techtalk #13 grokking: marrying elasticsearch with nlp to solve real-world search problems
TRANSCRIPT

© 2016 Knorex
Marrying Elasticsearch with NLP to solve real-world search problemsPhu Le, Knorex @ Grokking TechTalk
25 June 2016
Web : http://knorex.comEmail : [email protected]

© 2016 Knorex
Knorex Lumina Web ServicesTM
2 / 36

© 2016 Knorex
Knorex Lumina Web ServicesTM
3 / 36

© 2016 Knorex
Knorex Lumina Web ServicesTM
4 / 36

© 2016 Knorex
Knorex Lumina Web ServicesTM
5 / 36

© 2016 Knorex
1. Architecture2. Ingredients
• Data gathering• Content extraction• Preprocessing• Modelling: terms -> phrases, entities -> documents
3. Elasticsearch• Basic analysis, faceting and filtering• Do you mean• Percolator• Recommendation• Deduplication
4. Summary
Outline
6 / 36

© 2016 Knorex
Architecture
7 / 36

© 2016 Knorex
1. Data gathering• Deep crawler• Lazy crawler• Visual scraper• Social media adapters
2. Content extraction• Take news article as an example
• Title• Content• Published date• Author• Image• …
Ingredients
8 / 36

© 2016 Knorex
Content extraction
9 / 36
© 2016 Knorex
Content extraction
10 / 36

© 2016 Knorex
3. Preprocessing• Sentence splitting, Tokenization
• Stemming vs Lemmatizing• Stemming: cries, crying, cried => cri• Lemmatizing: dogs => dog; is, are => be
Ingredients
11 / 36

© 2016 Knorex
3. Modelling• Goal: synthesizing words, tokens into larger units and attach meaning to them
• Key phrases extractions• Named entity recognition
• Basic building block of knowledge• Basis for computing relatedness and extracting relations
• Sentiment analysis• Social media snippet• General article or towards concepts / named entities
• Emotion• Document classification
• Group search results into faceted categories• Recommend related articles by category
Ingredients
12 / 36

© 2016 Knorex
Terms
13 / 36

© 2016 Knorex
Phrases
14 / 36

© 2016 Knorex
Entities
15 / 36

© 2016 Knorex
Document classification
16 / 36

© 2016 Knorex
• First released Feb 2010, among fastest-growing open-source projects, total funding $104M (3 rounds)
• Based on Apache Lucene (same as Solr)• Written in Java, support HTTP interface, schema-free JSON document (yay no XML!)
• Designed to be scalable, distributed in nature
17 / 36

© 2016 Knorex
Analysis
”analyzer”: “standard” ”analyzer”: “whitespace” ”analyzer”: “keyword”
18 / 36

© 2016 Knorex
Analysis
Successful!
[“https”, “www.facebook.com”, ”events”, “194454270949757“]
No hits! WTH… it is not working!!!!
Default analyzer
as-is
• url => not_analyzed / keyword analyzer• Use match query instead of term filter
/ term query: field analyzer awareness• Custom analyzer: e.g. keyword
tokenizer + lowercase filter
19 / 36

© 2016 Knorex
AnalysisIn
Search analyzer
Index analyzer
Elasticsearch index
Search Index
• Design carefully what fields that search will be executed frequently on
• Determine what analyzers to use for each field (experimental based on application needs)
• Search analyzer and index analyzer might be different for the same field
• Use match query instead of term filter / term query: field analyzer awareness
• Exploit multi-field
20 / 36

© 2016 Knorex
Faceting and filtering
21 / 36

© 2016 Knorex
Do you mean• “grok” -> “grokking”, “sear” -> “search”• Natural approach:
• Compute terms aggregation (facet) across all text fields• title• description• content
• Use regex to filter matched terms, sort DESC by frequency, take most popular terms to suggest
DON’T!!!
22 / 36

© 2016 Knorex 23 / 36

© 2016 Knorex
Do you mean• Limitations
• Single terms only. Cannot suggest phrases• Terms occurring frequently might not be useful
• Improvements• Building another field “phrases” in the document
• adding entire title• Using key phrases extraction, named entity recognition to populate
meaningful phrases• Custom tokenizers: keyword, edgeNGram• edgeNGram example: “grokking” => “gro”, “grok”, “grokk”
• Query: “burs mal” => matched: “bursa malaysia”• memory explosion!!!
• Custom scoring (importance, popularity score) instead of term frequency
24 / 36

© 2016 Knorex
Do you mean• Elasticsearch built-in suggester
• FST example. Source: https://www.elastic.co/blog/you-complete-me
• Features:• Speed & scale: FST per-segment, build in real-time, scale
horizontally• Analysis: synonym, fuzzy• Support custom ordering and scoring
• Limitations: can’t find word anywhere within a phrase
25 / 36

© 2016 Knorex
Do you mean• Speed test: 1 millions articles, 2.7 GB index size on
single laptop with SSD
• Cautions• Don’t add all terms/phrases to suggestion (only meaningful
ones!)• Don’t start suggesting immediately. How many words starting
with “c”?• Don’t suggest terms that yield no search results
• Apply same filter condition of current query to the term suggestion query
Regex terms facet
Terms suggester
296.5 ms 13 ms
26 / 36
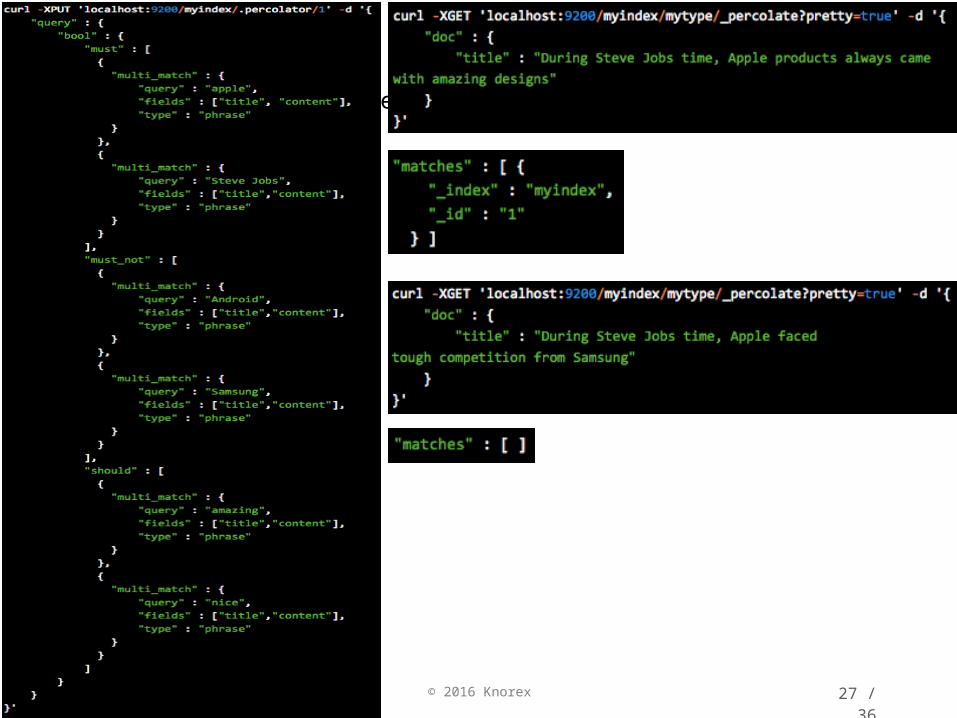
© 2016 Knorex
Percolator• percolate: match documents against queries
27 / 36

© 2016 Knorex
Percolator• Sample use case: segmenting articles using keywords
28 / 36

© 2016 Knorex
Recommendation• Natural approach
• More-like-this or fuzzy-like-this on title, content• Not accurate, bag-of-word approach.• Tricky in determining threshold. ”Good value” varies across
different document types and domains• Slow. The more terms allowed in the queries, the slower it is. If
cut off based on max terms, then accuracy drops
• Proposed approaches• Utilize NLP results (modelling step):
• Category: recommend articles from same categories• Key phrases: match and rank documents w.r.t target documents by key
phrases• Named entities: model with parent/child relationship
• Combine with function score feature to rescore results• Example: applying a Gauss decay function to favor more recent
results
29 / 36

© 2016 Knorex
Recommendation
• Sophisticated scoring and rankingcan be done outside of Elasticsearch• Still, can tap on Elasticsearch for facetingand filtering capability
30 / 36

© 2016 Knorex
Deduplication• Natural approach
• Term matching on URL, title• Failed if these are slightly different (very common!)
• More-like-this or fuzzy-like-this on content, with high matching threshold: e.g. 70%, 80%
• Not accurate, bag-of-word approach.• Tricky in determining threshold. ”Good value” varies across
different dcoument types and domains• Slow. The more terms allowed in the queries, the slower it is. If
cut off based on max terms, then accuracy drops
• Proposed approach• Semantic hashing: minhash, simhash
• for a document, compute a hash value• convert the hash value to binary string form• robust and efficient, can cater to near-duplicate
• Implement Hamming distance search using Elasticsearch fuzzy_like_this
31 / 36

© 2016 Knorex
Deduplication
• Do not index duplicate at allor• Collapse similar items in search results, display only the
one with highest score• Assign same id for articles that are duplicate (called it
groupid)• Use Elasticsearch Top Hits query to collapse result by groupid
Þ 64-bit hash:100001000100011110100101101111001011110100001
1100101101001011101
Modified version:101001000100011110101101101111001011110100001
1100101101000011101
Hamming distance: 3
32 / 36

© 2016 Knorex
Further reading• Dismax vs bool queries• Term vs text queries• Filter vs filtered• Facets (old) vs aggregations (facets reborn + statistics)• Geo
33 / 36

© 2016 Knorex
Summary• ES is very flexible with numerous features and knobs• Critical to understand basic analysis, different types of
queries• Indexing time and search time tradeoff• Precision and recall tradeoff• Complexity and memory estimation• Use NLP techniques as modelling step to improve search
quality• Pay great attention to data input and data gathering step
34 / 36

© 2016 Knorex
About KnorexFounded in 2010 as spin-off from Data Mining Dept. of A*STAR, Singapore
Enabling our customers to make smarter discovery and turn it into actionable insight
Mission
35 / 36

© 2016 Knorex
https://www.knorex.com
https://itviec.com/companies/knorex36 / 36

© 2016 Knorex
Thank you