streaming compression of triangle meshes martin isenburg university of california at berkeley jack...
Post on 21-Dec-2015
217 views
TRANSCRIPT

Streaming Compressionof Triangle Meshes
Martin IsenburgUniversity of California
at Berkeley
Jack SnoeyinkUniversity of North Carolina
at Chapel Hill
Peter LindstromLawrence Livermore
National Labs

Compression

Compression• physical
– sleeping bags
– compressed air
JPG GIF
• digital– text, programs …
– images
– voice, music
– movies

– Efficient Rendering
– Progressive Transmission
– Maximum Compression
• Connectivity
• Geometry
• Properties
Mesh Compression
“Geometry Compression” [Deering, 95]
storage / network
main memory
Maximum Compression

Current Schemes
“Triangle Mesh Compression” [Touma & Gotsman ‘98]
“Cut-Border Machine” [Gumhold & Strasser ‘98]
“Edgebreaker” [Rossignac ‘99]
“Face Fixer” [Isenburg & Snoeyink ‘00]
“Degree Duality Coder” [Isenburg ‘02]
“Angle Analyzer” [Lee, Alliez & Desbrun ‘02]
“FreeLence” [Kälberer et al. ‘05]
“Out-of-Core Compression” [Isenburg & Gumhold ‘03]

Current Approach

Current Approach

Underlying Assumption• original ordering of vertices and
triangles is not important– no need to preserve it
– compressor is allowed to re-order
• impose “canonical” ordering– only encode connectivity graph
– re-order mesh based on some deterministic traversal

Original Orderings
rendering the first 20to 40 percent of thetriangle array

Connectivity TraversalEntire Mesh As Input
triangles
vertices beforecompression
starts
createdata structurefor queryingand markingconnectivity
getNext(h_edge);getInv(h_edge);getOrigin(h_edge);isBorder(h_edge);isEncoded(h_edge);markAsEncoded(h_edge);
inv flags
Auxiliary Data Structures
001
11
1
1
1
1
11
11
1
1
1
1
1
1
1
0
0
0
00
0 0
00
0
00
0
0
0
0
00
0
0
0

Large Meshes
3D scans isosurfaces

Large Meshes
3D scans isosurfaces

Limited Main Memory
“Compressing Large Polygonal Models” [Ho et al. ‘01]
• cut mesh into pieces, compress separately, stitch back together
“Out-of-core Compression of Gigantic Polygon Meshes”[Isenburg and Gumhold. ‘03]
• use an external memory structure
• impossible to construct / store data structures for mesh traversal

Out-of-Core Compression• OoC-Mesh
– on-disk clustering
– construct in advance
– cache LRU clusters
• OoC-Compressor– make few queries

Out-of-Core Compression• OoC-Mesh
– on-disk clustering
– construct in advance
– cache LRU clusters
• OoC-Compressor– make few queries
• Decompression– “streaming”

Streaming

Streaming• physical
– water in a pipe
– drip coffee
• digital– streaming formats
• audio
• video
• triangle meshes

Two Types of Streaming• progressive
• non-progressive

Non-Progressive Streaming• consume immediately
• potentially without end
• keep small buffer
• delete data if no longer needed
small window

Streaming Mesh Formats•
interleave introduce finalizev 1.32 0.12 0.23v 1.43 0.23 0.92v 0.91 0.15 0.62f 1 2 3done 2 v 0.72 0.34 0.35f 4 1 3done 1 v 0.72 1.03 0.35
⋮ ⋮ ⋮ ⋮
vertex # 2finalized
not used bysubsequent
triangles
vertex # 2introduced
not used byprecedingtriangles
active
“Streaming Meshes” [Isenburg and Lindstrom ‘05]
number of active vertices“width”

Outputting Streaming Meshes• isosurface
– 235 million vertices
– 469 million trianglesover
8 Gigabyte
• marching cubes– extract layer by layer
– output elements as extracted
– finalize vertices of previous layer
Richtmeyer-Meshkov instability simulation at LLNL

Streaming Simplification
“Stream Algorithm for … ” [Wu & Kobbelt ‘03]
“Large Mesh Simplification …” [Isenburg et al. ‘03]

Streaming Compression

Streaming Compression (1)• streaming API
bool open(FILE* file, int bits);
bool write_vertex(float* position);bool write_triangle(int* index, bool* finalize);
bool close();
• compare to standard APIbool compress(FILE* file, int bits,
int num_pos, float* positions, int num_tri, int* indices);

Streaming Compression (2)
• when writing a triangle– look-up active vertices
– determine configuration
– compress triangle+ positions of new vertices
– remove finalized data structures
• when writing a vertex– insert in hash

Possible Configurations
start add
start1
fill
join end
written triangle
active elements

Compressing a Triangle– configuration
add
fill
– specify active vertex• log2(width) bits
• better: use cache
– specify other active vertices• use local edge lists
– position of new vertices• parallelogram prediction
– finalization flags
add
fill


Greedy Local Reordering
Improving connectivity compression by reordering triangles in a delay buffer
0
2
4
6
8
10
12
14
16
18
non
e 25 5010
025
050
0 1
K 5
K
10K
50K
delay buffer size
bpv
lucy
(original)
(spectral)
(geometric)
(breadth)
(depth)
st. matthew
(original)
(spectral)
(geometric)

out-of-core
compressed 344 MB
pre-process 7 hours
4 hourscompress
main memory 384 MB
disk space 11.2 GB
streaming
---
28 min
---
12 MB
392 MB(coordinates uniformly quantized to 18 bits)

Example Processing Pipeline
P1P1 P2P2 P3P3
P1P1P2P2
P3P3
P1P1 P2P2 P3P3
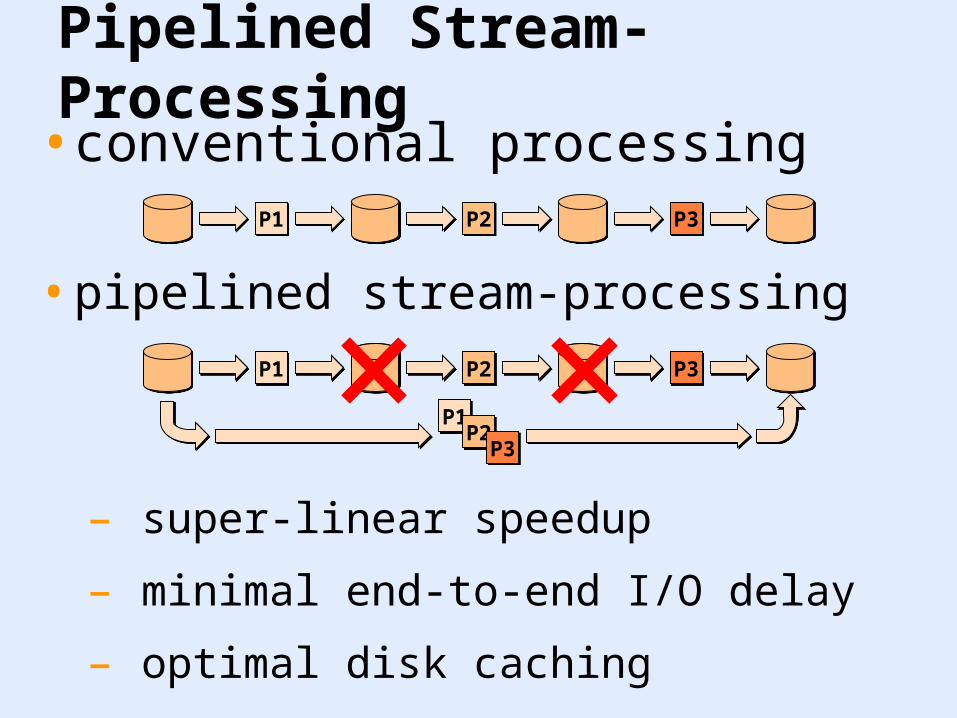
• pipelined stream-processing
Pipelined Stream-Processing• conventional processing
P1P1 P2P2 P3P3
– super-linear speedup
– minimal end-to-end I/O delay
– optimal disk caching

Demo Pipeline
256
256
256
regular volume grid
smextract | smclean | smsimp | smcompress
P2P2 P3P3P1P1 P4P4
grid.raw mesh.smc
v 1.32 0.12 0.23v 1.43 0.23 0.92v 0.91 0.15 0.62f 1 2 3done 2 v 0.72 0.34 0.35f 4 1 3done 1 ⋮ ⋮ ⋮ ⋮

Conclusion

Current Schemes do not Scale
9 GB1 MB

Problems of Current Schemes
372 milliontriangles
(4 GB)
186 million vertices(2 GB)
dedicatedout-of-core
data structure(11 GB)
global reordering ofmesh duringcompression
entire mesh as input IO-inefficient for large data

Streaming Approach
bool open(FILE* file, int bits);
bool write_vertex(float* position);bool write_triangle(int* index, bool* finalize);
bool close();

out-of-core
compressed 344 MB
pre-process 7 hours
4 hourscompress
main memory 384 MB
disk space 11.2 GB
streaming
---
28 min
---
12 MB
392 MB(coordinates uniformly quantized to 18 bits)

Alternate Approaches•
– different re-ordering strategy• higher correlation
– deterministic growing strategy • let compressor choose & correct
– degree-based coding• need to relax “max delay” constraint
• geometry– local coordinate system, angles, …
• connectivity

Compressing Volume Meshesstandard streaming
torso
fighter
2.14 bpt 3.88 bptrate
time 7 min
115 MB
8 sec
3 MBmemory
1.81 bpt 3.56 bptrate
time 11 min
140 MB
12 sec
6 MBmemory

Current/Future Work• implement more stream modules
– streaming surface reconstruction
– streaming stripification
– streaming re-meshing
– streaming smoothing
– streaming segmentation
– streaming feature extraction
– streaming …

Acknowledgements• meshes
– Stanford University, Cyberware
• support– NSF grant 0429901
"Collaborative Research: Fundamentalsand Algorithms for Streaming Meshes."
– U.S. DOE / LLNL # W-7405-Eng-48
– Max Planck Institute für Informatik

Thank You
streaming compression API :http://www.cs.unc.edu/~isenburg/smc


Stream-Processing Modules• tasks that process mesh elements
one at a time– e.g. for each triangle t …
• tasks that only require access to local neighbors– e.g. for each triangle t of vertex v …
• tasks that are order independent– e.g. collapse edges shorter than

# triceratops.obj## 2832 vertices# 2834 polygons#v 3.661 0.002 -0.738v 3.719 0.347 -0.833v 3.977 0.311 -0.725v 4.077 0.139 -0.654 ⋮ ⋮ ⋮ ⋮ f 2806 2810 2815 2821f 2797 2801 2811 2805f 2789 2793 2802 2796f 2783 2794 2788 ⋮ ⋮ ⋮ ⋮
2832! permutations2832! • 2834! • 4
differentorderings
= 1.6E+18810possible
descriptions
2834
4 rotations 2834
2834! permutations
2806