the power of both choices: practical load balancing for distributed stream processing engines
TRANSCRIPT

The Power of Both ChoicesPractical Load Balancing for Distributed Stream
Processing Engines Muhammad Anis Uddin Nasir, Gianmarco De Francisci Morales, David Garcia-Soriano
Nicolas Kourtellis, Marco Serafini
International Conference on Data Engineering (ICDE 2015)

Stream Processing Engines
• Streaming Application
– Online Machine Learning
– Real Time Query Processing
– Continuous Computation
• Streaming Frameworks
– Storm, Borealis, S4, Samza, Spark Streaming
2The Power of Both Choices
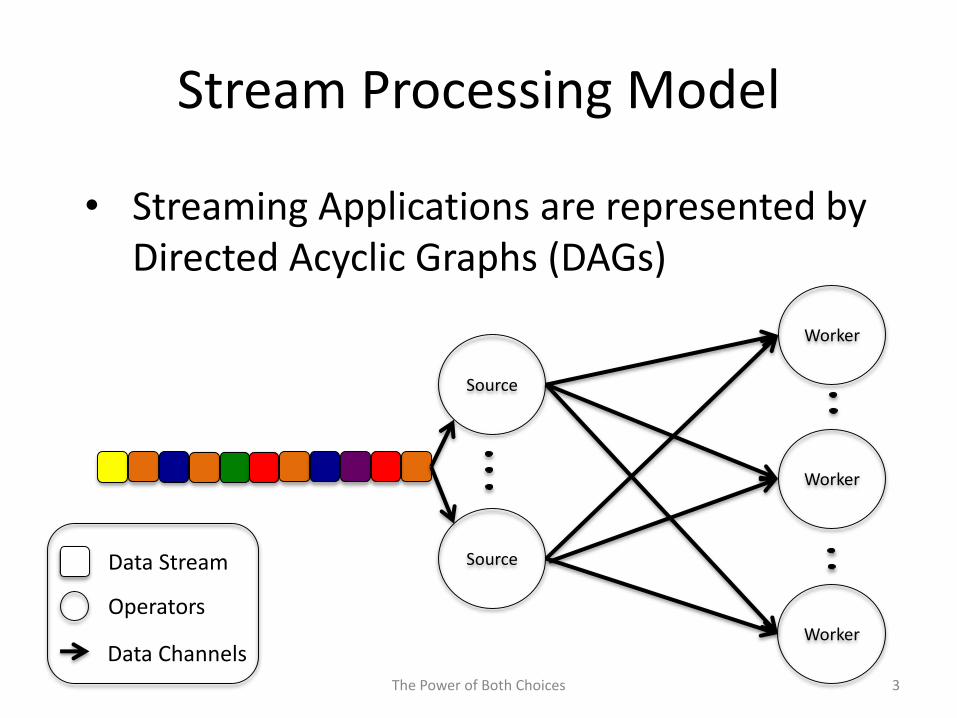
Stream Processing Model
• Streaming Applications are represented by Directed Acyclic Graphs (DAGs)
Worker
Worker
Worker
Source
Source
3The Power of Both Choices
Data Stream
Operators
Data Channels

Stream Grouping
• Key or Fields Grouping– Hash-based assignment
– Stateful operations, e.g., page rank, degree count
• Shuffle Grouping– Round-robin assignment
– Stateless operations, e.g., data logging, OLTP
4The Power of Both Choices
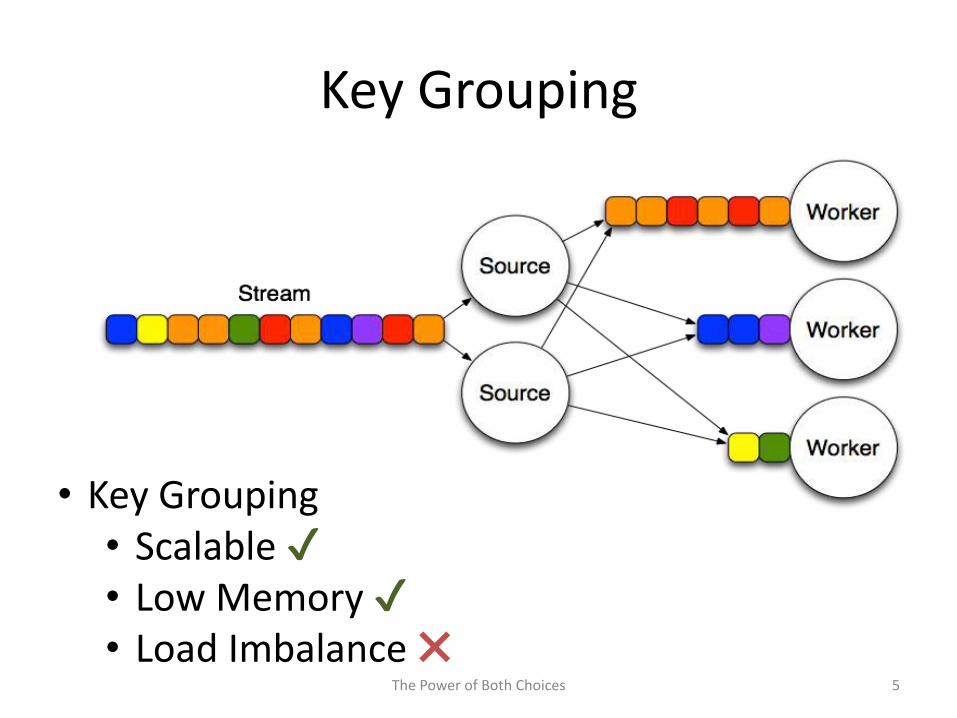
Key Grouping
5The Power of Both Choices
• Key Grouping• Scalable✔• Low Memory ✔• Load Imbalance ✖
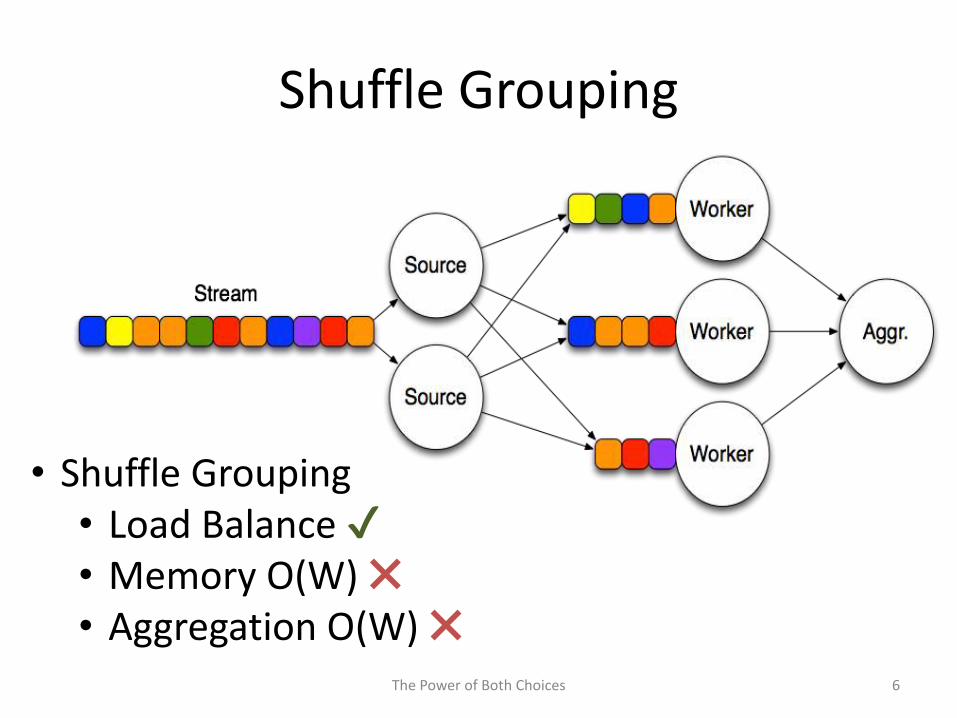
Shuffle Grouping
6The Power of Both Choices
• Shuffle Grouping• Load Balance ✔• Memory O(W) ✖• Aggregation O(W) ✖

Problem Formulation
• Input is a unbounded sequence of messages from a key distribution
• Each message is assigned to a worker for processing
• Load balance properties– Memory Load Balance– Network Load Balance– Processing Load Balance
• Metric: Load Imbalance
The Power of Both Choices 7

Power of two choices
• Balls-and-bins problem
• Algorithm– For each ball, pick two bins uniformly at random– Assign the ball to least loaded of the two bins
• Issues– Distributed ✖– Consensus on Keys ✖– Skewed distribution ✖– Continuous Data✖– Load Information ✖
8The Power of Both Choices
Img source: http://s17.postimg.org/qqctbpftr/Galton_prime_box.jpg

Partial Key Grouping (PKG)
• Key Splitting
– Split each key into two server
– Assign each instance using power of two choices
• Local Load Estimation
– each source estimates load on
– using the local routing history
9The Power of Both Choices
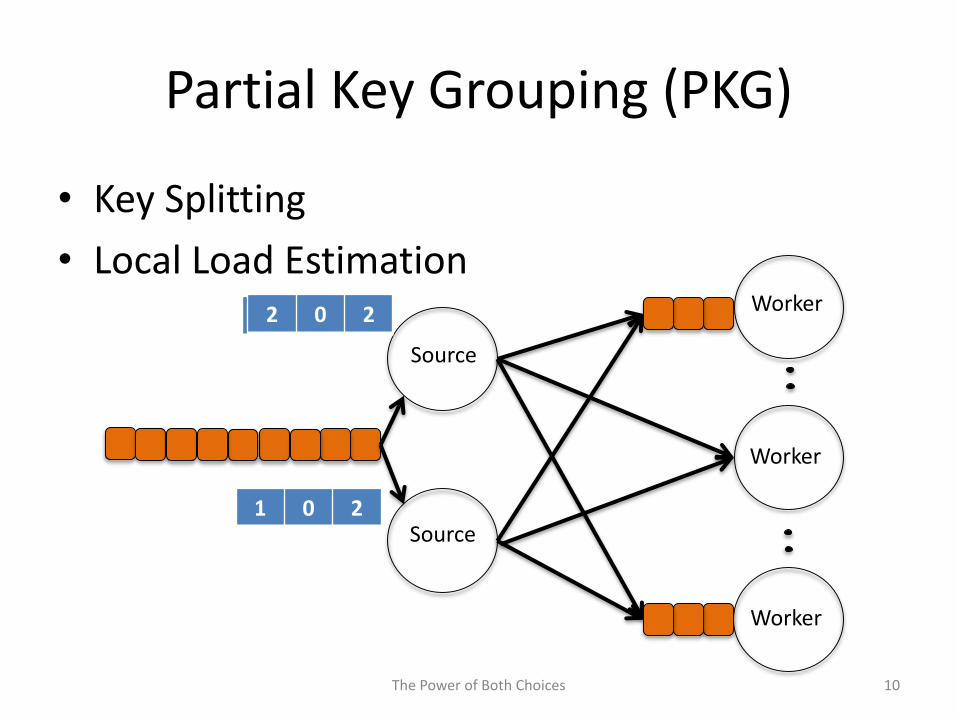
Partial Key Grouping (PKG)
• Key Splitting
• Local Load Estimation
The Power of Both Choices 10
Source
Source
Worker
Worker
Worker
2 0 1
1 0 2
2 0 2
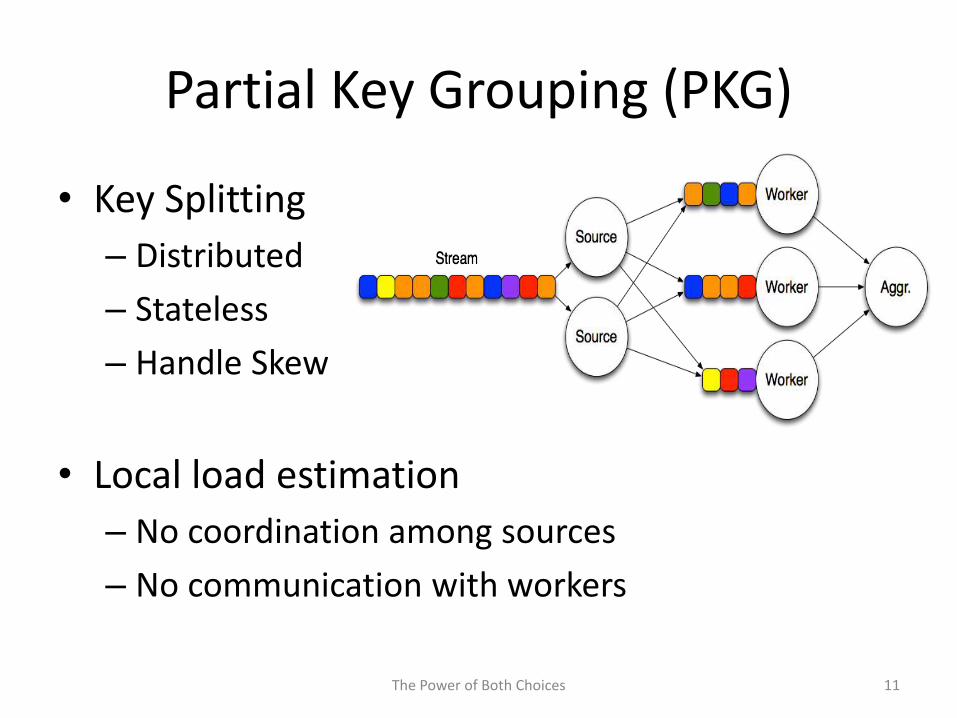
Partial Key Grouping (PKG)
• Key Splitting
– Distributed
– Stateless
– Handle Skew
• Local load estimation
– No coordination among sources
– No communication with workers
11The Power of Both Choices
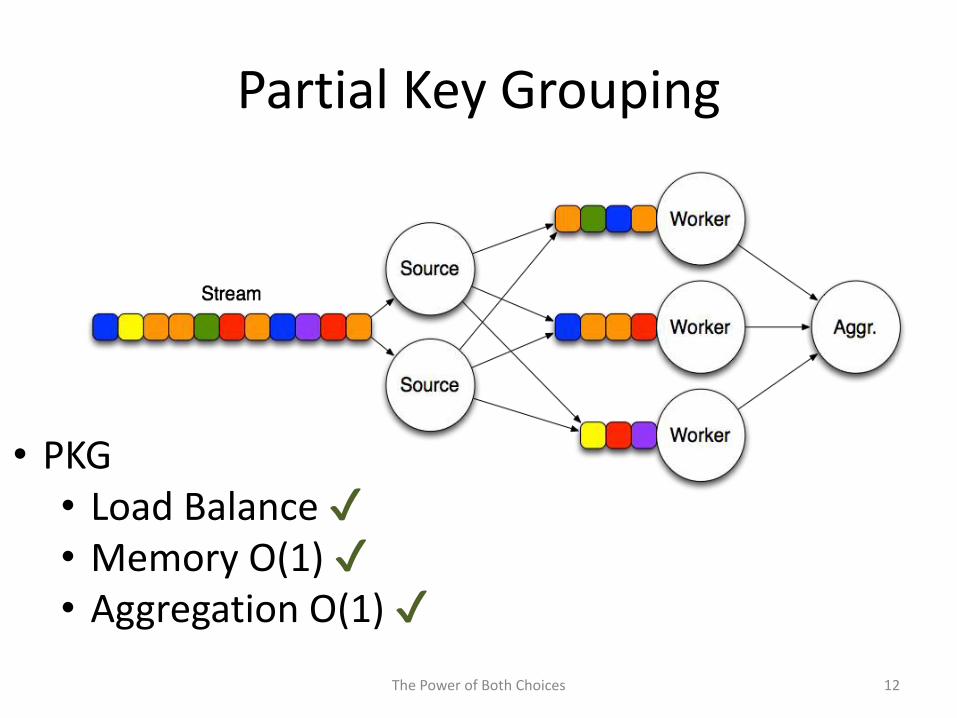
Partial Key Grouping
The Power of Both Choices 12
• PKG• Load Balance ✔• Memory O(1) ✔• Aggregation O(1) ✔

Analysis: Chromatic Balls and Bins
• Problem Formulation– If messages are drawn from a key distribution where
probabilities of keys are p1≥p2≥p3….. ≥pn
– Each key has d choices out of n workers
• Minimize the difference between maximum and average workload
The Power of Both Choices 13

Analysis
• Necessary Condition: If pi represents the probabilityof occurrence of a key i
• Bounds:
The Power of Both Choices 14

Streaming Applications
• Most algorithms that use Shuffle Grouping can be expressed using Partial Key Grouping to reduce:
– Memory footprint
– Aggregation overhead
• Algorithms that use Key Grouping can be rewritten to achieve load balance
The Power of Both Choices 15

Streaming Examples
• Naïve Bayes Classifier
• Streaming Parallel Decision Trees
• Heavy Hitters and Space Saving
The Power of Both Choices 16

Stream Grouping: Summary
Grouping • Pros • Cons
Key Grouping • Scalable• Memory
• Load Imbalance
Shuffle Grouping • Load Balance • Memory O(W)• Aggregation O(W)
Partial Key Grouping • Scalable• Load Balance• Memory O(1)• Aggregation O(1)
The Power of Both Choices 17

Experiments
• What is the effect of key splitting on POTC?
• How does local estimation compare to aglobal oracle?
• How does PKG perform on a real deploymenton Apache Storm?
The Power of Both Choices 18

Experimental Setup
• Metric– the difference of maximum and the average load of the workers
at time t
• Datasets– Twitter, 1.2G tweets (crawled July 2012)– Wikipedia, 22M access logs– Twitter, 690K cashtags (crawled Nov 2013)– Social Networks, 69M edges– Synthetic, 10M keys
19The Power of Both Choices
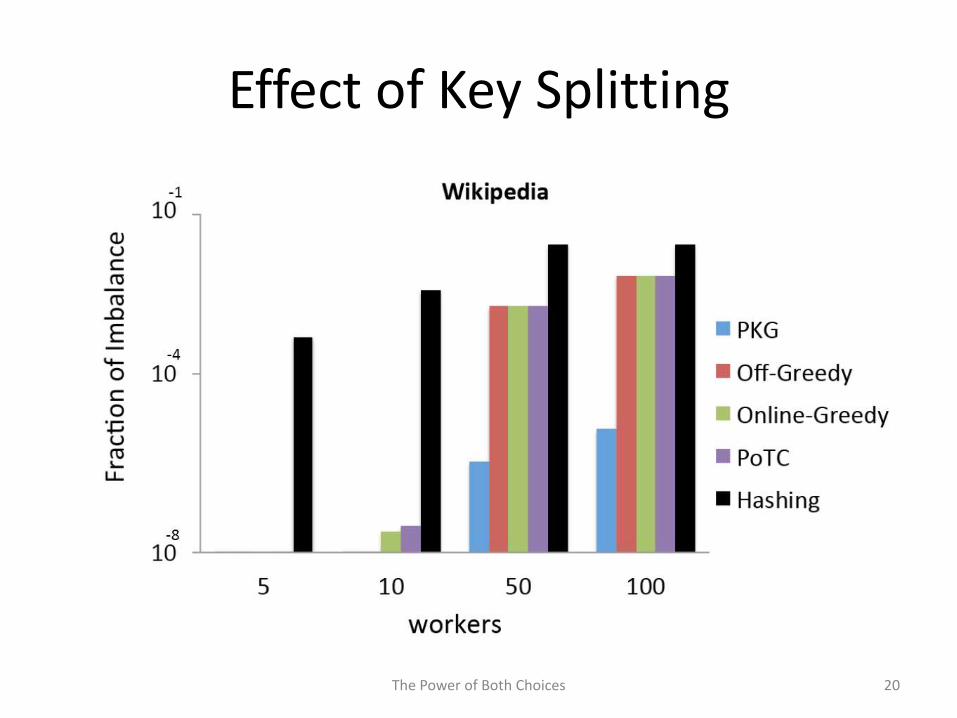
Effect of Key Splitting
The Power of Both Choices 20
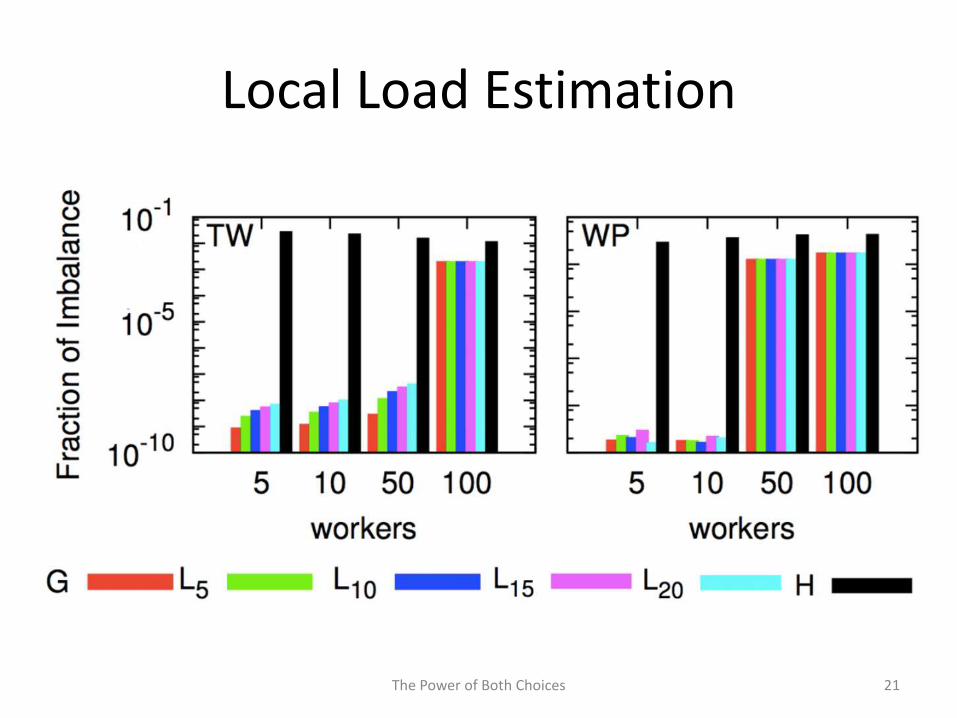
Local Load Estimation
The Power of Both Choices 21
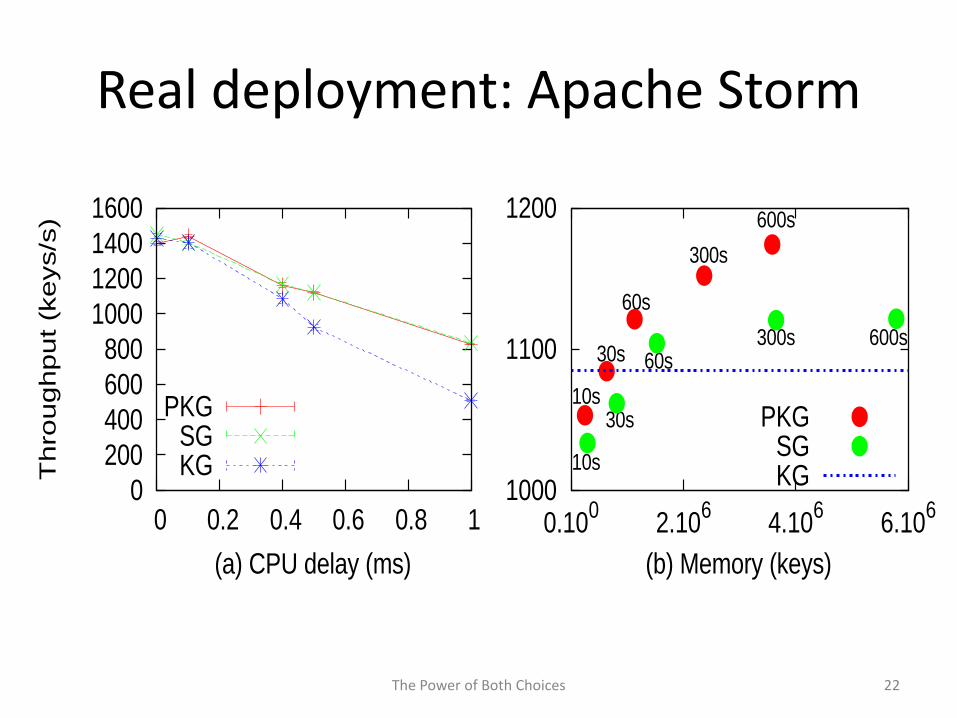
Real deployment: Apache Storm
The Power of Both Choices 22
0
200
400
600
800
1000
1200
1400
1600
0 0.2 0.4 0.6 0.8 1
Th
rou
ghp
ut
(ke
ys/s
)
(a) CPU delay (ms)
PKGSGKG
1000
1100
1200
0.100
2.106
4.106
6.106
(b) Memory (keys)
10s
10s30s
30s 60s
60s
300s
300s
600s
600s
PKGSGKG

Conclusion
• Partial Key Grouping (PKG) reduces the load imbalance byup to seven orders of magnitude compared to KeyGrouping
• PKG imposes constant memory and aggregation overhead,i.e., O(1), compared to Shuffle Grouping that is O(W)
• Apache Storm– 60% improvement in throughput– 45% improvement in latency
• PKG has been integrated in Apache Storm ver 0.10.
23The Power of Both Choices

Future Work
• Load Balancing for Stateful Operators using key migration
• Adaptive Load Balancing for highly skewed data
• Load Balancing for graph processing systems
The Power of Both Choices 24

The Power of Both ChoicesPractical Load Balancing for Distributed Stream
Processing Engines Muhammad Anis Uddin Nasir, Gianmarco De Francisci Morales, David Garcia-Soriano
Nicolas Kourtellis, Marco Serafini
International Conference on Data Engineering (ICDE) 2015