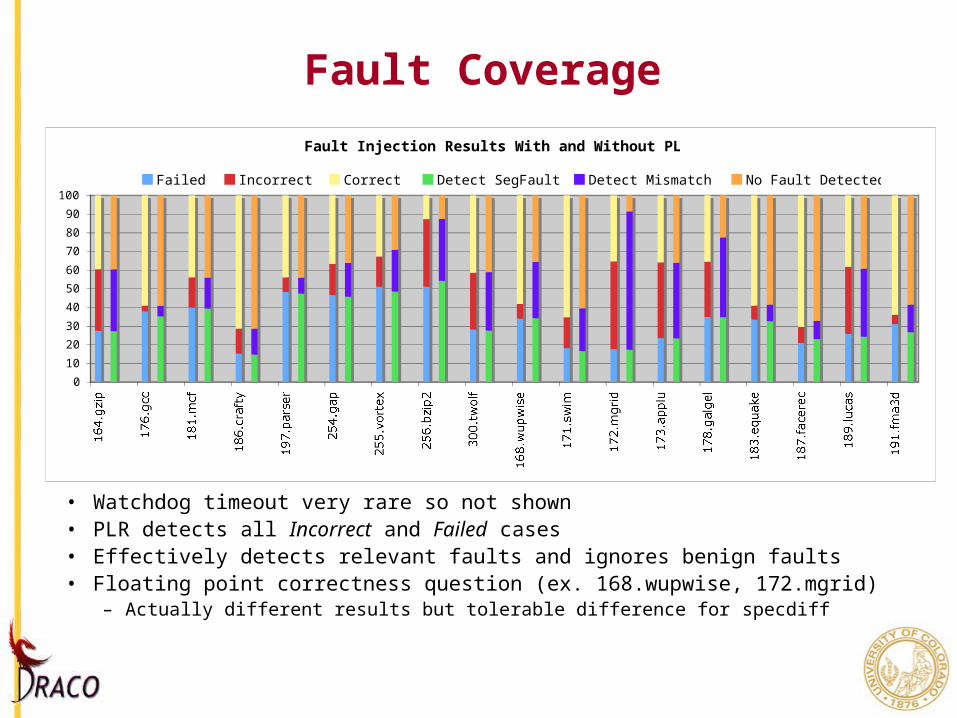
Fault Coverage
• Watchdog timeout very rare so not shown• PLR detects all Incorrect and Failed cases• Effectively detects relevant faults and ignores benign faults• Floating point correctness question (ex. 168.wupwise, 172.mgrid)
– Actually different results but tolerable difference for specdiff
Fault Injection Results With and Without PLR
0
10
20
30
40
50
60
70
80
90
100
164.gzip176.gcc181.mcf186.crafty197.parser
254.gap255.vortex256.bzip2300.twolf
168.wupwise
171.swim172.mgrid173.applu178.galgel183.equake187.facerec
189.lucas191.fma3d
Failed Incorrect Correct Detect SegFault Detect Mismatch No Fault Detected
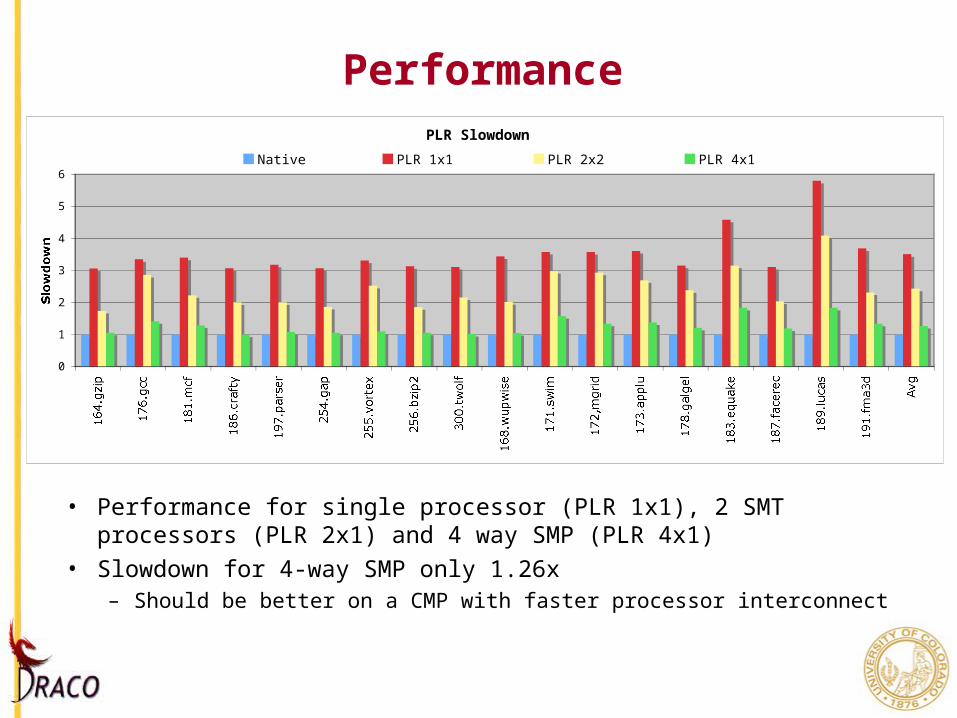
Performance
• Performance for single processor (PLR 1x1), 2 SMT processors (PLR 2x1) and 4 way SMP (PLR 4x1)
• Slowdown for 4-way SMP only 1.26x– Should be better on a CMP with faster processor interconnect
PLR Slowdown
0
1
2
3
4
5
6
164.gzip176.gcc181.mcf186.crafty197.parser
254.gap255.vortex256.bzip2300.twolf
168.wupwise
171.swim172,mgrid173.applu178.galgel183.equake187.facerec
189.lucas191.fma3d
Avg
Slowdown
Native PLR 1x1 PLR 2x2 PLR 4x1

Conclusion
• Present a different way to use existing general purpose SMT and CMP machines for transient fault tolerance
• Differentiate between hardware-centric and software-centric fault detection models– Show how software-centric can be effective in ignoring benign faults
• PLR on a 4-way SMP executes with only a 26% slowdown, a 36% improvement over the fastest compiler technique
• Future Work– Implementation in a run-time system allows for dynamically altering
amount of fault tolerance– Simple PLR model is presented; work on handling interrupts, shared
memory, and threads (the tough one)
Questions?