the promise of universal scale - qumulo · the promise of universal scale file storage at ... small...
TRANSCRIPT

The Promise ofUniversal ScaleFILE STORAGE AT THE CROSSROADS

Contents
Executive summary 1
A perfect storm 1
Universal-scale file storage 3
Rethinking the file storage industry 5
The limitations of on-premises storage appliances 5
Inadequacy of cloud-based file solutions 5
Qumulo File Fabric (QF2) 6
How QF2 works 14
The QF2 file system 15
Real-time quotas 15
Snapshots 15
Continuous replication 16
Scalable Block Store (SBS) 16
Object and file storage 17
Conclusion 18
Copyright © Qumulo, Inc., 2017. All rights reserved. 10/2017

1
Executive summaryLarge-scale file storage has reached a tipping point. The amount of file-based data has been growing steadily, and its growth has accelerated to the point that companies wonder how they will be able to manage the ever-increasing scale of digital assets. In addition, elastic resources and global reach of the public cloud are creating new demand for the mobility of file-based data.
As a result, new requirements for file-based storage are emerging. The new requirements point to the need for a universal-scale file storage system. For example, such a system has no upper limit on the number of files it can manage no matter their size, and it can run anywhere, whether on-premises or in the cloud.
Qumulo File Fabric (QF2) is a modern, highly scalable file storage system that spans the data center and the public cloud. It scales to billions of files, costs less and has lower TCO than legacy storage appliances. It is also the highest performance file storage system on premises and in the cloud. Real-time analytics let administrators easily manage data no matter how large the footprint or where it’s located globally. QF2’s continuous replication enables data to move where it’s needed when it’s needed, for example, between onpremises clusters and clusters running in the cloud.
QF2 runs on industry-standard hardware and was designed from the ground up to meet all of today’s requirements for scale. QF2 is the world’s first universal-scale file storage system, allowing the modern enterprise to easily represent and manage file sets numbering in the billions of files, in any operating environment, anywhere in the world.
A perfect stormIDC predicts that the amount of data created will reach 40 zettabytes (a zettabyte is a billion terabytes) by 2020, and that there will be more than 163 zettabytes by 2025. This is ten times the data generated in 2016.1 Approximately 90% of this growth will be for file and object storage.
Machine-generated data, virtually all of which is file based, is one of the primary factors behind the dramatic acceleration of data growth. Life sciences researchers developing the
latest medical breakthroughs use vast amounts of file data for genome sequences and share that data with colleagues around the world; oil and gas companies’ greatest assets are their file-based seismic data used for natural gas and oil discovery; every movie and
television program we watch is increasingly produced on computers and stored as files. Text-based log files—data about machines, created by machines—have proliferated to the point of becoming big data.
1. http://www.seagate.com/files/www-content/our-story/trends/files/Seagate-WP-DataAge2025-March-2017.pdf
One drop of human blood creates enough data to fill an entire laptop computer, and some
research projects require a million drops.

THE PROMISE OF UNIVERSAL SCALE 2
There is also a trend toward higher resolution digital assets. Uncompressed 4K video is the new standard in media and entertainment. The resolution of digital sensors and scientific equipment is constantly increasing. Higher resolution causes file sizes to grow more than linearly. A doubling of the resolution of a digital photograph increases its size by four times. As the world demands more fidelity from digital assets, its storage requirements grow.
At the same time, there have been huge advances in data analysis and machine learning over the past decade. These advances have suddenly made data more valuable over time rather than less. Scrambling to adapt to the new landscape of possibilities, businesses are forced into a “better to keep it than miss it later” philosophy.
The trend toward massive data footprints and the development of sophisticated analytical tools were paralleled by the advent of the public cloud. Its arrival overturned many basic assumptions about how storage should work.
The cloud meant that elastic compute resources and global reach were now achievable without building data centers across the world. Consequently, new ways of working have arrived and are here to stay. All businesses realize that, in the future, they will no longer be running their workloads out of single, selfmanaged data centers. Instead, they will be moving to multiple data centers, with one or more in the public cloud. This flexibility will help them adapt to a world with distributed employees and business partners. Companies will focus their resources on their core lines of business instead of IT expenditures. Most will improve their disaster recovery and business continuity plans, and many will do this by taking advantage of the elasticity provided by the cloud.
All these conditions have come together to form a perfect storm of storage disruption that existing largescale file systems will find hard to weather.
Users of legacy scale-up and scale-out file systems, the work horses of file-based data, find that those systems are inadequate for a future dominated by big data. A core part of the problem is that the metadata of large file systems—their directory structures and file attributes—have themselves become big data. All existing solutions rely on brute force to give insight into the storage system, and brute force has been defeated by scale. For example, tree walks, the sequential processes that scan nested directories as part of routine manage-ment tasks, have become computationally infeasible. Brute force methods are fundamental to the way legacy file systems are designed and cannot be fixed with patches.
Against this backdrop of profound change, users of file storage still need to maintain and safely manage large-scale, complex workflows that rely on collaborations between many distinct computer programs and humans. Moreover, the traditional buying criteria of price, performance, ease-of-use and reliability remain as important as ever, no matter how much the landscape has changed.
Storage is at the crossroads, and the new problems must be faced. Until that happens, users of large-scale file storage will continue to struggle to understand what is going on inside their systems. They will struggle to cope with massive amounts of data. They will struggle to meet the demands for global reach, with few good options for file-based data that spans the data center and the public cloud.

THE PROMISE OF UNIVERSAL SCALE 3
Universal-scale file stor ageTraditionally, companies faced two problems in deploying file-based storage systems: they needed to scale both capacity and performance. In the world of big data, scale is no longer limited to these two axes. New criteria for scale have emerged. They include number of files stored, the ability to control enormous data footprints in real time, global distribution
of data, and the flexibility to leverage elastic compute in the public cloud in a way that spans the data center as well. These requirements define a new market category called universal-scale file storage.
Universal-scale file storage scales to billions of files. The notion that capacity is only measured in terms of bytes of raw storage is giving way to a broader understanding that capacity is just as often defined by the number of digital assets that can be stored. Modern file-based workflows include a mix of large and small files, especially if they involve any amount of machine-generated data. As legacy file systems reach the limits in the number of digital assets they can effectively store, buyers can no longer assume that they will have adequate file capacity.
Today, capacity means more than terabytes of raw storage.

THE PROMISE OF UNIVERSAL SCALE 4
Universal-scale file storage scales across operating environments, including public cloud. Proprietary hardware is increasingly a dead end for users of large-scale file storage. Today’s businesses need flexibility and choice. They want to store files in data centers and in the public cloud, opting for one or the other based on business decisions only and not technical limitations of their storage platform.
Companies want to benefit from the rapid technical and economic advances of standard hardware, such as denser drives and lower-cost components. They want to reduce the complexity of hardware maintenance through standardization and streamlined configura-tions. The trend of smart software on standard hardware outpacing proprietary hardware will only increase. Users of large-scale file storage require their storage systems to run on a variety of operating environments and not be tied to proprietary hardware.
Universal-scale file storage scales across geographic locations with data mobility. Businesses are increasingly global. Their file-based storage systems must now scale across geographic locations. This may involve multiple data centers, and almost certainly the public cloud. A piecemeal approach and a label that says “Cloud Ready” won’t work. True mobility and geographic reach are now required.
Universal-scale file storage provides real-time visibility and control. As collections of digital assets have grown to billion-file scale, the ability to control storage resources in real time has become an urgent new requirement. Storage administrators must be able to monitor all aspects of performance and capacity, regardless of the size of the storage system.
Universal-scale file storage gives access to rapid innovation. Modern file storage needs a simple, elegant design and advanced engineering. Companies who develop universal-scale file storage will use Agile development processes that emphasize rapid release cycles and continual access to innovation. Threeyear update cycles, a result of cumbersome “waterfall” development processes, are a relic of the past that customers can no longer tolerate.
Universal-scale file storage enables elastic consumption of file storage. As the needs of lines of business surpass what central IT can provide in a reasonable time frame, access to elastic compute resources has become a requirement. A flexible, on-demand usage model is a hallmark of the public cloud. However, the shift to cloud has stranded users of large-scale file storage, who have no effective way to harness the power the cloud offers.

THE PROMISE OF UNIVERSAL SCALE 5
Rethinking the file stor age industryLegacy scale-up and scale-out file systems are not capable of meeting the emerging require-ments of universal scale. The engineers who designed them 20 years ago never anticipated the number of files and directories, and mixed file sizes, that characterize modern work-loads. They could also not foresee cloud computing.
The Limitations Of On-Premises Storage AppliancesCustomers tell us they’re in a scalability crisis as the rapid growth of their file-based data footprint exceeds the fundamental design assumptions of existing storage appliances. These solutions are difficult to install, difficult to maintain, and inefficient. Putting in one of these systems is usually a service engagement that can take a week, assuming the person doing the installation is experienced. These systems have many inherent limitations, such as volume sizes and the number of inodes, which interact and make it challenging to avoid bottlenecks.
Legacy systems are expensive, and their inefficiency adds even more to their cost. Generally, only 70% to 80% of the provisioned storage capacity is actually available. Performance suffers if the disk gets any fuller. Another problem is that legacy systems were not designed for the higher drive densities that are now available. Rebuild times in the event of a failed disk can stretch into days.
Finally, there is no visibility into the data. Getting information about how the system is being used is clumsy and slow. It can take so long to get the information that it is outdated even before the administrator sees it.
Inadequacy of cloud-based file solutionsWhile there is tremendous demand for running file-based workloads in the cloud, existing solutions for file in the public cloud are inadequate. These solutions are either sold by the
cloud providers themselves or by legacy storage vendors. In the first case, the solutions are imma-ture. In the second, they apply 1990s technology to 21st century problems.
There are no mature products among existing cloud-based file solutions.

THE PROMISE OF UNIVERSAL SCALE 6
For example, cloud-only file systems are limited by the fact that they don’t connect with a company’s onpremises data footprint in any way. Further, they lack important enterprise features, such as support for the Server Message Block (SMB) protocol, quotas, snapshots and replication, that are needed for modern filebased workflows in data-intensive industries.
The efforts of legacy storage appliance vendors to pivot to the cloud have resulted in solutions with limited capacity and no scalable performance. This inflexibility negates the opportunities for elastic resources that are the very reason people are turning to the cloud.
Gateway products are an alternative to cloud and legacy vendor solutions. These facilitate the connection between on-premises file storage and cloud compute instances, but they don’t store files where they are needed, especially for long-lived workloads.
None of the solutions provide visibility and control of the data footprint in the cloud, which leads to overprovisioning of capacity, performance or both. In general, current solutions for file storage in the cloud are piecemeal approaches that address only parts of the problem. Customers are stranded in their attempts to integrate file-based workloads with the cloud.
Qumulo File Fabric (QF2)Qumulo was founded in 2012, as the crisis in file storage was beginning to reach its tipping point. A group of storage pioneers, the inventors of scale-out NAS, joined forces and formed a different kind of storage company, one that would meet the new requirements head on.
The result of their work and of the team they assembled is Qumulo File Fabric (QF2), the world’s first universal-scale file storage system.
QF2 is a modern, highly scalable file storage system that spans the data center and the public cloud. It scales to billions of files, costs less and has lower TCO than legacy storage appliances. It is also the highest performance file storage system
on premises and in the cloud. Real-time analytics let administrators easily manage data no matter how large the footprint or where it’s located globally. QF2’s continuous replication enables data to move where it’s needed when it’s needed, for example, between on-premises clusters and clusters running in the cloud.
Qumulo File Fabric (QF2) is a modern, highly scalable filestorage system
that spans the data center and the public cloud.
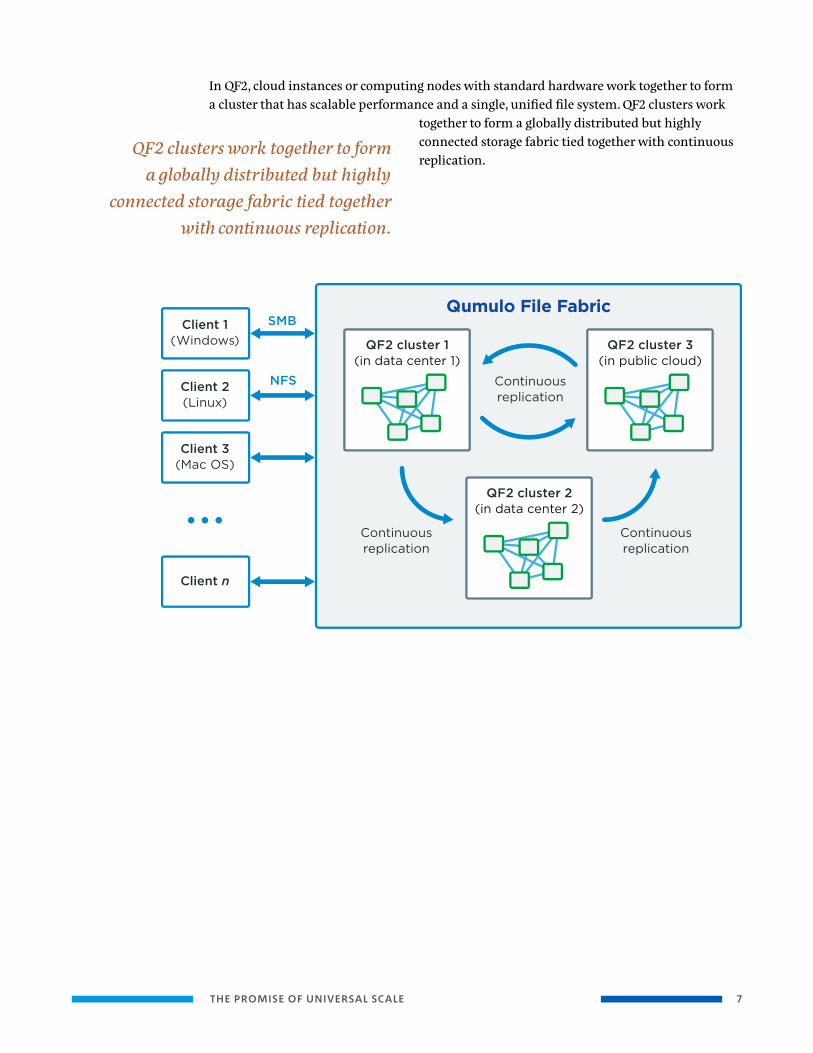
THE PROMISE OF UNIVERSAL SCALE 7
In QF2, cloud instances or computing nodes with standard hardware work together to form a cluster that has scalable performance and a single, unified file system. QF2 clusters work
together to form a globally distributed but highly connected storage fabric tied together with continuous replication.
QF2 clusters work together to form a globally distributed but highly
connected storage fabric tied together with continuous replication.
THE PROMISE OF UNIVERSAL SCALE 8
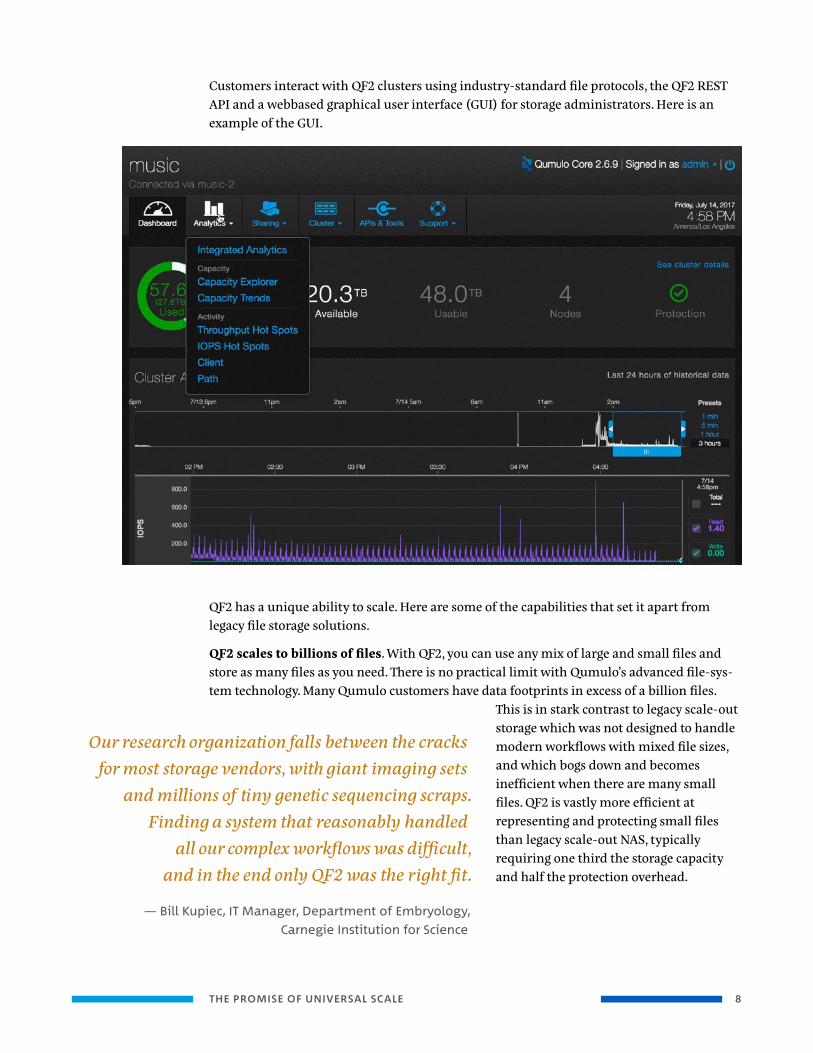
Customers interact with QF2 clusters using industry-standard file protocols, the QF2 REST API and a webbased graphical user interface (GUI) for storage administrators. Here is an example of the GUI.
QF2 has a unique ability to scale. Here are some of the capabilities that set it apart from legacy file storage solutions.
QF2 scales to billions of files. With QF2, you can use any mix of large and small files and store as many files as you need. There is no practical limit with Qumulo’s advanced file-sys-tem technology. Many Qumulo customers have data footprints in excess of a billion files.
This is in stark contrast to legacy scale-out storage which was not designed to handle modern workflows with mixed file sizes, and which bogs down and becomes inefficient when there are many small files. QF2 is vastly more efficient at representing and protecting small files than legacy scale-out NAS, typically requiring one third the storage capacity and half the protection overhead.
Our research organization falls between the cracks for most storage vendors, with giant imaging sets
and millions of tiny genetic sequencing scraps. Finding a system that reasonably handled
all our complex workflows was difficult, and in the end only QF2 was the right fit.
— Bill Kupiec, IT Manager, Department of Embryology, Carnegie Institution for Science

THE PROMISE OF UNIVERSAL SCALE 9
QF2 uses block-level protection and other advanced technologies. Because it operates at the block rather than the file level, it doesn’t have to protect each file individually, which also contributes to its scalability.
QF2 has the highest performance. QF2 is the highest performance file storage system on premises and in the cloud. It provides two times the price performance compared to legacy storage systems. On premises, QF2 is optimized for standard hardware with SSDs and HDDs, which cost less than proprietary hardware. In the cloud, QF2 intelligently trades off
between low-latency block resources and higher-latency, lower-cost block options. Its built-in, block-based tiering of hot and cold data delivers flash performance at hard disk prices.
QF2 has lower cost. QF2 costs less and has a lower TCO than legacy storage appliances on a capacity basis, as measured by cost per usable terabyte. QF2’s cost advantage comes from efficient use of storage capacity and from its use of standard hardware.
Although it may not seem immediately obvious, QF2’s cost efficiencies also make it extreme-ly reliable. Storage system reliability is usually measured in terms of mean time to data loss (MTTDL). MTTDL is the average number of years a given cluster will survive before there’s a hardware failure that causes a significant loss of data. At a minimum, MTTDLs should be measured in the tens of thousands of years.
With critical high-profile projects, you want to know exactly what you’re going to be leaning on
for successful delivery. When the La La Land project came around it was make or break,
and we were never down for a moment. Qumulo is our rock, allowing us to focus on the visual
effects with absolute confidence the data is safe.
— Tim LeDoux, Founder/VFX Supervisor, Crafty Apes

THE PROMISE OF UNIVERSAL SCALE 10
While some variables that affect reliability can’t be controlled by the storage system, one that can is the reprotect time, or how long it takes to recover data if a disk fails.
Reprotect times matter because the longer it takes to reprotect the cluster, the more vulnera-ble the cluster is to other failures and the poorer the MTTDL. As disks become denser, data footprints increase, and clusters grow, a legacy storage system’s reprotect times can turn into weeks.
QF2 uses sophisticated data protection techniques that enable the fastest reprotect times in the industry. They are measured in hours, not days or weeks. When reprotect times are fast,
reliability increases. Better reliability means that administrators can greatly reduce the level of redundancy they need to achieve target MTTDL standards, which in turn increases storage efficien-cy and lowers cost.
QF2 makes 100% of user-provisioned capacity available for user files, in contrast to legacy scale-up and scale-out NAS that only recommend using 70% to 80%.
QF2 provides real-time control at scale. The inability to manage large file systems (as opposed to simply storing them) is the Achilles heel of legacy systems. For example, as file systems get larger, a simple directory query can take days to run, which means even standard management tasks, such as setting quotas, become impossible.
Another drawback to legacy systems is that analytics is not an integral part of the software. It is a separate software package that is installed on external hardware and has its own management interface. There is also no single place where administrators can get an over-view of their system and then drill down into the details.
QF2 has real-time analytics that tell you what’s happening in your file system now. Analytics is a part of the QF2 codebase; it is not an afterthought. Instead of running multiple com-mands, parsing through pages of log files, and running separate programs, an administrator can simply look at the GUI and understand what’s happening. For example, an administra-tor can immediately see if a process or user is hogging system resources and, in real-time, apply a capacity quota.
For a critical digital media archive, QF2 is the safest place I can think to put
it short of directly in a backup vault. Soon we won’t need anything else but backup,
high-speed virtual storage, and QF2.
— Joel Hsia, Assistant Head for Systems Development, Marriott Library, University of Utah

THE PROMISE OF UNIVERSAL SCALE 11
QF2 gives you the freedom to store and access your data anywhere. QF2 is hardware independent and can run both in the data center and in the cloud, while still offering the same interface and capabilities to users, no matter if they are on-premises, off-premises, or spanning both. Administrators have the freedom to take advantage of the elastic compute resources that the cloud offers and then move data back to their data centers.
QF2 has industry-leading support. Many storage customers are dissatisfied with the support they receive from their vendors. They find them to be unresponsive and reactive rather than proactive. Qumulo offers responsive, personal customer support, with some of the highest Net Promoter Scores (NPS) in the industry.
Managing data with QF2 is so simple it’s hard to describe the impact. It has given us tremendous ROI in terms of time saved and problems eliminated, and having that
reliable storage we can finally trust makes us eager to use it more broadly throughout the company.
— John Beck, IT Manager, Hyundai MOBIS
QF2 allows us to move file-based data sets to a QF2 cluster on AWS, complete our analysis, and move the artifact back to our on-premises QF2 storage cluster,
saving us time and money. The flexibility for us to move our file-based data where we need it to be is something
that nobody else in the market can provide at scale.
—Tyrone Grandison, CIO, Institute for Health Metrics and Evaluation (IHME)

THE PROMISE OF UNIVERSAL SCALE 12
QF2 has simple subscription pricing. Businesses feel they are held hostage by the high cost of their existing storage appliances. If they want to upgrade their hardware after three years, they’re forced to throw out software licenses associated with their legacy hardware. Even if they wish to run their storage systems for seven years instead of three, their vendor forces them to replace their hardware by way of exorbitant support quotes. Pricing is complicated
and figuring out how much a system will cost is far from straightforward.
QF2 pricing is based on a single, simple subscription service that covers everything, includ-ing software, updates and support.
QF2 provides cloud-based monitoring and trends. A QF2 subscription includes cloud-based monitoring that proactively detects potential problems, such as disk failures.
Administrators can also access the QF2 trends service, which provides historical data about how the system is being used. This information can help lower costs and optimize workflows.
QF2 provides access to innovation. Qumulo follows Agile and other modern development practices, which means it has many small releases that steadily improve the product and keep it on the leading edge of what’s possible. This is in contrast to legacy storage vendors that have infrequent releases that can keep customers waiting for improvements for years.
Qumulo customer care is absolutely phenomenal – the best support I’ve
seen from any vendor. It’s been a real pleasure to deal with Qumulo.
— Nathan Larsen, Director of IT, Sinclair Oil Corporation
We use the same agile methodology at Sinclair, and I’ve seen first-hand the ability
to drive good products into production, so much faster than with traditional 18-month monolithic releases. Given Qumulo’s existing
lead on its competitors, I knew that fast development pace would help keep it out in
front of our needs.
— Nathan Larsen, Director of IT, Sinclair Oil Corporation

THE PROMISE OF UNIVERSAL SCALE 13
QF2 has no hardware lock-in. QF2 uses standard hardware provided by Qumulo or by partners such as HPE. In the cloud, it can use a range of instances that you can pick accord-ing to your capacity and performance requirements.
QF2 provides a fully programmable REST API. Customers get programmatic access to any feature or administrative setting in QF2. The QF2 REST API is built for developers. The API is suitable for DevOps and Agile operating approaches, which are how modern application stacks are constructed and managed, particularly in the cloud. For example, you can use tools such as Terraform and CloudFormation to automatically spin up QF2 clusters in the cloud.
QF2 has out-of-the-box simplicity. It seems obvious that storage administrators want a system that is easy to install and easy to manage. They have better ways to spend their time. Unfortunately, legacy storage systems can take days to set up and configure.
For data center installations, QF2 is extremely simple to install. Once the nodes are racked and cabled, all an administrator has to do is sign the end-user license agreement (EULA), name the cluster, set up an admin
name and password and perhaps enter some IP addresses. Installation is painless. From the moment QF2 is unboxed to when it can start serving data is a matter of hours, not days.
It is also extremely easy to create a QF2 cluster in the public cloud.
Right now, Qumulo’s the closest thing to an Apple unboxing, setup, and support
experience in the storage world.
— High-Level Executive, Top U.S.-Based Mobile Carrier

THE PROMISE OF UNIVERSAL SCALE 14
How QF2 worksQumulo is a new kind of storage company, based entirely on advanced software and modern development practices. Qumulo is part of a larger industry trend of software increasing in
value compared to hardware. Standard hardware running advanced, distributed software is the unchallenged basis of modern, low-cost, scalable computing. This is just as true for file storage at large scale as it is for search engines and social media platforms.
QF2 is unique in how it approaches the problems of scalability. Its design implements principles similar to those used by modern, large-scale, distributed databases. The result is a file system with unmatched scale characteristics.
Here is a diagram of what’s inside a QF2 cluster.
Software is eating the world.
— Marc Andreesen

THE PROMISE OF UNIVERSAL SCALE 15
The QF2 file systemFor massively scalable files and directories, the QF2 file system makes extensive use of index data structures known as B-trees. B-trees minimize the amount of I/O required for each operation as the amount of data increases. With B-trees as a foundation, the computational cost of reading or inserting data blocks grows very slowly as the amount of data increases.
Real-time analytics with QumuloDBWhen people are introduced to QF2’s real-time analytics and watch them perform at scale, their first question is usually, “How can it be that fast?” The breakthrough performance of
QF2’s analytics is possible because of a component called QumuloDB.
QumuloDB continually maintains up-to-date meta-data summaries for each directory. It uses the file system’s B-trees to collect information about the file system as changes occur. Various metadata fields are summarized inside the file system to create a virtual index. The performance analytics that you see in the
GUI and can pull out with the REST API are based on sampling mechanisms that are enabled by QumuloDB’s metadata aggregation.
QumuloDB is built-in and fully integrated with the file system itself. In contrast, metadata queries in legacy storage appliances are answered outside of the core file system by an unrelated software component.
Real-time quotasJust as real-time aggregation of metadata enables QF2’s real-time analytics, it also enables real-time capacity quotas. Quotas allow administrators to specify how much capacity a given directory is allowed to use for files.
Unlike legacy systems, in QF2 quotas are deployed immediately and do not have to be provisioned. They are enforced in real time, and changes to their capacities are immediately implemented. Quotas can be specified at any level of the directory tree.
SnapshotsSnapshots let system administrators capture the state of a file system or directory at a given point in time. If a file or directory is modified or deleted unintentionally, users or adminis-trators can revert it to its saved state.
Snapshots in QF2 have an extremely efficient and scalable implementation. A single QF2 cluster can have a virtually unlimited number of concurrent snapshots without perfor-mance or capacity degradation.
When people are introduced to QF2’s real-time analytics and watch them
perform at scale, their first question is usually, “How can it be that fast?”

THE PROMISE OF UNIVERSAL SCALE 16
Continuous replicationQF2 provides continuous replication across storage clusters, whether on premises or in the public cloud. Once a replication relationship between a source cluster and a target cluster has been established and synchronized, QF2 automatically keeps data consistent. There’s no need to manage the complex job queues for replication associated with legacy storage appliances.
Continuous replication in QF2 leverages QF2’s advanced snapshot capabilities to ensure consistent data replicas. With QF2 snapshots, a replica on the target cluster reproduces the state of the source directory at exact moments in time. QF2 replication relationships can be established on a per-directory basis for maximum flexibility.
Scalable Block Store (SBS)The QF2 file system sits on top of a transactional virtual layer of protected storage blocks
called the Scalable Block Store (SBS). Instead of a system where every file must figure out its protection for itself, data protection exists beneath the file system, at the block level. QF2’s block-based protection, as implemented by SBS, provides outstanding performance in environments that have petabytes of data and workloads with mixed file sizes.
SBS has many benefits, including:
• Fast rebuild times in case of a failed disk drive
• The ability to continue normal file operations during rebuild operations
• No performance degradation due to contention between normal file writes and rebuild writes
• Equal storage efficiency for small files as for large files
• Accurate reporting of usable space
• Efficient transactions that allow QF2 clusters to scale to many hundreds of nodes
• Built-in tiering of hot/cold data that gives flash performance at archive prices
The virtualized protected block functionality of SBS is a huge advantage for the QF2 file system. In legacy storage systems that do not have SBS, protection occurs on a file by file basis or using fixed RAID groups, which introduce many difficult problems such as long rebuild times, inefficient storage of small files and costly management of disk layouts.
Instead of a system where every file must figure out its protection for itself, data
protection in QF2 exists beneath the file system, at the block level.

THE PROMISE OF UNIVERSAL SCALE 17
Object and file stor ageObject storage allows for very large systems with petabytes of data and billions of objects and works well for its intended use. In fact, it’s becoming conventional wisdom to assert that object storage technologies are the solution to the scale and geo-distribution challenges of unstructured storage. Cloud providers believe wholeheartedly in object storage. Today, a customer wanting to store data in the cloud is practically forced to use it regardless of use case.
Adopting object storage in use cases for which it was never intended is a poor technical fit. In order to achieve their scale and geo-distribution properties, object stores have intentionally traded off features many users need and expect: transac-
tional consistency, modification of objects (e.g. files), fine-grained access control, and use of standard protocols such as NFS and SMB, to name a few.
Object storage also leaves unhandled the problem of organizing data. Instead, users are encouraged to index the data themselves in some sort of external database. This may suffice
for the storage needs of standalone applications, but it complicates collaboration between applications and between humans and those
applications. Modern workflows almost always involve applications that were developed independently but work together by exchanging file-based data, an interop scenario that is simply not possible with object storage. Further, object stores don’t offer the benefits of a file system for governance.
A surprising amount of valuable business logic is encoded in the directory structure of enterprise file systems. The need for file storage at scale remains compelling. QF2 provides the scalability benefits of object without sacrificing features.
Object stores have intentionally sacrificed features users need and expect.
A surprising amount of valuable business logic is encoded in the directory structure of enterprise file systems.

THE PROMISE OF UNIVERSAL SCALE 18
ConclusionAt Qumulo, we believe that file-based data is the engine of innovation and that it fuels the growth and longterm profitability of modern enterprises. File-based data is more important than ever, and there are new requirements for how file storage must scale.
QF2 opens new possibilities for its customers, who are makers in every sense of the word. With QF2, meeting the release date of a major animated motion picture gets easier. With QF2, it’s feasible to achieve medical breakthroughs from multi-petabyte experimental datasets. With QF2, identifying security threats in a billion-file network log is a daily reality.
At Qumulo, we believe that file-based data becomes transformative when it gives people the freedom to collaborate, to innovate, and to create. The needs of our customers, who are leaders and innovators in so many industries, are the sole drivers of our aggressive product roadmap.
In a modern file storage system, unparal-leled reliability, scale and performance are table stakes. A great system goes beyond that and gives companies the global access and data insight they need to make their own dreams of greatness come true. A great file storage system moves data where
it’s needed, when it’s needed and at massive scale, and it does these things with lower cost, higher performance, more reliability and greater ease of use than other systems.
Qumulo is a different kind of storage company. As the creators of the world’s most advanced file storage system, our own team of innovators puts what we believe into practice every day. File storage at universal scale is our vision and our passion.
I’ve worked with many different vendors, and while I’ve learned to expect problems
I’ve also learned no one’s going to knock themselves out to help me. Qumulo is the
complete opposite. I’ve never had so many smart people working so hard to curve the
product toward what we’re trying to do.
— Tim LeDoux, Founder/VFX Supervisor, Crafty Apes