the efficiency of two indexed priority queue algorithms
TRANSCRIPT

BIT t8 (1978), 320-333
THE EFFICIENCY OF TWO
INDEXED PRIORITY QUEUE ALGORITHMS
OLLI NEVALAINEN and JUKKA TEUHOLA
Abstract. Two priority queue algorithms, a linked linear sublist and a p-subtree algorithm, are
analysed. Both of them use a search index that speeds up finding the correct sublist/subtree. In most cases the methods ,require a short processing time for the so-called HOLD- operation of the discrete event simulation. The relative power of the algorithms depends on the ratio r of the total number of elements in the queue and the size of the search index. For large values of r (> 16) the p-subtree algorithm is to be preferred. However, the more primitive data structure used by the sublist algorithm makes it possible to use a larger index leading to a smaller ratio r.
Key words and Phrases: Priority queues, simulation, event chains, index organization, p- trees.
CR Categories: 3.74, 4.34, 4.6, 8.1.
1. Introduction.
A priority queue is generally a data structure for a finite set of elements together with a group of algorithms for performing certain operations on the set. At least two items of data are associated with each element: a label (also called a key or priority) giving the order of the elements, and a name giving the type of the element. The elements in the queue are waiting for service. The element with the smallest label is served next and deleted from the queue. The choosing and deletion of the smallest element is called the MIN-operation. The insertion of a new element is called the INSERT-operat ion. Besides these two basic operations it may be necessary (less frequently) to delete a random element (DELETE- operation) or to update a random element (UPDATE-operation).
Priority queues are used in process scheduling algorithms of operating systems where processes are served in order of priority, [9]. Two different cases can be
distinguished: 1) where dynamically varying priorities are used, and 2) where static external priorities are used. In the first case the system can change the labels of some of the queue elements. According to the above classification, the priority queue may or may not be subject to an UPDATE-operat ion.
Another important area of application for the priority queue is the time flow mechanism of discrete-event simulation systems. The queue contains the event notices (queue elements) of the future events in the simulation system. Each event
Received April 15, 1977. Revised May 8, 1978.

/ THE E F F I C I E N C Y O F T W O I N D E X E D PRIORITY Q U E U E A L G O R I T H M S 32'1
notice tells the event time (label) and the event type (name) of the corresponding future event. Because of the nature of the queue it is in this context often called the (future) event chain. It is necessary to make a restriction to the INSERT- operation because of the non-decreasing values taken by the system time: the event time of an event notice to be inserted may not be less than the system time (i.e. the time of the current event notice). For the priority queue algorithms to be considered here this restriction is of minor significance.
The set of algorithms suitable for the implementation of a priority queue is quite large. The algorithms are based on two different information structures: on search/sort trees and on linked linear lists. Promising among the tree methods are those using "post-order', "end-order" [12], "leftist", "AVL" and "2-3" tree organization and a method closely related to the "heap"-sort [1, 4, 5, 8]. AVL tree, 2-3 tree and the heap method give a good time complexity. By using a heap- ordered binary tree any sequence of n INSERT, DELETE and MIN-operations can be processed in O(n log n) time, [5]. The most recent approach is to use the so- called binomial trees [2]. It is Claimed that this type of data structure is "almost optimal" for the management of priority queues.
A single linear list organization gives for the MIN-operation the processing time O(1). The processing time of the DELETE or INSERT-operations, however, is of the order O(n). One way to decrease the INSERT/DELETE time is to reduce the length of the list to be scanned. The use of an index consisting of pointers to the list gives good results in the case of an event chain, see [12, 13, 10]. In [10] we improved the index structure by introducing a feedback mechanism that controls the organization of the search index. The variations in the number of elements and in the distribution of the label values are observed and the length of the time intervals is adjusted if necessary. Another kind of approach to an adaptive index- list method has been made by Franta and Maly [3]. Their method guarantees a good time complexity for the worst case.
The present paper is a direct extension of the previous papers [10] and [6]. We attempt to answer the following questions:
1. Is it possible to reduce further the processing time of a priority queue by replacing the linked sublists by some of the tree methods?
2. In what way does the expected number of key tests depend on the number of elements in the priority queue when the sublist index method is used? Here we consider the case of a MIN/INSERT-sequence, with an equal number of both operations (the so-called HOLD-operation sequence).
Our study is based on an internal report containing the details of the proofs, [11].
When selecting an alternative organization for the linear sublists attention is mainly paid to the expected processing time, not to the asymptotic behaviour, of the tree methods. That is why the use of a search index effectively reduces the mean length of the sublists. On the basis of the results by Vaucher et al. and
BIT 18 - - 22

322 OLLI NEVALAINEN AND JUKKA TEUHOLA
Jonassen et al. the p-tree method is selected. Among the tree methods, the processing time of the HOLD-operat ion is shortest for the p-trees, at least for the most important distributions of the HOLD-time (i.e. the time difference between the current event and the new event to be inserted). The asymptotic processing time of the p-tree algorithm is of the order O(1) for a MIN- and O((logn) 2) for an INSERT-operation. In spite of the power "two" in the order term of INSERT, the range in which the p-tree works faster than the other tree organizations is quite large.
In the following we first introduce the sublist index method. After this the processing time of the HOLD-operat ion is analysed for two different organizations of the sublists: for linked sublists and for p-subtrees. Finally we make a more accurate estimate of the number of key tests needed.
2. The adaptive sublist index organization.
The sublist index method divides the event chain into k + 1 separate sublists.
The elements in the index point to the appropriate sublists. A sublist contains the event notices belonging to the time interval of the sublist. Two different interval lengths DT1 and DT2, are used. The first k elements of the index are managed as a ring list, so that the list element 1 follows logically the list element k. The list k + 1 is an overflow list containing those elements with "large" event times. The index element pointing to the current list, i.e. to the part of the event chain with the smallest key values, is given by the pointer JC, where 1 < J C < k . The interval length of the first ( k - J C + 1) lists is DT1. Their pointers are to the right of the element JC in the index. The interval length of the last ( J C - 1) lists is DT2 and their pointers are to the left of the element JC.
In the case of an event chain the successive MIN/INSERT/DELETE- operations cause the current list to become empty at some moment. The pointer of the current list is then advanced by setting JC ,-- JC(mod k)+ 1. If this makes JC = 1, a recalculation of the key intervals is made by setting DT1 ~-- DT2 and determining a new value for DT2 on the basis of the statistics collected from the distribution of the HOLD-times and the number of the list elements. (This method presupposes that the smallest key in the queue continually increases. If this is not so, the reorganization part of the algorithm should be changed.) Each time the JC-pointer is advanced it may also be necessary to move some elements from the front of the overflow list to the kth list.
2.a. The p-tree organization of the sublists.
A p-tree is defined as either an empty or a non-increasing sequence of nodes (the so-called left path), such that with each node of the left path except the last one, there is associated a p-tree (tlae so-called right subtree), [6]. The nodes of the right subtree associated with a node, x, on the left path, are ranked between x and the left successor of x.

TIlE EFFICIENCY OF TWO INDEXED PRIORITY QUEUE ALGORITHMS 323
To make the MIN-operation efficient it is common to use a special pointer to the smallest node of the tree, called the left leaf There are a number of alternatives for the structure of the nodes. A three-link organization is used in what follows. The fields of the nodes are:
1. l(x), points to the left son, 2. r(x), points to the right son, 3. f (x) , points to the father, 4. v(x), gives the value of the key, and 5. b(x), gives the type of the node (x) ("node (x)" denotes the node whose address
is given by the pointer x).
Three algorithms are needed when using p-trees in the index organization, namely MIN, INSERT and CUT. The first two are basically the same as those given and analysed by Jonassen and Dahl. The third algorithm is new, and it is needed when advancing the JC pointer and forming the kth subtree from the overflow tree. This algorithm CUTs the overflow tree into two parts at a random point and transforms both parts into p-trees.
Each index element contains two pointers, first i and lasti, which point to the root and the left leaf of the subtree i, i= 1,2 . . . . . k + 1, respectively. An empty subtree is recognized from the condition Iastl = 0. The absence of a link in a node is denoted by a null link.
The cutting o f a p-tree, CUT. Let p point to a p-tree T and x point to a node in T(p). This algorithm separates a p-tree T 1 (possibly empty) from the tree T(p). The remaining p-tree, denoted by T (p) - T1, has the property v (z) > v (x) for all z ~ T (p) - T 1, while v(y)<v(x) for all y e T v
1. a) If T = O, set 3-1 = O (an empty tree) and terminate. b) If v(x)>v(root (T)), set T 1 =T, T = O and terminate. c) Else set T 1 = O and go to step 2.
2. Move along the left path of T until the first node (y) is found such that v(y)
<=v(x). a) If no such node is found, terminate. b) Else it is known that v(y) ~ v(x) < v(z), where y = l(z).
i) If T(r(z))=O, set T1 =T(y), T = T - T ( y ) and terminate. ii) Else connect T(r(z)) between z and the left son of the node (z) and leave
the right subtree of the node (z) empty. Search the left leaf of T(z) and connect the node (y) to it. Finally repeat step 2 by starting from the
node (z).
The cutting algorithm transforms the structure of a p-tree somewhat closer to a linked list. This is due to the fact that the left paths of T and T 1 are increased in
step 2b ii, see Fig. 1.

324 OLLI NEVALAINEN AND JUKKA TEUHOLA
1
I p s q 1 6 t
T
I t T q
t .... ' I T1"-l/ 3 I
l p 2 t . /
I , I a) Before the algorithm CUT b) After the algorithm CUT
Figure 1. The p-tree T is cut at point 3.5.
6 I
However, it would be possible to write a balancing step into the algorithm. The balancing can be made in such nodes where the right subtree is empty and the left path of the left subtree includes at least two nodes.
The processing time of CUT. It is assumed that the tree T is a "random p-tree", i.e. the result of successive insertions from a random permutation of n positive integers {1,2 . . . . . n}. Further the cutting point is drawn with equal probability from the set {0.5,1.5,..., n + 0.5}. The number of key tests for CUT is the same as that for INSERT, see formula 3.9. In addition to the key tests the algorithm searches the left leaf of each subtree where a cutting point occurs (step 2b ii). We next estimate the number of link value tests.
Let L(n) be the expected number of link value tests when searching the left leaves of the subtrees. Then
(1) L(n) = A(n)+ B(n) ,
where A(n) is the number of link value tests made in the left path of T and B(n) is the total number of link value tests made in the fight subtree. (Actually CUT does not search the left leaf of the left path of T. Thus L(n) is an upper limit.)
Jonassen et al. have shown that the length of the left path of a random p-tree with n nodes is
(2) ,~(n) = 2 ~ (1/0-1 i=1"
and the expected number of key tests made in the left path when a random element is inserted is

THE EFFICIENCY OF TWO INDEXED PRIORITY QUEUE ALGORITHMS 325
(3) V (n) = 2(n)/2 + n/(n + 1).
Thus it obviously follows that
(4) A(n) = 2 (n ) - (V(n) - 1) = V(n) - ( n - 1)/(n+ 1).
The value of L(n) can thus be calculated by a method similar to that used in [6] for determining the expected number of key tests S(n): if we denote by r,(-) the ~l a, k
probability that in a random p-tree with n nodes the nodes a and a + k + i are neighbours on some left path, we find that
(5) n - I n - a - 1
L(n) = A(n)+ 2 2 a = l k = O
n - 1 n - a - 1
< v(.)+ 2 Y. a = l k=O
= S ( n ) .
{q(."kL(k)(k + 1)/(n + 1)}
{q~)~S(k)(k + 1)/(n + 1)}
In the above formula
(6) ~¢") Ua.k = l / { ( n - a ) ( n - a + l)}+ l /{(a+k)(a+k + l)} .
The expected number of link value tests is thus less than the expected number of key tests. Further, we observe that the cutting of the overflow list is performed relatively infrequently. For example, in the case of the negative exponentially distributed HOLD-times the mean number of HOLD-operations between two p- tree cuttings is
(7) nc = n .DT/T ,
where DT is the length of an interval and T is the mean of the distribution. In formula (7) it is assumed that D T = D T I = D T 2 . The proof of (7) is given in section 6.
3. The execution time of the linked sublist and p-subtree algorithms.
In this section we estimate the execution time of two different sublist index methods: the p-subtree organization described in the previous section, and the linked sublist organization of [10]. Now the HOLD-operat ion is repeated successively. The HOLD-times x are drawn from a negative exponential distribution with mean T; the distribution function of x is
(I) F(x) = 1 - e -~'/T
for x_->O. It is assumed that the HOLD-operat ion is repeated for a sufficiently long time so that the process is stationary, with n event notices in the chain. A glance is taken at the process immediately after the rearrangement of the list

326 OLLI NEVALAINEN AND JUKKA TEUHOLA
index, i.e. after increasing the JC-poin ter . The current t ime is now t o and the time intervals of the search index are
[ to+(i-1)DT, to+iDT), i = 1 , 2 . . . . . k .
We try to est imate the number of key tests needed for the next H O L D - operat ion, after the rear rangement of the search index. To simplify the situation slightly it is assumed that the event chain includes an event notice with the time t o . (This need not, of course, be exactly the case, because the H O L D - o p e r a t i o n first removes the MIN-even t tha t includes an event t ime t~ greater than or equal to the current t ime t o. After this the current t ime is advanced to t;, and the new event t ime is T U -- t ; + x ( > to + x). The reliability of the est imate is tested in section 5.)
The probabi l i ty that the new event notice will hit an interval [ t , t+DT) is
(2) P{T U e [t, t + Dr)} = e - ~ / T ( l - - e - D T / T ) .
Thus by using the formula (2) the probabil i t ies are found for an event to hit any one of the intervals i, i = 1 , 2 . . . . . k:
(3) P, = P{rv e [ t o + ( i -1 )DT, to+iDT)}
= exp [ - (t o + ( i -1)DT)/T] (1 - e x p ( - D T / T ) ) .
Similarly, the probabi l i ty that a ne,¢ event will hit the overflow list is
(4) Pk+l = P{Tu ~ [to+k'DT,¢'o)} = e x p { - ( t o + k D T ) / T } •
Let n i be the number of event notices in the interval i, i = 1, 2 , . . . , k + 1. In the s ta t ionary state the expectat ion of n i (see [10]) turns out to be
(5) E{n,} = n - i I t°+iDT (l-Ftx))dx = (n-l)P~. T dto+(i-l)DT
It is further characteristic of the negative exponential distribution that in the stationary state a new event is inserted with equal probability between each successive pair of event notices in the chain. This is obviously also true when the event chain is divided into k + 1 sublists. For this reason it is possible to apply the analytical results obtained earlier for random p-trees and linear lists.
To make the comparison specific the sublist algorithm and p-subtree algorithm were implemented in a DEC-10 computer (KA-10 processor) with FORTRAN- i0. The times used for the generation of the HOLD-times and for determining the insertion lists are excluded because these times are the same for both organizations.
The processing time of the linked sublist index algorithm is
(6) Tt(n~) = 44.2 + 16.1C(n,),
where C(n~) is the expected number of key tests needed during insertion. When using a special end e lement we have

THE EFFICIENCY OF TWO INDEXED PRIORITY QUEUE ALGORITHMS
(7) C(nl) = (hi+ 2)/2 .
Similar ly the execution t ime of the p-subtree a lgor i thm is
(8) Tp(nl) = 75.1 + 19.6S(ni) - 2.3R(nl) + 9.7Q (ni) + 11.2E(ni).
The formulae of S, R and E are given by Jonassen and Dah l :
327
(9)
(lO)
S(n,) = (1/3)H 2, +1 + (10/9)H,, +1 - (t/3)H~,2)+ 1 - 28/27,
S(1) 1, S(O) = 0 where
k
H k = i~=k 1/i
H~ 2) = 2" 1/i2 i = l
tor ni> 2
(11) { R(ni)=(2/3)H"+l+l/9,(O) R(1) = ' 1 for n i ~ 2
~E(nO = 3/2-4/ni+[ni(ni+l)] -1, for n i ~ 2 (I2) (E(0) E(1) = 0 .
Q(nl) denotes the p robab i l i ty that a node will be inserted as a left son. By using the
probabi l i t i es -(',) and a rguments s imilar to those used for formula (2.5), we can ~/a, k
define a recursive formula for Q(ni) (for detai ls see [11]). I t turns out tha t
fQ(1) = 0 (13)
~Q(ni) 1/3, for n i ~ 2 .
Fig. 2 shows the expected H O L D - p r o c e s s i n g t imes as a funct ion of n, ca lcula ted
from formulae (6) and (8) for a single list and a single p-tree. We see tha t the l inear
list is s lower than the p-tree for p r ior i ty queues with more than 20 elements. (The
co r re spond ing exper imenta l l imit found by Jonassen with a CDC3300 compute r
is abou t 18 elements, see [6].)
The above results are now appl ied to the case of the sublist and subtree index
a lgor i thms*. The processing t ime of the H O L D - o p e r a t i o n at the m o m e n t t o is
now
k + l
(14) E{Tl(n,k)} = ~ P,T,(n~), i = 1
* It is not self-evident, however, that a random p-tree and a stationary p-tree have the same properties (9)-(13). Indeed, Jonassen [7] has shown that there are some differences in the above formulae in the stationary case, but they are of minor significance. We therefore venture to apply the results of a random p-tree.

328 OLLI N E V A L A I N E N A N D J U K K A T E U H O L A
where Tl(nl) is calculated from formula (6) and for the p-subtree index method
k + l
(15) = e , T p ( n , ) , i = 1
where Tp(ni) is calculated from formula (8). Fig. 2 shows the values of formulae 04) and (15) as functions of n/k. The curves intersect at the point n/k~15.5.
400 E l
300
200
T
T t
T P
100
I 1 I I I ............ 10 20 30 40 59 n~ n / k
Ffgure 2. The HOLD-processing time 1) for a single linked list Tl(n) and for a single p-tree Tp(n), 2) for sublists E{Tl(n/k)} and for p-subtrees E{Tp(n/k)}.
4 . E x p e r i m e n t a l r e s u l t s .
Both methods proposed were tested by repeating the HOLD-operat ion and measuring the CPU-time. The test method was identical to that used in [1(3]. Of
the HOLD-time distributions we used:
1. The negative exponential distribution with a mean T. 2. A distribution where 90 ~ of the cases are evenly distribt/ted over the interval
[0, T/10.5] and 1 0 ~ over the interval [100T/10.5, 10IT/10.5-1. 3. A distribution where the time increment T is constant.
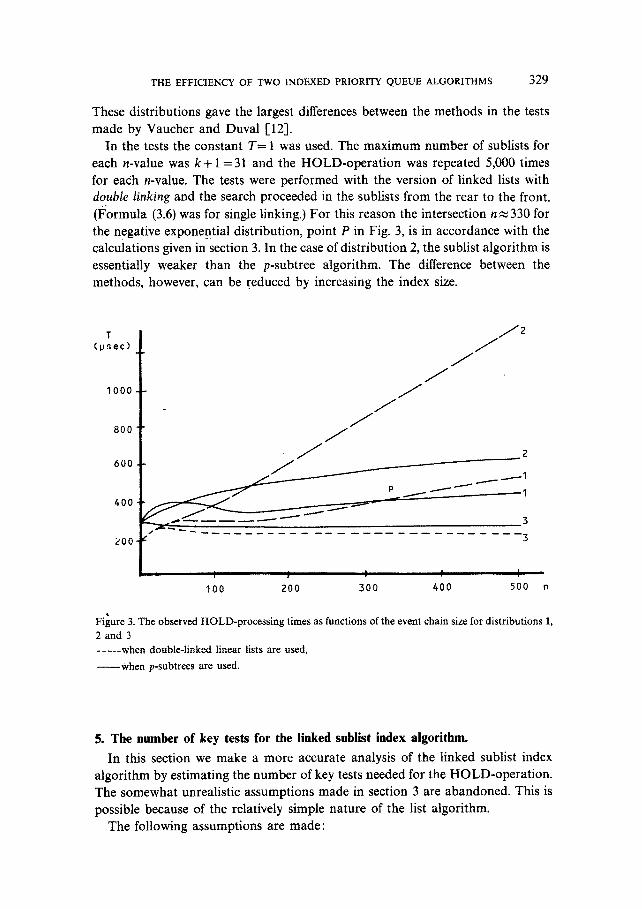
THE EFFICIENCY OF TWO INDEXED PRIORITY QUEUE ALGORITHMS 329
These distributions gave the largest differences between the methods in the tests made by Vaucher and Duval 1-12].
In the tests the constant T= t was used. The maximum number of sublists for each n-value was k + 1 =31 and the HOLD-operat ion was repeated 5,000 times for each n-value. The tests were performed with the version of linked lists with double linking and the search proceeded in the sublists from the rear to the front. (l~ormula (3.6) was for single linking.) For this reason the intersection n ~ 330 for the negative exponential distribution, point P in Fig. 3, is in accordance with the calculations given in section 3. In the case of distribution 2, the sublist algorithm is essentially weaker than the p-subtree algorithm. The difference between the methods, however, can be reduced by increasing the index size.
T (psec)
1000
8 0 0
6 0 0
400
2 0 0 ,
J J
J J
J J
J
j J 2
J
I f 1 1
- - ~ - - - - " " " " 3
I I I , , , I .... I ....
1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 n
F igu re 3. The obse rved H O L D - p r o c e s s i n g t imes as func t ions o f the event cha in size for d i s t r i bu t i ons 1,
2 a n d 3
. . . . . when double-linked linear lists are used, When p-subtrees are used.
5. The number of key tests for the linked sublist index algorithm.
In this section we make a more accurate analysis of the linked sublist index algorithm by estimating the number of key tests needed for the HOLD-operation. The somewhat unrealistic assumptions made in section 3 are abandoned. This is possible because of the relatively simple nature of the list algorithm.
The following assumptions are made:
330 OLLI NEVALAINEN AND JUKKA TEUHOLA
1. The number of event notices remains constant ( = n), so that when a new notice is being inserted there are n - 1 event notices in the chain.
2. The difference between the current time and the time of the new event notice, i.e. the HOLD- t ime x, has the distribution F(x). The corresponding density function is assumed to exist and is denoted by F'(x)=f(x) .
3. The insertion point is found by a search starting from the rear of the sublist. If there are r event notices in the sublist after the insertion point, one must perform r + 1 key tests. An empty sublist makes an exception and in this case no key tests are made. (The linking is thus assumed to be double.)
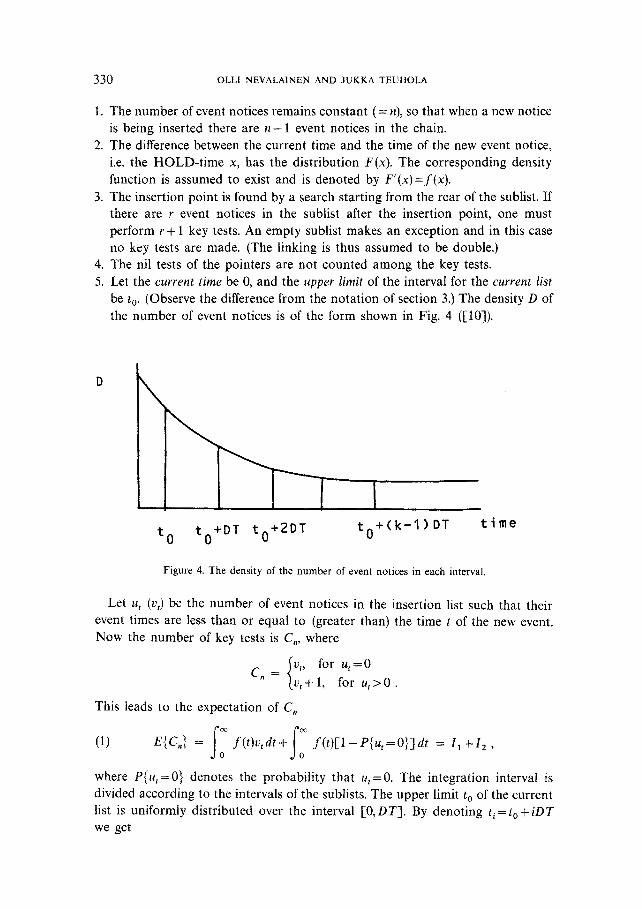
4. The nil tests of the pointers are not counted among the key tests. 5. Let the current time be 0, and the upper limit of the interval for the current list
be t 0. (Observe the difference from the notation of section 3.) The density D of the number of event notices is of the form shown in Fig. 4 ([10]).
D \
I I t o to+DT to+2DT to+(k-1) DT time
Figure 4. The density of the number of event notices in each interval.
Let u t (v,) be the number of event notices in the insertion list such that their event times are less than or equal to (greater than) the time t of the new event. Now the number of key tests is C,, where
C, = ~ vt' for U t ~ 0
l v t + l , for u~>0.
This leads to the expectation of C,
(1) E{C,} = f ( t )v td t+ f ( t ) [1 -P{u~=O}]d t = I 1 + I 2 , o
where P{u,=0} denotes the probability that u¢=0. The integration interval is divided according to the intervals of the sublists. The upper limit t o of the current list is uniformly distributed over the interval [0 ,DT]. By denoting t~=to+iDT we get

THE EFFICIENCY OF TWO INDEXED PRIORITY QUEUE AI GORITHMS 331
(2)
(3)
+ 2 (t) ( 1 - F ( x ) ) d x dt i = 1 t , - i t
"-~ / '~ 1 [ f ( t ) ~ 1 f ; (1--F(x))d'~]dt}dto
1 fDTtrt° [ ( i f : )n-11 - f ( t ) 1 - 1 - ( 1 - F l x ) ) d x dt 12 DT j o ~ j o
+ Z f ( t 1 - 1 - ~ ,,-1 dt i=l . ti a [(1; ).1]} - ( 1 - F ( x ) ) d x dt dt o. + ,~, f( t t 1 1 - ~ ,~,
It will be observed that E{C1}=0. Formula (1t with (2) and (3) holds for differentiable distributions. We next
suppose that n > 2 and F ( x ) = l - e x p ( - x / T ) is the negative exponential distribution. Formulae (2) and (3) can now be developed [11] to give
,4, exp,
(5) 12 = 1 - (l/n) + [r/(nZDr)][1 - exp ( - nDT/T)]
+[T/ (nDT)] 2=1L { ( ~ ) ( - 1 ) j ( 1 / j ) [ [ 1 - e x p ( - D T / T ) ] i
• [ 1 - exp ( - (k - 1)1) Tj/T)] + [ 1 - exp ( - 1) Tj/T)] exp ( - (k - 1 )1) Tj/T)] }
Using formulae (4) and (5) we obtain from (1):
(6) E{C.} = ( n - 1)/2{1 - (T/DT)[1 - e x p ( - D T / T ) I E 1 - e x p ( - ( 2 k - 1)DT/T)]}
+ 1 I - (1/n)+ [T/In2DT)]E1 - -exp ( - nDT/T)]
• [1 - e x p ( - ( k ~ 1)DTj/T)]
+ [ 1 - exp ( - D Tj/T)] exp ( - (k - 1)D Tj/T)} ~ . !

332 OLLI NEVALAINEN AND J U K K A TEUHOLA
In the above formula the most significant part is that before the vertical line. Thus the formula indicates that for a fixed value of (T/DT) the quantity E{C,} is linearly dependent on n. To check the validity of the formula a comparison with the results of the simulation experiments was made (see Table 1). The difference between E{C,} and the result of the simulation is less than 1.2 %. Because of the form of (6) it is tedious to calculate the terms in the sum for large values of n. However, a logarithmic transformation helps up to n=200. It should also be observed that E{C.} ~ [11,11 + 1] and thus (I~ +1) is a good approximation of E{C.} for large values n.
Table 1. A comparison between the theoretical and experimental values of the number of key tests.
n E{C.} Observed Difference value
1 0.0 0.0 0.0 2 0.577 0.578 - 0.001 5 1.106 1.119 -0.013
10 1.409 1.403 0.006 20 1.718 1.737 -0.019 50 2.362 2.360 0.002
100 3.408 3.396 0.012 200 5.733 5.677 0.056
6. The frequency of index updates.
Finally we turn to the question of the number (y) of HOLD-operat ions between two successive JC-pointer updates (see section 3). At a moment t the expecteti number of event notices~n the interval [t, t + dt] is
(n/T) (1 - F(x)) dx.
When t moves from the lower limit of the list to the upper limit we get the expected value of y
(1) E{y} = lim (DT/dt)(n/T) ~dt ( t -F(x))cIx . d t -~ O 3 o
Formula (1) is valid for a general F(x), if F(x) is continuous at the point 0. For the negative exponential distribution
nDT (2) E{y} = lim (DT/dt)n(1 - exp ( - d t / T ) ) = - -
d t ~ O T

THE EFFICIENCY OF TWO INDEXED PRIORITY QUEUE ALGORITHMS 333
7. Concluding remarks.
Two index methods for management of a priority queue were compared. The comparison was based on a simplified view of the HOLD-operation: only the situation just after the update of the index was considered and in addition a certain assumption was made concerning the key values. For the ratio n/k a limit was found below which the linear sublist method is to be preferred to the p- subtree method. This limit accords with the corresponding observations made in simulation experiments.
The sublist index method was also analysed with a more complete model. The number of key tests is very near to that found with the simplified model: for n=200, and k=30 the difference in the expected HOLD-processing times (calculated from (3.14) and (3.6) with (5.6)) is about 1.6 7o. The complete model in section 5 could' also, at least theoretically, be applied in the case of p-trees. However, the analysis would probably be too complex (see formula (3.9)). Moreover, the expected number of key tests does not show the exact execution time of a method; instead, a formula like (3.8) is needed.
R E F E R E N C E S
1. A. V. Aho, J. E. Hopcroft, and J. D. Utlman, The Design and Analysis of Computer Algorithms, Addison-Wesley, Reading, Mass., 1974.
2. M. R. Brown, Analysis of a Practical and Nearly-Optimal Priority Queue, Stanford University, STAN-CS-77-600 (1977).
3. W. R. Franta and K. Maly, An Efficient Data Structure for the Simulation Event Set, Communications of the ACM, Vol 20 Nr 2. (1977).
4. G. H. Gonnet, Heaps Applied to Event Driven Mechanisms, Communications of the ACM, Vol 19 Nr 7. (1976).
5. D. B. Johnson, Priority Queues with Update and Finding Minimum Spanning Trees, Information Processing Letters, Vol 4 Nr 3. (1975).
6. A. Jonassen and O.-J. Dahl, Analysis of an Algorithm for Priority Queue Administration, BIT Vol 15 Nr 4. (1975).
7. A. Jonassen, The Stationary p-tree Forest, Stanford University, STAN-CS-76-573 (1976). 8. D. E~ Knuth, The Art of Computer Programming, Vol 3. Addison-Wesley, Mass., 1973. 9. S. E. Madnick and J. J. Donovan, Operating Systems, McGraw-Hill, Inc., 1974.
10. O. Nevalainen and J. Teuhola, Priority Queue Administration by Subtist Index, (to appear in Computer Journal).
t 1. O. Nevalainen and J. Teuhola, Efficiency of two indexed priority queue algorithms (Extended version), Univ. of Turku, Dept. of Comp. Sci., Rept. A7 (1977).
12. J. G. Vaucher and P. Duval, A comparison of Simulation Event List Algorithms, Communications of the ACM, Vol 18 Nr 4. (1975).
13. P. F. Wyman, Improved Event Scanning Mechanisms for Discrete Event Simulation, Communications of the ACM, Vol 18 Nr 6. (1975).
DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TURKU SF-20500 TURKU 50 FINLAND