system setup (virtualbox, java, hadoop) & …eecs.csuohio.edu/~sschung/cis612/cis...
TRANSCRIPT

CIS 612
Lab 4_1 Hadoop Setup and Wordcount
Noreen Halley 2060266
System Setup (VirtualBox, Java, Hadoop) & Wordcount Job
A) VirtualBox Installation - Download and Installation of Oracle VirtualBox 5.1.18 for Windows10
NOTE: Used all of the default settings
- Application successfully installed!
B) Download and installation of Ubuntu Desktop 16.04.2

Issue: How access files from local laptop with virtual server?
Resolution: Create shared folder on the VirtualBox and mount the drive on the Linux instance.
Note: To share files between Host & Guest – see last entry in this exchange:
http://unix.stackexchange.com/questions/16199/how-to-transfer-files-from-windows-to-ubuntu-on-
virtualbox
- Steps to share files:
1. Before starting your Guest
2. Go to VirtualBox Manager
3. Select your interested Guest
4. Go to Guest Settings
5. In Guest Settings, scroll the left side-menu, and go to Shared Folders
6. In Shared Folders, add your interested folder in the Host machine
7. After adding your Host folder path, you will see an updated Folders List in Shared Folders. Remember your newly folder Name shown in this list. Say it is HOST_SHARE.
8. Click OK and save your changes.
9. Start your Guest machine
10. In Guest machine, create a new folder, e.g. GUEST_SHARE
11. In Guest terminal, type
sudo mount -t vboxsf HOST_SHARE GUEST_SHARE
12. You shall find your stuff in this GUEST_SHARE folder.
B) Installing Hadoop
1) Copying Hadoop download from local to server & extract the Hadoop files:

- Export the new Hadoop path to the .bashrc file
2) Java Setup:
- Remove open JDK versions of Java:
- Verify current version of Java installed:
- Installed the needed Java files/folders::
- Update .bashrc file with JAVA information
- Run ‘source ~/.bashrc’ command for changes to take affect

- Verify JAVA_HOME setting after update:
3) SSH Setup
- Install SSH package:
- SSH to the localhost
- Generate RSA key, add key to new folder, and then update the permissions on the
folder:
4) Hadoop Setup
- Go to location of Hadoop configuration files:
- Update several configuration files:

- Update bashrc file to contain the updated path for Hadoop & ‘source’ the file so the
changes take effect:
- Format the Namenode:

- Navigate back to Hadoop folder, start the dfs, then verify processes running with ‘jps’
command:
SUCCESS!!
- Create directory for MapReduce use:
- Test HDFS is working:
- Results after -put command:
- Test MapReduce:

- Check Hadoop commands available:
- Check processes running after starting YARN:
5) Running Wordcount Job
- Download Pride and Prejudice by Jane Austin, text file:

- Downloaded file:
- Copy file from local to dfs folder ‘input’:
Issue: First attempt at copying the file from local to dfs resulted in an error.
Resolution: Needed to remount the shared folder between the HOST & GUEST
servers, after running from ‘home’ directory.
Issue: The ‘input’ folder already had other files in it from the MapReduce test listed
above – wanted to isolate the wordcount text file source.
Resolution: Create a new folder for the book text file.
- Put (copied) the book text file to a new folder ‘pride’ so it is the only document in the
folder:
- Run the Wordcount job:
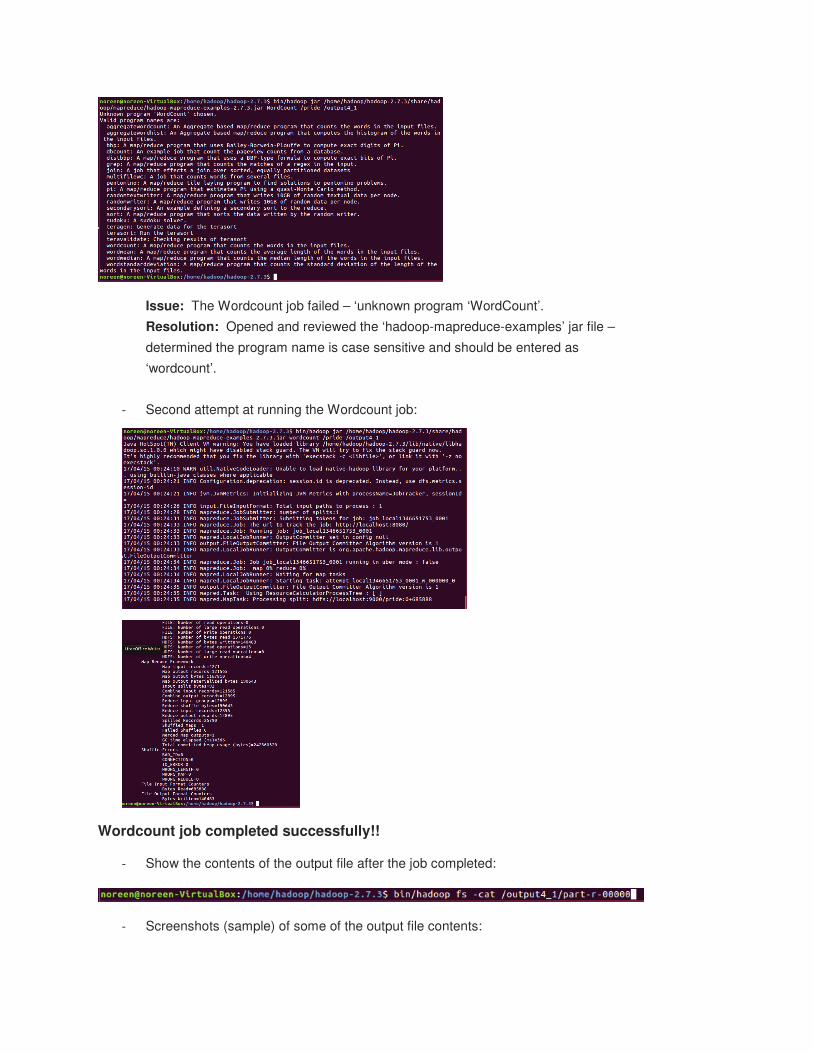
Issue: The Wordcount job failed – ‘unknown program ‘WordCount’.
Resolution: Opened and reviewed the ‘hadoop-mapreduce-examples’ jar file –
determined the program name is case sensitive and should be entered as
‘wordcount’.
- Second attempt at running the Wordcount job:
Wordcount job completed successfully!!
- Show the contents of the output file after the job completed:
- Screenshots (sample) of some of the output file contents:

- Copy output file ‘part-r-00000’ to the local shared folder to attach to homework:
Note: This took a few attempts to complete – copy, move, and put commands
resulted in errors. Found the ‘copyToLocal’ command in Ubuntu online
documentation. Also needed to run the command from the main Hadoop folder.
- Stop all Hadoop services:

ISSUES ENCOUNTERED DURING INSTALLATIONS/ASSIGNMENT
Attempted to fix the Java Client VM warning – suggestion did not work:
First install attempt, kept running into permission issues with user Noreen. Created a new
user and attempted to add the user ‘hadoop’ to the members group to see if I could give it
the permissions to run the commands.
Issue: Members program not installed.
Resolution: Installed the package, then added the user. Attempted to do the Hadoop
installation as user ‘hadoop’ with no luck – had to remove all the files/setup/changes, and
start from scratch with installing under user ‘noreen’.
Issue: Initial attempt to use ssh resulted in an error – program not installed.
Resolution: Installed the ssh package.

Issue: Permission issues accessing the Hadoop configuration files for updating & starting
Hadoop
Resolution: For starting Hadoop, created a ‘log’ folder with 775 permission set.
Issue: Not able to update the mapred-site.xml file because it was a template file.
Resolution: Copying the file and naming it mapred-site.xml, now it is ready for the
configuration property to be updated.

Issue: Attempt to setup SSH without a password – didn’t work on the first pass.
END OF DOCUMENTED ISSUES