tkttkt--2431 soc 2431 soc design - tkt.cs.tut.fi filetkttkt--2431 soc 2431 soc design lec 9 lec 9...
TRANSCRIPT
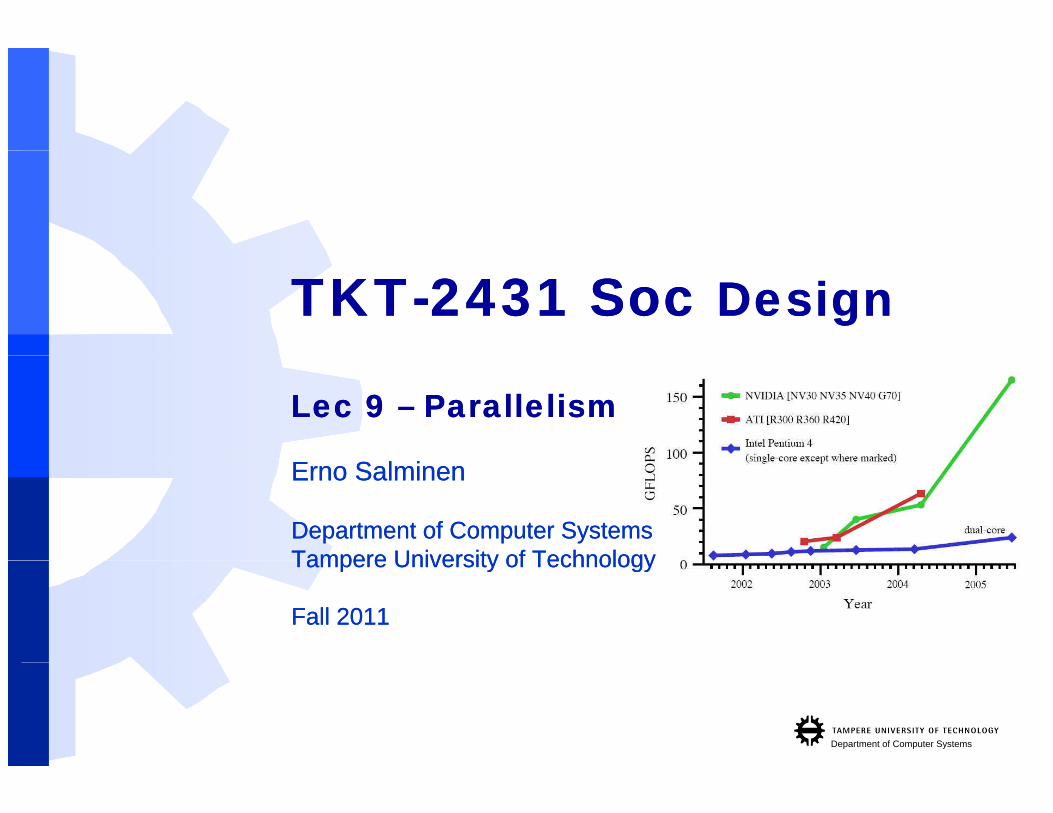
TKTTKT--2431 Soc 2431 Soc DesignDesign
Lec 9 Lec 9 –– ParallelismParallelism
ErnoErno SalminenSalminen
Department of Computer SystemsDepartment of Computer SystemsTampere University of TechnologyTampere University of TechnologyTampere University of TechnologyTampere University of Technology
Fall 2011Fall 2011
Department of Computer Systems

ContentsContents Introduction Amdahl’s law once againg
Computer classification by FlynnParallelization methodsParallelization methods Data-parallel Function-parallelp
Communication scheme and memoriesCase study: Data-parallel video encoderCase study: Data parallel video encoder
#2/48 Department of Computer Systems

Copyright noticeCopyright notice
Part of the slidesadapted from slide set by Albertoadapted from slide set by Alberto
Sangiovanni-Vincentelli course EE249 at University of California,
Berkeley http://www-
cad.eecs.berkeley.edu/~polis/class/lectures.shtml
Part of figures from: Ireneusz Karkowski and Henk Corporaal, Exploiting Fine- and
Coarse-grain Parallelism in Embedded ProgramsCoarse grain Parallelism in Embedded Programs, International Conference on Parallel Architectures and Compilation Techniques (PACT'98), Paris, October 1998, pp 60-67
#3/48 Department of Computer Systems

At firstAt first
Make sure that simple things worksimple things work before even tryingbefore even trying more complex onesmore complex ones
#4/48 Department of Computer Systems

Von Neumann (vN) Architecture Is Von Neumann (vN) Architecture Is Reaching Its Limits ...Reaching Its Limits ...gg
vN: vN: vN Bottleneck
unbalancedunbalanced
stolen from Bob Colwell
#5/48 Department of Computer Systems
Source: R. Hartenstein, Univ. Kaiserslautern
E. Maehle, E-Seminar IFIP Working Group 10.3 (Concurrent Systems) June 7, 2005

Benefits of parallel executionBenefits of parallel execution Increased performance in terms of throughput or accuracy
HUOM! OBS!
Muy importante!
g p y or similar performance with lower cost (lower freq
and lower Vdd!)Partial shutdown Allows more aggressive power reduction
Fault-tolerance Overcomes single-point of failure
Encapsulation, plug-and-play design process Parts are specialized to certain tasks
#6/48 Department of Computer Systems

Computer classification: Flynn Categories Computer classification: Flynn Categories
1. SISD (Single Instruction Single Data) Traditional uniprocessorp
2. MISD (Multiple Instruction Single Data) Systolic arrays / stream based processingy y p g Rare
D # simultaneouslyD, # simultaneously processed data
3. SIMD 4. MIMDMultiple
I # simultaneaously executed
1. SISD 2. MISDSingle
#7/48 Department of Computer Systems
I, # simultaneaously executed instrcutionsSingle Multiple

Flynn Categories (2) Flynn Categories (2) 3. SIMD (Single Instruction Multiple Data) Simple programming model (e.g. Intel MMX) Low overhead Now applied as sub-word parallelism E g count four 8-bit ADD operations with one
ALU
E.g. count four 8 bit ADD operations with one 32b ALU
Only one program counter (PC)
4. MIMD (Multiple Instruction Multiple Data) Multiple program counters, “real multiprocessor” Flexible may use off-the-shelf micros Flexible, may use off the shelf micros Special case: Single program, Multiple data
(SPMD)All CPU th d
#8/48 Department of Computer Systems
All CPUs use the same program code, saves memory!

IntroductionIntroduction of of chipchip multiprocessorsmultiprocessors
P t 1 CPU T d /f t lti l Past: 1 CPU, accelerator(s), memories
Today/future: multiple(tens of) processors, accelerator(s),
#9/48 Department of Computer Systems
memoriesRamchan Woo, Tampere Soc, 2004.

Multiprocessor SoC (MPMultiprocessor SoC (MP--SoC)SoC)Tremendous growth of integration capabilities
allow building chip multiprocessors (CMP)g p p ( ) Aka. multiprocessor SoC (MP-SoC) Even on single FPGA!
Heterogeneous IBM Cell broadband engine (PowerPC+8 PPE) TI OMAP (ARM+TI DSP)
Homogeneous Intel/AMD Dual/Quad Core DACI MP-SoC on FPGA
#10/48 Department of Computer Systems
Intel TeraFLOPS IBM Cell [Wikipedia]
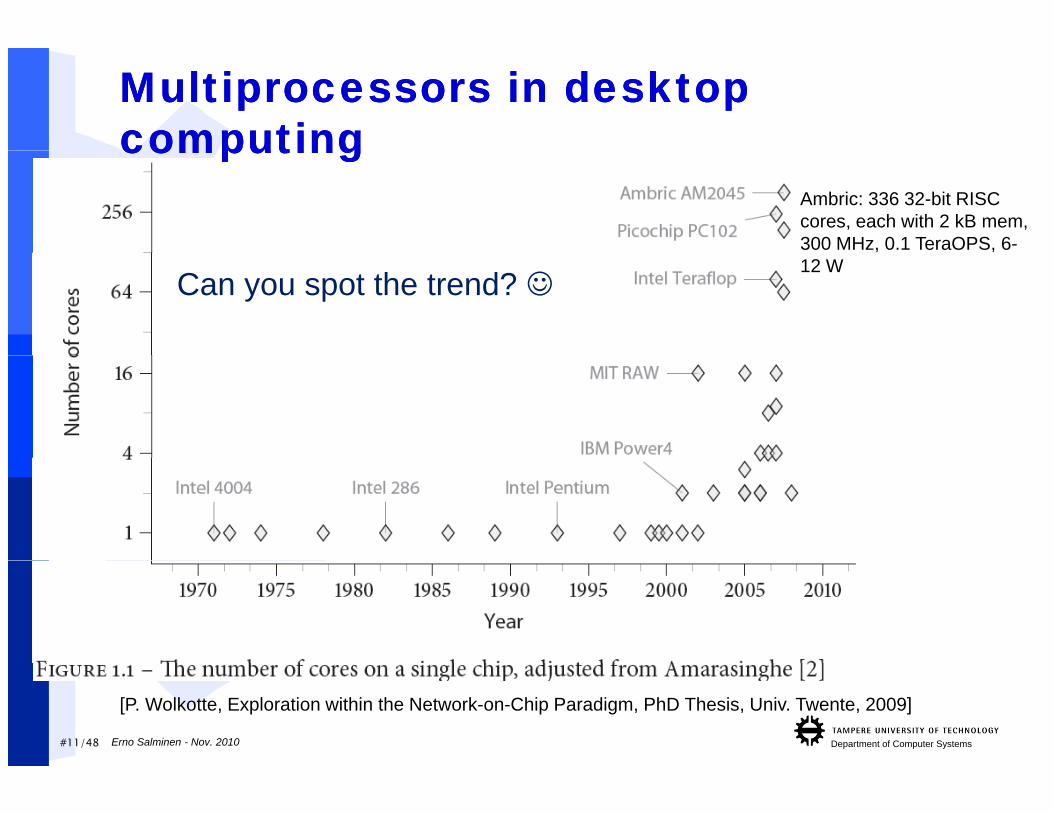
MultiprocessorsMultiprocessors in desktop in desktop computingcomputing
Ambric: 336 32-bit RISC cores, each with 2 kB mem, 300 MHz, 0.1 TeraOPS, 6-
computingcomputing
12 WCan you spot the trend?
#11/48 Department of Computer SystemsErno Salminen - Nov. 2010
[P. Wolkotte, Exploration within the Network-on-Chip Paradigm, PhD Thesis, Univ. Twente, 2009]

Parallelism and Amdahl’s lawParallelism and Amdahl’s lawSpeedup can be achieved via parallel
computation, but sequential part limits the th ti l dmax theoretical speedup
In practice, computation cannot cannot be distributed in arbitrary sized blocksdistributed in arbitrary sized blocks E.g. use 2 processing elements Divide work into 2 tasks: 0.55*orig and 0.45*orig Divide work into 2 tasks: 0.55 orig and 0.45 orig Max. speedup =1/0.55= 1.81x instead of 2.0x
In practice, seq. part may increase as p q p yparallelism increases More communication,
”M t ” h h d ti t di t ib t th l d
#12/48 Department of Computer Systems
”Master” has harder time to distribute the load
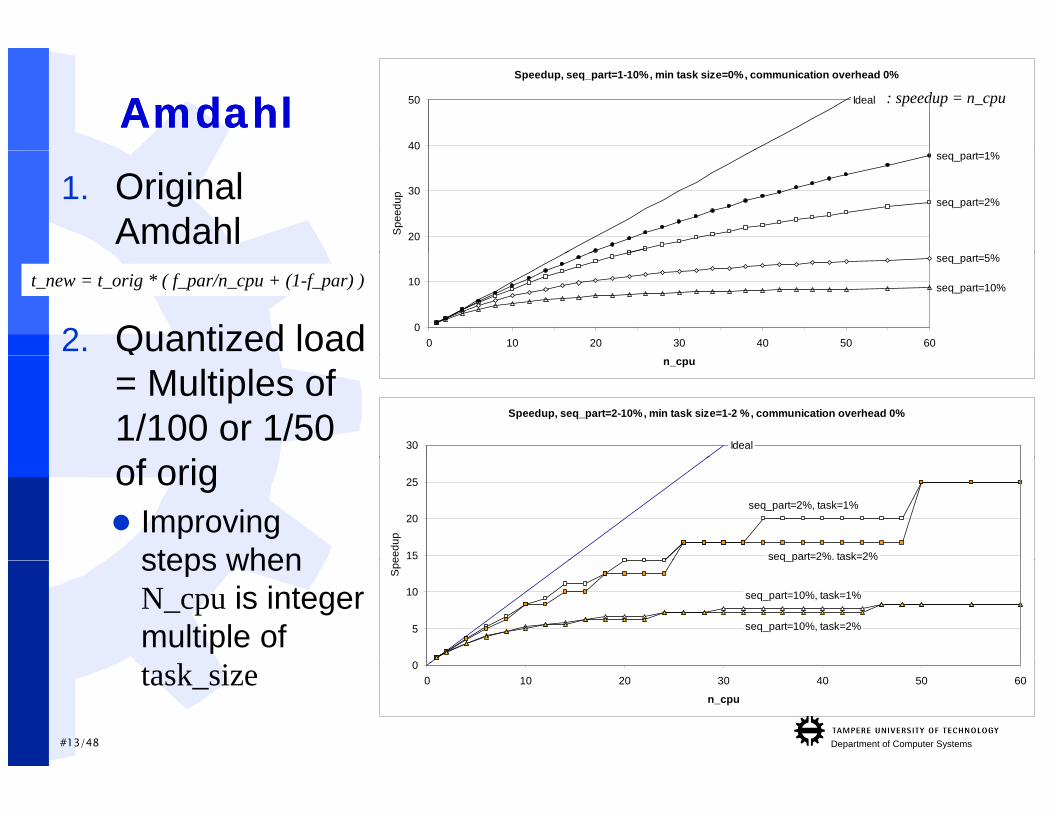
AmdahlAmdahlSpeedup, seq_part=1-10%, min task size=0%, communication overhead 0%
Ideal
40
50 : speedup = n_cpu
1. Original Amdahl
seq_part=2%
seq_part=1%
20
30
Spe
edup
2. Quantized load seq_part=10%
seq_part=5%
0
10
0 10 20 30 40 50 60
t_new = t_orig * ( f_par/n_cpu + (1-f_par) )
= Multiples of 1/100 or 1/50
n_cpu
Speedup, seq_part=2-10%, min task size=1-2 %, communication overhead 0%
Ideal30
of orig Improving
steps when
seq_part=2%, task=1%
seq part=2%. task=2%15
20
25
eedu
p
steps when N_cpu is integer multiple of
q_p
seq_part=10%, task=1%
seq_part=10%, task=2%
0
5
10
Spe
#13/48 Department of Computer Systems
task_size 00 10 20 30 40 50 60
n_cpu
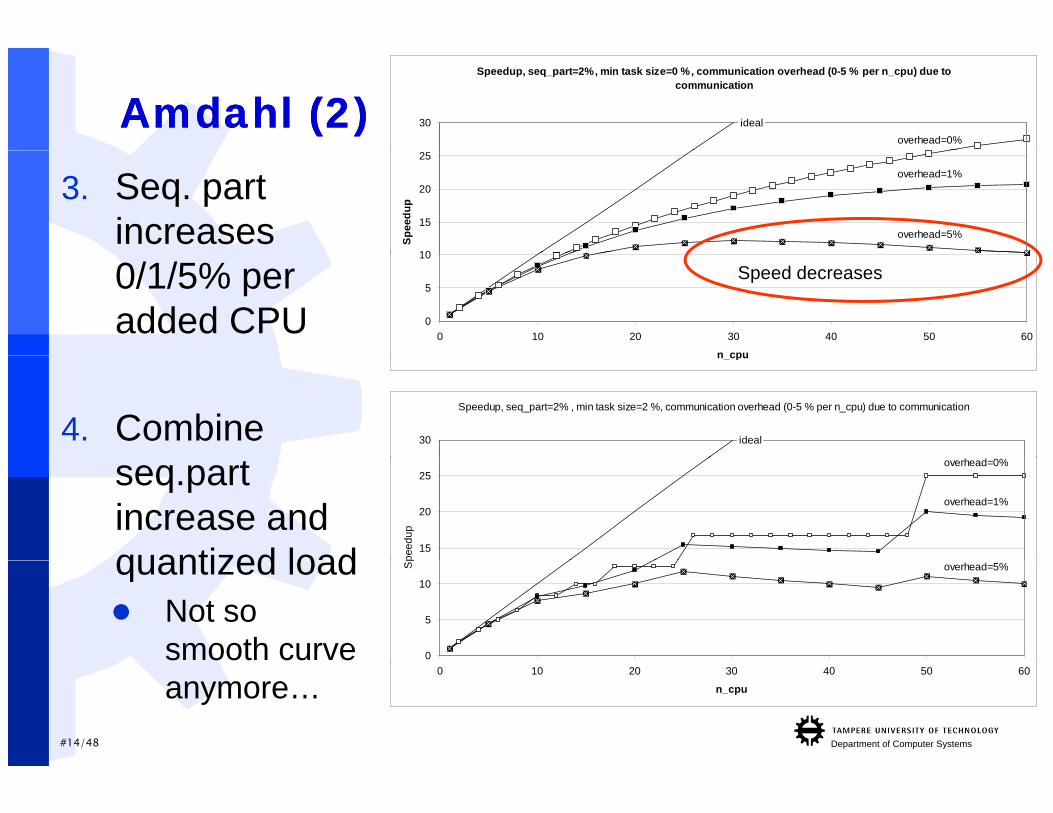
AmdahlAmdahl (2)(2)Speedup, seq_part=2%, min task size=0 %, communication overhead (0-5 % per n_cpu) due to
communication
idealoverhead=0%
30
3. Seq. part increases
overhead=1%
overhead=5%
10
15
20
25
Spee
dup
0/1/5% per added CPU 0
5
10
0 10 20 30 40 50 60
n cpu
Speed decreases
4. Combine
n_cpu
Speedup, seq_part=2% , min task size=2 %, communication overhead (0-5 % per n_cpu) due to communication
ideal30
seq.partincrease and quantized load
overhead=0%
overhead=1%
15
20
25
peed
up
quantized load Not so
smooth curve
overhead=5%
0
5
10
Sp
#14/48 Department of Computer Systems
anymore…0 10 20 30 40 50 60
n_cpu

DataData--parallel and parallel and DataData--parallel and parallel and functionfunction--parallelparallel
Department of Computer Systems
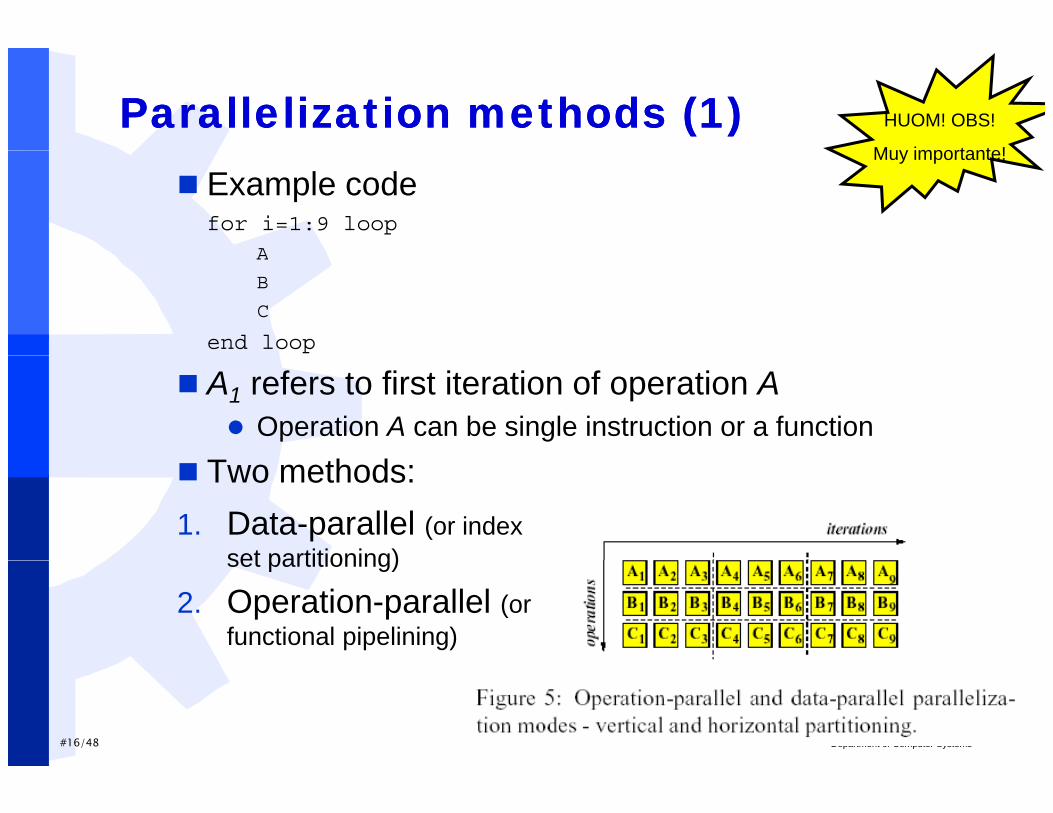
Parallelization methods (1)Parallelization methods (1) HUOM! OBS!
Muy importante!
Example codefor i=1:9 loop
A
Muy importante!
A
B
C
end loop
A1 refers to first iteration of operation A Operation A can be single instruction or a function
Two methods:1. Data-parallel (or index
set partitioning)set partitioning)
2. Operation-parallel (or functional pipelining)
#16/48 Department of Computer Systems
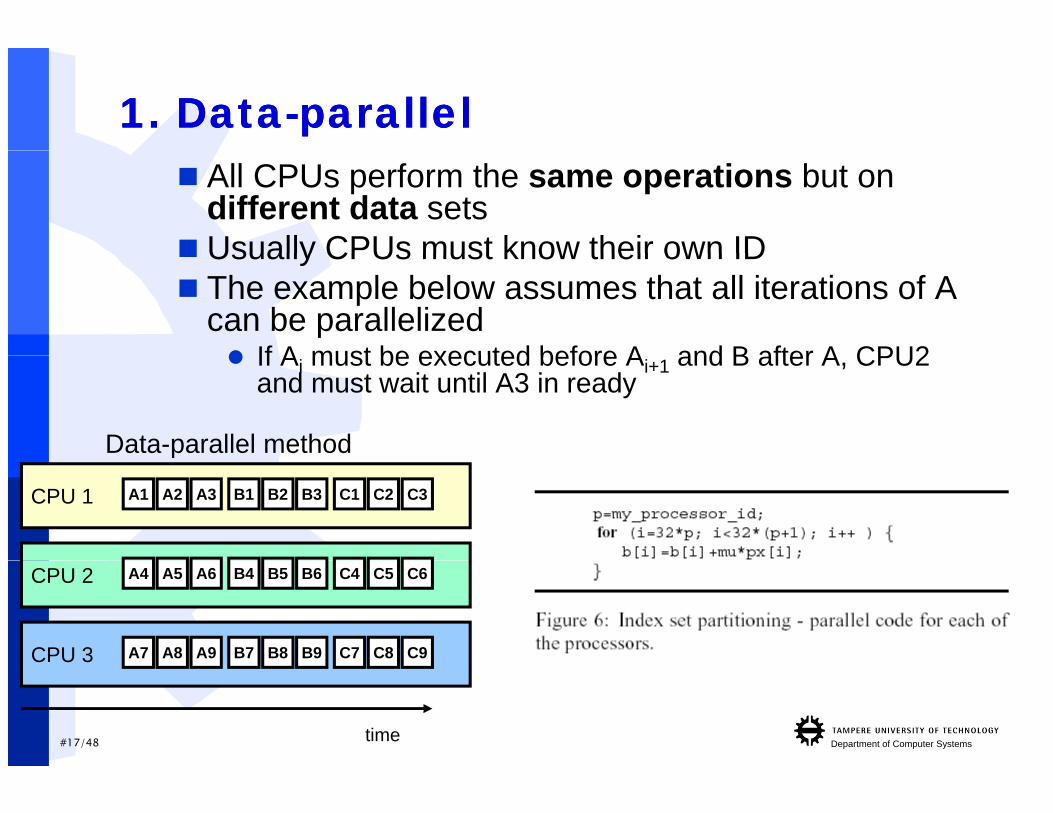
1. 1. DataData--parallelparallel All CPUs perform the same operations but on
different data sets Usually CPUs must know their own ID Usually CPUs must know their own ID The example below assumes that all iterations of A
can be parallelized If A must be executed before A and B after A CPU2 If Ai must be executed before Ai+1 and B after A, CPU2
and must wait until A3 in ready
Data-parallel method
CPU 1 A1 A2 A3 B1 B2 B3 C1 C2 C3
p
CPU 2 A4 A5 A6 B4 B5 B6 C4 C5 C6
CPU 3 A7 A8 A9 B7 B8 B9 C7 C8 C9
#17/48 Department of Computer Systemstime
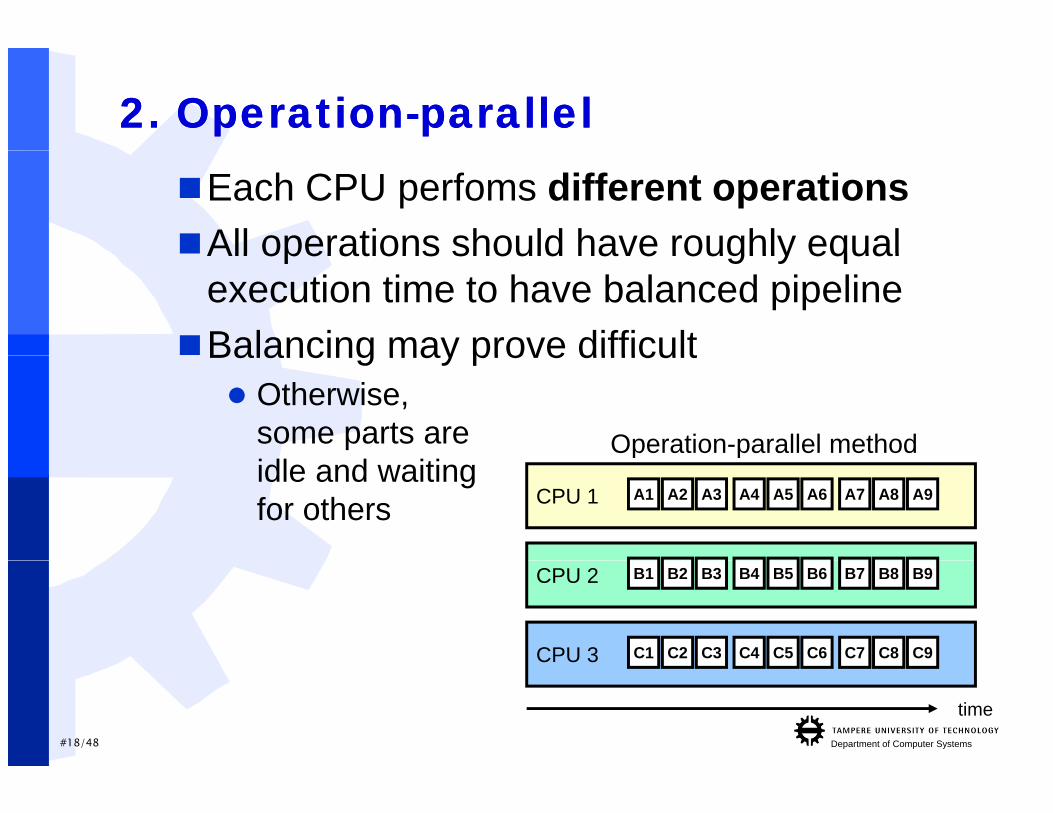
2. 2. OperationOperation--parallelparallelEach CPU perfoms different operationsAll operations should have roughly equalAll operations should have roughly equal
execution time to have balanced pipelineBalancing may prove difficultBalancing may prove difficult
Operation-parallel method
Otherwise, some parts are
CPU 1 A1 A2 A3 A4 A5 A6 A7 A8 A9
p pidle and waiting for others
CPU 2 B1 B2 B3 B4 B5 B6 B7 B8 B9
CPU 3 C1 C2 C3 C4 C5 C6 C7 C8 C9
#18/48 Department of Computer Systems
time

DependenciesDependencies complicatecomplicate parallelizationparallelization
Assume that Ai must be executed before Bi(which is executed before Ci)( i)Hence, it takes some time for the pipeline to
fill After that all units are active concurrently
Operation-parallel method with dependenciesNote that the CPU 1 A1 A2 A3 A4 A5 A6 A7 A8 A9
p p p
same may happen with data-
CPU 2 B1 B2 B3 B4 B5 B6 B7 B8 B9
CPU 3 C1 C2 C3 C4 C5 C6 C7 C8 C9
parallel as well E.g. Ai+1 depends
#19/48 Department of Computer Systemstime
on Ai
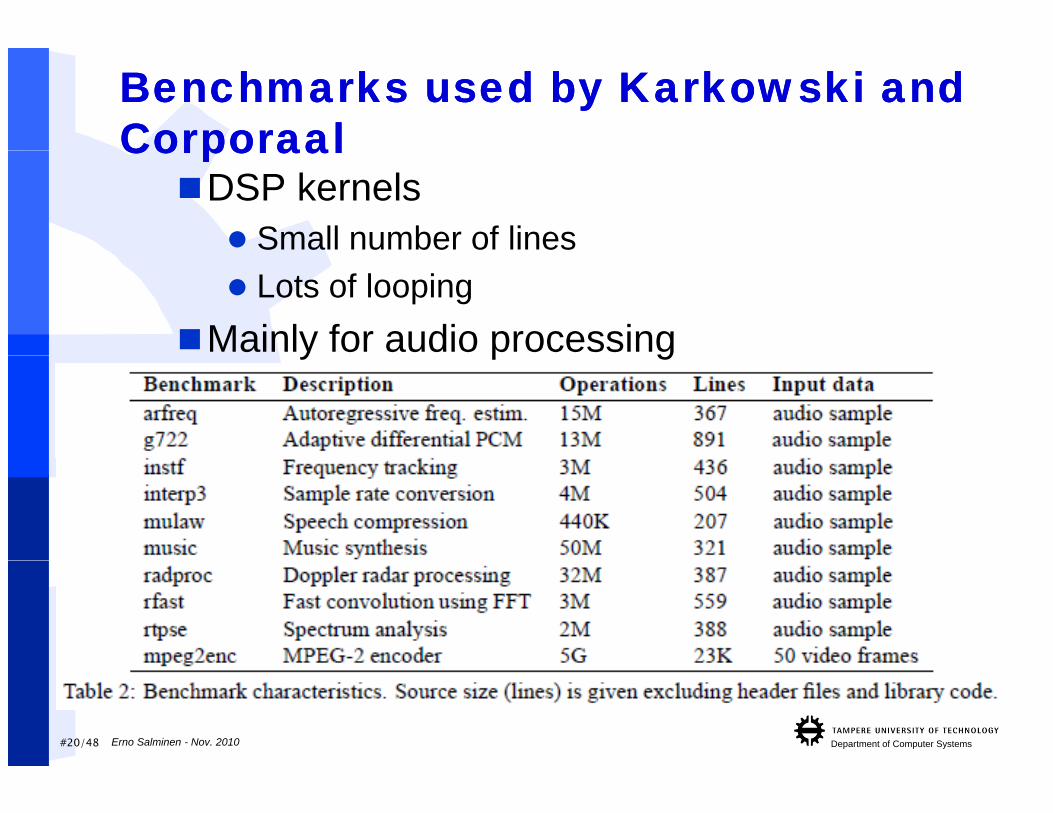
Benchmarks used by Karkowski and Benchmarks used by Karkowski and CorporaalCorporaalCorporaalCorporaalDSP kernels Small number of lines Lots of looping
Mainly for audio processingy p g
#20/48 Department of Computer SystemsErno Salminen - Nov. 2010
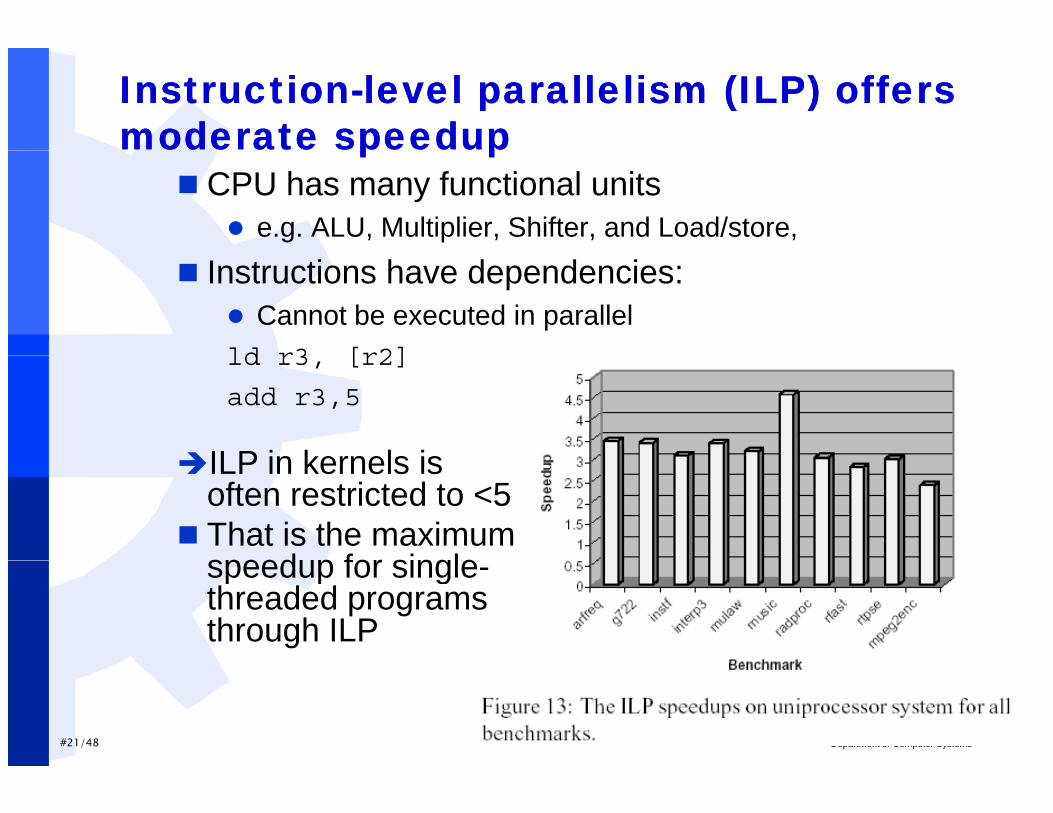
InstructionInstruction--levellevel parallelismparallelism (ILP) (ILP) offersoffersmoderatemoderate speedupspeedupp pp p
CPU has many functional units e.g. ALU, Multiplier, Shifter, and Load/store,
Instructions have dependencies: Cannot be executed in parallelld r3 [r2]ld r3, [r2]
add r3,5
ILP in kernels isILP in kernels is often restricted to <5
That is the maximum speedup for singlespeedup for single-threaded programs through ILP
#21/48 Department of Computer Systems
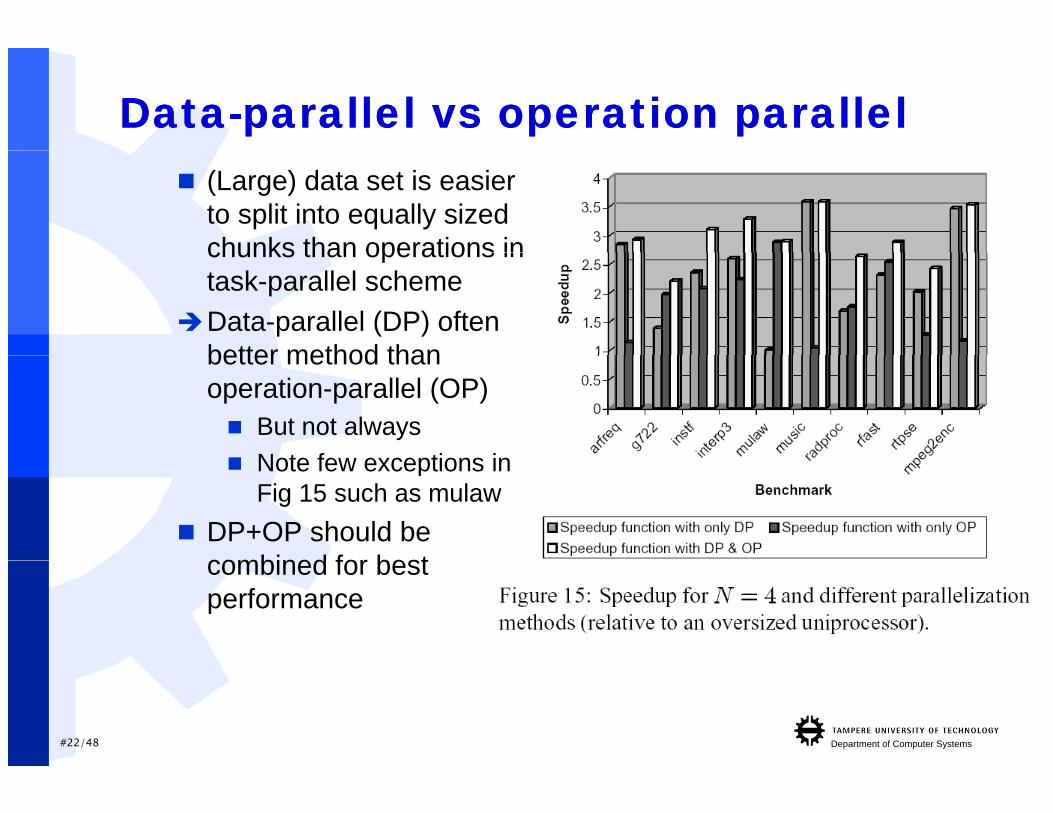
DataData--parallel vs operation parallelparallel vs operation parallel (Large) data set is easier
to split into equally sized chunks than operations inchunks than operations in task-parallel scheme
Data-parallel (DP) often better method thanbetter method than operation-parallel (OP) But not always Note fe e ceptions in Note few exceptions in
Fig 15 such as mulaw DP+OP should be
combined for bestcombined for best performance
#22/48 Department of Computer Systems
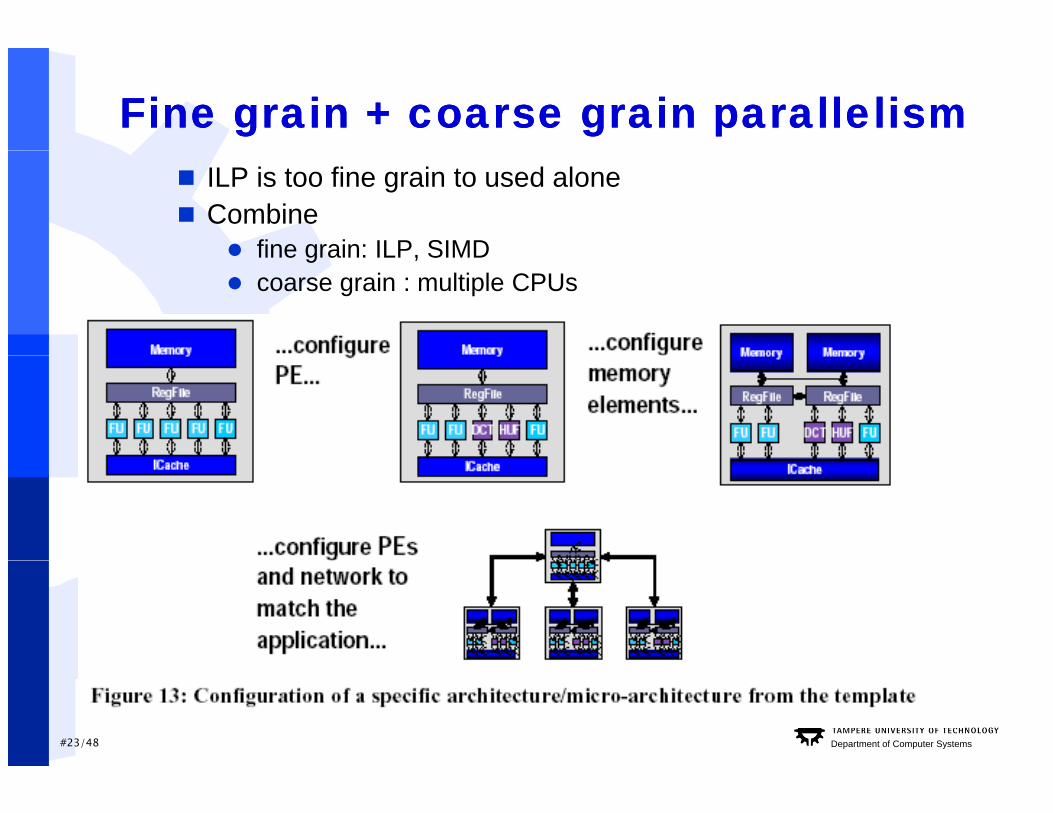
Fine grain + coarse grain parallelismFine grain + coarse grain parallelism ILP is too fine grain to used alone Combine
fine grain: ILP SIMD fine grain: ILP, SIMD coarse grain : multiple CPUs
#23/48 Department of Computer Systems
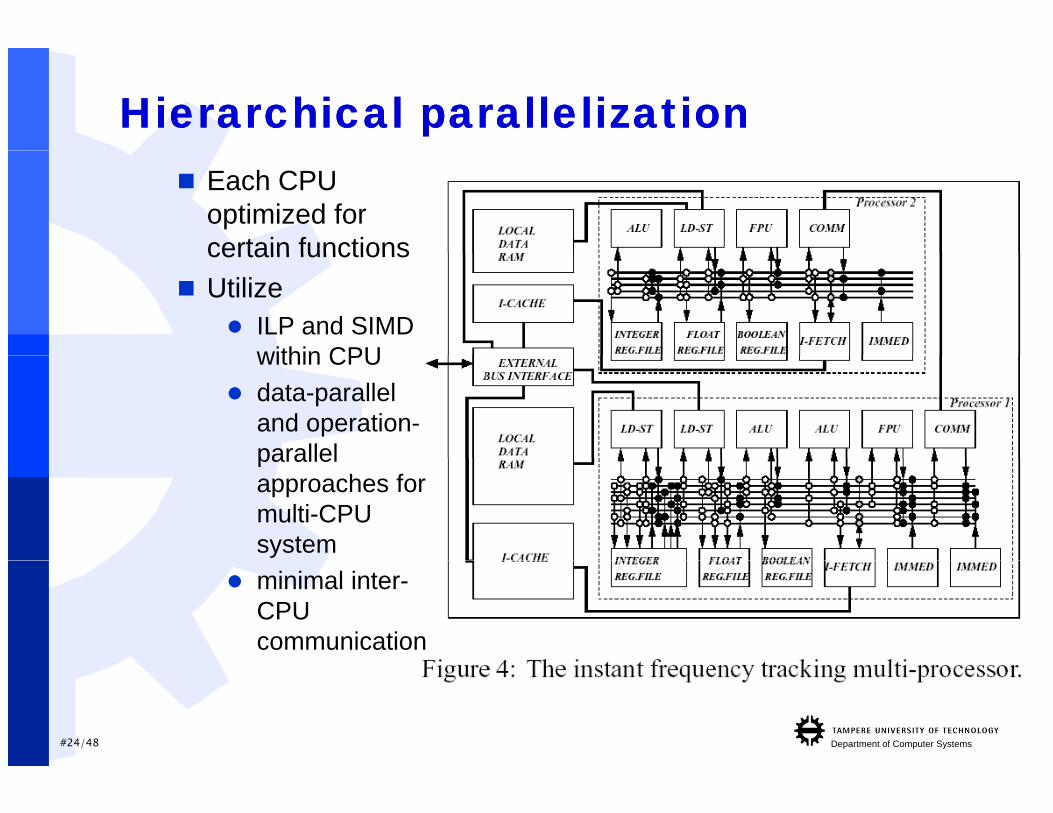
Hierarchical parallelizationHierarchical parallelization Each CPU
optimized for certain functionscertain functions
Utilize ILP and SIMD
within CPUwithin CPU data-parallel
and operation-parallelparallel approaches for multi-CPU system
minimal inter-CPU communication
#24/48 Department of Computer Systems
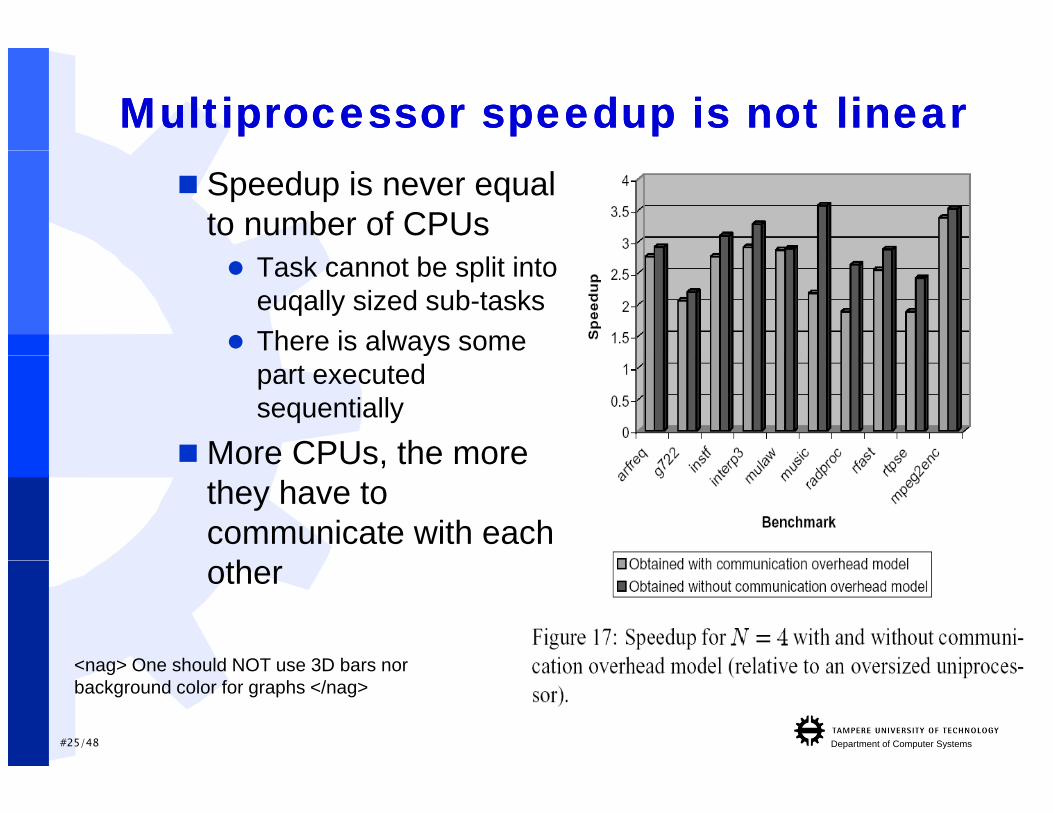
MultiprocessorMultiprocessor speedupspeedup is is notnot linearlinear Speedup is never equal
to number of CPUs Task cannot be split into
euqally sized sub-tasks There is always some y
part executed sequentially
More CPUs the moreMore CPUs, the more they have to communicate with each
th
<nag> One should NOT use 3D bars nor
other
#25/48 Department of Computer Systems
<nag> One should NOT use 3D bars nor background color for graphs </nag>
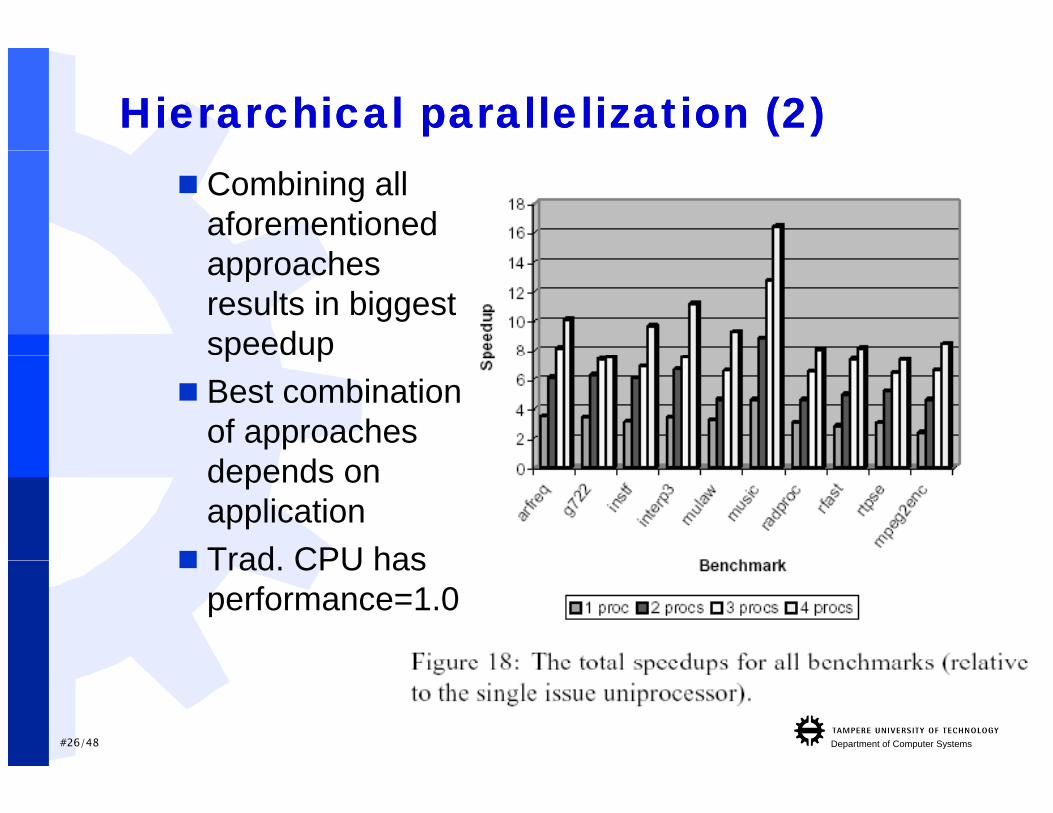
Hierarchical parallelization (2)Hierarchical parallelization (2) Combining all
aforementioned happroaches
results in biggest speedupp p
Best combination of approaches depends on application
Trad CPU has Trad. CPU has performance=1.0
#26/48 Department of Computer Systems
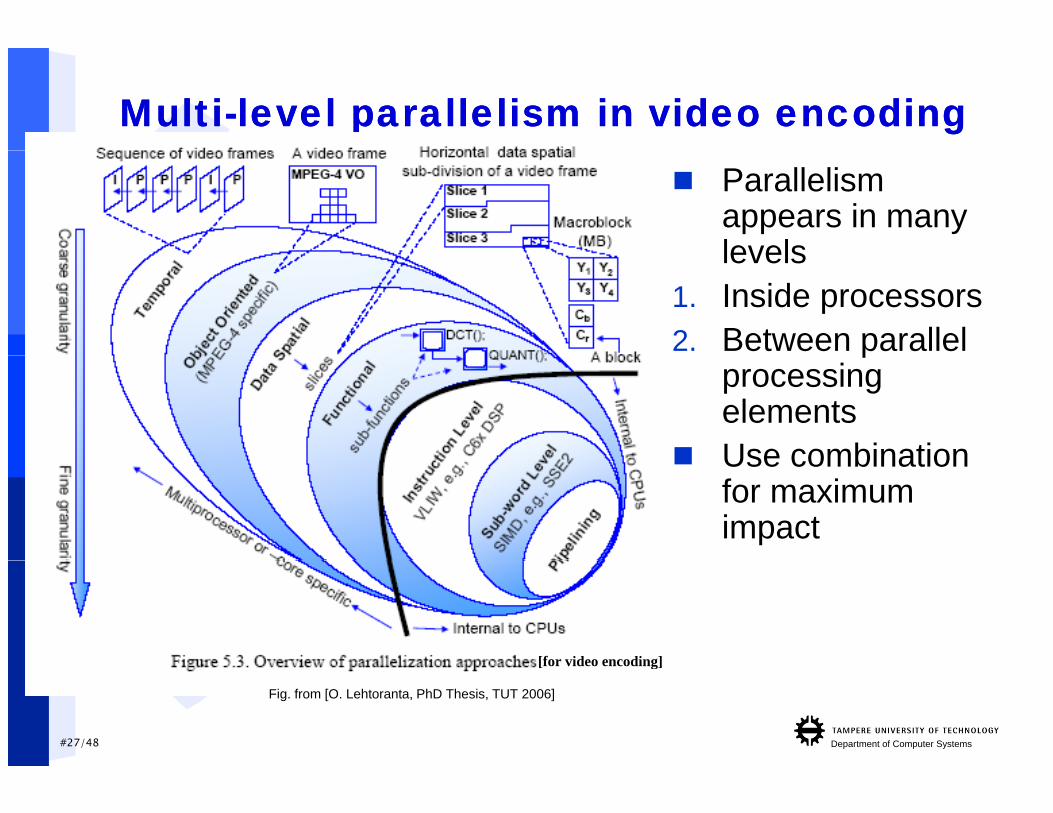
MultiMulti--level level parallelism in video encodingparallelism in video encoding Parallelism
appears in many levelslevels
1. Inside processors2. Between parallel p
processing elements
Use combination Use combination for maximum impact
[for video encoding]
#27/48 Department of Computer Systems
Fig. from [O. Lehtoranta, PhD Thesis, TUT 2006]
[for video encoding]
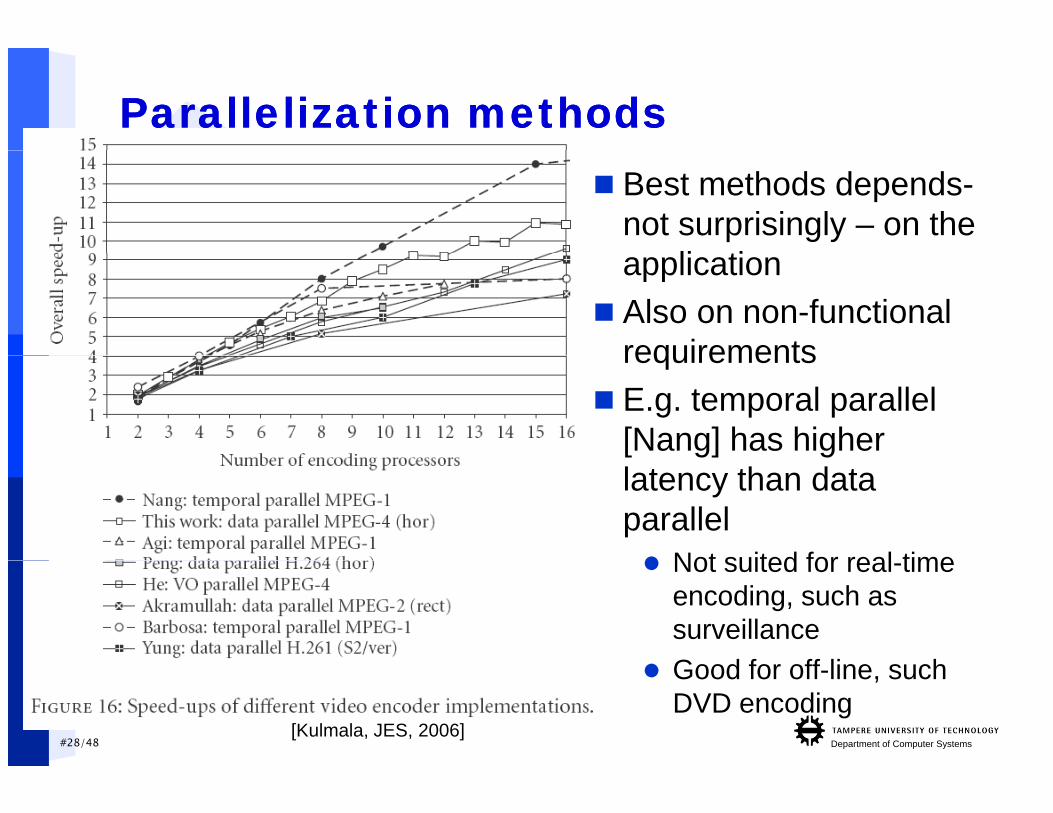
Parallelization methodsParallelization methods Best methods depends-
not surprisingly – on the li tiapplication
Also on non-functional requirementsrequirements
E.g. temporal parallel [Nang] has higher latency than data parallel Not suited for real time Not suited for real-time
encoding, such as surveillanceG d f ff li h
#28/48 Department of Computer Systems[Kulmala, JES, 2006]
Good for off-line, such DVD encoding
Communication schemeCommunication scheme
Department of Computer Systems
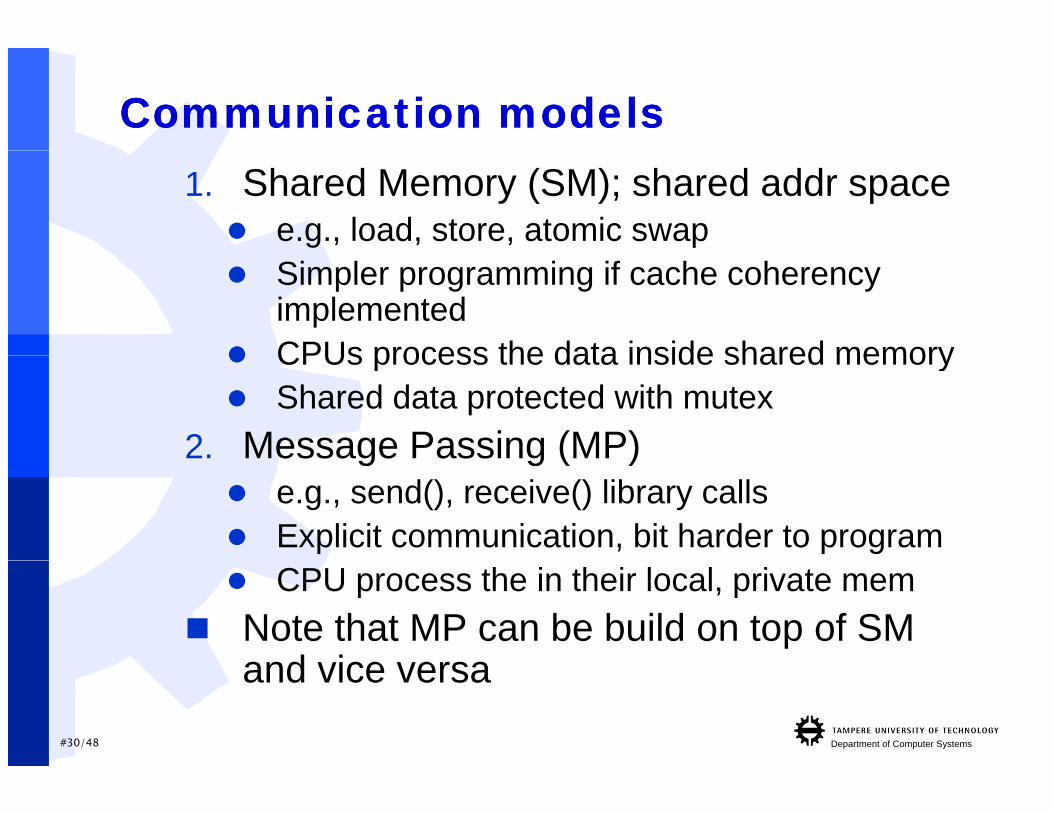
Communication modelsCommunication models1. Shared Memory (SM); shared addr space e.g., load, store, atomic swap Simpler programming if cache coherency
implemented CPUs process the data inside shared memory CPUs process the data inside shared memory Shared data protected with mutex
2. Message Passing (MP)2. Message Passing (MP) e.g., send(), receive() library calls Explicit communication, bit harder to program CPU process the in their local, private mem
Note that MP can be build on top of SM and vice versa
#30/48 Department of Computer Systems
and vice versa
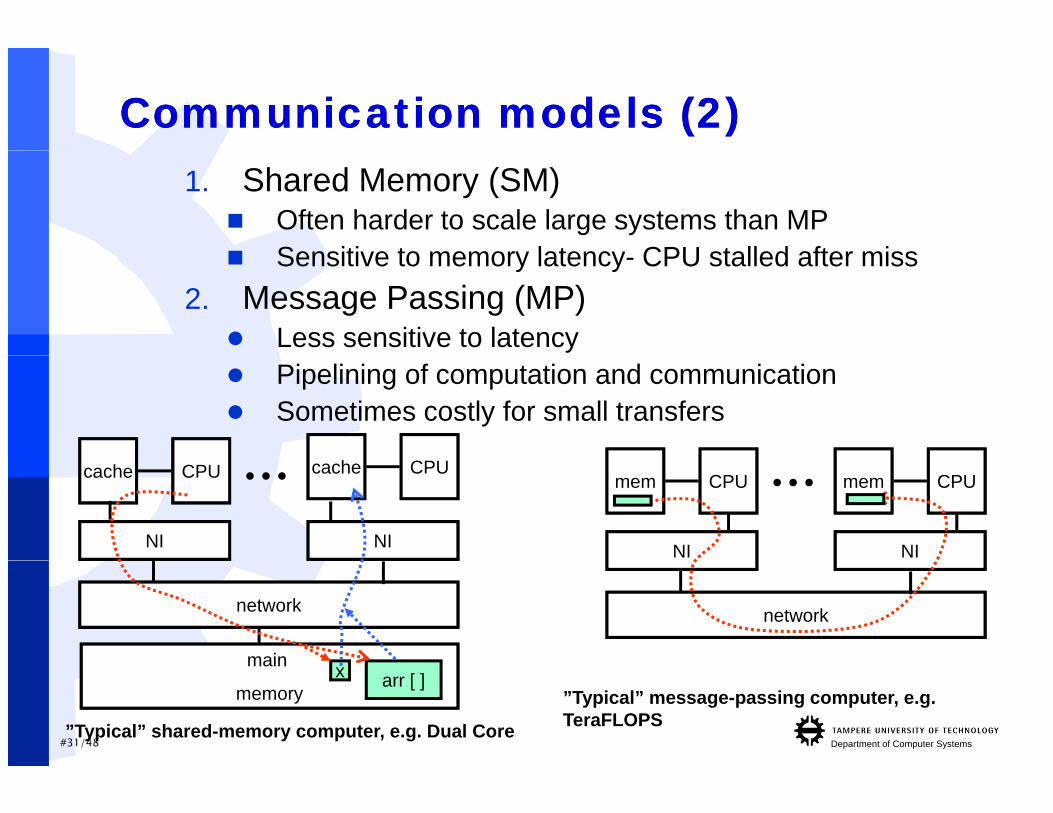
Communication models (2)Communication models (2)1. Shared Memory (SM) Often harder to scale large systems than MP Sensitive to memory latency CPU stalled after miss Sensitive to memory latency- CPU stalled after miss
2. Message Passing (MP) Less sensitive to latency Pipelining of computation and communication Sometimes costly for small transfers
CPUmem
NI
CPUmem
NI
...CPUcache
NI
CPUcache
NI
...
networknetwork
main
#31/48 Department of Computer Systems
main
memory
”Typical” shared-memory computer, e.g. Dual Core
”Typical” message-passing computer, e.g. TeraFLOPS
arr [ ]x

Centralized vs. distributed memory Centralized vs. distributed memory 1. Physically shared - Symmetric Multi Processors
(SMP) Centralized memory (memories) Centralized memory (memories) Equal access time for all CPUs
2. Physically distributed - Distributed Shared Memory (DSM) Each memory adjacent to one CPU Closest CPU has fast access, others have slower, Unequal access times to different parts of the memory
space More common than SMP in large systemsg y
Practically all msg-passing systems use distr.mem. Explicitly managed local memories are also called ”scratch-
pad memories”
#32/48 Department of Computer Systems
pad memories

MemoryMemoryMemory is no. 1 candidate for the system bottleneck
guilty until proven innocentM i d bi ( l k l )Memories need big area (causes leakage also)
Amount is limited especially inside FPGA Number of ports affects memory area, power, and p y , p ,
delay dramatically More than two ports seldom used Use many parallel memory banks Use many parallel memory banks
How to locate data efficiently?Off-chip memory is impractical for same reasons
M k l di ti ti b t bit (b) d b tMake clear disctinction between bits (b) and bytes (B) when presenting memory sizes
Distinguish kilos (k, 1000) and kibis (Ki, 1024)
#33/48 Department of Computer Systems
Distinguish kilos (k, 1000) and kibis (Ki, 1024)
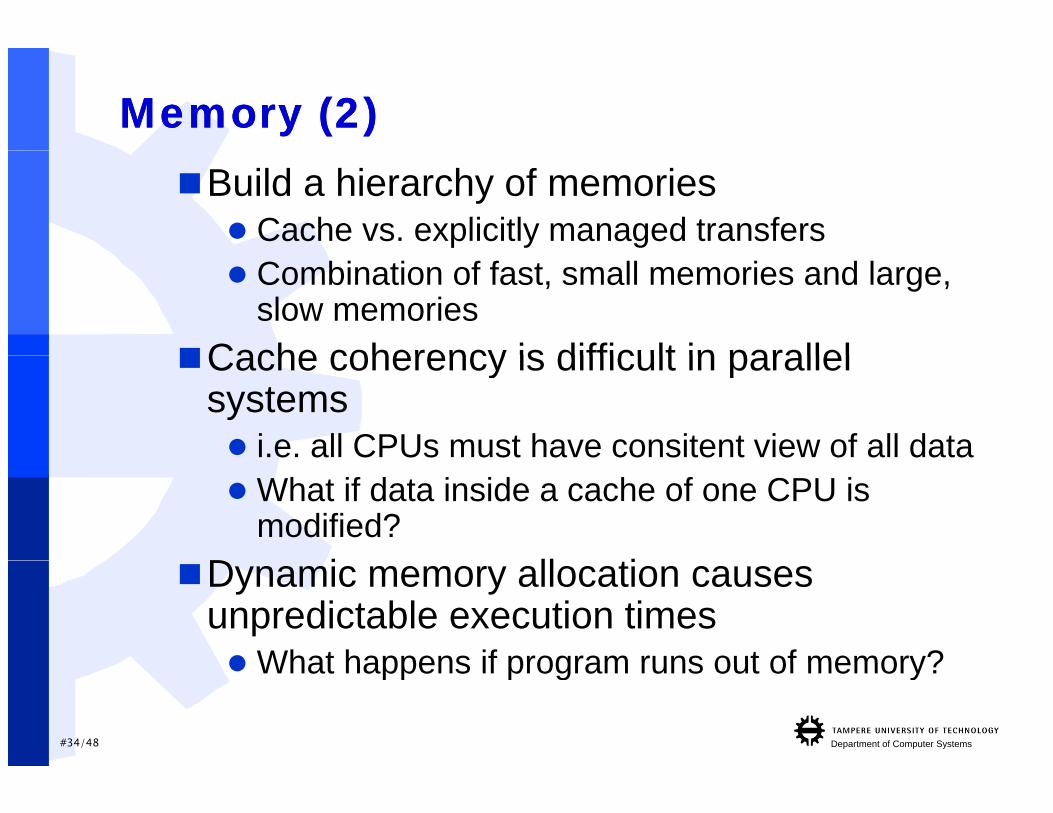
Memory (2)Memory (2)Build a hierarchy of memories Cache vs. explicitly managed transfers Combination of fast, small memories and large,
slow memoriesCache coherency is difficult in parallelCache coherency is difficult in parallel
systems i.e. all CPUs must have consitent view of all data What if data inside a cache of one CPU is
modified?D i ll tiDynamic memory allocation causes unpredictable execution times What happens if program runs out of memory?
#34/48 Department of Computer Systems
What happens if program runs out of memory?
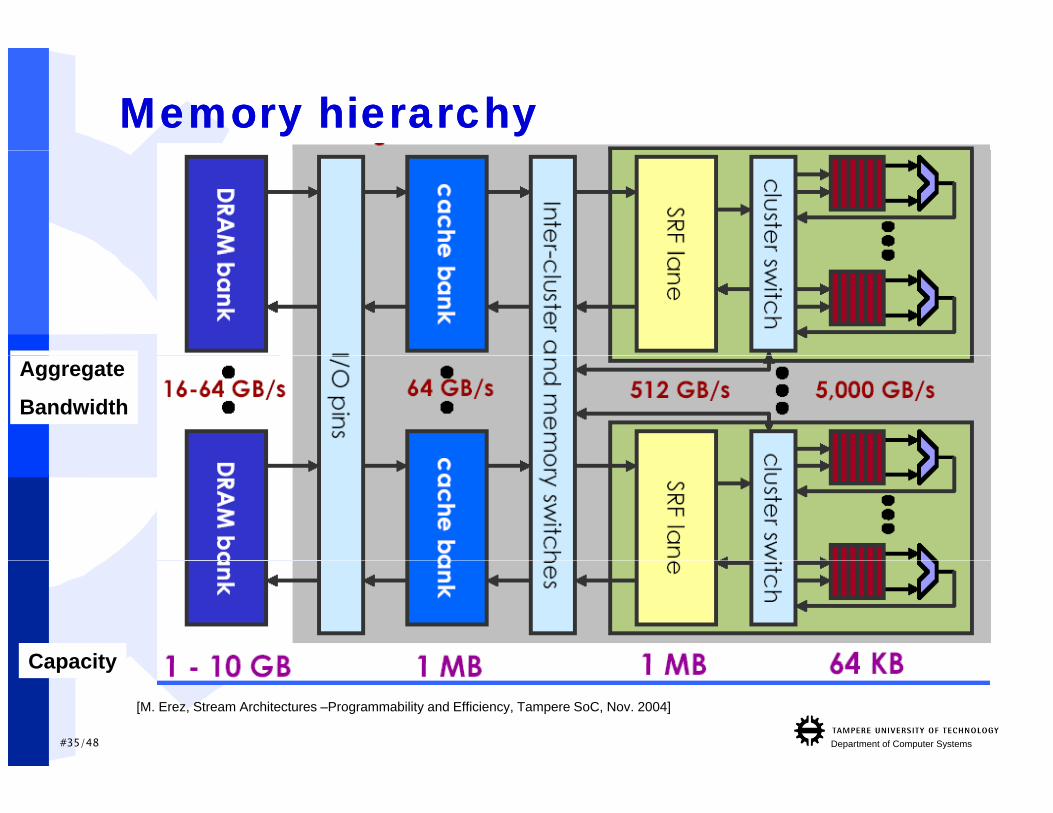
Memory hierarchyMemory hierarchy
Aggregate
Bandwidth
Capacity
#35/48 Department of Computer Systems
[M. Erez, Stream Architectures –Programmability and Efficiency, Tampere SoC, Nov. 2004]
Capacity
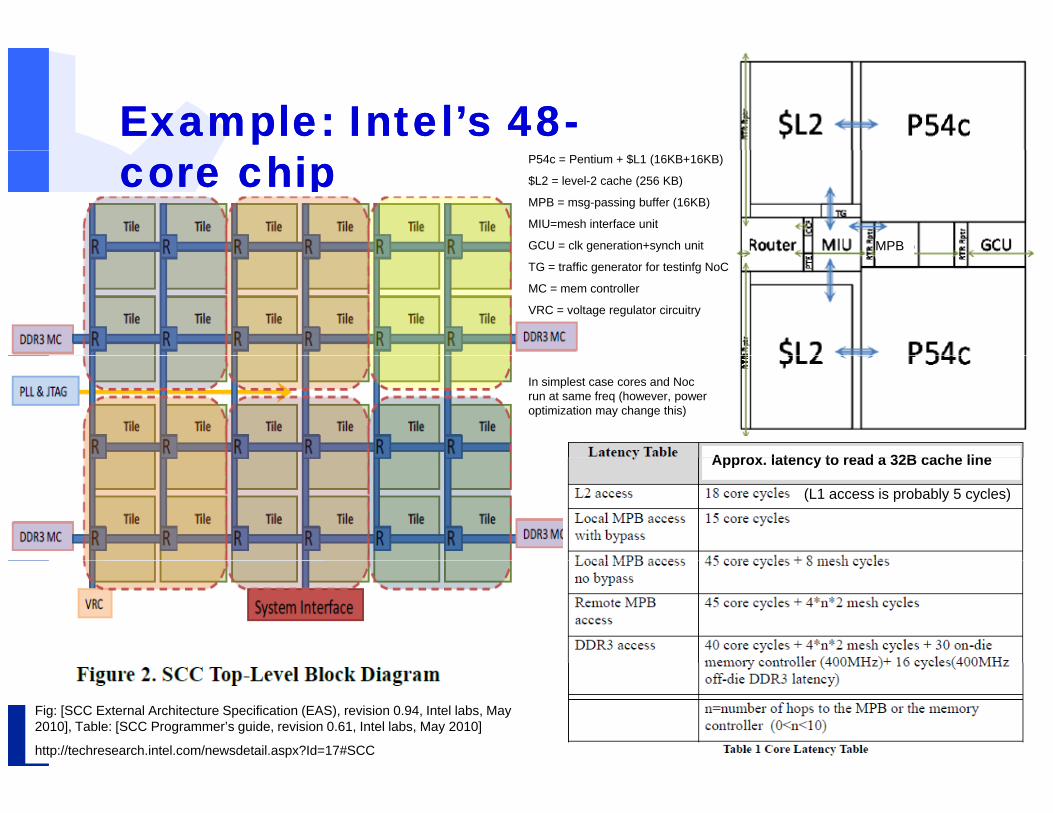
Example: Intel’s 48Example: Intel’s 48--core chipcore chip
MPB
P54c = Pentium + $L1 (16KB+16KB)
$L2 = level-2 cache (256 KB)
MPB = msg-passing buffer (16KB)
MIU=mesh interface unit
GCU = clk generation+synch unit
TG = traffic generator for testinfg NoC
MC = mem controller
VRC = voltage regulator circuitry
Approx latency to read a 32B cache line
In simplest case cores and Noc run at same freq (however, power optimization may change this)
Approx. latency to read a 32B cache line
(L1 access is probably 5 cycles)
#36/48 Department of Computer SystemsErno Salminen - Nov. 2010
Fig: [SCC External Architecture Specification (EAS), revision 0.94, Intel labs, May 2010], Table: [SCC Programmer’s guide, revision 0.61, Intel labs, May 2010]
http://techresearch.intel.com/newsdetail.aspx?Id=17#SCC

SynchronizationSynchronization Tasks runinng in parallel must be
synchronized every now and theny y1. Process (task) synchronization Multiple processes are to join up or handshake p p j p
at a certain point2. Data synchronization Keeps multiple copies of a dataset in coherence
with one another to maintains data integrity Process synchronization primitives are
commonly used to implement data synchronization
#37/48 Department of Computer Systems
synchronization

Synchronization (2)Synchronization (2)1. Semaphore (lock)
Variable for communicating status between parallel tasks Ensures that only one or limited number (usually exactly
1) of tasks updates shared data structure Require atomic test-set functionality q y Mutual exclusion (mutex) is binary semaphore
2. Barrier Ensures that all tasks have reached specific point in
program Tasks read barrier semaphore, stop, and keep waiting
until the last task ”arrives”
Also other types, such as thread join, non-blocking synchronization synchronous communication
#38/48 Department of Computer Systems
synchronization, synchronous communication

ConclusionConclusionAmdahl’s law offers idealistic but fundamental
limitCombine fine and coarse grain parallelismTwo basic methods: function parallel and
d t ll ldata-parallelTwo basic communication schemes: shared
memory and message passingmemory and message-passingLoad balancing is crucial in parallel systems Larger data set simplifies balancing in Data- Larger data set simplifies balancing in Data-
Parallel schemeCommunication between components has
#39/48 Department of Computer Systems
great impact on performance

C t i bl C t i bl Customizable Customizable Datapath Integrated Datapath Integrated p gp gLock UnitLock UnitPekka Jääskeläinen, Pekka Jääskeläinen, Erno SalminenErno Salminen, Otto Esko and , Otto Esko and Jarmo TakalaJarmo TakalaDepartment of Computer SystemsDepartment of Computer SystemsTampere University of TechnologyTampere University of TechnologyTampere University of TechnologyTampere University of Technology
SoC Symposium, Oct 31 SoC Symposium, Oct 31 -- Nov. 2 2011Nov. 2 2011
Department of Computer SystemsErno Salminen - November 2011
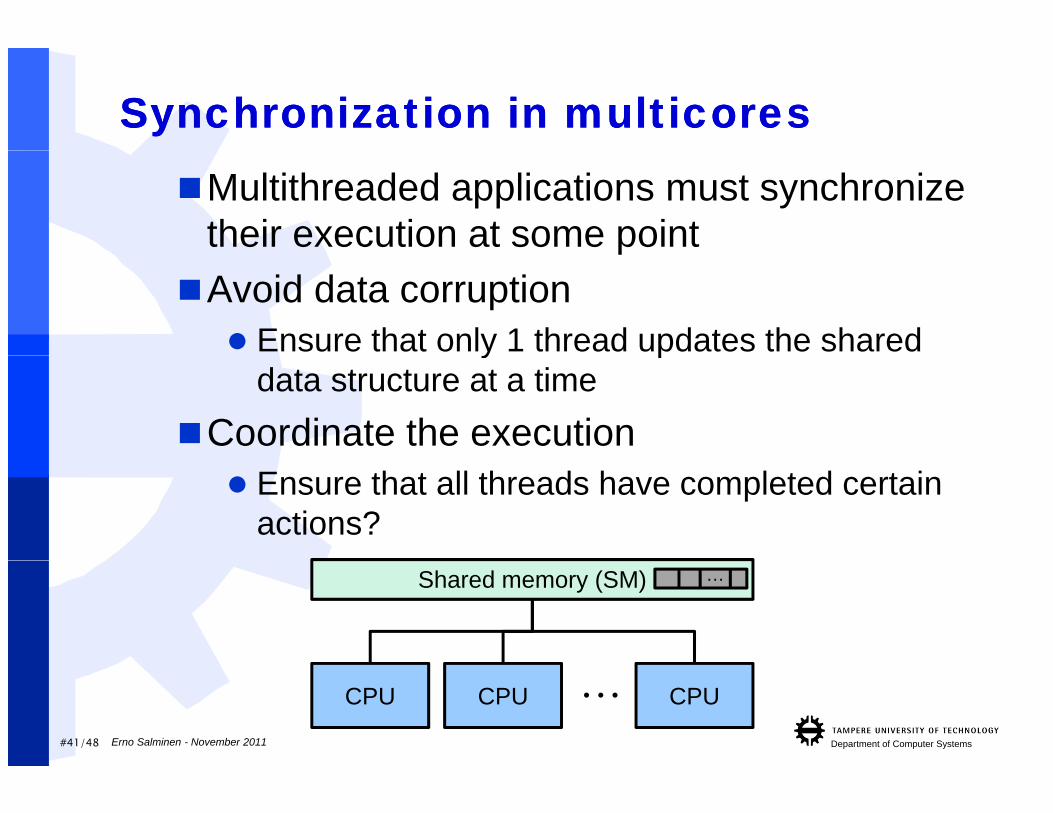
Synchronization in multicoresSynchronization in multicoresMultithreaded applications must synchronize
their execution at some pointpAvoid data corruption Ensure that only 1 thread updates the shared y p
data structure at a timeCoordinate the execution Ensure that all threads have completed certain
actions?Shared memory (SM) …
#41/48 Department of Computer SystemsErno Salminen - November 2011
CPU CPU CPU…
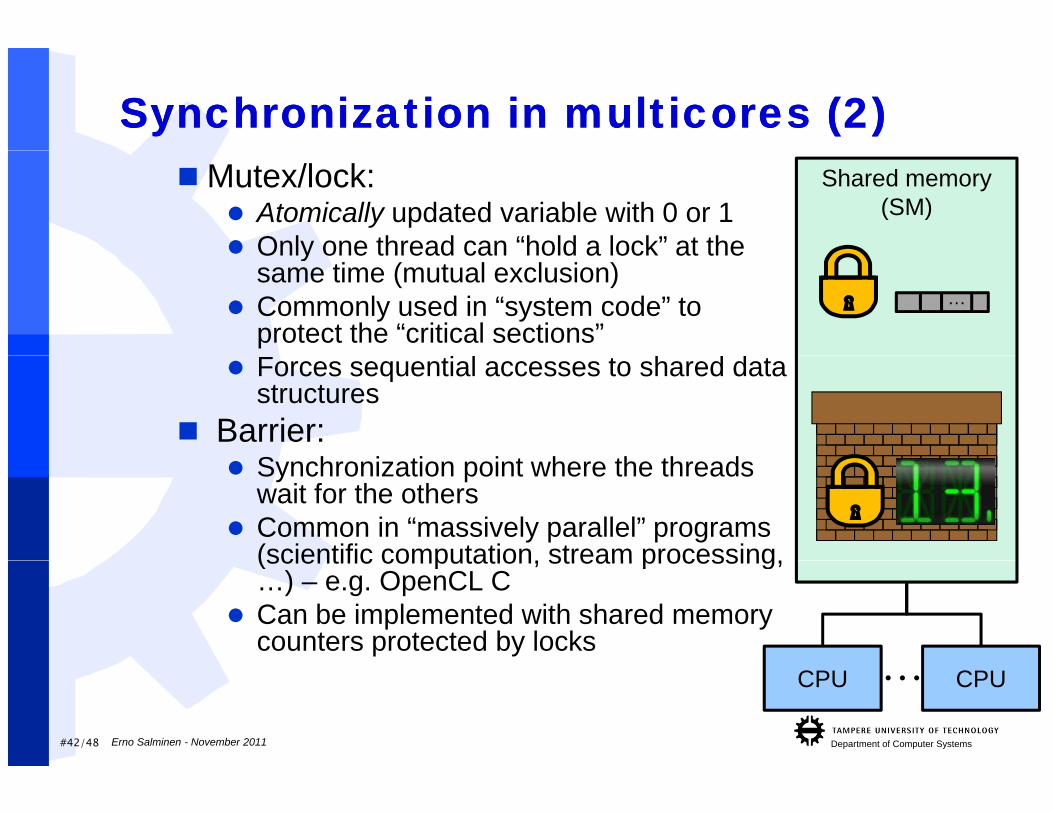
Synchronization in multicores (2)Synchronization in multicores (2)Shared memory
(SM)Mutex/lock:
Atomically updated variable with 0 or 1 Only one thread can “hold a lock” at the Only one thread can hold a lock at the
same time (mutual exclusion) Commonly used in “system code” to
protect the “critical sections”…
Forces sequential accesses to shared data structures
Barrier:S h i ti i t h th th d Synchronization point where the threads wait for the others
Common in “massively parallel” programs (scientific computation stream processing(scientific computation, stream processing, …) – e.g. OpenCL C
Can be implemented with shared memory counters protected by locks
#42/48 Department of Computer SystemsErno Salminen - November 2011
CPU CPU…

Overheads from synchronizationOverheads from synchronizationLocks typically use atomic Read-Modify-Write
(RMW) instructions to access shared memory variablesvariables E.g. If variable was 0, then write 1. Otherwise, try
again Operation must be atomic; others threads cannot Operation must be atomic; others threads cannot
interveneAccessing “lock variables” adds to the memory
bottleneckbottleneck Check for unlock status requires at least a L1 cache
read, and a main memory read in the worst case Total overhead depends on the memory hierarchy Total overhead depends on the memory hierarchy,
cache coherence implementation, etc.Moreover, these lock accesses prevent other
threads from accessing memory
#43/48 Department of Computer Systems
threads from accessing memory
Erno Salminen - November 2011
Proposed lock unitProposed lock unit
Department of Computer SystemsErno Salminen - November 2011

Datapath Integrated Lock Unit (DILU)Datapath Integrated Lock Unit (DILU) Our multicore ASIP (MCASIP) template provides easily
customizable manycores Configurable TTA cores Core counts tens-hundreds TCEMC toolset for simulation, compilation, and VHDL generation Programmer optimizes the local memory usage
Key idea of lightweight synchronization: Key idea of lightweight synchronization: Move the lock variables from the shared memory to a separate
lock register file Integrate the basic lock operations to the instruction set of the g p
ASIP core Benefits:
Minimize shared memory overhead when synchronizing (esp. when waiting in a barrier)when waiting in a barrier)
Provide fast synchronization even in case of manycores without coherent caches
#45/48 Department of Computer SystemsErno Salminen - November 2011
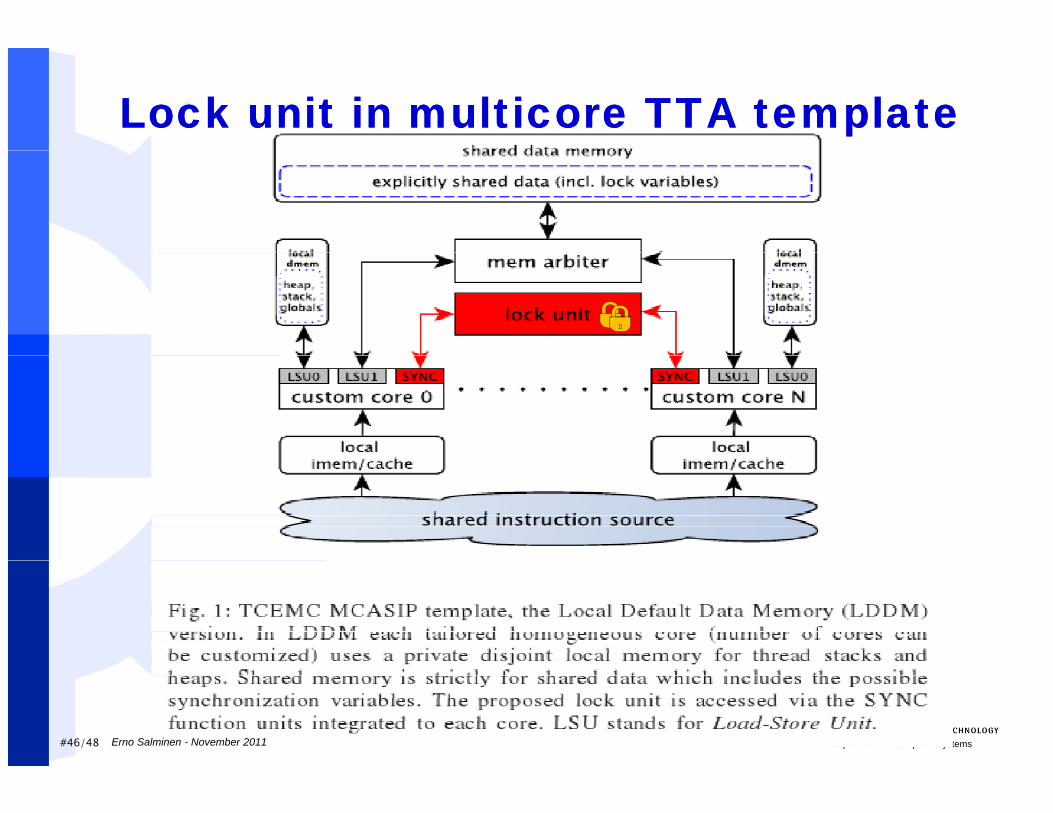
Lock unit in multicore TTA templateLock unit in multicore TTA template
#46/48 Department of Computer SystemsErno Salminen - November 2011

Three new instructions addedThree new instructions added
Special function unit (SFU) in TTA implements 3 instructions and interface to lock unit HW TRY_LOCK stores addr A into HW unit and returns 1 if
there is room UNLOCK does no ownership checking (assumes well-
behaving programs)behaving programs) READ_LOCK returns 1 in case A was locked No access to the shared memory
These enable multiple synchronization primitive These enable multiple synchronization primitive implementations Using more special lock registers vs. more shared memory
variables
#47/48 Department of Computer Systems
variables
Erno Salminen - November 2011
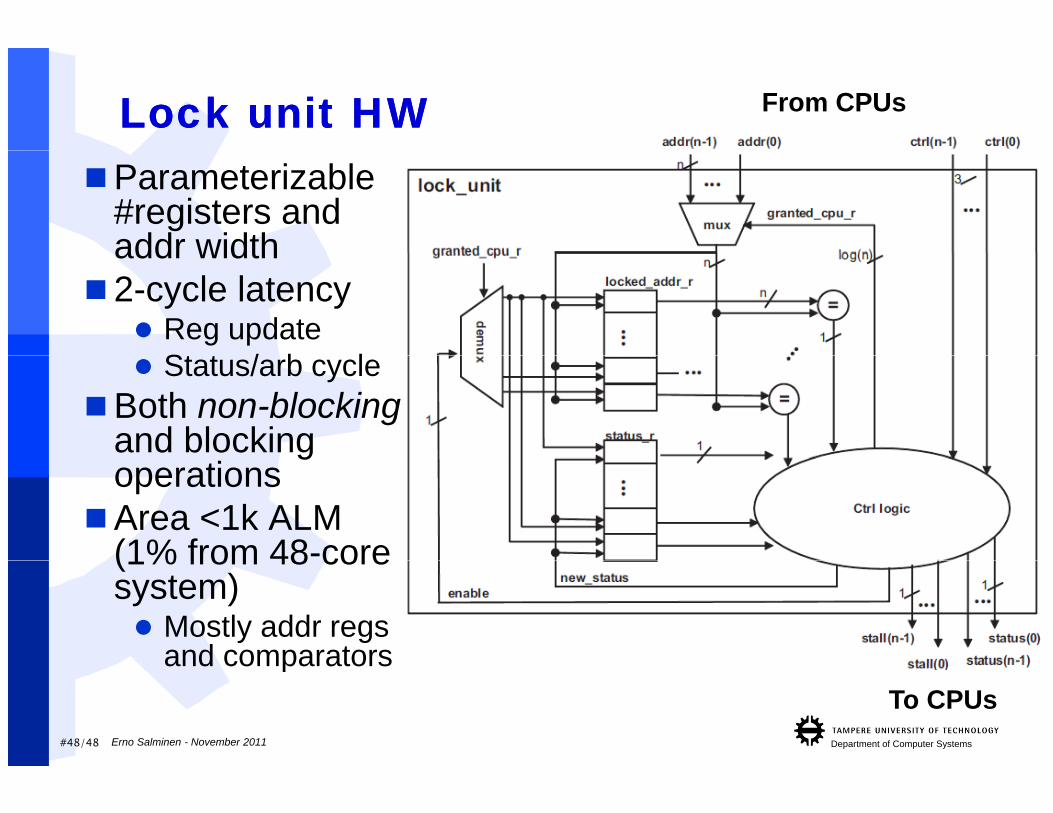
From CPUsLock unit HWLock unit HWParameterizable
#registers and addr widthaddr width
2-cycle latency Reg update
St t / b l Status/arb cycleBoth non-blocking
and blocking goperations
Area <1k ALM (1% from 48-core(1% from 48 core system) Mostly addr regs
and comparators
#48/48 Department of Computer SystemsErno Salminen - November 2011
To CPUsand comparators

Implementing lock and barrierImplementing lock and barrier2 versions of lock primitive Basic version uses 1 lock register and n variables g
in shared memory Register guards all n variables
F t i l l k i t Faster version uses only lock registers #locks active simultaneously must be known at
synthesis/compile timey
2 versions of barrier also Both have the counter variable in shared memoryy Basic version polls until that counter goes to 0 Faster version polls an additional lock register
#49/48 Department of Computer Systems
It will be unlocked by the last arriving thread
Erno Salminen - November 2011

DILU: Spin lock examplesDILU: Spin lock examples
#50/48 Department of Computer SystemsErno Salminen - November 2011

Barrier implementation examplesBarrier implementation examples
#51/48 Department of Computer SystemsErno Salminen - November 2011

ResultsResults
Department of Computer SystemsErno Salminen - November 2011

Summary of synchronization primitive Summary of synchronization primitive implementationsimplementationsimplementationsimplementations
#53/48 Department of Computer SystemsErno Salminen - November 2011
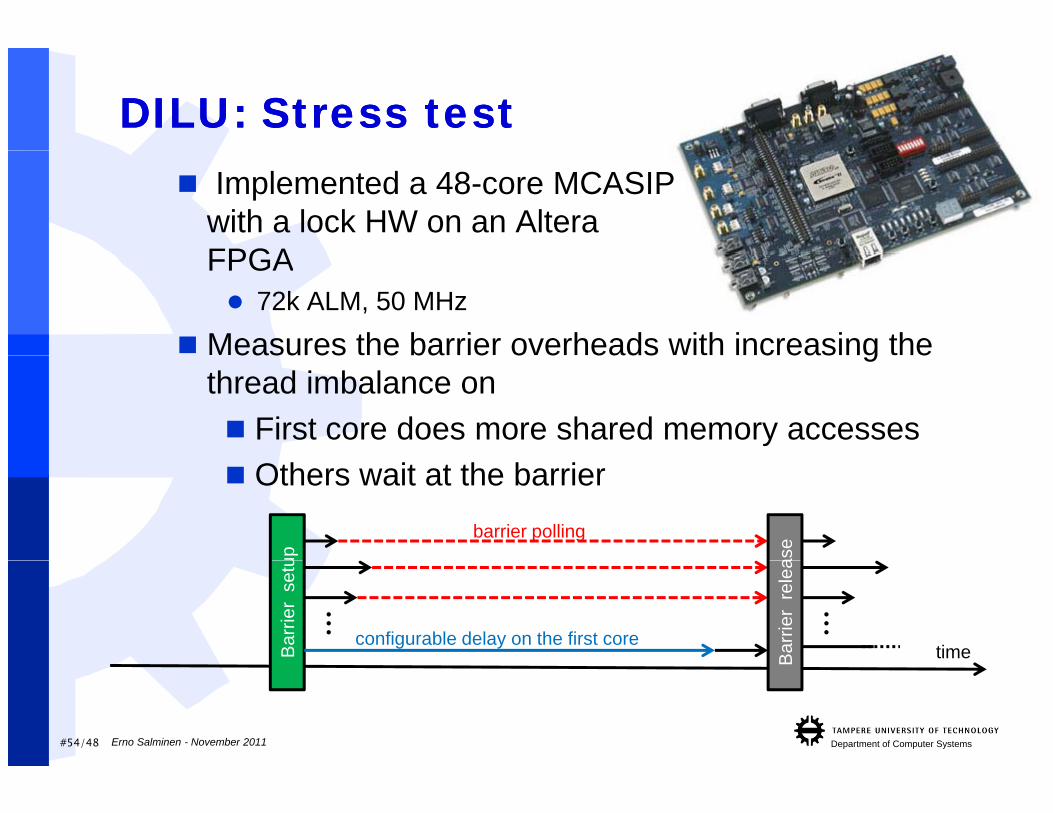
DILU: Stress testDILU: Stress test Implemented a 48-core MCASIP
with a lock HW on an Altera FPGA
Measures the barrier overheads with increasing the
FPGA 72k ALM, 50 MHz
easu es e ba e o e eads c eas g ethread imbalance on First core does more shared memory accesses Others wait at the barrier
up asebarrier polling
timeBar
rier
setu
Barr
ier
rele
a
… …
configurable delay on the first core
#54/48 Department of Computer SystemsErno Salminen - November 2011
B

Stress testStress testPractically no computation, just synchronizationCore 0 performs dummy memory accesses
before the barrierbefore the barrier Creates thread imbalance In basic case the other threads contend for memory
as they poll the barrier counteras they poll the barrier counter
#55/48 Department of Computer SystemsErno Salminen - November 2011
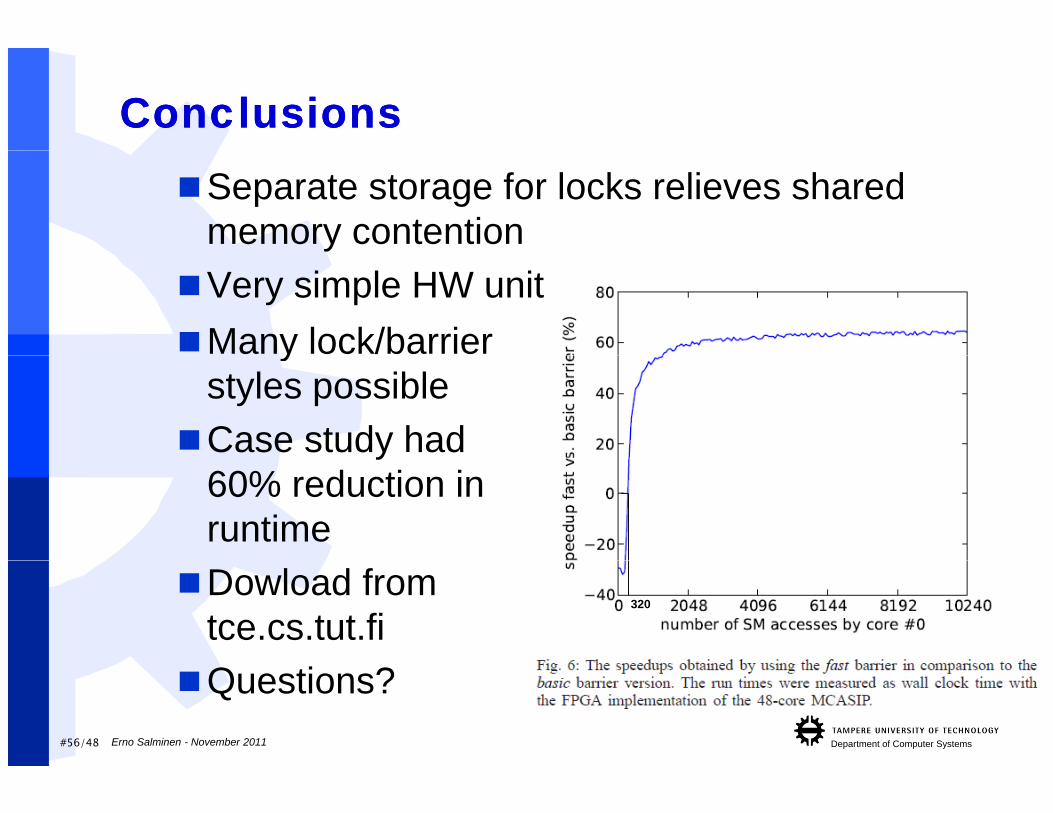
ConclusionsConclusionsSeparate storage for locks relieves shared
memory contention
Many lock/barrier Very simple HW unit
ystyles possible
Case study had y60% reduction in runtime
Dowload from tce.cs.tut.fi
320
#56/48 Department of Computer SystemsErno Salminen - November 2011
Questions?

For selfstudyFor selfstudy
Department of Computer SystemsErno Salminen - Nov. 2010

Automatic parallelizationAutomatic parallelization Research topic for several years
Only small scale success so far Ti S Tim Sweeney:
http://chipsandbs.blogspot.com/2006/03/auto-parallelization-of-c-code-is-not.html Actually from http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2377&p=3
Auto-parallelization of C++ code is not a serious notion Auto-parallelization of C++ code is not a serious notion These techniques applied to C/C++ programs are
completely infeasible on the scale of real applications Writing multithreaded software is very hard Writing multithreaded software is very hard It's about as unnatural to support multithreading in C++ as
it was to write object-oriented software in assembly languagelanguage.
The whole industry is starting to do it now, but it's pretty clear that a new programming model is needed if we're going to scale to ever more parallel architectures.
#58/48 Department of Computer Systems
g g p
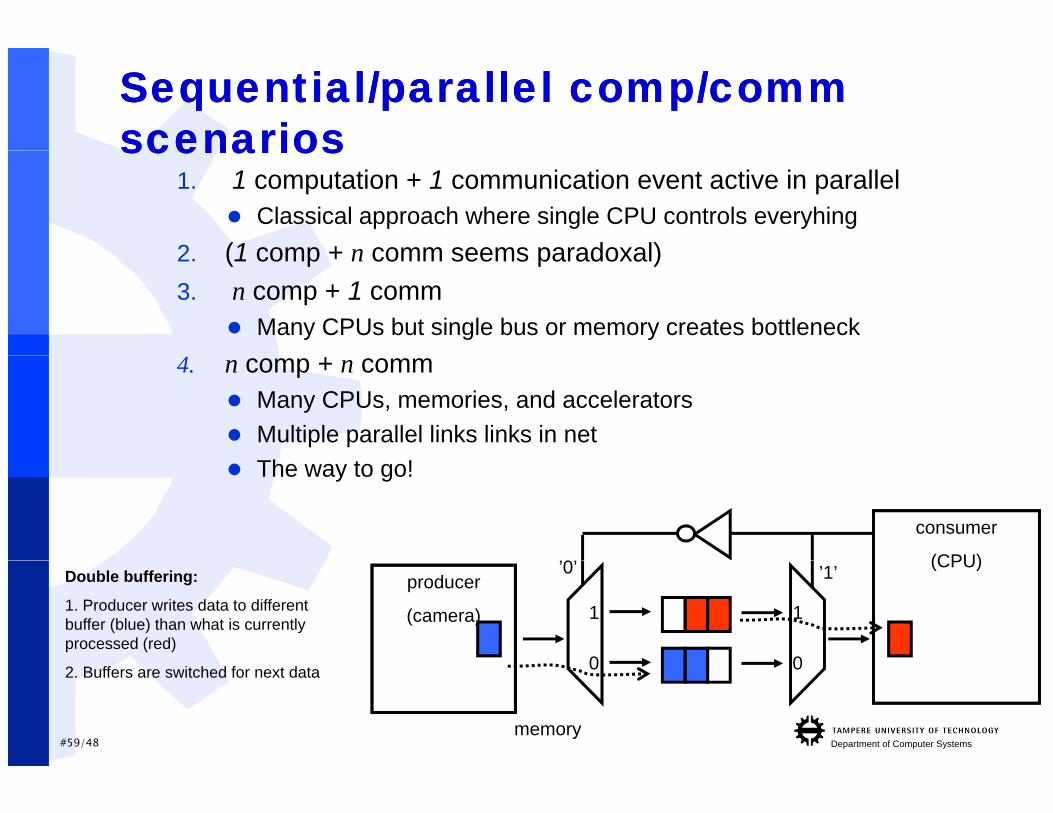
Sequential/parallelSequential/parallel comp/comm comp/comm scenariosscenariosscenariosscenarios
1. 1 computation + 1 communication event active in parallel Classical approach where single CPU controls everyhing
2 (1 comp + n comm seems paradoxal)2. (1 comp + n comm seems paradoxal)3. n comp + 1 comm
Many CPUs but single bus or memory creates bottleneck4. n comp + n comm
Many CPUs, memories, and accelerators Multiple parallel links links in net The way to go!
consumer
(CPU)’0’ (CPU)producer
(camera) 1
0
1
0
’1’’0’Double buffering:
1. Producer writes data to different buffer (blue) than what is currently processed (red)
#59/48 Department of Computer Systems
00
memory
2. Buffers are switched for next data
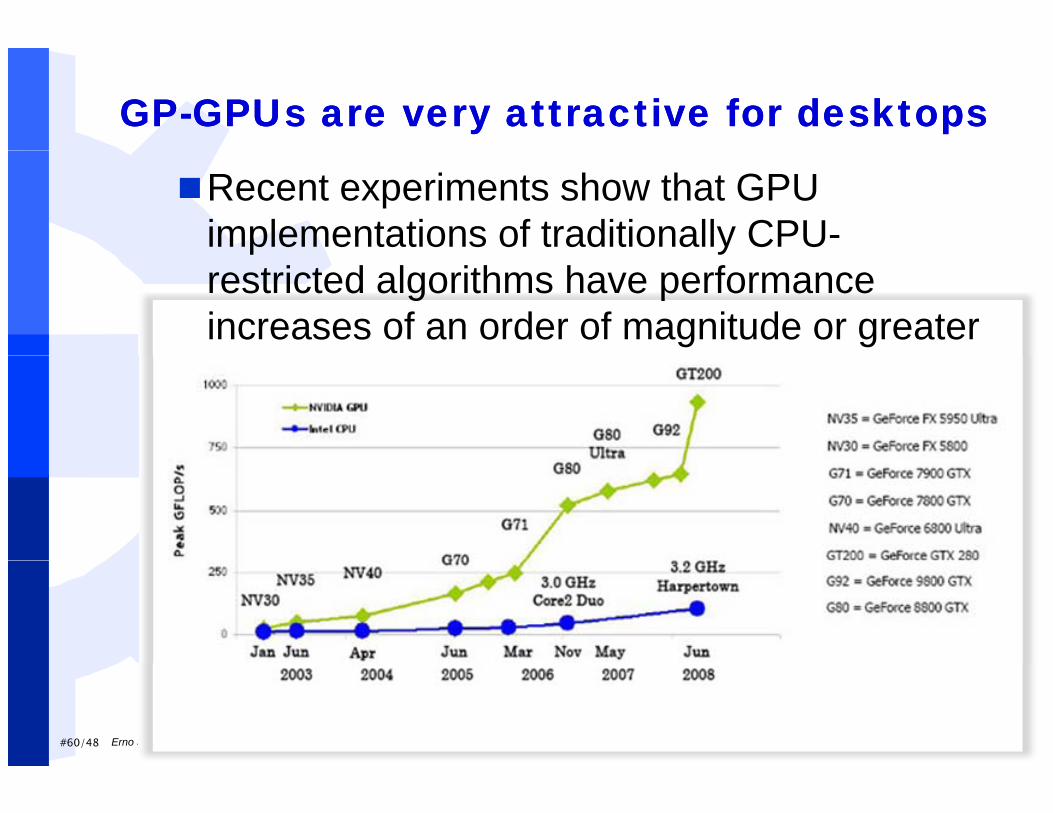
GPGP--GPUs are very attractive for desktopsGPUs are very attractive for desktops
Recent experiments show that GPU implementations of traditionally CPU-p yrestricted algorithms have performance increases of an order of magnitude or greater
#60/48 Department of Computer SystemsErno Salminen - Nov. 2010

HIBI Multiprocessor HIBI Multiprocessor HIBI Multiprocessor HIBI Multiprocessor ExampleExampleScalable Video Encoder
Department of Computer Systems
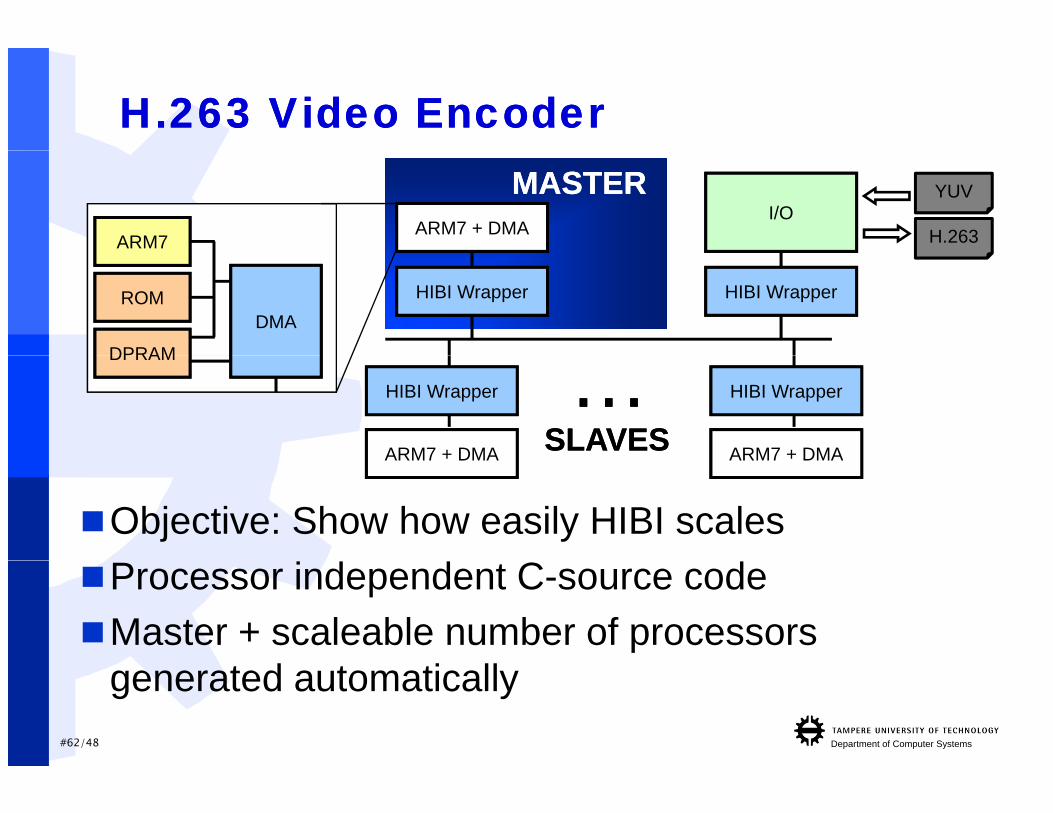
H.263 Video EncoderH.263 Video Encoder
I/OARM7 H.263
YUV
ARM7 + DMA
MASTERMASTER
DMA
DPRAM
ROM HIBI Wrapper HIBI Wrapper
DPRAM
HIBI Wrapper
ARM7 + DMA
HIBI Wrapper
ARM7 + DMA
……SLAVESSLAVES
Objective: Show how easily HIBI scales
ARM7 + DMA ARM7 + DMA
Processor independent C-source codeMaster + scaleable number of processors
#62/48 Department of Computer Systems
generated automatically
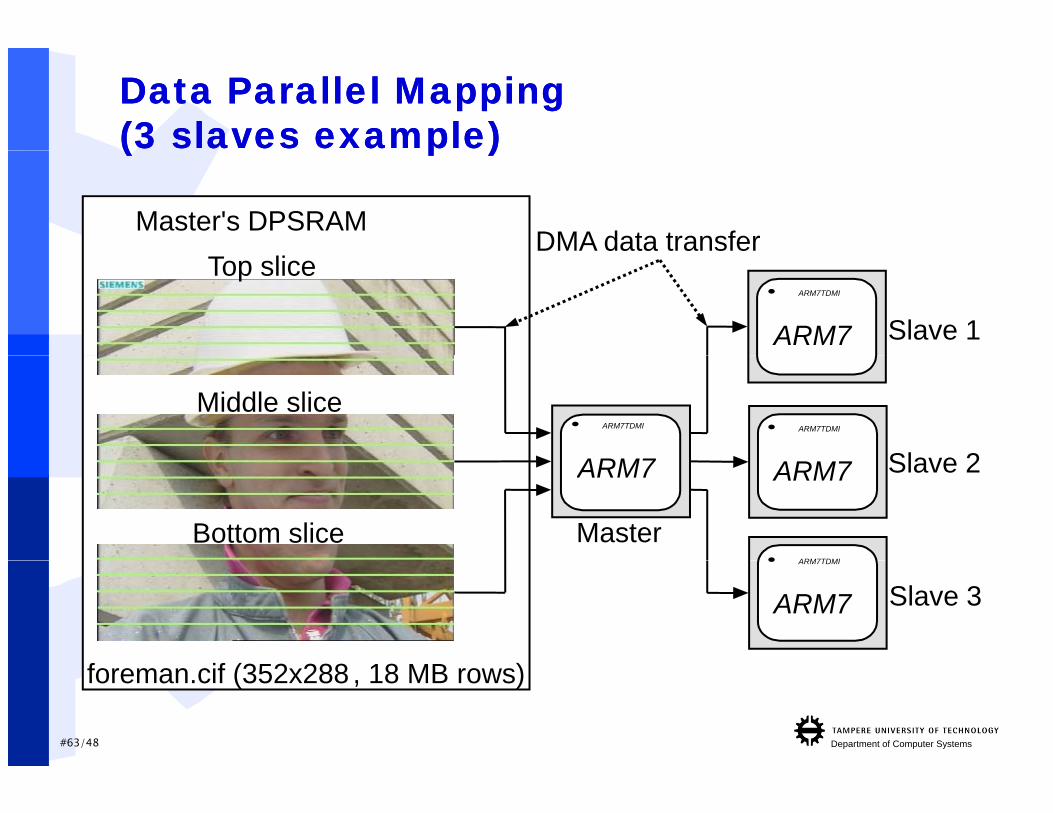
Data Parallel MappingData Parallel Mapping(3 slaves example)(3 slaves example)( p )( p )
Master's DPSRAMDMA data transfer
Top slice
Slave 1ARM7
ARM7TDMI
Middle slice
Slave 2ARM7
ARM7TDMI ARM7TDMI
Bottom slice
Slave 2ARM7
Master
ARM7
ARM7TDMI
Slave 3
f f (3 2 288 18 )
ARM7
ARM7TDMI
#63/48 Department of Computer Systems
foreman.cif (352x288 , 18 MB rows)
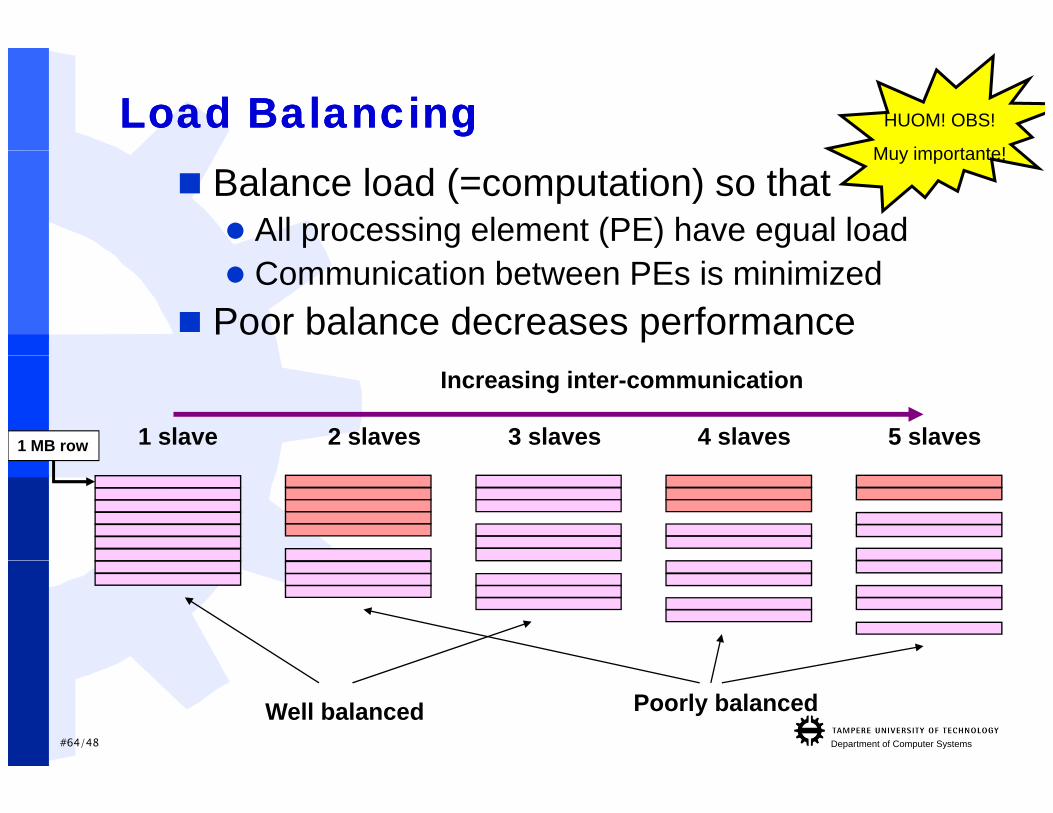
Load BalancingLoad Balancing HUOM! OBS!
Muy importante!Muy importante!
Balance load (=computation) so that All processing element (PE) have egual load Communication between PEs is minimized
Poor balance decreases performance
1 slave 2 slaves 3 slaves 4 slaves 5 slaves
Increasing inter-communication
1 MB row
#64/48 Department of Computer Systems
Well balanced Poorly balanced
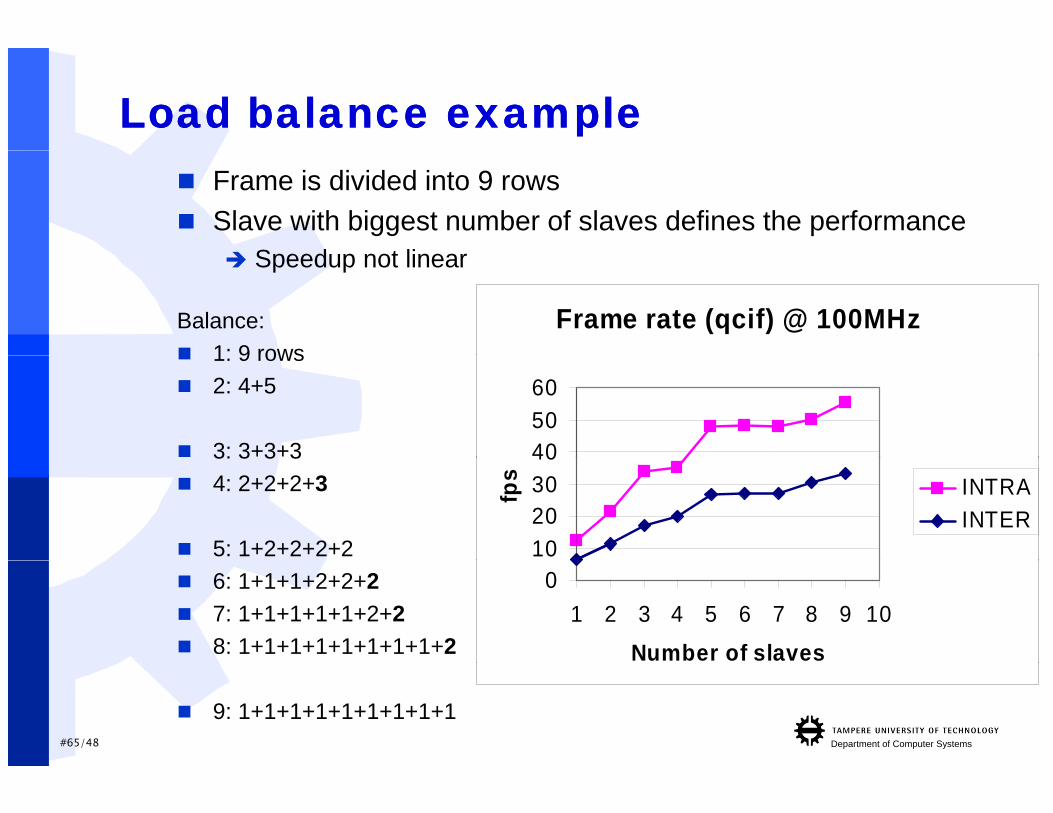
Load balance exampleLoad balance example Frame is divided into 9 rows Slave with biggest number of slaves defines the performance
S d t li
Frame rate (qcif) @ 100MHz
Speedup not linear
Balance: 1: 9 rows
405060
1: 9 rows 2: 4+5
3: 3+3+3
10203040
fps INTRA
INTER
3: 3 3 3 4: 2+2+2+3
5: 1+2+2+2+20
1 2 3 4 5 6 7 8 9 10
Number of slaves
6: 1+1+1+2+2+2 7: 1+1+1+1+1+2+2 8: 1+1+1+1+1+1+1+1+2
#65/48 Department of Computer Systems
9: 1+1+1+1+1+1+1+1+1
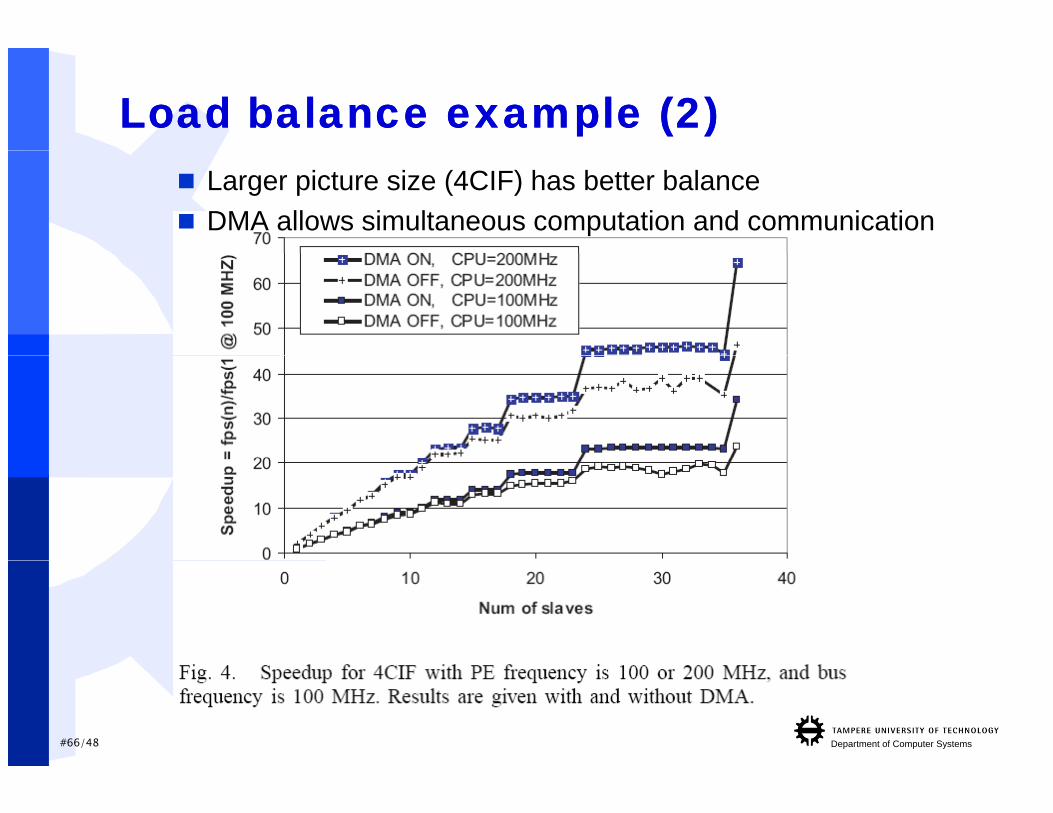
Load balance example (2)Load balance example (2) Larger picture size (4CIF) has better balance DMA allows simultaneous computation and communication
#66/48 Department of Computer Systems
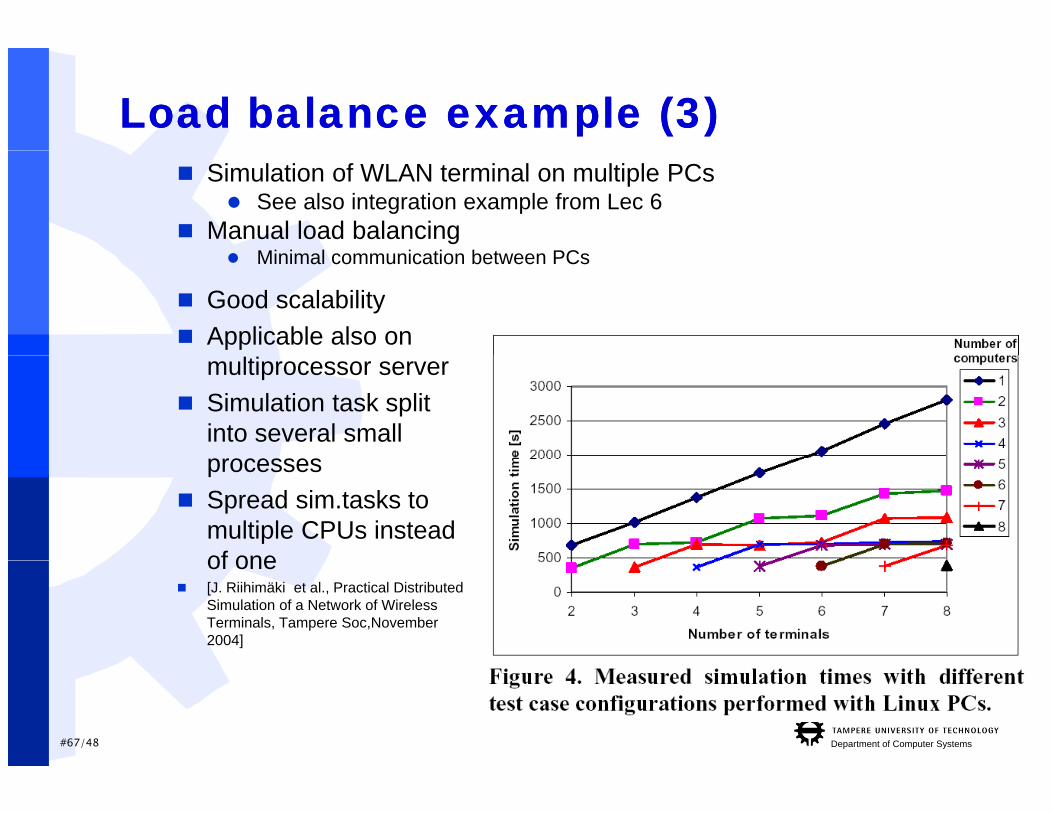
Load balance example (3)Load balance example (3) Simulation of WLAN terminal on multiple PCs
See also integration example from Lec 6 Manual load balancing
Mi i l i ti b t PC Minimal communication between PCs
Good scalability Applicable also on
multiprocessor server Simulation task split
into several small processes
Spread sim.tasks to multiple CPUs instead of oneof one
[J. Riihimäki et al., Practical Distributed Simulation of a Network of Wireless Terminals, Tampere Soc,November 2004]
#67/48 Department of Computer Systems