the ubercloud hpc experiment: compendium of case · pdf filewelcome! the ubercloud hpc...
TRANSCRIPT

The UberCloud HPC Experiment:
Compendium of Case Studies

Digital manufacturing technology and convenient access to High Performance Computing (HPC) in industry R&D are essential to increase the quality of our products and the competitiveness of our companies. Progress can only be achieved by educating our engineers, especially those in the “missing middle,” and making HPC easier to access and use for everyone who can benefit from this advanced technology.
The UberCloud HPC Experiment actively promotes the wider adoption of digital manufacturing technology. It is an example of a grass roots effort to foster collaboration among engineers, HPC experts, and service providers to address challenges at scale. The UberCloud HPC Experiment started in mid-2012 with the aim of exploring the end-to-end process employed by digital manufacturing engineers to access and use remote computing resources in HPC centers and in the cloud.
In the meantime, the UberCloud HPC Experiment has achieved the participation of 500 organizations and individuals from 48 countries. Over 80 teams have been involved so far. Each team consists of an industry end-user and a software provider; the organizers match them with a well-suited resource provider and an HPC expert. Together, the team members work on the end-user’s application – defining the requirements, implementing the application on the remote HPC system, running and monitoring the job, getting the results back to the end-user, and writing a case study.
Intel decided to sponsor this Compendium of 25 case studies selected from the first 60 teams to raise awareness in the digital manufacturing community about the benefits and best practices of using remote HPC capabilities. This document is an invaluable resource for engineers, managers and executives who believe in the strategic importance of this technology for their organizations.
Very special thanks to Wolfgang Gentzsch and Burak Yenier for making the UberCloud HPC Experiment possible.
This HPC UberCloud Compendium of Case Studies has been sponsored by Intel and produced in conjunction with Tabor Communications Custom Publishing, which includes HPCwire, HPC in the Cloud, and Digital Manufacturing Report.
If you are interested in participating in this experiment, either actively as a team member or passively as an observer, please register at http://www.hpcexperiment.com
The UberCloud HPC Experiment: Compendium of Case Studies
A Tabor Communications, Inc. (TCI) publication © 2013. This report cannot be duplicated without prior permission from TCI. While every effort is made to assure accuracy of the contents we do not assume liability for that accuracy, its presentation, or for any opinions presented.
Compendium Sponsor
OOMMUN NI ICC AT S
Media Partners

4 Welcome Note
5 Finding The Missing Middle
6 Executive Summary
Case Studies:
7 Team 1: Heavy Duty Abaqus Structural Analysis Using HPC in the Cloud
9 Team 2: Simulation of a Multi-resonant Antenna System Using CST MICROWAVE STUDIO
12 Team 4: Simulation of Jet Mixing in the Supersonic Flow with Shock
13 Team 5: Two-phase Flow Simulation of a Separation Column
15 Team 8: Flash Dryer Simulation with Hot Gas Used to Evaporate Water from a Solid
17 Team 9: Simulation of Flow in Irrigation Systems to Improve Product Reliability
19 Team 14: Electromagnetic Radiation and Dosimetry for High Resolution Human Body Phantoms and a Mobile Phone Antenna Inside a Car as Radiation Source
21 Team 15: Weather Research and Forecasting on Remote Computing Resources
22 Team 19: Parallel Solver of Incompressible, 2D and 3D Navier-Stokes Equations, Using the Finite Volume Method
23 Team 20: NPB2.4 Benchmarks and Turbo-machinery Application on Amazon EC2
25 Team 22: Optimization Study of Side Door Intrusion Bars
27 Team 25: Simulation of Spatial Hearing
28 Team 26: Development of stents for a narrowed artery
30 Team 30: Heat Transfer Use Case
34 Team 34: Analysis of Vertical and Horizontal Wind Turbine
36 Team 36: Advanced Combustion Modeling for Diesel Engines
38 Team 40: Simulation of Spatial Hearing (Round 2)
40 Team 44: CFD Simulation of Drifting Snow
42 Team 46: CAE Simulation of Water Flow Around a Ship Hull
46 Team 47: Heavy Duty Abaqus Structural Analysis Using HPC in the Cloud (Round 2)
49 Team 52: High-Resolution Computer Simulations of Blow-off in Combustion Systems
50 Team 53: Understanding Fluid Flow in Microchannels
52 Team 54: Analysis of a Pool in a Desalinization Plant
54 Team 56: Simulating Radial and Axial Fan Performance
57 Team 58: Simulating Wind Tunnel Flow Around Bicycle and Rider
The UberCloud HPC Experiment: Compendium of Case Studies
Table of Contents

Welcome!The UberCloud HPC Experiment started one year ago when Burak sent an email to Wolfgang with a seemingly simple question: “Hi Wolfgang, I am Burak. Why is cloud adoption in high performance computing so slow, compared to the rapid adoption of cloud computing in our enterprise community?”
After several email discussions and Skype conferences that elaborated on the fundamental differences between enterprise and high performance computing, Wolfgang got on a plane to San Francisco for a face-to-face conference with Burak. Four days of long discussions and many cups of tea later, a long list of challenges, hurdles, and solutions for HPC in the cloud covered the whiteboard in Burak’s office. The idea of the experiment was born. Later, after more than 30 HPC cloud providers had joined, we called it the UberCloud HPC Experiment.
We found that, in particular, small- and medium-sized enterprises in digital manufacturing would strongly benefit from HPC in the Cloud (or HPC as a Service). The major benefits they would realize by having access to additional remote compute resources are: the agility gained by speeding up product design cycles through shorter simulation run times; the superior quality achieved by simulating more sophisticated geometries or physics; and the discovery of the best product design by running many more iterations. These are benefits that increase a company’s competitiveness.
Tangible benefits like these make HPC, and more specifically HPC as a Service, quite attractive. But how far away are we from an ideal HPC cloud model? At this point, we don’t know. However, in the course of this experiment as we followed each team closely and monitored its challenges and progress, we gained an excellent insight into these roadblocks and how our teams have tackled them.
We are proud to present this Compendium of 25 selected use cases in digital manufacturing, with a focus on computational fluid dynamics and material analysis. It documents the results of over six months of hard work by the participating teams – their findings, challenges, lessons learned, and recommendations. We were amazed by how engaged all participants were, despite the fact that this was not their day job. But their inquiring minds and the chance of collaborating with the brightest people and companies in the world, as well as tackling some of today’s greatest challenges associated with accessing remote computing resources, were certainly their strongest motivator.
We want to thank all participants for their continuous commitment and for their voluntary contribution to their individual teams, to the Experiment, and thus to our whole HPC and digital manufacturing community. We want to thank John Kirkley from Kirkley Communications for his support with editing these use cases and our media sponsor Tabor Communications for this publication. Last but not least, we are deeply grateful to our sponsor, Intel, who made this Compendium possible.
Enjoy reading!
Wolfgang Gentzsch and Burak YenierNeutraubling and Los Altos, June 1, 2013
The UberCloud HPC Experiment: Compendium of Case Studies
A Tabor Communications, Inc. (TCI) publication © 2013. This report cannot be duplicated without prior permission from TCI. While every effort is made to assure accuracy of the contents we do not assume liability for that accuracy, its presentation, or for any opinions presented.

So far the application of high performance computing (HPC) to the manufacturing sector hasn’t lived up to expectations. Despite an attractive potential payoff, companies have been slow to take full advantage of today’s advanced HPC-based technologies such as modeling, simulation and analysis.
Fortunately, the situation is changing. Recently a number of important initiatives have gotten underway designed to bring the benefits of HPC to small- to medium- sized manufacturers (SMMs) – the so-called “missing middle.”
For example, in the United States the National Center for Manu-facturing Sciences is launching a network of Predictive Information Centers to bring the technology to these smaller manufacturers. The NCMS initiative is designed to help SMMs apply HPC-based modeling and simulation (M&S) to help solve their manufacturing problems and be more competitive in the global marketplace.
A UniqUe iniTiATiveThe UberCloud HPC Experiment is one of those initiatives – but
with a difference. It’s a grass roots effort, the result of the vision of two working
HPC professionals – Wolfgang Gentzsch and Burak Yenier. It’s also international in scope, involving more than 500 organizations and individuals from around the globe.
So far more than 80 teams – each consisting of an industry end-user (typically an SMM), a resource provider, a software provider, and an HPC expert – have explored the challenges and benefits associated with accessing and running engineering applications on cloud-provisioned HPC resources.
This team approach is unique. Its success is a tribute to the orga-nizers who not only conceived the idea, but also play matchmaker and mentor, bringing together winning combinations of team mem-bers – often from widely separated geographic locations.
In Rounds 1 and 2, reported in this document, the teams have enthusiastically addressed these challenges at scale. In the pro-cess they have identified and solved major problems that have limited the adoption of HPC solutions by the missing middle – those hundreds of thousands of small- to medium-sized compa-nies worldwide that have yet to realize the full benefits of HPC.
As you read through the case studies in this HPC UberCloud Compendium, as Yogi Berra once famously said, “It’s déjà vu all over again.” Among the 25 reports you will unquestionably find scenarios that resonate with your own situation. You will benefit from the candid descriptions of problems encountered, problems solved, and lessons learned.
These situations, many involving computational fluid dynamics, finite element analysis and multiphysics, are no longer the excep-tion in the digital manufacturing universe – they have become the rule. These reports are down-to-earth examples that speak directly to what you are trying to accomplish within your own organizations.
inTel involvemenTWhy is Intel supporting this Compendium and showing such an
interest in the UberCloud HPC Experiment? For one thing, it is clear that the potential market for HPC world-
wide is much larger than what we see today. And it has its problems. Recently the number of participants in the HPC community has
been somewhat stagnant. Without an influx of new talent across the board, basic skill sets are being lost. We need to include more participants to ensure the sector’s vibrancy over time.
Initiatives like the UberCloud HPC Experiment do just that. By ad-dressing the barriers confronting the missing middle, we are finding that we can indeed broaden the adoption of its capabilities within this underserved market segment. It’s a win-win situation all around: The SMMs gain new advanced capabilities and competitiveness; the HPC ecosystem expands; and companies like Intel and others that support HPC are part of a robust and growing business environment.
The UberCloud HPC Experiment fuels innovation – not just by end-users who are using HPC tools to create new solutions to their manu-facturing problems, but also on the part of the hardware and software vendors and the resource providers.
The initiative creates a virtuous cycle leading to the democrati-zation of HPC – it’s making M&S available to the masses.
The initiative satisfies the four strategies set forth by NCMS on what’s needed to revitalize manufacturing through the application of digital manufacturing.
First is to educate: providing a low risk environment that allows end users to learn about HPC and M&S. Next is entice: clarifying the value of advanced M&S through the use of HPC through entry-level evaluative solutions. engage and elevate take end users to the next levels of digital manufacturing as they become proficient in the use of HPC either through cloud services or by developing in-house capabilities.
leSSonS leArnedOne lesson that’s become very clear as the UberCloud HPC Ex-
periment continues – one size does not fit all. Manufacturing has many facets and virtually every solution reported in this Compendium had to be tailored to the individual situation. As one team commented in their report, “From an end user perspective, we observed that each cluster provider has a unique way of bringing the cloud HPC option to the end user.” Other teams ran into issues such as scalability, licensing, and unexpected fees for running their applications in the cloud.
Despite this diversity, there are a number of common threads running through all 25 reports that provide invaluable information about what to anticipate when running HPC-based applications and how to avoid or solve the speed bumps that inevitably arise.
The applications themselves are not the problem; it’s a question of understanding how the capabilities inherent in, say a CFD or FEA solver, can meet your needs. This is where the team approach shines – by bringing to bear a wide range of experience from all four categories of team members, the chances of finding a solution are greatly enhanced.
As the saying goes, “To compete, you must compute.” The sooner you become familiar with and start using this technology, the sooner you can compete more vigorously and broaden your marketplace. You can not only make your existing products more effective and desirable, but also create new products that are only possible with the application of HPC technology.
The competitive landscape is shifting. You need to ask, “Do I want to remain in the old world of manufacturing or embrace the new?”
Reading these 25 case studies will not only show you what’s possible, but also how to kick-off the activities that will allow you to take a quantum leap in competitiveness.
The UberCloud HPC Experiment – this energetic grass roots movement to bring HPC to the missing middle – continues. You just might want to become a part of it.
Dr. Stephen R. WheatGeneral Manager, High Performance Computing Intel Corp.
The UberCloud HPC Experiment: Compendium of Case Studies
Finding the missing middle

This is an extraordinary document. It is a collection of selected case studies written by the participants in Rounds 1 and 2 of the ambitious UberCloud HPC Experiment.
The goal of the HPC Experiment is to explore the end-to-end processes of accessing remote computing resources in HPC centers and HPC clouds. The project is the brain-child of Wolfgang Gentzsch and Burak Yenier, and had its inception in July 2012.
What makes this collection so unusual is that, without exception, the 25 teams reporting their experiences are totally frank and open. They share information about their failures as well as successes, and are more than willing to discuss in detail what they learned about the ins and outs of working with HPC in the cloud.
When Round 1 wrapped up in October 2012, 160 par-ticipating organizations and individuals from 25 countries – working together in 25 widely dispersed but tightly knit teams – had been involved.
With Round 2, completed in March 2013, another 35 teams and 360 individuals – some of them veterans of Round 1 – took up the challenge. (As of this writing, Round 3 is underway, with almost 500 participating organizations and another 25 enthusiastic teams.)
The PArTiCiPAnTSEach HPC Experiment team is made up of four types of
individuals:• Industry end-users, many of them small- to medium-
sized manufacturers, stand to realize substantial benefits from applying HPC to their manufacturing processes
• Computing and storage resource providers with par-ticular emphasis on those offering HPC in the cloud
• Software providers ranging from ISVs to open source and government software in the public domain
• HPC and cloud computing experts helping the teams – an essential ingredient
In addition to organizing the teams, Gentzsch and Yenier, and four dedicated team mentors from the HPC Experi-ment core team (Dennis Nagy, Gregory Shirin, Margarette Kesselman, and Sharan Kalwani) also provided guidance and mentoring whenever and wherever it was needed to help the teams navigate the sometimes rocky road to run-ning applications on remote HPC services.
CFd A hiTBy far, computational fluid dynamics (CFD) was the main
application run in the cloud by the Round 1 and Round 2 teams – 11 of the 25 teams presented here concentrated their efforts in this area. The other areas of interest included finite element analysis (FEA), multiphysics, and a variety of miscellaneous applications including biotech.
As you’ll read in the reports, quite a few teams encoun-tered major speed bumps during the three months spent on their project. Many of these problems were solved – some-times with simplex fixes, in other cases with ingenious so-lutions. Some proved difficult, others intractable.
For example, the pay-per-use billing feature of cloud comput-ing solves a major end-user dilemma – whether or not to make the considerable investment needed to build in-house computa-tional resources, which includes not just the HPC hardware, but also the infrastructure and human resources necessary to sup-port the company’s foray into high performance computing.
It seems like a no-brainer: pay only for what you need and leave all the rest to your cloud resource provider. But as several of the Experiment’s teams discovered, unless you pay close attention to the costs you’re incurring in the cloud, the price tag associated with remote computing can quickly mount up.
oTher SPeed BUmPSIn addition to unpredictable costs associated with pay-
per-use billing, incompatible software licensing models are a major headache. Fortunately many of the software vendors, especially those participating in the Experiment, are working on creating more flexible, compatible licensing models, including on-demand licensing in the cloud.
Other teams ran into problems of scalability when attempting to run jobs on multiple cores. Yet another group found that the main difficulty they encountered was the development of interactive vi-sualization tools to work with simulation data stored in the cloud.
Overall, the challenges were many and varied and, in most cases, they were solved. However, in a few instances, despite a team’s valiant efforts, the experiment had to be abandoned or postponed for a future round. On balance though, most of the teams, with the help of their incumbent HPC/cloud expert, worked their way to a solution and de-scribe in helpful detail the lessons learned in the process.
BeneFiTS oF hPC in The CloUdIn addition to recounting the challenges the team confront-
ed, each report contains a benefits section. As you read these results, it quickly becomes clear why the HPC Experiment has proven so popular and why many of the Round 1 and Round 2 teams have continued their explorations into Round 3.
The teams were not the only ones moving up the learning curve. In the course of the experiment the organizers – Gentzsch and Yenier – have learned and are continuing to learn their own set of lessons. As a result, they are continually modifying how the HPC Experiment is conducted to make the process run even more smoothly and the rewards even greater for the participants.
This compendium is a treasure trove of information. We rec-ommend you take your time reading through the individual re-ports – there is much of value to be gained. Each team seems to have run into and solved many problems that are sometimes ubiquitous and other times unique to their company’s situation and industry. Either way, the information is invaluable.
This report underscores the fact that HPC in the cloud is a viable and growing solution; especially for small- to me-dium-sized manufacturers looking to leverage the technol-ogy to speed up time to market, cut costs, improve quality, and be more competitive in the global marketplace.
The HPC Experiment is helping to make this a reality for companies both large and small that wish to make the most of what high performance computing has to offer.
John Kirkley, Co-Editor, Kirkley Communications, June 5, 2013
executive Summary

USe CASeAbaqus/Explicit and Abaqus/Stan-
dard are the major applications for this project – they provide the driving force behind using HPC cloud to ad-dress the need for sudden demand in compute. The applications in this experiment range from solving an-chorage tensile capacity and steel and wood connector load capacity, to special moment frame cyclic push-over analysis.
The existing HPC cluster at Simpson Strong-Tie is modest, consisting of about 32 cores of Intel x86-based gear. Therefore, when emergencies arise, the need for cloud bursting is critical. Also challenging is the ability to handle sudden large data transfers, as well as the need to perform visualization for ensuring that the design simulation is proceeding along correct lines.
The end-to-end process began with widely dispersed demand in the Pa-cific Time Zone, expertise at the other end of the US, and resources in the middle. Network bandwidth and la-tency were expected to play a major role since they impact the workflow and user perception of the ability to access cloud HPC capabilities.
Here is an example of the work-flow:
1. Pre-processing on the end user’s local workstation to prepare the CAE model.
2. Abaqus input file is transferred to the HPC cloud data staging area us-ing a secured FTP process.
3. The end user submits the job through the HPC cloud provider’s (Nimbix.net) web portal.
4. Once the job finishes, the end user receives a notification email. The result files can be transferred back to the end user’s workstation for post-processing, or the post-processing can be done using a remote desktop tool like HP RGS on the HPC provid-er’s visualization node.
Typical data transfer sizes (up-stream) were modest, ranging in the few hundred megabytes. The large number of output files (anywhere from 5 to 20) and output sizes of a few gi-gabytes described the data domain in this use case.
ChAllenGeS
Keeping everyone’s time demands in mind, we set up a weekly schedule – and we kept it very simple. We first
Team 1:
heavy duty Abaqus Structural Analysis Using hPC in the Cloud
“Clearly one of the first things established was that the HPC cloud model can indeed be made to work.”
MEET THE TEAM

identified the HPC simulation jobs and ensured that they were representative of a typical workload.
The cloud based infrastructure at Nimbix was the first challenge. In this case, for MPI parallel jobs, the Abaqus application needed a fast interconnect such as Infiniband, which was not available. However this was solved with “fat” nodes (with available scale as it true in the cloud) – the large number of cores and large memory allowed the workload job to be run close to the local cluster performance and avoid the need for a very fast interconnect. As this cluster is just a sandbox for testing out the cloud HPC workflow, the actual interconnect performance of this 12 core cluster was not a concern.
The second challenge was to address the need for simple and secure file storage and transfer. Surprisingly, this was accomplished very quickly using GLOBUS technology. This speaks volumes to the fact that these days cloud-based storage is mature and ready for prime time HPC, especially in the CAE arena.
The third challenge was how to push the limits and stream several tens of jobs simultaneously to the remote HPC cloud resource. This would provide solid evidence that “bursting” was indeed feasible. To the whole team’s surprise, it worked admirably and made no impact what-soever overall.
The fourth and final challenge was perhaps the most crit-ical – end user perception and acceptance of the cloud as a smooth part of the workflow. Here remote visualization was necessary to see if the simulation results (left remotely in the cloud) could be viewed and manipulated as if they were local on the end user desktop. After several iterations and brainstorming sessions, HP’s RGS was chosen to help deliver this capability.
RGS was selected because it is:• Application neutral • Has a clean and separate client (free) and server com-
ponent • Provides some tuning parameters that can help over-
come the bandwidth issues Several tests were conducted and carefully iterated, such
as image update rate, bandwidth selection, codecs, etc. A screen shot is shown below of the final successful user ac-ceptance of remote visualization settings:
BeneFiTSClearly one of the first things established was that the
HPC cloud model can indeed be made to work. What is required is a well-defined use case, which will vary by in-dustry verticals.
It is also important to have very capable and experienced participants – ISV, end user, and providers of the entire so-lution. This is distinct from the requirement to spin every-thing as a first time instance, since practically everyone’s infrastructure differs ever so slightly mandating the need for good service delivery setups.
ConClUSionS And reCommendATionS
At the conclusion of the experiment, a few key necessary factors emerged. Anyone who wishes to wander down this road needs to heed these four lessons:
1. Result file transfers are a major source of concern since most CAE result files can easily run over several gi-gabytes. It depends on the individual use case emergency, sizes, etc. For this CAE use case, a minimum of 2-4 MB/sec sustained and delivered bandwidth is necessary to be considered acceptable as an alternative to local cluster performance
2. The same applies to remote visualizations. In this case, 4 MB/sec is the threshold where a CAE analyst can per-form work and not get annoyed by bandwidth limitations. Latency is also a key concern, but, in this case, it was not an issue when connecting US East and West coasts to the Texas-based cloud facility.
3. In addition to the cloud service provider, a network sav-vy ISP is perhaps a necessary part of the team infrastruc-ture in order to deliver robust and production quality HPC cloud services. Everyone’s mileage will vary; an ROI analysis is recom-mended to help un-cover the necessary SLA requirements and costs associated with connectivity to and from the cloud.
4. Remote visualiza-tion provides a con-venient collaboration platform for a CAE analyst to access the analysis results any-where he has the need, but it requires a secure “behind the firewall” remote workspace.
Case Study Authors: Frank Ding, Matt Dunbar, Steve He-bert, Rob Sherrard, and Sharan Kalwani
Fig. 1 - Cloud Infrastructure: Nimbix Accel-erated Compute Cloud

USe CASeThe end user uses CAE for virtual
prototyping and design optimization on sensors and antenna systems used in NMR spectrometers. Advances in hardware and software have enabled the end-user to simulate the complete RF-portion of the involved antenna system. Simulation of the full system is still computationally intensive although there are parallelization and scale-out techniques that can be applied depending on the particular “solver” method being used in the simulation.
The end-user has a highly-tuned and over-clocked local HPC cluster. Benchmarks suggest that for certain “solvers” the local HPC cluster nodes are roughly 2x faster than the largest of the cloud-based Amazon Web Ser-vices resources used for this experi-ment. However, the local HPC cluster averages 70% utilization at all times and the larger research-oriented simu-lations the end-user was interested in could not be run during normal busi-ness hours without impacting produc-tion engineering efforts.
Remote cloud-based HPC resourc-es offered the end-user the ability to “burst” out of the local HPC system and onto the cloud. This was facili-
tated both by the architecture of the commercial CAE software as well as the parallelizable nature of many of the “solver” methods.
The CST software offers multiple methods to accelerate simulation runs. On the node level (single ma-chine) multithreading and GPGPU computing (for a subset of all avail-able solvers) can be used to acceler-ate simulations still small enough to be handled by a single machine. If a simulation project needs multiple in-dependent simulation runs (e.g. in a parameter sweep or for the calcula-tion of different frequency points) that are independent of each other, these simulations can be sent to different machines to execute in parallel. This is done by the CST Distributed Com-puting System, which takes care of all data transfer operations necessary to perform this parallel execution. In addition, very large models can be handled by MPI parallelization using a domain decomposition approach.
End-user effort: >25h for setup, problems and benchmarking. >100h for software related issues due to large simulation projects, bugs, and post-processing issues that would also have occurred for purely local work.
Team 2:
Simulation of a multi-resonant Antenna System Using CST miCroWAve STUdio
“The cloud is normally advertised as “enabling agility” and “enabling elasticity” but in several cases it was our own project team that was required to be agile/nimble simply to react to the rapid rate of change within the AWS environment.”
MEET THE TEAM

ISV effort: ~2-3 working days for creating license files, assembling documentation, following discussions, debug-ging problems with models in the setup, debugging prob-lems with hardware resources.
ProCeSS1. Define the ideal end-user experiment 2. Initial contacts with software provider (CST) and re-
source provider (AWS) 3. Solicit feedback from software provider on recom-
mended “cloud bursting” methods; secure licenses 4. Propose Hybrid Windows/Linux Cloud Architecture #1
(EU based) 5. Abandon Cloud Architecture #1; User prefers to keep
simulation input data within EU-protected regions. However, AWS has resources we require that did not yet exist in EU AWS regions. End-user modifies experi-ment to use synthetic simulation data, which enables the use of US, based cloud systems.
6. Propose Hybrid Windows/Linux Cloud Architecture #2 (US based) & implement at small scale for testing
7. Abandon Cloud Architecture #2. Heavily secured virtual private cloud (VPC) resource segregation front-ended by an internet-accessible VPN gateway looked good on paper however AWS did not have GPU nodes (or the large cc2.* instance types) within VPC at the time and the commercial CAE software had functionality issues when forced to deal with NAT translation via a VPN gateway server.
8. Propose Hybrid Windows/Linux Cloud Architecture #3 & implement at small scale for testing.
9. The third design pattern works well; user begins to scale up simulation size
10. Amazon announces support for GPU nodes in EU region and GPU nodes within VPC environments; end-user is also becoming more familiar with AWS and begins ex-perimenting with Amazon Spot Market to reduce hourly operating costs by very significant amount.
11. Hybrid Windows/Linux Cloud Architecture #3 is slightly modified. The License Server remains in the U.S. be-cause moving the server would have required a new license file from the software provider. However all solver and simulation systems are relocated to Amazon EU region in Ireland for performance reasons. End-user switches all simulation work to inexpensively sourced nodes from the Amazon Spot Market.
12. The “Modified Design #3” in which solver/simulation systems are running on AWS Spot Market Instances in Ireland, while a small license server remaining in the U.S. reflects the final “design.” As far as we under-stood, the VPN-Solution that did not work in the begin-ning of the project would actually have worked at the end of the project period because of changes within the AWS. In addition the preferred “heavily secured” solu-tion would have provided fixed MAC addresses, thus avoiding having to run a license instance all the time.
ChAllenGeSGeographic constraints on data – End-user had real sim-
ulation and design data that should not leave the EU. Unequal availability of AWS resources between Regions
– At the start of the experiment, some of the preferred EC2 instance types (including GPU nodes) were not yet avail-able in the EU region (Ireland). This disparity was fixed by Amazon during the course of the experiment. At the end of the experiment we had migrated the majority of our simula-tion systems back to Ireland.
Performance of Remote Desktop Protocol – The CAE software used in this experiment makes use of Microsoft Windows for experiment design, submission and visualiza-tion. Using RDP to access remote Windows systems was very difficult for the end-user, especially when the Windows systems were operating in the U.S.
CAE Software and Network Address Translation (NAT) – The simulation software assumes direct connections be-tween participating client, solver and front-end systems. The cloud architecture was redesigned so that essential systems were no longer isolated within secured VPC net-work zones.
Bandwidth between Linux solvers & Windows Front-End – The technical requirements of the CAE software allow for the Windows components to be run on relatively small AWS instance types. However, when large simulations are underway a tremendous volume of data flows between the Windows system and the Linux solver nodes. This was a significant performance bottleneck throughout the experi-ment. The project team ended up running Windows on much larger AWS instance types to gain access to 10GbE network connectivity options.
Node-locked software licenses – The CAE software li-cense breaks if the license server node changes its network hardware (MAC address). The project team ended up lever-aging multiple AWS services (VPC, ENI, ElasticIP) in order to operate a persistent, reliable license serving framework. We had to leave the license server in the US and let it run 24/7 because it would have lost the MAC-address upon re-boot. Only in the first setup did it have a fixed MAC and IP.
Spanning Amazon Regions – It is easy in theory to talk
Front-end and two GPU solvers in action

about cloud architectures that span multiple geographic regions. It is much harder to implement this “for real.” Our HPC resources switched between US and EU-based Ama-zon facilities several times during the lifespan of the proj-ect. Our project required the creation, management and maintenance of multiple EU and US specific SSH keys, server images (AMIs) and EBS disk volumes. Managing and maintaining capability to operate in the EU or US (or both) required significant effort and investment.
BeneFiTS
end-User• Confirmation that a full system simulation is indeed pos-
sible even though there are heavy constraints, mostly due to the CAE software. Model setup, meshing and post-processing are not optimal and require huge ef-forts in terms of manpower and CPU-time.
• Confirmation that a full system simulation can repro-duce certain problems occurring in real devices and can help to solve those issues.
• Realize the reasonable financial investment for addi-tional computation resources needed for cloud burst-ing approaches.
• Realize that the internet connection speed was the ma-jor bottleneck for a cloud bursting approach but also very limiting for RDP work.
Software Provider• Confirmation that the software is able to be setup and
run within a cloud environment and also, in principle, using a cloud bursting approach (see comments regard-ing the network speed). Some very valuable knowledge was gained on how to setup an “elastic cluster” in the cloud using best practices regarding security, stability and price in the Amazon EC 2 environment.
• Experience the limitations and pitfalls specific to the Amazon EC2 configuration (e.g. availability of resourc-es in different areas, VPC needed to preserve MAC ad-dresses for licensing setup, network speed, etc.).
• Experiencing the restrictions of the IT department of a company when it comes to the integration of cloud resources (specific to the cloud bursting approach).
hPC expert• Chance to use Windows-based HPC systems on the
cloud in a significant way was very helpful • New appreciation for the difficulties in spanning US/EU
regions within Amazon Web Services
ConClUSionS And reCommendATionSend-User• Internet transfer speed is the major bottleneck for se-
rious integration of cloud computing resources to the
end users design flow and local HPC systems. • Internet transfer speed is also a limiting factor to allow
for remote visualization. • Security and data protection issues as well as fears of
the end users IT department create a huge adminis-trative limitation for the integration of cloud based re-sources.
• Confirmation that a 10 GbE network can considerably speed up certain simulation tasks compared to the lo-cal clusters GbE network. The local cluster has been upgraded in the meantime to an IB network.
hPC expert• Rapid evolvement of our provider’s capability constantly
forced the project team to re-architect the HPC system design. The cloud is normally advertised as “enabling agility” and “enabling elasticity” but in several cases it was our own project team that was required to be agile/nimble simply to react to the rapid rate of change within the AWS environment.
• The AWS Spot Market has huge potential for HPC on the cloud. The price difference is extremely compelling and the relative stability of spot prices over time makes HPC usage worth pursuing.
• Our design pattern for the commercial license server is potentially a useful best-practice. By leveraging cus-tom/persistent MAC addresses via the use of Elastic Network Interfaces (ENI) within Amazon VPC we were able to build a license server that would not “break” should the underlying hardware characteristics change (common on the cloud).
• In a “real world” effort we would not have made as much use of the hourly on-demand server instance types. Outside of this experiment it is clear that a mix-ture of AWS Reserved Instances (license server, Win-dows front-end, etc.) and AWS Spot Market instances (solvers and compute nodes) would deliver the most power at the lowest cost.
• In a “real world” effort we would not have done all of our software installation, configuration management and patching by hand. These tasks would have been automated and orchestrated by a proper cloud-aware configuration management system such as Opscode Chef.
Software Provider:• The setup of a working setup in the cloud is quite com-
plex and needs quite some IT/Amazon EC2 expertise. Supporting such a setup can be quite challenging for an ISV as well as for an end user. Tools to provide sim-plified access to EC2 would be helpful.
Case Study Authors – Felix Wolfheimer and Chris Dagdi-gian

USe CASeThe hardware platform consisted of a
single desktop node, Ubuntu-10.04 64 bit, 8 GB RAM, 5.7 TB RAID storage. Currently available expertise: Two PhD research sci-entists with industrial-level CFD expertise, and a professor in fluid dynamics.
Benchmarking the OpenFOAM solv-er against an in-house FORTRAN code for supersonic CFD applications on re-mote HPC resources included the fol-lowing steps:1. Test OpenFOAM solver (sonicFoam)
on a 2D case at the same condi-tions as in an in-house simulation
2. Test OpenFOAM solver with dynam-ic mesh refinement (sonicDyMFoam) on the same 2D case – a series of simulation to be performed to find suitable refinement parameters for acceptable accuracy and mesh size
3. Production simulations with dynam-ic mesh refinement, which could be a 3D case or a series of 2D simula-tions with different parameters. The total estimate for resources was
1,120 CPU hours and 320 GB of disk space.
ChAllenGeSGenerally, the web interface provided
by CILEA was pretty convenient to run
the jobs, although some extra efforts were required to download the results. Both the traditional approach (secure shell access) and web interface were used to handle simulations.
The complete workflow included:• Create test case on the end-user
desktop• Upload it to CILEA computing re-
source through ssh• Run the case using the web interface• Receive email notification when
the case is finished• Download the results through ssh• Post-process the results on the
end-user desktopDirect access is beneficial for trans-
ferring large amount of data, provid-ing a noticeable advantage when us-ing the “rsync” utility. In fact, it might be desirable to run the jobs from the command line as well, although this may just be a matter of habit.
An alternative means of accessing remote data offered by CILEA is re-mote visualization. This approach re-ceives maximum benefit from the rel-evant HPC facilities where the remote visualization system is sitting on top of a 512 GB RAM node plus video-image compression tools. It provides exciting possibilities for remote, very
large data management, limiting the unpleasant (and unavoidable) remote-rendering delay effect.
ConClUSionSThe simulations were not completed
beyond step 1 due to unexpected nu-merical problems and the time spent investigating these problems. Approxi-mately 4 CPU hours were used in total.
Because the initial test program runs were not completed during this round of the experiment, both the end-user and the resource provider indicated they would like to participate in the second round. Also, the end-user was interested in evaluating the GPU capabilities of OpenFOAM.
Case Study Authors – Ferry Tap and Claudio Arlandini
Team 4:
Simulation of Jet mixing in the Supersonic Flow with Shock
“It (remote visualization) provides exciting possibilities for remote, very large data management, limiting the unpleasant (and unavoidable) remote-rendering delay effect.”
MEET THE TEAM
CILEA (Consor-zio Interuniversitario Lombardo per l’Elaborazione Automatica)
Dacol

USe CASeThis use case investigates the dy-
namics of a vapor-liquid compound in a distillation column with trays. Chemical reactions and phase transitions are not considered, instead the fluid dynamics is resolved with a high level of detail in order to predict properties of the col-umn like the pressure drop, or the resi-dence time of the liquid on a tray.
ChAllenGeSThe main challenge addressed in this
use case is the need for computational power, as a consequence of the large mesh resolution. The need for a large mesh (close to 109 mesh nodes – an am-bitious value in this field) stems from the complex physics of turbulent two-phase flow, and from the complex structure of fine droplet dispersions in the vapor. These difficulties are addressed, in the present case, with help of a highly efficient and scalable computational approach, mix-ing a so-called lattice Boltzmann method with a volume-of-fluid representation of the two-phase physics. Technology involved
The hardware used was a 128-core cluster with Infiniband interconnection network and an NFS file system. The nodes used 8-core Intel E5-2680 pro-cessors at 2.7GHz. The use case was
implemented and executed with help of the open-source Palabos library (www.palabos.org), which is based on the lattice Boltzmann method. Project execution – end-to-end process
• Finding a match between resource provider, software provider and end-user –While the needs for a soft-ware solution had been preliminarily analyzed by the end-user, and the match to the software provider was therefore straightforward, some ef-forts were invested by the organizers of the HPC Experiment to find an ad-equate resource provider to match the substantial needs for resources brought on the part of the end-user.
• Team setup and initial organization – The project partners agreed on the need for hardware resources and the general organization.
• Exchange of concepts and needs – The resource provider explained his approach to cloud computing. It was agreed that the resource pro-vider would not provide direct ssh access to the computing server. Instead, the application was com-piled and installed by the resource provider. The interface provided to the end-user consisted of an online XML editor to set up the parame-
ters of the program, and means of interactivity to launch the program and post-process the results.
• Benchmarks and feasibility tests – The compatibility of the soft-ware with the provided hardware resources was carefully tested as described above.
• Setup of the execution environment (ongoing at the time of this writing) – Palabos was recompiled on XF by the resource providers team using gcc and openmpi-1.6.2 (including IB support). The team also “published” a simple Palabos application in eX-treme Factory Studio by configuring a new job submission web form, in-cluding relevant job parameters for this Palabos experiment.
• Final test run (ongoing at the time of this writing) – Encountered and solved challenges that consisted of mostly human interactions – no technical challenges. We were concerned about inadequate hard-disk properties.
Team 5:
Two-phase Flow Simulation of a Separation Column
“Such detailed flow simulations of separation columns provides an insight into the flow phenomena which was previously not possible.”
MEET THE TEAM

BeneFiTS• For the software provider – The software provider had
the opportunity to learn about a new approach to cloud computing, implying the use of efficient dedicated hard-ware, and the implementation of a lightweight Software-as-a-Service model. At the end of this HPC experiment, the software provider is considering including this new approach into his business model.
• For the hardware provider – This was a great opportu-nity to host a new, exciting and very scalable CFD soft-ware, get in touch with the Flowkit and Palabos user community, and therefore envision a great partnership targeting real customers and real production.
• For the end-user – Such detailed flow simulations of separation columns provides an insight into the flow phenomena which was previously not possible. In order to resolve these results, large computational meshes are absolutely necessary. This HPC experiment allows for an assessment of whether such big simulations are computationally feasible for industry. Furthermore we gained valuable experience in handling of these kinds of bit simulation setups.
ConClUSionS And reCommendATionS• Definition of cloud computing – Different partners have a
different understanding of the term “cloud computing.” While some consider it a simple remote execution of a given software on pay-as-you-go hardware, others find it useful when it provides a software solution that is fully integrated in the web browser. In this project, we learned about an intermediate viewpoint defended by the re-source provider, where an adequate web interface can be custom-tailored to every software/end-user pair.
• Availability of specialized resources – Before entering this experiment, the software provider was familiar with generic cloud computing resources like those provided by Amazon Web Services. The project revealed the existence of cus-tom cloud solutions for high performance computing, with substantially more powerful and cost-effective hardware.
• Communication with three involved partners – The inter-action between the partners was dominated by technical aspects that had to be worked out between the software
and the resource providers. It appears that such a pro-cess leaves little room for the application end-user to im-pact the choice of the user interface and cloud computing model deployed between the software and the resource provider. Instead, it is likely that in such a framework the application end-user accepts the provided solution as it is, and decides if it is suitable for his needs or not.
notes from the resource provider • In our model, the end user can ask for basic improve-
ments to job submission forms for free. More complex ones are charged.
• Most HPC applications provided neither cloud API nor a web user interface. eXtreme Factory SaaS-enabling model partnered with the open source science community and software vendors to expose their applications in the cloud
• Enabling HPC applications in a cloud is not something everyone can do on their own. It requires a lot of experi-ence and R&D plus a team to deploy and tune applica-tions and support software users. This is one reason we think HPC as a Service is not ready yet for total cloud automation and on-line billing.
• SSH connections are surprisingly less secure than web portal isolation (we optionally add network isolation) because people who know how to use a job scheduler can discover a lot about the architecture and potentially look for security holes. This is because HPC job sched-ulers are, if not impossible, pretty difficult to secure.
• Web portal ergonomics coupled to remote visualization make it possible to execute a complete pre-process-ing/simulation/post-processing workflow on line, which is highly appreciated
improving the hPC experimentThe partners of this team appreciated the structure and
management of the HPC experiment and find that its ex-ecution was highly appropriate.
The following are minor suggestions that might be helpful for future repetition of the Experiment:
• It appears that the time frame of three month is very short, especially if a large amount of time must be spent finding appropriate partners and connecting them to each other.
• Participating partners are likely to have both industrial and academic interests in the HPC experiment. In the latter case, a certain amount of conceptual and theoreti-cal guidance could be inspiring. As an example, it might have been more realistic for the participants to contrib-ute and exchange their opinions on topics related to the actual definition of cloud computing if the framework for such a topic had been sketched more precisely by the organizers. It would be highly interesting for all partici-pants, as the project advances, to know more about the content and progress of the project of other teams. Why not conceive a mid-term webinar that is more practical-ly oriented, based on concrete examples of the results achieved so far in the various projects?
Case Study Authors – Jonas Latt, Marc Levrier, and Felix Muggli
Palabos job submission web form

USe CASeCFD multiphase flow models are
used to simulate a flash dryer. Increas-ing plant sizes in the cement and miner-al industries mean that current designs need to be expanded to fulfill custom-ers’ requests. The process is described by the Process Department and the structural geometry by the Mechanical Department – both departments come together using CFD tools that are part of end-user’s extensive CAE portfolio.
Currently, the multiphase flow model takes about five days for a realistic particle loading scenario on our local infrastructure (Intel Xeon X5667, 12M Cache, 3.06 GHz, 6.40 GT/s, 24 GB RAM). The differential equation solver of the Lagrangian particle tracking model requires several GBs of memory. ANSYS CFX 14 is used as the solver.
Simulations for this problem are made using 1.4 million cells, five species and a time step of one millisecond for a to-tal time of two seconds. A cloud solu-tion should allow the end-user to run the models faster to increase the turnover of sensitivity analyses and reducing time to customer implementation. It also would allow the end-user to focus on engineer-ing aspects instead of using valuable time on IT and infrastructure problems.
The ProjectThe most recent addition to the
company’s offerings is a flash dryer designed for a phosphate process-ing plant in Morocco. The dryer takes a wet filter cake and produces a dry product suitable for transport to mar-kets around the world.
The company was interested in re-ducing the solution time and, if pos-sible, increasing mesh size to improve the accuracy of their simulation re-sults without investing in a computing cluster that would be utilized only oc-casionally.
The project goal was defined based on current experiences with the in-house compute power. For the cho-sen model a challenge for reaching
Team 8:
Flash dryer Simulation with hot Gas Used to evaporate Water from a Solid
“The company was interested in reducing the solution time and, if possible, increasing mesh size to
improve the accuracy of their simulation results without investing
in a computing cluster that would be utilized only occasionally.”
MEET THE TEAM
Fig. 1 - Flash dryer model viewed with ANSYS CFD-Post

this goal was the scalability of the problem with the number of cores.
Next, the end-user needed to register for XF. After orga-nizational steps were completed, the XF team integrated ANSYS CFX for the end-user into their web user interface. This made it easy for the end-user to transfer data and run the application in the pre-configured batch system on the dedicated XF resources.
The model was then run on up to 128 Intel E5-2680 cores.The work was accomplished in three phases:• Setup phase – During the project period XF was very
busy with production customers and was also migrat-ing their Bull B500 blades (Intel Xeon X5670 sockets, 2.93 GHz, 6 cores, 6.40 GT/s, 12 MB) to B510 blades (Intel E5-2680 sockets, 2.70 GHz, 8 cores, 8.0 GT/s, 20 MB). The nodes are equipped with 64 GB Ram, 500 GB hard disks and connected with Infiniband QDR.
• Execution phase – After an initial hardware problem with the new blades, a solver run crashed after 35 hours due to a CFX stack memory overflow. This was handled by adding a new parameter to the job submission web form. A run using 64 cores still crashed after 12 hours despite 20% additional stack memory. This issue is not related to overall memory usage as the model never used more than 10% of the available memory as ob-served for one of the 64 cores runs.
Finally, a run on 128 cores and 30% additional stack memory successfully ran up to the 2s point. An integer stack memory error occurred at a later point – this still needs to be looked into.
• Post-processing phase – The XF team installed ANSYS CFD-Post, visualization software for ANSYS CFX, and made it available from the portal in a 3D remote visual-ization session. It was also possible to monitor the runs from the Solver Manager GUI and hence avoid down-loading large output log files.
Because the ANSYS CFX solver was designed from the ground up for parallel efficiency, all numerically intensive tasks are performed in parallel and all physical models work in parallel. So administrative tasks, such as simula-tion control and user interaction, as well as the input/output phases of a parallel run were performed in sequential mode by the master process.
BeneFiTSThe extreme factory team was quickly able to provide
ANSYS CFX as SaaS and configure any kind of HPC work-flow in extreme factory Studio (XF’s web front end). The XF team spent around three man days to setup, config-ure, execute and help debug the ANSYS CFX experiment. FLSmidth spent around two man days in order to under-stand, setup and utilize the XF Portal methodology.
XF also provides 3D remote visualization with good per-formance, which helps solve the problem of downloading large result files for local post-processing and checking the progress of the simulation.
Enabling HPC applications in a cloud requires a lot of ex-perience and R&D, plus a team to deploy and tune applica-tions and support software users. For the end-user the pri-mary goal of running the job in one to two days was met. The runtime of the successful job was about 46.5 hours. There was not enough time in the end to perform some scalability tests – these would have been helpful to optimize the size of the resources required with the runtime of the job.
The ANSYS CFX technology incorporates optimization for the latest multi-core processors and benefits greatly from recent improvements in processor architecture, algorithms for model partitioning combined with optimized communi-cations, and dynamic load balancing between processors.
ConClUSionS And reCommendATionSNo special problems occurred during the project, only
hardware provisioning delays. Pressure from production made it difficult to find free resources and tuning phases to get good results.
Providing the HPC application in form of SaaS made it easy for the end-user to get started with the cloud and con-centrate on his core business.
It would be helpful to have some more information about cluster metrics beyond what is currently readily available – e.g. memory, I/O-usage, etc.
Time needed for downloading the results files and mini-mizing risks to proprietary data need to be considered for each use case.
Due to the size of output data and transfer speed limitations, we determined that a remote visualization solution is required.
Case Study Authors – Ingo Seipp, Marc Levrier, Sam Zakrzewski, and Wim Slagter
Note: Some parts of this report are excerpted from a story on the project fea-tured in the Digital Manufacturing Report. You can read the full story at http://www.digitalmanufacturingreport.com/dmr/2013-04-22/on_cloud_nine.html
Fig. 2 - ANSYS CFX job submission web form

USe CASe In the industry of residential and
commercial irrigation products, prod-uct reliability is paramount – custom-ers want their equipment to work ev-ery time with low maintenance over a long product lifetime. For engineers, this means designing affordable prod-ucts that are rigorously tested before the device begins production. Irriga-tion equipment companies employ a large force of designers, researchers and engineers who use CAD pack-
ages to develop and manufacture the products, and CAE analysis programs to determine the products’ reliability, specifications and features.
ChAllenGeSAs the industry continues to demand
more efficiency along with greater en-vironmental stewardship, the usage rate of recycled and untreated wa-ter for irrigation grows. Fine silt and other debris often exist in untreated water sources (e.g. lakes, rivers and
wells), and cause malfunction of in-ternal components over the life of the product. In order to prevent against product failure, engineers are turning to increasingly fine meshes for CFD analysis, outpacing the resources of in-house workstations. To continue expanding the fidelity of these analy-ses within reasonable product design cycles, manufacturers are looking to cloud-based and remote computing for the heavy computation loads.
The single largest challenge we
Team 9:
Simulation of Flow in irrigation Systems to improve Product reliability
“HPC and cloud computing will certainly be a valuable tool as our company seeks to increase its reliance on CFD simulation to reduce costs and time associated with the build-and-test iteration model of prototyping and design.”
MEET THE TEAM

faced as end-users was the coordination with and applica-tion of the various resources presented to us.
For example, one roadblock was that when presented with a high-powered cluster, we discovered that the inter-face was Linux, which is prevalent throughout HPC. As in-dustry engineers with a focus on manufacturing, we have little or no experience with Linux and its navigation. In the end, we were assigned another cluster with a Windows vir-tualization to allow for quicker adoption. We consistently found that while the resources had great potential, we didn’t have the knowledge to take full advantage of all of the possibilities because of the Linux interface and compli-cations of HPC cluster configurations.
Additionally, we found that HPC required becoming famil-iar with software programs that we were not accustomed to. Engineers typically use multiple software packages on a daily basis, and the addition of new operating environ-ment, GUI, and user controls added another roadblock to the process. The increased use of scripting and software automation increased the time of the learning curve.
Knowledge of HPC-oriented simulation was lacking for the end-user. As the end-user engineer’s knowledge was limited to in-house and small-scale simulation, optimizing the model and mesh(es) for more powerful clusters proved to be cumbersome and time-intensive.
As we began to experiment with extremely fine mesh conditions, we ran into a major issue. While the CFD-solver itself scaled well across the computing cluster, every in-crease in mesh size took significantly more time for mesh-generation, in addition to dramatically slowing the set-up times. Therefore with larger/finer meshes, the bottleneck moved from the solve time to the preparation time.
BeneFiTSAt the conclusion of the experiment, the end-user was
able to determine the potential of HPC for the future of simulation within the company.
Another crucial benefit was the comparison of mesh refinements to accurately compromise both fidelity and practicality. A “sweet-spot” was suggested by the results – one that would balance user set-up time with computing costs and would deliver timely, consistent, precise results. As suggested by the experiment, performing a fine mesh with 32 compute cores proved to be a balance of afford-able hardware and timely, accurate results.
ConClUSionS And reCommendATionSThe original cluster configuration offered by SDSC was
Linux, but the standard Linux interface provided was not user-friendly for the end user’s purposes. In order to ac-commodate the end user’s needs, the SDSC team decided to try running Windows in a large, virtual shared memory
machine using the vSMP software on SDSC’s ‘Gordon’ su-percomputer. Using vSMP with Windows on the Gordon supercomputer offers the opportunity to provision a one terabyte Windows virtual machine which can provide a sig-nificant capability for large modeling and simulation prob-lems that do not scale well on a conventional cluster. Al-though the team was successful in getting ANSYS CFX to run in this configuration on up to 16 cores (we discovered the 16-core limitation was due to the version of Windows we installed on the virtual machine), various technical top-ics with remote access and licensing could not be com-pletely addressed within the timeframe of this project and precluded running actual simulations for this phase. Fol-lowing the Windows test, the SDSC team recommended moving back to the proven Linux environment, which as noted previously was not ideal for this particular end user.
Due to time constraints and the aforementioned Linux vs. Windows issues, end user simulations were not run on the SDSC resources for this phase of the project. However, SDSC has made the resource available for an additional time period should the end user desire to try simulations on the SDSC system. The end user states that they learned a lot, and are still intending to benchmark the results for the team members’ data, but do not have any performance or scalability data to show at this time. The results given above in terms of HPC performance were gathered using the Simutech Group’s Simucloud cloud computing HPC of-ferings.
From the SDSC perspective, this was a valuable exer-cise in interacting with and discovering the use cases and requirements of a typical SME end user. The experiment in running CFX for Windows on a large shared memory (1 TB) cluster was valuable and provided SDSC with an op-portunity to explore how this significant capability might be configured for scientific and industrial users computing on “Big Data.“ Another finding is that offering workshops for SMEs in running simulation software at HPC centers may be a service that SDSC can offer in the future, in conjunc-tion with its Industrial Affiliates (IA) program.
The end user noted, “Having short-term licenses which scale with the need of a simulation greatly reduces our costs by preventing the purchase of under-utilized HPC packs for our company’s in-house simulation.”
Summarizing his overall reaction to the project, the end user had this to say: “HPC and cloud computing will cer-tainly be a valuable tool as our company seeks to increase its reliance on CFD simulation to reduce costs and time associated with the build-and-test iteration model of pro-totyping and design.”
Case Study Authors – Rick James, Wim Slagter, and Ron Hawkins

USe CASeThe use case is a simulation of
electromagnetic radiation by mobile phone technology and dosimetry in human body phantoms inside a car model. The scenario is a car interior with seat and a highly detailed hu-man body phantom with a hands-free mobile phone. Simulation software is CST Studio Suite. The transient solver of CST Microwave Studio was used during the experiment.
ChAllenGeSThe goals were to reduce the run-
time of the current job and to increase model resolution to more than 750 million cells. A challenge to achiev-ing the goals was the scalability of the problems on many nodes with or without GPUs and high-speed net-work connections.
Based on experiences with perfor-mance of the problem, the preferred infrastructure included Windows nodes with GPUs and fast network connectivity, i.e. Infiniband. If no
GPUs were available, a multiple of the number of cores would be required to run the selected problem and achieve the same performance as with GPUs.
The ProJeCTIn the beginning, the project was
identified by the end-user. The goals were set based on current experienc-es with existing compute power. The runtime of the problem on the existing environment was from several days up to one or two weeks. Output data sizes were in the range of 60-200 GB depending on the size of the prob-lem.
The project was planned in three steps. At first a chip model simula-tion would be performed as a bench-mark problem. The aim was to set up the simulation environment, check the speed of the system itself and its visual-ization, and analyze first problems. The second step would then be a simulation with a car seat, hands-free equipment and a human body phantom. The last step featured a full car model.
Team 14:
electromagnetic radiation and dosimetry for high resolution human Body Phantoms and a mobile Phone Antenna inside a Car as radiation Source
“The goals were to reduce the runtime of the current job and to increase model resolution to more than 750 million cells.”
MEET THE TEAM

• Setup phase – Access to the resource provider was established via a VPN connection. HSR provides 33 compute nodes with 12 cores each, InfiniBand inter-connect, and workstations with GPU. Some VPN client versions did not succeed in connecting from the end user location to the resource provider although they were working from outside. With the latest VPN client version from one provider it was possible to connect. To let the Job Manager connect with the proper cre-dentials from a local machine to the resource provider it was necessary to connect with the appropriate cre-dentials and save them. Access to the cluster was then available through the Windows HPC Client. Batch jobs could be submitted and managed through Windows HPC Job Manager.
• Execution Phase – With the commitment from people at CST and HSR, the installation of CST on the HPC clus-ter has been completed and first jobs have been run. Testing the installation and debugging requires rdp ac-cess to the compute nodes, something that only cluster administrators are commonly allowed to do.
BeneFiTSBenefits from a cloud model to end-user are: the avail-
ability of additional resources on project demand; no tax-able hardware costs remaining after the project; and no hardware aging.
ConClUSionS And reCommendATionSEstablishing the access to the cloud resources through
the VPN- and HPC-Client is more complicated to setup. Once established, it works reliably. But an automated pro-cess is needed for integration into a workflow.
Because of the size of the result files for big problems, the time required for transferring the results can be very long. For post-processing an rdp-connection is required to reduce the amount of data that needs to be transferred. Remote visualization for big problems would require a high performance graphics card.
The CST software on Windows uses the graphical front-end in batch mode. For debugging and monitoring a job. An rdp-connection to the front-end node is required. This is a problem for many HPC cluster policies, where direct access of users to the compute nodes is prohibited.
Data availability and accountability for data security and loss must be defined.
Case Study Authors – Ingo Seipp, Carsten Cimala, Felix Wolfheimer, and Henrik Nordborg.
Fig. 1 - Applications for high fidelity simulations: seat with human body & hands-free equipment.

USe CASeIn this HPC Experiment, we attempt-
ed to evaluate the performance of WRF (Weather Research & Forecasting) open software on a computer cluster, which is larger than our existing computing cluster.
The Application Domain is Weather Research and Forecasting. The WRF software is currently implemented on a computer cluster of Beowulf class con-sisting of 12 nodes, each node being an 8-core CPU. This cluster is used 24x7 and the execution time is 24 hours for a 12 hour weather prediction cycle.
Currently, it has been empirically de-termined that the improvement in the system performance becomes negligible with an increase in the number of parallel computing cores beyond the current 96 computing cores. With the usage of ap-plicable High Performance Computing methods, we would like to investigate if it is feasible to reduce the overall process-ing time of the WRF software and thus provide faster weather predictions and/or higher-resolution predictions as well.
As our computer cluster is being used non-stop and since the team needs to send out regular weather reports, it is not possible to stop the same to perform any experiments, leave alone instrument and measure the various system parameters as these will slow down the process as well. In addition, as we are yet to deter-mine if there will be a time reduction in the first place and, if so, what is the ideal
computer cluster size before we can rec-ommend for building the same internally. This was the reason we looked to 3rd party resource providers.
end-to-end process – Our experi-ment was fairly straight forward as we were using open-source software and we already have it running on a computer cluster. Again, as the resource provider’s setup was similar (Beowulf class) and since the software (WRF) was already in-stalled, there were no challenges as well. We have executed a couple of runs and are currently reviewing the results.
ChAllenGeSWe would like to highlight a few (mi-
nor) challenges: 1. The time difference for the team
members was a challenge that de-layed responses from both ends.
2. The Spanish resource provider had to make additional efforts to cre-ate documentation in English for us so we could learn how to use the system
3. The job was not accepted initially when the ORTE parallel environment was set. Later when the parallel environment was changed to pmpi, the job was accepted, but then was shut down immediately citing that the queue was full. This hinted that the resource was not being dedicated.
4. Finally, we were not able to use all 256 cores. We had to settle for 192 cores as the other cores were assigned to another HPC Experiment team.
BeneFiTS In our view, the end-user is the key
beneficiary from this short three month experiment. The end-user was able to use additional resources to try out differ-ent software runtime configurations com-pared to those that were tried before.
We are looking forward to the next three months of the Round 2 experi-ment to iron out some of the issues we faced in this phase and produce effective results.
ConClUSionS And reCommendATionS
Resource providers should consider having staff respond to user queries on a 24x7 basis. This will reduce turn-around time and also ensure that their resources are being used effectively.
Resource providers should state the language in which the technical docu-mentation is available. In addition, a YouTube video on how to access and submit jobs would be useful.
The HPC experiments might consider listing the public holidays in the various countries that are participating in the experi-ments, especially when the team members are in different countries. We had at least two instances where it was a PH in Singa-pore and a PH in Spain and one party tried to reach the other party on this day.
Case Study Authors – S. P. T. Krishnan, Bharadwaj Veeravali, and Ranjani M. R
Team 15:
Weather research and Forecasting on remote Computing resources
“In our view, the end-user is the key beneficiary from this short three month experiment.”
MEET THE TEAM

USe CASeThis team’s application used MPI
to parallelize a solver of incompress-ible Navier-Stokes equations (both 2D and 3D) in rectangular domains, using Finite Volume Method.
In this application, pressure and ve-locity were linked by the Semi-Implicit Pressure Linked Equation – the “SIM-PLE” algorithm. The resulting discretized equations were solved by a line-by-line Gauss-Seidel solver. End-user Pratanu Roy has developed this application on the IBM iDataplex HPC cluster, as a graduate student at Texas A&M Univer-sity. The team attempted to port what is essentially a traditional HPC applica-tion to an Indiana University’s FutureGrid Nimbus IaaS cloud, with the intention of analyzing performance within the virtual-ized runtime environment of the cloud.
ChAllenGeS And ConClUSionS
Team 19 members were introduced to one another in late August 2012, and registered for access to Future-Grid resources over the Labor Day Weekend. Rapid support from Fu-
tureGrid experts Fox and von Lasze-wski facilitated prompt establishment of the team’s project under the Fu-tureGrid access regime.
Team members worked to become familiar with FutureGrid computing re-sources during early-mid September. FG tutorial documentation led to early successes including accessing the India cluster’s resources using batch job submission methods.
Subsequent attempts to establish Nimbus credentials and thereby ac-cess true IaaS-style cloud platforms (hotel and sierra virtualized cloud re-sources) required multiple support tickets to be filed. von Laszewski and Wang worked with the team members to address issues with hung VMs, failed Nimbus credential disposition, and tutorial documentation problems.
One problem with the FG ticket routing system resulted in a two-week delay in response to a techni-cal issue, which was not resolved un-til HPC Experiment organizers went out-of-channel to request support for the issue. FG experts routed the is-sue, and it was resolved immediately
by John Bresnahan, once the routing issue was recognized. (He updated the tutorial to the point to the correct, current VM/tarball, with additional co-ordination by Pierre Riteau to assure availability to all FG clouds.)
During early-mid October, the team worked through a learning curve re-garding FG authorization and authen-tication methods. The “anatomy and physiology” of ssh authentication was a significant challenge for an inexperi-enced user (relying on a busy, remote collaborator for support), which com-plicated working through the process of obtaining all the necessary creden-tials, and getting them to the right lo-cations for Nimbus cloud access.
Team efforts in late October made sub-stantial progress toward building a cus-tomized VM image to launch on Nimbus resources. The application runtime envi-ronment requires loading of a number of modules, as well as MPI, openssl, and many other dependencies that are not available in any known image that also includes Torque resource manager (for job queuing of multiple runs with varying data sizes and inputs).
Installing all the necessary packag-es on top of the base “hello cloud” im-age – which does include the Torque – was a work in progress at the end of Round 1. Significant computation-al results should be possible during Round 2, given this progress.
Case Study Authors – Lyn Gerner and Pratanu Roy
Team 19:
Parallel Solver of incompressible, 2d and 3d navier-Stokes equations, Using the Finite volume method
“Team efforts…made substantial progress toward building a customized VM image to launch on Nimbus resources.”
MEET THE TEAM

USe CASeWe used an application from ma-
chinery manufacturing in this experi-ment. The engineers who use CAE software on physical workstations or compute clusters can do the same operations on cloud resources based on their skills and knowledge of cre-ating, configuring and connecting to instances on Amazon EC2.
Advantages and Challenges of Complex engineering Applica-tions in Clouds
The rapid development and popularity of cloud computing are profoundly af-fecting and changing the resource sup-ply, resource management, and comput-ing modes of future applications. As one of the main supporting technologies of cloud computing, virtualization technol-ogy enables cloud computing to have the features of dynamical scalability, flexible customization and isolation of the envi-ronment, and transparent fault tolerance of applications, which are missing in the traditional platform of engineering appli-cations. Therefore, cloud computing pro-vides a good choice to solve engineering applications demand, but also brings new opportunities for the development of engineering applications and software.
Compared to traditional computing environments, two main advantages
of cloud computing for engineering applications are a customizable envi-ronment, and flexible usage and man-agement of resources.
However, the majority of current cloud systems and the corresponding tech-niques primarily aim at Internet-based applications. Engineering applications, especially complex engineering ap-plications, bring grand challenges to cloud computing since they are sig-nificantly different from those service-oriented Internet-based applications due to their inherent features, such as workload variations, process control, resource requirements, environment configurations, lifecycle management, and reliability maintenance.
The end-to-end Process 1. define end-user project with
help from end-user – During the def-inition of our experiment, we consulted with researchers from the School of Mechanical Science and Engineer-ing, Huazhong University of Science and Technology, and then decided to choose the NAS Parallel Benchmarks (NPB) and a real engineering applica-tion as the two experimental subjects.
2. Contact resource providers, set up project environment – Am-azon EC2 was our resource provider. After obtaining an “Amazon EC2 re-
deem code” voucher from the project organizers, we redeemed the resource immediately, then launch and login an instance, which was made into an AMI file later. This set the experiment envi-ronment with openmpi-1.4.3, which is the commonly used MPI Communica-tion Library, NAS Parallel Benchmarks (NPB2.4), and industry-renowned CFD software. We use scripts to build vir-tual clusters with the AMI file created above as the experiment environment.
Three types of EC2 instances were used in our experiment, namely EC2 Cluster Compute Instances (cc1.4xlarge), EC2 High CPU Extra Large Instances (c1.xlarge) and EC2 Extra Large Instanc-es (m1.large). Each CCI has 8 cores (the computing capability is equal to 33.5 EC2 Compute Units), with 23GB of memory. Each High CPU Extra Large Instances has 8 cores (the computing capability is equal to 20 EC2 Compute Units), with 7GB of memory. Each Extra Large Instances has 4 cores (the com-puting capability is equal to 8 EC2 Com-pute Units), with 23GB of memory.
We built virtual clusters consisting of 9 or 17 nodes to run the NPB pro-grams. One node of the virtual cluster is the NFS Server, which is an EC2 Ex-tra Large Instance; the other nodes are
Team 20:
nPB2.4 Benchmarks and Turbo-machinery Application on Amazon eC2
“We obtained first-hand experience in running engineering applications in the commercial cloud computing environment.”
MEET THE TEAM

compute nodes, which run EC2 Cluster Compute Instances or EC2 High CPU Extra Large Instances. The detailed setup of NPB experiment is depicted in Table 1.
3. initiate execution of the end-user project – After setting the experiment environment, we first carried out both class C and Class D of the NPB benchmarks on three virtual clusters consisting of 16 m1.large instances (64 cores), 16 c1.xlarge instances (128 cores) and 8 cc1.4xlarge (64 cores) instances separately. We ran each benchmark 10 times, and the experimental results are shown in the appendix.
Since we used Amazon EC2 for the first time, and had the expectation of cheap prices, we did the test in the same way that we would have done on the HPC cluster in our laboratory. This approach incurred significant costs at this stage of the experiment – so, it is not cheap, or not as cheap as we originally thought.
4. monitoring – We did not use specialized monitoring tools, but instead used the Xschell4, which is a terminal emu-lator for Windows platforms, to connect to virtual cluster con-sisting of EC2 instances, and to monitor the progress of our experiment. We used the runtime of the benchmark as the metric for evaluating the performance of the cloud resource.
5. review results (where needed) – Experimental re-sults show that there is substantially no performance fluc-tuation of tightly coupled benchmarks on the virtual cluster consisting of CCI instances. By contrast, the performance fluctuation of tightly coupled benchmarks on the virtual cluster consisting of non-CCI instances is obvious, and we find that the application performance on the virtual clus-ter consisting of non-CCI instances shows an increasingly positive trend from the first round to the tenth round.
ChAllenGeS• An objective fact is that China’s Internet speed is still lag-
ging behind comparable network speeds worldwide. • Currently, Chinese users cannot connect to the Ama-
zon EC2 instances. In order to do the scientific experi-ments, we access EC2 instances temporarily through some technical means.
• During uploading large files to EC2 instances by Xschell4, we often encountered the problem of instance crash. Our solution was to first upload files to DropBox, which is a free service that lets you bring your photos, docs, and videos anywhere and share them easily, and
then download them in the EC2 instances.• We also had budget issues. Running the NPB test exces-
sively on virtual clusters consisting of non-CCI instances at the first step of the experiment led to a budget over-run. The project organizers have solved this issue.
BeneFiTSWe are very grateful to the organizer for the opportunity
of participating in the project – we obtained first-hand ex-perience in running engineering applications in the com-mercial cloud computing environment.
We got a more profound understanding of the EC2 billing methods through the experiment.
We verified two main advantages of cloud computing for engineering applications, which are a customizable environ-ment, and the flexible usage and management of resources.
We found that the Standard Deviation of the benchmarks’ performance on the virtual cluster consisting of CCI instances is small. By contrast, the performance fluctuation of benchmarks on the virtual cluster consisting of non-CCI instances is obvious.
We observed that the performance of the real application on a virtual cluster consisting of non-CCI instances showed an increasingly positive trend from the first to the last round.
ConClUSionS And reCommendATionSDo not use commercial cloud resources in the same way
that you use them in your own physical cluster, because each operation in commercial cloud resources may incur costs.
Although you don’t need upfront investment on infrastruc-ture and commercial software in the cloud environment, you still need to pay for the hardware and software you have con-sumed. That is to say, you need comprehensive schedules re-garding using the cloud resource in order to adapt to the billing method before running engineering applications in the cloud.
Although the price of non-CCI instance is cheaper, manu-facturers need a precise model to choose the suitable type of instance according to their budget and the deadline of tasks.
Manufacturers need solutions, which are the basis of the comprehensive schedules mentioned above, to predict the running times of engineering application when the physical environment turns into a cloud environment.
Relative to the general engineering applications, we are more concerned about performance issues of complex en-gineering applications in the cloud computing environment, because it is more challenging! The key issues are:
• How to build a new cloud resource organization model for the characteristics of complex engineering applications
• How to design virtualized resource management tech-niques for complex engineering applications in the cloud environment
• How to schedule the cloud resources in order to en-hance complex engineering applications performance and cloud system capacity
Case Study Authors – Haibao Chen, Zhenjiang Xie, Song Wu, and Wenguang Chen
Number of Compute Node Number of Number ofProcess Instance Type Compute Node NFS node
64 EC2 Extra Large 16 1 Instance (m1.large)
64 EC2 Cluster Compute 8 1 Instance (cc1.4xlarge)
128 EC2 High CPU 16 1 Extra Large Instance (c1.xlarge)
Table 1 - Detailed setup of the NPB experiment.

USe CASeA research into optimization tech-
niques was conducted and a novel approach has been developed. To evaluate optimization scores, each model is subjected to a finite element analysis. A case study was designed and for its execution, high power computing resources were required. A cluster was utilized to analyze a large number of moderately sized jobs. Pre-processing was done locally, but the post-processing was done remotely, although no visualization was re-quired. The FEA for this “optimization study of side door intrusion bars” job was planned to be solved using the ABAQUS Standard solver.
There are a limited number of insti-tutions capable of providing required resources (for example there are only
five high power computer centers with ABAQUS licenses in all of AU). In situ-ations where an HPC cluster access is secured, there is a problem with a lim-ited availability of academic licenses. Having a reliable cloud service would definitely provide alternative options, versatility, and help in meeting the de-mand.
end-to-end Process1. end-user project – The user was
performing an optimization study of side door intrusion bars. The profiles of the bars are unconstrained and so have non-uniform thickness along and across the bars. The bars are meshed with solid elements and there were anywhere between 15,000 - 20,000 nodes and 30,000 - 50,000 elements per model. All models were computer
generated and auto-meshed. The user expected 2,000 - 3,000 design varia-tions in this study. The user defined their needs to the Resource Provider (PBS scripts, resources needed).
2. experiment setup environ-ment – The Linux HPC cluster was setup on Microsoft Azure with PBS scheduling system and CentOS op-erating system. The FEA software for the end-user, ABAQUS, was deployed and the license server configured as per the requirements.
3. experiment initiation – The end-user submitted his test jobs to the clus-ter. The HPC expert tested the cluster environment and observed seamless access to cloud resources. The re-source provider provided all the neces-sary accesses to the end-user and pro-vided technical support when needed.
Team 22:
optimization Study of Side door intrusion Bars
“The main benefits from the current experiment were exposure to cloud computing and the discovery of the limitations of the cloud computing
environment.”
MEET THE TEAM

4. experiment monitoring – The end-user constantly monitored the execution of the jobs and raised a support request when encountering a problem. The nodes that failed during simulation were corrected and reset as need-ed. The HPC expert monitored the progress of the experi-ment with his inputs.
ChAllenGeSLimiting the experiment to utilizing only nodes that were
online solved limited and unreliable access to the computer nodes.
Non-matching number of license tokens and computer nodes was solved by devising a strategy that maximized the available infrastructure.
Due to lack of scalability, adding more cores did not im-prove the speed, thus voiding the devised strategy and re-sulting in utilizing only 5 (on average) out of 10 nodes at a time.
Running license servers in the cloud is problematic as the licenses are tied to static hardware resources. Access to application licensing was resolved by using VPN back into an on-premise license server.
BeneFiTSThe main benefits from the current experiment were ex-
posure to cloud computing and the discovery of the limita-tions of the cloud computing environment.
• Benefits for the resource provider – Proved doing CAE simulation with Linux on Azure is feasible.
• Benefits for the hPC expert – Access to the cloud resources proved seamless. The expert was able to identify on-demand resources availability with technol-
ogy enhancements as and when needed with shorter turn-around-times.
Shortfalls from the current experiment were the very limited time (seven days) to assess suggested problem resolutions. Another shortfall was that cloud resources and the general Internet are not as stable as on-premise resources.
In the next experiment, we expect more time and access to a reliable cloud infrastructure.
ConClUSionS And reCommendATionS• For the end-User – Clusters built on public clouds are
more cost effective than dedicated hosted providers, but are generally not as reliable as hosted clusters.
• For the resource Provider – Doing pre/post on the cloud avoids data transfer issues. Licensing with dy-namic resources requires putting license servers in the data-center. VPN is the simplest mechanism to reach back into the data center to reach needed license serv-ers. Cloud HPC clusters (true cloud, not co-located or hosted clusters) and Internet WAN are not as stable as on-premise clusters, so system should be resilient to failure conditions.
• For the hPC expert – Cloud HPC seems feasible. However, a few things need to be addressed: e.g., company owned ISV licenses; security of company’s intellectual property; company compliance norms like ITAR; and confidence in the reliability of the resources and the resource provider’s capabilities.
Case Study Authors – Mldenko Kajtaz, Rod Mach, Matt Dunbar, and Satyanarayanaraju P.V.

USe CASeA sound emitted by an audio device
is perceived by the user of the device. The human perception of sound is, however, a personal experience. For ex-ample, the spatial hearing (the capabil-ity to distinguish the direction of sound) depends on the individual shape of the torso, head and pinna (i.e. so-called head-related transfer function, HRTF).
To produce directional sounds via headphones, one needs to use HRTF filters that “model” sound propagation in the vicinity of the ear. These filters can be generated using computer sim-ulations, but, to date, the computation-al challenges of simulating the HRTFs have been enormous due to: the need of a detailed geometry of head and torso; the large number of frequency steps needed to cover the audible fre-quency range; and the need of a dense set of observation points to cover the full 3D space surrounding the listener. In this project, we investigated the fast generation of HRTFs using simulations in the cloud. The simulation method relied on an extremely fast boundary element solver, which is scalable to a large number of CPUs.
The process for developing filters for 3D audio is long, but the simulation work of this study constitutes a crucial part of the development chain. In the first phase, a sufficient number of the 3D head-and-torso geometries need-ed to be generated. A laser-scanned geometry of a commercially available test dummy was used in these simu-
lations. Next, acoustic simulations to characterize acoustic field surrounding the head-and-torso were performed. This was our task in the HPC experi-ment. Finally, the filters were generated from the simulated data and they were evaluated by a listening test. The final part will be done by Aalto University and the end-user after the data from the HPC experiment is available.
The environmentSimulations were run via Kuava’s Wavel-
ler Cloud simulation tool using the system described below. The number of concur-rent instances ranged between 6 and 20.
• Service: Amazon Elastic Compute Cloud. Total CPU hour usage: 341h. Type: High-CPU Extra Large Instance.
• High-CPU Extra Large Instance: 7 GiB of memory. 20 EC2 Compute Units (8 virtual cores with 2.5 EC2 Compute Units each). 1690 GB of instance stor-age.
• One EC2 Compute Unit provides the equivalent CPU capacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon pro-cessor. This is also the equivalent to an early-2006 1.7 GHz Xeon processor.
ChAllenGeOur main challenge was to develop
interactive visualization tools for simula-tion data that was stored in the cloud.
BeneFiTSThe main benefit was realized from the
flexible resource allocation that is neces-sary for efficient acoustic simulations –
that is, a large number of instances can be obtained for a short period of time.
There was no need to invest in our own computing capacity. Especially in audio simulations, the capacity is needed in short bursts for fast simulation turnaround times and the time between the simula-tion bursts while the next simulation is planned. The fact that no computational capacity is needed is significant.
ConClUSionS And reCommendATionS
The main lessons learned were related to the optimal use of the cloud capacity. In particular, we obtained important expe-rience on running large simulations in the cloud. For example, the optimal number of instances was dependent on the size of the simulation task and the amount of data needed to transfer to and from the cloud.
The man hours logged during the experiment were: Kuava (60h), Aalto (1h) and end-user (4h). Total CPU hour usage during the experiment was 341h using High-CPU Extra Large Instance.
Case Study Authors – Antti Vanne, Kimmo Tuppurainen, Tomi Huttunen, Ville Pulkki, and Marko Hiipakka
Team 25:
Simulation of Spatial hearing“Our main challenge was to develop interactive visualization tools for simulation data that was stored in the cloud.”
MEET THE TEAM

USe CASeThis project focused on simulating
stent deployment using SIMULIA’s Abaqus/Standard and Remote Visu-alization Software from NICE to run Abaqus/CAE on SGI Cyclone. The intent was to determine the viability of shifting similar work to the cloud during periods of full-utilization of in-house compute resources.
information on Software and resource Providers
Abaqus from SIMULIA, the Dassault Systems’ brand for realistic simula-tion, is an industry leading product family that provides a comprehensive and scalable set of Finite Element Analysis (FEA) and multiphysics solv-ers and modeling tools for simulating a wide range of linear and nonlinear model types. It is used for stress, heat transfer crack initiation, failure and other types of analysis in me-chanical, structural, aerospace, auto-motive, bio-medical, civil, energy, and related engineering and research ap-plications. Abaqus includes four core products: Abaqus/CAE, Abaqus/Stan-dard, Abaqus/Explicit, and Abaqus/CFD. Abaqus/CAE provides users with a modeling and visualization en-vironment for Abaqus analysis.
NICE Desktop Cloud Visualization (DCV) is an advanced technology that enables technical computing users to remote access 2D/3D interactive ap-plications over a standard network. Engineers and scientists are immedi-
ately empowered by taking full advan-tage of high-end graphics cards, fast I/O performance and large memory nodes hosted in “Public or Private 3D Cloud”, rather than waiting for the next upgrade of the workstations.
SGI Cyclone is the world’s first large scale on-demand cloud computing ser-vice specifically dedicated to technical applications. Cyclone capitalizes on over twenty years of SGI HPC expertise to address the growing science and engineering technical markets that rely on extremely high-end computational hardware, software and networking equipment to achieve rapid results.
Current StateThe end user currently has two 8 core
PC workstations for pre- and post-pro-cessing with Abaqus/CAE, and a Linux based compute server with 40 cores and 128GB of available memory.
They do not use any batch job scheduling software. The typical size of model of the stent design that they run has 2-6 million degrees of freedom (DOF). Typical job uses 20 cores and takes six hours. After the job is run, the data is transferred to the worksta-tion for post-processing.
For the experiment it was agreed the Simulia and SGI would provide the end user with Abaqus licenses for up to 128 cores in order to see if running a job on more cores could reduce the time to finish the job, as well as provide access to NICE DCV remote graphics software to view the results in Northern
California before downloading them to the end user office in New Hampshire.
end-To-end Process1. Set up Cyclone account for End
User. 2. SGI License Server info sent to
Software Provider.3. Issuance of a 128 core temporary
license of Abaqus by Software Provider.
Team 26:
development of Stents for a narrowed Artery
“For an Abaqus user using SGI Cyclone this is a viable solution for both compute and visualization.”
MEET THE TEAM

4. End user uploads model to his home directory on Cy-clone login node and sends email to CAE Expert.
5. Benchmark scaling exercise to find core count sweet spot is done by CAE Expert.
6. Results of benchmark scaling exercise sent to End User by CAE Expert.
7. Remote Viz session to view data using Abaqus CAE is set up by CAE Expert.
8. Remote Viz demo via WebEx with End User. 9. PBS submission script written by CAE Expert and
shared with End User.10. End user uploads, runs, views and downloads test case. 11. 10 days of free access is given to End User.
ChAllenGeSThe team met via a con call and agreed upon the list of
steps that made up the end-to-end process. The setting up of the end user account and having the software licenses issued was quickly done. In order for the End User to up-load their model via SSH they needed to get permission from their internal IT group, which took some time. Once the model was uploaded, the CAE Expert ran the model at various core counts and produced a routine benchmark re-port for the End User to review (see results in table below). The remote viz demo went smoothly but when the End User tried to run the software themselves it took both the Resource and End User IT network teams to open the nec-essary ports, which took much longer than anticipated.
Once the ports were open, the remote viz post-process-ing experience was better than expected. Analysis output files still needed to be shipped back to the End User for future reuse, additional post-processing, etc. Data transfer via the network was found to be slow. Final results might be better transferred through an external USB hard drive via FedEx.
BeneFiTSHere are the top 3 benefits of participating in the experi-
ment for each of the team members:
end User 1. Gained an increased understanding of what is involved
in turning on and using a cloud-based solution for computational work with the Abaqus suite of finite ele-ment software.
2. Determined that shifting computational work to the cloud during periods of full-utilization of in-house compute resources is a viable approach to ensuring analysis throughput.
3. Participation in the experiment allowed direct assess-ment of the speed and integrity of remote visualization of computational models (both pre- and post-process-ing) for a variety of model and output database sizes. SGI/Nice DCV provided a robust solution, which per-mitted fast, and accurate manipulation of the compu-tational models used in the study.
Software Provider 1. I was able to hear from an experienced Abaqus user
that doing remote postprocessing using a client ma-chine in New Hampshire to an SGI Cyclone server in California provided a good user experience.
2. I was able to hear from an end user that managing the networking requirements (opening ports in firewalls) took some work but was manageable.
3. I have a reference point for an Abaqus user who views executing his Abaqus workflow on SGI Cyclone to be a viable solution.
CAe expert 1. Expanded my knowledge of analytical methods used
in medical stent engineering with Abaqus/Standard.2. Increased awareness of user interactions with cloud
based solution and networking requirements.3. The geographic distance of ~3100 miles between custom-
er and SGI Cyclone Cloud resources confirms distance is no longer a barrier in high performance computing and remote visualization. Based on the Abaqus Engineer, he comments the SGI Remote Visualization for cloud com-puting was “faster and smoother than I expected”.
resource Provider: 1. The ability to walk a new customer through our HPC
cloud process for usage.2. Testing our remote visualization solution, which is in
beta. 3. Working with a long time CAE ISV partner to offer
a joint cloud base solution to run and view Abaqus jobs.
ConClUSionFor an Abaqus user using SGI Cyclone this is a viable so-
lution for both compute and visualization. The Viz side was impressive.

USe CASeBackground
In many engineering problems fluid dynamics is coupled with heat transfer and many other multiphysics scenar-ios. The simulation of such problems in real cases produces large numeri-cal models to be solved, so that big computational power is required in or-der for simulation cycles to be afford-able. For SME industrial companies in particular it is hard to implement this kind of technology in-house, because of its investment cost and the IT spe-cialization needed.
There is great interest in making these technologies available to SME companies, in terms of easy-to-use HPC platforms that can be used on demand. Biscarri Consultoria SL, is committed to disseminate paral-lel open source simulation tools and HPC resources in the cloud.
CloudBroker is offering its platform for various multiphysics, fluid dynam-ics, and other engineering applica-tions, as well as life science for small, medium and large corporations along with related services. The CloudBro-ker Platform is also offered as a li-censed in-house solution.
Current StateBiscarri Consultoria SL is exploring
Team 30:
heat Transfer Use Case
“Concerning the ease of using cloud computing resources, we concluded that this working methodology is very friendly and easy to use through the CloudBroker Platform.”
MEET THE TEAM
ORGANIZATIONS INVOLVEDhttp://www.biscarri.cat
http://www.caelinux.co
http://www.cloudbroker.co

the capabilities of cloud computing resources for perform-ing highly coupled computational mechanics simulations, as an alternative to the acquisition of new computing serv-ers to increase the computing power available.
For a small company such as BCSL, the strategy of us-ing cloud computing resources to cover HPC needs has the benefit of not needing an IT expert to maintain in-house parallel servers thus concentrating on our efforts in our main field of competence.
To solve the needs of the end user, the following hard-ware and software resources existing on the provider side were employed by the team:
• Elmer (http://www.csc.fi/english/pages/elmer), an open source multi-physical simulation software mainly devel-oped by the CSC — IT Center for Science
• CAELinux (http://www.caelinux.com), a CAE Linux dis-tribution including the Elmer software as well as a CAE-Linux virtual machine image at the AWS Cloud
• CloudBroker Platform (public version under https://platform.cloudbroker.com), CloudBroker’s web-based application store offering scientific and technical Soft-ware as a Service (SaaS) on top of Infrastructure as a Service (IaaS) cloud resources, already interfaced to AWS and other clouds
• Amazon Web Services (AWS, http://aws.amazon.com), in particular Amazon’s IaaS cloud offerings EC2 (Elastic Compute Cloud) for compute and S3 (Simple Storage Service) for storage resources
experiment Procedure Technical SetupThe technical setup for the HPC Experiment was per-
formed in several steps. These followed the principle to start with the simplest possible solution and then to grow it to fulfil more complex requirements in an agile fashion. If possible, each step was first tested and iteratively improved before the next step was taken. The main steps were:
1. All team members were given access to the public CloudBroker Platform via their own account under a shared organization created specifically for the HPC Experiment. A new AWS account was opened by CloudBroker, the AWS credit loaded onto it, and the account registered in the CloudBroker Platform exclusively for the experiment team.
2. Elmer software on the existing CAELinux AWS machine image was made available in the CloudBroker Platform for serial runs and tested with minimal test cases by Cloud-Broker and Joël Cugnoni. The setup was then extended to allow parallel runs using NFS and MPI.
3. Via Skype calls, screen sharing, chatting, email and contributions on Basecamp, the team members exchanged knowledge on how to work with Elmer on the CloudBroker Platform. The CloudBroker Team gave further support for its platform throughout HPC Experiment Round 2. Cloud-Broker and BCSL performed corresponding validation case runs to test the functionality.
4. The original CAELinux image was only available for normal, non-HPC AWS virtual machine instance types.
Therefore, Joël Cugnoni provided Elmer 6.2 as optimized and non-optimized binaries for Cluster Compute instances. Also, the CloudBroker Team deployed these on the Cloud-Broker Platform for the AWS HPC instance types with 10GBit Ethernet network backbone, called Cluster Com-pute instances.
5. BCSL created a medium benchmark case, and per-formed scalability and performance runs with different numbers of cores and nodes of the Amazon Cluster Com-pute Quadruple and Eight Extra Large instance types and different I/O settings. The results were logged, analyzed and discussed within the team.
6. The CloudBroker Platform setup was improved as needed. This included, for example, a better display of the number of cores in the web UI, and the addition of artificial AWS instance types with fewer cores, as well as the ability to change the shared disk space.
7. BCSL tried to run a bigger benchmark case on the AWS instance type configuration that turned out to be pref-erable from the scalability runs – that is, single AWS Cluster Compute Eight Extra Large instances.
validation CaseFirst a validation case was defined to test the whole sim-
ulation procedure. This case was intentionally simple, but had the same characteristics as the more complex prob-lems that were used for the rest of the experiment. It was an idealized 2D room with a cold air inlet on the roof (T = 23ºC, V = 1m/s), a warm section on the floor (T = 30ºC, V = 0.01m/s) and an outlet on a lateral wall near the floor (P = 0.0Pa). The initial air temperature was 25ºC.
The mesh was created with Salome V6. It consists of 32,000 nodes and 62,000 linear triangular elements. The solution is transient. Navier-Stokes and Heat equations were solved in a strong coupled way. No turbulence mod-el was used. Free convection effects were included. The
Fig. 1 - This figure shows the model employed in the scalability bench-mark. The image on the right shows the temperature field, while the left image shows the velocity field at a certain time of the transient simula-tion.

mesh of the benchmark analysis was a much finer one of the same geometry domain, consisting of about 500,000 linear triangular elements. The warm section on the floor was removed and lateral boundaries had open condition (P = 0.0Pa).
Job executionThe submission of jobs to be run at AWS was done
through the web interface of the CloudBroker Platform. The procedure was as follows:
• A job was created on the CloudBroker Platform, speci-fying Job Name, Software, Instance Type and AWS Re-gion
• Case and mesh partition files were compressed and uploaded to the CloudBroker Platform attached to the created job
• The job was submitted to the selected AWS resource• Result files were downloaded from the CloudBroker
Platform and postprocessed in a local workstation• Scalability parameters were calculated from job output
log file data
ChAllenGeSend User
The first challenge for BCSL in this project was to learn if the procedure to run Elmer jobs in a cloud computing resource such as AWS is easy enough to be a practical alternative to in-house calculation servers.
The second challenge was to determine the level of scal-ability of the Elmer solver running at AWS. Here we en-countered good scalability when the instance employed is the only computational node. When running a job on an instances using two or more computational nodes the scalability is reduced dramatically, showing that commu-nications between cores of different computational nodes slows down the process. AWS uses 10Gbit Ethernet as
backbone network, which seems to be a limitation for this kind of simulations.
After the scalability study with the mesh of 500 Kelems was performed, a second scalability test was tried with a new mesh of about 2000 Kelems. However, jobs submitted for this study to Cluster Compute Quadruple Extra Large and Cluster Compute Eight Extra Large instances have not been successfully run yet. Further investigations are in progress to better characterize the network bottleneck is-sue as a function of problem size (number of elements per core) and to establish if it is related to MPI communication latency or NFS throughput of the results.
resource Provider and Team expertOn the technical side, most challenges were mastered by
already existing features of the CloudBroker Platform or by small improvements. For this it was essential to follow the stepwise agile procedure as outlined above, partly ignoring the stiffer framework suggested by the default HPC Experi-ment tasks on Basecamp.
Unfortunately AWS HPC Cloud resources are limited to a 10 GBit Ethernet network. 10 Gbit Ethernet was not suf-ficient in terms of latency and throughput to run the ex-periment efficiently on more than one node in parallel. The following options are possible:
1. Run the experiment on one large node only, that is the AWS Cluster Compute Eight Extra Large instances with 16 cores
2. Run several experiment jobs independently in paral-lel with different parameters on the AWS Cluster Compute Eight Extra Large instances
3. Run the experiment on another cloud infrastructure which provides low latency and high throughput using technology such as Infiniband
The CloudBroker Platform allows for all the variants as de-scribed above. Variants 2 and 3 were not part of this experi-ment, but would be the next reasonable step to explore in a further experiment round. In the given time, it was also not possible to try out all the different I/O optimization possibili-ties, which could provide another route to improve scalability.
A further challenge of the HPC Experiment was to bring together the expertise from all the different involved part-ners. Each of them has experience on a separate set of the technical layers that were needed to be combined here (actual engineering use case, Elmer CAE algorithms, Elmer software package, CloudBroker Platform, AWS Cloud).
For example, often it is difficult to say from the onset which layer causes a certain issue, or if the issue results from the combination of layers. Here it was essential for the success of the project to stimulate and coordinate the contributions of the team members. For the future, we envision making this procedure more efficient through decoupling – for example, by the software provider directly offering an already optimized Elmer setup in the CloudBroker Platform to the end users.
Fig. 2 – Streamline on the inlet section.

Finally, a general challenge of the HPC Experiment con-cept is that it is a non-funded effort (apart from the AWS credit). This means that the involved partners can only pro-vide manpower on a “best effort” basis, and paid projects during the same time usually have precedence. It is thus important that future HPC Experiment rounds take realistic business and commercialization aspects into account.
BeneFiTSConcerning the ease of using cloud computing resources,
we concluded that this working methodology is very friend-ly and easy to use through the CloudBroker Platform.
The main benefits for BCSL regarding the use of cloud computing resources were:
• To have external HPC capabilities available to run me-dium sized CAE simulations
• To have the ability to perform parametric studies, in which a big number of small/medium size simulations have to be submitted
• To externalize all IT stuff necessary to have in-house calculation servers
For CloudBroker, it was a pleasure to extend its platform and services to a new set of users and to Elmer as a new software. Through the responses and results we were able to further improve our platform and to gain additional ex-perience on the performance and scalability of AWS cloud resources, particularly for the Elmer software.
ConClUSionS And reCommendATionSThe main lesson learned at Biscarri Consultoria SL aris-
ing from our participation in HPC Experiment Round 2 is that collaborative work through the Internet, using on-line resources like cloud computing hardware, Open Source software such as Elmer and CAElinux, and middleware platforms like CloudBroker, is a very interesting alternative to in-house calculation servers.
A backbone network such as 10Gbit Ethernet connecting computational nodes of a cloud computing platform seems not to be suitable for computational mechanics calculations that need to be run on more than one large AWS Cluster Compute node in parallel. The need for network bandwidth for the solution of strongly coupled equations involved in such simulations makes the use of faster network proto-cols such as Infiniband necessary to achieve time savings when running it in parallel on more than a single AWS Clus-ter Compute instance with 16 cores.
For CloudBroker, HPC Experiment Round 2 has provided another proof of its methodology, which combines its au-tomated web application platform with remote consulting and support in an agile fashion. The CloudBroker Platform could easily work with CAELinux and the Elmer software at AWS. User requirements and test outcomes even resulted in additional improvements, which are now available to all platform users.
On the other hand, this round has shown again that there are still needs – for example, a reduction of latency and im-provement of throughput (i.e., by using Infiniband instead of 10 GBit Ethernet) to be fulfilled by dynamic cloud pro-viders such as AWS regarding highly scalable parallel HPC resources. Their cloud infrastructure is currently best suit-ed for loosely or embarrassingly parallel jobs such as pa-rameter sweeps, or highly coupled parallel jobs limited to single big machines. Finally, despite online tools, the effort necessary for a project involving several partners like this one should not be underestimated. CloudBroker expects though that in the future more software like Elmer can be directly offered through its platform in an already optimized way, making usage more efficient.
Case Study Authors - Lluís M. Biscarri, Pierre Lafortune, Wibke Sudholt, Nicola Fantini, Joël Cugnoni, and Peter Råback.

USe CASe The goal was to optimize the design of wind turbines us-
ing numerical simulations. The case of vertical axis turbines is particularly interesting, since the upwind turbine blades cre-ate vortices that interact with the blades downstream. The full influence of this can only be understood using transient flow simulations, requiring large models to run for a long time.
ChAllenGeSIn order test the performance of a particular wind turbine
design, a transient simulation had to be performed for each wind speed and each rotational velocity. This lead to a large number of very long simulations, even though each model might not be very large. Since the different wind speeds and rotational velocities were independent, the computations could be trivially distributed on a cluster or in the cloud.
Team 34:
Analysis of vertical and horizontal Wind Turbines
“Cloud computing would be an excellent option for these kind of simulations if the HPC provider offered remote visualization
and access to the required software licenses.”
MEET THE TEAM
Figure 1: 2D simulation of a rotating vertical wind turbine.

Another important use of HPC and cloud computing for wind power is parametric optimization. Again, if the effi-ciency of the turbine is used as target function, very long transient simulations will have to be performed to evaluate every configuration.
BeneFiTSThe massive computing power required to optimize a
wind turbine is typically not available locally. Since only some steps of the design require HPC and an on-site clus-ter would never be fully utilized, cloud computing offers an obvious solution.
ConClUSionS And reCommendATionS
The problem with cloud computing for simulations using commercial tools is that the number of licenses is typically the bottleneck. Obviously, having a large number of cores does not help if there are not enough parallel licenses. In our case, a number of test-licenses were provided by AN-SYS, which was very helpful.
It is not possible to transfer data back and forth between the cluster and a local workstation. Therefore, any HPC fa-cility needs to provide remote access for interactive use. Unfortunately, this was not available in our case.
A test performed on the Penguin cluster showed an 8% increase in speed (per core) as compared with our local Windows cluster. This speedup was surprisingly small, given that Penguin uses a newer generation of CPUs with a much better theoretical floating-point performance. This
again demonstrates that simulations on an unstructured grid are bandwidth limited.
To conclude, cloud computing would be an excellent op-tion for these kinds of simulations if the HPC provider of-fered remote visualization and access to the required soft-ware licenses.
Case Study Author – Juan Enriquez Paraled
Figure 2: CFD Simulation of a vertical wind turbine with 3 helical rotors.

USe CASeModeling combustion in Diesel engines
with CFD is a challenging task. The physi-cal phenomena occurring in the short combustion cycle are not fully understood. This especially applies to the liquid spray injection, the auto-ignition and flame de-velopment and formation of undesired emissions like NOx, CO and soot.
Dacolt has developed an advanced combustion model named Dacolt PSR+PDF, specifically meant to address these types of challenging cases where combustion initiating chemistry plays a large role. This Dacolt PSR+PDF model has been implemented in ANSYS Flu-ent and was validated on an academic test case (SAE paper 2012-01-0152.pdf). An IC engine case validation case is the next step, tackled in the context of the HPC Experiment in the Penguin Computing HPC cloud.
ChAllenGeSCurrent challenges for the end-user
operating with just his in-house re-sources include the fact that the com-putational resources needed for these simulations are significant (i.e. more than 16 cpus and one to three days of continuous running.
BeneFiT
The benefit for the end-user using remote resources was that the remote clusters allow small companies to conduct simulations that previously were only possible by large compa-nies and government labs.
End-user findings on the provided cloud access include:
• Startup:o POD environment setup went
smoothlyo ANSYS software installation and
licensing as well• System:o POD system OS comparable to
OS used at Dacolto ANSYS Fluent version same as
used at Dacolt
• Running:o Getting used to POD job schedul-
ing o No portability issues of the CFD
model in generalo Some MPI issues related to Dacolt’s
User Defined Functions (UDFs)
Team 36:
Advanced Combustion modeling for diesel engines
“…remote clusters allow small companies to conduct
simulations that previously were only possible by large companies
and government labs.”
MEET THE TEAM
Simulation result showing the flame (red) lo-cated on top of the evaporating fuel spray (light blue in the center)

o Solver crash during injection + combustion phase, to be investigated
Overall, we experienced easy-to use ssh access to the POD cluster. The environment and software set-up went smoothly with collaboration between POD and ANSYS. The remote environment, which nearly equaled the Dacolt environment, provided a head start. Main issue encoun-tered: the uploaded Dacolt UDF library for Fluent did not work in parallel out of the box. It is likely the Dacolt User Defined Functions would have to be recompiled on the re-mote system.
Project resultsAn IC-engine was successfully run until solver diver-
gence, to be reviewed by Dacolt with ANSYS support. Da-colt model validation seems promising.
Anticipated challenges included:• Account set-up and end-user access• Configuring end-user’s CFD environment with ANSYS
Fluent v14.5
• Educating end-user in using the batch queuing system• Get data in and out of the POD cloudActual barriers encountered:• Running end-user UDFs with Fluent in parallel gave
MPI problems
ConClUSionS And reCommendATionS • Use of POD remote HPC resources worked well with
ANSYS Fluent• Although the local and remote systems were quite com-
parable in terms of OS, etc, systems like MPI may not work out of the box
• Local and remote network bandwidth was good enough for data transfer, but not for tunneling CAE graphics us-ing X
• Future use of remote HPC resources depends on avail-ability of pay-as-you-go commercial CFD licensing schemes
Case Study Author – Ferry Tap
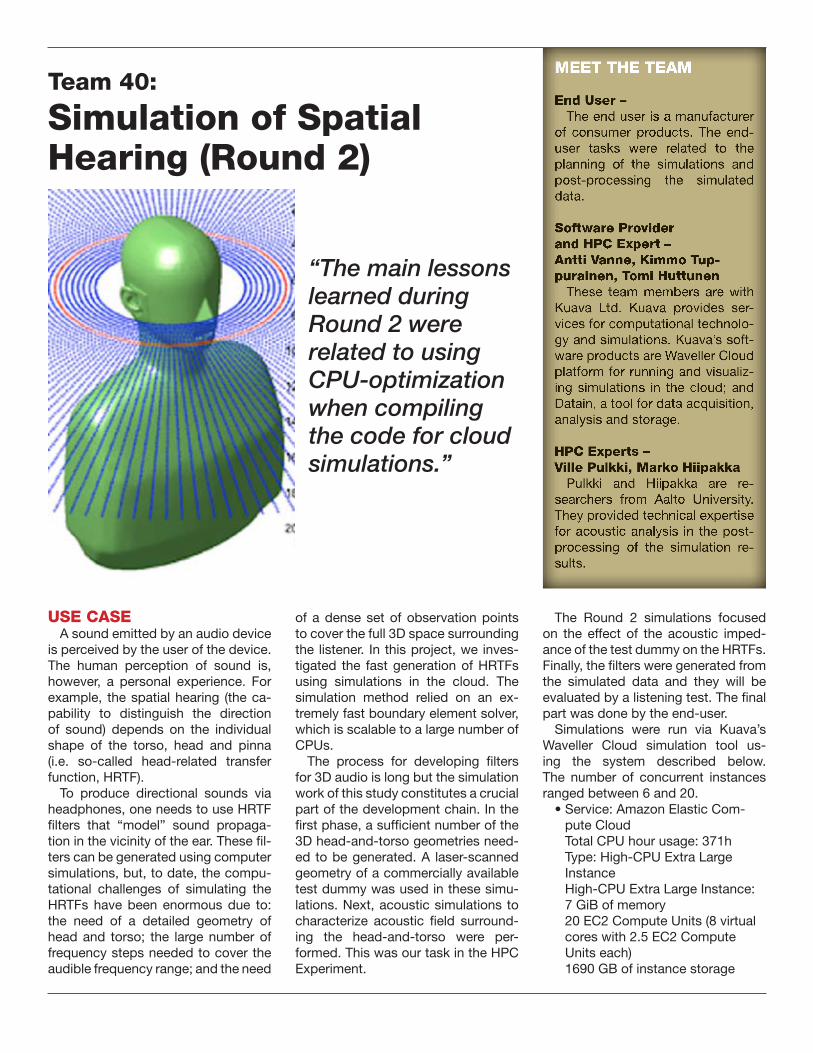
USe CASeA sound emitted by an audio device
is perceived by the user of the device. The human perception of sound is, however, a personal experience. For example, the spatial hearing (the ca-pability to distinguish the direction of sound) depends on the individual shape of the torso, head and pinna (i.e. so-called head-related transfer function, HRTF).
To produce directional sounds via headphones, one needs to use HRTF filters that “model” sound propaga-tion in the vicinity of the ear. These fil-ters can be generated using computer simulations, but, to date, the compu-tational challenges of simulating the HRTFs have been enormous due to: the need of a detailed geometry of head and torso; the large number of frequency steps needed to cover the audible frequency range; and the need
of a dense set of observation points to cover the full 3D space surrounding the listener. In this project, we inves-tigated the fast generation of HRTFs using simulations in the cloud. The simulation method relied on an ex-tremely fast boundary element solver, which is scalable to a large number of CPUs.
The process for developing filters for 3D audio is long but the simulation work of this study constitutes a crucial part of the development chain. In the first phase, a sufficient number of the 3D head-and-torso geometries need-ed to be generated. A laser-scanned geometry of a commercially available test dummy was used in these simu-lations. Next, acoustic simulations to characterize acoustic field surround-ing the head-and-torso were per-formed. This was our task in the HPC Experiment.
The Round 2 simulations focused on the effect of the acoustic imped-ance of the test dummy on the HRTFs. Finally, the filters were generated from the simulated data and they will be evaluated by a listening test. The final part was done by the end-user.
Simulations were run via Kuava’s Waveller Cloud simulation tool us-ing the system described below. The number of concurrent instances ranged between 6 and 20.
• Service: Amazon Elastic Com-pute Cloud Total CPU hour usage: 371h Type: High-CPU Extra Large Instance High-CPU Extra Large Instance: 7 GiB of memory 20 EC2 Compute Units (8 virtual cores with 2.5 EC2 Compute Units each) 1690 GB of instance storage
Team 40:
Simulation of Spatial hearing (round 2)
“The main lessons learned during Round 2 were related to usingCPU-optimization when compiling the code for cloud simulations.”
MEET THE TEAM
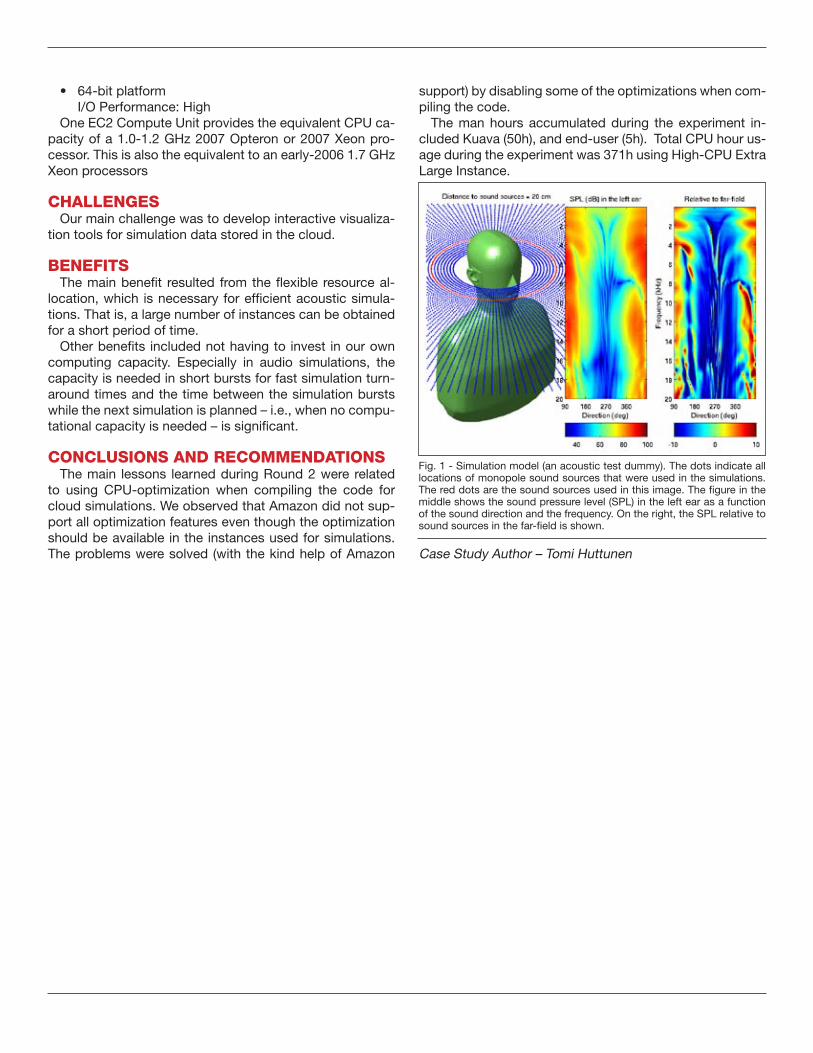
• 64-bit platform I/O Performance: High
One EC2 Compute Unit provides the equivalent CPU ca-pacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon pro-cessor. This is also the equivalent to an early-2006 1.7 GHz Xeon processors
ChAllenGeSOur main challenge was to develop interactive visualiza-
tion tools for simulation data stored in the cloud.
BeneFiTSThe main benefit resulted from the flexible resource al-
location, which is necessary for efficient acoustic simula-tions. That is, a large number of instances can be obtained for a short period of time.
Other benefits included not having to invest in our own computing capacity. Especially in audio simulations, the capacity is needed in short bursts for fast simulation turn-around times and the time between the simulation bursts while the next simulation is planned – i.e., when no compu-tational capacity is needed – is significant.
ConClUSionS And reCommendATionSThe main lessons learned during Round 2 were related
to using CPU-optimization when compiling the code for cloud simulations. We observed that Amazon did not sup-port all optimization features even though the optimization should be available in the instances used for simulations. The problems were solved (with the kind help of Amazon
support) by disabling some of the optimizations when com-piling the code.
The man hours accumulated during the experiment in-cluded Kuava (50h), and end-user (5h). Total CPU hour us-age during the experiment was 371h using High-CPU Extra Large Instance.
Case Study Author – Tomi Huttunen
Fig. 1 - Simulation model (an acoustic test dummy). The dots indicate all locations of monopole sound sources that were used in the simulations. The red dots are the sound sources used in this image. The figure in the middle shows the sound pressure level (SPL) in the left ear as a function of the sound direction and the frequency. On the right, the SPL relative to sound sources in the far-field is shown.

USe CASeBinkz Inc. is a Canadian-based
CFD consultancy firm with less than five employees, active in the areas of aerospace, automotive, environmen-tal and wind engineering, as well as naval hydrodynamics and process technologies. For Binkz’s consultancy activities, simulation of drifting snow is necessary in order to predict the re-distribution of accumulated snow by the wind around arbitrary structures. Such computations can be used to determine the snow load design pa-rameters of rooftops, which are not properly addressed by building codes at the present. Other applications can be found in hydrology and avalanche effects mitigation.
Realistic simulation of snow drift re-quires a 3D two-phase fully-coupled CFD model that easily takes sev-eral months of computing time on a powerful workstation (~16 cores) and memory requirements that can ex-ceed 100GB in some cases; hence the need for computing clusters to reduce
the computing time. The pay-per-use model of the cloud paradigm could be ideal for a small consultancy firm to reduce the fixed costs of acquiring and maintaining a computing cluster, and allow the direct billing of the com-puting resources in each project.
The snowdrift simulations were performed with a customized Open-FOAM two-phase solver. OpenFOAM is a free, open source CFD software package developed by OpenCFD Ltd at ESI Group and distributed by the OpenFOAM Foundation. It has a large user base across most areas of engi-neering and science, from both com-mercial and academic organizations.
The input data consisted of a com-putational mesh of several million cells and a number of ASCII input files to provide the physical and nu-merical parameters of the simulation. Output data consisted of several files containing the values of the velocity, pressure, volume fraction and turbu-lence variables for each of the air and
snow phases, in every computational cell and for each required flow time. These were used to generate snap-shots of the flow field and drifting snow as well as values of snow loads where required on and around the structure being analyzed.
end-to-end process:• Project definition was agreed upon
in an online meeting between team expert and the end user and the SDSC’s Compute Clus-ter ‘Triton’ was selected as hard-ware resource to fulfill the large memory demands (~100GB RAM) and fast interconnect required for good scalability. An initial budget of 1,000 core hours was assigned to the project.
• OpenFOAM was downloaded into
Team 44:
CFd Simulation of drifting Snow
“The main challenge during the setup of the configuration was getting
a successful build of OpenFOAM on the hardware resource.“
MEET THE TEAM

the home directories. An initial attempt to build the solver with the PGI compilers was unsuccessful. Build-ing with the Intel compilers was successful but subse-quent computational tests ended in segmentation faults never observed on other platforms. As a last ditch effort a final build was done with the gcc compiler, the Open-FOAM native compiler, albeit with several non-optimal fixes to make sure the build is available on time to get some tests done before the project deadline. At that point about 40% of the allocated CPU time had been spent.
• Limited speedup tests were done with the gcc build due to scarcity of time and resources left. The speedup tests showed the expected scalability behavior with one anomalous occurrence never before observed on other platforms. Thorough investigation of the anomaly was considered outside the context of the Experiment considering the non-optimal nature of the gcc build.
efforts invested:• Triton support: <10 hours, build attempts, system con-
figuration, tracking of the build.• End user: more than 100 hours in build attempts, solver
and testcase setup, testing the builds and analyzing the test results.
• Team expert: 10-20 hours of basic support, reporting and overall experiment management.
• Resources: ~900 core hours for building the software, testing the builds and performing initial tests for run-ning large jobs.
ChAllenGeSThe main challenge during the setup of the configuration
was getting a successful build of OpenFOAM on the hard-ware resource.
The main challenge during test execution was scheduling a test MPI simulation job requiring several parallel com-pute nodes on queues occupied by a high number of serial runs by other users prioritized in the queuing system. This resulted in deployment waiting times that were not accept-able in the workflow of the end user. There exist however other queues on Triton that could provide better prioritiza-tion and response times, but they were not tested due to the limited time frame of the experiment.
BeneFiTSThe first benefit of the experiment was the learning ex-
perience with building OpenFOAM with different compil-ers on different platforms. Past experience in compiling OpenFOAM on other CentOS systems led us to believe
this would not be a problem on Triton. Unfortunately, it was and in the future one should make sure in advance that an optimized OpenFOAM build exists on the target resource; or the project plan should anticipate the time and labor re-quired to obtain a good build. In this experiment, SDSC had agreed to provide computing time only, but even so support staff committed a significant amount of their own time to assist with the OpenFOAM build. Given enough time it is certain that the Triton support staff would have managed to provide optimal builds of OpenFOAM with all tested compilers.
Another benefit from the experiment is that, apart from a well-fitting hardware platform (as Triton would be), it is also important for production jobs to be launched on ap-propriate MPI queues that would not allow high numbers of smaller serial jobs to delay large parallel MPI jobs.
ConClUSionS And reCommendATionS• OpenFOAM (or more generally, a large open-source
software package such as OpenFOAM) is best built on the platform it will run on.
• OpenFOAM is most easily built with the third-party soft-ware as provided within the distribution.
• For the application of snow drift simulations, running on a public/academic resource using a standard (i.e. non-prioritized) account yields unpredictable waiting times and important computing delays when running concur-rently with a high number of serial runs by other users.
• In another experiment round, we would recommend testing an alternative platform/queue that has a differ-ent capacity, user base, or job queuing system that is a better fit to the end user’s work flow.
Case Study Authors -- Ziad Boutanios and Koos Huijssen
Fig. 1 - Closeup of the building model with simplified roof structure. The structured mesh is 1.25 million hexahedral cells.

USe CASeThe goal of this project was to run
CAE simulations of water flow around the hull of a ship much more quickly than was possible using available resources. Current simulations took a long time to compute, limiting the usefulness and usability of CAE for this problem. For instance, on the resources currently available to the end user, a simulation of 50-60 seconds of real time water flow took two to three weeks of com-putational time. We decided to run the existing software on a HPC resource to realize whatever runtime gains might be achieved by using larger amounts of computing resources.
Application software requirementsThis project required the TESIS
FlowVision 3.08.xx software. FlowVision is already parallelized using MPI so we expected it to be able to utilize the HPC resources. However, it does require the ability to connect to the software from a remote location while the software is running in order to access the software licenses and steer the computation. For the license keys, see description in FlowVision installation and preferences on Calendula Cluster.docx, https://base-camp.com/2047282/projects/1610899-team-46-simulation/uploads/42…
Team 46:
CAe Simulation of Water Flow Around a Ship hull
“The results of the simulation, performed in a wide range of towing speeds in the grid with about 1 mln computational cells, showed good agreement with the experimental data.”
MEET THE TEAM
Digital Ma-rine Technolog

Custom code or configuration of end-userThis project necessitated the upgrading of the operat-
ing system on the HPC system to support some libraries required by the FlowVision software. The Linux version on the system was not recent enough and one of the system main parts, glibc libraries, were not the correct version. We also had to open a number of ports to enable software to connect to and from specific external machines (specified by their IP address).
Computing resource: Resource requirement from the end-user: about 8-16 nodes
for the HPC machine, used for 5 runs of 24 hours each.Resource details: There are two processors on each node,
Intel Xeon E5450 @ 3.00GHz , with 4 real cores per proces-sor, so each compute node has 8 real cores. Each node also has 16GB of memory and two 1Gb Ethernet cards and one Mellanox Infiniband card. This experiment had been assigned 32 nodes (so 256 cores) to use for simulations.
How to request resources: To get access to the resources you e-mail the resource provider. They provide an account quickly (in around a day).
How to access resources: The front end of the resource is accessed using ssh; you will need an account on the system to do this using a command such as this:
ssh -X [email protected] -p 2222Once you have logged into the system. you can run jobs
using the Open Grid Scheduler/Grid Engine batch system. To use that system you need to submit a job script using the qsub command.
ChAllenGeS
Current simulations take a long time to compute, limiting the usefulness and usability of the CAE approach for this problem. For instance, on the resources currently available to the end user, a simulation of 50-60 seconds of real time water flow takes two to three weeks of computational time. To improve this time to solution we need to access to larger computational resources than we currently have available.
Scientific ChallengeSimulation of the viscous flow around the hull of a ship with
the free surface was provided. The object of research was the
hull of the river-sea dry-cargo vessel with extremely high block coefficient (Cb = 0.9). The hull flow included complex phenom-ena, e.g. wave pattern on the free surface, and fully developed turbulence flow in the boundary layer. The main purpose of the simulation was towing resistance determination.
In general, dependence of towing resistance on the speed of the ship was used for the prime mover’s power predic-tion at the design stage. The present case considered a test example for which there is reliable experimental data. In contrast to the conventional method of model tests, the methods of CFD simulation have not been fully studied re-garding the reliability of the results, as well as the compu-tational resources and time costs, etc. For these reasons, the computational grid formation and the scalability of the solution were the focus of this research.
resources FCSCL, the Foundation of Supercomputing Center of
Castile and León, Spain, provided HPC resources, in the form of a 288 HP blade nodes system with 8 cores and 16GB RAM per node.
SoftwareFlowVision is a new generation multi-purpose simulation sys-
tem for solving practical CFD (computational fluid dynamics) problems. The modern C++ implementation offers modularity and flexibility that allows addressing the most complex CFD areas. A unique approach to grid generation (geometry fitted sub-grid resolution) provides a natural link with CAD geometry and FE mesh. The ABAQUS integration through Multi-Physics (MP) Manager supports the most complex fluid-structure inter-action (FSI) simulations (e.g., hydroplaning of automotive tires).
FlowVision integrates 3D partial differential equations (PDE) describing different flows, viz., the mass, momentum (Navier-Stokes), and energy conservation equations. The system of the governing equations is completed by state equations. If the flow is coupled with physical-chemical processes like turbulence, free surface evolution, combustion, etc., the corresponding PDEs are added to the basic equations. All together the PDEs, state equations, and closure correlations (e. g., wall functions) constitute the mathematical model of the flow. FlowVision is based on the finite-volume approach to discretization of the governing equations. Implicit velocity-pressure split algorithm is used for integration of the Navier-Stokes equations.
FlowVision is integrated CFD software: its pre-processor, solver, and post-processor are combined into one system. A user sets the flow model(s), physical and method param-eters, initial and boundary conditions, etc. (pre-processor), performs and controls calculations (solver), and visualizes the results (post-processor) in the same window. He can stop the calculations at any time to change the required pa-rameters, and continue or recommence the calculations.
Additional ChallengesThis project continued from the first round of the cloud
experiment. In the first round we faced the challenge that
Fig. 1 - Wave pattern around the ship hull

the end user for this project had a particular piece of com-mercial simulation software they needed to use for this work. The software required a number of ports to be open from the front end of the HPC system to the end users ma-chines, both for accessing the licenses for the software and to enable visualization, computational steering, and job preparation for the simulations.
There were a number of issues to be resolved to enable these ports to be opened, including security issues for the resource provider (requiring the open ports to be restrict-ed to a single IP address or small range of IP addresses), and educating the end user about the configuration of the HPC system (with front-end and back-end resources and a batch system to access the main back-end resources). These issues were successfully tackled. However, another issues was encountered – the Linux version of the operat-ing system on the HPC resources was not recent enough and one of the system main parts, glibc libraries, were not the required version for the commercial software to be run. The resource provider was willing to upgrade the glibc li-braries to the required version; however this impacted an-other team during the first round. At the start of this sec-ond round of the experiment this problem was resolved so simulations could be undertaken.
outcome The dependence of the towing resistance on the resolu-
tion of computational grid (grid convergence) was investi-gated. The results show that grid convergence becomes good when grids with a number of computational cells of more than 1 mln are used.
The results of the simulation, performed in a wide range of towing speeds (Froude numbers) in the grid with about 1 mln computational cells, showed good agreement with the experimental data. CFD calculations were performed in full scale. The experimental results were obtained in the deep-
water towing tank of Krylov State Research Centre (model scale is 1:18.7). The full-scale CFD results were compared to the recalculated results of the model test. The maximum error in the towing resistance of the hull reached only 2.5%.
Visualization of the free surface demonstrated the wave pattern, which is in a good correspondence with the pho-tos of the model tests. High-quality visualization of other flow characteristics was also available.
Fig. 2 - Grid convergence, speed 12.5 knots
Fig. 3 - Comparison of the CFD and experimental data in dimensionless form (residual resistance coefficient versus Froude number)
Fig. 4 - Free surface – CFD, speed 13 knots (Fn = 0.182)
Fig. 5 - Pressure distribution on the hull surface (scale in Pa)

ConClUSionS And reCommendATionSUsing HPC clouds offers users incredible access to su-
percomputer resources. CFD users with the help of com-mercial software can greatly speed up their simulation of
hard industrial problems. Nevertheless, existing access to these resources has the following drawbacks:
1. Commercial software must be first installed on remote supercomputer
2. It is necessary to provide the license for the software, or to connect to a remote license server
3. User can be faced with a lot of problems during in-stallation process: e.g., incompatibility of the software with the operation system, and incompatibility of additional 3rd-party software like MPI, TBB libraries, etc.
4. All these steps require that the user be in contact with the software vendor or cluster administrator for technical support
From our point of view, it is necessary to overcome all these problems in order to use commercial software on HPC clouds. Commercial software packages used for sim-ulation often have requirements for licensing and operation that either means the resources they are being run on need to access external machines or software needs to be in-stalled locally to handle licenses, etc.
New users to HPC resources often require education in the general setup and use of such systems (e.g., the fact you generally access the computational resources through a batch system rather than logging on directly).
Basecamp has been useful to enable communication be-tween the project partners, sharing information, and ensur-ing that one person is does not hold up the whole project.
Communication between the client side and the solver side of modern CAE systems ordinarily uses network pro-tocol. Thus the organization of work over SSH protocol re-quires additional operations, including port forwarding and data translation. On the other hand, when properly config-ured, the client interface is able to manage the solving in the same manner as in local network.
Case Study Authors – Adrian Jackson, Jesus Lorenzana, Andrew Pechenyuk, and Andrey Aksenov.
Fig. 6 - Shear stress distribution on the hull surface (scale in Pa)
Fig. 7 - Scalability test results

USe CASeIn Round 1 of the HPC Cloud exper-
iment, the team established that in-deed computational use cases could be submitted successfully using the cloud API and infrastructure.
The objective of this Round 2 was to explore the following:
• How can the end user experience be improved? For example, how could the post processing of HPC CAE results kept in the cloud be viewed at the remote desktop?
• Was there any impact of the secu-rity layer on the end user experi-ence?
The end to end process remains – widely dispersed end user demand was tested in two different geo-graphic areas: Continental USA and Europe. The network bandwidth and latency were expected to play a ma-jor role since it impacts the workflow and user perception of the ability to deliver cloud HPC capability – not in the compute, but in the pixel manipu-lation domain. Here is an example of the workflow:
1. Once the job finishes, the end user receives a notification email, the results files remain at the cloud facility – i.e. they are NOT transferred back to
Team 47:
heavy duty Abaqus Structural Analysis using hPC in the Cloud – round 2
“The major challenge – and now widely accepted to be the most critical – was the end user perception and acceptance of the cloud as a smooth part of the workflow.”
MEET THE TEAM

the end user’s workstation for post-processing2. The post-processing is done using remote desktop
tool – in this case NICE-Software DCV infrastructure layer on the HPC provider’s visualization node(s).
Typical network transfer sizes (upstream and down-stream) were expected to be modest, and it is this impact that we hoped to measure – thus making them “tunables”. This represented the major component of the end user ex-perience.
The team also expanded by almost 100%, to help bring in more expertise and support to tackle the last stage of the whole process and make the end user experience “adjust-able” depending on several network layer related factors.
ChAllenGeThe major challenge – and now widely accepted to be
the most critical – was the end user perception and accep-tance of the cloud as a smooth part of the workflow. Here remote visualization was necessary to see if the simula-tion results (left remotely in the cloud) could be viewed and manipulated as if it were local on the end user desktop. To contrast with Round 1, and to get real network expertise to bear on this aspect, NICE’s DCV was chosen to help deliver this, as it is:
• Application neutral• Has a clean and separate client (free) and server com-
ponent• Provided some tuning parameters which can help over-
come the bandwidth issuesSeveral tests were conducted and carefully iterated, such
as image update rate, bandwidth selection, codecs, etc. A screen shot is shown below for the final successful user acceptance of remote visualization settings:
The post processing underlying Infrastructure (cloud end):
The post processing underlying Infrastructure (end user space):
SetupWe made a number of end user trails. First the DCV was
installed with both a Windows and Linux client. Next a por-tal window was opened, usually at the same time as the end user trial to observe the demand on the serving infra-
Fig 1. - Typical end user screen manipulation(s)
TABle 1. CAST-in-PlACe meChAniCAl AnChor ConCreTe AnChorAGe PUlloUT CAPACiTY AnAlYSiS
(FeA STATS)
Materials Steel & Concrete
Procedure 3D Nonlinear Contact, Fracture & Damage Analysis
Number of Elements 1,626,338
Number of DOF 1,937,301
Solver ABAQUS/Explicit in Parallel
Solving Time 11.5 hours on a 32-core Linux Cluster
ODB Result File Size 2.9 GB
Fig 2. - DCV layer setup
Fig 3. - DCV enabled post processing (end user view)

structure (see diagram). This ensured that there was suf-ficient bandwidth and capacity at the cloud end .
The end node was hosting an NVIDIA graphics accelera-tor card. An initial concern was if the version was supported or had an impact. DCV has the ability to do a “sliding scale” of the pixel compression and this involves skipping certain frames in order to keep the flow smooth.
Figure 4 basically shows us that the cloud Internet measure-ments peaked out at 12 Mbits/sec, but generally hover at or below 8 Mbits for this particular session. This profile graph is a good representation of what has been seen in the past on DCV sessions. The red line (2 Mbits/sec) is where consistent end user experience for this particular graphic size was “observed.”
ConClUSionS And reCommendATionSHere is a summary of the key results found during our
Round 2 experiment: • End point Internet bandwidth variability: Depending on
when it is conducted, a vendor neutral test applet result ranges from 1Mbps ~ 10Mbps. The pipe Bandwidth was expected to be 20 Mbits/sec, but when it was shared by the office site using normal enterprise applications such as server Exchange, Citrix, etc., such variation was not conducive to a qualitative end user experience.
• Switching to another pipe (with burst mode of 50 to 100 Mbits/sec): More testing showed that the connection was not stable, and ABAQUS/Viewer graphics windows freeze was experienced after being idle for a while. This required local IT to troubleshooting the issue.
• There were no significant differences between Windows or Linux hosted platforms. The NICE DCV/EnginFrame is a good platform for remote visualization if a stable Internet BW is available. Some of the parameters for the connection performance:
o VNC connection line-speed estimate: 1 ~ 6 Mbps, RTT ~ 62 ms
o DCV bandwidth usage: AVG 100 KiB ~ 1 MiB o DCV Frame Rate: 0~10 FPS, >5 FPS acceptable,
>10 FPS smooth• We tried both Linux and Windows desktop. Because
of the BW randomness & variability, it was not possible create a good baseline to compare the performance of the two desktops.
• The graphics cards did not have any impact on the end user experience. However the model size and graphic image pixel size perhaps play a major role, and the cur-rent experiment did not have enough time to study and characterize this issue. The ABAQUS model used in this test case does not put much demand on the graphics card. We’ve seen only 2% usage on the card.
• There was usually sufficient network capacity and bandwidth at the cloud serving end.
• The “last mile” delivery or capability at the end user site was the most important and perhaps only determining factor in-fluencing the end user experience and perception.
• Beyond the cloud service provider, a local or end user IT support person with network savvy is perhaps a nec-essary part of the infrastructure team in order to deliver robust and repeatable post processing visual delivery. This incurs a cost.
• The security aspect could not be tested, as the time and effort required were not sufficient in the time allotted.
• Part of the end user experience learned from Round 1 was to better document the setup which can be found in the Appendix and clearly shows a smooth and easy to follow up flow.
major single conclusion and recommendationsAny site that wishes to benefit from this experience needs
to prioritize the “last mile” issue.
End User Experience Observations & Data Tables:
Bandwidth Usage
Note: Image Quality: Specify the quality level of dynamic images when using TCP connections. Higher values correspond to higher image quality and more data transfer. Lower values reduce quality and reduce bandwidth usage.
Network Latency for round trip from the DCV remote visualization serverPing statistics for 70.36.18.101: Packets: Sent = 4, Received = 3, Lost = 1 (25% loss), Approximate round trip times in milliseconds: Min = 56ms, Max = 58ms, Average = 56ms
Case Study Authors – Frank Ding, Matt Dunbar, Steve He-bert, Rob Sherrard and Sharan Kalwani.
Fig 4. - Ingress/egress test results/profile

USe CASeThe undesired blow-off of turbulent flames in combustion de-
vices can be a very serious safety hazard. Hence, it is of interest to study how flames blow off. Simulations offer an attractive way to do this. However, due to the multi-scale nature of turbulent flames, and the fact that the simulations are unsteady, these simulations required significant computer resources. This makes the use of large, remote computational resources extremely useful. In this project, a canonical test problem of a turbulent premixed flame is simulated with OpenFOAM and run in extremefactory.com.
Application software requirementsOpenFOAM can handle this problem very well. It can be
downloaded from: http://www.openfoam.org/download/
Custom code or configuration of end-userOpenFOAM input files are available at http://dl.dropbox.
com/u/103340324/3dCoarse_125.tar.gz. These files were used in a 3D simulation that ran OpenFOAM (reactingFOAM to be precise) in 40 cores. To get an idea of how to run these files, have a look at the section “Run in parallel” in: https://sites.google.com/site/estebandgj/openfoam-training
Computing resource requirementsAt least 40 cores.
ChAllenGeSThe current challenges for the end-user (with just his in-
house resources is that the computational resources need-ed for these simulations are significant (i.e. more than 100 cpus and 1-3 days of continuous running).
BeneFiTS
Remote clusters allow small companies to conduct simu-lations that were previously only possible for large compa-nies and government labs.
ConClUSionSRunning reactingFOAM for a simulation of a bluff-body-
stabilized premixed flame requires a mesh of less than 1/4 million cells. This is not much, but the simulations need to run for a long time, and are part of a parametric study that needs more than 100 combinations of parameters. Run-ning one or two huge simulations is not the goal here.
The web interface was easy to use – so much easier than running in Amazon’s EC2, that I did not even read the instruc-tions and was able to properly run OpenFOAM. Nonetheless, it was not very clear how to download all the data once the simulation ended. In addition the simulation ran satisfactorily. There were some errors at the end, but these were expected.
The team has one suggestion: A key advantage of using OpenFOAM is that it allows us to tailor OpenFOAM appli-cations to different problems. This requires making some changes in the code and compiling with wmake, something that can be done in Amazon’s EC2. It is not clear how this can this be done with the present interface. A future test might be to run myReactingFOAM instead of reactingFOAM.
Case Study Author - Ferry Tap
Team 52:
high-resolution Computer Simulations of Blow-off in Combustion Systems
“Remote clusters allow small companies to conduct simulations that were previously only possible for large companies and government labs.”
MEET THE TEAM
Fig. 1 - Schematic of the bluff-body flame holder experiment. Sketch of the Volvo case: A premixed mixture of air and propane enters the left of a plane rectangular channel. A triangular cylinder is located at the center of the channel and serves as a flame holder.
Fig. 2 - Predicted temperature contours field for the Volvo case using OpenFOAM.

USe CASeProblem description
The end-user developed a parallel MPI solver for Navier-Stokes equation. With this solver, the end-user can simulate the flow in a microchannel with an obstacle for a single configuration of the fluid speed, the micro-channel size and the obstacle geom-etry (see Figure 1). A single simulation typically requires hundreds of CPU-hours.
The end-user sought to construct a phase diagram of possible fluid flow behav-iors to understand how input parameters affect the flow. Additionally, the end-user wanted to create a library of fluid flow patterns to enable analysis of their combi-nations. The problem has many significant applications in the context of medical diagnostics, bio-medical engineering, constructing structured materials, etc.
ChAllenGeSThe problem was challenging for the end-user as it required thousands of
MPI-based simulations, which collectively exceeded computational throughput offered by any individual HPC machine. Although the end-user had access to several high-end HPC resources, executing thousands of simulations requires complex coordination and fault-tolerance, which were not readily available. Fi-
Team 53:
Understanding Fluid Flow in microchannels
“…the experiment serves as a proof of concept of applying a user-oriented computational federation to solve large-scale computational problems in engineering.”
MEET THE TEAM
TEAM MEMBERS
Fig. 1 - Example flow in a microchannel with a pillar. Four variables characterize the simulation: chan-nel height, pillar location, pillar diameter, and Reynolds number.

nally, simulations are highly heterogeneous, and their com-putational requirements were hard to estimate a priori, add-ing another layer of complexity.
The SolutionTo tackle the problem, the team decided to use multiple
federated heterogeneous HPC resources. The team pro-ceeded in four stages:
1. Preparatory phase in which HPC experts gained un-derstanding of the domain problem, and formulated a de-tailed plan to solve it – this phase included face-to-face meeting between the end-user and HPC experts
2. Software-hardware deployment stage in which HPC experts deployed the end-user’s software, and imple-mented required integration components. Here, minimal or no interaction with systems administrators was required, thanks to the flexibility of the CometCloud platform used in the experiment
3. Computational phase in which the actual simulations were executed
4. Data analysis in which the output of simulations was summarized and postprocessed by the end-user.
The developed approach is based on the federation of distributed heterogeneous HPC resources aggregated completely in a user-space. Each aggregated resource acts as a worker executing simulations. However, each resource can join or leave the federation at any point of time without interrupting the overall progress of the computations.
Each aggregated resource acts as a temporal storage for the output data as well. The data is compressed on-the-fly, and transferred using the RSYNC protocol to the central re-pository for simple, sequential postprocessing. In general, the computational platform used in this experiment takes the concept of volunteer computing to the next level, in which desktops are replaced with HPC resources. As a re-sult the end-user’s application gains cloud-like capabilities. In addition to solving an important and urgent problem for the end-user, the experiment serves as a proof of concept of applying a user-oriented computational federation to solve large-scale computational problems in engineering.
ConClUSionS And reCommendATionSSeveral observations emerged from the experiment:• Good understanding of the domain specific details by
the HPC experts was important to the fluent progress of the experiment.
• Close collaboration with the end-user, including face-to-face meetings, was critical for the entire process.
• Although it may at first seem counterintuitive, working within limits set by different HPC centers – i.e. using only SSH access without special privileges – greatly simplified the development process.
• At the same time, maintaining “friendly” relationship with respective systems administrators helped to shorten response time to address common operational issues.
General Challenges and Benefits of Using UberCloud• The main difficulty was to obtain a sufficient num-
ber of HPC resources that collectively would provide throughput needed to solve the end-users’ problem. This challenge was solved by interacting with several HPC centers, and then exploiting elasticity offered by CometCloud to add extra resources during the experi-ment. For example, several machines were federated after the experiment was already running for five days.
• UberCloud greatly simplified the process of obtaining computational resources. The ability to quickly contact various HPC providers was central to the success of the experiment.
• UberCloud provided a well-structured and organized envi-ronment to test new approaches for solving large-scale sci-entific and engineering problems. Following well planned steps with clearly defined deadlines, as well as having a central message-board and documents repository, greatly simplified and accelerated the development process.
experiment highlightsThe main highlights of the experiment are summarized below:• 10 different HPC resources from 3 countries federated
using CometCloud• 16 days, 12 hours, 59 minutes and 28 seconds of con-
tinuous execution• 12,845 MPI-based flow simulations executed• 2,897,390 core-hours consumed• 400 GB of output data generated• The most comprehensive data to date on the effect of
pillars on microfluid channel flow gathered.
Case Study Authors - Javier Diaz-Montes, Baskar Ganap-athysubramanian, Manish Parashar, Ivan Rodero, Yu Xie, and Jaroslaw Zola.
AcknowledgmentsThis work is supported in part by the National Science Foundation (NSF)
via grants number IIP-0758566 and DMS-0835436 (RDI2 group), and CA-REER-1149365 and PHY-0941576 (Iowa State group). This project used resources provided by: the Extreme Science and Engineering Discovery Environment (XSEDE), which is supported by the NSF grant number OCI-1053575, FutureGrid, which is supported in part by the NSF grant number OCI- 0910812, and the National Energy Research Scientific Computing Cen-ter, which is supported by the Office of Science of the U.S. Department of Energy (DOE) under the contract number DE-AC02-05CH11231.
The authors would like to thank the SciCom research group at the Univer-sidad de Castillala Mancha, Spain (UCLM) for providing access to Hermes, and Distributed Computing research group at the Institute of High Perfor-mance Computing, Singapore (IHPC) for providing access to Libra. The au-thors would like to acknowledge the Consorzio Interuniversitario del Nord est Italiano Per il Calcolo Automatico, Italy (CINECA), Leibniz-Rechenzentrum, Germany (LRZ), Centro de Supercomputacion de Galicia, Spain (CESGA), and the National Institute for Computational Sciences (NICS) for willing to share their computational resources. The authors would like to thank Dr. Olga Wodo for discussion and help with development of the simulation soft-ware, and Dr. Dino DiCarlo for discussions about the problem definition.
The authors express gratitude to all administrators of systems used in this experiment, especially to Prentice Bisbal from RDI2 and Koji Tanaka from FutureGrid, for their efforts to minimize downtime of computational resourc-es, and a general support. The authors are grateful to Wolfgang Gentzsch and Burak Yenier for their overall support.

USe CASeMany areas in the world have no available fresh water
even though they are located in coastal areas. As a result, in recent years a completely new industry has been created to treat seawater and transform it into tap water. This wa-ter transformation requires that the water must be pumped into special equipment, which is very sensitive to cavitation. Therefore, a correct and precise water flow intake must be forecasted before building the installation.
The CFD analysis of air-water applications using free sur-faces modeling is a highly complex modelization. The com-putational mesh must correctly capture the fluid interface and the number of iterations required to obtain physically and numerically converged solution is very high. If both previous requirements are not matched, the forecasted so-lution will not even be close to the real world solution.
ChAllenGeSThe end-user needed to obtain a physical solution in a
short period of time as the time to analyze the current de-sign stage was limited. The time limitation mandated the use of remote HPC resources to meet the customer’s time requirements. As usual the main problem was the result data transfer between the end-user and the HPC resourc-es. To overcome this problem, the end-user used the visu-alization software Ensight to look at the solution and obtain images and animations completely through the Internet.
The table below provides an evaluation of the Gompute on demand solution:
remote visualizationThe end user categorized the Gompute VNC-based solu-
tion as excellent. It is possible to request a graphically accelerated node
when starting your programs with a GUI. This functionality substantially cuts virtual prototyping lead time, since all the data generated from a CAE simulation can be simulated directly in Gompute. Also, this omits time consuming data transfers and increases data security by removing the need to have multiple copies of the same data at different loca-tions – sometimes on insecure workstations.
Gompute accelerators allows the use of the desktop over links with latency over 300 ms. This allows Gompute resources
Team 54:
Analysis of a Pool in a desalinization Plant
“The bottleneck in all CAE simulations using commercial software is the cost of the commercial CFD licenses.”
MEET THE TEAM

to be used by locations separated by as much as 160 degrees longitude – i. e., the user may be in India and the cluster in De-troit. Collaborative workflow is allowed by the Gompute remote desktop sharing option so two users at different geographical locations can work together on the same simulation.
ease of UseGompute on demand provide a ready-to-use environ-
ment with an integrated repository of the applications re-quested, license connection, and queuing system based on SGE.
In order to establish the connection to the cluster, you just open ports 22 and 443 on the company’s firewall. Down-loading Gompute explorer and opening a remote desktop allows you to have the same user experience as working with your own in house machine. Compared to other tested HPC connection modes, Gompute connections were easy to setup and use. The connection allowed connecting and disconnecting to the HPC account to check how the calcu-lations were progressing.
As to costs, the Gompute quotation clearly described the services provided. Also, the technical support from Gom-pute personal was good
BeneFiTS• Compute remotely• Pre/post-process remotely• Gompute can be used as an extension of in-house re-
sources• Able to burst into Gompute On-Demand from an in-
house cluster
• Accelerated file transfers• Possible to have exclusive desktops• Support for multiple users on each graphics node• Applications integrated and ready to use• GPFS storage available• Handles high latency links between the user and the
Gompute cluster• Facilitates collaboration with clients and support
ConClUSionS And reCommendATionSThe bottleneck using commercial software in CAE is the
cost of the commercial CFD licenses. There were two lessons learned:• ANSYS has no CFD on demand license to use the
maximum number of available cores in a system while competitor software, such as Star-CCM+, already has such a license.
• Supercomputing centers must provide analysis/post-processing tools for customers to check results without the need to download result files – otherwise, many of the advantages of using cloud computing are lost be-cause of long data file transfer times.
• The future for the wider use of supercomputing centers is to find a way to have commercial CAE (CFD and FEA) licenses on demand in order to pay for the actual soft-ware usage. Commercial software must take full ad-vantage of current and future hardware developments for the wider spread of virtual engineering tools.
Case Study Authors – Juan Enriquez Paraled, Manager of ANALISIS-DSC; Ramon Diaz, Gompute

USe CASeFor the end user the aim of the ex-
ercise was to evaluate the HPC cloud service without the need to obtain new engineering insights. That’s why a relatively basic test case was cho-sen – a case for which they already had results from the end user’s own cluster, and which had a minimum of confidential content. The test case was the simulation of the perfor-mance of an axial fan in a duct similar to those found in the AMCA standard. A single ANSYS Fluent run simulated the performance of a fan under 10 dif-ferent conditions to reconstruct the fan curve. The mesh consisted of 12 million tetrahedral cells and was suit-ed to test parallel scalability.
ChAllenGeSThe main reason to look to HPC in
the cloud is cost. The end user has a highly fluctuating load with regard to simulations. This means that their current on-site cluster rarely has the correct capacity. When it is too large, they are paying too much for hard-ware and licences; and when it is too small they are losing money because the design teams are waiting for the results. With a flexible HPC solution in the cloud the end user can theoreti-cally avoid both costs.
evaluationHPC as a service will only be an al-
ternative to the current on-site solu-tion if it manages to meet a series of
well-defined criteria as set by the end user.
Team 56:
Simulating radial and Axial Fan Performance
“The main reason to look to HPC in the cloud is cost.”
MEET THE TEAM
Criteria local hPC ideal cloud Actual cloud Pass/Fail hPC hPCUpload speed 11.5 MB/s 2 MB/s 0.2 MB/s FailDownload speed 11.5 MB/s 2 MB/s 4-5 MB/s PassGraphical output possible possible inconvenient FailQuality of the excellent excellent good PassimageRefresh rate excellent excellent good PassLatency excellent excellent good PassCommand possible possible possible Passline accessOutput file possible possible possible PassaccessRun on the easy easy easy Passreserved clusterRun on the on N/A easy easy Passdemand clusterGraphical node excellent excellent good PassUsing UDF’s possible possible possible Passon the clusterState of the reasonable good good Passart hardware Scalability poor excellent excellent PassSecurity excellent excellent good PassHardware cost good excellent N/A N/ALicense cost good excellent N/A N/A
Table 1 - Evaluation results

Cluster AccessGridcore allows you to connect to its clusters through
the GomputeXplorer. This is a Java-based program that lets you monitor your jobs and launch virtual desktops. Es-tablishing the connection was actually not that easy. If the standard SSH and SSL ports (22 and 443) are open in your companies firewall then connecting is straightforward. This is however rarely the case.
Alternatively you can make your connection with the use of a VPN. Both options require that the end user make changes to the firewall. Because the end user had to wait a long time for these changes to be implemented, valuable time was lost. Only the port changes were implemented. So the VPN option was never tested.
Transfer SpeedInput files, and certainly result files, for typical calcula-
tions range from a couple of hundreds of megabytes to a couple of gigabytes in size. Therefore a good transfer speed is of vital importance. The target is a minimum of 2 MB/s for both upload and download. This means that it is theoreti-cally possible to transfer 1GB of data in 8.5 minutes.
When transferring files with the GomputeXplorer, upload speeds of 0.2MB/s and download speeds of about 4-5MB/s were measured. When transferring the files with a regular SSH client the upload speed was 1.7 MB/s and the download speed 0.9 MB/s. These speeds were measured during trans-ferring the same files several times. The tests were performed one after the other to ensure a fair comparison. These mea-surements show that theoretically reasonable to good transfer speeds are possible, but so far no solution was found to get the GomputeXplorer’s upload speed up to par.
As noted by resource provider, most clients get their speed depending on the bandwidth, and the low numbers measured are quite abnormal. Several tests were performed in the system seeking the root cause of the issue, but none was found. The investigations would have continued until the solution was found, but not within the time frame of the experiment. It might be more practical to wait for a new file transfer tool that is planned to be rolled out shortly by Gompute and might resolve this issue.
Graphical output in batchTo see how the flow develops over time, it is common
practice to output some images from the flow field. Flu-ent cannot do this with just a command line but requires an X-window to render to. The end user was not able to make this option work on the Gompute cluster within the allocated timeframe. Several suggestions (mainly different command line arguments) have been put forward to resolve this issue.
remote visualizationThe end user used the HP Remote Graphics Software
package that gave a like local experience. If we categorise HP RGS as excellent, the VNC based solution of Gompute
can surely be categorized as good. There was a noticeable difference between the dedicated cluster and the on-de-mand one with regard to the quality of the remote visualisa-tion (these are both remote Gompute clusters – the dedi-cated one was specifically reserved for the end user). The dedicated clusters render quality and latency was much better. It is entirely possible to do pre- and post-processing on the cluster. It is also possible to request a graphically accelerated node when starting your programs with a GUI.
ease of useThe Gompute remote cluster uses the same queuing sys-
tem (SGE) as the end user’s cluster so the commands are familiar. The fact that you can request a full virtual desktop makes using the system a breeze. This virtual desktop al-lows for easy compilation of the UDF’s (C-code to extend the capabilities of Fluent) on the architecture of the remote cluster. Submitting and monitoring jobs is just as easy as on the local cluster. The process is also identical on the dedicated and the on-demand cluster. Apart from the bill-ing method, there is no additional overhead when you tem-porarily want to expand your simulation capacity by using the on-demand cluster.
hardwareThe hardware that was made available to the end user
was less than two years old (Westmere Xeon’s). This was considered to be good. Sandy Bridge-based Xeon’s would have been considered excellent. The test case was used to benchmark the Gompute cluster against the end user’s own aging cluster.
The time it took to run the simulation on 16 cores of the local cluster is the reference where the speedup is defined relative to this time. The blue curve represents the old, lo-cal cluster and the red curve the on-demand cluster from Gompute. The green point is from a run on a workstation that has a similar hardware configuration as the cluster from Gompute but runs Windows instead of Linux.
The following points can be concluded from this graph:• The old cluster isn’t performing all that badly consid-
Fig. 1 - Comparison of run times of the test case.

ering its age. Either that or a larger speedup was ex-pected from the new hardware.
• The simulation scales nicely on the Gompute cluster, but not as well on the local cluster.
• The performance of the workstation is similar to that of the Gompute cluster.
CostThe resource provider only provides hardware; the cus-
tomer is still responsible for acquiring necessary software licenses. The cost benefit is therefore limited to hardware and support.
The most likely customer base for the On Demand Clus-ter service are companies that either rarely do a simula-tion or occasionally need extra capacity. In both cases they would have to pay for a set of licenses that are rarely used. It doesn’t seem to be a very good solution and may be-come a showstopper for adopting the HPC in the cloud. Hopefully, ANSYS will come up with a license model that would enable a service that is more in line with HPC in the cloud.
BeneFiTS
end User• Ease of use.• Post- and pre-processing can be done remotely.• Excellent opportunity to test the state of the art in cloud
based HPC.
ConClUSionS And reCommendATionS• HPC in the cloud is technically feasible. Most remain-
ing issues are implementation related that the resource provider should be able to solve.
• The remote visualisation solution was good and allowed the user to actually perform some real work. Of course, it remains to be seen if a stress test with multiple users from the same company yields the same results.
• The value of the HPC in the cloud solution is limited by the absence of appropriate license models from the software vendors that would allow Gompute to actu-ally sell simulation time and not just hardware and sup-port.
• Further rounds of this experiment can be used to anal-yse the abnormal uploading speed. File transfer might be tested using the VPN connection to guarantee no restrictions from the company’s firewall. Also of interest is the testing of the new release of Gompute file trans-fer tool, which implements a transferring accelerator.
• Different graphical node configurations can be tested to enhance the user experience.
Case Study Authors – Wim Slagter, Ramon Diaz, Oleh Khoma, and Dennis Nagy.
Note: The illustration on top of this report shows pressure contours in front/behind a 6-bladed axial fan.

USe CASeThe CAPRI to OpenFOAM Connec-
tor and the Sabalcore HPC Computing Cloud infrastructure were used to ana-lyze the airflow around bicycle design iterations from Trek Bicycle. The goal was to establish a great synergy be-tween iterative CAD design, CFD anal-ysis, and HPC cloud environments.
Trek has been heavily invested in engi-neering R&D, and does extensive proto-typing before producing a final produc-tion design. CAE has been an integral part of design process in accelerating the pace of R&D and rapidly increasing the number of design iterations. Ad-vanced CAE capabilities have helped Trek reduce cost and keep up with the demanding product development time necessary to stay competitive.
Automating iterative design chang-es in Computer Aided Design (CAD) models coupled with Computational Fluid Dynamics (CFD) simulations can significantly enhance the produc-tivity of engineers and enable them to make better decisions in order to achieve optimal product designs. Us-ing a cloud-based or On-Demand so-lution to meet the HPC requirements of computationally intensive applica-tions decreases the turn-around time in iterative design scenarios and re-duces the overall cost of the design.
With most of the software available
today, the process of importing CAD models into CAE tools, and executing a simulation workflow requires years of ex-perience and remains, for the most part, a human-intensive task. Coupling paramet-ric CAD systems with analysis tools to ensure reliable automation also presents significant interoperability challenges.
The upfront and ongoing costs of pur-chasing a high performance computing system are often underestimated. As most companies’ HPC needs fluctuate, it’s difficult to adequately size a system. Inevitably, this means resources will be idle for many hours and, at other times, will be inadequate for a project’s re-quirements. In addition, as servers age and more advanced hardware becomes available, companies may recognize a performance gap between themselves and their competitors.
Beyond the price of the hardware itself, a large computer cluster de-mands specialized power resources, consumes vast amounts of electrical power, and requires specialized cool-ing systems, valuable floor space and experienced experts to maintain and manage them. Using a HPC provider in the cloud overcomes these challenges in a cost effective, pay-per-use model.
experiment development The experiment was defined as an
iterative analysis of the performance
of a bike. Mio Suzuki at Trek, the end user, supplied the CAD model. The analysis was performed on two Sa-balcore provided cluster accounts.
The CADNexus CFD connector, an iterative preprocessor, was used to generate OpenFOAM cases using the SolidWorks CAD model as geom-etry. A custom version of the CAPRI-CAE interface, in the form of an Excel spreadsheet, was delivered to the end user by the team expert Mihai Pruna, who represented the Software Provid-er, CADNexus.
Team 58:
Simulating Wind Tunnel Flow Around Bicycle and rider
“Being able to quickly adapt a solution to a certain environment is a key competitiveness factor in the cloud-based CAE arena.”
MEET THE TEAM
Fig. 1 - Setting up the CAD model for tessellation

The CAPRI-CAE interface was modified to allow for the de-ployment and execution of OpenFOAM® cases on Sabalcore cluster machines. Mihai Pruna also ran test simulations and pro-vided advice in setting up the CAD model for tessellation, that is, the generation of an STL file suitable for meshing (Figure 1).
The cluster environment was set up by Kevin Van Workum with Sabalcore, allowing for rapid and frequent access to the cluster accounts via SSH as needed by the automation involved in copying and executing the OpenFOAM cases.
The provided bicycle was tested at two speeds: 10 and 15 mph. The CADNexus CFD connector was used to generate cutting planes and wake velocity linear plots. In addition, the full simula-tion results were archived and provided to the end user for review using ParaView, a free tool (see the figure on top of this report).
ParaView or other graphical post-processing applications can also be run directly on Sabalcore using their acceler-ated Remote Graphical Display capability.
Thanks to the modular design of the CAPRI powered OpenFOAM Connector and the flexible environment pro-vided by Sabalcore Computing, integration of the software and HPC provider resources was quite simple.
ChAllenGeSGeneral
Considering the interoperability required between several technologies, the set up went fairly smoothly. The CAPRI-CAE interface had to be modified to work with an HPC cluster. The production version was designed to work with discrete local or cloud based Ubuntu Linux machines. For the cluster environment, some programmatically generated scripts had to be changed to send jobs to a solver queue rather than execute the OpenFOAM utilities directly.
The CAD model was not a native SolidWorks project but rather a series of imported bodies, and surfaces exhibit-ed topological errors that were picked up by the CAPRI middleware. Defeaturing in SolidWorks, as well as turning off certain consistency checks in CAPRI, helped alleviate these issues and produce quality tessellations.
data Transfer issuesSometimes, a certain OpenFOAM dictionary would fail to
copy to the client, causing the OpenFOAM scripts to fail. This issue has not been resolved at this time, but it seems to occur only with large geometry files, although it is not the geometry file that fails to copy. Possible solutions include zipping up each case and sending it as a single file.
Retrieving the full results can take a long time. Solutions already developed involve doing some of the post process-ing on the client and retrieving only simulation results data specified by the user, as implemented by CADNexus in the Excel based CAPRI-CAE interface (2), or running ParaView directly on the cluster, as implemented by Sabalcore.
end User’s PerspectiveCapri is a fantastic tool to connect the end user desktop en-
vironment directly to a remote cluster. As an end user, the first
challenge I faced was thoroughly understanding the format-ting of the Excel sheet. As soon as I was able to identify what was wrong with my Excel entries, the rest of the workflow went relatively smoothly and as exactly specified in the templates’ workflow. I also experienced slowness in building up the cases and running the cases. If there is a way to increase the speed at each step (synchronizing the CAD, generating cases on the server, and running), that would enhance the user experience.
BeneFiTSThe CAPRI-CAE Connector and the CAPRI-FOAM con-
nector dramatically simplify the generation of design-anal-ysis iterations. The user has a lot fewer inputs to fill in, and the rest are generated automatically. The end user does not need to be proficient in OpenFOAM or Linux.
With respect to the HPC resource provider, the environ-ment provided to the user by Sabalcore was already setup to run OpenFOAM, which helped speedup the process of integrating the CADNexus OpenFOAM connector with Sabalcore’s services. The only required modification to the HPC environment made by Sabalcore was to allow a greater than normal number of SSH connections from the user, which was required by the software. With Sabalcore’s flexible environment, these changes were easily realized.
ConClUSionS And reCommendATionSAmong the lessons learned in the course of this project were:• Being able to quickly adapt a solution to a certain en-
vironment is a key competitiveness factor in the cloud-based CAE arena.
• A modular approach when developing your CAE solu-tion for HPC / cloud deployment helps speed up the process of adapting your solution to a new provider.
• Selecting an HPC resource provider that has a flexible environ-ment is also vital to quickly deploying a custom CAE solution.
From an end user perspective, we observed that each cluster provider has a unique way of bringing the cloud HPC option to the end user. Many of them seem to be very flexible with respect to the services and interface they provide based on the user’s prefer-ence. When choosing a cloud cluster service, we suggest that a CAE engineer investigate and select the service that is most suit-able for the organization’s particular engineering needs.
Case Study Authors – Mihai Pruna, Mio Suzuki, and Kevin Van Workum.
Figure 2: Z=0 Velocity Color Plot Generated with CADNexus Visualizer Lightweight Postprocessor

Thank you for your interest in the free and voluntary UberCloud HPC Experiment.
If you, or your organization would like to participate in this Experiment to explore hands-on the end-to-end process of HPC as a Service for your business then please register at:
http://www.hpcexperiment.com/why-participate
If you are interested in promoting your service/product at the UberCloud Exhibit then please register at
http://www.exhibit.hpcexperiment.com/